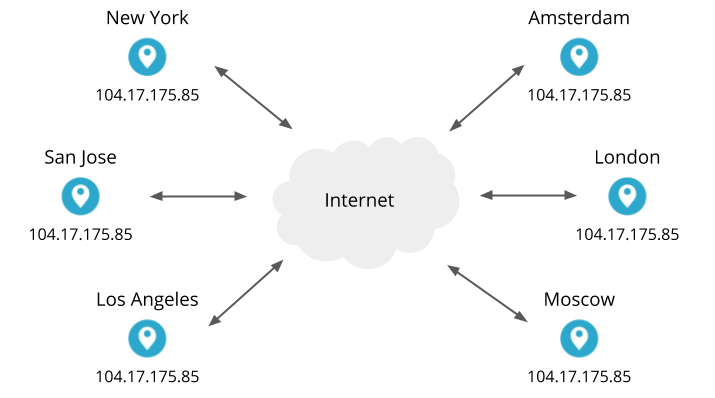
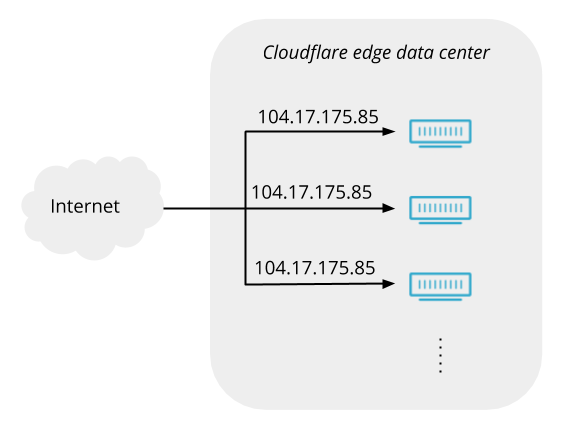
Today, we are excited to announce an expansion we’ve been working on behind the scenes for the last two years: a 25+ city partnership with one of the largest ISPs in Brazil. This is one of the largest simultaneous single-country expansions we’ve done so far.
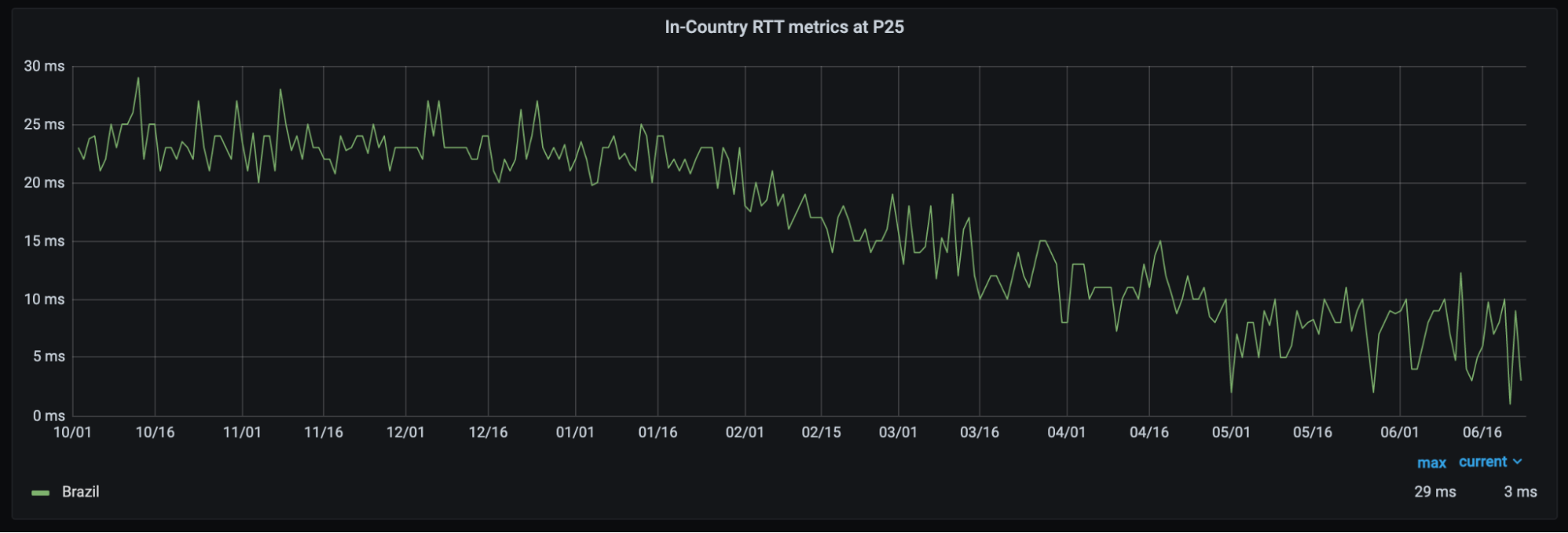
With this partnership, Brazilians throughout the country will see significant improvement to their Internet experience. Already, the 25th-percentile latency of non-bot traffic (we use that measure as an approximation of physical distance from our servers to end users) has dropped from the mid-20 millisecond range to sub-10 milliseconds. This benefit extends not only to the 25 million Internet properties on our network, but to the entire Internet with Cloudflare services like 1.1.1.1 and WARP. We expect that as we approach 25 cities in Brazil, latency will continue to drop while throughput increases.
25th percentile latency of non-bot traffic in Brazil has more than halved as new cities have gone live.
This partnership is part of our mission to help create a better Internet and the best development experience for all — not just those in major population centers or in Western markets — and we are excited to take this step on our journey to help build a better Internet. Whether you live in the heart of São Paulo or the outskirts of the Amazon rainforest in Manaus, expect an upgrade to your Internet experience soon.
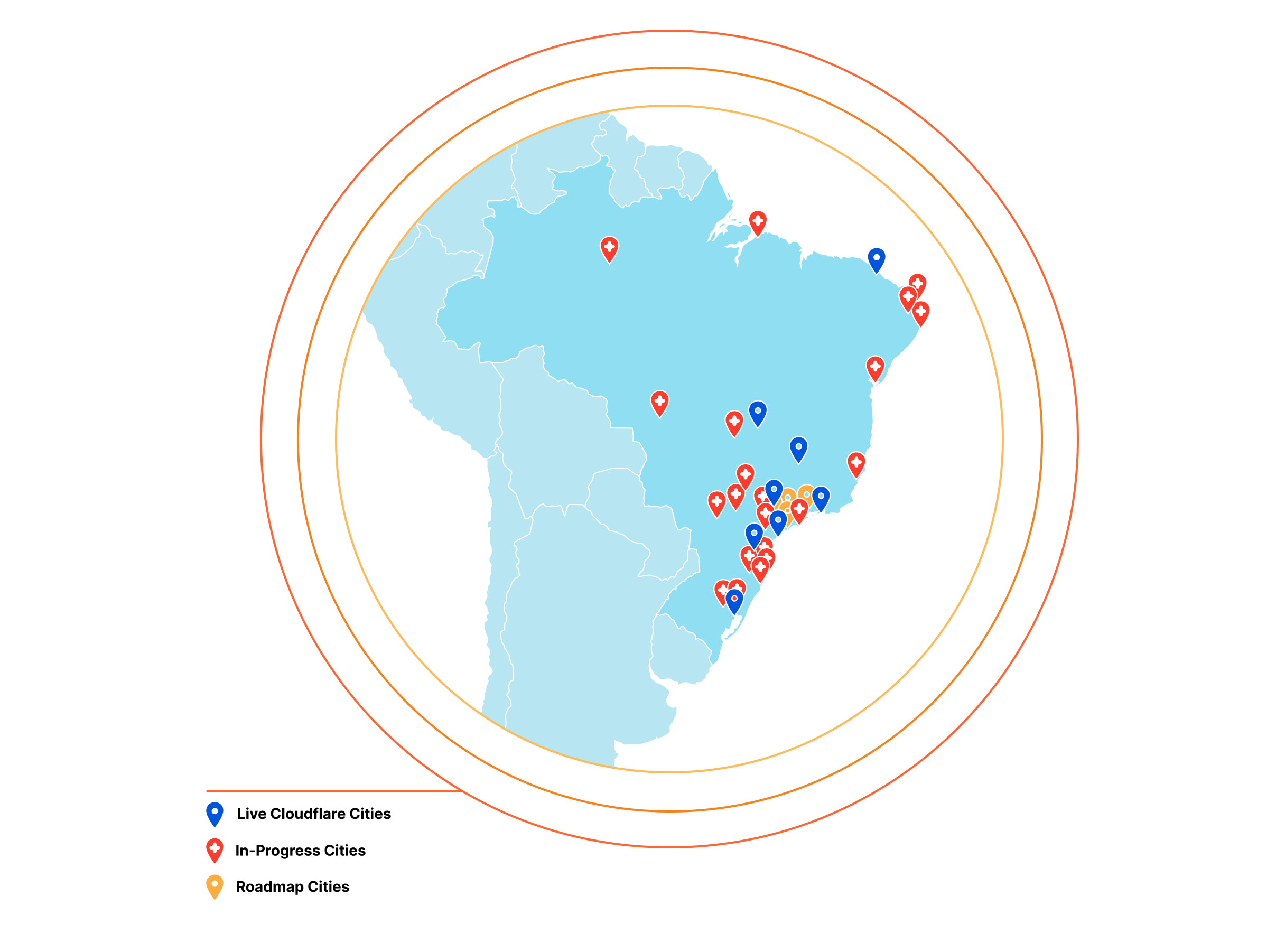
We have already launched in Porto Alegre, Belo Horizonte, Brasília, Campinas, Curitiba, and Fortaleza, with additional presences coming soon to Manaus, São Paulo, Blumenau, Joinville, Florianópolis, Itajai, Belém, Goiânia, Salvador, São José do Rio Preto, Americana, and Sorocaba.
From there, we’re planning on adding presences in the following cities: Guarulhos, Mogi das Cruzes, São José dos Campos, Vitória, Londrina, Maringá, Campina Grande, Caxias do Sul, Cuiabá, Lajeado, Natal, Recife, Osasco, Santo André, and Rio. The result will be a net expansion of Cloudflare in Brazil by 12 to 16 times.
We celebrate the benefits that this partnership will bring to Latin America. Our President and Chief Operating Officer Michelle Zatlyn likes to say that “we’re just getting started”. In that spirit, expect more exciting news about the Cloudflare network not only in Latin America, but worldwide!
Do you work at an ISP who is interested in bringing a better Internet experience to your users and better control over your network? Please reach out to our Edge Partnerships team at [email protected].
Are you passionate about working to expand our network to make the best edge platform on the globe? Do you thrive in an exciting, rapid-growth environment? Check out open roles on the Infrastructure team here!
Load Balancing — functionality that’s been around for the last 30 years to help businesses leverage their existing infrastructure resources. Load balancing works by proactively steering traffic away from unhealthy origin servers and — for more advanced solutions — intelligently distributing traffic load based on different steering algorithms. This process ensures that errors aren’t served to end users and empowers businesses to tightly couple overall business objectives to their traffic behavior.
What’s important for load balancing today?
We are no longer in the age where setting up a fixed amount of servers in a data center is enough to meet the massive growth of users browsing the Internet. This means that we are well past the time when there is a one size fits all solution to suffice the needs of different businesses. Today, customers look for load balancers that are easy to use, propagate changes quickly, and — especially now — provide the most feature flexibility. Feature flexibility has become so important because different businesses have different paths to success and, consequently, different challenges! Let’s go through a few common use cases:
You might have an application split into microservices, where specific origins support segments of your application. You need to route your traffic based on specific paths to ensure no single origin can be overwhelmed and users get sent to the correct server to answer the originating request.
You may want to route traffic based on a specific value within a header request such as “PS5” and send requests to the data center with the matching header.
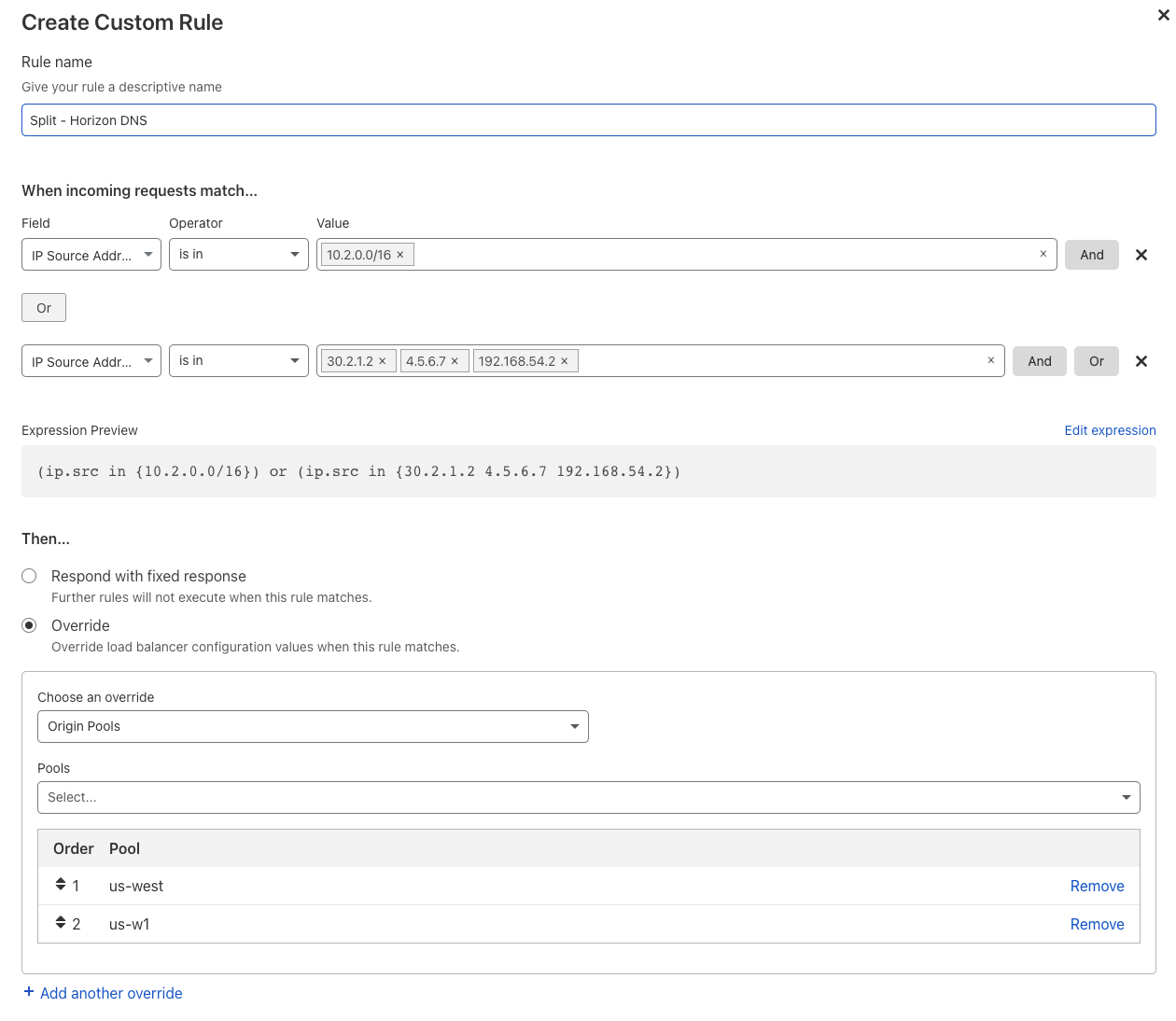
If you heavily prioritize security and privacy, you may adopt a split-horizon DNS setup within your network architecture. You might choose this architecture to separate internal network requests from public requests from the rest of the public Internet. Then, you could route each type of request to pools specifically suited to handle the amount and type of traffic.
As we continue to build new features and products, we also wanted to build a framework that would allow us to increase our velocity to add new items to our Load Balancing solution while we also take the time to create first class features as well. The result was the creation of our custom rule builder!
Now you can build complex, custom rules to direct traffic using Cloudflare Load Balancing, empowering customers to create their own custom logic around their traffic steering and origin selection decisions. As we mentioned, there is no one size fits all solution in today’s world. We provide the tools to easily and quickly create rules that meet the exact requirements needed for any customer’s unique situation and architecture. On top of that, we also support ‘and’ and ‘or’ statements within a rule, allowing very powerful and complex rules to be created for any situation!
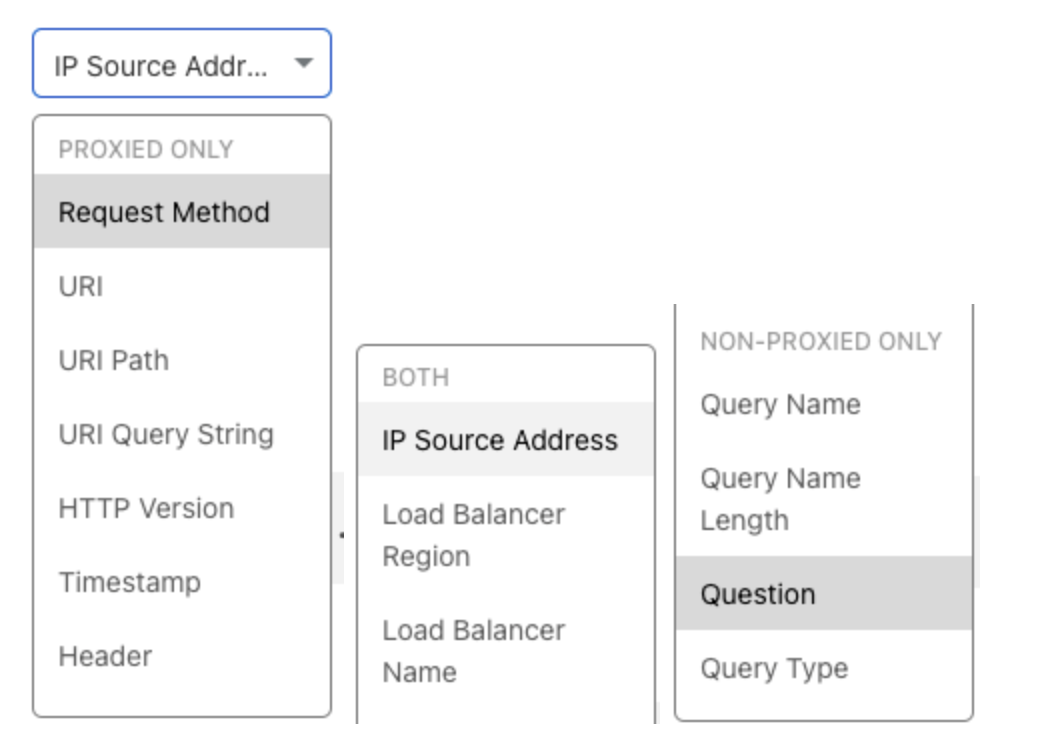
Load Balancing by path becomes easy, requiring just a few minutes to enter the paths and some boolean statements to create complex rules. Steer by a specific header, query string, or cookie. It’s no longer a pain point. Leverage a split horizon DNS design by creating a rule looking at the IP source address and then routing to the appropriate pool based on the value. This is just a small subset of the very robust capabilities that load balancing custom rules makes available to our users and this is just the start! Not only do we have a large amount of functionality right out of the box, but we’re also providing a consistent, intuitive experience by building on our Firewall Rules Engine.
Let’s go through some use cases to explore how custom rules can open new possibilities by giving you more granular control of your traffic.
High-volume transactions for ecommerce
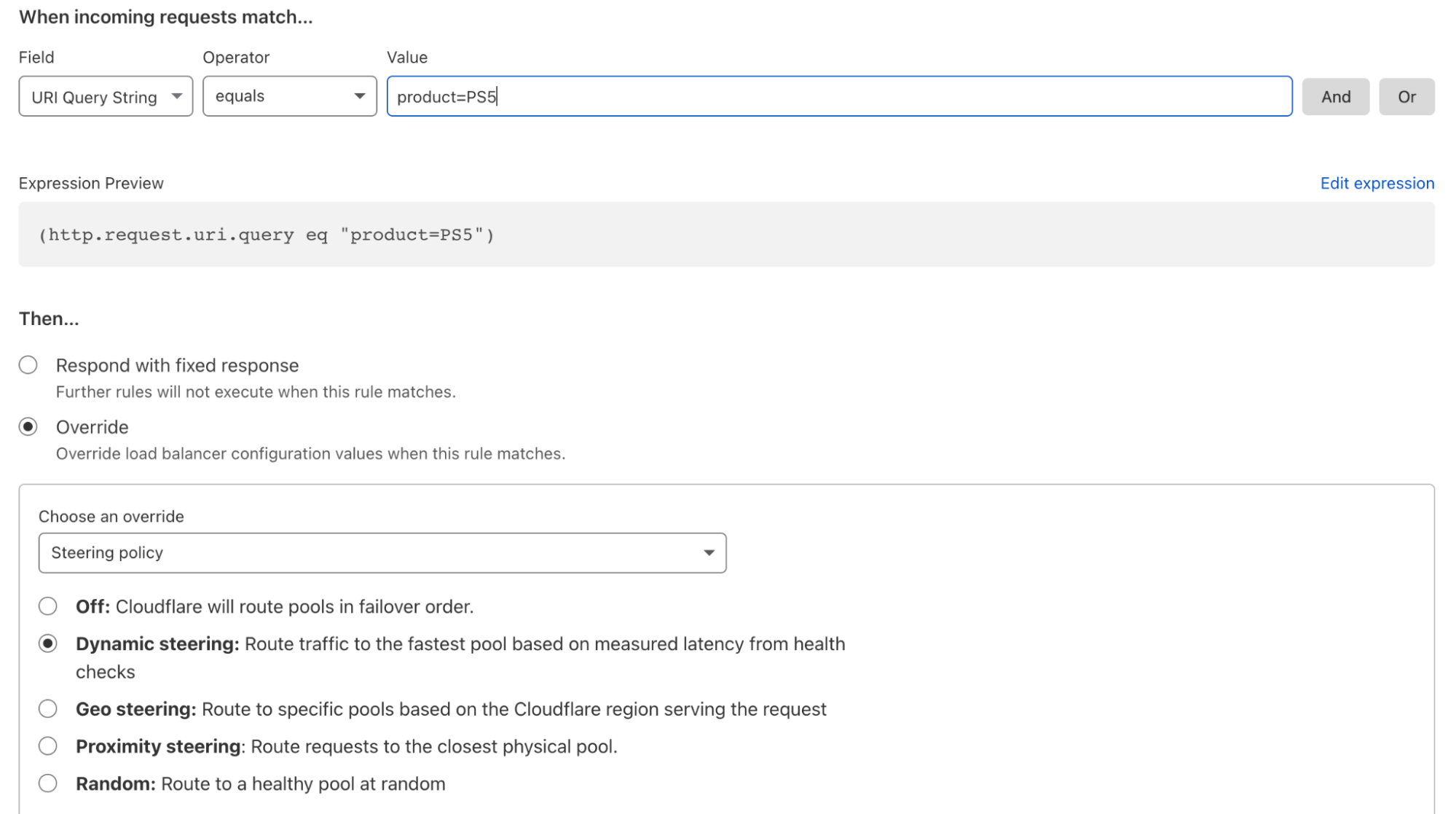
For any high-volume transaction business such as an ecommerce or retail store, ensuring the transactions go through as fast and reliably as possible is a table stakes requirement. As transaction volume increases, no single origin can handle the incoming traffic, and it doesn’t always make sense for it to do so. Why have a transaction request travel around the world to a specifically nominated origin for payment processing? This setup would only add latency, leading to degraded performance, increased errors, and a poor customer experience. But what if you could create custom logic to segment transactions to different origin servers based on a specific value in a query string, such as a PS5 (associated with Sony’s popular PlayStation 5)? What if you could then couple that value with dynamic latency steering to ensure your load balancer always chooses the most performant path to the origin? This would be game changing to not only ensure that table-stakes transactions are reliable and fast but also drastically improve the customer experience. You could do this in minutes with load balancing custom rules:
For any requests where the query string shows ‘PS5’, then route based on which pool is the most performant.
Load balance across multiple DNS vendors to support privacy and security
Some customers may want to use multiple DNS providers to bolster their resiliency along with their security and privacy for the different types of traffic going through their network. By utilizing two DNS providers, customers can not only be sure that they remain highly available in times of outages, but also direct different types of traffic, whether that be internal network traffic across offices or unknown traffic from the public Internet.
Without flexibility, however, it can be difficult to easily and intelligently route traffic to the proper data centers to maintain that security and privacy posture. Not anymore! With load balancing custom rules, supporting a split horizon DNS architecture takes as little as five minutes to set up a rule based on the IP source condition and then overwriting which pools or data centers that traffic should route to.
This can also be extremely helpful if your data centers are spread across multiple areas of the globe that don’t align with the 13 current regions within Cloudflare. By segmenting where traffic goes based on the IP source address, you can create a type of geo-steering setup that is also finely tuned to the requirements of the business!
How did we build it?
We built Load Balancing rules on top of our open-source wirefilter execution engine. People familiar with Firewall Rules and other products will notice similar syntax since both products are built on top of this execution engine.
By reusing the same underlying engine, we can take advantage of a battle-tested production library used by other products that have the performance and stability requirements of their own. For those experienced with our rule-based products, you can reuse your knowledge due to the shared syntax to define conditionals statements. For new users, the Wireshark-like syntax is often familiar and relatively simple.
DNS vs Proxied?
Our Load Balancer supports both DNS and Proxied load balancing. These two protocols operate very differently and as such are handled differently.
For DNS-based load balancing, our load balancer responses to DNS queries sent from recursive resolvers. These resolvers are normally not the end user directly requesting the traffic nor is there a 1-to-1 ratio between DNS query and end-user requests. The DNS makes extensive use of caching at all levels so the result of each query could potentially be used by thousands of users. Combined, this greatly limits the possible feature set for DNS. Since you don’t see the end user directly nor know if your response is going to be used by one or more users, all responses can only be customized to a limited degree.
Our Proxied load balancing, on the other hand, processes rules logic for every request going through the system. Since we act as a proxy for all these requests, we can invoke this logic for all requests and access user-specific data.
These different modes mean the fields available to each end up being quite different. The DNS load balancer gets access to DNS-specific fields such as “dns.qry.name” (the query name) while our Proxied load balancer has access to “http.request.method” (the HTTP method used to access the proxied resource). Some more general fields — like the name of the load balancer being used — are available in both modes.
How does it work under the hood?
When a load balancer rule is configured, that API call will validate that the conditions and actions of the rules are valid. It makes sure the condition only references known fields, isn’t excessively long, and is syntactically valid. The overrides are processed and applied to the load balancers configuration to make sure they won’t cause an invalid configuration. After validation, the new rule is saved to our database.
With the new rule saved, we take the load balancer’s data and all rules used by it and package that data together into one configuration to be shipped out to our edge. This process happens very quickly, so any changes are visible to you in just a few seconds.
While DNS and proxied load balancers have access to different fields and the protocols themselves are quite different, the two code paths overlap quite a bit. When either request type makes it to our load balancer, we first load up the load balancer specific configuration data from our edge datastore. This object contains all the “static” data for a load balancer, such as rules, origins, pools, steering policy, and so forth. We load dynamic data such as origin health and RTT data when evaluating each pool.
At the start of the load balancer processing, we run our rules. This ends up looking very much like a loop where we check each condition and — if the condition is true — we apply the effects specified by the rules. After each condition is processed and the effects are applied we then run our normal load balancing logic as if you have configured the load balancer with the overridden settings. This style of applying each override in turn allows more than one rule to change a given setting multiple times during execution. This lets users avoid extremely long and specific conditionals and instead use shorter conditionals and rule ordering to override specific settings creating a more modular ruleset.
What’s coming next?
For you, the next steps are simple. Start building custom load balancing rules! For more guidance, check out our developer documentation.
For us, we’re looking to expand this functionality. As this new feature develops, we are going to be identifying new fields for conditionals and new options for overrides to allow more specific behavior. As an example, we’ve been looking into exposing a means to creating more time-based conditionals, so users can create rules that only apply during certain times of the day or month. Stay tuned to the blog for more!
I love building products that solve real problems for our customers. These days I don’t get to do so as much directly with our Engineering teams. Instead, about half my time is spent with customers listening to and learning from their security challenges, while the other half of my time is spent with other Cloudflare Product Managers (PMs) helping them solve these customer challenges as simply and elegantly as possible. While I miss the deeply technical engineering discussions, I am proud to have the opportunity to look back every year on all that we’ve shipped across our application security teams.
Taking the time to reflect on what we’ve delivered also helps to reinforce my belief in the Cloudflare approach to shipping product: release early, stay close to customers for feedback, and iterate quickly to deliver incremental value. To borrow a term from the investment world, this approach brings the benefits of compounded returns to our customers: we put new products that solve real-world problems into their hands as quickly as possible, and then reinvest the proceeds of our shared learnings immediately back into the product.
It is these sustained investments that allow us to release a flurry of small improvements over the course of a year, and be recognized by leading industry analyst firms for the capabilities we’ve accumulated and distributed to our customers. Today we’re excited to announce that Frost & Sullivan has named Cloudflare the Innovation Leader in their Frost Radar™: Global Holistic Web Protection Market Report. Frost & Sullivan’s view that this market “will gradually absorb the markets formed around legacy and point solutions” is consistent with our view of the world, and we’re leading the way in “the consolidation of standalone WAF, DDoS mitigation, and Bot Risk Management solutions” they believe is “poised to happen before 2025”.
We are honored to receive this recognition, based on the analysis of 10 providers’ competitive strengths and opportunities as assessed by Frost & Sullivan. The rest of this post explains some of the capabilities that we shipped in 2020 across our Web Application Firewall (WAF), Bot Management, and Distributed Denial-of-Service product lines—the scope of Frost & Sullivan’s report. Get a copy of the Frost & Sullivan Frost Radar report to see why Cloudflare was named the Innovation Leader here.
2020 Web Security Themes and Roundup
Before jumping into specific product and feature launches, I want to briefly explain how we think about building and delivering our web security capabilities. The most important “product” by far that’s been built at Cloudflare over the past 10 years is the massive global network that moves bits securely around the world, as close to the speed of light as possible. Building our features atop this network allows us to reject the legacy tradeoff of performance or security. And equipping customers with the ability to program and extend the network with Cloudflare Workers and Firewall Rules allows us to focus on quickly delivering useful security primitives such as functions, operators, and ML-trained data—then later packaging them up in streamlined user interfaces.
We talk internally about building up the “toolbox” of security controls so customers can express their desired security posture, and that’s how we think about many of the releases over the past year that are discussed below. We begin by providing the saw, hammer, and nails, and let expert builders construct whatever defenses they see fit. By watching how these tools are put to use and observing the results of billions of attempts to evade the erected defenses, we learn how to improve and package them together as a whole for those less inclined to build from components. Most recently we did this with API Shield, providing a guided template to create “positive security” models within Firewall Rules using existing primitives plus new data structures for strong authentication such as Cloudflare-managed client SSL/TLS certificates. Each new tool added to the toolbox increases the value of the existing tools. Each new web request—good or bad—improves the models that our threat intelligence and Bot Management capabilities depend upon.
Web application firewall (WAF) usability at scale
Last year we spoke with many customers about our plan to decouple configuration from the zone/domain model and allow rules to be set for arbitrary paths and groups of services across an account. In 4Q2020 we put this granular control in the hands of a few developers and some of our most sophisticated enterprise customers, and we’re currently collecting and incorporating feedback before defaulting the capabilities on for new customers.
Rules are great, especially with increased flexibility, but without data structures and request enrichment at the edge (such as the Bot Management techniques described below) they cannot act on anything beyond static properties of the request. In 3Q2020 we released our IP Lists capabilities and customers have been steadily uploading their home-grown and third-party subscription lists. These lists can be referenced anywhere in a customer’s account as named variables and then combined with all other attributes of the request, even Bot Management scores, e.g., http.request.uri.path contains “/login” and (not ip.src in $pingdom_probes and cf.bot_management.score < 30) is a Firewall Rule filter that blocks all bots except Pingdom from accessing the login endpoint.
Built predominantly in 4Q2020 and currently being tested in the Firewall Rules engine is a brand new implementation of our Rate Limiting engine. By moving this matching and enforcement logic from a standalone tool to a component within a performant, memory-safe, expressive engine built in Rust, we have increased the utility of existing functions. Additional examples of improving this library of capabilities include the work completed in 1Q2020 to add HMAC functions and regex-based HTTP header and body inspection to the engine.
Bots and machine learning (ML)
In addition to making edge data sets accessible for request evaluation, we continued to invest heavily within our Bot Management team to provide actionable data so that our customers could decide what (if any) automated traffic they wanted to allow to interact with their applications. Our highest priority for Bot research and development has always been efficacy, and last year was no different. A significant portion of our engineering effort was dedicated to our detection engines — both updating and iterating on existing systems or creating entirely new detection engines from scratch.
In 1Q2020 we completed a total rewrite of our Machine Learning engine, and are continually focused on improving the efficacy of our ML engines. To do this, we draw on one of our major competitive advantages: the massive amount of data flowing through Cloudflare’s network. The early 2020 upgrade to our ML model nearly doubled the number of features we use to evaluate and score requests. And to help customers better understand why requests are flagged as bots, we have recently complemented the bot likelihood score in our logs with attribution to the specific engine that generated the score.
Also in 1Q2020, we upgraded our behavioral analysis engine to incorporate more features and increase overall accuracy. This engine conducts histogram-based outlier scoring and is now fully deployed to nearly all Bot Management zones.
In 2Q2020, we developed a lightweight JavaScript element that further advanced our browser fingerprinting capabilities and aids in detection. Specifically, we now silently challenge browsers and detect if a browser is misrepresenting its User Agent. This technique will be incorporated into our ML models and combined with our heuristics engine for more accurate browser fingerprinting. This feature is entirely optional and can be enabled or disabled by customers through our UI and API. Customers with extremely performance sensitive zones or traffic types that are unsuitable for JavaScript (such as API or some mobile app traffic) can still be accurately scored by our Bot Management engine.
In addition to detection, we also spent (and will continue to spend) engineering effort on mitigation. Our entire JavaScript and CAPTCHA challenge platform was rewritten in the last year and deployed to our customer zones in a staged fashion in the second half of 2020. Our new platform is faster and more robust at detecting automated systems attempting to solve the challenges. More importantly, this platform allows us to further invest in new challenge types and modes as we enter 2021.
The biggest and most well received feature released in 2020 was our dedicated Bot Management analytics, released in 3Q2020. We now present informative graphs that double as diagnostic tools. Customers have found that analytics are far more than interesting charts and statistics: in the case of Bot Management, analytics are essential to spotting and subsequently eliminating false positives.
Last but definitely not least, we announced the deprecation of the __cfduid cookie in 4Q2020 which was used primarily to detect bots but caused confusion for some customers including questions about whether they needed to display a cookie banner because of what we do.
To get a sense of the Bot Attack trends we saw in the first half of 2020, take a read through this blog post. And if you’re curious about how our ML models and heuristic engines work to keep your properties safe, this deep dive by Alex Bocharov, Machine Learning Tech Lead on the Bots team, is an excellent guide.
API and IoT security and protection
At the beginning of 4Q2020, we released a product called API Shield that was purpose built to secure, protect, and accelerate API traffic — and will eventually provide much of the common functionality expected in traditional API Gateways. The UI for API Shield was built on top of Firewall Rules for maximum flexibility, and will serve as the jump-off point for configuring additional API security features we have planned this year.
As part of API Shield, every customer now gets a fully managed, domain-scoped private CA generated for each of their zones, and we plan to continue working closely with the SSL/TLS team to expand CA management options based on feedback. Since the release, we’ve seen great adoption from in particular IoT companies focused on locking down their APIs using short-lived client certificates distributed out to devices. Customers can also now upload OpenAPI schemas to be matched against incoming requests from these devices, with bad requests being dropped at the edge rather than passed on to origin infrastructure.
Another capability we released in 4Q2020 was support for gRPC-based API traffic. Since that release, customers have expressed significant interest in using Cloudflare as a secure API gateway between easy-to-use customer-facing JSON endpoints and internal-facing gRPC or GraphQL endpoints. Like most customer challenges at Cloudflare, early adopters are looking to solve these use cases initially with Cloudflare Workers, but we’re keeping an eye on whether there are aspects for which we’ll want to provide first-class feature support.
Distributed Denial-of-Service (DDoS) protections for web applications and APIs
The application-layer security of a web application or API is of minimal importance if the service itself is not available due to a persistent DDoS attack at L3-L7. While mitigating such attacks has long been one of Cloudflare’s strengths, attack methodologies evolve and we continued to invest heavily in 2020 to drop attacks more quickly, more efficiently, and more precisely; as a result, automatic mitigation techniques are applied immediately and most malicious traffic is blocked in less than 3 seconds.
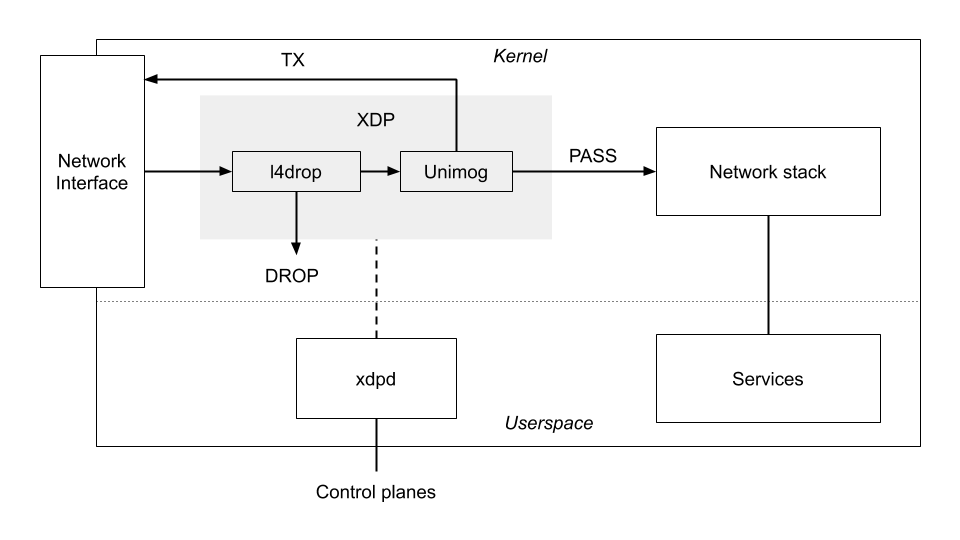
Early in 2020 we responded to a persistent increase in smaller, more localized attacks by fine-tuning a system that can autonomously detect attacks on any server in any datacenter. In the month prior to us first posting about this tool, it mitigated almost 300,000 network-layer attacks, roughly 55 times greater than the tool we previously relied upon. This new tool, dubbed “dosd”, leverages Linux’s eXpress Data Path (XDP) and allows our system to quickly — and automatically — deploy rules eBPF rules that run on each packet received. We further enhanced our edge mitigation capabilities in 3Q2020 by developing and releasing a protection layer that can operate even in environments where we only see one side of the TCP flow. These network layer protections help protect our customers who leverage both Magic Transit to protect their IP ranges and our WAF to protect their applications and APIs.
To document and provide visibility into these attacks, we released a GraphQL-backed interface in 1Q2020 called Network Analytics. Network Analytics extends the visibility of attacks against our customers’ services from L7 to L3, and includes detailed attack logs containing data such as top source and destination IPs and ports, ASNs, data centers, countries, bit rates, protocol and TCP flag distributions. A litany of improvements made to this graphical rendering engine over the course of 2020 have benefitted all analytics tools using the same front-end. In 4Q2020, Network Analytics was extended to provide traffic and attack insights into Cloudflare Spectrum-protected applications, which are terminated at L4 (TCP/UDP).
2020 was a tough year around the world. Throughout what has also been, and continues to be, a period of heightened cyberattacks and breaches, we feel proud that our teams were able to release a steady flow of new and improved capabilities across several critical security product areas reviewed by Frost & Sullivan. These releases culminated in far greater protections for customers at the end of the year than the beginning, and a recognition for our sustained efforts.
We are pleased to have been named the Innovation Leader in their Frost Radar™: Global Holistic Web Protection Market Report, which “addresses organizations’ demand for consolidated, single pane of glass solutions, which not only reduce the security gaps of legacy products but also provide simplified management capabilities”.
As we look towards 2021 we plan to continue releasing early and often, listening to feedback from our customers, and delivering incremental value along the way. If you have ideas on what additional capabilities you’d like to use to protect your applications and networks, we’d love to hear them below in the comments.
Making things fast is one of the things we do at Cloudflare. More responsive websites, apps, APIs, and networks directly translate into improved conversion and user experience. Today, Google announced that Google Search will directly take web performance and page experience data into account when ranking results on their search engine results pages (SERPs), beginning in May 2021.
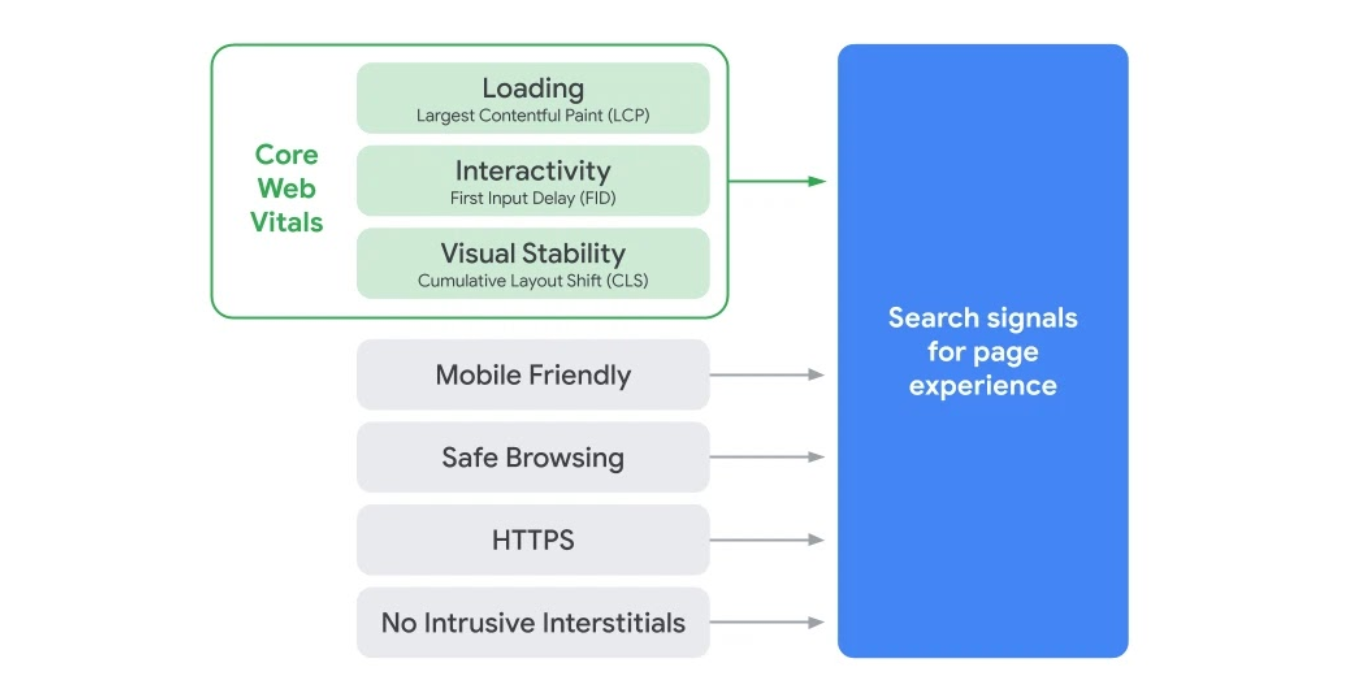
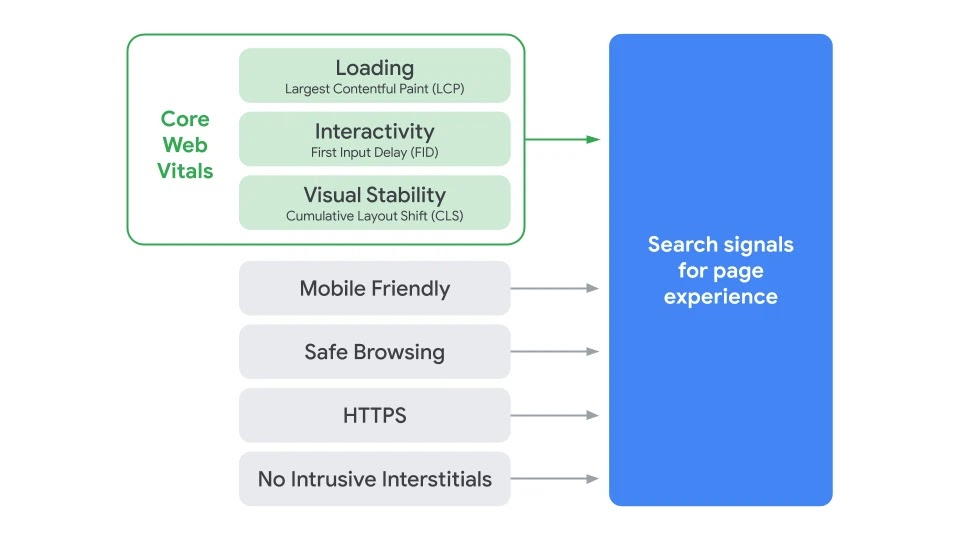
Specifically, Google Search will prioritize results based on how pages score on Core Web Vitals, a measurement methodology Cloudflare has worked closely with Google to establish, and we have implemented support for in our analytics tools.
Source: “Search Page Experience Graphic” by Google is licensed under CC BY 4.0
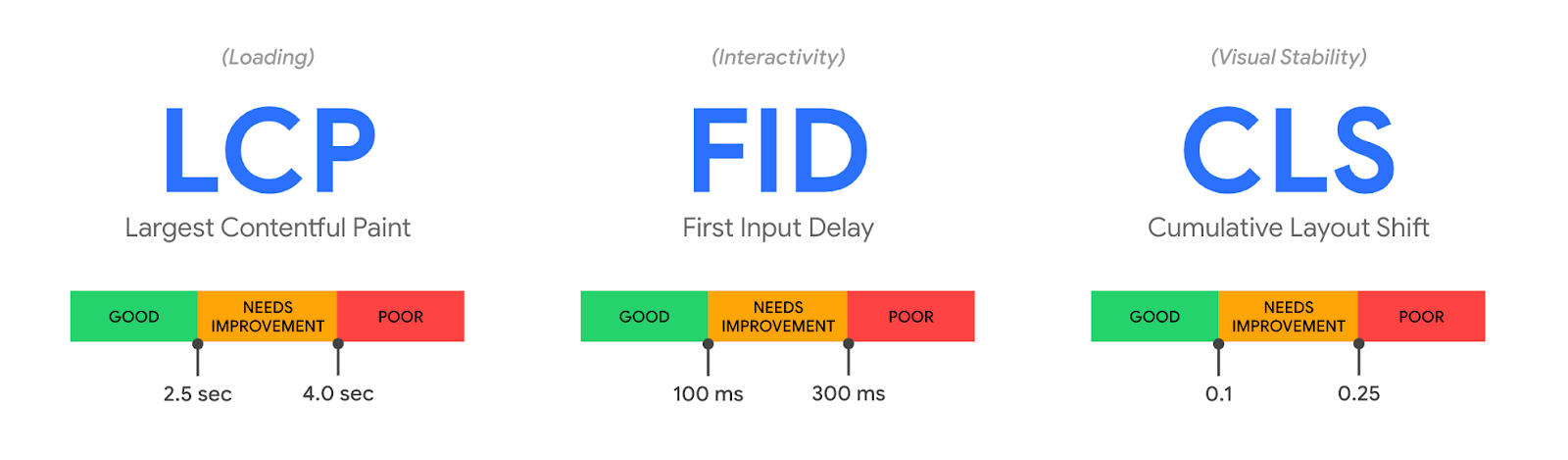
The Core Web Vitals metrics are Largest Contentful Paint (LCP, a loading measurement), First Input Delay (FID, a measure of interactivity), and Cumulative Layout Shift (CLS, a measure of visual stability). Each one is directly associated with user perceptible page experience milestones. All three can be improved using our performance products, and all three can be measured with our Cloudflare Browser Insights product, and soon, with our free privacy-aware Cloudflare Web Analytics.
SEO experts have always suspected faster pages lead to better search ranking. With today’s announcement from Google, we can say with confidence that Cloudflare helps you achieve the web performance trifecta: our product suite makes your site faster, gives you direct visibility into how it is performing (and use that data to iteratively improve), and directly drives improved search ranking and business results.
“Google providing more transparency about how Search ranking works is great for the open Web. The fact they are ranking using real metrics that are easy to measure with tools like Cloudflare’s analytics suite makes today’s announcement all the more exciting. Cloudflare offers a full set of tools to make sites incredibly fast and measure ‘incredibly’ directly.”
– Matt Weinberg, president of Happy Cog, a full-service digital agency.
Cloudflare helps make your site faster
Cloudflare offers a diverse, easy to deploy set of products to improve page experience for your visitors. We offer a rich, configurable set of tools to improve page speed, which this post is too small to contain. Unlike Fermat, who once famously described a math problem and then said “the margin is too small to contain the solution”, and then let folks spend three hundred plus years trying to figure out his enigma, I’m going to tell you how to solve web performance problems with Cloudflare. Here are the highlights:
Caching and Smart Routing
The typical website is composed of a mix of static assets, like images and product descriptions, and dynamic content, like the contents of a shopping cart or a user’s profile page. Cloudflare caches customers’ static content at our edge, avoiding the need for a full roundtrip to origin servers each time content is requested. Because our edge network places content very close (in physical terms) to users, there is less distance to travel and page loads are consequently faster. Thanks, Einstein.
And Argo Smart Routing helps speed page loads that require dynamic content. It analyzes and optimizes routing decisions across the global Internet in real-time. Think Waze, the automobile route optimization app, but for Internet traffic.
Just as Waze can tell you which route to take when driving by monitoring which roads are congested or blocked, Smart Routing can route connections across the Internet efficiently by avoiding packet loss, congestion, and outages.
Using caching and Smart Routing directly improves page speed and experience scores like Web Vitals. With today’s announcement from Google, this also means improved search ranking.
Content optimization
Caching and Smart Routing are designed to reduce and speed up round trips from your users to your origin servers, respectively. Cloudflare also offers features to optimize the content we do serve.
Cloudflare Image Resizing allows on-demand sizing, quality, and format adjustments to images, including the ability to convert images to modern file formats like WebP and AVIF.
Delivering images this way to your end-users helps you save bandwidth costs and improve performance, since Cloudflare allows you to optimize images already cached at the edge.
For WordPress operators, we recently launched Automatic Platform Optimization (APO). With APO, Cloudflare will serve your entire site from our edge network, ensuring that customers see improved performance when visiting your site. By default, Cloudflare only caches static content, but with APO we can also cache dynamic content (like HTML) so the entire site is served from cache. This removes round trips from the origin drastically improving TTFB and other site performance metrics. In addition to caching dynamic content, APO caches third party scripts to further reduce the need to make requests that leave Cloudflare’s edge network.
Workers and Workers Sites
Reducing load on customer origins and making sure we serve the right content to the right clients at the right time are great, but what if customers want to take things a step further and eliminate origin round trips entirely? What if there was no origin? Before we get into Schrödinger’s cat/server territory, we can make this concrete: Cloudflare offers tools to serve entire websites from our edge, without an origin server being involved at all. For more on Workers Sites, check out our introductory blog post and peruse our Built With Workers project gallery.
As big proponents of dogfooding, many of Cloudflare’s own web properties are deployed to Workers Sites, and we use Web Vitals to measure our customers’ experiences.
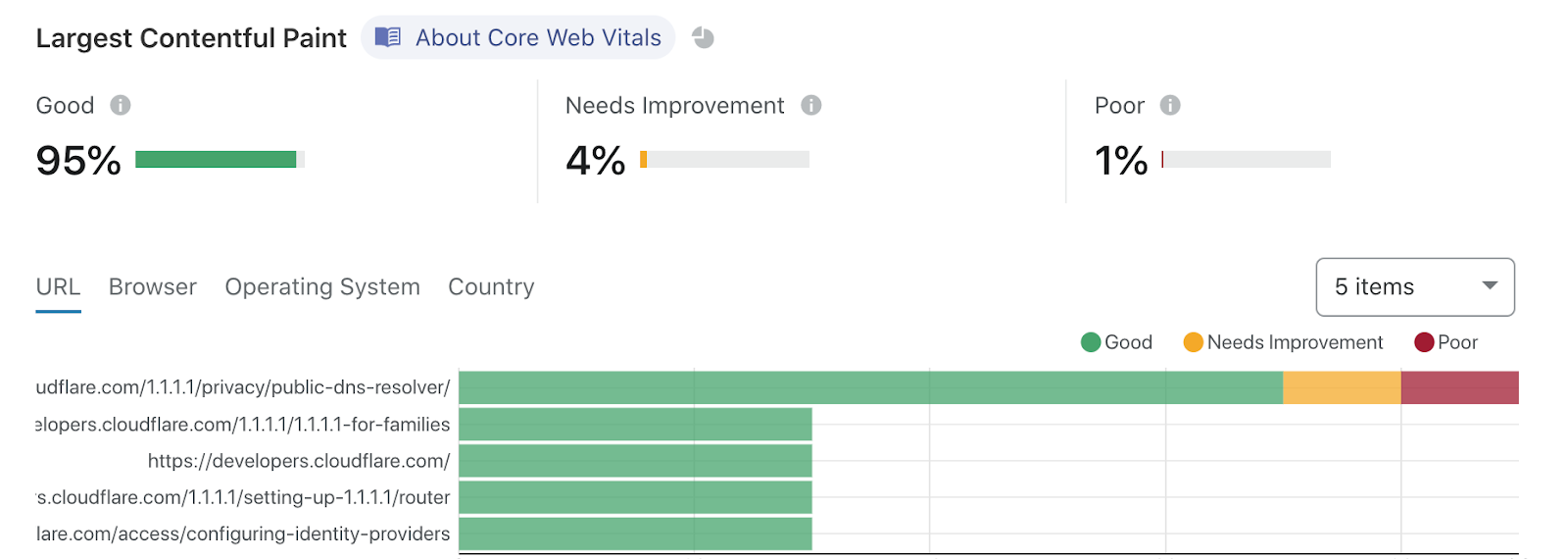
Using Workers Sites, our developers.cloudflare.com site, which gets hundreds of thousands of visits a day and is critical to developers building atop our platform, is able to attain incredible Web Vitals scores:
These scores are superb, showing the performance and ease of use of our edge, our static website delivery system, and our analytics toolchain.
Cloudflare Web Analytics and Browser Insights directly measure the signals Google is prioritizing
As illustrated above, Cloudflare makes it easy to directly measure Web Vitals with Browser Insights. Enabling Browser Insights for websites proxied by Cloudflare takes one click in the Speed tab of the Cloudflare dashboard. And if you’re not proxying sites through Cloudflare, Web Vitals measurements will be supported in our upcoming, free, Cloudflare Web Analytics product that any site, using Cloudflare’s proxy or not, can use.
Web Vitals breaks down user experience into three components:
Loading: How long did it take for content to become available?
Interactivity: How responsive is the website when you interact with it?
Visual stability: How much does the page move around while loading?
It’s challenging to create a single metric that captures these high-level components. Thankfully, the folks at Google Chrome team have thought about this, and earlier this year introduced three “Core” Web Vitals metrics: Largest Contentful Paint, First Input Delay, and Cumulative Layout Shift.
Cloudflare Browser Insights measures all three metrics directly in your users’ browsers, all with one-click enablement from the Cloudflare dashboard.
Once enabled, Browser Insights works by inserting a JavaScript “beacon” into HTML pages. You can control where the beacon loads if you only want to measure specific pages or hostnames. If you’re using CSP version 3, we’ll even automatically detect the nonce (if present) and add it to the script.
To start using Browser Insights, just head over to the Speed tab in the dashboard.
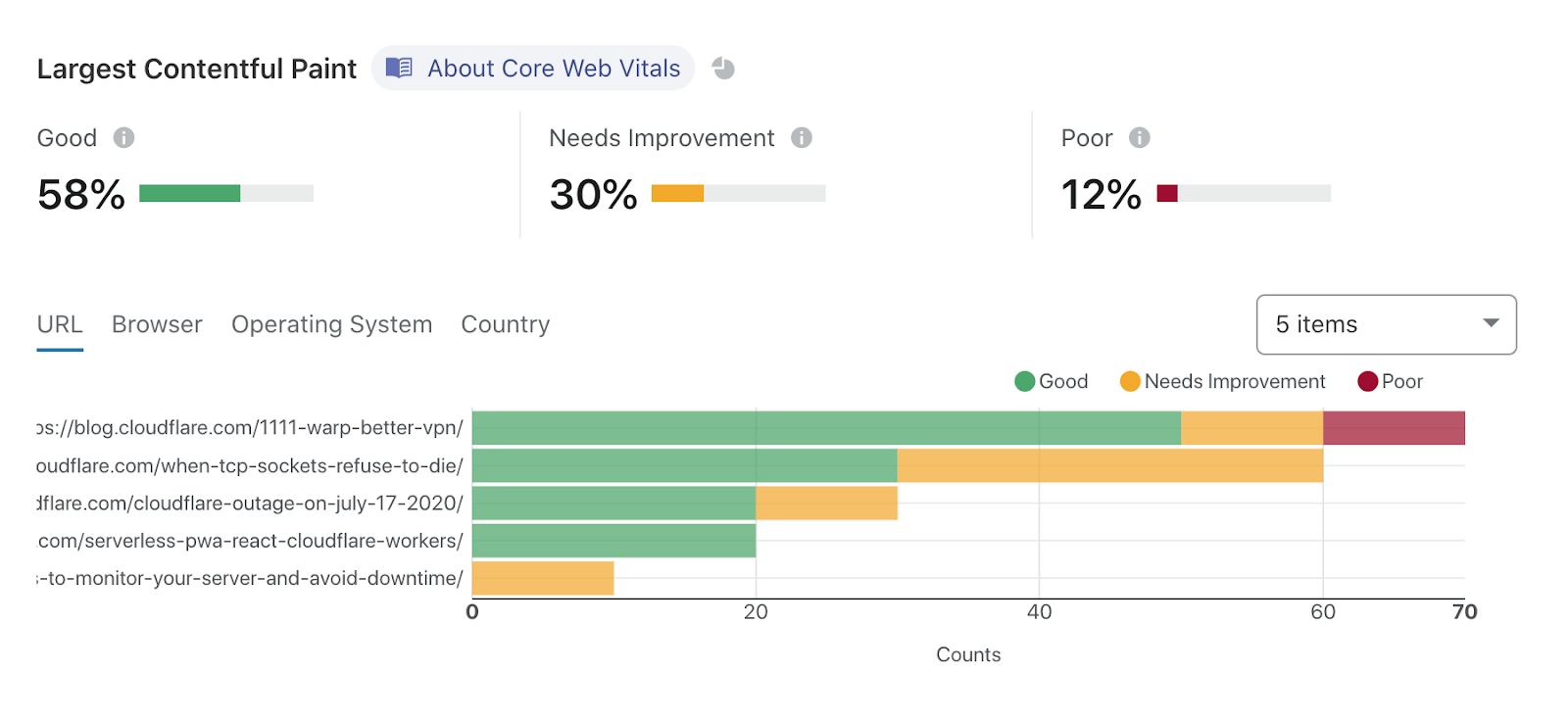
An example Browser Insights report, showing what pages on blog.cloudflare.com need improvement.
Making pages fast is better for everyone
Google’s announcement today, that Web Vitals measurements will be a key part of search ranking starting in May 2021, places even more emphasis on running fast, accessible websites.
Using Cloudflare’s performance tools, like our best-of-breed caching, Argo Smart Routing, content optimization, and Cloudflare Workers® products, directly improves page experience and Core Web Vitals measurements, and now, very directly, where your pages appear in Google Search results. And you don’t have to take our word for this — our analytics tools directly measure Web Vitals scores, instrumenting your real users’ experiences.
We’re excited to help our customers build fast websites, understand exactly how fast they are, and rank highly on Google search as a result. Render on!
Brotli is a state of the art lossless compression format, supported by all major browsers. It is capable of achieving considerably better compression ratios than the ubiquitous gzip, and is rapidly gaining in popularity. Cloudflare uses the Google brotli library to dynamically compress web content whenever possible. In 2015, we took an in-depth look at how brotli works and its compression advantages.
One of the more interesting features of the brotli file format, in the context of textual web content compression, is the inclusion of a built-in static dictionary. The dictionary is quite large, and in addition to containing various strings in multiple languages, it also supports the option to apply multiple transformations to those words, increasing its versatility.
The open sourced brotli library, that implements an encoder and decoder for brotli, has 11 predefined quality levels for the encoder, with higher quality level demanding more CPU in exchange for a better compression ratio. The static dictionary feature is used to a limited extent starting with level 5, and to the full extent only at levels 10 and 11, due to the high CPU cost of this feature.
We improve on the limited dictionary use approach and add optimizations to improve the compression at levels 5 through 9 at a negligible performance impact when compressing web content.
Brotli Static Dictionary
Brotli primarily uses the LZ77 algorithm to compress its data. Our previous blog post about brotli provides an introduction.
To improve compression on text files and web content, brotli also includes a static, predefined dictionary. If a byte sequence cannot be matched with an earlier sequence using LZ77 the encoder will try to match the sequence with a reference to the static dictionary, possibly using one of the multiple transforms. For example, every HTML file contains the opening <html> tag that cannot be compressed with LZ77, as it is unique, but it is contained in the brotli static dictionary and will be replaced by a reference to it. The reference generally takes less space than the sequence itself, which decreases the compressed file size.
The dictionary contains 13,504 words in six languages, with lengths from 4 to 24 characters. To improve the compression of real-world text and web data, some dictionary words are common phrases (“The current”) or strings common in web content (‘type=”text/javascript”’). Unlike usual LZ77 compression, a word from the dictionary can only be matched as a whole. Starting a match in the middle of a dictionary word, ending it before the end of a word or even extending into the next word is not supported by the brotli format.
Instead, the dictionary supports 120 transforms of dictionary words to support a larger number of matches and find longer matches. The transforms include adding suffixes (“work” becomes “working”) adding prefixes (“book” => “ the book”) making the first character uppercase (“process” => “Process”) or converting the whole word to uppercase (“html” => “HTML”). In addition to transforms that make words longer or capitalize them, the cut transform allows a shortened match (“consistently” => “consistent”), which makes it possible to find even more matches.
Methods
With the transforms included, the static dictionary contains 1,633,984 different words – too many for exhaustive search, except when used with the slow brotli compression levels 10 and 11. When used at a lower compression level, brotli either disables the dictionary or only searches through a subset of roughly 5,500 words to find matches in an acceptable time frame. It also only considers matches at positions where no LZ77 match can be found and only uses the cut transform.
Our approach to the brotli dictionary uses a larger, but more specialized subset of the dictionary than the default, using more aggressive heuristics to improve the compression ratio with negligible cost to performance. In order to provide a more specialized dictionary, we provide the compressor with a content type hint from our servers, relying on the Content-Type header to tell the compressor if it should use a dictionary for HTML, JavaScript or CSS. The dictionaries can be furthermore refined by colocation language in the future.
Fast dictionary lookup
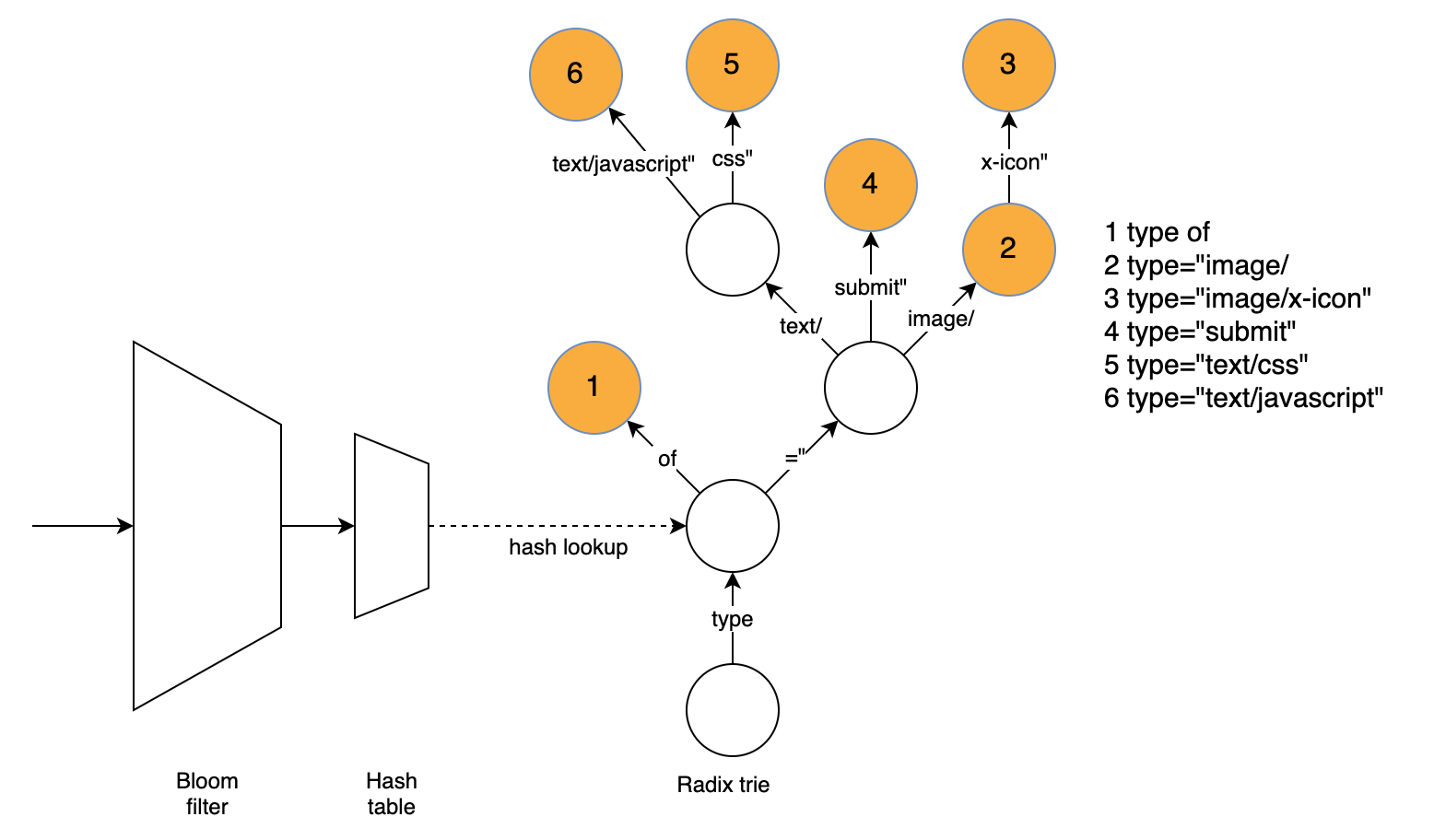
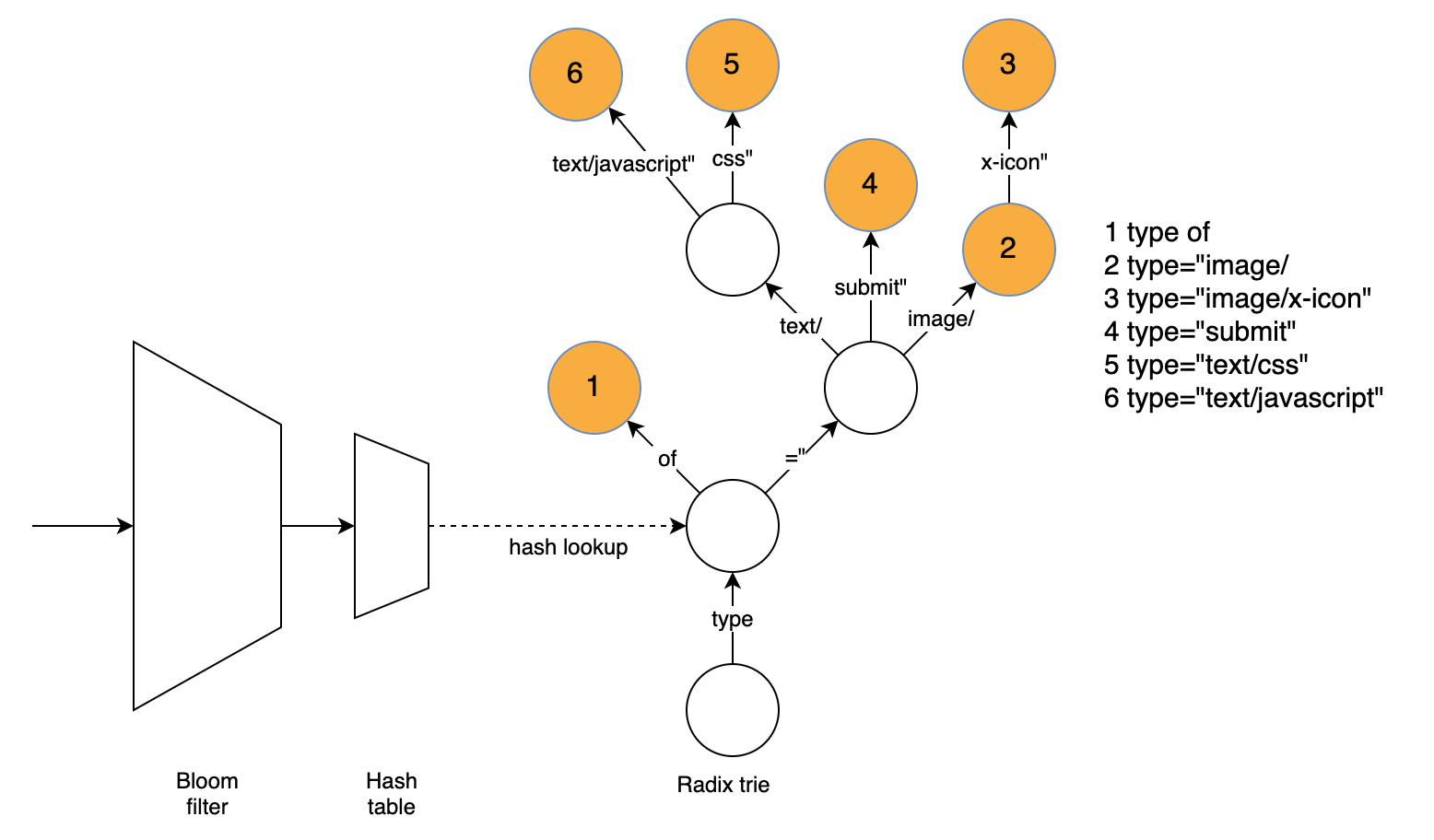
To improve compression without sacrificing performance, we needed a fast way to find matches if we want to search the dictionary more thoroughly than brotli does by default. Our approach uses three data structures to find a matching word directly. The radix trie is responsible for finding the word while the hash table and bloom filter are used to speed up the radix trie and quickly eliminate many words that can’t be matched using the dictionary.
Lookup for a position starting with “type”
The radix trie easily finds the longest matching word without having to try matching several words. To find the match, we traverse the graph based on the text at the current position and remember the last node with a matching word. The radix trie supports compressed nodes (having more than one character as an edge label), which greatly reduces the number of nodes that need to be traversed for typical dictionary words.
The radix trie is slowed down by the large number of positions where we can’t find a match. An important finding is that most mismatching strings have a mismatching character in the first four bytes. Even for positions where a match exists, a lot of time is spent traversing nodes for the first four bytes since the nodes close to the tree root usually have many children.
Luckily, we can use a hash table to look up the node equivalent to four bytes, matching if it exists or reject the possibility of a match. We thus look up the first four bytes of the string, if there is a matching node we traverse the trie from there, which will be fast as each four-byte prefix usually only has a few corresponding dict words. If there is no matching node, there will not be a matching word at this position and we do not need to further consider it.
While the hash table is designed to reject mismatches quickly and avoid cache misses and high search costs in the trie, it still suffers from similar problems: We might search through several 4-byte prefixes with the hash value of the given position, only to learn that no match can be found. Additionally, hash lookups can be expensive due to cache misses.
To quickly reject words that do not match the dictionary, but might still cause cache misses, we use a k=1 bloom filter to quickly rule out most non-matching positions. In the k=1 case, the filter is simply a lookup table with one bit indicating whether any matching 4-byte prefixes exist for a given hash value. If the hash value for the given bit is 0, there won’t be a match. Since the bloom filter uses at most one bit for each four-byte prefix while the hash table requires 16 bytes, cache misses are much less likely. (The actual size of the structures is a bit different since there are many empty spaces in both structures and the bloom filter has twice as many elements to reject more non-matching positions.)
This is very useful for performance as a bloom filter lookup requires a single memory access. The bloom filter is designed to be fast and simple, but still rejects more than half of all non-matching positions and thus allows us to save a full hash lookup, which would often mean a cache miss.
Heuristics
To improve the compression ratio without sacrificing performance, we employed a number of heuristics:
Only search the dictionary at some positions This is also done using the stock dictionary, but we search more aggressively. While the stock dictionary only considers positions where the LZ77 match finder did not find a match, we also consider positions that have a bad match according to the brotli cost model: LZ77 matches that are short or have a long distance between the current position and the reference usually only offer a small compression improvement, so it is worth trying to find a better match in the static dictionary.
Only consider the longest match and then transform it Instead of finding and transforming all matches at a position, the radix trie only gives us the longest match which we then transform. This approach results in a vast performance improvement. In most cases, this results in finding the best match.
Only include some transforms While all transformations can improve the compression ratio, we only included those that work well with the data structures. The suffix transforms can easily be applied after finding a non-transformed match. For the upper case transforms, we include both the non-transformed and the upper case version of a word in the radix trie. The prefix and cut transforms do not play well with the radix trie, therefore a cut of more than 1 byte and prefix transforms are not supported.
Generating the reduced dictionary
At low compression levels, brotli searches a subset of ~5,500 out of 13,504 words of the dictionary, negatively impacting compression. To store the entire dictionary, we would need to store ~31,700 words in the trie considering the upper case transformed output of ASCII sequences and ~11,000 four-byte prefixes in the hash. This would slow down hash table and radix trie, so we needed to find a different subset of the dictionary that works well for web content.
For this purpose, we used a large data set containing representative content. We made sure to use web content from several world regions to reflect language diversity and optimize compression. Based on this data set, we identified which words are most common and result in the largest compression improvement according to the brotli cost model. We only include the most useful words based on this calculation. Additionally, we remove some words if they slow down hash table lookups of other, more common words based on their hash value.
We have generated separate dictionaries for HTML, CSS and JavaScript content and use the MIME type to identify the right dictionary to use. The dictionaries we currently use include about 15-35% of the entire dictionary including uppercase transforms. Depending on the type of data and the desired compression/speed tradeoff, different options for the size of the dictionary can be useful. We have also developed code that automatically gathers statistics about matches and generates a reduced dictionary based on this, which makes it easy to extend this to other textual formats, perhaps data that is majority non-English or XML data and achieve better results for this type of data.
Results
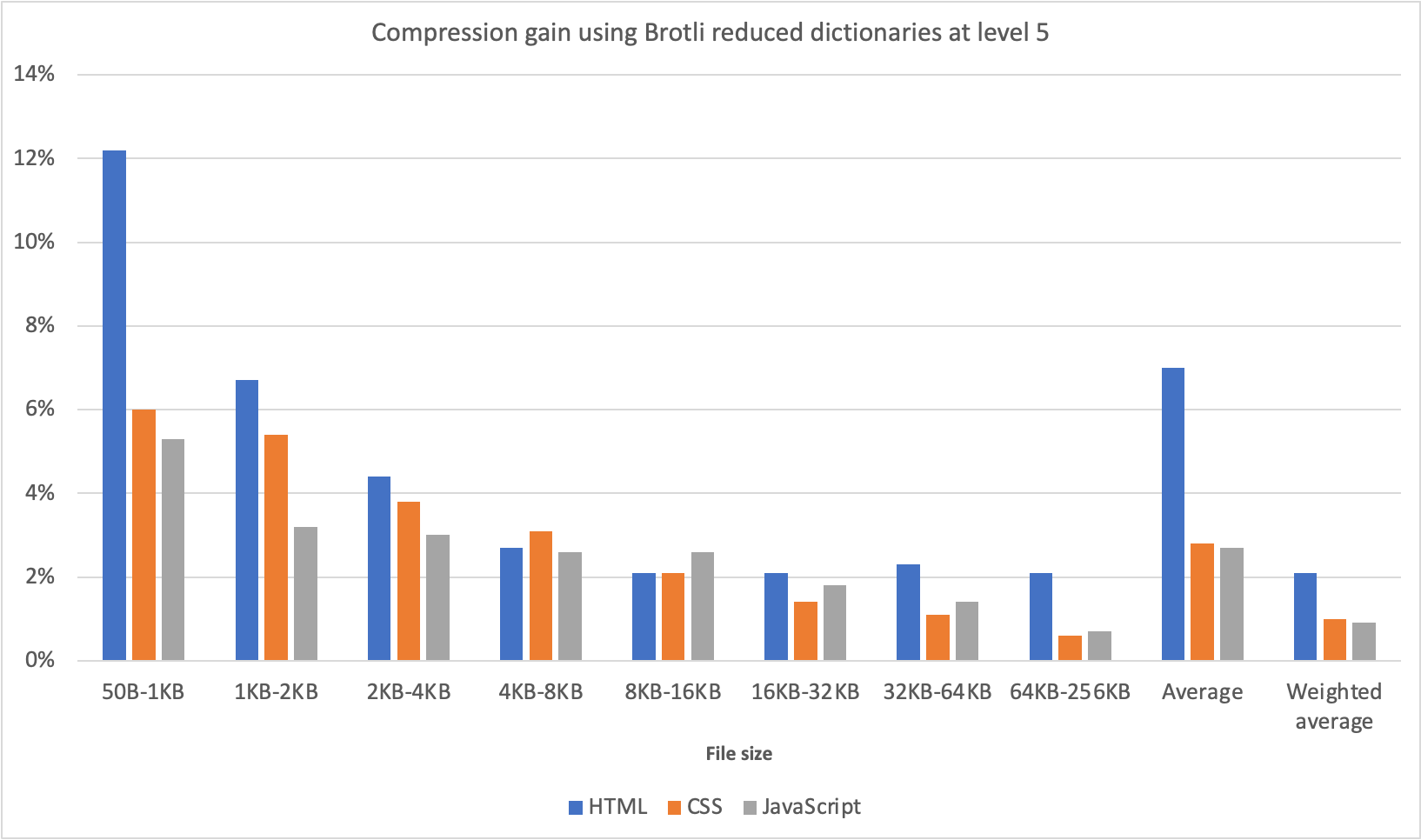
We tested the reduced dictionary on a large data set of HTML, CSS and JavaScript files.
The improvement is especially big for small files as the LZ77 compression is less effective on them. Since the improvement on large files is a lot smaller, we only tested files up to 256KB. We used compression level 5, the same compression level we currently use for dynamic compression on our edge, and tested on a Intel Core i7-7820HQ CPU.
Compression improvement is defined as 1 – (compressed size using the reduced dictionary / compressed size without dictionary). This ratio is then averaged for each input size range. We also provide an average value weighted by file size. Our data set mirrors typical web traffic, covering a wide range of file sizes with small files being more common, which explains the large difference between the weighted and unweighted average.
With the improved dictionary approach, we are now able to compress HTML, JavaScript and CSS files as well, or sometimes even better than using a higher compression level would allow us, all while using only 1% to 3% more CPU. For reference using compression level 6 over 5 would increase CPU usage by up to 12%.
We’ve added support for the new AVIF image format in Image Resizing. It compresses images significantly better than older-generation formats such as WebP and JPEG. It’s supported in Chrome desktop today, and support is coming to other Chromium-based browsers, as well as Firefox.
What’s the benefit?
More than a half of an average website’s bandwidth is spent on images. Improved image compression can save bandwidth and improve overall performance of the web. The compression in AVIF is so good that images can reduce to half the size of JPEG and WebP
Currently JPEG is the most popular image format on the Web. It’s doing remarkably well for its age, and it will likely remain popular for years to come thanks to its excellent compatibility. There have been many previous attempts at replacing JPEG, such as JPEG 2000, JPEG XR and WebP. However, these formats offered only modest compression improvements, and didn’t always beat JPEG on image quality. Compression and image quality in AVIF is better than in all of them, and by a wide margin.
JPEG (17KB)
WebP (17KB)
AVIF (17KB)
Why a new image format?
One of the big things AVIF does is it fixes WebP’s biggest flaws. WebP is over 10 years old, and AVIF is a major upgrade over the WebP format. These two formats are technically related: they’re both based on a video codec from the VPx family. WebP uses the old VP8 version, while AVIF is based on AV1, which is the next generation after VP10.
WebP is limited to 8-bit color depth, and in its best-compressing mode of operation, it can only store color at half of the image’s resolution (known as chroma subsampling). This causes edges of saturated colors to be smudged or pixelated in WebP. AVIF supports 10- and 12-bit color at full resolution, and high dynamic range (HDR).
JPEG
WebP
WebP (sharp YUV option)
AVIF
AV1 also uses a new compression technique: chroma-from-luma. Most image formats store brightness separately from color hue. AVIF uses the brightness channel to guess what the color channel may look like. They are usually correlated, so a good guess gives smaller file sizes and sharper edges.
Adoption of AV1 and AVIF
VP8 and WebP suffered from reluctant industry adoption. Safari only added WebP support very recently, 10 years after Chrome.
Chrome 85 supports AVIF already. It’s a work in progress in other Chromium-based browsers, and Firefox. Apple hasn’t announced whether Safari will support AVIF. However, this time Apple is one of the companies in the Alliance for Open Media, creators of AVIF. The AV1 codec is already seeing faster adoption than the previous royalty-free codecs. Latest GPUs from Nvidia, AMD, and Intel already have hardware decoding support for AV1.
AVIF uses the same HEIF container as the HEIC format used in iOS’s camera. AVIF and HEIC offer similar compression performance. The difference is that HEIC is based on a commercial, patent-encumbered H.265 format. In countries that allow software patents, H.265 is illegal to use without obtaining patent licenses. It’s covered by thousands of patents, owned by hundreds of companies, which have fragmented into two competing licensing organizations. Costs and complexity of patent licensing used to be acceptable when videos were published by big studios, and the cost could be passed on to the customer in the price of physical discs and hardware players. Nowadays, when video is mostly consumed via free browsers and apps, the old licensing model has become unsustainable. This has created a huge incentive for Web giants like Google, Netflix, and Amazon to get behind the royalty-free alternative. AV1 is free to use by anyone, and the alliance of tech giants behind it will defend it from patent troll’s lawsuits.
Non-standard image formats usually can only be created using their vendor’s own implementation. AVIF and AV1 are already ahead with multiple independent implementations: libaom, Intel SVT-AV1, libgav1, dav1d, and rav1e. This is a sign of a healthy adoption and a prerequisite to be a Web standard. Our Image Resizing is implemented in Rust, so we’ve chosen the rav1e encoder to create a pure-Rust implementation of AVIF.
Caveats
AVIF is a feature-rich format. Most of its features are for smartphone cameras, such as “live” photos, depth maps, bursts, HDR, and lossless editing. Browsers will support only a fraction of these features. In our implementation in Image Resizing we’re supporting only still standard-range images.
Two biggest problems in AVIF are encoding speed and lack of progressive rendering.
AVIF images don’t show anything on screen until they’re fully downloaded. In contrast, a progressive JPEG can display a lower-quality approximation of the image very quickly, while it’s still loading. When progressive JPEGs are delivered well, they make websites appear to load much faster. Progressive JPEG can look loaded at half of its file size. AVIF can fully load at half of JPEG’s size, so it somewhat overcomes the lack of progressive rendering with the sheer compression advantage. In this case only WebP is left behind, which has neither progressive rendering nor strong compression.
Decoding AVIF images for display takes relatively more CPU power than other codecs, but it should be fast enough in practice. Even low-end Android devices can play AV1 videos in full HD without help of hardware acceleration, and AVIF images are just a single frame of an AV1 video. However, encoding of AVIF images is much slower. It may take even a few seconds to create a single image. AVIF supports tiling, which accelerates encoding on multi-core CPUs. We have lots of CPU cores, so we take advantage of this to make encoding faster. Image Resizing doesn’t use the maximum compression level possible in AVIF to further increase compression speed. Resized images are cached, so the encoding speed is noticeable only on a cache miss.
We will be adding AVIF support to Polish as well. Polish converts images asynchronously in the background, which completely hides the encoding latency, and it will be able to compress AVIF images better than Image Resizing.
Note about benchmarking
It’s surprisingly difficult to fairly and accurately judge which lossy codec is better. Lossy codecs are specifically designed to mainly compress image details that are too subtle for the naked eye to see, so “looks almost the same, but the file size is smaller!” is a common feature of all lossy codecs, and not specific enough to draw conclusions about their performance.
Lossy codecs can’t be compared by comparing just file sizes. Lossy codecs can easily make files of any size. Their effectiveness is in the ratio between file size and visual quality they can achieve.
The best way to compare codecs is to make each compress an image to the exact same file size, and then to compare the actual visual quality they’ve achieved. If the file sizes differ, any judgement may be unfair, because the codec that generated the larger file may have done so only because it was asked to preserve more details, not because it can’t compress better.
How and when to enable AVIF today?
We recommend AVIF for websites that need to deliver high-quality images with as little bandwidth as possible. This is important for users of slow networks and in countries where the bandwidth is expensive.
Browsers that support the AVIF format announce it by adding image/avif to their Accept request header. To request the AVIF format from Image Resizing, set the format option to avif.
addEventListener('fetch', event => {
const imageURL = "https://jpeg.speedcf.com/cat/4.jpg";
const resizingOptions = {
// You can set any options here, see:
// https://developers.cloudflare.com/images/worker
width: 800,
sharpen: 1.0,
};
const accept = event.request.headers.get("accept");
const isAVIFSupported = /image\/avif/.test(accept);
if (isAVIFSupported) {
resizingOptions.format = "avif";
}
event.respondWith(fetch(imageURL), {cf:{image: resizingOptions}})
})
The above script will auto-detect the supported format, and serve AVIF automatically. Alternatively, you can use URL-based resizing together with the <picture> element:
This uses our /cdn-cgi/image/… endpoint to perform the conversion, and the alternative source will be picked only by browsers that support the AVIF format.
We have the format=auto option, but it won’t choose AVIF yet. We’re cautious, and we’d like to test the new format more before enabling it by default.
Today, we are announcing a new service to serve more than just the static content of your website with the Automatic Platform Optimization (APO) service. With this launch, we are supporting WordPress, the most popular website hosting solution serving 38% of all websites. Our testing, as detailed below, showed a 72% reduction in Time to First Byte (TTFB), 23% reduction to First Contentful Paint, and 13% reduction in Speed Index for desktop users at the 90th percentile, by serving nearly all of your website’s content from Cloudflare’s network. This means visitors to your website see not only the first content sooner but all content more quickly.
With Automatic Platform Optimization for WordPress, your customers won’t suffer any slowness caused by common issues like shared hosting congestion, slow database lookups, or misbehaving plugins. This service is now available for anyone using WordPress. It costs $5/month for customers on our Free plan and is included, at no additional cost, in our Professional, Business, and Enterprise plans. No usage fees, no surprises, just speed.
How to get started
The easiest way to get started with APO is from your WordPress admin console.
1. First, install the Cloudflare WordPress plugin on your WordPress website or update to the latest version (3.8.2 or higher). 2. Authenticate the plugin (steps here) to talk to Cloudflare if you have not already done that. 3. From the Home screen of the Cloudflare section, turn on Automatic Platform Optimization.
Free customers will first be directed to the Cloudflare Dashboard to purchase the service.
Why We Built This
At Cloudflare, we jump at the opportunity to make hard problems for our customers disappear with the click of a button. Running a consistently fast website is challenging. Many businesses don’t have the time nor money to spend on complicated and expensive performance solutions for their site. Even if they do, it can be extremely costly to pay for specialized attention to ensure you get the best performance possible. Having a fast website doesn’t have to be complicated, though. The closer your content is to your customers, the better your site will perform. Static content caching does this for files like images, CSS and JavaScript, but that is only part of the equation. Dynamic content is still fetched from the origin incurring costly round trips and additional processing time. For more info on dynamic versus static content, see our learning center.
WordPress is one of the most open platforms in the world, but that means you are always at risk of incurring performance penalties because of plugins or other sources that, while necessary, may be hard to pinpoint and resolve. With the Automatic Platform Optimization service, we put your website into our network that is within 10 milliseconds of 99% of the Internet-connected population in the developed world, all without having to change your existing hosting provider. This means that for most requests your customers won’t even need to go to your origin, reducing many costly round trips and server processing time. These optimizations run on our edge network, so they also will not impact render or interactivity since no additional JavaScript is run on the client.
How We Measure Web Performance
Evaluating performance of a website is difficult. There are many different metrics you can track and it is not always obvious which metrics most meaningfully represent a user’s experience. As discussed when we blogged about our new Speed page, we aim to simplify this for customers by automating tests using the infrastructure of webpagetest.org, and summarizing both the results visually and numerically in one place.
The visualization gives you a clear idea of what customers are going to see when they come to your site, and the Critical Loading Times provide the most important metrics to judge your performance. On top of seeing your site’s performance, we provide a list of recommendations for ways to even further increase your performance. If you are using WordPress, then we will test your site with Automatic Platform Optimizations to estimate the benefit you will get with the service.
The Benefits of Automatic Platform Optimization
We tested APO on over 500 Cloudflare customer websites that run on WordPress to understand what the performance improvements would be. The results speak for themselves:
Note: Results are based on test results of 505 randomly selected websites that are cached by Cloudflare. Tests were run using WebPageTest from South Carolina, USA and the following environment: Chrome, Cable connection speed.
Most importantly, with APO, a site’s TTFB is made both fast and consistent. Because we now serve the html from Cloudflare’s edge with 0 origin processing time, getting the first byte to the eyeball is consistently fast. Under heavy load, a WordPress origin can suffer delays in building the html and returning it to visitors. APO removes the variance due to load resulting in consistent TTFB <400 ms.
Additionally, between faster TTFB and additional caching of third party fonts, we see performance improvements in both FCP and SI for both the fastest and slowest of the sites we tested. Some of this comes naturally from reducing the TTFB, since every millisecond you shave off of TTFB is a potential millisecond gain for other metrics. Caching additional third party fonts allows us to reduce the time it takes to fetch that content. Given fonts can often block paints due to text rendering, this improves the rate at which the page paints, and improves the Speed Index.
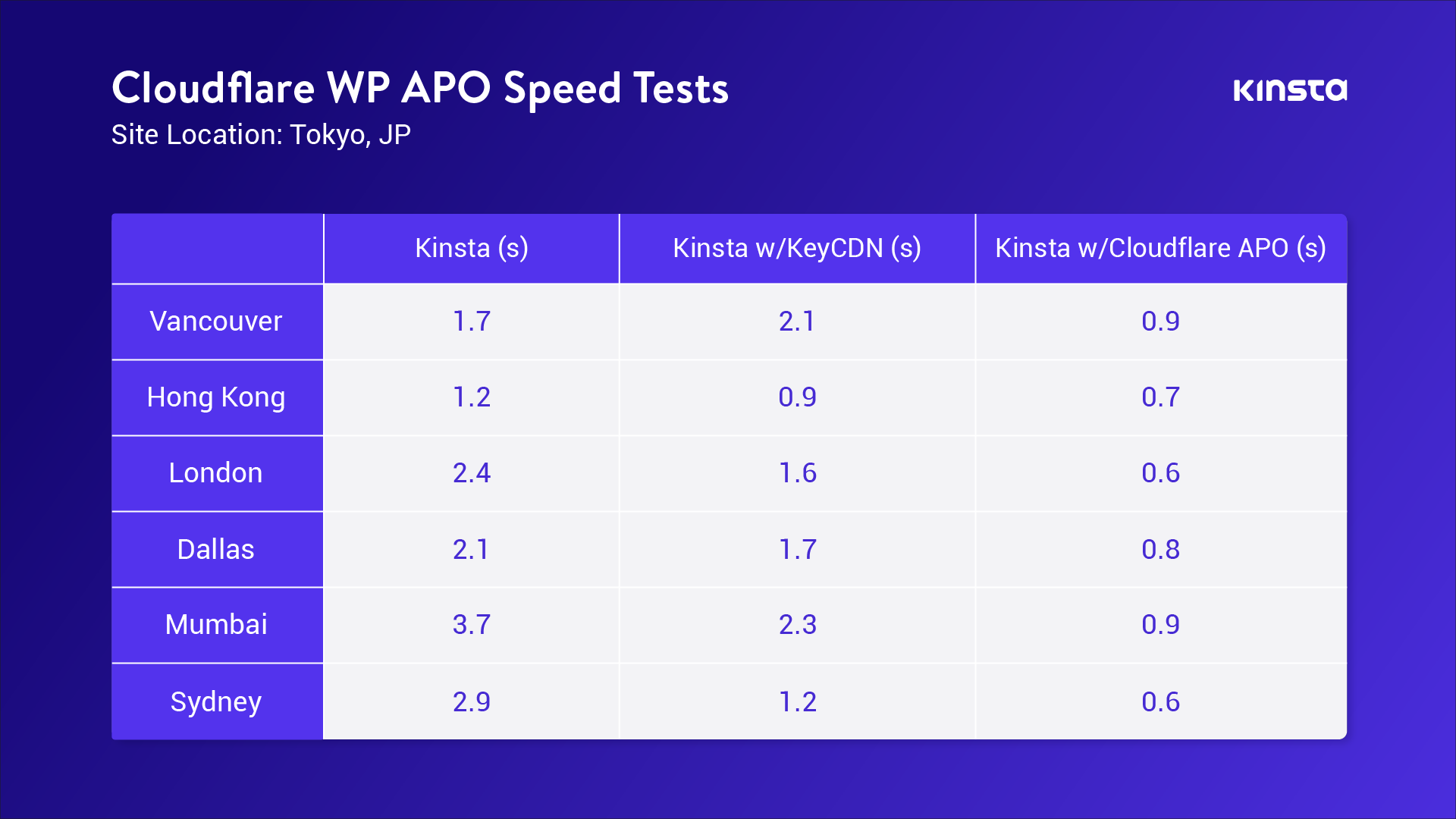
We asked the folks at Kinsta to try out APO, given their expertise in WordPress, and tell us what they think. Brian Li, a Website Content Manager at Kinsta, ran a set of tests from around the world on a website hosted in Tokyo. I’ll let him explain what they did and the results:
At Kinsta, WordPress performance is something that’s near and dear to our hearts. So, when Cloudflare reached out about testing their new Automatic Platform Optimization (APO) service for WordPress, we were all ears.
This is what we did to test out the new service:
We set up a test site in Tokyo, Japan – one of the 24 high-performance data center locations available for Kinsta customers.
We ran several speed tests from six different locations around the world with and without Cloudflare’s APO.
The results were incredible!
By caching static HTML on Cloudflare’s edge network, we saw a 70-300% performance increase. As expected, the testing locations furthest away from Tokyo saw the biggest reduction in load time.
If your WordPress site uses a traditional CDN that only caches CSS, JS, and images, upgrading to Cloudflare’s WordPress APO is a no-brainer and will help you stay competitive with modern Jamstack and static sites that live on the edge by default.
Brian’s test results are summarized in this image:
Page Load Speeds for loading a website hosted in Tokyo from 6 locations worldwide – comparing Kinsta, Kinsta with KeyCDN, and Kinsta with Cloudflare APO.
One of the clear benefits, from Kinsta’s testing of APO, is the consistency of performance for serving your site no matter where your visitors are in the world. The consistent sub-second performance shown with APO versus two or three second load times in other setups makes it clear that if you have a global customer base, APO delivers an improved experience for all visitors.
How Automatic Platform Optimization Works
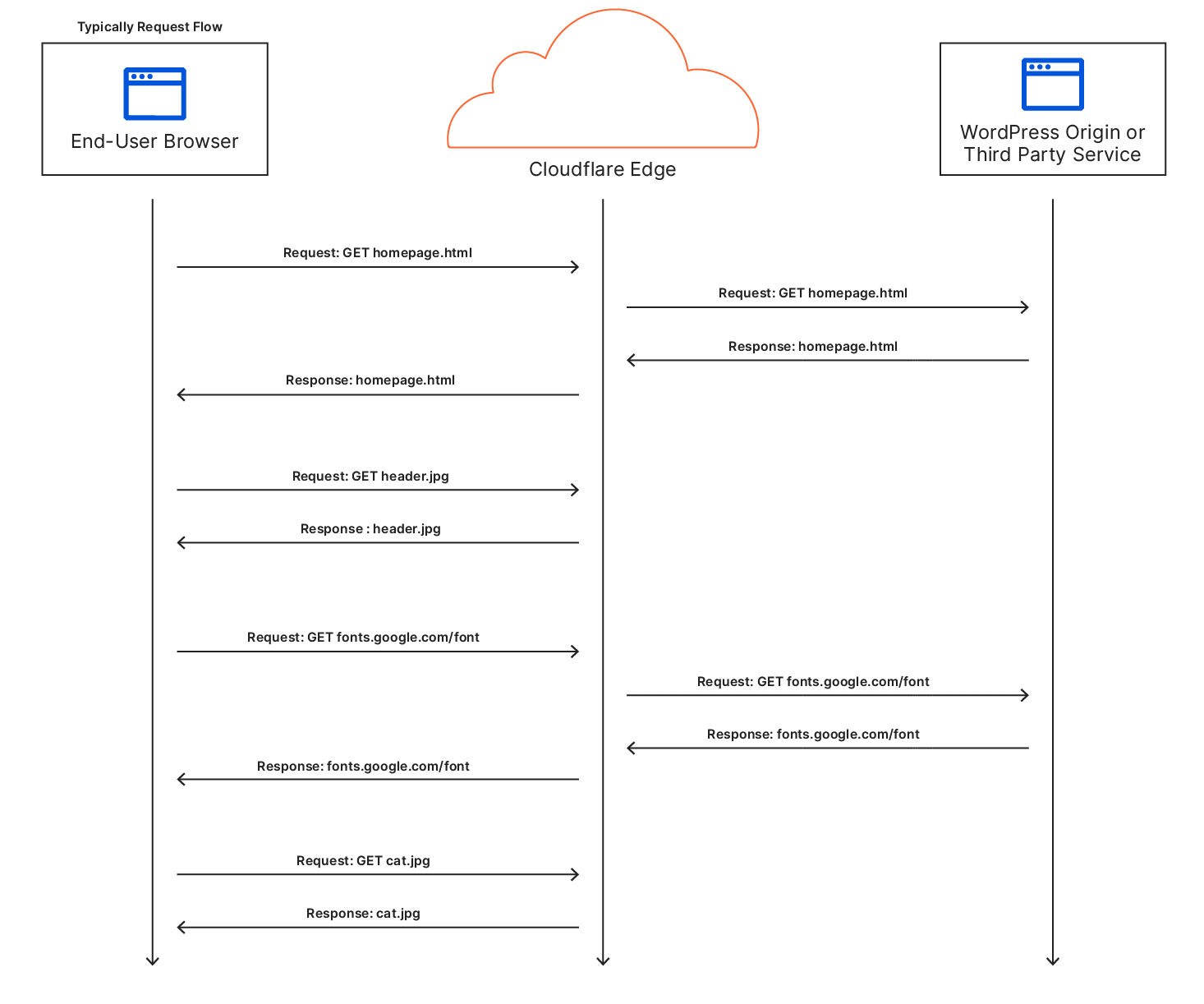
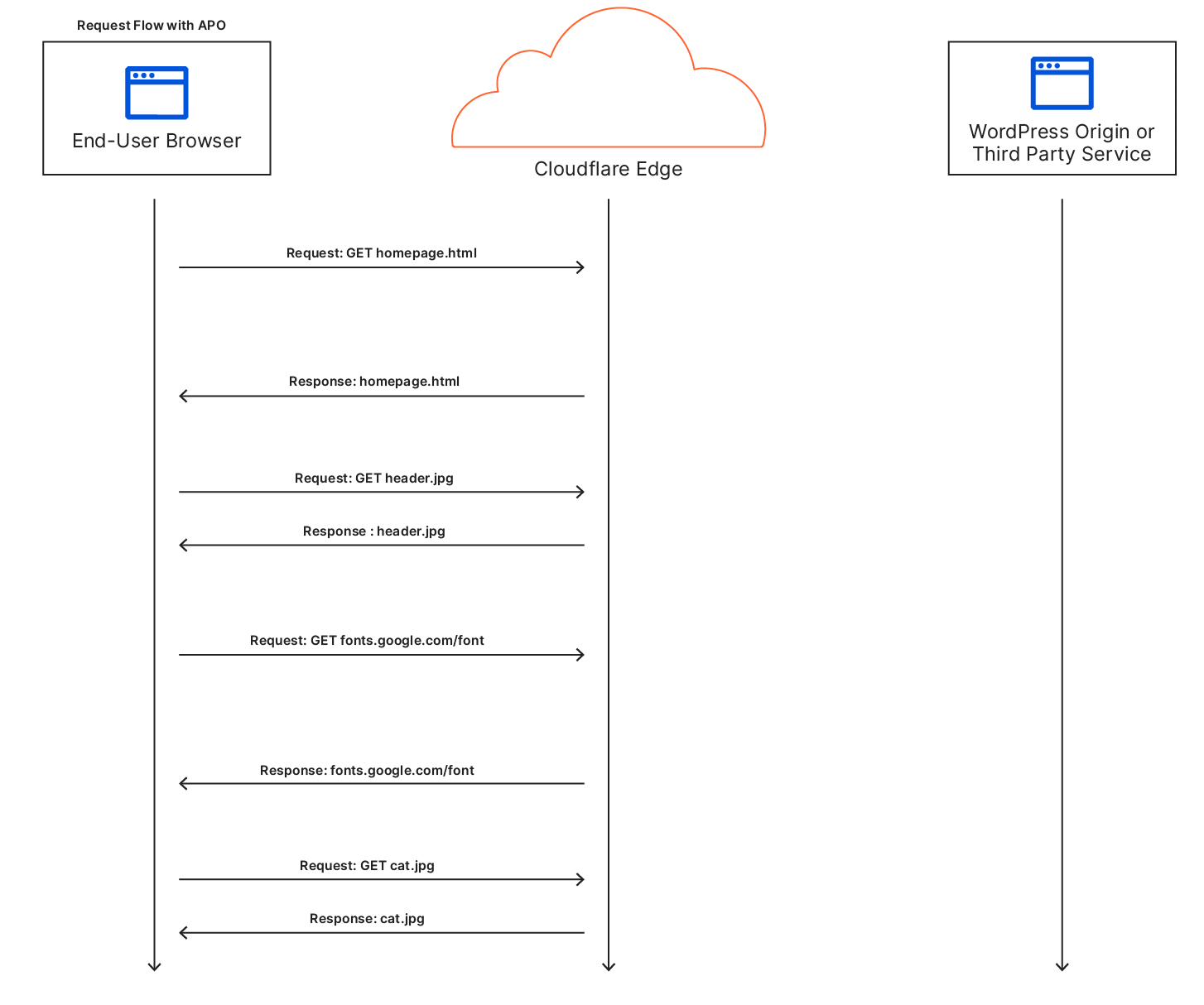
Automatic Platform Optimization is the result of being able to use the power of Cloudflare Workers to intelligently cache dynamic content. By caching dynamic content, we can serve the entire website from our edge network. Think ‘static site’ but without any of the work of having to build or maintain a static site. Customers can keep managing and updating content on their website in the same way and leave the hard work for performance to us. Serving both static and dynamic content from our network results, generally, in no origin requests or origin processing time. This means all the communication occurs between the user’s device and our edge. Reducing the multitude of round trips typically required from our edge to the origin for dynamic content is what makes this service so effective. Let’s first see what it normally looks like to load a WordPress site for a visitor.
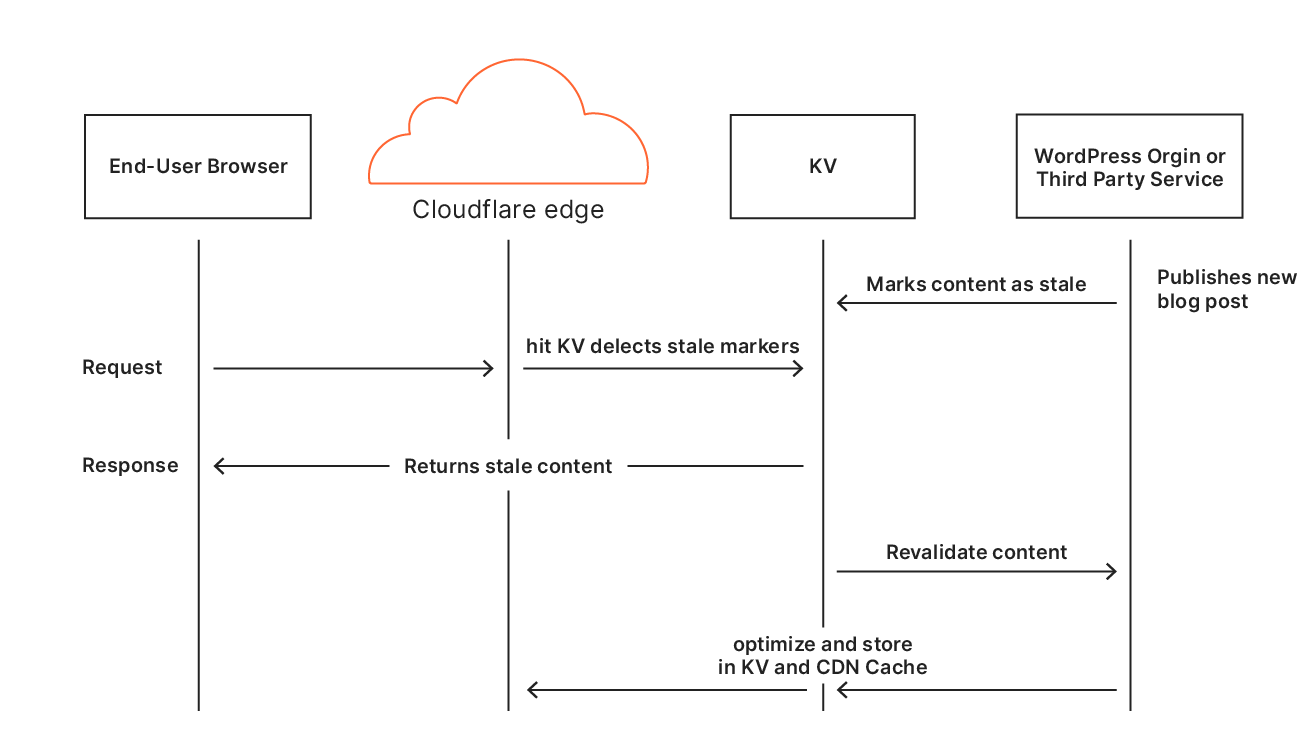
A sequence diagram for a typical user visiting a site
In a regular request flow, Cloudflare is able to cache some of the content like images, CSS, or JS, while other requests go to either the origin or a third party service in order to fetch the content. Most importantly the first request to fetch the HTML for the site needs to go to the origin which is a typical cause of long TTFB, since no other requests get made until the client can receive the HTML and parse it to make subsequent requests.
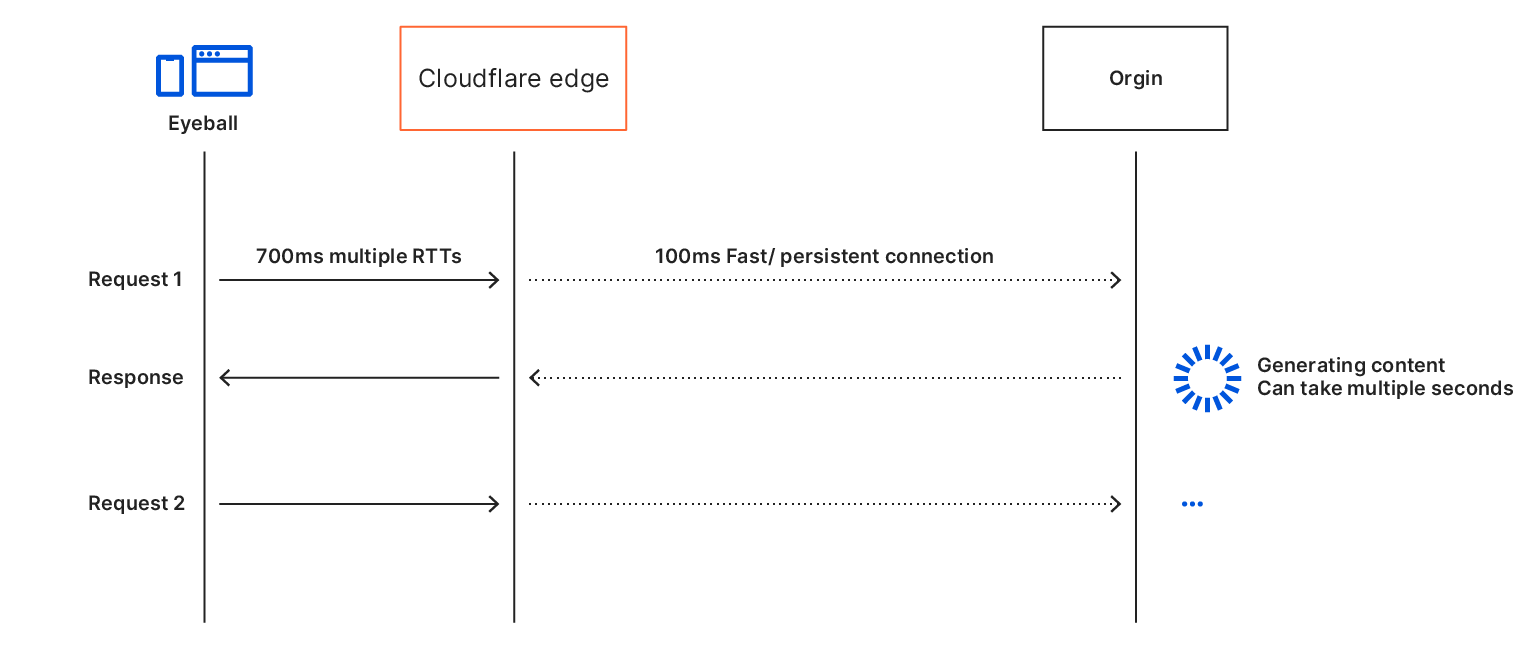
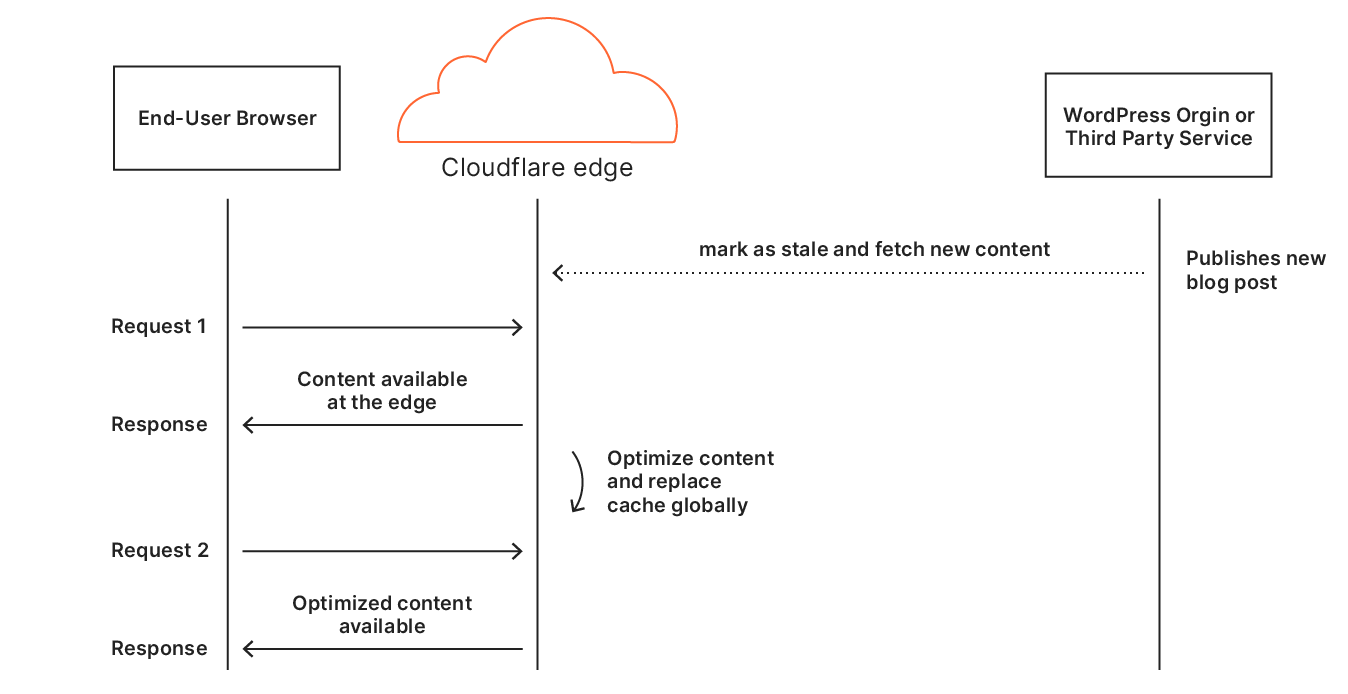
The same site visit but with APO enabled.
Once APO is enabled, all those trips to the origin are removed. TTFB benefits greatly because the first hop starts and ends at Cloudflare’s network. This also means the browser starts working on fetching and painting the webpage sooner meaning each paint event occurs earlier. Last by caching third party fonts, we remove additional requests that would need to leave Cloudflare’s network and extend the time to display text to the user. Often, websites use fonts hosted on third-party domains. While this saves bandwidth costs that would be incurred from hosting it on the origin, depending on where those fonts are hosted, it can still be a costly operation to fetch them. By rehosting the fonts and serving them from our cache, we can reduce one of the remaining costly round trips.
With APO for WordPress, you can say bye bye to database congestion or unwieldy plugins slowing down your customers’ experience. These benefits are stacked on top of our already fast TLS connection times and industry leading protocol support like HTTP/2 that ensure we are using the most efficient and the fastest way to connect and deliver your website to your customers.
For customers with WordPress sites that support authenticated sessions, you do not have to worry about us caching content from authenticated users and serving it to others. We bypass the cache on standard WordPress and WooCommerce cookies for authenticated users. This ensures customized content for a specific user is only visible to that user. While this has been available to customers with our Business-level service, it is now available for any WordPress customer that enables APO.
You might be wondering: “This all sounds great, but what about when I change content on my site?” Because this service works in tandem with our WordPress plugin, we are able to understand when you make changes and ensure we quickly purge the content in Cloudflare’s edge and refresh it with the new content. With the plugin installed, we detect content changes and update our edge network worldwide with automatic cache purges. As part of this release, we have updated our WordPress plugin, so whether or not you use APO, you should upgrade to the latest version today. If you do not or cannot use our WordPress plugin, then APO will still provide the same performance benefits, but may serve stale content for up to 30 minutes and when the content is requested again.
This service was built on the prototype work originally blogged about here and here. For a more in depth look at the technical side of the service and how Cloudflare Workers allowed us to build the Automatic Platform Optimization service, see the accompanying blog post.
WordPress Today, Other Platforms Coming Soon
While today’s announcement is focused on supporting WordPress, this is just the start. We plan to bring these same capabilities to other popular platforms used for web hosting. If you operate a platform and are interested in how we may be able to work together to improve things for all your customers, please get in touch. If you are running a website, let us know what platform you want to see us bring Automatic Platform Optimization to next.
This post explains how we implemented the Automatic Platform Optimization for WordPress. In doing so, we have defined a new place to run WordPress plugins, at the edge written with Cloudflare Workers. We provide the feature as a Cloudflare service but what’s exciting is that anyone could build this using the Workers platform.
The service is an evolution of the ideas explained in an earlier zero-config edge caching of HTML blog post. The post will explain how Automatic Platform Optimization combines the best qualities of the regular Cloudflare cache with Workers KV to improve cache cold starts globally.
The optimization will work both with and without the Cloudflare for WordPress plugin integration. Not only have we provided a zero config edge HTML caching solution but by using the Workers platform we were also able to improve the performance of Google font loading for all pages.
We are launching the feature first for WordPress specifically but the concept can be applied to any website and/or content management system (CMS).
A new place to run WordPress plugins?
There are many individual WordPress plugins for performance that use similar optimizations to existing Cloudflare services. Automatic Platform Optimization is bringing them all together into one easy to use solution, deployed at the edge.
Traditionally you have to maintain server plugins with your WordPress installation. This comes with maintenance costs and can require a deep understanding of how to fine tune performance and security for each and every plugin. Providing the optimizations on the client side can also lead to performance problems due to the costs of JavaScript execution. In contrast most of the optimizations could be built-in in Cloudflare’s edge rather than running on the server or the client. Automatic Platform Optimization will be always up to date with the latest performance and security best practices.
How to optimize for WordPress
By default Cloudflare CDN caches assets based on file extension and doesn’t cache HTML content. It is possible to configure HTML caching with a Cache Everything Page rule but it is a manual process and often requires additional features only available on the Business and Enterprise plans. So for the majority of the WordPress websites even with a CDN in front them, HTML content is not cached. Requests for a HTML document have to go all the way to the origin.
Even if a CDN optimizes the connection between the closest edge and the website’s origin, the origin could be located far away and also be slow to respond, especially under load.
Move content closer to the user
One of the primary recommendations for speeding up websites is to move content closer to the end-user. This reduces the amount of time it takes for packets to travel between the end-user and the web server – the round-trip time (RTT). This improves the speed of establishing a connection as well as serving content from a closer location.
We have previously blogged about the benefits of edge caching HTML. Caching and serving from HTML from the Cloudflare edge will greatly improve the time to first byte (TTFB) by optimizing DNS, connection setup, SSL negotiation, and removing the origin server response time.If your origin is slow in generating HTML and/or your user is far from the origin server then all your performance metrics will be affected.
Most HTML isn’t really dynamic. It needs to be able to change relatively quickly when the site is updated but for a huge portion of the web, the content is static for months or years at a time. There are special cases like when a user is logged-in (as the admin or otherwise) where the content needs to differ but the vast majority of visits are of anonymous users.
Zero config edge caching revisited
The goal is to make updating content to the edge happen automatically. The edge will cache and serve the previous version content until there is new content available. This is usually achieved by triggering a cache purge to remove existing content. In fact using a combination of our WordPress plugin and Cloudflare cache purge API, we already support Automatic Cache Purge on Website Updates. This feature has been in use for many years.
Building automatic HTML edge caching is more nuanced than caching traditional static content like images, styles or scripts. It requires defining rules on what to cache and when to update the content. To help with that task we introduced a custom header to communicate caching rules between Cloudflare edge and origin servers.
The Cloudflare Worker runs from every edge data center, the serverless platform will take care of scaling to our needs. Based on the request type it will return HTML content from Cloudflare Cache using Worker’s Cache API or serve a response directly from the origin. Specifically designed custom header provides information from the origin on how the script should handle the response. For example worker script will never cache responses for authenticated users.
HTML Caching rules
With or without Cloudflare for WordPress plugin, HTML edge caching requires all of the following conditions to be met:
Origin responds with 200 status
Origin responds with "text/html" content type
Request method is GET.
Request path doesn’t contain query strings
Request doesn’t contain any WordPress specific cookies: "wp-*", "wordpress*", "comment_*", "woocommerce_*" unless it’s "wordpress_eli" or "wordpress_test_cookie".
Request doesn’t contain any of the following headers:
"Cache-Control: no-cache"
"Cache-Control: private"
"Pragma:no-cache"
"Vary: *"
Note that the caching is bypassed if the devtools are open and the “Disable cache” option is active.
Bypass HTML caching based on presence of WordPress specific cookies
Decrease load on origin servers. If a request is fetched from Cloudflare CDN Cache we skip the request to the origin server.
How is this implemented?
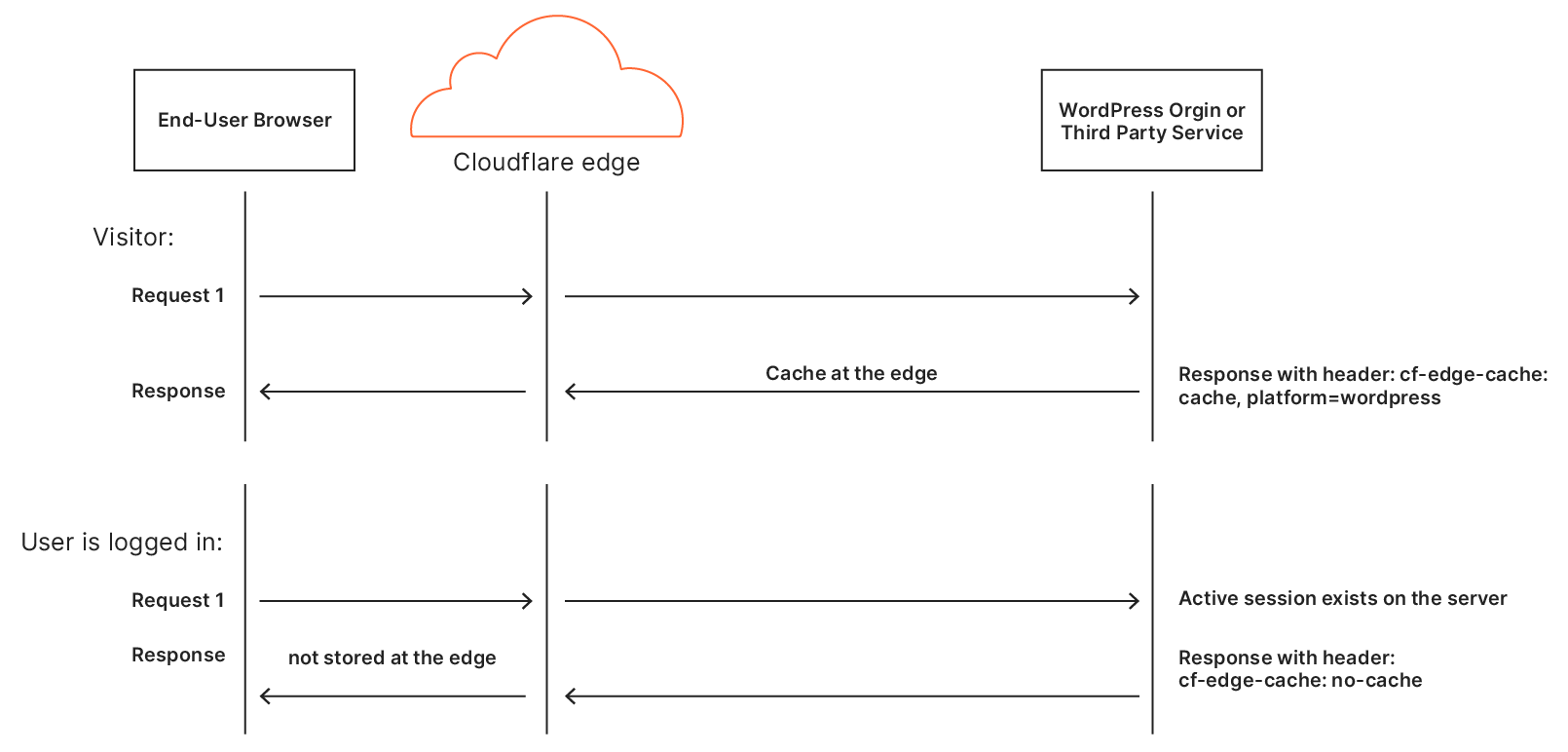
When an eyeball requests a page from a website and Cloudflare doesn’t have a copy of the content it will be fetched from the origin. As the response is sent from the origin and goes through Cloudflare’s edge, Cloudflare for WordPress plugin adds a custom header: cf-edge-cache. It allows an origin to configure caching rules applied on responses.
Based on the X-HTML-Edge-Cache proposal the plugin adds a cf-edge-cache header to every origin response. There are 2 possible values:
cf-edge-cache: no-cache
The page contains private information that shouldn’t be cached by the edge. For example, an active session exists on the server.
cf-edge-cache: cache, platform=wordpress
This combination of cache and platform will ensure that the HTML page is cached. In addition, we ran a number of checks against the presence of WordPress specific cookies to make sure we either bypass or allow caching on the Edge.
If the header isn’t present we assume that the Cloudflare for WordPress plugin is not installed or up-to-date. In this case the feature operates without a plugin support.
Edge caching without plugin
Using the Automatic Platform Optimization feature in combination with Cloudflare for WordPress plugin is our recommended solution. It provides the best feature set together with almost instant cache invalidation. Still, we wanted to provide performance improvements without the need for any installation on the origin server.
We provide the following features set when the plugin is not activated:
HTML edge caching with 30 days TTL
Cache invalidation may take up to 30 minutes. A manual cache purge could be triggered to speed up cache invalidation
Bypass HTML caching based on presence of WordPress specific cookies
No decreased load on origin servers. If a request is fetched from Cloudflare CDN Cache we still require an origin response to apply cache invalidation logic.
Without Cloudflare for WordPress plugin we still cache HTML on the edge and serve the content from the cache when possible. The logic of cache revalidation happens after serving the response to the eyeball. Worker’s waitUntil() callback allows the user to run code without affecting the response to the eyeball and is run in background.
We rely on the following headers to detect whether the content is stale and requires cache update:
ETag. If the cached version and origin response both include ETag and they are different we replace cached version with origin response. The behavior is the same for strong and weak ETag values.
Last-Modified. If the cached version and origin response both include Last-Modified and origin has a later Last-Modified date we replace cached version with origin response.
Date. If no ETag or Last-Modified header is available we compare cached version and origin response Date values. If there was more than a 30 minutes difference we replace cached version with origin response.
Getting content everywhere
Cloudflare Cache works great for the frequently requested content. Regular requests to the site make sure the content stays in cache. For a typical personal blog, it will be more common that the content stays in cache only in some parts of our vast edge network. With the Automatic Platform Optimization release we wanted to improve loading time for cache cold start from any location in the world. We explored different approaches and decided to use Workers KV to improve Edge Caching.
In addition to Cloudflare’s CDN cache we put the content into Workers KV. It only requires a single request to the page to cache it and within a minute it is made available to be read back from KV from any Cloudflare data center.
Updating content
After an update has been made to the WordPress website the plugin makes a request to Cloudflare’s API which both purges cache and marks content as stale in KV. The next request for the asset will trigger revalidation of the content. If the plugin is not enabled cache revalidation logic is triggered as detailed previously.
We serve the stale copy of the content still present in KV and asynchronously fetch new content from the origin, apply possible optimizations and then cache it (both regular local CDN cache and globally in KV).
To store the content in KV we use a single namespace. It’s keyed with a combination of a zone identifier and the URL. For instance:
For marking content as stale in KV we write a new key which will be read from the edge. If the key is present we will revalidate the content.
stale:1:example.com/blog-post-1.html => ""
Once the content was revalidated the stale marker key is deleted.
Moving optimizations to the edge
On top of caching HTML at the edge, we can pre-process and transform the HTML to make the loading of websites even faster for the user. Moving the development of this feature to our Cloudflare Workers environment makes it easy to add performance features such as improving Google Font loading. Using Google Fonts can cause significant performance issues as to load a font requires loading the HTML page; then loading a CSS file and finally loading the font. All of these steps are using different domains.
The solution is for the worker to inline the CSS and serve the font directly from the edge minimizing the number of connections required.
If you read through the previous blog post’s implementation it required a lot of manual work to provide streaming HTML processing support and character encodings. As the set of worker APIs have improved over time it is now much simpler to implement. Specifically the addition of a streaming HTML rewriter/parser with CSS-selector based API and the ability to suspend the parsing to asynchronously fetch a resource has reduced the code required to implement this from ~600 lines of source code to under 200.
The HTML transformation doesn’t block the response to the user. It’s running as a background task which when complete will update kv and replace the global cached version.
Making edge publishing generic
We are launching the feature for WordPress specifically but the concept can be applied to any website and content management system (CMS).
Cloudflare powers cdnjs, an open-source project that accelerates websites by delivering popular JavaScript libraries and resources via Cloudflare’s network. Since our major update in December, we focused on remodelling cdnjs for scalability and resilience. Today, we are excited to announce how Cloudflare delivers cdnjs—a migration to a serverless infrastructure using Cloudflare Workers and its distributed key-value store Workers KV!
What is cdnjs and why do I care?
For those unfamiliar, cdnjs is an acronym describing a Content Delivery Network (CDN) for JavaScript (JS). A CDN simply refers to a geographically distributed network of servers that provide Internet content, whether it is memes, cat videos, or HTML pages. In our case, the CDN refers to Cloudflare’s ever expanding network of over 200 globally distributed data centers.
And here’s why this is relevant to you: it makes page load times lightning-fast. Virtually every website you visit needs to fetch JS libraries in order to load, including this one. Let’s say you visit a Sydney-based website that contains a local file from jQuery, a popular library found in 76.2% of websites. If you are located in New York, you may notice a delay, as it can easily exceed 300ms to fetch the file—not to mention the time it takes for the round trips involved with the TLS handshake. However, if the website references jQuery using cdnjs.cloudflare.com, you can retrieve the file from the closest Cloudflare data center in Buffalo, reducing the latency to a blazing 20ms.
While cdnjs operates behind the scenes, it is used by over 11% of websites, making the Internet a much faster and more reliable place. In July, cdnjs served almost 190 billion requests—an enormous 3.46PB of data.
Where are the files stored?
While cdnjs speeds up the Internet, it certainly isn’t magic!
Historically, a number of load-balanced machines at one of Cloudflare’s core data centers would periodically pull cdnjs files from a backing store, acting as the origin for cdnjs.cloudflare.com. When a new file is requested, it is cached by Cloudflare, allowing it to be fetched quickly from any of our data centers.
The backing store is a catalogue of JS, CSS, and other web libraries in the form of an open-source GitHub repository. What this means is that anyone—including you—can contribute to it, subject to review and other processes.
However, until recently, these existing operations were very labor intensive and fragile.
This blog post will explain why we changed the infrastructure behind cdnjs to make it faster, more reliable, and easier to maintain. First, we will discuss how the community used to contribute to cdnjs, outlining the pains and concerns of the old system. Then, we will explore the benefits of migrating to Workers KV. After, we will dive into the new architecture, as well as upgrades to the website and cdnjs API. Finally, we will review the history of cdnjs, and where it is headed in the future.
If you think you know how to make a PR, think again
For the non-technical reader, a pull request (PR) is a request to merge changes you’ve made to a repository. Traditionally, if you wanted to include your JavaScript library in cdnjs, you would first create a PR on GitHub to cdnjs/cdnjs with a JSON file describing your package and additional files for any version you wished to include. Once your PR was approved by our old bot, manually reviewed, and then merged by a maintainer, your package would be integrated with cdnjs.
Sounds easy, right? You can just fork the repo, clone it, and copy paste a few files, no?
Exactly. Contributing was easy if you had several hours to burn, a case-sensitive file system, and a couple hundred gigabytes of free disk space to git clone the 300GB repo. If you were short on time—no problem, you could always use your advanced knowledge of git sparse-checkout to get the job done. Don’t know git? Just add one file at a time manually through GitHub’s UI.
I think you get the point. I know I certainly did when I naively spent 10 hours cloning the repo, only to discover that macOS is case-insensitive by default.
However, updating cdnjs was not only difficult for the contributors, but also the maintainers. Historically, the community was able to contribute version files directly, which could potentially be malicious. This created lots of work for maintainers, requiring them to inspect each file manually, diffing files against the official library source and running malware checks. So how did packages update once they were in cdnjs? In the JSON file describing each package, there was an optional auto-update definition telling the bot where to look for new versions of the library. If present, when your package released a new version from npm or GitHub, the bot would download it, pushing the files to cdnjs/cdnjs and computed Subresource Integrity (SRI) hashes to cdnjs/SRIs. If the auto-update property was missing, it would be your responsibility to make manual PRs to update cdnjs with any future versions.
A wake-up call for cdnjs
In April, during maintenance at one of our core data centers, a technician accidentally disconnected the cables supplying all external connections to our other data centers, causing the data center to go offline for approximately four hours. This incident served as the first wake-up call for cdnjs, especially since the affected data center housed the primary cdnjs origin web servers. In this case, we did have a backup running on an external provider, but what really saved us was Cloudflare’s global cache, which minimized the impact of the outage as only uncached assets failed to load.
We started to think about how we can improve both the reliability and performance of how we serve cdnjs. We went straight to Cloudflare Workers, our own platform for developing on the edge. One powerful tool built into Workers is Workers KV—a low-latency, globally distributed key-value store optimized for high-read applications.
We put two and two together, realizing that instead of pulling the cdnjs/cdnjs repository and serving files from disk, we could cut the physical machines out entirely, distributing the data around the world and serving files straight from the edge. That way, cdnjs would be able to recover from any origin data center failure, while also increasing its scalability.
Workers KV to the rescue
At first glance, the decision to use Workers KV was a no-brainer. Since files in cdnjs never change but require frequent reads, Workers KV was a perfect fit.
However, as we planned our migration, we became concerned that with over 7 million assets in cdnjs, there would undoubtedly exist files that exceed Workers KV’s 10MiB value limit. After investigating, we discovered that several hundred cdnjs files were oversized, the majority being JavaScript Source Maps.
Then the idea hit us. We could store compressed versions of cdnjs files in Workers KV, not only solving our oversized file issue, but also optimizing how we serve files.
If you pay the Internet bill, you’ll know that bandwidth is expensive! For this reason, all modern browsers will try to fetch compressed web content whenever it is available. Similarly, within Cloudflare we often experiment with on-the-fly compression to reduce our bandwidth, always serving compressed content to the eyeball when it is accepted. As a result, we decided to compress all cdnjs files ahead of time, writing them to Workers KV with both optimal Brotli and gzip forms. That way, we could increase the compression level compared to on-the-fly compression as we no longer have the latency requirements.
This means we now serve cdnjs files faster and smaller!
A complete makeover for cdnjs
Today, if you want to include your JavaScript library in cdnjs, you first create a PR on GitHub to our new repository cdnjs/packages. The repo is easily cloneable at 50MB and consists of thousands of JSON files, each describing a cdnjs package and how it is auto-updated from npm or git. Once your file is validated by our automated CI—powered by a new bot—and merged by a maintainer, your package would be automatically enrolled in our auto-update service.
In the new system, security and maintainability are prioritized. For starters, cdnjs version files arecreated by our bot, minimizing the possibility of human error when merging a new version. While the JSON files in cdnjs/packages are added by error-prone humans, they are inspected by our bot before being approved by a maintainer. Each file is automatically validated against a JSON schema, as well as checked for popularity on npm or GitHub.
When the bot discovers a new release, it pushes Brotli and gzip-compressed versions of the files to a files namespace in Workers KV. With each entry, the bot writes some metadata in Workers KV for the ETag and Last-Modified HTTP headers. Similar to before, the bot also computes Subresource Integrity (SRI) hashes of the uncompressed files, but now pushes them instead to a SRIs namespace in Workers KV.
Then, when a new file is requested from cdnjs.cloudflare.com, a Cloudflare Worker will inspect the client’s Accept-Encoding header, fetching either the Brotli or gzip-compressed version with its ETag and Last-Modified metadata from Workers KV. As the compressed file travels back through Cloudflare, it is cached for future requests and uncompressed on-the-fly if needed.
At the moment, there are still a handful of files exceeding Workers KV’s size limit. Consequently, if the Cloudflare Worker fails to retrieve a file from Workers KV, it is fetched from the origin backed by the original git repo. In the coming months, we plan on gradually removing this infrastructure.
Scaling the website and API
Besides the core cdnjs infrastructure, many of its other components received upgrades as well!
On the cdnjs project’s homepage, you will be greeted by a slick new beta website built by Matt. Constructed with Vue and Nuxt, the beta website is powered entirely by the cdnjs API. As a result, it is always up-to-date with the latest package information and requires low resource usage to serve the site—which runs completely on the client-side after the first page load—helping us scale with cdnjs’s never-ending growth.
In fact, the cdnjs API also strengthened its scalability, benefitting from a serverless architecture close to the one we have seen with cdnjs and Workers KV.
Before migrating to Workers KV, the cdnjs API relied on a regularly scheduled process that involved generating about 300MB of metadata. The cdnjs API’s backend would then fetch this enormous “package.min.js” file into memory and use it to operate the API. If you are curious, the file is still being hosted here, but be warned—it may lag your browser! Similarly, file SRIs were pushed to cdnjs/SRIs, which was cloned by the API locally to serve SRI responses.
After all cdnjs files (within the permitted size limit) were moved to Workers KV, these legacy processes became unsustainable, requiring millions of reads and an unreasonable amount of time. Therefore, we decided to upload all metadata found into Workers KV. We split the metadata into four namespaces—one for package-level metadata, one for version-specific metadata, one containing aggregated metadata, and one for file SRIs.
Similar to cdnjs’s serverless design, a Cloudflare Worker sits on top of metadata.speedcdnjs.com, serving data from Workers KV using several public endpoints. Currently, the cdnjs API is fully integrated with these endpoints, which provide an elegant solution as cdnjs continues to scale.
Transparency and the future of cdnjs
Since its birth in January 2011, cdnjs has always been deeply rooted in transparency, deriving its strength from the community. Even when cdnjs exploded in size and its founders Ryan Kirkman and Thomas Davis teamed up with us in June 2011, the project remained entirely open-source on GitHub.
As the years passed, it became harder for the founders to stay active, heavily depending on the community for support. With a nearly nonexistent budget and little access to the repository, core cdnjs maintainers were challenged every day to keep the project alive.
However, as we remove our reliance on the legacy system and store files in Workers KV, there are concerns that cdnjs will become proprietary. Don’t worry, we are working hard to ensure that cdnjs remains as transparent and open-source as possible. To help the community audit updates to Workers KV, there is a new repository, cdnjs/logs, which is used by the bot to log all Workers KV-related events. Furthermore, anyone can validate the integrity of cdnjs files by fetching SRIs from the cdnjs API.
Conclusion
Overall, this past year has been a turbulent time for cdnjs, but all of its shortcomings have acted as red flags to help us build a better system. Most recently, we have mitigated the risks of depending on physical machines at a single location, migrating cdnjs to a serverless infrastructure where its files are stored in Workers KV.
Today, cdnjs is in good hands, and is not going away anytime soon. Shout out especially to the maintainers Sven and Matt for creating tons of momentum with the project, working on everything from scaling cdnjs to editing this post.
Moving forward, we are committed to making cdnjs as transparent as possible. As we continue to improve cdnjs, we will release more blog posts to keep the community up to date. If you are interested, please subscribe to our blog. After all, it is the community that makes cdnjs possible! A special thanks to our active GitHub contributors and members of the cdnjs Community Forum for sticking with us!
As the scale of Cloudflare’s edge network has grown, we sometimes reach the limits of parts of our architecture. About two years ago we realized that our existing solution for spreading load within our data centers could no longer meet our needs. We embarked on a project to deploy a Layer 4 Load Balancer, internally called Unimog, to improve the reliability and operational efficiency of our edge network. Unimog has now been deployed in production for over a year.
This post explains the problems Unimog solves and how it works. Unimog builds on techniques used in other Layer 4 Load Balancers, but there are many details of its implementation that are tailored to the needs of our edge network.
The role of Unimog in our edge network
Cloudflare operates an anycast network, meaning that our data centers in 200+ cities around the world serve the same IP addresses. For example, our own cloudflare.com website uses Cloudflare services, and one of its IP addresses is 104.17.175.85. All of our data centers will accept connections to that address and respond to HTTP requests. By the magic of Internet routing, when you visit cloudflare.com and your browser connects to 104.17.175.85, your connection will usually go to the closest (and therefore fastest) data center.
Inside those data centers are many servers. The number of servers in each varies greatly (the biggest data centers have a hundred times more servers than the smallest ones). The servers run the application services that implement our products (our caching, DNS, WAF, DDoS mitigation, Spectrum, WARP, etc). Within a single data center, any of the servers can handle a connection for any of our services on any of our anycast IP addresses. This uniformity keeps things simple and avoids bottlenecks.
But if any server within a data center can handle any connection, when a connection arrives from a browser or some other client, what controls which server it goes to? That’s the job of Unimog.
There are two main reasons why we need this control. The first is that we regularly move servers in and out of operation, and servers should only receive connections when they are in operation. For example, we sometimes remove a server from operation in order to perform maintenance on it. And sometimes servers are automatically removed from operation because health checks indicate that they are not functioning correctly.
The second reason concerns the management of the load on the servers (by load we mean the amount of computing work each one needs to do). If the load on a server exceeds the capacity of its hardware resources, then the quality of service to users will suffer. The performance experienced by users degrades as a server approaches saturation, and if a server becomes sufficiently overloaded, users may see errors. We also want to prevent servers being underloaded, which would reduce the value we get from our investment in hardware. So Unimog ensures that the load is spread across the servers in a data center. This general idea is called load balancing (balancing because the work has to be done somewhere, and so for the load on one server to go down, the load on some other server must go up).
Note that in this post, we’ll discuss how Cloudflare balances the load on its own servers in edge data centers. But load balancing is a requirement that occurs in many places in distributed computing systems. Cloudflare also has a Layer 7 Load Balancing product to allow our customers to balance load across their servers. And Cloudflare uses load balancing in other places internally.
Deploying Unimog led to a big improvement in our ability to balance the load on our servers in our edge data centers. Here’s a chart for one data center, showing the difference due to Unimog. Each line shows the processor utilization of an individual server (the colour of the lines indicates server model). The load on the servers varies during the day with the activity of users close to this data center.The white line marks the point when we enabled Unimog. You can see that after that point, the load on the servers became much more uniform. We saw similar results when we deployed Unimog to our other data centers.
How Unimog compares to other load balancers
There are a variety of techniques for load balancing. Unimog belongs to a category called Layer 4 Load Balancers (L4LBs). L4LBs direct packets on the network by inspecting information up to layer 4 of the OSI network model, which distinguishes them from the more common Layer 7 Load Balancers.
The advantage of L4LBs is their efficiency. They direct packets without processing the payload of those packets, so they avoid the overheads associated with higher level protocols. For any load balancer, it’s important that the resources consumed by the load balancer are low compared to the resources devoted to useful work. At Cloudflare, we already pay close attention to the efficient implementation of our services, and that sets a high bar for the load balancer that we put in front of those services.
The downside of L4LBs is that they can only control which connections go to which servers. They cannot modify the data going over the connection, which prevents them from participating in higher-level protocols like TLS, HTTP, etc. (in contrast, Layer 7 Load Balancers act as proxies, so they can modify data on the connection and participate in those higher-level protocols).
L4LBs are not new. They are mostly used at companies which have scaling needs that would be hard to meet with L7LBs alone. Google has published about Maglev, Facebook open-sourced Katran, and Github has open-sourced their GLB.
Unimog is the L4LB that Cloudflare has built to meet the needs of our edge network. It shares features with other L4LBs, and it is particularly strongly influenced by GLB. But there are some requirements that were not well-served by existing L4LBs, leading us to build our own:
Unimog is designed to run on the same general-purpose servers that provide application services, rather than requiring a separate tier of servers dedicated to load balancing.
It performs dynamic load balancing: measurements of server load are used to adjust the number of connections going to each server, in order to accurately balance load.
It supports long-lived connections that remain established for days.
Virtual IP addresses are managed as ranges (Cloudflare serves hundreds of thousands of IPv4 addresses on behalf of our customers, so it is impractical to configure these individually).
Unimog is tightly integrated with our existing DDoS mitigation system, and the implementation relies on the same XDP technology in the Linux kernel.
The rest of this post describes these features and the design and implementation choices that follow from them in more detail.
For Unimog to balance load, it’s not enough to send the same (or approximately the same) number of connections to each server, because the performance of our servers varies. We regularly update our server hardware, and we’re now on our 10th generation. Once we deploy a server, we keep it in service for as long as it is cost effective, and the lifetime of a server can be several years. It’s not unusual for a single data center to contain a mix of server models, due to expansion and upgrades over time. Processor performance has increased significantly across our server generations. So within a single data center, we need to send different numbers of connections to different servers to utilize the same percentage of their capacity.
It’s also not enough to give each server a fixed share of connections based on static estimates of their capacity. Not all connections consume the same amount of CPU. And there are other activities running on our servers and consuming CPU that are not directly driven by connections from clients. So in order to accurately balance load across servers, Unimog does dynamic load balancing: it takes regular measurements of the load on each of our servers, and uses a control loop that increases or decreases the number of connections going to each server so that their loads converge to an appropriate value.
Refresher: TCP connections
The relationship between TCP packets and connections is central to the operation of Unimog, so we’ll briefly describe that relationship.
(Unimog supports UDP as well as TCP, but for clarity most of this post will focus on the TCP support. We explain how UDP support differs towards the end.)
Here is the outline of a TCP packet:
The TCP connection that this packet belongs to is identified by the four labelled header fields, which span the IPv4/IPv6 (i.e. layer 3) and TCP (i.e. layer 4) headers: the source and destination addresses, and the source and destination ports. Collectively, these four fields are known as the 4-tuple. When we say the Unimog sends a connection to a server, we mean that all the packets with the 4-tuple identifying that connection are sent to that server.
A TCP connection is established via a three-way handshake between the client and the server handling that connection. Once a connection has been established, it is crucial that all the incoming packets for that connection go to that same server. If a TCP packet belonging to the connection is sent to a different server, it will signal the fact that it doesn’t know about the connection to the client with a TCP RST (reset) packet. Upon receiving this notification, the client terminates the connection, probably resulting in the user seeing an error. So a misdirected packet is much worse than a dropped packet. As usual, we consider the network to be unreliable, and it’s fine for occasional packets to be dropped. But even a single misdirected packet can lead to a broken connection.
Cloudflare handles a wide variety of connections on behalf of our customers. Many of these connections carry HTTP, and are typically short lived. But some HTTP connections are used for websockets, and can remain established for hours or days. Our Spectrum product supports arbitrary TCP connections. TCP connections can be terminated or stall for many reasons, and ideally all applications that use long-lived connections would be able to reconnect transparently, and applications would be designed to support such reconnections. But not all applications and protocols meet this ideal, so we strive to maintain long-lived connections. Unimog can maintain connections that last for many days.
Forwarding packets
The previous section described that the function of Unimog is to steer connections to servers. We’ll now explain how this is implemented.
To start with, let’s consider how one of our data centers might look without Unimog or any other load balancer. Here’s a conceptual view:
Packets arrive from the Internet, and pass through the router, which forwards them on to servers (in reality there is usually additional network infrastructure between the router and the servers, but it doesn’t play a significant role here so we’ll ignore it).
But is such a simple arrangement possible? Can the router spread traffic over servers without some kind of load balancer in between? Routers have a feature called ECMP (equal cost multipath) routing. Its original purpose is to allow traffic to be spread across multiple paths between two locations, but it is commonly repurposed to spread traffic across multiple servers within a data center. In fact, Cloudflare relied on ECMP alone to spread load across servers before we deployed Unimog. ECMP uses a hashing scheme to ensure that packets on a given connection use the same path (Unimog also employs a hashing scheme, so we’ll discuss how this can work in further detail below) . But ECMP is vulnerable to changes in the set of active servers, such as when servers go in and out of service. These changes cause rehashing events, which break connections to all the servers in an ECMP group. Also, routers impose limits on the sizes of ECMP groups, which means that a single ECMP group cannot cover all the servers in our larger edge data centers. Finally, ECMP does not allow us to do dynamic load balancing by adjusting the share of connections going to each server. These drawbacks mean that ECMP alone is not an effective approach.
Ideally, to overcome the drawbacks of ECMP, we could program the router with the appropriate logic to direct connections to servers in the way we want. But although programmable network data planes have been a hot research topic in recent years, commodity routers are still essentially fixed-function devices.
We can work around the limitations of routers by having the router send the packets to some load balancing servers, and then programming those load balancers to forward packets as we want. If the load balancers all act on packets in a consistent way, then it doesn’t matter which load balancer gets which packets from the router (so we can use ECMP to spread packets across the load balancers). That suggests an arrangement like this:
And indeed L4LBs are often deployed like this.
Instead, Unimog makes every server into a load balancer. The router can send any packet to any server, and that initial server will forward the packet to the right server for that connection:
We have two reasons to favour this arrangement:
First, in our edge network, we avoid specialised roles for servers. We run the same software stack on the servers in our edge network, providing all of our product features, whether DDoS attack prevention, website performance features, Cloudflare Workers, WARP, etc. This uniformity is key to the efficient operation of our edge network: we don’t have to manage how many load balancers we have within each of our data centers, because all of our servers act as load balancers.
The second reason relates to stopping attacks. Cloudflare’s edge network is the target of incessant attacks. Some of these attacks are volumetric – large packet floods which attempt to overwhelm the ability of our data centers to process network traffic from the Internet, and so impact our ability to service legitimate traffic. To successfully mitigate such attacks, it’s important to filter out attack packets as early as possible, minimising the resources they consume. This means that our attack mitigation system needs to occur before the forwarding done by Unimog. That mitigation system is called l4drop, and we’ve written about it before. l4drop and Unimog are closely integrated. Because l4drop runs on all of our servers, and because l4drop comes before Unimog, it’s natural for Unimog to run on all of our servers too.
XDP and xdpd
Unimog implements packet forwarding using a Linux kernel facility called XDP. XDP allows a program to be attached to a network interface, and the program gets run for every packet that arrives, before it is processed by the kernel’s main network stack. The XDP program returns an action code to tell the kernel what to do with the packet:
PASS: Pass the packet on to the kernel’s network stack for normal processing.
DROP: Drop the packet. This is the basis for l4drop.
TX: Transmit the packet back out of the network interface. The XDP program can modify the packet data before transmission. This action is the basis for Unimog forwarding.
XDP programs run within the kernel, making this an efficient approach even at high packet rates. XDP programs are expressed as eBPF bytecode, and run within an in-kernel virtual machine. Upon loading an XDP program, the kernel compiles its eBPF code into machine code. The kernel also verifies the program to check that it does not compromise security or stability. eBPF is not only used in the context of XDP: many recent Linux kernel innovations employ eBPF, as it provides a convenient and efficient way to extend the behaviour of the kernel.
XDP is much more convenient than alternative approaches to packet-level processing, particularly in our context where the servers involved also have many other tasks. We have continued to enhance Unimog since its initial deployment. Our deployment model for new versions of our Unimog XDP code is essentially the same as for userspace services, and we are able to deploy new versions on a weekly basis if needed. Also, established techniques for optimizing the performance of the Linux network stack provide good performance for XDP.
There are two main alternatives for efficient packet-level processing:
Kernel-bypass networking (such as DPDK), where a program in userspace manages a network interface (or some part of one) directly without the involvement of the kernel. This approach works best when servers can be dedicated to a network function (due to the need to dedicate processor or network interface hardware resources, and awkward integration with the normal kernel network stack; see our old post about this). But we avoid putting servers in specialised roles. (Github’s open-source GLB uses DPDK, and this is one of the main factors that made GLB unsuitable for us.)
Kernel modules, where code is added to the kernel to perform the necessary network functions. The Linux IPVS (IP Virtual Server) subsystem falls into this category. But developing, testing, and deploying kernel modules is cumbersome compared to XDP.
The following diagram shows an overview of our use of XDP. Both l4drop and Unimog are implemented by an XDP program. l4drop matches attack packets, and uses the DROP action to discard them. Unimog forwards packets, using the TX action to resend them. Packets that are not dropped or forwarded pass through to the normal Linux network stack. To support our elaborate use of XPD, we have developed the xdpd daemon which performs the necessary supervisory and support functions for our XDP programs.
Rather than a single XDP program, we have a chain of XDP programs that must be run for each packet (l4drop, Unimog, and others we have not covered here). One of the responsibilities of xdpd is to prepare these programs, and to make the appropriate system calls to load them and assemble the full chain.
Our XDP programs come from two sources. Some are developed in a conventional way: engineers write C code, our build system compiles it (with clang) to eBPF ELF files, and our release system deploys those files to our servers. Our Unimog XDP code works like this. In contrast, the l4drop XDP code is dynamically generated by xdpd based on information it receives from attack detection systems.
xdpd has many other duties to support our use of XDP:
XDP programs can be supplied with data using data structures called maps. xdpd populates the maps needed by our programs, based on information received from control planes.
Programs (for instance, our Unimog XDP program) may depend upon configuration values which are fixed while the program runs, but do not have universal values known at the time their C code was compiled. It would be possible to supply these values to the program via maps, but that would be inefficient (retrieving a value from a map requires a call to a helper function). So instead, xdpd will fix up the eBPF program to insert these constants before it is loaded.
Cloudflare carefully monitors the behaviour of all our software systems, and this includes our XDP programs: They emit metrics (via another use of maps), which xdpd exposes to our metrics and alerting system (prometheus).
When we deploy a new version of xdpd, it gracefully upgrades in such a way that there is no interruption to the operation of Unimog or l4drop.
Although the XDP programs are written in C, xdpd itself is written in Go. Much of its code is specific to Cloudflare. But in the course of developing xdpd, we have collaborated with Cilium to develop https://github.com/cilium/ebpf, an open source Go library that provides the operations needed by xdpd for manipulating and loading eBPF programs and related objects. We’re also collaborating with the Linux eBPF community to share our experience, and extend the core eBPF technology in ways that make features of xdpd obsolete.
In evaluating the performance of Unimog, our main concern is efficiency: that is, the resources consumed for load balancing relative to the resources used for customer-visible services. Our measurements show that Unimog costs less than 1% of the processor utilization, compared to a scenario where no load balancing is in use. Other L4LBs, intended to be used with servers dedicated to load balancing, may place more emphasis on maximum throughput of packets. Nonetheless, our experience with Unimog and XDP in general indicates that the throughput is more than adequate for our needs, even during large volumetric attacks.
Unimog is not the first L4LB to use XDP. In 2018, Facebook open sourced Katran, their XDP-based L4LB data plane. We considered the possibility of reusing code from Katran. But it would not have been worthwhile: the core C code needed to implement an XDP-based L4LB is relatively modest (about 1000 lines of C, both for Unimog and Katran). Furthermore, we had requirements that were not met by Katran, and we also needed to integrate with existing components and systems at Cloudflare (particularly l4drop). So very little of the code could have been reused as-is.
Encapsulation
As discussed as the start of this post, clients make connections to one of our edge data centers with a destination IP address that can be served by any one of our servers. These addresses that do not correspond to a specific server are known as virtual IPs (VIPs). When our Unimog XDP program forwards a packet destined to a VIP, it must replace that VIP address with the direct IP (DIP) of the appropriate server for the connection, so that when the packet is retransmitted it will reach that server. But it is not sufficient to overwrite the VIP in the packet headers with the DIP, as that would hide the original destination address from the server handling the connection (the original destination address is often needed to correctly handle the connection).
Instead, the packet must be encapsulated: Another set of packet headers is prepended to the packet, so that the original packet becomes the payload in this new packet. The DIP is then used as the destination address in the outer headers, but the addressing information in the headers of the original packet is preserved. The encapsulated packet is then retransmitted. Once it reaches the target server, it must be decapsulated: the outer headers are stripped off to yield the original packet as if it had arrived directly.
Encapsulation is a general concept in computer networking, and is used in a variety of contexts. The headers to be added to the packet by encapsulation are defined by an encapsulation format. Many different encapsulation formats have been defined within the industry, tailored to the requirements in specific contexts. Unimog uses a format called GUE (Generic UDP Encapsulation), in order to allow us to re-use the glb-redirect component from github’s GLB (glb-redirect is discussed below).
GUE is a relatively simple encapsulation format. It encapsulates within a UDP packet, placing a GUE-specific header between the outer IP/UDP headers and the payload packet to allow extension data to be carried (and we’ll see how Unimog takes advantage of this):
When an encapsulated packet arrives at a server, the encapsulation process must be reversed. This step is called decapsulation. The headers that were added during the encapsulation process are removed, leaving the original packet to be processed by the network stack as if it had arrived directly from the client.
An issue that can arise with encapsulation is hitting limits on the maximum packet size, because the encapsulation process makes packets larger. The de-facto maximum packet size on the Internet is 1500 bytes, and not coincidentally this is also the maximum packet size on ethernet networks. For Unimog, encapsulating a 1500-byte packet results in a 1536-byte packet. To allow for these enlarged encapsulated packets, we have enabled jumbo frames on the networks inside our data centers, so that the 1500-byte limit only applies to packets headed out to the Internet.
Forwarding logic
So far, we have described the technology used to implement the Unimog load balancer, but not how our Unimog XDP program selects the DIP address when forwarding a packet. This section describes the basic scheme. But as we’ll see, there is a problem, so then we’ll describe how this scheme is elaborated to solve that problem.
In outline, our Unimog XDP program processes each packet in the following way:
Determine whether the packet is destined for a VIP address. Not all of the packets arriving at a server are for VIP addresses. Other packets are passed through for normal handling by the kernel’s network stack. (xdpd obtains the VIP address ranges from the Unimog control plane.)
Determine the DIP for the server handling the packet’s connection.
Encapsulate the packet, and retransmit it to the DIP.
In step 2, note that all the load balancers must act consistently – when forwarding packets, they must all agree about which connections go to which servers. The rate of new connections arriving at a data center is large, so it’s not practical for load balancers to agree by communicating information about connections amongst themselves. Instead L4LBs adopt designs which allow the load balancers to reach consistent forwarding decisions independently. To do this, they rely on hashing schemes: Take the 4-tuple identifying the packet’s connection, put it through a hash function to obtain a key (the hash function ensures that these key values are uniformly distributed), then perform some kind of lookup into a data structure to turn the key into the DIP for the target server.
Unimog uses such a scheme, with a data structure that is simple compared to some other L4LBs. We call this data structure the forwarding table, and it consists of an array where each entry contains a DIP specifying the server target server for the relevant packets (we call these entries buckets). The forwarding table is generated by the Unimog control plane and broadcast to the load balancers (more on this below), so that it has the same contents on all load balancers.
To look up a packet’s key in the forwarding table, the low N bits from the key are used as the index for a bucket (the forwarding table is always a power-of-2 in size):
Note that this approach does not provide per-connection control – each bucket typically applies to many connections. All load balancers in a data center use the same forwarding table, so they all forward packets in a consistent manner. This means it doesn’t matter which packets are sent by the router to which servers, and so ECMP re-hashes are a non-issue. And because the forwarding table is immutable and simple in structure, lookups are fast.
Although the above description only discusses a single forwarding table, Unimog supports multiple forwarding tables, each one associated with a trafficset – the traffic destined for a particular service. Ranges of VIP addresses are associated with a trafficset. Each trafficset has its own configuration settings and forwarding tables. This gives us the flexibility to differentiate how Unimog behaves for different services.
Precise load balancing requires the ability to make fine adjustments to the number of connections arriving at each server. So we make the number of buckets in the forwarding table more than 100 times the number of servers. Our data centers can contain hundreds of servers, and so it is normal for a Unimog forwarding table to have tens of thousands of buckets. The DIP for a given server is repeated across many buckets in the forwarding table, and by increasing or decreasing the number of buckets that refer to a server, we can control the share of connections going to that server. Not all buckets will correspond to exactly the same number of connections at a given point in time (the properties of the hash function make this a statistical matter). But experience with Unimog has demonstrated that the relationship between the number of buckets and resulting server load is sufficiently strong to allow for good load balancing.
But as mentioned, there is a problem with this scheme as presented so far. Updating a forwarding table, and changing the DIPs in some buckets, would break connections that hash to those buckets (because packets on those connections would get forwarded to a different server after the update). But one of the requirements for Unimog is to allow us to change which servers get new connections without impacting the existing connections. For example, sometimes we want to drain the connections to a server, maintaining the existing connections to that server but not forwarding new connections to it, in the expectation that many of the existing connections will terminate of their own accord. The next section explains how we fix this scheme to allow such changes.
Maintaining established connections
To make changes to the forwarding table without breaking established connections, Unimog adopts the “daisy chaining” technique described in the paper Stateless Datacenter Load-balancing with Beamer.
To understand how the Beamer technique works, let’s look at what can go wrong when a forwarding table changes: imagine the forwarding table is updated so that a bucket which contained the DIP of server A now refers to server B. A packet that would formerly have been sent to A by the load balancers is now sent to B. If that packet initiates a new connection (it’s a TCP SYN packet), there’s no problem – server B will continue the three-way handshake to complete the new connection. On the other hand, if the packet belongs to a connection established before the change, then the TCP implementation of server B has no matching TCP socket, and so sends a RST back to the client, breaking the connection.
This explanation hints at a solution: the problem occurs when server B receives a forwarded packet that does not match a TCP socket. If we could change its behaviour in this case to forward the packet a second time to the DIP of server A, that would allow the connection to server A to be preserved. For this to work, server B needs to know the DIP for the bucket before the change.
To accomplish this, we extend the forwarding table so that each bucket has two slots, each containing the DIP for a server. The first slot contains the current DIP, which is used by the load balancer to forward packets as discussed (and here we refer to this forwarding as the first hop). The second slot preserves the previous DIP (if any), in order to allow the packet to be forwarded again on a second hop when necessary.
For example, imagine we have a forwarding table that refers to servers A, B, and C, and then it is updated to stop new connections going to server A, but maintaining established connections to server A. This is achieved by replacing server A’s DIP in the first slot of any buckets where it appears, but preserving it in the second slot:
In addition to extending the forwarding table, this approach requires a component on each server to forward packets on the second hop when necessary. This diagram shows where this redirector fits into the path a packet can take:
The redirector follows some simple logic to decide whether to process a packet locally on the first-hop server or to forward it on the second-hop server:
If the packet is a SYN packet, initiating a new connection, then it is always processed by the first-hop server. This ensures that new connections go to the first-hop server.
For other packets, the redirector checks whether the packet belongs to a connection with a corresponding TCP socket on the first-hop server. If so, it is processed by that server.
Otherwise, the packet has no corresponding TCP socket on the first-hop server. So it is forwarded on to the second-hop server to be processed there (in the expectation that it belongs to some connection established on the second-hop server that we wish to maintain).
In that last step, the redirector needs to know the DIP for the second hop. To avoid the need for the redirector to do forwarding table lookups, the second-hop DIP is placed into the encapsulated packet by the Unimog XDP program (which already does a forwarding table lookup, so it has easy access to this value). This second-hop DIP is carried in a GUE extension header, so that it is readily available to the redirector if it needs to forward the packet again.
This second hop, when necessary, does have a cost. But in our data centers, the fraction of forwarded packets that take the second hop is usually less than 1% (despite the significance of long-lived connections in our context). The result is that the practical overhead of the second hops is modest.
When we initially deployed Unimog, we adopted the glb-redirect iptables module from github’s GLB to serve as the redirector component. In fact, some implementation choices in Unimog, such as the use of GUE, were made in order to facilitate this re-use. glb-redirect worked well for us initially, but subsequently we wanted to enhance the redirector logic. glb-redirect is a custom Linux kernel module, and developing and deploying changes to kernel modules is more difficult for us than for eBPF-based components such as our XDP programs. This is not merely due to Cloudflare having invested more engineering effort in software infrastructure for eBPF; it also results from the more explicit boundary between the kernel and eBPF programs (for example, we are able to run the same eBPF programs on a range of kernel versions without recompilation). We wanted to achieve the same ease of development for the redirector as for our XDP programs.
To that end, we decided to write an eBPF replacement for glb-redirect. While the redirector could be implemented within XDP, like our load balancer, practical concerns led us to implement it as a TC classifier program instead (TC is the traffic control subsystem within the Linux network stack). A downside to XDP is that the packet contents prior to processing by the XDP program are not visible using conventional tools such as tcpdump, complicating debugging. TC classifiers do not have this downside, and in the context of the redirector, which passes most packets through, the performance advantages of XDP would not be significant.
The result is cls-redirect, a redirector implemented as a TC classifier program. We have contributed our cls-redirect code as part of the Linux kernel test suite. In addition to implementing the redirector logic, cls-redirect also implements decapsulation, removing the need to separately configure GUE tunnel endpoints for this purpose.
There are some features suggested in the Beamer paper that Unimog does not implement:
Beamer embeds generation numbers in the encapsulated packets to address a potential corner case where a ECMP rehash event occurs at the same time as a forwarding table update is propagating from the control plane to the load balancers. Given the combination of circumstances required for a connection to be impacted by this issue, we believe that in our context the number of affected connections is negligible, and so the added complexity of the generation numbers is not worthwhile.
In the Beamer paper, the concept of daisy-chaining encompasses third hops etc. to preserve connections across a series of changes to a bucket. Unimog only uses two hops (the first and second hops above), so in general it can only preserve connections across a single update to a bucket. But our experience is that even with only two hops, a careful strategy for updating the forwarding tables permits connection lifetimes of days.
To elaborate on this second point: when the control plane is updating the forwarding table, it often has some choice in which buckets to change, depending on the event that led to the update. For example, if a server is being brought into service, then some buckets must be assigned to it (by placing the DIP for the new server in the first slot of the bucket). But there is a choice about which buckets. A strategy of choosing the least-recently modified buckets will tend to minimise the impact to connections.
Furthermore, when updating the forwarding table to adjust the balance of load between servers, Unimog often uses a novel trick: due to the redirector logic, exchanging the first-hop and second-hop DIPs for a bucket only affects which server receives new connections for that bucket, and never impacts any established connections. Unimog is able to achieve load balancing in our edge data centers largely through forwarding table changes of this type.
Control plane
So far, we have discussed the Unimog data plane – the part that processes network packets. But much of the development effort on Unimog has been devoted to the control plane – the part that generates the forwarding tables used by the data plane. In order to correctly maintain the forwarding tables, the control plane consumes information from multiple sources:
Server information: Unimog needs to know the set of servers present in a data center, some key information about each one (such as their DIP addresses), and their operational status. It also needs signals about transitional states, such as when a server is being withdrawn from service, in order to gracefully drain connections (preventing the server from receiving new connections, while maintaining its established connections).
Health: Unimog should only send connections to servers that are able to correctly handle those connections, otherwise those servers should be removed from the forwarding tables. To ensure this, it needs health information at the node level (indicating that a server is available) and at the service level (indicating that a service is functioning normally on a server).
Load: in order to balance load, Unimog needs information about the resource utilization on each server.
IP address information: Cloudflare serves hundreds of thousands of IPv4 addresses, and these are something that we have to treat as a dynamic resource rather than something statically configured.
The control plane is implemented by a process called the conductor. In each of our edge data centers, there is one active conductor, but there are also standby instances that will take over if the active instance goes away.
We use Hashicorp’s Consul in a number of ways in the Unimog control plane (we have an independent Consul server cluster in each data center):
Consul provides a key-value store, with support for blocking queries so that changes to values can be received promptly. We use this to propagate the forwarding tables and VIP address information from the conductor to xdpd on the servers.
Consul provides server- and service-level health checks. We use this as the source of health information for Unimog.
The conductor stores its state in the Consul KV store, and uses Consul’s distributed locks to ensure that only one conductor instance is active.
The conductor obtains server load information from Prometheus, which we already use for metrics throughout our systems. It balances the load across the servers using a control loop, periodically adjusting the forwarding tables to send more connections to underloaded servers and less connections to overloaded servers. The load for a server is defined by a Prometheus metric expression which measures processor utilization (with some intricacies to better handle characteristics of our workloads). The determination of whether a server is underloaded or overloaded is based on comparison with the average value of the load metric, and the adjustments made to the forwarding table are proportional to the deviation from the average. So the result of the feedback loop is that the load metric for all servers converges on the average.
Finally, the conductor queries internal Cloudflare APIs to obtain the necessary information on servers and addresses.
Unimog is a critical system: incorrect, poorly adjusted or stale forwarding tables could cause incoming network traffic to a data center to be dropped, or servers to be overloaded, to the point that a data center would have to be removed from service. To maintain a high quality of service and minimise the overhead of managing our many edge data centers, we have to be able to upgrade all components. So to the greatest extent possible, all components are able to tolerate brief absences of the other components without any impact to service. In some cases this is possible through careful design. In other cases, it requires explicit handling. For example, we have found that Consul can temporarily report inaccurate health information for a server and its services when the Consul agent on that server is restarted (for example, in order to upgrade Consul). So we implemented the necessary logic in the conductor to detect and disregard these transient health changes.
Unimog also forms a complex system with feedback loops: The conductor reacts to its observations of behaviour of the servers, and the servers react to the control information they receive from the conductor. This can lead to behaviours of the overall system that are hard to anticipate or test for. For instance, not long after we deployed Unimog we encountered surprising behaviour when data centers became overloaded. This is of course a scenario that we strive to avoid, and we have automated systems to remove traffic from overloaded data centers if it does. But if a data center became sufficiently overloaded, then health information from its servers would indicate that many servers were degraded to the point that Unimog would stop sending new connections to those servers. Under normal circumstances, this is the correct reaction to a degraded server. But if enough servers become degraded, diverting new connections to other servers would mean those servers became degraded, while the original servers were able to recover. So it was possible for a data center that became temporarily overloaded to get stuck in a state where servers oscillated between healthy and degraded, even after the level of demand on the data center had returned to normal. To correct this issue, the conductor now has logic to distinguish between isolated degraded servers and such data center-wide problems. We have continued to improve Unimog in response to operational experience, ensuring that it behaves in a predictable manner over a wide range of conditions.
UDP Support
So far, we have described Unimog’s support for directing TCP connections. But Unimog also supports UDP traffic. UDP does not have explicit connections between clients and servers, so how it works depends upon how the UDP application exchanges packets between the client and server. There are a few cases of interest:
Request-response UDP applications
Some applications, such as DNS, use a simple request-response pattern: the client sends a request packet to the server, and expects a response packet in return. Here, there is nothing corresponding to a connection (the client only sends a single packet, so there is no requirement to make sure that multiple packets arrive at the same server). But Unimog can still provide value by spreading the requests across our servers.
To cater to this case, Unimog operates as described in previous sections, hashing the 4-tuple from the packet headers (the source and destination IP addresses and ports). But the Beamer daisy-chaining technique that allows connections to be maintained does not apply here, and so the buckets in the forwarding table only have a single slot.
UDP applications with flows
Some UDP applications have long-lived flows of packets between the client and server. Like TCP connections, these flows are identified by the 4-tuple. It is necessary that such flows go to the same server (even when Cloudflare is just passing a flow through to the origin server, it is convenient for detecting and mitigating certain kinds of attack to have that flow pass through a single server within one of Cloudflare’s data centers).
It’s possible to treat these flows by hashing the 4-tuple, skipping the Beamer daisy-chaining technique as for request-response applications. But then adding servers will cause some flows to change servers (this would effectively be a form of consistent hashing). For UDP applications, we can’t say in general what impact this has, as we can for TCP connections. But it’s possible that it causes some disruption, so it would be nice to avoid this.
So Unimog adapts the daisy-chaining technique to apply it to UDP flows. The outline remains similar to that for TCP: the same redirector component on each server decides whether to send a packet on a second hop. But UDP does not have anything corresponding to TCP’s SYN packet that indicates a new connection. So for UDP, the part that depends on SYNs is removed, and the logic applied for each packet becomes:
The redirector checks whether the packet belongs to a connection with a corresponding UDP socket on the first-hop server. If so, it is processed by that server.
Otherwise, the packet has no corresponding TCP socket on the first-hop server. So it is forwarded on to the second-hop server to be processed there (in the expectation that it belongs to some flow established on the second-hop server that we wish to maintain).
Although the change compared to the TCP logic is not large, it has the effect of switching the roles of the first- and second-hop servers: For UDP, new flows go to the second-hop server. The Unimog control plane has to take account of this when it updates a forwarding table. When it introduces a server into a bucket, that server should receive new connections or flows. For a TCP trafficset, this means it becomes the first-hop server. For UDP trafficset, it must become the second-hop server.
This difference between handling of TCP and UDP also leads to higher overheads for UDP. In the case of TCP, as new connections are formed and old connections terminate over time, fewer packets will require the second hop, and so the overhead tends to diminish. But with UDP, new connections always involve the second hop. This is why we differentiate the two cases, taking advantage of SYN packets in the TCP case.
The UDP logic also places a requirement on services. The redirector must be able to match packets to the corresponding sockets on a server according to their 4-tuple. This is not a problem in the TCP case, because all TCP connections are represented by connected sockets in the BSD sockets API (these sockets are obtained from an accept system call, so that they have a local address and a peer address, determining the 4-tuple). But for UDP, unconnected sockets (lacking a declared peer address) can be used to send and receive packets. So some UDP services only use unconnected sockets. For the redirector logic above to work, services must create connected UDP sockets in order to expose their flows to the redirector.
UDP applications with sessions
Some UDP-based protocols have explicit sessions, with a session identifier in each packet. Session identifiers allow sessions to persist even if the 4-tuple changes. This happens in mobility scenarios – for example, if a mobile device passes from a WiFi to a cellular network, causing its IP address to change. An example of a UDP-based protocol with session identifiers is QUIC (which calls them connection IDs).
Our Unimog XDP program allows a flow dissector to be configured for different trafficsets. The flow dissector is the part of the code that is responsible for taking a packet and extracting the value that identifies the flow or connection (this value is then hashed and used for the lookup into the forwarding table). For TCP and UDP, there are default flow dissectors that extract the 4-tuple. But specialised flow dissectors can be added to handle UDP-based protocols.
We have used this functionality in our WARP product. We extended the Wireguard protocol used by WARP in a backwards-compatible way to include a session identifier, and added a flow dissector to Unimog to exploit it. There are more details in our post on the technical challenges of WARP.
Conclusion
Unimog has been deployed to all of Cloudflare’s edge data centers for over a year, and it has become essential to our operations. Throughout that time, we have continued to enhance Unimog (many of the features described here were not present when it was first deployed). So the ease of developing and deploying changes, due to XDP and xdpd, has been a significant benefit. Today we continue to extend it, to support more services, and to help us manage our traffic and the load on our servers in more contexts.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.