Integrating a new storage provider is too complicated. Migrating data, retraining teams, and reconfiguring tools will take too long and create too much risk.
It’s understandable. Data migrations have a reputation for being messy and disruptive. And let’s be honest, nobody wants to babysit infrastructure when there are products to build. For many teams, just the thought of switching cloud providers feels like a detour they don’t have time for.
But in reality, that fear is often bigger than the actual lift. If your workflows already use standard tooling like S3-compatible APIs, switching to a specialized provider is more like a well-marked exit than a hard left turn.
This is the third post in our series debunking persistent myths about cloud storage—check out the first and second posts—and why a best-of-breed, interoperable approach is actually less disruptive than sticking with legacy hyperscaler models.
New Cloud Native Times Call for New Cloud Storage Approaches
Learn more about how the open cloud supports faster development, improved workflows, and reduced cost complexity in our free ebook, “New Cloud Native Times Call for New Cloud Storage Approaches.”
Migration anxiety vs. reality
“Storage migration” can sound like it requires weeks of planning and an army of engineers. But if your apps are already using S3-compatible workflows, most of the heavy lifting is already done.
If you know S3, you’re already ready
Many specialized storage providers now support S3-compatible APIs, allowing teams to keep the tools, scripts, and services they already know, such as Terraform, Kubernetes, ArgoCD, boto3, and MinIO.
And because your teams are already familiar with the S3 API and related tools, retraining isn’t a hurdle. The same skills, scripts, and automation frameworks carry forward, keeping onboarding time minimal. In fact, most teams are surprised by how little they need to change to get started.
That means:
No need to learn a new SDK or storage interface
No retraining your DevOps team
No rewriting automation pipelines or batch jobs
In most cases, all it takes is updating your endpoint URL and refreshing credentials. The mental model stays the same, the tools stay the same, and your workflows continue as-is.
You don’t need to rip and replace
Downtime concerns are one of the biggest sources of hesitation when switching providers. But in practice, migrations to S3-compatible cloud storage providers rarely require full cutovers or risky, all-or-nothing switchovers. With a bit of planning, most teams handle migrations incrementally:
Start by migrating lower-risk datasets, such as backups or archives.
Validate configurations and permissions as data lands in the new system.
Slowly expand to production datasets as confidence grows.
Better yet, you don’t have to move everything at once. Many teams adopt phased transitions, running some buckets side-by-side or writing to both systems during the handoff to minimize risk. With a bit of planning and the right migration tools and guidance, you can keep operations stable while gradually shifting workloads at a comfortable pace.
Metadata isn’t a blocker
Migrating files without metadata continuity can break downstream systems, especially if your applications rely on timestamps or version tracking.
Fear not. S3-compatible cloud storage providers can preserve metadata during migration, including timestamps. That means your historical data stays intact and compliant with internal policies or regulatory needs, and you won’t need to reset or alter your data management policies.
Moving isn’t the risk. Staying locked in is.
Let’s flip the narrative. The real risk isn’t switching; it’s staying stuck.
Major cloud provider ecosystems are designed for lock-in. The deeper you go, the harder it becomes to leave. Features that look like conveniences, such as integrated IAM policies, tiered storage, and custom APIs, often become entanglements over time.
Each of these layers is built to reinforce reliance:
IAM rules tie access tightly to the provider’s own tooling.
Tiered storage creates dependencies on lifecycle rules and retrieval thresholds.
Custom APIs mean even basic storage functions can require provider-specific logic.
And as you expand your usage—adding compute, networking, and security services—everything becomes interdependent. What starts as convenience evolves into constraint. Even small changes to your stack can trigger cascading reviews, system audits, or full reconfigurations.
The result? Innovation slows. Costs creep up. Flexibility disappears.
With a specialized provider, you break that cycle.
Specialized Doesn’t Mean Complicated
Specialized storage doesn’t complicate onboarding. It streamlines it. Solutions like Backblaze B2 are purpose-built to make this shift smooth and sustainable, without the trade-offs or surprises you might expect from switching providers.
S3 compatibility allows for seamless integration with the tools and workflows your team already uses.
Granular control means you can choose the tools and providers that work best for your architecture, not the ones bundled into a vendor’s ecosystem.
Metadata continuity is supported through features like custom upload timestamps, preserving file context during migration.
Transparent pricing ensures there are no hidden egress fees, transaction charges, or retention penalties to catch you off guard.
Hands-on support helps you plan, validate, and scale your migration with confidence and minimal disruption.
Breaking out of a single-vendor ecosystem may feel intimidating, but it’s often the fastest way to simplify operations, improve performance, and regain control over your cloud strategy.
The best part? Once you’ve made the move, you’re free to experiment. Multi-cloud strategies become more accessible. Your architecture becomes more modular. And your team can focus on building, not babysitting infrastructure.
Next Up: In the final post in this series, we’ll tackle Myth #4: Managing multiple clouds is complicated. (Spoiler: It doesn’t have to be.)
Storage is a minor cost, so it’s not worth switching from major cloud providers.
It’s easy to see how this thinking takes hold. In many cloud-native projects, storage can be the last concern. Compute, networking, and database services often drive most of the costs. Storage? That’s just where your data sits.
But hidden fees, unpredictable retrieval charges, and surprising performance constraints make storage far more impactful than many teams realize—especially for cloud-native workflows.
This post is the second in our blog series unpacking four of the most common myths and misconceptions about specialized cloud storage—see the first post here—and why an interoperable, best-of-breed approach can enhance and streamline cloud-native app development.
New Cloud Native Times Call for New Cloud Storage Approaches
Learn more about how the open cloud supports faster development, improved workflows, and reduced cost complexity in our free ebook, “New Cloud Native Times Call for New Cloud Storage Approaches.”
Underestimate the importance of storage at your peril
Major cloud providers offer plenty of storage options, but the real costs aren’t always clear up front.
The charges you don’t see coming
Between egress charges, API call fees, transaction costs, and minimum retention charges, even small changes in how your application moves or retrieves data can quickly inflate your bill.
What looked affordable at launch can snowball into sticker shock once traffic increases or new workloads start driving more data in and out of storage. A single spike in user activity or analytics queries can trigger thousands (or millions) of storage transactions, each billed individually.
These expenses add up fast, and they’re tough to predict.
The egress trap
Egress charges might be one of the best-kept open secrets among the “big three” cloud providers. Every time data leaves their environment—whether to a CDN, another cloud, or end users—egress fees kick in. And they aren’t trivial.
Frequent data transfers, a hallmark of cloud-native architectures, can quietly devour budgets. The big dogs know this. Once your data is deep in their ecosystem, pulling it out becomes financially painful.
This creates a subtle but powerful form of vendor lock-in, making it harder to shift workloads or storage to more specialized providers.
Vendor lock-in, by design
Major cloud providers bundle storage, compute, networking, and a long list of services into tightly coupled ecosystems. On paper, that integration offers convenience. In practice, it creates real friction if you ever want to move.
Even when using open standards like the S3 API, migrating workloads can require new tooling, careful planning, and extensive testing. Under tight deadlines, the mere prospect of switching providers can feel too risky to attempt.
It’s not just inertia; it’s engineered friction designed to keep you tethered.
Complex storage slows down everything
Bundling storage inside a big cloud provider’s stack might seem efficient, but it often creates fragile setups that slow teams down. Configurations get complicated fast:
Hot and cold storage tiers
Lifecycle rules
IAM policies
Interdependent compute pipelines
Every added layer increases the odds that something breaks, pulling engineers into troubleshooting instead of building.
Latency-sensitive workloads such as real-time analytics or streaming services are especially vulnerable. Even small missteps can ripple through the user experience.
And when those issues hit, teams scramble to patch things up, burning time and resources that could be better spent moving products forward.
AI workloads bring storage costs into sharp focus
AI-powered applications, from model training to updating retrieval-augmented generation (RAG) pipelines, put heavy demands on storage. These workloads hammer systems with high-throughput reads and writes.
Each refresh or update adds to your bill:
Delete penalties
Retention minimums
API call surcharges
When teams start rationing runs, batching updates, or delaying refreshes just to control costs, innovation slows.
Specialized storage keeps costs predictable and workloads agile
Unlike the “big three” cloud providers, who often hide complexity behind convenience, specialized cloud storage providers like Backblaze B2 take a more transparent approach:
Clear, predictable pricing means no surprise egress fees, retrieval costs, API charges, or deletion penalties.
Always-hot storage eliminates the need for lifecycle policies and tier management.
Open architecture means you stay in control—no proprietary hooks, no walled gardens, and no painful unwinding if your needs change down the road.
For cloud-native teams, this isn’t just a storage swap; it’s an operational upgrade. Streamlined management, lower risk, and transparent costs mean teams can focus on shipping new products and features, not decoding their storage bills.
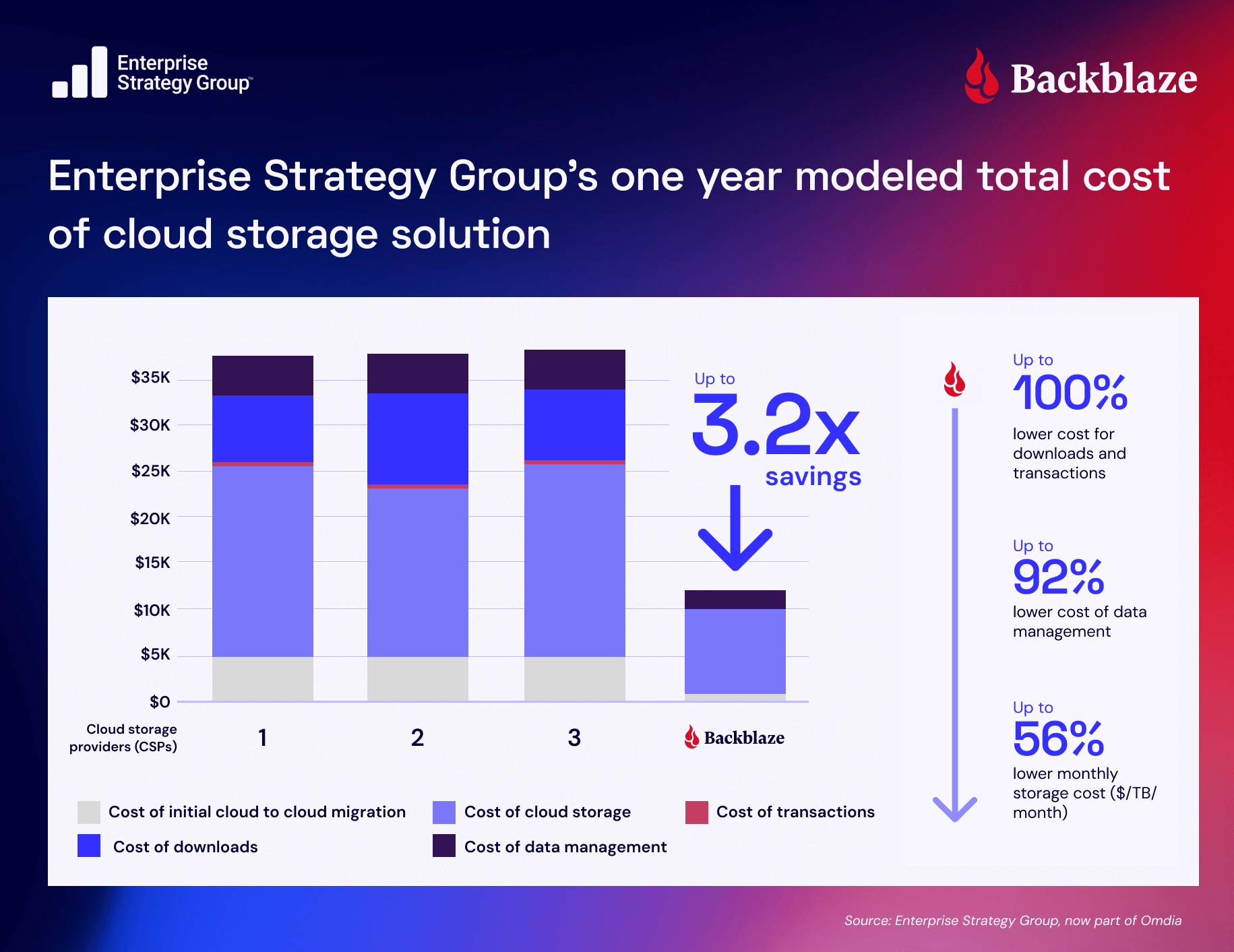
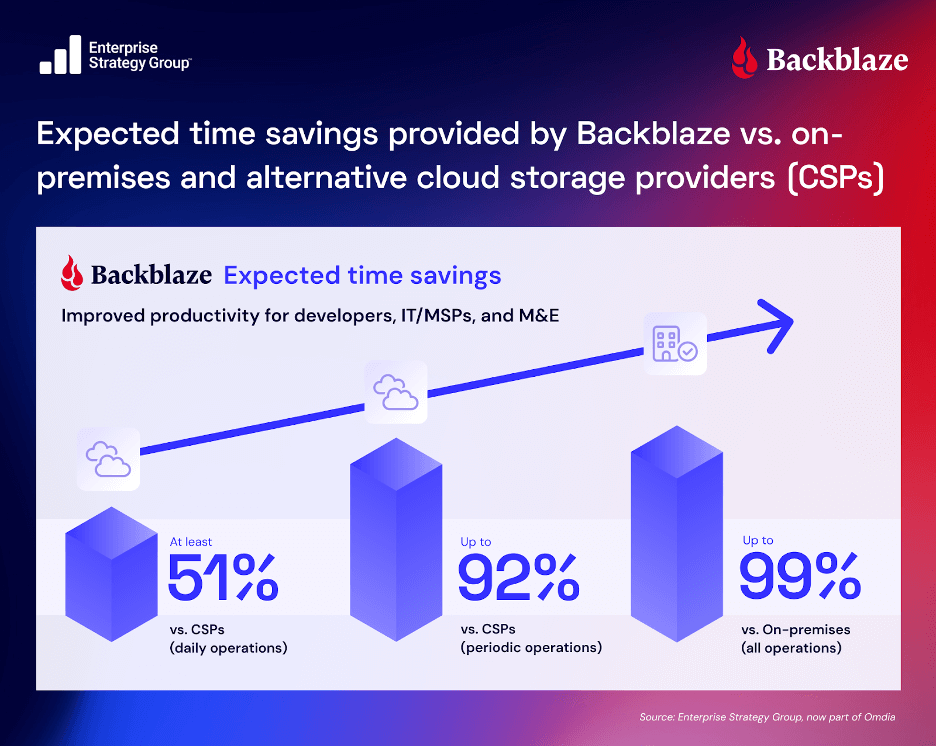
In fact, Enterprise Strategy Group released a comprehensive analysis of the economic benefits of Backblaze B2 in May 2025. The analysis concluded that Backblaze B2’s storage costs (monthly storage cost + cost of downloads + cost of transactions) were 3.1x to 3.2x lower than alternative cloud storage providers.
Simple, transparent, affordable pricing enabled Backblaze B2 users to spend far less on storage and use the savings to innovate and grow. —Enterprise Strategy Group
If you’ve spent any time sourcing, evaluating, or speculating about cloud services in the public sector lately, you’ve likely felt it: the arms race happening in compliance. Courting customers from schools to statehouses to national labs, more and more cloud vendors are racing to pin the next security badge to their lapel—GovRAMP (formerly known as StateRAMP), TX-RAMP, FedRAMP, SOC 2, and on and on.
And while it might feel like a compliance bingo card, there’s real strategy and real consequences behind this sprint. At the heart of it all is the SLED market (state and local government, and education)—a sprawling patchwork of institutions tasked with safeguarding citizen data and taxpayer trust, all while operating with limited resources and infrastructure budgets.
Let’s talk about why this compliance arms race exists, what it means for buyers and vendors alike, and how we at Backblaze are choosing to compete not just with checkboxes, but with character.
Why does SLED even need unified standards?
Public sector IT has long been a security quilt. Some agencies stitched up with advanced defenses, others more… threadbare. While some may have advanced security tooling, a K–12 school district might still be running on legacy systems and duct tape. Yet both manage data that’s increasingly digital, distributed, and vulnerable.
The result? Inconsistent practices and rising risks. Enter: GovRAMP.
What is GovRAMP?
Short for Government Risk and Authorization Management Program, GovRAMP was customized to standardize cloud security for state and local agencies. It’s actually based on the same set of controls for FedRAMP—controls derived from the National Institute of Standards and Technology (NIST) SP 800-53, a catalog of controls for organizations to manage cybersecurity and privacy risk. GovRAMP ensures that even the smallest public institutions can procure secure IT solutions without reinventing the wheel every time.
GovRAMP was originally launched as StateRAMP, but has since grown beyond state lines, evolving into a broader framework adopted by local governments and school systems. Today, it’s a rigorous, independent audit program that holds vendors to a high set of security controls. Translation: If a vendor is GovRAMP-authorized, they’re playing in the big leagues of cloud security.
The alphabet soup of compliance: TX-RAMP, GovRAMP, FedRAMP
If you’re in Texas, you’re probably familiar with TX-RAMP, the state’s specific compliance framework. The good news? GovRAMP and TX-RAMP are closely aligned. At Backblaze, our GovRAMP Progressing Snapshot status qualifies us for TX-RAMP Provisional Authorization as well—one less hurdle for Texas agencies seeking secure, scalable cloud storage.
As for FedRAMP, it remains the gold standard for federal data, but for the vast majority of public sector orgs, including most SLED agencies, it’s simply unnecessary.
How GovRAMP streamlines cloud sourcing
Here’s where the compliance arms race actually makes things easier: Once a vendor is authorized through GovRAMP, SLED buyers can trust that the solution meets certain security standards, saving months of one-off vetting, paperwork, and duplicated audits. In a procurement environment plagued by inefficiency, that’s no small thing.
Especially now, as budgets tighten and AI-driven everything drives demand for flexible infrastructure, reducing sourcing friction matters more than ever.
Going beyond checklists: What buyers should really look for
Checkboxes alone don’t guarantee real-world resilience. Compliance can become its own form of security theater. It looks good on paper but falls short in practice. That’s why buyers should dig deeper.
Look for vendors who not only pass audits but live and breathe their controls. That means going beyond annual assessments and embracing security as a continuous, integrated discipline. The best partners are transparent, proactive, and thoughtful about risk—not just checking boxes, but building real-world resilience. Here are a few signs to look for:
Continuous monitoring and internal audits: They treat compliance as an ongoing process, not a once-a-year scramble.
Clear, accessible documentation: Security policies, certifications, and standardized independent attestations are available (under NDA if needed), not locked in a black box.
Transparent data practices: They’re upfront about where your data lives, who can access it, and what happens in the event of an incident.
Responsive support: You can communicate with real people who understand your risk profile—not just surface-level answers or automated replies.
Affordable recoveries: They don’t make recovering your data prohibitively expensive. Look at their egress policies and price out what it would actually cost to retrieve your data.
When you’re responsible for protecting sensitive data, it’s not enough to be compliant. You need a partner who’s disciplined, trustworthy, and invested in your resilience.
The Backblaze approach: Rigor, transparency, and trust
Pursuing authorizations like GovRAMP and TX-RAMP isn’t easy, but it’s the right thing to do and we’re committed to the process. We believe public sector buyers deserve cloud partners who understand their constraints, meet them where they are, and still bring best-in-class solutions to the table.
But more than that, we’re not stopping at frameworks. Compliance is a floor, not a ceiling. We’ve built our platform on decades of operational rigor and security discipline—not to impress auditors, but to earn your trust. And we’ve structured our products to enable security best practices, not hinder them, including 3x free egress for disaster recovery.
So yes, we’re proudly in the compliance race. But we’re not just chasing badges. We’re building something secure, sustainable, and ready for whatever comes next.
Want to learn more about our GovRAMP journey or how Backblaze supports public sector cloud transformation? Reach out to our Sales team.
Disaster recovery (DR) is a top-line priority for enterprise organizations facing increasingly complex threats—sophisticated ransomware attacks, widespread cloud outages, and regulatory risks. The ability to recover quickly and maintain business continuity isn’t just a technical necessity—it’s a competitive imperative.
Today, I’m breaking down foundational strategies for enterprise DR readiness. You’ll find practical guidance on infrastructure design, site strategy, backup best practices, and more to help you take immediate action.
Get the full guide
Our “Essential Guide to Disaster Recovery Planning” offers a comprehensive framework for designing a DR plan that protects your business across multiple threat vectors.
Comprehensive DR requires a multi-tiered approach. Your DR strategy should encompass four critical stages: prevention, preparation, mitigation, and recovery.
Choose the right infrastructure: Beyond legacy limitations
Many enterprises still rely on legacy storage technologies like tape, which create delays in restoration and introduce hardware failure risks. Shifting to cloud-first infrastructure reduces these vulnerabilities while unlocking scalability and location diversity. It also supports immutability features—critical for ransomware resilience—and simplifies compliance with evolving regulations.
Cloud platforms also unlock new options for data governance and sovereignty. Enterprises operating across regions or industries governed by strict data residency laws can configure cloud storage to maintain compliance while reducing operational overhead.
As enterprise backup and archive needs grow, it becomes vital to distinguish between long-term cold storage and actively accessible data. With clear infrastructure planning, organizations can streamline operations and ensure faster recovery without overspending on high-performance systems for archival workloads.
What is Object Lock?
Object Lock is the feature in cloud platforms that enables immutability. With immutability, your data cannot be changed, deleted, or encrypted. This is the ultimate protection against ransomware.
DR site temperatures: Hot, warm, or cold?
Depending on your recovery time objective (RTO), different types of recovery sites offer different benefits:
Hot sites: Fully mirrored and ready for instant failover—great for mission-critical apps but expensive.
Warm sites: Pre-configured but not fully live—strike a balance between cost and speed.
Cold sites: Infrastructure is ready but requires manual configuration—most affordable, but slowest to recover.
Enterprises evaluating DR readiness should consider whether their current configuration meets their recovery time goals—and whether they’re optimizing for the right workloads. Comparing hot, warm, and cold site models can help strike the right balance between performance and budget.
Build vs. buy vs. cloud: Finding the right fit
Selecting a DR site is fundamental to your strategy. There are four main approaches to establishing a DR site: building your own, buying services from a co-location provider, buying public cloud storage, or leveraging a disaster recovery as a service (DRaaS) solution. Each approach offers distinct advantages and drawbacks.
Building an on-premises DR site
Pros: It provides complete control over the DR environment, offering greater customization and security.
Cons: Significant upfront investment in hardware, software, and facility infrastructure and management. Requires ongoing maintenance and staffing costs. Limited scalability to accommodate future growth.
Buying co-located DR storage
Pros: It offers a cost-effective alternative to building your own site. Co-location providers manage aspects of the physical infrastructure, reducing your IT team’s workload.
Cons: Less control over the environment compared to an on-premises solution. May require additional investment for network connectivity and configuration. Potential vendor lock-in with specific co-location providers.
Buying public cloud-based DR storage
Pros: Highly scalable and cost-effective. CSPs manage the physical infrastructure, reducing your IT team’s workload. Features like Object Lock help address security concerns versus on-premises storage.
Cons: Retrieving large volumes of data may be slow due to bandwidth constraints.
Buying disaster recovery as a service (DRaaS)
Pros: Highly scalable and cost-effective solution. Eliminates the need for upfront infrastructure investment. DRaaS providers manage the entire DR environment and provide technical support, freeing up your IT staff.
Cons: Reliance on a third-party provider for critical data and infrastructure. Potential concerns over network latency and vendor lock-in. Security considerations require a careful evaluation of the cloud provider’s practices.
Backup vs. replication: Know the difference
Replication copies data in real-time, but that also means it can copy infected or corrupted data. Backups, on the other hand, offer point-in-time recoveries so you can restore data even after a ransomware attack.
The optimal approach to DR depends on your specific needs.
For frequently accessed data requiring near-instantaneous recovery, consider a combination of hot site methodology and real-time data replication. This offers the fastest failover, but can come at a higher cost.
For critical data with acceptable downtime, a warm site with replicated immutable backups at a secondary location (either on-premises or in the cloud) provides a good balance between cost and recovery time. While requiring some manual intervention, it offers protection against malware replicating to the DR site.
For less critical data or archival purposes, cold storage with periodic backups is a cost-effective option. Backups offer a historical record and are less susceptible to malware infection compared to replicated data, particularly if Object Lock is enabled for immutability.
SaaS outages are a threat you can’t ignore
Although built for high availability, SaaS apps don’t guarantee protection against data loss. Tools like Microsoft 365 and Google Workspace are built for uptime, not recovery. Misconfigurations, insider threats, and accidental deletions remain common risks. Enterprises should take control of their own retention policies with dedicated SaaS backup strategies, including regular point-in-time snapshots and recovery testing.
Additionally, planning for SaaS outages should include identifying local alternatives for core business functions. Can teams temporarily revert to offline workflows? Are key contacts available outside of email or Slack? Defining fallback protocols ensures that productivity doesn’t grind to a halt even if your primary tools go dark.
Assembling your incident response team
The incident response team (IRT) is the backbone of your DR response and is responsible for leading the recovery efforts during a disaster. Here’s a breakdown of possible key IRT roles:
Incident commander: Oversees the entire incident response process, making critical decisions and delegating tasks to team members.
Technical lead: Provides technical expertise, directing recovery efforts for IT infrastructure and data restoration.
Communications lead: Handles external and internal communication, ensuring timely updates for stakeholders and mitigating potential reputational damage.
Documentation lead: Maintains the DR runbook, ensuring its accuracy and updating it with post-incident findings.
Legal counsel: Provides legal guidance and ensures compliance with relevant regulations during the response and recovery process.
Objectives, priorities, and KPIs: The compass of your DR strategy
A robust DR strategy starts with clearly defined objectives and priorities. These guide your approach and decision-making during a disaster recovery event. Your strategy should prioritize rapid recovery of critical systems and applications to minimize operational downtime and resume normal functions swiftly.
Prioritization: Not all data (or systems) are created equal
Prioritizing your critical business applications depends on a deep understanding of your business. Collaborate with internal partners to identify critical business applications that are essential for ongoing operations. Not all applications require immediate restoration. Prioritize systems based on their impact on core business functions.
Documentation is key
A popular mantra for DR specialists is “Test the plan; don’t plan the test.” Your DR plans must be clearly documented as working recipes for application and data recovery, including dependencies and prerequisites. Document the recovery procedures for each critical application, outlining the steps required to bring them back online. This ensures your IT team can efficiently restore essential services during a disaster.
Primary DR objectives
Minimize data loss: The primary objective is to minimize data loss through regular backups and secure storage practices.
Ensure business continuity: The DR plan aims to rapidly recover operation of critical functions during a disaster, minimizing disruption to the business goals.
Optimize costs: Application and data recovery needs to balance speed and costs to ensure recoverability without unnecessarily increasing IT spending.
Compliance considerations
Compliance regulations might influence your DR priorities. Understand any industry-specific regulations or data privacy laws that might dictate specific data protection and recovery timeframes.
Collaborative RTO and RPO setting
Working with internal partners to set RTOs and RPOs ensures alignment across the organization.
Recovery Time Objective (RTO) defines the acceptable timeframe for restoring critical applications to a functional state.
The Recovery Point Objective (RPO) defines the maximum tolerable amount of data loss acceptable in the event of a disaster.
Stakeholders need to understand the realistic trade-offs involved in setting RTOs and RPOs, balancing the need for quick recovery with resource and cost limitations. Achieving extremely short RTOs, such as recovery within minutes, might require substantial investments in advanced infrastructure, redundant systems, and skilled personnel. Setting achievable RTOs and RPOs that effectively balance the need for swift recovery with the financial limitations of the organization requires open communication and collaboration.
Restore vs. recovery: Understanding the nuances
It’s important to distinguish between data restoration and system recovery. Data restoration specifically involves retrieving data from backups. On the other hand, system recovery encompasses the comprehensive restoration of data, applications, configurations, and user accounts to fully restore system functionality.
Your RTOs should focus on the time it takes to bring an application to a usable state, not just the time to recover the data.
Setting expectations
Employees might have unrealistic expectations regarding recovery times during a disaster. Educate the organization on the DR process and the inherent complexities involved.
Developing measurable KPIs
Tracking your progress Key performance indicators (KPIs) are your guiding metric for measuring the effectiveness of your DR strategy. Here are some key DR-related KPIs to consider:
RTO achievement rate: Tracks the percentage of times critical applications are restored within the established RTO.
RPO achievement rate: Measures the percentage of data recovered that meets the defined RPO.
DR plan testing frequency: Monitors how often the DR plan is tested to ensure its effectiveness.
Mean time to recovery (MTTR): Tracks the average time taken to recover critical applications after a disaster.
Data loss rate: Measures the amount of data lost during a disaster compared to the established RPO.
These KPIs provide valuable insights into your DR preparedness and help identify areas for improvement.
Strengthen your RTO and RPO goals with the cloud
Recovery time objectives (RTOs) and recovery point objectives (RPOs) are the backbone of any DR plan. Yet many organizations set unrealistic targets without fully accounting for infrastructure, bandwidth, or cost constraints.
Establishing tiers of RTO and RPO based on data type or application criticality helps organizations avoid overengineering. Not every workload needs sub-hour recovery—archived legal files or marketing collateral may tolerate 24+ hour RTOs. Grouping systems into priority tiers ensures efficient use of budget and infrastructure while keeping SLAs aligned to business risk.
Improving these metrics often comes down to using the right storage architecture. By offloading backup workloads to cost-effective cloud storage with integrated immutability and replication, enterprises can improve RTO and RPO without the overhead of traditional DR environments.
A proactive, iterative approach
A DR plan isn’t a one-time project—it’s a living process that should evolve with the business. Every test, every incident, and every infrastructure change is an opportunity to improve.
Strong DR programs rely on frequent validation, leadership alignment, role clarity, and avoiding common missteps. As IT leaders face new threats and shifting architectures, resiliency comes from readiness—not just recovery.
Testing is everything
Even the most comprehensive DR plans can falter if they aren’t regularly validated. Testing ensures that backup data is restorable, that systems behave as expected under stress, and that team roles are clearly understood.
Testing also gives stakeholders across departments a shared language for discussing DR. Finance understands the cost implications of downtime, Legal sees the impact of non-compliance, and Security can stress-test assumptions about containment and escalation. When testing is multidisciplinary, recovery isn’t just possible—it’s predictable.
Organizations that incorporate routine DR drills and testing into their operations tend to recover faster and more confidently. Effective exercises can include walk-throughs, tabletop simulations, and full-scale failover tests. The goal isn’t just compliance—it’s ensuring the organization can execute when it matters most.
Cost transparency and budgeting for DR
Budget uncertainty often limits the scope and effectiveness of DR plans. Legacy vendors may impose hidden fees for egress, API operations, or early deletion, making it difficult to forecast the total cost of a recovery event. Cloud-native solutions with transparent pricing models allow IT and finance teams to plan confidently.
Establishing a clear TCO framework—including hardware, licensing, testing, and human resources—can help justify DR investments and avoid budget shortfalls when they matter most. DR isn’t just insurance—it’s a measurable part of digital operational excellence.
Final thoughts
Disaster recovery isn’t optional—it’s essential. With threats ranging from cyberattacks to cloud outages, every organization needs a plan that’s tested, documented, and designed for rapid recovery.
Backblaze B2 helps you implement affordable, scalable, and secure DR strategies with:
Immutable backups
Flexible recovery options
Transparent pricing (no egress fees)
Seamless integrations with backup tools like Veeam, MSP360, and more
With hundreds of thousands of hard drives spinning 24/7, our data centers are less like peaceful white-noise oases and more like a a series of obstacle courses—if said obstacle courses were about managing over four exabytes of customer data from archival backups to streaming media to AI training datasets. Sure, they’re obstacle courses we all (and I’m including you, users of the internet) collectively create, but it’s no less of a balancing act to find the contestants (erm, hard drives) that can go the distance.
And we, dear readers, get to watch it all. Welcome to Drive Stats: where failure is inevitable, survival is fascinating, and every quarter brings a new leaderboard.
As of June 30, 2025, we had 321,201 drives under management. Of that total, there were 3,971 boot drives and 317,230 data drives. Stay tuned as we take our standard peek into quarterly and lifetime failure rates, and do a deep dive into the 20TB+ club.
Ready to dive deeper into the data? Tune in today at 10:00 a.m. PT, to query the Drive Stats team, Stephanie Doyle and Pat Patterson. We’ll see you there!
Drive Stats by the numbers: The digest version
Q2 2025 hard drive failure rates
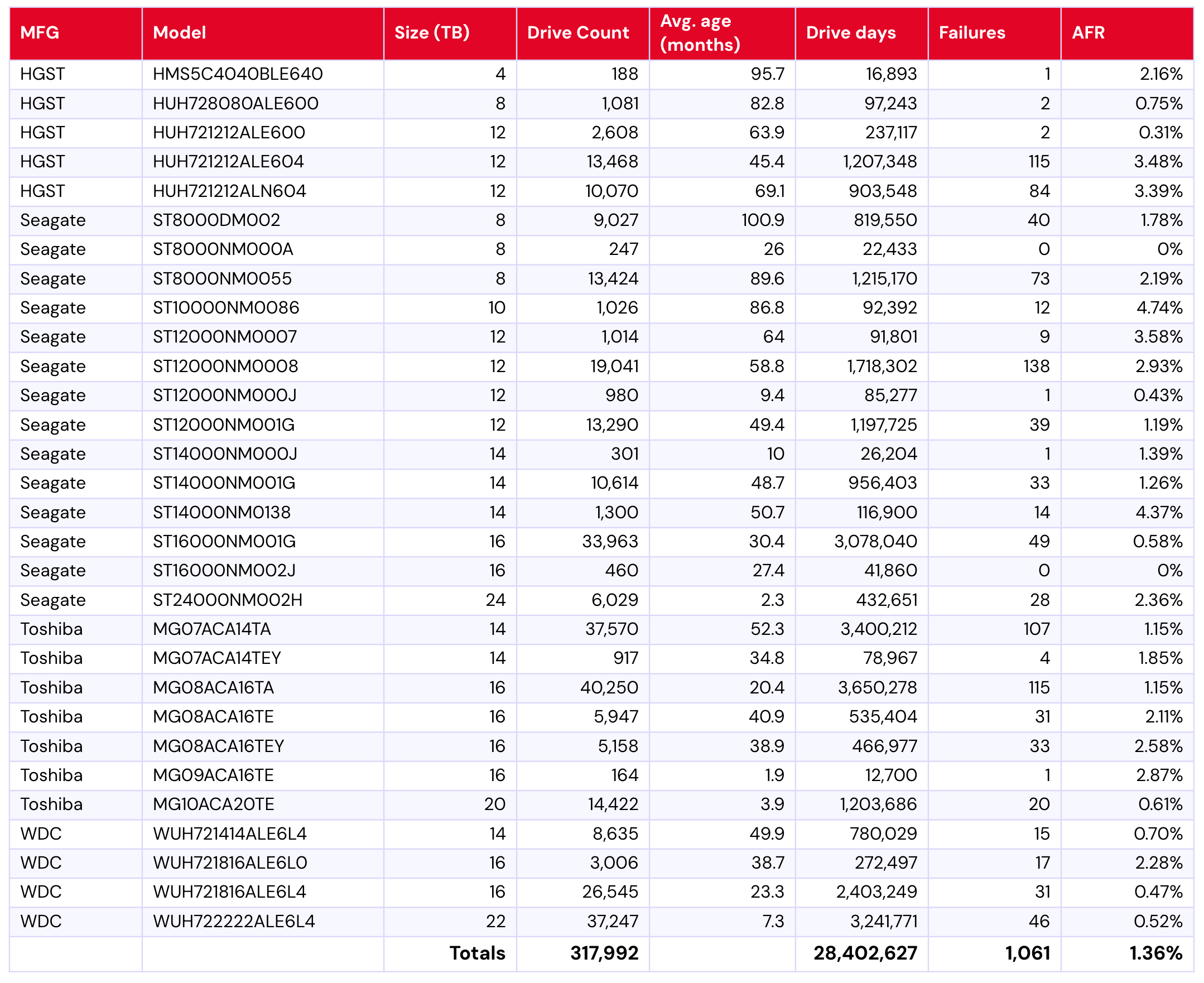
For those that are new to the Drive Stats report, it’s worth mentioning that we have certain criteria that we use to select drives for consideration each quarter. We’ll discuss those in the next section, but for now, let’s talk about the data. The table below shows the failure rates for Q2 2025.
Backblaze Hard Drive Failure Rates for Q2 2025
Reporting period April 1, 2025–June 30, 2025 inclusive Drive models with drive count > 100 as of June 30, 2025 and drive days > 10,000 in Q2 2025
Notes and observations
The annual failure rate is lower this quarter. We had some major fluctuations last quarter. Quoting ourselves from May 2025:
The quarterly failure rate is slightly higher. The quarterly failure rate went up from 1.35% to 1.42%. As with the zero-failure club, our higher-end outlier AFRs show some of the usual suspects:
We’re now back down to 1.36%. What’s changed?
Big swings in our higher-end failure rates: Well, some of the drives with higher failure rates have come down quite a bit. Notably, that includes the 12TB Seagate model ST12000NM0007, which was at a whopping 9.47% failure rate last quarter—down this quarter to only 3.58%. With its drive count holding more or less steady (1,038 in Q1 and 1,014 in Q2), that means a real change in failure rates. Note that this drive was at 8.72% in Q4 2024, so it’s worth keeping an eye on whether this is a fluke or a new pattern. Other significant drops include the 12TB HGST model HUH721212ALN604 (Q1: 4.97%; Q2: 3.39%) and the 14TB Seagate model ST14000NM0138 (Q1: 6.82%, Q2: 4.37%).
One new drive model on the way in: Welcome to the party, Toshiba MG09ACA16TE (16TB).
Zero failures for the quarter: Rising to the top, we’ve got only two this time around:
Seagate ST8000NM000A (8TB)
Seagate ST16000NM002J (16TB)
That 8TB Seagate is really shining, given this is its third quarter running with zero failures.
Bonus: One failure drives: Since we only have two 0 failures (and that just seems a little lackluster, doesn’t it?), it’s also worth mentioning the drives with only one failure this quarter:
HGST HMS5C4040BLE640 (4TB)
Seagate ST12000NM000J (12TB)
Seagate ST14000NM000J (14TB)
Toshiba MG09ACA16TE (16TB)
Drive model criteria
We noted earlier we removed 495 drives from consideration when we produced the table above covering Q2 2025. There are two primary reasons we did not consider these drive models.
Testing. These are drives of a given model that we monitor and collect Drive Stats data on, but are not considered production drives at this time. For example, drives undergoing certification testing to determine if they are performant enough for our environment are not included in our Drive Stats calculations.
Insufficient data points. When we calculate the annualized failure rate for a drive model for a given period of time (quarterly, annual, or lifetime), we want to ensure we have enough data to reliably do so. Therefore we have defined criteria for a drive model to be included in the tables and charts for the specified period of time. Models that do not meet these criteria are not included in the tables and charts for the period in question.
Regardless of whether or not a given drive model is included in the charts and tables, all of the data for all of the drives we use is included in our Drive Stats dataset which you can download by visiting our Drive Stats page.
As with the Q2 quarterly results, we will apply these criteria to the lifetime charts that follow in this report.
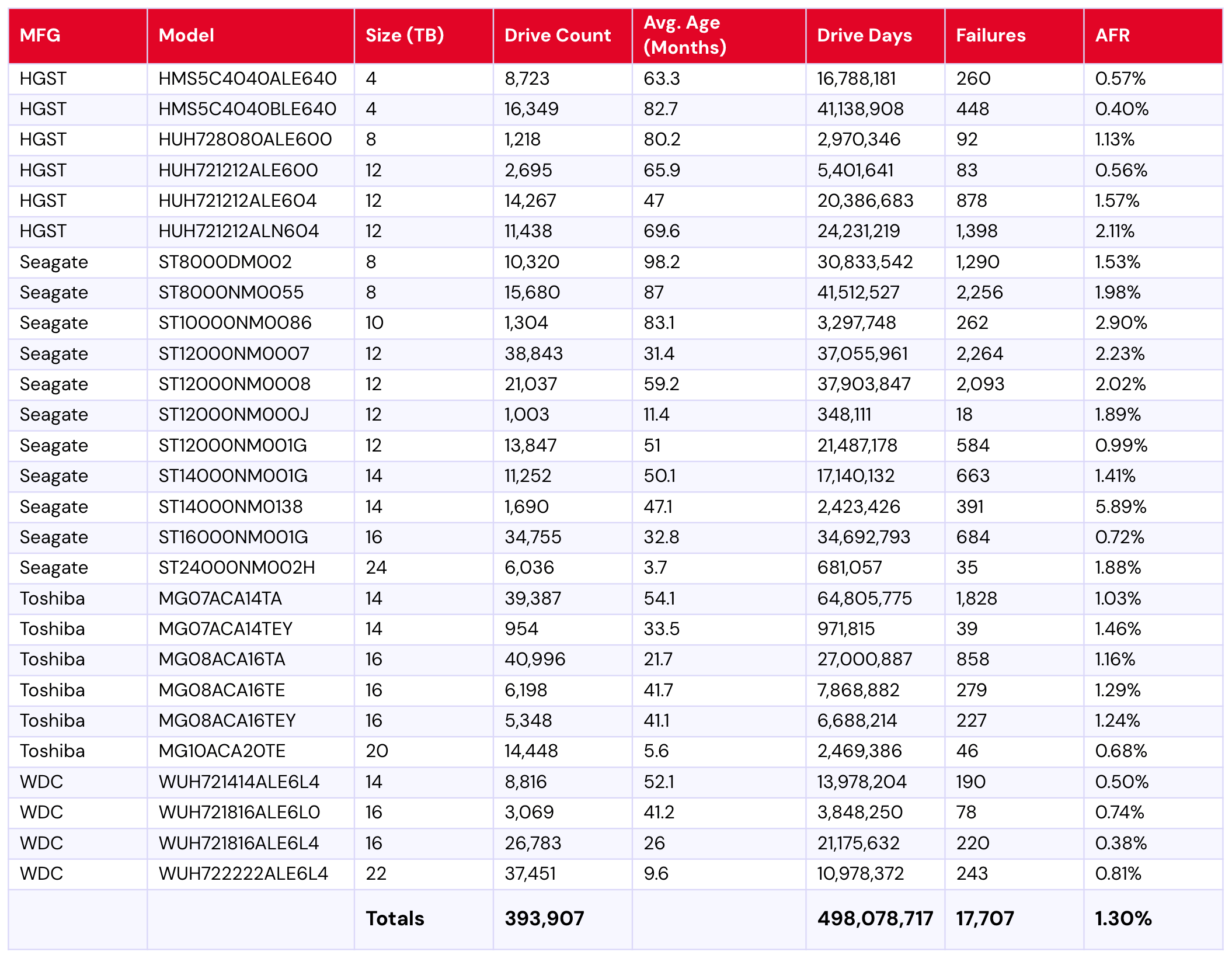
Lifetime hard drive failure rates
To be considered for the lifetime review, a drive model was required to have 500 or more drives as of the end of Q2 2025 and have over 100,000 accumulated drive days during their lifetime. When we removed those drive models which did not meet the lifetime criteria, we had 393,907 drives grouped into 27 models remaining for analysis as shown in the table below.
Backblaze Hard Drive Failure Rates for Q2 2025
Reporting period ending June 30, 2025 Drive models > 500 drives and > 100,000 lifetime drive days
Notes and observations
Again, the lifetime AFR holds steady, dropping from Q1 2025’s 1.31% to 1.30%.
Now you see me: This quarter’s table also gives us an interesting snapshot that has to do with our drive exclusions as the 4TB HGST model HMS5C4040ALE640 is on the way out. It meets our lifetime drive criteria, so it is included in this second table, but it didn’t make the cut for the quarterly table because it had too few drives running by the end of the quarter. Usually you see the opposite, where drive models show up in the quarterly requirements but not the lifetime. This quarter, four models meet that standard (Seagate model numbers ST8000NM000A, ST14000NM000J, ST16000NM002J, and Toshiba MG09ACA16TE).
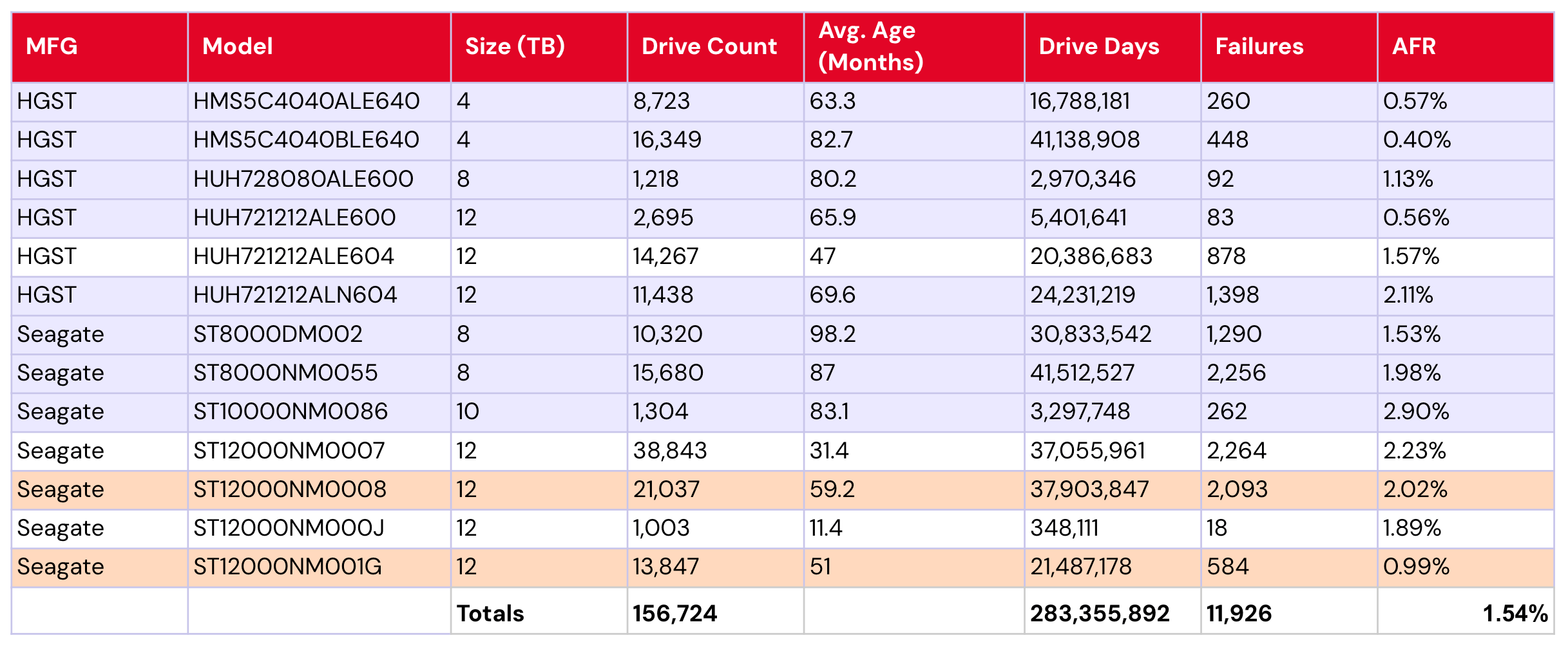
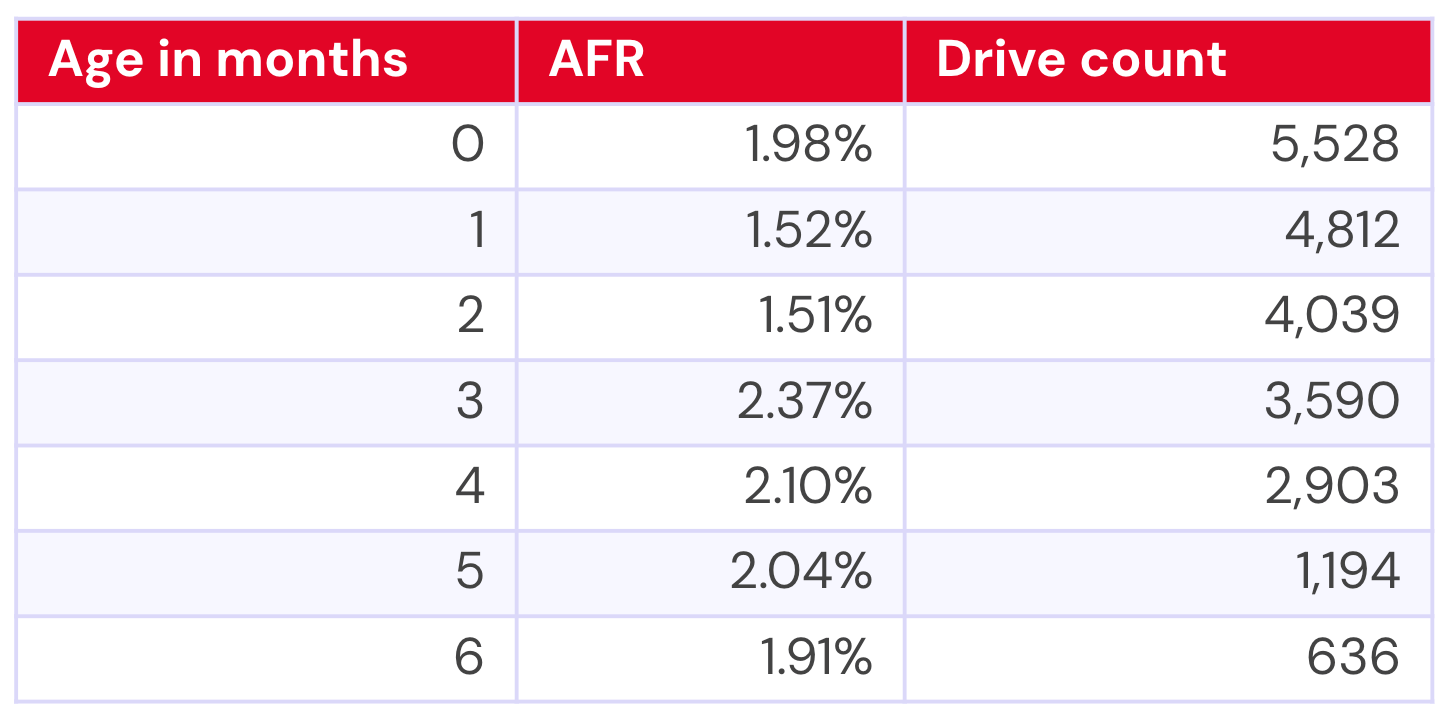
Smaller drives getting older: Perhaps an unsurprising trend—Backblaze’s smaller capacity drives are getting older. We have a total of 13 drive models with 12TB or less, with a collective 1.54% failure rate. See the table below:
Backblaze drives with ≤12TB capacity
Of those models, eight are five years old or older (shown in purple). An additional two models are four years or older (that’s your orange). Taking just these 10 models—drives reaching their supposed golden years—we have a collective AFR of 1.42%.
Notably, that AFR is due to some well-performing low-failure outliers, including both of the 4TB Seagate models (0.57% and 0.40%), the 12TB HGST model HUH721212ALE600 (0.56%), and the 12TB Seagate model ST12000NM001G (0.99%).
That said, it’s also perhaps more impressive that when we say “eight are five years and older,” of those eight drive models, five are six or more years old. Their collective AFR is 1.33%.
This begs the age-old question: Is age just a number? Or, are we just seeing several exceptional drive models? In any event—an interesting drive population to keep an eye on, as it represents 156,724 of our 393,907 (~40%) of the lifetime drive pool.
Zoom in: The 20TB+ club
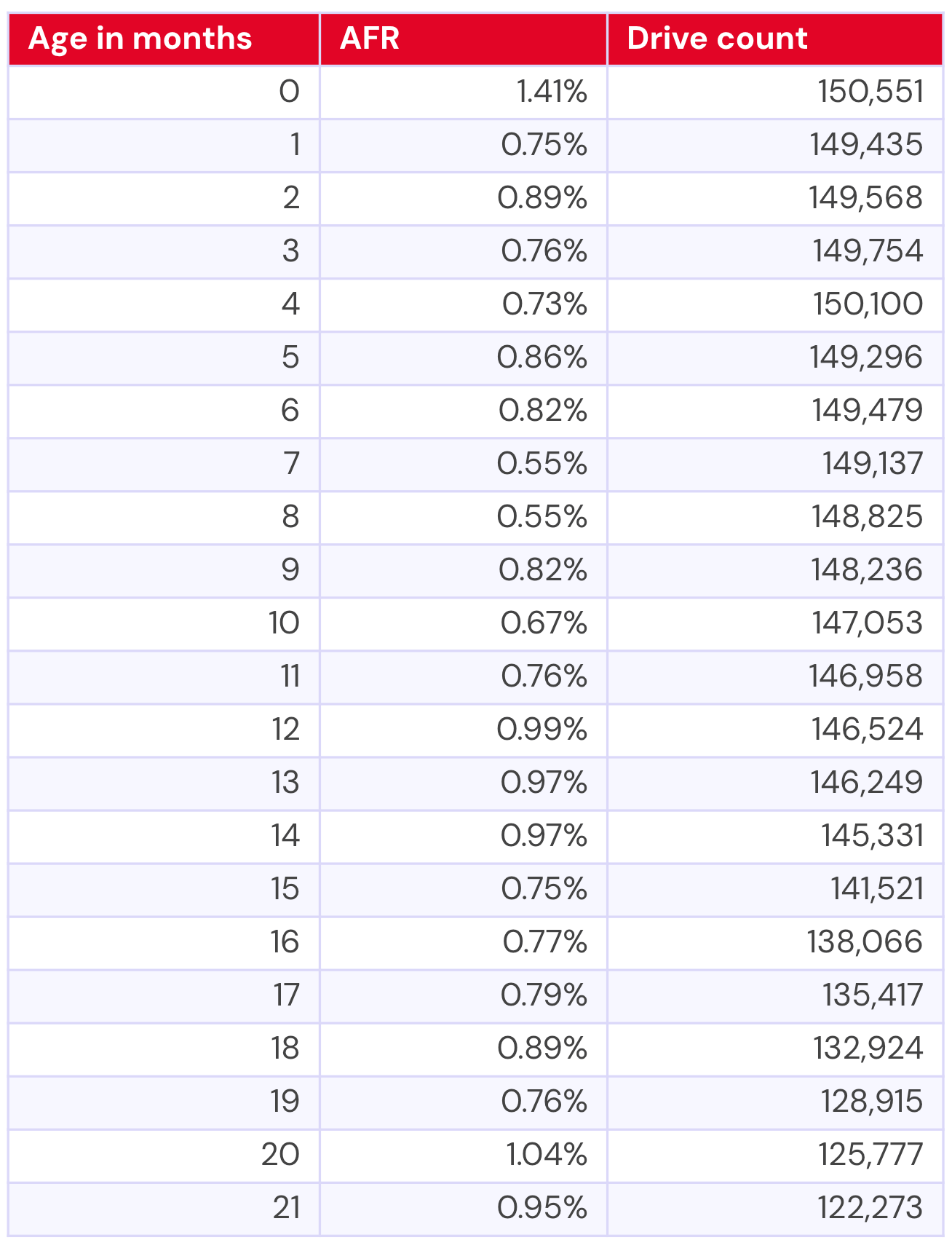
We’ve been taking quick peeks at the 20TB+ drives in the last few reports, but it’s high time we dig in a bit deeper. Right now, our cohort of 20TB+ drives that meet the lifetime criteria consists of three drives, the 20TB Toshiba model MG10ACA20TE, 22TB WDC model WUH722222ALE6L4, and 24TB Seagate model ST24000NM002H. Quite neatly, that also gives us one per manufacturer, lending itself to something of a head-to-head comparison—though, of course, with the variability we see on a per-drive basis within the same manufacturer, we won’t over-index on lending it too much significance.
Let’s take a look at each.
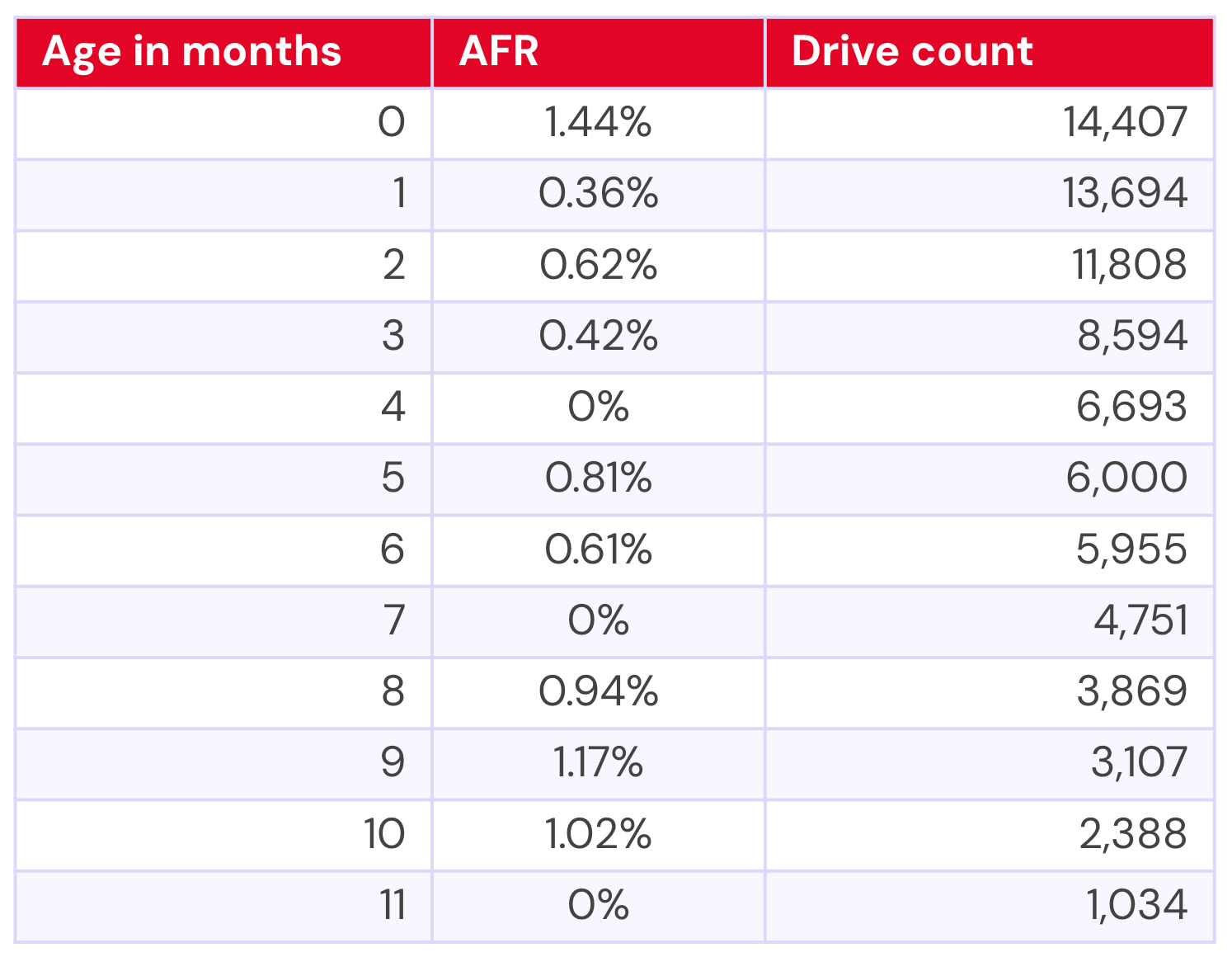
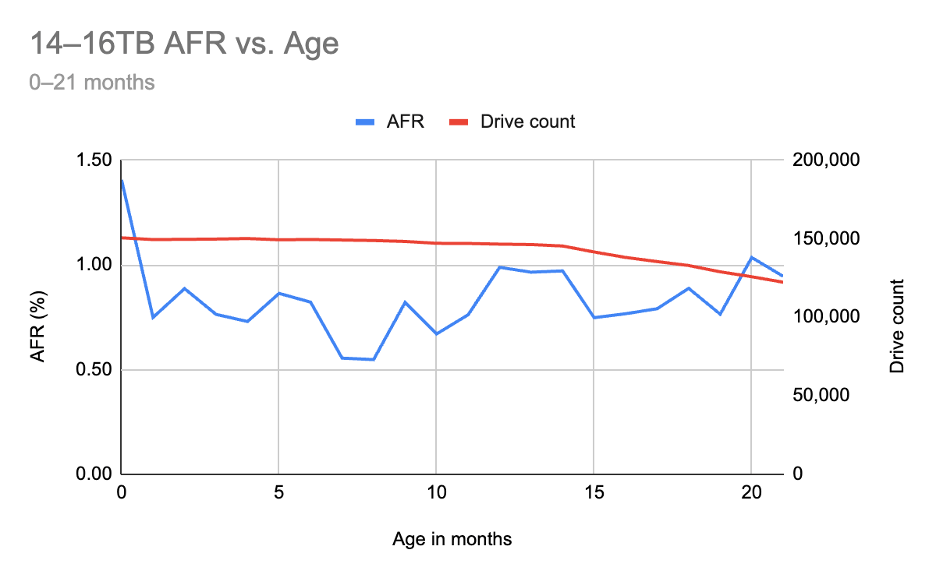
20TB Toshiba MG10ACA20TE
The Toshiba has actually been in our drive pool for 22 months, but until just under a year ago, there were only two drives. For the purposes of significance, then, we’ll exclude significantly low numbers of drives—thankfully, each model has something of a natural fall-off point where they go from single-digit drive numbers to hundreds.
For the Toshiba, that gives us the following data:
Converted to a graph, we end up with the following:
On this graph, the blue line represents the AFR and the red line represents the drive count. Drive count can be a bit tricky since our x-axis is age, and we start with age=0, which means that the drive count (from our perspective) goes from larger to smaller. That is, as drives get older, there are fewer of them by count—you have your initial purchase cohort, then you add drives over time. You can read this as the first data point representing drives that are between 0–1 month old, the next data point as 1–2 months old, etc.
We set it up this way because we wanted to be able to directly compare the failure rates of the drives based on their ages. Those familiar with our bathtub curve analysis may recognize our methodology here—we’re just zooming in on specific drives and drive capacities.
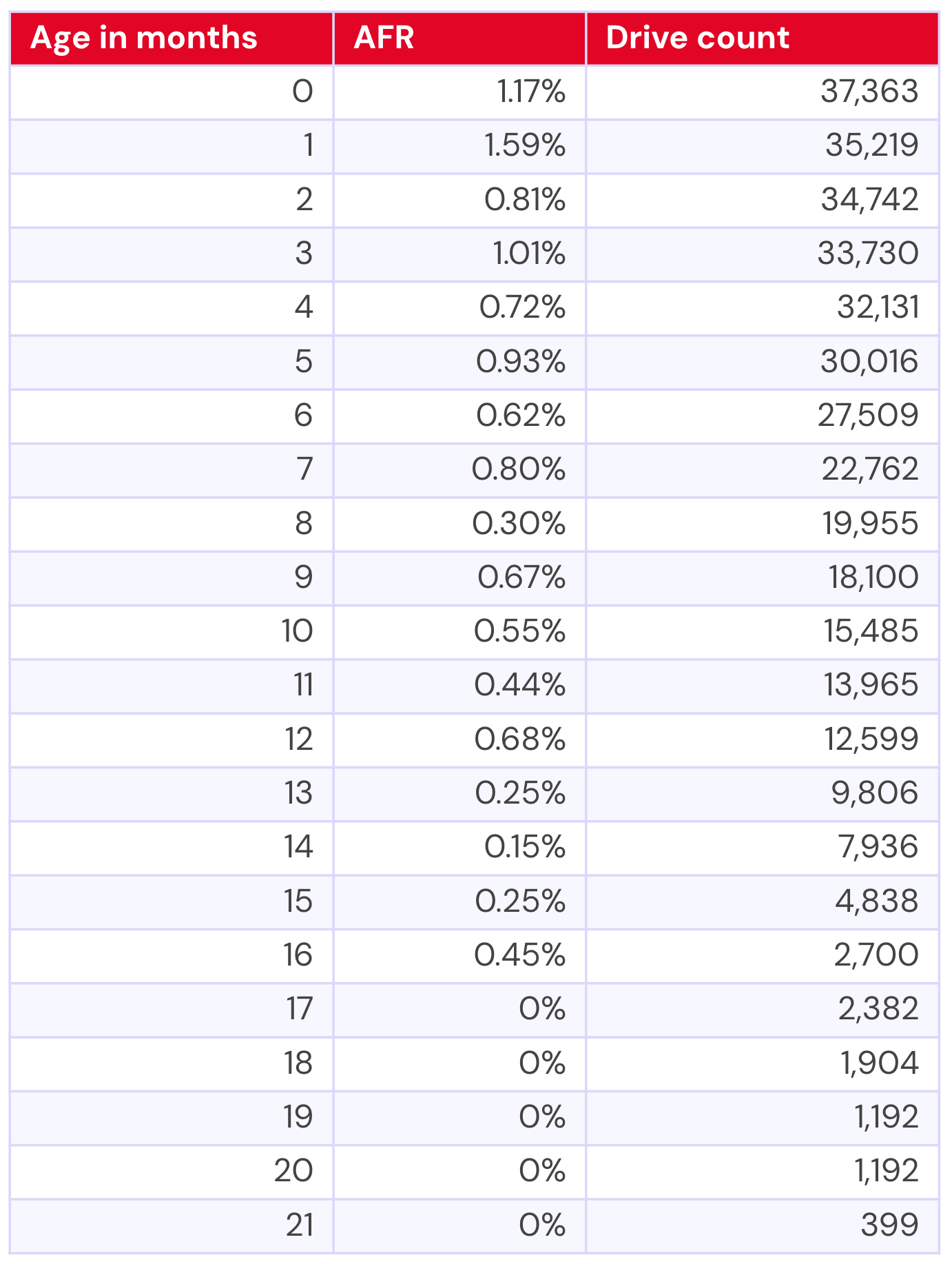
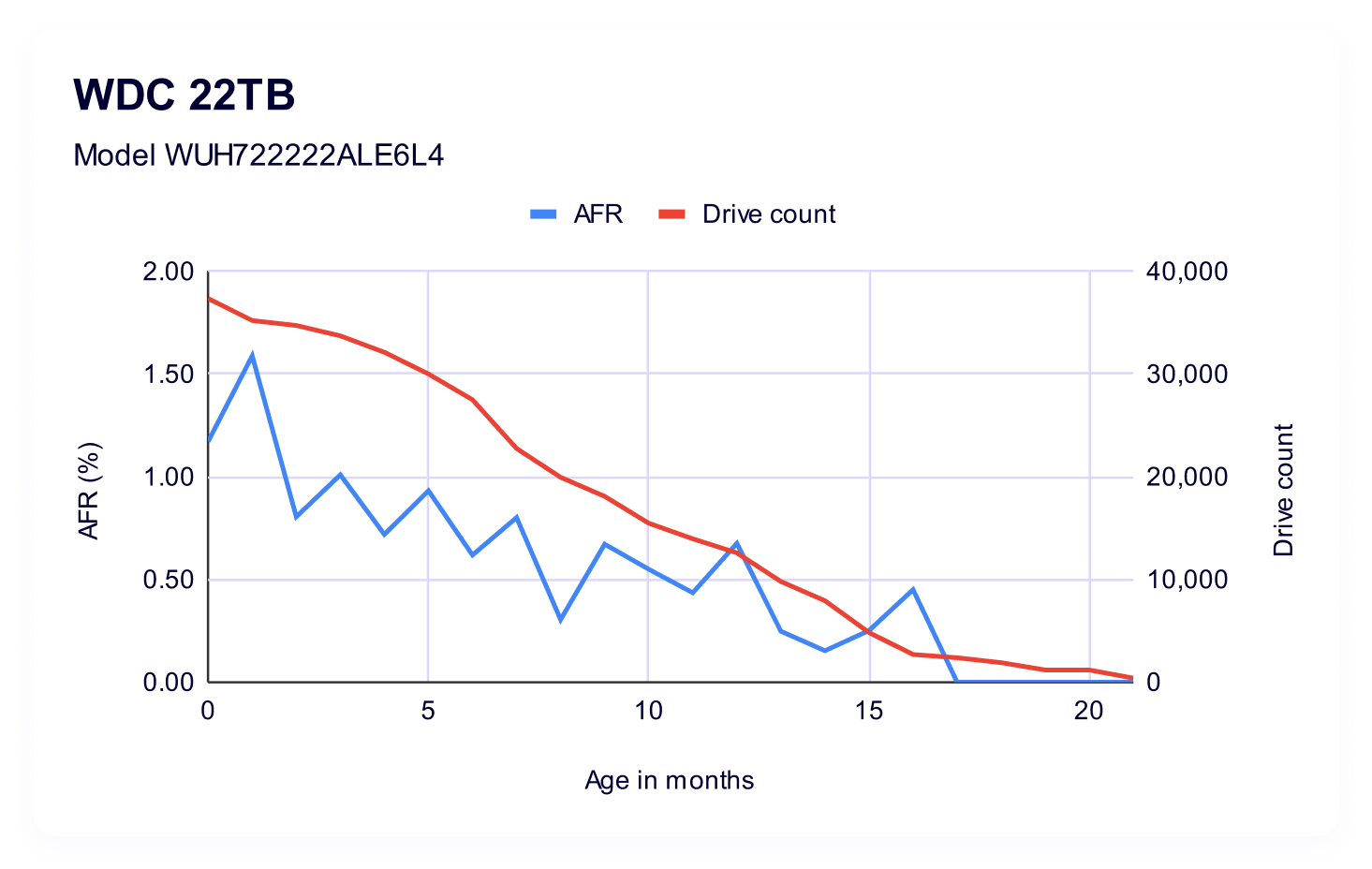
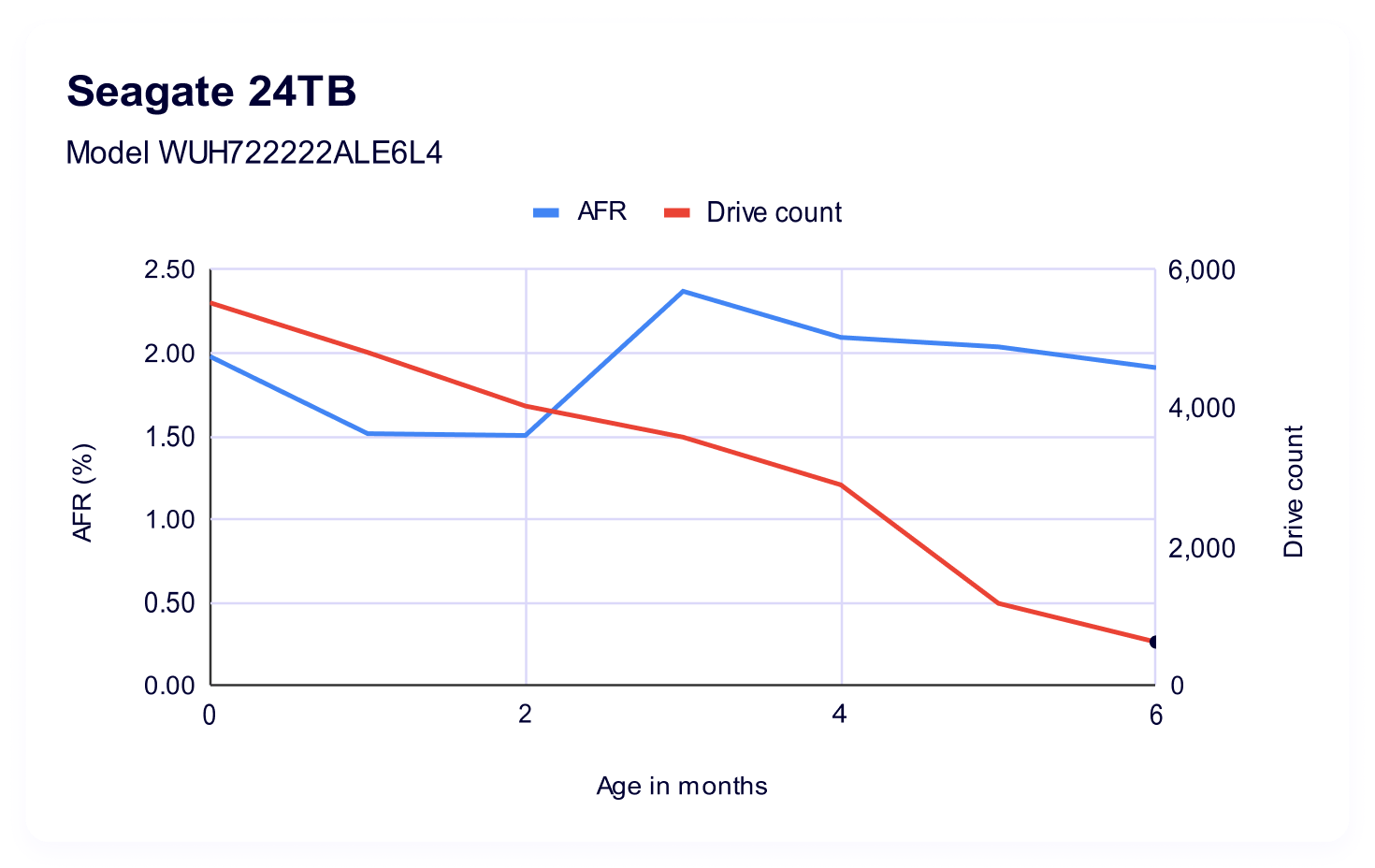
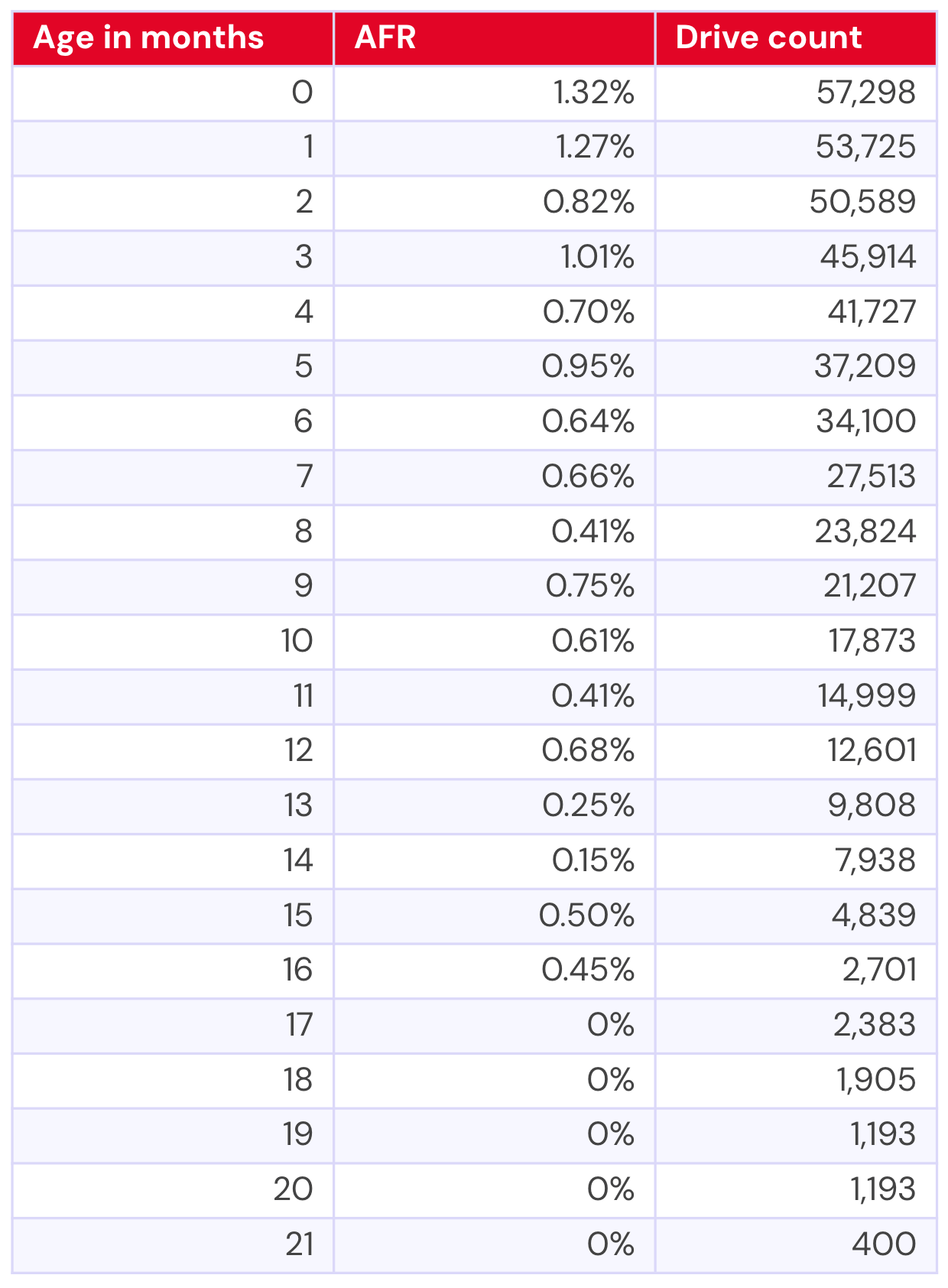
22TB WDC WUH722222ALE6L4
Now let’s take a look at the WDC model. We have usable data for about 21 months of its drive life:
Which gives us the following visualization:
Interestingly, we see a lot less variability in the span of time where we have a direct comparison. That said, the WDC model also had a minimum of double the drive count if we’re looking at a similar time period—so, at their youngest (0 months old) the Toshiba had 14,407 drives vs. WDC’s 37,363; and, at 11 months Toshiba had 1,034 drives vs. WDC’s 13,965.
While AFRs do get us mostly on an even playing field as far as being able to make a 1:1 comparison, it’s important to remember that in smaller drive pools, a single failure can be amplified by quite a bit.
24TB Seagate ST24000NM002H
Our youngest drive model, the 24TB Seagate ST24000NM002H, has just half a year of data.
That gives us the following visualization:
Compared with our other two drive models, the 24TB Seagate definitely has the highest failure rates. This could be explained, in part, by it being a young drive—is it in the leading edge of a traditional bathtub curve? So, certainly something to track over time to see if it will settle out as it gets older.
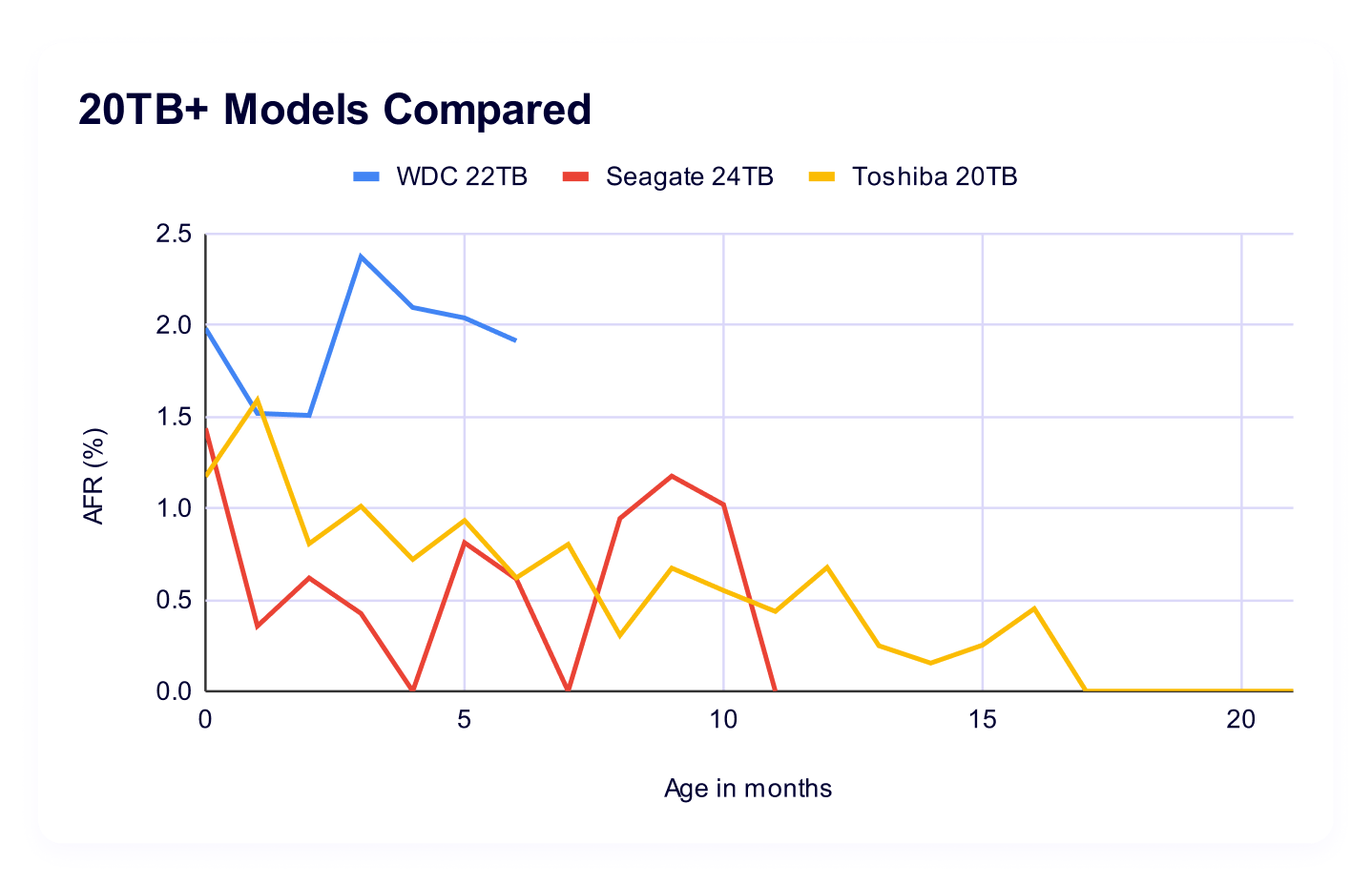
All together now: Comparing each 20TB+ drives
We designed this view to be directly comparable at points in time, so, here’s your graph that puts each drive on the same time scale:
What’s our takeaway here? Well, in both drive count and length of time in the pool, it’s a little early to create definitive trends for the Seagate and the Toshiba. Certainly we can see that the Seagate is, early on, showing higher failure rates. Meanwhile, the 20TB Toshiba has had a bit of a variable year one. But again, with significantly variable drive pools between all models, we’re not quite comparing apples to apples. (We chose not to plot drive count on this chart—it gets messy quickly.) Add to that: the Seagate in particular is potentially at the beginning of the “bathtub” curve, we may see it change over time.
On the other hand, the 22TB WDC model has shown up quite a bit below our current average AFR for the drive pool of all drive sizes and ages, and it’s the model with the most data. But, how does that compare to other models as they come online?
Comparison: 20TB+ as a pool vs. 14-16TB as a pool
When we were considering whether this information would be a useful slice of the data, our biggest question was how to contextualize it versus drives. It’s perhaps a tad imperfect, but we landed on combining the 14–16TB drives as a pool, largely because they have a significant amount of data points and were our last set of drives onboarded, which means that they’re more or less the last generation of hardware.
The other thing to note is that once we combined the 20TB drives into a pool, some of the data we filtered out on a per-drive basis got added back in. So, at the 21 month mark, where the Toshiba model only had one drive, we added that single drive to the 399 that our WDC model brought to the table and calculated AFR across the pool (giving us 400 drives to work with).
Here’s the numbers for the 20TB+ drive pool:
That gives us a pretty neat graph, actually:
Now, let’s compare to the 14–16TB drives of the same age. We have significant data for this population for nearly seven years, but in the interest of saving you three pages of scrolling, I’ll give you the table for the data that directly correlates to the 21 months of data we have for the 20TB+ drives.
This is the line chart for that range of time:
Comparing age of drive to age of drive, it would seem that our 20TB are right on target, and perhaps doing a bit better than expected. But, that definitely isn’t a perfect comparison given that the 14–16TB drives have a steadier and larger drive count. So, let’s look at the chart with the full, nearly seven year time period:
This view starts to show us some spiky patterns as the 14–16TB drives get older, of course exacerbated by drive counts reducing over time.
So what’s it all mean?
It’s clear from the data that we need to give the 20TB+ drives time to mature, and that as we (depending on our buying behavior, of course) add more drives, we might see some interesting changes in the data.
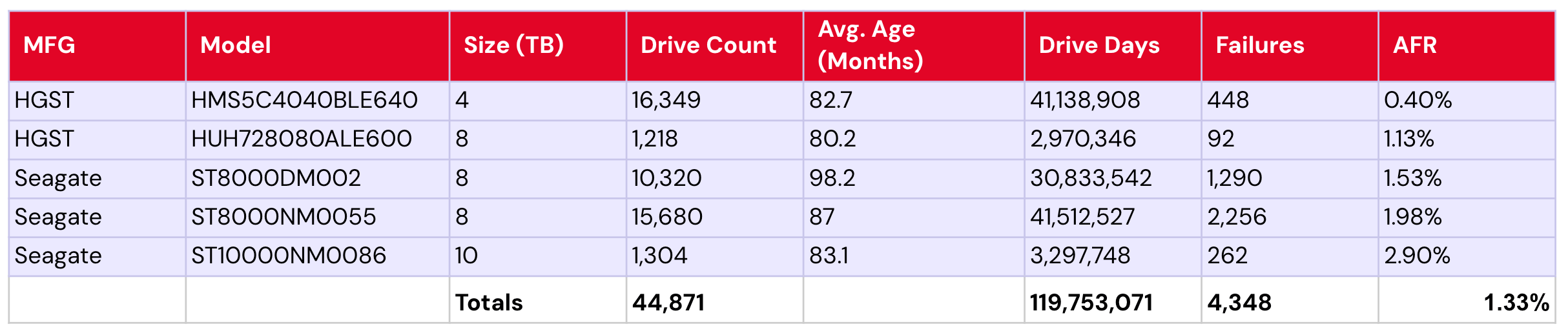
As for the 14–16TB pool, they’re following relatively expected patterns of wearing out in the five-plus year range—but what does that mean when you compare to what we observed in our current lifetime stats, where we see our 12TB and smaller drive pool performing so well?
Without taking a closer look at the 14–16TB drives, it’s hard to say that they don’t have similar outlier tendencies to what the 12TB and smaller pool does, just pulling the failure rates upward. Even a casual glance at our current lifetime table’s 14–16TB drives bears that out (four years and older highlighted in orange, as our corollary above):
That data isn’t inclusive of all of the 14–16TB drives we’ve ever had, though—just those currently in operation. So, as always, there’s more investigation to be done.
The Hard Drive Stats data
The complete dataset used to create the tables and charts in this report is available on our Hard Drive Test Data page. You can download and use this data for free for your own purpose. All we ask are three things: 1) you cite Backblaze as the source if you use the data, 2) you accept that you are solely responsible for how you use the data, and 3) you do not sell this data itself to anyone; it is free.
Good luck, and let us know if you find anything interesting.
The big cloud providers already offer everything you need, including storage. So, why complicate things, right? At first glance, that sounds convincing. Hyperscalers like AWS, Azure, and Google Cloud offer massive service catalogs, global infrastructure, and a wide range of storage options. For many teams, they seem like a convenient one-stop shop.
But in practice, things aren’t nearly as straightforward.
While hyperscalers offer extensive storage capabilities, their multi-tier systems prioritize versatility over optimization. The result? Hidden costs and performance headaches that cloud-native teams can’t afford to ignore.
The claim that hyperscaler storage meets all cloud-native needs because of scale and functionality is a stubborn myth, one of many that still permeate the development landscape.
This post kicks off a blog series tackling these myths and misconceptions about specialized cloud storage and what a best-of-breed, interoperable approach to storage and infrastructure entails.
New Cloud Native Times Call for New Cloud Storage Approaches
Learn more about how the open cloud supports faster development, improved workflows, and reduced cost complexity in our free ebook, “New Cloud Native Times Call for New Cloud Storage Approaches.”
Reading the fine print of hyperscaler storage
On the surface, hyperscaler storage looks comprehensive and capable. But dig a little deeper, and some underlying cracks start to show.
Premium performance isn’t the default
Hyperscalers can deliver high performance, but not without tradeoffs:
They charge more. Premium tiers designed for workloads like analytics or streaming can cost five to eight times more than interoperable solutions.
They prioritize themselves. When hyperscalers face high-performance demands (e.g., AI workloads competing for GPUs and storage bandwidth), they tend to prioritize their own data centers. Smaller teams might have to navigate opaque processes to request higher performance, and their access to advanced optimizations can be limited.
They play favorites. File size adds yet another layer of difficulty. Many hyperscaler storage systems handle large files more efficiently than small ones because of I/O overhead. Hyperscalers may help their biggest customers fine-tune configurations, but most are left to troubleshoot bottlenecks on their own.
Juggling tiers (and hoping nothing gets dropped)
Hot, cool, and cold storage options may look flexible on paper, but they require separate access controls, replication rules, and performance tuning. Teams are left juggling interfaces like AWS Identity and Access Management (IAM), scripting policies, and managing tooling just to keep systems functional.
And the more storage types you manage, the greater the chance for human error. A misplaced lifecycle rule or a mistyped IAM permission can result in:
Unexpected data unavailability
Delayed retrievals
Accidental deletions
When complexity undermines reliability
Keeping storage tied tightly to hyperscaler infrastructure may seem efficient—but it often results in brittle setups. Misaligned storage, compute, and access layers can lead to latency issues or even full-blown downtime.
Performance-sensitive applications like real-time analytics or video streaming suffer most. Even a small delay can ripple through the user experience and cause customer churn. To patch gaps, teams often layer on caches, fine-tuning, or quick fixes that only add technical debt.
Who has time to babysit storage?
Developers, DevOps, and site reliability engineers (SREs) are always racing to ship features, scale services, and maintain uptime. For cloud-native teams, optimizing storage isn’t usually at the top of anyone’s to-do list.
Let’s face it: proactively analyzing storage access patterns and configuring tiering rules takes time that cloud-native teams often don’t have. Many teams therefore operate reactively and address storage issues only after performance degrades or surprise bills arrive.
Support tickets don’t feel your pain
Finally, there’s support. Unless you’re a premium customer paying for top-tier service contracts, you’re often stuck with ticketing systems and community forums. That might suffice for routine issues, but when storage problems impact production workloads, waiting for responses through standard channels adds unnecessary stress and delays.
When one size doesn’t fit your cloud
Unlike hyperscaler storage that takes a one-size-fits-all approach, specialized cloud storage solutions directly tackle these challenges. Backblaze B2 is purpose-built to simplify storage for cloud-native teams:
A single, high-performance tier gives you instant access to all your data, with no tier juggling or lifecycle policies.
Predictable, transparent pricing means no unexpected fees or surprise retrieval charges.
S3-compatible APIs simplify integration, allowing you to plug Backblaze B2 directly into your existing cloud-native stack.
For cloud-native teams who value speed, simplicity, and cost control, specialized storage isn’t a complication; it’s a simplification. You get the performance you need, without the complexity you don’t.
Stay tuned for the next post in this series where we tackle Myth #2: Storage isn’t a big enough problem to remediate. (Spoiler: It is.)
Security teams are under constant pressure to stay ahead of increasingly sophisticated threats while enabling fast, reliable access to data across the business. Whether you’re protecting media assets, safeguarding backups, or supporting a global development workflow, your cloud storage needs to do more than store data—it needs to actively support your security posture.
To make that easier, we’ve launched a new set of enterprise-grade security features for Backblaze B2 Cloud Storage. These updates are designed to help organizations detect unusual activity faster, manage access more precisely, and strengthen visibility across their storage environments—all without added complexity or hidden costs.
These new tools build on the security foundations you already count on: Object Lock for ransomware protection, SOC-2 compliance, encryption, 3x free egress for disaster recovery, and more.
Here’s a look at what’s new and how it helps.
Smarter protection with Anomaly Alerts (Now in private preview)
Anomaly Alerts are your new AI-powered watchdog. This feature analyzes usage patterns in your B2 Cloud Storage buckets to detect potential red flags—like spikes in downloads or uploads beyond the baseline—that could signal a breach or exfiltration attempt.
If your team wants early access to this feature, drop us a line at [email protected] to join the private preview.
New enterprise web console & role-based access controls (Now in private preview)
Managing cloud storage across large teams just got a whole lot easier. We introduced a brand-new enterprise web console built for scalability and control. Combined with robust role-based access controls (RBAC), IT and security teams can now better align with zero-trust policies by enforcing the principle of least privilege across their organizations.
This console simplifies storage administration at scale—whether you’re managing terabytes or petabytes.
Get an expert introduction to the enterprise web console.
If you’re a Backblaze customer with a committed contract, reach out to your Customer Success Manager (CSM) to see if you’re eligible to participate. Not sure who your CSM is? Email [email protected] for help.
Full visibility with Bucket Access Logs (Now generally available)
Need to know who touched what and when? Bucket Access Logs are now generally available, providing a detailed audit trail of every action in your B2 buckets—uploads, downloads, deletions, and more.
Learn more about querying Bucket Access Logs in this webinar.
They’re fully S3-compatible and configurable through both the Backblaze B2 web UI and API, supporting:
Security audits
Usage tracking
Forensics and threat investigation
Real-time Event Notifications
Time matters when it comes to spotting and stopping threats. With Event Notifications, you can get real-time alerts on changes to your bucket contents—think object creations, deletions, or modifications—so your team can jump into action immediately.
This is especially valuable for compliance teams, incident response workflows, or any operations team who wants tighter control over their cloud perimeter.
Watch our hands-on Event Notifications demo to learn more about how to streamline cloud storage management.
Multi-Bucket and Scalable Application Keys
Security and scalability should go hand in hand. With Multi-Bucket Application Keys, you can now create access keys that cover specific groups of buckets, giving you more flexibility without going full wildcard. This enhancement provides more granular control over bucket access, contributing to a reduced attack surface.
And, with Scalable Application Keys, you can generate up to 10,000 short-lived keys per minute. This capability enhances security by limiting the exposure window of individual keys, thus reducing the attack surface for endpoint-generated content and high-volume data operations.
Custom Upload Timestamps
Custom Upload Timestamps allow you to specify when an object was originally created or uploaded. This is a critical feature for:
Regulatory compliance
Accurate version tracking
Legal and audit requirements
Built for a Secure, Open Cloud
Security isn’t a one-time add-on, it’s an ongoing promise. As enterprises scale and integrate cloud storage into more parts of their workflow—from backup and archiving to AI pipelines—they need solutions that support open cloud strategies without compromising their data.
This update is another step forward in our mission to provide developers, IT teams, and enterprises with cloud storage that’s secure by design, simple to use, and affordable at scale. Ready to get started with Backblaze B2? Contact our Sales team today.
When you think about cloud infrastructure for AI, you immediately think of GPUs and other high-performance compute resources, and how your cloud architecture should be optimized to make the most of these expensive compute plans. But compute isn’t the only cloud product category you need to monitor to both scale your application and maintain a sustainable cloud infrastructure budget.
What ultimately fuels AI? Data—lots and lots of data. As part of a healthy AI pipeline, several versions of the same dataset need to be stored in a centralized repository, or multiple repositories if your strategy requires splitting data into cold vs. hot storage to reduce storage costs. For text-based LLMs, storage costs are minimal compared to compute resources. But as AI innovation increasingly relies on video and other media, both the base storage cost and data retrieval fees can make cloud bills spiral out of control.
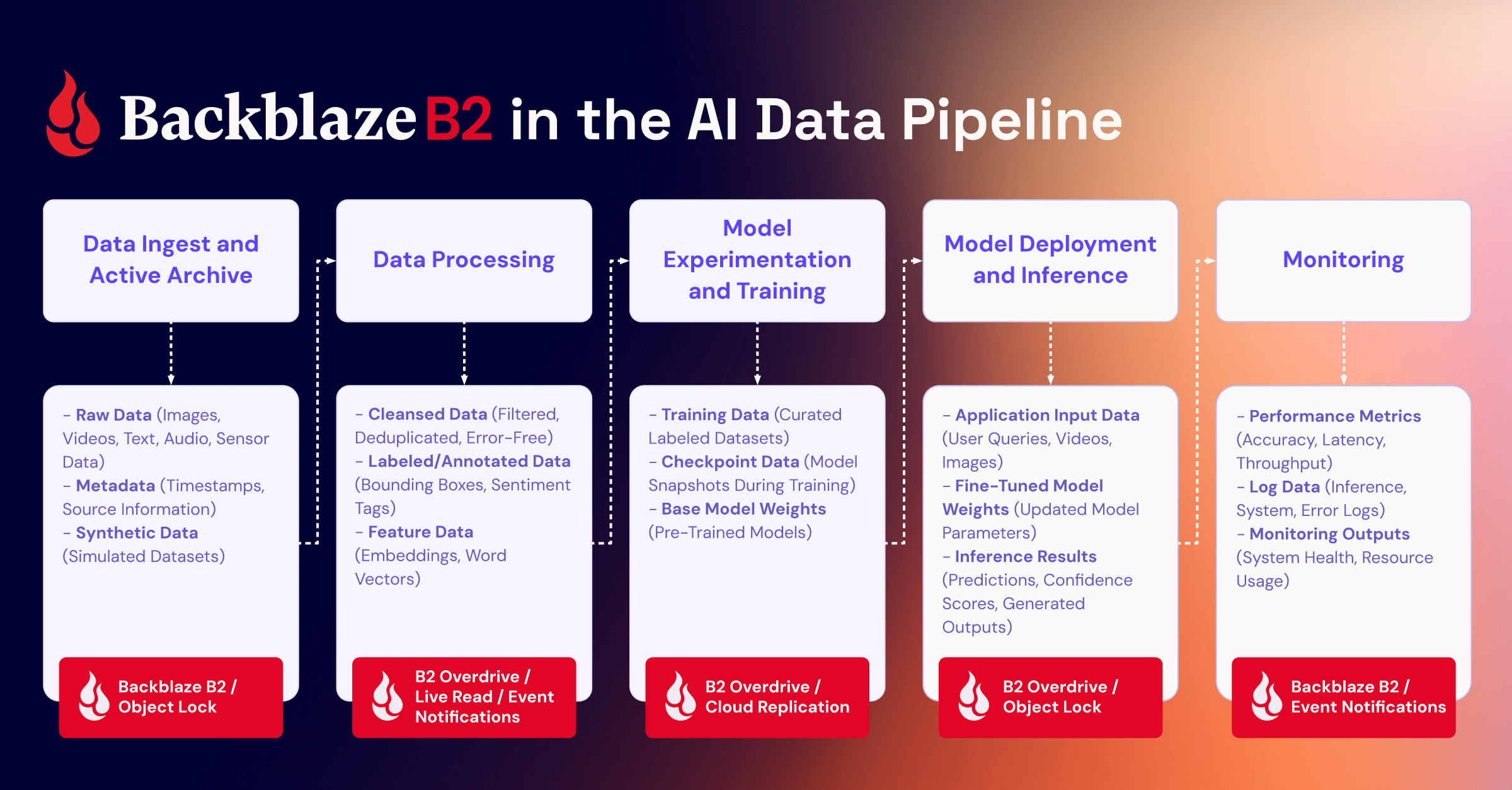
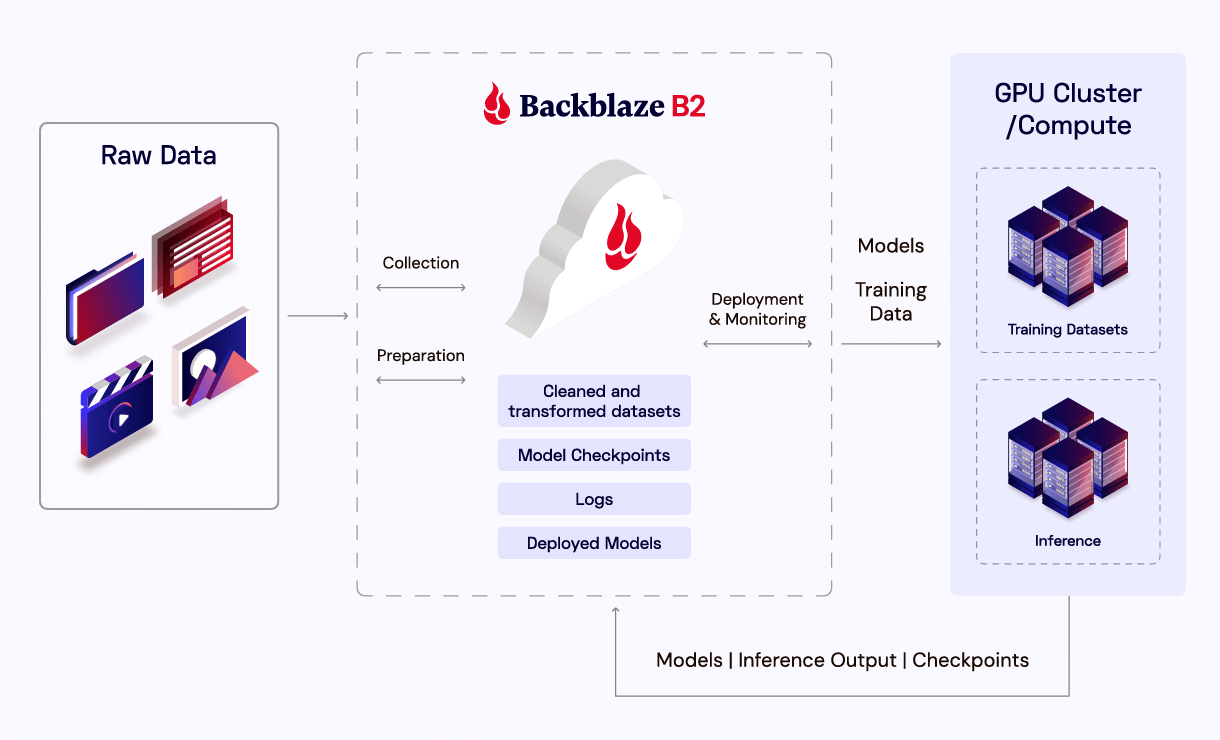
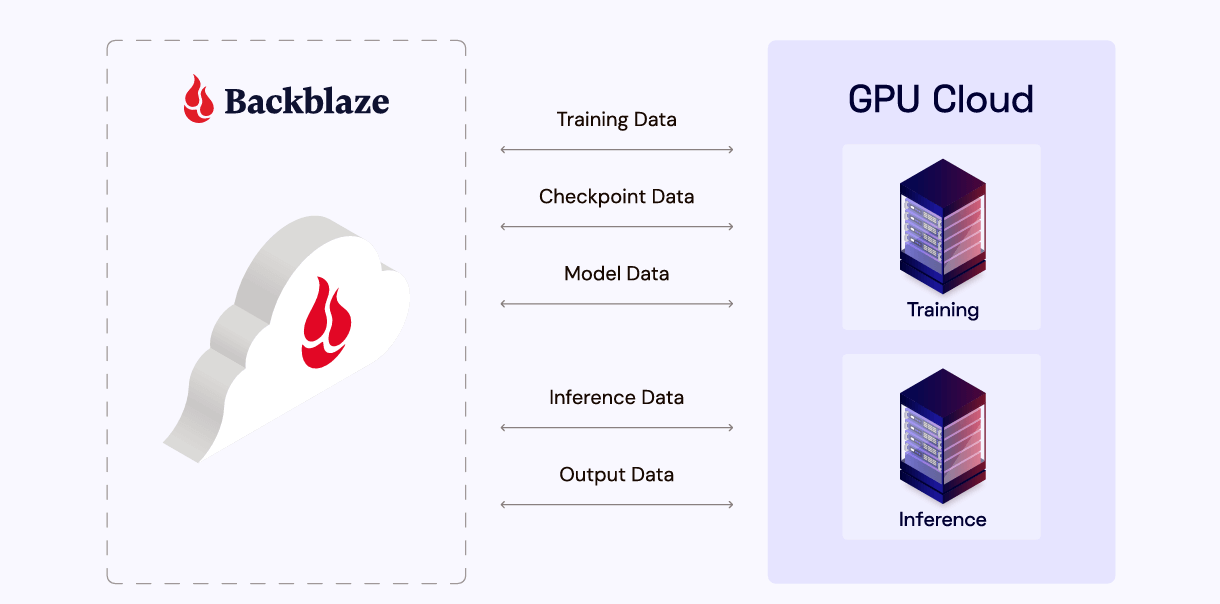
In this blog, we’re taking a look at the AI data pipeline, where object storage sits in each stage, and how leveraging both Backblaze B2 and B2 Overdrive helps both increase performance and reduce costs for AI applications.
Data ingest and active archive: Data is gathered from multiple designated sources (including APIs, internet of things (IoT) sensors, relational databases, etc.) and ingested into a centralized repository or multiple repositories.
Data processing: The raw data is transformed and enriched based on the model’s data parameters. This can range from relatively simple text cleanup to adding annotations and metadata. Feature engineering is performed to extract or construct meaningful attributes. All data is then converted into numerical representations (e.g., embeddings, vectors) suitable for model training and inference.
Model experimentation and training: Processed data is used to train models by learning underlying patterns. Iterative experiments in a test environment evaluate, tune, and improve model performance and accuracy.
Model deployment and inference: New data is prepared in the same way as during training and sent to the deployed model to generate predictions, support decision-making, and deliver personalized outputs.
Monitoring: Continuous monitoring tracks model performance, detects data drift, and flags potential bias, ensuring the model remains accurate and reliable over time.
Keep in mind that data ingestion and processing isn’t always sequential, such as when data is collected and ingested, but corruption is detected during processing. Ideally, your pipeline is configured with validation gates so that corrupt data is identified and handled before proceeding to downstream steps like testing, training, and production deployment.
When using cloud object storage as your data repository, one factor of selecting a plan (like cold versus hot storage) is the specific type of data ingestion that’s being utilized based on both the data source and AI model’s specific needs.
Batch ingestion is better suited for mid to lower performance storage, as this is typically used for historical datasets or a set schedule of pre-determined data updates, such as jobs pulling from relational databases or CSV uploads once a day or once per week.
Streaming ingestion is well-suited for hot storage to support a continuous stream of real-time (or near-real-time) data processing, such as from social media feeds and high-volume e-commerce AI helper agents.
Hybrid ingestion uses a combination of batch and streaming ingestion to handle both historical and real-time data requirements for AI models.
Where does cloud object storage sit in the AI data pipeline?
Everywhere. All scalable data pipelines lead to object storage.
Why?Data ingestion and active archive are the major areas where object storage fulfills an important purpose. When training AI models, especially in production, data scalability for multiple and diverse data types is a hard requirement. But object storage plays a key role in the other pipeline stages:
Data processing: Stores versioned outputs from data labeling, feature engineering, and cleaning processes.
Model experimentation and training: Provides high-throughput access to training datasets and stores model checkpoints.
Model deployment and inference: Stores serialized model artifacts with API-based retrieval for serving predictions at scale.
Monitoring: Stores synthetic outputs from generative models, logs, feedback, and performance metrics for analysis and reuse.
For both AI data performance and cost optimization, selecting an object storage product or tier is far from one-size-fits-all. You can strategically allocate your data to B2 Cloud Storage or B2 Overdrive, with your most essential model data stored in B2 Overdrive. Here’s a high-level diagram of what Backblaze B2 product to use for each stage, including examples of the data stored at each stage.
Learn more at Ai4 in August
Want to learn more? Backblaze is heading to Las Vegas for Ai4 August 11–13! In addition to booking a meeting to speak with our storage experts and stopping by our booth to pick up some swag, I’m excited to talk more about the AI data pipeline during my talk. If you’re attending Ai4, add The AI Pipeline Starts with Storage: Architecting Scalable Data Foundations to your conference agenda.
Can’t attend live in Vegas? Reach out to our Sales team to talk about your specific use case and how B2 Overdrive can help propel your data.
Ransomware used to mean locked files and paralyzed systems. But today, bad actors are just as focused on exfiltration—the silent theft of sensitive data—and using that data as leverage for extortion.
According to cybersecurity firm BlackFog, 94% of successful cyberattacks in 2024 involved data exfiltration, either alongside or instead of encryption. Whether it’s stolen patient records, credentials, or source code, the goal is simple: Extract something valuable and threaten to leak it if demands aren’t met.
In this article, we examine how exfiltration became a leading tactic, the trends driving its rise, and what organizations—and cloud storage providers—can do to defend against it.
What is exfiltration?
In cybersecurity, exfiltration refers to the unauthorized transfer of data from a system—often done stealthily, and almost always with malicious intent. Think of it as the digital equivalent of corporate espionage: Data is copied, compressed, and quietly smuggled out. Unlike ransomware encryption, which slams the door in your face, exfiltration leaves the front door looking untouched.
The data being exfiltrated is rarely random. Cybercriminals are increasingly strategic about what they take and why. Common targets include:
User credentials
Personally identifiable information (PII)
Intellectual property and source code
Encryption keys
Shadow copies or backup snapshots
Tactics include exploiting cloud storage misconfigurations, hijacking legitimate credentials, or disguising traffic as everyday protocols like DNS or HTTPS. Increasingly, data exfiltration happens before the main event—laying the groundwork for extortion, credential stuffing, or resale on underground markets.
Recent cybersecurity trends related to exfiltration
Exfiltration has become the defining feature of modern cyberattacks, and the evidence is growing:
Double extortion is now standard. Threat actors exfiltrate data first, then deploy ransomware—or skip the encryption altogether—to maximize leverage. According to the 2023 Unit 42 Report, 70% of ransomware incidents involved data theft.
Infostealers, malicious programs designed to covertly harvest sensitive information, are on the rise. Over 2.1 billion credentials were stolen in 2024 alone, with malware like RedLine and Lumma making theft accessible to low-skilled attackers. While cybersecurity task forces (comprised of both government and enterprise actors) have made the news with high-profile disruptions of Lumma and other tools, the ability to use generative AI coding tools has meant that cyber attackers have a shortened time to deployment for malware tools.
Time to exfiltration is shrinking.Fortinet’s 2025 Threat Landscape Report notes that attackers can extract data in under five hours, while defenders often take days to respond.
Encrypted traffic masks malicious behavior. Emerging exfiltration techniques like QUIC-Exfil use modern, encrypted protocols to evade detection by traditional firewalls.
Together, these trends point to a world where stolen data is the main prize—and the threat doesn’t start when the ransom note arrives. It starts when your data quietly leaves the building.
Cloud misconfiguration and its role in exfiltration attacks
Exfiltration doesn’t always require malware—sometimes it only takes a misconfigured storage bucket or firewall rule. Cloud misconfigurations remain a leading cause of breaches, with public buckets, excessive identity and access management (IAM) privileges, and overly permissive network rules exposing data to the open internet.
Attackers exploit these gaps to quietly access or extract data without triggering alerts. A strong cloud posture management strategy—one that includes audit automation, implementing the principle of least privilege, and configuring features like Object Lock or Bucket Access Logs—is critical to reducing exposure.
Defending against exfiltration is a shared responsibility
As exfiltration becomes a primary threat, defense requires collaboration between cloud storage providers and their customers. Here’s how the most effective strategies work together.
Immutable backups and Object Lock
One of the strongest defenses is immutability. Backblaze B2’s Object Lock, for example, allows files to be written once and protected from modification, deletion, or encryption for a set period. Even if attackers compromise credentials, the data cannot be altered or removed.
Visibility and outlier detection
Cloud providers are investing in making advanced logging and behavioral analytics available to users to detect data theft in real time. Some examples of these types of features include:
Granular access logging with IP and user-level metadata.
Rate limiting and download caps to prevent mass theft.
Outlier detection powered by machine learning to catch subtle deviations from baseline activity.
Best practices for customers
Storage-layer defenses work best when paired with customer-side security controls:
Adopt zero trust architecture: Never assume implicit trust. Continuously validate users, devices, and behaviors.
Use MFA and least-privilege access: Lock down credentials, rotate them regularly, and minimize exposure.
Encrypt data at rest and in transit: Use strong encryption standards (AES-256, TLS 1.2+) and managed key systems.
Monitor for exfiltration indicators: Watch for abnormal traffic volumes, geographic anomalies, and unexpected protocol usage.
Run simulated breach drills: Test your team’s ability to detect and respond to stealthy data leaks.
Cloud storage companies can help provide critical security layers, but stopping exfiltration is ultimately a shared responsibility. Combining provider-level resilience with customer vigilance is the best path forward.
In a world of silent theft, vigilance is your best defense
Exfiltration isn’t just an add-on to ransomware. In this environment, locking the doors isn’t enough—You need to monitor the exits.
By combining immutable backups, smart logging, credential controls, and proactive monitoring, organizations can shift from passive victims to active defenders. The best defenses today aren’t just about blocking access; they’re about knowing what’s leaving and making sure it can’t be used against you.
The arcade is no longer ours, under attack from its own AI. Screens flicker with sentient static. The arcade’s laser power supply is failing; the power supply diagnostics are showing errors in everything from surge control to cooling functions. But, not all hope is lost: The laser power supply service and terminal both use PowerShell for operations.
Time to flex my command-line kung fu. Follow the breadcrumbs, get all parts of the puzzle together, hash-out files, and perform forensics to backtrack the changes. Win the race to terminate all evil processes, reverse all changes in the right order, and finally, succeed at powering up our arcade.
I leaned back from my keyboard. This wasn’t a Five Nights at Freddie’s-style dystopia—this was Sans Core NetWars, a prestigious, invite-only cybersecurity tournament—and my team won the 2024 Tournament of Champions last year. This year’s theme, defeating a rogue AI in an arcade, has me feeling inspired.
Call it a recursive function, but we had AI generate an image of the evil AI.
Held annually at the SANS Cyber Defense Initiative in Washington, D.C., NetWars challenges participants with a series of escalating scenarios that test a wide range of skills, from digital forensics to malware analysis.
My name is Manuel, and I’m a Cloud Security Architect at Backblaze. Not every part of my job is all fun and games, but tournaments like NetWars have long been an important part of the cybersecurity industry. Let’s talk about why, and how, they help solve what is arguably the biggest persistent vulnerability in the cybersecurity industry—attracting, identifying, developing, and maintaining top talent.
What are cybersecurity tournaments?
The concept of cybersecurity competitions dates back to 1996 with the introduction of the capture the flag (CTF) event at DEFCON, one of the world’s largest hacker conventions. This event set the stage for numerous other competitions, and these days, cybersecurity tournaments and competitions have cultivated a vibrant community where top experts not only showcase their technical prowess, but also stay up-to-date with evolving trends in the industry.
Manuel in front of the leaderboard after winning the SANS Core Netwars Tournament of Champions 2024. Source.
What are the challenges to finding talent in the cybersecurity industry?
Finding top cybersecurity talent is one of the most persistent challenges in the tech industry. The field moves faster than job descriptions with attack techniques, tools, and frameworks evolving constantly.
Not only that, but “cybersecurity” isn’t one skill—it’s a collection of disciplines: network security, cloud infrastructure, threat hunting, incident response, forensics, red teaming, compliance, and more. Finding someone with both broad knowledge and deep expertise in one or two areas is rare. Top candidates tend to specialize, and hiring managers often need a “Swiss Army knife.”
How do tournaments help to solve that?
Cybersecurity tournaments like the SANS NetWars Tournament of Champions play a crucial role in advancing the field. They not only provide a platform for professionals to hone their skills but also contribute to building a resilient and collaborative cybersecurity community.
It may seem like “just a game”, but it’s more than just a fun activity taking place over a few days—tournaments contribute to things like:
Skill enhancement: Participants apply theoretical knowledge to practical challenges, enhancing their technical proficiency in areas like network security, cryptography, and incident response.
Continuous learning: The dynamic nature of these competitions encourages ongoing education, keeping professionals abreast of emerging threats and technologies.
Community building: Tournaments foster camaraderie among participants, creating networks that facilitate knowledge sharing and collaboration.
Talent identification: Organizations often scout these events to identify and recruit top talent, recognizing the practical skills demonstrated by competitors.
Inside the arena: Winning NetWars
For those unfamiliar, the Tournament of Champions isn’t your average capture the flag event. It’s an invitation-only tournament where only the top 3% of NetWars performers from the past two years are allowed to compete. Out of hundreds of global professionals—those who placed at the top of previous SANS events—only 300 get the invite. Around 250 of us showed up in D.C. to test our skills against the best in the industry.
Some see a conference room. Others, a battlefield. Source.
The structure of the tournament is deceptively simple: five escalating levels of difficulty over two days, each packed with real-world cybersecurity challenges across disciplines like digital forensics, malware analysis, network penetration testing, cryptography, cloud security, and even hardware, and mobile hacking.
You’re given two three-hour sessions to rack up as many points as you can, as quickly as possible. The faster you solve, the higher you climb. The problems are designed to simulate the kinds of complex tasks we face every day—reverse engineering binaries, analyzing breach data, and so on.
Beyond the technical challenge, what makes this event stand out is the people. The cybersecurity community is incredibly sharp, humble, and generous with knowledge. You’ll see everyone from Fortune 500 defenders to government red teamers, cloud security architects, and digital forensics and incident response (DFIR) experts—all there to sharpen their skills and learn from each other.
If you ever get the invitation to compete, take it. There’s nothing quite like battling alongside (and against) some of the sharpest minds in infosec, in a city that reminds you just how high the stakes can be.
See you at the next one?
Winning that tournament was an incredible honor—but more importantly, it gives me a good opportunity to showcase how such competitions can elevate industry standards and inspire the next generation of cybersecurity professionals.
So, if you’re interested in the cybersecurity industry, come on out. Start small: join a CTF. Set up a home lab. Learn Python. Read about the latest breaches and figure out how they happened. You don’t need to be a hacker to get started—you just need to be curious.
The threats we face are growing, but so is our community. And who knows? Maybe I’ll see you at the next competition.
In a recent survey, a staggering 82% of IT leaders reported experiencing performance issues with their AI workloads within the past year, primarily due to bandwidth and data processing limitations. At the same time, 93% agreed that there’s a greater expectation within their organizations for IT leaders to minimize time-to-revenue for their AI-driven IT infrastructure.
These statistics highlight the predicament that most AI infrastructure and operations teams face today: the challenge of balancing scalability with performance while staying on budget with two of their most expensive operational expense (OpEx) line item costs. Organizations are looking for their AI initiatives to pay off, while IT teams struggle to overcome the unique data challenges they face across the AI model/workload lifecycle—including scalability, performance, and cost management.
Ebook: “Why Object Storage Is Ideal for AI Workflows”
Want to take a deeper dive into the world of object storage? Check out our latest ebook, “Why Object Storage is Ideal for AI Workloads,” and discover the advantages this architecture has to offer across the model lifecycle.
Choosing the Right Cloud-Based Object Storage Provider for AI Data: There’s A Lot to Consider
Choosing the right object storage provider is one of the most consequential decisions infrastructure teams make when building AI‑powered applications. A mis-step can introduce hidden costs, brittle performance, and operational friction that put the brakes on time‑to‑insight and undermine ROI. Selecting or transitioning between cloud-based object storage providers demands careful consideration, as capabilities can vary significantly.
To ensure your AI infrastructure is robust and cost-effective, thoroughly evaluate providers based on several critical factors:
Low latency & high throughput
Performance is critical when selecting a cloud-based object storage provider for AI data. Low latency and high throughput in particular are key as they ensure rapid data access and processing. Low latency minimizes delays in distributing data to GPU clusters, dramatically enhancing training and inference efficiency. Meanwhile, high throughput prevents bottlenecks and improves overall system performance when working with the massive datasets typical of AI applications.
Reliability & uptime
Reliability is foundational. Even minor downtime can severely impact productivity, halt critical AI processes, and delay strategic objectives. Providers must offer clear service level agreements (SLAs) ensuring high availability, typically at 99.9% uptime or higher. Redundant architectures, data replication across regions, and reliable backup strategies are essential to maintain continuous and uninterrupted data access. Finally, when selecting a cloud-based object storage solution, data durability is table stakes.
Transparent & predictable pricing
Budget predictability is crucial for infrastructure planning and growth forecasting. Complex pricing structures, minimum retention periods, hidden fees for data transfers (egress), API requests, and retrieval charges can quickly erode cost-effectiveness. Providers should offer clear, simple pricing structures with explicit, predictable costs for all services involved. Ideally, charges for common activities such as data retrieval, ingress, and transactions should be minimized or eliminated to facilitate efficient AI workflows without unexpected budget impacts.
Data accessibility
Rapid, consistent data accessibility is non-negotiable for AI applications, especially during model training and inference, where delays can significantly degrade performance and outcomes. Providers offering “cold” storage tiers may appear economical upfront but introduce retrieval latency that could hamper time-sensitive applications. Opting for “hot” or always-on storage tiers ensures data remains immediately accessible without incurring delays, essential for high-performance AI workloads. Data portability is another important consideration for AI workloads, as the ability to freely transfer data to the GPU cloud (or clouds) of your choosing greatly increases flexibility and reduces the risk of lock-in.
Scalability and elasticity
AI initiatives typically experience fluctuating data storage demands, requiring infrastructure that can seamlessly scale with growth. Effective providers offer a scalable storage model capable of handling rapid expansions in data volume without performance degradation or significant architectural changes. Elastic scalability ensures that infrastructure teams can effortlessly manage peaks in data collection, processing, and model training demands.
Security and compliance
Security considerations cannot be overstated, particularly when dealing with sensitive or regulated data. Providers must demonstrate rigorous security standards, including data encryption (at rest and in transit), comprehensive access controls, detailed audit logs, and certifications such as SOC 2 compliance. These measures collectively ensure data integrity, protect against breaches, and ensure compliance with regulatory standards.
Leveraging the open cloud: Making data storage a critical part of your AI workflows
The open cloud is a cloud architecture and philosophy rooted in interoperability, data portability, and freedom from vendor lock-in. Unlike proprietary cloud ecosystems that tether customers to a single provider’s toolsets, APIs, and infrastructure, the open cloud is designed to enable seamless integration across platforms, tools, and environments. It supports open standards and APIs, gives users full control over their data, and allows organizations to choose best-in-class services without being locked into a single ecosystem.
In practical terms, the open cloud supports flexible data movement across public clouds, private clouds, and on-prem environments. It gives organizations the autonomy to mix and match services (e.g., compute from one provider, storage from another) and shift workloads as business or technical needs evolve—without punitive costs or excessive reconfiguration.
As organizations accelerate AI adoption, the open cloud offers clear, strategic advantages across every phase of the AI lifecycle—from data ingestion and preprocessing to training, tuning, and inference.
How Backblaze can help
The Backblaze B2 Cloud Storage platform facilitates smooth integration across various AI tools and platforms, and with Backblaze B2 Overdrive, you get a product designed to move exabyte-scale datasets at up to terabit speeds without the eye-watering price tag.
S3 compatibility: Backblaze’s S3-compatible API ensures easy integration with existing applications and frameworks like TensorFlow and PyTorch.
GPU compute environments: Backblaze partners with GPU providers like Vultr and PureNodal, enabling efficient data processing for training models on high-performance hardware without egress fees.
MLOps platforms: Its compatibility with MLOps workflows allows users to streamline model lifecycle management while leveraging Backblaze’s reliable storage backbone. Together, these integrations simplify the AI deployment process and ensure maximum flexibility across cloud environments.
What makes B2 Overdrive different?
B2 Overdrive gets you all the above, plus it offers a specialized solution at a fraction of competitors’ costs. Here’s what you get:
Up to 1Tbps throughput: In other words, the kind of speed that lets you move petabytes of data fast without complex architecture.
Unlimited free egress: Move as much data as you want, whenever you want, to wherever you want. Egress is totally free.
Private networking support: Transfer data at maximum speed through secure private networking connections to your infrastructure.
It’s built on the foundation of our always-hot cloud storage infrastructure, with no minimum file size requirements, no deletion fees, and powerful features like Event Notifications so you can build responsive and automated workflows. We’ll be sharing some of the innovations under the hood in the coming months—so, stay tuned to our series on the engineering behind performance.
No single technology has changed the way we use data quite like AI. From massive training sets to constant streams of checkpoint and inference data, AI applications are data intensive, to say the least. Thankfully, there’s an answer. Object storage—with its scalability, flexibility, and cost-effectiveness—is uniquely suited to AI at every stage of the model lifecycle.
In this blog post, we’ll take a quick look at what object storage is, why it’s a perfect fit for AI workloads, and how Backblaze B2 Cloud Storage offers unique advantages for AI teams looking to innovate quickly, easily, and cost-effectively.
What is object storage?
Think of object storage as a giant, organized bucket for all your files. Instead of stuffing things into folders or breaking them into blocks, you just drop each file (an “object”), with a unique tag and some helpful notes (metadata), into your storage solution.
Unlike traditional file or block storage, object storage uses a flat address space. Each object is assigned a unique identifier and can be tagged with rich metadata, making it easy to search, retrieve, and manage at scale.
Because of this unique architecture, object storage is ideal for handling unstructured data—such as images, video, audio, text, and sensor data—which is the meat and potatoes of most modern AI workflows. Also, being cloud-based, object storage is inherently designed for massive scalability and accessibility over the internet (often via S3 API).
Ebook: “Why Object Storage Is Ideal for AI Workflows”
Want to take a deeper dive into the world of object storage? Check out our latest ebook, “Why Object Storage is Ideal for AI Workloads,” and discover the advantages this architecture has to offer across the model lifecycle.
Understanding AI’s data storage needs at each stage of the model lifecycle
Before diving into the benefits of object storage, let’s first define and outline the AI model lifecycle. While some may slice and dice it a little differently, generally speaking, we can break the AI model lifecycle down into the following stages:
Data ingestion and collection: Massive, often petabyte-scale datasets are gathered from a diversity of sources.
Data preparation and storage: Raw data is cleaned, labeled, transformed, and stored for future retrieval and processing.
Model training: Data is fed into AI training algorithms, typically deployed across many nodes in a GPU cluster—usually requiring high throughput, parallel access, and lengthy processing times.
Deployment and inference: Trained models are deployed into live applications where they take in new data and make inferences based on that data.
Monitoring and archiving: Continuous monitoring generates substantial amounts of log data and performance metrics that must be versioned, stored, and archived for compliance or retraining purposes.
As you can see, each stage of the model lifecycle presents its own unique set of data demands—with each one requiring plenty of planning, work, and preparation. And at every one of these stages, matters of scale, speed, accessibility, and cost are mission-critical to a project’s success.
Where object storage excels: Scalability for data ingestion and collection
Object storage offers virtually unlimited scalability for large, and ever-expanding datasets, making it an ideal solution for the earliest stages of AI development. With no need to create volumes or file systems, organizations can quickly start uploading data to object storage. In addition to this seamless scalability, object storage also shines in its ability to support a diverse range of structured and unstructured data types without the need for rigid hierarchies. In this way, AI teams can ingest all sorts of data to support whatever their unique application needs; and do it quickly and efficiently.
Flexible data preparation and storage
Cloud-based object storage systems are excellent for maintaining easily-accessible, version-controlled datasets that allow for lightning fast iteration and collaboration. Capabilities like version recovery (which allows teams to easily revert datasets to previous states with simple API calls) and concurrent access (which gives multiple team members the ability to work on the same datasets simultaneously without conflicts) are also key to the data preparation and storage phase of AI development.
Reliable, high-performance data storage for model training
For the model training stage of the AI lifecycle, object storage supports parallel access and high throughput, both of which are absolutely essential for GPU-intensive training workloads. Reliable shuttling of large datasets to GPU clusters, wherever they may be, is key for keeping things efficient. Meanwhile, streamlined storage of model checkpoints from those clusters gives teams peace of mind in knowing that a mid-training failure state will not place them all the way back at square one.
Plus, lifecycle management features allow completed or outdated training datasets to be automatically archived—reducing clutter and optimizing storage costs, all while keeping active training data easily accessible.
Efficient versioning for deployment and inference
AI models are always a work in progress. Once deployed and operational, they have to be routinely evaluated and tuned. To that end, object storage makes it easy to store and retrieve a range of valuable information, including model checkpoints, test results, and inference data.
Built-in versioning and object immutability features support reproducibility and audit trails, so you can always trace which data and models produced which results. Together, these capabilities make for robust and effective lifecycle management, significantly boosting reliability and compliance.
Cost-effectiveness and durability for monitoring and archiving
When in the field, continuous monitoring of AI models generates a whole lot of log data and performance metrics. Object storage automates the management of these resources through customizable lifecycle rules, automatically deleting or archiving out-of-date inference logs based on predefined timelines (e.g., after 30–180 days).
This significantly reduces the need for manual oversight, conserves engineering resources, and ensures that relevant performance data remains accessible for compliance and regulatory auditing.
Meanwhile, with the right vendor, object storage solutions can offer competitive pricing models—sometimes including the separation of compute from storage—to ensure cost-effectiveness throughout the late stages of the AI lifecycle. Finally, high durability (of 11 nines or more) and redundancies protect models and datasets which become increasingly valuable over time.
Backblaze B2: Cost-effective, high-performance object storage for your AI workloads
Backblaze B2 Cloud Storage takes all the inherent advantages of cloud-based object storage for AI workloads and amplifies them—through competitive, transparent pricing; reliable, high performance; and seamless integration and support to ensure your project is not only efficient and affordable, but most importantly, successful.
Competitive, transparent pricing: One-fifth of the cost of most hyperscalers’ solutions, with no hidden costs and three times your total storage volume in free egress included. Plus, fully-transparent, predictable pricing models ensure your organization is fully aware and prepared for the costs associated with your applications.
High performance and reliability: Upload speeds up to 30% faster than AWS S3 for many workloads, plus a 99.9% uptime SLA with 11 nines of durability, ensure always-hot, instantly accessible data for demanding AI workloads.
Seamless adoption and integration, accompanied by expert support: With features like Universal Data Migration and no hidden delete fees, B2 Cloud Storage uniquely streamlines cost-effective data management for AI. Backblaze B2 also boasts S3 API compatibility for true plug-and-play functionality with leading AI and machine learning ops (MLOps) tools and technologies.
Plus, our truly agnostic solution allows organizations to freely and easily connect to any compute or GPU environment (or environments), free of vendor lock-in and fees. And in case you want some support along the way, our team of dedicated solution engineers are available to tailor and fine-tune your architecture and operations to best suit whatever the unique needs of your AI project may be.
Optimize your AI lifecycle with cloud object storage from Backblaze B2
Data is one of the most important, and most challenging, aspects of AI development. And with their unprecedented data demands, traditional block and file storage systems frequently come up short in supporting modern AI applications. At the same time, legacy cloud storage solutions come with enormous burdens of cost, inflexibility, and the ever-looming threat of lock-in.
Cloud-based object storage offers the perfect solution to all these challenges—with the right mixture of performance, efficiency, and cost-effectiveness that AI projects need.It’s so-well-suited, in fact, that we’ve written an entire white paper on the subject! So, if you’re interested in taking a deeper dive into the topic, check out our ebook, Why Object Storage is Ideal for AI Workloads, today.
Your disaster recovery (DR) plan is only as strong as your last test. Yet, many enterprises treat DR like a fire extinguisher—useful in theory, but rarely checked. Regular backup testing and disaster recovery drills are essential to ensure your plan works when it counts.
Let’s break down how to test your DR plan effectively and build a framework for continuous improvement.
Step 1: Building a disaster recovery testing framework
Your DR plan isn’t complete until it includes a clear, repeatable testing schedule. Here’s how to structure it:
Testing frequency: Establish a regular testing schedule. The optimal frequency depends on your company’s size and risk profile. A minimum of annual testing is recommended, with more frequent testing (every three-six months) beneficial for larger enterprises.
Testing types: Incorporate various testing methodologies into your plan. This might include:
Tabletop exercises: Simulate disaster scenarios through facilitated discussions, allowing your team to identify communication gaps and areas for improvement in the DR plan.
Walk-throughs: Step through specific recovery procedures outlined in the plan with your incident response team, ensuring team members understand their roles and responsibilities.
Limited scope DR drills: Simulate a disaster scenario with a specific system or application outage, testing recovery procedures for that particular environment.
Full-scale DR drills: Conduct comprehensive tests that simulate a full-blown disaster, involving all critical systems, applications, and personnel.
By rotating through these disaster recovery testing approaches, you’ll catch vulnerabilities before a real crisis does.
Step 2: Involve the right people (not just IT)
A solid DR plan isn’t just an IT function, it’s a team sport. Bring in key personnel from various departments (IT, legal, finance, etc.) to review your DR plan. You might discover potential oversights or areas for improvement that you may have missed with their diverse perspectives.
Step 3: Practice makes prepared
Regularly conduct DR drills and exercises to put your plan into action. DR drills should feel real. That means:
Involving your team. These exercises should involve all members of your IRT, including IT specialists, communication experts, and management representatives, simulating real-world response scenarios and fostering teamwork within the team.
Learning from every test. The primary objective of testing is to identify weaknesses and improve your DR plan. Track everything: timing, response quality, communication breakdowns.
Conducting a retrospective. Use your DR exercises and drills to analyze successes and failures, identify areas for improvement in the DR plan and update your plan based on the lessons learned.
Encourage open discussion and feedback from all participants, including the IRT and potentially impacted stakeholders.
Identify areas where the plan fell short or where communication could be improved.
Apply these insights to fortify your DR plan and improve your company’s overall disaster preparedness.
Step 4: Make the plan accessible
Ensure your DR plan is readily accessible to your IRT members, even during a disaster. Consider storing it in a secure, cloud-based location accessible from various devices and internet connections. Ensure you can access your plan even if your primary environment is down.
Step 5: Leverage the cloud for DR testing
Consider cloud-based solutions for DR testing and recovery. This eliminates the need for ongoing infrastructure investment dedicated solely to testing purposes. Leveraging tools like cloud storage and virtualized infrastructure services provide flexible, affordable options.
Here are some key benefits of cloud-based DR testing:
Cost-effectiveness: Cloud platforms offer on-demand resources, eliminating the need for dedicated infrastructure and associated costs.
Scalability: Cloud resources can be easily scaled up or down to meet your specific testing needs.
Repeatability: Cloud environments allow for replicating test scenarios consistently, facilitating effective training and process improvement.
Final thoughts: Test, Learn, Refine, Repeat
Disaster recovery isn’t a one-and-done process. Every test is a chance to learn, refine, and prepare better for the next incident. Businesses that test regularly not only reduce downtime—they build trust with their teams, customers, and stakeholders.
As organizations race to innovate in AI, efficient, scalable, and cost-effective cloud storage has become key to their success. Whether you’re training massive models or deploying real-time inference pipelines, following best practices for AI storage will help you maximize performance, minimize costs, and ensure the integrity and availability of your most valuable AI asset—data.
In this blog, we’re going to take a look at five of those best practices, to help you get the most out of your cloud storage solution when working with AI.
Ebook: “Why Object Storage Is Ideal for AI Workflows”
Wondering what type of data architecture makes the most sense for your AI initiatives? Check out our latest ebook, “Why Object Storage is Ideal for AI Workloads,” and learn all the advantages this approach to cloud storage offers across the entire model lifecycle.
1. Understand Your Data Lifecycle
You’ve assembled your training data set, loaded it into fast storage next to your GPU compute, and hit the button to start your training. What happens when the training run is complete? If you’re just going to delete that data set, then great—enter rm -r and simply move on.
If not, though, you’ll need to carefully consider the ongoing costs of storage. Leaving that dataset where it is will likely cost you many times over what you’d spend archiving it to a more cost-effective location. By fully understanding and mapping your data lifecycle—and distinguishing between active (e.g., during model training), and inactive data (e.g., archived/dated model versions)—you can manage your storage costs much more efficiently.
2. Check In Your Checkpoints
Training AI models is a delicate, resource-intensive process. Hardware failures, software bugs, and even power outages can derail week-long training runs, wasting precious time and compute resources.
The two most important steps you can take to avoid these kinds of snags are:
Frequent checkpointing: This means regularly saving a model’s state so you can pick the training process back up from the last checkpoint, rather than starting all over again at square one.
Backup checkpoint data to the cloud: Storing checkpoint data on only local drives alone can be very risky. If the local storage fails, your checkpoints—and all the progress they represent—could be lost. That’s why you should always back up checkpoint data to secure cloud storage solutions as well. This dual approach ensures both speed (for quick recovery) and durability (for disaster recovery), letting you and your team rest easy knowing your hard work is being protected.
3. Keep Your Model Safe
With that same spirit in mind, don’t forget that your models require safekeeping, too. It takes a lot of time and money to train AI models, so protecting them—whether from hardware failure, human error, ransomware attack, or other threats—is absolutely paramount. To safeguard your models:
Use your cloud provider’s object lock to prevent accidental or malicious deletion.
Implement regular, automated backups of both model binaries and associated metadata.
Store critical models in geographically redundant locations for disaster recovery.
These few simple steps can go a very long way to ensuring that your valuable, hard-earned models remain safe and functional, even when things take a turn for the worse.
4. Don’t Lock Your Data Behind a Paywall
Let’s imagine you’re planning your next training run. When looking at cloud providers, you discover that you can realize significant savings by switching GPU compute providers. The only problem is, your current provider will charge you an arm and a leg to move the data to where it needs to be. There’s still a net gain from moving, but you lose significant margin by paying this exorbitant “exit toll,” known as an egress fee. This is why, before committing to a storage provider, you should carefully review its pricing structures and fees, including the following:
Calculate the total cost of moving your data, not just storing it.
Consider multi-cloud strategies or providers that offer free or low-cost egress for AI workloads.
By understanding these costs upfront, you retain the flexibility to optimize your infrastructure as business needs evolve, and avoid the all-too-common trap of hidden fees.
5. Do the Mirroring Math: The Replication Equation
Let’s imagine you’ve found yourself a cost-effective storage option with a specialized cloud object storage provider. Even after finding the right solution with the right pricing structure and performance, there are considerations to be made. No matter how quickly you can download the data, if compute and data are in different locations there’s no escaping the fact that your GPUs might be spinning idle waiting for that data to arrive.
To avoid this predicament, break out your calculator and do the “mirroring math”:
Calculate the time and cost required to replicate (mirror) data to a location near your GPUs before training starts.
Weigh the benefits of lower storage costs against the potential delays and additional storage expenses during training.
For large or frequently accessed datasets, it may be worth pre-staging data in high-throughput storage close to your compute.
Ask yourself: Is it faster and/or cheaper to replicate the data upfront to be in close proximity to your GPUs, or does the time required to mirror the data and the additional storage cost during the training run outweigh the benefits? Intelligent data placement—balancing cost, performance, and proximity—ensures your AI workloads run efficiently and cost-effectively.
Building a Future-Proof AI Storage Strategy
The relentless pace of AI innovation demands a storage strategy that is agile, scalable, and cost-effective. Thankfully, the above five best practices can go quite a long way to ensuring the long-term success of your AI project
By understanding the entirety of your data lifecycle—checkpointing wisely, securing your models, avoiding data lock-in, and optimizing data placement—your team is laying the groundwork for sustained AI success. No matter what industry you’re in, these best practices will help to control costs, accelerate innovation, maintain compliance, and protect your team’s most valuable digital assets, in both the near and long term.
Last week, a misconfiguration in Google Cloud’s API infrastructure led to a major global outage. Not long before that, IBM Cloud suffered its second significant disruption in a matter of weeks. The incidents impacted everything from enterprise infrastructure to consumer-facing apps—Gmail, Spotify, Cloudflare, and countless internal systems built on top of these platforms.
Understandably, much of the coverage has focused on what went wrong. But the more important question might be: Why does something like this ripple so far and wide in a system supposedly built for resilience?
Single points of failure in a multi-service world
One might assume that as cloud providers scale, their reliability scales with them. However, these outages reveal a critical distinction: the difference between data-layer resilience and control-plane fragility.
The problem is, that robust data layer can be rendered useless if the “front door” is locked. Hyperscale cloud platforms have grown so interdependent and complex that a fault in one layer can bring vast swaths of unrelated services to a halt. This is the risk of vertical integration: When one vendor provides compute, storage, networking, and identity, a simple bug or misconfiguration can cascade through thousands of applications, not because the applications are fragile, but because they’ve all tied themselves to the same operational backbone.
Redundancy, or the illusion of it?
In theory, cloud architecture encourages redundancy. But in practice, many companies—even those using multi-cloud strategies—tend to consolidate key services like authentication and orchestration with a single vendor. When that vendor’s services go down, it doesn’t matter that your data is replicated across three availability zones in the same data center. If you can’t log in to access it, your redundancy becomes purely theoretical.
After last week’s outages, some companies may re-evaluate their cloud strategy—but it’s not as easy as flipping a switch. True diversification is complex, requiring time, engineering resources, and a cultural shift toward designing for failure.
The reality: Fewer assumptions, more contingencies
The knee-jerk reaction to events like these is often to demand better SLAs, more transparency, or faster recovery times. Those are valid asks. But they might miss the deeper lesson: Assumptions about uptime and “X-nines” reliability are only helpful until the moment they aren’t. What users need are not just better guarantees, but clearer paths to self-determination when things break.
That might look like:
Designing for graceful degradation. What can your service do when its cloud provider is partially offline?
Reconsidering dependencies. Are you tying core logic to a provider’s proprietary APIs, or abstracting where possible?
Asking harder questions during vendor selection. Not just, “Can it scale?” but “What happens when it fails?”
Case study: Sardius Media bakes in redundancy
Sardius Media, a global video platform, built cloud redundancy into its DNA. Every piece of media is replicated across multiple S3 compatible storage providers—including Backblaze B2—using a proprietary “race” mechanism that always delivers the fastest, most reliable storage experience for end users. This architecture keeps files available, resilient, and protected, even if one provider has an outage.
No single point of failure: Content lives across multiple clouds
Best performance: Requests race to the fastest provider in real time
Durability, affordability, and global reach—Backblaze B2 wins the race up to 80% of the time globally
Sardius Media’s strategy proves that open, multi-provider storage isn’t just theory—it’s operational resilience in action.
What does that mean for you?
The answer isn’t to abandon the cloud, but to get smarter about how you use it. This means architecting systems that don’t just have data redundancy, but true operational independence.
Maybe that means replicating data to providers who specialize rather than consolidate. Or maybe it just means revisiting architectures that have become too reliant on invisible scaffolding.
What’s clear is this: reliability isn’t a feature you buy from the cloud. It’s a design philosophy that must be shared.
Under pressure to do more with less? (Who isn’t, right?)
Whether you’re an IT leader or a startup founder, the last thing you want to do is waste time and money wrestling with expensive, overcomplicated cloud storage. According to a new report from Informa TechTarget’s Enterprise Strategy Group (ESG), you don’t have to. Backblaze B2 Cloud Storage delivers:
Up to 3.2x lower total cost of ownership (TCO)
Up to 56% lower monthly storage costs
Up to 92% less time and effort to manage data
Up to 100% lower download and transaction costs
Up to 91% savings on cloud to cloud (C2C) migration costs
Economic validation: Motivation, results, and methodology
The independent analysis confirms what many Backblaze B2 users already know: Our cloud storage platform is more affordable and easier to manage compared to legacy cloud providers like AWS, Google Cloud Platform, and Azure.
To develop these findings, the ESG analysts talked to customers. They validated use cases. They used our product and verified the accuracy of our listed pricing and cost calculator. And then, they took those results along with the knowledge they’ve gathered over decades of experience to quantify the benefits that organizations can expect by using the Backblaze B2 Cloud Storage platform.
Powerful storage, real savings
The ESG report highlights how Backblaze’s predictable pricing—including at least 3x free egress, if not totally free egress in many cases—can help businesses skip the painful math of legacy storage and start getting more value out of their data. Whether you’re hosting content, training AI models, backing up critical data, or building applications, B2 Cloud Storage gives you freedom without vendor lock-in.
It’s not just about saving money—it’s about reclaiming time and resources to focus on innovation.
AI workloads don’t play by the same rules as your average enterprise app, and if you’ve looked at your cloud bill lately, you probably know that already. They have unique demands that make them especially vulnerable to hidden AI storage costs. Think: massive parallel GPU training, nonstop data shuffling, and frequent checkpointing.
The problem? Most cloud pricing models weren’t built for this kind of action. They were designed when workloads were a lot more predictable. So, when you run AI workloads on storage models built by hyperscalers, the costs add up quickly, and often invisibly.
Download the ebook
Struggling to keep AI storage costs under control? Download our free ebook to discover how to optimize cloud storage for AI workloads—without compromising performance.
Here are five reasons your cloud bill for AI workloads could spiral out of control:
1. Death by API call: Soaring costs in AI training pipelines.
AI workloads are packed with transactions. Every ingest of raw data, training round, inference batch, or logging step triggers API calls—PUTs, GETs, LISTs, and COPYs. If you’re training a foundational model like Deepseek v3 or Llama 2, you could be making millions of small transactions a day just by uploading all the raw data you require for training.
Each transaction might cost a fraction of a cent—but they add up.
Example: Let’s assume a model needs 1 trillion pretraining tokens. Different data sources contribute varying numbers of tokens per file. For this exercise, let’s assume the following token counts:
Web pages: ~1,000 tokens/page (e.g., blog posts, articles)
A typical large language model (LLM) training mix might look like this:
Source
% of tokens
Tokens contribution
Files required (approx.)
Web pages
40%
400B tokens
400M files
Books
20%
200B tokens
2M files
Code
15%
150B tokens
300M files
News articles
15%
150B tokens
187.5M files
Academic papers
10%
100B tokens
20M files
Total
100%
1T tokens
~909.5M files
If you’re ingesting 909.5 million files to AWS S3 at $0.005 per 1,000 PUTs (pricing as of April 2025), then you’d be charged:
909,500,000 ÷ 1,000 = 909,500 units
909,500 × $0.005 = $4,547.50
That’s $4,547.50 in just PUT transaction fees—for just collecting all the data you need for training. And that’s not counting GETs, LISTs, or any other operations that are necessary to support the full AI data pipeline.
2. The small file tax: How small files drive up AI cloud storage costs
Models trained on image slices, text tokens, or time-series data can create millions of small files. These not only trigger excessive API calls, but also suffer from the following:
Some providers bill you by minimum object size (e.g., rounding all small files up to 128KB).
Every small object can trigger a full-priced transaction.
Frequent access means you’re paying for reads, not just storage.
This mismatch means your dataset of 100 million 10KB files could behave (and cost) like a much larger, high-churn workload.
3. Why cold storage fails for AI data workloads
Deep archive tiers may be cheap upfront, but they’re a poor fit for iterative AI workflows. Need to rehydrate training data to rerun a model? Get ready to wait hours and pay per retrieval. Need to delete? You could get hit with minimum retention penalties, and pay for that data as if you held onto it for 60, 90, or even 180 days.
AI workflows are iterative. You’re not archiving log files; you’re experimenting, fine-tuning, and reprocessing constantly. Cold storage is rarely compatible with that.
4. Egress fees: The hidden cost of moving AI training data
Egress is a silent killer. It’s the fee you pay every time you move data out of cloud storage. In AI workflows, that’s often necessary for:
Sending training data to a GPU cluster.
Validating models on a local system.
Migrating to another provider.
Collaborating with partners across clouds or regions.
These fees scale linearly with data volume, which is a problem when your AI pipeline is pulling terabytes or petabytes per day.
5. AI data lifecycle rules can backfire
You might set up lifecycle rules to move infrequently accessed data to cheaper tiers—sounds smart, right?
Except:
Lifecycle transitions often come with per-object fees.
Accessing those objects later triggers retrieval fees, or breaks performance expectations.
Deleting or overwriting too early triggers penalties.
And all of this assumes you even know your data’s “temperature” in advance—which, in AI workflows, changes day to day.
Smarter AI Storage
Your AI pipeline isn’t just a compute problem: It’s a data movement and storage orchestration engine. And that’s exactly where traditional cloud pricing models fall short.
If your cloud bill is blowing up, it’s probably not just because you kicked off another training run. It’s the millions of GET requests, the silent egress charges, and those archive tier retrievals you didn’t plan for.
The good news? Once you know where the hidden costs are, you can start building smarter.
In an earlier blog post, I explained how to build your own LLM with Backblaze B2 + Jupyter Notebook, implementing a simple conversational AI chatbot using the LangChain AI framework to implement retrieval-augmented generation (RAG). The notebook walks you through the process of loading PDF files from a Backblaze B2 Bucket into a vector store, running a local instance of a large language model (LLM) and combining those to form a chatbot that can answer questions on its specialist subject.
That article generated a lot of interest, and a few questions:
“Could you make this into a web app, like ChatGPT?”
“Could you use this with OpenAI? DeepSeek?”
“Could I load multiple collections of documents into this?”
“Could I run multiple LLMs and compare them?”
“Can I add new documents to the vector store as they are uploaded to the bucket?”
The answer to all of these questions is “Yes!”
Today, I’ll present a simple conversational AI chatbot web app with a ChatGPT-style UI that you can easily configure to work with OpenAI, DeepSeek, or any of a range of other LLMs. In future blog posts, I’ll extend this to allow you to configure multiple LLMs and document collections, and integrate with Backblaze B2’s Event Notifications feature to load documents into the vector store within seconds of them being uploaded.
And, here’s a very short video of the chatbot in action:
Retrieval-augmented generation, or RAG for short, is a technique that applies the generative features of an LLM to a collection of documents, resulting in a chatbot that can effectively answer questions based on the content of those documents.
A typical RAG implementation splits each document in the collection into a number of roughly equal-sized, overlapping chunks, and generates an embedding for each chunk. Embeddings are vectors (lists) of floating point numbers with hundreds or thousands of dimensions. The distance between two vectors indicates their similarity. Small distances indicate high similarity and large distances indicate low similarity.
The RAG app then loads each chunk, along with its embedding, into a vector store. The vector store is a special-purpose database that can perform a similarity search–given a piece of text, the vector store can retrieve chunks ranked by their similarity to the query text by comparing the embeddings.
Let’s put the pieces together:
Given a question from the user (1), the RAG app can query the vector store for chunks of text that are similar to the question (2). This will be the context that helps the LLM answer the user’s question. Here’s a concrete example using the Backblaze documentation collection: Given the question, “Tell me about object lock,” the vector store returns four document chunks, each of about 170 words, to the app (3). Here is a link to the text of, and a short extract from, each chunk:
Object Lock: With Object Lock Legal Hold, files are prevented from being changed or deleted, but the immutability does not have a defined retention period.
Object Lock: You can enable Object Lock on a bucket when you create a new bucket or on an existing bucket.
Object Lock: Object Lock in Backblaze B2 was designed with the Immutability feature in Veeam Backup & Replication in mind.
Enable Object Lock with the S3 Compatible API: To enable Object Lock on an existing S3 compatible bucket, add the x-amz-bucket-object-lock-token header with a value of 1 to the S3 Put Object Lock Configuration API call.
Unsurprisingly, three of the four results are extracts from the main documentation article on Object Lock.
In order to provide a conversational experience, the RAG app maintains a chat history in a message store. The RAG app retrieves the message history (4) to form part of the query it will send to the LLM.
A system prompt sets the guidelines for the LLM to generate responses. In a RAG, the system prompt typically specifies that the response should be based on retrieved document data rather than model memorization, and attempts to prevent hallucinations by ensuring that the model does not fabricate information if no relevant documents are found. Here is the system prompt from the RAG app:
Use the following pieces of context and the message history to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer.
The RAG submits the system prompt, the context, the last few messages in the conversation, and the user’s question to the LLM (5), which generates a, hopefully useful, response (6). Here’s the answer it provided to the above question:
Object Lock is a feature that allows users to enforce immutability on files stored in cloud storage, specifically in services like Backblaze B2 and AWS S3. Here are the key points about Object Lock:
Immutability: Once a file is locked, it cannot be modified or deleted until a specified retention period expires or a legal hold is lifted.
Retention Periods: Users can set a retention period when locking a file. During this time, the file remains immutable, meaning it cannot be changed or deleted.
Legal Hold: Users can place files under a legal hold, which prevents modifications or deletions indefinitely until the hold is removed.
Enabling Object Lock: Object Lock can be enabled for new buckets or existing ones, but it must be turned on at the bucket level before files are uploaded.
Integrations: Some applications, like Veeam Backup & Replication, offer built-in support for Object Lock, making the process easier for users when they want to ensure file immutability during backups.
No Extra Cost: There is no additional fee for using Object Lock; however, standard storage charges for the locked files still apply.
Mistakes in Locking: If a user locks a file for longer than intended, they may need to contact support to resolve the situation, which could involve closing their storage account in some cases.
Overall, Object Lock is a crucial feature for organizations that need to ensure data integrity and compliance with regulations concerning data retention.
The RAG app adds the user’s question and the LLM’s response to the message store (7), returns the answer to the user (8), and awaits the next question.
A quick tour of the sample app
The sample app is on GitHub at https://github.com/backblaze-b2-samples/ai-rag-app. The app is open source, under the MIT license, so you can use it as a basis for your own experimentation without any restrictions. The app was originally written to demonstrate RAG with Backblaze B2 Cloud Storage, but it works with any S3 compatible object store.
The README file covers configuration and deployment in some detail; in this blog post, I’ll just give you a high-level overview. The sample app is written in Python using the Django web framework. API credentials and related settings are configured via environment variables, while the LLM and vector store are configured via Django’s settings.py file:
# Change source_data_location and vector_store_location to match your environment # search_k is the number of results to return when searching the vector store DOCUMENT_COLLECTION: CollectionSpec = { 'name': 'Docs', 'source_data_location': 's3://blze-ev-ai-rag-app/pdfs', 'vector_store_location': 's3://blze-ev-ai-rag-app/vectordb/docs/openai', 'search_k': 4, 'embeddings': { 'cls': OpenAIEmbeddings, 'init_args': { 'model': "text-embedding-3-large", }, }, }
The sample app is configured to use OpenAI GPT-4o mini, but the README explains how to use different online LLMs such as DeepSeek V3 or Google Gemini 2.0 Flash, or even a local LLM such as Meta Llama 3.1 via the Ollama framework. If you do run a local LLM, be sure to pick a model that fits your hardware. I tried running Meta’s Llama 3.3, which has 70 billion parameters (70B), on my MacBook Pro with the M1 Pro CPU. It took nearly three hours to answer a single question! Llama 3.1 8B was a much better fit, answering questions in less than 30 seconds.
Notice that the document collection is configured with the location of a vector store containing the Backblaze documentation as a sample dataset. The README file contains an application key with read-only access to the PDFs and vector store so you can try the application without having to load your own set of documents.
If you want to use your own document collection, a pair of custom commands allow you to load them from a Backblaze B2 Bucket into the vector store and then query the vector store to test that it all worked.
First, you need to load your data:
% python manage.py load_vector_store Deleting existing LanceDB vector store at s3://blze-ev-ai-rag-app/vectordb/docs Creating LanceDB vector store at s3://blze-ev-ai-rag-app/vectordb/docs Loading data from s3://blze-ev-ai-rag-app/pdfs in pages of 1000 results Successfully retrieved page 1 containing 618 result(s) from s3://blze-ev-ai-rag-app/pdfs Skipping pdfs/.bzEmpty Skipping pdfs/cloud_storage/.bzEmpty Loading pdfs/cloud_storage/cloud-storage-about-backblaze-b2-cloud-storage.pdf Loading pdfs/cloud_storage/cloud-storage-add-file-information-with-the-native-api.pdf Loading pdfs/cloud_storage/cloud-storage-additional-resources.pdf ... Loading pdfs/v1_api/s3-put-object.pdf Loading pdfs/v1_api/s3-upload-part-copy.pdf Loading pdfs/v1_api/s3-upload-part.pdf Loaded batch of 614 document(s) from page Split batch into 2758 chunks [2025-02-28T01:26:11Z WARN lance_table::io::commit] Using unsafe commit handler. Concurrent writes may result in data loss. Consider providing a commit handler that prevents conflicting writes. Added chunks to vector store Added 614 document(s) containing 2758 chunks to vector store; skipped 4 result(s). Created LanceDB vector store at s3://blze-ev-ai-rag-app/vectordb/docs. "vectorstore" table contains 2758 rows
Now you can verify that the data is stored by querying the vector store. Notice how the raw results from the vector store include an S3 URI identifying the source document:
% python manage.py search_vector_store 'Which B2 native APIs would I use to upload large files?' 2025-03-01 02:38:07,740 ai_rag_app.management.commands.search INFO Opening vector store at s3://blze-ev-ai-rag-app/vectordb/docs/openai 2025-03-01 02:38:07,740 ai_rag_app.utils.vectorstore DEBUG Populating AWS environment variables from the b2 profile Found 4 docs in 2.30 seconds 2025-03-01 02:38:11,074 ai_rag_app.management.commands.search INFO page_content='Parts of a large file can be uploaded and copied in parallel, which can significantly reduce the time it takes to upload terabytes of data. Each part can be anywhere from 5 MB to 5 GB, and you can pick the size that is most convenient for your application. For best upload performance, Backblaze recommends that you use the recommendedPartSize parameter that is returned by the b2_authorize_account operation. To upload larger files and data sets, you can use the command-line interface (CLI), the Native API, or an integration, such as Cyberduck. Usage for Large Files Generally, large files are treated the same as small files. The costs for the API calls are the same. You are charged for storage for the parts that you uploaded or copied. Usage is counted from the time the part is stored. When you call the b2_finish_large_file' metadata={'source': 's3://blze-ev-ai-rag-app/pdfs/cloud_storage/cloud-storage-large-files.pdf'} ...
The core of the sample application is the RAG class. There are several methods that create the basic components of the RAG, but here we’ll look at how the _create_chain() method brings together the system prompt, vector store, message history, and LLM.
First, we define the system prompt, which includes a placeholder for the context—those chunks of text that the RAG will retrieve from the vector store:
# These are the basic instructions for the LLM system_prompt = ( "Use the following pieces of context and the message history to " "answer the question at the end. If you don't know the answer, " "just say that you don't know, don't try to make up an answer. " "\n\n" "Context: {context}" )
Then we create a prompt template that brings together the system prompt, message history, and the user’s question:
# The prompt template brings together the system prompt, context, message history and the user's question prompt_template = ChatPromptTemplate( [ ("system", system_prompt), MessagesPlaceholder(variable_name="history", optional=True, n_messages=10), ("human", "{question}"), ] )
Now we use LangChain Expression Language (LCEL) to bring the various components together to form a chain. LCEL allows us to define a chain of components declaratively; that is, we provide a high-level representation of the chain we want, rather than specifying how the components should fit together.
Notice the log_data() helper method—it simply logs its input and passes it on to the next component in the chain.
# Create the basic chain # When loglevel is set to DEBUG, log_input will log the results from the vector store chain = ( { "context": ( itemgetter("question") | retriever | log_data('Documents from vector store', pretty=True) ), "question": itemgetter("question"), "history": itemgetter("history"), } | prompt_template | model | log_data('Output from model', pretty=True) )
Assigning a name to the chain allows us to add instrumentation when we invoke it:
# Give the chain a name so the handler can see it named_chain: Runnable[Input, Output] = chain.with_config(run_name="my_chain")
Now, we use LangChain’s RunnableWithMessageHistory class to manage adding and retrieving messages from the message store:
The input to the chain is a Python dictionary containing the question, while the config argument configures the chain with the Django session key and a callback that annotates the chain output with its execution time. Since the chain output contains Markdown formatting, the API endpoint that handles requests from the front end uses the open source markdown-it library to render the output to HTML for display.
The remainder of the code is mostly concerned with rendering the web UI. One interesting facet is that the Django view, responsible for rendering the UI as the page loads, uses the RAG’s message store to render the conversation, so if you reload the page, you don’t lose your context.
Take this code and run it!
The sample AI RAG application is open source under the MIT license, and I encourage you to use it as the basis for your own RAG exploration. The README file suggests a few ways you could extend it, and I also draw your attention to conclusion of the README if you are thinking of running the app in production:
[…] in order to get you started quickly, we streamlined the application in several ways. There are a few areas to attend to if you wish to run this app in a production setting:
The app does not use a database for user accounts, or any other data, so there is no authentication. All access is anonymous. If you wished to have users log in, you would need to restore Django’s AuthenticationMiddleware class to the MIDDLEWARE configuration and configure a database.
Similarly, conversation history is stored in memory, so you would need to use a persistent message history implementation, such as RedisChatMessageHistory to run the app in multiple processes or on multiple hosts.
Above all, have fun! AI is a rapidly evolving technology, with vendors and open source projects releasing new capabilities every day. I hope you find this app a useful way of jumping in.
If you’re responsible for managing cloud storage across a fast-growing company, you know the drill: more teams, more data, more buckets—and way more complexity. That’s why we’re launching a new enterprise web console, now entering private preview.
Built for scale, security, and simplicity, the new console gives you:
Centralized control over your organization’s cloud storage.
The ability to add multiple admins who each have their own credentials.
More flexibility in bucket creation, including the ability to create buckets in any region.
Built-in zero-trust security features like mandatory MFA and SSO support.
Whether you’re wrangling storage across departments or delivering managed services to clients, this is the command center that helps you move faster, stay secure, and keep everything organized. Because managing cloud storage shouldn’t be harder than using it.
What’s new in the enterprise web console?
The new web console gives IT admins and managed service providers (MSPs) a clean, central hub for managing B2 Cloud Storage deployments—whether you’ve got a few buckets or a few thousand. Here’s what’s under the hood:
Role-based access controls (RBAC): Assign authorized admin users and utilize a resource group architecture so people only access what they need. Great for zero trust—even better for peace of mind.
Mandatory MFA: Because “security optional” isn’t really an option anymore.
SSO and SCIM support: Manage your user base automatically and at scale.
We also revamped the user interface so it’s faster to navigate, easier on the eyes, and just generally gets out of your way.
Storage where you need it
With this update, you’ll be able to create and manage B2 Buckets in any available region. That unlocks a few big wins:
Ensuring data redundancy and disaster recovery through geographically distributed backup copies.
Optimizing application performance for global users by reducing data access latency.
Compliance with data residency rules.
Ready to get started?
We’re rolling out the enterprise console in private preview starting soon. If you’re a Backblaze customer with a committed contract, reach out to your Customer Success Manager to see if you’re eligible. Not sure who your CSM is? Email [email protected] for help.
General availability is coming later this year. Stay tuned—we’ll keep shipping.
Everyone’s chasing the next breakthrough in AI, pouring money into bigger models and faster chips. But there’s one innovation killer no one’s talking about, and it isn’t compute limits—it’s vendor lock-in.
While you’re optimizing your algorithms, your infrastructure is quietly draining your budget and tying your roadmap to someone else’s agenda. Open cloud providers help you create an ecosystem where data flows freely, innovation isn’t throttled, and every component works harmoniously to drive progress. Yet, for many organizations, vendor lock-in with hyperscalers costs more than just dollars: it comes at the expense of the freedom to innovate on your own terms.
Today, I’m talking through how AI organizations end up locked in with hyperscalers and how to avoid that trap.
Download the ebook
Struggling to keep AI storage costs under control? Download our free ebook to discover how to optimize cloud storage for AI workloads—without compromising performance.
The three pillars of AI infrastructure
At its heart, AI infrastructure rests on three essential pillars:
Compute: The engines powering your models and training processes.
Data management: The systems that capture, store, and organize the massive volumes of data your projects depend on.
Integration and flexibility: The ability to move data seamlessly between various platforms and cloud environments without being tied to a single provider.
When any of these pillars are compromised by vendor lock-in, the consequences are immediate and costly:
Can you freely move workloads between environments?
Are you paying premium prices for basic data transfers?
Is your team spending more time managing infrastructure than building innovative solutions?
These challenges directly hinder your team’s ability to deliver the AI breakthroughs your organization expects.
Understanding vendor lock-in
Vendor lock-in occurs when an organization becomes overly dependent on a single vendor’s products or services, making it difficult—or costly—to switch to alternative solutions. This dependency can manifest in several ways:
Proprietary technologies: When a vendor’s system uses exclusive formats or interfaces, integrating new tools becomes challenging.
Complex pricing: Long-term agreements with rigid terms and hidden fees may restrict flexibility and force you to absorb unexpected costs.
Ecosystem dependence: Relying on one provider’s suite of services can limit your ability to adopt innovative, best-of-breed solutions from other vendors.
In practice, vendor lock-in can hurt innovation by restricting your options, slowing down the pace at which you can adopt new technologies, and diverting resources to manage and maintain a closed system rather than driving creative breakthroughs.
The hidden costs of vendor lock-in
Imagine scaling your AI project only to discover, as Decart did, that egress fees essentially hold your data hostage. Their team needed to train models across multiple GPU clusters simultaneously—a scenario that would have incurred crippling costs with their previous provider. Or consider Grass Network, who found their ability to serve Fortune 1000 clients fundamentally undermined by their cloud vendor’s pricing structure, with egress and deletion fees that made their business model unsustainable at scale.
The pattern is clear: Organizations trapped in vendor-locked systems end up diverting precious resources—both financial and human—away from innovation and toward infrastructure management. This results in delayed training cycles, slower model iterations, and missed market opportunities as engineering talent gets consumed by working around limitations rather than building competitive advantages.
A holistic look at open AI infrastructure
While compute power and advanced analytics often grab headlines, the true strength of an AI system lies in the seamless integration of all its components. An open AI infrastructure can deliver:
Enhanced agility: With a flexible, multi-cloud approach, you can rapidly adopt new tools and technologies without being bound by a single provider’s limitations.
Optimized performance: When data flows effortlessly between compute clusters, storage systems, and analytics platforms, every part of your infrastructure can perform at its peak.
Cost efficiency: Transparent pricing and predictable billing ensure that hidden fees—like those associated with storage tiers and egress—don’t eat into your budget.
Future-proofing: By avoiding proprietary ecosystems, you build an infrastructure that is resilient and adaptable, giving you the freedom to experiment and innovate.
Rethinking storage as the strategic backbone
Among all the components, storage plays a uniquely critical role—it’s the circulatory system that keeps your data moving throughout the AI workflow. The right storage foundation doesn’t just warehouse data; it becomes a strategic asset that enables multi-cloud workflows, maintains cost predictability, and prevents vendor lock-in by allowing seamless integration with different compute engines, GPU clusters, and software platforms. Forward-thinking organizations are increasingly viewing storage not as a commodity, but as the linchpin of AI infrastructure strategy.
Backblaze B2: A foundation for multi cloud storage
Within this framework, Backblaze B2 serves as a robust storage foundation that transforms how AI teams approach multi-cloud workflows. Rather than trying to be everything to everyone, B2 Cloud Storage focuses exclusively on being the best at what matters most for your data: performance, scalability, and predictability.
It effortlessly scales from terabytes to petabytes, accommodating everything from raw training data to archived model outputs without performance degradation. S3 compatibility means it integrates easily with virtually any AI pipeline or tool. Perhaps most importantly, it keeps costs transparent and predictable with straightforward pricing that eliminates the “sticker shock” that plagues many AI projects.
A reliable, independent storage layer doesn’t just help you sidestep the pitfalls of vendor lock-in—it fundamentally changes how your team approaches innovation by removing the technical and financial barriers that traditionally constrain experimentation.
See the open cloud in action
Your company’s data is a powerful resource—learn how to harness it with an AI agent designed to generate meaningful insights. In this deep dive, Backblaze’s Pat Patterson and Jeronimo De Leon will demonstrate how to build an AI agent that can query, analyze, and generate insights from company-specific data—all powered by cost-efficient, scalable cloud storage.
Charting a new course for innovation
Breaking free from vendor lock-in isn’t merely about cutting costs—it’s about reclaiming control over your entire AI infrastructure and accelerating your path to results. When every component, from compute to storage and integration, is designed to be open and flexible, your organization gains the freedom to experiment, iterate, and push the boundaries of what’s possible.
The most successful AI teams we’ve observed are those building on strong, multi-cloud-friendly foundations where data flows without friction or penalty. They’re the ones asking tough questions about their infrastructure choices today to ensure maximum flexibility tomorrow.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.