Post Syndicated from Chad Schmutzer original https://aws.amazon.com/blogs/compute/optimizing-aws-lambda-cost-and-performance-using-aws-compute-optimizer/
This post is authored by Brooke Chen, Senior Product Manager for AWS Compute Optimizer, Letian Feng, Principal Product Manager for AWS Compute Optimizer, and Chad Schmutzer, Principal Developer Advocate for Amazon EC2
Optimizing compute resources is a critical component of any application architecture. Over-provisioning compute can lead to unnecessary infrastructure costs, while under-provisioning compute can lead to poor application performance.
Launched in December 2019, AWS Compute Optimizer is a recommendation service for optimizing the cost and performance of AWS compute resources. It generates actionable optimization recommendations tailored to your specific workloads. Over the last year, thousands of AWS customers reduced compute costs up to 25% by using Compute Optimizer to help choose the optimal Amazon EC2 instance types for their workloads.
One of the most frequent requests from customers is for AWS Lambda recommendations in Compute Optimizer. Today, we announce that Compute Optimizer now supports memory size recommendations for Lambda functions. This allows you to reduce costs and increase performance for your Lambda-based serverless workloads. To get started, opt in for Compute Optimizer to start finding recommendations.
Overview
With Lambda, there are no servers to manage, it scales automatically, and you only pay for what you use. However, choosing the right memory size settings for a Lambda function is still an important task. Computer Optimizer uses machine-learning based memory recommendations to help with this task.
These recommendations are available through the Compute Optimizer console, AWS CLI, AWS SDK, and the Lambda console. Compute Optimizer continuously monitors Lambda functions, using historical performance metrics to improve recommendations over time. In this blog post, we walk through an example to show how to use this feature.
Using Compute Optimizer for Lambda
This tutorial uses the AWS CLI v2 and the AWS Management Console.
In this tutorial, we setup two compute jobs that run every minute in AWS Region US East (N. Virginia). One job is more CPU intensive than the other. Initial tests show that the invocation times for both jobs typically last for less than 60 seconds. The goal is to either reduce cost without much increase in duration, or reduce the duration in a cost-efficient manner.
Based on these requirements, a serverless solution can help with this task. Amazon EventBridge can schedule the Lambda functions using rules. To ensure that the functions are optimized for cost and performance, you can use the memory recommendation support in Compute Optimizer.
In your AWS account, opt in to Compute Optimizer to start analyzing AWS resources. Ensure you have the appropriate IAM permissions configured – follow these steps for guidance. If you prefer to use the console to opt in, follow these steps. To opt in, enter the following command in a terminal window:
$ aws compute-optimizer update-enrollment-status --status Active
Once you enable Compute Optimizer, it starts to scan for functions that have been invoked for at least 50 times over the trailing 14 days. The next section shows two example scheduled Lambda functions for analysis.
Example Lambda functions
The code for the non-CPU intensive job is below. A Lambda function named lambda-recommendation-test-sleep is created with memory size configured as 1024 MB. An EventBridge rule is created to trigger the function on a recurring 1-minute schedule:
import json
import time
def lambda_handler(event, context):
time.sleep(30)
x=[0]*100000000
return {
'statusCode': 200,
'body': json.dumps('Hello World!')
}
The code for the CPU intensive job is below. A Lambda function named lambda-recommendation-test-busy is created with memory size configured as 128 MB. An EventBridge rule is created to trigger the function on a recurring 1-minute schedule:
import json
import random
def lambda_handler(event, context):
random.seed(1)
x=0
for i in range(0, 20000000):
x+=random.random()
return {
'statusCode': 200,
'body': json.dumps('Sum:' + str(x))
}
Understanding the Compute Optimizer recommendations
Compute Optimizer needs a history of at least 50 invocations of a Lambda function over the trailing 14 days to deliver recommendations. Recommendations are created by analyzing function metadata such as memory size, timeout, and runtime, in addition to CloudWatch metrics such as number of invocations, duration, error count, and success rate.
Compute Optimizer will gather the necessary information to provide memory recommendations for Lambda functions, and make them available within 48 hours. Afterwards, these recommendations will be refreshed daily.
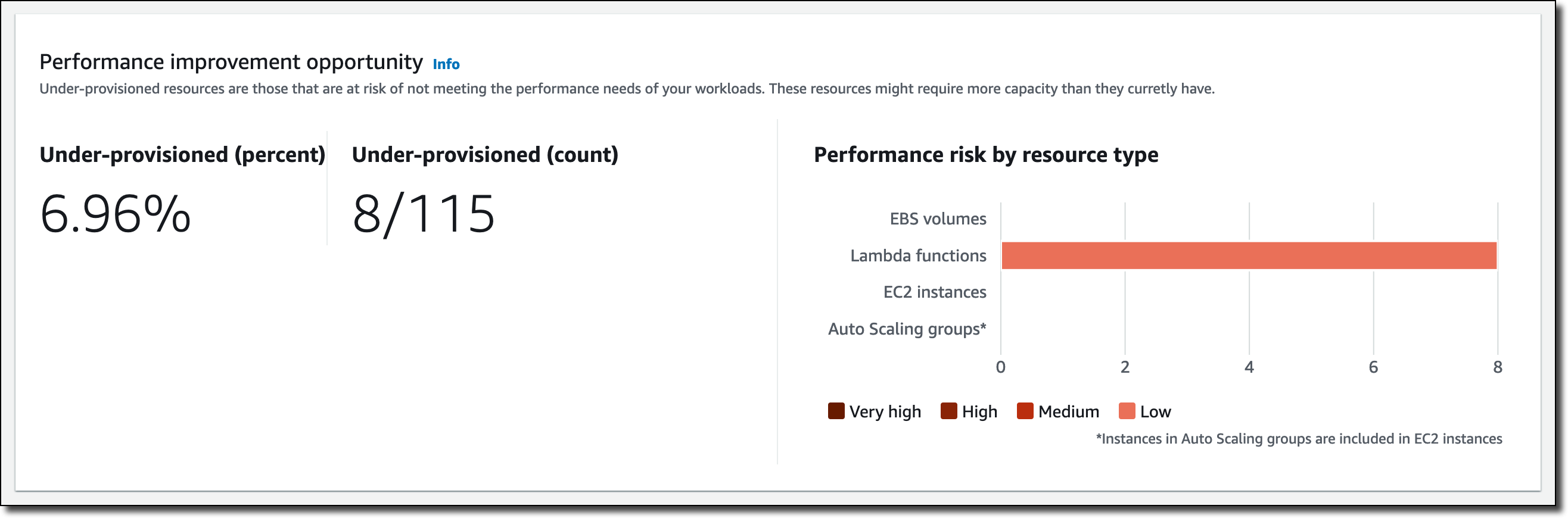
These are recent invocations for the non-CPU intensive function:

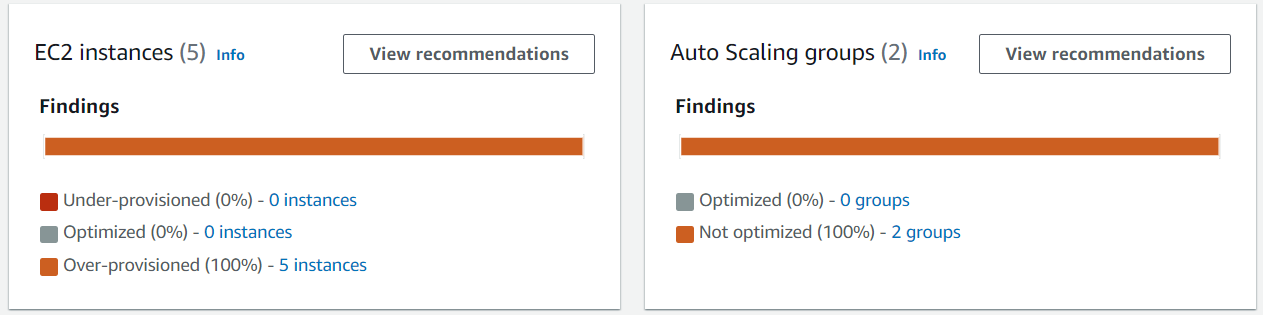
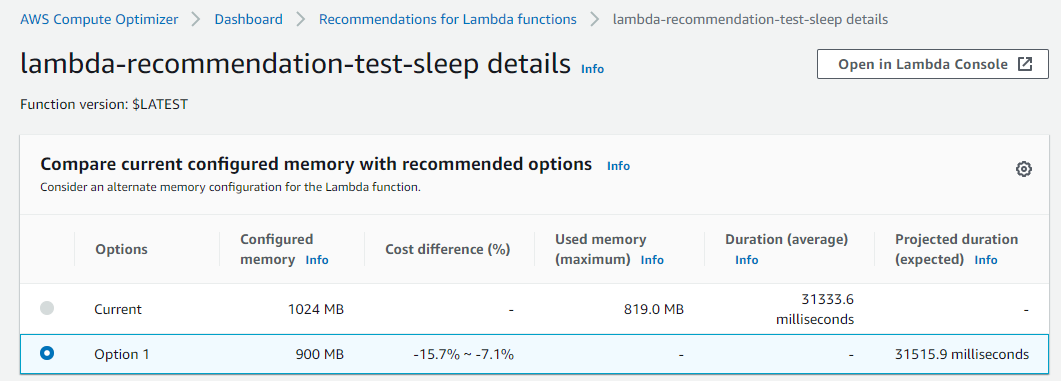
Function duration is approximately 31.3 seconds with a memory setting of 1024 MB, resulting in a duration cost of about $0.00052 per invocation. Here are the recommendations for this function in the Compute Optimizer console:

The function is Not optimized with a reason of Memory over-provisioned. You can also fetch the same recommendation information via the CLI:
$ aws compute-optimizer \
get-lambda-function-recommendations \
--function-arns arn:aws:lambda:us-east-1:123456789012:function:lambda-recommendation-test-sleep
{
"lambdaFunctionRecommendations": [
{
"utilizationMetrics": [
{
"name": "Duration",
"value": 31333.63587049883,
"statistic": "Average"
},
{
"name": "Duration",
"value": 32522.04,
"statistic": "Maximum"
},
{
"name": "Memory",
"value": 817.67049838188,
"statistic": "Average"
},
{
"name": "Memory",
"value": 819.0,
"statistic": "Maximum"
}
],
"currentMemorySize": 1024,
"lastRefreshTimestamp": 1608735952.385,
"numberOfInvocations": 3090,
"functionArn": "arn:aws:lambda:us-east-1:123456789012:function:lambda-recommendation-test-sleep:$LATEST",
"memorySizeRecommendationOptions": [
{
"projectedUtilizationMetrics": [
{
"name": "Duration",
"value": 30015.113193697029,
"statistic": "LowerBound"
},
{
"name": "Duration",
"value": 31515.86878891883,
"statistic": "Expected"
},
{
"name": "Duration",
"value": 33091.662123300975,
"statistic": "UpperBound"
}
],
"memorySize": 900,
"rank": 1
}
],
"functionVersion": "$LATEST",
"finding": "NotOptimized",
"findingReasonCodes": [
"MemoryOverprovisioned"
],
"lookbackPeriodInDays": 14.0,
"accountId": "123456789012"
}
]
}
The Compute Optimizer recommendation contains useful information about the function. Most importantly, it has determined that the function is over-provisioned for memory. The attribute findingReasonCodes shows the value MemoryOverprovisioned. In memorySizeRecommendationOptions, Compute Optimizer has found that using a memory size of 900 MB results in an expected invocation duration of approximately 31.5 seconds.
For non-CPU intensive jobs, reducing the memory setting of the function often doesn’t have a negative impact on function duration. The recommendation confirms that you can reduce the memory size from 1024 MB to 900 MB, saving cost without significantly impacting duration. The new duration cost per invocation saves approximately 12%.
The Compute Optimizer console validates these calculations:

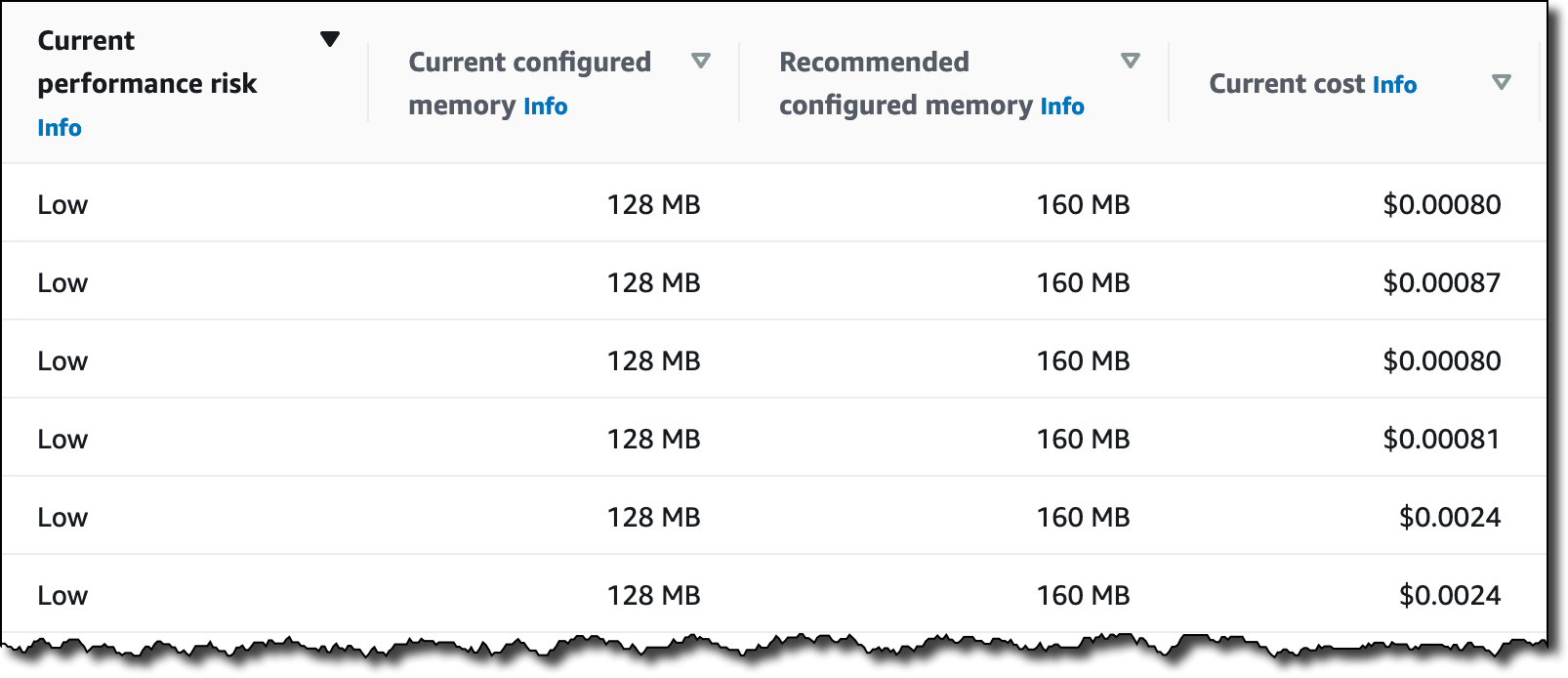
These are recent invocations for the second function which is CPU-intensive:

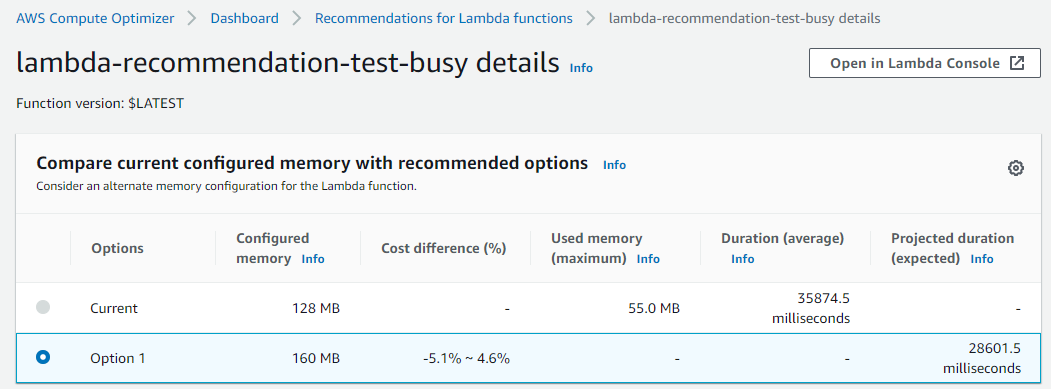
The function duration is about 37.5 seconds with a memory setting of 128 MB, resulting in a duration cost of about $0.000078 per invocation. The recommendations for this function appear in the Compute Optimizer console:

The function is also Not optimized with a reason of Memory under-provisioned. The same recommendation information is available via the CLI:
$ aws compute-optimizer \
get-lambda-function-recommendations \
--function-arns arn:aws:lambda:us-east-1:123456789012:function:lambda-recommendation-test-busy
{
"lambdaFunctionRecommendations": [
{
"utilizationMetrics": [
{
"name": "Duration",
"value": 36006.85851551957,
"statistic": "Average"
},
{
"name": "Duration",
"value": 38540.43,
"statistic": "Maximum"
},
{
"name": "Memory",
"value": 53.75978407557355,
"statistic": "Average"
},
{
"name": "Memory",
"value": 55.0,
"statistic": "Maximum"
}
],
"currentMemorySize": 128,
"lastRefreshTimestamp": 1608725151.752,
"numberOfInvocations": 741,
"functionArn": "arn:aws:lambda:us-east-1:123456789012:function:lambda-recommendation-test-busy:$LATEST",
"memorySizeRecommendationOptions": [
{
"projectedUtilizationMetrics": [
{
"name": "Duration",
"value": 27340.37604781184,
"statistic": "LowerBound"
},
{
"name": "Duration",
"value": 28707.394850202432,
"statistic": "Expected"
},
{
"name": "Duration",
"value": 30142.764592712556,
"statistic": "UpperBound"
}
],
"memorySize": 160,
"rank": 1
}
],
"functionVersion": "$LATEST",
"finding": "NotOptimized",
"findingReasonCodes": [
"MemoryUnderprovisioned"
],
"lookbackPeriodInDays": 14.0,
"accountId": "123456789012"
}
]
}
For this function, Compute Optimizer has determined that the function’s memory is under-provisioned. The value of findingReasonCodes is MemoryUnderprovisioned. The recommendation is to increase the memory from 128 MB to 160 MB.
This recommendation may seem counter-intuitive, since the function only uses 55 MB of memory per invocation. However, Lambda allocates CPU and other resources linearly in proportion to the amount of memory configured. This means that increasing the memory allocation to 160 MB also reduces the expected duration to around 28.7 seconds. This is because a CPU-intensive task also benefits from the increased CPU performance that comes with the additional memory.
After applying this recommendation, the new expected duration cost per invocation is approximately $0.000075. This means that for almost no change in duration cost, the job latency is reduced from 37.5 seconds to 28.7 seconds.
The Compute Optimizer console validates these calculations:

Applying the Compute Optimizer recommendations
To optimize the Lambda functions using Compute Optimizer recommendations, use the following CLI command:
$ aws lambda update-function-configuration \
--function-name lambda-recommendation-test-sleep \
--memory-size 900
After invoking the function multiple times, we can see metrics of these invocations in the console. This shows that the function duration has not changed significantly after reducing the memory size from 1024 MB to 900 MB. The Lambda function has been successfully cost-optimized without increasing job duration:

To apply the recommendation to the CPU-intensive function, use the following CLI command:
$ aws lambda update-function-configuration \
--function-name lambda-recommendation-test-busy \
--memory-size 160
After invoking the function multiple times, the console shows that the invocation duration is reduced to about 28 seconds. This matches the recommendation’s expected duration. This shows that the function is now performance-optimized without a significant cost increase:

Final notes
A couple of final notes:
- Not every function will receive a recommendation. Compute optimizer only delivers recommendations when it has high confidence that these recommendations may help reduce cost or reduce execution duration.
- As with any changes you make to an environment, we strongly advise that you test recommended memory size configurations before applying them into production.
Conclusion
You can now use Compute Optimizer for serverless workloads using Lambda functions. This can help identify the optimal Lambda function configuration options for your workloads. Compute Optimizer supports memory size recommendations for Lambda functions in all AWS Regions where Compute Optimizer is available. These recommendations are available to you at no additional cost. You can get started with Compute Optimizer from the console.
To learn more visit Getting started with AWS Compute Optimizer.