Post Syndicated from Omer Yoachimik original https://blog.cloudflare.com/cloudflare-mitigates-record-breaking-71-million-request-per-second-ddos-attack/


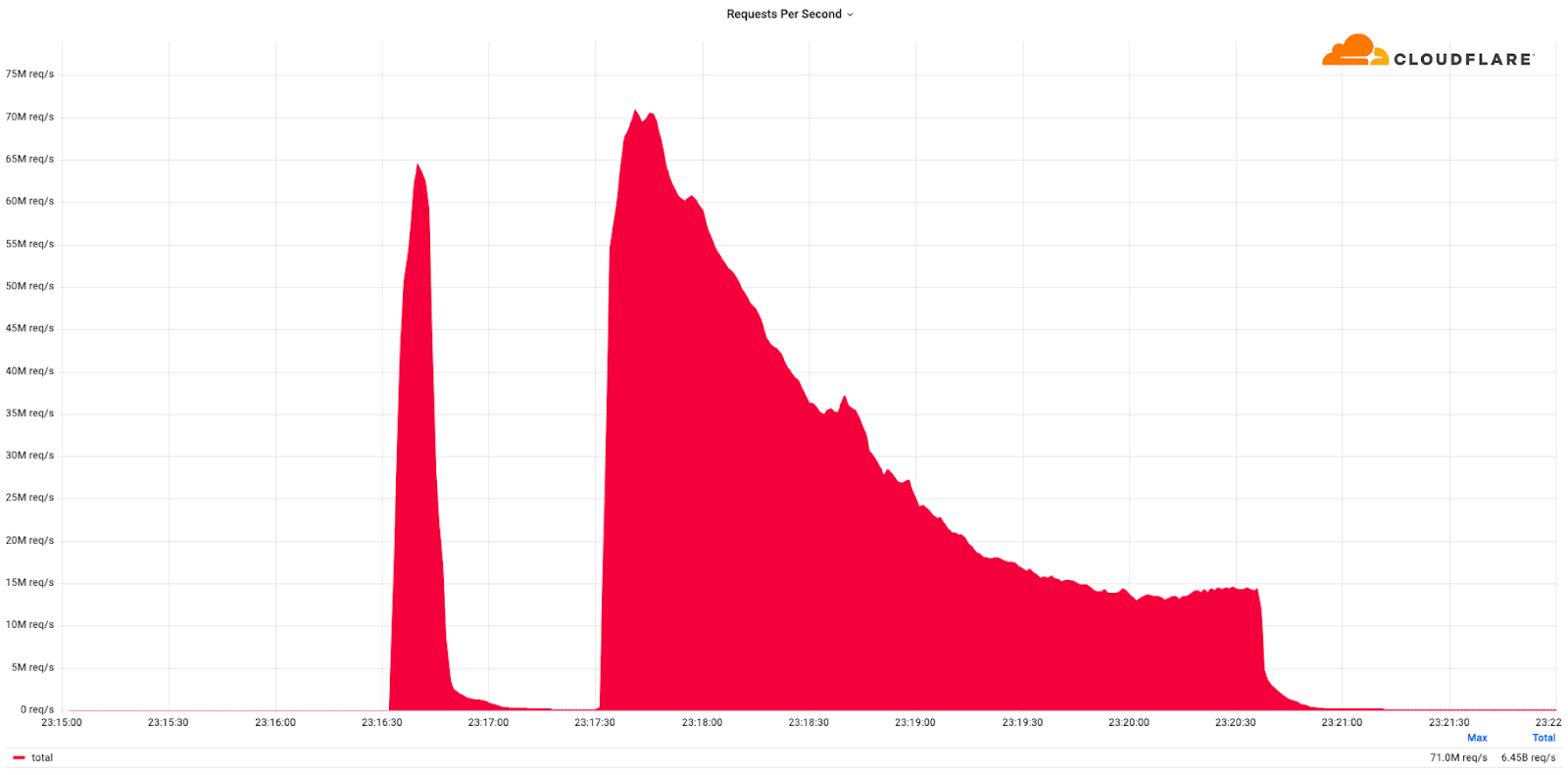
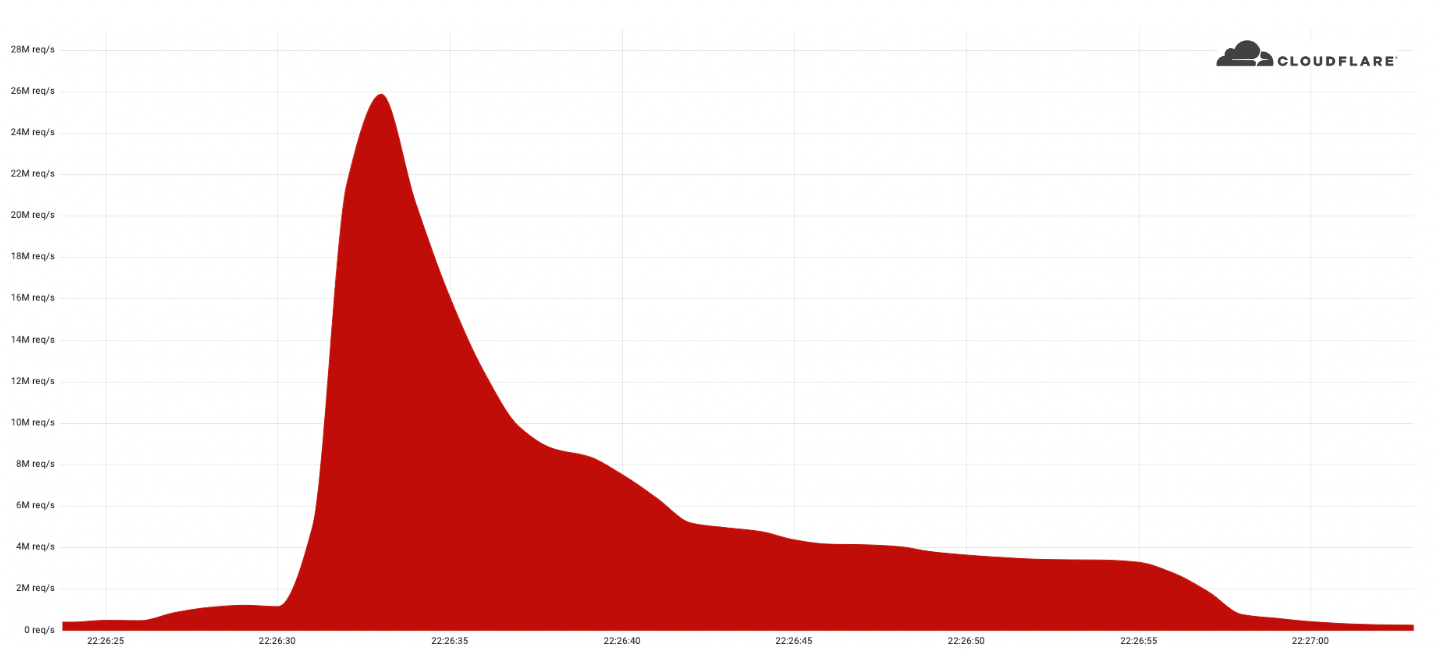
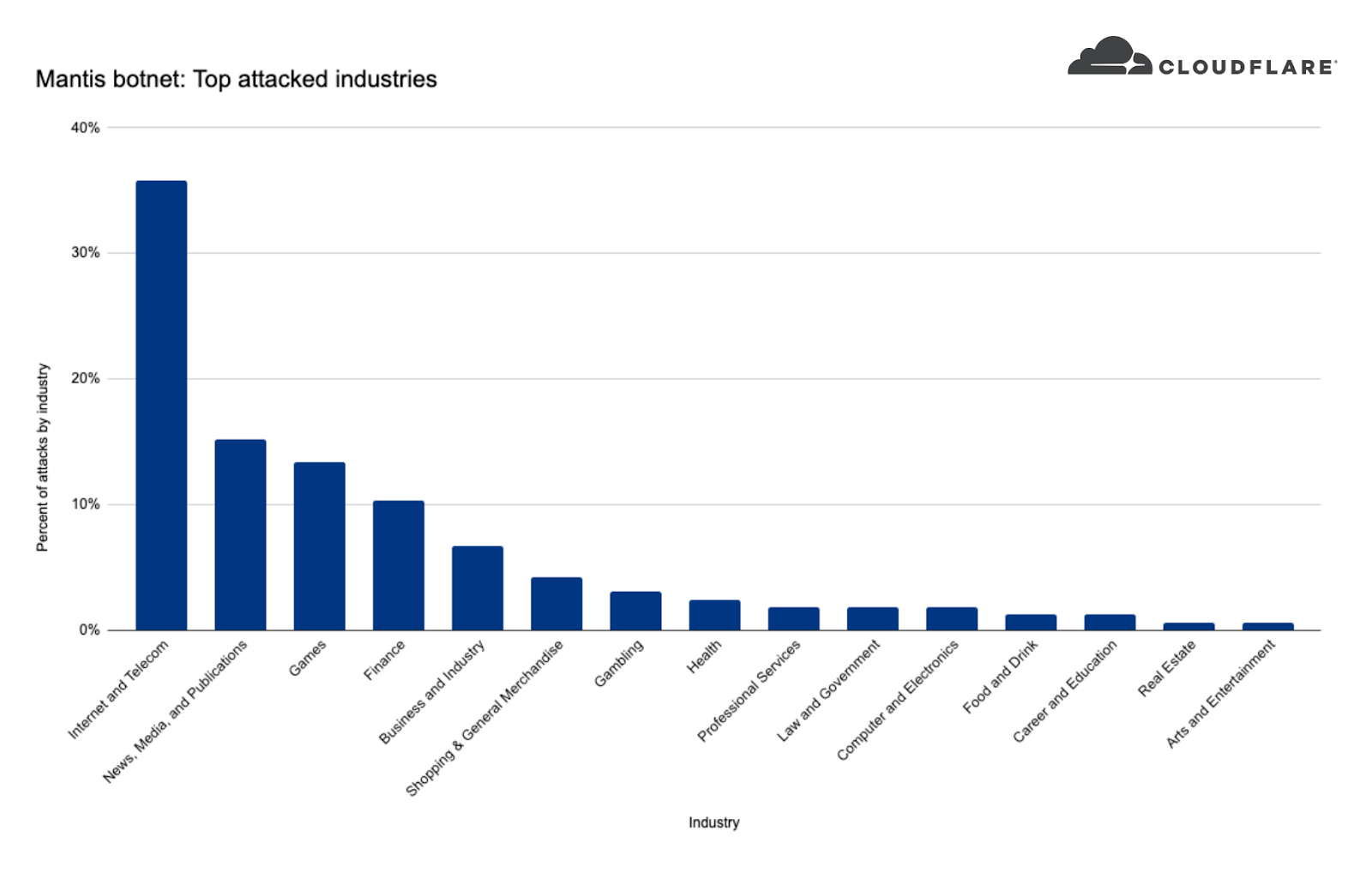
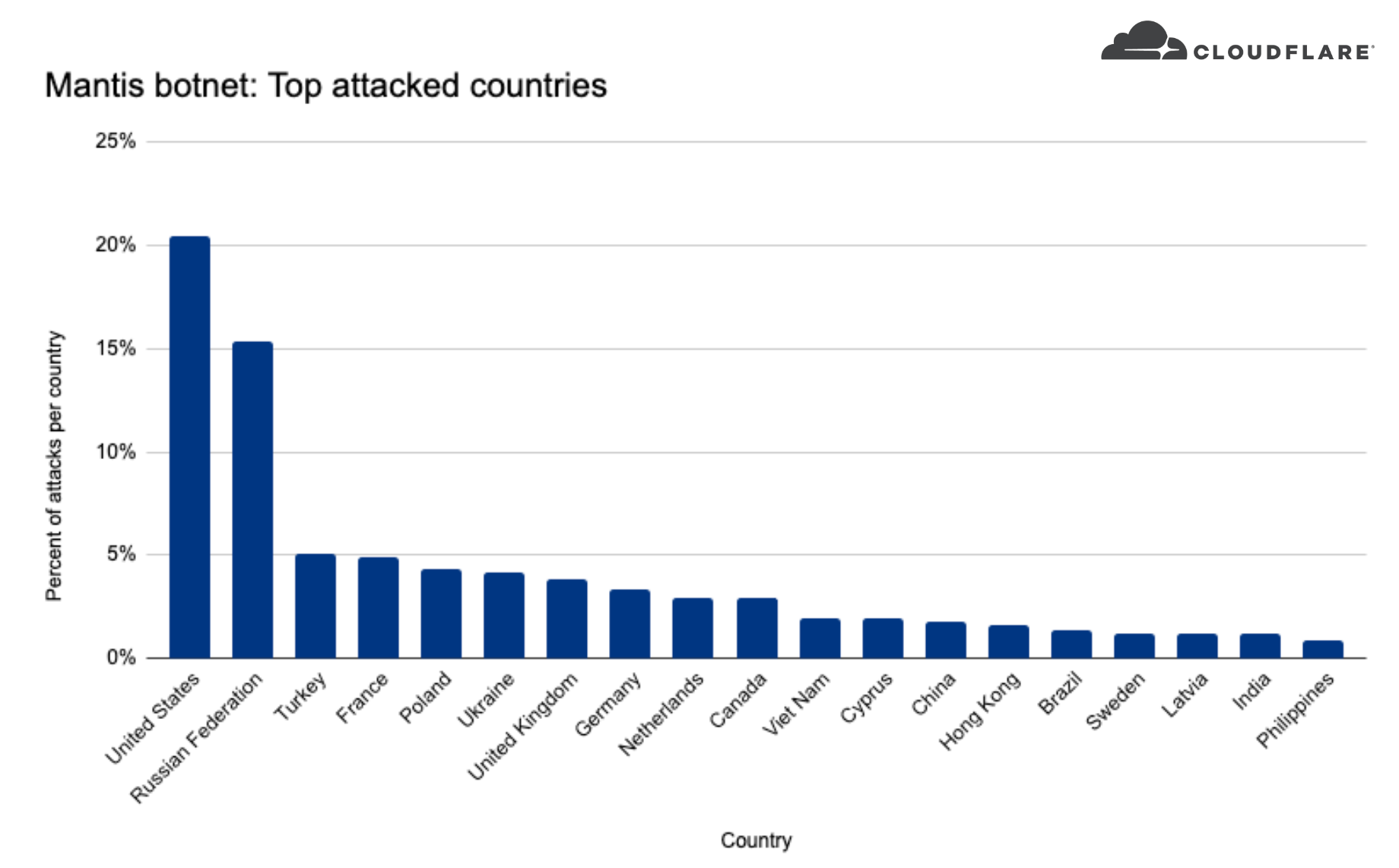
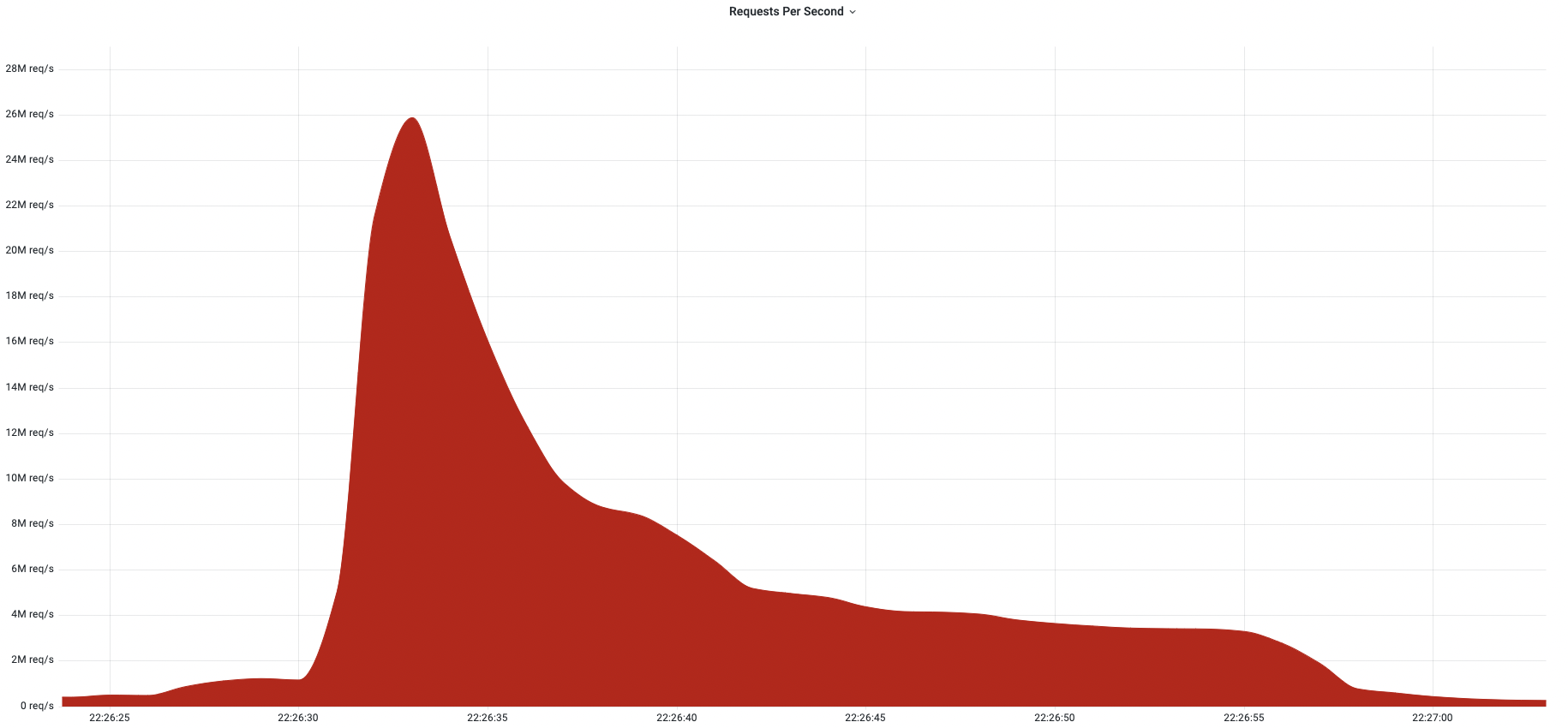
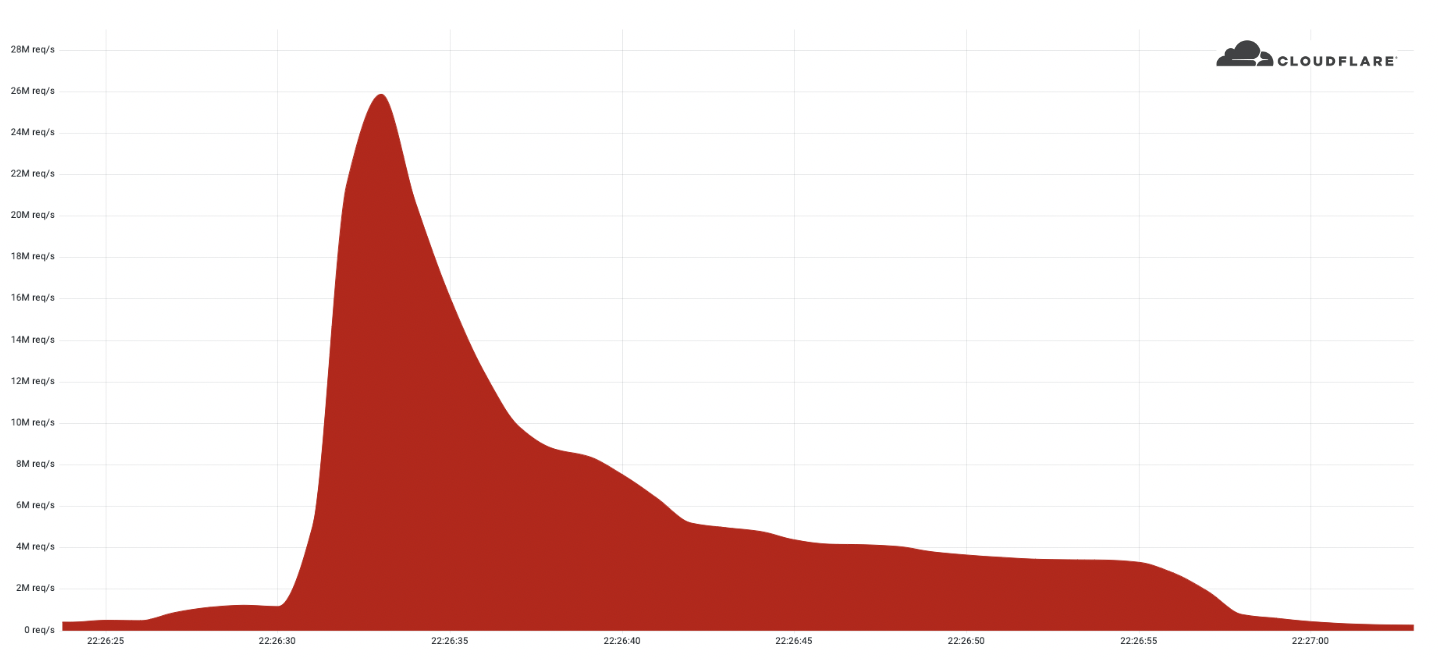
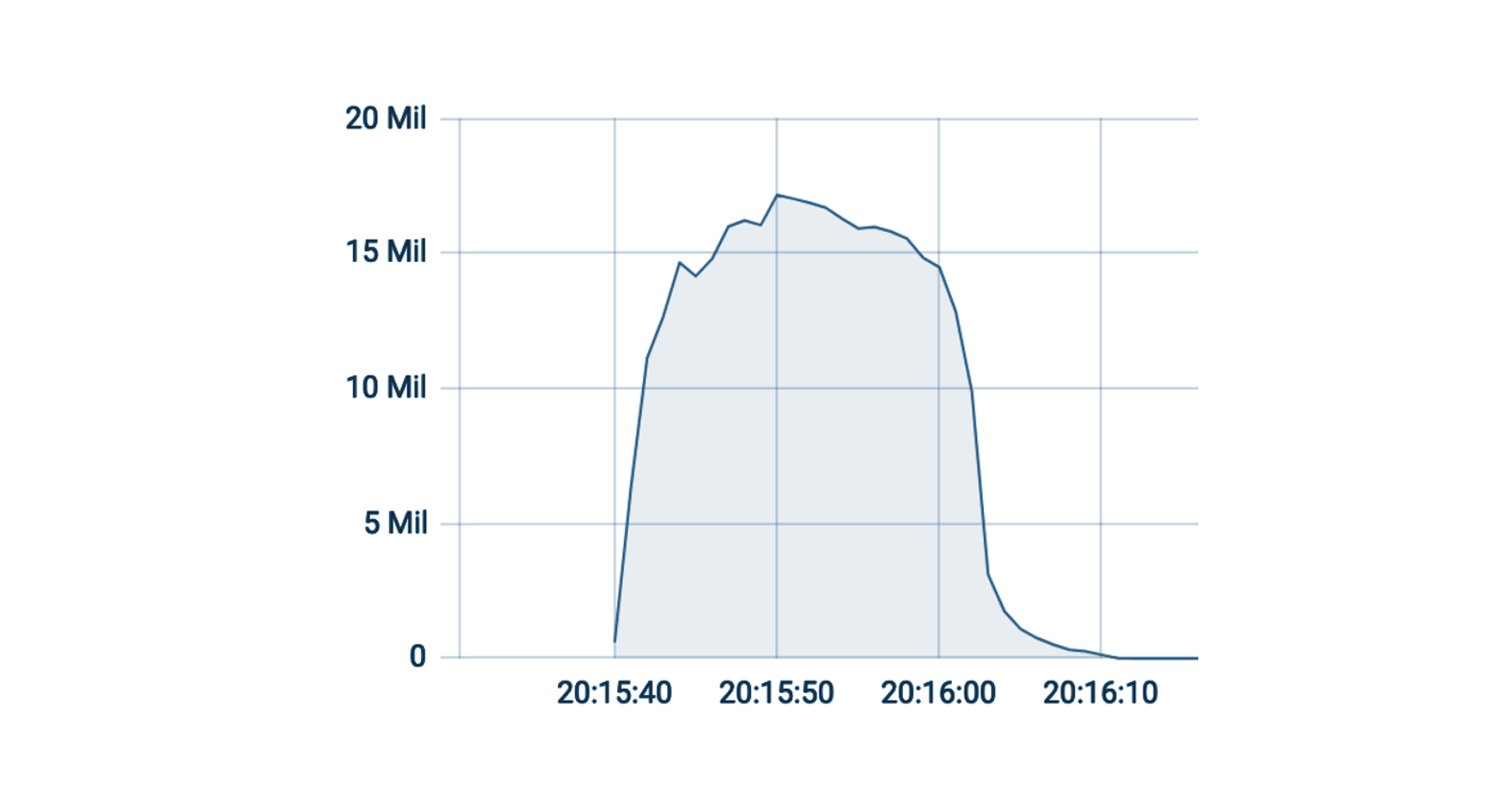
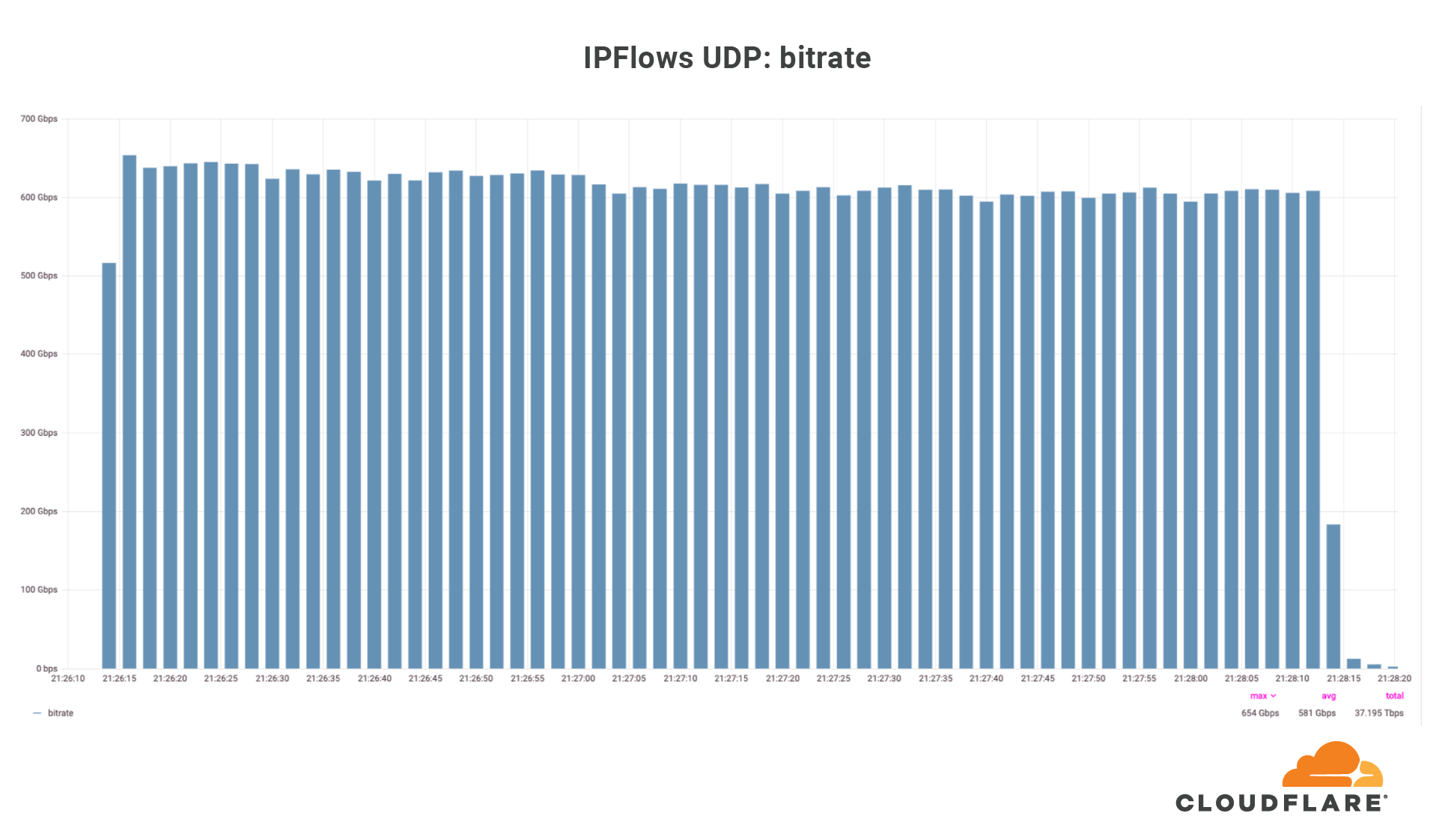
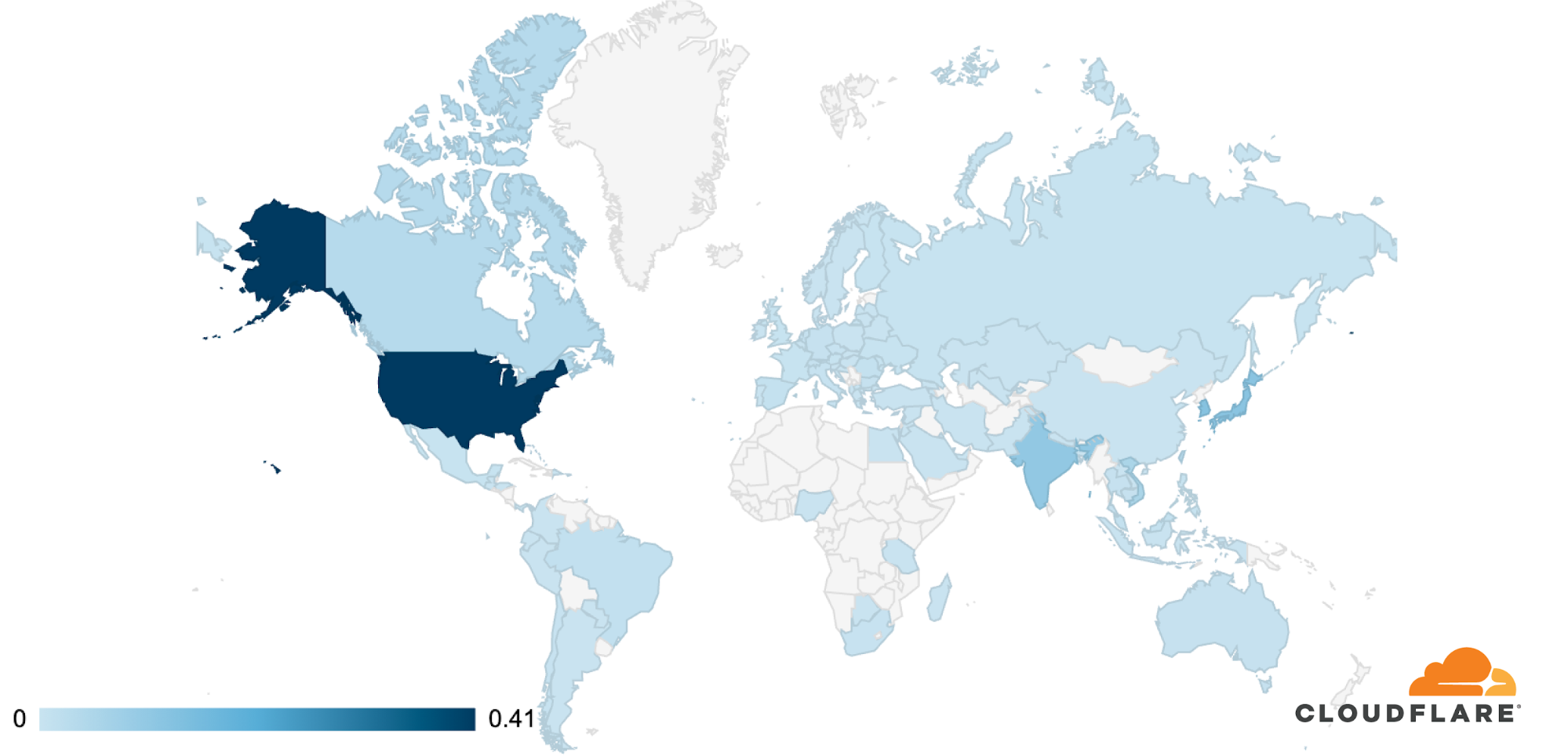
This was a weekend of record-breaking DDoS attacks. Over the weekend, Cloudflare detected and mitigated dozens of hyper-volumetric DDoS attacks. The majority of attacks peaked in the ballpark of 50-70 million requests per second (rps) with the largest exceeding 71 million rps. This is the largest reported HTTP DDoS attack on record, more than 35% higher than the previous reported record of 46M rps in June 2022.
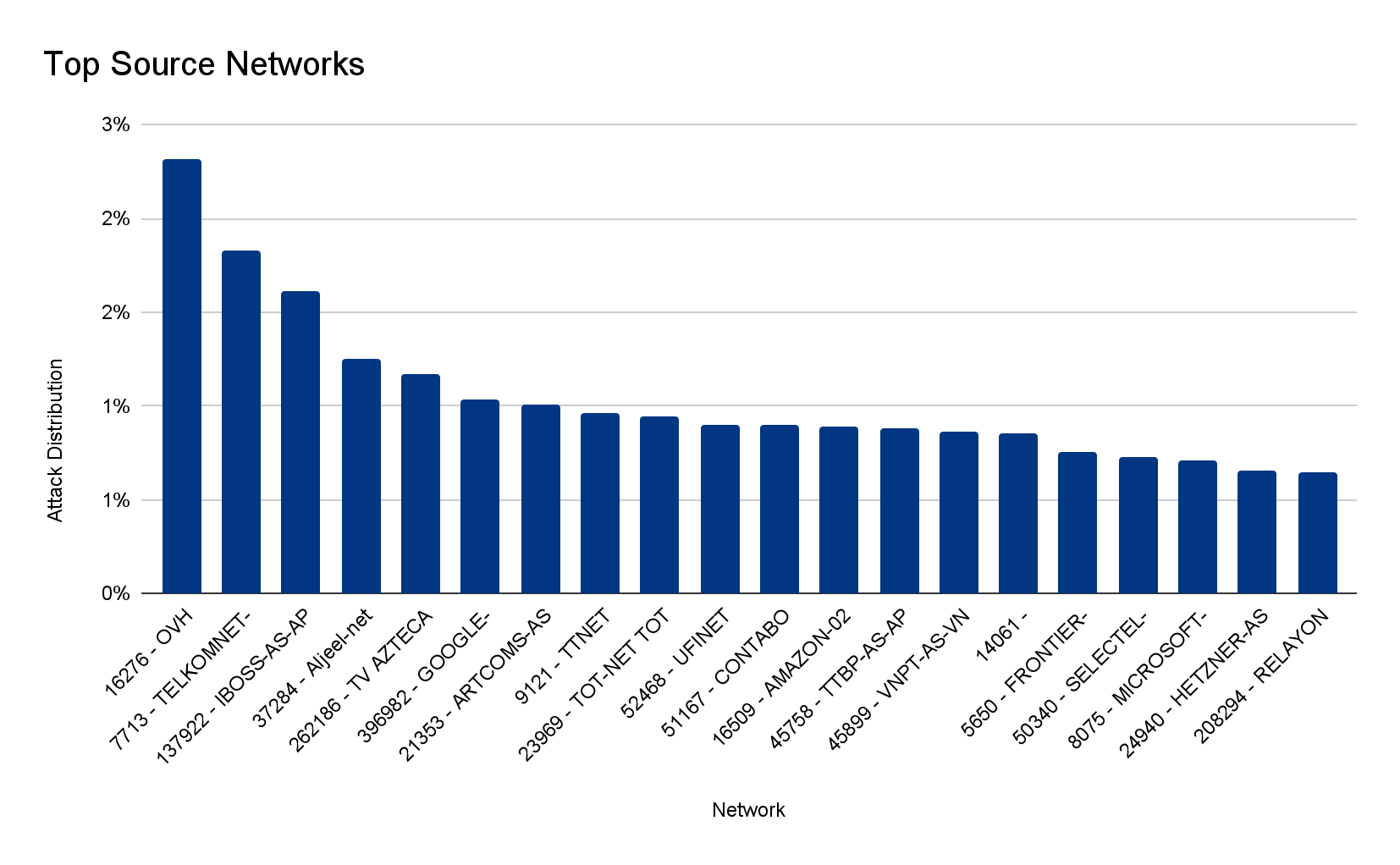
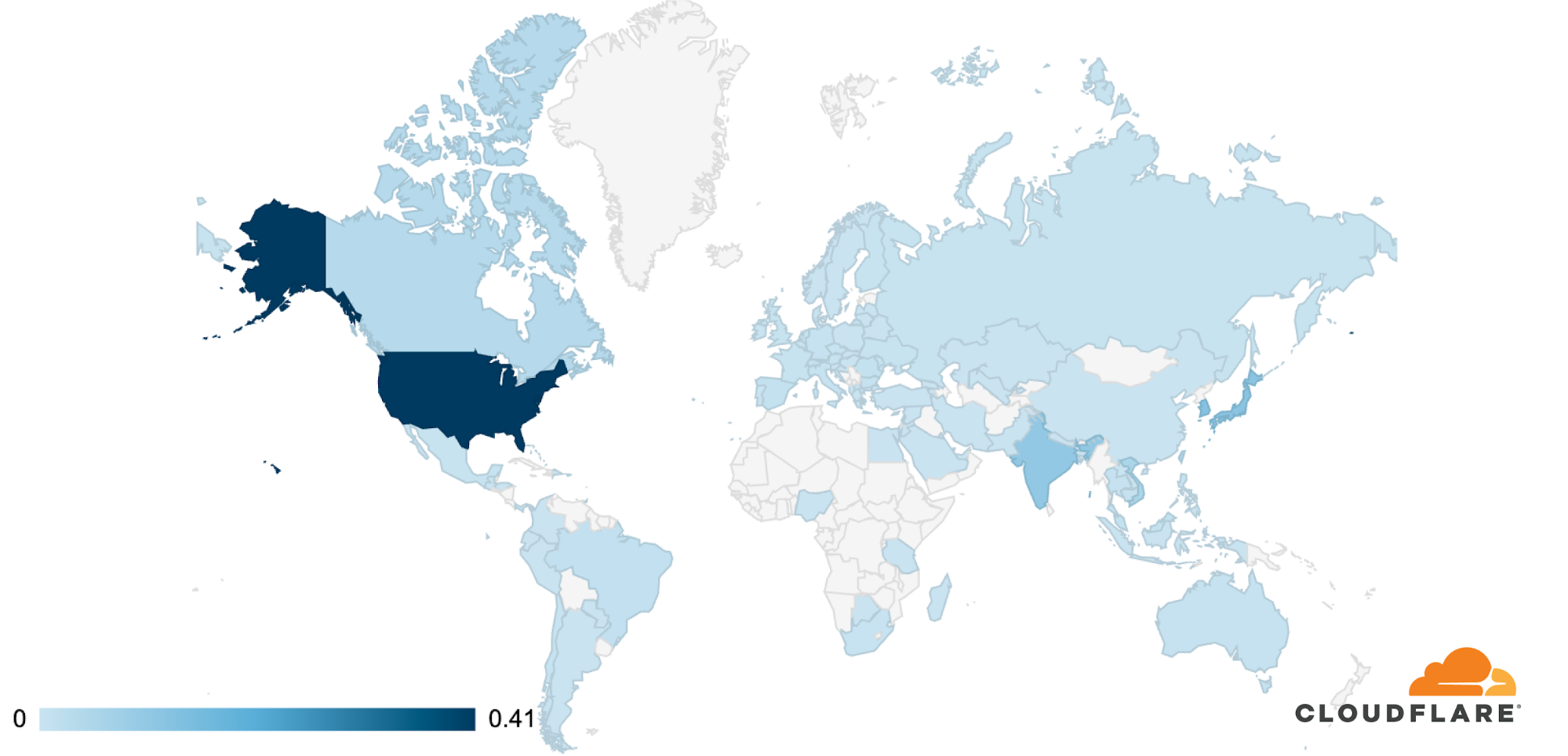
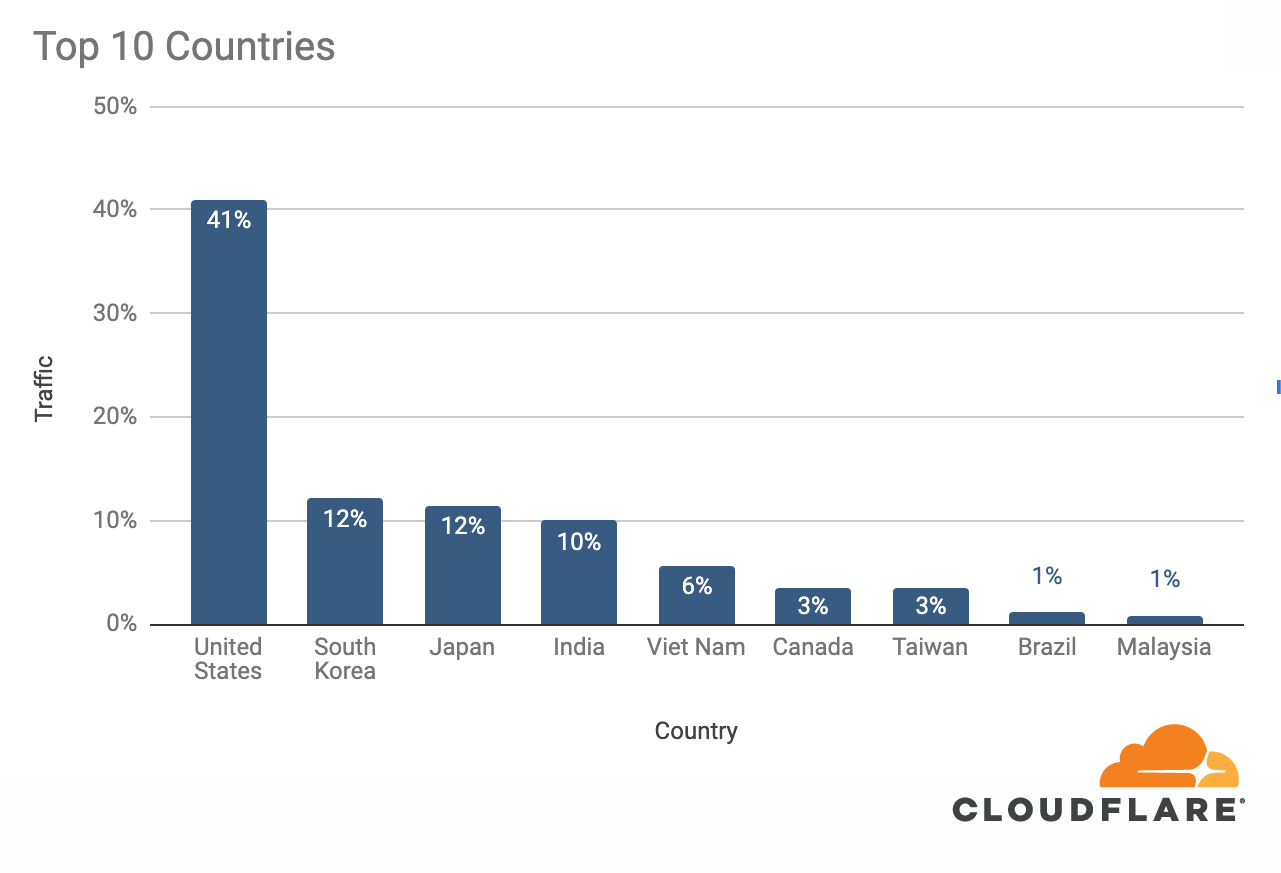
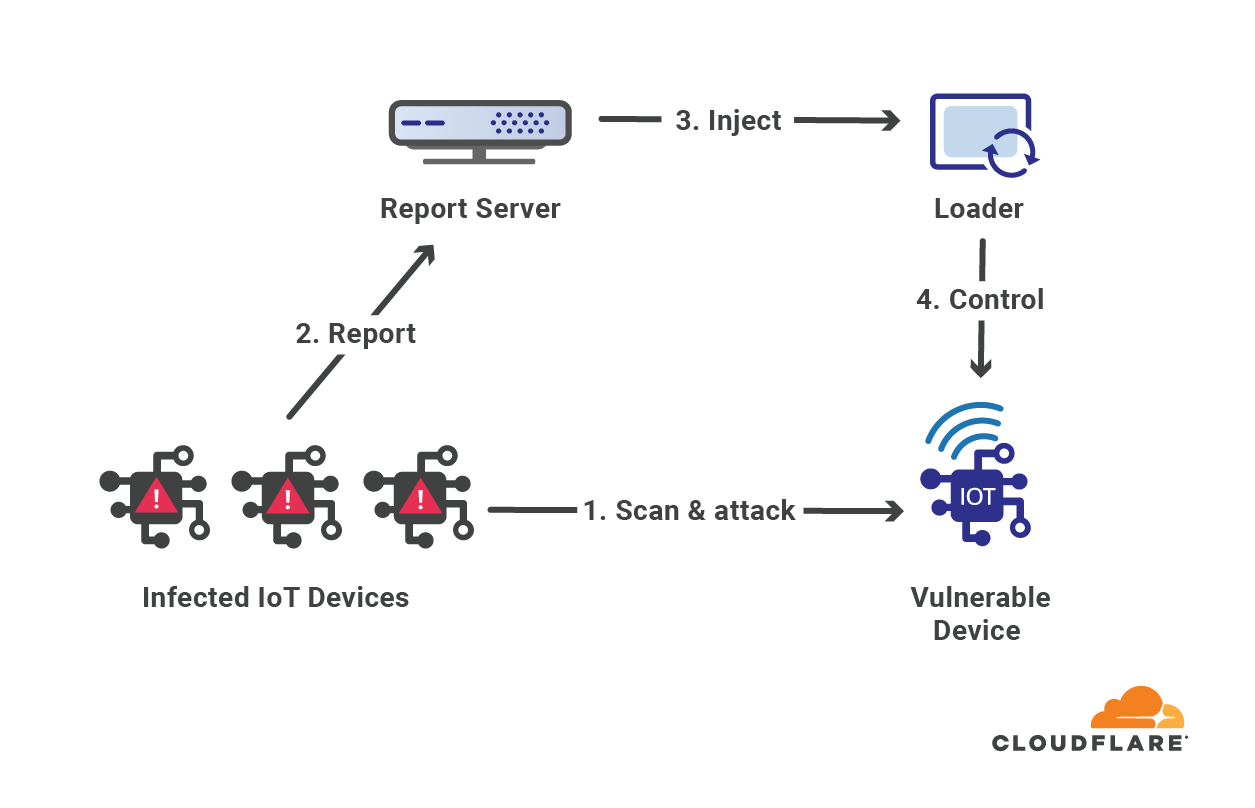
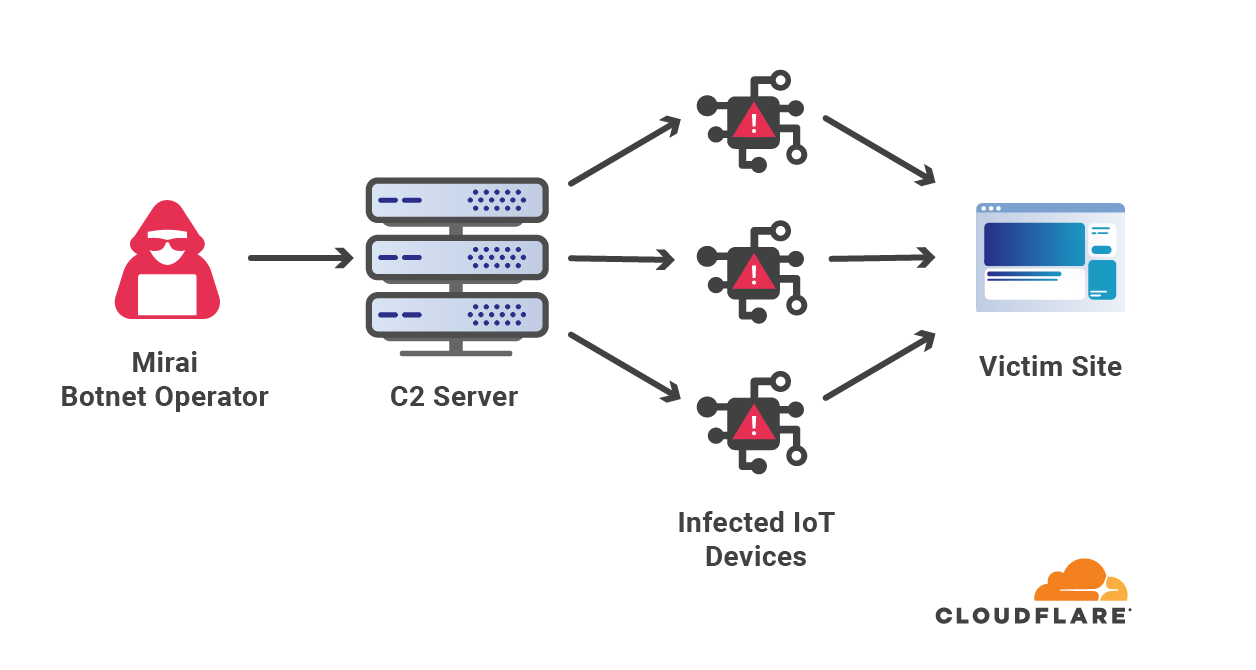
The attacks were HTTP/2-based and targeted websites protected by Cloudflare. They originated from over 30,000 IP addresses. Some of the attacked websites included a popular gaming provider, cryptocurrency companies, hosting providers, and cloud computing platforms. The attacks originated from numerous cloud providers, and we have been working with them to crack down on the botnet.
Over the past year, we’ve seen more attacks originate from cloud computing providers. For this reason, we will be providing service providers that own their own autonomous system a free Botnet threat feed. The feed will provide service providers threat intelligence about their own IP space; attacks originating from within their autonomous system. Service providers that operate their own IP space can now sign up to the early access waiting list.
Is this related to the Super Bowl or Killnet?
No. This campaign of attacks arrives less than two weeks after the Killnet DDoS campaign that targeted healthcare websites. Based on the methods and targets, we do not believe that these recent attacks are related to the healthcare campaign. Furthermore, yesterday was the US Super Bowl, and we also do not believe that this attack campaign is related to the game event.
What are DDoS attacks?
Distributed Denial of Service attacks are cyber attacks that aim to take down Internet properties and make them unavailable for users. These types of cyberattacks can be very efficient against unprotected websites and they can be very inexpensive for the attackers to execute.
An HTTP DDoS attack usually involves a flood of HTTP requests towards the target website. The attacker’s objective is to bombard the website with more requests than it can handle. Given a sufficiently high amount of requests, the website’s server will not be able to process all of the attack requests along with the legitimate user requests. Users will experience this as website-load delays, timeouts, and eventually not being able to connect to their desired websites at all.
To make attacks larger and more complicated, attackers usually leverage a network of bots — a botnet. The attacker will orchestrate the botnet to bombard the victim’s websites with HTTP requests. A sufficiently large and powerful botnet can generate very large attacks as we’ve seen in this case.
However, building and operating botnets requires a lot of investment and expertise. What is the average Joe to do? Well, an average Joe that wants to launch a DDoS attack against a website doesn’t need to start from scratch. They can hire one of numerous DDoS-as-a-Service platforms for as little as $30 per month. The more you pay, the larger and longer of an attack you’re going to get.
Why DDoS attacks?
Over the years, it has become easier, cheaper, and more accessible for attackers and attackers-for-hire to launch DDoS attacks. But as easy as it has become for the attackers, we want to make sure that it is even easier – and free – for defenders of organizations of all sizes to protect themselves against DDoS attacks of all types.
Unlike Ransomware attacks, Ransom DDoS attacks don’t require an actual system intrusion or a foothold within the targeted network. Usually Ransomware attacks start once an employee naively clicks an email link that installs and propagates the malware. There’s no need for that with DDoS attacks. They are more like a hit-and-run attack. All a DDoS attacker needs to know is the website’s address and/or IP address.
Is there an increase in DDoS attacks?
Yes. The size, sophistication, and frequency of attacks has been increasing over the past months. In our latest DDoS threat report, we saw that the amount of HTTP DDoS attacks increased by 79% year-over-year. Furthermore, the amount of volumetric attacks exceeding 100 Gbps grew by 67% quarter-over-quarter (QoQ), and the number of attacks lasting more than three hours increased by 87% QoQ.
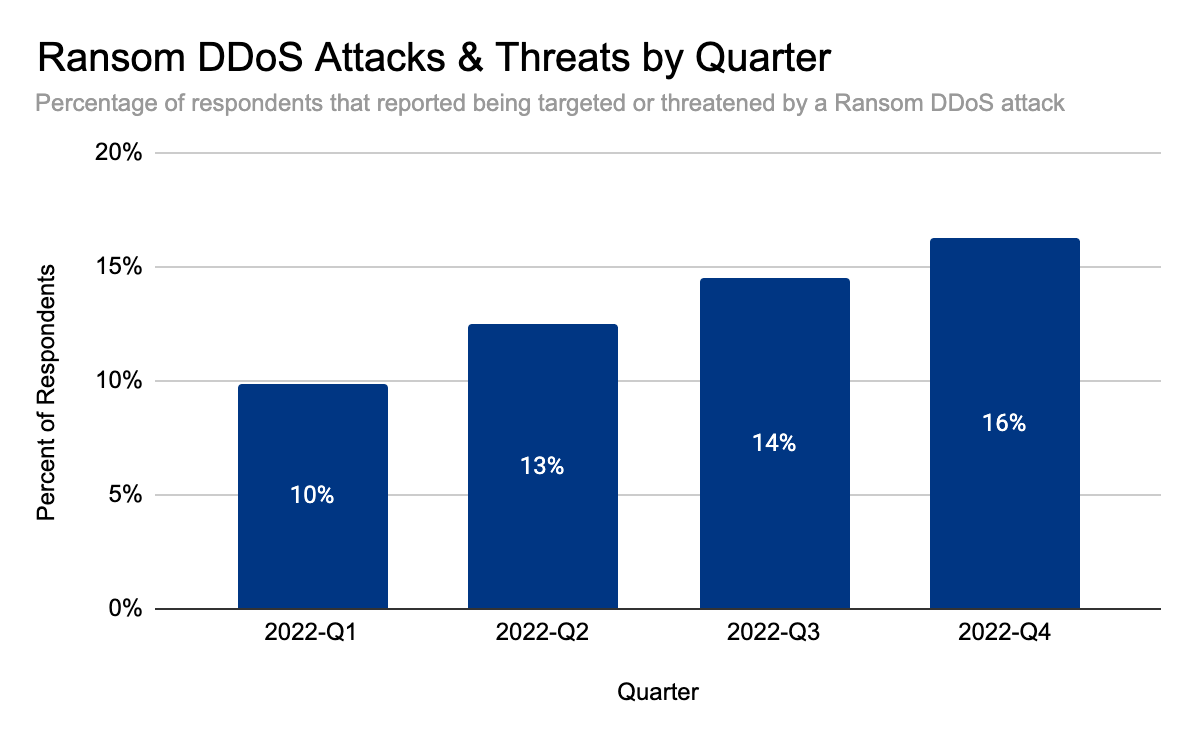
But it doesn’t end there. The audacity of attackers has been increasing as well. In our latest DDoS threat report, we saw that Ransom DDoS attacks steadily increased throughout the year. They peaked in November 2022 where one out of every four surveyed customers reported being subject to Ransom DDoS attacks or threats.
Should I be worried about DDoS attacks?
Yes. If your website, server, or networks are not protected against volumetric DDoS attacks using a cloud service that provides automatic detection and mitigation, we really recommend that you consider it.
Cloudflare customers shouldn’t be worried, but should be aware and prepared. Below is a list of recommended steps to ensure your security posture is optimized.
What steps should I take to defend against DDoS attacks?
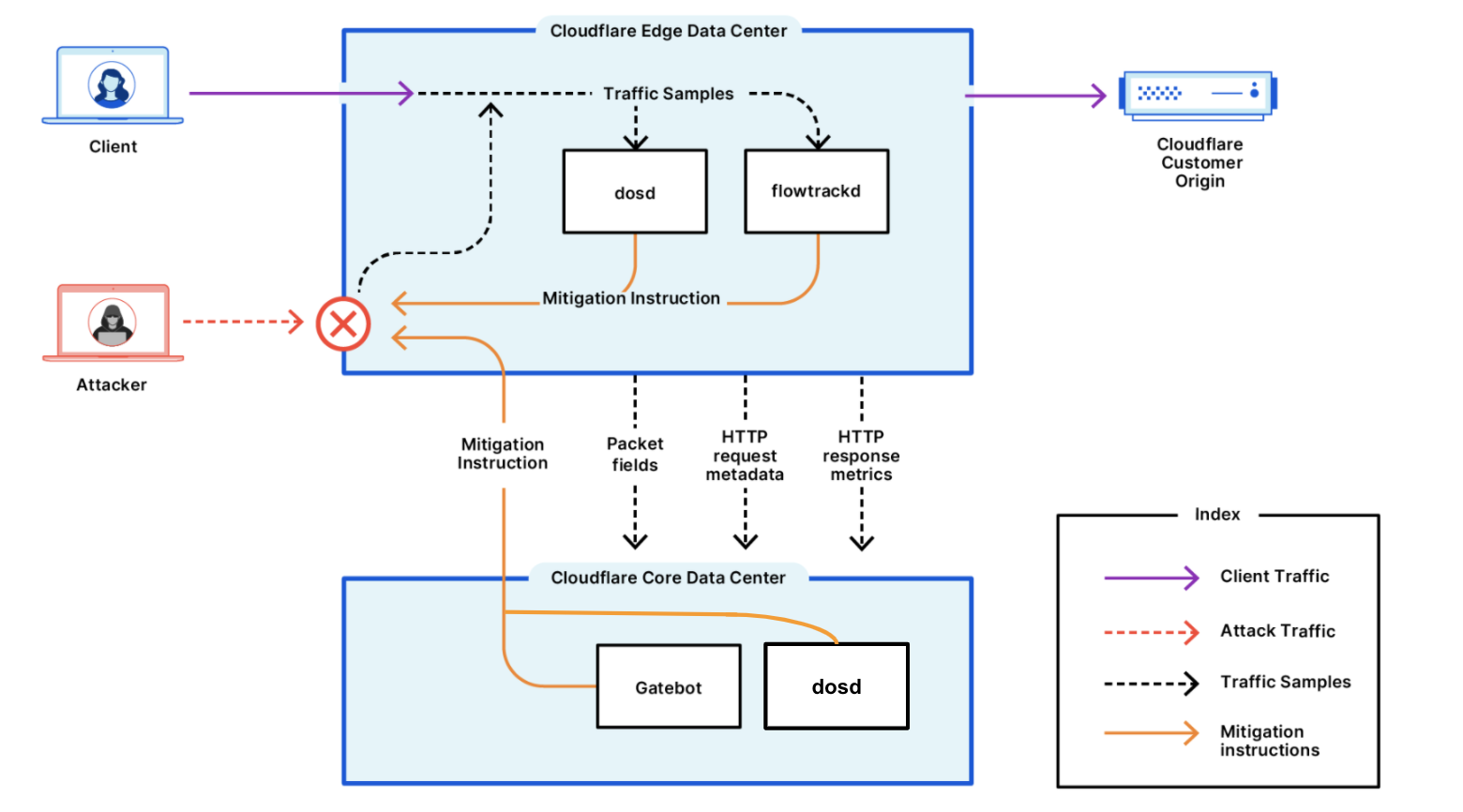
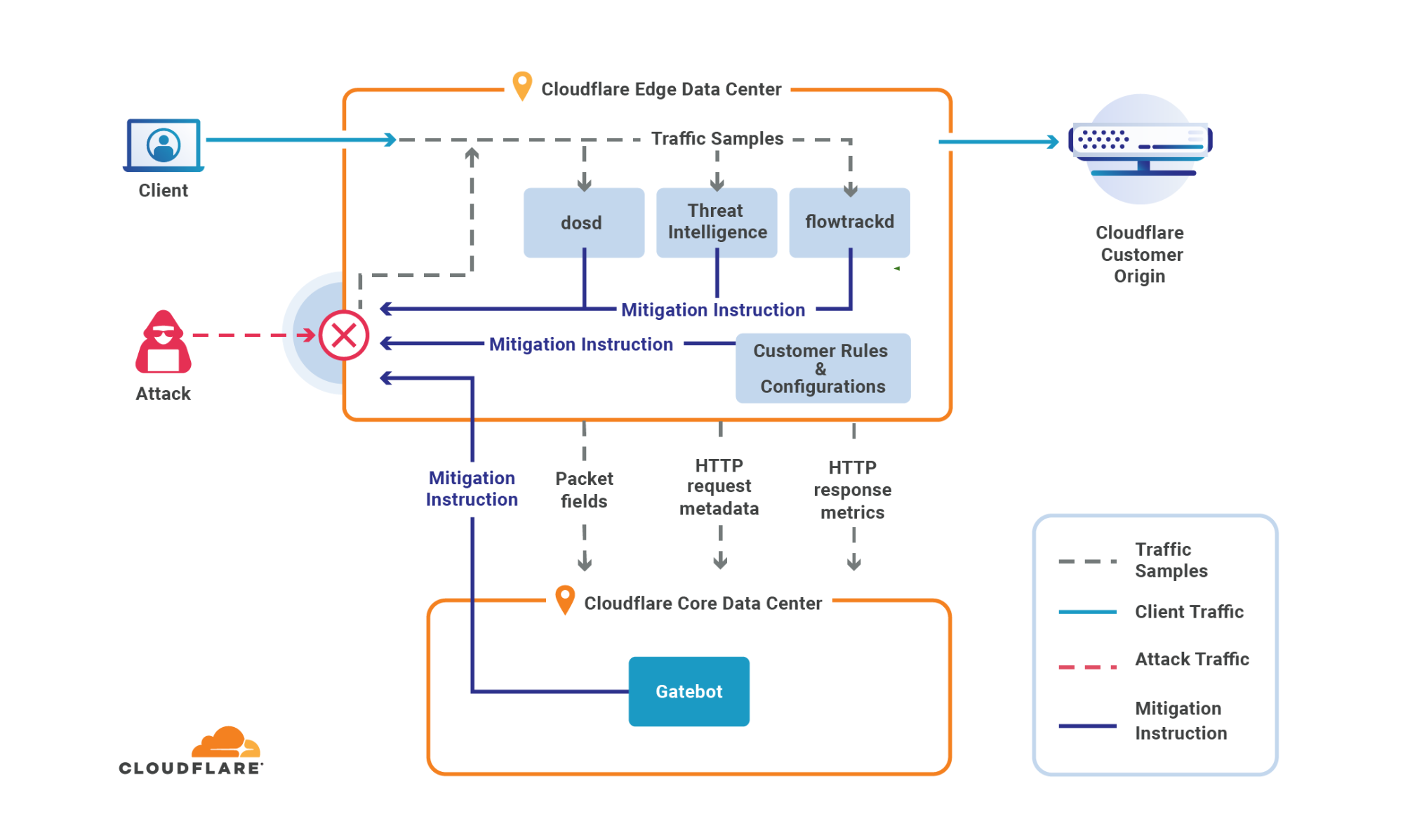
Cloudflare’s systems have been automatically detecting and mitigating these DDoS attacks.
Cloudflare offers many features and capabilities that you may already have access to but may not be using. So as extra precaution, we recommend taking advantage of these capabilities to improve and optimize your security posture:
- Ensure all DDoS Managed Rules are set to default settings (High sensitivity level and mitigation actions) for optimal DDoS activation.
- Cloudflare Enterprise customers that are subscribed to the Advanced DDoS Protection service should consider enabling Adaptive DDoS Protection, which mitigates attacks more intelligently based on your unique traffic patterns.
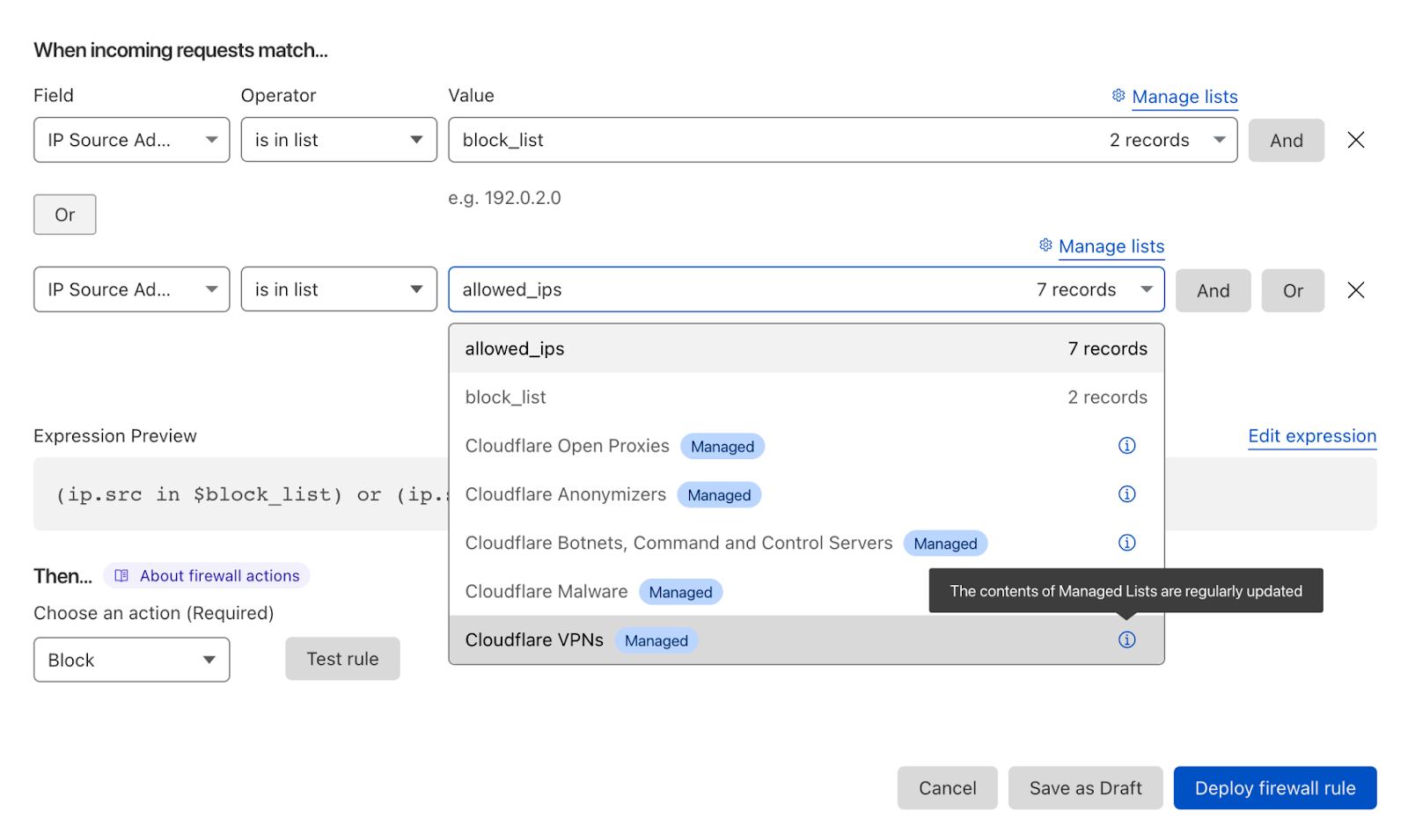
- Deploy firewall rules and rate limiting rules to enforce a combined positive and negative security model. Reduce the traffic allowed to your website based on your known usage.
- Ensure your origin is not exposed to the public Internet (i.e., only enable access to Cloudflare IP addresses). As an extra security precaution, we recommend contacting your hosting provider and requesting new origin server IPs if they have been targeted directly in the past.
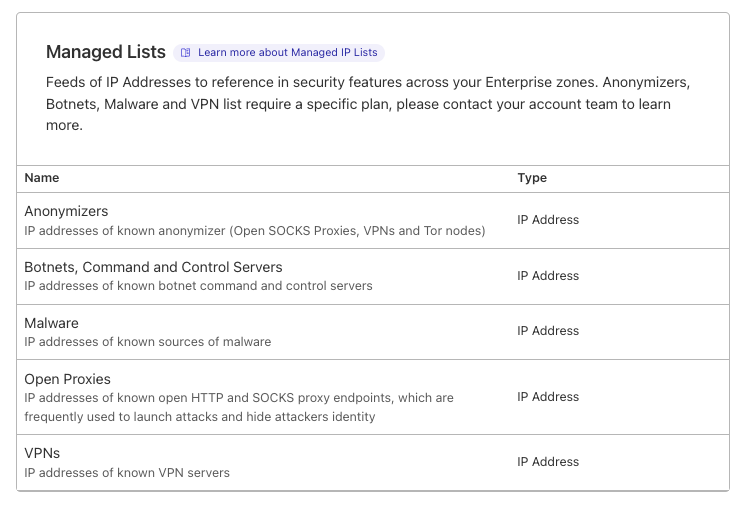
- Customers with access to Managed IP Lists should consider leveraging those lists in firewall rules. Customers with Bot Management should consider leveraging the threat scores within the firewall rules.
- Enable caching as much as possible to reduce the strain on your origin servers, and when using Workers, avoid overwhelming your origin server with more subrequests than necessary.
- Enable DDoS alerting to improve your response time.
Preparing for the next DDoS wave
Defending against DDoS attacks is critical for organizations of all sizes. While attacks may be initiated by humans, they are executed by bots — and to play to win, you must fight bots with bots. Detection and mitigation must be automated as much as possible, because relying solely on humans to mitigate in real time puts defenders at a disadvantage. Cloudflare’s automated systems constantly detect and mitigate DDoS attacks for our customers, so they don’t have to. This automated approach, combined with our wide breadth of security capabilities, lets customers tailor the protection to their needs.
We’ve been providing unmetered and unlimited DDoS protection for free to all of our customers since 2017, when we pioneered the concept. Cloudflare’s mission is to help build a better Internet. A better Internet is one that is more secure, faster, and reliable for everyone – even in the face of DDoS attacks.



















{kind=link}