Post Syndicated from Greg Hamer original https://www.backblaze.com/blog/storing-and-querying-analytical-data-in-backblaze-b2/

Have You Ever Used Backblaze B2 Cloud Storage for Your Data Analytics?
Backblaze customers find that Backblaze B2 Cloud Storage is optimal for a wide variety of use cases. However, one application that many teams might not yet have tried is using Backblaze B2 for data analytics. You may find that having a highly reliable pre-provisioned storage option like Backblaze B2 Cloud Storage for your data lakes can be a useful and very cost-effective alternative for your data analytic workloads.
This article is an introductory primer on getting started using Backblaze B2 for data analytics that uses our Drive Stats as the example of the data being analyzed. For readers new to data lakes, this article can help you get your own data lake up and going on Backblaze B2 Cloud Storage.
As you probably know, a commonly used technology for data analytics is SQL (Structured Query Language). Most people know SQL from databases. However, SQL can be used against collections of files stored outside of databases, now commonly referred to as data lakes. We will focus here on several options using SQL for analyzing Drive Stats data stored on Backblaze B2 Cloud Storage.
It should be noted that data lakes most frequently prove optimal for read-only or append-only datasets. Whereas databases often remain optimal for “hot” data with active insert, update and delete of individual rows, and especially updates of individual column values on individual rows.
We can only scratch the surface of storing, querying, and analyzing tabular data in a single blog post. So for this introductory article, we will:
- Briefly explain the Drive Stats data.
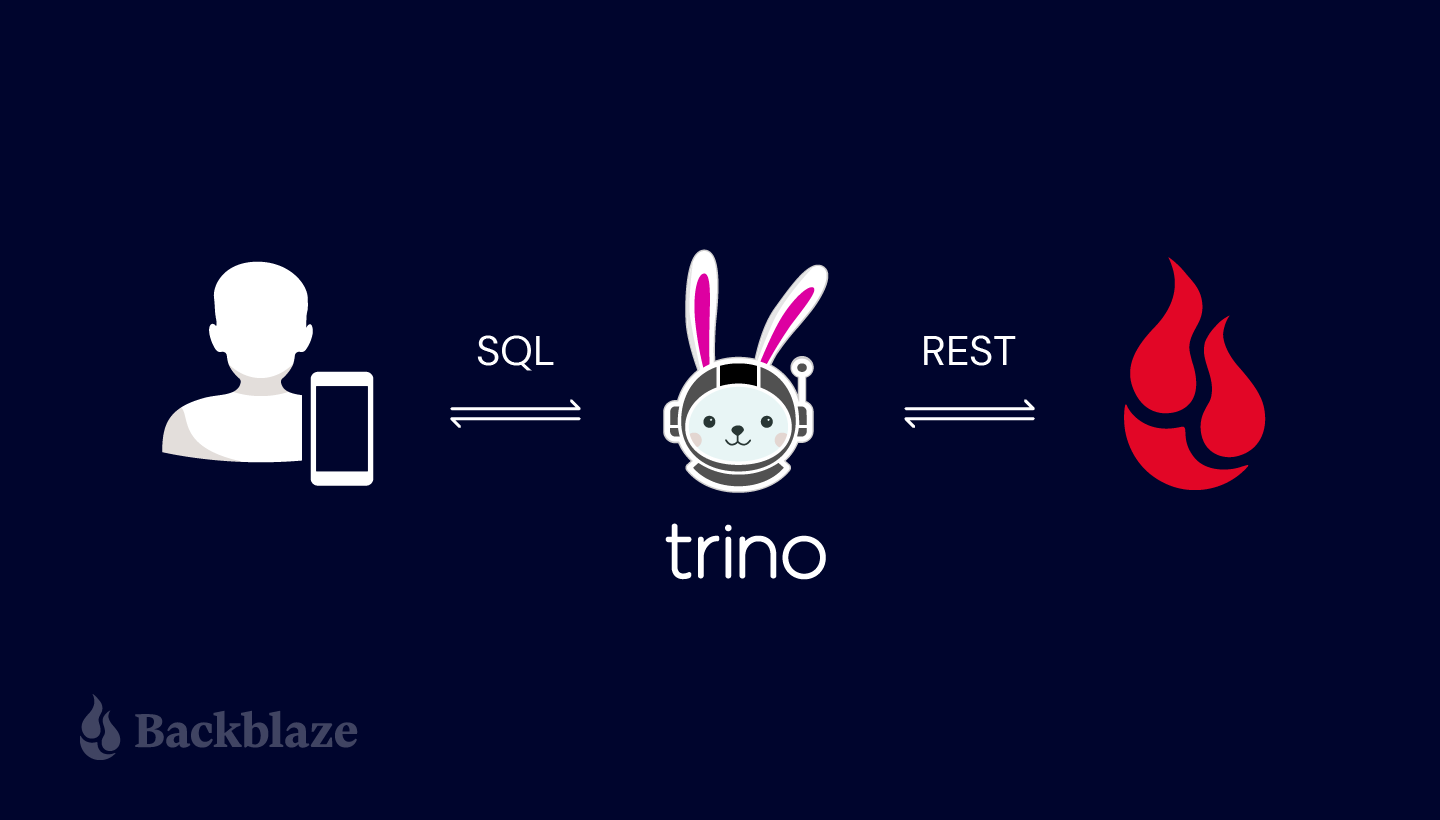
- Introduce open-source Trino as one option for executing SQL against the Drive Stats data.
- Query Drive Stats data both in raw CSV format versus enhanced performance after transforming the data into the open-source Apache Parquet format.
The sections below take a step-by-step approach including details on the performance improvements realized when implementing recommended data engineering options. We start with a demonstration of analysis of raw data. Then progress through “data engineering” that transforms the data into formats that are optimal for accelerating repeated queries of the dataset. We conclude by highlighting our hosted, consolidated, complete Drive Stats dataset.
As mentioned earlier, this blog post is intended only as an introductory primer. In future blog posts, we will detail additional best practices and other common issues and opportunities with data analysis using Backblaze B2.
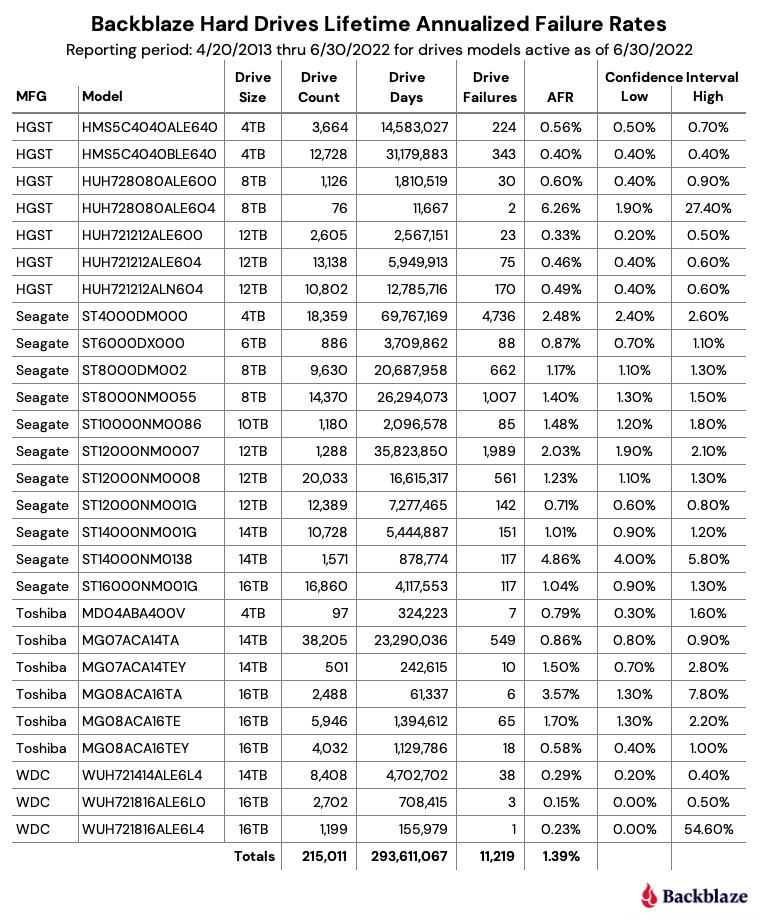
Backblaze Hard Drive Data and Stats (aka Drive Stats)
Drive Stats is an open-source data set of the daily metrics on the hard drives in Backblaze’s cloud storage infrastructure that Backblaze has open-sourced starting with April 2013. Currently, Drive Stats comprises nearly 300 million records, occupying over 90GB of disk space in raw comma-separated values (CSV) format, rising by over 200,000 records, or about 75MB of CSV data, per day. Drive Stats is an append-only dataset effectively logging daily statistics that once written are never updated or deleted.
The Drive Stats dataset is not quite “big data,” where datasets range from a few dozen terabytes to many zettabytes, but enough that physical data architecture starts to have a significant effect in both the amount of space that the data occupies and how the data can be accessed.
At the end of each quarter, Backblaze creates a CSV file for each day of data, ZIP those 90 or so files together, and make the compressed file available for download from a Backblaze B2 Bucket. While it’s easy to download and decompress a single file containing three months of data, this data architecture is not very flexible. With a little data engineering, though, it’s possible to make analytical data, such as the Drive Stats data set, available for modern data analysis tools to directly access from cloud storage, unlocking new opportunities for data analysis and data science.
Later, for comparison, we include a brief demonstration of performance of the data lake versus a traditional relational database. Architecturally, a difference between a data lake and a database is that databases integrate together both the query engine and the data storage. When data is either inserted or loaded into a database, the database has optimized internal storage structures it uses. Alternatively, with a data lake, the query engine and the data storage are separate. What we highlight below are basics for optimizing data storage in a data lake to enable the query engine to deliver the fastest query response times.
As with all data analysis, it is helpful to understand details of what the data represents. Before showing results, let’s take a deeper dive into the nature of the Drive Stats data. (For readers interested in first reviewing outcomes and improved query performance results, please skip ahead to the later sections “Compressed CSV” and “Enter Apache Parquet.”)
Navigating the Drive Stats Data
At Backblaze we collect a Drive Stats record from each hard drive, each day, containing the following data:
- date: the date of collection.
- serial_number: the unique serial number of the drive.
- model: the manufacturer’s model number of the drive.
- capacity_bytes: the drive’s capacity, in bytes.
- failure: 1 if this was the last day that the drive was operational before failing, 0 if all is well.
- A collection of SMART attributes. The number of attributes collected has risen over time; currently we store 87 SMART attributes in each record, each one in both raw and normalized form, with field names of the form smart_n_normalized and smart_n_raw, where n is between 1 and 255.
In total, each record currently comprises 179 fields of data describing the state of an individual hard drive on a given day (the number of SMART attributes collected has risen over time).
Comma-Separated Values, a Lingua Franca for Tabular Data
A CSV file is a delimited text file that, as its name implies, uses a comma to separate values. Typically, the first line of a CSV file is a header containing the field names for the data, separated by commas. The remaining lines in the file hold the data: one line per record, with each line containing the field values, again separated by commas.
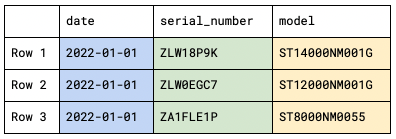
Here’s a subset of the Drive Stats data represented as CSV. We’ve omitted most of the SMART attributes to make the records more manageable.
date,serial_number,model,capacity_bytes,failure,
smart_1_normalized,smart_1_raw
2022-01-01,ZLW18P9K,ST14000NM001G,14000519643136,0,73,20467240
2022-01-01,ZLW0EGC7,ST12000NM001G,12000138625024,0,84,228715872
2022-01-01,ZA1FLE1P,ST8000NM0055,8001563222016,0,82,157857120
2022-01-01,ZA16NQJR,ST8000NM0055,8001563222016,0,84,234265456
2022-01-01,1050A084F97G,TOSHIBA MG07ACA14TA,14000519643136,0,100,0
Currently, we create a CSV file for each day’s data, comprising a record for each drive that was operational at the beginning of that day. The CSV files are each named with the appropriate date in year-month-day order, for example, 2022-06-28.csv. As mentioned above, we make each quarter’s data available as a ZIP file containing the CSV files.
At the beginning of the last Drive Stats quarter, Jan 1, 2022, we were spinning over 200,000 hard drives, so each daily file contained over 200,000 lines and occupied nearly 75MB of disk space. The ZIP file containing the Drive Stats data for the first quarter of 2022 compressed 90 files totaling 6.63GB of CSV data to a single 1.06GB file made available for download here.
Big Data Analytics in the Cloud with Trino
Zipped CSV files allow users to easily download, inspect, and analyze the data locally, but a new generation of tools allows us to explore and query data in situ on Backblaze B2 and other cloud storage platforms. One example is the open-source Trino query engine (formerly known as Presto SQL). Trino can natively query data in Backblaze B2, Cassandra, MySQL, and many other data sources without copying that data into its own dedicated store.
A powerful capability of Trino is that it is a distributed query engine and offers what is sometimes referred to as massively parallel processing (MPP). Thus, adding more nodes in your Trino compute cluster consistently delivers dramatically shorter query execution times. Faster results are always desirable. We achieved the results we report below running Trino on only a single node.
Note: If you are unfamiliar with Trino, the open-source project was previously known as Presto and leverages the Hadoop ecosystem.
In preparing this blog post, our team used Brian Olsen’s excellent Hive connector over MinIO file storage tutorial as a starting point for integrating Trino with Backblaze B2. The tutorial environment includes a preconfigured Docker Compose environment comprising the Trino Docker image and other required services for working with data in Backblaze B2. We brought up the environment in Docker Desktop; alternately on ThinkPads and MacBook Pros.
As a first step, we downloaded the data set for the most recent quarter, unzipped it to our local disks, and then finally reuploaded the unzipped CSV into Backblaze B2 buckets. As mentioned above, the uncompressed CSV data occupies 6.63GB of storage, so we confined our initial explorations to just a single day’s data: over 200,000 records, occupying 72.8MB.
A Word About Apache Hive
Trino accesses analytical data in Backblaze B2 and other cloud storage platforms via its Hive connector. Quoting from the Trino documentation:
The Hive connector allows querying data stored in an Apache Hive data warehouse. Hive is a combination of three components:
- Data files in varying formats, that are typically stored in the Hadoop Distributed File System (HDFS) or in object storage systems such as Amazon S3.
- Metadata about how the data files are mapped to schemas and tables. This metadata is stored in a database, such as MySQL, and is accessed via the Hive metastore service.
- A query language called HiveQL. This query language is executed on a distributed computing framework such as MapReduce or Tez.
Trino only uses the first two components: the data and the metadata. It does not use HiveQL or any part of Hive’s execution environment.
The Hive connector tutorial includes Docker images for the Hive metastore service (HMS) and MariaDB, so it’s a convenient way to explore this functionality with Backblaze B2.
Configuring Trino for Backblaze B2
The tutorial uses MinIO, an open-source implementation of the Amazon S3 API, so it was straightforward to adapt the sample MinIO configuration to Backblaze B2’s S3 Compatible API by just replacing the endpoint and credentials. Here’s the b2.properties file we created:
connector.name=hive
hive.metastore.uri=thrift://hive-metastore:9083
hive.s3.path-style-access=true
hive.s3.endpoint=https://s3.us-west-004.backblazeb2.com
hive.s3.aws-access-key=
hive.s3.aws-secret-key=
hive.non-managed-table-writes-enabled=true
hive.s3select-pushdown.enabled=false
hive.storage-format=CSV
hive.allow-drop-table=true
Similarly, we edited the Hive configuration files, again replacing the MinIO configuration with the corresponding Backblaze B2 values. Here’s a sample core-site.xml:
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>s3a://b2-trino-getting-started</value>
</property>
<!-- B2 properties -->
<property>
<name>fs.s3a.connection.ssl.enabled</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.endpoint</name>
<value>https://s3.us-west-004.backblazeb2.com</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value><my b2 application key id></value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value><my b2 application key id></value>
</property>
<property>
<name>fs.s3a.path.style.access</name>
<value>true</value>
</property>
<property>
<name>fs.s3a.impl</name>
<value>org.apache.hadoop.fs.s3a.S3AFileSystem</value>
</property>
</configuration>
We made a similar set of edits to metastore-site.xml and restarted the Docker instances so our changes took effect.
Uncompressed CSV
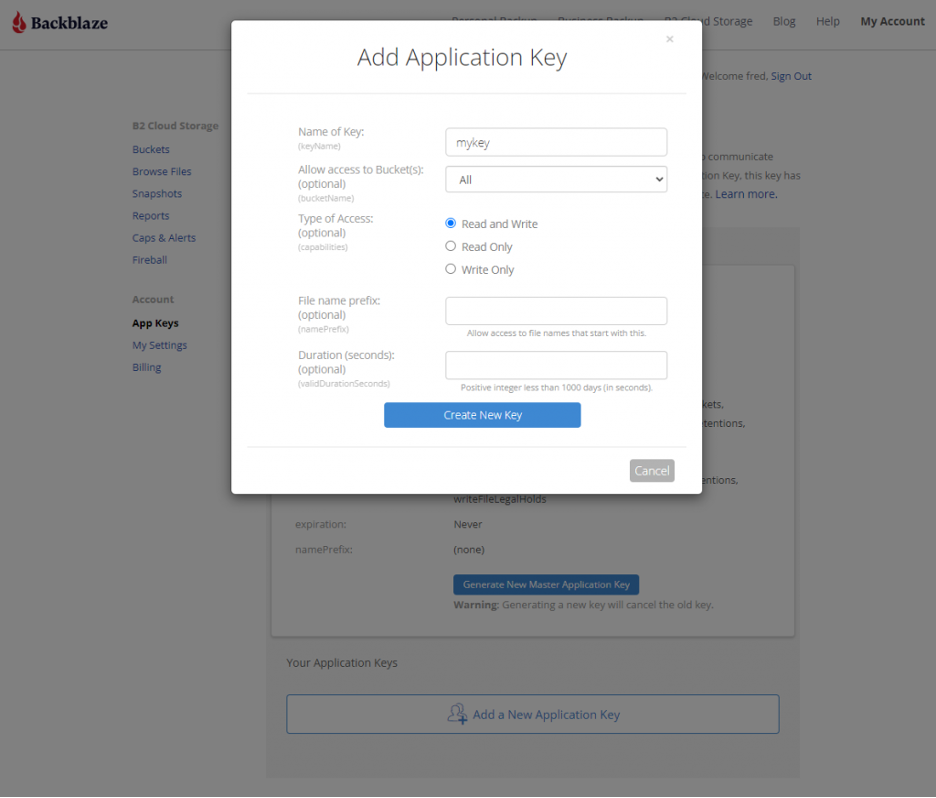
Our first test validated creating a table and running a query on a single-day CSV data set. Hive tables are configured with the directory containing the actual data files, so we uploaded 2020-01-01.csv from a local disk to data_20220101_csv/2020-01-01.csv in a Backblaze B2 bucket, opened the Trino CLI, and created a schema and a table:
CREATE SCHEMA b2.ds
WITH (location = 's3a://b2-trino-getting-started/');
USE b2.ds;
CREATE TABLE jan1_csv (
date VARCHAR,
serial_number VARCHAR,
model VARCHAR,
capacity_bytes VARCHAR,
failure VARCHAR,
smart_1_normalized VARCHAR,
smart_1_raw VARCHAR,
...
smart_255_normalized VARCHAR,
smart_255_raw VARCHAR)
WITH (format = 'CSV',
skip_header_line_count = 1,
external_location = '
s3a://b2-trino-getting-started/data_20220101_csv');
Unfortunately, the Trino Hive connector only supports the VARCHAR data type when accessing CSV data, but, as we’ll see in a moment, we can use the CAST function in queries to convert character data to numeric and other types.
Now to run some queries! A good test is to check if all the data is there:
trino:ds> SELECT COUNT(*) FROM jan1_csv;
_col0
--------
206954
(1 row)
Query 20220629_162533_00024_qy4c6, FINISHED, 1 node
Splits: 8 total, 8 done (100.00%)
8.23 [207K rows, 69.4MB] [25.1K rows/s, 8.43MB/s]
Note: If you’re wondering about the discrepancy between the size of the CSV file–72.8MB–and the amount of data read by Trino–69.4MB–it’s accounted for in the different usage of the ‘MB’ abbreviation. For instance Mac interprets MB as a
megabyte, 1,000,000 bytes, while Trino is reporting
mebibytes, 1,048,576 bytes. Strictly speaking, Trino should use the abbreviation MiB. Pat
opened an issue for this (with a goal of fixing it and submitting a pull request to the Trino project).
Now let’s see how many drives failed that day, grouped by the drive model:
trino:ds> SELECT model, COUNT(*) as failures
-> FROM jan1_csv
-> WHERE failure = 1
-> GROUP BY model
-> ORDER BY failures DESC;
model | failures
--------------------+----------
TOSHIBA MQ01ABF050 | 1
ST4000DM005 | 1
ST8000NM0055 | 1
(3 rows)
Query 20220629_162609_00025_qy4c6, FINISHED, 1 node
Splits: 17 total, 17 done (100.00%)
8.23 [207K rows, 69.4MB] [25.1K rows/s, 8.43MB/s]
Notice that the query execution time is identical between the two queries. This makes sense–the time taken to run the query is dominated by the time required to download the data from Backblaze B2.
Finally, we can use the CAST function with SUM and ROUND to see how many exabytes of storage we were spinning on that day:
trino:ds> SELECT ROUND(SUM(CAST(capacity_bytes AS bigint))/1e+18, 2) FROM jan1_csv;
_col0
-------
2.25
(1 row)
Query 20220629_172703_00047_qy4c6, FINISHED, 1 node
Splits: 12 total, 12 done (100.00%)
7.83 [207K rows, 69.4MB] [26.4K rows/s, 8.86MB/s]
Although this performance may seem too long running, please note that this is against raw data. What we are highlighting here with Drive Stats data can also be used for querying data in log files. As new records are written on this append-only dataset they immediately appear as new rows in the query. This is very powerful for both real-time and near real-time analysis, and faster performance is easily achieved by scaling out the Trino cluster. Remember, Trino is a distributed query engine. For this demonstration, we have limited Trino to running on just a single node.
Compressed CSV
This is pretty neat, but not exactly fast. Extrapolating, we might expect it to take about 12 minutes to run a query against a whole quarter of Drive Stats data.
Can we improve performance? Absolutely–we simply need to reduce the amount of data that needs to be downloaded for each query!
Commonplace in the world of data analytics are data pipelines, often known as ETL for Extract, Transform, and Load. Where data is repeatedly queried, it is often advantageous to “transform” data from the raw form that it originates in into some format more optimized for the repeated queries that follow through the next stages of that data’s life cycle.
For our next test we will perform an elementary transformation of the data using a lossless compression of the CSV data with Hive’s preferred gzip format, resulting in an 11.7 MB file, 2020-01-01.csv.gz. After uploading the compressed file to data_20220101_csv_gz/2020-01-01.csv.gz, we created a second table, copying the schema from the first:
CREATE TABLE jan1_csv_gz (
LIKE jan1_csv
)
WITH (FORMAT = 'CSV',
EXTERNAL_LOCATION = 's3a://b2-trino-getting-started/data_20220101_csv_gz');
Trying the failure count query:
trino:ds> SELECT model, COUNT(*) as failures
-> FROM jan1_csv_gz
-> WHERE failure = 1
-> GROUP BY model
-> ORDER BY failures DESC;
model | failures
--------------------+----------
TOSHIBA MQ01ABF050 | 1
ST8000NM0055 | 1
ST4000DM005 | 1
(3 rows)
Query 20220629_162713_00027_qy4c6, FINISHED, 1 node
Splits: 15 total, 15 done (100.00%)
2.71 [207K rows, 11.1MB] [76.4K rows/s, 4.1MB/s]
As you might expect, given that Trino has to download less than ⅙ as much data as previously, the query time fell dramatically–from just over 8 seconds to under 3 seconds. Can we do even better than this?
Enter Apache Parquet
The issue with running this kind of analytical query is that it often results in a “full table scan”–Trino has to read the model and failure fields from every record to execute the query. The row-oriented layout of CSV data means that Trino ends up reading the entire file. We can get around this by using a file format designed specifically for analytical workloads.
While CSV files comprise a line of text for each record, Parquet is a column-oriented, binary file format, storing the binary values for each column contiguously. Here’s a simple visualization of the difference between row and column orientation:
Table representation:

Row orientation:

Column Orientation:

Parquet also implements run-length encoding and other compression techniques. Where a series of records have the same value for a given field the Parquet file need only store the value and the number of repetitions:

The result is a compact file format well suited for analytical queries.
There are many tools to manipulate tabular data from one format to another. In this case, we wrote a very simple Python script that used the pyarrow library to do the job:
import pyarrow.csv as csv
import pyarrow.parquet as parquet
filename = '2022-01-01.csv'
parquet.write_table(csv.read_csv(filename),
filename.replace('.csv', '.parquet'))
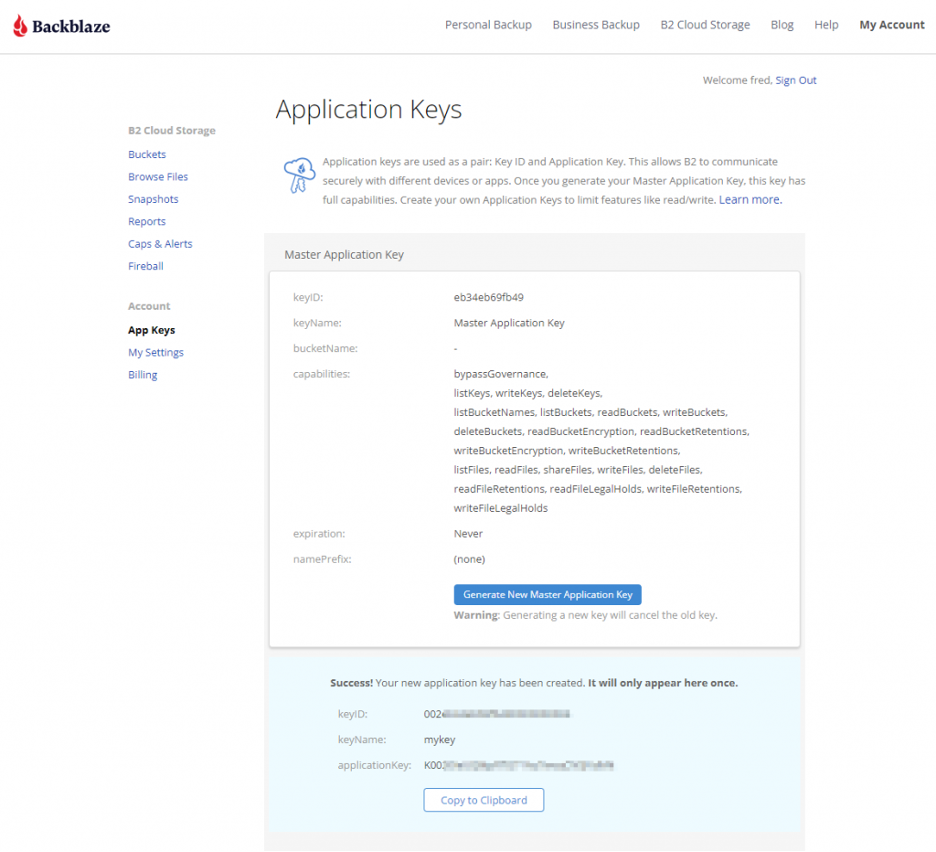
The resulting Parquet file occupies 12.8MB–only 1.1MB more than the gzip file. Again, we uploaded the resulting file and created a table in Trino.
CREATE TABLE jan1_parquet (
date DATE,
serial_number VARCHAR,
model VARCHAR,
capacity_bytes BIGINT,
failure TINYINT,
smart_1_normalized BIGINT,
smart_1_raw BIGINT,
...
smart_255_normalized BIGINT,
smart_255_raw BIGINT)
WITH (FORMAT = 'PARQUET',
EXTERNAL_LOCATION =
's3a://b2-trino-getting-started/data_20220101_parquet);
Note that the conversion to Parquet automatically formatted the data using appropriate types, which we used in the table definition.
Let’s run a query and see how Parquet fares against compressed CSV:
trino:ds> SELECT model, COUNT(*) as failures
-> FROM jan1_parquet
-> WHERE failure = 1
-> GROUP BY model
-> ORDER BY failures DESC;
model | failures
--------------------+----------
TOSHIBA MQ01ABF050 | 1
ST4000DM005 | 1
ST8000NM0055 | 1
(3 rows)
Query 20220629_163018_00031_qy4c6, FINISHED, 1 node
Splits: 15 total, 15 done (100.00%)
0.78 [207K rows, 334KB] [265K rows/s, 427KB/s]
The test query is executed in well under a second! Looking at the last line of output, we can see that the same number of rows were read, but only 334KB of data was retrieved. Trino was able to retrieve just the two columns it needed, out of the 179 columns in the file, to run the query.
Similar analytical queries execute just as efficiently. Calculating the total amount of storage in exabytes:
trino:ds> SELECT ROUND(SUM(capacity_bytes)/1e+18, 2) FROM jan1_parquet;
_col0
-------
2.25
(1 row)
Query 20220629_163058_00033_qy4c6, FINISHED, 1 node
Splits: 10 total, 10 done (100.00%)
0.83 [207K rows, 156KB] [251K rows/s, 189KB/s]
What was the capacity of the largest drive in terabytes?
trino:ds> SELECT max(capacity_bytes)/1e+12 FROM jan1_parquet;
_col0
-----------------
18.000207937536
(1 row)
Query 20220629_163139_00034_qy4c6, FINISHED, 1 node
Splits: 10 total, 10 done (100.00%)
0.80 [207K rows, 156KB] [259K rows/s, 195KB/s]
Parquet’s columnar layout excels with analytical workloads, but if we try a query more suited to an operational database, Trino has to read the entire file, as we would expect:
trino:ds> SELECT * FROM jan1_parquet WHERE serial_number = 'ZLW18P9K';
date | serial_number | model | capacity_bytes | failure
------------+---------------+---------------+----------------+--------
2022-01-01 | ZLW18P9K | ST14000NM001G | 14000519643136 | 0
(1 row)
Query 20220629_163206_00035_qy4c6, FINISHED, 1 node
Splits: 5 total, 5 done (100.00%)
2.05 [207K rows, 12.2MB] [101K rows/s, 5.95MB/s]
Scaling Up
After validating our Trino configuration with just a single day’s data, our next step up was to create a Parquet file containing an entire quarter. The file weighed in at 1.0GB, a little smaller than the zipped CSV.
Here’s the failed drives query for the entire quarter, limited to the top 10 results:
trino:ds> SELECT model, COUNT(*) as failures
-> FROM q1_2022_parquet
-> WHERE failure = 1
-> GROUP BY model
-> ORDER BY failures DESC
-> LIMIT 10;
model | failures
----------------------+----------
ST4000DM000 | 117
TOSHIBA MG07ACA14TA | 88
ST8000NM0055 | 86
ST12000NM0008 | 73
ST8000DM002 | 38
ST16000NM001G | 24
ST14000NM001G | 24
HGST HMS5C4040ALE640 | 21
HGST HUH721212ALE604 | 21
ST12000NM001G | 20
(10 rows)
Query 20220629_183338_00050_qy4c6, FINISHED, 1 node
Splits: 43 total, 43 done (100.00%)
3.38 [18.8M rows, 15.8MB] [5.58M rows/s, 4.68MB/s]
Of course, those are absolute failure numbers; they don’t take account of how many of each drive model are in use. We can construct a more complex query that tells us the percentages of failed drives, by model:
trino:ds> SELECT drives.model AS model, drives.drives AS drives,
-> failures.failures AS failures,
-> ROUND((CAST(failures AS double)/drives)*100, 6) AS percentage
-> FROM
-> (
-> SELECT model, COUNT(*) as drives
-> FROM q1_2022_parquet
-> GROUP BY model
-> ) AS drives
-> RIGHT JOIN
-> (
-> SELECT model, COUNT(*) as failures
-> FROM q1_2022_parquet
-> WHERE failure = 1
-> GROUP BY model
-> ) AS failures
-> ON drives.model = failures.model
-> ORDER BY percentage DESC
-> LIMIT 10;
model | drives | failures | percentage
----------------------+--------+----------+------------
ST12000NM0117 | 873 | 1 | 0.114548
ST10000NM001G | 1028 | 1 | 0.097276
HGST HUH728080ALE604 | 4504 | 3 | 0.066607
TOSHIBA MQ01ABF050M | 26231 | 13 | 0.04956
TOSHIBA MQ01ABF050 | 24765 | 12 | 0.048455
ST4000DM005 | 3331 | 1 | 0.030021
WDC WDS250G2B0A | 3338 | 1 | 0.029958
ST500LM012 HN | 37447 | 11 | 0.029375
ST12000NM0007 | 118349 | 19 | 0.016054
ST14000NM0138 | 144333 | 17 | 0.011778
(10 rows)
Query 20220629_191755_00010_tfuuz, FINISHED, 1 node
Splits: 82 total, 82 done (100.00%)
8.70 [37.7M rows, 31.6MB] [4.33M rows/s, 3.63MB/s]
This query took twice as long as the last one! Again, data transfer time is the limiting factor–Trino downloads the data for each subquery. A real-world deployment would take advantage of the Hive Connector’s storage caching feature to avoid repeatedly retrieving the same data.
Picking the Right Tool for the Job
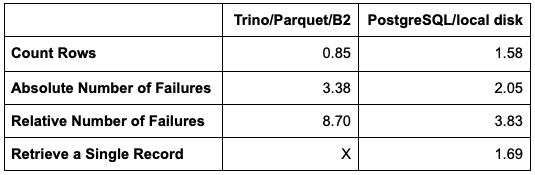
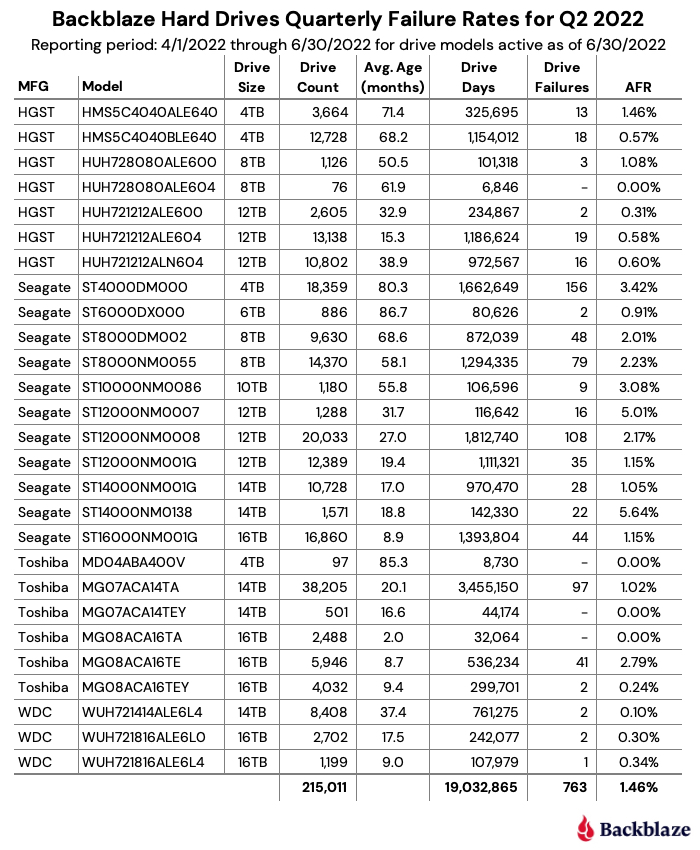
You might be wondering how a relational database would stack up against the Trino/Parquet/Backblaze B2 combination. As a quick test, we installed PostgreSQL 14 on a MacBook Pro, loaded the same quarter’s data into a table, and ran the same set of queries:
Count Rows
sql_stmt=# \timing
Timing is on.
sql_stmt=# SELECT COUNT(*) FROM q1_2022;
count
----------
18845260
(1 row)
Time: 1579.532 ms (00:01.580)
Absolute Number of Failures
sql_stmt=# SELECT model, COUNT(*) as failures FROM q1_2022 WHERE failure = 't' GROUP BY model ORDER BY failures DESC LIMIT 10;
model | failures
----------------------+----------
ST4000DM000 | 117
TOSHIBA MG07ACA14TA | 88
ST8000NM0055 | 86
ST12000NM0008 | 73
ST8000DM002 | 38
ST14000NM001G | 24
ST16000NM001G | 24
HGST HMS5C4040ALE640 | 21
HGST HUH721212ALE604 | 21
ST12000NM001G | 20
(10 rows)
Time: 2052.019 ms (00:02.052)
Relative Number of Failures
sql_stmt=# SELECT drives.model AS model, drives.drives AS drives, failures.failures, ROUND((CAST(failures AS numeric)/drives)*100, 6) AS percentage FROM ( SELECT model, COUNT(*) as drives FROM q1_2022 GROUP BY model ) AS drives RIGHT JOIN ( SELECT model, COUNT(*) as failures FROM q1_2022 WHERE failure = 't' GROUP BY model ) AS failures ON drives.model = failures.model ORDER BY percentage DESC LIMIT 10;
model | drives | failures | percentage
----------------------+--------+----------+------------
ST12000NM0117 | 873 | 1 | 0.114548
ST10000NM001G | 1028 | 1 | 0.097276
HGST HUH728080ALE604 | 4504 | 3 | 0.066607
TOSHIBA MQ01ABF050M | 26231 | 13 | 0.049560
TOSHIBA MQ01ABF050 | 24765 | 12 | 0.048455
ST4000DM005 | 3331 | 1 | 0.030021
WDC WDS250G2B0A | 3338 | 1 | 0.029958
ST500LM012 HN | 37447 | 11 | 0.029375
ST12000NM0007 | 118349 | 19 | 0.016054
ST14000NM0138 | 144333 | 17 | 0.011778
(10 rows)
Time: 3831.924 ms (00:03.832)
Retrieve a Single Record by Serial Number and Date
Modifying the query, since we have an entire quarter’s data:
sql_stmt=# SELECT * FROM q1_2022 WHERE serial_number = 'ZLW18P9K' AND date = '2022-01-01';
date | serial_number | model | capacity_bytes | failure
------------+---------------+---------------+----------------+--------
2022-01-01 | ZLW18P9K | ST14000NM001G | 14000519643136 | f (1 row)
Time: 1690.091 ms (00:01.690)
For comparison, we tried to run the same query against the quarter’s data in Parquet format, but Trino crashed with an out of memory error after 58 seconds. Clearly some tuning of the default configuration is required!
Bringing the numbers together for the quarterly data sets. All times are in seconds.

PostgreSQL is faster for most operations, but not by much, especially considering that its data is on the local SSD, rather than Backblaze B2!
It’s worth mentioning that there are yet more tuning optimizations that we have not demonstrated in this exercise. For instance, the Trino Hive connector supports storage caching. Implementing a cache yields further performance gains by avoiding repeatedly retrieving the same data from Backblaze B2. Further, Trino is a distributed query engine. Trino’s architecture is horizontally scalable. This means that Trino can also deliver shorter query run times by adding more nodes in your Trino compute cluster. We have limited all timings in this demonstration to Trino running on just a single node.
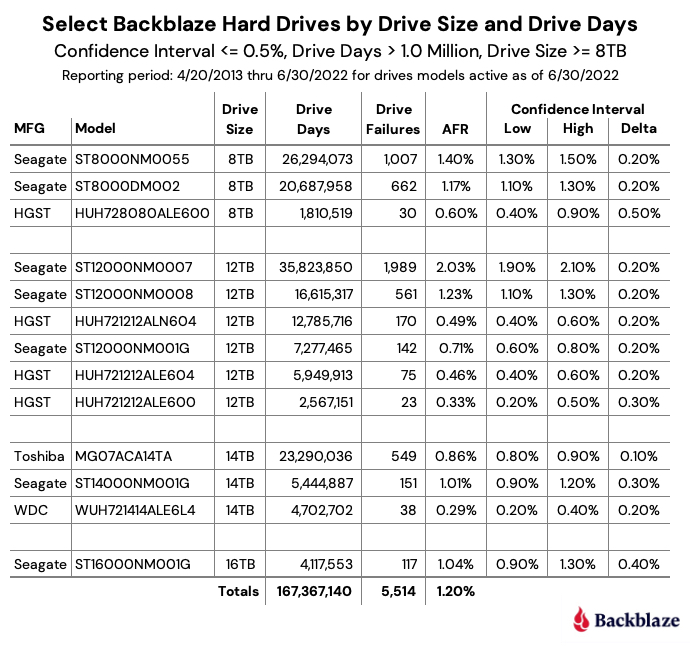
Partitioning Your Data Lake
Our final exercise was to create a single Drive Stats dataset containing all nine years of Drive Stats data. As stated above, at the time of writing the full Drive Stats dataset comprises nearly 300 million records, occupying over 90GB of disk space when in raw CSV format, rising by over 200,000 records per day, or about 75MB of CSV data.
As the dataset grows in size, an additional data engineering best practice is to include partitions.
In the introduction we mentioned that databases use optimized internal storage structures. Foremost among these are indexes. Data lakes have limited support for indexes. Data lakes do, however, support partitions. Data lake partitions are functionally similar to what databases alternately refer to as either a primary key index or index-organized tables. Regardless of the name, they effectively achieve faster data retrieval by having the data itself physically sorted. Since Drive Stats is append-only, when sorting on a date field, new records are appended to the dataset.
Having the data physically sorted greatly aids retrieval in cases that are known as range queries. To achieve fastest retrieval on a given query, it is important to only retrieve data that resolves true on the predicate in the WHERE clause. In the case of Drive Stats, for a query on only a single month or several consecutive months we get the fastest time to the result if we can read only the data for these months. Without partitioning Trino would need to do a full table scan, resulting in slower response due to the overhead of reading records for which the WHERE clause logic resolves to false. Organizing the Drive Stats data into partitions enables Trino to efficiently skip records that resolve the WHERE clause to false. Thus with partitions, many queries are far more efficient and incur the read cost only of those records whose WHERE clause logic resolves to true.
Our final transformation required a tweak to the Python script to iterate over all of the Drive Stats CSV files, writing Parquet files partitioned by year and month, so the files have prefixes of the form.
/drivestats/year={year}/month={month}/
For example:
/drivestats/year=2021/month=12/
The number of SMART attributes reported can change from one day to the next, and a single Parquet file can have only one schema, so there are one or more files with each prefix, named
{year}-{month}-{index}.parquet
For example:
2021-12-1.parquet
Again, we uploaded the resulting files and created a table in Trino.
CREATE TABLE drivestats (
serial_number VARCHAR,
model VARCHAR,
capacity_bytes BIGINT,
failure TINYINT,
smart_1_normalized BIGINT,
smart_1_raw BIGINT,
...
smart_255_normalized BIGINT,
smart_255_raw BIGINT,
day SMALLINT,
year SMALLINT,
month SMALLINT
)
WITH (format = 'PARQUET',
PARTITIONED_BY = ARRAY['year', 'month'],
EXTERNAL_LOCATION = 's3a://b2-trino-getting-started/drivestats-parquet');
Note that the conversion to Parquet automatically formatted the data using appropriate types, which we used in the table definition.
This command tells Trino to scan for partition files.
CALL system.sync_partition_metadata('ds', 'drivestats', 'FULL');
Let’s run a query and see the performance against the full Drive Stats dataset in Parquet format, partitioned by month:
trino:ds> SELECT COUNT(*) FROM drivestats;
_col0
-----------
296413574
(1 row)
Query 20220707_182743_00055_tshdf, FINISHED, 1 node
Splits: 412 total, 412 done (100.00%)
15.84 [296M rows, 5.63MB] [18.7M rows/s, 364KB/s]
It takes 16 seconds to count the total number of records, reading only 5.6MB of the 15.3GB total data.
Next, let’s run a query against just one month’s data:
trino:ds> SELECT COUNT(*) FROM drivestats WHERE year = 2022 AND month = 1;
_col0
---------
6415842
(1 row)
Query 20220707_184801_00059_tshdf, FINISHED, 1 node
Splits: 16 total, 16 done (100.00%)
0.85 [6.42M rows, 56KB] [7.54M rows/s, 65.7KB/s]
Counting the records for a given month takes less than a second, retrieving just 56KB of data–partitioning is working!
Now we have the entire Drive Stats data set loaded into Backblaze B2 in an efficient format and layout for running queries. Our next blog post will look at some of the queries we’ve run to clean up the data set and gain insight into nine years of hard drive metrics.
Conclusion
We hope that this article inspires you to try using Backblaze for your data analytics workloads if you’re not already doing so, and that it also serves as a useful primer to help you set up your own data lake using Backblaze B2 Cloud Storage. Our Drive Stats data is just one example of the type of data set that can be used for data analytics on Backblaze B2.
Hopefully, you too will find that Backblaze B2 Cloud Storage can be a useful, powerful, and very cost effective option for your data lake workloads.
If you’d like to get started working with analytical data in Backblaze B2, sign up here for 10 GB storage, free of charge, and get to work. If you’re already storing and querying analytical data in Backblaze B2, please let us know in the comments what tools you’re using and how it’s working out for you!
If you already work with Trino (or other data lake analytic engines), and would like connection credentials for our partitioned, Parquet, complete Drive Stats data set that is now hosted on Backblaze B2 Cloud Storage, please contact us at [email protected].
Future blog posts focused on Drive Stats and analytics will be using this complete Drive Stats dataset.
Similarly, please let us know if you would like to run a proof of concept hosting your own data in a Backblaze B2 data lake and would like the assistance of the Backblaze Developer Evangelism team.
And lastly, if you think this article may be of interest to your colleagues, we’d very much appreciate you sharing it with them.
The post Storing and Querying Analytical Data in Backblaze B2 appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.



















 for the IT industry. The partnership—which was enabled by our recent launch of a capacity-based pricing bundle, Backblaze B2 Reserve—solves both the budgeting and procurement challenges public sector CIOs are facing. And Carahsoft is a strategic distributor for Veritas, so public sector customers can take advantage of the joint solution as well.
for the IT industry. The partnership—which was enabled by our recent launch of a capacity-based pricing bundle, Backblaze B2 Reserve—solves both the budgeting and procurement challenges public sector CIOs are facing. And Carahsoft is a strategic distributor for Veritas, so public sector customers can take advantage of the joint solution as well.



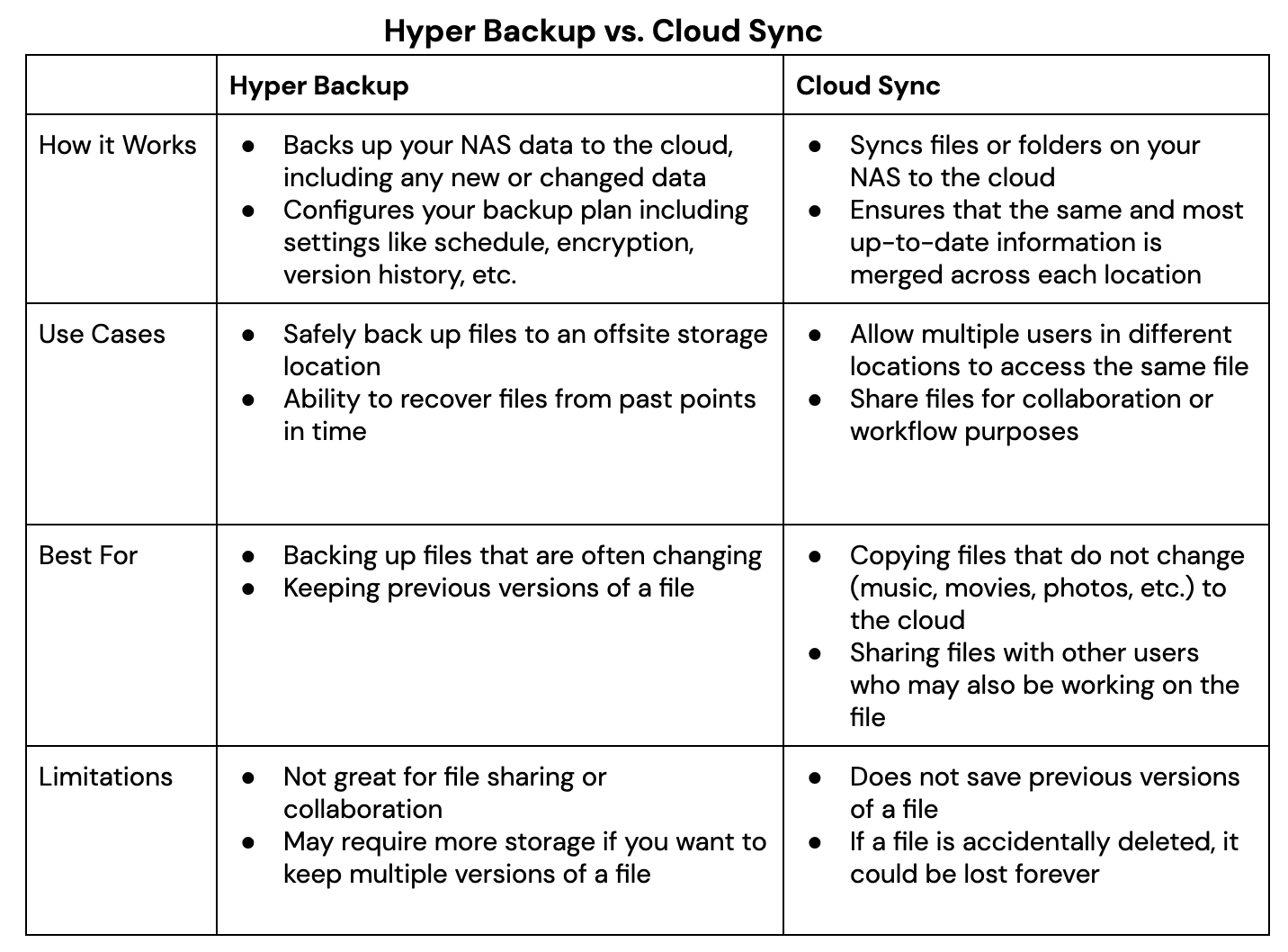 Whether you plan to utilize the backup and sync features Synology offers via Hyper Backup and Cloud Sync, securing your files to the cloud will help you create an effective
Whether you plan to utilize the backup and sync features Synology offers via Hyper Backup and Cloud Sync, securing your files to the cloud will help you create an effective