Post Syndicated from Nathan Liefting original https://blog.zabbix.com/running-zabbix-with-mariadb-and-galera-active-active-clustering/31104/

High availability on a platform like Zabbix is a hard requirement for many users. With native high availability on the Zabbix servers, proxies, and at the frontend through various solutions for web servers, all that’s left is at the database layer. Any downtime in your MariaDB database would disrupt your monitoring availability, at the least on the frontend side of things in case of proxy buffering. Let’s have a look at the easiest way to create a high availability (HA) architecture for Zabbix using MariaDB with built-in Galera clustering – by removing single points of failure from your database and finalizing the HA puzzle for Zabbix.
Architecture overview
Let’s start of with the MariaDB + Galera number one design requirement. For a proper quorum to be made, 3 nodes should be used in the cluster. With only two nodes in a Galera cluster, quorum rules become a bit of a headache, as Galera uses a majority vote (more than half the nodes) to decide if the cluster can still accept writes. In a two-node setup, all is good when the database is online. But when we lose one node, quorum is lost and that node needs to rejoin.
This makes a two-node setup fragile but not impossible, and it does work with Zabbix since we do only have one Zabbix server active at the time. In a split-brain scenario where both nodes either think they are the last to leave, you might have to decide which node you think has your up-to-date data. We will detail both scenario’s, but the principle remains the same. We will use MariaDB as our database and Galera will be used to create a primary/primary cluster. In such a cluster, all nodes in the cluster are writeable, which is great for the Zabbix native HA.
When we look in the Zabbix database, we can see that Zabbix keeps all of it’s Zabbix server HA information and states in the database.
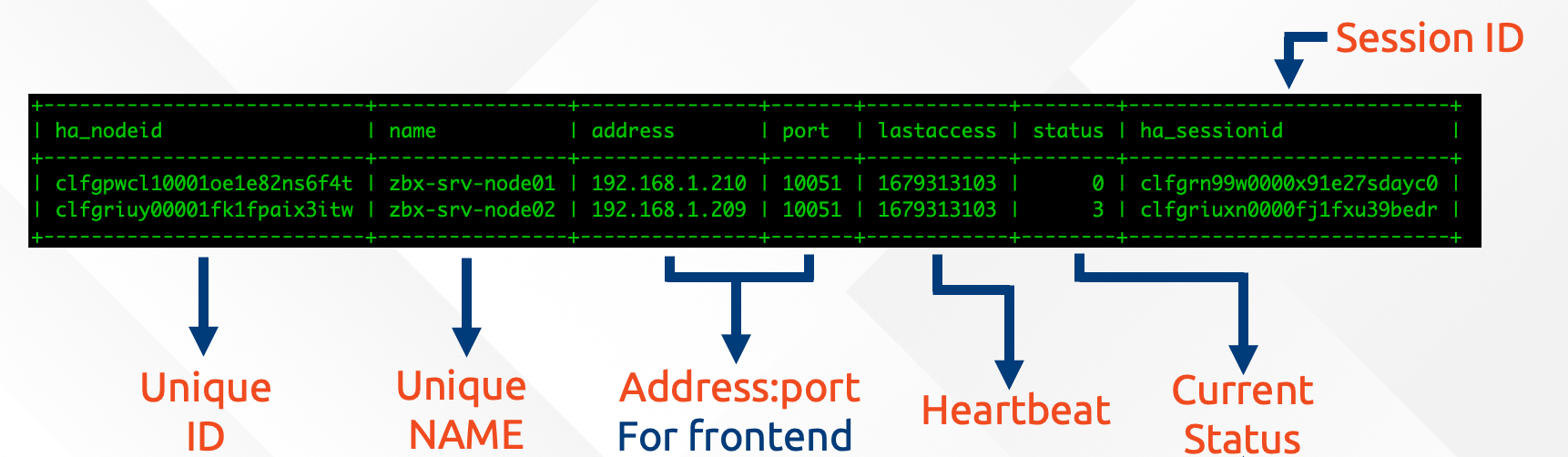
This means that whatever one Zabbix server node writes into the database will also be replicated to all other nodes in the MariaDB Galera cluster.
The design
Knowing what we know now, we can create a very simple design for a solid Zabbix HA setup with Mariadb + Galera. When we have a single Zabbix frontend and we keep to the MariaDB + Galera requirement of having 3 database nodes, we get a fairly simple setup, as seen below.
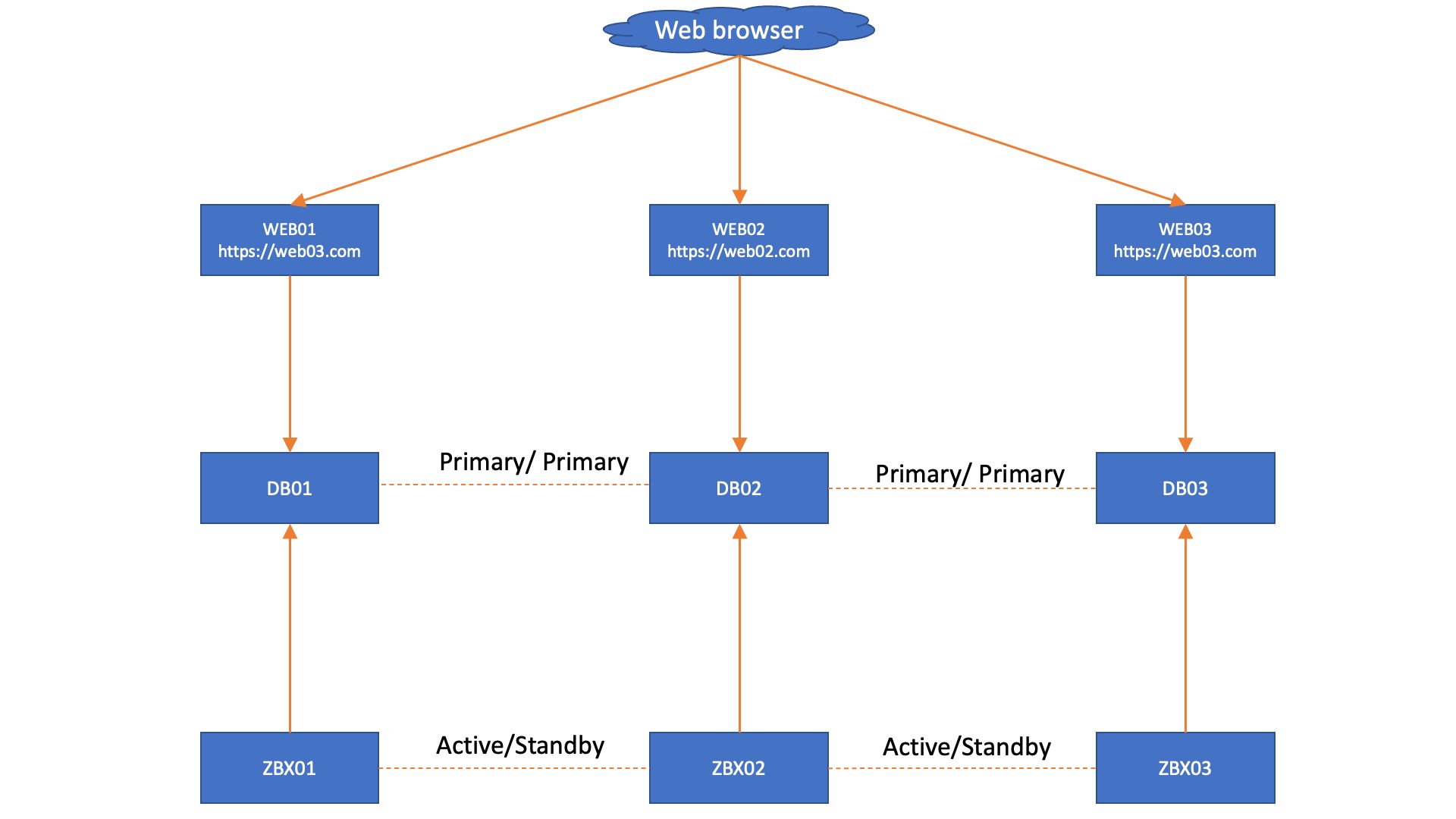
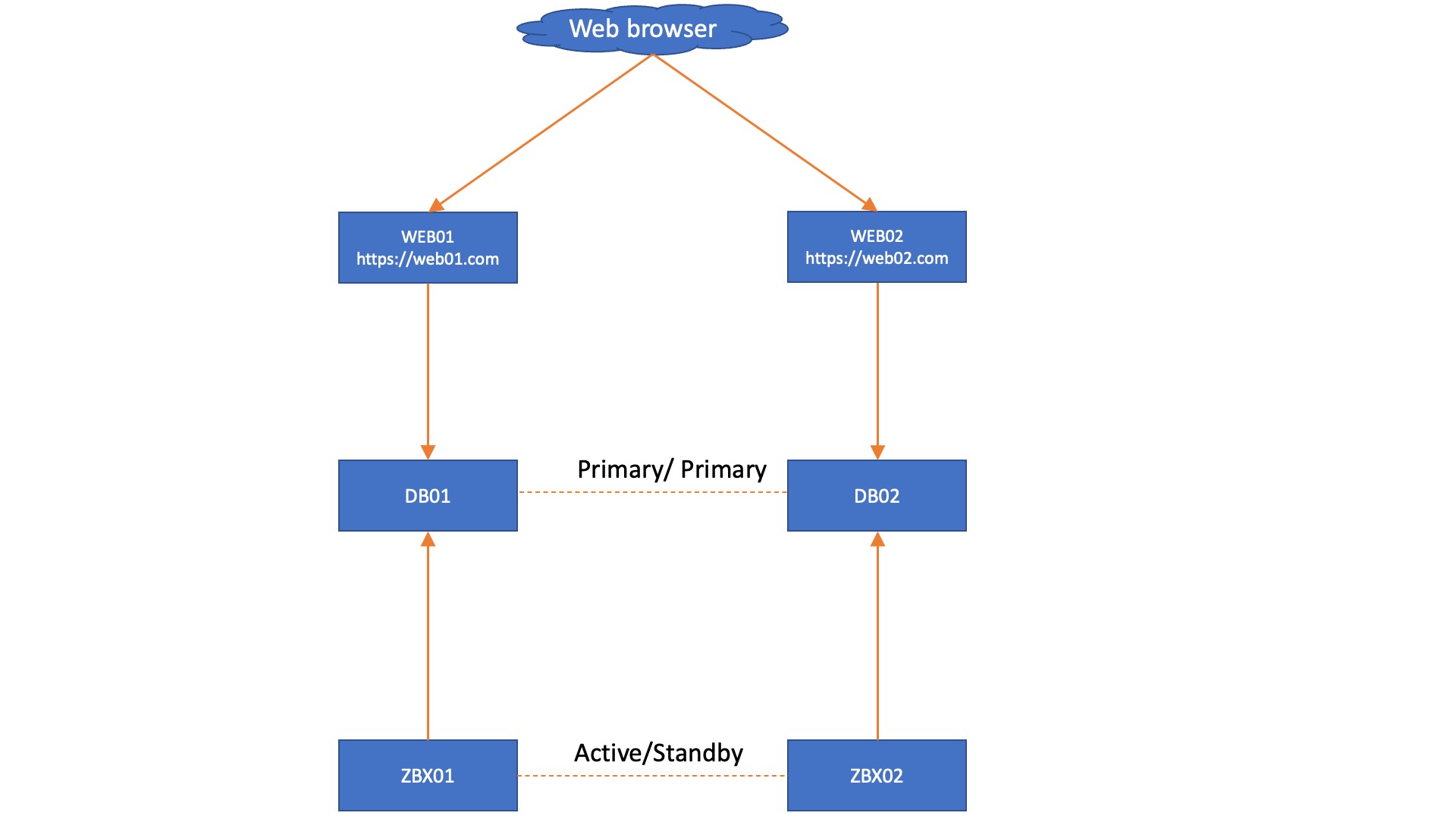
In this setup, each Zabbix server connects to its own Database node and we don’t need added complexity by using load balancers. However, we do get an automatic failover from the Zabbix servers, as they know exactly which node is active through the database. However, in this situation we are still left with 3 frontends that do not have automatic failover, simply because we do not have database aware Apache or NGINX. This also works in a two database setup, with the side note that you might have quorum issues to manually resolve after an outage:
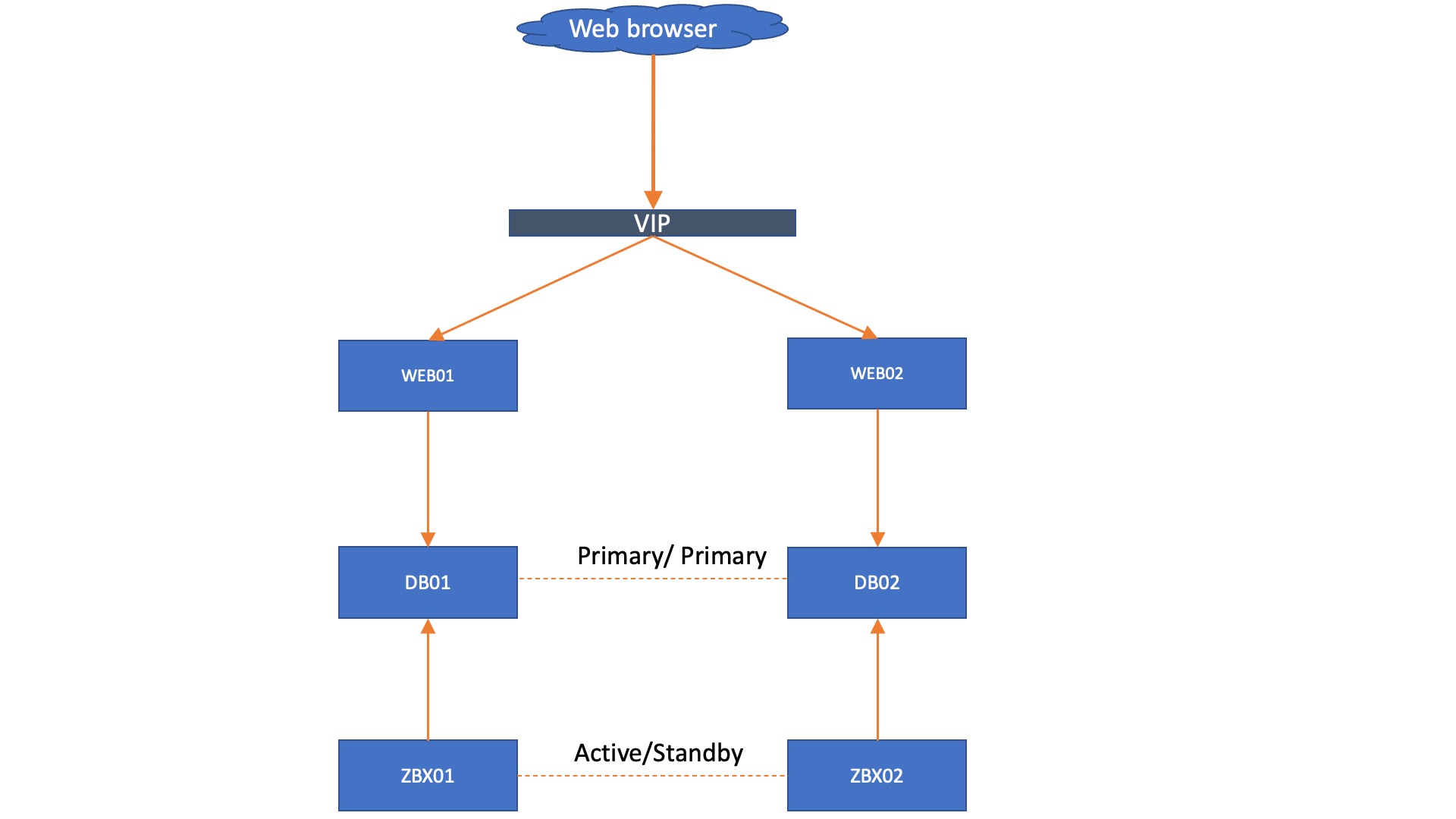
Adding onto this setup, we could install a VIP, load balancer, or something like HA proxy in front of the frontend to make a failover happen there as well. Keep in mind though, the failover needs to happen based on whether or not the webfrontend can reach a writeable database.
Optional Arbitrator
If you are set on running only 2 database nodes (your wallet is thankful), but still worried about quorums, we can bring in the ARBITRATOR.

What about load balancing?
Lastly, it is also possible to add load balancing to the mix. Let’s say, for example, you cannot add a VIP to your environment but still need your WEB servers to failover. A load balancer can provide the solution here.
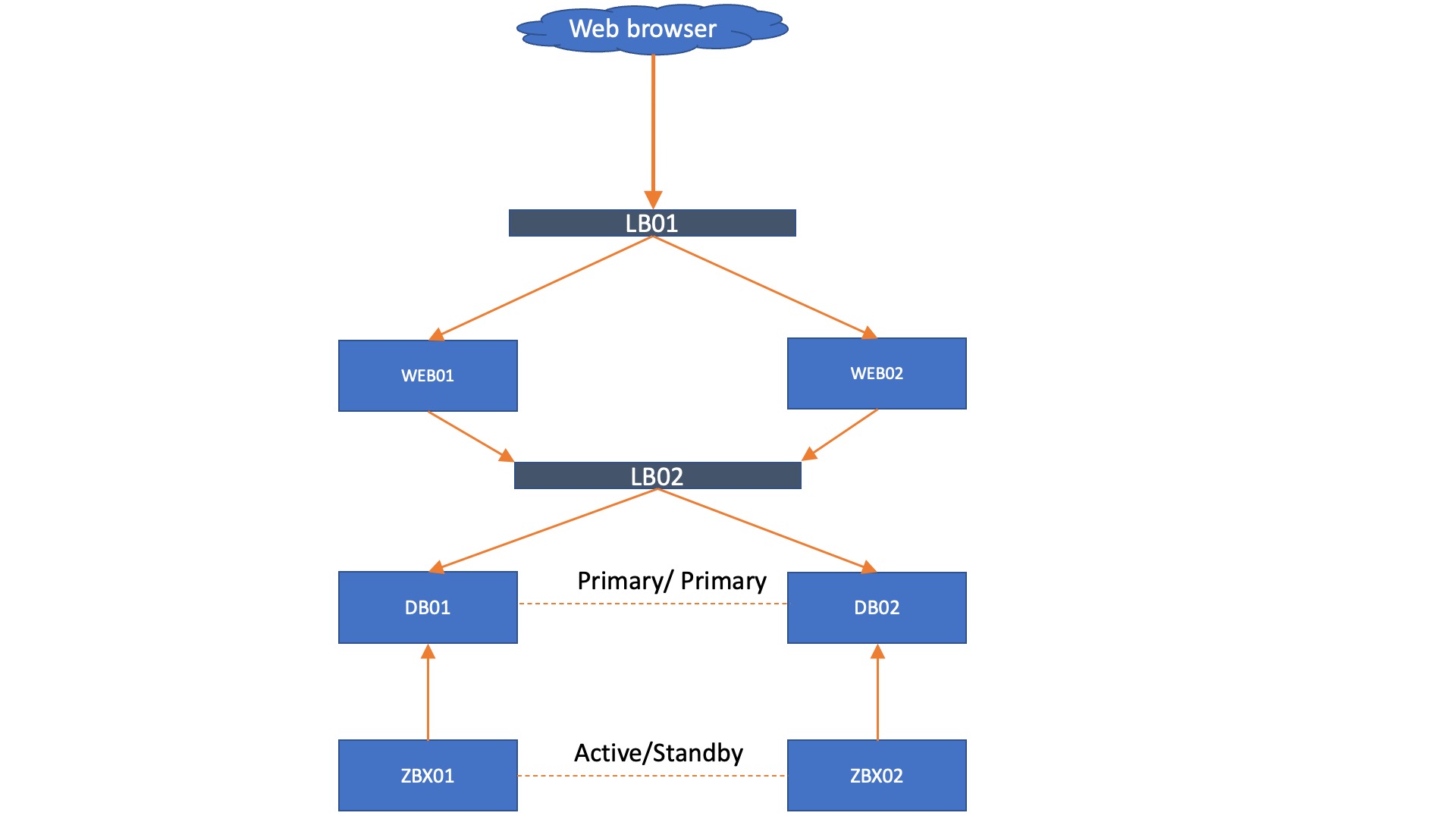
We still prefer to run the Zabbix servers with a direct database connection, but even there a load balancer could be added if you wish. However, please keep in mind that the more load balancers you add, the more complex troubleshooting might become. The whole idea about the setup without load balancers is to have a solid Zabbix setup that is easy to maintain, while providing high availability.
Conclusion
In the end, even with a minimal setup of 2 DB nodes, 2 Zabbix servers, and 2 WEB frontends, we can make a high availability setup. As we’ve shown with Galera, this setup becomes highly flexible, allowing us to run without automatic WEB failover all the way up to including complicated load balancers.
High availability doesn’t have to be overly complicated in a setup like this – it really is all about how far you want to push things. Besides that, in this setup everything is horizontally scalable on the database side. Do keep in mind, however, that Zabbix does still run in an Active/Passive setup.
I hope you enjoyed reading this blog post. If you have any questions or need help configuring anything in your Zabbix setup feel free to contact me and the team at Opensource ICT Solutions. We build a ton of cool stuff like this and more!
Nathan Liefting
![]()
The post Running Zabbix with MariaDB and Galera Active/Active Clustering appeared first on Zabbix Blog.