Post Syndicated from Amy Hunt original https://blog.rapid7.com/2022/01/24/the-great-resignation-4-ways-cybersecurity-can-win/

Pandemics change everything.
In the Middle Ages, the Black Death killed half of Europe’s population. It also killed off the feudal system of landowning lords exploiting laborer serfs. Rampant death caused an extreme labor shortage and forced the lords to pay wages. Eventually, serfs had bargaining power and escalating wages as aristocrats competed for people to work their lands.
Think we invented “The Great Resignation?” 14th-century peasants did.
Last year, more than 40 million Americans quit their jobs. The trend raged across Europe. Workers in China went freelance. The Harvard Business Review reports resignations are highest in tech and healthcare, both seriously strained by the pandemic. Of course, cybersecurity has had a talent shortage for years now. As 2022 and back-to-office plans take shape, expect another tidal wave.
Here are four ideas about how to prepare for it and win.
1. You’ll do better if you label it The Great Rethinking
COVID-19’s daily specter of illness and death has spurred existential questions. “If life is so short, what am I doing? Is this all there is?”
Isolated with family every day, month after month, some of us have decided we’re happier than ever. Others are causing a big spike in divorce and the baby bust. Either way, people are confronting the quality of their relationships. Some friendships have made it into our small, carefully considered “safety pods,” and others haven’t.
As we rethink our most profound human connections, we’re surely going to rethink work and how we spend most of our waking hours.
2. Focus on our collective search for meaning
A mere 17% of us say jobs or careers are a source of meaning in life. But here, security professionals have a rare advantage.
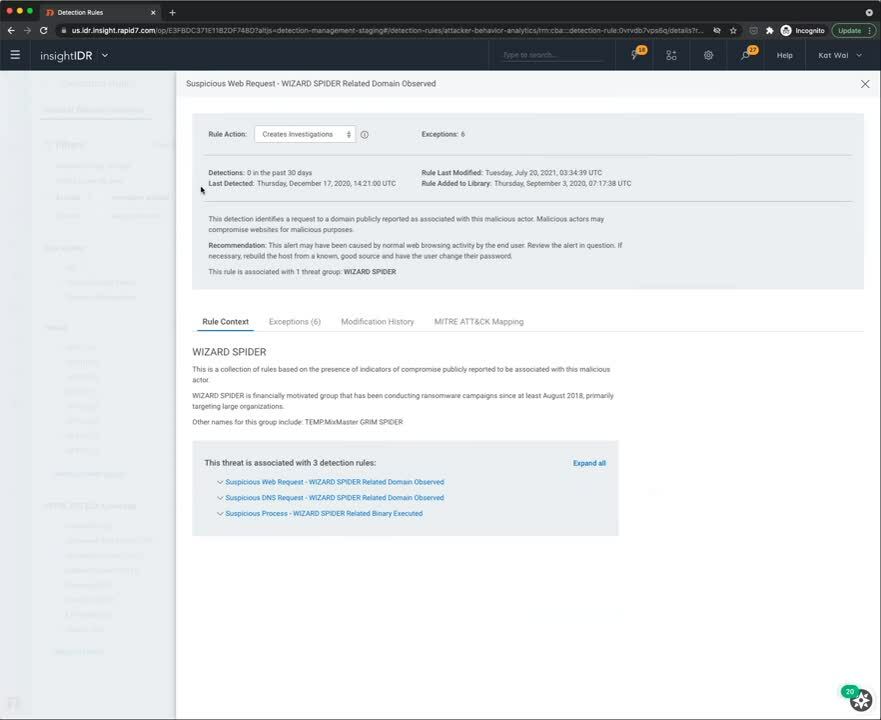
Nearly all cybercrime is conducted by highly organized criminal gangs and adversarial nation states. They’ve breached power grids and pipelines, air traffic, nuclear installations, hospitals, and the food supply. Roughly 1 in 20 people a year suffer identity theft, which can produce damaging personal consequences that drag on and on. In December, hackers shut down city bus service in Honolulu and the Handi-Van, which people with disabilities count on to get around.
How many jobs can be defined simply and accurately as good vs evil? How many align everyday people with the aims of the FBI and the Department. of Justice? With lower-wage workers leading the Great Resignation last year, the focus has been on salary and raises. But don’t underestimate meaning.
3. Winners know silos equal stress and will get rid of them
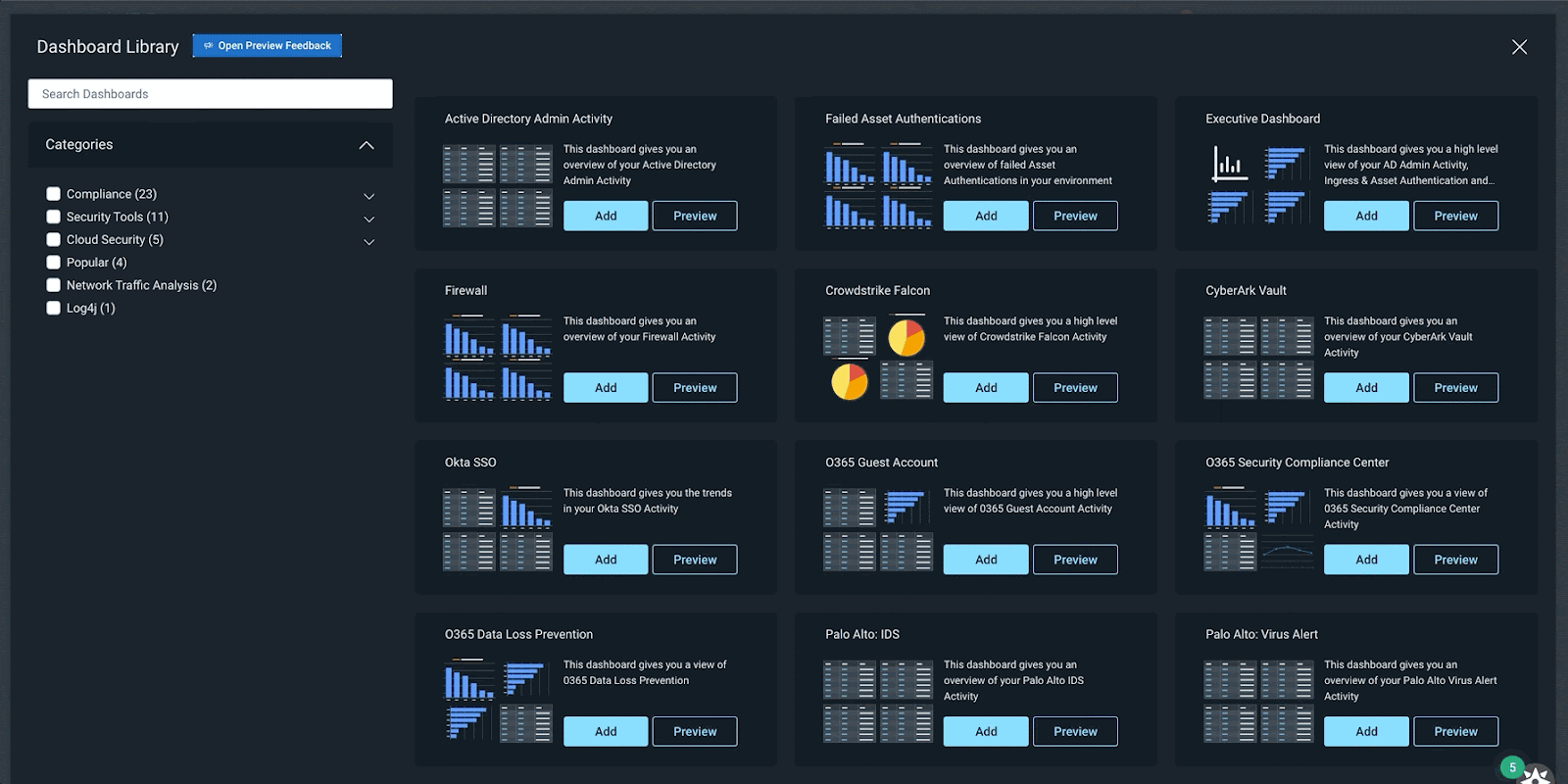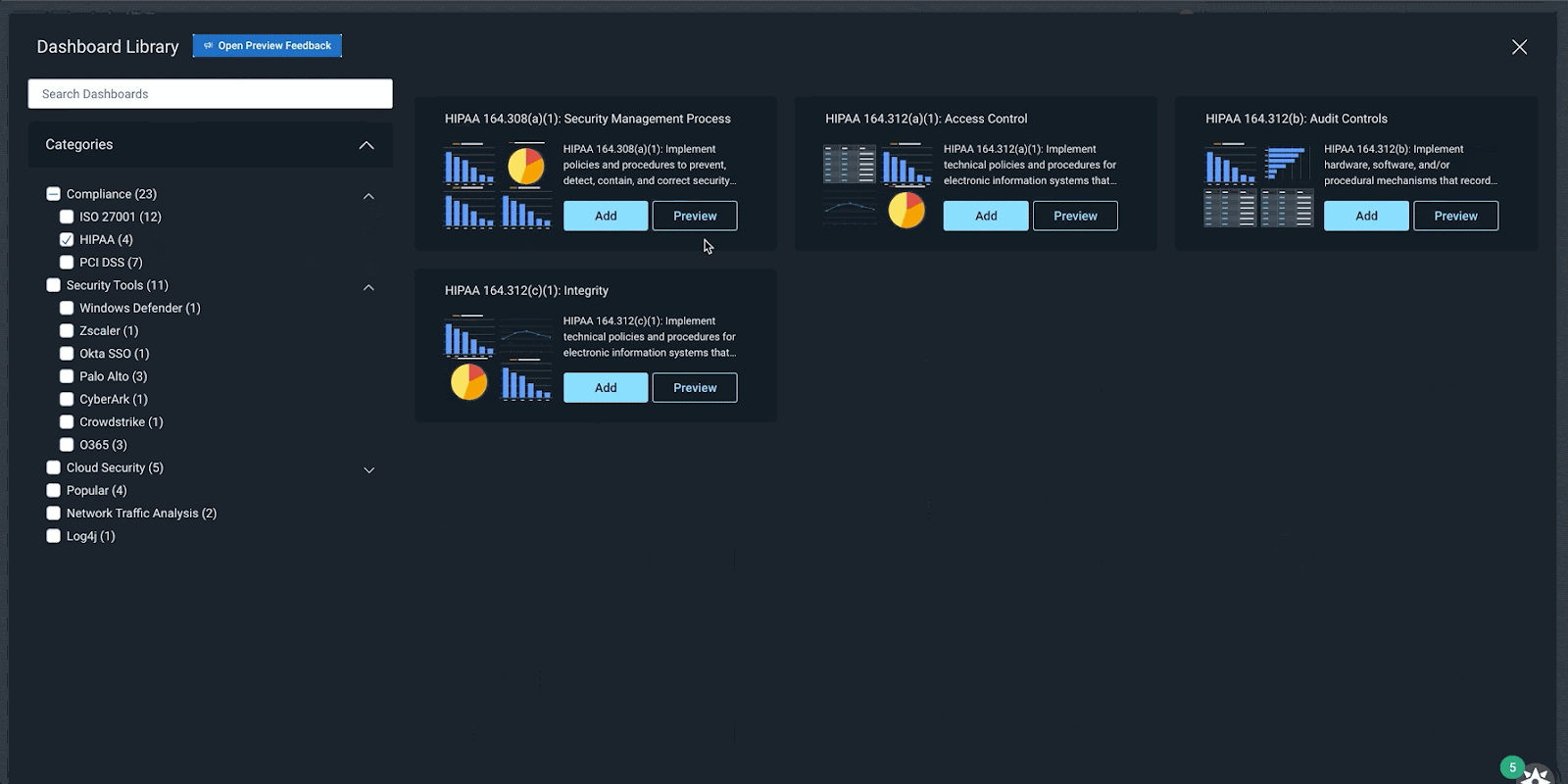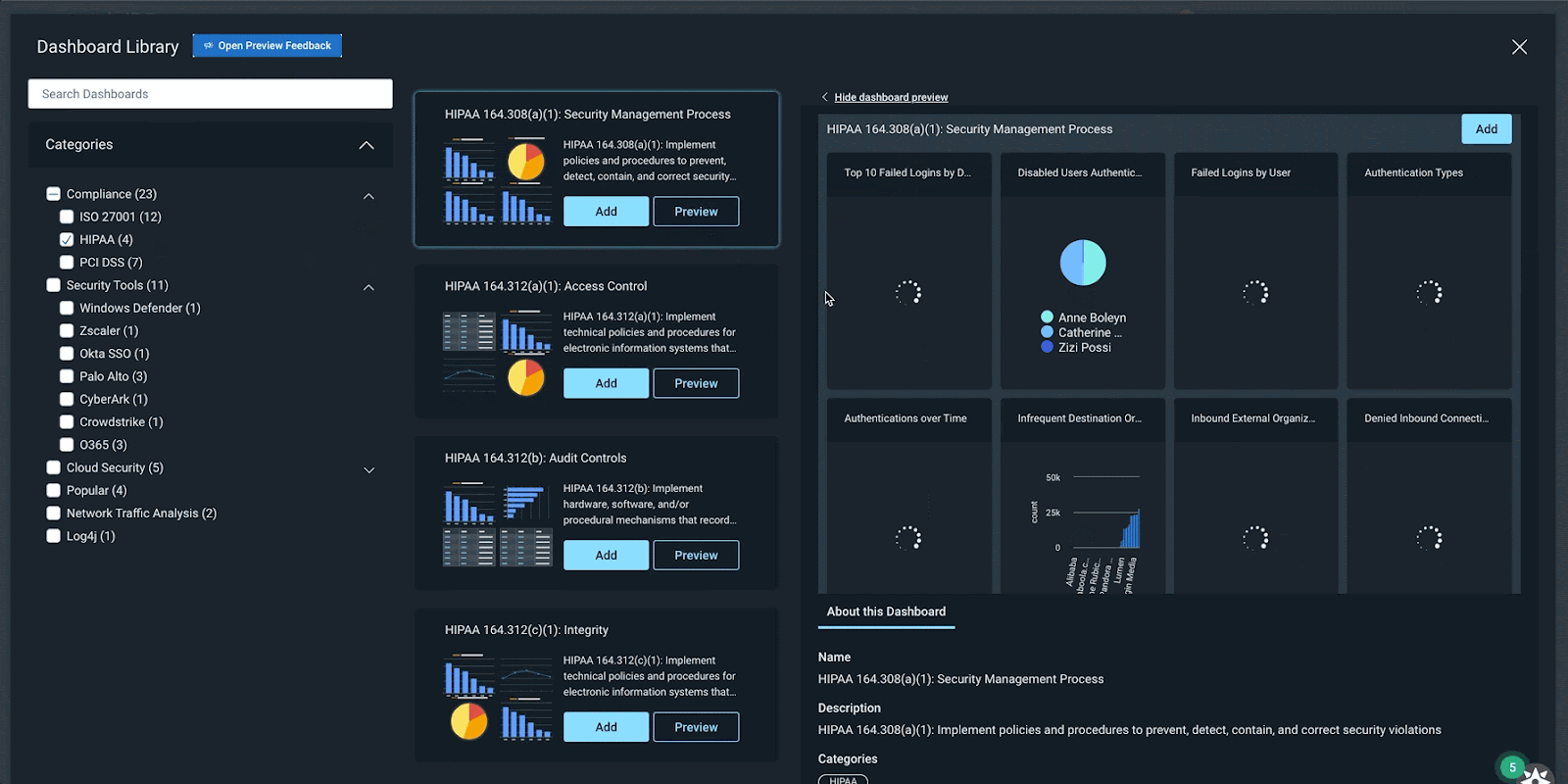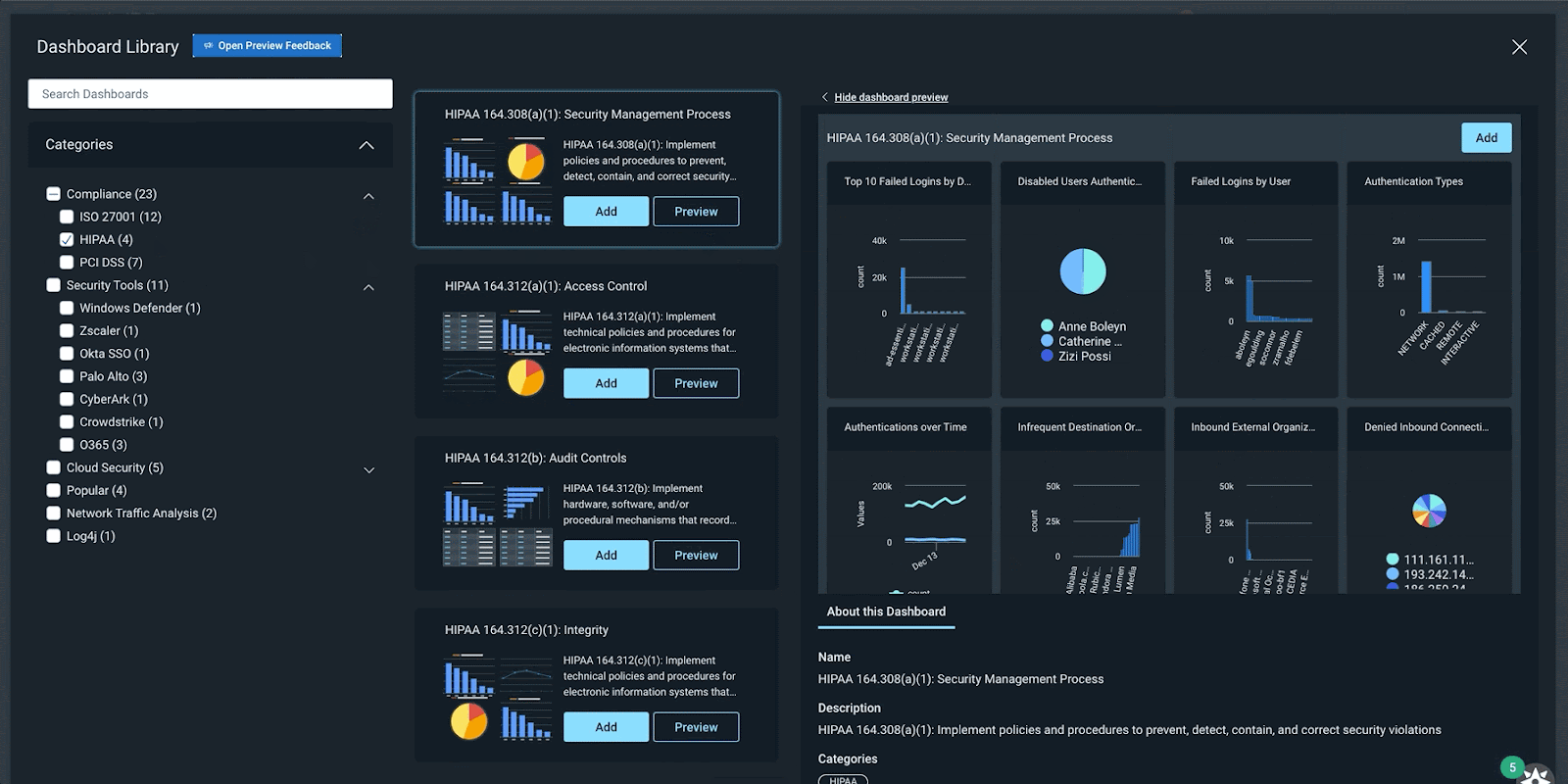
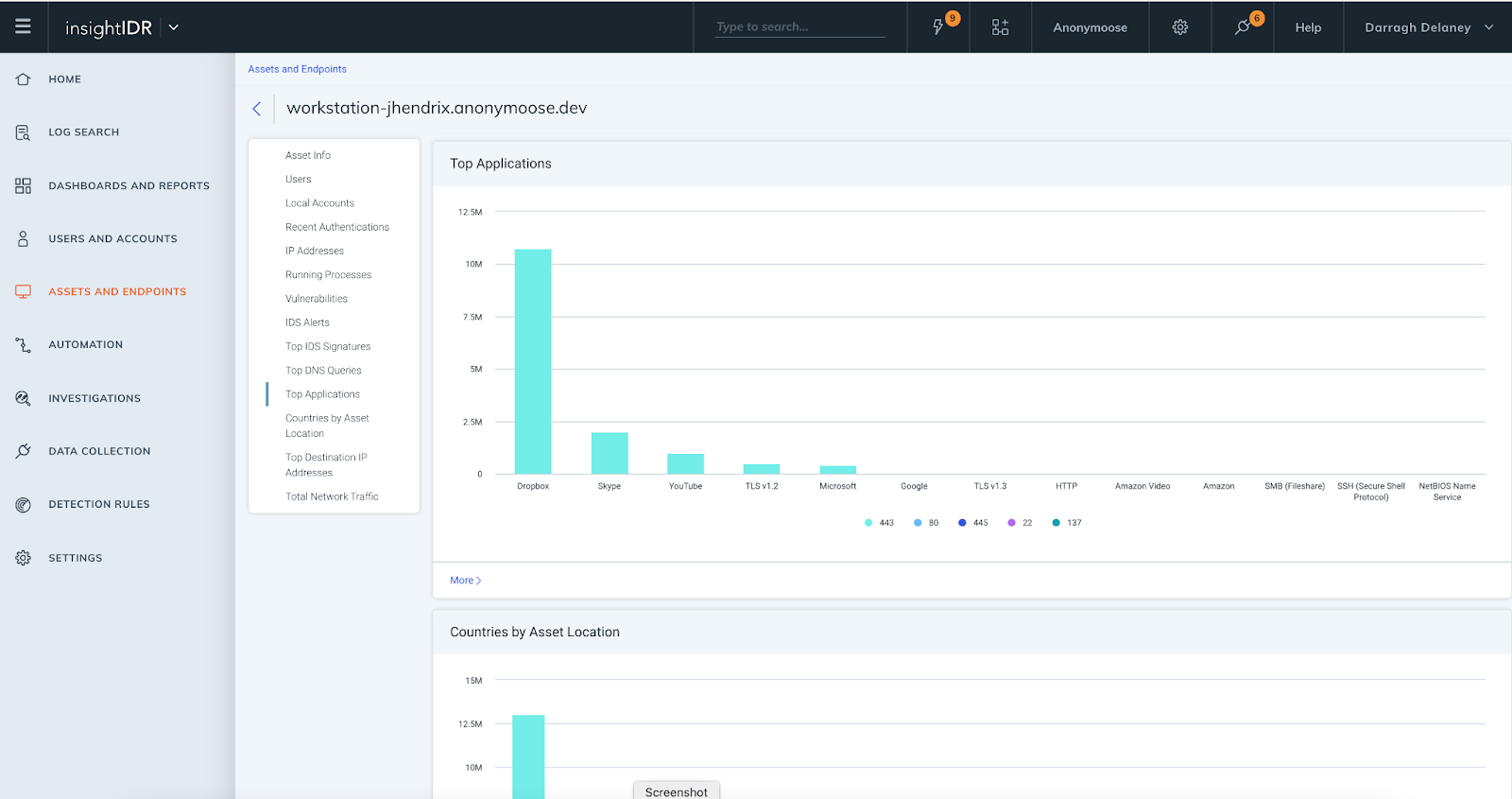
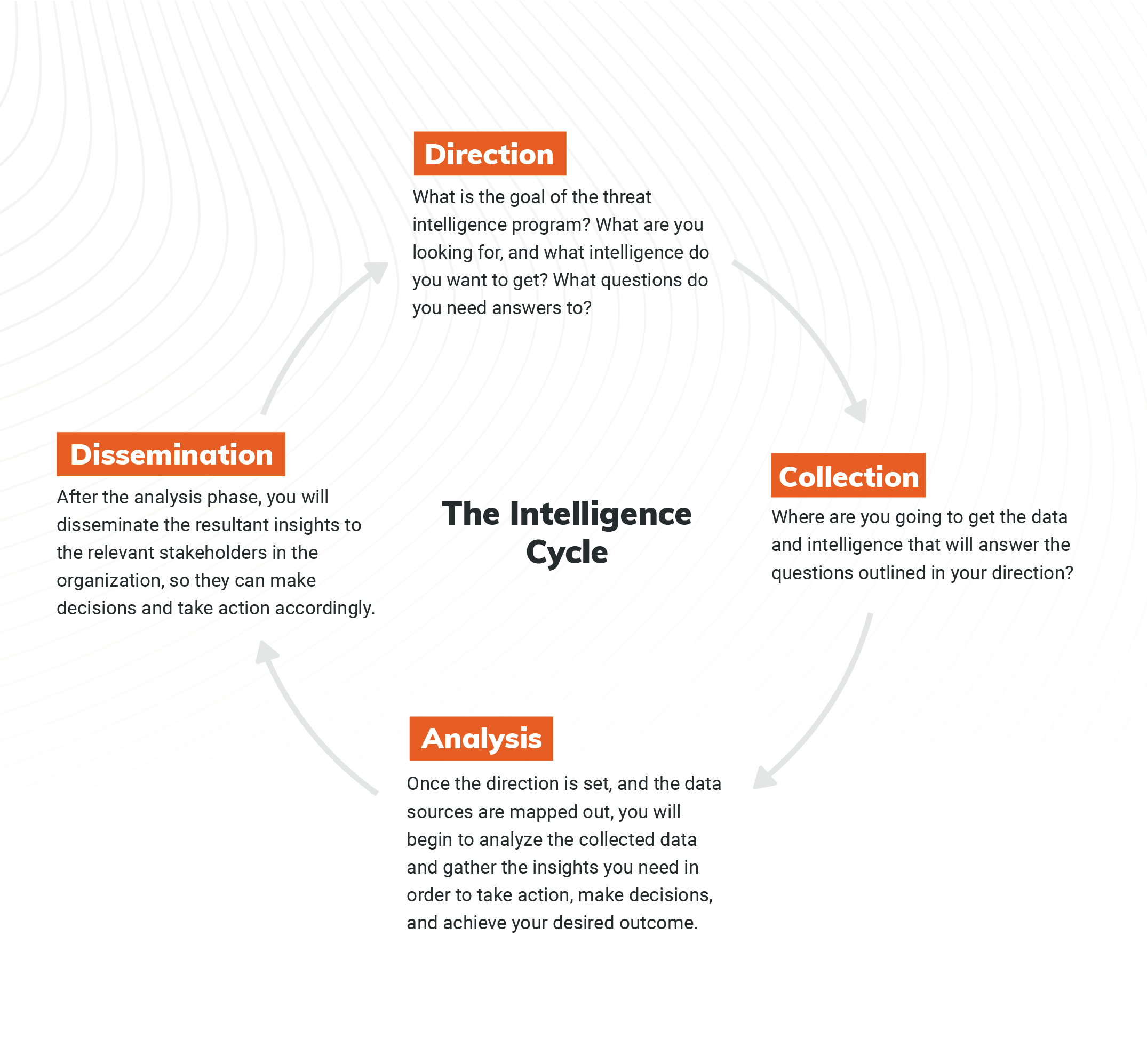
Along with meaning and good pay, consider ways to make your security operations center (SOC) a better place to be. Consolidate your tools. Integrate systems. Extend your visibility. Improve signal-to-noise ratio. The collision of security information and event management (SIEM) and extended detection and response (XDR) protects you from a whole lot more than malicious attacks.
Remote work, hybrid work, and far-flung digital infrastructure are here to stay. So are attackers who’ve thrived in the last two years, shattering all records. If you’re among the 76% of security professionals who admit they really don’t understand XDR, know you’re not alone – but also know that XDR will soon separate winners from losers. Transforming your SOC with it will change what work is like for both you and your staff, and give you a competitive advantage.
4. You can take this message to the C-suite
Lower-wage workers started the trend, but CEO resignations are surging now (and it’s not just Jeff Bezos and Jack Dorsey). They’re employees, too, and the Great Rethinking has also arrived in their homes. Maybe COVID-19 meant they finally spent real time with their kids, and they’d like more of it, please. Maybe they’re exhausted from communicating on Zoom for the last two years. Maybe they think a new deal is in order for everyone.
As you make the case for XDR, consider your ability to give new, compelling context to your recommendations. XDR is the ideal collaboration between humans and machines, each doing what they do best. It reduces the chance executives will have to explain themselves on the evening news. It helps create work-life balance. Of course it makes sense.
And what about when things get back to normal? The history of diseases is they don’t really leave and we don’t really return to “normal.” Things change. We change. You can draw a straight line from the Black Death, to the idea of a middle class, then to the Renaissance. Here’s hoping.














![[The Lost Bots] Episode 6: D&R + VM = WINNING!](https://blog.rapid7.com/content/images/2021/10/-The-Lost-Bots--Episode-1--External-Threat-Intelligence.jpeg)
![[The Lost Bots] Episode 6: D&R + VM = WINNING!](https://play.vidyard.com/sEgEy3WJVZJ7j2oQG5kNJ5.jpg)

![[The Lost Bots] Episode 5: Insider Threat](https://blog.rapid7.com/content/images/2021/09/-The-Lost-Bots--Episode-1--External-Threat-Intelligence.jpeg)
![[The Lost Bots] Episode 5: Insider Threat](https://play.vidyard.com/fEtK639L5UQ8jreJDqLByG.jpg)



![[The Lost Bots] Episode 4: Deception Technology](https://blog.rapid7.com/content/images/2021/08/-The-Lost-Bots--Episode-1--External-Threat-Intelligence-1.jpeg)
![[The Lost Bots] Episode 4: Deception Technology](https://play.vidyard.com/sevYSb7wMxXQdz6WDYQUPz.jpg)
![[R]Evolution of the Cyber Threat Intelligence Practice](https://blog.rapid7.com/content/images/2021/08/evolution-threat-intelligence.jpg)
![[R]Evolution of the Cyber Threat Intelligence Practice](https://blog.rapid7.com/content/images/2021/08/Evolution-of-CTIP_Traditional.png)
![[R]Evolution of the Cyber Threat Intelligence Practice](https://blog.rapid7.com/content/images/2021/08/Evolution-of-CTIP_Updated.png)
