Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=D9O3CMVgB74
Yearly Archives: 2024
Security updates for Wednesday
Post Syndicated from jzb original https://lwn.net/Articles/987519/
Security updates have been issued by Fedora (calibre, dotnet8.0, dovecot, webkit2gtk4.0, and webkitgtk), Oracle (nodejs:20), Red Hat (bind, bind and bind-dyndb-ldap, postgresql:16, and squid), Slackware (kcron and plasma), SUSE (keepalived and webkit2gtk3), and Ubuntu (drupal7).
Command with Confidence: Insights from Andrew Bustamante
Post Syndicated from Emma Burdett original https://blog.rapid7.com/2024/08/28/command-with-confidence-insights-from-andrew-bustamante/

At the recent Take Command Summit, former CIA intelligence officer and US Air Force combat veteran Andrew Bustamante shared valuable tools, tactics, and techniques from elite intelligence agencies with Rapid7’s Americas Field CTO Jeffrey Gardner in an informal chat. His session, “Command with Confidence,” offered cybersecurity professionals insights to enhance their security strategies with clarity and confidence.
Key Takeaways:
- The Four C’s Framework: Bustamante introduced the “Four C’s” framework—consideration, consistency, collaboration, and control. This structured approach is designed to build rapport, ensure consistent performance, and effectively lead teams by taking proactive control.
- Goal Setting Techniques: Highlighting a three-step framework for goal setting, Bustamante emphasized starting with SMART goals, then stretching them, and finally aiming for “scary goals” to push boundaries and achieve exceptional outcomes.
- The Power of Soft Skills and Persuasion: Bustamante explained how persuasion is rooted in emotional connections rather than logical arguments. By assessing individuals and understanding their emotional triggers, professionals can create compelling narratives that drive action. These soft skills are critical in building effective teams and leading security projects successfully.
“Consideration, consistency, collaboration, and control—these are the pillars of effective leadership and influence. Mastering these can make you unstoppable in any professional environment.” – Andrew Bustamante
Survey Insight: We surveyed our attendees on the importance of soft skills versus technical skills in new security projects. The results showed:
- 37.5% agree and 34.38% strongly agree that the security community prioritizes technical skills over soft skills.
Ransomware attacks are a significant threat, but with the right strategies and proactive measures, organizations can enhance their defenses and build resilience. To dive deeper into these strategies and hear more from the experts, watch the full video from the Rapid7 Take Command Summit.
Sleep: A History of the Bed
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=inn_gjjkoTs
Matthew Green on Telegram’s Encryption
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/08/matthew-green-on-telegrams-encryption.html
Matthew Green wrote a really good blog post on what Telegram’s encryption is and is not.
EDITED TO ADD (8/28): Another good explainer from Kaspersky.
Bridging the gap from Scratch to Python: Introducing ‘Paint with Python’
Post Syndicated from Marc Scott original https://www.raspberrypi.org/blog/learn-to-code-python/
We have developed an innovative activity to support young people as they transition from visual programming languages like Scratch to text-based programming languages like Python.

This activity introduces a unique interface that empowers learners to easily interact with Python while they create a customised painting app.
“The kids liked the self-paced learning, it allowed them to work at their own rate. They liked using RGB tables to find their specific colours.” – Code Club mentor
Why learn to code Python?
We’ve long been championing Python as an ideal tool for young people who want to start text-based programming. Python has simple syntax and needs very few lines of code to get started, and there is a vibrant community of supportive programmers surrounding it.
However, we know that starting with Python can be challenging for young people who have never done any text-based coding. They can face obstacles such as software installation issues, getting used to a new syntax, and the need for appropriate typing skills.
How ‘Paint with Python’ helps learners get started
‘Paint with Python’ is an online educational activity that addresses many of these challenges and helps young people learn to code Python for the first time. It’s entirely web-based, requiring no software installation beyond a web browser. Instructions are displayed in a side panel, allowing learners to read and code without needing to switch tabs.
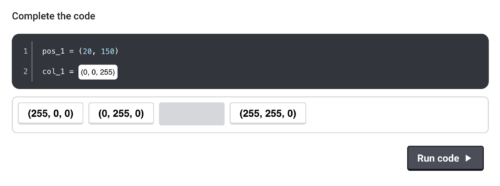
To help young people with creating their painting app, much of the initial code is pre-written behind the scenes, which enables learners to focus on experimenting with Python and observing the outcomes. They engage with the code by clicking on suggested options or, in some cases, by typing small snippets of Python. For example, they can select colours from a range of options or, as they grow more confident, type RGB values to create custom colours.
The activity is fully responsive for mobile and tablet devices and provides a final view of the full program on the last page, together with suggested routes to continue learning text-based programming.
An accessible introduction to text-based programming
We believe this activity offers an accessible way for young learners to begin their journey with text-based programming and learning to code Python. The code they write is straightforward and the activity is designed to minimise errors. When mistakes do occur, the interface provides clear, constructive feedback, guiding learners to make corrections.
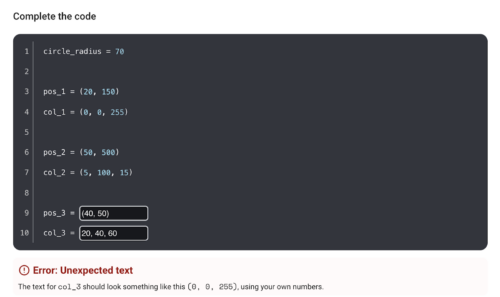
Try out ‘Paint with Python’ at rpf.io/paint-with-python. We’d love to hear your feedback! Please send any thoughts you have to [email protected].
This activity was developed with support from the Cisco Foundation. Through our funding partnership with them, we’ve been able to provide thousands of young people with the inspiration and opportunity to progress their coding skills anywhere, and on any device.
The post Bridging the gap from Scratch to Python: Introducing ‘Paint with Python’ appeared first on Raspberry Pi Foundation.
Microsoft MAIA 100 AI Accelerator for Azure
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/microsoft-maia-100-ai-accelerator-for-azure/
We learned more about the Microsoft Maia 100 which is the company’s AI accelerator to run OpenAI models at lower costs
The post Microsoft MAIA 100 AI Accelerator for Azure appeared first on ServeTheHome.
Jamestown Settlers versus Spanish Pirates
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=wG6GoajNYro
Comic for 2024.08.28 – Eating
Post Syndicated from Explosm.net original https://explosm.net/comics/eating
New Cyanide and Happiness Comic
Stranded
Post Syndicated from xkcd.com original https://xkcd.com/2978/

Ampere AmpereOne Architecture at Hot Chips 2024
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/ampere-ampereone-at-hot-chips-2024-arm/
At Hot Chips 2024, Ampere went into the AmpereOne microarchitecture details and discussed how it designed and built its custom Arm processor
The post Ampere AmpereOne Architecture at Hot Chips 2024 appeared first on ServeTheHome.
Harness Zero Copy data sharing from Salesforce Data Cloud to Amazon Redshift for Unified Analytics – Part 1
Post Syndicated from Rajkumar Irudayaraj original https://aws.amazon.com/blogs/big-data/harness-zero-copy-data-sharing-from-salesforce-data-cloud-to-amazon-redshift-for-unified-analytics-part-1/
This post is co-authored by Rajkumar Irudayaraj, Sr. Director of Product, Salesforce Data Cloud.
In today’s ever-evolving business landscape, organizations must harness and act on data to fuel analytics, generate insights, and make informed decisions to deliver exceptional customer experiences. Salesforce and Amazon have collaborated to help customers unlock value from unified data and accelerate time to insights with bidirectional Zero Copy data sharing between Salesforce Data Cloud and Amazon Redshift.
In a previous post, we showed how Zero Copy data federation empowers businesses to access Amazon Redshift data within the Salesforce Data Cloud to enrich customer 360 data with operational data. This two-part series explores how analytics teams can access customer 360 data from Salesforce Data Cloud within Amazon Redshift to generate insights on unified data without the overhead of extract, transform, and load (ETL) pipelines. In this post, we cover data sharing between Salesforce Data Cloud and customers’ AWS accounts in the same AWS Region. Part 2 covers cross-Region data sharing between Salesforce Data Cloud and customers’ AWS accounts.
What is Salesforce Data Cloud?
Salesforce Data Cloud is a data platform that unifies all of your company’s data into Salesforce’s Einstein 1 Platform, giving every team a 360-degree view of the customer to drive automation, create analytics, personalize engagement, and power trusted artificial intelligence (AI). Salesforce Data Cloud creates a holistic customer view by turning volumes of disconnected data into a unified customer profile that’s straightforward to access and understand. This unified view helps your sales, service, and marketing teams build personalized customer experiences, invoke data-driven actions and workflows, and safely drive AI across all Salesforce applications.
What is Amazon Redshift?
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence (BI) tools. It’s optimized for datasets ranging from a few hundred gigabytes to petabytes and delivers better price-performance compared to other data warehousing solutions. With a fully managed, AI-powered, massively parallel processing (MPP) architecture, Amazon Redshift makes business decision-making quick and cost-effective. Amazon Redshift Spectrum enables querying structured and semi-structured data in Amazon Simple Storage Service (Amazon S3) without having to load the data into Redshift tables. Redshift Spectrum integration with AWS Lake Formation enables querying auto-mounted AWS Glue Data Catalog tables with AWS Identity and Access Management (IAM) credentials and harnessing Lake Formation for permission grants and access control policies on Data Catalog views. Salesforce Data Cloud Data sharing with Amazon Redshift leverages AWS Glue Data Catalog support for multi-engine views and Redshift Spectrum integration with Lake Formation.
What is Zero Copy data sharing?
Zero Copy data sharing enables Amazon Redshift customers to query customer 360 data stored in Salesforce Data Cloud without the need for traditional ETL to move or copy the data. Instead, you simply connect and use the data in place, unlocking its value immediately with on demand access to the most recent data. Data sharing is supported with both Amazon Redshift Serverless and provisioned RA3 clusters. Data can be shared with a Redshift Serverless or provisioned cluster in the same Region or with a Redshift Serverless cluster in a different Region. To get an overview of Salesforce Zero Copy integration with Amazon Redshift, please refer to this Salesforce Blog.
Solution overview
Salesforce Data Cloud provides a point-and-click experience to share data with a customer’s AWS account. On the Lake Formation console, you can accept the data share, create the resource link, mount Salesforce Data Cloud objects as data catalog views, and grant permissions to query the live and unified data in Amazon Redshift.
The following diagram depicts the end-to-end process involved for sharing Salesforce Data Cloud data with Amazon Redshift in the same Region using a Zero Copy architecture. This architecture follows the pattern documented in Cross-account data sharing best practices and considerations.

The data share setup consists of the following high-level steps:
- The Salesforce Data Cloud admin creates the data share target with the target account for the data share.
- The Salesforce Data Cloud admin selects the data cloud objects to be shared with Amazon Redshift and creates a data share.
- The Salesforce Data Cloud admin links the data share to the data share target, which invokes the following operations to create a cross-account resource share:
- Create a Data Catalog view for the Salesforce Data Cloud Apache Iceberg tables by invoking the Catalog API.
- Use Lake Formation sharing to create a cross-account Data Catalog share.
- In the customer AWS account, the Lake Formation admin logs in to the Lake Formation console to accept the resource share, create a resource link, and grant access permissions to the Redshift role.
- The data analyst launches the Amazon Redshift Query Editor with the appropriate role to query the data share and join with native Redshift tables.
Prerequisites
The following are the prerequisites to enable data sharing:
- A Salesforce Data Cloud account.
- An AWS account with AWS Glue and Lake Formation enabled.
- Either a Redshift Serverless or a Redshift provisioned cluster with RA3 instance types (ra3.16xlarge, ra3.4xlarge, ra3.xlplus). Data sharing is not supported for other provisioned instance types like DC2 or DS2 and must be set up before accessing the data share. If you don’t have an existing provisioned Redshift RA3 cluster, we recommend using a Redshift Serverless namespace for ease of operations and maintenance.
- The Amazon Redshift service must be running in the same Region where the Salesforce Data Cloud is running.
- AWS admin roles for Lake Formation and Amazon Redshift:
- Lake Formation – A data lake admin for accepting the share and providing access to users. For more details, see Lake Formation personas and IAM permissions reference.
- Amazon Redshift – A Redshift database owner, admin, or superuser who creates the database and provides access to developers or analysts. For more details, see Default database user permissions.
Create the data share target
Complete the following steps to create the data share target:
- In Salesforce Data Cloud, choose App Launcher and choose Data Share Targets.


- Choose New and choose Amazon Redshift, then choose Next.


- Enter the details for Label, API Name, and Account for the data share target.
- Choose Save.
After you save these settings, the S3 Tenant Folder value is populated.

- Choose the S3 Tenant Folder link and copy the verification token.
If you’re not signed in to the AWS Management Console, you’ll be redirected to the login page.

- Enter the verification token and choose Save.


The data share target turns to active status.
Create a data share
Complete the following steps to create a data share:
- Navigate to the Data Share tab in your Salesforce org.
- Choose App Launcher and choose Data Shares.


Alternatively, you can navigate to the Data Share tab from your org’s home page.

- Choose New, then choose Next.


- Provide a label, name, data space, and description, then choose Next.


- Select the objects to be included in the share and choose Save.


Link the data share target to the data share
To link the data share target to the data share, complete the following steps:
- On the data share record home page, choose Link/Unlink Data Share Target.
- Select the data share target you want to link to the data share and choose Save.


The data share must be active before you can accept the resource share on the Lake Formation console.

Accept the data share in Lake Formation
This section provides the detailed steps for accepting the data share invite and configuration steps to mount the data share with Amazon Redshift.
- After the data share is successfully linked to the data share target, navigate to the Lake Formation console.
The data share invitation banner is displayed.
- Choose Accept and create.


The Accept and create page shows a resource link and provides the option to set up IAM permissions.
- In the Principals section, choose the IAM users and roles to grant the default permissions (describe and select) for the data share resource link.


- Choose Create.


The resource link created in the previous step appears next to the AWS Glue database resource share on the Lake Formation console.

Query the data share from Redshift Serverless
Launch the query editor for Redshift Serverless and log in as a federated user with the role that has describe and select permissions for the resource link.

The data share tables are auto-mounted, appear under awsdatacatalog, and can be queried as shown in the following screenshot.

Query the data share from the Redshift provisioned cluster
To query the data share from the Redshift provisioned cluster, log in to the provisioned cluster as the superuser.

On an editor tab, run the following SQL statement to grant an IAM user access to the Data Catalog:
IAM:myIAMUser is an IAM user that you want to grant usage privilege to the Data Catalog. Alternatively, you can grant usage privilege to IAMR:myIAMRole for an IAM role. For more details, refer to Querying the AWS Glue Data Catalog.

Log in as the user with the role from the previous step using temporary credentials.

You should be able to expand awsdatacatalog and query the data share tables as shown in the following screenshot.

Conclusion
Zero Copy data sharing between Salesforce Data Cloud and Amazon Redshift represents a significant advancement in how organizations can use their customer 360 data. By eliminating the need for data movement, this approach offers real-time insights, reduced costs, and enhanced security. As businesses continue to prioritize data-driven decision-making, Zero Copy data sharing will play a crucial role in unlocking the full potential of customer data across platforms.
This integration empowers organizations to break down data silos, accelerate analytics, and drive more agile customer-centric strategies. To learn more, refer to the following resources:
- AWS Glue Data Catalog supports multi engine views with AWS Analytics Engines
- Data sharing in AWS Lake Formation
- Salesforce Zero Copy Integration
- Apache Iceberg
- Transform Your Data Strategy with the Power of Salesforce Data Cloud’s Zero Copy Integration to Amazon Redshift
About the Authors
 Rajkumar Irudayaraj is a Senior Product Director at Salesforce with over 20 years of experience in data platforms and services, with a passion for delivering data-powered experiences to customers.
Rajkumar Irudayaraj is a Senior Product Director at Salesforce with over 20 years of experience in data platforms and services, with a passion for delivering data-powered experiences to customers.
 Jason Berkowitz is a Senior Product Manager with AWS Lake Formation. He comes from a background in machine learning and data lake architectures. He helps customers become data-driven.
Jason Berkowitz is a Senior Product Manager with AWS Lake Formation. He comes from a background in machine learning and data lake architectures. He helps customers become data-driven.
 Ravi Bhattiprolu is a Senior Partner Solutions Architect at AWS. Ravi works with strategic ISV partners, Salesforce and Tableau, to deliver innovative and well-architected products & solutions that help joint customers achieve their business and technical objectives.
Ravi Bhattiprolu is a Senior Partner Solutions Architect at AWS. Ravi works with strategic ISV partners, Salesforce and Tableau, to deliver innovative and well-architected products & solutions that help joint customers achieve their business and technical objectives.
 Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music.
Avijit Goswami is a Principal Solutions Architect at AWS specialized in data and analytics. He supports AWS strategic customers in building high-performing, secure, and scalable data lake solutions on AWS using AWS managed services and open source solutions. Outside of his work, Avijit likes to travel, hike, watch sports, and listen to music.
 Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field.
Ife Stewart is a Principal Solutions Architect in the Strategic ISV segment at AWS. She has been engaged with Salesforce Data Cloud over the last 2 years to help build integrated customer experiences across Salesforce and AWS. Ife has over 10 years of experience in technology. She is an advocate for diversity and inclusion in the technology field.
 Michael Chess is a Technical Product Manager at AWS Lake Formation. He focuses on improving data permissions across the data lake. He is passionate about ensuring customers can build and optimize their data lakes to meet stringent security requirements.
Michael Chess is a Technical Product Manager at AWS Lake Formation. He focuses on improving data permissions across the data lake. He is passionate about ensuring customers can build and optimize their data lakes to meet stringent security requirements.
 Mike Patterson is a Senior Customer Solutions Manager in the Strategic ISV segment at AWS. He has partnered with Salesforce Data Cloud to align business objectives with innovative AWS solutions to achieve impactful customer experiences. In his spare time, he enjoys spending time with his family, sports, and outdoor activities.
Mike Patterson is a Senior Customer Solutions Manager in the Strategic ISV segment at AWS. He has partnered with Salesforce Data Cloud to align business objectives with innovative AWS solutions to achieve impactful customer experiences. In his spare time, he enjoys spending time with his family, sports, and outdoor activities.
XiangShan High-Performance RISC-V Processors at Hot Chips 2024
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/xiangshan-high-performance-risc-v-processors-at-hot-chips-2024/
The XiangShan RISC-V CPU project from Chinese universities is designing and delivering cores targeting Arm Neoverse N2 and Cortex A76 designs
The post XiangShan High-Performance RISC-V Processors at Hot Chips 2024 appeared first on ServeTheHome.
Cerebras Enters AI Inference Blows Away Tiny NVIDIA H100 GPUs by Besting HBM
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/cerebras-enters-ai-inference-blows-away-tiny-nvidia-h100-gpus-by-besting-hbm/
Cerebras enters AI inference and uses its giant chip to run circles around NVIDIA HGX H100 platform performance
The post Cerebras Enters AI Inference Blows Away Tiny NVIDIA H100 GPUs by Besting HBM appeared first on ServeTheHome.
Има ли наистина скок в раждаемостта след пандемията?
Post Syndicated from Боян Юруков original https://yurukov.net/blog/2024/ima-li-skok-v-rajdamostta/
Наскоро коментирах под няколко интересни и няколко най-малкото подвеждащи поста на тема демография. Усетих се, че някои от наблюденията ми се базират на данни от преди няколко години. Затова реших да включа в таблиците си последните от НСИ, включително преброяването.
По традиция това пак свърши с 30-тина свалени таблици и затъване в заешка дупка на моделите ми. Ще пусна данните от тях скоро.
Междувременно, ето нещо бързо, което бях започнал в края на миналата година, но реших да изчакам официалните данни на НСИ за ревизията на населението. По някое време след всяко преброяване, те пускат таблица, с корекция на преценката си за населението. През времето неизменно се натрупва грешка и тя се наблюдава във всички държави. Бях направил своя корекция и макар да смятам тяхната за твърде изкривена, следва да използвам нея. Та вкарах в модела си техните данни и преизчислих тоталния коефициент на плодовитост, сравних го с официалния и получих следната графика.
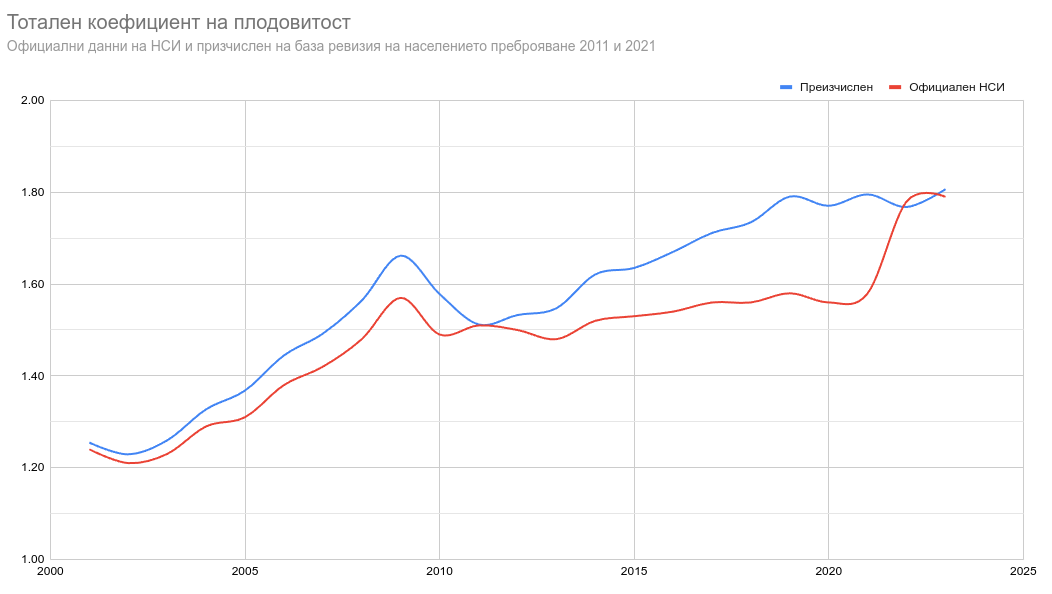
Както виждаме тук. Тоталният коефициент на плодовитост най-общо може да се определи като колко деца биха имали жените в рамките на живота си, ако имаха възможностите, здравето и изборът на жените родили в рамките на една календарна година. В изчисляването му влиза броят родени деца по възраст на майката и колко жени има в тази група. Методологията ще откриете тук. Консенсусът е, че при ниската детска смъртност в наши дни е достатъчен коефициент от 2.1 за да се запази размерът на едно население. В действителност има и други фактори, но дългосрочно този е най-важният.
След 2021-ва попаднахме на няколко изказвания и заглавия, които отбелязваха рекордната раждаемост в страната. Тогава многократно обяснявах, че това е заради по-реалистичната представа за броя жени, които са в детеродна възраст. Преди това е бил нисък, защото сме смятали, че има повече жени във всяка възрастова група. С корекцията се вижда, че растежът на плодовитостта е растял равномерно.
Трябва да знаете, че въпреки, че НСИ публикува ревизия на данните си, те не ги прилагат в официалните таблици за населението. От там следва, че не ревизират индекси като този за смъртността, раждаемостта и прочие. За това има причини, но прави сравнението по-трудно. Затова и създадох свой модел да правят такива преценки, включително как ще се развива населението на база родените сега деца. Впрочем – забелязва се увеличение на момичетата влизащи в детеродна възраст.
Има два проблема с моето преизчисление на този коефициент. Когато го приложа с оригиналните, неревизирани данни за населението не получавам същия тотален коефициент на плодовитост както НСИ. Причината е, че имам достъп само до 5-годишни групи за население и възраст на раждалите майки. Вариацията между тези възрасти води до грешка в изчисленията и от средно 0.54% (медиана 0.44%, мин. 0.13%, макс 1.19%) за последните 14 години.
Вторият проблем, който виждам, е че ревизията на населението представена от НСИ има твърде силен скок веднага след преброяването през 2011-та и почти никаква промяна във времената на пандемията, когато смъртността скочи драстично, макар и предимно след по-възрастните. Това ми се струва крайно странно, но предполагам, че имат причини за това, за които ще ги питам. Долу виждате разликата в червено. Вертикалната скала показва средният брой жени във всяка от възрастовите групи включени в детеродна възраст.
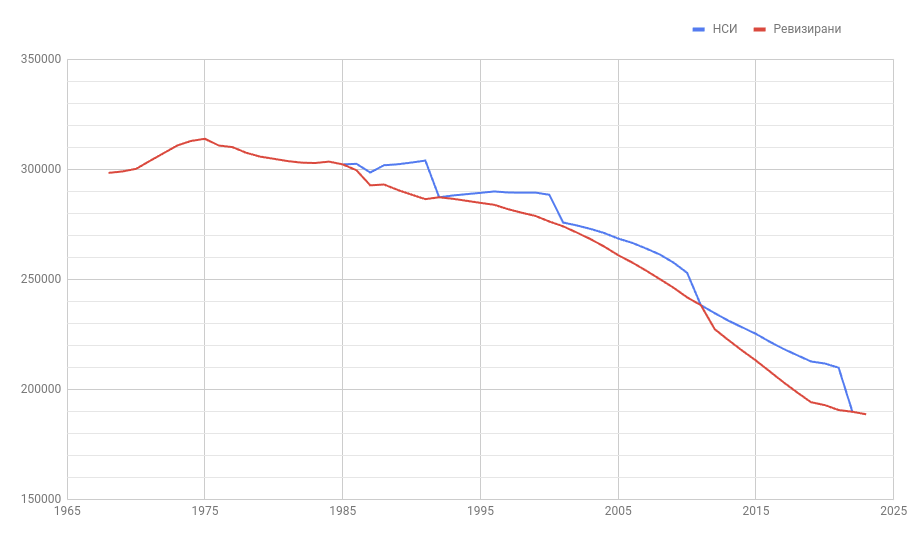
Ефектът от този рязък спад в оценката за населението през 2012-та се отразява и на привидната привиден скок в раждаемостта тогава. Аналогично спадът в намаляването на населението след 2020-та създава впечатление, че има застой в раждаемостта. Една причина за това може да бъде, че имаше увеличение на връщащите се в България наши сънародници, често вече с деца. Пример за това съм аз самият.
Повече по темата може да прочетете в анализа, който направих преди почти 10 години с данните за раждаемостта между 1968-ма и 2014-та. Обнових ги в края на 2021-ва с данните до преброяването, но там не съм включил ревизията, за която говоря тук. Ще ги обновя с тях и данните за следващите няколко години в близките седмици.
The post Има ли наистина скок в раждаемостта след пандемията? first appeared on Блогът на Юруков.
WineHQ to take over Mono
Post Syndicated from corbet original https://lwn.net/Articles/987465/
The Mono project was started in 2001 to develop a .NET environment for
Linux systems. Microsoft has owned that project since 2016, but has not
made a major release since 2019. The company has now announced that Mono is being
handed over to the WineHQ organization, which will maintain the repository going
forward. Microsoft, meanwhile, is steering users toward its “modern
” that it continues to maintain.
fork
Intel 4Tbps Optical Chiplet for XPU to XPU Connectivity Detailed
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/intel-4tbps-optical-chiplet-for-xpu-to-xpu-connectivity-detailed/
At Hot Chips 2024 Intel showed off a 4Tbps optical chiplet to displace copper chip-to-chip links with longer reach efficient optics
The post Intel 4Tbps Optical Chiplet for XPU to XPU Connectivity Detailed appeared first on ServeTheHome.
Enfabrica ACF-S A HUGE Multi-Tbps SuperNIC at Hot Chips 2024
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/enfabrica-acf-s-a-huge-multi-tbps-supernic-at-hot-chips-2024/
The Enfabrica ACF-S takes aspects of scale-up and scale-up combining up to 3.2Tbps of networking and 10x PCIe Gen5 x16 links into one chip
The post Enfabrica ACF-S A HUGE Multi-Tbps SuperNIC at Hot Chips 2024 appeared first on ServeTheHome.
Members from the cast of Wicked celebrating 20 years of their show
Post Syndicated from Talks at Google original https://www.youtube.com/watch?v=XJqzYwvUgsA
Tesla DOJO Exa-Scale Lossy AI Network using the Tesla Transport Protocol over Ethernet TTPoE
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/tesla-dojo-exa-scale-lossy-ai-network-using-the-tesla-transport-protocol-over-ethernet-ttpoe/
Tesla brought its Dojo V1 networking hardware to Hot Chips 2024 and announced that it is donating its own TTPoE protocol to the Ultra Ethernet Consortium
The post Tesla DOJO Exa-Scale Lossy AI Network using the Tesla Transport Protocol over Ethernet TTPoE appeared first on ServeTheHome.