Post Syndicated from Vinodh Subramanian original https://www.backblaze.com/blog/how-to-choose-the-right-enterprise-nas-for-your-business/

When it comes to enterprise storage, we’ve seen a rapid move to cloud-based infrastructure. But, recently, tech leaders have started to question the assumptions behind a cloud-only approach, and there are industries (particularly media and entertainment) where on-premises storage has tangible benefits. With all that in mind, enterprise-level network attached storage (NAS) in hybrid cloud setups presents a strong storage foundation for many companies.
With recent reports showing the global NAS market size is projected to grow from $26 billion to $82.9 billion in 2030, it’s clear that NAS isn’t going anywhere. So, let’s talk about how to choose an enterprise-level NAS solution.
What Is an Enterprise NAS?
Enterprise NAS is a large-scale data storage system that is connected to a local network to provide data storage and access to the organization. It’s designed for large-scale business environments that require high-capacity storage, superior performance, and advanced data management capabilities.
Compared with home-use NAS devices, enterprise NAS devices often come with superior hardware specifications, including powerful processors, large amounts of memory (RAM), and numerous drive bays to accommodate vast amounts of data.
How Do Enterprises Use NAS Devices?
Enterprises use NAS devices for a wide range of use cases and applications:
- File storage and sharing: NAS devices provide a centralized platform for storing and sharing files across a network. This fosters collaboration, as employees can easily access shared files regardless of their physical location.
- Data protection: With built-in redundancy features, NAS devices offer robust data protection. This ensures data remains safe and accessible even in the event of a disk failure.
- Disaster recovery: Snapshot and replication features allow for quick restoration of data minimizing downtime and data loss from hardware failures, cyberattacks, or natural disasters. However, it’s important to note that NAS devices alone don’t provide this protection—they’re subject to the same vulnerabilities as all on-premises devices. Rather, this benefit comes from a NAS setup that tiers to the cloud.
- Hosting business applications: Businesses can also use NAS devices to host business applications. Much the same as how you would use a server, since these devices can handle high volumes of data traffic and support multiple connections, they are well suited for running enterprise-level applications that require high availability and performance.
- Running virtual machines (VMs): Virtualization software providers, like VMware, support running their products on NAS. With proper configuration, including potentially adding RAM to your device, you can easily spin up virtual machines using NAS.
- Using NAS as a file server: NAS devices can function as dedicated file servers, offering high-performance, stable environments, which are useful for businesses with large user bases requiring concurrent access to shared files.
- Archiving: Long-term storage and archiving is another key application of NAS devices in the enterprise. There are benefits to having archival data on-premises. It can reduce recovery times in case you need to restore from backups.
Enterprise NAS vs. Server Area Networks (SAN)
As you’re choosing how to create an enterprise-level storage system, it’s important to know the differences between NAS and SAN. The short answer: From the perspective of the user, there’s not much difference. From the perspective of the person managing the system, SAN setups are more complex and have more customization options, particularly in your network connections.
However, NAS companies have done an excellent job of adding functionality to NAS devices, making those features easily manageable. Since they’re less complex, they may be easier for your internal IT team to manage—and that can translate to OpEx savings and more time for your IT team to stay on top of challenges in an ever-changing tech landscape.
What Is the Difference Between Entry-Level, Mid-Market, and Enterprise NAS Devices?
NAS devices can be grouped into three major categories based on factors such as storage capacity, performance, and scalability. The following table provides a side-by-side comparison of the key features and differences between entry-level, mid-market, and enterprise NAS devices.
| Feature | Entry-Level NAS | Mid-Market NAS | Enterprise NAS |
|---|---|---|---|
| Storage Capacity | Up to a few terabytes. | Can range from a few terabytes to tens of terabytes. | Usually hundreds of terabytes or more, scalable to meet enterprise needs. |
| Performance | Adequate for home use and basic file sharing. | Enhanced performance for small to medium businesses with higher data traffic. | High-performance systems designed to handle heavy workloads and concurrent access. |
| Reliability & Redundancy | Basic redundancy usually with RAID 1 or RAID 5 options. | More advanced redundancy options, including multiple RAID configurations. | Highly reliable with advanced redundancy features (RAID, replication, etc.). |
| Scalability | Limited scalability. | Moderate scalability, depending on model. | Highly scalable with clustering options. |
| Advanced Features | Basic features like media streaming, remote access, and basic data redundancy. | More advanced features like virtualization, data encryption, access control, and snapshot capability. | Enterprise-grade features like high-speed data transfers, advanced backup and disaster recovery options, deduplication, encryption, and virtualization support. |
How Do I Choose an Enterprise NAS Device?
Now that you understand the difference between the different types of NAS devices and their respective features, it’s crucial to understand your specific business needs before choosing an enterprise NAS device. There are several aspects to consider, so let’s take them one by one.
1. Storage Capacity
One of the first things to consider is the amount of storage your enterprise requires. This isn’t just about your current needs, but also about the projected growth of your data over time. In a NAS system, storage is defined by the number of drives, the total amount of shared volume they create, and their striping scheme. A striping scheme defines where data is stored and what kinds of redundancies it has, and is also known as RAID levels that are usually defined like so: RAID 0, 1 5, 6, etc.
There are a few ways to add storage to a NAS device.
- You can add drives to your NAS unit if you originally provisioned one with extra bays. This is most applicable to entry-level units.
- You can purchase another NAS device and network it with your first device. On the enterprise level, you’ll likely have a more complex architecture of connected NAS devices acting as clusters or nodes on your network.
- Finally, cloud-connected NAS devices mean that you can provision both primary and backup data to the cloud, so your setup is infinitely scalable. This means you can also nimbly add more storage on a short time frame—no need to wait for hardware upgrades (though you may still want to make upgrades in the longer term).
2. Data Access Speeds
The speed at which data can be accessed from your NAS device is another crucial factor. NAS devices are built to be directly connected to your local area network (LAN) and usually require a direct ethernet connection. An entry-level NAS system will have a gigabit ethernet connection (1GigE), and is suitable for entry-level or home NAS users.
But for enterprises that want to provide frequent and intensive data access to a large number of users, NAS vendors offer higher capacity ethernet connections on their systems. Some vendors offer 2.5 Gb/s or 5 Gb/s connections on their systems, but they usually require that you get a compatible network switch, USB adapters, or expansion cards. Still other NAS systems provide the option of Thunderbolt connections in addition to ethernet connections to provide higher bandwidth—up to 40GigE—and are good for systems that need to edit large files directly on the NAS.
3. Scalability
As your business grows, your data needs will likely increase. Therefore, it’s essential that your NAS device has the ability to grow with your business. You may not know exactly how much data you’ll need in a year or five, but you can certainly make an estimate based on your product roadmap, current rate of growth, and so on. And, we put together this handy NAS Buyer’s Guide so you can compare that potential growth to existing NAS features.
4. Data Protection and Backup Features
Effective backups are the cornerstone of any good disaster recovery (DR) plan, which is defined as the (hopefully tested!) step-by-step procedure to get your business back online and your data restored after a disruptive event like accidental deletions, cyberattacks, or natural disasters. We recommend the 3-2-1 backup strategy at minimum, and you’ll want to consider things like what kinds of restore options you prefer, compliance requirements in your industry, and how long you want to keep your backups.
With any good backup strategy, you’ll want to set up recurring and automatic backups of all your systems. Also, in complex environments like a business, backups are just as much about data management—that is, knowing where all your data is stored (the shared file system vs. employee workstations vs. the cloud) and how to back it up effectively.
Enterprise NAS devices provide advanced data protection and backup features to protect NAS data against data loss and enhance accessibility. These include advanced RAID configurations (i.e. on what server and how redundant your data storage is), automated backup features, cloud storage integrations, enterprise grade encryption features, advanced backup and disaster recovery options, data deduplication, encryption, and virtualization support, etc.
Other features to look for can include snapshot technology, which allows capturing the state of the system at different points in time, and replication features which enable copying of data from one NAS device to another for redundancy.
5. Evaluating Total Cost of Ownership
When evaluating an investment in an enterprise NAS device, it’s important to not limit your focus on the initial purchase price of the NAS device itself. Keep in mind that with a NAS device, you’ll need to purchase hard drives (HDDs) or solid-state drives (SSDs) (and possibly other devices) to complete your setup.
Depending on the kind of data durability you want to create, the storage hardware cost can add up if you’re aiming for high capacity storage with advanced RAID configurations. Also, make sure to take into account energy consumption, software licenses, labor and IT costs, and maintenance costs.
6. Vendor Support and Warranty
One of the often ignored and underestimated parts of selecting an enterprise NAS device is the support and warranty provided by the NAS vendors. Enterprise NAS devices are complex pieces of technology. NAS devices, in general, are designed to be user-friendly, but once you’re networking NAS devices on the enterprise level, things get more complex.
When you encounter an issue, addressing the challenges as quickly as possible can mean the difference between prolonged downtime and quick resolution. Of course, this means having in-house IT support, but it’s also absolutely critical to choose an enterprise NAS vendor that provides robust support and a good warranty to ensure the resilience and longevity of your enterprise NAS solution.
Level Up: Connect Your Enterprise NAS to the Cloud
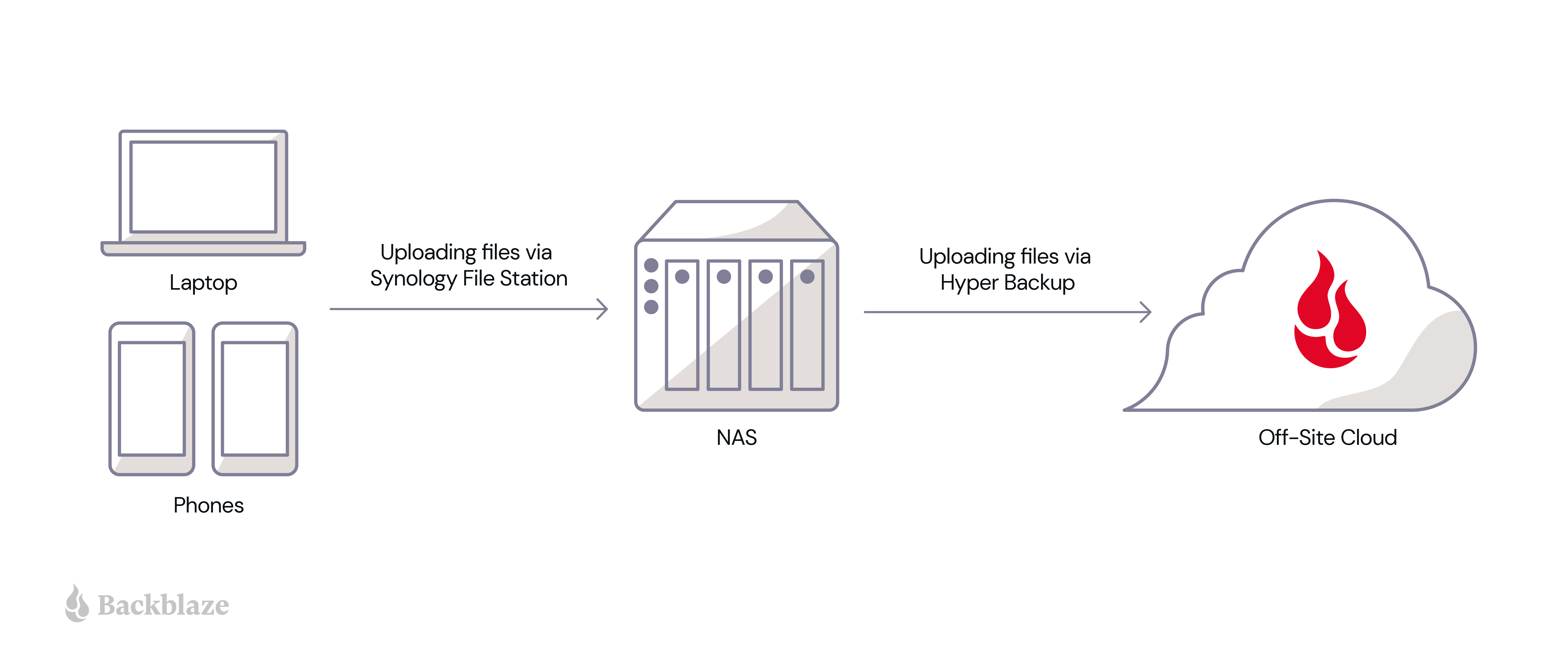
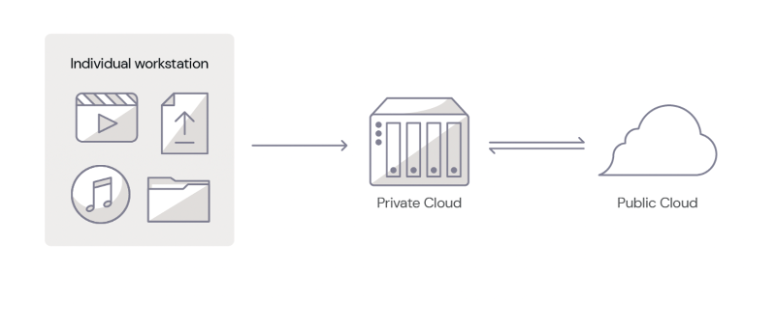
Okay, so you’ve chosen your enterprise NAS and devised your on-site, connected NAS solution. In industry parlance, what you’ve essentially done is to create a private cloud: storage dedicated solely to your organization, but accessible from anywhere. But, if you only have on-site storage, your data is vulnerable to theft, natural disasters, fire, and so on; and, as we mentioned above, you always want to have multiple copies of your data with at least one copy stored off-site.
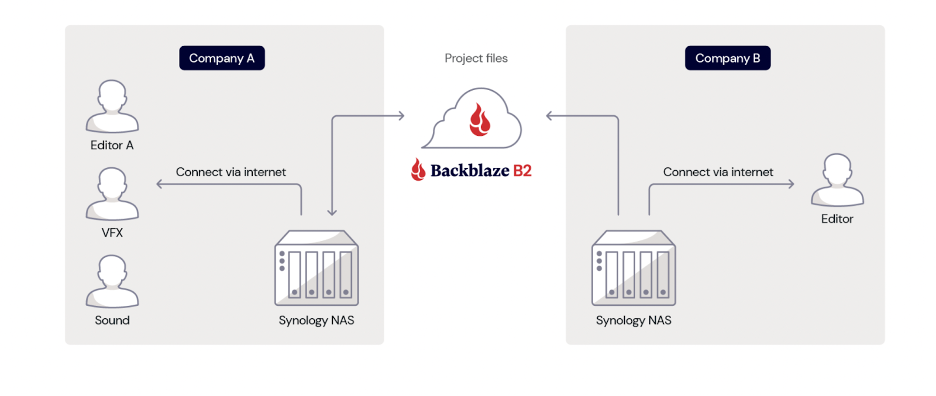
The easiest way to achieve this is to connect your NAS to a public cloud service provider (CSP) like Backblaze. Make sure that you take into account the location of the CSP’s data centers to ensure that you have adequate geographic separation between your data. And, once connected to a CSP, you can take advantage of services like cloud replication to create yet another redundant copy of your data automatically.
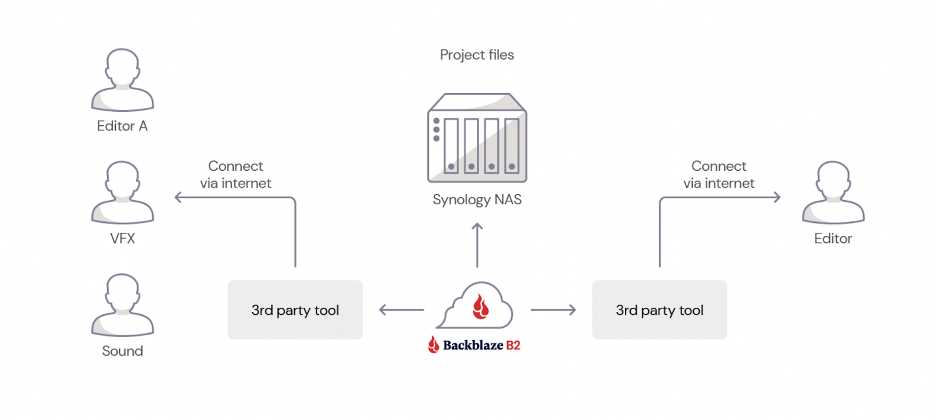
Beyond backups, data storage on your NAS vs. in the cloud can have performance (speed) differences. This has implications on both your internal workflows and your external workflows. Take the use case of a media and entertainment company: when you’re editing files, you’re typically working with large, raw files that take time to transmit. That means that on-site storage can be faster for your team. But, teams have become more remote, and you might be using freelancers.
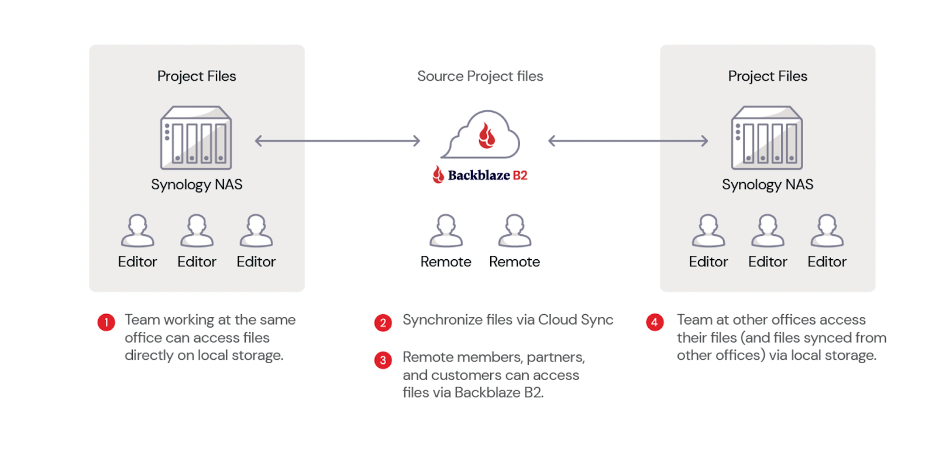
The great news is that most NAS devices have data management and syncing features, as noted above. A NAS hybrid cloud setup lets your employees or freelancers access remotely. They can access data via cloud storage, and your NAS client takes care of making sure all versions are up-to-date.
Once you have your business’ hybrid cloud setup, then you’ve opened up several opportunities to enhance how you store, manage, and use your data.
- Store your data closer to delivery endpoints for faster speeds. If you’re creating, editing, or delivering large files like you would in the media and entertainment industry, the physical location of your data makes a difference to how fast you can deliver it to the end user. Depending on where your endpoints are located and what region you choose, using cloud storage as an active archive allows you to store data closer to delivery endpoints for fast access.
- Integrate your NAS device with software as a service (SaaS) tools. In our SaaS landscape, all of our programs are internet-connected, and all of them need to be connected to storage. Many of these tools have their own clouds (like Google Drive or Adobe Creative Cloud) that you can bypass by connecting your own cloud storage account. Your NAS client then has excellent sync tools to keep your files updated as necessary, and, since that file is on your network instead of the tool’s cloud, it will be protected by your backup rules.
- Actively strengthen your backups. We’ve talked about the need for geographic separation, and storing in the cloud is the easiest way to do this. (People used to ship tape backups back in the distant past of the 1990s and early 2000s.) You can also set up different rules for your different files. Your primary storage obviously needs to be modifiable, but you can use tools like Object Lock to set immutable rules on your backups as well.
- Scale your storage flexibly. One of the biggest challenges of on-site storage is that adding more storage means buying more drives—it’s not an instant solution—and you’re more vulnerable to fluctuations in the supply chain. (Remember the Thailand Drive Crisis?) While you want to plan for future storage needs, cloud storage lets you add more storage immediately should you have unexpected needs.
Sum Up and Get Started
As you can see, having a clear understanding of your business needs is crucial before you build your storage strategy. Choosing an enterprise NAS is not only about getting a device that works now, but one that will continue to serve your business efficiently as your organization grows and evolves. A well thought-out enterprise NAS selection can boost your data management, provide robust data protection, and support your business’s growth goals.
If you have any questions or thoughts, please feel free to share them in the comments.
The post How to Choose the Right Enterprise NAS for Your Business appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.







![A tweet from user Leo Guinan @leo_guinan that says (I also got my AWS bill for last month and it was about 4x what I was expecting after my credits ran out, so a little more push to get paid users [laughing emoji])](https://www.backblaze.com/blog/wp-content/uploads/2023/05/5_Cloud-Credits-Tweet.png)