Post Syndicated from Debadatta Mohapatra original https://aws.amazon.com/blogs/big-data/how-epos-now-modernized-their-data-platform-by-building-an-end-to-end-data-lake-with-the-aws-data-lab/
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their business from anywhere, and reach customers both in-store and online.
Epos Now currently provides real-time and near-real-time reports and dashboards to their merchants on top of their operational database (Microsoft SQL Server). With a growing customer base and new data needs, the team started to see some issues in the current platform.
First, they observed performance degradation for serving the reporting requirements from the same OLTP database with the current data model. A few metrics that needed to be delivered in real time (seconds after a transaction was complete) and a few metrics that needed to be reflected in the dashboard in near-real-time (minutes) took several attempts to load in the dashboard.
This started to cause operational issues for their merchants. The end consumers of reports couldn’t access the dashboard in a timely manner.
Cost and scalability also became a major problem because one single database instance was trying to serve many different use cases.
Epos Now needed a strategic solution to address these issues. Additionally, they didn’t have a dedicated data platform for doing machine learning and advanced analytics use cases, so they decided on two parallel strategies to resolve their data problems and better serve merchants:
- The first was to rearchitect the near-real-time reporting feature by moving it to a dedicated Amazon Aurora PostgreSQL-Compatible Edition database, with a specific reporting data model to serve to end consumers. This will improve performance, uptime, and cost.
- The second was to build out a new data platform for reporting, dashboards, and advanced analytics. This will enable use cases for internal data analysts and data scientists to experiment and create multiple data products, ultimately exposing these insights to end customers.
In this post, we discuss how Epos Now designed the overall solution with support from the AWS Data Lab. Having developed a strong strategic relationship with AWS over the last 3 years, Epos Now opted to take advantage of the AWS Data lab program to speed up the process of building a reliable, performant, and cost-effective data platform. The AWS Data Lab program offers accelerated, joint-engineering engagements between customers and AWS technical resources to create tangible deliverables that accelerate data and analytics modernization initiatives.
Working with an AWS Data Lab Architect, Epos Now commenced weekly cadence calls to come up with a high-level architecture. After the objective, success criteria, and stretch goals were clearly defined, the final step was to draft a detailed task list for the upcoming 3-day build phase.
Overview of solution
As part of the 3-day build exercise, Epos Now built the following solution with the ongoing support of their AWS Data Lab Architect.
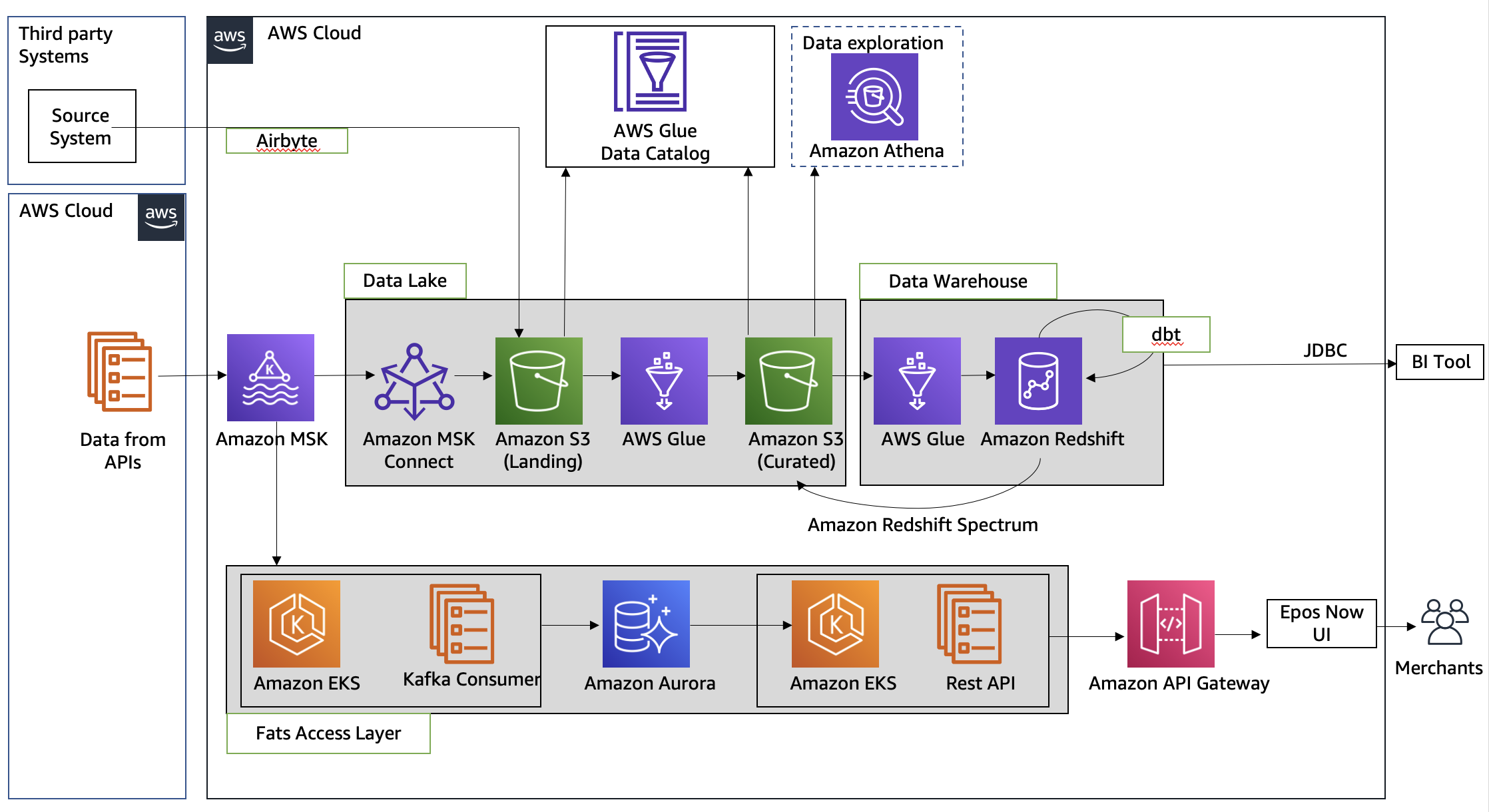
The platform consists of an end-to-end data pipeline with three main components:
- Data lake – As a central source of truth
- Data warehouse – For analytics and reporting needs
- Fast access layer – To serve near-real-time reports to merchants
We chose three different storage solutions:
- Amazon Simple Storage Service (Amazon S3) for raw data landing and a curated data layer to build the foundation of the data lake
- Amazon Redshift to create a federated data warehouse with conformed dimensions and star schemas for consumption by Microsoft Power BI, running on AWS
- Aurora PostgreSQL to store all the data for near-real-time reporting as a fast access layer
In the following sections, we go into each component and supporting services in more detail.
Data lake
The first component of the data pipeline involved ingesting the data from an Amazon Managed Streaming for Apache Kafka (Amazon MSK) topic using Amazon MSK Connect to land the data into an S3 bucket (landing zone). The Epos Now team used the Confluent Amazon S3 sink connector to sink the data to Amazon S3. To make the sink process more resilient, Epos Now added the required configuration for dead-letter queues to redirect the bad messages to another topic. The following code is a sample configuration for a dead-letter queue in Amazon MSK Connect:

Because Epos Now was ingesting from multiple data sources, they used Airbyte to transfer the data to a landing zone in batches. A subsequent AWS Glue job reads the data from the landing bucket , performs data transformation, and moves the data to a curated zone of Amazon S3 in optimal format and layout. This curated layer then became the source of truth for all other use cases. Then Epos Now used an AWS Glue crawler to update the AWS Glue Data Catalog. This was augmented by the use of Amazon Athena for doing data analysis. To optimize for cost, Epos Now defined an optimal data retention policy on different layers of the data lake to save money as well as keep the dataset relevant.
Data warehouse
After the data lake foundation was established, Epos Now used a subsequent AWS Glue job to load the data from the S3 curated layer to Amazon Redshift. We used Amazon Redshift to make the data queryable in both Amazon Redshift (internal tables) and Amazon Redshift Spectrum. The team then used dbt as an extract, load, and transform (ELT) engine to create the target data model and store it in target tables and views for internal business intelligence reporting. The Epos Now team wanted to use their SQL knowledge to do all ELT operations in Amazon Redshift, so they chose dbt to perform all the joins, aggregations, and other transformations after the data was loaded into the staging tables in Amazon Redshift. Epos Now is currently using Power BI for reporting, which was migrated to the AWS Cloud and connected to Amazon Redshift clusters running inside Epos Now’s VPC.
Fast access layer
To build the fast access layer to deliver the metrics to Epos Now’s retail and hospitality merchants in near-real time, we decided to create a separate pipeline. This required developing a microservice running a Kafka consumer job to subscribe to the same Kafka topic in an Amazon Elastic Kubernetes Service (Amazon EKS) cluster. The microservice received the messages, conducted the transformations, and wrote the data to a target data model hosted on Aurora PostgreSQL. This data was delivered to the UI layer through an API also hosted on Amazon EKS, exposed through Amazon API Gateway.
Outcome
The Epos Now team is currently building both the fast access layer and a centralized lakehouse architecture-based data platform on Amazon S3 and Amazon Redshift for advanced analytics use cases. The new data platform is best positioned to address scalability issues and support new use cases. The Epos Now team has also started offloading some of the real-time reporting requirements to the new target data model hosted in Aurora. The team has a clear strategy around the choice of different storage solutions for the right access patterns: Amazon S3 stores all the raw data, and Aurora hosts all the metrics to serve real-time and near-real-time reporting requirements. The Epos Now team will also enhance the overall solution by applying data retention policies in different layers of the data platform. This will address the platform cost without losing any historical datasets. The data model and structure (data partitioning, columnar file format) we designed greatly improved query performance and overall platform stability.
Conclusion
Epos Now revolutionized their data analytics capabilities, taking advantage of the breadth and depth of the AWS Cloud. They’re now able to serve insights to internal business users, and scale their data platform in a reliable, performant, and cost-effective manner.
The AWS Data Lab engagement enabled Epos Now to move from idea to proof of concept in 3 days using several previously unfamiliar AWS analytics services, including AWS Glue, Amazon MSK, Amazon Redshift, and Amazon API Gateway.
Epos Now is currently in the process of implementing the full data lake architecture, with a rollout to customers planned for late 2022. Once live, they will deliver on their strategic goal to provide real-time transactional data and put insights directly in the hands of their merchants.
About the Authors
 Jason Downing is VP of Data and Insights at Epos Now. He is responsible for the Epos Now data platform and product direction. He specializes in product management across a range of industries, including POS systems, mobile money, payments, and eWallets.
Jason Downing is VP of Data and Insights at Epos Now. He is responsible for the Epos Now data platform and product direction. He specializes in product management across a range of industries, including POS systems, mobile money, payments, and eWallets.
 Debadatta Mohapatra is an AWS Data Lab Architect. He has extensive experience across big data, data science, and IoT, across consulting and industrials. He is an advocate of cloud-native data platforms and the value they can drive for customers across industries.
Debadatta Mohapatra is an AWS Data Lab Architect. He has extensive experience across big data, data science, and IoT, across consulting and industrials. He is an advocate of cloud-native data platforms and the value they can drive for customers across industries.