Post Syndicated from David Johnson original https://www.backblaze.com/blog/5-ways-event-notifications-strengthens-your-backup-strategy-automatically/
“Our backups are good, right?”
If you’re responsible for backup operations, you’ve probably heard this question more times than you can count. While the answer should be a simple “yes,” staying on top of backup activities often involves checking multiple systems, reviewing logs, and maintaining manual tracking processes.
Today, I’m sharing five ways you can implement Backblaze Event Notifications into your data protection strategy to keep you and your team informed. If you’re interested in Event Notifications for other use cases, check out our posts for media production and application workflows.
Event Notifications for IT backup: Simplified automation
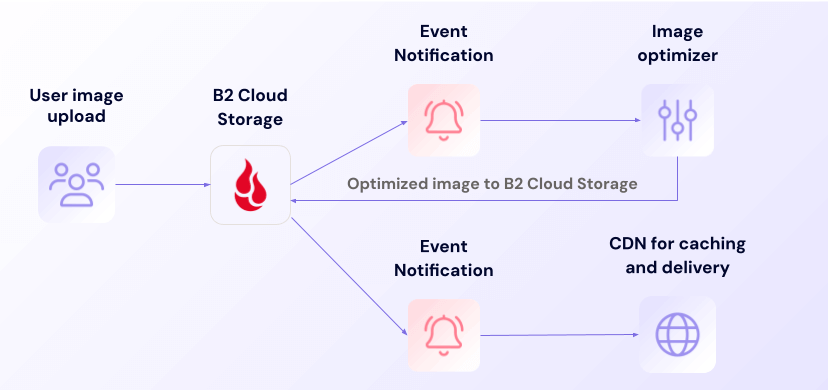
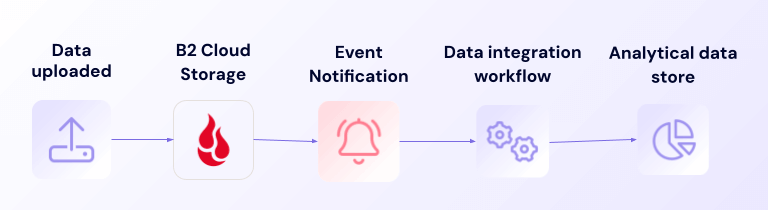
Event Notifications monitors your B2 Cloud Storage buckets for data changes that you designate—like completed backups, file deletions, or policy violations—and delivers real-time alerts where you want them. These alerts can trigger automated actions in any system that accepts webhooks, from PagerDuty to Zendesk to Slack channels and more.
Think of it as your storage system’s notification service: instead of discovering changes during routine recovery verification checks, you get instant awareness when something happens to the data in your buckets.
What are webhooks?
Webhooks, if you’re not familiar, are a way for applications to communicate with each other by sending data automatically based on specific events, e.g., HTTP POST requests with a JSON payload. What sets Backblaze Event Notifications apart is that it works with any service that accepts webhooks. This means you can integrate backup monitoring into your existing tools and processes, rather than being locked into specific vendors’ ecosystems.
5 ways to stay in the know with your backup strategy
Here are specific, practical ways you can take advantage of Event Notifications for immediate benefits to your backup and archive workflows.
1. Backup verification and reporting
When your backup software writes files to B2 Cloud Storage, Event Notifications helps verify successful completion of backup jobs. Each time a backup file lands in a bucket, you’ll receive a notification with key details like file size, timestamp, and backup job name. By feeding this data directly into communication tools like Slack, you can maintain comprehensive logs of backup activity without manual checks.
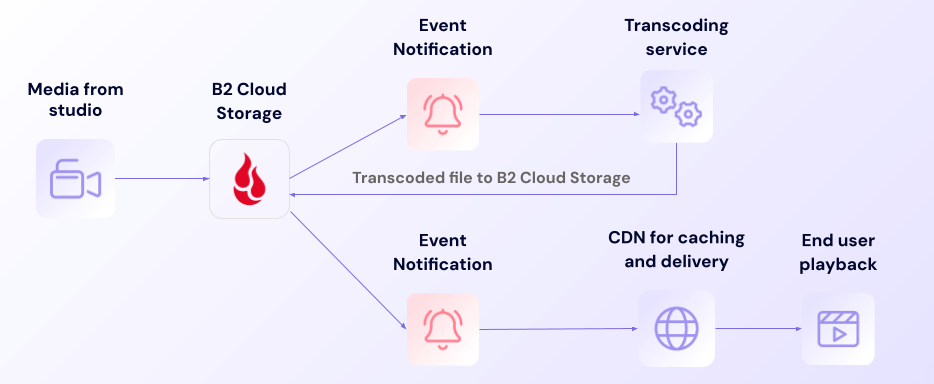
Backup monitoring workflow
Gone are the days of discovering backup issues hours or days later during routine reviews—you’ll know exactly when backups are uploaded. Teams can configure custom alerts for backup size thresholds, receive immediate confirmation of successful backups, and, with the help of Zapier, you can enable an alert when Event Notifications did not trigger, indicating a backup was not uploaded during a specified window.
2. Security and compliance monitoring
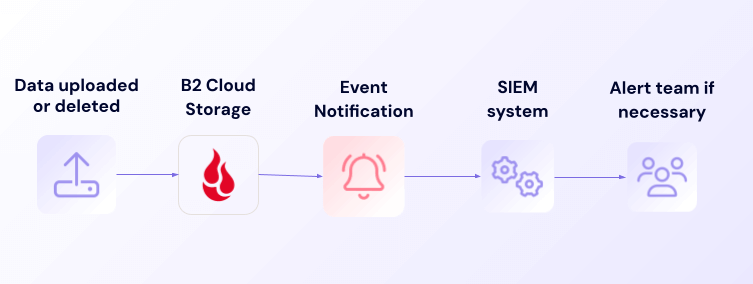
Event Notifications can help protect your backup data from unauthorized changes. Security teams can establish automated alerts for suspicious activities like mass deletions or modifications. These alerts integrate with your existing security information and event management (SIEM) systems to provide unified threat monitoring.
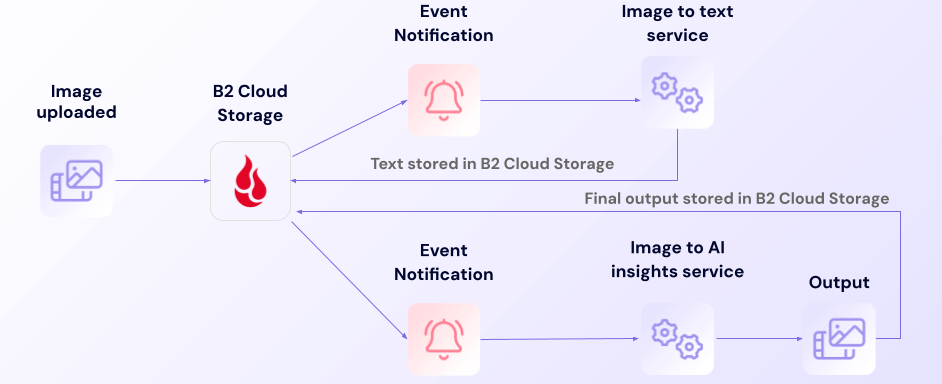
Security alert workflow

Beyond threat detection, Event Notifications enables preemptive policy enforcement. Teams can configure automatic notifications that guide employees when their actions might conflict with backup policies—like modifying file names, moving files, or even deletion. For persistent policy conflicts, managers can receive automated escalation alerts to address potential training needs or process gaps. This systematic approach helps maintain backup integrity through education and awareness before issues occur, rather than just detecting violations after the fact.
3. Storage management automation
Storage management becomes more efficient when Event Notifications feeds activity data directly to your management tools. As files are uploaded to and removed from your buckets over time, Event Notifications provides valuable data that helps you analyze storage utilization trends and backup data growth patterns.
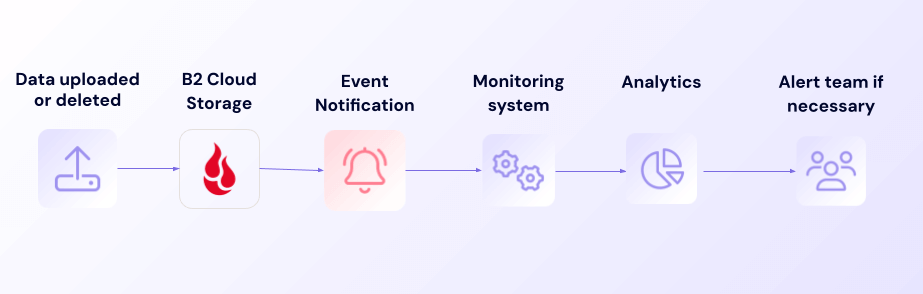
Data usage monitoring workflow
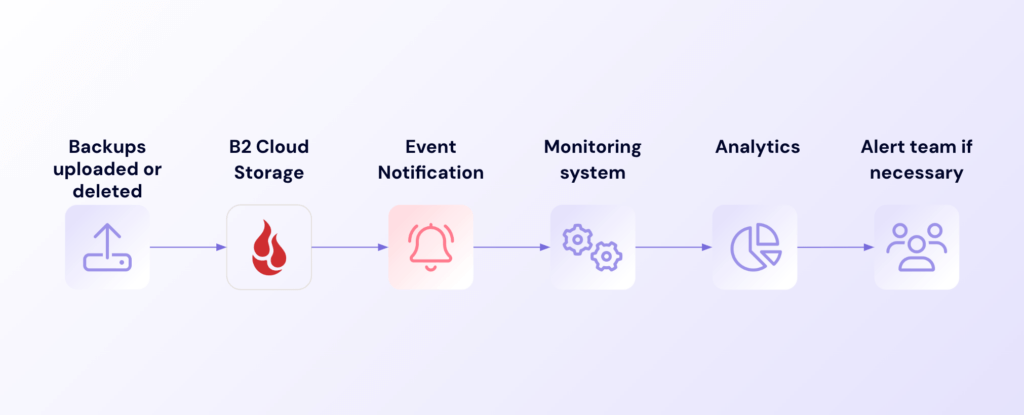
This constant flow of information empowers teams to anticipate capacity needs and optimize resource allocation. Moving from reactive to proactive storage management helps control costs by notifying you when backups become larger on average.
4. Cross-bucket backup monitoring
Organizations using Cloud Replication or managing backups across multiple buckets gain valuable oversight through Event Notifications. This capability tracks file replication between regions and monitors backup activity across your entire footprint, giving you a comprehensive view of your distributed backup strategy. Teams can spot replication delays or issues immediately, rather than waiting for scheduled status checks.
Cloud Replication notification workflow
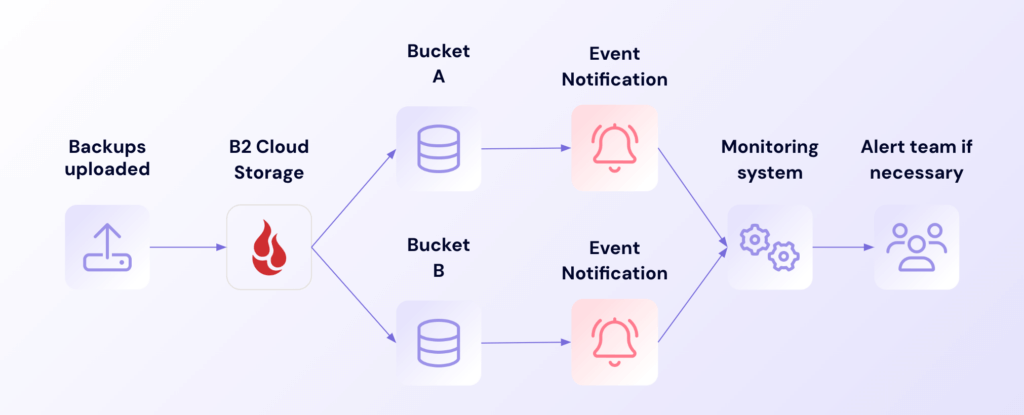
Understanding how data moves and grows across different locations ensures your distributed backup strategy performs as designed. Event Notifications makes it possible to track successful replications, monitor consistency between primary and replica buckets, and receive immediate alerts about any issues. This visibility is especially valuable for organizations maintaining geographic redundancy or managing complex multi-site backup strategies.
5. Integration with IT workflows
Event Notifications connects seamlessly with existing IT tools and processes through standard webhooks. Backup events can automatically flow into ticketing systems like Jira Service Management, monitoring dashboards like Grafana, or team communication channels like Microsoft Teams and Mattermost. This integration means teams can manage backup operations through familiar tools and processes, without needing to constantly switch between different interfaces or learn new systems.
Data integration workflow
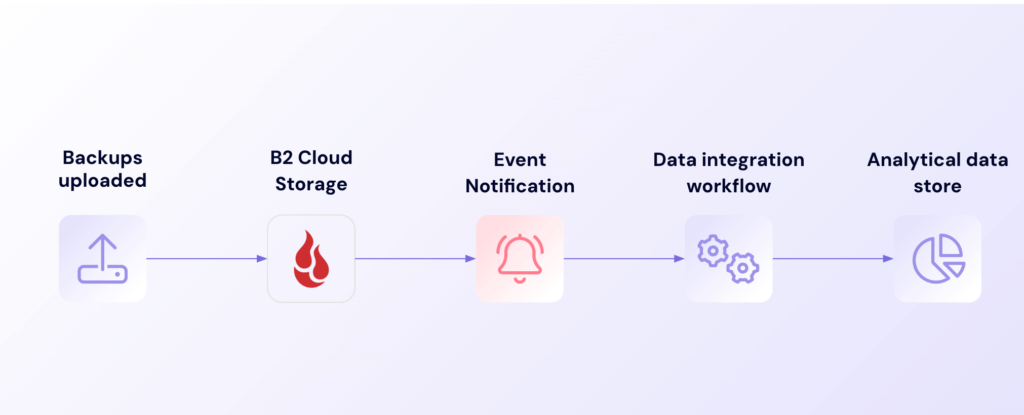
The result is streamlined operations without the need for separate backup monitoring systems, ensuring backup activities receive proper attention within normal IT procedures. Teams can create ServiceNow tickets for failed backups, update Jira boards with backup status, or send notifications to Teams channels—all automatically and in real-time.
Why Event Notifications makes sense for backup teams
Managing backup operations has traditionally meant juggling multiple monitoring tools and hoping you catch issues before they impact recovery capabilities. Event Notifications transforms this approach by providing:
- Automated awareness: Replace manual checks with instant visibility into bucket changes.
- Enhanced security: Track backup data access and modifications as they happen.
- Simplified monitoring: Feed backup activity data directly to your management tools.
- Better operations: Free up time to focus on improving backup strategies rather than monitoring them.
- Flexible integration: Adapt backup monitoring to fit your existing processes, not the other way around.
How it works with your environment
Unlike traditional backup monitoring solutions that often require specific software for notification handling, Event Notifications works with any service that accepts webhooks. This fundamental difference means you aren’t locked into specific vendors’ ecosystems or forced to use particular monitoring tools.
Event Notifications is designed for reliability with at-least-once delivery, ensuring critical backup events are never missed. This reliability is especially important for teams building automated workflows that require consistency and transparency in their backup monitoring.
The pricing model is straightforward and predictable: Backblaze B2 Reserve customers receive unlimited notifications at no additional cost, while pay-as-you-go customers get 2,500 notifications free each day and pay just $0.004 per 10,000 additional calls. This transparent pricing applies regardless of which services you’re connecting to, enabling teams to build comprehensive backup monitoring without worrying about unpredictable costs.
Ready to automate your backup monitoring?
If you’re working with a Backblaze account manager, Event Notifications are already enabled—just ask them for setup guidance. Other existing customers can contact our Support team to request access.
New to Backblaze? Contact our Sales team to learn how Event Notifications can strengthen your backup operations.
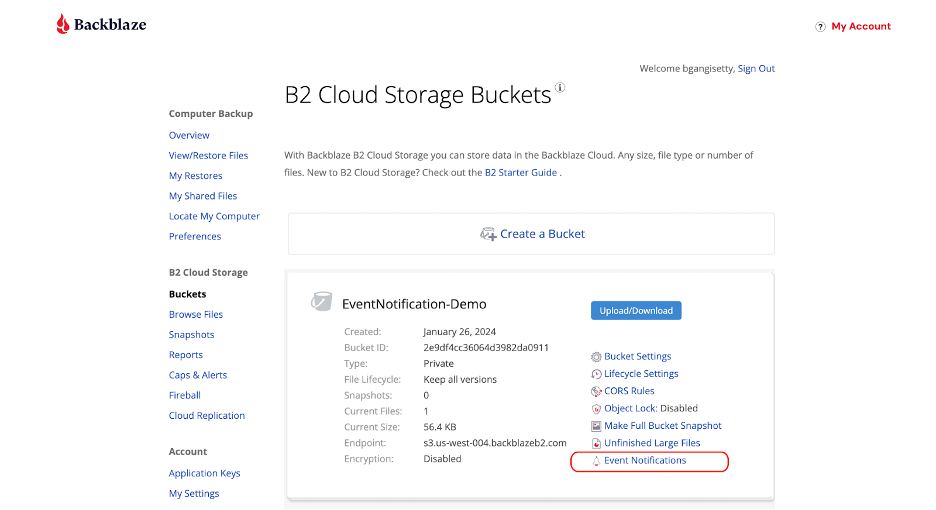
Once enabled, visit the Event Notifications section in your B2 Cloud Storage buckets to configure your alerts. For detailed setup instructions and best practices, check out our Event Notifications documentation.
The post 5 Ways Event Notifications Strengthens Your Backup Strategy Automatically appeared first on Backblaze Blog | Cloud Storage & Cloud Backup