Post Syndicated from Channy Yun (윤석찬) original https://aws.amazon.com/blogs/aws/introducing-checkpointless-and-elastic-training-on-amazon-sagemaker-hyperpod/
Today, we’re announcing two new AI model training features within Amazon SageMaker HyperPod: checkpointless training, an approach that mitigates the need for traditional checkpoint-based recovery by enabling peer-to-peer state recovery, and elastic training, enabling AI workloads to automatically scale based on resource availability.
- Checkpointless training – Checkpointless training eliminates disruptive checkpoint-restart cycles, maintaining forward training momentum despite failures, reducing recovery time from hours to minutes. Accelerate your AI model development, reclaim days from development timelines, and confidently scale training workflows to thousands of AI accelerators.
- Elastic training – Elastic training maximizes cluster utilization as training workloads automatically expand to use idle capacity as it becomes available, and contract to yield resources as higher-priority workloads like inference volumes peak. Save hours of engineering time per week spent reconfiguring training jobs based on compute availability.
Rather than spending time managing training infrastructure, these new training techniques mean that your team can concentrate entirely on enhancing model performance, ultimately getting your AI models to market faster. By eliminating the traditional checkpoint dependencies and fully utilizing available capacity, you can significantly reduce model training completion times.
Checkpointless training: How it works
Traditional checkpoint-based recovery has these sequential job stages: 1) job termination and restart, 2) process discovery and network setup, 3) checkpoint retrieval, 4) data loader initialization, and 5) training loop resumption. When failures occur, each stage can become a bottleneck and training recovery can take up to an hour on self-managed training clusters. The entire cluster must wait for every single stage to complete before training can resume. This can lead to the entire training cluster sitting idle during recovery operations, which increases costs and extends the time to market.
Checkpointless training removes this bottleneck entirely by maintaining continuous model state preservation across the training cluster. When failures occur, the system instantly recovers by using healthy peers, avoiding the need for a checkpoint-based recovery that requires restarting the entire job. As a result, checkpointless training enables fault recovery in minutes.
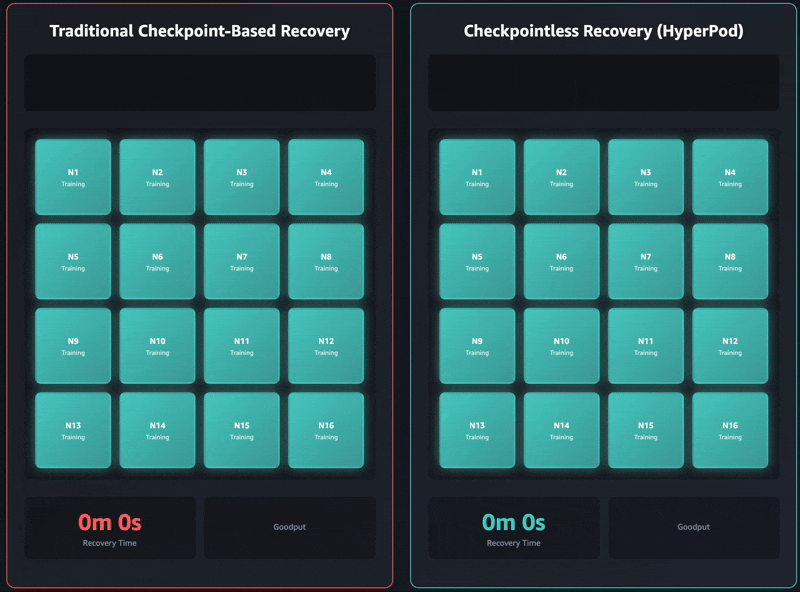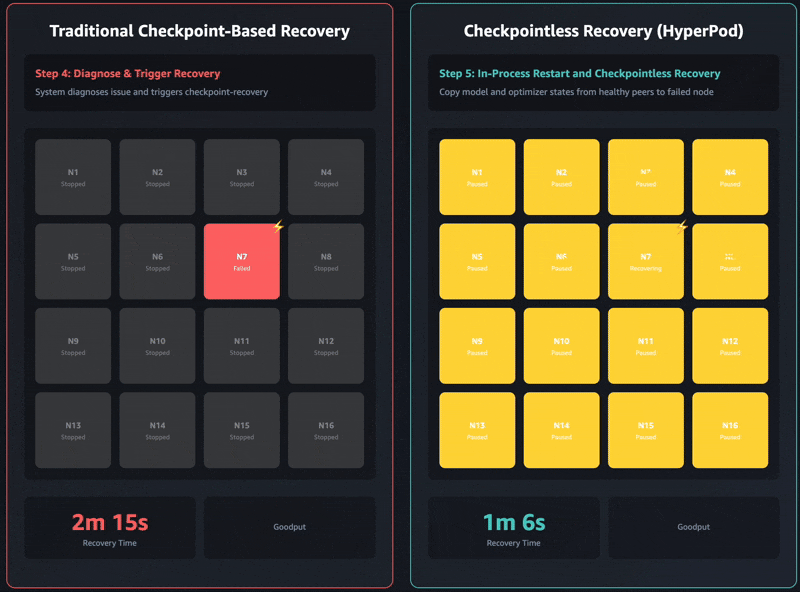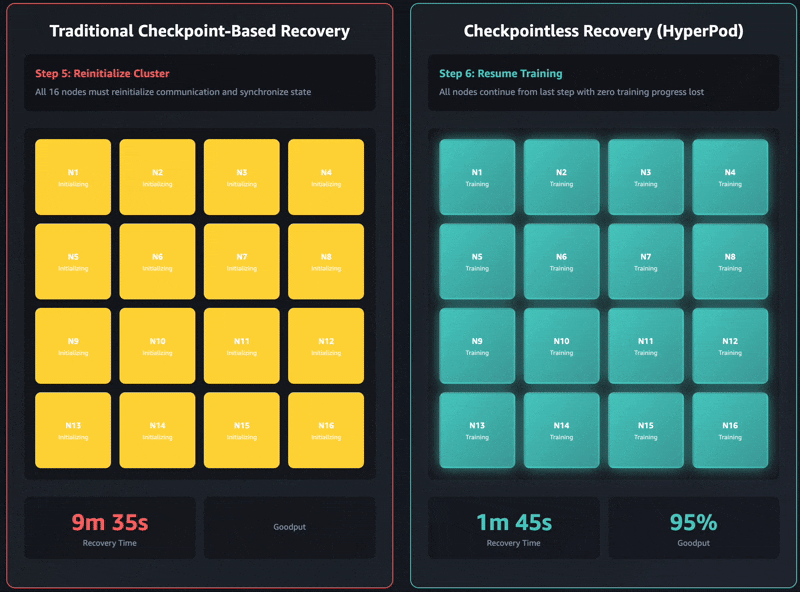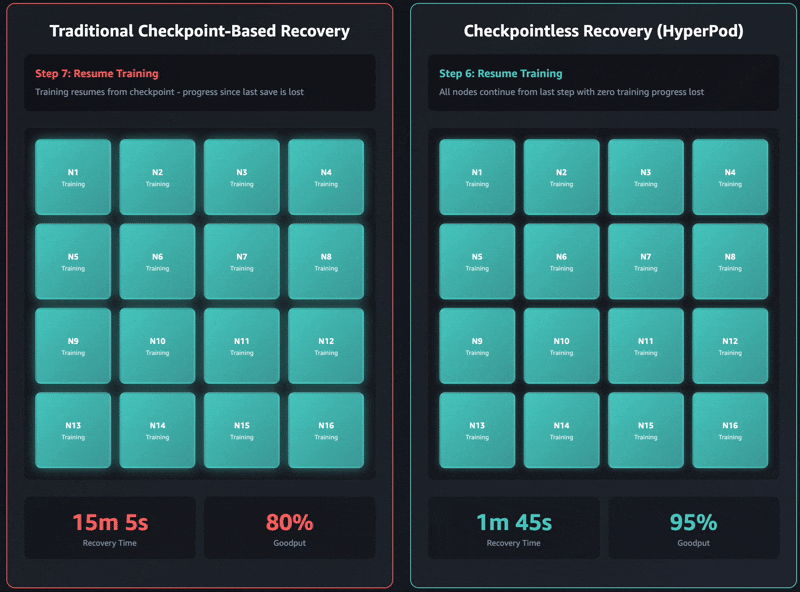
Checkpointless training is designed for incremental adoption and built on four core components that work together: 1) collective communications initialization optimizations, 2) memory-mapped data loading that enables caching, 3) in-process recovery, and 4) checkpointless peer-to-peer state replication. These components are orchestrated through the HyperPod training operator that is used to launch the job. Each component optimizes a specific step in the recovery process, and together they enable automatic detection and recovery of infrastructure faults in minutes with zero manual intervention, even with thousands of AI accelerators. You can progressively enable each of these features as your training scales.
The latest Amazon Nova models were trained using this technology on tens of thousands of accelerators. Additionally, based on internal studies on cluster sizes ranging between 16 GPUs to over 2,000 GPUs, checkpointless training showcased significant improvements in recovery times, reducing downtime by over 80% compared to traditional checkpoint-based recovery.
To learn more, visit HyperPod Checkpointless Training in the Amazon SageMaker AI Developer Guide.
Elastic training: How it works
On clusters that run different types of modern AI workloads, accelerator availability can change continuously throughout the day as short-duration training runs complete, inference spikes occur and subside, or resources free up from completed experiments. Despite this dynamic availability of AI accelerators, traditional training workloads remain locked into their initial compute allocation, unable to take advantage of idle accelerators without manual intervention. This rigidity leaves valuable GPU capacity unused and prevents organizations from maximizing their infrastructure investment.
 Elastic training transforms how training workloads interact with cluster resources. Training jobs can automatically scale up to utilize available accelerators and gracefully contract when resources are needed elsewhere, all while maintaining training quality.
Elastic training transforms how training workloads interact with cluster resources. Training jobs can automatically scale up to utilize available accelerators and gracefully contract when resources are needed elsewhere, all while maintaining training quality.
Workload elasticity is enabled through the HyperPod training operator that orchestrates scaling decisions through integration with the Kubernetes control plane and resource scheduler. It continuously monitors cluster state through three primary channels: pod lifecycle events, node availability changes, and resource scheduler priority signals. This comprehensive monitoring enables near-instantaneous detection of scaling opportunities, whether from newly available resources or requests from higher-priority workloads.
The scaling mechanism relies on adding and removing data parallel replicas. When additional compute resources become available, new data parallel replicas join the training job, accelerating throughput. Conversely, during scale-down events (for example, when a higher-priority workload requests resources), the system scales down by removing replicas rather than terminating the entire job, allowing training to continue at reduced capacity.
Across different scales, the system preserves the global batch size and adapts learning rates, preventing model convergence from being adversely impacted. This enables workloads to dynamically scale up or down to utilize available AI accelerators without any manual intervention.
You can start elastic training through the HyperPod recipes for publicly available foundation models (FMs) including Llama and GPT-OSS. Additionally, you can modify your PyTorch training scripts to add elastic event handlers, which enable the job to dynamically scale.
To learn more, visit the HyperPod Elastic Training in the Amazon SageMaker AI Developer Guide. To get started, find the HyperPod recipes available in the AWS GitHub repository.
Now available
Both features are available in all the Regions in which Amazon SageMaker HyperPod is available. You can use these training techniques without additional cost. To learn more, visit the SageMaker HyperPod product page and SageMaker AI pricing page.
Give it a try and send feedback to AWS re:Post for SageMaker or through your usual AWS Support contacts.
— Channy