The developer of ICEBlock, an iOS app for anonymously reporting sightings of US Immigration and Customs Enforcement (ICE) officials, promises that it “ensures user privacy by storing no personal data.” But that claim has come under scrutiny. ICEBlock creator Joshua Aaron has been accused of making false promises regarding user anonymity and privacy, being “misguided” about the privacy offered by iOS, and of being an Apple fanboy. The issue isn’t what ICEBlock stores. It’s about what it could accidentally reveal through its tight integration with iOS.
I recently wrote about the new iOS feature that forces an iPhone to reboot after it’s been inactive for a longish period of time.
Here are the technical details, discovered through reverse engineering. The feature triggers after seventy-two hours of inactivity, even it is remains connected to Wi-Fi.
Both Apple and Google have recently reported critical vulnerabilities in their systems—iOS and Chrome, respectively—that are ultimately the result of the same vulnerability in the libwebp library:
On Thursday, researchers from security firm Rezillion published evidence that they said made it “highly likely” both indeed stemmed from the same bug, specifically in libwebp, the code library that apps, operating systems, and other code libraries incorporate to process WebP images.
Rather than Apple, Google, and Citizen Lab coordinating and accurately reporting the common origin of the vulnerability, they chose to use a separate CVE designation, the researchers said. The researchers concluded that “millions of different applications” would remain vulnerable until they, too, incorporated the libwebp fix. That, in turn, they said, was preventing automated systems that developers use to track known vulnerabilities in their offerings from detecting a critical vulnerability that’s under active exploitation.
Citizen Lab says two zero-days fixed by Apple today in emergency security updates were actively abused as part of a zero-click exploit chain (dubbed BLASTPASS) to deploy NSO Group’s Pegasus commercial spyware onto fully patched iPhones.
The two bugs, tracked as CVE-2023-41064 and CVE-2023-41061, allowed the attackers to infect a fully-patched iPhone running iOS 16.6 and belonging to a Washington DC-based civil society organization via PassKit attachments containing malicious images.
“We refer to the exploit chain as BLASTPASS. The exploit chain was capable of compromising iPhones running the latest version of iOS (16.6) without any interaction from the victim,” Citizen Lab said.
“The exploit involved PassKit attachments containing malicious images sent from an attacker iMessage account to the victim.”
Kaspersky is reporting a zero-click iOS exploit in the wild:
Mobile device backups contain a partial copy of the filesystem, including some of the user data and service databases. The timestamps of the files, folders and the database records allow to roughly reconstruct the events happening to the device. The mvt-ios utility produces a sorted timeline of events into a file called “timeline.csv,” similar to a super-timeline used by conventional digital forensic tools.
Using this timeline, we were able to identify specific artifacts that indicate the compromise. This allowed to move the research forward, and to reconstruct the general infection sequence:
The target iOS device receives a message via the iMessage service, with an attachment containing an exploit.
Without any user interaction, the message triggers a vulnerability that leads to code execution.
The code within the exploit downloads several subsequent stages from the C&C server, that include additional exploits for privilege escalation.
After successful exploitation, a final payload is downloaded from the C&C server, that is a fully-featured APT platform.
The initial message and the exploit in the attachment is deleted
The malicious toolset does not support persistence, most likely due to the limitations of the OS. The timelines of multiple devices indicate that they may be reinfected after rebooting. The oldest traces of infection that we discovered happened in 2019. As of the time of writing in June 2023, the attack is ongoing, and the most recent version of the devices successfully targeted is iOS 15.7.
Note: Timestamps used in this article are in UTC+8 Singapore time, unless stated otherwise.
Background
When we upgraded to Xcode 13.1 in April 2022, we noticed a few issues such as instability of the CI tests and other problems related to the switch to Xcode 13.1.
After taking a step back, we investigated this issue by integrating some observability tools into our iOS CI development process. This gave us a comprehensive perspective of the entire process, from the beginning to the end of the UITest job. In this article, we share the improvements we made, the insights we gathered, and the impact of these improvements on the overall process and resource utilisation.
Solution
In the following sections, we elaborate the various steps we took to investigate the issues, like unstable CI tests and high CPU utilisation, and the improvements we made to make our iOS CI infrastructure more reliable.
Analyse Xcode 13.1 CPU utilisation
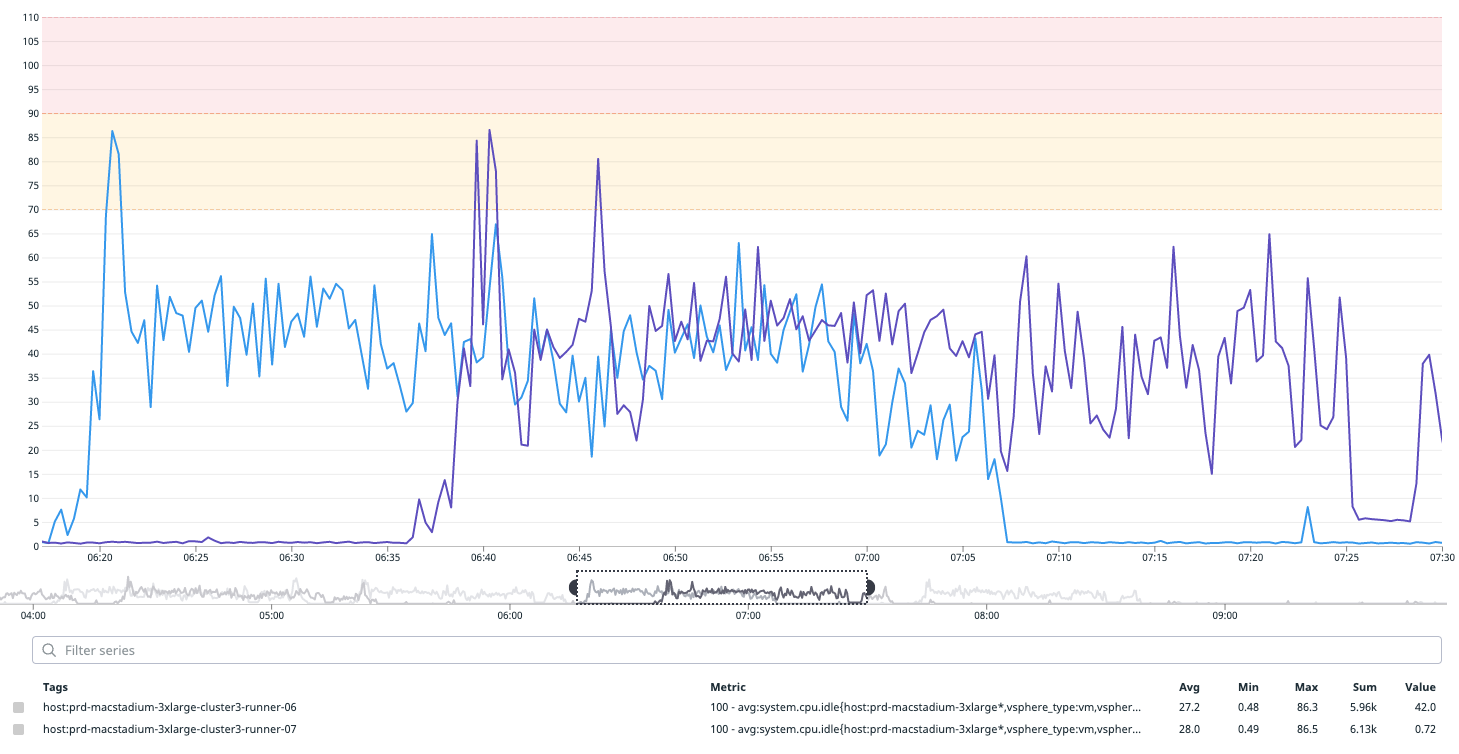
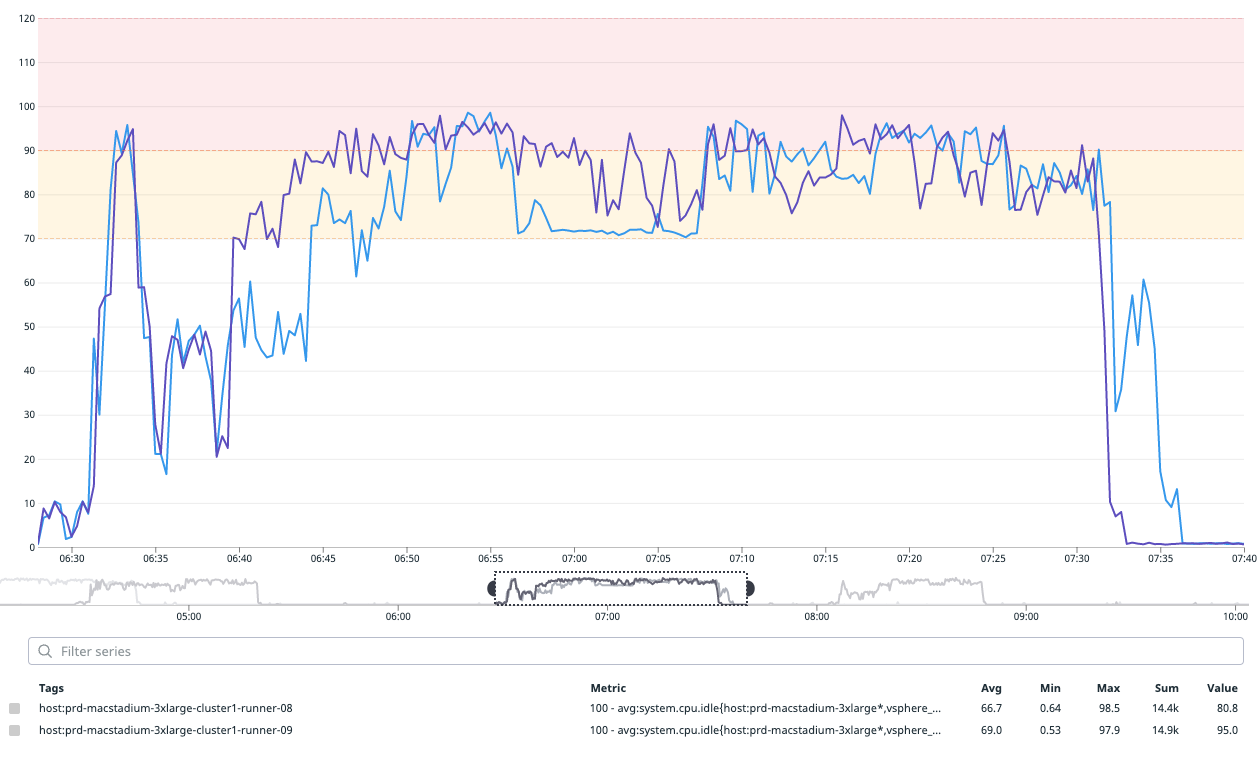
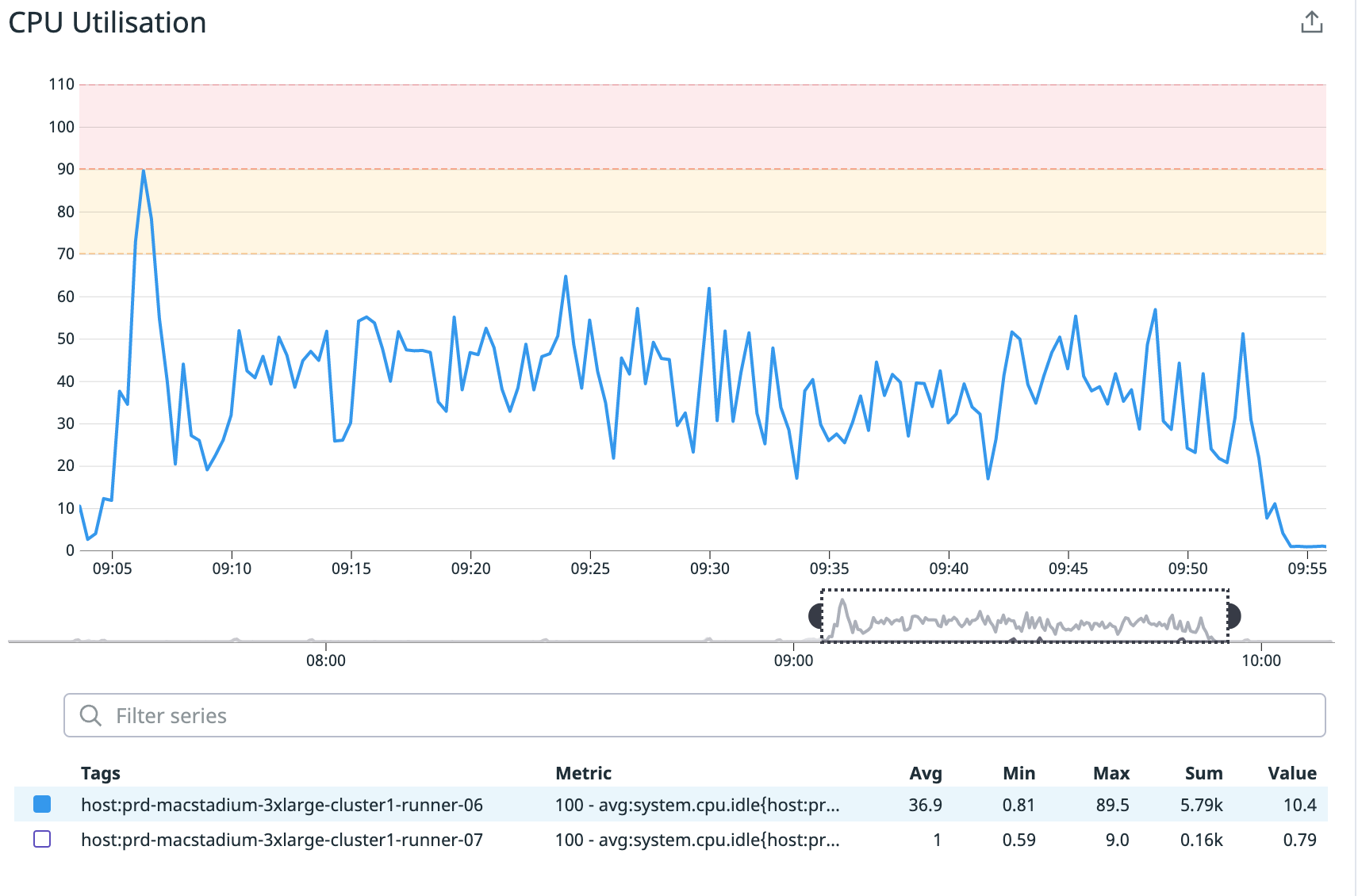
As an iOS developer, we are certain that you have also experienced Spotlight process-related CPU usage problems with Xcode 13.1, which have since been resolved in Xcode 13.2. After investigating, we found that the CPU usage issues were one of the root causes of UITest’s instability and it was something we needed to fix urgently. We decided not to wait for Apple’s update as it would cost us more time to perform another round of migration.
Before we started UITest, we moved the spotlight.app into a new folder. When the test was complete, we restored the application to its original location. This significantly decreased CPU utilisation by more than 50%.
This section helps you better visualise how the different versions of Xcode affected CPU utilisation.
Xcode 12.1
Xcode 13.1 before fix
Xcode 13.1 after fix
Remove iOS Safari’s dependency during deep link testing
As a superapp, there are countless scenarios that need to be thoroughly tested at Grab before the feature is released in production. One of these tests is deep link testing.
More than 10% of the total number of tests are deep link tests. Typically, it is advised to mock the dependencies throughout the test to ensure that it runs quickly and reliably. However, this creates another reliance on iOS Safari.
As a result, we created a mock browser in UITest. We used the URL to the mock browser as the launch argument, and the same URL is then called back. This method results in a 20% reduction in CI time and more stable tests.
Boot the iOS simulator with permission
It is always a good idea to reset the simulator before running UITest so that there are no residual presets or simulated data from a different test. Additionally, using any of the simulator’s services (location, ATT, contacts, etc.) will prompt the simulator to request permission, which slows down execution. We used UIInterruptionHandler (a handler block for managing alerts and other dialogues) to manage asynchronous UI interruptions during the test.
We wanted to reduce the time taken for test execution, which we knew includes many permissions. Therefore, in order to speed up execution, we boot the simulator with permissions. This removes the need for permissions during UITest, which speeds up performance by 5%.
Monitor HTTP traffic during the UITest
When writing tests, it is important to mock all resources as this enables us to focus on the code that’s being tested and not how external dependencies interact or respond. However, with a large team working concurrently, it can be challenging to ensure that nothing is actually downloaded from the internet.
Developers often make changes to code, and UITests are essential for ensuring that these modifications do not adversely affect existing functionality. It is advised to mock all dependencies while writing tests to simulate all possible behavior. We discovered that a significant number of resources were being downloaded each time we ran the tests, which was highly inefficient.
In large teams working simultaneously, preventing downloads from the internet can be quite challenging. To tackle this issue, we devised a custom tool that tracks all URLs accessed throughout the UITest. This enabled us to identify resources being downloaded from the internet during the testing process.
By using our custom tool to analyse network traffic, we were able to ensure that no resources were being downloaded during testing. Instead, we relied on mocked dependencies, resulting in reduced testing times and improved stability.
GitLab load runner analysis
At Grab, we have many teams of developers who maintain the app, make code changes, and raise merge requests (MRs) on a daily basis. To make sure that new changes don’t conflict with existing code, these MRs are integrated with CI.
Additionally, to manage the number of MRs, we maintain a list of clusters that run test runners concurrently for better resource utilisation and performance. We frequently run these tests to determine how many parallel processors are required for stable results.
####Return HTTP responses to the local mock server
We have a tool that we use to mock API requests, which we improved to also support HTML responses. This increases the scope of testing and ensures the HTML response sequences work properly.
Use explicit waiting commands
When running multiple tests, timing issues are inevitable and they cause tests to occasionally pass and fail. To mitigate this, most of the developers prefer to add a sleep command so there is time for the element to render properly before we verify it – but this slows down execution. In order to improve CI execution, we introduced a link that allows us to track sleep function usage and suggest developers use waitForExistence wrappers in UI tests.
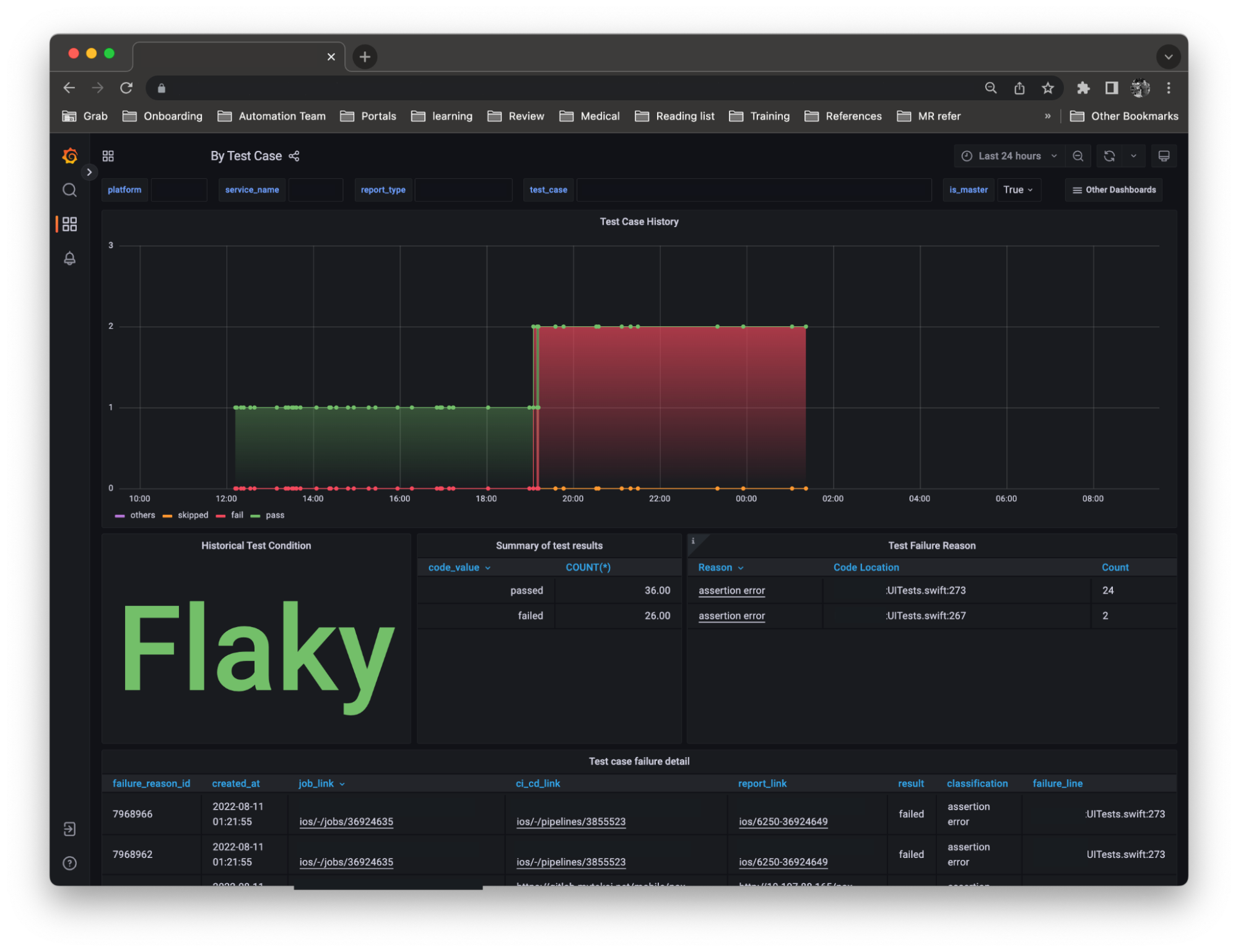
Track each failure state
With large codebases, it is quite common to see flakiness in UITests, where tests occasionally succeed and fail without any code changes. This means that test results can be inconsistent and in some cases, faulty. Faulty testing can be frustrating, and quite expensive. This is because engineers need to re-trigger entire builds, which ends up consuming more time.
Initially, we used an internal tool that required all tests to pass on the first run, before merging was allowed. However, we realised that this significantly increased engineers’ manual retry time, hence, we modified the rules to allow merging as long as a subsequent retry passes the tests. This minor change improved our engineers’ CI overall experience and did not result in more flaky tests.
Learnings/Conclusion
Our journey to improve iOS CI infrastructure is still ongoing, but from this experience, we learnt several things:
Focus on the feature being tested by ensuring all external responses are mocked.
A certain degree of test flakiness is expected, but you should monitor past trends. If flakiness increases, there’s probably a deeper lying issue within your code.
Regularly monitor resource utilisation and performance – detecting a sudden spike early could save you a lot of time and money.
Citizen Lab has identified three zero-click exploits against iOS 15 and 16. These were used by NSO Group’s Pegasus spyware in 2022, and deployed by Mexico against human rights defenders. These vulnerabilities have all been patched.
One interesting bit is that Apple’s Lockdown Mode (part of iOS 16) seems to have worked to prevent infection.
The most recent iPhone update—to version 16.1.2—patches a zero-day vulnerability that “may have been actively exploited against versions of iOS released before iOS 15.1.”
Apple said security researchers at Google’s Threat Analysis Group, which investigates nation state-backed spyware, hacking and cyberattacks, discovered and reported the WebKit bug.
WebKit bugs are often exploited when a person visits a malicious domain in their browser (or via the in-app browser). It’s not uncommon for bad actors to find vulnerabilities that target WebKit as a way to break into the device’s operating system and the user’s private data. WebKit bugs can be “chained” to other vulnerabilities to break through multiple layers of a device’s defenses.
Researchers claim that supposedly anonymous device analytics information can identify users:
On Twitter, security researchers Tommy Mysk and Talal Haj Bakry have found that Apple’s device analytics data includes an iCloud account and can be linked directly to a specific user, including their name, date of birth, email, and associated information stored on iCloud.
Apple has long claimed otherwise:
On Apple’s device analytics and privacy legal page, the company says no information collected from a device for analytics purposes is traceable back to a specific user. “iPhone Analytics may include details about hardware and operating system specifications, performance statistics, and data about how you use your devices and applications. None of the collected information identifies you personally,” the company claims.
Apple was just sued for tracking iOS users without their consent, even when they explicitly opt out of tracking.
People have suspected this for a while, but Apple has made it official. It only commits to fully patching the latest version of its OS, even though it claims to support older versions.
In other words, while Apple will provide security-related updates for older versions of its operating systems, only the most recent upgrades will receive updates for every security problem Apple knows about. Apple currently provides security updates to macOS 11 Big Sur and macOS 12 Monterey alongside the newly released macOS Ventura, and in the past, it has released security updates for older iOS versions for devices that can’t install the latest upgrades.
This confirms something that independent security researchers have been aware of for a while but that Apple hasn’t publicly articulated before. Intego Chief Security Analyst Joshua Long has tracked the CVEs patched by different macOS and iOS updates for years and generally found that bugs patched in the newest OS versions can go months before being patched in older (but still ostensibly “supported”) versions, when they’re patched at all.
I haven’t written about Apple’s Lockdown Mode yet, mostly because I haven’t delved into the details. This is how Apple describes it:
Lockdown Mode offers an extreme, optional level of security for the very few users who, because of who they are or what they do, may be personally targeted by some of the most sophisticated digital threats, such as those from NSO Group and other private companies developing state-sponsored mercenary spyware. Turning on Lockdown Mode in iOS 16, iPadOS 16, and macOS Ventura further hardens device defenses and strictly limits certain functionalities, sharply reducing the attack surface that potentially could be exploited by highly targeted mercenary spyware.
At launch, Lockdown Mode includes the following protections:
Messages: Most message attachment types other than images are blocked. Some features, like link previews, are disabled.
Web browsing: Certain complex web technologies, like just-in-time (JIT) JavaScript compilation, are disabled unless the user excludes a trusted site from Lockdown Mode.
Apple services: Incoming invitations and service requests, including FaceTime calls, are blocked if the user has not previously sent the initiator a call or request.
Wired connections with a computer or accessory are blocked when iPhone is locked.
Configuration profiles cannot be installed, and the device cannot enroll into mobile device management (MDM), while Lockdown Mode is turned on.
What Apple has done here is really interesting. It’s common to trade security off for usability, and the results of that are all over Apple’s operating systems—and everywhere else on the Internet. What they’re doing with Lockdown Mode is the reverse: they’re trading usability for security. The result is a user experience with fewer features, but a much smaller attack surface. And they aren’t just removing random features; they’re removing features that are common attack vectors.
There aren’t a lot of people who need Lockdown Mode, but it’s an excellent option for those who do.
Apple has introducedlockdown mode for high-risk users who are concerned about nation-state attacks. It trades reduced functionality for increased security in a very interesting way.
Researchers have figured how how to intercept and fake an iPhone reboot:
We’ll dissect the iOS system and show how it’s possible to alter a shutdown event, tricking a user that got infected into thinking that the phone has been powered off, but in fact, it’s still running. The “NoReboot” approach simulates a real shutdown. The user cannot feel a difference between a real shutdown and a “fake shutdown.” There is no user-interface or any button feedback until the user turns the phone back “on.”
Historically, when malware infects an iOS device, it can be removed simply by restarting the device, which clears the malware from memory.
However, this technique hooks the shutdown and reboot routines to prevent them from ever happening, allowing malware to achieve persistence as the device is never actually turned off.
I see this as another manifestation of the security problems that stem from all controls becoming software controls. Back when the physical buttons actually did things — like turn the power, the Wi-Fi, or the camera on and off — you could actually know that something was on or off. Now that software controls those functions, you can never be sure.
Early tests show that it can tolerate image resizing and compression, but not cropping or rotations.
We also have the first collision: two images that hash to the same value.
The next step is to generate innocuous images that NeuralHash classifies as prohibited content.
This was a bad idea from the start, and Apple never seemed to consider the adversarial context of the system as a whole, and not just the cryptography.
At Grab, we build a seamless user experience that addresses more and more of the daily lifestyle needs of people across South East Asia. We’re proud of our Grab rides, payments, and delivery services, and want to provide a unified experience across these offerings.
Here is couple of examples of what Grab does for millions of people across South East Asia every day:
Grab Service Offerings
The Grab Passenger application reached super app status more than a year ago and continues to provide hundreds of life-changing use cases in dozens of areas for millions of users.
With the big product scale, it brings with it even bigger technical challenges. Here are a couple of dimensions that can give you a sense of the scale we’re working with.
Engineering and product structure
Technical and product teams work in close collaboration to outserve our customers. These teams are combined into dedicated groups to form Tech Families and focus on similar use cases and areas.
Grab consists of many Tech Families who work on food, payments, transport, and other services, which are supported by hundreds of engineers. The diverse landscape makes the development process complicated and requires the industry’s best practices and approaches.
Codebase scale overview
The Passenger Applications (Android and iOS) contain more than 2.5 million lines of code each and it keeps growing. We have 1000+ modules in the Android App and 700+ targets in the iOS App. Hundreds of commits are merged by all the mobile engineers on a daily basis.
To maintain the health of the codebase and product stability, we run 40K+ unit tests on Android and 30K+ unit tests on iOS, as well as thousands of UI tests and hundreds of end-to-end tests on both platforms.
Build time challenges
The described complexity and scale do not come without challenges. A huge codebase propels the build process to the ultimate extreme- challenging the efficiency of build systems and hardware used to compile the super app, and creating out of the line challenges to be addressed.
Local build time
Local build time (the build on engineers’ laptop) is one of the most obvious challenges. More code goes in the application binary, hence the build system requires more time to compile it.
ADR local build time
The Android ecosystem provides a great out-of-the-box tool to build your project called Gradle. It’s flexible and user friendly, and provides huge capabilities for a reasonable cost. But is this always true? It appears to not be the case due to multiple reasons. Let’s unpack these reasons below.
Gradle performs well for medium sized projects with say 1 million line of code. Once the code surpasses that 1 million mark (or so), Gradle starts failing in giving engineers a reasonable build time for the given flexibility. And that’s exactly what we have observed in our Android application.
At some point in time, the Android local build became ridiculously long. We even encountered cases where engineers’ laptops simply failed to build the project due to hardware resources limits. Clean builds took by the hours, and incremental builds easily hit dozens of minutes.
iOS local build time
Xcode behaved a bit better compared to Gradle. The Xcode build cache was somehow bearable for incremental builds and didn’t exceed a couple of minutes. Clean builds still took dozens of minutes though. When Xcode failed to provide the valid cache, engineers had to rerun everything as a clean build, which killed the experience entirely.
CI pipeline time
Each time an engineer submits a Merge Request (MR), our CI kicks in running a wide variety of jobs to ensure the commit is valid and doesn’t introduce regression to the master branch. The feedback loop time is critical here as well, and the pipeline time tends to skyrocket alongside the code base growth. We found ourselves on the trend where the feedback loop came in by the hours, which again was just breaking the engineering experience, and prevented us from delivering the world’s best features to our customers.
As mentioned, we have a large number of unit tests (30K-40K+) and UI tests (700+) that we run on a pre-merge pipeline. This brings us to hours of execution time before we could actually allow MRs to land to the master branch.
The number of daily commits, which is by the hundreds, adds another stone to the basket of challenges.
All this clearly indicated the area of improvement. We were missing opportunities in terms of engineering productivity.
The extra mile
The biggest question for us to answer was how to put all this scale into a reasonable experience with minimal engineering idle time and fast feedback loop.
Build time critical path optimization
The most reasonable thing to do was to pay attention to the utilization of the hardware resources and make the build process optimal.
This literally boiled down to the simplest approach:
Decouple building blocks
Make building blocks as small as possible
This approach is valid for any build system and applies for both iOS and Android. The first thing we focused on was to understand what our build graph looked like, how dependencies were distributed, and which blocks were bottlenecks.
Given the scale of the apps, it’s practically not possible to manage a dependency tree manually, thus we created a tool to help us.
Critical path overview
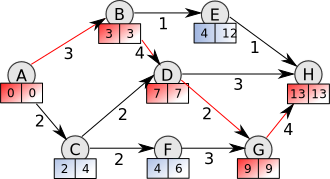
We introduced the Critical Path concept:
The critical path is the longest (time) chain of sequential dependencies, which must be built one after the other.
Critical Path build
Even with an infinite number of parallel processors/cores, the total build time cannot be less than the critical path time.
We implemented the tool that parsed the dependency trees (for both Android and iOS), aggregated modules/target build time, and calculated the critical path.
The concept of the critical path introduced a number of action items, which we prioritized:
The critical path must be as short as possible.
Any huge module/target on the critical path must be split into smaller modules/targets.
Depend on interfaces/bridges rather than implementations to shorten the critical path.
The presence of other teams’ implementation modules/targets in the critical path of the given team is a red flag.
Stack representation of the Critical Path build time
Project’s scale factor
To implement the conceptually easy action items, we ran a Grab-wide program. The program has impacted almost every mobile team at Grab and involved 200+ engineers to some degree. The whole implementation took 6 months to complete.
During this period of time, we assigned engineers who were responsible to review the changes, provide support to the engineers across Grab, and monitor the results.
Results
Even though the overall plan seemed to be good on paper, the results were minimal – it just flattened the build time curve of the upcoming trend introduced by the growth of the codebase. The estimated impact was almost the same for both platforms and gave us about a 7%-10% cut in the CI and local build time.
Open source plan
The critical path tool proved to be effective to illustrate the projects’ bottlenecks in a dependency tree configuration. It is currently widely used by mobile teams at Grab to analyze their dependencies and cut out or limit an unnecessary impact on the respective scope.
The tool is currently considered to be open-sourced as we’d like to hear feedback from other external teams and see what can be built on top of it. We’ll provide more details on this in future posts.
Remote build
Another pillar of the build process is the hardware where the build runs. The solution is really straightforward – put more muscles on your build to get it stronger and to run faster.
Clearly, our engineers’ laptops could not be considered fast enough. To have a fast enough build we were looking at something with 20+ cores, ~200Gb of RAM. None of the desktop or laptop computers can reach those numbers within reasonable pricing. We hit a bottleneck in hardware. Further parallelization of the build process didn’t give any significant improvement as all the build tasks were just queueing and waiting for the resources to be released. And that’s where cloud computing came into the picture where a huge variety of available options is ready to be used.
ADR mainframer
We took advantage of the Mainframer tool. When the build must run, the code diff is pushed to the remote executor, gets compiled, and then the generated artifacts are pushed back to the local machine. An engineer might still benefit from indexing, debugging, and other features available in the IDE.
To make the infrastructure mature enough, we’ve introduced Kubernetes-based autoscaling based on the load. Currently, we have a stable infrastructure that accommodates 100+ Android engineers scaling up and down (saving costs).
This strategy gave us a 40-50% improvement in the local build time. Android builds finished, in the extreme case, x2 faster.
iOS
Given the success of the Android remote build infrastructure, we have immediately turned our attention to the iOS builds. It was an obvious move for us – we wanted the same infrastructure for iOS builds. The idea looked good on paper and was proven with Android infrastructure, but the reality was a bit different for our iOS builds.
Our very first roadblock was that Xcode is not that flexible and the process of delegating build to remote is way more complicated compared to Android. We tackled a series of blockers such as running indexing on a remote machine, sending and consuming build artifacts, and even running the remote build itself.
The reality was that the remote build was absolutely possible for iOS. There were minor tradeoffs impacting engineering experience alongside obvious gains from utilizing cloud computing resources. But the problem is that legally iOS builds are only allowed to be built on an Apple machine.
Even if we get the most powerful hardware – a macPro – the specs are still not ideal and are unfortunately not optimized for the build process. A 24 core, 194Gb RAM macPro could have given about x2 improvement on the build time, but when it had to run 3 builds simultaneously for different users, the build efficiency immediately dropped to the baseline value.
Android remote machines with the above same specs are capable of running up to 8 simultaneous builds. This allowed us to accommodate up to 30-35 engineers per machine, whereas iOS’ infrastructure would require to keep this balance at 5-6 engineers per machine. This solution didn’t seem to be scalable at all, causing us to abandon the idea of the remote builds for iOS at that moment.
Test impact analysis
The other battlefront was the CI pipeline time. Our efforts in dependency tree optimizations complemented with comparably powerful hardware played a good part in achieving a reasonable build time on CI.
CI validations also include the execution of unit and UI tests and may easily take 50%-60% of the pipeline time. The problem was getting worse as the number of tests was constantly growing. We were to face incredibly huge tests’ execution time in the near future. We could mitigate the problem by a muscle approach – throwing more runners and shredding tests – but it won’t make finance executives happy.
So the time for smart solutions came again. It’s a known fact that the simpler solution is more likely to be correct. The simplest solution was to stop running ALL tests. The idea was to run only those tests that were impacted by the codebase change introduced in the given MR.
Behind this simple idea, we’ve found a huge impact. Once the Test Impact Analysis was applied to the pre-merge pipelines, we’ve managed to cut down the total number of executed tests by up to 90% without any impact on the codebase quality or applications’ stability. As a result, we cut the pipeline for both platforms by more than 30%.
Today, the Test Impact Analysis is coupled with our codebase. We are looking to invest some effort to make it available for open sourcing. We are excited to be on this path.
The end of the Native Build Systems
One might say that our journey was long and we won the battle for the build time.
Today, we hit a limit to the native build systems’ efficiency and hardware for both Android and iOS. And it’s clear to us that in our current setup, we would not be able to scale up while delivering high engineering experience.
Let’s move to Bazel
To introduce another big improvement to the build time, we needed to make some ground-level changes. And this time, we focused on the build system itself.
Native build systems are designed to work well for small and medium-sized projects, however they have not been as successful in large scale projects such as the Grab Passenger applications.
With these assumptions, we considered options and found the Bazel build system to be a good contender. The deep comparison of build systems disclosed that Bazel was promising better results almost in all key areas:
Bazel enables remote builds out of box
Bazel provides sustainable cache capabilities (local and remote). This cache can be reused across all consumers – local builds, CI builds
Bazel was designed with the big codebase as a cornerstone requirement
The majority of the tooling may be reused across multiple platforms
Ways of adopting
On paper, Bazel was awesome and shining. All our playground investigations showed positive results:
Cache worked great
Incremental builds were incredibly fast
But the effort to shift to this new build system was huge. We made sure that we foresee all possible pitfalls and impediments. It took us about 5 months to estimate the impact and put together a sustainable proof of concept, which reflected the majority of our use cases.
Migration limitations
After those 5 months of investigation, we got the endless list of incompatible features and major blockers to be addressed. Those blockers touched even such obvious things as indexing and the jump to definition IDE feature, which we used to take for granted.
But the biggest challenge was the need to keep the pace of the product release. There was no compromise of stopping the product development even for a day. The way out appeared to be a hybrid build concept. We figured out how to marry native and Bazel build systems to live together in harmony. This move gave us a chance to start migrating target by target, project by project moving from the bottom to top of the dependency graph.
This approach was a valid enabler, however we were still faced with a challenge of our app’s scale. The codebase of over 2.5 million of LOC cannot be migrated overnight. The initial estimation was based on the idea of manually migrating the whole codebase, which would have required us to invest dozens of person-months.
Team capacity limitations
This approach was immediately pushed back by multiple teams arguing with the priority and concerns about the impact on their own product roadmap.
We were left with not much choice. On one hand, we had a pressingly long build time. And on the other hand, we were asking for a huge effort from teams. We clearly needed to get buy-ins from all of our stakeholders to push things forward.
Getting buy-in
To get all needed buy-ins, all stakeholders were grouped and addressed separately. We defined key factors for each group.
Key factors
C-level stakeholders:
Impact. The migration impact must be significant – at least a 40% decrease on the build time.
Costs. Migration costs must be paid back in a reasonable time and the positive impact is extended to the future.
Engineering experience. The user experience must not be compromised. All tools and features engineers used must be available during migration and even after.
Engineers:
Engineering experience. Similar to the criteria established at the C-level factor.
Early adopters engagement. A common core experience must be created across the mobile engineering community to support other engineers in the later stages.
Education. Awareness campaigns must be in place. Planned and conducted a series of tech talks and workshops to raise awareness among engineers and cut the learning curve. We wrote hundreds of pages of documentation and guidelines.
Product teams:
No roadmap impact. Migration must not affect the product roadmap.
Minimize the engineering effort. Migration must not increase the efforts from engineering.
Migration automation (separate talks)
The biggest concern for the majority of the stakeholders appeared to be the estimated migration effort, which impacted the cost, the product roadmap, and the engineering experience. It became evident that we needed to streamline the process and reduce the effort for migration.
Fortunately, the actual migration process was routine in nature, so we had opportunities for automation. We investigated ideas on automating the whole migration process.
The tools we’ve created
We found that it’s relatively easy to create a bunch of tools that read the native project structure and create an equivalent Bazel set up. This was a game changer.
Things moved pretty smoothly for both Android and iOS projects. We managed to roll out tooling to migrate the codebase in a single click/command (well with some exceptions as of now. Stay tuned for another blog post on this). With this tooling combined with the hybrid build concept, we addressed all the key buy-in factors:
Migration cost dropped by at least 50%.
Less engineers required for the actual migration. There was no need to engage the wide engineering community as a small group of people can manage the whole process.
There is no more impact on the product roadmap.
Where do we stand today
When we were in the middle of the actual migration, we decided to take a pragmatic path and migrate our applications in phases to ensure everything was under control and that there were no unforeseen issues.
The hybrid build time is racing alongside our migration progress. It has a linear dependency on the amount of the migrated code. The figures look positive and we are confident in achieving our impact goal of decreasing at least 40% of the build time.
Plans to open source
The automated migration tooling we’ve created is planned to be open sourced. We are doing a bit better on the Android side decoupling it from our applications’ implementation details and plan to open source it in the near future.
The iOS tooling is a bit behind, and we expect it to be available for open-sourcing by the end of Q1’2021.
Is it worth it all?
Bazel is not a silver bullet for the build time and your project. There are a lot of edge cases you’ll never know until it punches you straight in your face.
It’s far from industry standard and you might find yourself having difficulty hiring engineers with such knowledge. It has a steep learning curve as well. It’s absolutely an overhead for small to medium-sized projects, but it’s undeniably essential once you start playing in a high league of super apps.
If you were to ask whether we’d go this path again, the answer would come in a fast and correct way – yes, without any doubts.
Authored by Sergii Grechukha on behalf of the Passenger App team at Grab. Special thanks to Madushan Gamage, Mikhail Zinov, Nguyen Van Minh, Mihai Costiug, Arunkumar Sampathkumar, Maryna Shaposhnikova, Pavlo Stavytskyi, Michael Goletto, Nico Liu, and Omar Gawish for their contributions.
Join us
Grab is more than just the leading ride-hailing and mobile payments platform in Southeast Asia. We use data and technology to improve everything from transportation to payments and financial services across a region of more than 620 million people. We aspire to unlock the true potential of Southeast Asia and look for like-minded individuals to join us on this ride.
If you share our vision of driving South East Asia forward, apply to join our team today.
Over the last few years Netflix has been developing a mobile app called Prodicle to innovate in the physical production of TV shows and movies. The world of physical production is fast-paced, and needs vary significantly between the country, region, and even from one production to the next. The nature of the work means we’re developing write-heavy software, in a distributed environment, on devices where less than ⅓ of our users have very reliable connectivity whilst on set, and with a limited margin for error. For these reasons, as a small engineering team, we’ve found that optimizing for reliability and speed of product delivery is required for us to serve our evolving customers’ needs successfully.
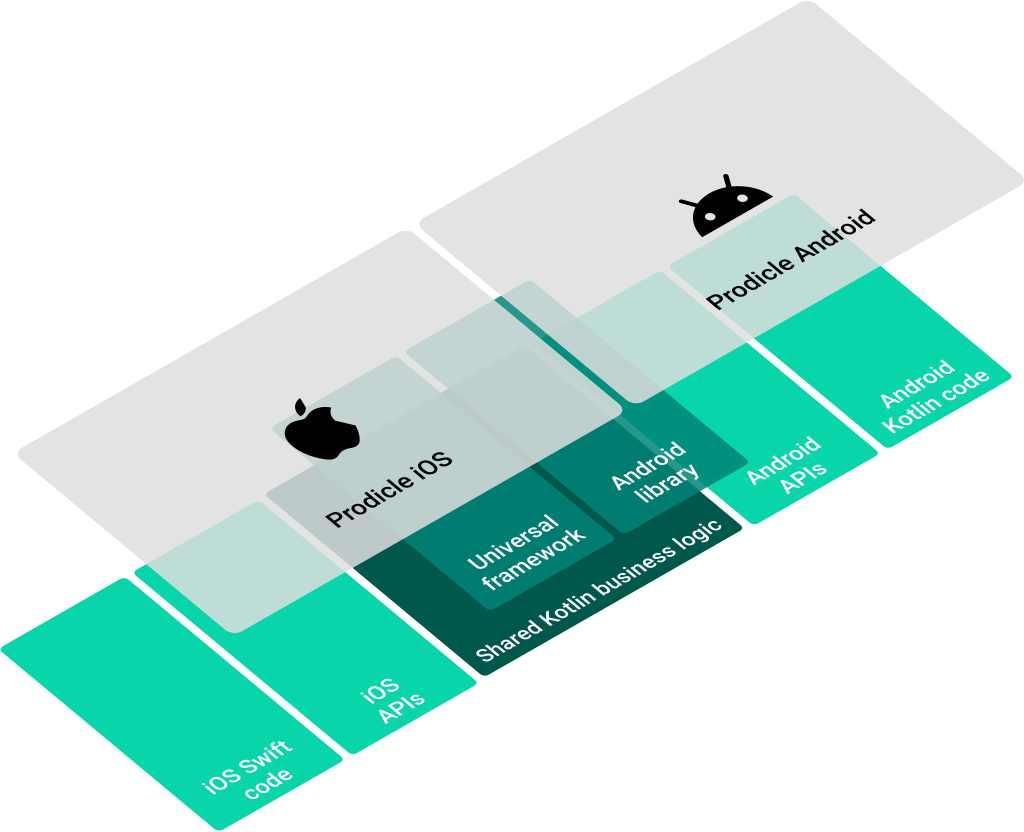
The high likelihood of unreliable network connectivity led us to lean into mobile solutions for robust client side persistence and offline support. The need for fast product delivery led us to experiment with a multiplatform architecture. Now we’re taking this one step further by using Kotlin Multiplatform to write platform agnostic business logic once in Kotlin and compiling to a Kotlin library for Android and a native Universal Framework for iOS via Kotlin/Native.
Kotlin Multiplatform
Kotlin Multiplatform allows you to use a single codebase for the business logic of iOS and Android apps. You only need to write platform-specific code where it’s necessary, for example, to implement a native UI or when working with platform-specific APIs.
Kotlin Multiplatform approaches cross-platform mobile development differently from some well known technologies in the space. Where other technologies abstract away or completely replace platform specific app development, Kotlin Multiplatform is complementary to existing platform specific technologies and is geared towards replacing platform agnostic business logic. It’s a new tool in the toolbox as opposed to replacing the toolbox.
This approach works well for us for several reasons:
Our Android and iOS studio apps have a shared architecture with similar or in some cases identical business logic written on both platforms.
Almost 50% of the production code in our Android and iOS apps is decoupled from the underlying platform.
Our appetite for exploring the latest technologies offered by respective platforms (Android Jetpack Compose, Swift UI, etc) isn’t hampered in any way.
So, what are we doing with it?
Experience Management
As noted earlier, our user needs vary significantly from one production to the next. This translates to a large number of app configurations to toggle feature availability and optimize the in-app experience for each production. Decoupling the code that manages these configurations from the apps themselves helps to reduce complexity as the apps grow. Our first exploration with code sharing involves the implementation of a mobile SDK for our internal experience management tool, Hendrix.
At its core, Hendrix is a simple interpreted language that expresses how configuration values should be computed. These expressions are evaluated in the current app session context, and can access data such as A/B test assignments, locality, device attributes, etc. For our use-case, we’re configuring the availability of production, version, and region specific app feature sets.
Poor network connectivity coupled with frequently changing configuration values in response to user activity means that on-device rule evaluation is preferable to server-side evaluation.
This led us to build a lightweight Hendrix mobile SDK — a great candidate for Kotlin Multiplatform as it requires significant business logic and is entirely platform agnostic.
Implementation
For brevity, we’ll skip over the Hendrix specific details and touch on some of the differences involved in using Kotlin Multiplatform in place of Kotlin/Swift.
Build
For Android, it’s business as usual. The Hendrix Multiplatform SDK is imported via gradle as an Android library project dependency in the same fashion as any other dependency. On the iOS side, the native binary is included in the Xcode project as a universal framework.
Developer ergonomics
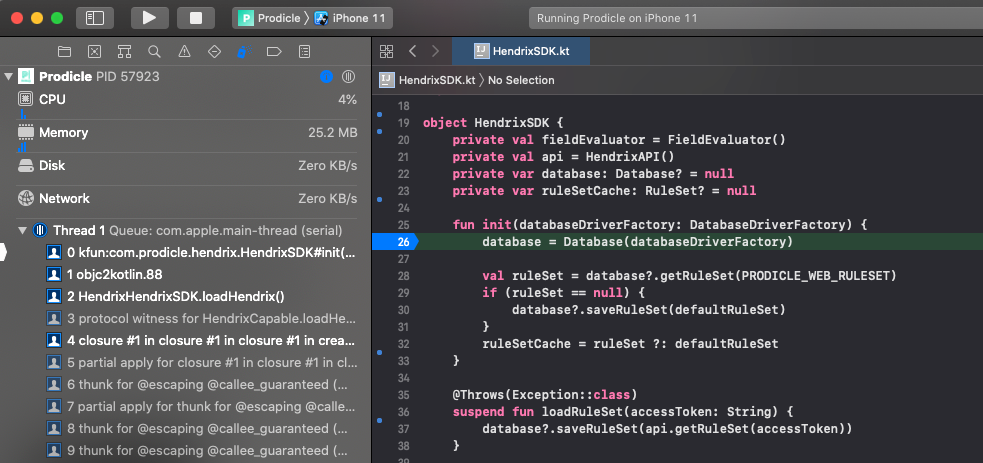
Kotlin Multiplatform source code can be edited, recompiled, and can have a debugger attached with breakpoints in Android Studio and Xcode (including lldb support). Android Studio works out of the box, Xcode support is achieved via TouchLabs’ xcode-kotlin plugin.
Debugging Kotlin source code from Xcode.
Networking
Hendrix interprets rule set(s) — remotely configurable files that get downloaded to the device. We’re using Ktor’s Multiplatform HttpClient to embed our networking code within the SDK.
Disk cache
Of course, network connectivity may not always be available so downloaded rule sets need to be cached to disk. For this, we’re using SQLDelight along with it’s Android and Native Database drivers for Multiplatform persistence.
Final thoughts
We’ve followed the evolution of Kotlin Multiplatform keenly over the last few years and believe that the technology has reached an inflection point. The tooling and build system integrations for Xcode have improved significantly such that the complexities involved in integration and maintenance are outweighed by the benefit of not having to write and maintain multiple platform specific implementations.
Opportunities for additional code sharing between our Android and iOS studio apps are plentiful. Potential future applications of the technology become even more interesting when we consider that Javascript transpilation is also possible.
We’re excited by the possibility of evolving our studio mobile apps into thin UI layers with shared business logic and will continue to share our learnings with you on that journey.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.