Post Syndicated from Channy Yun (윤석찬) original https://aws.amazon.com/blogs/aws/aws-transform-for-mainframe-introduces-reimagine-capabilities-and-automated-testing-functionality/
In May, 2025, we launched AWS Transform for mainframe, the first agentic AI service for modernizing mainframe workloads at scale. The AI-powered mainframe agent accelerates mainframe modernization by automating complex, resource-intensive tasks across every phase of modernization—from initial assessment to final deployment. You can streamline the migration of legacy mainframe applications, including COBOL, CICS, DB2, and VSAM to modern cloud environments—cutting modernization timelines from years to months.
Today, we’re announcing enhanced capabilities in AWS Transform for mainframe that include AI-powered analysis features, support for the Reimagine modernization pattern, and testing automation. These enhancements solve two critical challenges in mainframe modernization: the need to completely transform applications rather than merely move them to the cloud, and the extensive time and expertise required for testing.
- Reimagining mainframe modernization – This is a new AI-driven approach that completely reimagines the customer’s application architecture using modern patterns or moving from batch process to real-time functions. By combining the enhanced business logic extraction with new data lineage analysis and automated data dictionary generation from the legacy source code through AWS Transform, customers transform monolithic mainframe applications written in languages like COBOL into more modern architectural styles, like microservices.
- Automated testing – Customers can use new automated test plan generation, test data collection scripts, and test case automation scripts. AWS Transform for mainframe also provides functional testing tools for data migration, results validation, and terminal connectivity. These AI-powered capabilities work together to accelerate testing timelines and improve accuracy through automation.
Let’s learn more about reimagining mainframe modernization and automated testing capabilities.
How to reimagine mainframe modernization
We recognize that mainframe modernization is not a one-size-fits-all proposition. Whereas tactical approaches focus on augmentation and maintaining existing systems, strategic modernization offers distinct paths: Replatform, Refactor, Replace, or the new Reimagine.
In the Reimagine pattern, AWS Transform AI-powered analysis combines mainframe system analysis with organizational knowledge to create detailed business and technical documentation and architecture recommendations. This helps preserve critical business logic while enabling modern cloud-native capabilities.
AWS Transform provides new advanced data analysis capabilities that are essential for successful mainframe modernization, including data lineage analysis and automated data dictionary generation. These features work together to define the structure and meaning to accompany the usage and relationships of mainframe data. Customers gain complete visibility into their data landscape, enabling informed decision-making for modernization. Their technical teams can confidently redesign data architectures while preserving critical business logic and relationships.
![]()
The Reimagining strategy follows the principle of human in the loop validation, which means that AI-generated application specifications and code such as AWS Transform and Kiro are continuously validated by domain experts. This collaborative approach between AI capabilities and human judgment significantly reduces transformation risk while maintaining the speed advantages of AI-powered modernization.
The pathway has a three-phase methodology to transform legacy mainframe applications into cloud-native microservices:
![]()
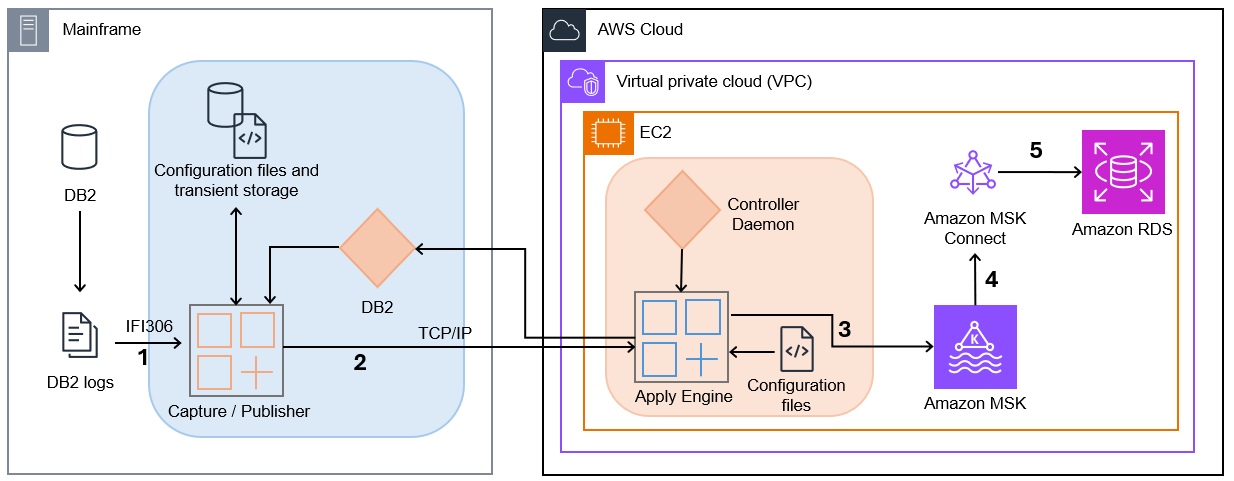
- Reverse engineering to extract business logic and rules from existing COBOL or job control language (JCL) code using AWS Transform for mainframe.
- Forward engineering to generate microservice specification, modernized source code, infrastructure as code (IaC), and modernized database.
- Deploy and test to deploy the generated microservices to Amazon Web Services (AWS) using IaC and to test the functionality of the modernized application.
Although microservices architecture offers significant benefits for mainframe modernization, it’s crucial to understand that it’s not the best solution for every scenario. The choice of architectural patterns should be driven by the specific requirements and constraints of the system. The key is to select an architecture that aligns with both current needs and future aspirations, recognizing that architectural decisions can evolve over time as organizations mature their cloud-native capabilities.
The flexible approach supports both do-it-yourself and partner-led development, so you can use your preferred tools while maintaining the integrity of your business processes. You get the benefits of modern cloud architecture while preserving decades of business logic and reducing project risk.
Automated testing in action
The new automated testing feature supports IBM z/OS mainframe batch application stack at launch, which helps organizations address a wider range of modernization scenarios while maintaining consistent processes and tooling.
Here are the new mainframe capabilities:
- Plan test cases – Create test plans from mainframe code, business logic, and scheduler plans.
- Generate test data collection scripts – Create JCL scripts for data collection from your mainframe to your test plan.
- Generate test automation scripts – Generate execution scripts to automate testing of modernized applications running in the target AWS environment.
To get started with automated testing, you should set up a workspace, assign a specific role to each user, and invite them to onboard your workspace. To learn more, visit Getting started with AWS Transform in the AWS Transform User Guide.
Choose Create job in your workspace. You can see all types of supported transformation jobs. For this example, I select the Mainframe Modernization job to modernize mainframe applications.
![]()
After a new job is created, you can kick off modernization for tests generation. This workflow is sequential and it is a place for you to answer the AI agent’s questions, providing the necessary input. You can add your collaborators and specify resource location where the codebase or documentation is located in your Amazon Simple Storage Service (Amazon S3) bucket.
I use a sample application for a credit card management system as the mainframe banking case with the presentation (BMS screens), business logic (COBOL) and data (VSAM/DB2), including online transaction processing and batch jobs.
![]()
After finishing the steps of analyzing code, extracting business logic, decomposing code, planning migration wave, you can experience new automated testing capabilities such as planning test cases, generating test data collection scripts, and test automation scripts.
![]()
The new testing workflow creates a test plan for your modernization project and generates test data collection scripts. You will have three planning steps:
- Configure test plan inputs – You can link your test plan to your other job files. The test plan is generated based on analyzing the mainframe application code and can provide more details optionally using the extracted business logic, the technical documentation, the decomposition, and using a scheduler plan.
- Define test plan scope – You can define the entry point, the specific program where the application’s execution flow begins. For example, the JCL for a batch job. In the test plan, each functional test case is designed to start the execution from a specific entry point.
- Refine test plan – A test plan is made up of sequential test cases. You can reorder them, add new ones, merge multiple cases, or split one into two on the test case detail page. Batch test cases are composed of a sequence of JCLs following the scheduler plan.
Generating test data collection scripts collects test data from mainframe applications for functional equivalence testing. This step actively generates JCL scripts that will help you gather test data from the sample application’s various data sources (such as VSAM files or DB2 databases) for use in testing the modernized application. The step is designed to create automated scripts that can extract test data from VSAM datasets, query DB2 tables for sample data, collect sequential data sets, and generate data collection workflows. After this step is completed, you’ll have comprehensive test data collection scripts ready to use.
To learn more about automated testing, visit Modernization of mainframe applications in the AWS Transform User Guide.
Now available
The new capabilities in AWS Transform for mainframe are available today in all AWS Regions where AWS Transform for mainframe is offered. For Regional availability and future roadmap, visit the AWS Capabilities by Region. Currently, we offer our core features—including assessment and transformation—at no cost to AWS customers. To learn more, visit AWS Transform Pricing page.
Give it a try in the AWS Transform console. To learn more, visit the AWS Transform for mainframe product page and send feedback to AWS re:Post for AWS Transform for mainframe or through your usual AWS Support contacts.
— Channy