Post Syndicated from Mahmoud Abid original https://aws.amazon.com/blogs/architecture/classifying-millions-of-amazon-items-with-machine-learning-part-i-event-driven-architecture/
As part of AWS Professional Services, we work with customers across different industries to understand their needs and supplement their teams with specialized skills and experience.
Some of our customers are internal teams from the Amazon retail organization who request our help with their initiatives. One of these teams, the Global Environmental Affairs team, identifies the number of electronic products sold. Then they classify these products according to local laws and accurately report this data to regulators. This process covers the products’ end-of-life costs and ensures a high quality of recycling.
These electronic products have classification codes that differ from country to country, and these codes change according to each country’s latest regulations. This poses a complex technical problem. How do we automate our compliance teams’ work to efficiently and accurately classify over three million product classifications every month, in more than 38 countries, while also complying with evolving classification regulations?
To solve this problem, we used Amazon Machine Learning (Amazon ML) capabilities to build a resilient architecture. It ingests and processes data, trains ML models, and predicts (also known as inference workflow) monthly sales data for all countries concurrently.
In this post, we outline how we used AWS Lambda, Amazon EventBridge, and AWS Step Functions to build a scalable and cost-effective solution. We’ll also show you how to keep the data secure while processing it in Amazon ML flows.
Solution overview
Our solution consists of three main parts, which are summarized here and detailed in the following sections:
- Training the ML models
- Evaluating their performance
- Using them to run an inference workflow (in other words, label) the sold items with the correct classification codes
Training the Amazon ML model
For training our Amazon ML model, we use the architecture in Figure 1. It starts with a periodic query against the Amazon.com data warehouse in Amazon Redshift.

Figure 1. Training workflow
- A labeled dataset containing pre-recorded classification codes is extracted from Amazon Redshift. This dataset is stored in an Amazon Simple Storage Service (Amazon S3) bucket and split up by country. The data is encrypted at rest with server-side encryption using an AWS Key Management Service (AWS KMS) key. This is also known as server-side encryption with AWS KMS (SSE-KMS). The extraction query uses the AWS KMS key to encrypt the data when storing it in the S3 bucket.
- Each time a country’s dataset is uploaded to the S3 bucket, a message is sent to an Amazon Simple Queue Service (Amazon SQS) queue. This prompts a Lambda function. We use Amazon SQS to ensure resiliency. If the Lambda function fails, the message will be tried again automatically. Overall, the message is either processed successfully, or ends up in a dead letter queue that we monitor (not displayed in Figure 1).
- If the message is processed successfully, the Lambda function generates necessary input parameters. Then it starts a Step Functions workflow execution for the training process.
- The training process involves orchestrating Amazon SageMaker Processing jobs to prepare the data. Once the data is prepared, a hyperparameter optimization job invokes multiple training jobs. These run in parallel with different values from a range of hyperparameters. The model that performs the best is chosen to move forward.
- After the model is trained successfully, an EventBridge event is prompted, which will be used to invoke the performance comparison process.
Comparing performance of Amazon ML models
Because Amazon ML models are automatically trained periodically, we want to assess their performance automatically too. Newly created models should perform better than their predecessors. To measure this, we use the flow in Figure 2.

Figure 2. Model performance comparison workflow
- The flow is activated by the EventBridge event at the end of the training flow.
- A Lambda function gathers the necessary input parameters and uses them to start an inference workflow, implemented as a Step Function.
- The inference workflow use SageMaker Processing jobs to prepare a new test dataset. It performs predictions using SageMaker Batch Transform jobs with the new model. The test dataset is a labeled subset that was not used in model training. Its prediction gives an unbiased estimation of the model’s performance, proving that the model can generalize.
- After the inference workflow is completed and the results are stored on Amazon S3, an EventBridge event is performed, which prompts another Lambda function. This function runs the performance comparison Step Function.
- The performance comparison workflow uses a SageMaker Processing job to analyze the inference results and calculate its performance score based on ground truth. For each country, the job compares the performance of the new model with the performance of the last used model to determine which one was best, otherwise known as the “winner model.” The metadata of the winner model is saved in an Amazon DynamoDB table so it can be queried and used in the next production inference job.
- At the end of the performance comparison flow, an informational notification is sent to an Amazon Simple Notification Service (Amazon SNS) topic, which will be received by the MLOps team.
Running inference
The inference flow starts with a periodic query against the Amazon.com data warehouse in Amazon Redshift, as shown in Figure 3.
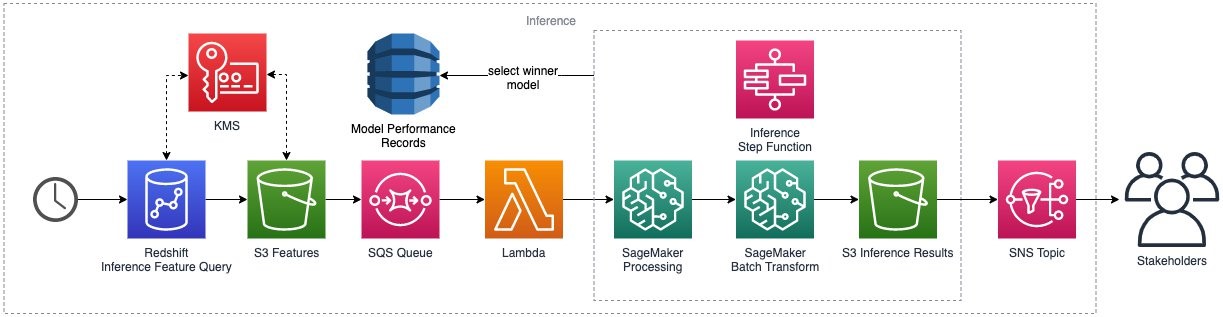
Figure 3. Inference workflow
- As with training, the dataset is extracted from Amazon Redshift, split up by country, and stored in an S3 bucket and encrypted at rest using the AWS KMS key.
- Every country dataset upload prompts a message to an SQS queue, which invokes a Lambda function.
- The Lambda function gathers necessary input parameters and starts a workflow execution for the inference process. This is the same Step Function we used in the performance comparison. Now it runs against the real dataset instead of the test set.
- The inference Step Function orchestrates the data preparation and prediction using the winner model for each country, as stored in the model performance DynamoDB table. The predictions are uploaded back to the S3 bucket to be further consumed for reporting.
- Lastly, an Amazon SNS message is sent to signal completion of the inference flow, which will be received by different stakeholders.
Data encryption
One of the key requirements of this solution was to provide least privilege access to all data. To achieve this, we use AWS KMS to encrypt all data as follows:
- We configured SSE-KMS as the default behavior on the S3 bucket.
- We restricted the AWS KMS key policy to allow only a set of predefined AWS Identity and Access Management (IAM) roles to use it so no other role or user could use it to decrypt the data.
- We set the S3 bucket policy to deny PutObject requests that do not explicitly specify the key in the request header, as shown in Figure 4.

Figure 4. Restriction of data decryption permissions
Conclusion
In this post, we outline how we used a serverless architecture to handle the end-to-end flow of data extraction, processing, and storage. We also talk about how we use this data for model training and inference.
With this solution, our customer team onboarded 38 countries and brought 60 Amazon ML models to production to classify 3.3 million items on a monthly basis.
In the next post, we show you how we use AWS Developer Tools to build a comprehensive continuous integration/continuous delivery (CI/CD) pipeline that safeguards the code behind this solution.


