Post Syndicated from Raj Patel original https://aws.amazon.com/blogs/big-data/attribute-amazon-emr-on-ec2-costs-to-your-end-users/
Amazon EMR on EC2 is a managed service that makes it straightforward to run big data processing and analytics workloads on AWS. It simplifies the setup and management of popular open source frameworks like Apache Hadoop and Apache Spark, allowing you to focus on extracting insights from large datasets rather than the underlying infrastructure. With Amazon EMR, you can take advantage of the power of these big data tools to process, analyze, and gain valuable business intelligence from vast amounts of data.
Cost optimization is one of the pillars of the Well-Architected Framework. It focuses on avoiding unnecessary costs, selecting the most appropriate resource types, analyzing spend over time, and scaling in and out to meet business needs without overspending. An optimized workload maximizes the use of all available resources, delivers the desired outcome at the most cost-effective price point, and meets your functional needs.
The current Amazon EMR pricing page shows the estimated cost of the cluster. You can also use AWS Cost Explorer to get more detailed information about your costs. These views give you an overall picture of your Amazon EMR costs. However, you may need to attribute costs at the individual Spark job level. For example, you might want to know the usage cost in Amazon EMR for the finance business unit. Or, for chargeback purposes, you might need to aggregate the cost of Spark applications by functional area. After you have allocated costs to individual Spark jobs, this data can help you make informed decisions to optimize your costs. For instance, you could choose to restructure your applications to utilize fewer resources. Alternatively, you might opt to explore different pricing models like Amazon EMR on EKS or Amazon EMR Serverless.
In this post, we share a chargeback model that you can use to track and allocate the costs of Spark workloads running on Amazon EMR on EC2 clusters. We describe an approach that assigns Amazon EMR costs to different jobs, teams, or lines of business. You can use this feature to distribute costs across various business units. This can assist you in monitoring the return on investment for your Spark-based workloads.
Solution overview
The solution is designed to help you track the cost of your Spark applications running on EMR on EC2. It can help you identify cost optimizations and improve the cost-efficiency of your EMR clusters.
The proposed solution uses a scheduled AWS Lambda function that operates on a daily basis. The function captures usage and cost metrics, which are subsequently stored in Amazon Relational Database Service (Amazon RDS) tables. The data stored in the RDS tables is then queried to derive chargeback figures and generate reporting trends using Amazon QuickSight. The utilization of these AWS services incurs additional costs for implementing this solution. Alternatively, you can consider an approach that involves a cron-based agent script installed on your existing EMR cluster, if you want to avoid the use of additional AWS services and associated costs for building your chargeback solution. This script stores the relevant metrics in an Amazon Simple Storage Service (Amazon S3) bucket, and uses Python Jupyter notebooks to generate chargeback numbers based on the data files stored in Amazon S3, using AWS Glue tables.
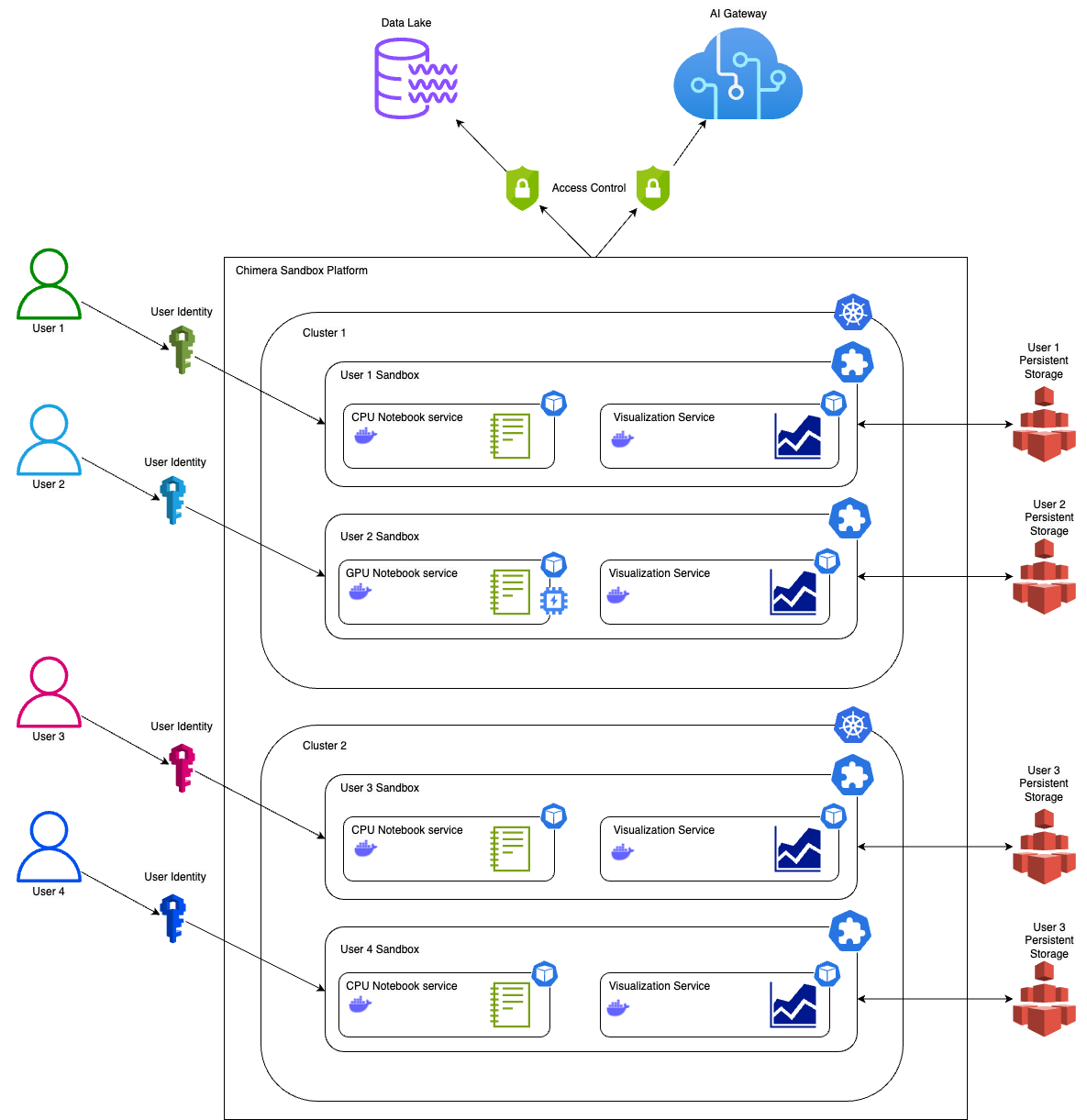
The following diagram shows the current solution architecture.

The workflow consists of the following steps:
- A Lambda function gets the following parameters from Parameter Store, a capability of AWS Systems Manager:
{
"yarn_url": "http://dummy.compute-1.amazonaws.com:8088/ws/v1/cluster/apps",
"tbl_applicationlogs_lz": "public.emr_applications_execution_log_lz",
"tbl_applicationlogs": "public.emr_applications_execution_log",
"tbl_emrcost": "public.emr_cluster_usage_cost",
"tbl_emrinstance_usage": "public.emr_cluster_instances_usage",
"emrcluster_id": "j-xxxxxxxxxx",
"emrcluster_name": "EMR_Cost_Measure",
"emrcluster_role": "dt-dna-shared",
"emrcluster_linkedaccount": "xxxxxxxxxxx",
"postgres_rds": {
"host": "xxxxxxxxx.amazonaws.com",
"dbname": "postgres",
"user": "postgresadmin",
"secretid": "postgressecretid"
}
}
- The Lambda function extracts Spark application run logs from the EMR cluster using the Resource Manager API. The following metrics are extracted as part of the process: vcore-seconds, memory MB-seconds, and storage GB-seconds.
- The Lambda function captures the daily cost of EMR clusters from Cost Explorer.
- The Lambda function also extracts EMR On-Demand and Spot Instance usage data using the Amazon Elastic Compute Cloud (Amazon EC2) Boto3 APIs.
- Lambda function loads these datasets into an RDS database.
- The cost of running a Spark application is determined by the amount of CPU resources it uses, compared to the total CPU usage of all Spark applications. This information is used to distribute the overall cost among different teams, business lines, or EMR queues.
The extraction process runs daily, extracting the previous day’s data and storing it in an Amazon RDS for PostgreSQL table. The historical data in the table needs to be purged based on your use case.
The solution is open source and available on GitHub.
You can use the AWS Cloud Development Kit (AWS CDK) to deploy the Lambda function, RDS for PostgreSQL data model tables, and a QuickSight dashboard to track EMR cluster cost at the job, team, or business unit level.
The following schema show the tables used in the solution which are queried by QuickSight to populate the dashboard.
- emr_applications_execution_log_lz or public.emr_applications_execution_log – Storage for daily run metrics for all jobs run on the EMR cluster:
- appdatecollect – Log collection date
- app_id – Spark job run ID
- app_name – Run name
- queue – EMR queue in which job was run
- job_state – Job running state
- job_status – Job run final status (
Succeeded or Failed)
- starttime – Job start time
- endtime – Job end time
- runtime_seconds – Runtime in seconds
- vcore_seconds – Consumed vCore CPU in seconds
- memory_seconds – Memory consumed
- running_containers – Containers used
- rm_clusterid – EMR cluster ID
- emr_cluster_usage_cost – Captures Amazon EMR and Amazon EC2 daily cost consumption from Cost Explorer and loads the data into the RDS table:
- costdatecollect – Cost collection date
- startdate – Cost start date
- enddate – Cost end date
- emr_unique_tag – EMR cluster associated tag
- net_unblendedcost – Total unblended daily dollar cost
- unblendedcost – Total unblended daily dollar cost
- cost_type – Daily cost
- service_name – AWS service for which the cost incurred (Amazon EMR and Amazon EC2)
- emr_clusterid – EMR cluster ID
- emr_clustername – EMR cluster name
- loadtime – Table load date/time
- emr_cluster_instances_usage – Captures the aggregated resource usage (vCores) and allocated resources for each EMR cluster node, and helps identify the idle time of the cluster:
- instancedatecollect – Instance usage collect date
- emr_instance_day_run_seconds – EMR instance active seconds in the day
- emr_region – EMR cluster AWS Region
- emr_clusterid – EMR cluster ID
- emr_clustername – EMR cluster name
- emr_cluster_fleet_type – EMR cluster fleet type
- emr_node_type – Instance node type
- emr_market – Market type (on-demand or provisioned)
- emr_instance_type – Instance size
- emr_ec2_instance_id – Corresponding EC2 instance ID
- emr_ec2_status – Running status
- emr_ec2_default_vcpus – Allocated vCPU
- emr_ec2_memory – EC2 instance memory
- emr_ec2_creation_datetime – EC2 instance creation date/time
- emr_ec2_end_datetime – EC2 instance end date/time
- emr_ec2_ready_datetime – EC2 instance ready date/time
- loadtime – Table load date/time
Prerequisites
You must have the following prerequisites before implementing the solution:
- An EMR on EC2 cluster.
- The EMR cluster must have a unique tag value defined. You can assign the tag directly on the Amazon EMR console or using Tag Editor. The recommended tag key is
cost-center along with a unique value for your EMR cluster. After you create and apply user-defined tags, it can take up to 24 hours for the tag keys to appear on your cost allocation tags page for activation
- Activate the tag in AWS Billing. It takes about 24 hours to activate the tag if not done before. To activate the tag, follow these steps:
- On the AWS Billing and Cost Management console, choose Cost allocation tags from navigation pane.
- Select the tag key that you want to activate.
- Choose Activate.
- The Spark application’s name should follow the standardized naming convention. It consists of seven components separated by underscores:
<business_unit>_<program>_<application>_<source>_<job_name>_<frequency>_<job_type>. These components are used to summarize the resource consumption and cost in the final report. For example: HR_PAYROLL_PS_PSPROD_TAXDUDUCTION_DLY_LD, FIN_CASHRECEIPT_GL_GLDB_MAIN_DLY_LD, or MKT_CAMPAIGN_CRM_CRMDB_TOPRATEDCAMPAIGN_DLY_LD. The application name must be supplied with the spark submit command using the --name parameter with the standardized naming convention. If any of these components don’t have a value, hardcode the values with the following suggested names:
frequencyjob_typeBusiness_unit
- The Lambda function should be able to connect to Cost Explorer, connect to the EMR cluster through the Resource Manager APIs, and load data into the RDS for PostgreSQL database. To do this, you need to configure the Lambda function as follows:
- VPC configuration – The Lambda function should be able to access the EMR cluster, Cost Explorer, AWS Secrets Manager, and Parameter Store. If access is not in place already, you can do this by creating a virtual private cloud (VPC) that includes the EMR cluster and create VPC endpoint for Parameter Store and Secrets Manager and attach it to the VPC. Because there is no VPC endpoint available for Cost Explorer and in order to have Lambda connect to Cost Explorer, a private subnet and a route table are required to send VPC traffic to public NAT gateway. If your EMR cluster is in public subnet, you must create a private subnet including a custom route table and a public NAT gateway, which will allow the Cost Explorer connection to flow from the VPC private subnet. Refer to How do I set up a NAT gateway for a private subnet in Amazon VPC? for setup instructions and attach the newly created private subnet to the Lambda function explicitly.
- IAM role – The Lambda function needs to have an AWS Identity and Access Management (IAM) role with the following permissions:
AmazonEC2ReadOnlyAccess, AWSCostExplorerFullAccess, and AmazonRDSDataFullAccess. This role will be created automatically during AWS CDK stack deployment; you don’t need to set it up separately.
- The AWS CDK should be installed on AWS Cloud9 (preferred) or another development environment such as VSCode or Pycharm. For more information, refer to Prerequisites.
- The RDS for PostgreSQL database (v10 or higher) credentials should be stored in Secrets Manager. For more information, refer to Storing database credentials in AWS Secrets Manager.
Create RDS tables
Create the data model tables mentioned in emr-cost-rds-tables-ddl.sql by logging in to postgres rds manually into the public schema.
Use DBeaver or any compatible SQL clients to connect to the RDS instance and validate the tables have been created.
Deploy AWS CDK stacks
Complete the steps in this section to deploy the following resources using the AWS CDK:
- Parameter Store to store required parameter values
- IAM role for the Lambda function to help connect to Amazon EMR and underlying EC2 instances, Cost Explorer, CloudWatch, and Parameter Store
- Lambda function
- Clone the GitHub repo:
git clone [email protected]:aws-samples/attribute-amazon-emr-costs-to-your-end-users.git
- Update the following the environment parameters in
cdk.context.json (this file can be found in the main directory):
- yarn_url – YARN ResourceManager URL to read job run logs and metrics. This URL should be accessible within the VPC where Lambda would be deployed.
- tbl_applicationlogs_lz – RDS temp table to store EMR application run logs.
- tbl_applicationlogs – RDS table to store EMR application run logs.
- tbl_emrcost – RDS table to capture daily EMR cluster usage cost.
- tbl_emrinstance_usage – RDS table to store EMR cluster instance usage info.
- emrcluster_id – EMR cluster instance ID.
- emrcluster_name – EMR cluster name.
- emrcluster_tag – Tag key assigned to EMR cluster.
- emrcluster_tag_value – Unique value for EMR cluster tag.
- emrcluster_role – Service role for Amazon EMR (EMR role).
- emrcluster_linkedaccount – Account ID under which the EMR cluster is running.
- postgres_rds – RDS for PostgreSQL connection details.
- vpc_id – VPC ID in which the EMR cluster is configured and the cost metering Lambda function would be deployed.
- vpc_subnets – Comma-separated private subnets ID associated with the VPC.
- sg_id – EMR security group ID.
The following is a sample cdk.context.json file after being populated with the parameters:
{
"yarn_url": "http://dummy.compute-1.amazonaws.com:8088/ws/v1/cluster/apps",
"tbl_applicationlogs_lz": "public.emr_applications_execution_log_lz",
"tbl_applicationlogs": "public.emr_applications_execution_log",
"tbl_emrcost": "public.emr_cluster_usage_cost",
"tbl_emrinstance_usage": "public.emr_cluster_instances_usage",
"emrcluster_id": "j-xxxxxxxxxx",
"emrcluster_name": "EMRClusterName",
"emrcluster_tag": "EMRClusterTag",
"emrcluster_tag_value": "EMRClusterUniqueTagValue",
"emrcluster_role": "EMRClusterServiceRole",
"emrcluster_linkedaccount": "xxxxxxxxxxx",
"postgres_rds": {
"host": "xxxxxxxxx.amazonaws.com",
"dbname": "dbname",
"user": "username",
"secretid": "DatabaseUserSecretID"
},
"vpc_id": "xxxxxxxxx",
"vpc_subnets": "subnet-xxxxxxxxxxx",
"sg_id": "xxxxxxxxxx"
}
You can choose to deploy the AWS CDK stack using AWS Cloud9 or any other development environment according to your needs. For instructions to set up AWS Cloud9, refer to Getting started: basic tutorials for AWS Cloud9.
- Go to AWS Cloud9 and choose File and Upload local files upload the project folder.
- Deploy the AWS CDK stack with the following code:
cd attribute-amazon-emr-costs-to-your-end-users/
pip install -r requirements.txt
cdk deploy –-all
The deployed Lambda function requires two external libraries: psycopg2 and requests. The corresponding layer needs to be created and assigned to the Lambda function. For instructions to create a Lambda layer for the requests module, refer to Step-by-Step Guide to Creating an AWS Lambda Function Layer.
Creation of the psycopg2 package and layer is tied to the Python runtime version of the Lambda function. Provided that the Lambda function uses the Python 3.9 runtime, complete the following steps to create the corresponding layer package for peycopog2:
- Download
psycopg2_binary-2.9.9-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl from https://pypi.org/project/psycopg2-binary/#files.
- Unzip and move the contents to a directory named
python:
- Create a Lambda layer for
psycopg2 using the zip file.
- Assign the layer to the Lambda function by choosing Add a layer in the deployed function properties.
- Validate the AWS CDK deployment.
Your Lambda function details should look similar to the following screenshot.

On the Systems Manager console, validate the Parameter Store content for actual values.

The IAM role details should look similar to the following code, which allows the Lambda function access to Amazon EMR and underlying EC2 instances, Cost Explorer, CloudWatch, Secrets Manager, and Parameter Store:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"ce:GetCostAndUsage",
"ce:ListCostAllocationTags",
"ec2:AttachNetworkInterface",
"ec2:CreateNetworkInterface",
"ec2:DeleteNetworkInterface",
"ec2:DescribeInstanceTypes",
"ec2:DescribeInstances",
"ec2:DescribeNetworkInterfaces",
"elasticmapreduce:Describe*",
"elasticmapreduce:List*",
"ssm:Describe*",
"ssm:Get*",
"ssm:List*"
],
"Resource": "*",
"Effect": "Allow"
},
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:DescribeLogStreams",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*",
"Effect": "Allow"
},
{
"Action": "secretsmanager:GetSecretValue",
"Resource": "arn:aws:secretsmanager:*:*:*",
"Effect": "Allow"
}
]
}

Test the solution
To test the solution, you can run a Spark job that combines multiple files in the EMR cluster, and you can do this by creating separate steps within the cluster. Refer to Optimize Amazon EMR costs for legacy and Spark workloads for more details on how to add the jobs as steps to EMR cluster.
- Use the following sample command to submit the Spark job (
emr_union_job.py).
It takes in three arguments:
- <input_full_path> – The Amazon S3 location of the data file that is read in by the Spark job. The path should not be changed. The
input_full_path is s3://aws-blogs-artifacts-public/artifacts/BDB-2997/sample-data/input/part-00000-a0885743-e0cb-48b1-bc2b-05eb748ab898-c000.snappy.parquet
- <output_path> – The S3 folder where the results are written to.
- <number of copies to be unioned> – By changing the input to the Spark job, you can make sure the job runs for different amounts of time and also change the number of Spot nodes used.
spark-submit --deploy-mode cluster --name HR_PAYROLL_PS_PSPROD_TAXDUDUCTION_DLY_LD s3://aws-blogs-artifacts-public/artifacts/BDB-2997/scripts/emr_union_job.py s3://aws-blogs-artifacts-public/artifacts/BDB-2997/sample-data/input/part-00000-a0885743-e0cb-48b1-bc2b-05eb748ab898-c000.snappy.parquet s3://<output_bucket>/<output_path>/ 6
spark-submit --deploy-mode cluster --name FIN_CASHRECEIPT_GL_GLDB_MAIN_DLY_LD s3://aws-blogs-artifacts-public/artifacts/BDB-2997/scripts/emr_union_job.py s3://aws-blogs-artifacts-public/artifacts/BDB-2997/sample-data/input/part-00000-a0885743-e0cb-48b1-bc2b-05eb748ab898-c000.snappy.parquet s3://<output_bucket>/<output_path>/ 12
The following screenshot shows the log of the steps run on the Amazon EMR console.

- Run the deployed Lambda function from the Lambda console. This loads the daily application log, EMR dollar usage, and EMR instance usage details into their respective RDS tables.
The following screenshot of the Amazon RDS query editor shows the results for public.emr_applications_execution_log.

The following screenshot shows the results for public.emr_cluster_usage_cost.

The following screenshot shows the results for public.emr_cluster_instances_usage.

Cost can be calculated using the preceding three tables based on your requirements. In the following SQL query, you calculate the cost based on relative usage of all applications in a day. You first identify the total vcore-seconds CPU consumed in a day and then find out the percentage share of an application. This drives the cost based on overall cluster cost in a day.
Consider the following example scenario, where 10 applications ran on the cluster for a given day. You would use the following sequence of steps to calculate the chargeback cost:
- Calculate the relative percentage usage of each application (consumed vcore-seconds CPU by app/total vcore-seconds CPU consumed).
- Now you have the relative resource consumption of each application, distribute the cluster cost to each application. Let’s assume that the total EMR cluster cost for that date is $400.
| app_id |
app_name |
runtime_seconds |
vcore_seconds |
% Relative Usage |
Amazon EMR Cost ($) |
| application_00001 |
app1 |
10 |
120 |
5% |
19.83 |
| application_00002 |
app2 |
5 |
60 |
2% |
9.91 |
| application_00003 |
app3 |
4 |
45 |
2% |
7.43 |
| application_00004 |
app4 |
70 |
840 |
35% |
138.79 |
| application_00005 |
app5 |
21 |
300 |
12% |
49.57 |
| application_00006 |
app6 |
4 |
48 |
2% |
7.93 |
| application_00007 |
app7 |
12 |
150 |
6% |
24.78 |
| application_00008 |
app8 |
52 |
620 |
26% |
102.44 |
| application_00009 |
app9 |
12 |
130 |
5% |
21.48 |
| application_00010 |
app10 |
9 |
108 |
4% |
17.84 |
A sample chargeback cost calculation SQL query is available on the GitHub repo.
You can use the SQL query to create a report dashboard to plot multiple charts for the insights. The following are two examples created using QuickSight.
The following is a daily bar chart.

The following shows total dollars consumed.

Solution cost
Let’s assume we’re calculating for an environment that runs 1,000 jobs daily, and we run this solution daily:
- Lambda costs – One run requires 30 Lambda function invocations per month.
- Amazon RDS cost – The total number of records in the
public.emr_applications_execution_log table for a 30-day month would be 30,000 records, which translates to 5.72 MB of storage. If we consider the other two smaller tables and storage overhead, the overall monthly storage requirement would be approximately 12 MB.
In summary, the solution cost according to the AWS Pricing Calculator is $34.20/year, which is negligible.
Clean up
To avoid ongoing charges for the resources that you created, complete the following steps:
- Delete the AWS CDK stacks:
- Delete the QuickSight report and dashboard, if created.
- Run the following SQL to drop the tables:
drop table public.emr_applications_execution_log_lz;
drop table public.emr_applications_execution_log;
drop table public.emr_cluster_usage_cost;
drop table public.emr_cluster_instances_usage;
Conclusion
With this solution, you can deploy a chargeback model to attribute costs to users and groups using the EMR cluster. You can also identify options for optimization, scaling, and separation of workloads to different clusters based on usage and growth needs.
You can collect the metrics for a longer duration to observe trends on the usage of Amazon EMR resources and use that for forecasting purposes.
If you have any thoughts or questions, leave them in the comments section.
About the Authors
 Raj Patel is AWS Lead Consultant for Data Analytics solutions based out of India. He specializes in building and modernising analytical solutions. His background is in data warehouse/data lake – architecture, development and administration. He is in data and analytical field for over 14 years.
Raj Patel is AWS Lead Consultant for Data Analytics solutions based out of India. He specializes in building and modernising analytical solutions. His background is in data warehouse/data lake – architecture, development and administration. He is in data and analytical field for over 14 years.
 Ramesh Raghupathy is a Senior Data Architect with WWCO ProServe at AWS. He works with AWS customers to architect, deploy, and migrate to data warehouses and data lakes on the AWS Cloud. While not at work, Ramesh enjoys traveling, spending time with family, and yoga.
Ramesh Raghupathy is a Senior Data Architect with WWCO ProServe at AWS. He works with AWS customers to architect, deploy, and migrate to data warehouses and data lakes on the AWS Cloud. While not at work, Ramesh enjoys traveling, spending time with family, and yoga.
 Gaurav Jain is a Sr Data Architect with AWS Professional Services, specialized in big data and helps customers modernize their data platforms on the cloud. He is passionate about building the right analytics solutions to gain timely insights and make critical business decisions. Outside of work, he loves to spend time with his family and likes watching movies and sports.
Gaurav Jain is a Sr Data Architect with AWS Professional Services, specialized in big data and helps customers modernize their data platforms on the cloud. He is passionate about building the right analytics solutions to gain timely insights and make critical business decisions. Outside of work, he loves to spend time with his family and likes watching movies and sports.
 Dipal Mahajan is a Lead Consultant with Amazon Web Services based out of India, where he guides global customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings extensive experience on Software Development, Architecture and Analytics from industries like finance, telecom, retail and healthcare.
Dipal Mahajan is a Lead Consultant with Amazon Web Services based out of India, where he guides global customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings extensive experience on Software Development, Architecture and Analytics from industries like finance, telecom, retail and healthcare.