Cloud solutions architects should ideally “build today with tomorrow in mind,” meaning their solutions need to cater to current scale requirements as well as the anticipated growth of the solution. This growth can be either the organic growth of a solution or it could be related to a merger and acquisition type of scenario, where its size is increased dramatically within a short period of time.
Still, when a solution scales, many architects experience added complexity to the overall architecture in terms of its manageability, performance, security, etc. By architecting your solution or application to scale reliably, you can avoid the introduction of additional complexity, degraded performance, or reduced security as a result of scaling.
Generally, a solution or service’s reliability is influenced by its up time, performance, security, manageability, etc. In order to achieve reliability in the context of scale, take into consideration the following primary design principals.
Modularity
Modularity aims to break a complex component or solution into smaller parts that are less complicated and easier to scale, secure, and manage.
Figure 1: Monolithic architecture vs. modular architecture
Modular design is commonly used in modern application developments. where an application’s software is constructed of multiple and loosely coupled building blocks (functions). These functions collectively integrate through pre-defined common interfaces or APIs to form the desired application functionality (commonly referred to as microservices architecture).
This design principle can also be applied to different components of the solution’s architecture. For example, when building a cloud solution on a single Amazon VPC, it may reach certain scaling limits and make it harder to introduce changes at scale due to the higher level of dependencies. This single complex VPC can be divided into multiple smaller and simpler VPCs. The architecture based on multiple VPCs can vary. For example, the VPCs can be divided based on a service or application building block, a specific function of the application, or on organizational functions like a VPC for various departments. This principle can also be leveraged at a regional level for very high scale global architectures. You can make the architecture modular at a global level by distributing the multiple VPCs across different AWS Regions to achieve global scale (facilitated by AWS Global Infrastructure).
In addition, modularity promotes separation of concerns by having well-defined boundaries among the different components of the architecture. As a result, each component can be managed, secured, and scaled independently. Also, it helps you avoid what is commonly known as “fate sharing,” where a vertically scaled server hosts a monolithic application, and any failure to this server will impact the entire application.
Horizontal scaling
Horizontal scaling, commonly referred to as scale-out, is the capability to automatically add systems/instances in a distributed manner in order to handle an increase in load. Examples of this increase in load could be the increase of number of sessions to a web application. With horizontal scaling, the load is distributed across multiple instances. By distributing these instances across Availability Zones, horizontal scaling not only increases performance, but also improves the overall reliability.
In order for the application to work seamlessly in a scale-out distributed manner, the application needs to be designed to support a stateless scaling model, where the application’s state information is stored and requested independently from the application’s instances. This makes the on-demand horizontal scaling easier to achieve and manage.
This principle can be complemented with a modularity design principle, in which the scaling model can be applied to certain component(s) or microservice(s) of the application stack. For example, only scale-out Amazon Elastic Cloud Compute (EC2) front-end web instances that reside behind an Elastic Load Balancing (ELB) layer with auto-scaling groups. In contrast, this elastic horizontal scalability might be very difficult to achieve for a monolithic type of application.
Leverage the content delivery network
Leveraging Amazon CloudFront and its edge locations as part of the solution architecture can enable your application or service to scale rapidly and reliably at a global level, without adding any complexity to the solution. The integration of a CDN can take different forms depending on the solution use case.
For example, CloudFront played an important role to enable the scale required throughout Amazon Prime Day 2020 by serving up web and streamed content to a worldwide audience, which handled over 280 million HTTP requests per minute.
Go serverless where possible
As discussed earlier in this post, modular architectures based on microservices reduce the complexity of the individual component or microservice. At scale it may introduce a different type of complexity related to the number of these independent components (microservices). This is where serverless services can help to reduce such complexity reliably and at scale. With this design model you no longer have to provision, manually scale, maintain servers, operating systems, or runtimes to run your applications.
For example, you may consider using a microservices architecture to modernize an application at the same time to simplify the architecture at scale using Amazon Elastic Kubernetes Service (EKS) with AWS Fargate.
Figure 3: Example of a serverless microservices architecture
To avoid any major changes at a later stage to accommodate security requirements, it’s essential that security is taken into consideration as part of the initial solution design. For example, if the cloud project is new or small, and you don’t consider security properly at the initial stages, once the solution starts to scale, redesigning the entire cloud project from scratch to accommodate security best practices is usually not a simple option, which may lead to consider suboptimal security solutions that may impact the desired scale to be achieved. By leveraging CDN as part of the solution architecture (as discussed above), using Amazon CloudFront, you can minimize the impact of distributed denial of service (DDoS) attacks as well as perform application layer filtering at the edge. Also, when considering serverless services and the Shared Responsibility Model, from a security lens you can delegate a considerable part of the application stack to AWS so that you can focus on building applications. See The Shared Responsibility Model for AWS Lambda.
Design with security in mind by incorporating the necessary security services as part of the initial cloud solution. This will allow you to add more security capabilities and features as the solution grows, without the need to make major changes to the design.
Design for failure
The reliability of a service or solution in the cloud depends on multiple factors, the primary of which is resiliency. This design principle becomes even more critical at scale because the failure impact magnitude typically will be higher. Therefore, to achieve a reliable scalability, it is essential to design a resilient solution, capable of recovering from infrastructure or service disruptions. This principle involves designing the overall solution in such a way that even if one or more of its components fail, the solution is still be capable of providing an acceptable level of its expected function(s). See AWS Well-Architected Framework – Reliability Pillar for more information.
Conclusion
Designing for scale alone is not enough. Reliable scalability should be always the targeted architectural attribute. The design principles discussed in this blog act as the foundational pillars to support it, and ideally should be combined with adopting a DevOps model.
Getting stuck in traffic is one of the most frustrating experiences for drivers around the world. Everyone slows to a crawl, sometimes for a minor issue or sometimes for no reason at all. As engineers at Netflix, we are constantly reevaluating how to redesign traffic management. What if we knew the urgency of each traveler and could selectively route cars through, rather than making everyone wait?
In Netflix engineering, we’re driven by ensuring Netflix is there when you need it to be. Yet, as recent as last year, our systems were susceptible to metaphorical traffic jams; we had on/off circuit breakers, but no progressive way to shed load. Motivated by improving the lives of our members, we’ve introduced priority-based progressive load shedding.
The animation below shows the behavior of the Netflix viewer experience when the backend is throttling traffic based on priority. While the lower priority requests are throttled, the playback experience remains uninterrupted and the viewer is able to enjoy their title. Let’s dig into how we accomplished this.
Failure can occur due to a myriad of reasons: misbehaving clients that trigger a retry storm, an under-scaled service in the backend, a bad deployment, a network blip, or issues with the cloud provider. All such failures can put a system under unexpected load, and at some point in the past, every single one of these examples has prevented our members’ ability to play. With these incidents in mind, we set out to make Netflix more resilient with these goals:
Consistently prioritize requests across device types (Mobile, Browser, and TV)
Progressively throttle requests based on priority
Validate assumptions by using Chaos Testing (deliberate fault injection) for requests of specific priorities
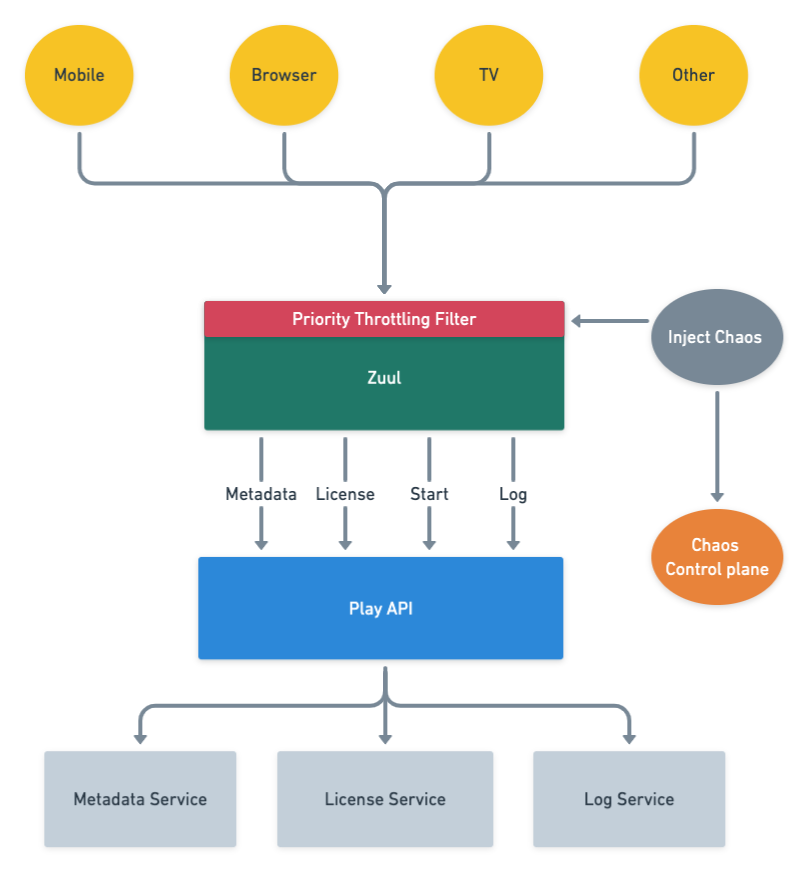
The resulting architecture that we envisioned with priority throttling and chaos testing included is captured below.
High level playback architecture with priority throttling and chaos testing
Building a request taxonomy
We decided to focus on three dimensions in order to categorize request traffic: throughput, functionality, and criticality. Based on these characteristics, traffic was classified into the following:
NON_CRITICAL: This traffic does not affect playback or members’ experience. Logs and background requests are examples of this type of traffic. These requests are usually high throughput which contributes to a large percentage of load in the system.
DEGRADED_EXPERIENCE: This traffic affects members’ experience, but not the ability to play. The traffic in this bucket is used for features like: stop and pause markers, language selection in the player, viewing history, and others.
CRITICAL: This traffic affects the ability to play. Members will see an error message when they hit play if the request fails.
Using attributes of the request, the API gateway service (Zuul) categorizes the requests into NON_CRITICAL, DEGRADED_EXPERIENCE and CRITICAL buckets, and computes a priority score between 1 to 100 for each request given its individual characteristics. The computation is done as a first step so that it is available for the rest of the request lifecycle.
Most of the time, the request workflow proceeds normally without taking the request priority into account. However, as with any service, sometimes we reach a point when either one of our backends is in trouble or Zuul itself is in trouble. When that happens requests with higher priority get preferential treatment. The higher priority requests will get served, while the lower priority ones will not. The implementation is analogous to a priority queue with a dynamic priority threshold. This allows Zuul to drop requests with a priority lower than the current threshold.
Finding the best place to throttle traffic
Zuul can apply load shedding in two moments during the request lifecycle: when it routes requests to a specific back-end service (service throttling) or at the time of initial request processing, which affects all back-end services (global throttling).
Service throttling
Zuul can sense when a back-end service is in trouble by monitoring the error rates and concurrent requests to that service. Those two metrics are approximate indicators of failures and latency. When the threshold percentage for one of these two metrics is crossed, we reduce load on the service by throttling traffic.
Global throttling
Another case is when Zuul itself is in trouble. As opposed to the scenario above, global throttling will affect all back-end services behind Zuul, rather than a single back-end service. The impact of this global throttling can cause much bigger problems for members. The key metrics used to trigger global throttling are CPU utilization, concurrent requests, and connection count. When any of the thresholds for those metrics are crossed, Zuul will aggressively throttle traffic to keep itself up and healthy while the system recovers. This functionality is critical: if Zuul goes down, no traffic can get through to our backend services, resulting in a total outage.
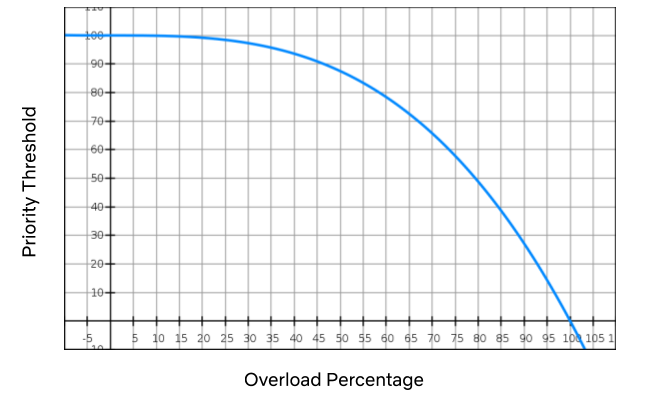
Once we had the prioritization piece in place, we were able to combine it with our load shedding mechanism to dramatically improve streaming reliability. When we’re in a bad situation (i.e. any of the thresholds above are exceeded), we progressively drop traffic, starting with the lowest priority. A cubic function is used to manage the level of throttling. If things get really, really bad the level will hit the sharp side of the curve, throttling everything.
The graph above is an example of how the cubic function is applied. As the overload percentage increases (i.e. the range between the throttling threshold and the max capacity), the priority threshold trails it very slowly: at 35%, it’s still in the mid-90s. If the system continues to degrade, we hit priority 50 at 80% exceeded and then eventually 10 at 95%, and so on.
Given that a relatively small amount of requests impact streaming availability, throttling low priority traffic may affect certain product features but will not prevent members pressing “play” and watching their favorite show. By adding progressive priority-based load shedding, Zuul can shed enough traffic to stabilize services without members noticing.
Handling retry storms
When Zuul decides to drop traffic, it sends a signal to devices to let them know that we need them to back off. It does this by indicating how many retries they can perform and what kind of time window they can perform them in. For example:
Using this backpressure mechanism, we can stop retry storms much faster than we could in the past. We automatically adjust these two dials based on the priority of the request. Requests with higher priority will retry more aggressively than lower ones, also increasing streaming availability.
Validating which requests are right for the job
To validate our request taxonomy assumptions on whether a specific request fell into the NON_CRITICAL, DEGRADED, or CRITICAL bucket, we needed a way to test the user’s experience when that request was shed. To accomplish this, we leveraged our internal failure injection tool (FIT) and created a failure injection point in Zuul that allowed us to shed any request based on a supplied priority. This enabled us to manually simulate a load shedded experience by blocking ranges of priorities for a specific device or member, giving us an idea of which requests could be safely shed without impacting the user.
Continually ensuring those requests are still right for the job
One of the goals here is to reduce members’ pain by shedding requests that are not expected to affect the user’s streaming experience. However, Netflix changes quickly and requests that were thought to be noncritical can unexpectedly become critical. In addition, Netflix has a wide variety of client devices, client versions, and ways to interact with the system. To make sure we weren’t causing members pain when throttling NON_CRITICAL requests in any of these scenarios, we leveraged our infrastructure experimentation platform ChAP.
This platform allows us to stage an A/B experiment that will allocate a small number of production users to either a control or treatment group for 45 minutes while throttling a range of priorities for the treatment group. This lets us capture a variety of live use cases and measure the impact to their playback experience. ChAP analyzes the members’ KPIs per device to determine if there is a deviation between the control and the treatment groups.
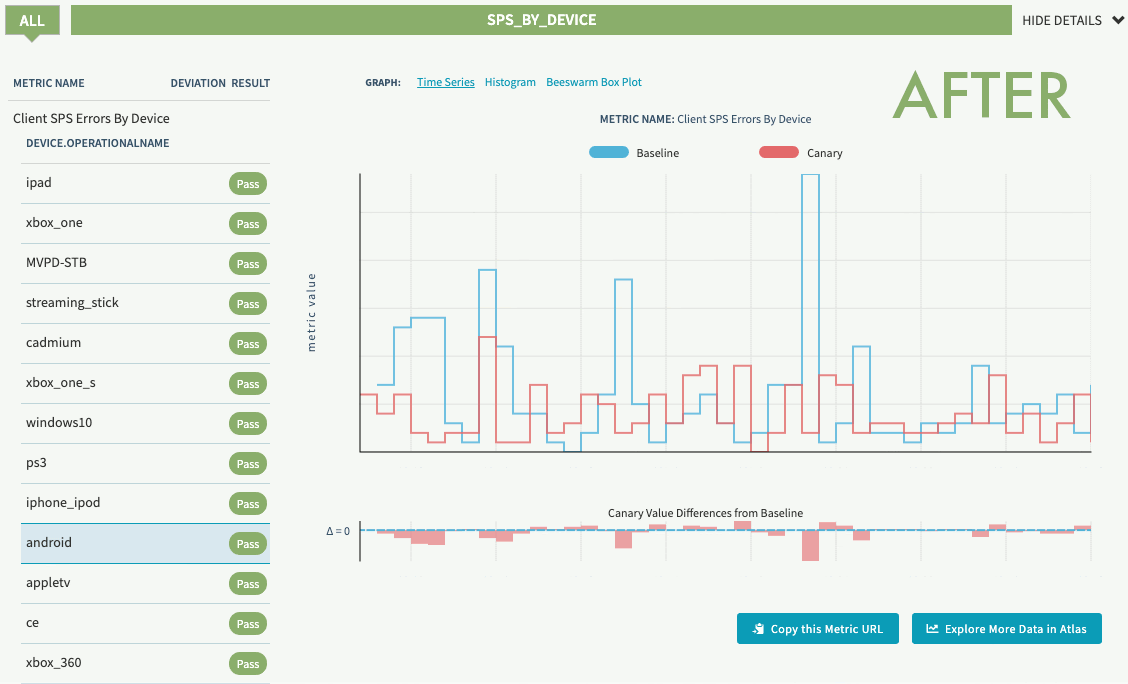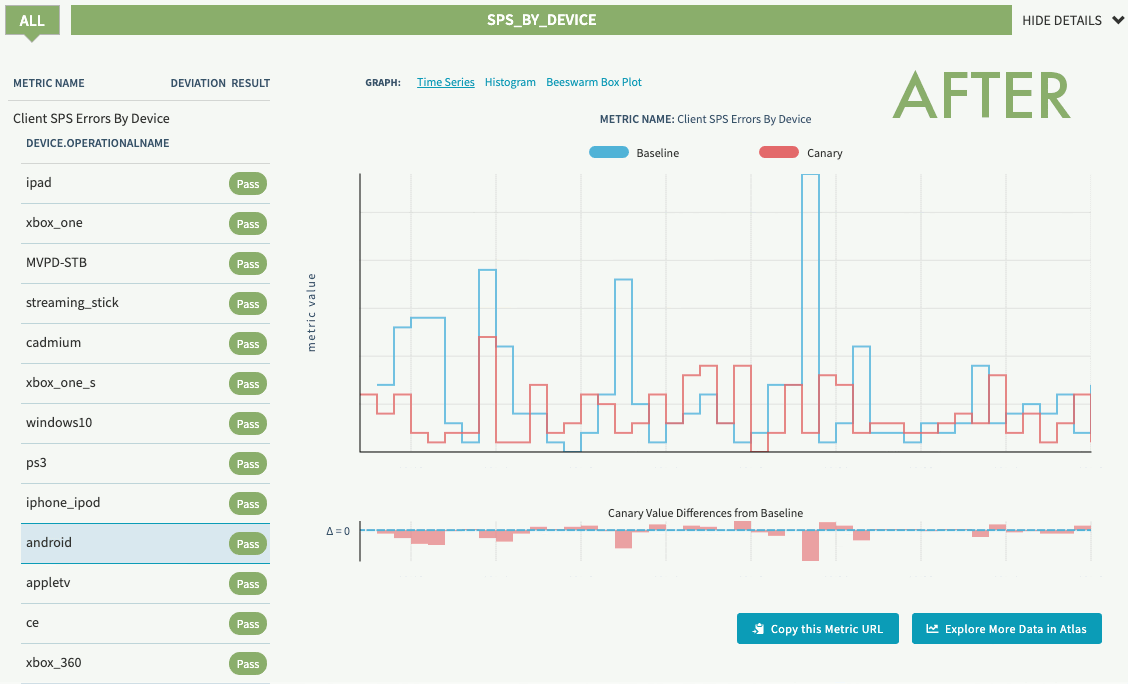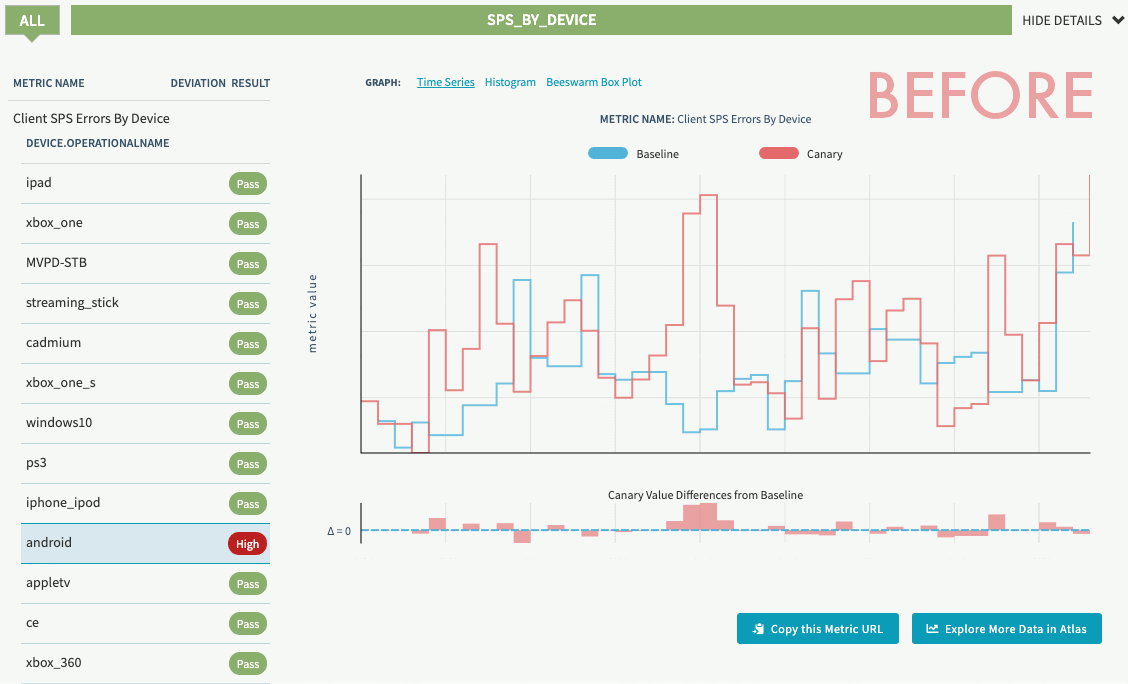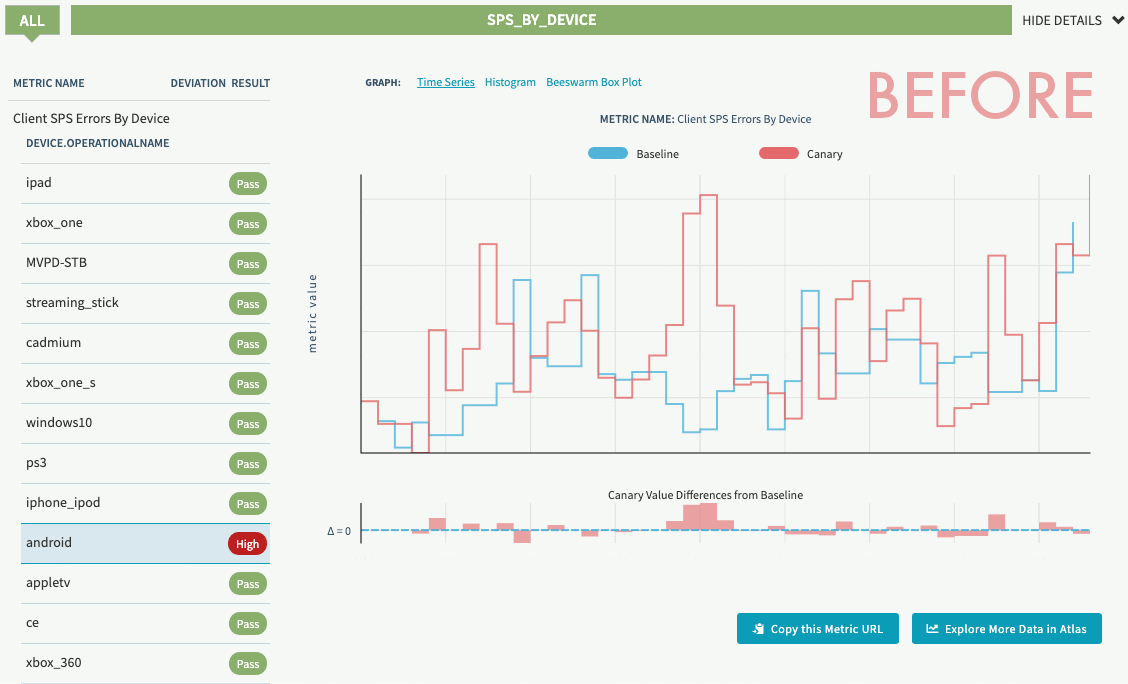
In our first experiment, we detected a race condition in both Android and iOS devices for a low priority request that caused sporadic playback errors. Since we practice continuous experimentation, once the initial experiments were run and the bugs were fixed, we scheduled them to run on a periodic basis. This allows us to detect regressions early and keep users streaming.
Experiment regression detection before and after fix (SPS indicates streaming availability)
Reaping the benefits
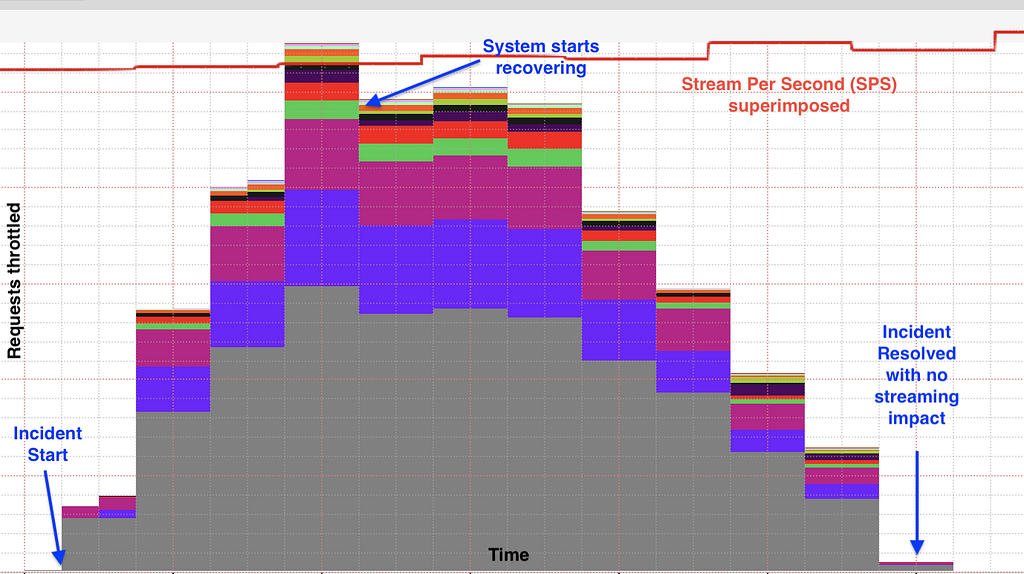
In 2019, before progressive load shedding was in place, the Netflix streaming services experienced an outage that resulted in a sizable percentage of members who were not able to play for a period of time. In 2020, days after the implementation was deployed, the team started seeing the benefit of the solution. Netflix experienced a similar issue with the same potential impact as the outage seen in 2019. Unlike then, Zuul’s progressive load shedding kicked in and started shedding traffic until the service was in a healthy state without impacting members’ ability to play at all.
The graph below shows a stable streaming availability metric stream per second (SPS) while Zuul is performing progressive load shedding based on request priority during the incident. The different colors in the graph represent requests with different priority being throttled.
Members were happily watching their favorite show on Netflix while the infrastructure was self-recovering from a system failure.
We are not done yet
For future work, the team is looking into expanding the use of request priority for other use cases like better retry policies between devices and back-ends, dynamically changing load shedding thresholds, tuning the request priorities using Chaos Testing as a guiding principle, and other areas that will make Netflix even more resilient.
If you’re interested in helping Netflix stay up in the face of shifting systems and unexpected failures, reach out to us. We’re hiring!
October 1 was this year’s DNS Flag Day. Read on to find out all about DNS Flag Day and how it affects Cloudflare’s DNS services (hint: it doesn’t, we already did the work to be compliant).
What is DNS Flag Day?
DNS Flag Day is an initiative by several DNS vendors and operators to increase the compliance of implementations with DNS standards. The goal is to make DNS more secure, reliable and robust. Rather than a push for new features, DNS flag day is meant to ensure that workarounds for non-compliance can be reduced and a common set of functionalities can be established and relied upon.
Last year’s flag day was February 1, and it set forth that servers and clients must be able to properly handle the Extensions to DNS (EDNS0) protocol (first RFC about EDNS0 are from 1999 – RFC 2671). This way, by assuming clients have a working implementation of EDNS0, servers can resort to always sending messages as EDNS0. This is needed to support DNSSEC, the DNS security extensions. We were, of course, more than thrilled to support the effort, as we’re keen to push DNSSECadoption forward .
DNS Flag Day 2020
The goal for this year’s flag day is to increase DNS messaging reliability by focusing on problems around IP fragmentation of DNS packets. The intention is to reduce DNS message fragmentation which continues to be a problem. We can do that by ensuring cleartext DNS messages sent over UDP are not too large, as large messages risk being fragmented during the transport. Additionally, when sending or receiving large DNS messages, we have the ability to do so over TCP.
Problem with DNS transport over UDP
A potential issue with sending DNS messages over UDP is that the sender has no indication of the recipient actually receiving the message. When using TCP, each packet being sent is acknowledged (ACKed) by the recipient, and the sender will attempt to resend any packets not being ACKed. UDP, although it may be faster than TCP, does not have the same mechanism of messaging reliability. Anyone still wishing to use UDP as their transport protocol of choice will have to implement this reliability mechanism in higher layers of the network stack. For instance, this is what is being done in QUIC, the new Internet transport protocol used by HTTP/3 that is built on top of UDP.
Even the earliest DNS standards (RFC 1035) specified the use of sending DNS messages over TCP as well as over UDP. Unfortunately, the choice of supporting TCP or not was up to the implementer/operator, and then firewalls were sometimes set to block DNS over TCP. More recent updates to RFC 1035, on the other hand, require that the DNS server is available to query using DNS over TCP.
DNS message fragmentation
Sending data over networks and the Internet is restricted to the limitation of how large each packet can be. Data is chopped up into a stream of packets, and sized to adhere to the Maximum Transmission Unit (MTU) of the network. MTU is typically 1500 bytes for IPv4 and, in the case of IPv6, the minimum is 1280 bytes. Subtracting both the IP header size (IPv4 20 bytes/IPv6 40 bytes) and the UDP protocol header size (8 bytes) from the MTU, we end up with a maximum DNS message size of 1472 bytes for IPv4 and 1232 bytes in order for a message to fit within a single packet. If the message is any larger than that, it will have to be fragmented into more packets.
Sending large messages causes them to get fragmented into more than one pack. This is not a problem with TCP transports since each packet is ACK:ed to ensure proper delivery. However, the same does not hold true when sending large DNS messages over UDP. For many intents and purposes, UDP has been treated as a second-class citizen to TCP as far as network routing is concerned. It is quite common to see UDP packet fragments being dropped by routers and firewalls, potentially causing parts of a message to be lost. To avoid fragmentation over UDP it is better to truncate the DNS message and set the Truncation Flag in the DNS response. This tells the recipient that more data is available if the query is retried over TCP.
DNS Flag Day 2020 wants to ensure that DNS message fragmentation does not happen. When larger DNS messages need to be sent, we need to ensure it can be done reliably over TCP.
DNS servers need to support DNS message transport over TCP in order to be compliant with this year’s flag day. Also, DNS messages sent over UDP must never exceed the limit over which they risk being fragmented.
Cloudflare authoritative DNS and 1.1.1.1
We fully support the DNS Flag Day initiative, as it aims to make DNS more reliable and robust, and it ensures a common set of features for the DNS community to evolve on. In the DNS ecosystem, we are as much a client as we are a provider. When we perform DNS lookups on behalf of our customers and users, we rely on other providers to follow standards and be compliant. When they are not, and we can’t work around the issues, it leads to problems resolving names and reaching resources.
Both our public resolver 1.1.1.1 as well as our authoritative DNS service, set and enforce reasonable limits on DNS message sizes when sent over UDP. Of course, both services are available over TCP. If you’re already using Cloudflare, there is nothing you need to do but to keep using our DNS services! We will continually work on improving DNS.
If you already understand how Secondary DNS works, please feel free to skip this section. It does not provide any Cloudflare-specific information.
Secondary DNS has many use cases across the Internet; however, traditionally, it was used as a synchronized backup for when the primary DNS server was unable to respond to queries. A more modern approach involves focusing on redundancy across many different nameservers, which in many cases broadcast the same anycasted IP address.
Secondary DNS involves the unidirectional transfer of DNS zones from the primary to the Secondary DNS server(s). One primary can have any number of Secondary DNS servers that it must communicate with in order to keep track of any zone updates. A zone update is considered a change in the contents of a zone, which ultimately leads to a Start of Authority (SOA) serial number increase. The zone’s SOA serial is one of the key elements of Secondary DNS; it is how primary and secondary servers synchronize zones. Below is an example of what an SOA record might look like during a dig query.
example.com 3600 IN SOA ashley.ns.cloudflare.com. dns.cloudflare.com.
2034097105 // Serial
10000 // Refresh
2400 // Retry
604800 // Expire
3600 // Minimum TTL
Each of the numbers is used in the following way:
Serial – Used to keep track of the status of the zone, must be incremented at every change.
Refresh – The maximum number of seconds that can elapse before a Secondary DNS server must check for a SOA serial change.
Retry – The maximum number of seconds that can elapse before a Secondary DNS server must check for a SOA serial change, after previously failing to contact the primary.
Expire – The maximum number of seconds that a Secondary DNS server can serve stale information, in the event the primary cannot be contacted.
Minimum TTL – Per RFC 2308, the number of seconds that a DNS negative response should be cached for.
Using the above information, the Secondary DNS server stores an SOA record for each of the zones it is tracking. When the serial increases, it knows that the zone must have changed, and that a zone transfer must be initiated.
Serial Tracking
Serial increases can be detected in the following ways:
The fastest way for the Secondary DNS server to keep track of a serial change is to have the primary server NOTIFY them any time a zone has changed using the DNS protocol as specified in RFC 1996, Secondary DNS servers will instantly be able to initiate a zone transfer.
Another way is for the Secondary DNS server to simply poll the primary every “Refresh” seconds. This isn’t as fast as the NOTIFY approach, but it is a good fallback in case the notifies have failed.
One of the issues with the basic NOTIFY protocol is that anyone on the Internet could potentially notify the Secondary DNS server of a zone update. If an initial SOA query is not performed by the Secondary DNS server before initiating a zone transfer, this is an easy way to perform an amplification attack. There is two common ways to prevent anyone on the Internet from being able to NOTIFY Secondary DNS servers:
Using transaction signatures (TSIG) as per RFC 2845. These are to be placed as the last record in the extra records section of the DNS message. Usually the number of extra records (or ARCOUNT) should be no more than two in this case.
Using IP based access control lists (ACL). This increases security but also prevents flexibility in server location and IP address allocation.
Generally NOTIFY messages are sent over UDP, however TCP can be used in the event the primary server has reason to believe that TCP is necessary (i.e. firewall issues).
Zone Transfers
In addition to serial tracking, it is important to ensure that a standard protocol is used between primary and Secondary DNS server(s), to efficiently transfer the zone. DNS zone transfer protocols do not attempt to solve the confidentiality, authentication and integrity triad (CIA); however, the use of TSIG on top of the basic zone transfer protocols can provide integrity and authentication. As a result of DNS being a public protocol, confidentiality during the zone transfer process is generally not a concern.
Authoritative Zone Transfer (AXFR)
AXFR is the original zone transfer protocol that was specified in RFC 1034 and RFC 1035 and later further explained in RFC 5936. AXFR is done over a TCP connection because a reliable protocol is needed to ensure packets are not lost during the transfer. Using this protocol, the primary DNS server will transfer all of the zone contents to the Secondary DNS server, in one connection, regardless of the serial number. AXFR is recommended to be used for the first zone transfer, when none of the records are propagated, and IXFR is recommended after that.
Incremental Zone Transfer (IXFR)
IXFR is the more sophisticated zone transfer protocol that was specified in RFC 1995. Unlike the AXFR protocol, during an IXFR, the primary server will only send the secondary server the records that have changed since its current version of the zone (based on the serial number). This means that when a Secondary DNS server wants to initiate an IXFR, it sends its current serial number to the primary DNS server. The primary DNS server will then format its response based on previous versions of changes made to the zone. IXFR messages must obey the following pattern:
Current latest SOA
Secondary server current SOA
DNS record deletions
Secondary server current SOA + changes
DNS record additions
Current latest SOA
Steps 2,3,4,5,6 can be repeated any number of times, as each of those represents one change set of deletions and additions, ultimately leading to a new serial.
IXFR can be done over UDP or TCP, but again TCP is generally recommended to avoid packet loss.
How Does Secondary DNS Work at Cloudflare?
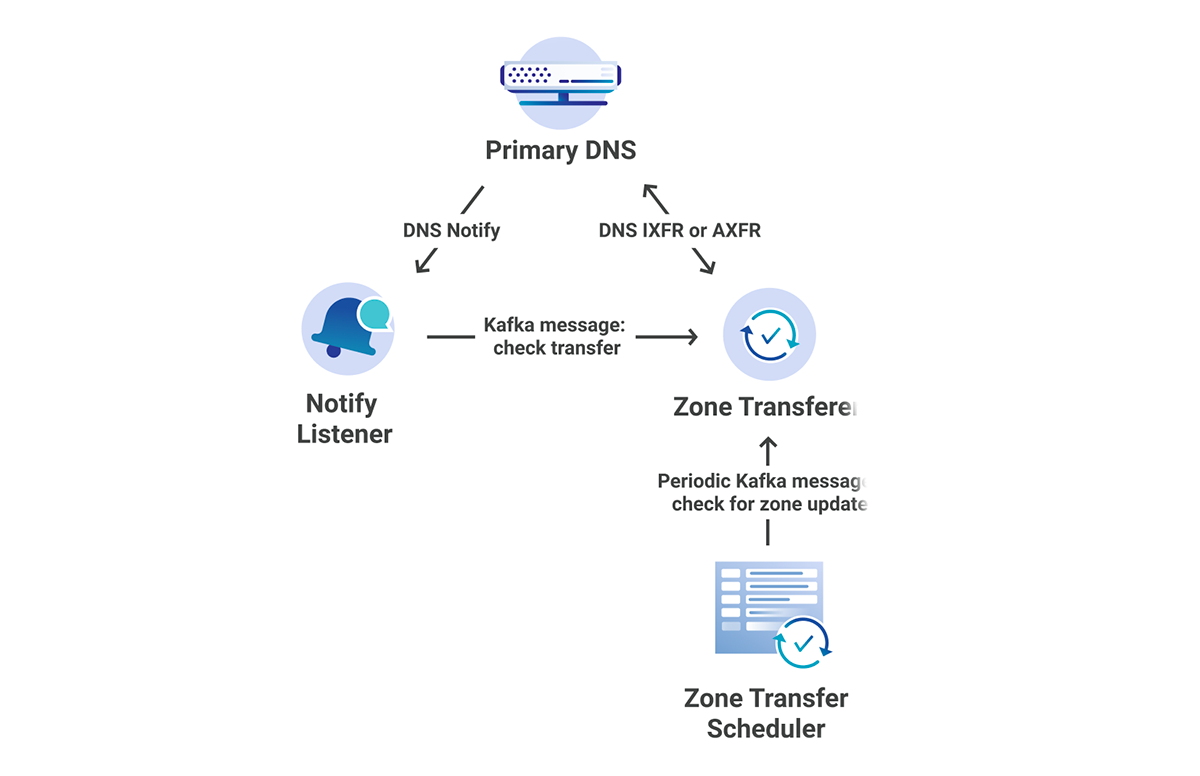
The DNS team loves microservice architecture! When we initially implemented Secondary DNS at Cloudflare, it was done using Mesos Marathon. This allowed us to separate each of our services into several different marathon apps, individually scaling apps as needed. All of these services live in our core data centers. The following services were created:
Zone Transferer – responsible for attempting IXFR, followed by AXFR if IXFR fails.
Zone Transfer Scheduler – responsible for periodically checking zone SOA serials for changes.
Rest API – responsible for registering new zones and primary nameservers.
In addition to the marathon apps, we also had an app external to the cluster:
Notify Listener – responsible for listening for notifies from primary servers and telling the Zone Transferer to initiate an AXFR/IXFR.
Each of these microservices communicates with the others through Kafka.
Figure 1: Secondary DNS Microservice Architecture
Once the zone transferer completes the AXFR/IXFR, it then passes the zone through to our zone builder, and finally gets pushed out to our edge at each of our 200 locations.
Although this current architecture worked great in the beginning, it left us open to many vulnerabilities and scalability issues down the road. As our Secondary DNS product became more popular, it was important that we proactively scaled and reduced the technical debt as much as possible. As with many companies in the industry, Cloudflare has recently migrated all of our core data center services to Kubernetes, moving away from individually managed apps and Marathon clusters.
What this meant for Secondary DNS is that all of our Marathon-based services, as well as our NOTIFY Listener, had to be migrated to Kubernetes. Although this long migration ended up paying off, many difficult challenges arose along the way that required us to come up with unique solutions in order to have a seamless, zero downtime migration.
Challenges When Migrating to Kubernetes
Although the entire DNS team agreed that kubernetes was the way forward for Secondary DNS, it also introduced several challenges. These challenges arose from a need to properly scale up across many distributed locations while also protecting each of our individual data centers. Since our core does not rely on anycast to automatically distribute requests, as we introduce more customers, it opens us up to denial-of-service attacks.
The two main issues we ran into during the migration were:
How do we create a distributed and reliable system that makes use of kubernetes principles while also making sure our customers know which IPs we will be communicating from?
When opening up a public-facing UDP socket to the Internet, how do we protect ourselves while also preventing unnecessary spam towards primary nameservers?.
Issue 1:
As was previously mentioned, one form of protection in the Secondary DNS protocol is to only allow certain IPs to initiate zone transfers. There is a fine line between primary servers allow listing too many IPs and them having to frequently update their IP ACLs. We considered several solutions:
Allowlist all Cloudflare IPs and dynamically update
Proxy egress traffic
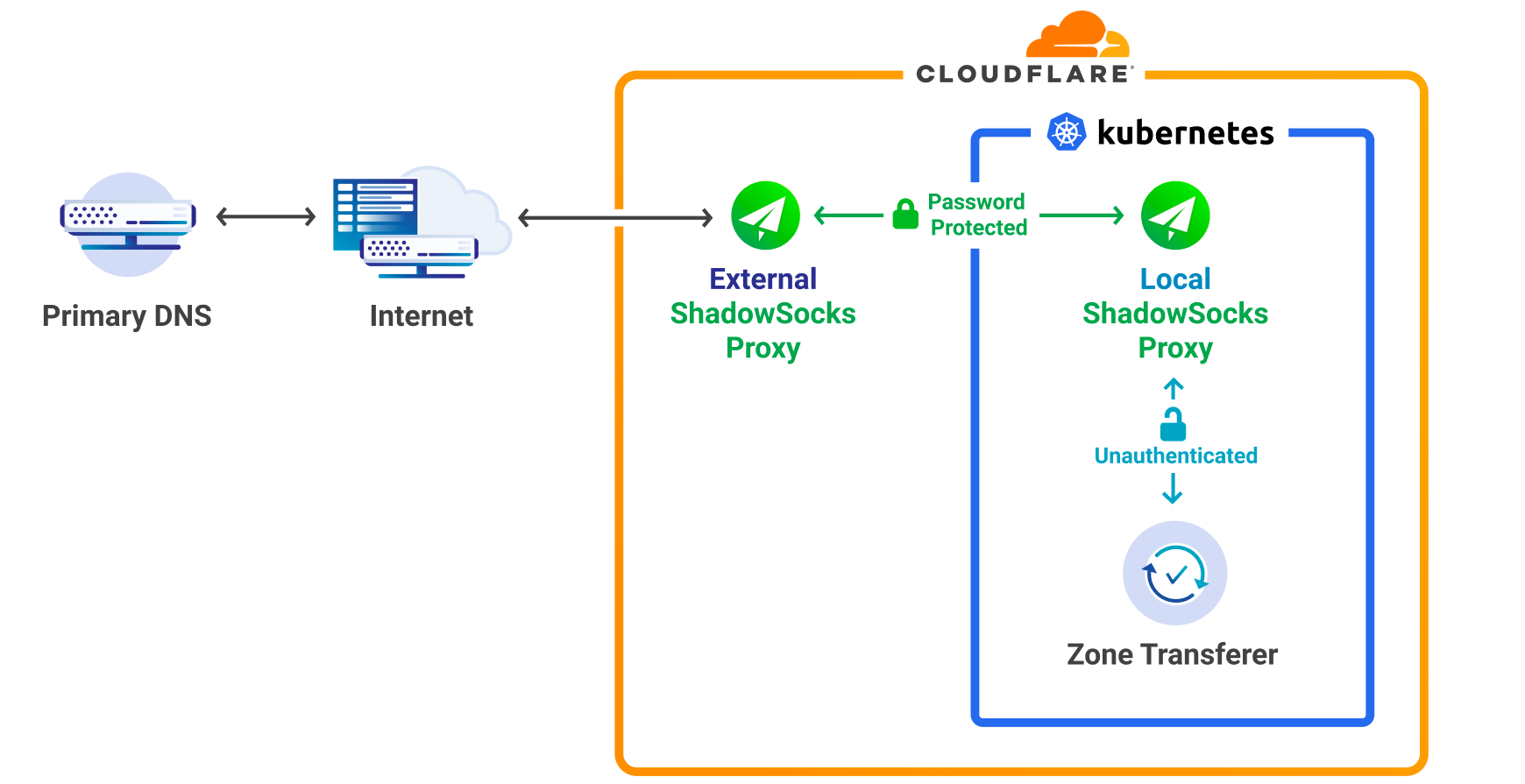
Ultimately we decided to proxy our egress traffic from k8s, to the DNS primary servers, using static proxy addresses. Shadowsocks-libev was chosen as the SOCKS5 implementation because it is fast, secure and known to scale. In addition, it can handle both UDP/TCP and IPv4/IPv6.
Figure 2: Shadowsocks proxy Setup
The partnership of k8s and Shadowsocks combined with a large enough IP range brings many benefits:
Horizontal scaling
Efficient load balancing
Primary server ACLs only need to be updated once
It allows us to make use of kubernetes for both the Zone Transferer and the Local ShadowSocks Proxy.
Shadowsocks proxy can be reused by many different Cloudflare services.
Issue 2:
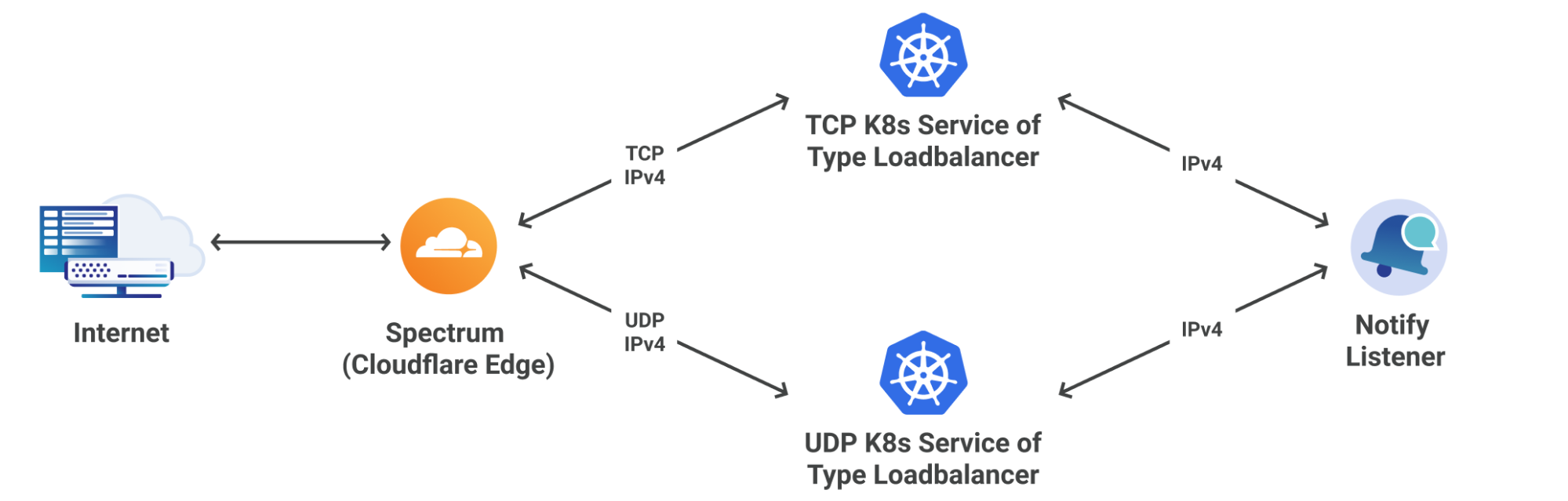
The Notify Listener requires listening on static IPs for NOTIFY Messages coming from primary DNS servers. This is mostly a solved problem through the use of k8s services of type loadbalancer, however exposing this service directly to the Internet makes us uneasy because of its susceptibility to attacks. Fortunately DDoS protection is one of Cloudflare’s strengths, which lead us to the likely solution of dogfooding one of our own products, Spectrum.
Spectrum provides the following features to our service:
Figure 3: Spectrum interaction with Notify Listener
Figure 3 shows two interesting attributes of the system:
Spectrum <-> k8s IPv4 only:
This is because our custom k8s load balancer currently only supports IPv4; however, Spectrum has no issue terminating the IPv6 connection and establishing a new IPv4 connection.
Spectrum <-> k8s routing decisions based of L4 protocol:
This is because k8s only supports one of TCP/UDP/SCTP per service of type load balancer. Once again, spectrum has no issues proxying this correctly.
One of the problems with using a L4 proxy in between services is that source IP addresses get changed to the source IP address of the proxy (Spectrum in this case). Not knowing the source IP address means we have no idea who sent the NOTIFY message, opening us up to attack vectors. Fortunately, Spectrum’s proxy protocol feature is capable of adding custom headers to TCP/UDP packets which contain source IP/Port information.
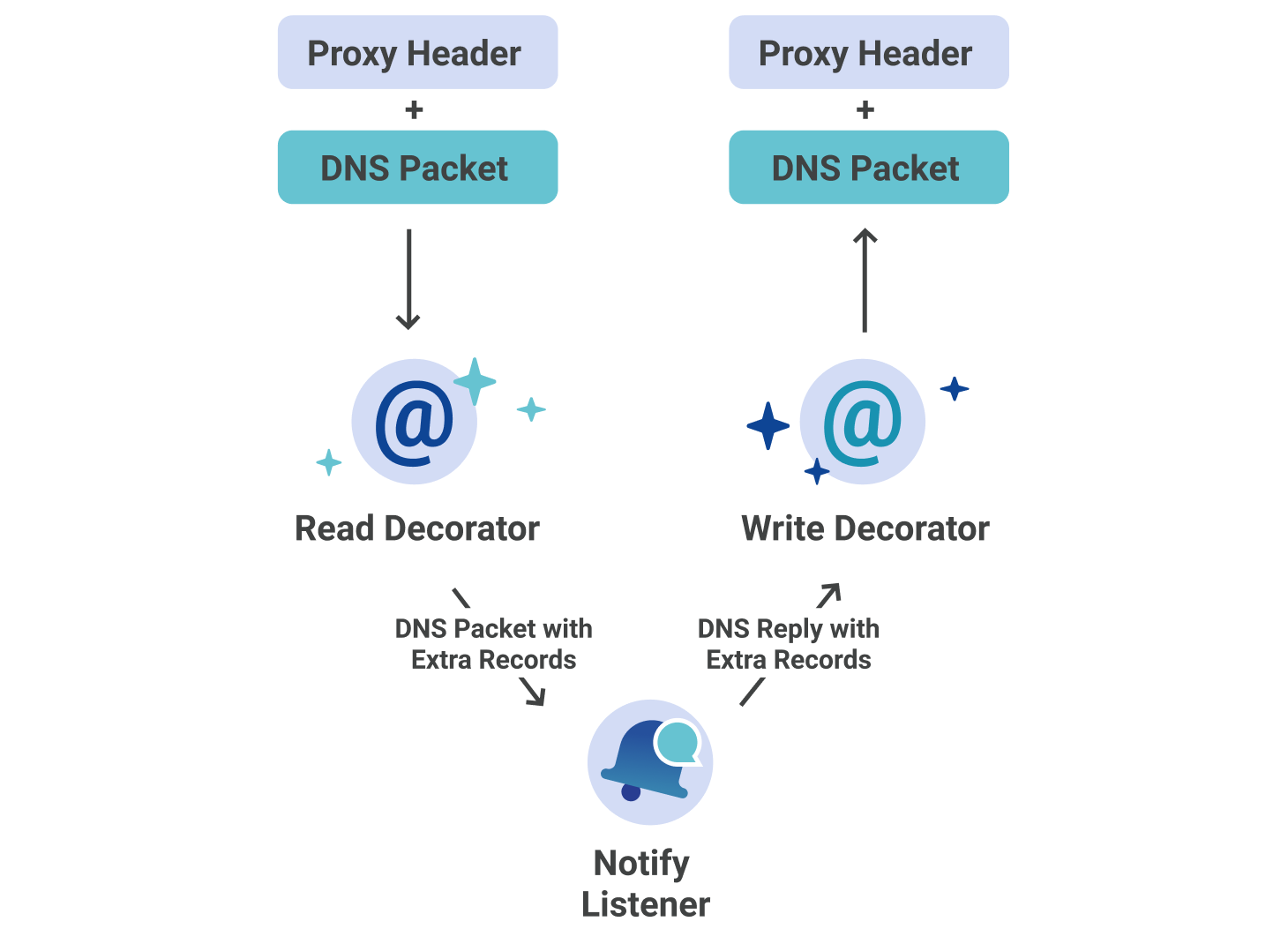
As we are using miekg/dns for our Notify Listener, adding proxy headers to the DNS NOTIFY messages would cause failures in validation at the DNS server level. Alternatively, we were able to implement custom read and write decorators that do the following:
Reader: Extract source address information on inbound NOTIFY messages. Place extracted information into new DNS records located in the additional section of the message.
Writer: Remove additional records from the DNS message on outbound NOTIFY replies. Generate a new reply using proxy protocol headers.
There is no way to spoof these records, because the server only permits two extra records, one of which is the optional TSIG. Any other records will be overwritten.
Figure 4: Proxying Records Between Notifier and Spectrum
This custom decorator approach abstracts the proxying away from the Notify Listener through the use of the DNS protocol.
Although knowing the source IP will block a significant amount of bad traffic, since NOTIFY messages can use both UDP and TCP, it is prone to IP spoofing. To ensure that the primary servers do not get spammed, we have made the following additions to the Zone Transferer:
Always ensure that the SOA has actually been updated before initiating a zone transfer.
Only allow at most one working transfer and one scheduled transfer per zone.
Additional Technical Challenges
Zone Transferer Scheduling
As shown in figure 1, there are several ways of sending Kafka messages to the Zone Transferer in order to initiate a zone transfer. There is no benefit in having a large backlog of zone transfers for the same zone. Once a zone has been transferred, assuming no more changes, it does not need to be transferred again. This means that we should only have at most one transfer ongoing, and one scheduled transfer at the same time, for any zone.
If we want to limit our number of scheduled messages to one per zone, this involves ignoring Kafka messages that get sent to the Zone Transferer. This is not as simple as ignoring specific messages in any random order. One of the benefits of Kafka is that it holds on to messages until the user actually decides to acknowledge them, by committing that messages offset. Since Kafka is just a queue of messages, it has no concept of order other than first in first out (FIFO). If a user is capable of reading from the Kafka topic concurrently, it is entirely possible that a message in the middle of the queue be committed before a message at the end of the queue.
Most of the time this isn’t an issue, because we know that one of the concurrent readers has read the message from the end of the queue and is processing it. There is one Kubernetes-related catch to this issue, though: pods are ephemeral. The kube master doesn’t care what your concurrent reader is doing, it will kill the pod and it’s up to your application to handle it.
Consider the following problem:
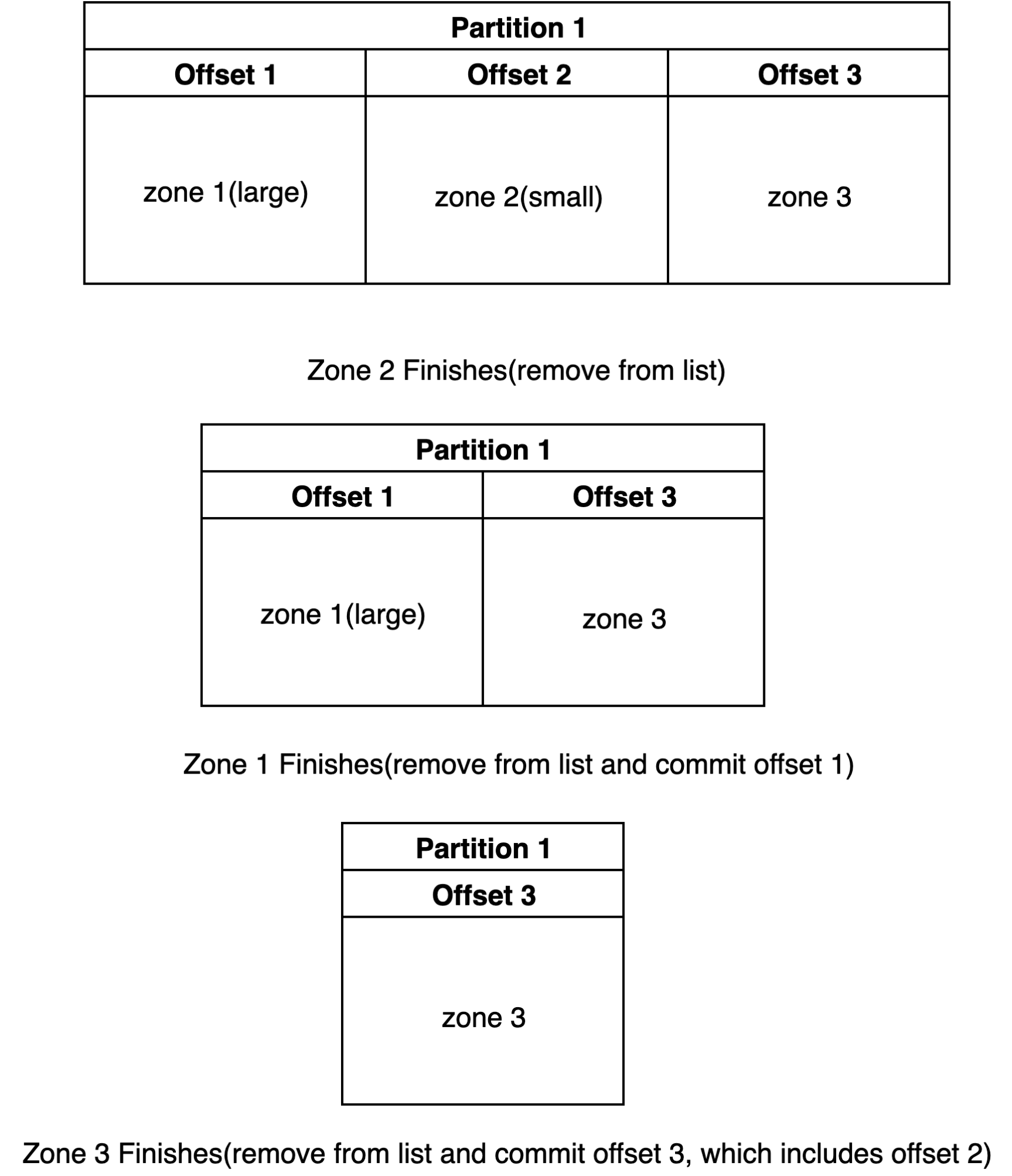
Figure 5: Kafka Partition
Read offset 1. Start transferring zone 1.
Read offset 2. Start transferring zone 2.
Zone 2 transfer finishes. Commit offset 2, essentially also marking offset 1.
Restart pod.
Read offset 3 Start transferring zone 3.
If these events happen, zone 1 will never be transferred. It is important that zones stay up to date with the primary servers, otherwise stale data will be served from the Secondary DNS server. The solution to this problem involves the use of a list to track which messages have been read and completely processed. In this case, when a zone transfer has finished, it does not necessarily mean that the kafka message should be immediately committed. The solution is as follows:
Keep a list of Kafka messages, sorted based on offset.
If finished transfer, remove from list:
If the message is the oldest in the list, commit the messages offset.
Figure 6: Kafka Algorithm to Solve Message Loss
This solution is essentially soft committing Kafka messages, until we can confidently say that all other messages have been acknowledged. It’s important to note that this only truly works in a distributed manner if the Kafka messages are keyed by zone id, this will ensure the same zone will always be processed by the same Kafka consumer.
Life of a Secondary DNS Request
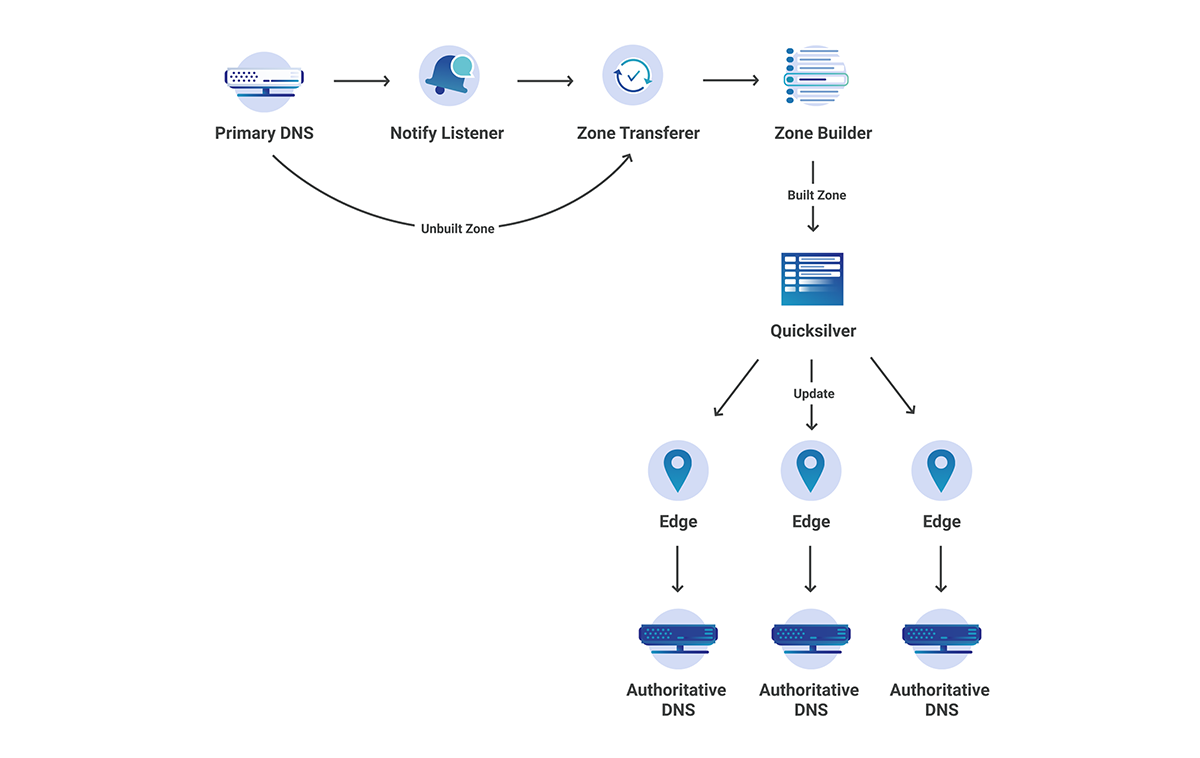
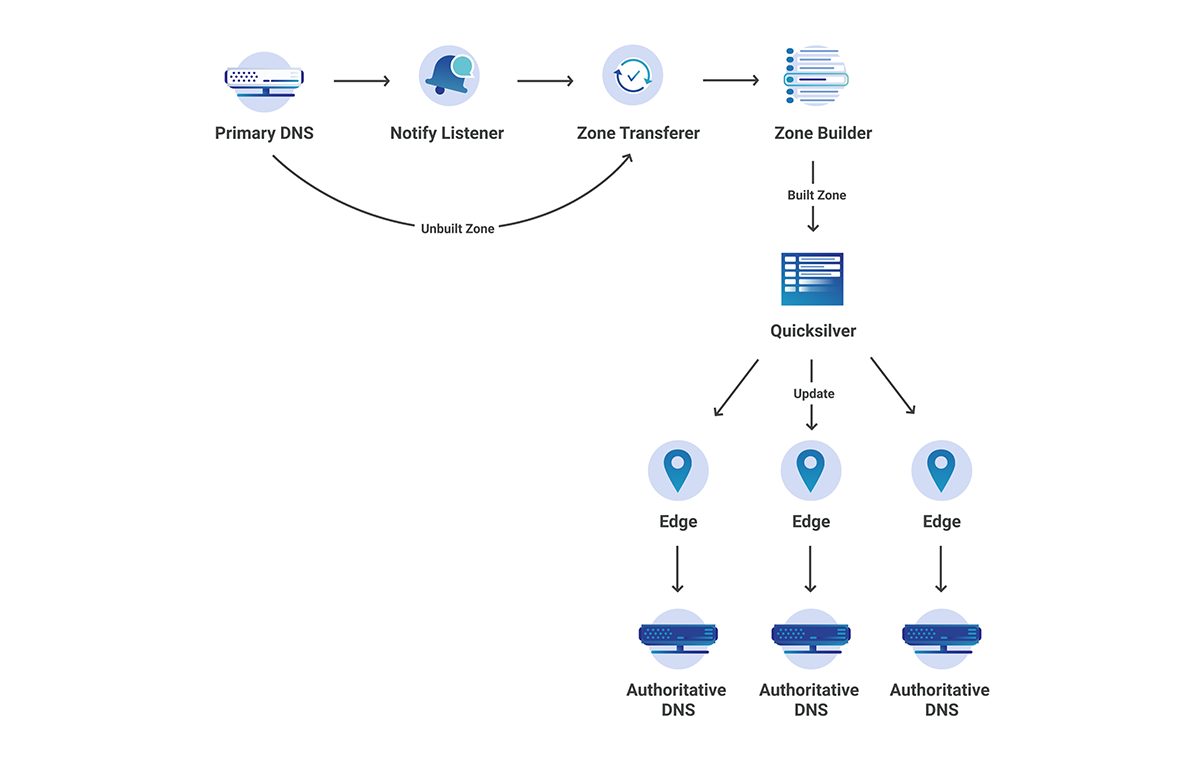
Although Cloudflare has a large global network, as shown above, the zone transferring process does not take place at each of the edge datacenter locations (which would surely overwhelm many primary servers), but rather in our core data centers. In this case, how do we propagate to our edge in seconds? After transferring the zone, there are a couple more steps that need to be taken before the change can be seen at the edge.
Zone Builder – This interacts with the Zone Transferer to build the zone according to what Cloudflare edge understands. This then writes to Quicksilver, our super fast, distributed KV store.
Authoritative Server – This reads from Quicksilver and serves the built zone.
Figure 7: End to End Secondary DNS
What About Performance?
At the time of writing this post, according to dnsperf.com, Cloudflare leads in global performance for both Authoritative and Resolver DNS. Here, Secondary DNS falls under the authoritative DNS category here. Let’s break down the performance of each of the different parts of the Secondary DNS pipeline, from the primary server updating its records, to them being present at the Cloudflare edge.
Primary Server to Notify Listener – Our most accurate measurement is only precise to the second, but we know UDP/TCP communication is likely much faster than that.
NOTIFY to Zone Transferer – This is negligible
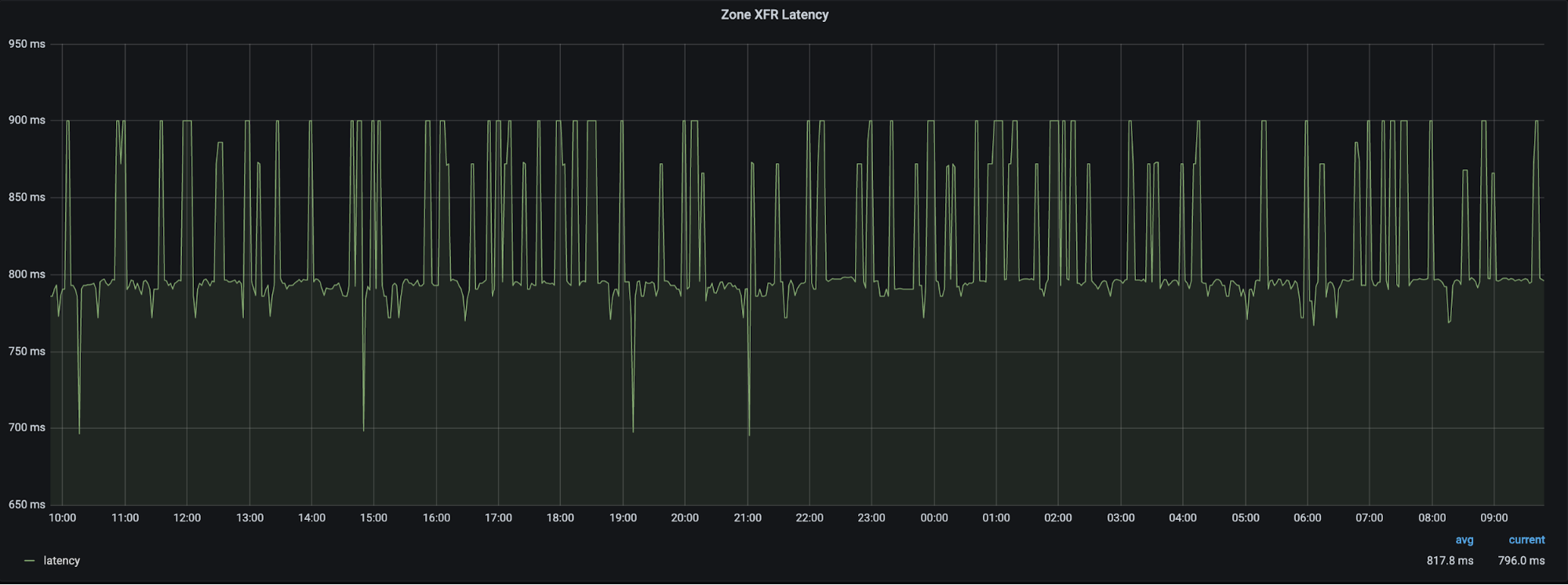
Zone Transferer to Primary Server – 99% of the time we see ~800ms as the average latency for a zone transfer.
Figure 8: Zone XFR latency
4. Zone Transferer to Zone Builder – 99% of the time we see ~10ms to build a zone.
Figure 9: Zone Build time
5. Zone Builder to Quicksilver edge: 95% of the time we see less than 1s propagation.
Figure 10: Quicksilver propagation time
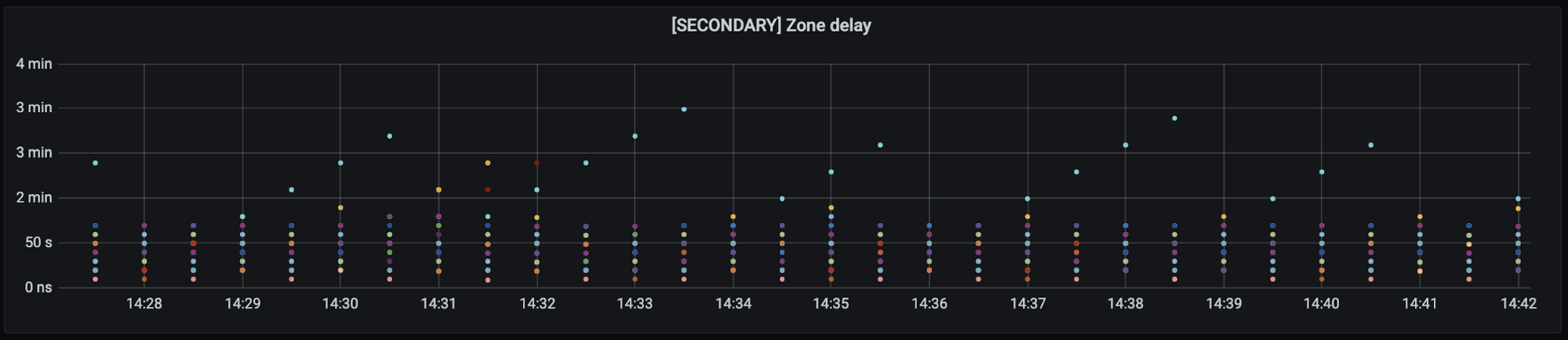
End to End latency: less than 5 seconds on average. Although we have several external probes running around the world to test propagation latencies, they lack precision due to their sleep intervals, location, provider and number of zones that need to run. The actual propagation latency is likely much lower than what is shown in figure 10. Each of the different colored dots is a separate data center location around the world.
Figure 11: End to End Latency
An additional test was performed manually to get a real world estimate, the test had the following attributes:
Primary server: NS1 Number of records changed: 1 Start test timer event: Change record on NS1 Stop test timer event: Observe record change at Cloudflare edge using dig Recorded timer value: 6 seconds
Conclusion
Cloudflare serves 15.8 trillion DNS queries per month, operating within 100ms of 99% of the Internet-connected population. The goal of Cloudflare operated Secondary DNS is to allow our customers with custom DNS solutions, be it on-premise or some other DNS provider, to be able to take advantage of Cloudflare’s DNS performance and more recently, through Secondary Override, our proxying and security capabilities too. Secondary DNS is currently available on the Enterprise plan, if you’d like to take advantage of it, please let your account team know. For additional documentation on Secondary DNS, please refer to our support article.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.