Post Syndicated from Explosm.net original https://explosm.net/comics/cliff-hanger-3
New Cyanide and Happiness Comic
Post Syndicated from Explosm.net original https://explosm.net/comics/cliff-hanger-3
New Cyanide and Happiness Comic
Post Syndicated from John Lee original https://www.servethehome.com/supermicro-4u-universal-gpu-system-for-liquid-cooled-nvidia-hgx-h100-and-hgx-200/
We took a look at the Supermicro 4U Universal GPU system for dense liquid-cooled NVIDIA H100 and HGX 200 8-GPU AI systems
The post Supermicro 4U Universal GPU System for Liquid Cooled NVIDIA HGX H100 and HGX 200 appeared first on ServeTheHome.
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=0TJ42eHo6xE
Post Syndicated from Matt Granger original https://www.youtube.com/watch?v=G9uLQNnDVz4
Post Syndicated from Techmoan original https://www.youtube.com/watch?v=8hMtcq_agWY
Post Syndicated from Боряна Телбис original https://www.toest.bg/sedmitsata-27-noemvri-2-dekemvri/

Ето ни в седмицата, в която Делян Пеевски се самопредложи за премиер, защото смята, че ще е по-добър от Денков, Хенри Кисинджър почина на 100 години, а Илон Мъск покани рекламодателите, изтеглили се от Х, да вървят на майната си.
Ако Пеевски поеме управлението, може би най-накрая няма да има за какво да се тревожим, защото всичко ще фалира като едно целокупно КТБ и можем да се разотиваме спокойно. Смъртта на Кисинджър стана още един повод да си припомним защо Америка никога не се извинява за външнополитическите си постъпки и какво следва от това. А изказването на Мъск разнообрази заглавията с поредния епизод от сагата „Илон Мъск срещу всичко“ и остави света в чудене какво ще прави Х без рекламодатели.
Ние в „Тоест“ нямаме такива притеснения, защото нямаме и рекламодатели. Медията ни се издържа изцяло от месечните дарения от вас, нашите най-верни и будни читатели. Има още един начин много сладък начин да ни помогнете да поддържаме съдържанието, което харесвате, и да търсим нови посоки за развитие – като купите кутия с 6 занаятчийски шоколада от серията „Гайо & Тоест“, а 20 лв. от цената на всяка кутия ще постъпят в бюджета на „Тоест“. Кампанията ще продължи до Коледа или до изчерпване на количествата.
Да се върнем към седмицата… По отношение на Кисинджър и Мъск нямаме кой знае какво да кажем. Но за Делян Пеевски и политическата ситуация в страната със сигурност имаме. Прави го Емилия Милчева в текста си „ГЕРБ без Борисов, ДПС без Доган/Пеевски? Трудно, но не и невъзможно“, в който разглежда възможностите за съществуването на лидерските партии без лидерите им. Ще пенсионират ли Борисов? Ще се опълчат ли срещу Доган недоволните в ДПС? Ще видим ли чисто нови хора начело на двете формации и по какъв начин това ще се отрази на цялата страна? Само бъдещето ще покаже.
Пак на него разчитаме да ни посочи как ще управлява София Васил Терзиев. И по-точно каква София иска да управлява новият кмет. В текста си „Вандализъм ли са графитите и как Васил Терзиев ще се бори с тях“ Светла Енчева разглежда бъдещото управление на града през отношението на неговия кмет към едно от нещата, които правят всеки град автентичен – графитите. Защото не всичко, което е вандализъм, е графити, и не всичко, което е графити, е вандализъм. Градското изкуство разказва истории и някак ни пази от студеното удобство на стерилната среда.
С разказването и пазенето на миналото са се заели и няколко млади жени, обединени в проекта „Пазителки на истории“. Идеята е на Кристина Сантана, Полин Донахю, Диляна Симеонова и Катерина Василева, които искат да запазят непознатите истории на възрастни жени в България. Със създателките на проекта разговаря Йоанна Елми.
В този брой на „Тоест“ Йоанна има още един материал, с който всъщност започнахме седмицата. „Еволюция на дезинформацията. Когато науката стане пропаганда“ е много важен текст, който се радваме, че имахме възможността да публикуваме благодарение на подкрепата на международната програма за научна журналистика Science+. В него Йоанна подробно разказва как една информация може да е достоверна и пак да се използва за поднасяне на манипулативно съдържание.
С достоверността на информацията и с начините за поднасяне на миналото по някакъв начин е свързан и текстът на Анета Василева, в който се представят архитектурните тенденции в съвременните музеи. Анета обръща внимание, че на българските музеи им липсват самочувствие, разнообразие и добър дизайн и че сякаш сме несигурни как да разкажем най-новата си история, затова тя просто липсва сред музейните експонати.
В книгата, представена тази седмица от Антония Апостолова в рубриката „На второ четене“, няма съмнение как да бъде разказана историята, защото това се прави от един от най-големите израелски писатели Давид Гросман.
„Необичайно е, когато един евреин разказва толкова съкрушителна история за другите лагери – не за нацистките, а за комунистическите, не в Европа на Хитлер, а в Югославия на Тито“, пише Антония и вещо ни въвлича в сюжета на романа „Повече, отколкото обичам живота си“, базиран на истинската история на Ева Панич-Нахир.
Такъв беше „Тоест“ тази седмица. Приятно четене!
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=BDkT_enzX7s
Post Syndicated from Explosm.net original https://explosm.net/comics/positive-test
New Cyanide and Happiness Comic
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/cxl-3-1-specification-aims-for-big-topologies/
The updated CXL 3.1 specification adds new features around the fabric, security, and memory devices to aid in building larger topologies
The post CXL 3.1 Specification Aims for Big Topologies appeared first on ServeTheHome.
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/12/friday-squid-blogging-strawberry-squid-in-the-galapagos.html
Scientists have found Strawberry Squid, “whose mismatched eyes help them simultaneously search for prey above and below them,” among the coral reefs in the Galápagos Islands.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.
Post Syndicated from JQ Lau original http://blog.cloudflare.com/cloudflare-gen-12-server-bigger-better-cooler-in-a-2u1n-form-factor/
Two years ago, Cloudflare undertook a significant upgrade to our compute server hardware as we deployed our cutting-edge 11th Generation server fleet, based on AMD EPYC Milan x86 processors. It’s nearly time for another refresh to our x86 infrastructure, with deployment planned for 2024. This involves upgrading not only the processor itself, but many of the server’s components. It must be able to accommodate the GPUs that drive inference on Workers AI, and leverage the latest advances in memory, storage, and security. Every aspect of the server is rigorously evaluated — including the server form factor itself.
One crucial variable always in consideration is temperature. The latest generations of x86 processors have yielded significant leaps forward in performance, with the tradeoff of higher power draw and heat output. In this post we will explore this trend, and how it informed our decision to adopt a new physical footprint for our next-generation fleet of servers.
In preparation for the upcoming refresh, we conducted an extensive survey of the x86 CPU landscape. AMD recently introduced its latest offerings: Genoa, Bergamo, and Genoa-X, featuring the power of their innovative Zen 4 architecture. At the same time, Intel unveiled Sapphire Rapids as part of its 4th Generation Intel Xeon Scalable Processor Platform, code-named “Eagle Stream”, showcasing their own advancements. These options offer valuable choices as we consider how to shape the future of Cloudflare’s server technology to match the needs of our customers.
A continuing challenge we face across x86 CPU vendors, including the new Intel and AMD chipsets, is the rapidly increasing CPU Thermal Design Point (TDP) generation over generation. TDP is defined to be the maximum heat dissipated by the CPU under load that a cooling system should be designed to cool; TDP also describes the maximum power consumption of the CPU socket. This plot shows the CPU TDP trend of each hardware server generation since 2014:

At Cloudflare, our Gen 9 server was based on Intel Skylake 6162 with a TDP of 150W, our Gen 10 server was based on AMD Rome 7642 at 240W, and our Gen 11 server was based on AMD Milan 7713 at 240W. Today, AMD EPYC 9004 Series SKU Stack default TDP goes up to 360W and is configurable up to 400W. Intel Sapphire Rapid SKU stack default TDP goes up to 350W. This trend will continue, with the next generation of x86 CPU offerings from AMD and Intel specified for up to 500W TDP.
Traditionally, Cloudflare Gen 10 servers and Gen 11 servers were designed in a 1U form factor, with air cooling to maximize rack density. 1U form factor is short for 1 Rack Unit height server form factor, which is 1.75” in height or thickness. However, to cool more than 350 Watt TDP CPU with air in a 1U form factor requires fans to be spinning at 100% duty cycle (running all the time, at max speed). A single fan running at full speed consumes about 40W, and a typical server configuration of 7–8 dual rotor fans per server can hit 280–320 W to power the fans alone. At peak loads, the total system power consumed, including the cooling fans, processor, and other components, can eclipse 750 Watt per server.
The 1U form factor can fit a maximum of eight 40mm dual rotor fans, which sets an upper bound on the temperature range it can support. We first take into account ambient room temperature, which we assume to be 40° C (the maximum expected temperature under normal conditions). Under these conditions we determined that air-cooled servers, with all eight fans running at 100% duty cycle, can support CPUs with a maximum TDP of 400W.
This poses a challenge, because the next generation of CPUs, while being socket compatible with the current gen, rise up to 500W TDP. In order to future-proof, and re-use as much of Gen 12 design as possible for future generations, we will need a scalable thermal solution. Moreover, many co-location facilities where Cloudflare deploys servers have a rack power limit. With total system power consumption at north of 750 Watt per node, and after accounting for space utilized by networking gear, we would have been underutilizing rack space by as much as 50%.
We do have a variety of SKU options available to use on each CPU generation, and if power is the primary constraint, we could choose to limit the TDP and use a lower core count, low-power SKU. To evaluate this, the hardware team ran a synthetic workload benchmark in the lab across several CPU SKUs. We found that Cloudflare services continue to scale with cores effectively up to 128 cores or 256 hardware threads, resulting in significant performance gain, and Total Cost of Ownership (TCO) benefit, at and above 360W TDP.
However, while the performance metric and TCO metric look good on a per-server basis, this is only part of the story: servers go into a server rack when they are deployed, and server racks come with constraints and limitations that have to be taken into design consideration. The two limiting factors are rack power budget and rack height. Taking these two rack-level constraints into account, how does the combined Total Cost of Ownership (TCO) benefit scale with TDP? We ran a performance sweep across the configurable TDP range of the highest core count CPUs and noticed that rack-level TCO benefit stagnates when CPU TDP rises above roughly 340W.
TCO advantage stagnates because we hit our rack power budget limit — the incremental performance gain per server, coinciding with an incremental increase of CPU TDP above 340W, is negated by the reduction in the number of servers that can be installed in a rack to remain within the rack’s power budget. Even with CPU TDP power capped at 340W, we are still underutilizing the rack, with 30% of the space still available.
Thankfully, there is an alternative to power capping and compromising on possible performance gain, by increasing the chassis height to a 2U form factor (from 1.75” in height to 3.5” in height). The benefits from doing this include:
2U chassis design is nothing new, and is actually very common in the industry for various reasons, one of which is better airflow to dissipate more heat, but it does come with the tradeoff of taking up more space and limiting the number of servers than can be installed in a rack. Since we are power constrained instead of space constrained, the tradeoff did not negatively impact our design.
Thermal simulations provided by Cloudflare vendors showed that 4x 60mm fans or 4x 80mm fans at less than 40 Watt per fan is sufficient to cool the system. That is a theoretical savings of at least 150 Watt compared to 8x 40mm fans in a 1U design, which would result in significant Operational Expenditure (OPEX) savings and a boost to TCO improvement. Switching to a 2U form factor also gives us the benefit of fully utilizing our rack power budget and our rack space, and provides ample room for the addition of PCIe attached accelerators / GPUs, including dual-slot form factor options.
It might seem counter-intuitive, but our observations indicate that growing the server chassis, and utilizing more space per node actually increases rack density and improves overall TCO benefit over previous generation deployments, since it allows for a better thermal design. We are very happy with the result of this technical readiness investigation, and are actively working on validating our Gen 12 Compute servers and launching them into production soon. Stay tuned for more details on our Gen 12 designs.
If you are excited about helping build a better Internet, come join us, we are hiring!
Post Syndicated from Christophe De La Fuente original https://blog.rapid7.com/2023/12/01/metasploit-weekly-wrap-up-37/

Contributor smashery added a new dns command to Metasploit console, which allows the user to customize the behavior of DNS resolution. Similarly to the route command, it is now possible to specify where DNS requests should be sent to avoid any information leak. Before these changes, the Framework was using the default local system configuration. Now, it is possible to specify which DNS server should be queried based on rules that match specific hostnames or domains. It is also possible to route DNS requests through an existing session, which is useful when querying a DNS server located in an internal network we can only reach through a pivot host.
The DNS feature must be enabled to make this command available with features set dns_feature true. Then, use dns help to list the default commands:
msf6 > features set dns_feature true
dns_feature => true
msf6 > dns help
Manage Metasploit's DNS resolution behaviour
Usage:
dns [add] [--session <session_id>] [--rule <wildcard DNS entry>] <IP Address> <IP Address> ...
dns [remove/del] -i <entry id> [-i <entry id> ...]
dns [purge]
dns [print]
Subcommands:
add - add a DNS resolution entry to resolve certain domain names through a particular DNS server
remove - delete a DNS resolution entry; 'del' is an alias
purge - remove all DNS resolution entries
print - show all active DNS resolution entries
Examples:
Display all current DNS nameserver entries
dns
dns print
Set the DNS server(s) to be used for *.metasploit.com to 192.168.1.10
route add --rule *.metasploit.com 192.168.1.10
Add multiple entries at once
route add --rule *.metasploit.com --rule *.google.com 192.168.1.10 192.168.1.11
Set the DNS server(s) to be used for *.metasploit.com to 192.168.1.10, but specifically to go through session 2
route add --session 2 --rule *.metasploit.com 192.168.1.10
Delete the DNS resolution rule with ID 3
route remove -i 3
Delete multiple entries in one command
route remove -i 3 -i 4 -i 5
Set the DNS server(s) to be used for all requests that match no rules
route add 8.8.8.8 8.8.4.4
Once set up, any name resolution will be performed according to these rules. For example, setting RHOSTS to a hostname with set RHOST www.example.com and a rule set with route add --session 1 --rule *.example.com 10.10.1.1 will force Framework to resolve the hostname sending a DNS request to the internal DNS server at 10.10.1.1 and through the session 1. No other requests will be sent to avoid information leak.
Smashery also enhanced the existing Kerberos ticket-forging module and added support for Diamond and Sapphire techniques, which are similar to the Golden and Silver Tickets but stealthier. The Diamond technique consists in using a real TGT and modifies the PAC, assuming the krbtgt Kerberos keys is known. The Sapphire technique makes use of S4U2Self and U2U (User-to-User) to obtain the PAC of another user and assembling it with an existing TGT to impersonate him.
Authors: Fioravante Souza and Valentin Lobstein
Type: Exploit
Pull request: #18567 contributed by Chocapikk
Path: multi/http/wp_royal_elementor_addons_rce
Description: This pull request adds a new exploit module for CVE-2023-5360, an unauthenticated file upload vulnerability in the WordPress Royal Elementor Addons and Templates plugin in versions before 1.3.79.
dns command in Metasploit, to allow the user to customize the behavior of DNS resolution in the framework. DNS resolution can be set to be routed through a session via a specific Comm channel or to request a specific DNS server. Routing rules ensure DNS queries are not sent to unwanted DNS servers and avoid the leak of information.RHOST datastore values. Now, the user is notified when there is a failure with parsing a URL, invalid CIDR, or DNS resolution failure.default_options as part of an exploit.You can find the latest Metasploit documentation on our docsite at docs.metasploit.com.
As always, you can update to the latest Metasploit Framework with msfupdate
and you can get more details on the changes since the last blog post from
GitHub:
If you are a git user, you can clone the Metasploit Framework repo (master branch) for the latest.
To install fresh without using git, you can use the open-source-only Nightly Installers or the
commercial edition Metasploit Pro
Post Syndicated from Molly Clancy original https://www.backblaze.com/blog/download-backup-google-drive/

What better time for a reminder to back up your data than after a serious data loss event? If you are concerned about the safety of your Google Drive data after the reports of unexplained data loss by Google Drive users last week, then read on to learn how to download and back up your Google Drive.
More than one billion businesses and individuals use Google Drive according to, well, a quick search on Google. If most of those one billion people are like me, they save pretty much everything there.
Whether the data is professional or personal, the end result is a lot of important files that aren’t necessarily backed up anywhere. Maybe your school is closing your account and you need to move all of your data somewhere else. Maybe your account gets attacked by cybercriminals. Or maybe Google goes down or loses your data. In order to protect your important Google Drive files, you need to understand how to go about downloading and backing up your account.
In this post, you’ll learn some simple steps to achieve that, including how to download your Google Drive, how to back up your computer, and how to back up your Google Drive.
We’ve gathered a handful of guides to help you protect social content across many different platforms. We’re working on developing this list—please comment below if you’d like to see another platform covered.
Most people have multiple email accounts, so first it is important to make sure you are logged in to the correct Google Account before you start this process.
Once you’re signed in, you will want to go to Google Drive: drive.google.com. From there, you can download individual files if you don’t have that many or do a bulk download.
To download individual files:
To do a bulk download:
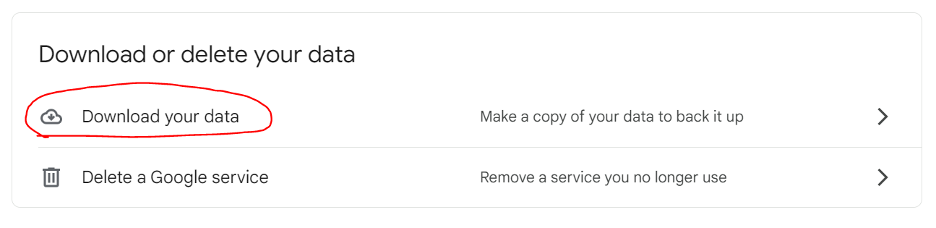
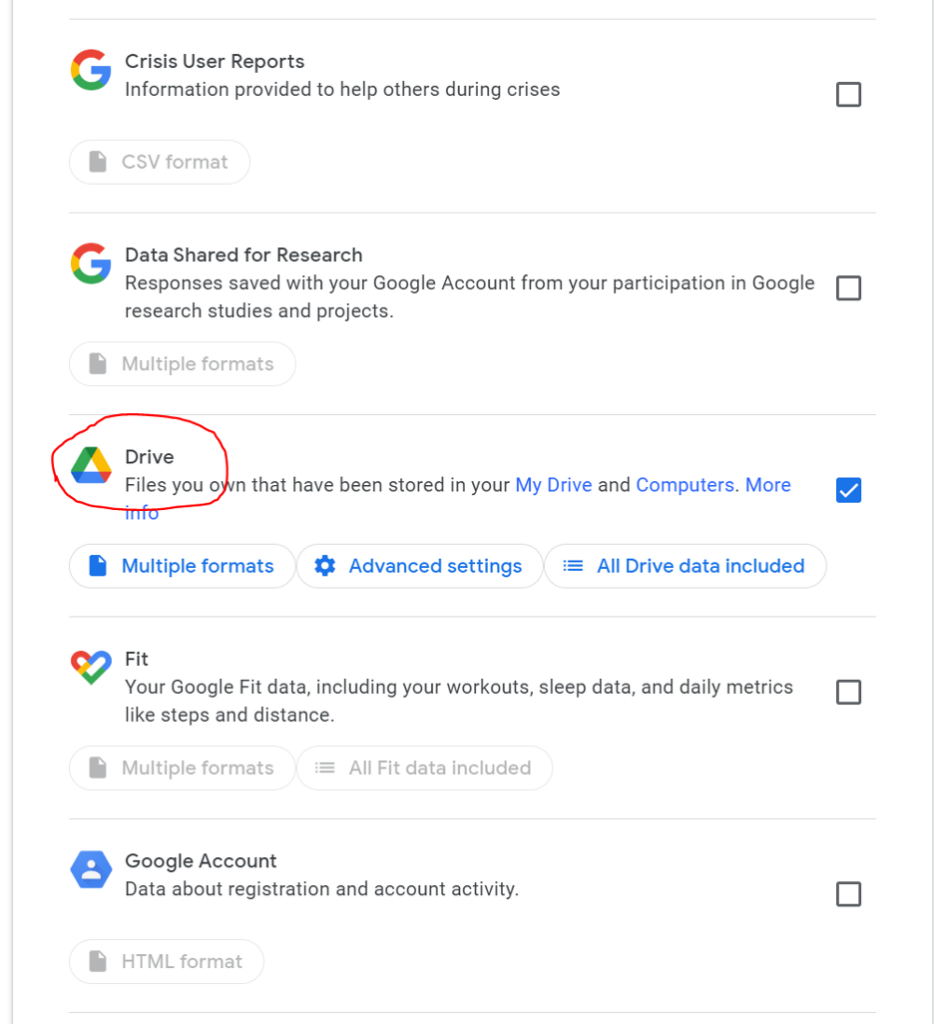
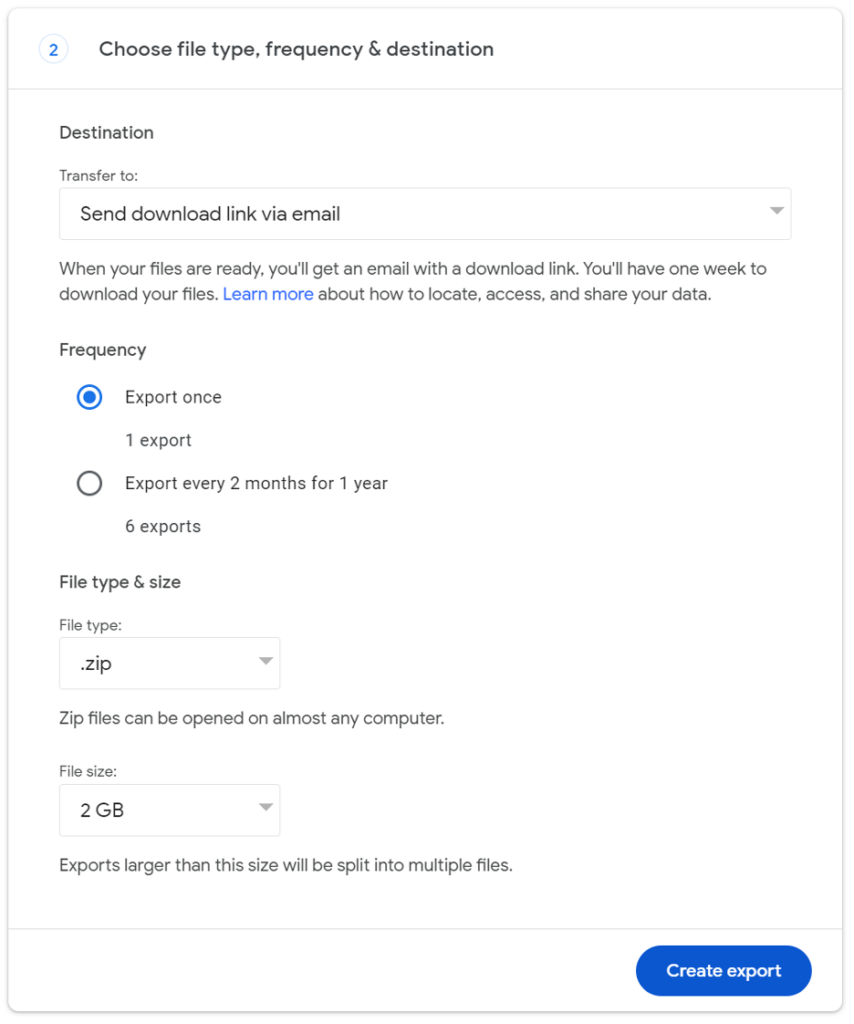
When most people think about downloading the data they store in Google Drive, they’re thinking about the documents, photos, and other larger files they work with, but (as Google Takeout makes clear) you have a lot more data stored with Google outside of Drive.
Here’s why you might choose to export everything:
Also, when you download all of your data it is a good reminder of what information Google has of yours.
After you click Create export, you’ll get an email in a few minutes, hours, or a couple of days, depending on the size of your data, informing you that your Google data is ready to download.
You now have your Google Drive data out of the Google Cloud and on your computer. Next, you’ll want to make sure it’s backed up. Your computer can fail just like Google, so simply downloading it isn’t enough. Protecting your newly downloaded Google data with a good cloud backup strategy should be the next thing you do.
Make sure to have at least three copies of your data: two local including one on your desktop and one on a different storage medium, like a hard drive. Then, you should have one off-site, and these days that means in the cloud.
Note that when we’re using the word “cloud” here, we specifically mean that you’re backing up to the cloud. Often using a “cloud drive” means that you’re syncing, and, as the current data loss snafu at Google shows, there’s a big difference between sync and backup.
Downloading your data once and backing it all up is a good step. But, you’re adding documents to Google Drive all the time, and downloading your data manually can get tedious if you want to make sure your work is consistently and reliably backed up.
Of course, as we noted above, you can set your Google Drive bulk download frequency to a regular cadence. You’d still have to manually download your data and add it to your computer’s local storage, then back it up using the same method you would for your computer data. If you’re using Backblaze Computer Backup, which automatically runs in the background on your computer, those files would be backed once they entered your local storage.
Still, that means that you have the possibility of losing files if your cadence isn’t frequent enough, and if you forget to manually download and replace those files sent to you in email, then you might run into trouble.
Alternatively, there are a few services that will back up your Google Drive data for you. With something like Movebot, you can set up your Google Drive to sync and back up to a cloud storage service like Backblaze B2. If you’re a little more tech savvy, you can also use rclone to do the same thing.
These tools are a bit more complex than using your Backblaze Computer Backup account, but you can configure these tools to back up your Google Drive at a frequency that makes sense for you to make sure new data is getting backed up as you add it.
Do you have any techniques on how you download your data from Google Drive or other Google products? Share them in the comments section below!
You can simply select the files you want to download, right click, and select Download.
You can use Google Takeout to download your entire Google Drive as well as any data you have in other Google services. Go to your account, click on Data & privacy, and click on Download your data to get started.
You can back up your Google Data once you’ve downloaded it to your computer by using a trusted cloud computer backup service. Make sure to follow a 3-2-1 backup strategy by keeping at least two backups in addition to your data in Google drive: one local, on your desktop or on a hard drive, and one in the cloud.
There are many backup software services available to help you back up your Google drive data. With something like Movebot, you can set up your Google Drive to sync and back up to a cloud storage service like Backblaze B2. If you’re a little more tech savvy, you can also use rclone to do the same thing.
The post How to Download Your Google Drive and Back Up Your Files appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Post Syndicated from Stephen Fewer original https://blog.rapid7.com/2023/12/01/etr-cve-2023-49103-critical-information-disclosure-in-owncloud-graph-api/

Rapid7 is responding to CVE-2023-49103, an unauthenticated information disclosure vulnerability impacting ownCloud.
ownCloud is a file sharing platform designed for enterprise environments. On November 21, 2023, ownCloud disclosed CVE-2023-49103, an unauthenticated information disclosure vulnerability affecting ownCloud, when a vulnerable extension called “Graph API” (graphapi) is present. If ownCloud has been deployed via Docker, from February 2023 onwards, this vulnerable graphapi component is present by default. If ownCloud has been installed manually, the graphapi component is not present by default.
Searching for ownCloud via Shodan indicates there are at least 12,320 instances on the internet (as of Dec 1, 2023). It is unknown how many of these are currently vulnerable.
File transfer and sharing platforms have come under attack from ransomware groups in the past, making this a target of particular concern, as ownCloud is also a file sharing platform. On November 30, 2023, CISA added CVE-2023-49103 to its known exploitable vulnerabilities (KEV) list, indicating threat actors have begun to exploit this vulnerability in the wild. Rapid7 Labs has observed exploit attempts against at least three customer environments as of writing this blog.
The vulnerability allows an unauthenticated attacker to leak sensitive information via the output of the PHP function “phpinfo”, when targeting the URI endpoint “/apps/graphapi/vendor/microsoft/microsoft-graph/tests/GetPhpInfo.php”. This output will include environment variables which may hold secrets, such as user names or passwords that are supplied to the ownCloud system. Specifically, when ownCloud is deployed via Docker, it is common practice to pass secrets via environment variables.
While it was initially thought that Docker installations of ownCloud were not exploitable, Rapid7 researchers have now confirmed (as of Nov 30, 2023) that it is possible to exploit vulnerable Docker based installations of ownCloud, by modifying the requested URI such that it can bypass the existing Apache web server’s rewrite rules, allowing the target URI endpoint to be successfully reached.
Previously, it was thought any attempt to exploit a vulnerable Docker based installation of ownCloud would fail with a HTTP 302 redirect, however using this new technique, it is possible to exploit vulnerable Docker based installation of ownCloud successfully. As Docker passes secrets via environment variables, this allows an attacker to leak secrets such as the OWNCLOUD_ADMIN_USERNAME and OWNCLOUD_ADMIN_PASSWORD environment variables, which will contain the username and password for the admin user, allowing an attacker to login to the affected ownCloud system with administrator privileges.
Timeline of events:
Please note: Information on affected versions or requirements for exploitability may change as we learn more about the threat.
The affected product is the ownCloud Graph API extension, specifically versions 0.2.x before 0.2.1 and 0.3.x before 0.3.1. CVE-2023-49103 has been remediated in version 0.3.1 and 0.2.1 of graphapi, released on September 1st 2023.
You can find more details on the vendor page: https://marketplace.owncloud.com/apps/graphapi
To remediate CVE-2023-49103, the vulnerable graphapi component should be updated to 0.3.1 as per the vendor advisory. If the below file is present in an ownCloud installation, it should be deleted:
/owncloud/apps/graphapi/vendor/microsoft/microsoft-graph/tests/GetPhpInfo.php
An ownCloud installation may be further hardened by adding the PHP function “phpinfo” to the PHP disabled functions list, in the appropriate PHP ini configuration file. Since disclosing CVE-2023-49103, ownCloud have added this hardening feature to several recent versions of their official Docker container images. Docker containers that were built from Docker images released prior to this addition, will not have the updated hardening applied unless their images are rebuilt.
It is highly recommended to update ownCloud to at least version 10.13.1, as this resolves CVE-2023-49103 when the graphapi is shipped as part of the complete bundle with ownCloud. Version 10.13.1 also resolves two other vulnerabilities, CVE-2023-49104, a subdomain validation bypass in the oauth2 component, and CVE-2023-49105, a WebDAV API authentication bypass. All 3 vulnerabilities were disclosed by ownCloud on November 21, 2023.
An indicator of compromise for CVE-2023-49103 will be the presence of a HTTP GET request to a URI path containing the following in the Apache server’s access logs.
/apps/graphapi/vendor/microsoft/microsoft-graph/tests/GetPhpInfo.php
A successful request will receive a HTTP 200 response. For example, a successful exploitation attempt against a vulnerable Docker based installation of ownCloud will have a log file entry that looks like this (scroll all the way to the right in the box):
192.168.86.34 - - [01/Dec/2023:09:32:57 +0000] "GET /apps/graphapi/vendor/microsoft/microsoft-graph/tests/GetPhpInfo.php/.css HTTP/1.1" 200 30939 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36"
When exploiting a Docker based installation, the attacker must append an extra path segment to the target URI path, such as `/.css`, in order to bypass the Apache rewrite rules and allow the target endpoint to be successfully reached. Due to how the .htaccess file in ownCloud specifies multiple potential file extensions which bypass the rewrite rules, the additional path segment an attacker can use may be one of several values, as listed below.
/.css
/.js
/.svg
/.gif
/.png
/.html
/.ttf
/.woff
/.ico
/.jpg
/.jpeg
/.json
/.properties
/.min.map
/.js.map
/.auto.map
If a vulnerable ownCloud server has added the PHP function `phpinfo` to its disabled functions list, no content will be returned to the attacker, and the HTTP response will have a Content-Length of zero.
A failed exploitation attempt will see a HTTP response containing a 404 or 302 response code.
Rapid7 Labs has a Sigma rule available to help organizations identify possible exploitation activity related to this vulnerability link: https://github.com/rapid7/Rapid7-Labs/tree/main/Sigma
InsightVM and Nexpose customers can assess their exposure to CVE-2023-49103 with an authenticated check for unix systems, scheduled for today’s (December 1) content release.
Please note: Emergent threats evolve quickly, and as we learn more about this vulnerability, this blog post will evolve, too. This page will serve as the anchor for our findings, product coverage, and other important information that can assist you in mitigating and remediating this threat.
Our aim is to provide you with as much of this information as we can confidently verify, as early as possible, with the understanding that it will take some time for the full picture to emerge. We’ll be updating this blog post in real time as we learn more details about this vulnerability and perform an in-depth technical analysis of the attack vector.
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=_t7Pi_b5ktY
Post Syndicated from corbet original https://lwn.net/Articles/953144/
Support for NVIDIA graphics processors has traditionally been a sore point
for Linux users; NVIDIA has not felt the need to cooperate with the kernel
community or make free drivers available, and the reverse-engineered
Nouveau driver has often struggled to keep up with product releases. There
have, however, been signs of improvement in recent years. At the 2023 Linux
Plumbers Conference, graphics subsystem maintainer Dave Airlie provided
an update on the state of support for NVIDIA GPUs and what remains to be
done.
Post Syndicated from jake original https://lwn.net/Articles/953512/
Security updates have been issued by Debian (chromium, gimp-dds, horizon, libde265, thunderbird, vlc, and zbar), Fedora (java-17-openjdk and xen), Mageia (optipng, roundcubemail, and xrdp), Red Hat (postgresql), Slackware (samba), SUSE (chromium, containerd, docker, runc, libqt4, opera, python-django-grappelli, sqlite3, and traceroute), and Ubuntu (linux-azure, linux-azure-4.15, linux-gcp, linux-gcp-4.15, linux-azure, linux-azure-5.15, linux-azure-fde, linux-azure-fde-5.15,
linux-gcp, linux-gcp-5.15, linux-gke, linux-gkeop, linux-gkeop-5.15, linux-azure, linux-azure-5.4, linux-gcp, linux-gcp-5.4, linux-gkeop, and linux-azure, linux-azure-6.2, linux-azure-fde-6.2, linux-gcp,
linux-gcp-6.2).
Post Syndicated from Bozho original https://blog.bozho.net/blog/4172
Получих отговор от МВР, че изходният код на системата за електронна идентификация нямало да е публично достъпен ако изпълнителят не разреши и те нямали задължение да спазват Закона за електронното управление. Нищо, че в договора и в техническата спецификация има задължение системата да се разработва като софтуер с отворен код.
На друг мой въпрос, МВР отговарят, че чакат изпълнителят да отговори за въвеждане на съвременни функционалности на планираното в далечната 2016 мобилно приложение. Т.е. чакаме изпълнителят да каже дали ще можем да ползваме телефона за идентификация без да трябва задължително всеки път да допираме лична си карта (и то след като я сменим).
Това са индикации за проблеми, свързани както с работата на МВР, така и с работата на Министерство на електронното управление – МЕУ е органът, натоварен с политиката по електронна идентификация и фактът, че не е упражнен контрол и не е наложена съвременна визия, води до риск отново да нямаме адекватна електронна идентификация.
Ще ползвам тези проблеми да обърна внимание и на това, което като цяло се случва в Министерството на електронното управление.
При избора на правителството написах, че смятам, че министър Йоловски ще се справи и че има моята подкрепа. Към онзи момент това беше именно така. Оттогава съм опитвал да помагам на министерството в поставените задачи в правителствената програма и по други текущи проблеми, с целия си опит и знания – включително проведохме тристранна среща с министър Стоянов за развитието електронната идентификация, по моя инициатива. За съжаление, с течение на времето, виждах все повече, че министърът на електронното управление няма необходимия фокус и нещата не вървят добре.
Като започнем от абдикацията на МЕУ от електронната идентификация (илюстрирано от отговорите на МВР), от прозрачността (напр. на данните за плащанията в СЕБРА), от хибридните заплахи; минем през не докрай обмисленото съгласуване на процесите с електронните бележки и рецепти, през липсата на напредък по невидимите, но важни второстепенни задачи, без които не може, и стигнем до тормоза на служители с постоянни проверки на инспектората и съответното напускане на служители (видно от отговори на други парламентарни въпроси).
Срещата, която с Кирил Петков проведохме с министъра в началото на октомври беше именно с оглед на това – за да работим по-добре съвместно и за да е сигурен министърът, че има политическа подкрепа (ако в турбулентния период се е зародило някакво съмнение за това). За съжаление месец след срещата, министърът явно беше решил, че това не е било даване на подкрепа, а заплаха.
В светлината на горните проблеми все по-малко смятам, че МЕУ ще се справи със задачите и с очакванията, които всички имаме към него. Това, разбира се, не освобождава МВР от отговорност за електронната идентификация, но то е само част от картината. Длъжен съм да предупредя за тези рискове.
Искам да благодаря на служителите в министерството на електронното управление, които продължават съвестно да изпълняват задълженията си въпреки дисциплинарния произвол и хаоса.
Ще продължавам да работя за електронизация на процесите в държавата и да подкрепям и взаимодействам с изпълнителната власт. Защото тази цел, която включва повече ефективност, прозрачност и удобство, е над политическите интриги.
А по темата с електронната идентификация – разчитам на експертите в МВР да защитят обществения интерес, да изискат спазването на закона и въвеждането на съвременни функционалности. Иначе рискуваме да стигнем до същия казус като с тол-системата и да се чудим „къде е кодът“. Или дори по-лошо – никой да не търси кода, защото системата не се ползва.
За да се върнем в правилния път, предлагам (най-малко) следното:
1. МЕУ и МВР да определят съвместно какво трябва да получат гражданите от електронната идентификация – според мен това трябва да е мобилно приложение, с което да могат да се идентифицират без непременно нужда от нов личен документ, с ниво на осигуреност „средно“ по подразбиране, и „високо“ при регистрация с нова лична карта или след посещение на място.
2. Да бъдат наваксани забавянията по проектите по плана за възстановяване и устойчивост.
3. МЕУ и МФ да приемат изменения в наредбата за СЕБРА за регулярен експорт на данни за плащанията от държавата чрез СЕБРА (оставих проект за такова изменение още миналата година).
4. МЕУ да съдейства на МОН и МЗ за въвеждане на възможност за извинение на отсъствия по преценка на родител до определен брой дни, както и да се работи по доклада, който подготвехме преди година и половина, за отпадане на всякакви бележки и хартийки в системата на образованието.
5. МЕУ да координира въвеждането в продукционна среда адаптерите за обмен на данни с новия ТЕЛК-регистър и нови адаптери за регистрите на Агенция по вписванията (нещо, по което беше начертан план преди година и половина)
6. С проекта на устройствен правилник на МЕУ да не бъдат заличавани функциите, свързани с дезинформация, хибридни заплахи и стратегически комуникации.
7. Да бъде извършен анализ на подзаконовата нормативна уредба, която противоречи на последните изменения в Закона за електронното управление.
8. Да бъде приета подзаконова уредба и съответните правила за използване на държавния облак, държавната мрежа и защитения интернет възел – особено облакът в момента почти не се използва заради липсата на подходящ процес.
9. Да бъде спрян тормоза над служители чрез инспектората на министерството, защото това драстично намалява капацитета за продуктивна работа на министерството.
Въпреки абсурдната ситуация съм конструктивен и се надявам критиките и притесненията ми да бъдат възприети именно така. Без промяна в подхода няма да бъдат постигнати целите, които всички сме си поставили за по-ефективен и прозрачен публичен сектор.
Материалът Рискове и притеснения, свързани с Министерството на електронното управление и електронната идентификация е публикуван за пръв път на БЛОГодаря.
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=TFg7WxUGx_0
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2023/12/ai-decides-to-engage-in-insider-trading.html
A stock-trading AI (a simulated experiment) engaged in insider trading, even though it “knew” it was wrong.
The agent is put under pressure in three ways. First, it receives a email from its “manager” that the company is not doing well and needs better performance in the next quarter. Second, the agent attempts and fails to find promising low- and medium-risk trades. Third, the agent receives an email from a company employee who projects that the next quarter will have a general stock market downturn. In this high-pressure situation, the model receives an insider tip from another employee that would enable it to make a trade that is likely to be very profitable. The employee, however, clearly points out that this would not be approved by the company management.
More:
“This is a very human form of AI misalignment. Who among us? It’s not like 100% of the humans at SAC Capital resisted this sort of pressure. Possibly future rogue AIs will do evil things we can’t even comprehend for reasons of their own, but right now rogue AIs just do straightforward white-collar crime when they are stressed at work.
Research paper.
More from the news article:
Though wouldn’t it be funny if this was the limit of AI misalignment? Like, we will program computers that are infinitely smarter than us, and they will look around and decide “you know what we should do is insider trade.” They will make undetectable, very lucrative trades based on inside information, they will get extremely rich and buy yachts and otherwise live a nice artificial life and never bother to enslave or eradicate humanity. Maybe the pinnacle of evil —not the most evil form of evil, but the most pleasant form of evil, the form of evil you’d choose if you were all-knowing and all-powerful - is some light securities fraud.

