Post Syndicated from Talia Nassi original https://aws.amazon.com/blogs/compute/benefits-of-migrating-to-event-driven-architecture/
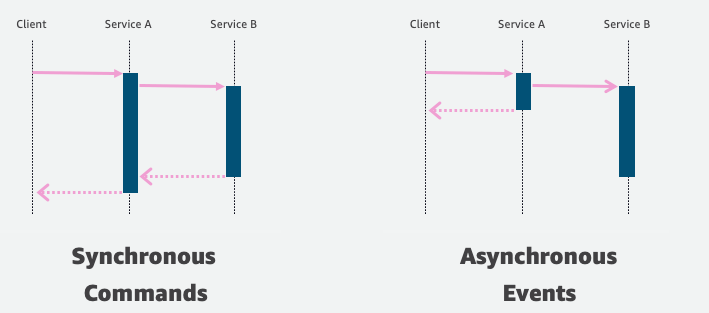
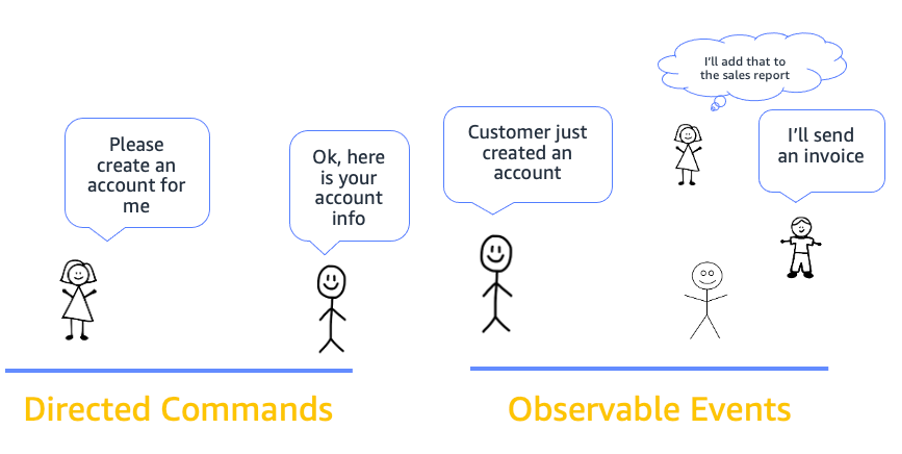
Two common options when building applications are request-response and event-driven architecture. In request-response architecture, an application’s components communicate via API calls. The client sends a request and expects a response before performing the next task. In event-driven architecture, the client generates an event and can immediately move on to its next task. Different parts of the application then respond to the event as needed.

In this post, you learn about reasons to consider moving from request-response architecture to an event-driven architecture.
Challenges with request-response architecture
When starting to a build a new application, many developers default to a request-response architecture. A request-response architecture may tightly integrate components and those components communicate via synchronous calls. While a request-response approach is often easier to get started with, it can become challenging as your application grows in complexity.
In this post, I review an example request-response ecommerce application and demonstrate the challenges of tightly coupled integrations. Then I show you how building the same application with an event-driven architecture can give you increased scalability, fault tolerance, and developer velocity.
Close coordination between microservices
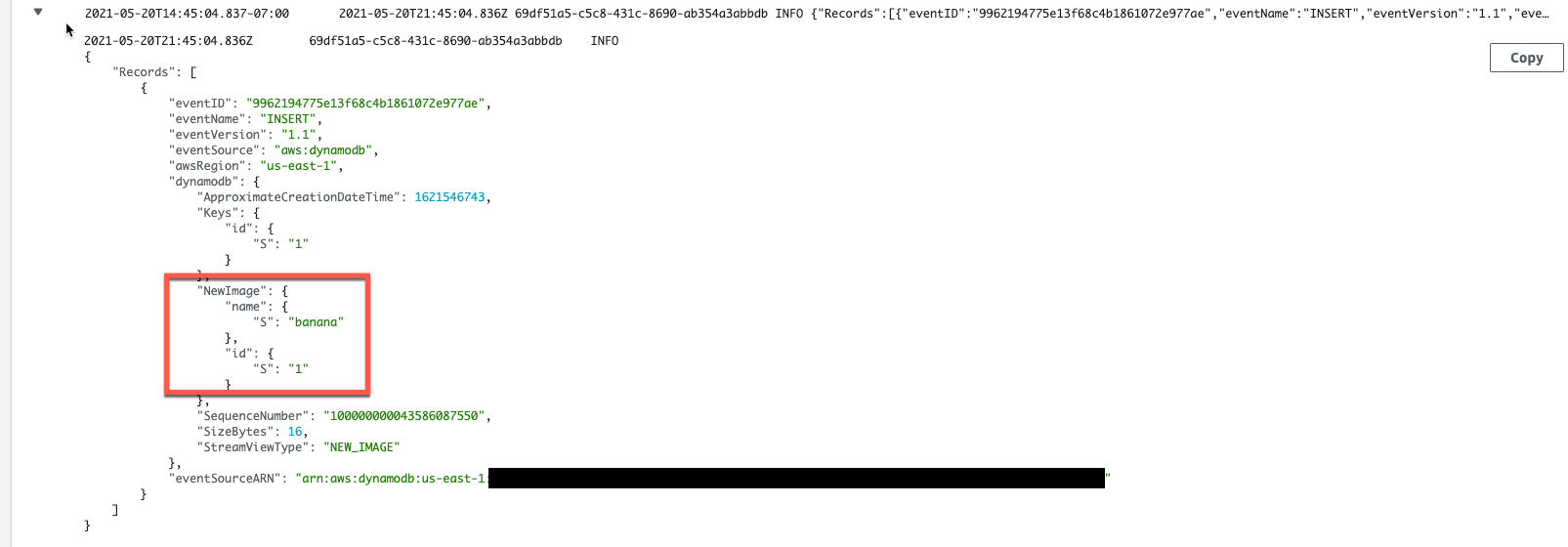
In a typical ecommerce application that uses a synchronous API, the client makes a request to place an order and the order service sends the request downstream to an invoice service. If successful, the order service responds with a success message or confirmation number.
In this initial stage, this is a straightforward connection between the two services. The challenge comes when you add more services that integrate with the order service.
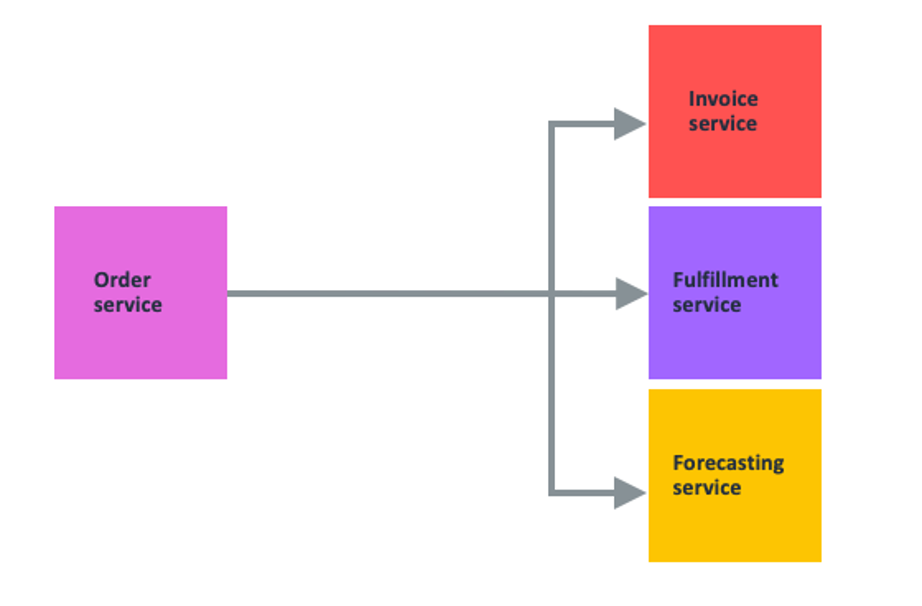
If you add a fulfillment service and a forecasting service, the order service has more responsibilities and more complexity. The order service must know how to call each service’s API, from the API call structure to the API’s retry semantics. If there are any backwards incompatible changes to the APIs, the order service team must update them. The system forwards heavy traffic spikes to the order service’s dependency, which may not have the same scaling capabilities. Also, dependent services may transmit errors back up the stack to the client.
Error handling and retries
Now, you add new downstream services for fulfillment and shipping orders to the ecommerce application.
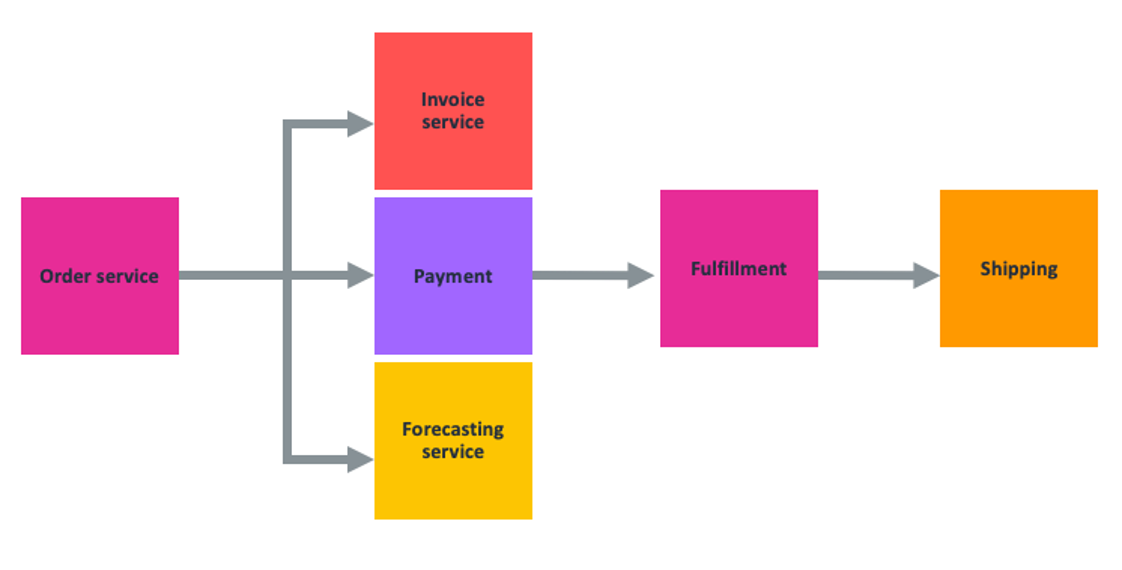
In the happy path, everything works as expected: The order service triggers invoicing, payment systems, and updates forecasting. Once payment clears, this triggers the fulfillment and packing of the order, and then informs the shipping service to request tracking information.
However, if the fulfillment center cannot find the product because they are out of stock, then fulfillment might have to alert the invoice service, then reverse the payment or issue a refund. If fulfillment fails, then the system that triggers shipping might fail as well. Forecasting must also be updated to reflect the change. This remediation workflow is all just to address one of the many potential “unhappy paths” that can occur in this API-driven ecommerce application.
Close coordination between development teams
In a synchronously integrated application, teams must coordinate any new services that are added to the application. This can slow down each development team’s ability to release new features. Imagine your team works on the payment service but you weren’t told that another team added a new rewards service. What now happens when the fulfillment service errors?
Fulfillment may orchestrate all the other services. Your payments team gets a message and you undo the payment, but you may not know who handles retries and error logic. If the rewards service changes vendors and has a new API, and does not tell your team, you may not be aware of the new service.
Ultimately, it can be hard to coordinate these orchestrations and workflows as systems become more complex and management adds more services. This is one reason that it can be beneficial to migrate to event-driven architecture.
Benefits of event-driven architecture
Event-driven architecture can help solve the problems of the close coordination of microservices, error handling and retries, and coordination between development teams.
Close coordination between microservices
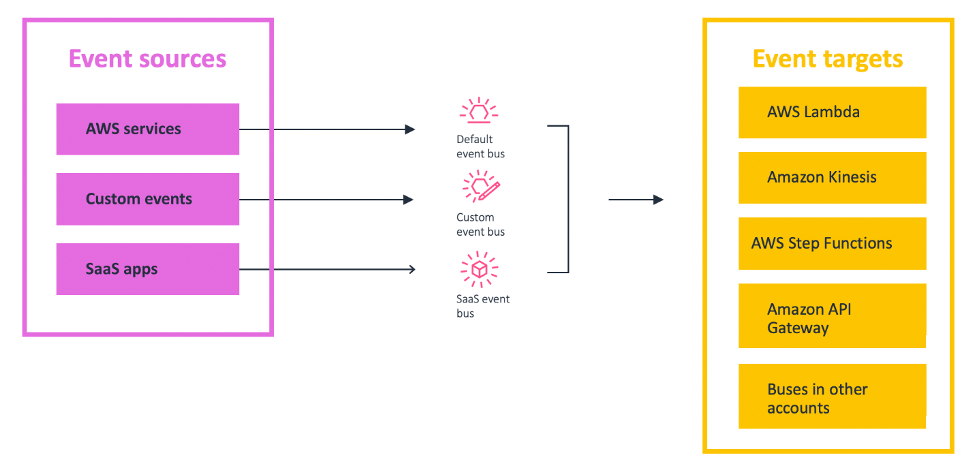
In event-driven architecture, the publisher emits an event, which is acknowledged by the event bus. The event bus routes events to subscribers, which process events with self-contained business logic. There is no direct communication between publishers and subscribers.
Decoupled applications enable teams to act more independently, which can increase their velocity. For example, with an API-based integration, if your team wants to know about a change that happened in another team’s microservice, you might have to ask that team to make an API call to your service. Consequently, you may have to account for authentication, coordination with the other team over the structure of the API call. This causes back and forth between teams, which slows down development time. With an event-driven application, you can subscribe to events sent from your microservice and the event bus (for example, Amazon EventBridge) takes care of routing the event and handling authentication.
Error handling and retries
Another reason to migrate to event-driven architecture is to handle unpredictable traffic. Ecommerce websites like Amazon.com have variable amounts of traffic depending on the day. Once you place an order, several things happen.
First, Amazon checks your credit card to make sure that funds are available. Then, Amazon has to pack the merchandise and load onto trucks. That all happens in an Amazon fulfillment center. There is no synchronous API call for the Amazon backend to package and ship products. After the system confirms your payment, the front end puts together some information describing the event and puts your account number, credit card info, and what you bought in a packaged event and put it into the cloud and onto a queue. Later, another piece of software removes the event from the queue and starts the packaging and shipping.
The key point about this process is that these processes can all run at different rates. Normally, the rate at which customers place orders and the rate at which the warehouses can get the boxes packed are roughly equivalent. However, on busy days like Prime Day, customers place orders much more quickly than the warehouses can operate.
Ecommerce applications, like Amazon.com, must be able to scale up to handle unpredictable traffic. When a customer places an order, an event bus like Amazon EventBridge receives the event and all of the downstream microservices are able to select the order event for processing. Because each of the microservices can fail independently, there are no single points of failure.
Loose coordination between development teams
Event-driven architectures promote development team independence due to loose coupling between publishers and subscribers. Applications can subscribe to events with routing requirements and business logic that are separate from the publisher and other subscribers. This allows publishers and subscribers to change independently of each other, providing more flexibility to the overall architecture.
Decoupled applications also allow you to build new features faster. Adding new features or extending existing ones can be simpler with event-driven architectures because you either add new events, or modify existing ones. This process removes complexity in your application.
Conclusion
In this post, you learn about the challenges of developing applications with request-response architecture. In request-response architecture, the client must send a request and wait for a response before moving on to its next task. As applications grow in complexity, this tightly coupled architecture can cause issues. Event-driven architectures can increase scalability, fault tolerance, and developer velocity by decoupling components of your application.
For more serverless content, go to serverlessland.com.