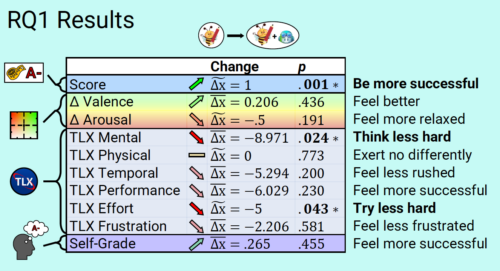
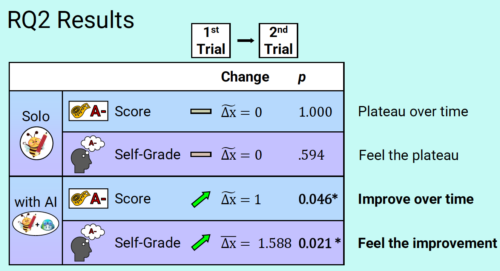
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2024/12/trust-issues-in-ai.html
This essay was written with Nathan E. Sanders. It originally appeared as a response to Evgeny Morozov in Boston Review‘s forum, “The AI We Deserve.”
For a technology that seems startling in its modernity, AI sure has a long history. Google Translate, OpenAI chatbots, and Meta AI image generators are built on decades of advancements in linguistics, signal processing, statistics, and other fields going back to the early days of computing—and, often, on seed funding from the U.S. Department of Defense. But today’s tools are hardly the intentional product of the diverse generations of innovators that came before. We agree with Morozov that the “refuseniks,” as he calls them, are wrong to see AI as “irreparably tainted” by its origins. AI is better understood as a creative, global field of human endeavor that has been largely captured by U.S. venture capitalists, private equity, and Big Tech. But that was never the inevitable outcome, and it doesn’t need to stay that way.
The internet is a case in point. The fact that it originated in the military is a historical curiosity, not an indication of its essential capabilities or social significance. Yes, it was created to connect different, incompatible Department of Defense networks. Yes, it was designed to survive the sorts of physical damage expected from a nuclear war. And yes, back then it was a bureaucratically controlled space where frivolity was discouraged and commerce was forbidden.
Over the decades, the internet transformed from military project to academic tool to the corporate marketplace it is today. These forces, each in turn, shaped what the internet was and what it could do. For most of us billions online today, the only internet we have ever known has been corporate—because the internet didn’t flourish until the capitalists got hold of it.
AI followed a similar path. It was originally funded by the military, with the military’s goals in mind. But the Department of Defense didn’t design the modern ecosystem of AI any more than it did the modern internet. Arguably, its influence on AI was even less because AI simply didn’t work back then. While the internet exploded in usage, AI hit a series of dead ends. The research discipline went through multiple “winters” when funders of all kinds—military and corporate—were disillusioned and research money dried up for years at a time. Since the release of ChatGPT, AI has reached the same endpoint as the internet: it is thoroughly dominated by corporate power. Modern AI, with its deep reinforcement learning and large language models, is shaped by venture capitalists, not the military—nor even by idealistic academics anymore.
We agree with much of Morozov’s critique of corporate control, but it does not follow that we must reject the value of instrumental reason. Solving problems and pursuing goals is not a bad thing, and there is real cause to be excited about the uses of current AI. Morozov illustrates this from his own experience: he uses AI to pursue the explicit goal of language learning.
AI tools promise to increase our individual power, amplifying our capabilities and endowing us with skills, knowledge, and abilities we would not otherwise have. This is a peculiar form of assistive technology, kind of like our own personal minion. It might not be that smart or competent, and occasionally it might do something wrong or unwanted, but it will attempt to follow your every command and gives you more capability than you would have had without it.
Of course, for our AI minions to be valuable, they need to be good at their tasks. On this, at least, the corporate models have done pretty well. They have many flaws, but they are improving markedly on a timescale of mere months. ChatGPT’s initial November 2022 model, GPT-3.5, scored about 30 percent on a multiple-choice scientific reasoning benchmark called GPQA. Five months later, GPT-4 scored 36 percent; by May this year, GPT-4o scored about 50 percent, and the most recently released o1 model reached 78 percent, surpassing the level of experts with PhDs. There is no one singular measure of AI performance, to be sure, but other metrics also show improvement.
That’s not enough, though. Regardless of their smarts, we would never hire a human assistant for important tasks, or use an AI, unless we can trust them. And while we have millennia of experience dealing with potentially untrustworthy humans, we have practically none dealing with untrustworthy AI assistants. This is the area where the provenance of the AI matters most. A handful of for-profit companies—OpenAI, Google, Meta, Anthropic, among others—decide how to train the most celebrated AI models, what data to use, what sorts of values they embody, whose biases they are allowed to reflect, and even what questions they are allowed to answer. And they decide these things in secret, for their benefit.
It’s worth stressing just how closed, and thus untrustworthy, the corporate AI ecosystem is. Meta has earned a lot of press for its “open-source” family of LLaMa models, but there is virtually nothing open about them. For one, the data they are trained with is undisclosed. You’re not supposed to use LLaMa to infringe on someone else’s copyright, but Meta does not want to answer questions about whether it violated copyrights to build it. You’re not supposed to use it in Europe, because Meta has declined to meet the regulatory requirements anticipated from the EU’s AI Act. And you have no say in how Meta will build its next model.
The company may be giving away the use of LLaMa, but it’s still doing so because it thinks it will benefit from your using it. CEO Mark Zuckerberg has admitted that eventually, Meta will monetize its AI in all the usual ways: charging to use it at scale, fees for premium models, advertising. The problem with corporate AI is not that the companies are charging “a hefty entrance fee” to use these tools: as Morozov rightly points out, there are real costs to anyone building and operating them. It’s that they are built and operated for the purpose of enriching their proprietors, rather than because they enrich our lives, our wellbeing, or our society.
But some emerging models from outside the world of corporate AI are truly open, and may be more trustworthy as a result. In 2022 the research collaboration BigScience developed an LLM called BLOOM with freely licensed data and code as well as public compute infrastructure. The collaboration BigCode has continued in this spirit, developing LLMs focused on programming. The government of Singapore has built SEA-LION, an open-source LLM focused on Southeast Asian languages. If we imagine a future where we use AI models to benefit all of us—to make our lives easier, to help each other, to improve our public services—we will need more of this. These may not be “eolithic” pursuits of the kind Morozov imagines, but they are worthwhile goals. These use cases require trustworthy AI models, and that means models built under conditions that are transparent and with incentives aligned to the public interest.
Perhaps corporate AI will never satisfy those goals; perhaps it will always be exploitative and extractive by design. But AI does not have to be solely a profit-generating industry. We should invest in these models as a public good, part of the basic infrastructure of the twenty-first century. Democratic governments and civil society organizations can develop AI to offer a counterbalance to corporate tools. And the technology they build, for all the flaws it may have, will enjoy a superpower that corporate AI never will: it will be accountable to the public interest and subject to public will in the transparency, openness, and trustworthiness of its development.