Post Syndicated from Ann Ming Samborski original https://blog.cloudflare.com/browser-based-rdp/
Short-lived SSH access made its debut on Cloudflare’s SASE platform in October 2024. Leveraging the knowledge gained through the BastionZero acquisition, short-lived SSH access enables organizations to apply Zero Trust controls in front of their Linux servers. That was just the beginning, however, as we are thrilled to announce the release of a long-requested feature: clientless, browser-based support for the Remote Desktop Protocol (RDP). Built on top of Cloudflare’s modern proxy architecture, our RDP proxy offers a secure and performant solution that, critically, is also easy to set up, maintain, and use.
Remote Desktop Protocol (RDP) was born in 1998 with Windows NT 4.0 Terminal Server Edition. If you have never heard of that Windows version, it’s because, well, there’s been 16 major Windows releases since then. Regardless, RDP is still used across thousands of organizations to enable remote access to Windows servers. It’s a bit of a strange protocol that relies on a graphical user interface to display screen captures taken in very close succession in order to emulate the interactions on the remote Windows server. (There’s more happening here beyond the screen captures, including drawing commands, bitmap updates, and even video streams. Like we said — it’s a bit strange.) Because of this complexity, RDP can be computationally demanding and poses a challenge for running at high performance over traditional VPNs.
Beyond its quirks, RDP has also had a rather unsavory reputation in the security industry due to early vulnerabilities with the protocol. The two main offenders are weak user sign-in credentials and unrestricted port access. Windows servers are commonly protected by passwords, which often have inadequate security to start, and worse still, may be shared across multiple accounts. This leaves these RDP servers open to brute force or credential stuffing attacks.
Bad actors have abused RDP’s default port, 3389, to carry out on-path attacks. One of the most severe RDP vulnerabilities discovered is called BlueKeep. Officially known as CVE-2019-0708, BlueKeep is a vulnerability that allows remote code execution (RCE) without authentication, as long as the request adheres to a specific format and is sent to a port running RDP. Worse still, it is wormable, meaning that BlueKeep can spread to other machines within the network with no user action. Because bad actors can compromise RDP to gain unauthorized access, attackers can then move laterally within the network, escalating privileges, and installing malware. RDP has also been used to deploy ransomware such as Ryuk, Conti, and DoppelPaymer, earning it the nickname “Ransomware Delivery Protocol.”
This is a subset of vulnerabilities in RDP’s history, but we don’t mean to be discouraging. Thankfully, due to newer versions of Windows, CVE patches, improved password hygiene, and better awareness of privileged access, many organizations have reduced their attack surface. However, for as many secured Windows servers that exist, there are still countless unpatched or poorly configured systems online, making them easy targets for ransomware and botnets.
Despite its security risks, RDP remains essential for many organizations, particularly those with distributed workforces and third-party contractors. It provides value for compute-intensive tasks that require high-powered Windows servers with CPU/GPU resources greater than users’ machines can offer. For security-focused organizations, RDP grants better visibility into who is accessing Windows servers and what actions are taken during those sessions.
Because issuing corporate devices to contractors is costly and cumbersome, many organizations adopt a bring-your-own-device (BYOD) policy. This decision instead requires organizations to provide contractors with a means to RDP to a Windows server with the necessary corporate resources to fulfill their role.
Traditional RDP requires client software on user devices, so this is not an appropriate solution for contractors (or any employees) using personal machines or unmanaged devices. Previously, Cloudflare customers had to rely on self-hosted third-party tools like Apache Guacamole or Devolutions Gateway to enable browser-based RDP access. This created several operational pain points:
-
Infrastructure complexity: Deploying and maintaining RDP gateways increases operational overhead.
-
Maintenance burden: Commercial and open-source tools may require frequent updates and patches, sometimes even necessitating custom forks.
-
Compliance challenges: Third-party software requires additional security audits and risk management assessments, particularly for regulated industries.
-
Redundancy, but not the good kind – Customers come to Cloudflare to reduce the complexity of maintaining their infrastructure, not add to it.
We’ve been listening. Cloudflare has architectured a high-performance RDP proxy that leverages the modern security controls already part of our Zero Trust Network Access (ZTNA) service. We feel that the “security/performance tradeoff” the industry commonly touts is a dated mindset. With the right underlying network architecture, we can help mitigate RDP’s most infamous challenges.
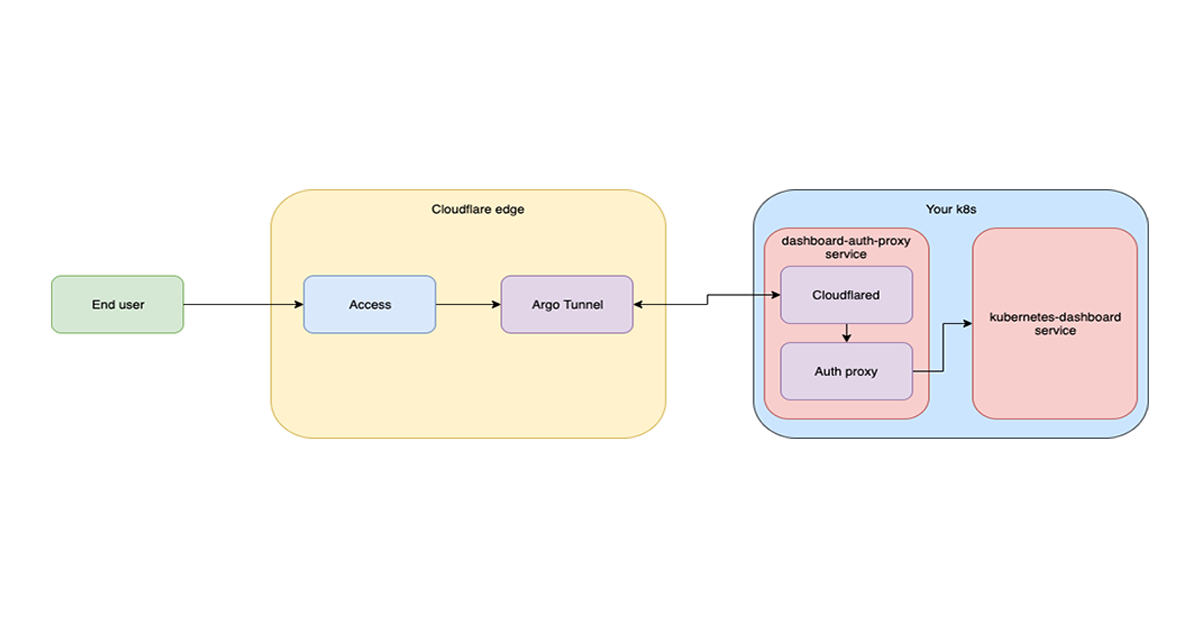
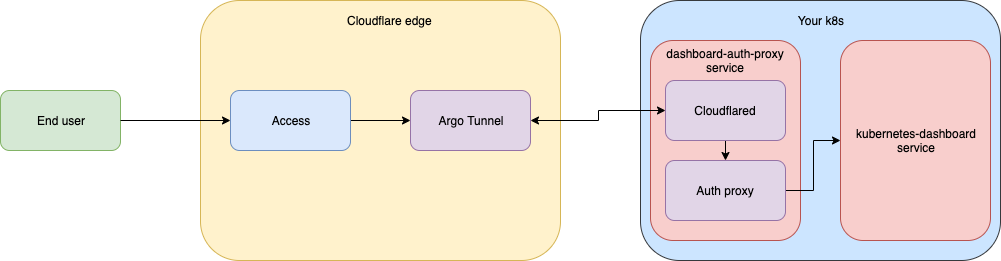
Cloudflare’s browser-based RDP solution is the newest addition to Cloudflare Access alongside existing clientless SSH and VNC offerings, enabling secure, remote Windows server access without VPNs or RDP clients. Built natively within Cloudflare’s global network, it requires no additional infrastructure.
Our browser-based RDP access combines the power of self-hosted Access applications with the additional flexibility of targets, introduced with Access for Infrastructure. Administrators can enforce:
-
Authentication: Control how users authenticate to your internal RDP resources with SSO, MFA, and device posture.
-
Authorization: Use policy-based access control to determine who can access what target and when.
-
Auditing: Provide Access logs to support regulatory compliance and visibility in the event of a security breach.
Users only need a web browser — no native RDP client is necessary! RDP servers are accessed through our app connector, Cloudflare Tunnel, using a common deployment model of existing Access customers. There is no need to provision user devices to access particular RDP servers, making for minimal setup to adopt this new functionality.
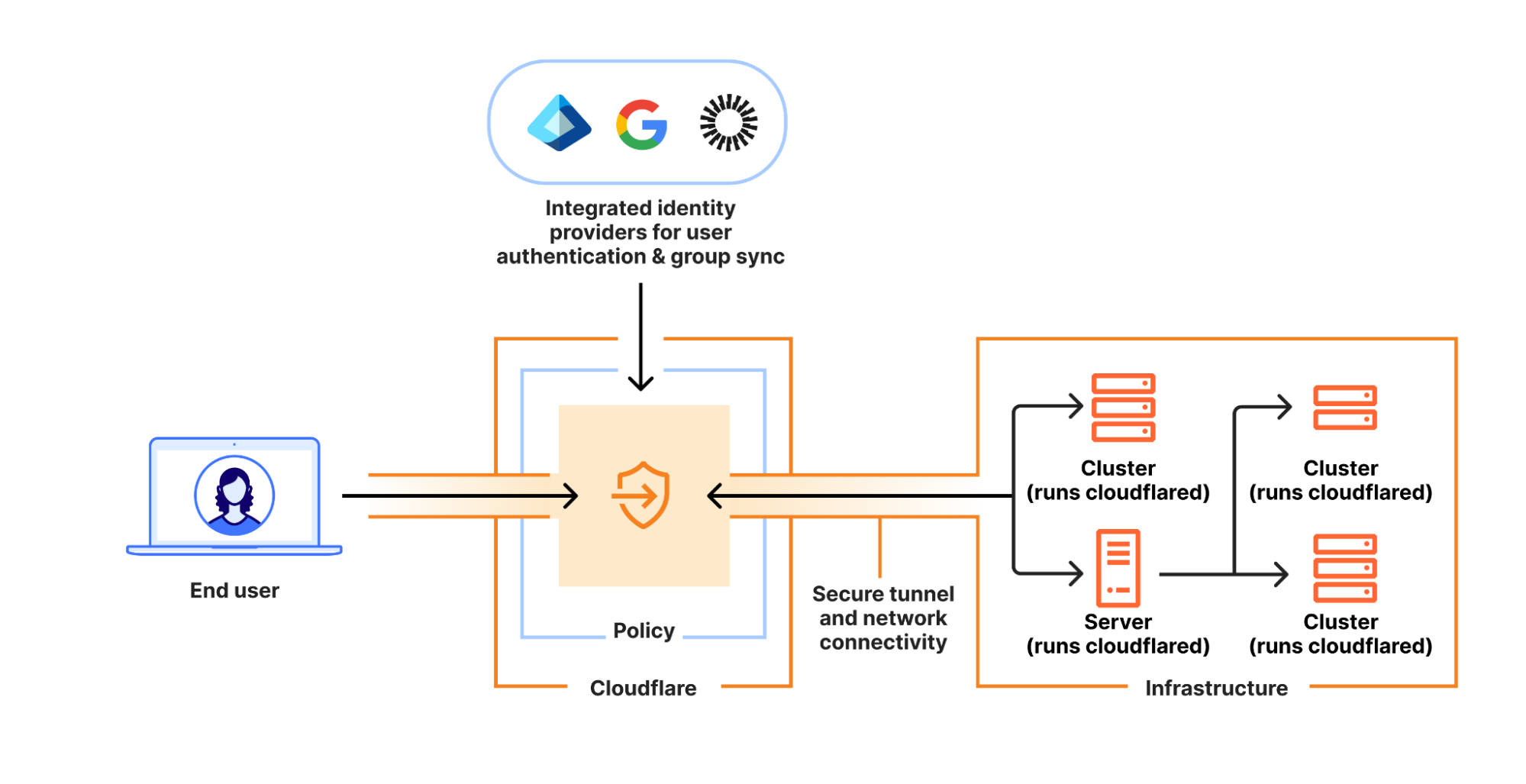
How it works
The client
Cloudflare’s implementation leverages IronRDP, a high-performance RDP client that runs in the browser. It was selected because it is a modern, well-maintained, RDP client implementation that offers an efficient and responsive experience. Unlike Java-based Apache Guacamole, another popular RDP client implementation, IronRDP is built with Rust and integrates very well with Cloudflare’s development ecosystem.
While selecting the right tools can make all the difference, using a browser to facilitate an RDP session faces some challenges. From a practical perspective, browsers just can’t send RDP messages. RDP relies directly on the Layer 4 Transmission Control Protocol (TCP) for communication, and while browsers can use TCP as the underlying protocol, they do not expose APIs that would let apps build protocol support directly on raw TCP sockets.
Another challenge is rooted in a security consideration: the username and password authentication mechanism that is native to RDP leaves a lot to be desired in the modern world of Zero Trust.
In order to tackle both of these challenges, the IronRDP client encapsulates the RDP session in a WebSocket connection. Wrapping the Layer 4 TCP traffic in HTTPS enables the client to use native browser APIs to communicate with Cloudflare’s RDP proxy. Additionally, it enables Cloudflare Access to secure the entire session using identity-aware policies. By attaching a Cloudflare Access authorization JSON Web Token (JWT) via cookie to the WebSocket connection, every inter-service hop of the RDP session is verified to be coming from the authenticated user.
A brief aside into how security and performance is optimized: in conventional client-based RDP traffic, the client and server negotiate a TLS connection to secure and verify the session. However, because the browser WebSocket connection is already secured with TLS to Cloudflare, we employ IronRDP’s RDCleanPath protocol extension to eliminate this second encapsulation of traffic. Removing this redundancy avoids unnecessary performance degradation and increased complexity during session handshakes.
The server
The IronRDP client initiates a WebSocket connection to a dedicated WebSocket proxy, which is responsible for authenticating the client, terminating the WebSocket connection, and proxying tunneled RDP traffic deeper into Cloudflare’s infrastructure to facilitate connectivity. The seemingly simple task of determining how this WebSocket proxy should be built turned out to be the most challenging decision in the development process.
Our initial proposal was to develop a new service that would run on every server within our network. While this was feasible, operating a new service would introduce a non-trivial maintenance burden, which ultimately turned out to be more overhead than value-add in this case. The next proposal was to build it into Front Line (FL), one of Cloudflare’s oldest services that is responsible for handling tens of millions of HTTP requests per second. This approach would have sidestepped the need to expose new IP addresses and benefitted from the existing scaffolding to let the team move quickly. Despite being promising at first, this approach was decided against because FL is undergoing significant investment, and the team didn’t want to build on shifting sands.
Finally, we identified a solution that implements the proxy service using Cloudflare Workers! Fortunately, Workers automatically scales to massive request rates, which eliminates some of the groundwork we’d lay if we had chosen to build a new service. Candidly, this approach was not initially preferred due to some ambiguities around how Workers communicates with internal Cloudflare services, but with support from the Workers team, we found a path forward.
From the WebSocket proxy Worker, the tunneled RDP connection is sent to the Apollo service, which is responsible for routing traffic between on-ramps and off-ramps for Cloudflare Zero Trust. Apollo centralizes and abstracts these complexities to let other services focus on application-specific functionality. Apollo determines which Cloudflare colo is closest to the target Cloudflare Tunnel and establishes a connection to an identical Apollo instance running in that colo. The egressing Apollo instance can then facilitate the final connection to the Cloudflare Tunnel. By using Cloudflare’s global network to traverse the distance between the ingress colo and the target Cloudflare Tunnel, network disruptions and congestion is managed.
Apollo connects to the RDP server and passes the ingress and egress connections to Oxy-teams, the service responsible for inspecting and proxying the RDP traffic. It functions as a pass-through (strictly enabling traffic connectivity) as the web client authenticates to the RDP server. Our initial release makes use of NT Lan Manager (NTLM) authentication, a challenge-response authentication protocol requiring username and password entry. Once the client has authenticated with the server, Oxy-teams is able to proxy all subsequent RDP traffic!
This may sound like a lot of hops, but every server in our network runs every service. So believe it or not, this complex dance takes place on a single server and by using UNIX domain sockets for communication, we also minimize any performance impact. If any of these servers become overloaded, experience a network fault, or have a hardware problem, the load is automatically shifted to a neighboring server with the help of Unimog, Cloudflare’s L4 load balancer.
Putting it all together
-
User initiation: The user selects an RDP server from Cloudflare’s App Launcher (or accesses it via a direct URL). Each RDP server is associated with a public hostname secured by Cloudflare.
-
Ingress: This request is received by the closest data center within Cloudflare’s network.
-
Authentication: Cloudflare Access authenticates the session by validating that the request contains a valid JWT. This token certifies that the user is authorized to access the selected RDP server through the specified domain.
-
Web client delivery: Cloudflare Workers serves the IronRDP web client to the user’s browser.
-
Secure tunneling: The client tunnels RDP traffic from the user’s browser over a TLS-secured WebSocket to another Cloudflare Worker.
-
Traffic routing: The Worker that receives the IronRDP connection terminates the WebSocket and initiates a connection to Apollo. From there, Apollo creates a connection to the RDP server.
-
Authentication relay: With a connection established, Apollo relays RDP authentication messages between the web client and the RDP server.
-
Connection establishment: Upon successful authentication, Cloudflare serves as an RDP proxy between the web browser and the RDP server, connecting the user to the RDP server with free-flowing traffic.
-
Policy enforcement: Cloudflare’s secure web gateway, Oxy-teams, applies Layer 4 policy enforcement and logging of the RDP traffic.
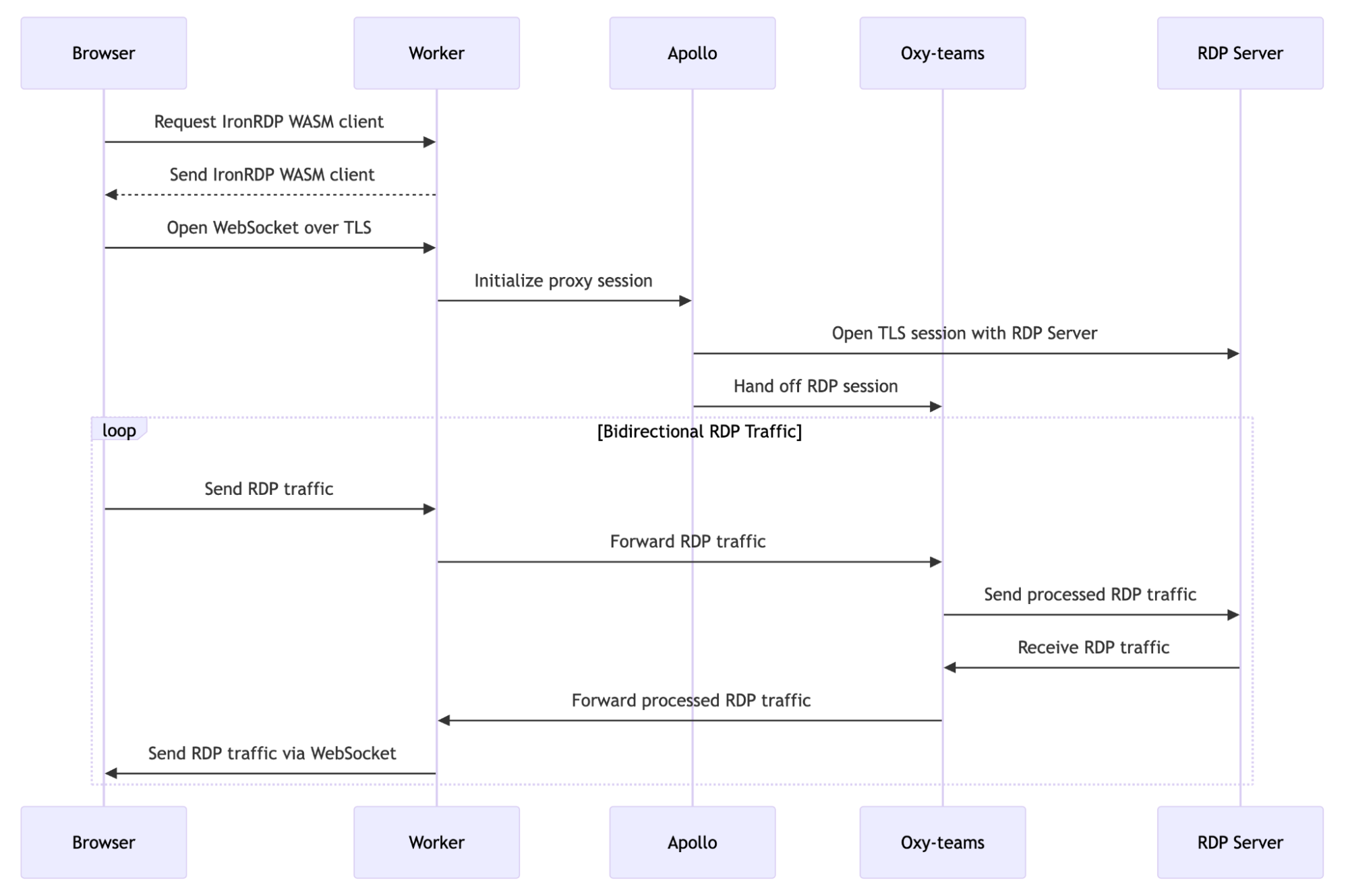
Key benefits of this architecture:
-
No additional software: Access Windows servers directly from a browser.
-
Low latency: Cloudflare’s global network minimizes performance overhead.
-
Enhanced security: RDP access is protected by Access policies, preventing lateral movement.
-
Integrated logging and monitoring: Administrators can observe and control RDP traffic.
To learn more about Cloudflare’s proxy capabilities, take a look at our related blog post explaining our proxy framework.
Cloudflare’s browser-based RDP solution exclusively supports modern RDP authentication mechanisms, enforcing best practices for secure access. Our architecture ensures that RDP traffic using outdated or weak legacy security features from older versions of the RDP standard, such as unsecured password-based authentication or RC4 encryption, are never allowed to reach customer endpoints.
Cloudflare supports secure session negotiation using the following principles:
-
TLS-based WebSocket connection for transport security.
-
Fine-grained policies that enforce single sign on (SSO), multi-factor authentication (MFA), and dynamic authorization.
-
Integration with enterprise identity providers via SAML (Security Assertion Markup Language) and OIDC (OpenID Connect).
Every RDP session that passes through Cloudflare’s network is encrypted and authenticated.
What’s next?
This is only the beginning for our browser-based RDP solution! We have already identified a few areas for continued focus:
-
Enhanced visibility and control for administrators: Because RDP traffic passes through Cloudflare Workers and proxy services, browser-based RDP will expand to include session monitoring. We are also evaluating data loss prevention (DLP) support, such as restricting actions like file transfers and clipboard use, to prevent unauthorized data exfiltration without compromising performance.
-
Advanced authentication: Long-lived credentials are a thing of the past. Future iterations of browser-based RDP will include passwordless functionality, eliminating the need for end users to remember passwords and administrators from having to manage them. To that end, we are evaluating methods such as client certificate authentication, passkeys and smart cards, and integration with third-party authentication providers via Access.
Compliance and FedRAMP High certification
We plan to include browser-based RDP in our FedRAMP High offering for enterprise and government organizations, a high-priority initiative we announced in early February. This certification will validate that our solution meets the highest standards for:
-
Data protection
-
Identity and access management
-
Continuous monitoring
-
Incident response
Seeking FedRAMP High compliance demonstrates Cloudflare’s commitment to securing sensitive environments, such as those in the federal government, healthcare, and financial sectors.
By enforcing a modern, opinionated, and secure implementation of RDP, Cloudflare provides a secure, scalable, and compliant solution tailored to the needs of organizations with critical security and compliance mandates.
At Cloudflare, we are committed to providing the most comprehensive solution for ZTNA, which now also includes privileged access to sensitive infrastructure like Windows servers over browser-based RDP. Cloudflare’s browser-based RDP solution is in closed beta with new customers being onboarded each week. You can request access here to try out this exciting new feature.
In the meantime, check out our Access for Infrastructure documentation to learn more about how Cloudflare protects privileged access to sensitive infrastructure. Access for Infrastructure is currently available free to teams of under 50 users, and at no extra cost to existing pay-as-you-go and Contract plan customers through an Access or Zero Trust subscription. Stay tuned as we continue to natively rebuild BastionZero’s technology into Cloudflare’s Access for Infrastructure service!






 ) need not abandon their precious
) need not abandon their precious