Post Syndicated from Sheila Busser original https://aws.amazon.com/blogs/compute/enabling-load-balancing-of-non-https-traffic-on-aws-wavelength/
This blog post is written by Jack Chen, Telco Solutions Architect, and Robert Belson, Developer Advocate.
AWS Wavelength embeds AWS compute and storage services within 5G networks, providing mobile edge computing infrastructure for developing, deploying, and scaling ultra-low-latency applications. AWS recently introduced support for Application Load Balancer (ALB) in AWS Wavelength zones. Although ALB addresses Layer-7 load balancing use cases, some low latency applications that get deployed in AWS Wavelength Zones rely on UDP-based protocols, such as QUIC, WebRTC, and SRT, which can’t be load-balanced by Layer-7 Load Balancers. In this post, we’ll review popular load-balancing patterns on AWS Wavelength, including a proposed architecture demonstrating how DNS-based load balancing can address customer requirements for load-balancing non-HTTP(s) traffic across multiple Amazon Elastic Compute Cloud (Amazon EC2) instances. This solution also builds a foundation for automatic scale-up and scale-down capabilities for workloads running in an AWS Wavelength Zone.
Load balancing use cases in AWS Wavelength
In the AWS Regions, customers looking to deploy highly-available edge applications often consider Amazon Elastic Load Balancing (Amazon ELB) as an approach to automatically distribute incoming application traffic across multiple targets in one or more Availability Zones (AZs). However, at the time of this publication, AWS-managed Network Load Balancer (NLB) isn’t supported in AWS Wavelength Zones and ALB is being rolled out to all AWS Wavelength Zones globally. As a result, this post will seek to document general architectural guidance for load balancing solutions on AWS Wavelength.
As one of the most prominent AWS Wavelength use cases, highly-immersive video streaming over UDP using protocols such as WebRTC at scale often require a load balancing solution to accommodate surges in traffic, either due to live events or general customer access patterns. These use cases, relying on Layer-4 traffic, can’t be load-balanced from a Layer-7 ALB. Instead, Layer-4 load balancing is needed.
To date, two infrastructure deployments involving Layer-4 load balancers are most often seen:
- Amazon EC2-based deployments: Often the environment of choice for earlier-stage enterprises and ISVs, a fleet of EC2 instances will leverage a load balancer for high-throughput use cases, such as video streaming, data analytics, or Industrial IoT (IIoT) applications
- Amazon EKS deployments: Customers looking to optimize performance and cost efficiency of their infrastructure can leverage containerized deployments at the edge to manage their AWS Wavelength Zone applications. In turn, external load balancers could be configured to point to exposed services via NodePort objects. Furthermore, a more popular choice might be to leverage the AWS Load Balancer Controller to provision an ALB when you create a Kubernetes
Ingress.
Regardless of deployment type, the following design constraints must be considered:
- Target registration: For load balancing solutions not managed by AWS, seamless solutions to load balancer target registration must be managed by the customer. As one potential solution, visit a recent HAProxyConf presentation, Practical Advice for Load Balancing at the Network Edge.
- Edge Discovery: Although DNS records can be populated into Amazon Route 53 for each carrier-facing endpoint, DNS won’t deterministically route mobile clients to the most optimal mobile endpoint. When available, edge discovery services are required to most effectively route mobile clients to the lowest latency endpoint.
- Cross-zone load balancing: Given the hub-and-spoke design of AWS Wavelength, customer-managed load balancers should proxy traffic only to that AWS Wavelength Zone.
Solution overview – Amazon EC2
In this solution, we’ll present a solution for a highly-available load balancing solution in a single AWS Wavelength Zone for an Amazon EC2-based deployment. In a separate post, we’ll cover the needed configurations for the AWS Load Balancer Controller in AWS Wavelength for Amazon Elastic Kubernetes Service (Amazon EKS) clusters.
The proposed solution introduces DNS-based load balancing, a technique to abstract away the complexity of intelligent load-balancing software and allow your Domain Name System (DNS) resolvers to distribute traffic (equally, or in a weighted distribution) to your set of endpoints.
Our solution leverages the weighted routing policy in Route 53 to resolve inbound DNS queries to multiple EC2 instances running within an AWS Wavelength zone. As EC2 instances for a given workload get deployed in an AWS Wavelength zone, Carrier IP addresses can be assigned to the network interfaces at launch.
Through this solution, Carrier IP addresses attached to AWS Wavelength instances are automatically added as DNS records for the customer-provided public hosted zone.
To determine how Route 53 responds to queries, given an arbitrary number of records of a public hosted zone, Route53 offers numerous routing policies:
Simple routing policy – In the event that you must route traffic to a single resource in an AWS Wavelength Zone, simple routing can be used. A single record can contain multiple IP addresses, but Route 53 returns the values in a random order to the client.
Weighted routing policy – To route traffic more deterministically using a set of proportions that you specify, this policy can be selected. For example, if you would like Carrier IP A to receive 50% of the traffic and Carrier IP B to receive 50% of the traffic, we’ll create two individual A records (one for each Carrier IP) with a weight of 50 and 50, respectively. Learn more about Route 53 routing policies by visiting the Route 53 Developer Guide.
The proposed solution leverages weighted routing policy in Route 53 DNS to route traffic to multiple EC2 instances running within an AWS Wavelength zone.
Reference architecture
The following diagram illustrates the load-balancing component of the solution, where EC2 instances in an AWS Wavelength zone are assigned Carrier IP addresses. A weighted DNS record for a host (e.g., www.example.com) is updated with Carrier IP addresses.

When a device makes a DNS query, it will be returned to one of the Carrier IP addresses associated with the given domain name. With a large number of devices, we expect a fair distribution of load across all EC2 instances in the resource pool. Given the highly ephemeral mobile edge environments, it’s likely that Carrier IPs could frequently be allocated to accommodate a workload and released shortly thereafter. However, this unpredictable behavior could yield stale DNS records, resulting in a “blackhole” – routes to endpoints that no longer exist.
Time-To-Live (TTL) is a DNS attribute that specifies the amount of time, in seconds, that you want DNS recursive resolvers to cache information about this record.
In our example, we should set to 30 seconds to force DNS resolvers to retrieve the latest records from the authoritative nameservers and minimize stale DNS responses. However, a lower TTL has a direct impact on cost, as a result of increased number of calls from recursive resolvers to Route53 to constantly retrieve the latest records.
The core components of the solution are as follows:
- EC2 Launch Template – specifies instance configuration information, such as the Amazon Machine Image (AMI), Amazon Elastic Block Storage (Amazon EBS)type and size, and Elastic Network Interface (ENI) attachment with a Carrier IP association, instance tags, among other attributes.
- AWS Auto Scaling Group– a collection of EC2 instances logically grouped together for the purpose of automatic scaling.
Alongside the services above in the AWS Wavelength Zone, the following services are also leveraged in the AWS Region:
- AWS Lambda – a serverless event-driven function that makes API calls to the Route 53 service to update DNS records.
- Amazon EventBridge– a serverless event bus that reacts to EC2 instance lifecycle events and invokes the Lambda function to make DNS updates.
- Route 53– cloud DNS service with a domain record pointing to AWS Wavelength-hosted resources.
In this post, we intentionally leave the specific load balancing software solution up to the customer. Customers can leverage various popular load balancers available on the AWS Marketplace, such as HAProxy and NGINX. To focus our solution on the auto-registration of DNS records to create functional load balancing, this solution is designed to support stateless workloads only. To support stateful workloads, sticky sessions – a process in which routes requests to the same target in a target group – must be configured by the underlying load balancer solution and are outside of the scope of what DNS can provide natively.
Automation overview
Using the aforementioned components, we can implement the following workflow automation:
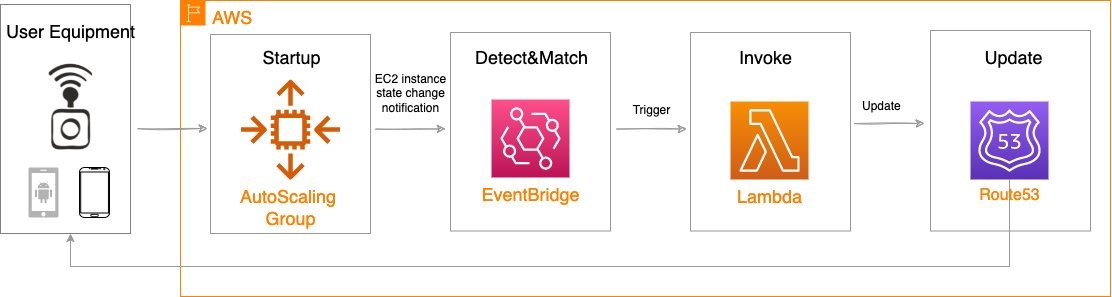
Amazon CloudWatch alarm can trigger the Auto Scaling group Scale out or Scale in event by adding or removing EC2 instances. Eventbridge will detect the EC2 instance state change event and invoke the Lambda function. This function will update the DNS record in Route53 by either adding (scale out) or deleting (scale in) a weighted A record associated with the EC2 instance changing state.
Configuration of the automatic auto scaling policy is out of the scope of this post. There are many auto scaling triggers that you can consider using, based on predefined and custom metrics such as memory utilization. For the demo purposes, we will be leveraging manual auto scaling.
In addition to the core components that were already described, our solution also utilizes AWS Identity and Access Management (IAM) policies and CloudWatch. Both services are key components to building AWS Well-Architected solutions on AWS. We also use AWS Systems Manager Parameter Store to keep track of user input parameters. The deployment of the solution is automated via AWS CloudFormation templates. The Lambda function provided should be uploaded to an AWS Simple Storage Service (Amazon S3) bucket.
Amazon Virtual Private Cloud (Amazon VPC), subnets, Carrier Gateway, and Route Tables are foundational building blocks for AWS-based networking infrastructure. In our deployment, we are creating a new VPC, one subnet in an AWS Wavelength zone of your choice, a Carrier Gateway, and updating the route table for this subnet to point the default route to the Carrier Gateway.

Deployment prerequisites
The following are prerequisites to deploy the described solution in your account:
- Access to an AWS Wavelength zone. If your account is not allow-listed to use AWS Wavelength zones, then opt-in to AWS Wavelength zones here.
- Public DNS Hosted Zone hosted in Route 53. You must have access to a registered public domain to deploy this solution. The zone for this domain should be hosted in the same account where you plan to deploy AWS Wavelength workloads.
If you don’t have a public domain, then you can register a new one. Note that there will be a service charge for the domain registration. - Amazon S3 bucket. For the Lambda function that updates DNS records in Route 53, store the source code as a .zip file in an Amazon S3 bucket.
- Amazon EC2 Key pair. You can use an existing Key pair for the deployment. If you don’t have a KeyPair in the region where you plan to deploy this solution, then create one by following these instructions.
- 4G or 5G-connected device. Although the infrastructure can be deployed independent of the underlying connected devices, testing the connectivity will require a mobile device on one of the Wavelength partner’s networks. View the complete list of Telecommunications providers and Wavelength Zone locations to learn more.
Conclusion
In this post, we demonstrated how to implement DNS-based load balancing for workloads running in an AWS Wavelength zone. We deployed the solution that used the EventBridge Rule and the Lambda function to update DNS records hosted by Route53. If you want to learn more about AWS Wavelength, subscribe to AWS Compute Blog channel here.