Post Syndicated from Suvojit Dasgupta original https://aws.amazon.com/blogs/big-data/deploy-apache-yunikorn-batch-scheduler-for-amazon-emr-on-eks/
As organizations successfully grow their Apache Spark workloads on Amazon EMR on EKS, they may seek to optimize resource scheduling to further enhance cluster utilization, minimize job queuing, and maximize performance. Although Kubernetes’ default scheduler, kube-scheduler, works well for most containerized applications, it lacks feature sets capable of managing complex big data workloads with specific requirements such as gang scheduling, resource quotas, job priorities, multi-tenancy, and hierarchical queue management. This limitation can result in inefficient resource utilization, longer job completion times, and increased operational costs for organizations running large-scale data processing workloads.
Apache YuniKorn addresses these limitations by providing a custom resource scheduler specifically designed for big data and machine learning (ML) workloads running on Kubernetes. Unlike kube-scheduler, YuniKorn offers features such as gang scheduling, making sure all containers of a Spark application start together, resource fairness amongst multiple tenants, priority and preemption capabilities, and queue management with hierarchical resource allocation. For data engineering and platform teams managing large-scale Spark workloads on Amazon EMR on EKS, YuniKorn can improve resource utilization rates, reduce job completion times, and provide improved resource allocation for multi-tenant clusters. This is particularly valuable for organizations running mixed workloads with varying resource requirements, strict SLA requirements, or complex resource sharing policies across different teams and applications.
This post explores Kubernetes scheduling fundamentals, examines the limitations of the default kube-scheduler for batch workloads, and demonstrates how YuniKorn addresses these challenges. We discuss how to deploy YuniKorn as a custom scheduler for Amazon EMR on EKS, its integration with job submissions, how to configure queues and placement rules, and how to establish resource quotas. We also show these features in action through practical Spark job examples.
Understanding Kubernetes scheduling and the need for YuniKorn
In this section, we dive into the details of Kubernetes scheduling and the need for YuniKorn.
How Kubernetes scheduling works
Kubernetes scheduling is the process of assigning pods to nodes within a cluster while considering resource requirements, scheduling constraints, and isolation constraints. The scheduler evaluates each pod individually against all schedulable worker nodes, considering multiple factors, including resource requirements such as CPU, memory and I/O requests, node affinity preferences for specific node characteristics, inter-pod affinity and anti-affinity rules that determine whether the pods should be distributed across multiple worker nodes or require colocation, taints and tolerations that dictate scheduling constraints, and Quality of Service classifications that influence scheduling priority.
The scheduling process operates through a two-phase approach. During the filtering phase, the scheduler identifies all worker nodes that could potentially host the pod by eliminating those that don’t meet the basic requirements. The scoring phase then ranks all feasible worker nodes using scoring algorithms to determine the optimal placement, ultimately selecting the highest-scoring node for pod assignment.
Default implementation of kube-scheduler
kube-scheduler serves as the Kubernetes default scheduler. This scheduler operates on a pod-by-pod basis, treating each scheduling decision as an independent operation without consideration for the broader application context.When kube-scheduler processes scheduling requests, it follows a continuous workflow. The API server is monitored for newly created pods awaiting node assignment, applies filtering logic to eliminate unsuitable worker nodes, executes its scoring algorithm to rank the remaining candidates, binds the selected pod to the optimal node, and repeats the process with the next unscheduled pod in the queue.This individual pod scheduling approach works well for microservices and web applications where each pod has fewer interdependencies. However, this design creates significant challenges when applied to distributed big data frameworks like Spark that require coordinated scheduling of multiple interdependent pods.
Challenges using kube-scheduler for batch jobs
Batch processing workloads, particularly those built on Spark, present different scheduling requirements that expose limitations in kube-scheduler algorithm. Such applications consist of multiple pods that must operate as a cohesive unit, yet kube-scheduler lacks the application-level awareness necessary to handle coordinated scheduling requirements.
Gang scheduling challenges
The most significant challenge emerges from the need for gang scheduling, where all components of a distributed application must be scheduled simultaneously. A typical Spark application requires a driver pod and multiple executor pods running in parallel to function correctly. Without YuniKorn, kube-scheduler first schedules the driver pod without knowing the total amount of resources that the driver and executors will need together. When the driver pod starts running, it attempts to spin up the required executor pods but might fail to find sufficient resources in the cluster. This sequential approach can result in the driver being scheduled successfully while some or all executor pods remain in a pending state due to insufficient cluster capacity.This partial scheduling creates a problematic scenario where the application consumes cluster resources but can’t execute meaningful work. The partially scheduled application will hold onto allocated resources indefinitely while waiting for the missing components, preventing other applications from utilizing those resources and resulting in a deadlock situation.
Resource fragmentation issues
Resource fragmentation represents another critical issue that emerges from individual pod scheduling. When multiple batch applications compete for cluster resources, the lack of coordinated scheduling leads to scenarios where sufficient total resources exist for a given application, but they become fragmented across multiple incomplete applications. This fragmentation prevents efficient resource utilization and can leave applications in perpetual pending states.
The absence of hierarchical queue management further compounds these challenges. kube-scheduler provides limited support for hierarchical resource allocation, making it difficult to implement fair sharing policies across different tenants. Organizations can’t easily establish resource quotas that guarantee minimum allocations while setting maximum limits, nor can they implement preemption policies that allow higher-priority jobs to reclaim resources from lower-priority workloads.
The Need for YuniKorn
YuniKorn addresses these batch scheduling limitations through a set of features designed for distributed computing workloads. Unlike the pod-centric approach of kube-scheduler, YuniKorn operates with application-level awareness, understanding the relationships between different components of distributed applications and making scheduling decisions accordingly. The features are as follows:
- Gang scheduling for atomic application deployment – Gang scheduling represents YuniKorn’s advantage for batch workloads. This capability makes sure pods belonging to an application are scheduled atomically—either all components receive node assignments, or none are scheduled until sufficient resources become available. YuniKorn’s all-or-nothing approach to scheduling minimizes resource deadlocks and partial application failures that impact
kube-schedulerbased deployments, resulting in more predictable job execution and higher completion rates. - Hierarchical queue management and resource organization – YuniKorn’s queue management system provides the hierarchical resource organization that enterprise batch processing environments require. Organizations can establish multi-level queue structures that mirror their organizational hierarchy, implementing resource quotas at each level to facilitate fair resource distribution. The scheduler supports guaranteed resource allocations that provide minimum resource commitments and maximum limits that prevent a single queue from monopolizing cluster resources.
- Dynamic resource preemption based on priority – The preemption capabilities built into YuniKorn enable dynamic resource reallocation based on job priorities and queue policies. When higher-priority applications require resources currently allocated to lower-priority workloads, YuniKorn can gracefully stop lower-priority pods and reallocate their resources, making sure critical jobs receive the resources they need without manual intervention.
- Intelligent resource pooling and fair share distribution – Resource pooling and fair share scheduling further enhance YuniKorn’s effectiveness for batch workloads. Rather than treating each scheduling decision in isolation, YuniKorn considers the broader resource allocation landscape, implementing fair-share algorithms that facilitate equitable resource distribution across different applications and users while maximizing overall cluster utilization.
These features add to the existing capabilities of Amazon EMR on EKS by establishing an enhanced environment in which the unique requirements of distributed computing workloads are satisfied.
Solution overview
Consider HomeMax, a fictitious company operating a shared Amazon EMR on EKS cluster where three teams regularly submit Spark jobs with distinct characteristics and priorities:
- Analytics team – Runs time-sensitive customer analysis jobs requiring immediate processing for business decisions
- Marketing team – Executes large overnight batch jobs for campaign optimization with predictable resource patterns
- Data science team – Runs experimental workloads with varying resource needs throughout the day for model development and research
Without proper resource scheduling, these teams face common challenges: resource contention, job failures due to partial scheduling, and inability to guarantee SLAs for critical workloads.For our YuniKorn demonstration, we configured an Amazon EMR on EKS cluster with the following specifications:
- Amazon EKS cluster: Four worker nodes using m5.2xlarge Amazon Elastic Compute Cloud (Amazon EC2) instances
- Per-node resources: 8 vCPUs, 32 GiB memory
- Total cluster capacity: 32 vCPU cores and 128 GiB memory
- Available for Spark: Approximately 30 vCPUs and approximately 120 GiB memory (after system overhead)
- Kubernetes version: 1.30+ (required for YuniKorn 1.6.x compatibility)
The following code shows the node group configuration:
We intentionally use a fixed-capacity cluster to provide a controlled environment that showcases YuniKorn’s scheduling capabilities with consistent, predictable resources. This approach makes resource contention scenarios more apparent and demonstrates how YuniKorn resolves them.
Amazon EMR on EKS offers robust scaling capabilities through Karpenter. The principles demonstrated in this fixed environment apply equally to dynamic environments, where YuniKorn’s capabilities complement the scaling features of Amazon EMR on EKS to optimize resource utilization during peak demand periods or when scaling limits are reached.
The following diagram shows the high-level architecture of the YuniKorn scheduler running on Amazon EMR on EKS. This solution also includes a secure bastion host not shown in the architecture diagram that provides access to the EKS cluster via AWS Systems Manager (SSM) Session Manager. The bastion host is deployed in a private subnet with all necessary tools pre-installed with proper permissions for seamless cluster interaction.
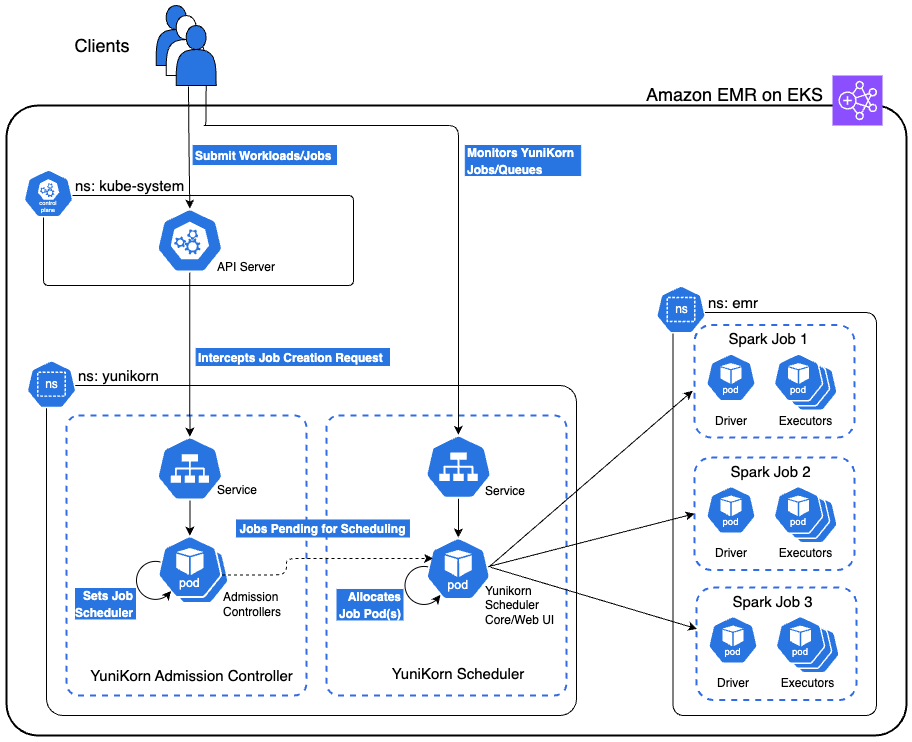
In the following sections, we explore YuniKorn’s queue architecture optimized for this use case. We examine various demonstration scenarios, including gang scheduling, queue-based resource management, priority-based preemption, and fair share distribution. We walk through the process of deploying an Amazon EMR on EKS cluster, implementing the YuniKorn scheduler, configuring the specified queues, and submitting Spark jobs to showcase these scenarios.
YuniKorn integration on Amazon EMR on EKS
The integration involves three key components working together: the Amazon EMR on EKS virtual cluster configuration, YuniKorn’s admission webhook system, and job-level queue annotations.
Namespace and virtual cluster foundation
The integration begins with a dedicated Kubernetes namespace where your Amazon EMR on EKS jobs will run. In our demonstration, we use the emr namespace, created as a standard Kubernetes namespace:
The Amazon EMR on EKS virtual cluster is configured to deploy all jobs within this specific namespace. When creating the virtual cluster, you specify the namespace in the container provider configuration:
This configuration makes sure all jobs submitted to this virtual cluster will be deployed in the emr namespace, establishing the foundation for YuniKorn integration.
The YuniKorn interception mechanism
When YuniKorn is installed using Helm, it automatically registers a MutatingAdmissionWebhook with the Kubernetes API server. This webhook acts as an interceptor that monitors pod creation events in your designated namespace. The webhook registration tells Kubernetes to call YuniKorn whenever pods are created in the emr namespace:
This webhook is triggered by any pod creation in the emr namespace, not specifically by YuniKorn annotations. However, the webhook’s logic only modifies pods that contain YuniKorn queue annotations, leaving other pods unchanged.
End-to-end job flow
When you submit a Spark job through the Spark Operator, the following sequence occurs:
- Your Spark job includes YuniKorn queue annotations on both driver and executor pods:
- The Spark Operator processes your
SparkApplicationand creates individual Kubernetes pods for the driver and executors. These pods inherit the YuniKorn annotations from your job template. - When the Spark Operator attempts to create pods in the
emrnamespace, Kubernetes calls YuniKorn’s admission webhook. The webhook examines each pod and performs the following actions:- Detects pods with
yunikorn.apache.org/queueannotations. - Adds
schedulerName: yunikornto those pods. - Leaves pods without YuniKorn annotations unchanged.
- Detects pods with
This interception means you don’t need to manually specify schedulerName: yunikorn in your Spark jobs—YuniKorn claims the pods transparently based on the presence of queue annotations.
- The YuniKorn scheduler receives the scheduling requests and applies the queue placement rules configured in the YuniKorn
ConfigMap:
The provided rule reads the yunikorn.apache.org/queue annotation and places the job in the specified queue (for example, root.analytics-queue). YuniKorn then applies gang scheduling logic, holding all pods until sufficient resources are available for the entire application, preventing the partial scheduling issues that come with kube-scheduler.
- After YuniKorn determines that all pods can be scheduled according to the queue’s resource guarantees and limits, it schedules all driver and executor pods. The Spark job begins execution with the guaranteed resource allocation defined in the queue configuration.
The combination of namespace-based virtual cluster configuration, admission webhook interception, and annotation-driven queue placement creates an integration that transforms Amazon EMR on EKS job scheduling without disrupting existing workflows.
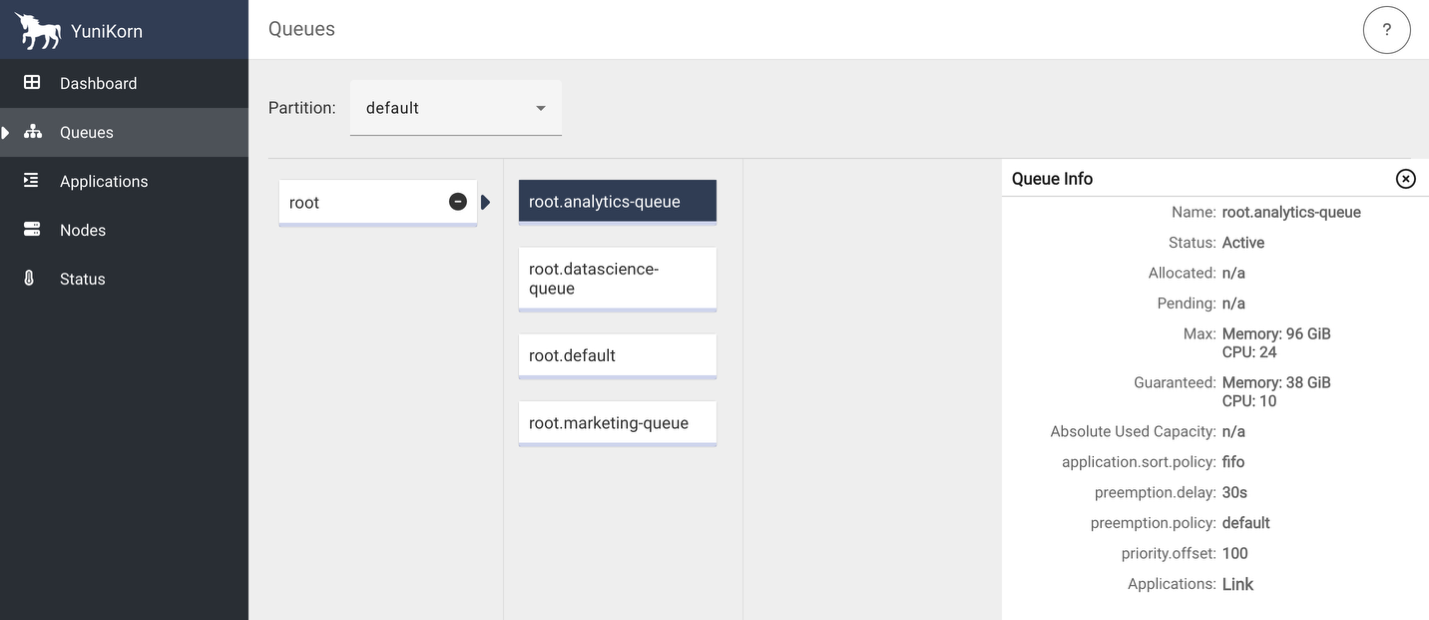
YuniKorn queue architecture
To demonstrate the various YuniKorn features described in the next section, we configured three job-specific queues and a default queue representing our enterprise teams with carefully balanced resource allocations:
Demonstration scenarios
This section outlines key YuniKorn scheduling capabilities and their corresponding Spark job submissions. These scenarios demonstrate guaranteed resource allocation and burst capacity usage. Guaranteed resources represent minimum allocations that queues can always access, but jobs might exceed these allocations when additional cluster capacity is available. The marketing-job specifically demonstrates burst capacity usage beyond its guaranteed allocation.
- Gang scheduling – In this scenario, we submit
analytics-job.py(analytics-queue, 9 total cores) andmarketing-job.py(marketing-queue, 17 total cores) simultaneously. YuniKorn makes sure all pods for each job are scheduled atomically, preventing partial resource allocation that could cause job failures in our resource-constrained cluster. - Queue-based resource management – We run all three jobs concurrently to observe guaranteed resource allocation. YuniKorn distributes remaining capacity proportionally based on queue weights and maximum limits.
analytics-job.py(analytics-queue) receives guaranteed 10 vCPUs and 38 GB memory.marketing-job.py(marketing-queue) receives guaranteed 8 vCPUs and 32 GB memory.datascience-job.py(datascience-queue) receives guaranteed 6 vCPUs and 26 GB memory.
- Priority-based preemption – We start
datascience-job.py(datascience-queue, priority 25) andmarketing-job.py(marketing-queue, priority 50) consuming cluster resources, then submit high-priorityanalytics-job.py(analytics-queue, priority 100). YuniKorn preempts lower-priority jobs to make sure the time-sensitive analytics workload gets its guaranteed resources, maintaining SLA compliance. - Fair share distribution – We submit multiple jobs to each queue when all queues have available capacity. YuniKorn applies configured fair share policies within queues—the analytics queue uses First In, First Out (FIFO) method for predictable scheduling, and the marketing and data science queues use fair sharing method for balanced resource distribution.
Source code
You can find the codebase in the AWS Samples GitHub repository.
Prerequisites
Before you deploy this solution, make sure the following prerequisites are in place:
- Access to a valid AWS account
- The AWS Command Line Interface (AWS CLI) is installed on your local machine
- AWS Session Manager plugin installed for secure bastion host access
- Git, Docker, eksctl, kubectl, Helm, and jq utilities are installed on your local machine
- Permission to create AWS resources
- Familiarity with Kubernetes, Apache Spark, Amazon EKS, and Amazon EMR on EKS
Set up the solution infrastructure
Complete the following steps to set up the infrastructure:
- Clone the repository to your local machine and set the two environment variables. Replace
<AWS_REGION>with the AWS Region where you want to deploy these resources.
- Execute the following script to create the infrastructure:
- To verify successful infrastructure deployment, open the AWS CloudFormation console, choose your stack, and check the Events, Resources, and Outputs tabs for completion status, details, and list of resources created.
Deploy YuniKorn on Amazon EMR on EKS
Run the following script to deploy the Yunikorn helm chart and update the configmap with the queues and placement rules:
Establish EKS cluster connectivity
Complete the following steps to establish secure connectivity to your private EKS cluster:
- Execute the following script in a new terminal window. This script establishes port forwarding through the bastion host to make your private EKS cluster accessible from your local machine. Keep this terminal window open and running throughout your work session. The script maintains the connection to your EKS cluster.
- Test
kubectlconnectivity in the main terminal window to verify that you can successfully communicate with the EKS cluster. You should see the EKS worker nodes listed, confirming that the port forwarding is working correctly.
kubectl get nodes
Verify successful YuniKorn deployment
Complete the following steps to verify a successful deployment:
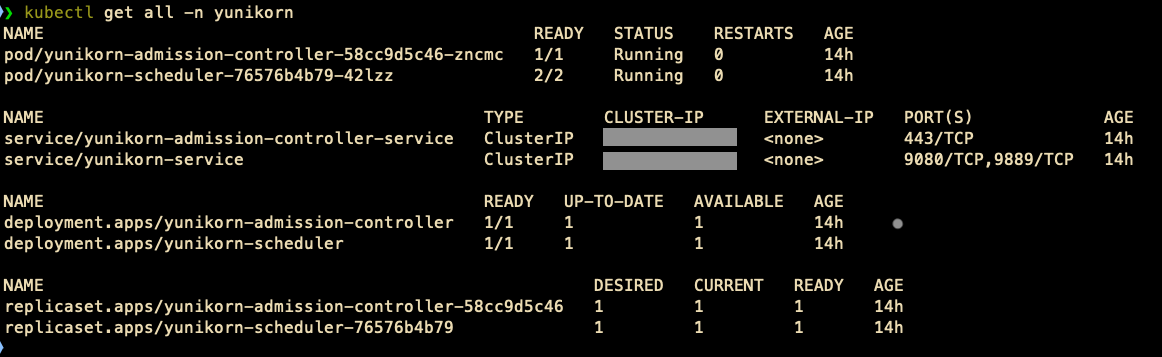
- List all Kubernetes objects in the yunikorn namespace:
kubectl get all -n yunikorn
You will see details like the following screenshot.
- Check the YuniKorn scheduler logs for configuration loading and look for queue configuration messages:
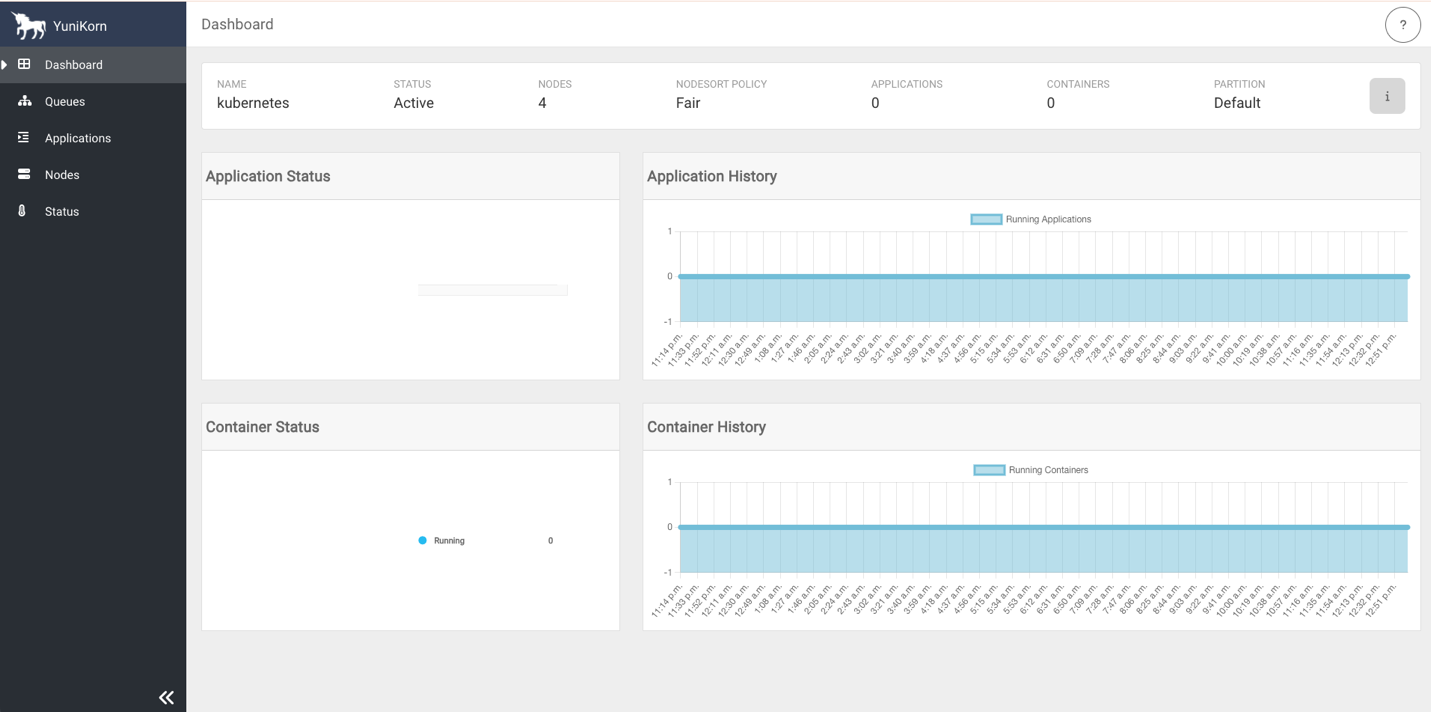
- Access the YuniKorn web UI by navigating to http://127.0.0.1:9889 in your browser. Port
9889is the default port for the YuniKorn web UI.
The following screenshots show the YuniKorn web UI with queues but no running applications.
Run Spark jobs with YuniKorn on Amazon EMR on EKS
Complete the following steps to run Spark jobs with YuniKorn on Amazon EMR on EKS:
- Execute the following script to set up the Spark jobs environment. The script uploads PySpark scripts to Amazon Simple Storage Service (Amazon S3) bucket locations and creates ready-to-use
YAMLfiles from templates.
- Submit analytics, marketing, and data science Spark jobs using the following commands. YuniKorn will place the jobs in their respective queues and allocate resources to execution. Refer to Using YuniKorn as a custom scheduler for Apache Spark on Amazon EMR on EKS for supported job submission methods with YuniKorn as a custom scheduler.
- Review the previous section describing different demonstration scenarios and submit the Spark jobs using various combinations to see YuniKorn scheduler’s capabilities in action. We encourage you to adjust the
cores,instances, andmemoryparameters and explore the scheduler’s behavior by executing the jobs. We also encourage you to modify the queues’guaranteedandmaxcapacities in the fileyunikorn/queue-config-provided.yaml, apply the changes, and submit jobs to further understand Yunikorn scheduler behavior under various circumstances.
Clean up
To avoid incurring future charges, complete the following steps to delete the resources you created:
- Stop the port forwarding sessions:
- Remove all created AWS resources:
Conclusion
YuniKorn addresses the scheduling limitations of default kube-scheduler while running Spark workloads on Amazon EMR on EKS through gang scheduling, intelligent queue management, and priority-based resource allocation. This post showed how YuniKorn’s queue system enables better resource utilization, prevents job failure due to poor allocation of resources, and supports multi-tenant environments.
To get started with YuniKorn on Amazon EMR on EKS, explore the Apache YuniKorn documentation for implementation guides, review Amazon EMR on EKS best practices for optimization strategies, and engage with the YuniKorn community for ongoing support.
About the authors
 Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for diverse customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for diverse customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
 Peter Manastyrny is a Senior Product Manager at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it straightforward and efficient to run open-source data analytics frameworks such as Spark on Amazon EKS.
Peter Manastyrny is a Senior Product Manager at AWS Analytics. He leads Amazon EMR on EKS, a product that makes it straightforward and efficient to run open-source data analytics frameworks such as Spark on Amazon EKS.
 Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructure tailored to each project’s unique challenges.
Matt Poland is a Senior Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructure tailored to each project’s unique challenges.
 Gregory Fina is a Principal Startup Solutions Architect for Generative AI at Amazon Web Services, where he empowers startups to accelerate innovation through cloud adoption. He specializes in application modernization, with a strong focus on serverless architectures, containers, and scalable data storage solutions. He is passionate about using generative AI tools to orchestrate and optimize large-scale Kubernetes deployments, as well as advancing GitOps and DevOps practices for high-velocity teams. Outside of his customer-facing role, Greg actively contributes to open source projects, especially those related to Backstage.
Gregory Fina is a Principal Startup Solutions Architect for Generative AI at Amazon Web Services, where he empowers startups to accelerate innovation through cloud adoption. He specializes in application modernization, with a strong focus on serverless architectures, containers, and scalable data storage solutions. He is passionate about using generative AI tools to orchestrate and optimize large-scale Kubernetes deployments, as well as advancing GitOps and DevOps practices for high-velocity teams. Outside of his customer-facing role, Greg actively contributes to open source projects, especially those related to Backstage.






 Sri Potluri is a Cloud Infrastructure Architect at AWS. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructures tailored to each project’s unique challenges.
Sri Potluri is a Cloud Infrastructure Architect at AWS. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, providing scalable and reliable infrastructures tailored to each project’s unique challenges. Suvojit Dasgupta is a Principal Data Architect at AWS. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
Suvojit Dasgupta is a Principal Data Architect at AWS. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.





 Umair Nawaz is a Senior DevOps Architect at Amazon Web Services. He works on building secure architectures and advises enterprises on agile software delivery. He is motivated to solve problems strategically by utilizing modern technologies.
Umair Nawaz is a Senior DevOps Architect at Amazon Web Services. He works on building secure architectures and advises enterprises on agile software delivery. He is motivated to solve problems strategically by utilizing modern technologies. Ravikiran Rao is a Data Architect at Amazon Web Services and is passionate about solving complex data challenges for various customers. Outside of work, he is a theater enthusiast and amateur tennis player.
Ravikiran Rao is a Data Architect at Amazon Web Services and is passionate about solving complex data challenges for various customers. Outside of work, he is a theater enthusiast and amateur tennis player. Sri Potluri is a Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, ensuring scalable and reliable infrastructure tailored to each project’s unique challenges.
Sri Potluri is a Cloud Infrastructure Architect at Amazon Web Services. He is passionate about solving complex problems and delivering well-structured solutions for diverse customers. His expertise spans across a range of cloud technologies, ensuring scalable and reliable infrastructure tailored to each project’s unique challenges. Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
Suvojit Dasgupta is a Principal Data Architect at Amazon Web Services. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.



 Salim Tutuncu is a Sr. PSA Specialist on Data & AI, based from Amsterdam with a focus on the EMEA North and EMEA Central regions. With a rich background in the technology sector that spans roles as a Data Engineer, Data Scientist, and Machine Learning Engineer, Salim has built a formidable expertise in navigating the complex landscape of data and artificial intelligence. His current role involves working closely with partners to develop long-term, profitable businesses leveraging the AWS Platform, particularly in Data and AI use cases.
Salim Tutuncu is a Sr. PSA Specialist on Data & AI, based from Amsterdam with a focus on the EMEA North and EMEA Central regions. With a rich background in the technology sector that spans roles as a Data Engineer, Data Scientist, and Machine Learning Engineer, Salim has built a formidable expertise in navigating the complex landscape of data and artificial intelligence. His current role involves working closely with partners to develop long-term, profitable businesses leveraging the AWS Platform, particularly in Data and AI use cases. Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to Data Analytics and Artificial Intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on Data and AI.
Angel Conde Manjon is a Sr. PSA Specialist on Data & AI, based in Madrid, and focuses on EMEA South and Israel. He has previously worked on research related to Data Analytics and Artificial Intelligence in diverse European research projects. In his current role, Angel helps partners develop businesses centered on Data and AI.
 Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running.
Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running. Vara Bonthu is a dedicated technology professional and Worldwide Tech Leader for Data on EKS, specializing in assisting AWS customers ranging from strategic accounts to diverse organizations. He is passionate about open-source technologies, data analytics, AI/ML, and Kubernetes, and boasts an extensive background in development, DevOps, and architecture. Vara’s primary focus is on building highly scalable data and AI/ML solutions on Kubernetes platforms, helping customers harness the full potential of cutting-edge technology for their data-driven pursuits.
Vara Bonthu is a dedicated technology professional and Worldwide Tech Leader for Data on EKS, specializing in assisting AWS customers ranging from strategic accounts to diverse organizations. He is passionate about open-source technologies, data analytics, AI/ML, and Kubernetes, and boasts an extensive background in development, DevOps, and architecture. Vara’s primary focus is on building highly scalable data and AI/ML solutions on Kubernetes platforms, helping customers harness the full potential of cutting-edge technology for their data-driven pursuits.


 Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects, especially those focused on underprivileged Children’s education.
Sekar Srinivasan is a Sr. Specialist Solutions Architect at AWS focused on Big Data and Analytics. Sekar has over 20 years of experience working with data. He is passionate about helping customers build scalable solutions modernizing their architecture and generating insights from their data. In his spare time he likes to work on non-profit projects, especially those focused on underprivileged Children’s education. Prabu Ravichandran is a Senior Data Architect with Amazon Web Services, focussed on Analytics, data Lake architecture and implementation. He helps customers architect and build scalable and robust solutions using AWS services. In his free time, Prabu enjoys traveling and spending time with family.
Prabu Ravichandran is a Senior Data Architect with Amazon Web Services, focussed on Analytics, data Lake architecture and implementation. He helps customers architect and build scalable and robust solutions using AWS services. In his free time, Prabu enjoys traveling and spending time with family.



