Post Syndicated from Charles H. original https://aws.amazon.com/blogs/architecture/streaming-the-aws-wickr-desktop-client-with-amazon-appstream-2-0/
Amazon Web Services (AWS) customers using AWS Wickr who want to find a way to access their AWS Wickr Windows desktop client though a web browser, can use Amazon AppStream 2.0 to stream the application through to their users.
Using this architecture, you can provide lightweight access to the AWS Wickr desktop client for users that cannot install it onto their local device. By using AppStream 2.0, you can focus on managing your AWS Wickr network while AppStream 2.0 manages the AWS resources required to host and run the application, scaling automatically and providing on-demand access to your users.
If you want to ensure that AWS Wickr user data persists between streaming sessions, you can make use of AppStream 2.0 user persistence to securely save user data (including AWS Wickr client data) to Amazon Simple Storage Service (Amazon S3).
In this post, we discuss how to build an AppStream 2.0 image for AWS Wickr on Windows, enable persistence for users, and deploy a stack.
Solution overview
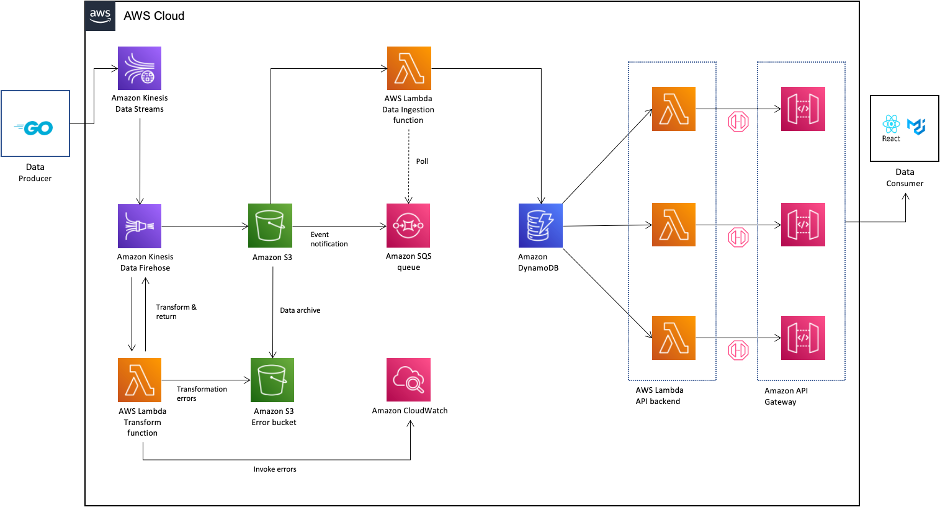
These steps will illustrate deploying an AppStream 2.0 Windows Image Builder to a single availability zone. Then we deploy an AppStream 2.0 fleet with internet access and user data persistence to three availability zones for high availability.
Review the Regions and Availability Zones documentation and the AWS Regional Services List to choose the best Region for your deployment, as well as the networking and bandwidth requirements for User Connections to Amazon AppStream 2.0.

Figure 1. AWS Wickr with Amazon AppStream 2.0 Architecture
Cost
The costs associated with using AWS services when deploying AppStream 2.0 and AWS Wickr in your AWS account can be estimated on the pricing pages for the services used.
Walkthrough
This walkthrough takes you from installing the AWS Wickr for Windows desktop client onto an AppStream 2.0 Image Builder, to configuring the client for persistence, and finally to deploying a fleet and stack for your users to consume:
- Install AWS Wickr for Windows client onto your AppStream 2.0 Windows Image Builder.
- Configure the client using the Image Assistant to set up user data and settings persistence.
- Create an on-demand instance streaming fleet.
- Create a user stack and enable user data and settings persistence.
- Create a user pool.
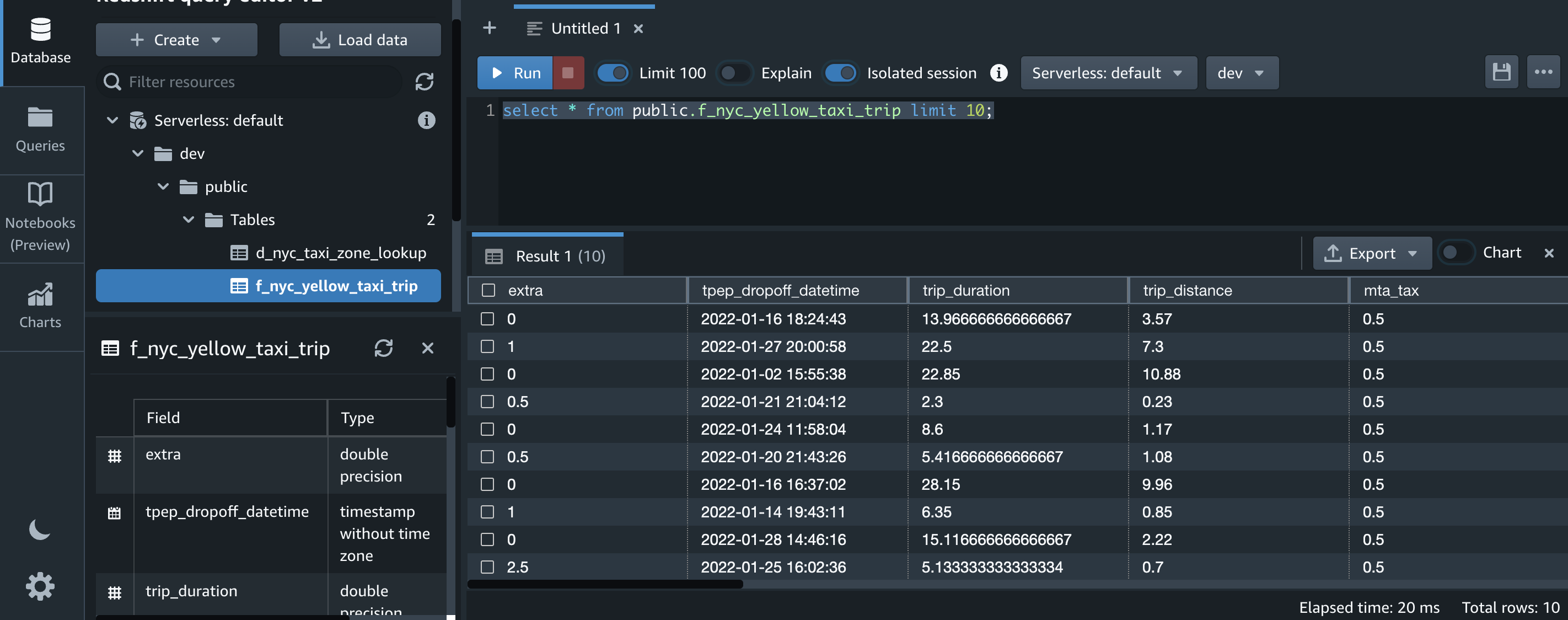
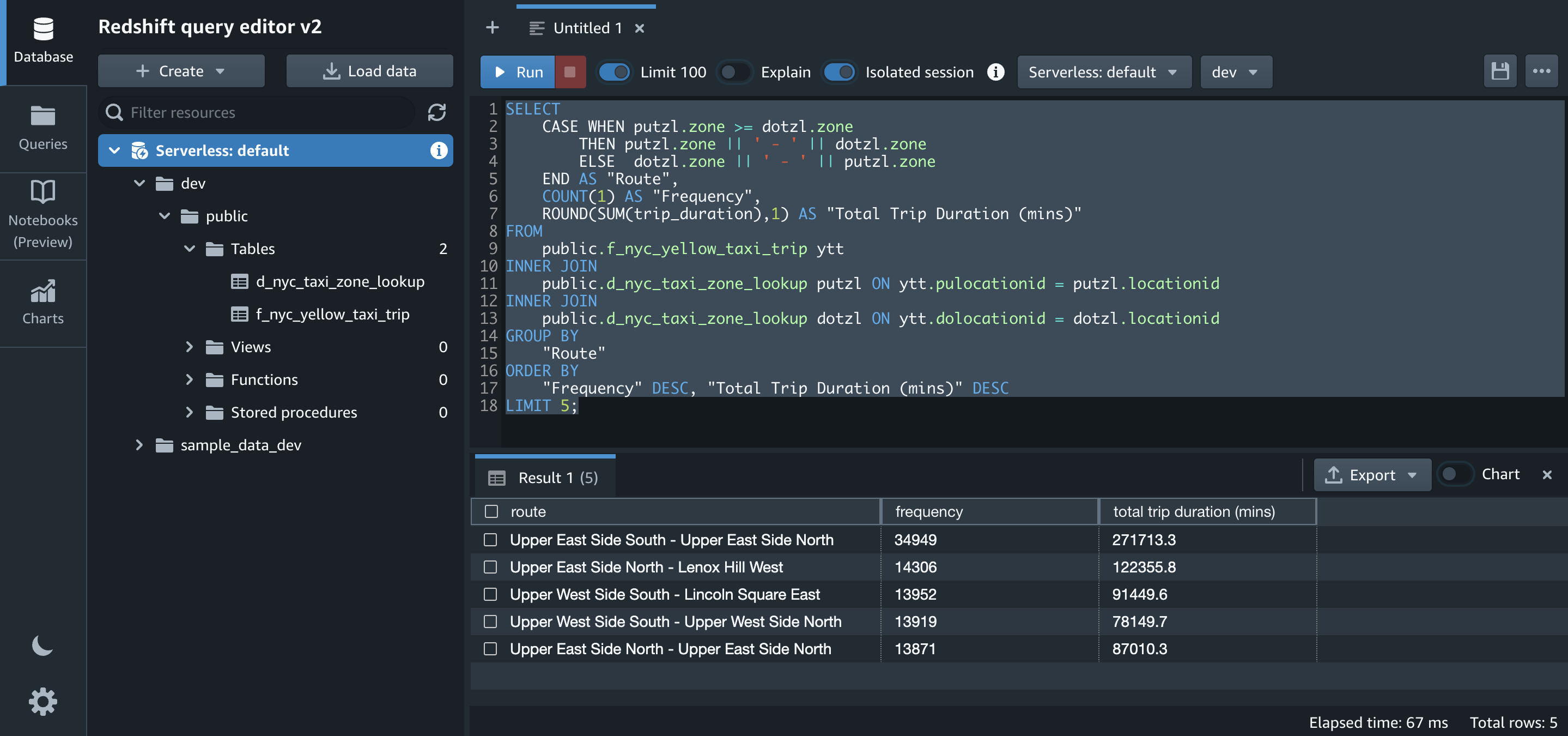
- Test your streaming application and prove data persistence.
Prerequisites
You should have the following prerequisites:
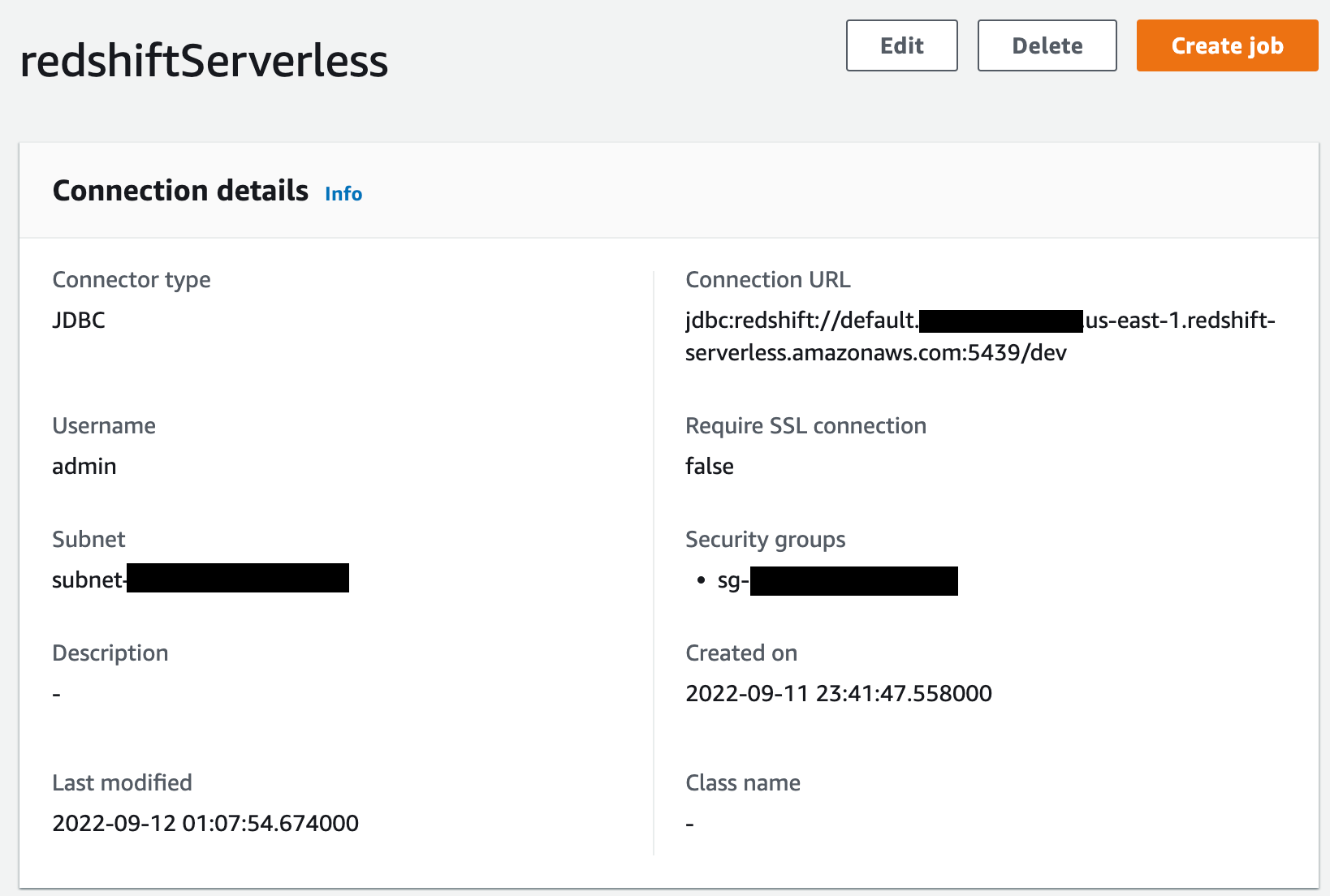
- Familiarity with AppStream 2.0 and an existing AWS Wickr account with associated credentials. Currently, it is not possible for an AWS Wickr user to register their account over AppStream 2.0.
- An AWS account with access to AppStream 2.0. Instructions for setting up an AWS account can be found at Setting Up for Amazon AppStream 2.0.
- A running AppStream 2.0 image builder, based on the WinServer2019-10-05-2022 base image with the AWS Wickr for Windows client installer downloaded to it.
- An up-to-date Google Chrome browser (if you want to use your device’s webcam).
Install AWS Wickr
AppStream 2.0 uses Amazon Elastic Compute Cloud (Amazon EC2) instances to stream applications. You launch instances from base images, called image builders. In this step you will install the AWS Wickr client onto your image builder before moving on to configuration.
- Connect to your image builder as an Administrator.
- Run the AWS Wickr installer and carry out the following steps:
- On the Welcome to the AWS Wickr Setup Wizard prompt, choose Next.
- For Installation Type, choose Everybody (all users).
- Choose Next to accept the default installation folder.
- Choose Install.
- Once the AWS Wickr client has finished installing, uncheck Launch Wickr on the final screen, and then choose Finish.
Run the Image Assistant
To create your own custom image, connect to an image builder instance, install and configure your applications for streaming with guidance from the Image Assistant, and then create your image by creating a snapshot of the image builder instance:
- Run the Image Assistant shortcut found on the desktop.
- Under 1. ADD APPS, choose Add App.
- Choose Program Files, Amazon Web Services, Wickr, and AWS Wickr.
- Scroll to the bottom, choose the Wickr application, and then choose Open.
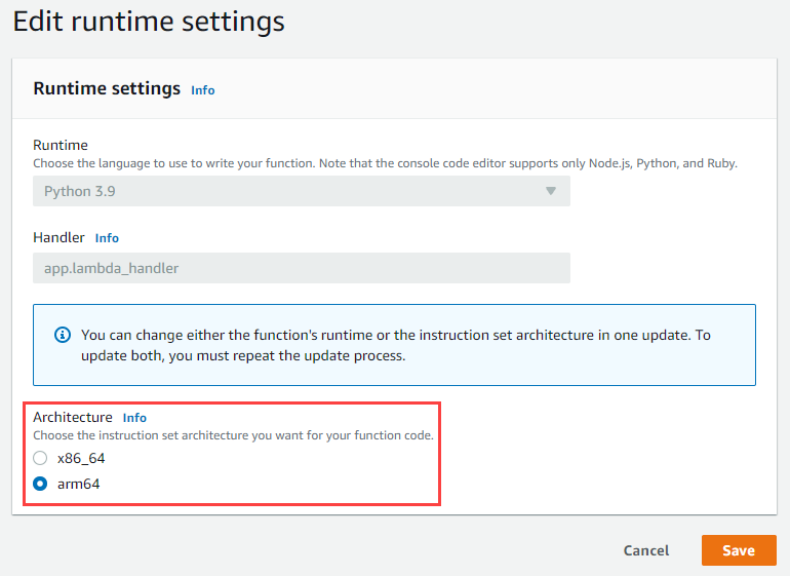
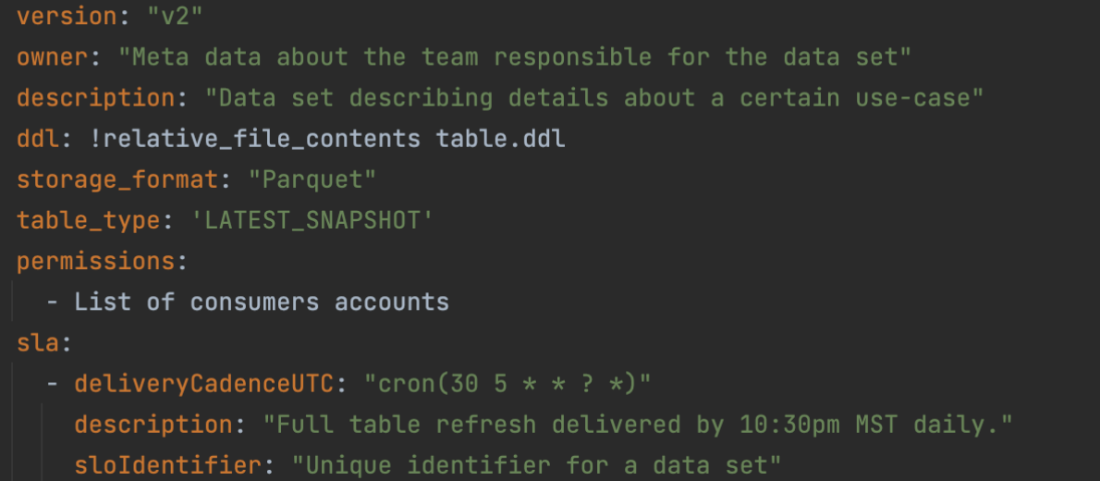
- In the pop-up that appears, customize the Name and Display Name (if needed), and then in the Launch Parameters box, enter
-datalocation “C:\Users\%username%”(Figure 2).
Figure 2. Updating Launch Parameters
Note: If you want to mask the name of the application within the URL used for streaming, replace the Display Name field text with something else.
- Choose Save.
- Wickr will now appear as an app on the Image Assistant screen. Choose Next.
- Under the 2. CONFIGURE APPS stage, follow the instructions from 1-5, choose Save settings, and choose Next (Figure 3).

Figure 3. Configuring the Application with Image Assistant
- Under the 3. TEST stage, carry out steps 1-3.
- Under the 4. OPTIMIZE stage, select Launch.
- As instructed, once the app has launched successfully, select Continue and wait for the app to be optimized.
- Under the 5. CONFIGURE IMAGE stage, give the image that will be created a Name, Display name, and Description.
- Choose the Always use latest agent version checkbox. This ensures that new image builders or fleet instances that are launched from your image always use the latest AppStream 2.0 agent version, and then select Next (Figure 4).
Figure 4. Finalizing the Application Image
- Under the 6. REVIEW stage, select Disconnect and Create Image. Your session will be terminated while your image is being created.



Create an AppStream 2.0 fleet
With AppStream 2.0, you create fleet instances and stacks as part of the process of streaming applications. A fleet consists of streaming instances that run the image that you specify.
- Return to the AppStream 2.0 management console.
- Choose Fleets from the menu on the left.
- Choose your Fleet type (this demonstration uses On-Demand) and choose Next.
- Give the Fleet a Name, Display name, and a Description.
Note: If you wish to mask the name of the fleet within the URL used for streaming, replace the Name and Display name section with something else. - Choose your Fleet instance type (this walkthrough uses a general purpose stream.standard.large instance type).
- Adjust the Fleet capacity as required, leave the other sections as they’re displayed by default, and choose Next.
- On the Choose an Image screen, choose the image you created earlier.
- On the Configure network screen, choose Enable default internet access and choose your VPC, along with three subnets that you will deploy into. Finally, choose the Security group that you will use to restrict access (the default is to allow access from all IPs). Choose Next.
- Review your settings and then choose Create fleet.
Create an AppStream 2.0 stack
A stack consists of an associated fleet, user access policies, and storage configurations. In this step, you will create a stack, enable application settings persistence, and associate the stack with the fleet you provisioned previously.
- From the menu in the AppStream 2.0 management console, choose Stacks.
- Choose Create Stack.
- Give the stack a Name, and optionally a Display name and Description.
- Leave all other options as they’re displayed by default and choose Next.
- In the Enable storage window, ensure that Enable home folders is selected, leave all the settings as they are, and choose Next.
- In the Edit user settings section, modify the copy and paste functionality to your requirements, and ensure that Enable application settings persistence is selected. Choose Next.
- Review your configuration and choose Create stack.
- You will now be presented with an overview of the stack you have created. Choose the Action dropdown list and choose Associate fleet.
- From the dropdown list, choose the fleet that you previously provisioned and choose Associate.
Create an AppStream 2.0 user pool
Users can access application stacks through a persistent URL and login credentials by using their email address and a password that they choose. In this step, you will create a user and assign it to a stack so you can access your AppStream 2.0 streaming session.
- Choose User pool.
- Choose Create user.
- Enter an email address, first name, and last name, and then choose Create User.
- In the User pool window, choose the User and then choose Action.
- Choose Assign stack, choose the newly created stack, and choose Send email notification to user.
- Choose Assign stack.
- You will receive two emails. Follow the instructions on the one titled Start accessing your apps using AppStream 2.0 to access your app.
Launch your AppStream 2.0 streaming session
In this step, you will use the user created earlier to log in to an AppStream 2.0 streaming session. You will then prove AWS Wickr user data persistence by exiting and logging back into your session.
Note: You will only be able to launch your session once your fleet has been provisioned. This can take around 15-20 minutes.
- Choose the login page link from the email you received in the previous section and log in.
- You will be presented with the AWS Wickr client icon. Choose it to start your session.
- Log in to the AWS Wickr client with your credentials.
- As you have application persistence enabled, you can close the tab and the session will pick up from where you left it when you log back in (Figure 5).

Figure 5. Accessing the Streaming Application
Cleanup
To avoid incurring future charges, delete the stack, user, fleet, custom image, and image builder that you have created.
Conclusion
In this post, we demonstrated how customers can take advantage of AppStream 2.0 as a managed service to enable the provisioning of AWS Wickr clients for users, with persistence between sessions, through a web browser.






































 Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 15+ years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking.
Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 15+ years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking. Omama Khurshid is an Acceleration Lab Solutions Architect at Amazon Web Services. She focuses on helping customers across various industries build reliable, scalable, and efficient solutions. Outside of work, she enjoys spending time with her family, watching movies, listening to music, and learning new technologies.
Omama Khurshid is an Acceleration Lab Solutions Architect at Amazon Web Services. She focuses on helping customers across various industries build reliable, scalable, and efficient solutions. Outside of work, she enjoys spending time with her family, watching movies, listening to music, and learning new technologies. Raza Hafeez is a Senior Product Manager at Amazon Redshift. He has over 13 years of professional experience building and optimizing enterprise data warehouses and is passionate about enabling customers to realize the power of their data. He specializes in migrating enterprise data warehouses to AWS Modern Data Architecture.
Raza Hafeez is a Senior Product Manager at Amazon Redshift. He has over 13 years of professional experience building and optimizing enterprise data warehouses and is passionate about enabling customers to realize the power of their data. He specializes in migrating enterprise data warehouses to AWS Modern Data Architecture. Jason Pedreza is an Analytics Specialist Solutions Architect at AWS with data warehousing experience handling petabytes of data. Prior to AWS, he built data warehouse solutions at Amazon.com. He specializes in Amazon Redshift and helps customers build scalable analytic solutions.
Jason Pedreza is an Analytics Specialist Solutions Architect at AWS with data warehousing experience handling petabytes of data. Prior to AWS, he built data warehouse solutions at Amazon.com. He specializes in Amazon Redshift and helps customers build scalable analytic solutions. Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms. Eren Baydemir, a Technical Product Manager at AWS, has 15 years of experience in building customer-facing products and is currently focusing on data lake and file ingestion topics in the Amazon Redshift team. He was the CEO and co-founder of DataRow, which was acquired by Amazon in 2020.
Eren Baydemir, a Technical Product Manager at AWS, has 15 years of experience in building customer-facing products and is currently focusing on data lake and file ingestion topics in the Amazon Redshift team. He was the CEO and co-founder of DataRow, which was acquired by Amazon in 2020. Eesha Kumar is an Analytics Solutions Architect with AWS. He works with customers to realize the business value of data by helping them build solutions using the AWS platform and tools.
Eesha Kumar is an Analytics Solutions Architect with AWS. He works with customers to realize the business value of data by helping them build solutions using the AWS platform and tools. Satish Sathiya is a Senior Product Engineer at Amazon Redshift. He is an avid big data enthusiast who collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs.
Satish Sathiya is a Senior Product Engineer at Amazon Redshift. He is an avid big data enthusiast who collaborates with customers around the globe to achieve success and meet their data warehousing and data lake architecture needs.