Post Syndicated from Bastien Dhiver original https://blog.cloudflare.com/a-story-about-af-xdp-network-namespaces-and-a-cookie/


A crash in a development version of flowtrackd (the daemon that powers our Advanced TCP Protection) highlighted the fact that libxdp (and specifically the AF_XDP part) was not Linux network namespace aware.
This blogpost describes the debugging journey to find the bug, as well as a fix.
flowtrackd is a volumetric denial of service defense mechanism that sits in the Magic Transit customer’s data path and protects the network from complex randomized TCP floods. It does so by challenging TCP connection establishments and by verifying that TCP packets make sense in an ongoing flow.
It uses the Linux kernel AF_XDP feature to transfer packets from a network device in kernel space to a memory buffer in user space without going through the network stack. We use most of the helper functions of the C libbpf with the Rust bindings to interact with AF_XDP.
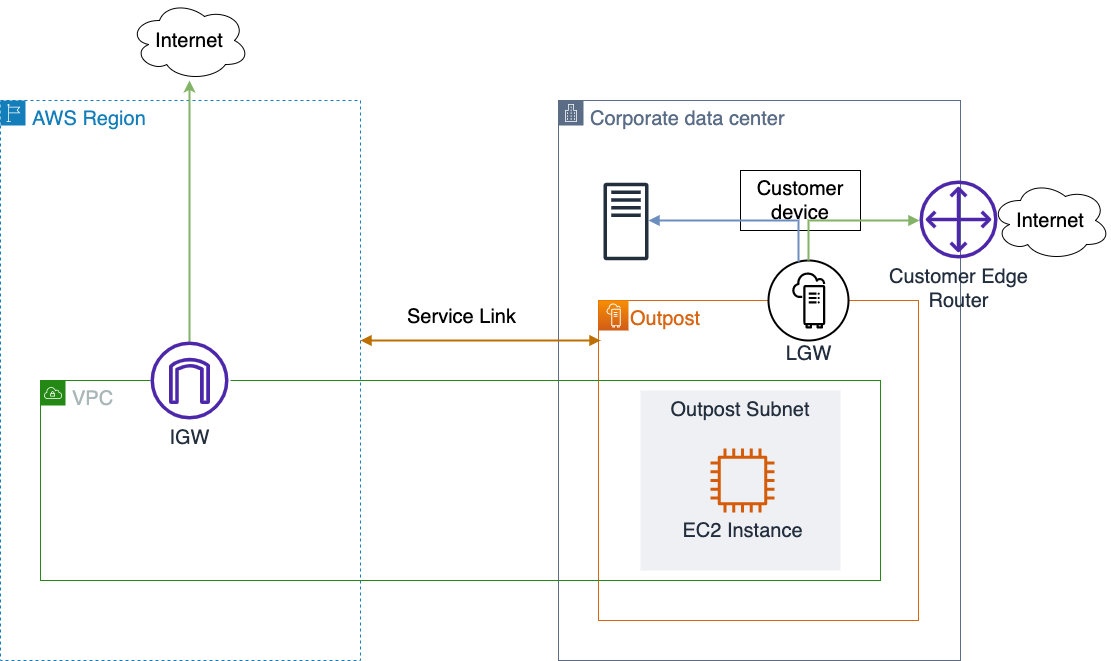
In our setup, both the ingress and the egress network interfaces are in different network namespaces. When a packet is determined to be valid (after a challenge or under some thresholds), it is forwarded to the second network interface.
For the rest of this post the network setup will be the following:
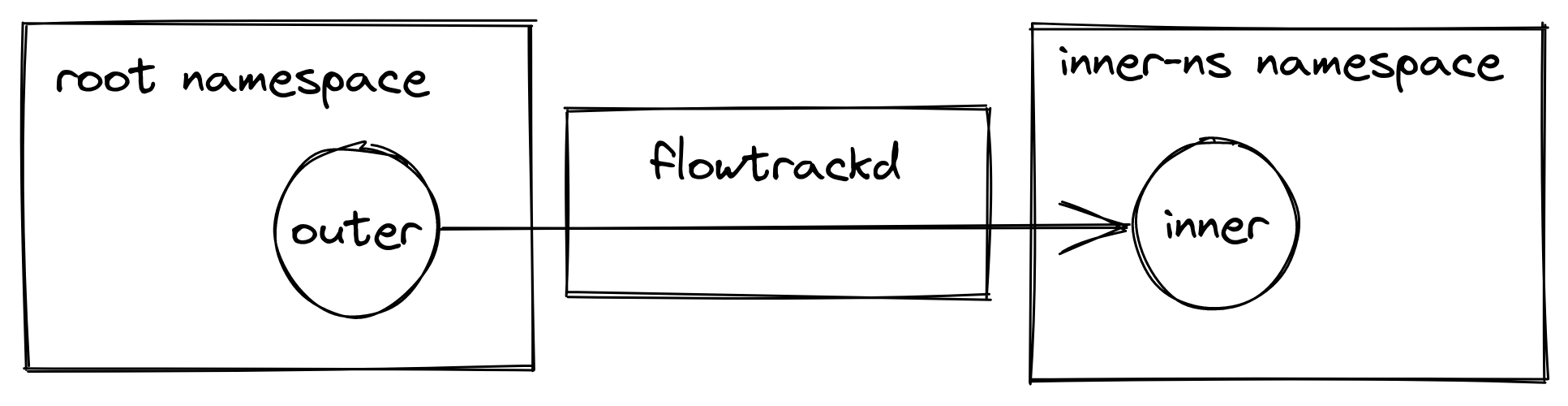
e.g. eyeball packets arrive at the outer device in the root network namespace, they are picked up by flowtrackd and then forwarded to the inner device in the inner-ns namespace.
AF_XDP
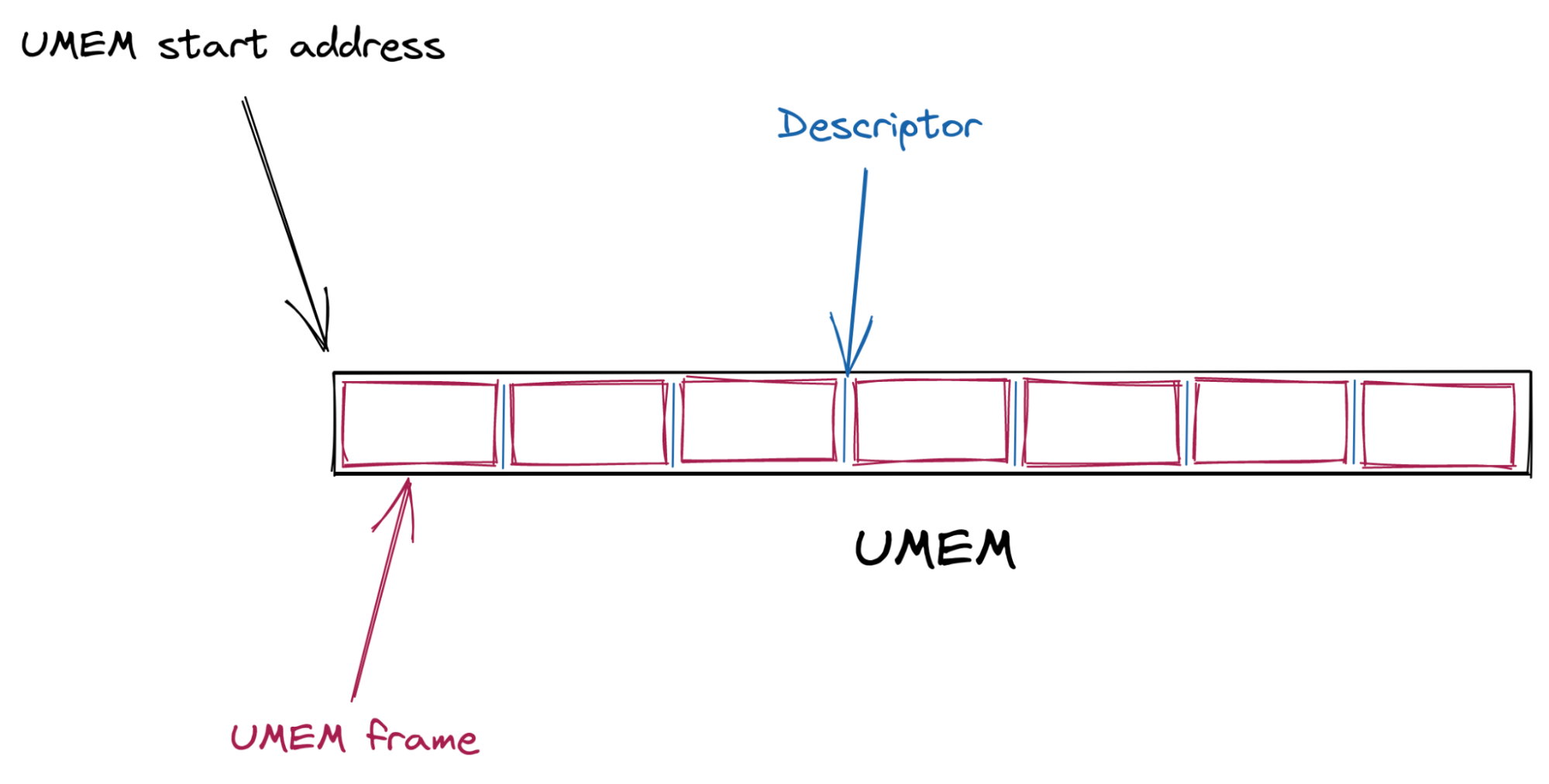
The kernel and the userspace share a memory buffer called the UMEM. This is where packet bytes are written to and read from.
The UMEM is split in contiguous equal-sized “frames” that are referenced by “descriptors” which are just offsets from the start address of the UMEM.
The interactions and synchronization between the kernel and userspace happen via a set of queues (circular buffers) as well as a socket from the AF_XDP family.
Most of the work is about managing the ownership of the descriptors. Which descriptors the kernel owns and which descriptors the userspace owns.
The interface provided for the ownership management are a set of queues:
| Queue | User space | Kernel space | Content description |
|---|---|---|---|
| COMPLETION | Consumes | Produces | Frame descriptors that have successfully been transmitted |
| FILL | Produces | Consumes | Frame descriptors ready to get new packet bytes written to |
| RX | Consumes | Produces | Frame descriptors of a newly received packet |
| TX | Produces | Consumes | Frame descriptors to be transmitted |
When the UMEM is created, a FILL and a COMPLETION queue are associated with it.
An RX and a TX queue are associated with the AF_XDP socket (abbreviated Xsk) at its creation. This particular socket is bound to a network device queue id. The userspace can then poll() on the socket to know when new descriptors are ready to be consumed from the RX queue and to let the kernel deal with the descriptors that were set on the TX queue by the application.
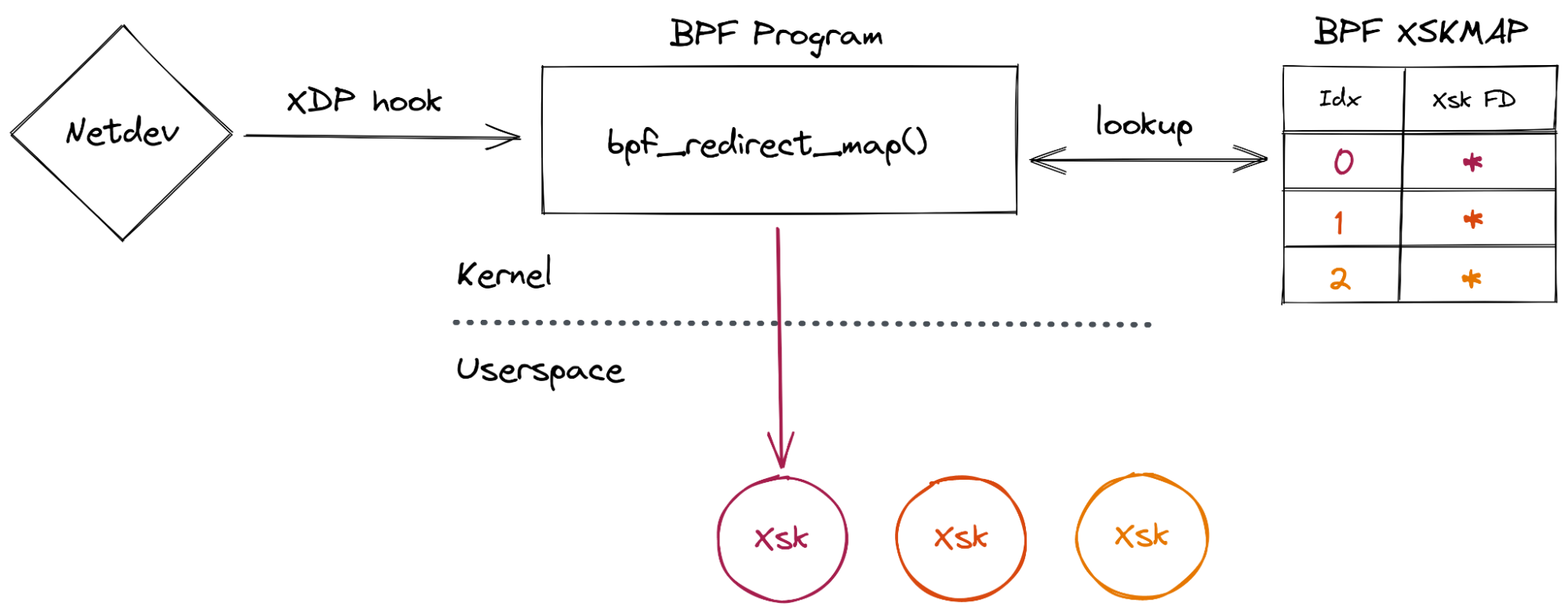
The last plumbing operation to be done to use AF_XDP is to load a BPF program attached with XDP on the network device we want to interact with and insert the Xsk file descriptor into a BPF map (of type XSKMAP). Doing so will enable the BPF program to redirect incoming packets (with the bpf_redirect_map() function) to a specific socket that we created in userspace:
Once everything has been allocated and strapped together, what I call “the descriptors dance” can start. While this has nothing to do with courtship behaviors it still requires a flawless execution:
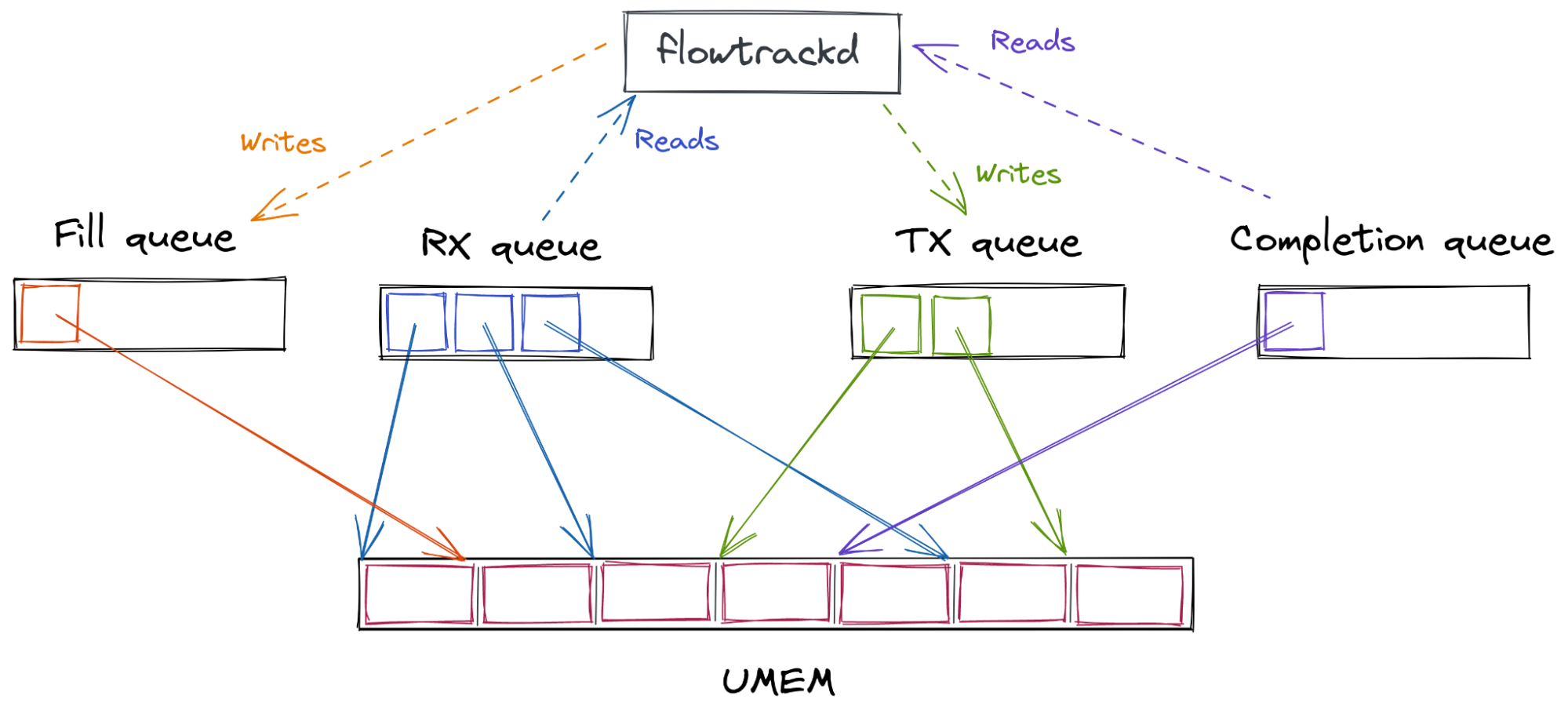
When the kernel receives a packet (more specifically the device driver), it will write the packet bytes to a UMEM frame (from a descriptor that the userspace put in the FILL queue) and then insert the frame descriptor in the RX queue for the userspace to consume. The userspace can then read the packet bytes from the received descriptor, take a decision, and potentially send it back to the kernel for transmission by inserting the descriptor in the TX queue. The kernel can then transmit the content of the frame and put the descriptor from the TX to the COMPLETION queue. The userspace can then “recycle” this descriptor in the FILL or TX queue.
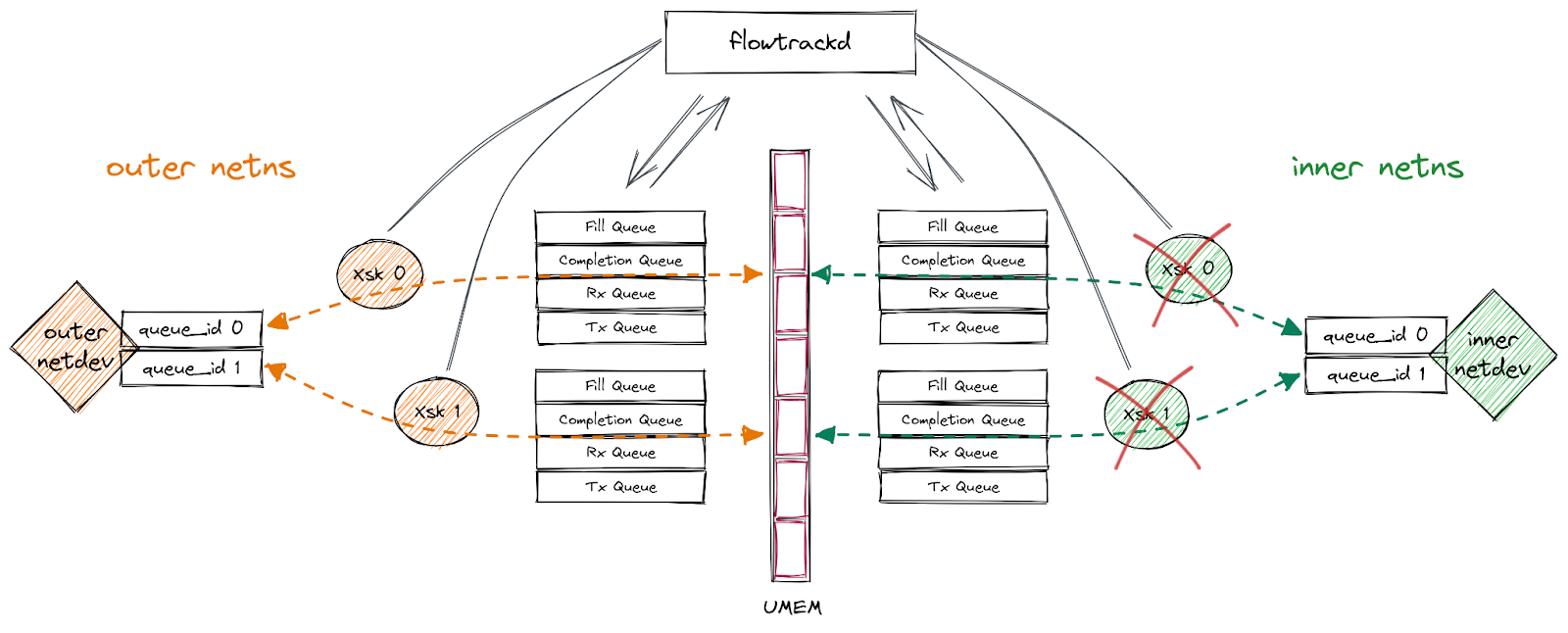
The overview of the queue interactions from the application perspective is represented on the following diagram (note that the queues contain descriptors that point to UMEM frames):
flowtrackd I/O rewrite project
To increase flowtrackd performance and to be able to scale with the growth of the Magic Transit product we decided to rewrite the I/O subsystem.
There will be a public blogpost about the technical aspects of the rewrite.
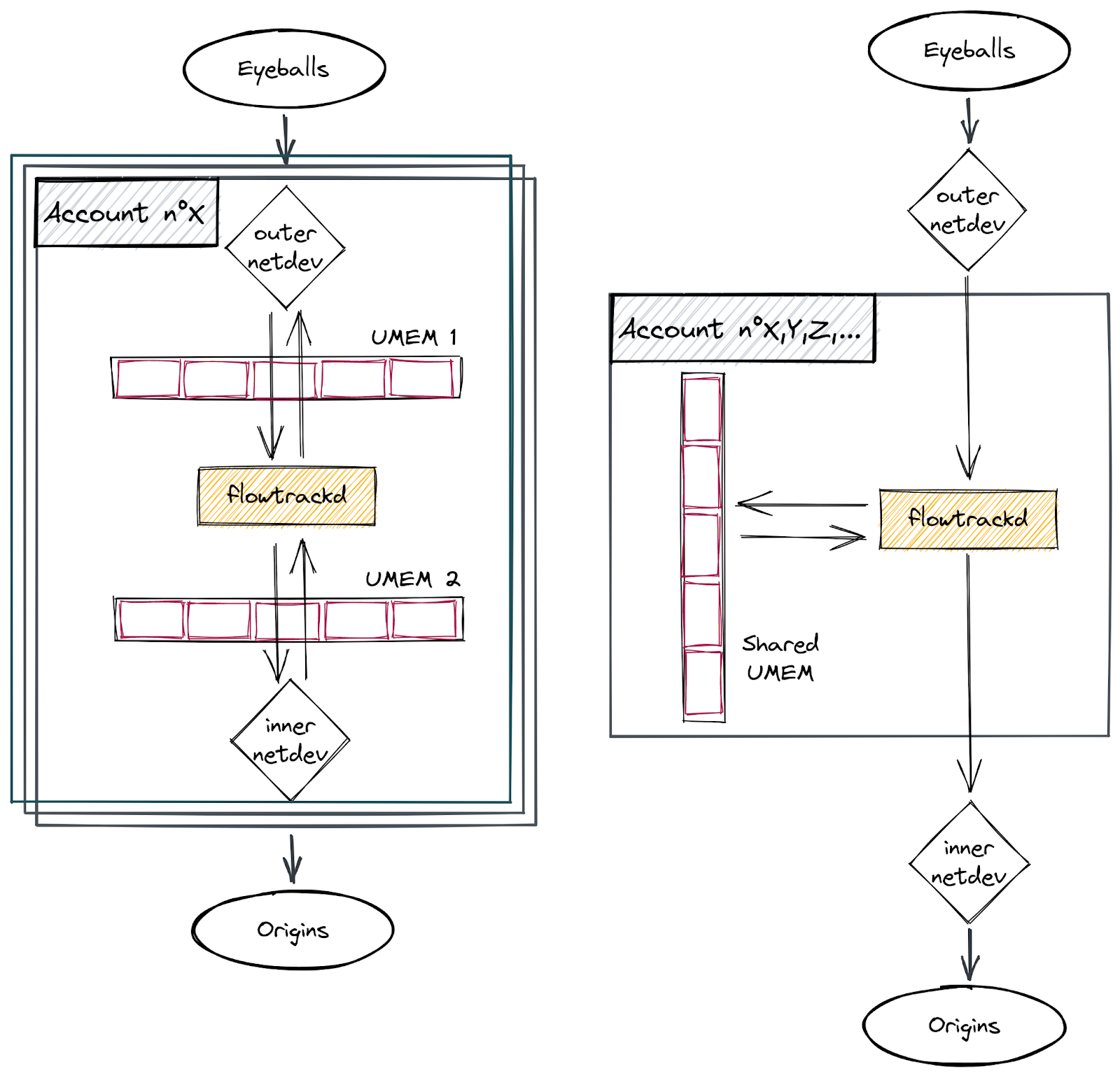
Prior to the rewrite, each customer had a dedicated flowtrackd instance (Unix process) that attached itself to dedicated network devices. A dedicated UMEM was created per network device (see schema on the left side below). The packets were copied from one UMEM to the other.
In this blogpost, we will only focus on the new usage of the AF_XDP shared UMEM feature which enables us to handle all customer accounts with a single flowtrackd instance per server and with a single shared UMEM (see schema on the right side below).
The Linux kernel documentation describes the additional plumbing steps to share a UMEM across multiple AF_XDP sockets:

Followed by the instructions for our use case:

Hopefully for us a helper function in libbpf does it all for us: xsk_socket__create_shared()

The final setup is the following: Xsks are created for each queue of the devices in their respective network namespaces. flowtrackd then handles the descriptors like a puppeteer while applying our DoS mitigation logic on the packets that they reference with one exception… (notice the red crosses on the diagram):
What “Invalid argument” ??!
We were happily near the end of the rewrite when, suddenly, after porting our integration tests in the CI, flowtrackd crashed!
The following errors was displayed:
[...]
Thread 'main' panicked at 'failed to create Xsk: Libbpf("Invalid argument")', flowtrack-io/src/packet_driver.rs:144:22
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
According to the line number, the first socket was created with success and flowtrackd crashed when the second Xsk was created:
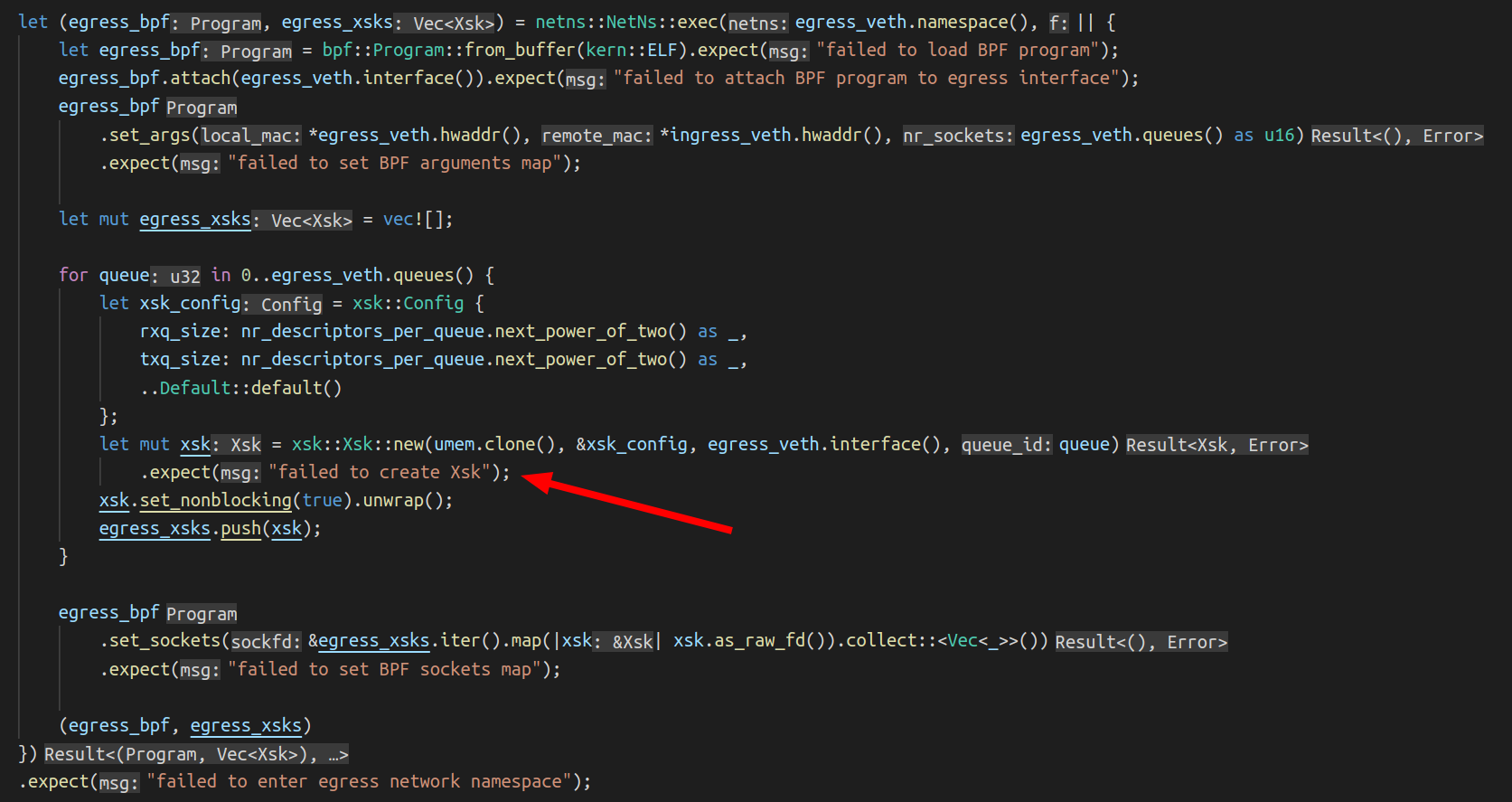
Here is what we do: we enter the network namespace where the interface sits, load and attach the BPF program and for each queue of the interface, we create a socket. The UMEM and the config parameters are the same with the ingress Xsk creation. Only the ingress_veth and egress_veth are different.
This is what the code to create an Xsk looks like:
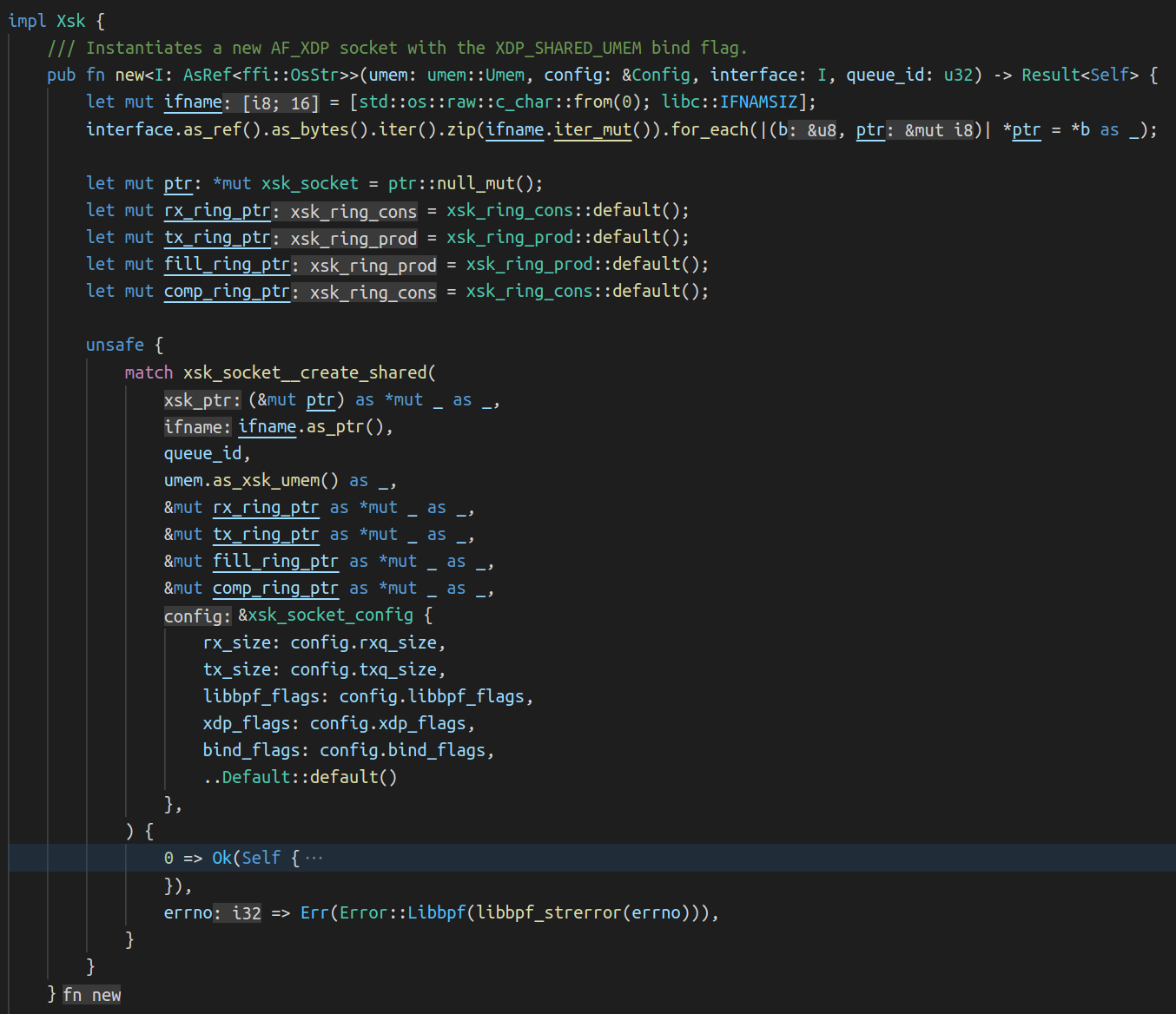
The call to the libbpf function xsk_socket__create_shared() didn’t return 0.
The libxdp manual page doesn’t help us here…
Which argument is “invalid”? And why is this error not showing up when we run flowtrackd locally but only in the CI?
We can try to reproduce locally with a similar network setup script used in the CI:
#!/bin/bash
set -e -u -x -o pipefail
OUTER_VETH=${OUTER_VETH:=outer}
TEST_NAMESPACE=${TEST_NAMESPACE:=inner-ns}
INNER_VETH=${INNER_VETH:=inner}
QUEUES=${QUEUES:=$(grep -c ^processor /proc/cpuinfo)}
ip link delete $OUTER_VETH &>/dev/null || true
ip netns delete $TEST_NAMESPACE &>/dev/null || true
ip netns add $TEST_NAMESPACE
ip link \
add name $OUTER_VETH numrxqueues $QUEUES numtxqueues $QUEUES type veth \
peer name $INNER_VETH netns $TEST_NAMESPACE numrxqueues $QUEUES numtxqueues $QUEUES
ethtool -K $OUTER_VETH tx off rxvlan off txvlan off
ip link set dev $OUTER_VETH up
ip addr add 169.254.0.1/30 dev $OUTER_VETH
ip netns exec $TEST_NAMESPACE ip link set dev lo up
ip netns exec $TEST_NAMESPACE ethtool -K $INNER_VETH tx off rxvlan off txvlan off
ip netns exec $TEST_NAMESPACE ip link set dev $INNER_VETH up
ip netns exec $TEST_NAMESPACE ip addr add 169.254.0.2/30 dev $INNER_VETH
For the rest of the blogpost, we set the number of queues per interface to 1. If you have questions about the set command in the script, check this out.
Not much success triggering the error.
What differs between my laptop setup and the CI setup?
I managed to find out that when the outer and inner interface index numbers are the same then it crashes. Even though the interfaces don’t have the same name, and they are not in the same network namespace. When the tests are run by the CI, both interfaces got index number 5 which was not the case on my laptop since I have more interfaces:
$ ip -o link | cut -d' ' -f1,2
1: lo:
2: wwan0:
3: wlo1:
4: virbr0:
7: br-ead14016a14c:
8: docker0:
9: br-bafd94c79ff4:
29: outer@if2:
We can edit the script to set a fixed interface index number:
ip link \
add name $OUTER_VETH numrxqueues $QUEUES numtxqueues $QUEUES index 4242 type veth \
peer name $INNER_VETH netns $TEST_NAMESPACE numrxqueues $QUEUES numtxqueues $QUEUES index 4242
And we can now reproduce the issue locally!
Interesting observation: I was not able to reproduce this issue with the previous flowtrackd version. Is this somehow related to the shared UMEM feature that we are now using?
Back to the “invalid” argument. strace to the rescue:
sudo strace -f -x ./flowtrackd -v -c flowtrackd.toml --ingress outer --egress inner --egress-netns inner-ns
[...]
// UMEM allocation + first Xsk creation
[pid 389577] brk(0x55b485819000) = 0x55b485819000
[pid 389577] mmap(NULL, 8396800, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f85037fe000
[pid 389577] socket(AF_XDP, SOCK_RAW|SOCK_CLOEXEC, 0) = 9
[pid 389577] setsockopt(9, SOL_XDP, XDP_UMEM_REG, "\x00\xf0\x7f\x03\x85\x7f\x00\x00\x00\x00\x80\x00\x00\x00\x00\x00\x00\x08\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00", 32) = 0
[pid 389577] setsockopt(9, SOL_XDP, XDP_UMEM_FILL_RING, [2048], 4) = 0
[pid 389577] setsockopt(9, SOL_XDP, XDP_UMEM_COMPLETION_RING, [2048], 4) = 0
[pid 389577] getsockopt(9, SOL_XDP, XDP_MMAP_OFFSETS, "\x00\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00\x00\x00\x00\x00\x00\x40\x01\x00\x00\x00\x00\x00\x00\xc4\x00\x00\x00\x00\x00\x00\x00"..., [128]) = 0
[pid 389577] mmap(NULL, 16704, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE, 9, 0x100000000) = 0x7f852801b000
[pid 389577] mmap(NULL, 16704, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE, 9, 0x180000000) = 0x7f8528016000
[...]
[pid 389577] setsockopt(9, SOL_XDP, XDP_RX_RING, [2048], 4) = 0
[pid 389577] setsockopt(9, SOL_XDP, XDP_TX_RING, [2048], 4) = 0
[pid 389577] getsockopt(9, SOL_XDP, XDP_MMAP_OFFSETS, "\x00\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00\x00\x00\x00\x00\x00\x40\x01\x00\x00\x00\x00\x00\x00\xc4\x00\x00\x00\x00\x00\x00\x00"..., [128]) = 0
[pid 389577] mmap(NULL, 33088, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE, 9, 0) = 0x7f850377e000
[pid 389577] mmap(NULL, 33088, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE, 9, 0x80000000) = 0x7f8503775000
[pid 389577] bind(9, {sa_family=AF_XDP, sa_data="\x08\x00\x92\x10\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00"}, 16) = 0
[...]
// Second Xsk creation
[pid 389577] socket(AF_XDP, SOCK_RAW|SOCK_CLOEXEC, 0) = 62
[...]
[pid 389577] setsockopt(62, SOL_XDP, XDP_RX_RING, [2048], 4) = 0
[pid 389577] setsockopt(62, SOL_XDP, XDP_TX_RING, [2048], 4) = 0
[pid 389577] getsockopt(62, SOL_XDP, XDP_MMAP_OFFSETS, "\x00\x00\x00\x00\x00\x00\x00\x00\x80\x00\x00\x00\x00\x00\x00\x00\x40\x01\x00\x00\x00\x00\x00\x00\xc4\x00\x00\x00\x00\x00\x00\x00"..., [128]) = 0
[pid 389577] mmap(NULL, 33088, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE, 62, 0) = 0x7f85036e4000
[pid 389577] mmap(NULL, 33088, PROT_READ|PROT_WRITE, MAP_SHARED|MAP_POPULATE, 62, 0x80000000) = 0x7f85036db000
[pid 389577] bind(62, {sa_family=AF_XDP, sa_data="\x01\x00\x92\x10\x00\x00\x00\x00\x00\x00\x09\x00\x00\x00"}, 16) = -1 EINVAL (Invalid argument)
[pid 389577] munmap(0x7f85036db000, 33088) = 0
[pid 389577] munmap(0x7f85036e4000, 33088) = 0
[pid 389577] close(62) = 0
[pid 389577] write(2, "thread '", 8thread ') = 8
[pid 389577] write(2, "main", 4main) = 4
[pid 389577] write(2, "' panicked at '", 15' panicked at ') = 15
[pid 389577] write(2, "failed to create Xsk: Libbpf(\"In"..., 48failed to create Xsk: Libbpf("Invalid argument")) = 48
[...]
Ok, the second bind() syscall returns the EINVAL value.
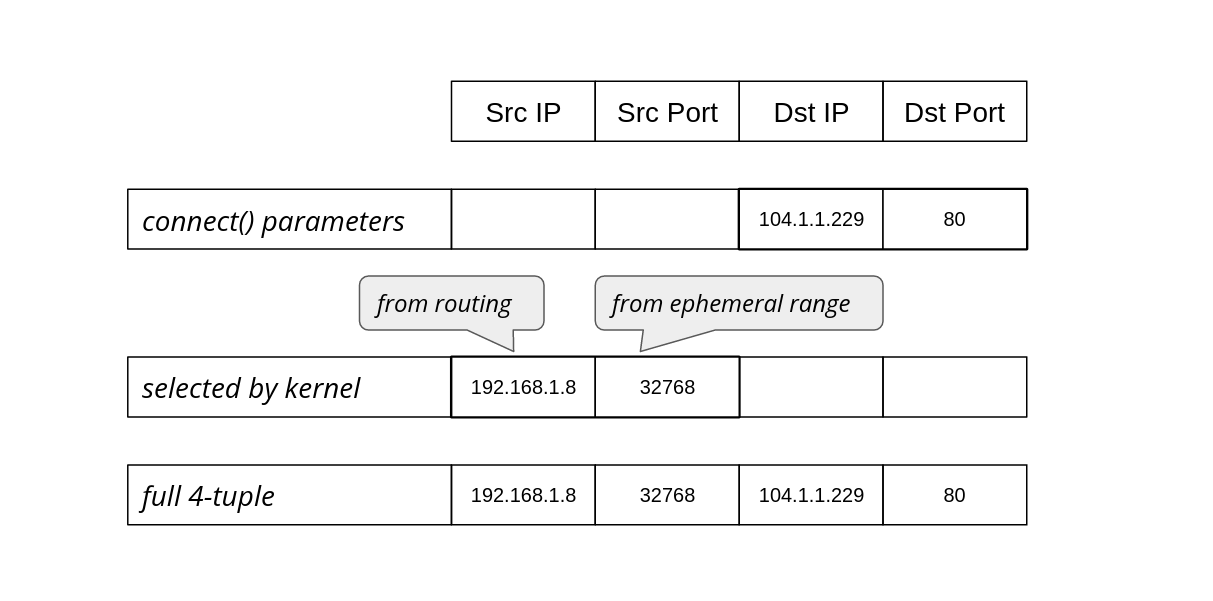
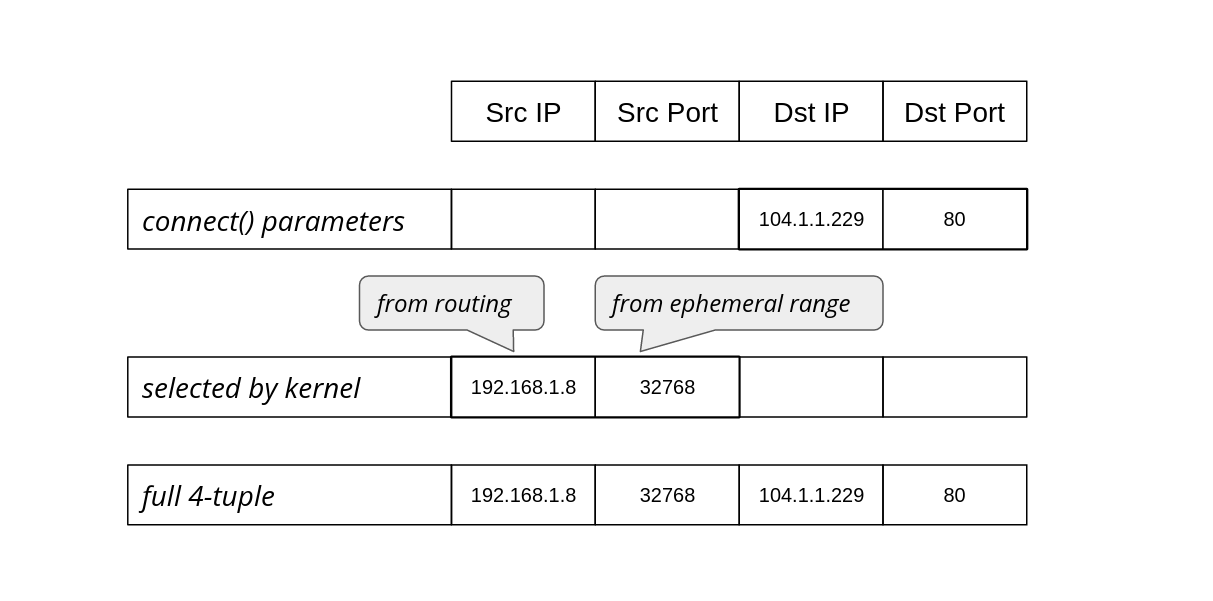
The sa_family is the right one. Is something wrong with sa_data="\x01\x00\x92\x10\x00\x00\x00\x00\x00\x00\x09\x00\x00\x00" ?
Let’s look at the bind syscall kernel code:
err = sock->ops->bind(sock, (struct sockaddr *) &address, addrlen);
The bind function of the protocol specific socket operations gets called. Searching for “AF_XDP” in the code, we quickly found the bind function call related to the AF_XDP socket address family.
So, where in the syscall could this value be returned?
First, let’s examine the syscall parameters to see if the libbpf xsk_socket__create_shared() function sets weird values for us.
We use the pahole tool to print the structure definitions:
$ pahole sockaddr
struct sockaddr {
sa_family_t sa_family; /* 0 2 */
char sa_data[14]; /* 2 14 */
/* size: 16, cachelines: 1, members: 2 */
/* last cacheline: 16 bytes */
};
$ pahole sockaddr_xdp
struct sockaddr_xdp {
__u16 sxdp_family; /* 0 2 */
__u16 sxdp_flags; /* 2 2 */
__u32 sxdp_ifindex; /* 4 4 */
__u32 sxdp_queue_id; /* 8 4 */
__u32 sxdp_shared_umem_fd; /* 12 4 */
/* size: 16, cachelines: 1, members: 5 */
/* last cacheline: 16 bytes */
};
Translation of the arguments of the bind syscall (the 14 bytes of sa_data) for the first bind() call:
| Struct member | Big Endian value | Decimal | Meaning | Observation |
|---|---|---|---|---|
| sxdp_flags | \x08\x00 | 8 | XDP_USE_NEED_WAKEUP | expected |
| sxdp_ifindex | \x92\x10\x00\x00 | 4242 | The network interface index | expected |
| sxdp_queue_id | \x00\x00\x00\x00 | 0 | The network interface queue id | expected |
| sxdp_shared_umem_fd | \x00\x00\x00\x00 | 0 | The umem is not shared yet | expected |
Second bind() call:
| Struct member | Big Endian value | Decimal | Meaning | Observation |
|---|---|---|---|---|
| sxdp_flags | \x01\x00 | 1 | XDP_SHARED_UMEM | expected |
| sxdp_ifindex | \x92\x10\x00\x00 | 4242 | The network interface index | expected |
| sxdp_queue_id | \x00\x00\x00\x00 | 0 | The network interface queue id | expected |
| sxdp_shared_umem_fd | \x09\x00\x00\x00 | 9 | File descriptor of the first AF_XDP socket associated to the UMEM | expected |
The arguments look good…
We could statically try to infer where the EINVAL was returned looking at the source code. But this analysis has its limits and can be error-prone.
Overall, it seems that the network namespaces are not taken into account somewhere because it seems that there is some confusion with the interface indexes.
Is the issue on the kernel-side?
Digging deeper
It would be nice if we had step-by-step runtime inspection of code paths and variables.
Let’s:
- Compile a Linux kernel version closer to the one used on our servers (5.15) with debug symbols.
- Generate a root filesystem for the kernel to boot.
- Boot in QEMU.
- Attach gdb to it and set a breakpoint on the syscall.
- Check where the EINVAL value is returned.
We could have used buildroot with a minimal reproduction code, but it wasn’t funny enough. Instead, we install a minimal Ubuntu and load our custom kernel. This has the benefit of having a package manager if we need to install other debugging tools.
Let’s install a minimal Ubuntu server 21.10 (with ext4, no LVM and a ssh server selected in the installation wizard):
qemu-img create -f qcow2 ubuntu-21.10-live-server-amd64.qcow2 20G
qemu-system-x86_64 \
-smp $(nproc) \
-m 4G \
-hda ubuntu-21.10-live-server-amd64.qcow2 \
-cdrom /home/bastien/Downloads/ubuntu-21.10-live-server-amd64.iso \
-enable-kvm \
-cpu host \
-net nic,model=virtio \
-net user,hostfwd=tcp::10022-:22
And then build a kernel (link and link) with the following changes in the menuconfig:
- Cryptographic API -> Certificates for signature checking -> Provide system-wide ring of trusted keys
- change the additional string to be EMPTY ("")
- Device drivers -> Network device support -> Virtio network driver
- Set to Enable
- Device Drivers -> Network device support -> Virtual ethernet pair device
- Set to Enable
- Device drivers -> Block devices -> Virtio block driver
- Set to Enable
git clone git://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git && cd linux/
git checkout v5.15
make menuconfig
make -j$(nproc) bzImage
We can now run Ubuntu with our custom kernel waiting for gdb to be connected:
qemu-system-x86_64 \
-kernel /home/bastien/work/linux/arch/x86_64/boot/bzImage \
-append "root=/dev/sda2 console=ttyS0 nokaslr" \
-nographic \
-smp $(nproc) \
-m 8G \
-hda ubuntu-21.10-live-server-amd64.qcow2 \
-boot c \
-cpu host \
-net nic,model=virtio \
-net user,hostfwd=tcp::10022-:22 \
-enable-kvm \
-s -S
And we can fire up gdb and set a breakpoint on the xsk_bind function:
$ gdb -ex "add-auto-load-safe-path $(pwd)" -ex "file vmlinux" -ex "target remote :1234" -ex "hbreak start_kernel" -ex "continue"
(gdb) b xsk_bind
(gdb) continue
After executing the network setup script and running flowtrackd, we hit the xsk_bind breakpoint:
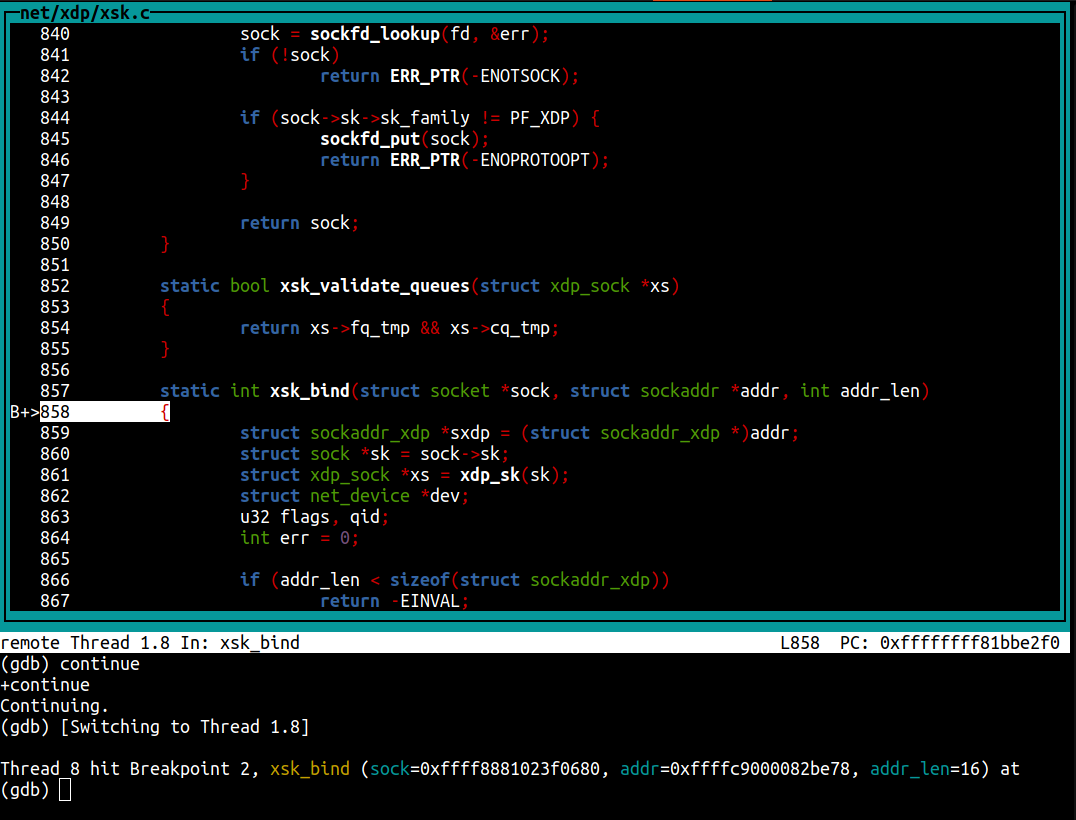
We continue to hit the second xsk_bind breakpoint (the one that returns EINVAL) and after a few next and step commands, we find which function returned the EINVAL value:
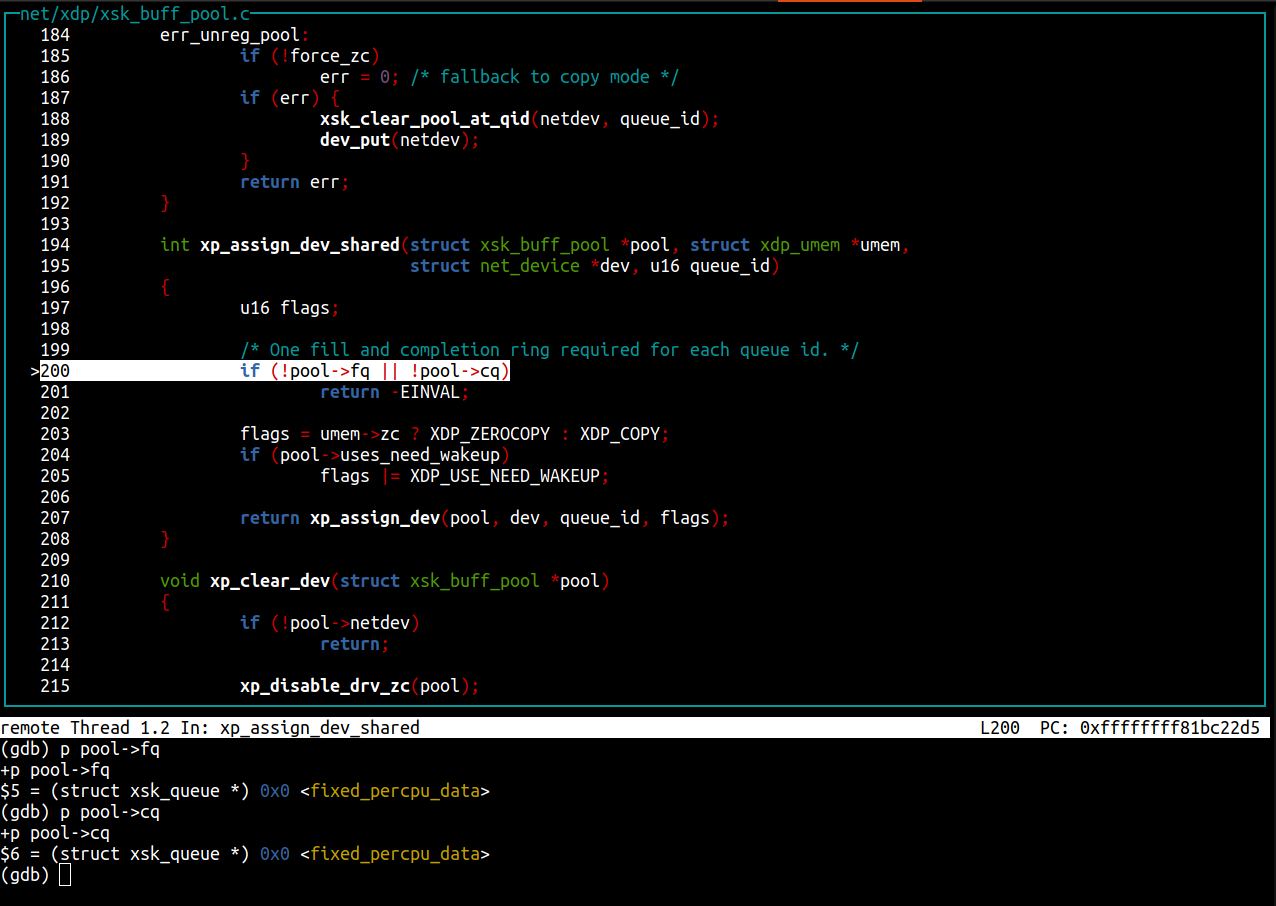
In our Rust code, we allocate a new FILL and a COMPLETION queue for each queue id of the device prior to calling xsk_socket__create_shared(). Why are those set to NULL? Looking at the code, pool->fq comes from a struct field named fq_tmp that is accessed from the sock pointer (print ((struct xdp_sock *)sock->sk)->fq_tmp). The field is set in the first call to xsk_bind() but isn’t in the second call. We note that at the end of the xsk_bind() function, fq_tmp and cq_tmp are set to NULL as per this comment: “FQ and CQ are now owned by the buffer pool and cleaned up with it.”.
Something is definitely going wrong in libbpf because the FILL queue and COMPLETION queue pointers are missing.
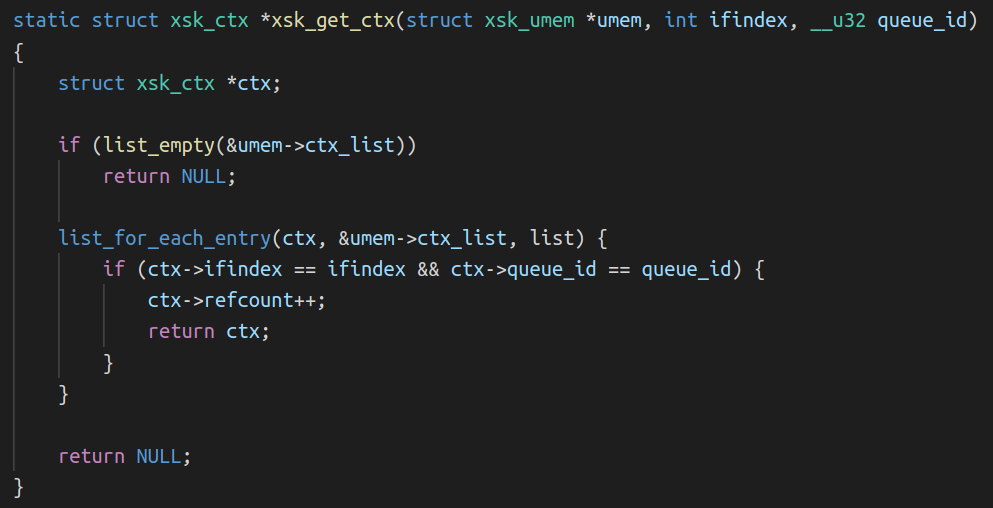
Back to the libbpf xsk_socket__create_shared() function to check where the queues are set for the socket and we quickly notice two functions that interact with the FILL and COMPLETION queues:
The first function called is xsk_get_ctx():
The second is xsk_create_ctx():
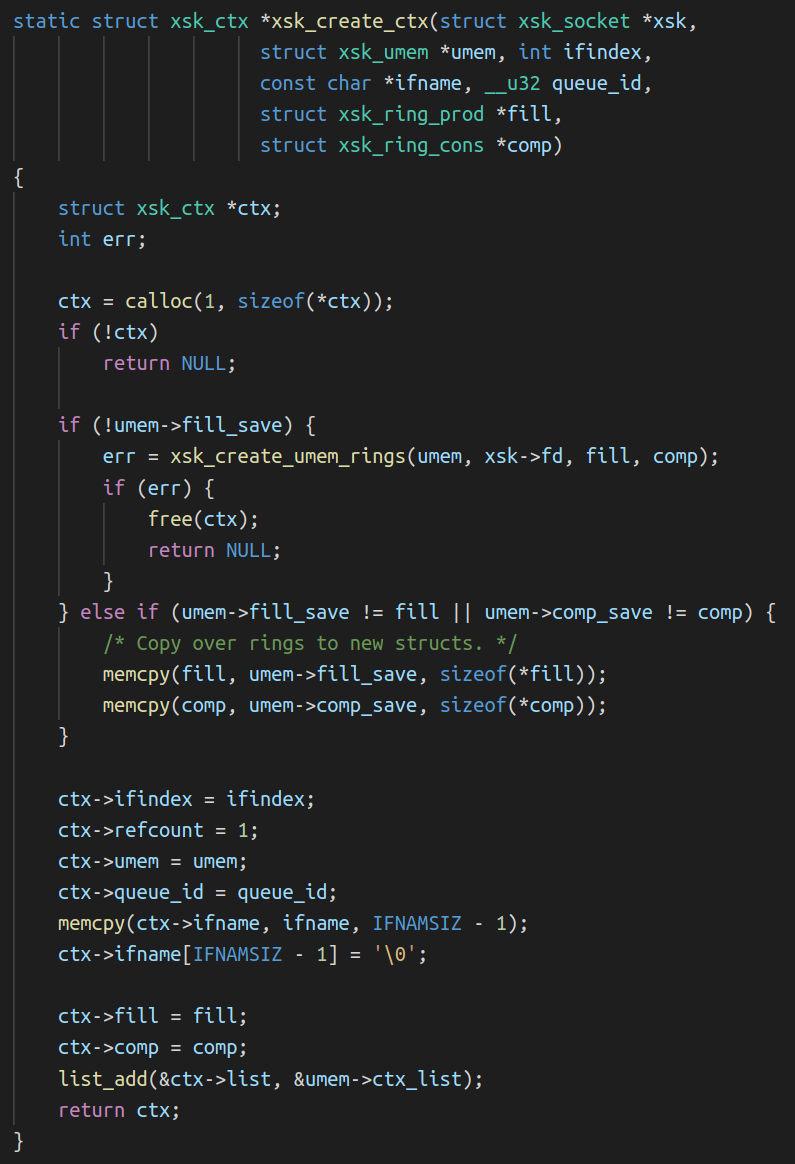
Remembering our setup, can you spot what the issue is?
The bug / missing feature
The issue is in the comparison performed in the xsk_get_ctx() to find the right socket context structure associated with the (ifindex, queue_id) pair in the linked-list. The UMEM being shared across Xsks, the same umem->ctx_list linked list head is used to find the sockets that use this UMEM. Remember that in our setup, flowtrackd attaches itself to two network devices that live in different network namespaces. Using the interface index and the queue_id to find the right context (FILL and COMPLETION queues) associated to a socket is not sufficient because another network interface with the same interface index can exist at the same time in another network namespace.
What can we do about it?
We need to tell apart two network devices “system-wide”. That means across the network namespace boundaries.
Could we fetch and store the network namespace inode number of the current process (stat -c%i -L /proc/self/ns/net) at the context creation and then use it in the comparison? According to man 7 inode: “Each file in a filesystem has a unique inode number. Inode numbers are guaranteed to be unique only within a filesystem”. However, inode numbers can be reused:
# ip netns add a
# stat -c%i /run/netns/a
4026532570
# ip netns delete a
# ip netns add b
# stat -c%i /run/netns/b
4026532570
Here are our options:
- Do a quick hack to ensure that the interface indexes are not the same (as done in the integration tests).
- Explain our use case to the libbpf maintainers and see how the API for the
xsk_socket__create_shared()function should change. It could be possible to pass an opaque “cookie” as a parameter at the socket creation and pass it to the functions that access the socket contexts. - Take our chances and look for Linux patches that contain the words “netns” and “cookie”
Well, well, well: [PATCH bpf-next 3/7] bpf: add netns cookie and enable it for bpf cgroup hooks
This is almost what we need! This patch adds a kernel function named bpf_get_netns_cookie() that would get us the network namespace cookie linked to a socket:

A second patch enables us to get this cookie from userspace:
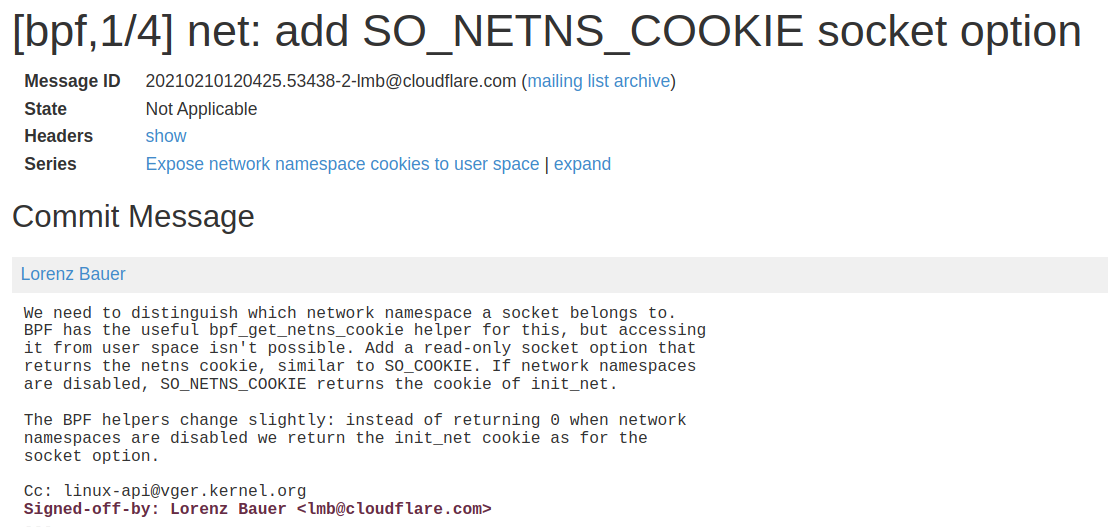
I know this Lorenz from somewhere 😀
Note that this patch was shipped with the Linux v5.14 release.
We have more guaranties now:
- The cookie is generated for us by the kernel.
- There is a strong bound to the socket from its creation (the netns cookie value is present in the socket structure).
- The network namespace cookie remains stable for its lifetime.
- It provides a global identifier that can be assumed unique and not reused.
A patch
At the socket creation, we retrieve the netns_cookie from the Xsk file descriptor with getsockopt(), insert it in the xsk_ctx struct and add it in the comparison performed in xsk_get_ctx().
Our initial patch was tested on Linux v5.15 with libbpf v0.8.0.
Testing the patch
We keep the same network setup script, but we set the number of queues per interface to two (QUEUES=2). This will help us check that two sockets created in the same network namespace have the same netns_cookie.
After recompiling flowtrackd to use our patched libbpf, we can run it inside our guest with gdb and set breakpoints on xsk_get_ctx as well as xsk_create_ctx. We now have two instances of gdb running at the same time, one debugging the system and the other debugging the application running in that system. Here is the gdb guest view:
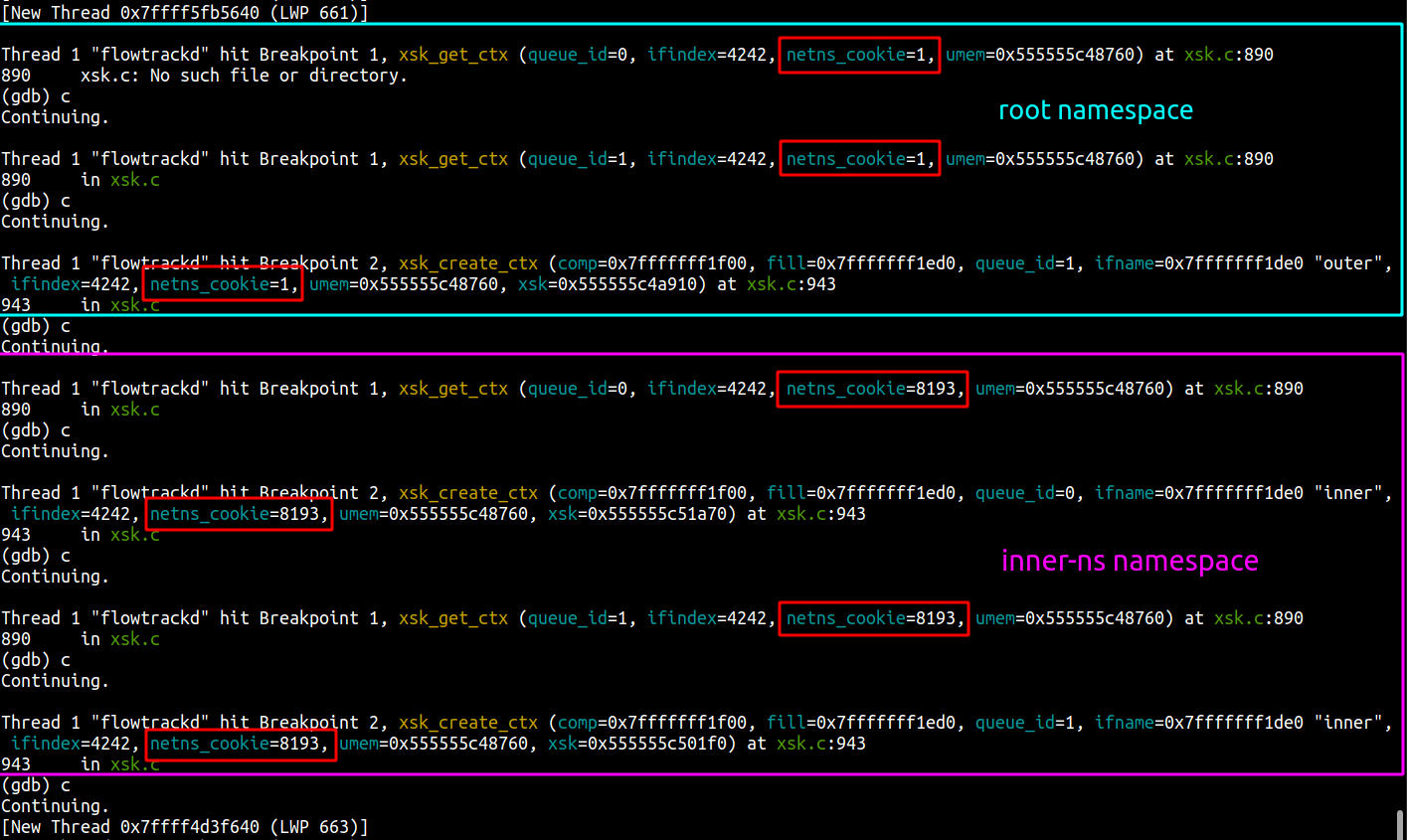
Here is the gdb system view:
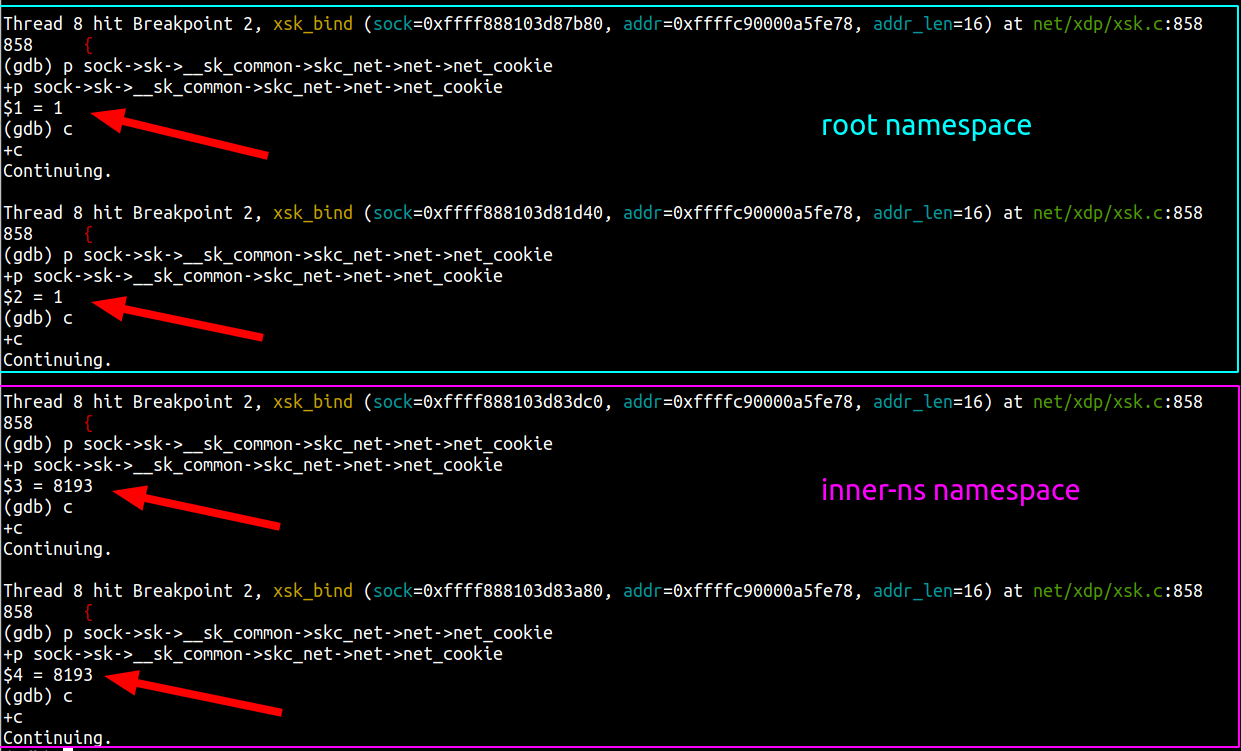
We can see that the netns_cookie value for the first two Xsks is 1 (root namespace) and the net_cookie value for the two other Xsks is 8193 (inner-ns namespace).
flowtrackd didn’t crash and is behaving as expected. It works!
Conclusion
Situation
Creating AF_XDP sockets with the XDP_SHARED_UMEM flag set fails when the two devices’ ifindex (and the queue_id) are the same. This can happen with devices in different network namespaces.
In the shared UMEM mode, each Xsk is expected to have a dedicated fill and completion queue. Context data about those queues are set by libbpf in a linked-list stored by the UMEM object. The comparison performed to pick the right context in the linked-list only takes into account the device ifindex and the queue_id which can be the same when devices are in different network namespaces.
Resolution
We retrieve the netns_cookie associated with the socket at its creation and add it in the comparison operation.
The fix has been submitted and merged in libxdp which is where the AF_XDP parts of libbpf now live.
We’ve also backported the fix in libbpf and updated the libbpf-sys Rust crate accordingly.