Post Syndicated from Channy Yun (윤석찬) original https://aws.amazon.com/blogs/aws/deepseek-r1-models-now-available-on-aws/
During this past AWS re:Invent, Amazon CEO Andy Jassy shared valuable lessons learned from Amazon’s own experience developing nearly 1,000 generative AI applications across the company. Drawing from this extensive scale of AI deployment, Jassy offered three key observations that have shaped Amazon’s approach to enterprise AI implementation.
First is that as you get to scale in generative AI applications, the cost of compute really matters. People are very hungry for better price performance. The second is actually quite difficult to build a really good generative AI application. The third is the diversity of the models being used when we gave our builders freedom to pick what they want to do. It doesn’t surprise us, because we keep learning the same lesson over and over and over again, which is that there is never going to be one tool to rule the world.

As Andy emphasized, a broad and deep range of models provided by Amazon empowers customers to choose the precise capabilities that best serve their unique needs. By closely monitoring both customer needs and technological advancements, AWS regularly expands our curated selection of models to include promising new models alongside established industry favorites. This ongoing expansion of high-performing and differentiated model offerings helps customers stay at the forefront of AI innovation.
This leads us to Chinese AI startup DeepSeek. DeepSeek launched DeepSeek-V3 on December 2024 and subsequently released DeepSeek-R1, DeepSeek-R1-Zero with 671 billion parameters, and DeepSeek-R1-Distill models ranging from 1.5–70 billion parameters on January 20, 2025. They added their vision-based Janus-Pro-7B model on January 27, 2025. The models are publicly available and are reportedly 90-95% more affordable and cost-effective than comparable models. Per Deepseek, their model stands out for its reasoning capabilities, achieved through innovative training techniques such as reinforcement learning.
Today, you can now deploy DeepSeek-R1 models in Amazon Bedrock and Amazon SageMaker AI. Amazon Bedrock is best for teams seeking to quickly integrate pre-trained foundation models through APIs. Amazon SageMaker AI is ideal for organizations that want advanced customization, training, and deployment, with access to the underlying infrastructure. Additionally, you can also use AWS Trainium and AWS Inferentia to deploy DeepSeek-R1-Distill models cost-effectively via Amazon Elastic Compute Cloud (Amazon EC2) or Amazon SageMaker AI.
With AWS, you can use DeepSeek-R1 models to build, experiment, and responsibly scale your generative AI ideas by using this powerful, cost-efficient model with minimal infrastructure investment. You can also confidently drive generative AI innovation by building on AWS services that are uniquely designed for security. We highly recommend integrating your deployments of the DeepSeek-R1 models with Amazon Bedrock Guardrails to add a layer of protection for your generative AI applications, which can be used by both Amazon Bedrock and Amazon SageMaker AI customers.
You can choose how to deploy DeepSeek-R1 models on AWS today in a few ways: 1/ Amazon Bedrock Marketplace for the DeepSeek-R1 model, 2/ Amazon SageMaker JumpStart for the DeepSeek-R1 model, 3/ Amazon Bedrock Custom Model Import for the DeepSeek-R1-Distill models, and 4/ Amazon EC2 Trn1 instances for the DeepSeek-R1-Distill models.
Let me walk you through the various paths for getting started with DeepSeek-R1 models on AWS. Whether you’re building your first AI application or scaling existing solutions, these methods provide flexible starting points based on your team’s expertise and requirements.
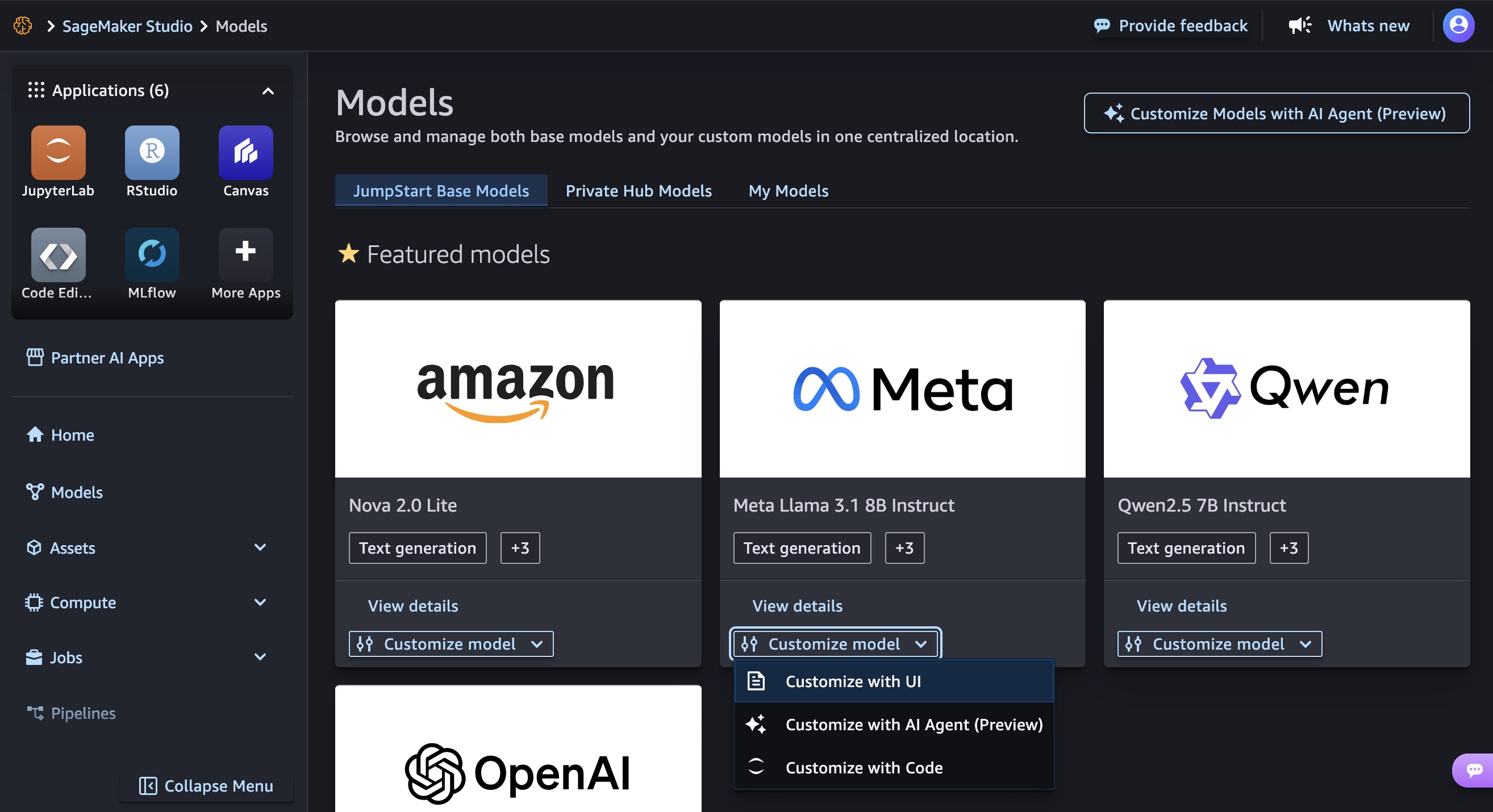
1. The DeepSeek-R1 model in Amazon Bedrock Marketplace
Amazon Bedrock Marketplace offers over 100 popular, emerging, and specialized FMs alongside the current selection of industry-leading models in Amazon Bedrock. You can easily discover models in a single catalog, subscribe to the model, and then deploy the model on managed endpoints.
To access the DeepSeek-R1 model in Amazon Bedrock Marketplace, go to the Amazon Bedrock console and select Model catalog under the Foundation models section. You can quickly find DeepSeek by searching or filtering by model providers.

After checking out the model detail page including the model’s capabilities, and implementation guidelines, you can directly deploy the model by providing an endpoint name, choosing the number of instances, and selecting an instance type.

You can also configure advanced options that let you customize the security and infrastructure settings for the DeepSeek-R1 model including VPC networking, service role permissions, and encryption settings. For production deployments, you should review these settings to align with your organization’s security and compliance requirements.
With Amazon Bedrock Guardrails, you can independently evaluate user inputs and model outputs. You can control the interaction between users and DeepSeek-R1 with your defined set of policies by filtering undesirable and harmful content in generative AI applications. The DeepSeek-R1 model in Amazon Bedrock Marketplace can only be used with Bedrock’s ApplyGuardrail API to evaluate user inputs and model responses for custom and third-party FMs available outside of Amazon Bedrock. To learn more, read Implement model-independent safety measures with Amazon Bedrock Guardrails.
Amazon Bedrock Guardrails can also be integrated with other Bedrock tools including Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases to build safer and more secure generative AI applications aligned with responsible AI policies. To learn more, visit the AWS Responsible AI page.
Refer to this step-by-step guide on how to deploy the DeepSeek-R1 model in Amazon Bedrock Marketplace. To learn more, visit Deploy models in Amazon Bedrock Marketplace.
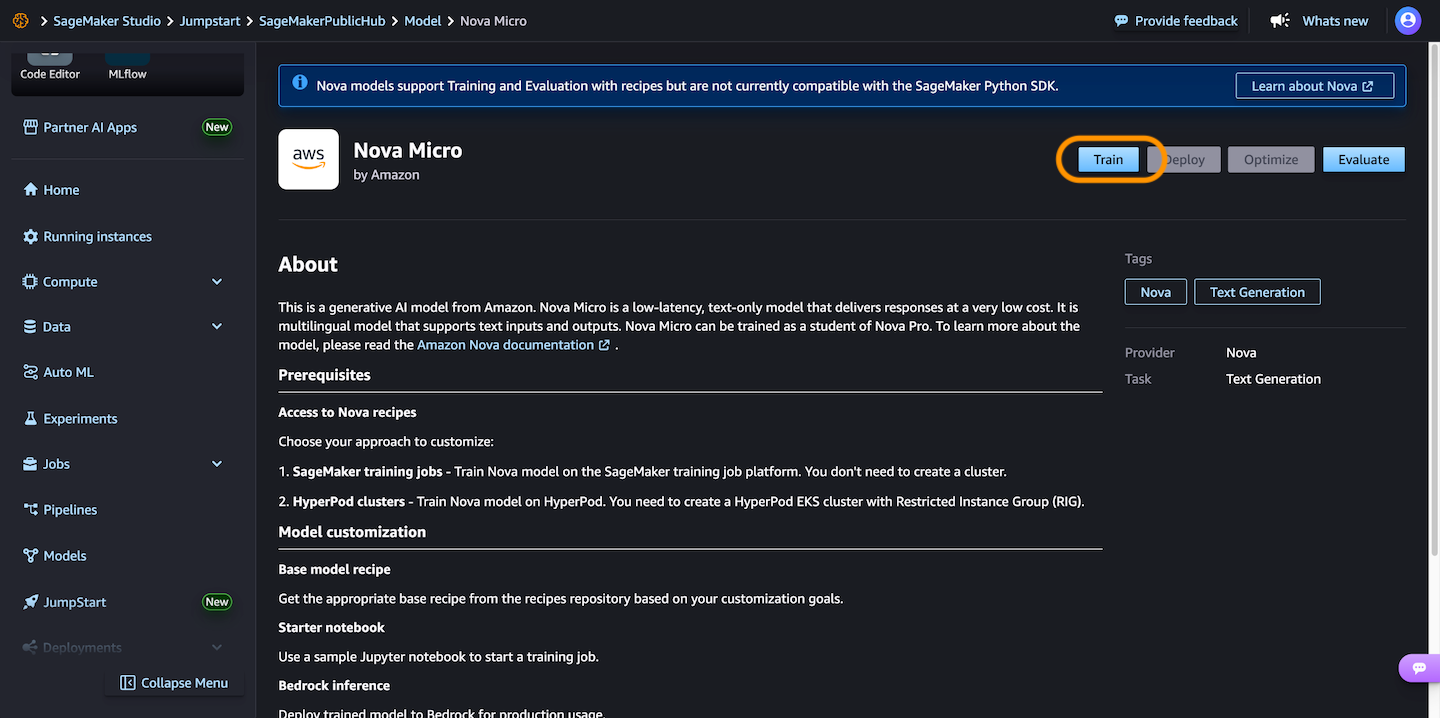
2. The DeepSeek-R1 model in Amazon SageMaker JumpStart
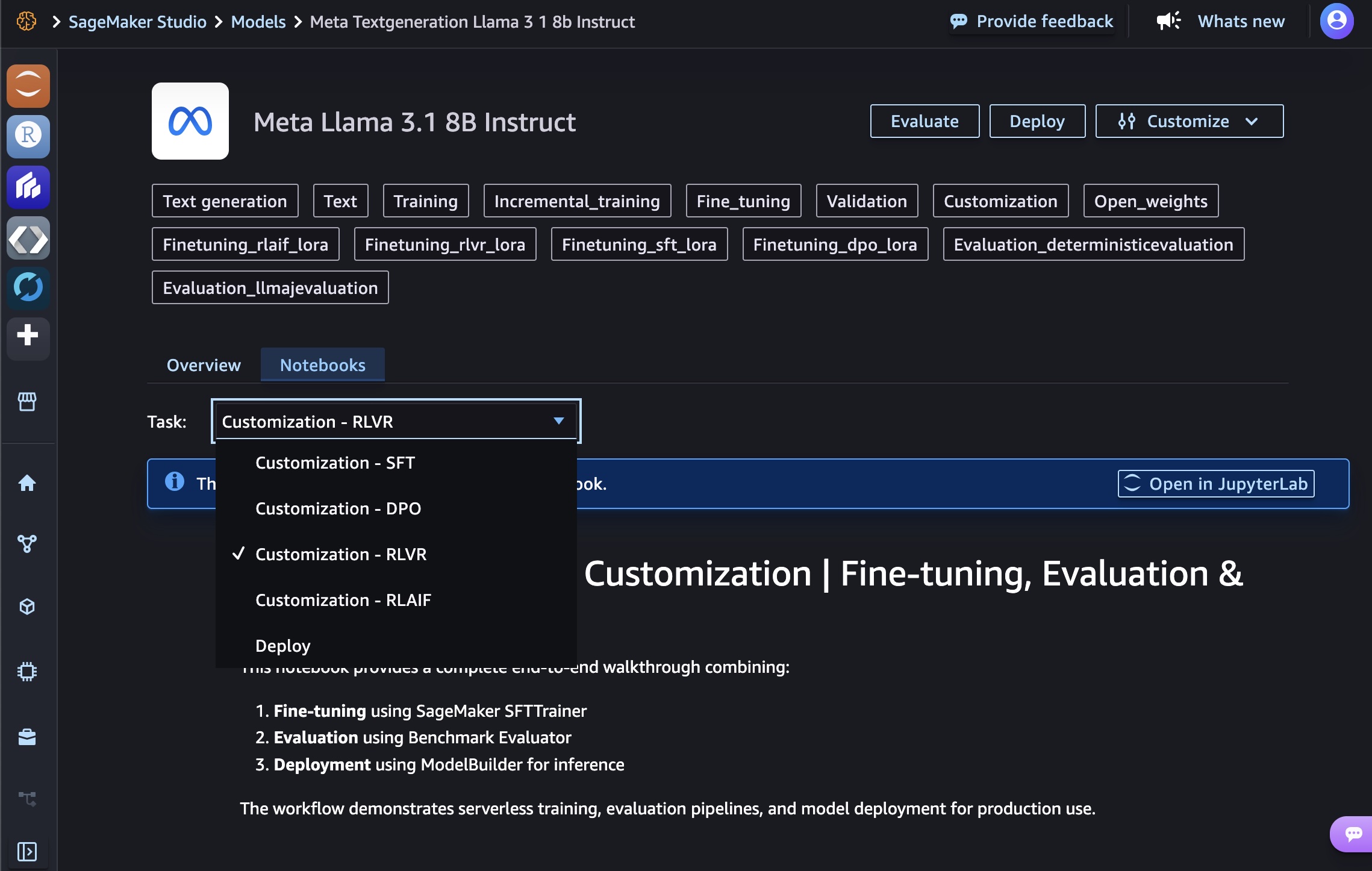
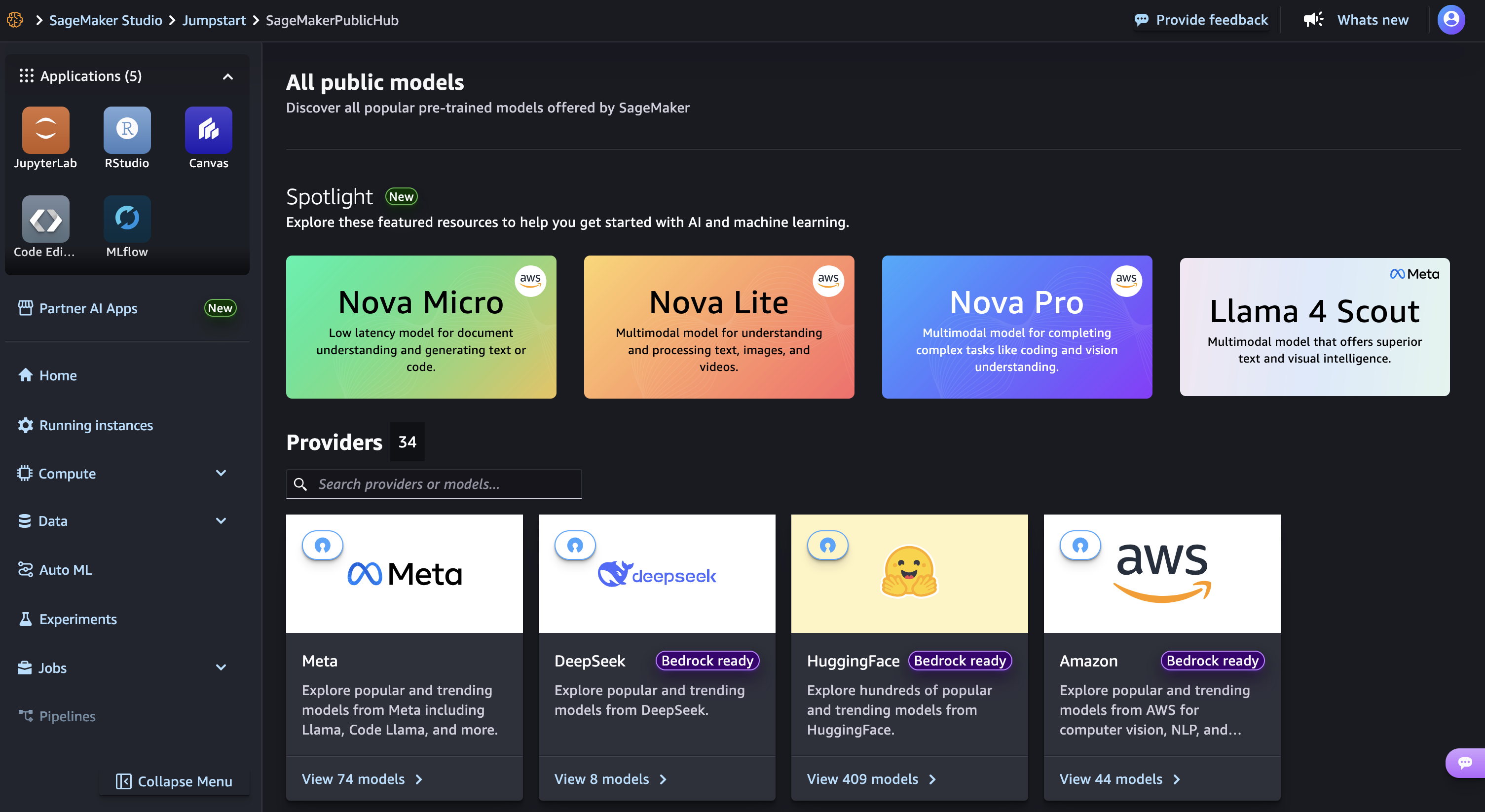
Amazon SageMaker JumpStart is a machine learning (ML) hub with FMs, built-in algorithms, and prebuilt ML solutions that you can deploy with just a few clicks. To deploy DeepSeek-R1 in SageMaker JumpStart, you can discover the DeepSeek-R1 model in SageMaker Unified Studio, SageMaker Studio, SageMaker AI console, or programmatically through the SageMaker Python SDK.
In the Amazon SageMaker AI console, open SageMaker Unified Studio or SageMaker Studio. In case of SageMaker Studio, choose JumpStart and search for “DeepSeek-R1” in the All public models page.

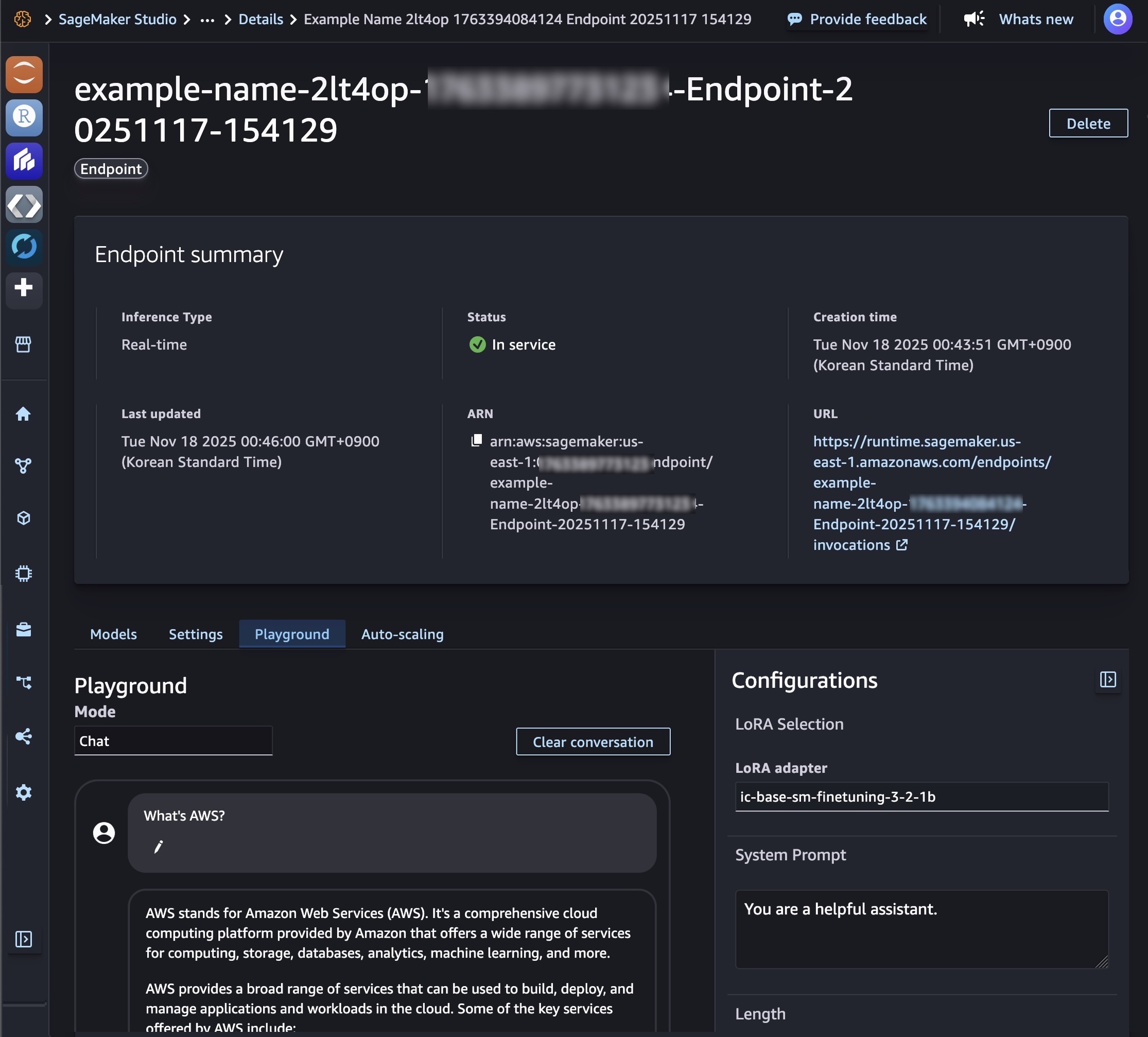
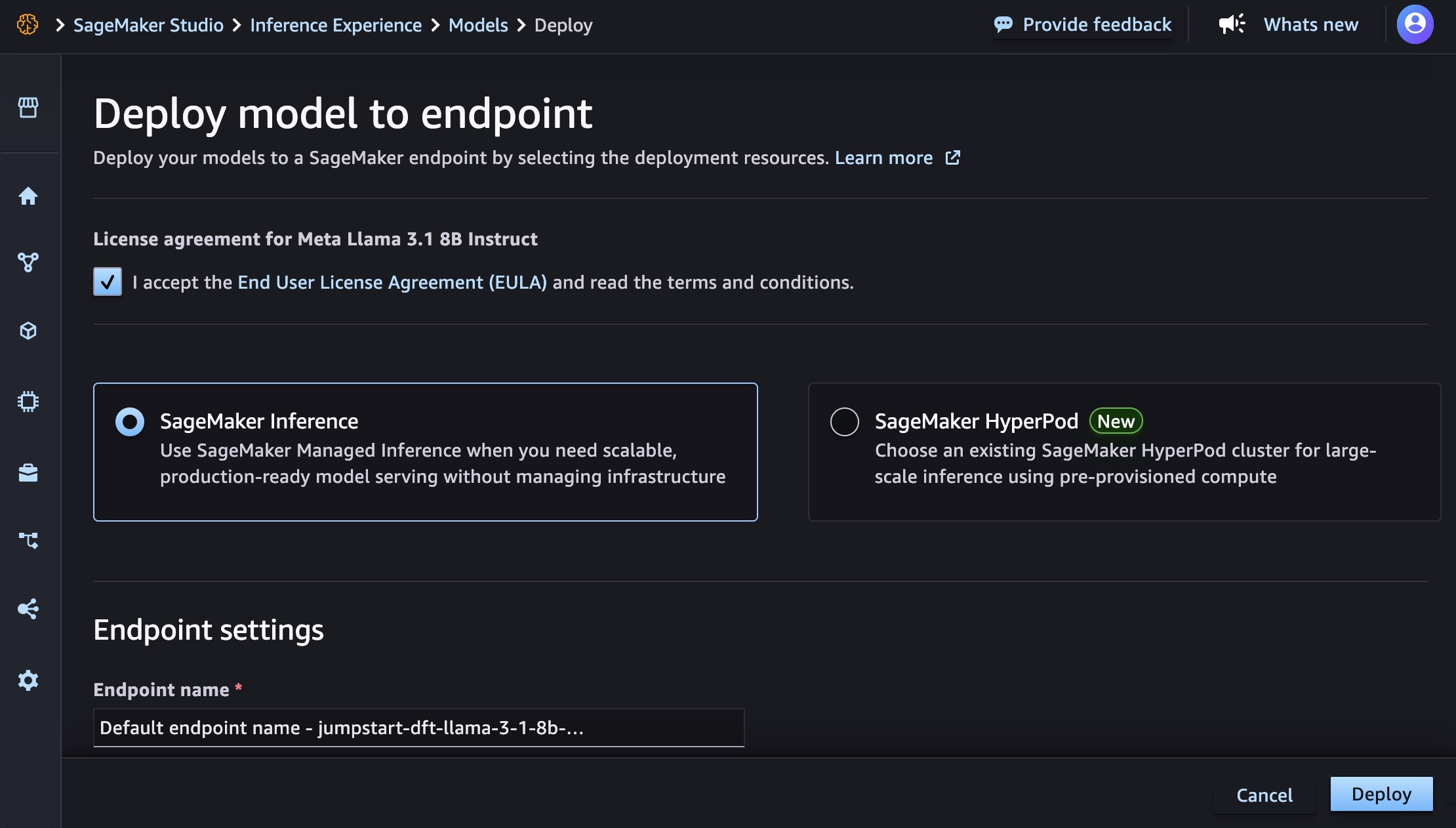
You can select the model and choose deploy to create an endpoint with default settings. When the endpoint comes InService, you can make inferences by sending requests to its endpoint.

You can derive model performance and ML operations controls with Amazon SageMaker AI features such as Amazon SageMaker Pipelines, Amazon SageMaker Debugger, or container logs. The model is deployed in an AWS secure environment and under your virtual private cloud (VPC) controls, helping to support data security.
As like Bedrock Marketpalce, you can use the ApplyGuardrail API in the SageMaker JumpStart to decouple safeguards for your generative AI applications from the DeepSeek-R1 model. You can now use guardrails without invoking FMs, which opens the door to more integration of standardized and thoroughly tested enterprise safeguards to your application flow regardless of the models used.
Refer to this step-by-step guide on how to deploy DeepSeek-R1 in Amazon SageMaker JumpStart. To learn more, visit Discover SageMaker JumpStart models in SageMaker Unified Studio or Deploy SageMaker JumpStart models in SageMaker Studio.
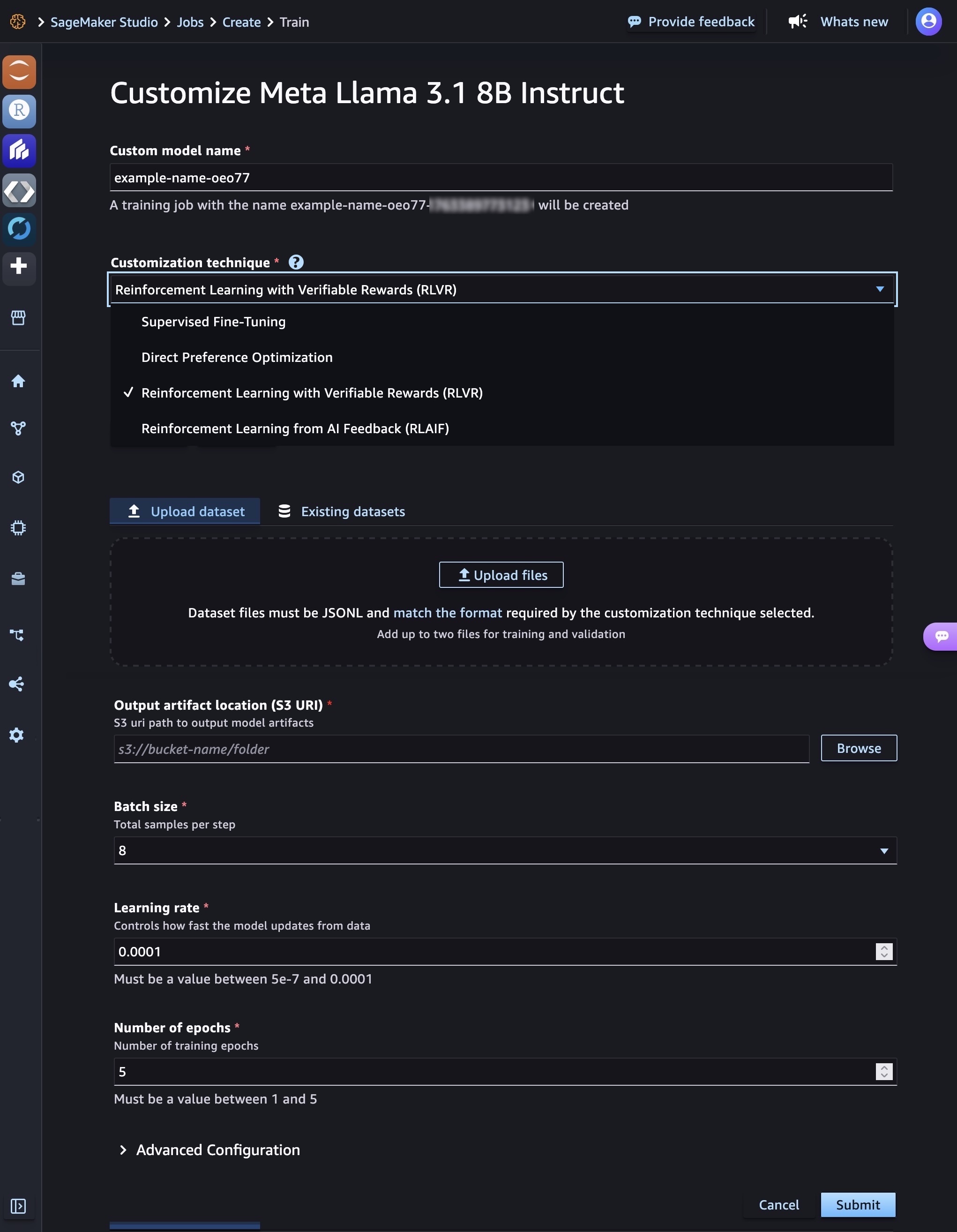
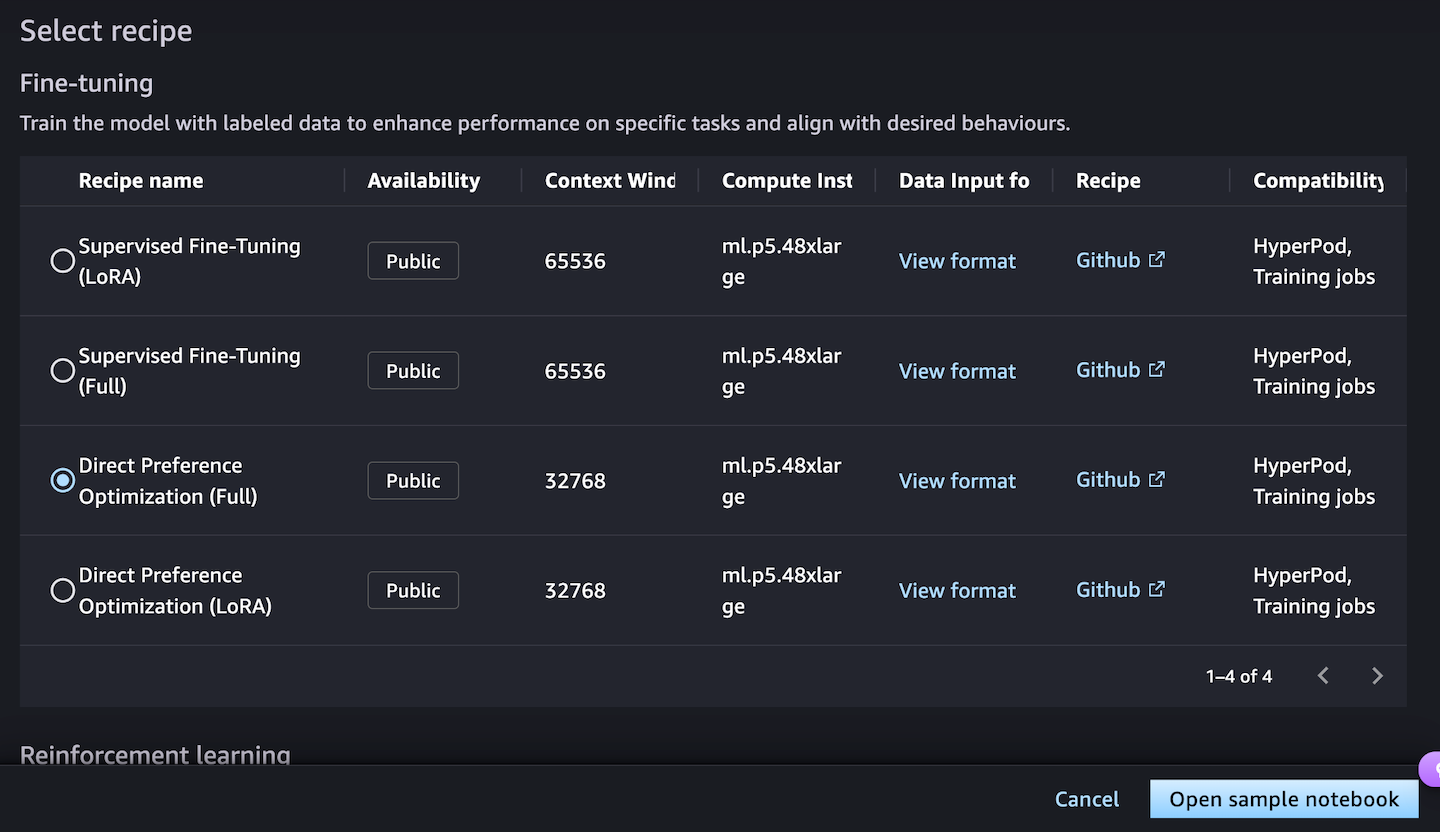
3. DeepSeek-R1-Distill models using Amazon Bedrock Custom Model Import
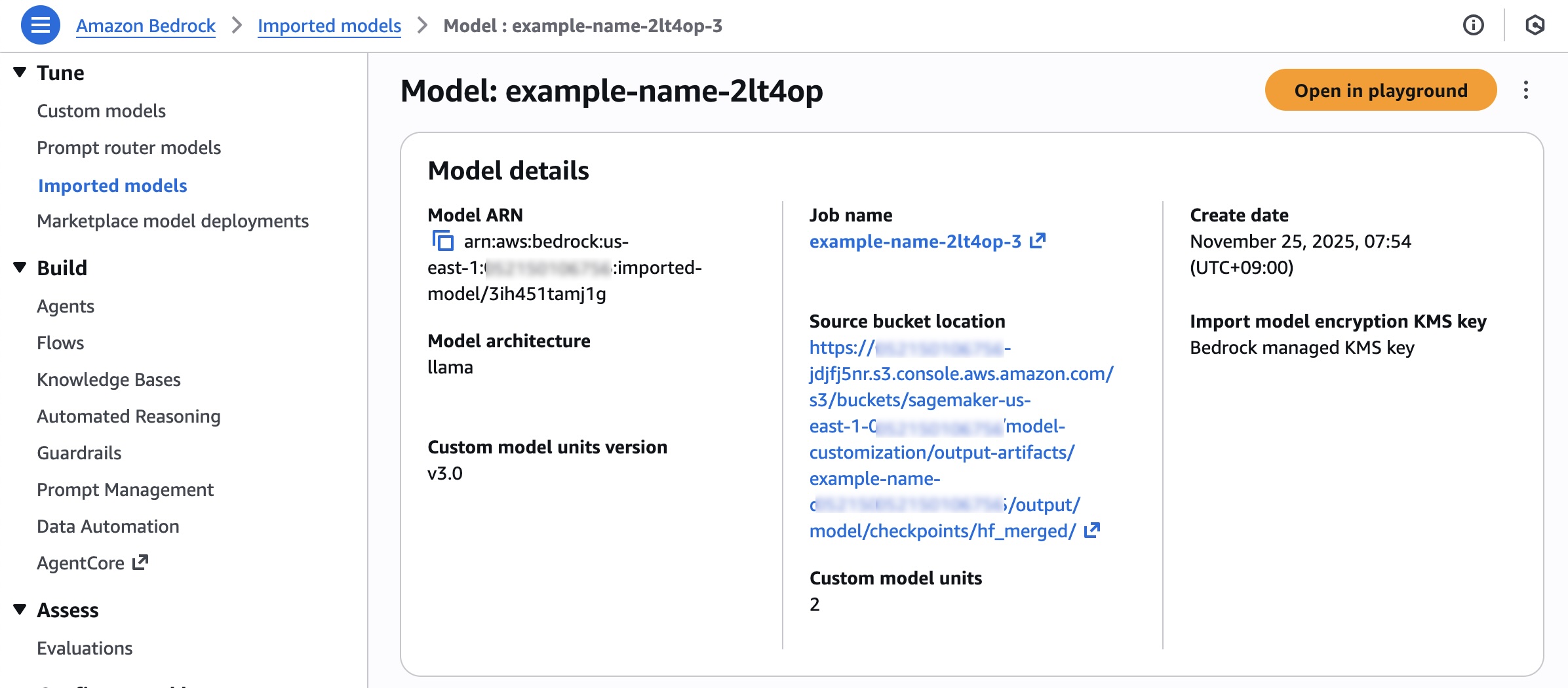
Amazon Bedrock Custom Model Import provides the ability to import and use your customized models alongside existing FMs through a single serverless, unified API without the need to manage underlying infrastructure. With Amazon Bedrock Custom Model Import, you can import DeepSeek-R1-Distill Llama models ranging from 1.5–70 billion parameters. As I highlighted in my blog post about Amazon Bedrock Model Distillation, the distillation process involves training smaller, more efficient models to mimic the behavior and reasoning patterns of the larger DeepSeek-R1 model with 671 billion parameters by using it as a teacher model.
After storing these publicly available models in an Amazon Simple Storage Service (Amazon S3) bucket or an Amazon SageMaker Model Registry, go to Imported models under Foundation models in the Amazon Bedrock console and import and deploy them in a fully managed and serverless environment through Amazon Bedrock. This serverless approach eliminates the need for infrastructure management while providing enterprise-grade security and scalability.

Refer to this step-by-step guide on how to deploy DeepSeek-R1 models using Amazon Bedrock Custom Model Import. To learn more, visit Import a customized model into Amazon Bedrock.
4. DeepSeek-R1-Distill models using AWS Trainium and AWS Inferentia
AWS Deep Learning AMIs (DLAMI) provides customized machine images that you can use for deep learning in a variety of Amazon EC2 instances, from a small CPU-only instance to the latest high-powered multi-GPU instances. You can deploy the DeepSeek-R1-Distill models on AWS Trainuim1 or AWS Inferentia2 instances to get the best price-performance.
To get started, go to Amazon EC2 console and launch a trn1.32xlarge EC2 instance with the Neuron Multi Framework DLAMI called Deep Learning AMI Neuron (Ubuntu 22.04).

Once you have connected to your launched ec2 instance, install vLLM, an open-source tool to serve Large Language Models (LLMs) and download the DeepSeek-R1-Distill model from Hugging Face. You can deploy the model using vLLM and invoke the model server.
To learn more, refer to this step-by-step guide on how to deploy DeepSeek-R1-Distill Llama models on AWS Inferentia and Trainium.
You can also visit the DeepSeek-R1-Distill-Llama-8B or deepseek-ai/DeepSeek-R1-Distill-Llama-70B model cards on Hugging Face. Choose Deploy and then Amazon SageMaker. From the AWS Inferentia and Trainium tab, copy the example code for deploy DeepSeek-R1-Distill Llama models.

Since the release of DeepSeek-R1, various guides of its deployment for Amazon EC2 and Amazon Elastic Kubernetes Service (Amazon EKS) have been posted. Here is some additional material for you to check out:
Things to know
Here are a few important things to know.
- Pricing – For publicly available models like DeepSeek-R1, you are charged only the infrastructure price based on inference instance hours you select for Amazon Bedrock Markeplace, Amazon SageMaker JumpStart, and Amazon EC2. For the Bedrock Custom Model Import, you are only charged for model inference, based on the number of copies of your custom model is active, billed in 5-minute windows. To learn more, check out the Amazon Bedrock Pricing, Amazon SageMaker AI Pricing, and Amazon EC2 Pricing pages.
- Data security – You can use enterprise-grade security features in Amazon Bedrock and Amazon SageMaker to help you make your data and applications secure and private. This means your data is not shared with model providers, and is not used to improve the models. This applies to all models—proprietary and publicly available—like DeepSeek-R1 models on Amazon Bedrock and Amazon SageMaker. To learn more, visit Amazon Bedrock Security and Privacy and Security in Amazon SageMaker AI.
Now available
DeepSeek-R1 is generally available today in Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. You can also use DeepSeek-R1-Distill models using Amazon Bedrock Custom Model Import and Amazon EC2 instances with AWS Trainum and Inferentia chips.
Give DeepSeek-R1 models a try today in the Amazon Bedrock console, Amazon SageMaker AI console, and Amazon EC2 console, and send feedback to AWS re:Post for Amazon Bedrock and AWS re:Post for SageMaker AI or through your usual AWS Support contacts.
— Channy