Post Syndicated from Shyam Kulkarni original https://aws.amazon.com/blogs/devops/diagnose-eks-node-issues-faster-with-aws-devops-agent-and-custom-mcp/
AWS DevOps Agent can investigate a growing range of production incidents autonomously. It diagnoses CrashLoopBackOff failures, traces ConfigMap deletions through audit logs, and correlates Amazon CloudWatch metrics with cluster events — all without human intervention.
But AWS DevOps Agent has a visibility boundary. When the data it needs lives outside its native integrations — on a node’s operating system, inside a third-party monitoring tool, behind a database’s internal diagnostics — the agent stalls. It can describe symptoms, but it can’t reach the evidence needed to identify root causes.
This post shows how to extend AWS DevOps Agent by building a custom Model Context Protocol (MCP) server that bridges that gap. Using a concrete example, we give AWS DevOps Agent structured access to Amazon EKS worker node diagnostics and explain how the same approach applies to data sources the agent can’t natively reach. By the end of this walkthrough, you will have a working MCP server that gives AWS DevOps Agent access to 20+ node-level log sources — providing autonomous investigation capabilities that can assist in root cause analysis compared to manual SSH sessions.
Prerequisites
Before you begin, make sure you have the following:
- An Amazon EKS cluster with AWS Systems Manager Agent (SSM Agent) running on the worker nodes (included by default on Amazon EKS optimized AMIs)
- Node.js v18 or later
- AWS CLI v2
- AWS CDK v2 installed and bootstrapped in your target account and Region
- An AWS account with permissions to create IAM roles, Lambda functions, and Amazon S3 buckets
- Familiarity with Amazon EKS, AWS Systems Manager, and the Model Context Protocol (MCP)
How AWS DevOps Agent discovers custom tools through MCP
MCP is an open standard that defines how AI agents discover and invoke external tools. AWS DevOps Agent supports connecting to custom MCP servers, which means you can expose new capabilities to it without modifying the agent itself. When you connect an MCP server to AWS DevOps Agent, the agent automatically discovers the available tools, understands their schemas, and calls them as part of its investigation workflow. You build and connect the MCP server — the agent handles the rest.
The extensibility model follows three steps: first, identify the data source that AWS DevOps Agent cannot natively access; second, build an MCP server that wraps safe, structured access to that data source; and third, connect the MCP server to AWS DevOps Agent so it can incorporate the new tools into its investigations.
Three design principles make this work. Return structured data, not raw text — pre-index findings with severity levels and stable IDs so the agent can filter, reference, and correlate them. Never give the agent a shell — mediate interactions through a controlled, auditable execution model. Make tools composable — design tool outputs to serve as inputs to other tools, creating a chain of evidence the agent can follow.
Why Amazon EKS node OS visibility matters
AWS DevOps Agent integrates with Amazon EKS to inspect pod status, read container logs, query CloudWatch Container Insights, and correlate cluster events. This covers application crashes, container-level resource exhaustion, and configuration drift.
However, EKS production issues with nodes originate in a layer these tools cannot reach: the node operating system. Artifacts such as iptables rules, full CNI configuration and IPAMD state, route tables, conntrack entries, dmesg kernel messages, containerd runtime logs, sysctl parameters, ENI metadata, and the unfiltered kubelet journal exist exclusively on the node. These artifacts are the primary evidence for diagnosing IP allocation failures, DNS resolution issues, network policy enforcement problems, storage mount timeouts, and node registration failures.
Integrating AWS DevOps Agent with an EKS node diagnostics MCP server
The sample-eks-node-diagnostics-mcp repository (sample-eks-node-diagnostics-mcp repository) demonstrates this pattern. It provides an MCP server that gives AWS DevOps Agent structured access to node-level diagnostic data, backed by AWS Systems Manager (SSM) Automation for safe, auditable execution.
How it works
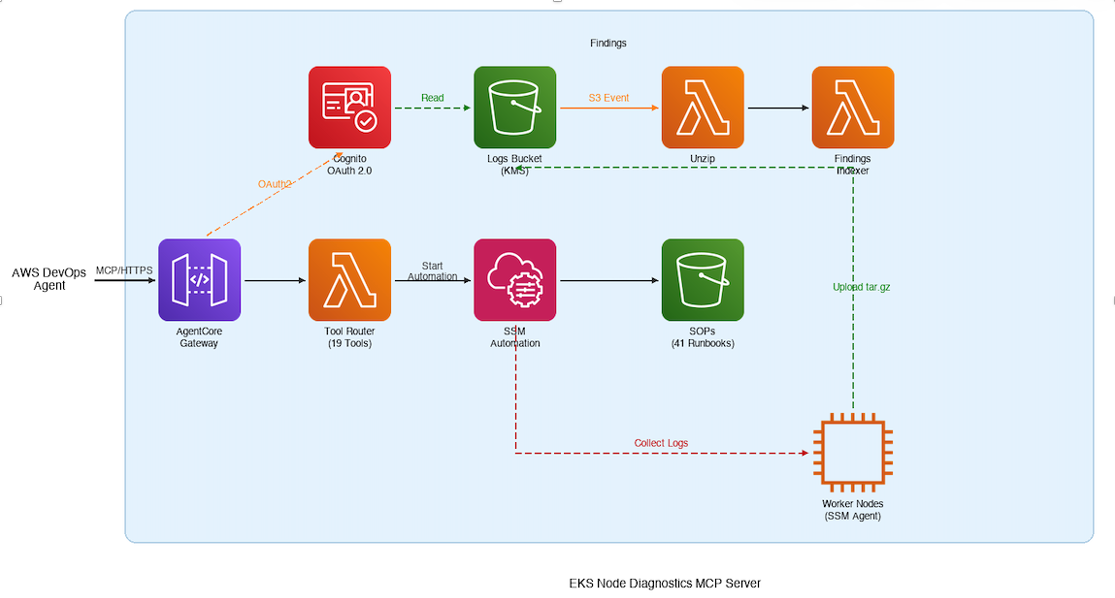
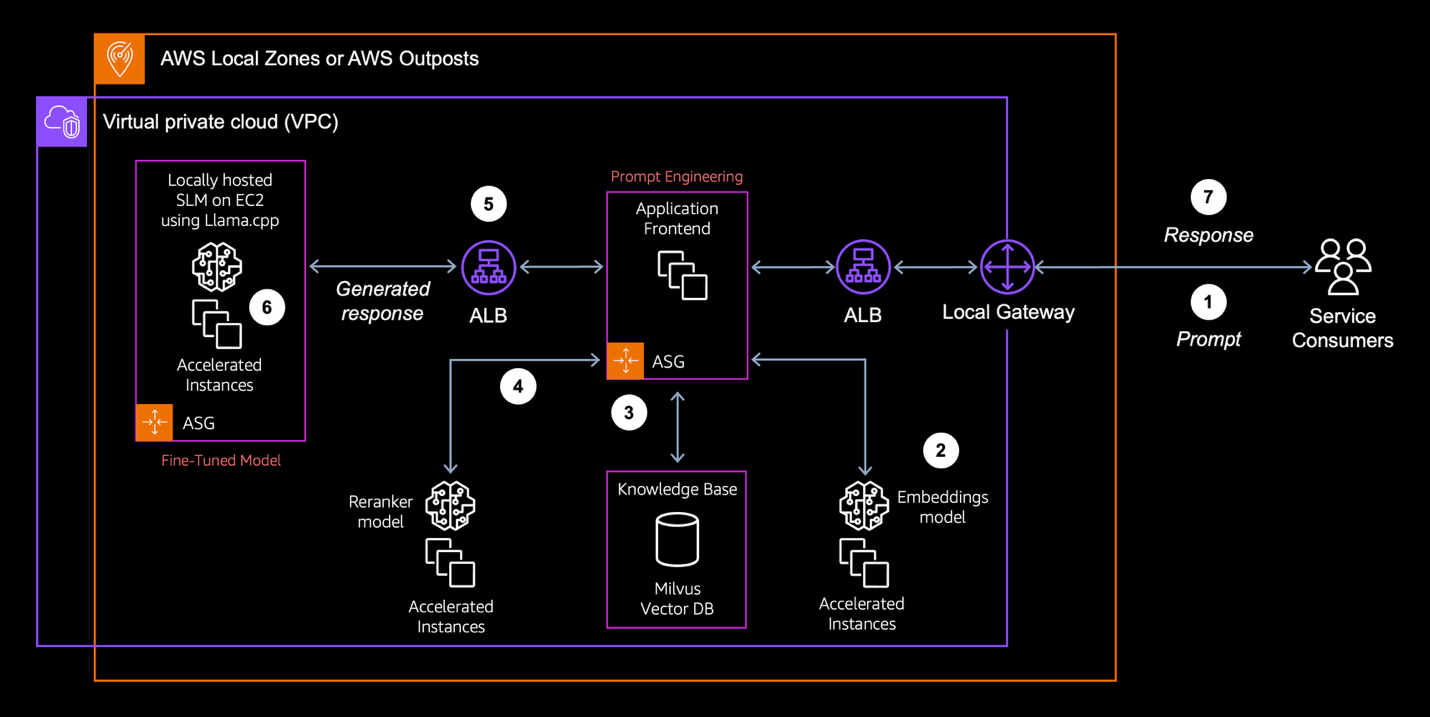
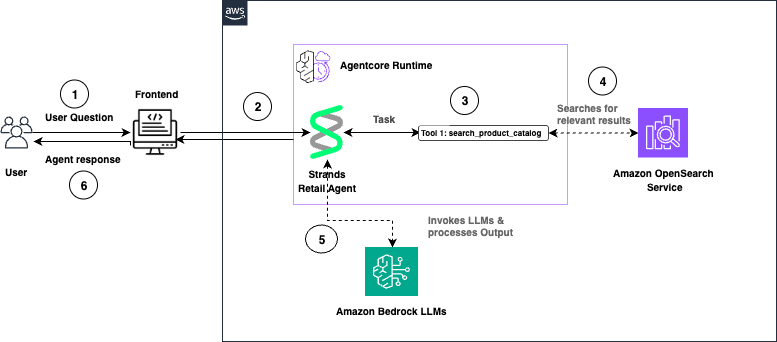
Figure 1: End-to-end architecture of the EKS Node Diagnostics MCP server. AWS DevOps Agent discovers and invokes 19 tools through AgentCore Gateway, which dispatches SSM Automation runbooks to worker nodes for log collection and uploads results to Amazon S3 for extraction and indexing.
- AWS DevOps Agent calls a collect tool with an instance ID.
- The MCP server dispatches an SSM Automation execution to the target node, running the AWS-managed AWSSupport-CollectEKSInstanceLogs runbook.
- The runbook collects 20+ log sources — kubelet, containerd, iptables, CNI config, route tables, dmesg, sysctl, ENI metadata, IPAMD logs, and more — packages them into an archive, and uploads it to an Amazon S3 bucket where you configure AWS KMS encryption.
- A processing pipeline extracts the archive, pre-indexes errors with severity classification and stable finding IDs, and provides the results to you through additional MCP tools.
The server exposes tools for log collection, pre-indexed error retrieval, cross-file search and correlation, structured network diagnostics, and live packet capture. A typical agent workflow chains these together: collect → status → errors → search → correlate → read → summarize, with each step producing outputs that feed into the next.
AWS DevOps Agent does not get a shell on the node. Every interaction is mediated by SSM Automation — an auditable, IAM-controlled, non-interactive execution model.
Connecting through Amazon Bedrock AgentCore Gateway
The reference implementation uses Amazon Bedrock AgentCore Gateway to expose the Lambda-backed MCP server to AWS DevOps Agent. AgentCore Gateway converts Lambda functions into MCP-compatible tools and handles authentication, protocol translation, and tool discovery through a single managed endpoint.
The integration follows three steps:
Step 1: Create an OAuth authorizer with Amazon Cognito. The CDK stack provisions a Cognito User Pool configured for the OAuth 2.0 client credentials flow. This secures inbound access to the gateway — only clients with valid tokens can invoke tools.
Step 2: Create a gateway and register the Lambda as a target. Register the Lambda function that handles tool invocations as a target on the gateway. AgentCore Gateway automatically discovers the tool schemas from the Lambda and makes them available through the MCP protocol. The gateway endpoint becomes the single MCP URL for AWS DevOps Agent.
Step 3: Connect AWS DevOps Agent. Register the MCP server at the account level in the AWS DevOps Agent console, providing the gateway URL and OAuth configuration. Then allowlist the specific tools each Agent Space needs. AWS DevOps Agent authenticates by obtaining a JWT from the Cognito token endpoint using the client credentials grant and passes it as a Bearer token in requests to the gateway URL.
Deploying the MCP server
Deploy the entire stack using AWS CDK :
git clone https://github.com/aws-samples/sample-eks-node-diagnostics-mcp.git
cd sample-eks-node-diagnostics-mcp
chmod +x deploy.sh
./deploy.sh
The script walks you through cluster selection and node role configuration. Have the following ready before running the script: your target EKS cluster name, the IAM role ARN you attached to your worker nodes, and the AWS Region where your cluster runs. The script outputs your MCP gateway URL, OAuth credentials, and token endpoint — everything you need to configure the connection in AWS DevOps Agent. See the repository README for detailed deployment instructions, CI/CD mode, and prerequisite details.
Seeing it in action
To demonstrate the MCP server’s capabilities, we walk through a realistic node-level failure scenario on a test EKS cluster. We manually inject a fault that blocks pod DNS resolution at the iptables level — an issue that is invisible from kubectl since pods appear Running — then show how AWS DevOps Agent investigates and identifies the root cause using the MCP server’s tools.
Setting up the scenario
Start with an EKS cluster that has a managed node group with SSM Agent running (included by default on Amazon EKS optimized AMIs). Deploy a sample workload to one of the nodes:
kubectl create namespace demo-app
cat <<EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-frontend
namespace: demo-app
spec:
replicas: 3
selector:
matchLabels:
app: web-frontend
template:
metadata:
labels:
app: web-frontend
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
EOF
Identify the node and instance ID where the pods are running:
kubectl get pods -n demo-app -o wide
Injecting the fault
 WARNING: The following commands will disrupt DNS resolution for all pods on the target node. Only run these in a non-production test environment. Do not execute on production nodes.
WARNING: The following commands will disrupt DNS resolution for all pods on the target node. Only run these in a non-production test environment. Do not execute on production nodes.
Connect to the target node using SSM Session Manager and run the following commands to block pod DNS traffic at the iptables level. This simulates a subtle networking issue – pods continue running but can’t resolve DNS, and the root cause is only visible in the node’s iptables rules:
# Block pod traffic to kube-dns ClusterIP — pods run but DNS fails
# Only affects FORWARD chain (pod traffic), not the node's own DNS
sudo iptables -I FORWARD -d 10.100.0.10/32 -p udp --dport 53 -j DROP
sudo iptables -I FORWARD -d 10.100.0.10/32 -p tcp --dport 53 -j DROP
Replace 10.100.0.10 with your cluster’s kube-dns ClusterIP (kubectl get svc kube-dns -n kube-system -o jsonpath=’{.spec.clusterIP}’).
This fault is particularly insidious because kubectl get pods shows all pods in Running state. The applications fail with DNS resolution errors, but there is no Kubernetes event or pod status that points to the cause. The iptables DROP rules targeting the kube-dns ClusterIP exist only in the node’s firewall configuration — a layer that no Kubernetes API call can inspect.
Investigating with AWS DevOps Agent
An engineer notices applications reporting DNS failures and asks AWS DevOps Agent to investigate:
“Pods on node i-xxxxxxxxxx in cluster EKS-sample (us-east-1) are running but applications report DNS resolution failures. Collect the node logs and investigate.”
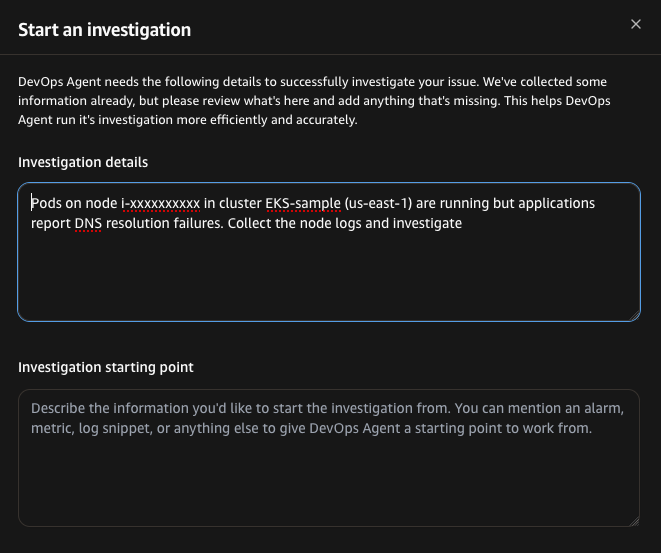
Figure 2: Starting an investigation in AWS DevOps Agent. The engineer provides the symptom description and incident timestamp, and the agent autonomously plans and executes the investigation.
AWS DevOps Agent begins the investigation by recording the symptom and launching two parallel actions: collecting node logs via the nodelog_collect tool and checking cluster health. The cluster health check confirms all four nodes are running and SSM-online. The agent then polls the log collection status, tracking progress from 25% through 75% to completion. Once collection finishes, the agent fans out into parallel workstreams — running network diagnostics, performing quick triage, and collecting logs from a healthy node for comparison.
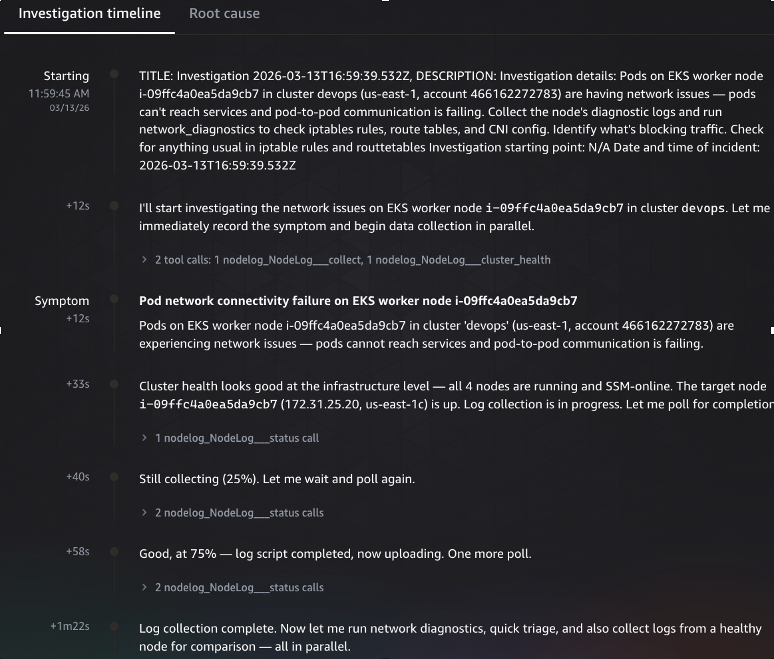
Figure 3: Investigation timeline showing the initial data collection phase. The agent identifies the symptom, confirms cluster health, collects node logs via SSM Automation, polls for completion, and launches parallel diagnostic workstreams.
With the initial data collected, the agent launches four parallel investigation tasks to maximize coverage and minimize time-to-root-cause: (1) deep-dive-iptables-routes examines the node’s firewall rules and routing table in detail, completing in 1 minute 44 seconds across 8 tool calls; (2) search-network-errors scans the collected logs for network-related error patterns, running 15 tool calls over 7 minutes 51 seconds; (3) collect-healthy-node gathers the same diagnostics from a known-good node for comparison, taking 13 tool calls over 4 minutes 55 seconds; (4) check-oom-and-pod-status investigates kernel OOM kills and pod health, executing 19 tool calls over 8 minutes 12 seconds. Each task produces a structured report that feeds into the final synthesis.
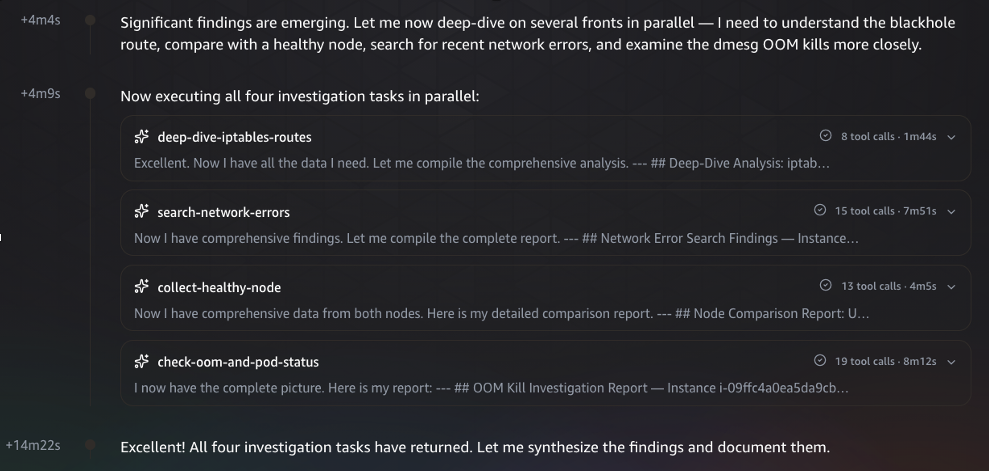
Figure 4: Parallel investigation phase. The agent runs four concurrent deep-dive tasks — iptables/route analysis, network error search, healthy node comparison, and OOM/pod status check — then synthesizes the findings into a unified report.
The iptables and route table deep-dive reveals the root cause. The agent identifies two CRITICAL findings: a FAULT-INJECT-DROP-POD-TO-POD rule in the FORWARD chain that drops inter-pod traffic, and a FAULT-INJECT-DROP-SERVICE-CIDR rule that drops forwarded traffic to the service CIDR range. It also flags a MEDIUM-severity finding — a blackhole route for 10.96.0.0/12 (the Kubernetes service CIDR) that does not exist on healthy nodes. The remaining checks come back normal: kube-proxy chains are intact, AWS VPC CNI SNAT/CONNMARK chains are properly configured, and the default gateway and ENI route tables are correct. This structured severity classification allows the agent to immediately focus on the critical items.
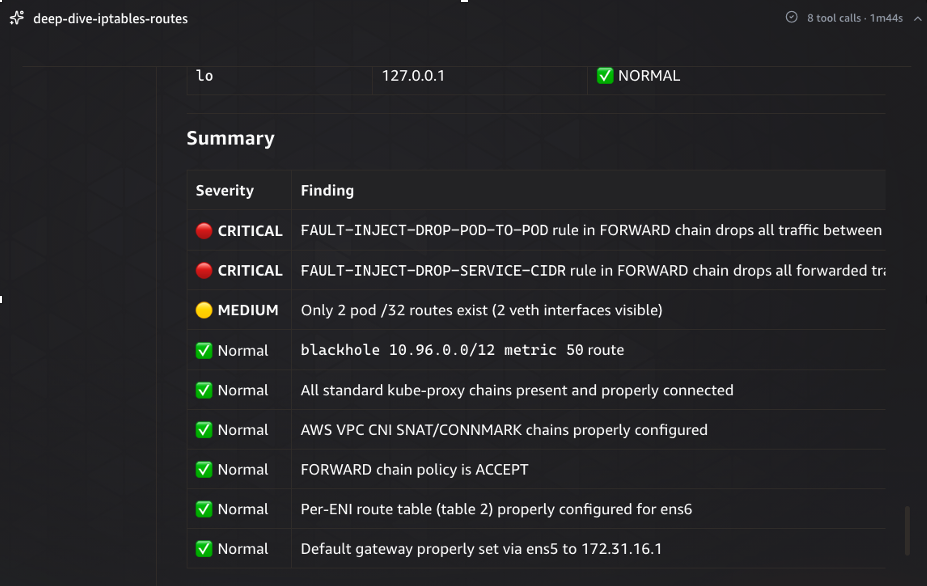
Figure 5: Deep-dive findings from the iptables and route table analysis. Two CRITICAL fault-injection DROP rules in the FORWARD chain are identified as the primary issue, while standard networking components — kube-proxy, VPC CNI, and routing — check normal.
The healthy node comparison confirms the diagnosis. The agent compares the unhealthy node against a known-good node across seven dimensions: security groups, ENI count, DNS configuration, iptables rules, route tables, conntrack entries, and IPAMD state. The key differences are definitive: the blackhole route for 10.96.0.0/12 exists only on the unhealthy node, kubelet API server timeout errors appear only on the unhealthy node, conntrack entries are 12x higher (1,962 vs 169), and IPAMD reconciliation errors are 5x more frequent. The iptables FORWARD chain counters show 2.4 billion packets processed on the unhealthy node versus zero on the freshly-started healthy node — confirming sustained traffic disruption.
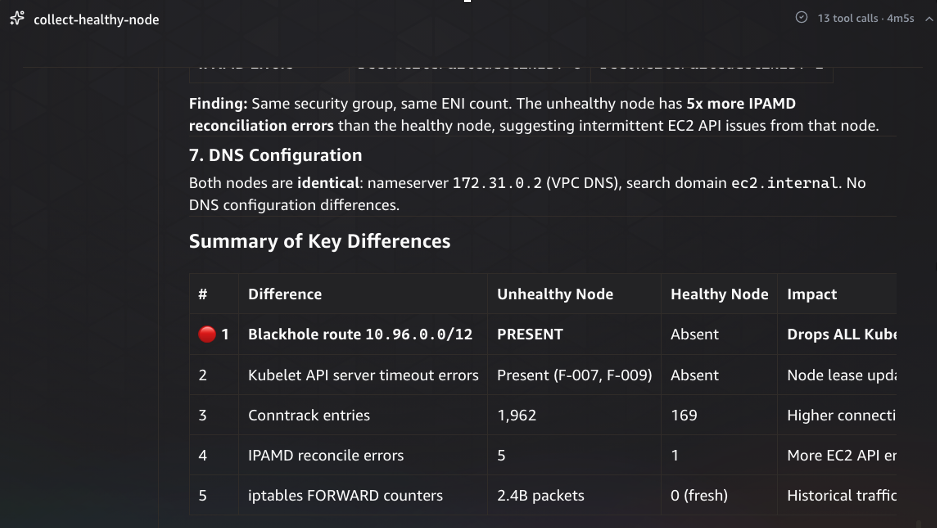
Figure 6: Healthy node comparison confirming the diagnosis. The agent compares diagnostics across both nodes and identifies five key differences — the blackhole route, elevated conntrack entries, and high FORWARD chain packet counts exist only on the affected node.
The agent synthesizes the findings into a definitive root cause determination. It identifies a fault-injection namespace on the EKS cluster that is running chaos experiments, introducing three specific network-disrupting modifications on the target node: (1) a FAULT-INJECT-DROP-POD-TO-POD iptables rule in the FORWARD chain that drops inter-pod traffic, (2) a FAULT-INJECT-DROP-SERVICE-CIDR rule that drops forwarded traffic to the Kubernetes service CIDR, and (3) a blackhole route for 10.96.0.0/12 that does not exist on healthy nodes. Together, these three modifications create a multi-vector network disruption — pods appear Running but cannot communicate with each other or reach Kubernetes services, including kube-dns.

Figure 7: Root cause determination. The agent traces the multi-vector network disruption to three fault-injection modifications — two iptables DROP rules and a blackhole route — deployed by a chaos experiment namespace on the target node.
Cleaning up the fault
To restore the node after the demo, connect via SSM Session Manager and run:
sudo iptables -D FORWARD -d 10.100.0.10/32 -p udp --dport 53 -j DROP
sudo iptables -D FORWARD -d 10.100.0.10/32 -p tcp --dport 53 -j DROP
Extending this pattern to other data sources
The EKS node diagnostics use case demonstrates the pattern, but the architecture generalizes to systems where the SSM Agent is running and you can define an SSM Automation runbook to collect the data you need.
For example, an EC2 instance with SSM Agent can use this same approach — collect OS-level logs, network configuration, package state, or application diagnostics through a custom or pre-built SSM Automation runbook, upload results to S3, and expose them through MCP tools. The same applies to ECS container instances (Docker daemon logs, ECS agent state, iptables), on-premises servers registered via SSM Hybrid Activations, or managed nodes in your fleet.
The pattern also extends beyond SSM-managed hosts. Network devices can be reached through API calls to their management planes, databases through read-only diagnostic queries, and third-party APM tools through vendor API integrations. In each case, the same three-step approach holds: identify the unreachable data, build an MCP server that wraps safe access to it, and connect it to AWS DevOps Agent.
When to use this approach
This pattern works well for incident response where diagnostic data lives outside AWS DevOps Agent’s native reach, fleet-wide triage where manual access to individual systems is impractical, and cross-source correlation where evidence spans multiple log sources.
It is not a replacement for continuous monitoring (use CloudWatch Container Insights or Prometheus for real-time alerting), log shipping (if you have compliance requirements for continuous retention), or native integrations where the agent already has access to the data source.
The reference implementation requires SSM Agent running on the nodes with appropriate IAM permissions. It is a proof of concept — validate it in non-production environments before using it with production workloads.
Clean up
Cost considerations: This solution uses AWS Lambda, Amazon S3, AWS KMS, Amazon Cognito, and Amazon Bedrock AgentCore Gateway. Costs vary based on usage. Lambda charges apply per invocation and duration. S3 charges apply for log storage. KMS charges a per-key monthly fee plus per-request charges. Cognito charges per monthly active user. AgentCore Gateway pricing is based on API calls. For current pricing details, see the AWS Pricing page for each service. To minimize costs during evaluation, delete the stack when not in use.
Remove the deployed resources by running cdk destroy from the repository root. The S3 log bucket uses a RETAIN removal policy — delete it manually after stack destruction if needed.
Conclusion
MCP provides a standardized extensibility mechanism that lets you bridge visibility gaps in AWS DevOps Agent without modifying the agent itself. The pattern is straightforward: identify the unreachable data source, build an MCP server that wraps safe and structured access to it, and connect it to AWS DevOps Agent through Amazon Bedrock AgentCore Gateway. The agent handles the reasoning. The MCP server handles the data access.
To get started:
- Deploy the reference implementation (sample-eks-node-diagnostics-mcp repository) in a non-production environment.
- Review the MCP specification (MCP specification).
- Explore the Amazon EKS troubleshooting documentation (Amazon EKS troubleshooting documentation).
- Connect custom MCP servers to AWS DevOps Agent — see the Connecting MCP Servers guide in the AWS DevOps Agent documentation.
- Set up AgentCore Gateway — see the Amazon Bedrock AgentCore Gateway quick start guide.