Post Syndicated from Justin Mazzola Paluska original https://blog.cloudflare.com/d1-read-replication-beta/
Read replication of D1 databases is in public beta!
D1 read replication makes read-only copies of your database available in multiple regions across Cloudflare’s network. For busy, read-heavy applications like e-commerce websites, content management tools, and mobile apps:
-
D1 read replication lowers average latency by routing user requests to read replicas in nearby regions.
-
D1 read replication increases overall throughput by offloading read queries to read replicas, allowing the primary database to handle more write queries.
The main copy of your database is called the primary database and the read-only copies are called read replicas. When you enable replication for a D1 database, the D1 service automatically creates and maintains read replicas of your primary database. As your users make requests, D1 routes those requests to an appropriate copy of the database (either the primary or a replica) based on performance heuristics, the type of queries made in those requests, and the query consistency needs as expressed by your application.
All of this global replica creation and request routing is handled by Cloudflare at no additional cost.
To take advantage of read replication, your Worker needs to use the new D1 Sessions API. Click the button below to run a Worker using D1 read replication with this code example to see for yourself!

D1’s read replication feature is built around the concept of database sessions. A session encapsulates all the queries representing one logical session for your application. For example, a session might represent all requests coming from a particular web browser or all requests coming from a mobile app used by one of your users. If you use sessions, your queries will use the appropriate copy of the D1 database that makes the most sense for your request, be that the primary database or a nearby replica.
The sessions implementation ensures sequential consistency for all queries in the session, no matter what copy of the database each query is routed to. The sequential consistency model has important properties like “read my own writes” and “writes follow reads,” as well as a total ordering of writes. The total ordering of writes means that every replica will see transactions committed in the same order, which is exactly the behavior we want in a transactional system. Said another way, sequential consistency guarantees that the reads and writes are executed in the order in which you write them in your code.
Some examples of consistency implications in real-world applications:
-
You are using an online store and just placed an order (write query), followed by a visit to the account page to list all your orders (read query handled by a replica). You want the newly placed order to be listed there as well.
-
You are using your bank’s web application and make a transfer to your electricity provider (write query), and then immediately navigate to the account balance page (read query handled by a replica) to check the latest balance of your account, including that last payment.
Why do we need the Sessions API? Why can we not just query replicas directly?
Applications using D1 read replication need the Sessions API because D1 runs on Cloudflare’s global network and there’s no way to ensure that requests from the same client get routed to the same replica for every request. For example, the client may switch from WiFi to a mobile network in a way that changes how their requests are routed to Cloudflare. Or the data center that handled previous requests could be down because of an outage or maintenance.
D1’s read replication is asynchronous, so it’s possible that when you switch between replicas, the replica you switch to lags behind the replica you were using. This could mean that, for example, the new replica hasn’t learned of the writes you just completed. We could no longer guarantee useful properties like “read your own writes”. In fact, in the presence of shifty routing, the only consistency property we could guarantee is that what you read had been committed at some point in the past (read committed consistency), which isn’t very useful at all!
Since we can’t guarantee routing to the same replica, we flip the script and use the information we get from the Sessions API to make sure whatever replica we land on can handle the request in a sequentially-consistent manner.
Here’s what the Sessions API looks like in a Worker:
export default {
async fetch(request: Request, env: Env) {
// A. Create the session.
// When we create a D1 session, we can continue where we left off from a previous
// session if we have that session's last bookmark or use a constraint.
const bookmark = request.headers.get('x-d1-bookmark') ?? 'first-unconstrained'
const session = env.DB.withSession(bookmark)
// Use this session for all our Workers' routes.
const response = await handleRequest(request, session)
// B. Return the bookmark so we can continue the session in another request.
response.headers.set('x-d1-bookmark', session.getBookmark())
return response
}
}
async function handleRequest(request: Request, session: D1DatabaseSession) {
const { pathname } = new URL(request.url)
if (request.method === "GET" && pathname === '/api/orders') {
// C. Session read query.
const { results } = await session.prepare('SELECT * FROM Orders').all()
return Response.json(results)
} else if (request.method === "POST" && pathname === '/api/orders') {
const order = await request.json<Order>()
// D. Session write query.
// Since this is a write query, D1 will transparently forward it to the primary.
await session
.prepare('INSERT INTO Orders VALUES (?, ?, ?)')
.bind(order.orderId, order.customerId, order.quantity)
.run()
// E. Session read-after-write query.
// In order for the application to be correct, this SELECT statement must see
// the results of the INSERT statement above.
const { results } = await session
.prepare('SELECT * FROM Orders')
.all()
return Response.json(results)
}
return new Response('Not found', { status: 404 })
}To use the Session API, you first need to create a session using the withSession method (step A). The withSession method takes a bookmark as a parameter, or a constraint. The provided constraint instructs D1 where to forward the first query of the session. Using first-unconstrained allows the first query to be processed by any replica without any restriction on how up-to-date it is. Using first-primary ensures that the first query of the session will be forwarded to the primary.
// A. Create the session.
const bookmark = request.headers.get('x-d1-bookmark') ?? 'first-unconstrained'
const session = env.DB.withSession(bookmark)Providing an explicit bookmark instructs D1 that whichever database instance processes the query has to be at least as up-to-date as the provided bookmark (in case of a replica; the primary database is always up-to-date by definition). Explicit bookmarks are how we can continue from previously-created sessions and maintain sequential consistency across user requests.
Once you’ve created the session, make queries like you normally would with D1. The session object ensures that the queries you make are sequentially consistent with regards to each other.
// C. Session read query.
const { results } = await session.prepare('SELECT * FROM Orders').all()For example, in the code example above, the session read query for listing the orders (step C) will return results that are at least as up-to-date as the bookmark used to create the session (step A).
More interesting is the write query to add a new order (step D) followed by the read query to list all orders (step E). Because both queries are executed on the same session, it is guaranteed that the read query will observe a database copy that includes the write query, thus maintaining sequential consistency.
// D. Session write query.
await session
.prepare('INSERT INTO Orders VALUES (?, ?, ?)')
.bind(order.orderId, order.customerId, order.quantity)
.run()
// E. Session read-after-write query.
const { results } = await session
.prepare('SELECT * FROM Orders')
.all()Note that we could make a single batch query to the primary including both the write and the list, but the benefit of using the new Sessions API is that you can use the extra read replica databases for your read queries and allow the primary database to handle more write queries.
The session object does the necessary bookkeeping to maintain the latest bookmark observed across all queries executed using that specific session, and always includes that latest bookmark in requests to D1. Note that any query executed without using the session object is not guaranteed to be sequentially consistent with the queries executed in the session.
When possible, we suggest continuing sessions across requests by including bookmarks in your responses to clients (step B), and having clients passing previously received bookmarks in their future requests.
// B. Return the bookmark so we can continue the session in another request.
response.headers.set('x-d1-bookmark', session.getBookmark())This allows all of a client’s requests to be in the same session. You can do this by grabbing the session’s current bookmark at the end of the request (session.getBookmark()) and sending the bookmark in the response back to the client in HTTP headers, in HTTP cookies, or in the response body itself.
In this section, we will explore the classic scenario of a read-after-write query to showcase how using the new D1 Sessions API ensures that we get sequential consistency and avoid any issues with inconsistent results in our application.
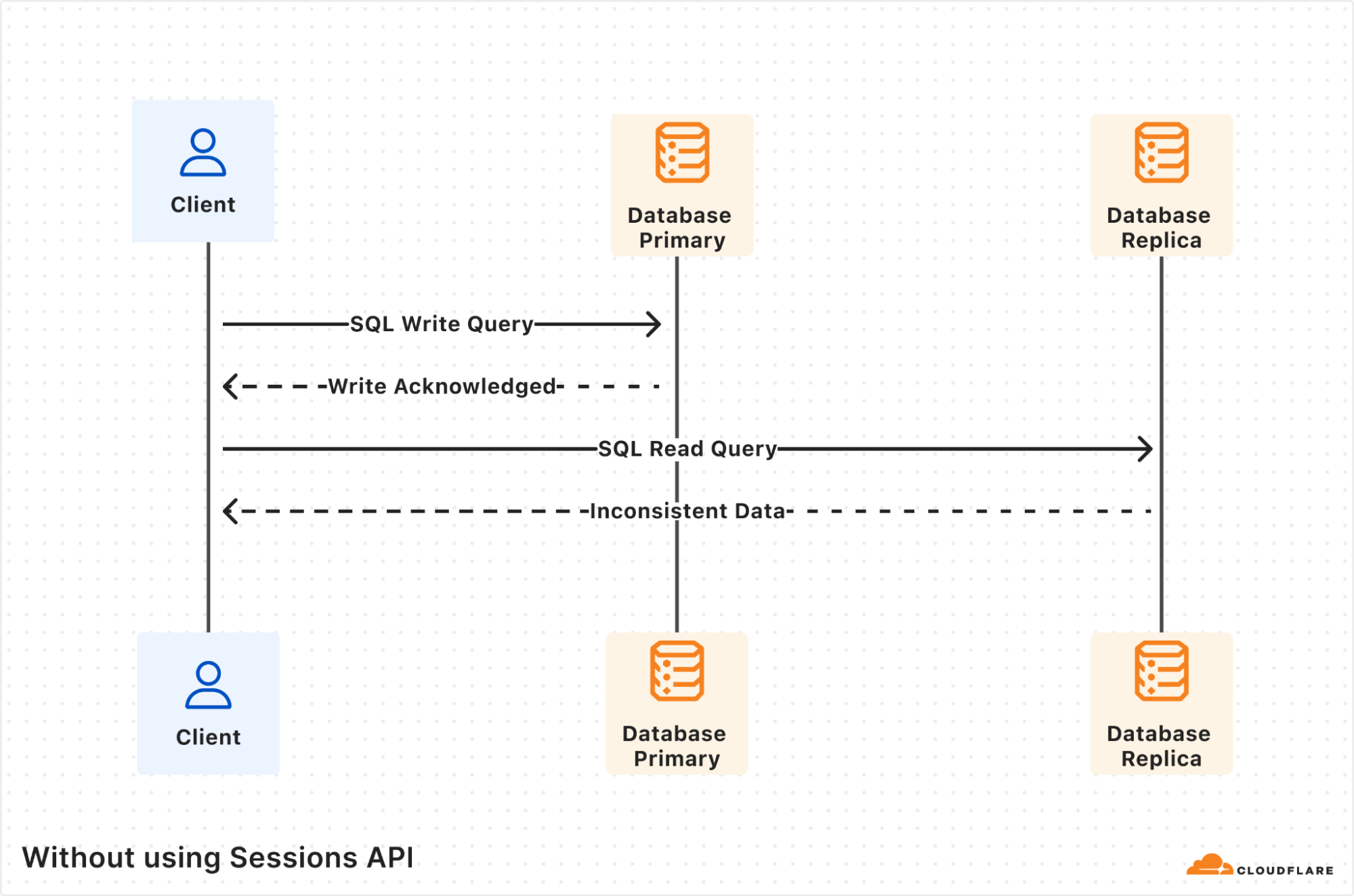
The Client, a user Worker, sends a D1 write query that gets processed by the database primary and gets the results back. However, the subsequent read query ends up being processed by a database replica. If the database replica is lagging far enough behind the database primary, such that it does not yet include the first write query, then the returned results will be inconsistent, and probably incorrect for your application business logic.
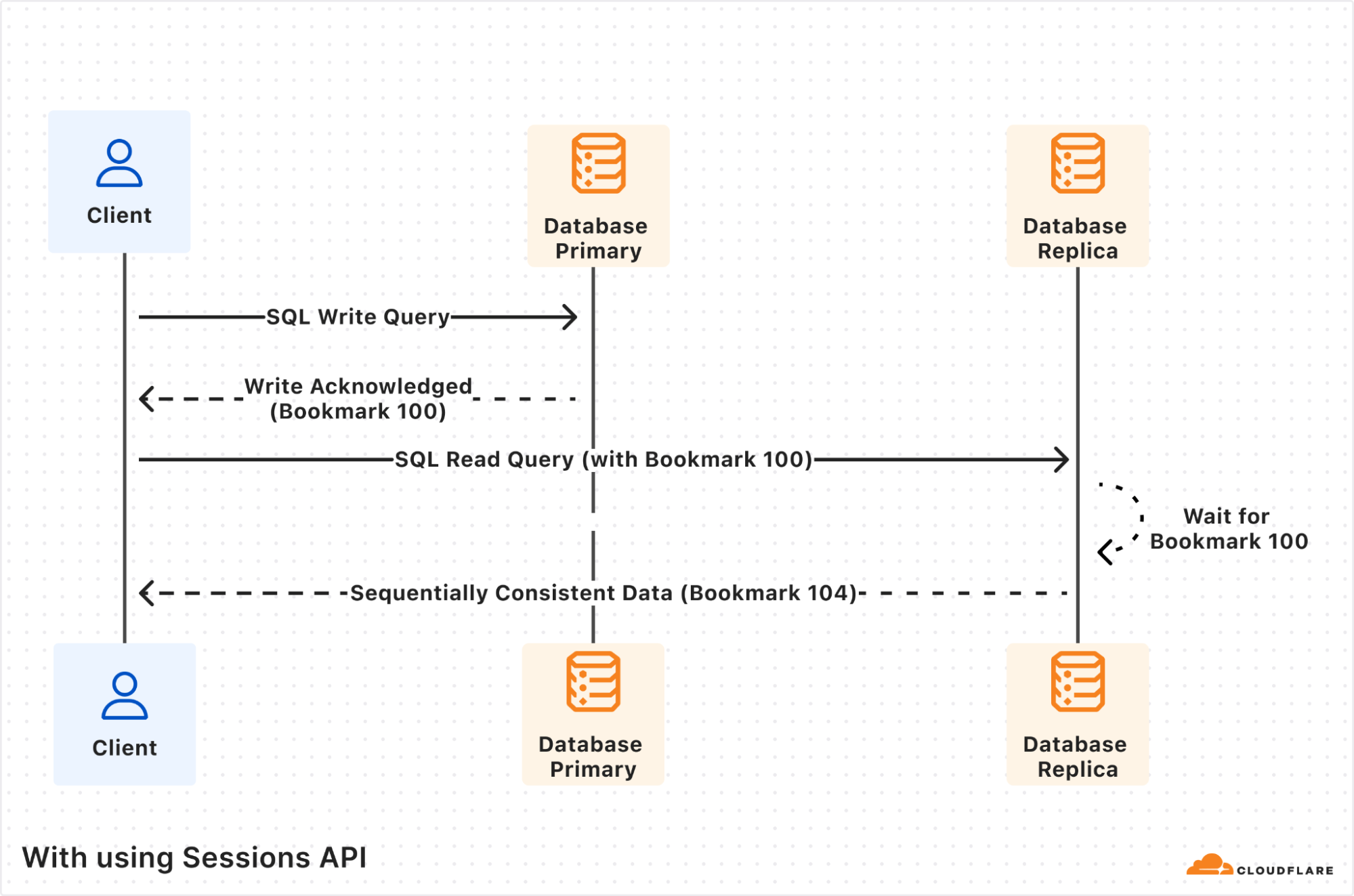
Using the Sessions API fixes the inconsistency issue. The first write query is again processed by the database primary, and this time the response includes “Bookmark 100”. The session object will store this bookmark for you transparently.
The subsequent read query is processed by database replica as before, but now since the query includes the previously received “Bookmark 100”, the database replica will wait until its database copy is at least up-to-date as “Bookmark 100”. Only once it’s up-to-date, the read query will be processed and the results returned, including the replica’s latest bookmark “Bookmark 104”.
Notice that the returned bookmark for the read query is “Bookmark 104”, which is different from the one passed in the query request. This can happen if there were other writes from other client requests that also got replicated to the database replica in-between the two queries our own client executed.
To start using D1 read replication:
-
Update your Worker to use the D1 Sessions API to tell D1 what queries are part of the same database session. The Sessions API works with databases that do not have read replication enabled as well, so it’s safe to ship this code even before you enable replicas. Here’s an example.
-
Enable replicas for your database via Cloudflare dashboard > Select D1 database > Settings.
D1 read replication is built into D1, and you don’t pay extra storage or compute costs for replicas. You incur the exact same D1 usage with or without replicas, based on rows_read and rows_written by your queries. Unlike other traditional database systems with replication, you don’t have to manually create replicas, including where they run, or decide how to route requests between the primary database and read replicas. Cloudflare handles this when using the Sessions API while ensuring sequential consistency.
Since D1 read replication is in beta, we recommend trying D1 read replication on a non-production database first, and migrate to your production workloads after validating read replication works for your use case.
If you don’t have a D1 database and want to try out D1 read replication, create a test database in the Cloudflare dashboard.
Once you’ve enabled D1 read replication, read queries will start to be processed by replica database instances. The response of each query includes information in the nested meta object relevant to read replication, like served_by_region and served_by_primary. The first denotes the region of the database instance that processed the query, and the latter will be true if-and-only-if your query was processed by the primary database instance.
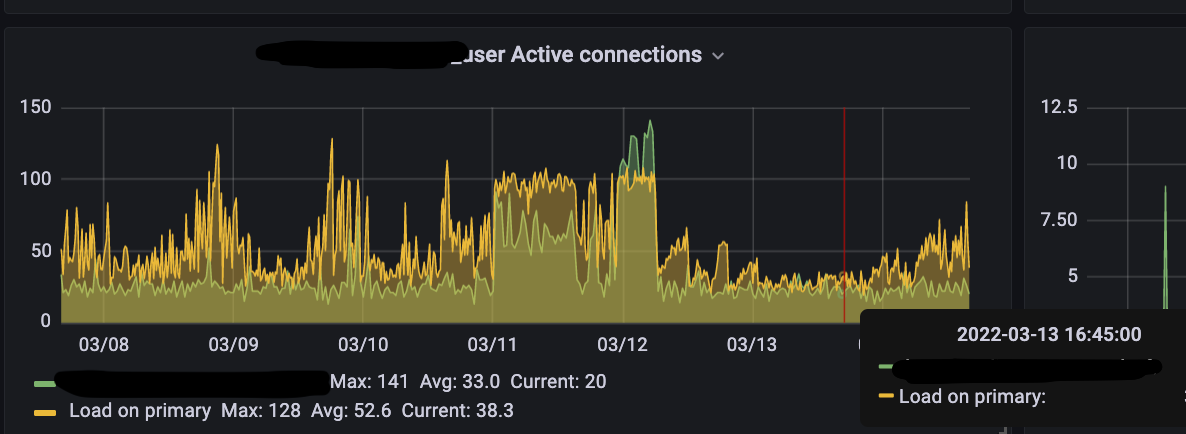
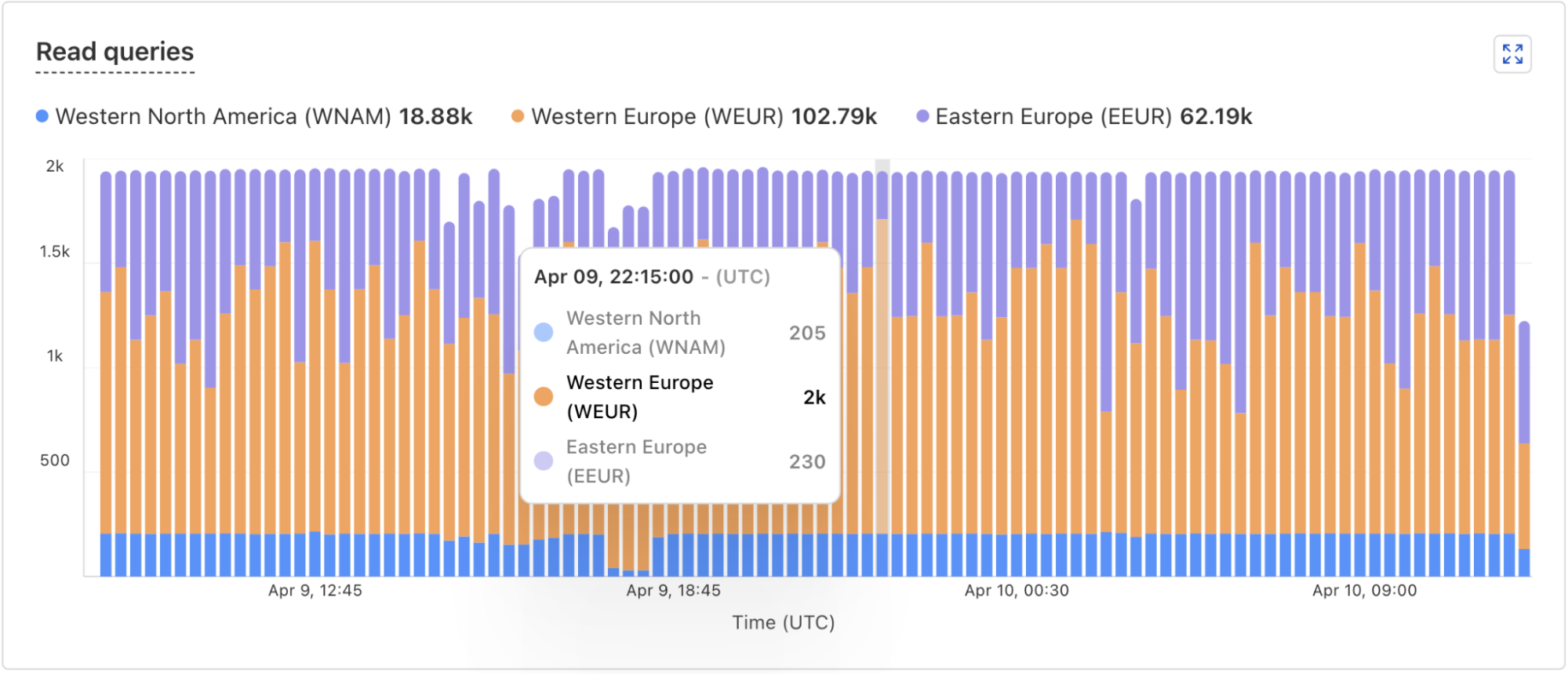
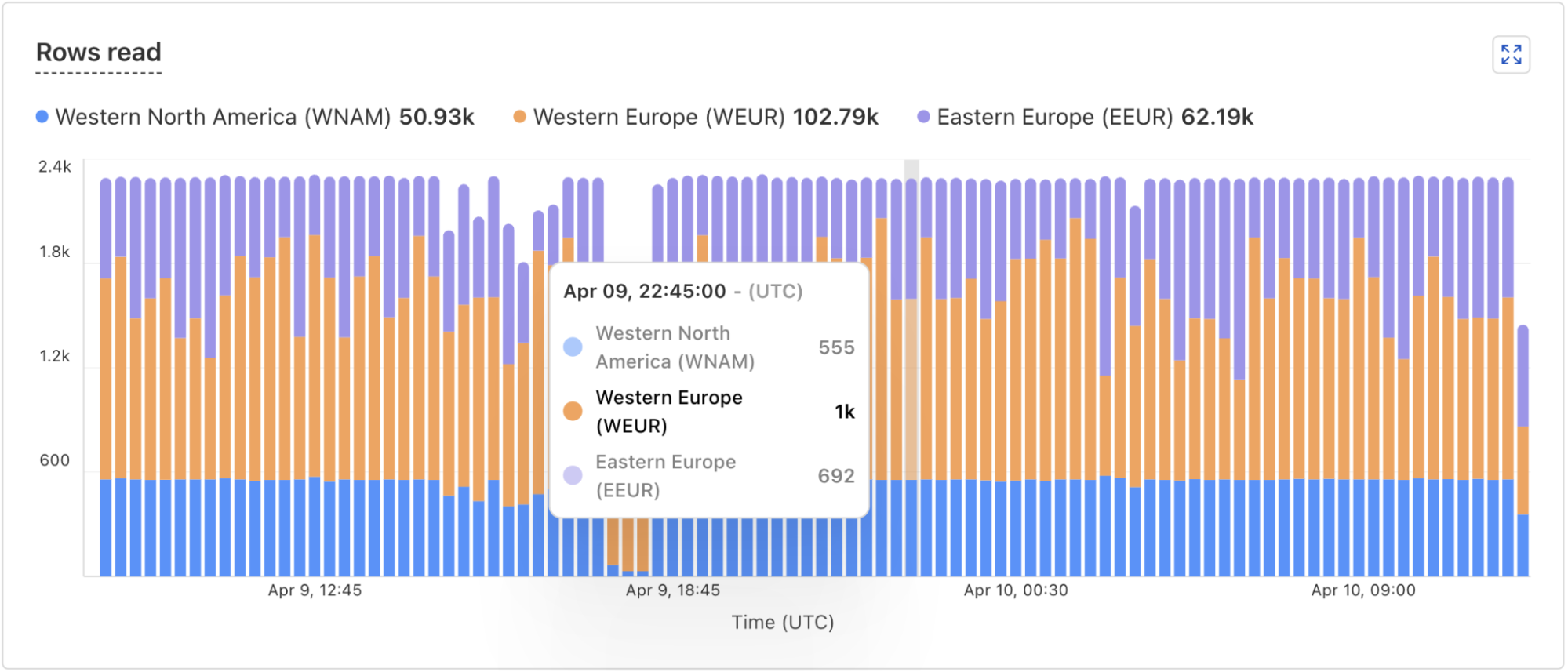
In addition, the D1 dashboard overview for a database now includes information about the database instances handling your queries. You can see how many queries are handled by the primary instance or by a replica, and a breakdown of the queries processed by region. The example screenshots below show graphs displaying the number of queries executed and number of rows read by each region.
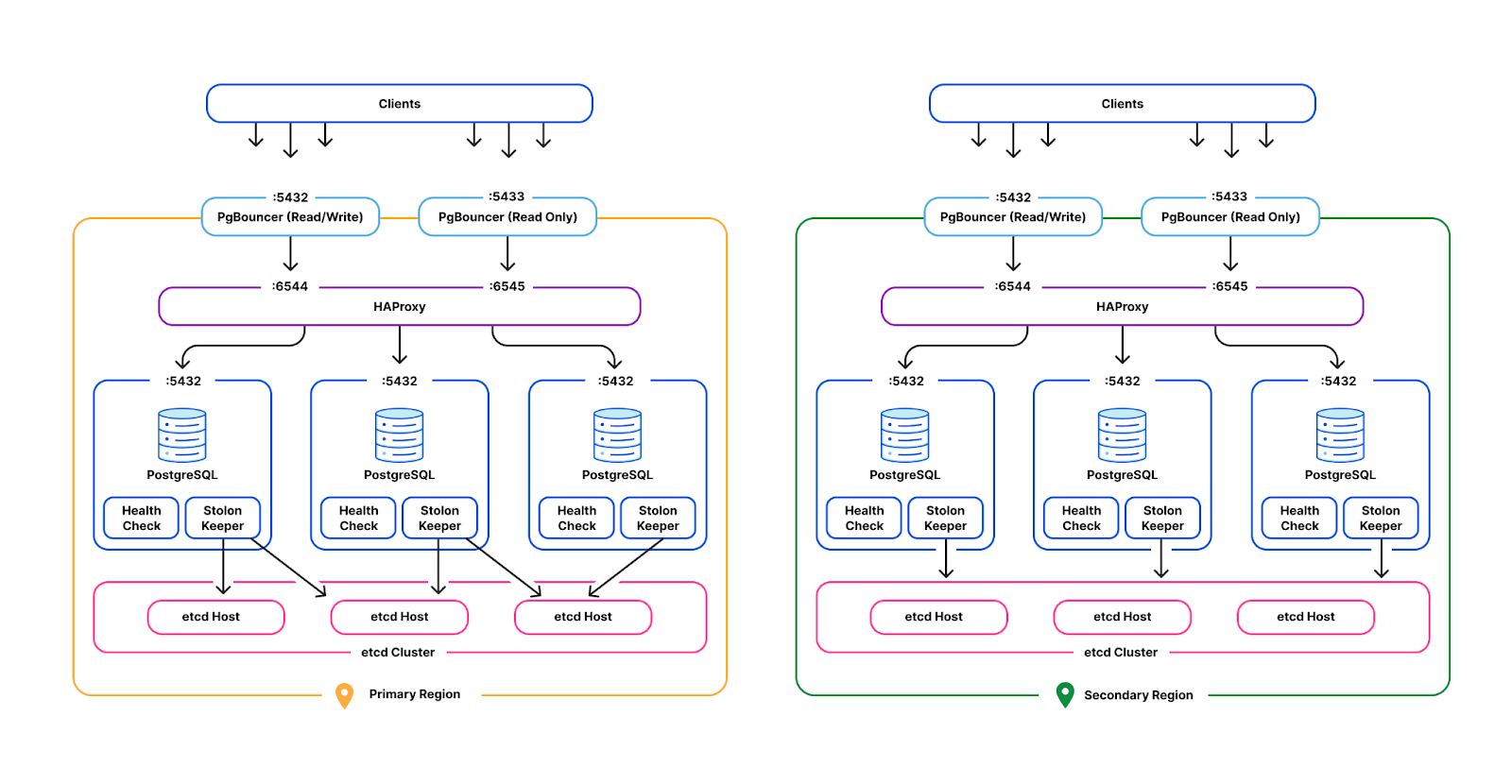
D1 is implemented on top of SQLite-backed Durable Objects running on top of Cloudflare’s Storage Relay Service.
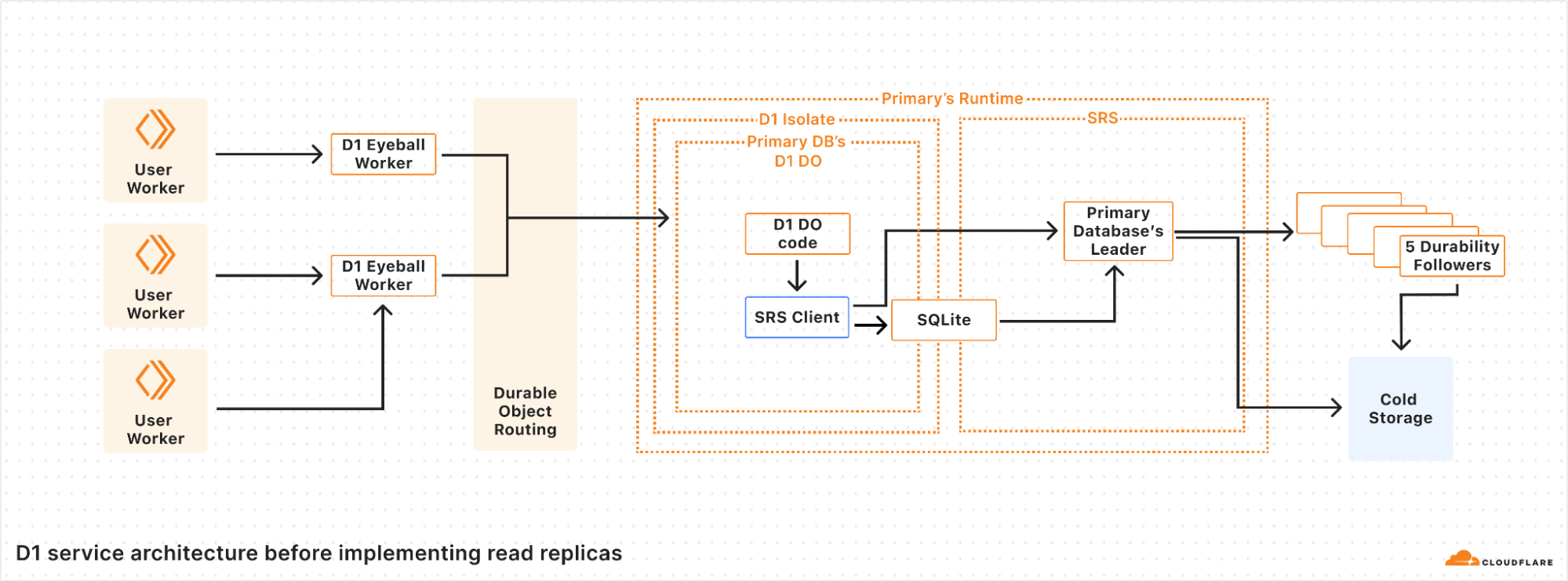
D1 is structured with a 3-layer architecture. First is the binding API layer that runs in the customer’s Worker. Next is a stateless Worker layer that routes requests based on database ID to a layer of Durable Objects that handle the actual SQL operations behind D1. This is similar to how most applications using Cloudflare Workers and Durable Objects are structured.
For a non-replicated database, there is exactly one Durable Object per database. When a user’s Worker makes a request with the D1 binding for the database, that request is first routed to a D1 Worker running in the same location as the user’s Worker. The D1 Worker figures out which D1 Durable Object backs the user’s D1 database and fetches an RPC stub to that Durable Object. The Durable Objects routing layer figures out where the Durable Object is located, and opens an RPC connection to it. Finally, the D1 Durable Object then handles the query on behalf of the user’s Worker using the Durable Objects SQL API.
In the Durable Objects SQL API, all queries go to a SQLite database on the local disk of the server where the Durable Object is running. Durable Objects run SQLite in WAL mode. In WAL mode, every write query appends to a write-ahead log (the WAL). As SQLite appends entries to the end of the WAL file, a database-specific component called the Storage Relay Service leader synchronously replicates the entries to 5 durability followers on servers in different datacenters. When a quorum (at least 3 out of 5) of the durability followers acknowledge that they have safely stored the data, the leader allows SQLite’s write queries to commit and opens the Durable Object’s output gate, so that the Durable Object can respond to requests.
Our implementation of WAL mode allows us to have a complete log of all of the committed changes to the database. This enables a couple of important features in SQLite-backed Durable Objects and D1:
-
We identify each write with a Lamport timestamp we call a bookmark.
-
We construct databases anywhere in the world by downloading all of the WAL entries from cold storage and replaying each WAL entry in order.
-
We implement Point-in-time recovery (PITR) by replaying WAL entries up to a specific bookmark rather than to the end of the log.
Unfortunately, having the main data structure of the database be a log is not ideal. WAL entries are in write order, which is often neither convenient nor fast. In order to cut down on the overheads of the log, SQLite checkpoints the log by copying the WAL entries back into the main database file. Read queries are serviced directly by SQLite using files on disk — either the main database file for checkpointed queries, or the WAL file for writes more recent than the last checkpoint. Similarly, the Storage Relay Service snapshots the database to cold storage so that we can replay a database by downloading the most recent snapshot and replaying the WAL from there, rather than having to download an enormous number of individual WAL entries.
WAL mode is the foundation for implementing read replication, since we can stream writes to locations other than cold storage in real time.
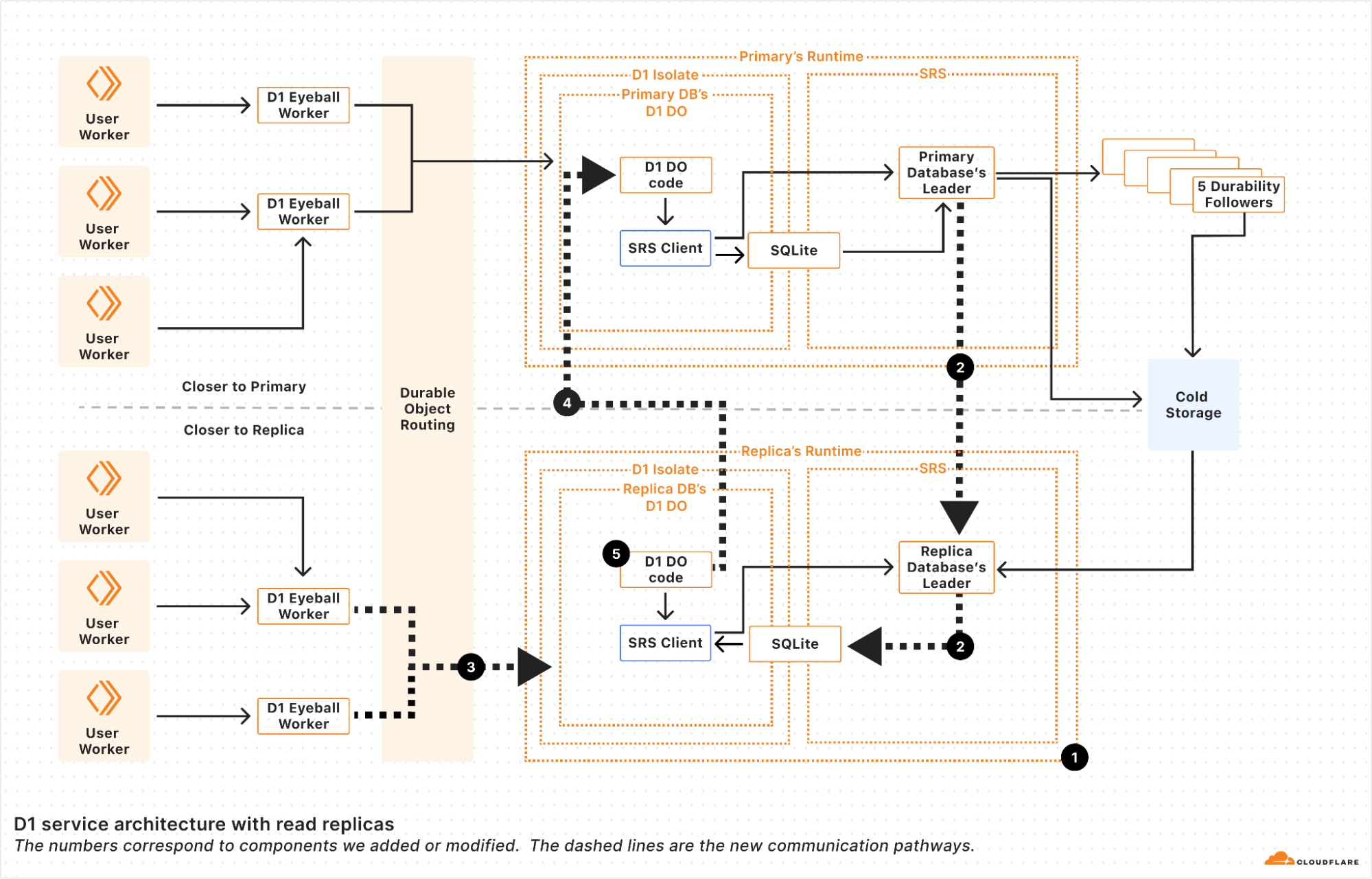
We implemented read replication in 5 major steps.
First, we made it possible to make replica Durable Objects with a read-only copy of the database. These replica objects boot by fetching the latest snapshot and replaying the log from cold storage to whatever bookmark primary database’s leader last committed. This basically gave us point-in-time replicas, since without continuous updates, the replicas never updated until the Durable Object restarted.
Second, we registered the replica leader with the primary’s leader so that the primary leader sends the replicas every entry written to the WAL at the same time that it sends the WAL entries to the durability followers. Each of the WAL entries is marked with a bookmark that uniquely identifies the WAL entry in the sequence of WAL entries. We’ll use the bookmark later.
Note that since these writes are sent to the replicas before a quorum of durability followers have confirmed them, the writes are actually unconfirmed writes, and the replica leader must be careful to keep the writes hidden from the replica Durable Object until they are confirmed. The replica leader in the Storage Relay Service does this by implementing enough of SQLite’s WAL-index protocol, so that the unconfirmed writes coming from the primary leader look to SQLite as though it’s just another SQLite client doing unconfirmed writes. SQLite knows to ignore the writes until they are confirmed in the log. The upshot of this is that the replica leader can write WAL entries to the SQLite WAL immediately, and then “commit” them when the primary leader tells the replica that the entries have been confirmed by durability followers.
One neat thing about this approach is that writes are sent from the primary to the replica as quickly as they are generated by the primary, helping to minimize lag between replicas. In theory, if the write query was proxied through a replica to the primary, the response back to the replica will arrive at almost the same time as the message that updates the replica. In such a case, it looks like there’s no replica lag at all!
In practice, we find that replication is really fast. Internally, we measure confirm lag, defined as the time from when a primary confirms a change to when the replica confirms a change. The table below shows the confirm lag for two D1 databases whose primaries are in different regions.
|
Replica Region |
Database A (Primary region: ENAM) |
Database B |
|
ENAM |
N/A |
30 ms |
|
WNAM |
45 ms |
N/A |
|
WEUR |
55 ms |
75 ms |
|
EEUR |
67 ms |
75 ms |
Confirm lag for 2 replicated databases. N/A means that we have no data for this combination. The region abbreviations are the same ones used for Durable Object location hints.
The table shows that confirm lag is correlated with the network round-trip time between the data centers hosting the primary databases and their replicas. This is clearly visible in the difference between the confirm lag for the European replicas of the two databases. As airline route planners know, EEUR is appreciably further away from ENAM than WNAM, but from WNAM, both European regions (WEUR and EEUR) are about equally as far away. We see that in our replication numbers.
The exact placement of the D1 database in the region matters too. Regions like ENAM and WNAM are quite large in themselves. Database A’s placement in ENAM happens to be further away from most data centers in WNAM compared to database B’s placement in WNAM relative to the ENAM data centers. As such, database B sees slightly lower confirm lag.
Try as we might, we can’t beat the speed of light!
Third, we updated the Durable Object routing system to be aware of Durable Object replicas. When read replication is enabled on a Durable Object, two things happen. First, we create a set of replicas according to a replication policy. The current replication policy that D1 uses is simple: a static set of replicas in every region that D1 supports. Second, we turn on a routing policy for the Durable Object. The current policy that D1 uses is also simple: route to the Durable Object replica in the region close to where the user request is. With this step, we have updateable read-only replicas, and can route requests to them!
Fourth, we updated D1’s Durable Object code to handle write queries on replicas. D1 uses SQLite to figure out whether a request is a write query or a read query. This means that the determination of whether something is a read or write query happens after the request is routed. Read replicas will have to handle write requests! We solve this by instantiating each replica D1 Durable Object with a reference to its primary. If the D1 Durable Object determines that the query is a write query, it forwards the request to the primary for the primary to handle. This happens transparently, keeping the user code simple.
As of this fourth step, we can handle read and write queries at every copy of the D1 Durable Object, whether it’s a primary or not. Unfortunately, as outlined above, if a user’s requests get routed to different read replicas, they may see different views of the database, leading to a very weak consistency model. So the last step is to implement the Sessions API across the D1 Worker and D1 Durable Object. Recall that every WAL entry is marked with a bookmark. These bookmarks uniquely identify a point in (logical) time in the database. Our bookmarks are strictly monotonically increasing; every write to a database makes a new bookmark with a value greater than any other bookmark for that database.
Using bookmarks, we implement the Sessions API with the following algorithm split across the D1 binding implementation, the D1 Worker, and D1 Durable Object.
First up in the D1 binding, we have code that creates the D1DatabaseSession object and code within the D1DatabaseSession object to keep track of the latest bookmark.
// D1Binding is the binding code running within the user's Worker
// that provides the existing D1 Workers API and the new withSession method.
class D1Binding {
// Injected by the runtime to the D1 Binding.
d1Service: D1ServiceBinding
function withSession(initialBookmark) {
return D1DatabaseSession(this.d1Service, this.databaseId, initialBookmark);
}
}
// D1DatabaseSession holds metadata about the session, most importantly the
// latest bookmark we know about for this session.
class D1DatabaseSession {
constructor(d1Service, databaseId, initialBookmark) {
this.d1Service = d1Service;
this.databaseId = databaseId;
this.bookmark = initialBookmark;
}
async exec(query) {
// The exec method in the binding sends the query to the D1 Worker
// and waits for the the response, updating the bookmark as
// necessary so that future calls to exec use the updated bookmark.
var resp = await this.d1Service.handleUserQuery(databaseId, query, bookmark);
if (isNewerBookmark(this.bookmark, resp.bookmark)) {
this.bookmark = resp.bookmark;
}
return resp;
}
// batch and other SQL APIs are implemented similarly.
}The binding code calls into the D1 stateless Worker (d1Service in the snippet above), which figures out which Durable Object to use, and proxies the request to the Durable Object.
class D1Worker {
async handleUserQuery(databaseId, query) {
var doId = /* look up Durable Object for databaseId */;
return await this.D1_DO.get(doId).handleWorkerQuery(query, bookmark)
}
}Finally, we reach the Durable Objects layer, which figures out how to actually handle the request.
class D1DurableObject {
async handleWorkerQuery(queries, bookmark) {
var bookmark = bookmark ?? "first-primary";
var results = {};
if (this.isPrimaryDatabase()) {
// The primary always has the latest data so we can run the
// query without checking the bookmark.
var result = /* execute query directly */;
bookmark = getCurrentBookmark();
results = result;
} else {
// This is running on a replica.
if (bookmark === "first-primary" || isWriteQuery(query)) {
// The primary must handle this request, so we'll proxy the
// request to the primary.
var resp = await this.primary.handleWorkerQuery(query, bookmark);
bookmark = resp.bookmark;
results = resp.results;
} else {
// The replica can handle this request, but only after the
// database is up-to-date with the bookmark.
if (bookmark !== "first-unconstrained") {
await waitForBookmark(bookmark);
}
var result = /* execute query locally */;
bookmark = getCurrentBookmark();
results = result;
}
}
return { results: results, bookmark: bookmark };
}
}The D1 Durable Object first figures out if this instance can handle the query, or if the query needs to be sent to the primary. If the Durable Object can execute the query, it ensures that we execute the query with a bookmark at least as up-to-date as the bookmark requested by the binding.
The upshot is that the three pieces of code work together to ensure that all of the queries in the session see the database in a sequentially consistent order, because each new query will be blocked until it has seen the results of previous queries within the same session.
D1’s new read replication feature is a significant step towards making globally distributed databases easier to use without sacrificing consistency. With automatically provisioned replicas in every region, your applications can now serve read queries faster while maintaining strong sequential consistency across requests, and keeping your application Worker code simple.
We’re excited for developers to explore this feature and see how it improves the performance of your applications. The public beta is just the beginning—we’re actively refining and expanding D1’s capabilities, including evolving replica placement policies, and your feedback will help shape what’s next.
Note that the Sessions API is only available through the D1 Worker Binding for now, and support for the HTTP REST API will follow soon.
Try out D1 read replication today by clicking the “Deploy to Cloudflare” button, check out documentation and examples, and let us know what you build in the D1 Discord channel!