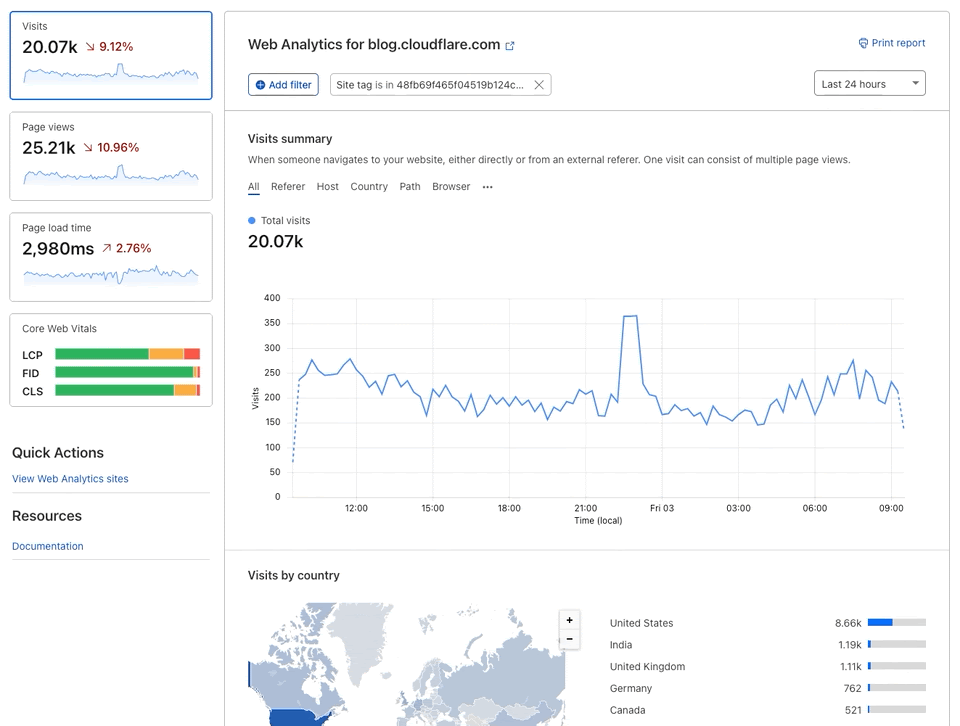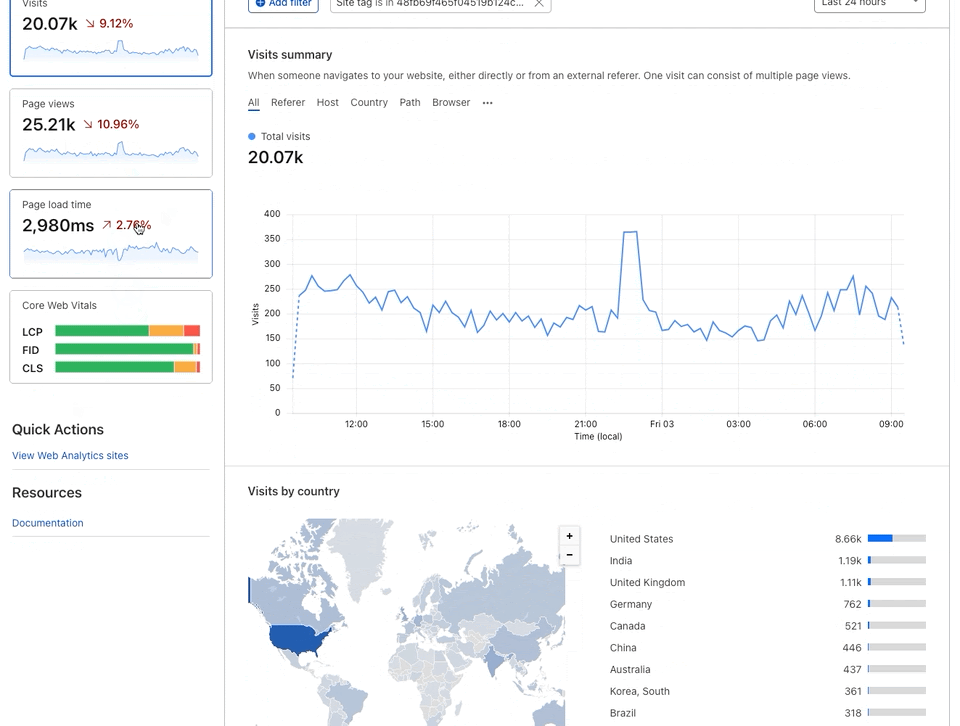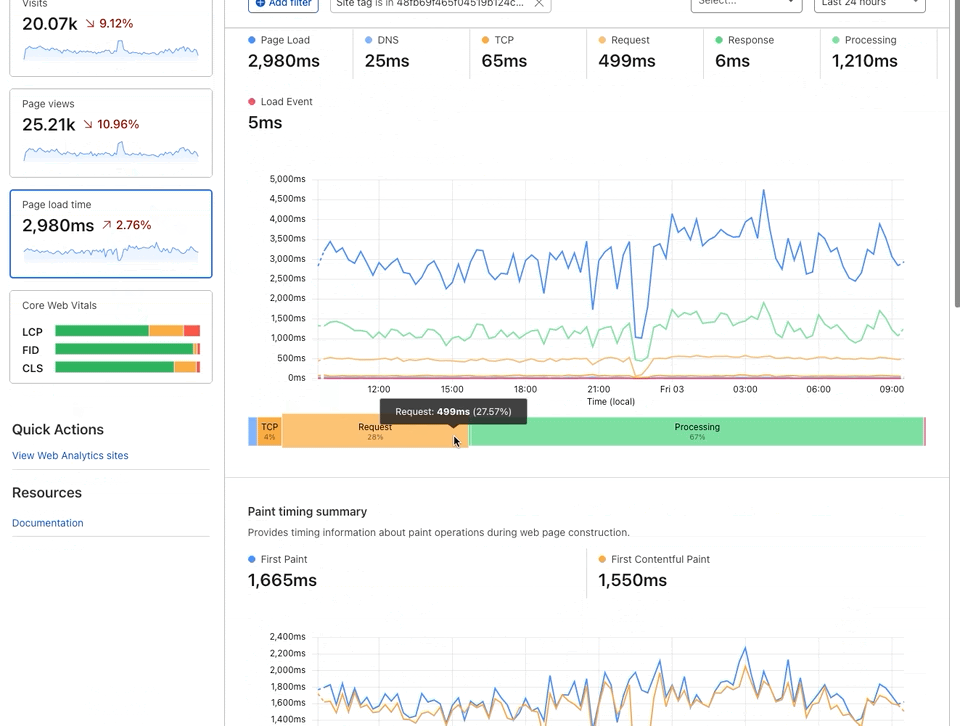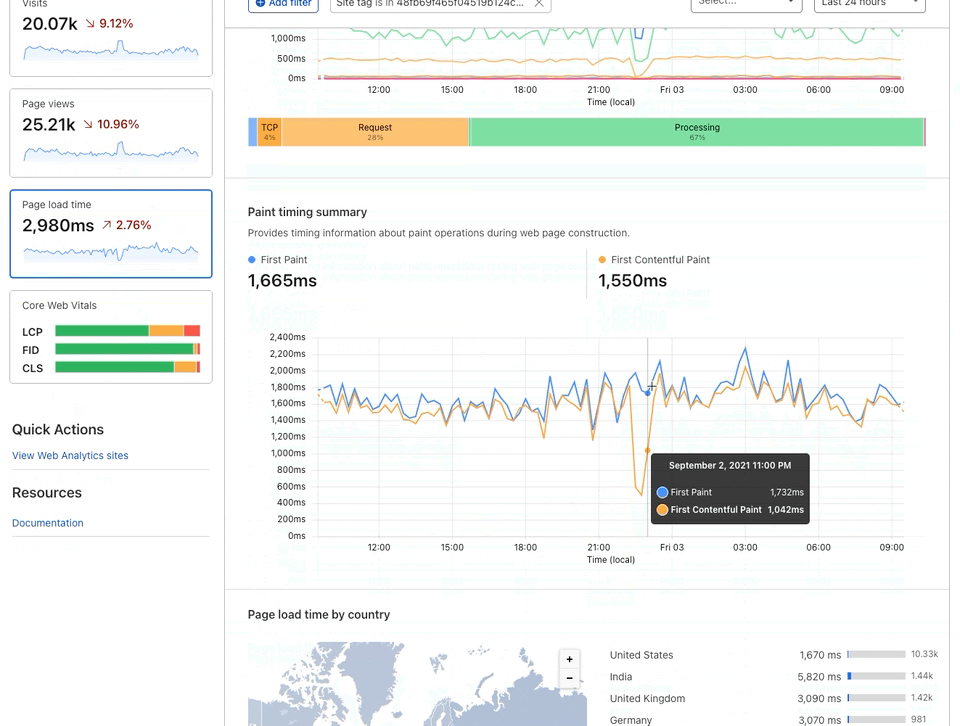
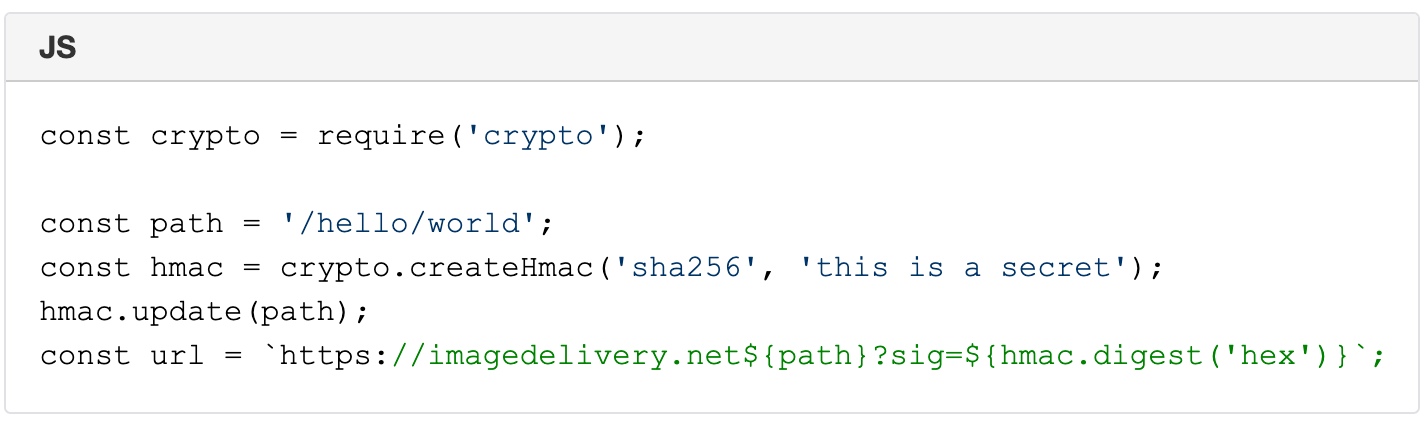
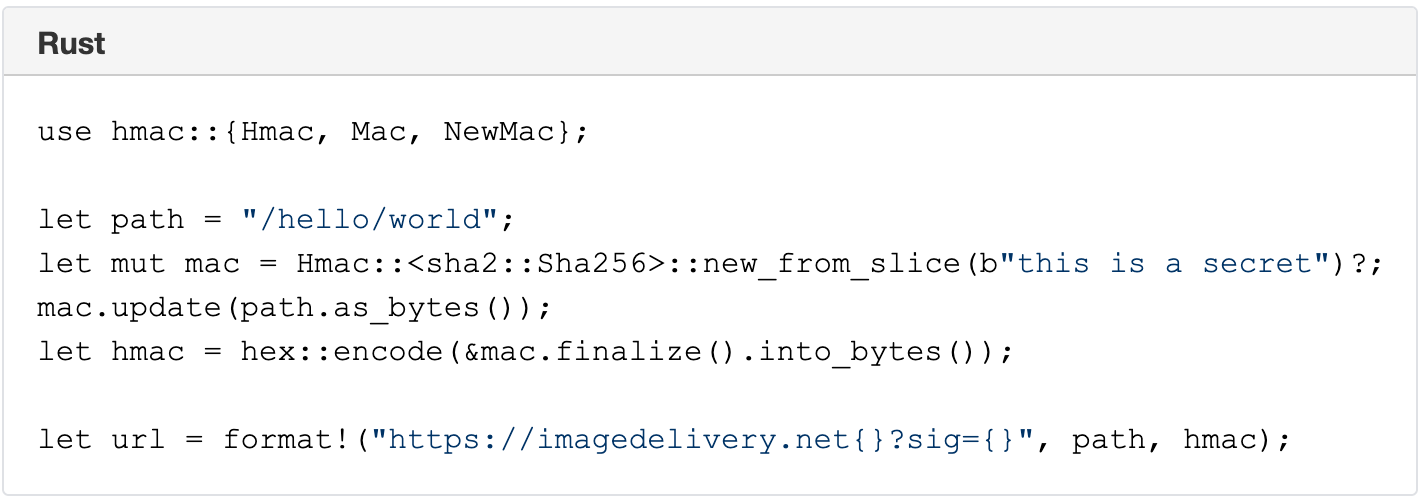
Earlier this month, Cloudflare’s systems automatically detected and mitigated a 15.3 million request-per-second (rps) DDoS attack — one of the largest HTTPS DDoS attacks on record.
While this isn’t the largest application-layer attack we’ve seen, it is the largest we’ve seen over HTTPS. HTTPS DDoS attacks are more expensive in terms of required computational resources because of the higher cost of establishing a secure TLS encrypted connection. Therefore it costs the attacker more to launch the attack, and for the victim to mitigate it. We’ve seen very large attacks in the past over (unencrypted) HTTP, but this attack stands out because of the resources it required at its scale.
The attack, lasting less than 15 seconds, targeted a Cloudflare customer on the Professional (Pro) plan operating a crypto launchpad. Crypto launchpads are used to surface Decentralized Finance projects to potential investors. The attack was launched by a botnet that we’ve been observing — we’ve already seen large attacks as high as 10M rps matching the same attack fingerprint.
Cloudflare customers are protected against this botnet and do not need to take any action.
The attack
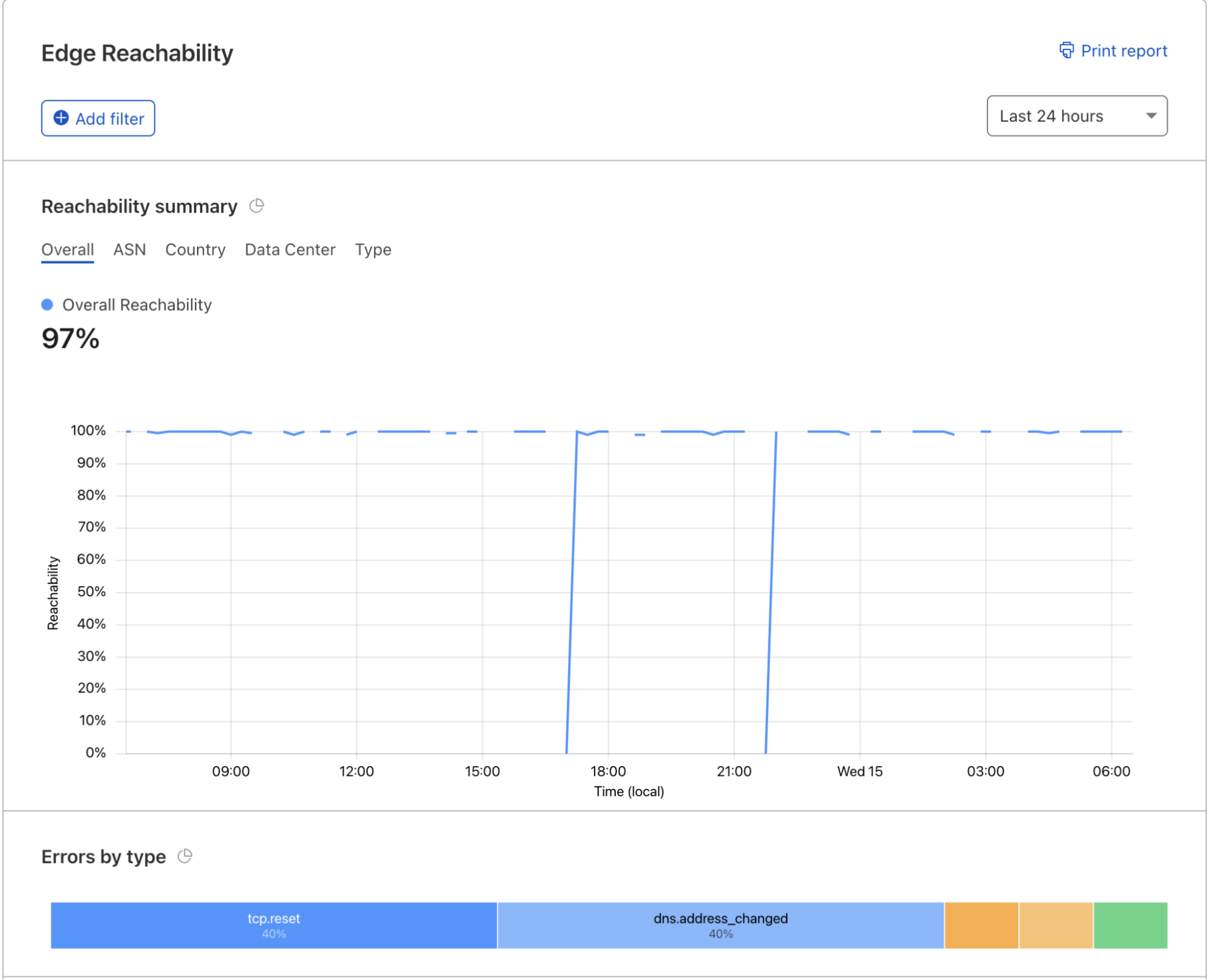
What’s interesting is that the attack mostly came from data centers. We’re seeing a big move from residential network Internet Service Providers (ISPs) to cloud compute ISPs.
This attack was launched from a botnet of approximately 6,000 unique bots. It originated from 112 countries around the world. Almost 15% of the attack traffic originated from Indonesia, followed by Russia, Brazil, India, Colombia, and the United States.
Within those countries, the attack originated from over 1,300 different networks. The top networks included the German provider Hetzner Online GmbH (Autonomous System Number 24940), Azteca Comunicaciones Colombia (ASN 262186), OVH in France (ASN 16276), as well as other cloud providers.
How this attack was automatically detected and mitigated
To defend organizations against DDoS attacks, we built and operate software-defined systems that run autonomously. They automatically detect and mitigate DDoS attacks across our entire network — and just as in this case, the attack was automatically detected and mitigated without any human intervention.
Our system starts by sampling traffic asynchronously; it then analyzes the samples and applies mitigations when needed.
Sampling
Initially, traffic is routed through the Internet via BGP Anycast to the nearest Cloudflare data centers that are located in over 250 cities around the world. Once the traffic reaches our data center, our DDoS systems sample it asynchronously allowing for out-of-path analysis of traffic without introducing latency penalties.
Analysis and mitigation
The analysis is done using data streaming algorithms. HTTP request samples are compared to conditional fingerprints, and multiple real-time signatures are created based on dynamic masking of various request fields and metadata. Each time another request matches one of the signatures, a counter is increased. When the activation threshold is reached for a given signature, a mitigation rule is compiled and pushed inline. The mitigation rule includes the real-time signature and the mitigation action, e.g. block.
Cloudflare customers can also customize the settings of the DDoS protection systems by tweaking the HTTP DDoS Managed Rules.
You can read more about our autonomous DDoS protection systems and how they work in our deep-dive technical blog post.
Helping build a better Internet
At Cloudflare, everything we do is guided by our mission to help build a better Internet. The DDoS team’s vision is derived from this mission: our goal is to make the impact of DDoS attacks a thing of the past. The level of protection that we offer is unmetered and unlimited — It is not bounded by the size of the attack, the number of the attacks, or the duration of the attacks. This is especially important these days because as we’ve recently seen, attacks are getting larger and more frequent.
Not using Cloudflare yet? Start now with our Free and Pro plans to protect your websites, or contact us for comprehensive DDoS protection for your entire network using Magic Transit.
In July 2021, as part of Impact Innovation Week, we announced our intention to launch Crawler Hints as a means to reduce the environmental impact of web searches. We spent the weeks following the announcement hard at work, and in October 2021, we announced General Availability for the first iteration of the product. This post explains how we built it, some of the interesting engineering problems we had to solve, and shares some metrics on how it’s going so far.
Before We Begin…
Search indexers crawl sites periodically to check for new content. Algorithms vary by search provider, but are often based on either a regular interval or cadence of past updates, and these crawls are often not aligned with real world content changes. This naive crawling approach may harm customer page rank and also works to the detriment of search engines with respect to their operational costs and environmental impact. To make the Internet greener and more energy efficient, the goal of Crawler Hints is to help search indexers make more informed decisions on when content has changed, saving valuable compute cycles/bandwidth and having a net positive environmental impact.
Cloudflare is in an advantageous position to help inform crawlers of content changes, as we are often the “front line” of the interface between site visitors and the origin server where the content updates take place. This grants us knowledge of some key data points like headers, content hashes, and site purges among others. For customers who have opted in to Crawler Hints, we leverage this data to generate a “content freshness score” using an ensemble of active and passive signals from our customer base and request flow. To help with efficiency, Crawler Hints helps to improve SEO for websites behind Cloudflare, improves relevance for search engine users, and improves origin responsiveness by reducing bot traffic to our customers’ origin servers.
A high level design of the system we built looks as follows:
In this blog we will dig into each aspect of it in more detail.
Keeping Things Fresh
Cloudflare has a large global network spanning 250 cities. A popular use case for Cloudflare is to use our CDN product to cache your website’s assets so that users accessing your site can benefit from lightning fast response times. You can read more about how Cloudflare manages our cache here. The important thing to call out for the purpose of this post is that the cache is Data Center local. A cache hit in London might be a cache miss in San Francisco unless you have opted-in to tiered-caching, but that is beyond the scope of this post.
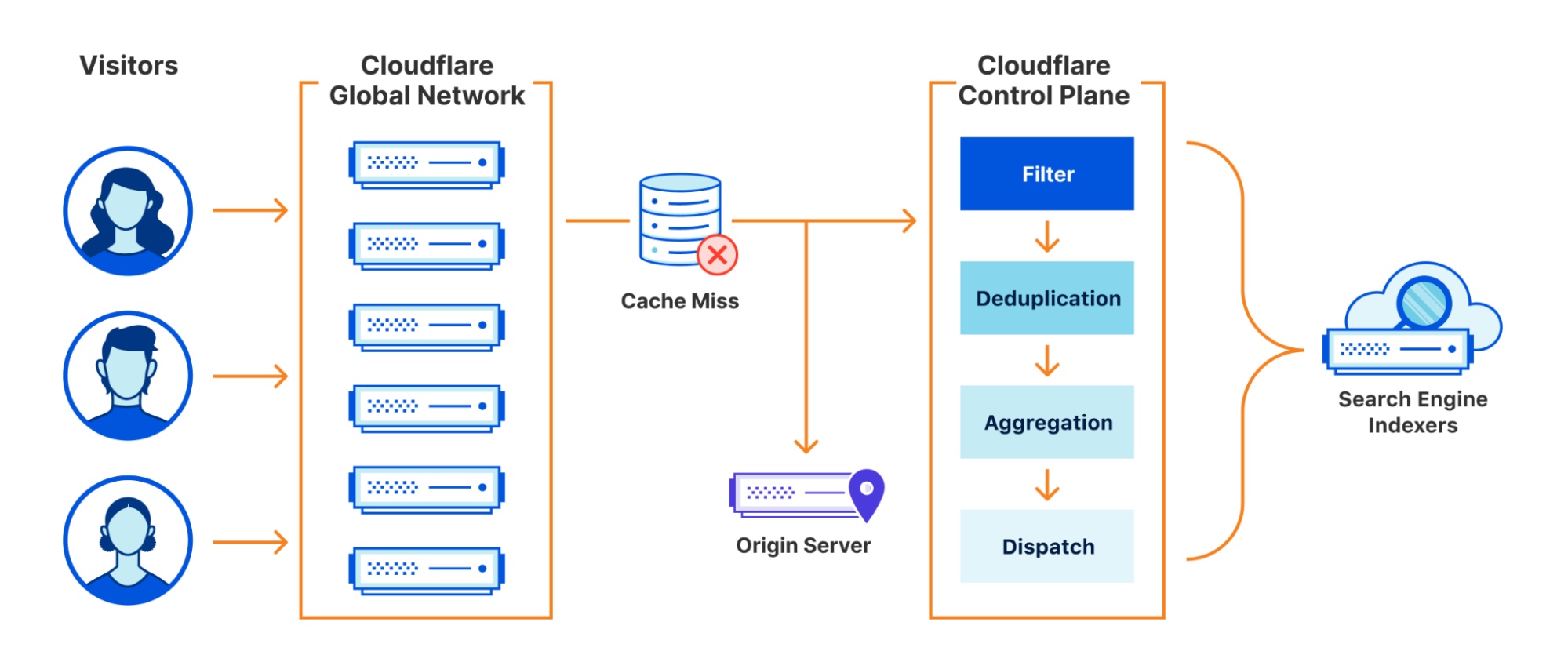
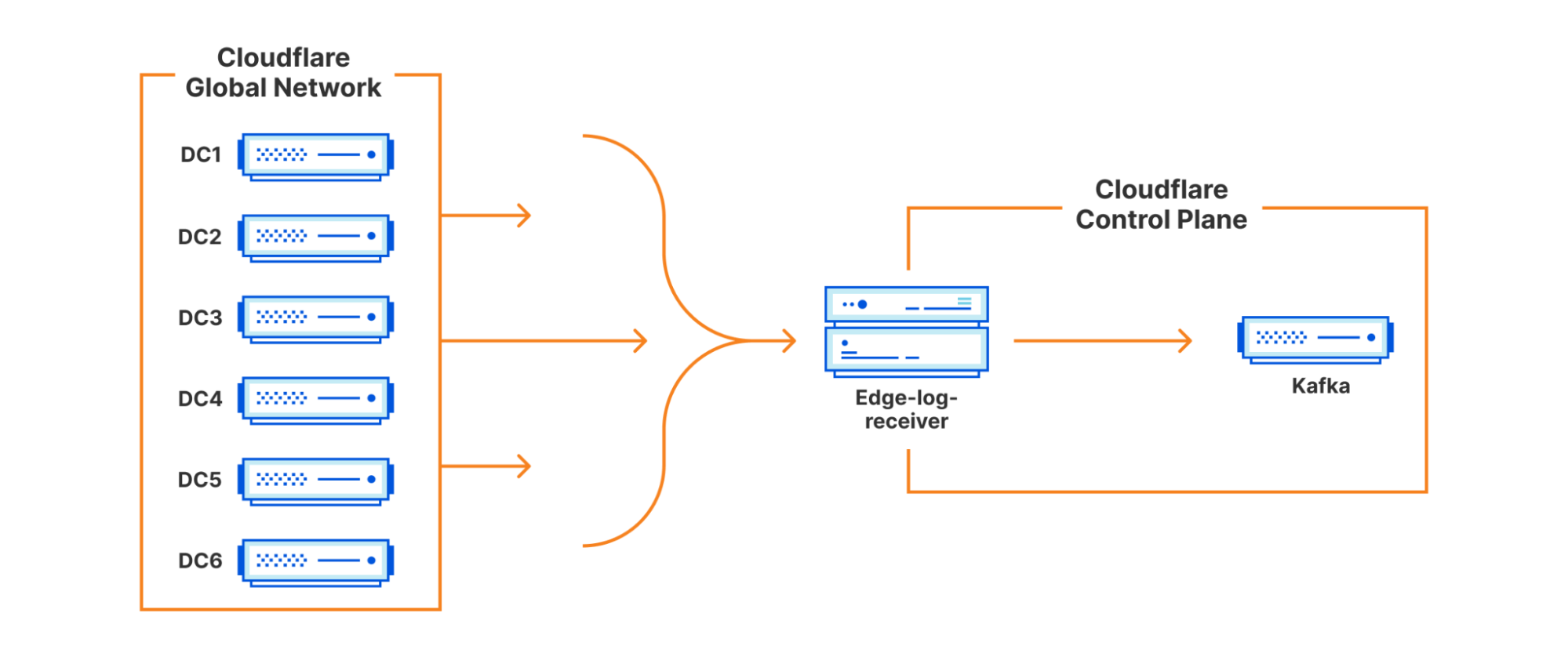
For Crawler Hints to work, we make use of a number of signals available at request time to make an informed decision on the “freshness” of content. For our first iteration of Crawler Hints, we used a cache miss from Cloudflare’s cache as a starting basis. Although a naive signal on its own, getting the data pipelines in place to forward cache miss data from our global network to our control plane meant we would have everything in place to iterate on and improve the signal processing quickly going forward. To do this, we leveraged some existing services from our data team that takes request data , marshalls it into Cap’n Proto format, and forwards it to a message bus (we use apache Kafka). These messages include the URLs of the resources that have met the signal criteria, along with some additional metadata for analytics/future improvement.
The amount of traffic our global network receives is substantial. We serve over 28 million HTTP requests per second on average, with more than 35 million HTTP requests per second at peak. Typically, Cloudflare teams sample this data to enable products such as being alerted when you are under attack. For Crawler Hints, every cache miss is important. Therefore, 100% of all cache misses for opted-in sites were sent for further processing, and we’ll discuss more on opt-in later.
Redis as a Distributed Buffer
With messages buffered in Kafka, we can now begin the work of aggregation and deduplication. We wrote a consumer service that we call an ingestor. The ingestor reads the data from Kafka. The ingestor performs validation to ensure proper sanitization and data integrity and passes this data onto the next stage of the system. We run the ingestor as part of a Kafka consumer group, allowing us to scale our consumer count up to the partition size as throughput increases.
We ultimately want to deliver a set of “fresh” content to our search partners on a dynamic interval. For example, we might want to send a batch of 10,000 URLs every two minutes. There are, however, a couple of important things to call out though:
There should be no duplicate resources in each batch.
We should strike a balance in our size and frequency such that overall request size isn’t too large, but big enough to remove some pressure on the receiving API by not sending too many requests at once.
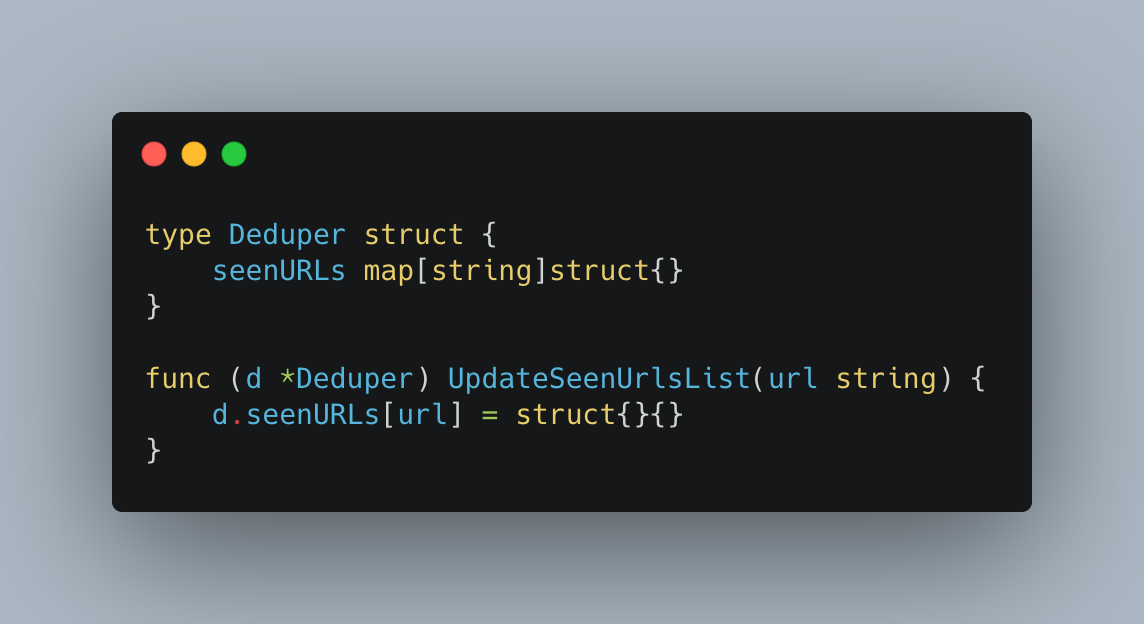
For the deduplication, the simplest thing to do would be to have an in-memory map in our service to track resources between a pre-specified interval. A naive implementation in Go might look something like this.
The problem with this approach is we have little resilience. If the service was to crash, we would lose all the data for our current batch. Furthermore, if we were to run multiple instances of our services, they would all have a different “view” of which resources they had seen before and therefore we would not be deduplicating.To mitigate this issue, we decided to use a specialist caching service. There are a number of distributed caches that would fit the bill, but we chose Redis given our team’s familiarity with operating it at scale.
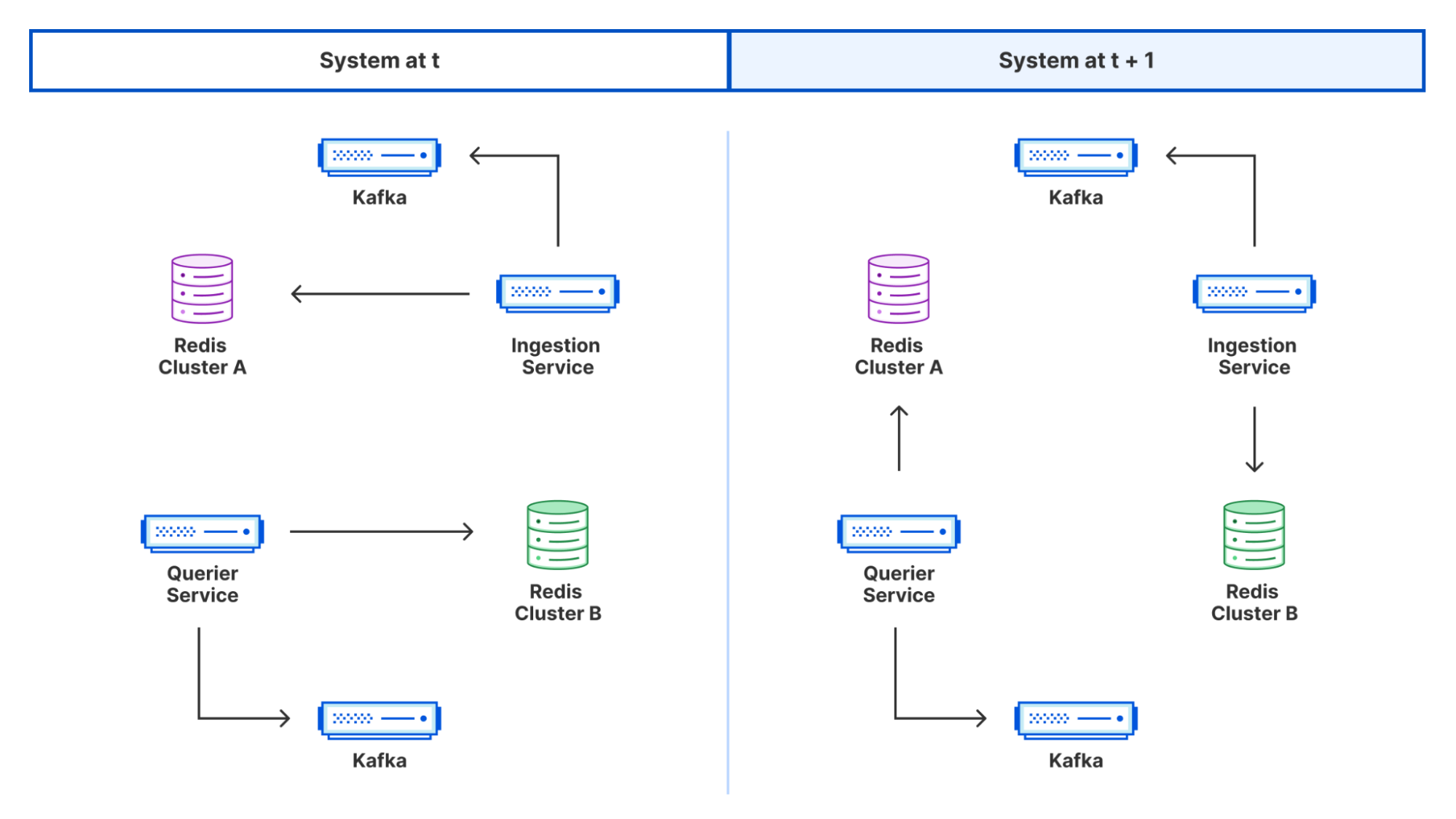
Redis is well known as a Key Value(KV) store often used for caching things,optionally with a specified Time To Live(TTL). Perhaps slightly less obvious is its value as a distributed buffer, housing ephemeral data with periodic flush/tear-downs. For Crawler Hints, we leveraged both these traits via a multi-generational, multi-cluster setup to achieve a highly available rolling aggregation service.
Two standalone Redis clusters were spun up. For each generation of request data, one cluster would be designated as the active primary. The validated records would be inserted as keys on the primary, serving the dual purpose of buffering while also deduplicating since Redis keys are unique. Separately, a downstream service (more on this later!) would periodically issue the command for these inserters to switch from the active primary (cluster A) to the inactive cluster (cluster B). Cluster A could then be flushed with records being batch read in a size of our choosing.
Buffering for Dispatch
At this point, we have clean, batched data. Things are looking good! However, there’s one small hiccup in the plan: we’re reading these batches from Redis at some set interval. What if it takes longer to dispatch than the interval itself? What if the search partner API is having issues?
We need a way to ensure the durability of the batch URLs and reduce the impact of any dispatch issues. To do this, we revisit an old friend from earlier: Kafka. The batches that get read from Redis are then fed into a Kafka topic. We wrote a Kafka consumer that we call the “dispatcher service” which runs within a consumer group to enable us to scale it if necessary just like the ingestor. The dispatcher reads from the Kafka topic and sends a batch of resources to each of our API partners.
Launching in tandem with Cloudflare, Crawler Hints was a joint venture between a few early adopters in the search engine space to provide a means for sites to inform indexers of content changes called IndexNow. You can read more about this launch here. IndexNow is a large part of what makes Crawler Hints possible. As part of its manifest, it provides a common API spec to publish resources that should be re-indexed. The standardized API makes abstracting the communication layer quite simple for the partners that support it. “Pushing” these signals to our search engine partners is a big step away from the inefficient “Pull” based model that is used today (you can read more about that here). We launched with Yandex and Bing as Search Engine Partners.
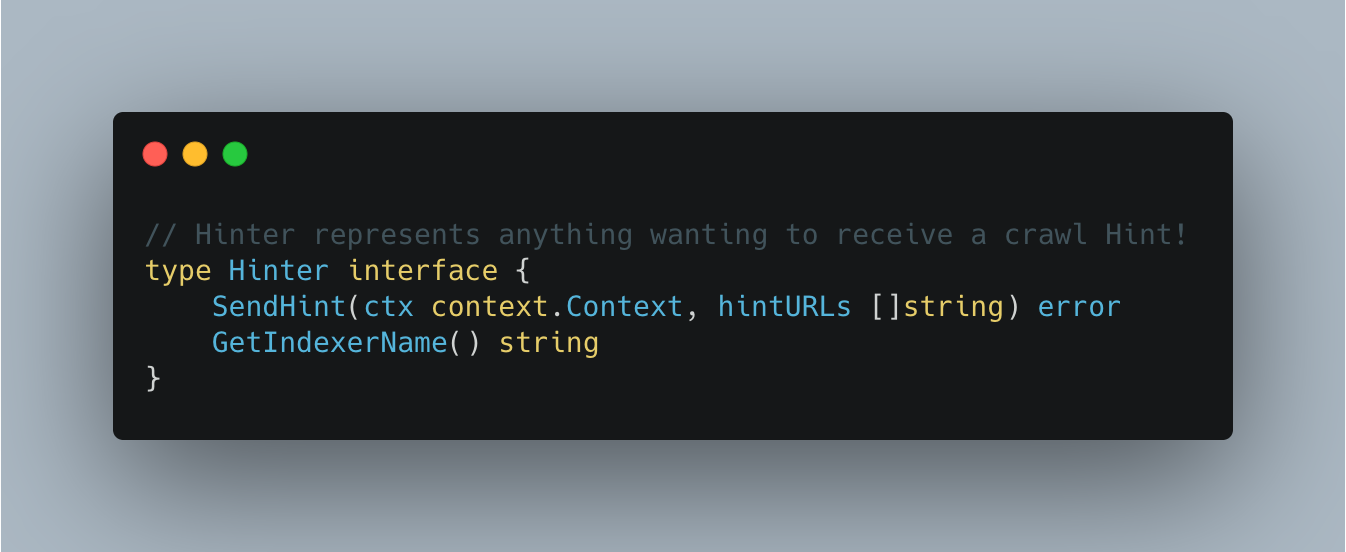
To ensure we can add more partners in the future, we defined an interface which we call a “Hinter”.
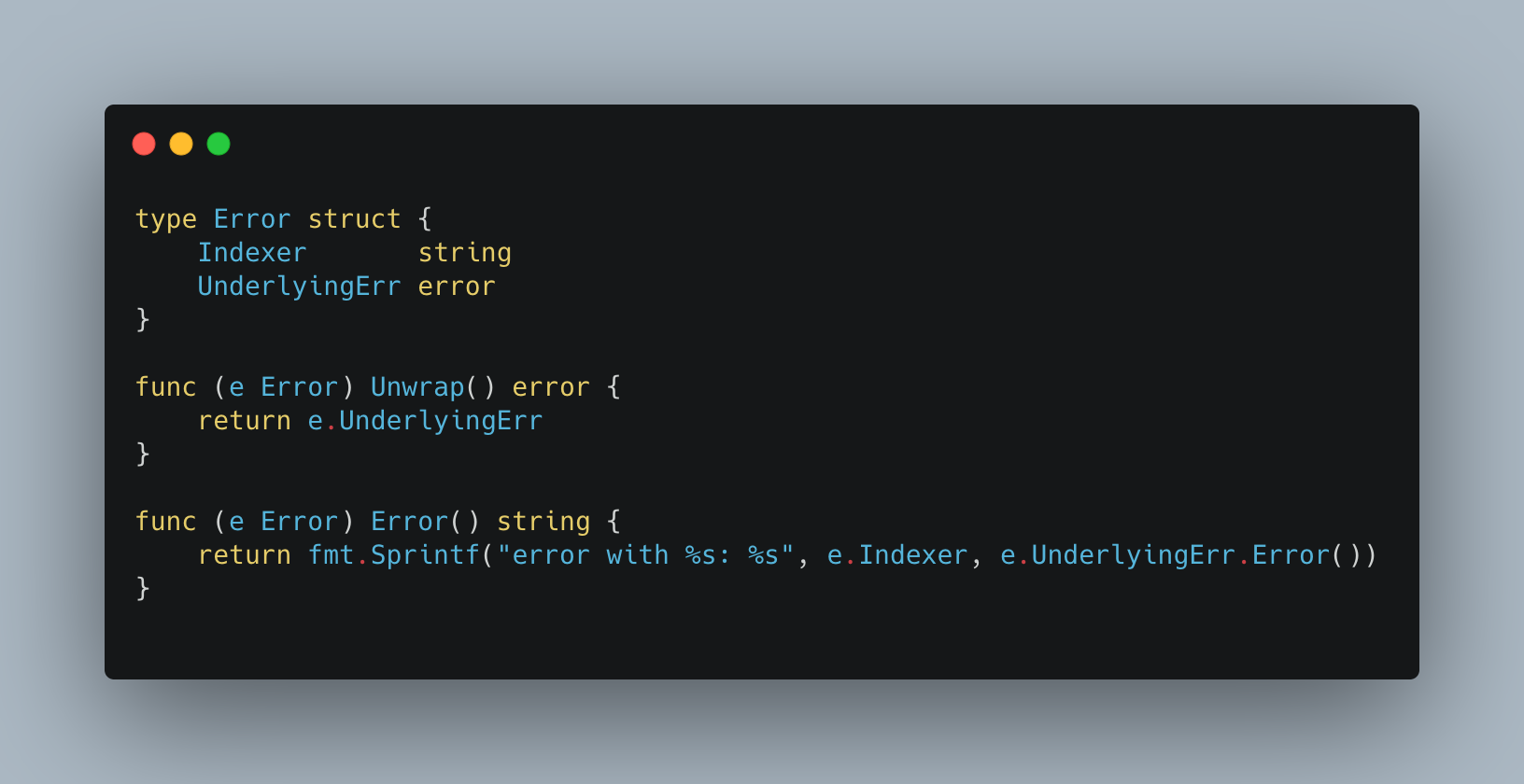
We then satisfy this interface for each partner that we work with. We return a custom error from the Hinter service that is of type *indexers.Error. The definition of which is:
This allows us to “bubble up” information about which indexer has failed and increment metrics and retry only those calls to indexers which have failed.
This all culminates together with the following in our service layer:
Simple, performant, maintainable, AND easy to add more partners in the future.
Rolling out Crawler Hints
At Cloudflare, we often release things that haven’t been done before at scale. This project is a great example of that. Trying to gauge how many users would be interested in this product and what the uptake might be like on day one, day ten, and day one thousand is close to impossible. As engineers responsible for running this system, it is essential we build in checks and balances so that the system does not become overwhelmed and responds appropriately. For this particular project, there are three different types of “protection” we put in place. These are:
Customer opt-in
Monitoring & Alerts
System resilience via “self-healing”
Customer opt-in
Cloudflare takes any changes that can impact customer traffic flow seriously. Considering Crawler Hints has the potential to change how sites are seen externally (even if in this instance the site’s viewers are robots!) and can impact things like SEO and bandwidth usage, asking customers to opt-in is a sensible default. By asking customers to opt-in to the service, we can start to get an understanding of our system’s capacity and look for bottle necks and how to remove them. To do this, we make extensive use of Prometheus, Grafana, and Kibana.
Monitoring & Alerting
We do our best to make our systems as “self-healing” and easy to run as possible, but as they say, “By failing to prepare, you are preparing to fail.” We therefore invest a lot of time creating ways to track the health and performance of our system and creating automated alerts when things fall outside of expected bounds.
Below is a small sample of the Grafana dashboard we created for this project. As you can see, we can track customer enablement and the rate of hint dispatch in real time. The bottom two panels show the throughput of our Kafka clusters by partition. Even just these four metrics give us a lot of insight into how things are going, but we also track (as well as other things):
Lag on Kafka by partition (how far behind real time we are)
Bad messages received from Kafka
Amount of URLs processed per “run”
Response code per index partner over time
Response time of partner API over time
Health of the Redis clusters (how much memory is used, frequency of commands we are using received by the cluster)
Memory, CPU usage, and pods available against configured limits/requests
It seems a lot to track, but this information is invaluable to us, and we use it to generate alerts that notify the on-call engineer if a threshold is breached. For example, we have an alert that would escalate to an engineer if our Redis cluster approached 80% capacity. For some thresholds we specify, we may want the system to “self-heal.” In this instance, we would want an engineer to investigate as this is outside the bounds of “normal,” and it might be that something is not working as expected. An alternative reason that we might receive alerts is that our product has increased in popularity beyond our expectations, and we simply need to increase the memory limit. This requires context and is therefore best left to a human to make this decision.
System Resilience via “self-healing”
We do everything we can to not disturb on-call engineers, and therefore, we try to make the system as “self-healing” as possible. We also don’t want to have too much extra resource running as it can be expensive and use limited capacity that another Cloudflare service might need more – it’s a trade off. To do this, we make use of a few patterns and tools common in every distributed engineer’s toolbelt. Firstly, we deploy on Kubernetes. This enables us to make use of great features like Horizontal Pod Autoscaling. When any of our pods reach ~80% memory usage, a new pod is created which will pick up some of the slack up to a predefined limit.
Secondly, by using a message bus, we get a lot of control over the amount of “work” our services have to do in a given time frame. In general, a message bus is “pull” based. If we want more work, we ask for it. If we want less work, we pull less. This holds for the most part, but with a system where being close to real time is important, it is essential that we monitor the “lag” of the topic, or how far we are behind real time. If we are too far behind, we may want to introduce more partitions or consumers.
Finally, networks fail. We therefore add retry policies to all HTTP calls we make before reporting them a failure. For example, if we were to receive a 500 (Internal Server Error) from one of our partner APIs, we would retry up to five times using an exponential backoff strategy before reporting a failure.
Data from the first couple of months
Since the release of Crawler Hints on October 18, 2021 until December 15, 2021, Crawler Hints has processed over twenty five billion crawl signals, has been opted-in to by more than 81,000 customers, and has handled roughly 18,000 requests per second. It’s been an exciting project to be a part of, and we are just getting started.
What’s Next?
We will continue to work with our partners to improve the standard even further and continue to improve the signaling on our side to ensure the most valuable information is being pushed on behalf of our customers in a timely manner.
If you’re interested in building scalable services and solving interesting technical problems, we are hiring engineers on our team in Austin, Lisbon, and London.
In the midst of the hottest summer on record, Cloudflare held its first ever Impact Week. We announced a variety of products and initiatives that aim to make the Internet and our planet a better place, with a focus on environmental, social, and governance projects. Today, we’re excited to share an update on Crawler Hints, an initiative announced during Impact Week. Crawler Hints is a service that improves the operating efficiency of the approximately 45% of Internet traffic that comes from web crawlers and bots.
Crawler Hints achieves this efficiency improvement by ensuring that crawlers get information about what they’ve crawled previously and if it makes sense to crawl a website again.
Today we are excited to announce two updates for Crawler Hints:
The first: Crawler Hints now supports IndexNow, a new protocol that allows websites to notify search engines whenever content on their website content is created, updated, or deleted. By collaborating with Microsoft and Yandex, Cloudflare can help improve the efficiency of their search engine infrastructure, customer origin servers, and the Internet at large.
The second: Crawler Hints is now generally available to all Cloudflare customers for free. Customers can benefit from these more efficient crawls with a single button click. If you want to enable Crawler Hints, you can do so in the Cache Tab of the Dashboard.
What problem does Crawler Hints solve?
Crawlers help make the Internet work. Crawlers are automated services that travel the Internet looking for… well, whatever they are programmed to look for. To power experiences that rely on indexing content from across the web, search engines and similar services operate massive networks of bots that crawl the Internet to identify the content most relevant to a user query. But because content on the web is always changing, and there is no central clearinghouse for when these changes happen on websites, search engine crawlers have a Sisyphean task. They must continuously wander the Internet, making guesses on how frequently they should check a given site for updates to its content.
Companies that run search engines have worked hard to make the process as efficient as possible, pushing the state-of-the-art for crawl cadence and infrastructure efficiency. But there remains one clear area of waste: excessive crawl.
At Cloudflare, we see traffic from all the major search crawlers, and have spent the last year studying how often these bots revisit a page that hasn’t changed since they last saw it. Every one of these visits is a waste. And, unfortunately, our observation suggests that 53% of this crawler traffic is wasted.
With Crawler Hints, we expect to make this task a bit more tractable by providing an additional heuristic to the people who run these crawlers. This will allow them to know when content has been changed or added to a site instead of relying on preferences or previous changes that might not reflect the true change cadence for a site. Crawler Hints aims to increase the proportion of relevant crawls and limit crawls that don’t find fresh content, improving customer experience and reducing the need for repeated crawls.
Cloudflare sits in a unique position on the Internet to help give crawlers hints about when they should recrawl a site. Don’t knock on a website’s door every 30 seconds to see if anything is new when Cloudflare can proactively tell your crawler when it’s the best time to index new or changed content. That’s Crawler Hints in a nutshell!
If you want to learn more about Crawler Hints, see the original blog.
What is IndexNow?
IndexNow is a standard that was written by Microsoft and Yandex search engines. The standard aims to provide an efficient manner of signaling to search engines and other crawlers for when they should crawl content. Cloudflare’s Crawler Hints now supports IndexNow.
In its simplest form, IndexNow is a simple ping so that search engines know that a URL and its content has been added, updated, or deleted, allowing search engines to quickly reflect this change in their search results. – www.indexnow.org
By enabling Crawler Hints on your website, with the simple click of a button, Cloudflare will take care of signaling to these search engines when your content has changed via the IndexNow protocol. You don’t need to do anything else!
What does this mean for search engine operators? With Crawler Hints you’ll receive a near real-time, pushed feed of change events of Cloudflare websites (that have opted in). This, in turn, will dramatically improve not just the quality of your results, but also the energy efficiency of running your bots.
Collaborating with Industry leaders
Cloudflare is in a unique position to have a sizable portion of the Internet proxied behind us. As a result, we are able to see trends in the way bots access web resources. That visibility allows us to be proactive about signaling which crawls are required vs. not. We are excited to work with partners to make these insights useful to our customers. Search engines are key constituents in this equation. We are happy to collaborate and share this vision of a more efficient Internet with Microsoft Bing, and Yandex. We have been testing our interaction via IndexNow with Bing and Yandex for months with some early successes.
This is just the beginning. Crawler Hints is a continuous process that will require working with more and more partners to improve Internet efficiency more generally. While this may take time and participation from other key parts of the industry, we are open to collaborate with any interested participant who relies on crawling to power user experiences.
“The cache data from CDNs is a really valuable signal for content freshness. Cloudflare, as one of the top CDNs, is key in the adoption of IndexNow to become an industry-wide standard with a large portion of the internet actually using it. Cloudflare has built a really easy 1-click button for their users to start using it right away. Cloudflare’s mission of helping build a better Internet resonates well with why I started IndexNow i.e. to build a more efficient and effective Search.” – Fabrice Canel, Principal Program Manager
“Yandex is excited to join IndexNow as part of our long-term focus on sustainability. We have been working with the Cloudflare team in early testing to incorporate their caching signals in our crawling mechanism via the IndexNow API. The results are great so far.” – Maxim Zagrebin, Head of Yandex Search
“DuckDuckGo is supportive of anything that makes search more environmentally friendly and better for end users without harming privacy. We’re looking forward to working with Cloudflare on this proposal.” – Gabriel Weinberg, CEO and Founder
How do Cloudflare customers benefit?
Crawler Hints doesn’t just benefit search engines. For our customers and origin owners, Crawler Hints will ensure that search engines and other bot-powered experiences will always have the freshest version of your content, translating into happier users and ultimately influencing search rankings. Crawler Hints will also mean less traffic hitting your origin, improving resource consumption. Moreover, your site performance will be improved as well: your human customers will not be competing with bots!
And for Internet users? When you interact with bot-fed experiences — which we all do every day, whether we realize it or not, like search engines or pricing tools — these will now deliver more useful results from crawled data, because Cloudflare has signaled to the owners of the bots the moment they need to update their results.
How can I enable Crawler Hints for my website?
Crawler Hints is free to use for all Cloudflare customers and promises to revolutionize web efficiency. If you’d like to see how Crawler Hints can benefit how your website is indexed by the worlds biggest search engines, please feel free to opt-into the service:
Sign in to your Cloudflare Account.
In the dashboard, navigate to the Cache tab.
Click on the Configuration section.
Locate the Crawler Hints sign up card and enable. It’s that easy.
Once you’ve enabled it, we will begin sending hints to search engines about when they should crawl particular parts of your website. Crawler Hints holds tremendous promise to improve the efficiency of the Internet.
What’s next?
We’re thrilled to collaborate with industry leaders Microsoft Bing, and Yandex to bring IndexNow to Crawler Hints, and to bring Crawler Hints to a wide audience in general availability. We look forward to working with additional companies who run crawlers to help make this process more efficient for the whole Internet.
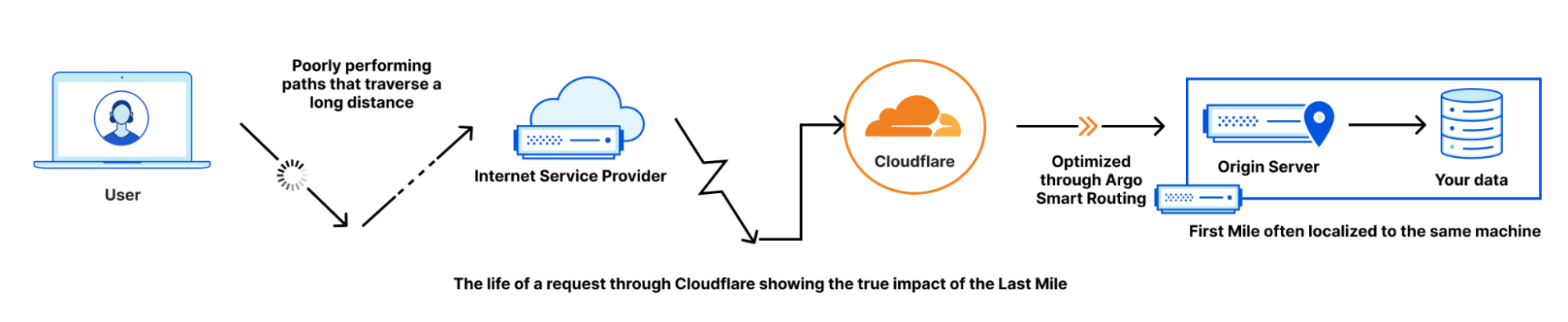
Something that comes up a lot at Cloudflare is how well our network and systems are performing. Like many service providers, we need to be engaged in a constant process of introspection to evaluate aspects of Cloudflare’s service with respect to customers, within our own network and systems and, as was the case in a recent blog post, the clients (such as web browsers). Many of these questions are obvious, but answering them is decisive in opening paths to new and improved services. The important point here is that it’s relatively straightforward to monitor and assess aspects of our service we can see or measure directly.
However, for certain aspects of our performance we may not have access to the necessary data, for a number of reasons. For instance, the data sources may be outside our network perimeter, or we may avoid collecting certain measurements that would violate the privacy of end users. In particular, the questions below are important to gain a better understanding of our performance, but harder to answer due to limitations in data availability:
How much better (or worse!) are we doing compared to other service providers (CDNs) by being in certain locations?
Can we know “a priori” and rank where data centers will have the greatest improvement and know which locations might deteriorate service?
The last question is particularly important because it requires the predictive power of synthesising available network measurements to model and infer network features that cannot be directly observed. For such predictions to be informative and meaningful, it’s critical to distill our measurements in a way that illuminates the interdependence of network structure, content distribution practices and routing policies, and their impact on network performance.
Active measurements are inadequate or unavailable
Measuring and comparing the performance of Content Distribution Networks (CDN) is critical in terms of understanding the level of service offered to end users, detecting and debugging network issues, and planning the deployment of new network locations. Measuring our own existing infrastructure is relatively straightforward, for example, by collecting DNS and HTTP request statistics received at each one of our data centers.
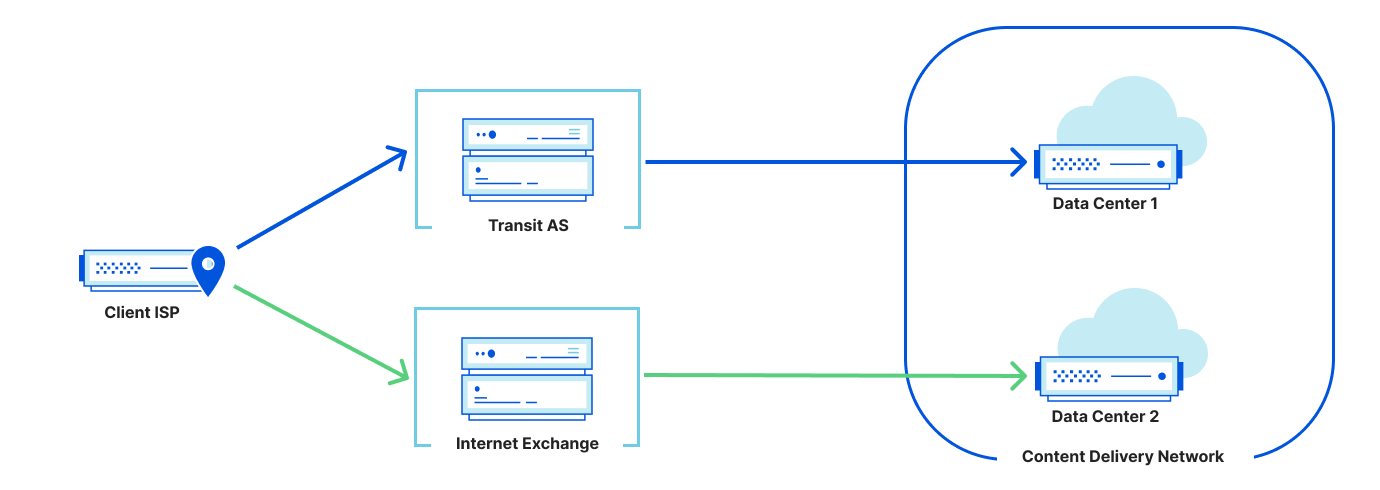
But what if we want to understand and evaluate the performance of other networks? Understandably, such data is not shared among networks due to privacy and business concerns. An alternative to data sharing is direct observation with what are called “active measurements.” An example of active measurement is when a measuring tape is used to determine the size of a room — one must take an action to perform the measurement.
Active measurements from Cloudflare data centers to other CDNs, however, don’t say much about the client experience. The only way to actively measure CDNs is by probing from third-party points of view, namely some type of end-client or globally distributed measurement platform. For example, ping probes might be launched from RIPE Atlas clients to many CDNs; alternatively, we might rely on data obtained from Real User Measurements (RUM) services that embed JavaScript requests into various services and pages around the world.
Active measurements are extremely valuable, and we heavily rely on them to collect a wide range of performance metrics. However, active measurements are not always reliable. Consider ping probes from RIPE Atlas. A collection of direct pings is most assuredly accurate. The weakness is that the distribution of its probes is heavily concentrated in Europe and North America, and it offers very sparse coverage of Autonomous Systems (ASes) in other regions (Asia, Africa, South America). Additionally the distribution of RIPE Atlas probes to ASes does not reflect the distribution of users to ASes, instead university networks and hosting providers or enterprises are overrepresented in the probes population.
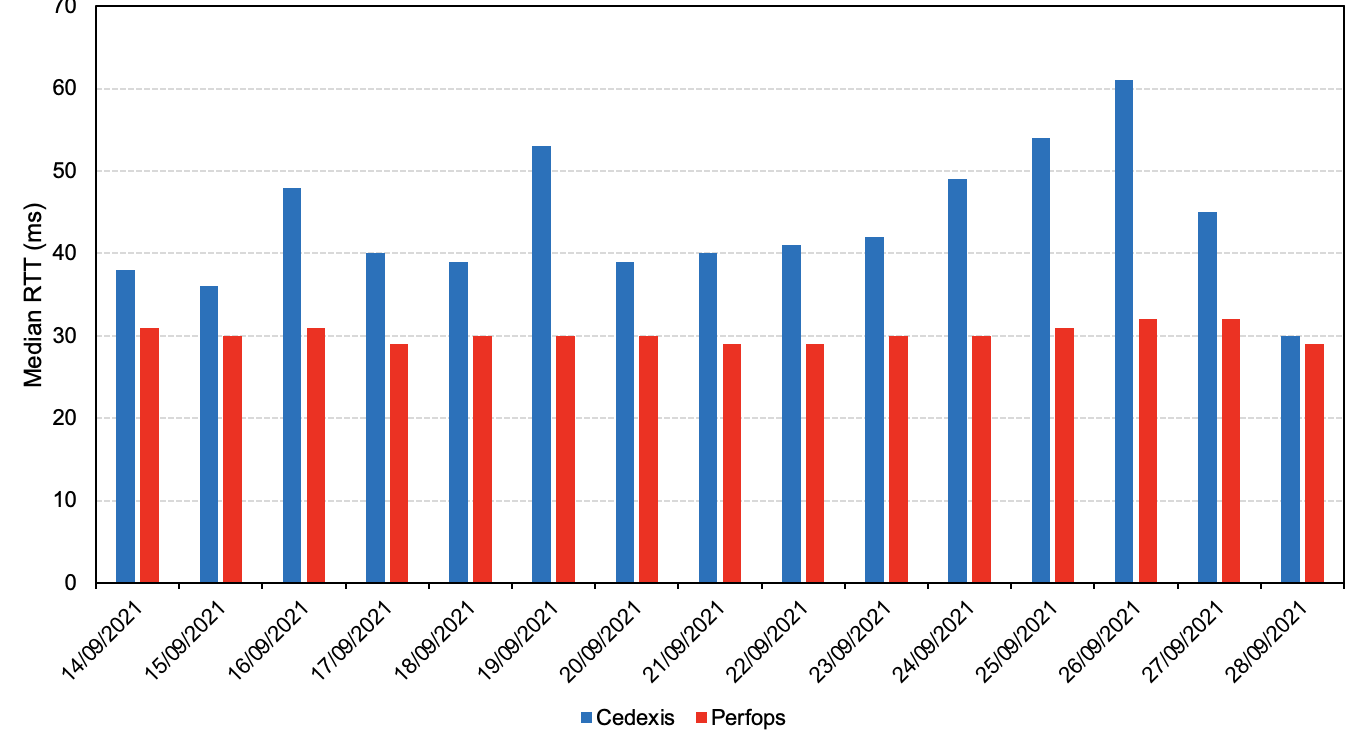
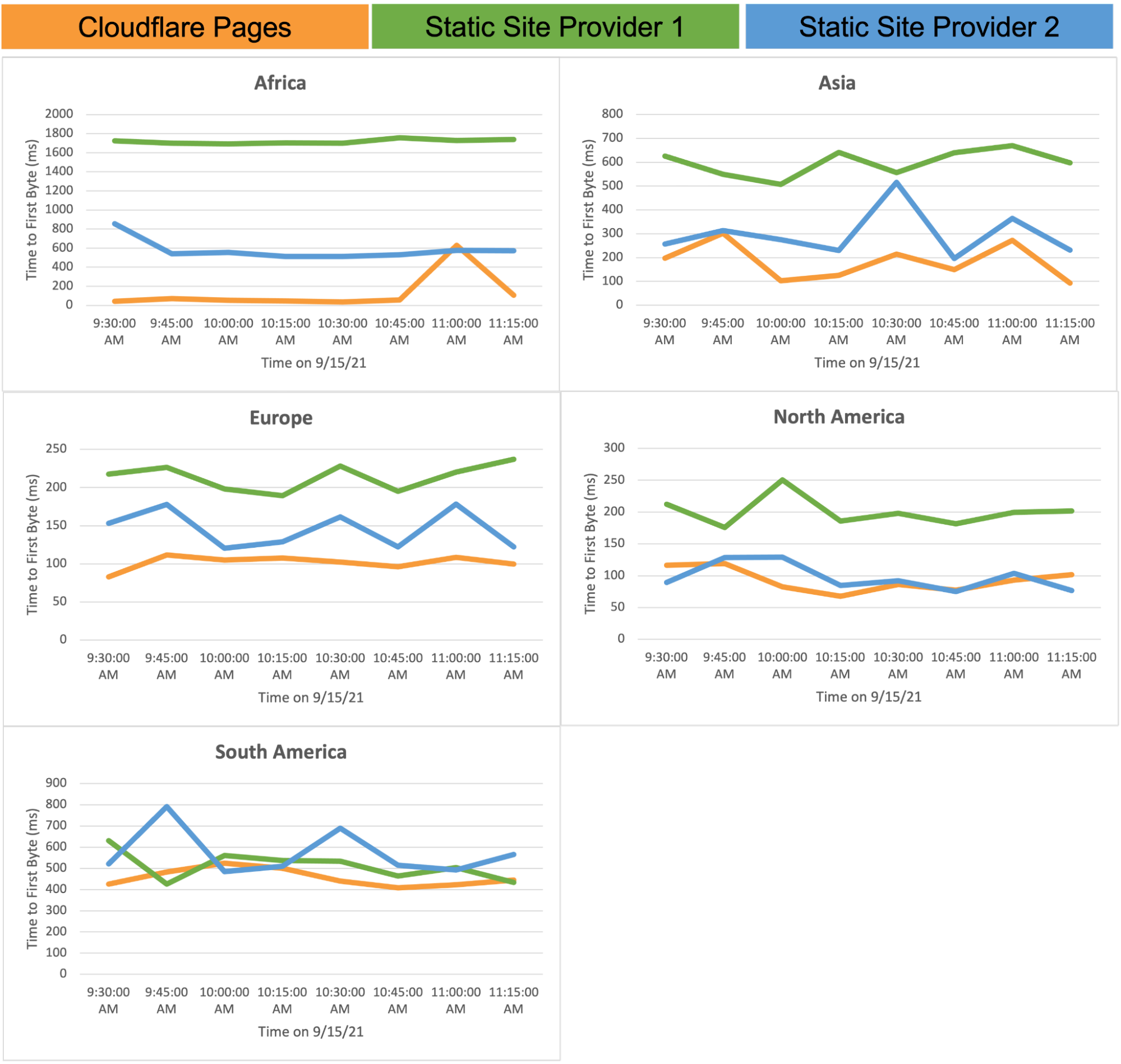
Similarly, data from third party Real User Measurements (RUM) services have weaknesses too. RUM platforms compare CDNs by embedding JavaScript request probes in websites visited by users all over the world. This sounds great, except the data cannot be validated by outside parties, which is an important aspect of measurement. For example, consider the following chart that shows Cloudfront’s median Round-Trip Time (RTT) in Greece as measured by the two leading RUM platforms, Cedexis and Perfops. While both platforms follow the same measurement method, their results for the same time period and the same networks differ considerably. If the two sets of measurements for the same thing differ, then neither can be relied upon.
Comparison of Real User Measurements (RUM) from two leading RUM providers, Cedexis and Perfops. While both RUM datasets were collected during the same period for the same location, there is a pronounced disparity between the two measurements which highlights the sensitivity of RUM data on specific deployment details.
Ultimately, active measurements are always limited to and by the things that they directly see. Simply relying on existing measurements does not in and of itself translate to predictive models that help assess the potential impact of infrastructure and policy changes on performance. However, when the biases of active measurements are well understood, they can do two things really well: inform our understanding, and help validate models of our understanding of the world — and we’re going to showcase both as we develop a mechanism for evaluating CDN latencies passively.
Predicting CDNs’ RTTs with Passive Network Measurements
So, how might we measure without active probes? We’ve devised a method to understand latency across CDNs by using our own RTT measurements. In particular, we can use these measurements as a proxy for estimating the latency between clients and other CDNs. With this technique, we can understand latency to locations where CDNs have deployed their infrastructure, as well as show performance improvements in locations where one CDN exists but others do not. Importantly, we have validated the assumptions shown below through a large-scale traceroute and ping measurement campaign, and we’ve designed this technique so that it can be reproduced by others. After all, independent validation is important across measurement communities.
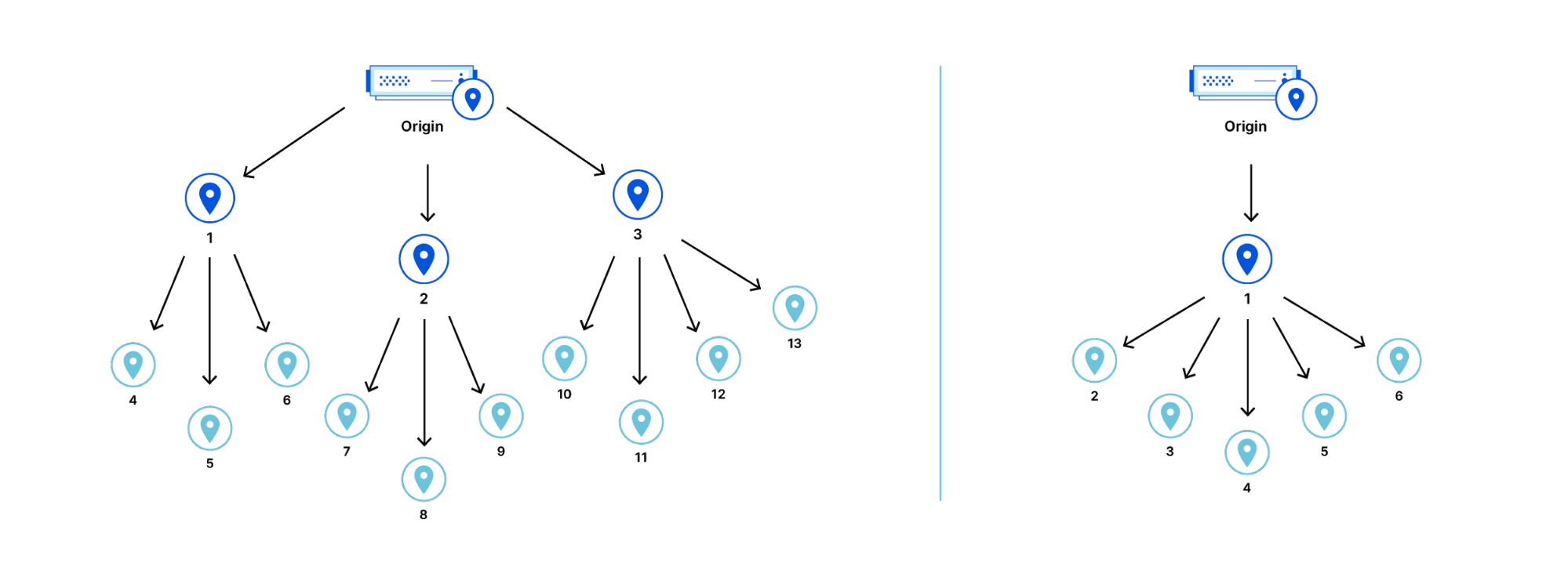
Step 1. Predicting Anycast Catchments
The first step in RTT inference is to predict the anycast catchments, namely predict the set of data centers that will be used by an IP. To this end, we compile the network footprint of each CDN provider whose performance we want to predict, which allows us to predict the CDN location where a request from a particular client AS will arrive. In particular, we collect the following data:
List of ISPs that host off-net server caches of CDNs using the methodology and code developed in Gigis et al. paper.
List of on-net city-level data centers according to PeeringDB, the network maps in the websites of each individual CDN, and IP geolocation measurements.
List of Internet eXchange Points (IXPs) where each CDN is connected, in conjunction with the other ASes that are also members of the same IXPs, from IXP databases such as PeeringDB, the Euro-IX IXP-DB, and Packet Clearing House.
List of CDN interconnections to other ASes extracted from BGP data collected from RouteViews and RIPE RIS.
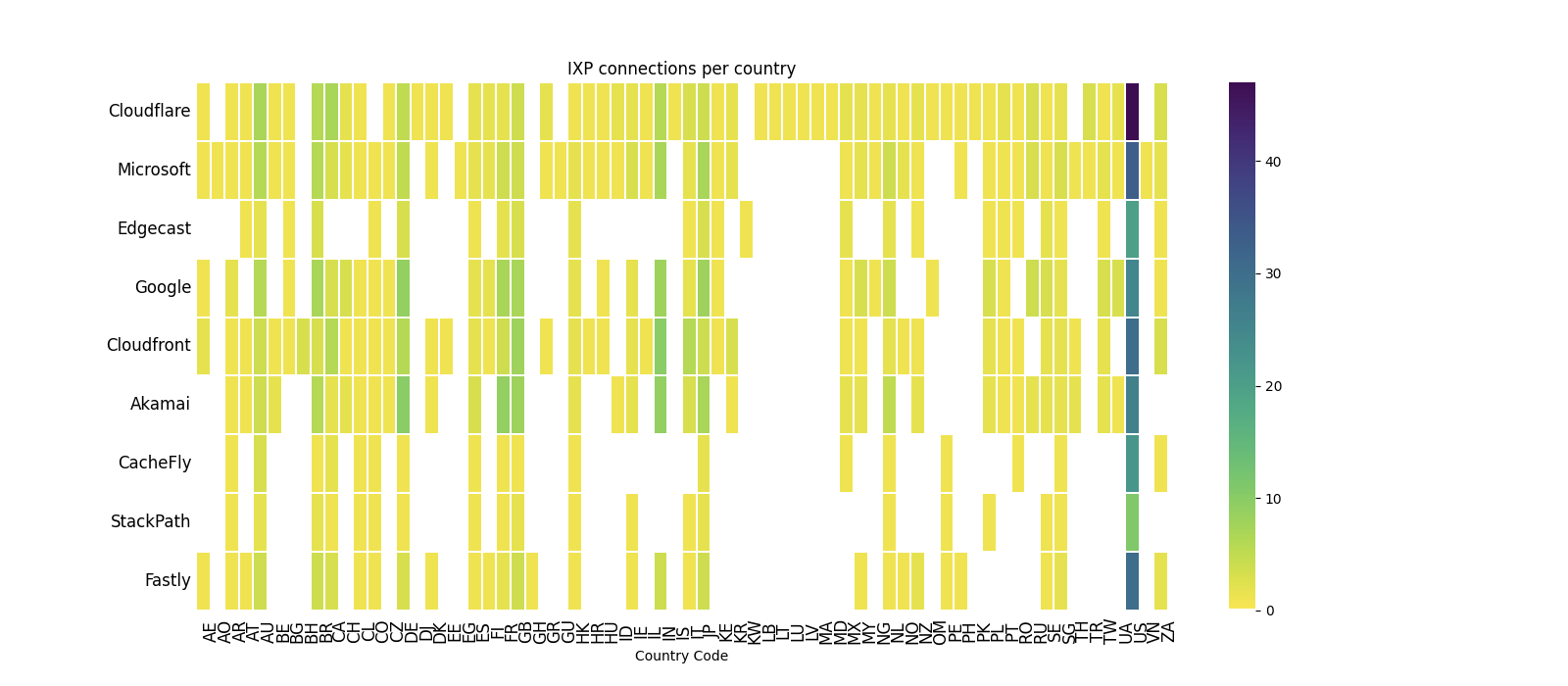
The figure below shows the IXP connections for nine CDNs, according to the above-mentioned datasets. Cloudflare is present in 258 IXPs, which is 56 IXPs more than Google, the second CDN in the list.
Heatmap of IXP connections per country for 9 major service providers, according to data from PeeringDB, Euro-IX and Packet Clearing House (PCH) for October 2021.
With the above data, we can compute the possible paths between a client AS and the CDN’s data centers and infer the Anycast Catchments using techniques similar to the recent papers by Zhang et al. and Sermpezis and Kotronis, which predict paths by reproducing the Internet inter-domain routing policies. For CDNs that use BGP-based Anycast, we can predict which data center will receive a request based on the possible routing paths between the client and the CDN. For CDNs that rely on DNS-based redirection, we don’t make an inference yet, but we first predict the latency to each data center, and we select the path with the lowest latency assuming that CDN operators manage to offer the path with the smallest latency.
The challenge in predicting paths emanates from the incomplete knowledge of the varying routing policies implemented by individual ASes, which are either hosting web clients (for instance an ISP or an enterprise network), or are along the path between the CDN and the client’s network. However, in our prediction problem, we can already partition the IP address space to Anycast Catchment regions (as proposed by Schomp and Al-Dalky) based on our extensive data center footprint, which allows us to reverse engineer the routing decisions of client ASes that are visible to Cloudflare. That’s a lot to unpack, so let’s go through an example.
Example
First, assume that an ISP has two potential paths to a CDN: one over a transit provider and one through a direct peering connection over an IXP, and each path terminates at a different data center, as shown in the figure below. In the example below, routing through a transit AS incurs a cost, while IXP peering links do not incur transit exchange costs. Therefore, we would predict that the client ISP would use the path to data center 2 through the IXP.
A client ISP may have paths to multiple data centers of a CDN. The prediction of which data center will eventually be used by the client, the so-called anycast catchment, combines both topological and routing policy data.
Step 2. Predicting CDN Path Latencies
The next step is to estimate the RTT between the client AS and the corresponding CDN location. To this end, we utilize passive RTT measurements from Cloudflare’s own infrastructure. For each of our data centers, we calculate the median TCP RTT for each IP /24 subnet that sends us HTTP requests. We then assume that a request from a given IP subnet to a data center that is common between Cloudflare and another CDN will have a comparable RTT (our approach focuses on the performance of the anycast network and omits host software differences). This assumption is generally true, because the distance between two endpoints is the dominant factor in determining latency. Note that the median RTT is selected to represent client performance. In contrast, the minimum RTT is an indication of closeness to clients (not expected performance). Our approach on estimating latencies is similar to the work of Madhyastha et al. who combined the median RTT of existing measurements with a path prediction technique informed by network topologies to infer end-to-end latencies that cannot be measured directly. While this work reported an accuracy of 65% for arbitrary ASes, we focus on CDNs which, on average, have much smaller paths (most clients are within 1 AS hop) making the path prediction problem significantly easier (as noted by Chiu et al. and Singh and Gill). Also note that for the purposes of RTT estimation, it’s important to predict which CDN data center the request from a client IP will use, not the actual hops along the path.
Example
Assume that for a certain IP subnet used by AS3379 (a Greek ISP), the following table shows the median RTT for each Cloudflare data center that receives HTTP requests from that subnet. Note that while requests from an IP typically land at the nearest data center (Athens in that case), some requests may arrive at different data centers due to traffic load management and different service tiers.
Data Center
Athens
Sofia
Milan
Frankfurt
Amsterdam
Median RTT
22 ms
42 ms
43 ms
70 ms
75 ms
Assume that another CDN B does not have data centers or cache servers in Athens and Sofia, but only in Milan, Frankfurt, and Amsterdam. Based on the topology and colocation data of CDN B, we will predict the anycast catchments, and we find that for AS3379 the data center in Frankfurt will be used. In that case, we will use the corresponding latency as an estimate of the median latency between CDN B and the given prefix.
The above methodology works well because Cloudflare’s global network allows us to collect network measurements between 63,832 ASes (virtually every AS which hosts clients), and 300 cities in 115 different countries where Cloudflare infrastructure is deployed, allowing us to cover the vast majority of regions where other CDNs have deployed infrastructure.
Step 3. Validation
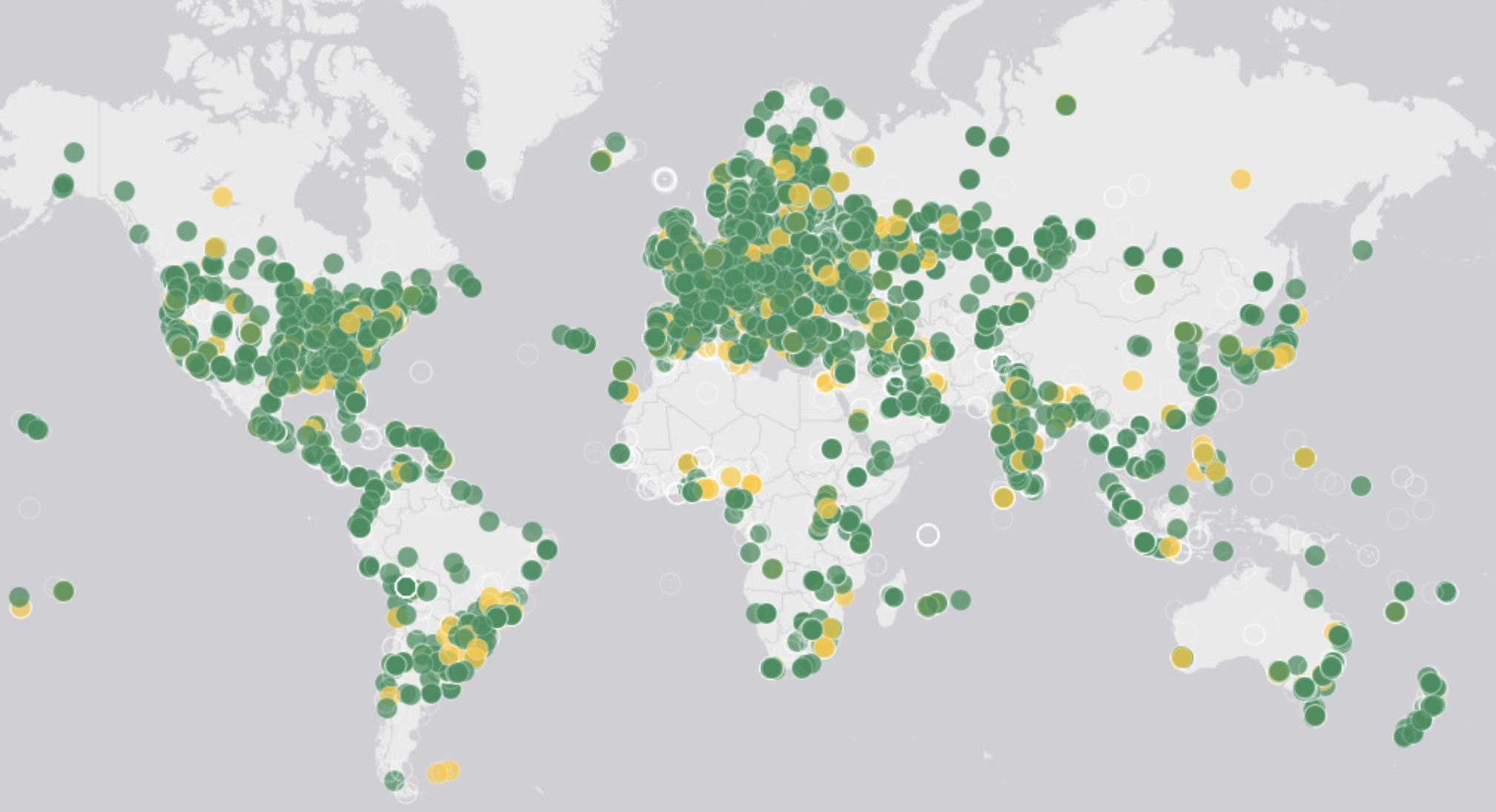
To validate the above measurement, we run a global campaign of traceroute and ping measurements from 9,990 Atlas probes in 161 different countries (see the interactive map for real-time data on the geographical distribution of probes).
Geographical distribution of the RIPE Atlas probes used for the validation of our predictions
For each CDN as a measurement target, we selected a destination hostname that is anycasted from all locations, and we selected the DNS resolution to run on each measurement probe so that the returned IP corresponds to the probe’s nearest location.
After the measurements were completed, we first evaluated the Anycast Catchment prediction, namely the prediction of which CDN data center will be used by each RIPE Atlas probe. To this end, we geolocated the destination IPs of each completed traceroute measurement against the predicted data center. Nearly 90% of our predicted data centers agreed with the measured data centers.
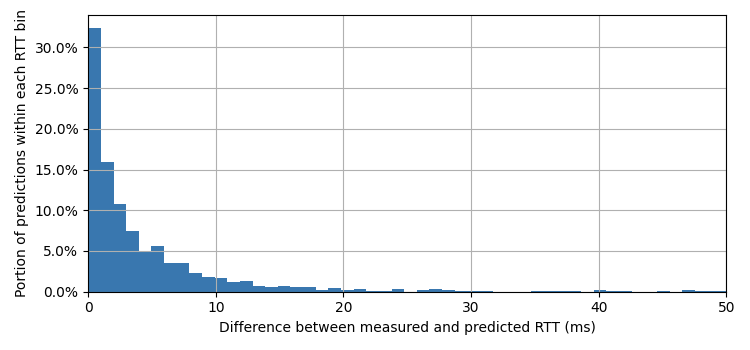
We also validated our RTT predictions. The figure below shows the absolute difference between the measured RTT and the predicted RTT in milliseconds, across all data centers. More than 50% of the predictions have an RTT difference of 3 ms or less, while almost 95% of the predictions have an RTT difference of at most 10 ms.
Histogram of the absolute difference in milliseconds between the predicted RTT and the RTT measured through the RIPE Atlas measurement campaign.
Results
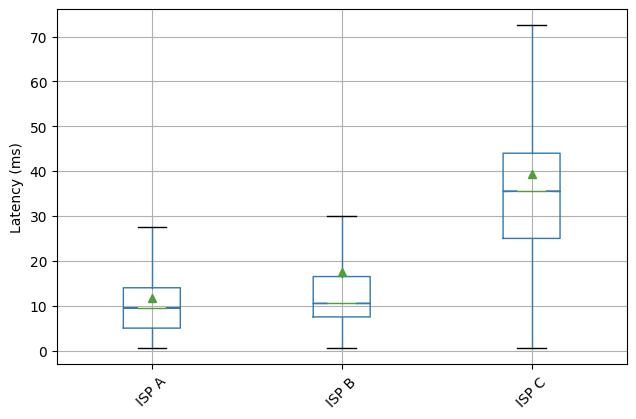
We applied our methodology on nine major CDNs, including Cloudflare, in September 2021. As shown in the boxplot below, Cloudflare exhibits the lowest median RTT across all observed clients, with a median RTT close to 10 ms.
Boxplot of the global RTT distributions for each of the 9 networks we considered in our experiments. We anonymize the rest of the networks since the focus on this measurement is not to provide a ranking of content providers but to contextualize the performance of Cloudflare’s network compared to other comparable networks.
Limitations of measurement methodology
Because our approach relies on estimating latency, it is not possible to obtain millisecond-accurate measurements. However, such measurements are essentially infeasible even when using real user measurements because the network conditions are highly dynamic, meaning that measured RTT may differ significantly between different measurements.
Secondly, our approach obviously cannot be used to monitor network hygiene in real time and detect performance issues that may often lie outside Cloudflare’s network. Instead, our approach is useful for understanding the expected performance of our network topology and connectivity, and we can test what-if scenarios to predict the impact on performance that different events may have (e.g. deployment of a new data center, interruption of connectivity to an ISP or IXP).
Finally, while Cloudflare has the most extensive coverage of data centers and IXPs compared to other CDNs, there are certain countries where Cloudflare does not have a data center in contrast to other CDNs. In some other countries, Cloudflare is present to a partner data center but not in a carrier-neutral data center which may restrict the number of direct peering links between Cloudflare’s and other regional ISPs. In such countries, client IPs may be routed to a data center outside the country because the BGP decision process typically prioritizes cost over proximity. Therefore, for about 7% of the client /24 IP prefixes, we do not have a measured RTT between a data center in the same country as the IP. We are working to alleviate this with traceroute measurements and will report back later.
Looking Ahead
The ability to predict and compare the performance of different CDN networks allows us to evaluate the impact of different peering and data center strategies, as well as identify shortcomings in our Anycast Catchments and traffic engineering policies. Our ongoing work focuses on measuring and quantifying the impact of peering on IXPs on end-to-end latencies, as well as identifying cases of local Internet ecosystems where an open peering policy may lead to latency increases. This work will eventually enable us to optimize our infrastructure placement and control-plane policies to the specific topological properties of different regions and minimize latency for end users.
When we announced Cloudflare Pages in April, our goal wasn’t to bring just any web development tool to the table. As a front-end developer, it’s your responsibility to bring the ideas of your marketing, product and engineering teams to life by crafting a beautifully engaging experience for every customer. With all the hard work that goes into the development process — turning mock-ups to code, getting input from your team, staging and testing changes — you want the best performance possible for your site to showcase your work and optimize your customers’ experience.
Cloudflare Pages is the most secure and most scalable Jamstack platform to build and deploy your sites on the edge. But how is Pages so fast?
It comes down to three key reasons:
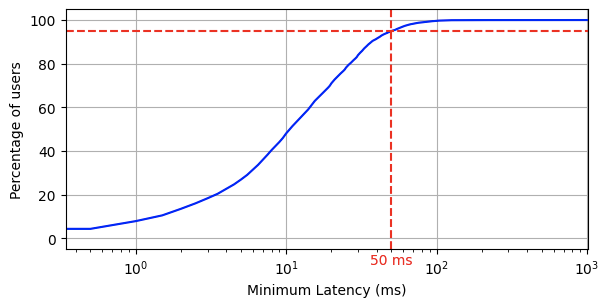
Pages is built on one of the fastest networks in the world, putting us within 50 ms of 95% of the world’s Internet-connected population. Delivering Pages from this network is the basis of our speed.
Cloudflare helps define and implement next generation standards, like QUIC + HTTP/3 and Early Hints, that push Pages performance to the next level.
Pages has a killer developer experience that makes it easy to build the fastest websites on the planet.
Pages is delivered from one of the fastest networks in the world
After all the sweat, finger cramps, and facepalms you’ve managed to survive through development, the last thing you need is poor performance and load times for your site. This not only drives off frustrated customers, but if the site is a storefront, it can also have revenue implications.
We’ve got you covered! With Cloudflare’s extensive network, consisting of 250+ cities, your Pages site is deployed directly to the edge in seconds. With even more optimizations to our network routing, your customers are routed to the best data center, ensuring optimal loading and performance globally.
How does our performance compare?
Optimized routing, a giant CDN network, support for the latest standards, more performance enhancements — these all sound great! But let’s put them to the ultimate test: benchmarking. How do our Pages sites’ performance compare to those of our competitors?
The TTFB test
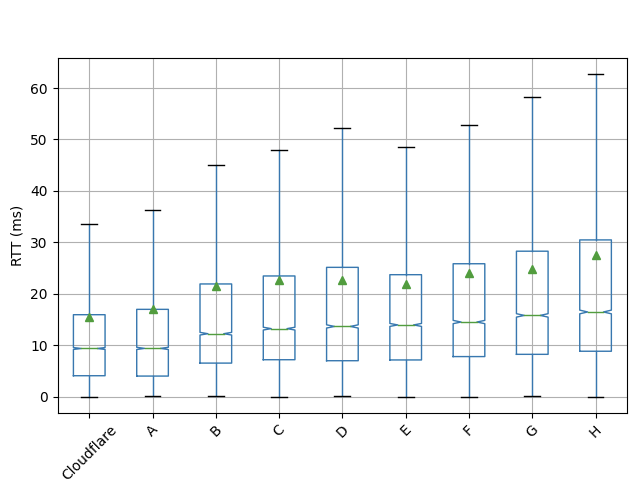
We deployed the same static site on Pages and on two other popular deployment platforms for comparison. We understand that benchmark tools like Google Lighthouse may introduce some geographic bias; performing a benchmarking analysis from San Francisco and hitting a local data center doesn’t tell us much about performance on a global scale. We wanted to create a simulation to run tests from different locations to give us a globally accurate representation. Using a tool called Catchpoint, we executed our test from 35 different cities around the world to measure the Time to First Byte (TTFB) for different providers. To give as accurate a reading as possible, we ran our test up to eight times, and averaged the result per city and per provider.
Around the world in 80ms
It’s common to see good performance in regions like the US and Europe, but at Cloudflare, we think even more globally. Cloudflare’s network allows you to reach a myriad of regions around the world without any additional effort or cost. Everytime our map grows, your global reach does too.
In our TTFB comparison, Cloudflare Pages is leading the race to your customers against two leading providers.
Pages gets early access to the latest, greatest, and fastest standards and network protocols
But it’s not just our network. We are proud of both driving and adopting the latest web standards. Our mission has always been to help build a better Internet, and collaborating on the latest standards is an essential part of that goal, especially when thinking about your Pages sites.
TLS 1.3: As the new encryption protocol, TLS 1.3 sets out to improve both speed and security for Internet users everywhere. With 1.3, during the course of that infamous “TLS handshake” you hear so much about, only one round trip, or back and forth communication, is required instead of two, thus shortening the process by milliseconds. A huge step forward for web security and performance, TLS 1.3 is available to all Pages users with no additional action required — let the client and server handle it all.
IPv6: Today it’s extremely common for every person to have more than one Internet connected device, making the shift to IPv6 extremely crucial, now more than ever. Not only is IPv6 the answer to the “no more addresses” issue, but is also another added layer for performance and security with its ability to handle packets more efficiently, getting faster and faster as adoption of the standard increases.
QUIC & HTTP/3: The new internet transport protocol, QUIC & HTTP/3, team up to enable faster, reliable and more secure connections for your customers to web endpoints like your Pages site. QUIC, a transport layer protocol, aims to reduce connection and transport latency and avoid congestion and runs underneath HTTP/3. Enabled by default on every pages.dev domain, QUIC & HTTP/3 work in tandem to provide improved performance and security so long as the client complies.
With support for the latest standards like HTTP/3 and IPv6, as we work on support for dynamic frameworks, we will be able to offer response streaming, a feature other platforms don’t provide.
“Pages gives us more confidence than other providers, making it easier to migrate our app over and build new products that can easily scale with growing traffic.” — David Simpson, COO at Designed.org
But we know that speed doesn’t just matter from a user perspective. It also matters from a developer perspective, too — and we’ve worked to make that just as great an experience.
A developer experience that we’d want to have
Generally speaking, performance of anything on the web is only as fast as the weakest link. A fast network, or support for the latest standards, doesn’t mean very much if we make it hard for a developer to do their job, or to optimize their code. So we knew the developer experience had to be a priority, too.
Fast for your users. Fast for you, too.
We set out to simplify every step of your developer experience by looking for ways to integrate into your existing publishing workflow. With Pages’ full git integration, grab your repo, tell us your framework and go! Collaborate with all members of your team — developers, PMs, marketers — quickly and efficiently with a protected preview URL per deployment to speed up the turnaround time for feedback. A simple Git commit and git push, and we’ll have your site up and running in seconds, and ready for you to share with your team or your customers.
Of course, even with lightning fast set-up and collaboration, we realize there’s more to the productivity of you and your team. From the time we launched Pages, we’ve been working on making our build times faster every day. Today, Pages builds are 3x faster than they were when we first launched the platform, but we’re not done yet. We’re aiming to have the fastest build times, so you can focus on what you do best — code, test, deploy, repeat — minus any wait.
Performance tuning, built in
In May of last year, Google announced a new program — Web Core Vitals — to provide unified guidance on how to measure the quality of a website, and to identify areas of improvement for developers, business owners, and marketers to deliver a better user experience. There are three key metrics as part of the program:
Largest Contentful Paint: measures loading performance
Fast-forward a year to 2021, Google officially announced that performance on these metrics will now be incorporated into Google Search results.
Performance is becoming an ever important aspect of the success of any site on the web.
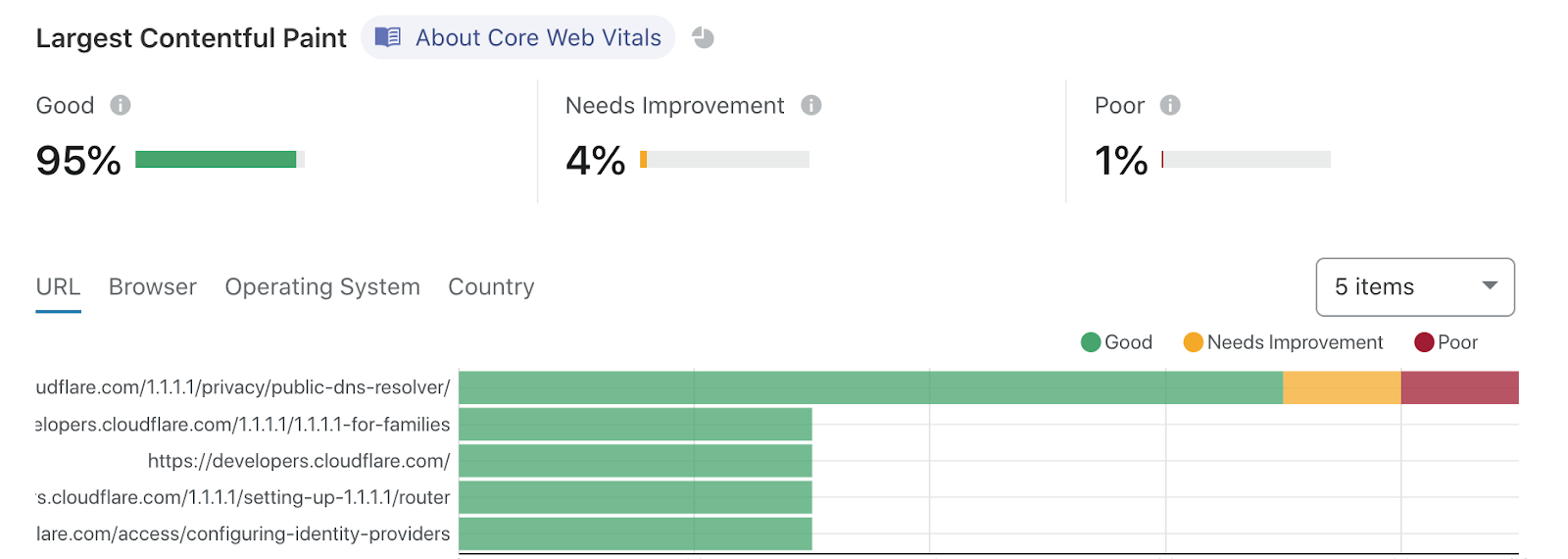
We recognize this, and it’s part of why we’re so relentlessly focused on making sites hosted on Pages so fast. But you don’t need to just take our word for it. In addition to providing you with stellar performance across the globe, our Web Analytics tool is available to Pages customers with one click — so you can track your site’s Web Core Vitals and understand specific areas of improvement. As an example, here’s the Web Analytics on our very own Cloudflare Docs site.
We’re big believers in dogfooding — running our Docs site on Pages, and then using our Web Analytics to identify areas of improvement. It’s a big part of the Cloudflare ethos, and it’s how we can be confident in recommending our products to you.
What’s Next
With the increasing momentum behind the Jamstack movement, it’s a great time to be in the field. With Pages, you can rest easy knowing you’re taken care of every step of the way. We are so excited about the future of Cloudflare Pages — integrating with Cloudflare Workers, supporting monorepos, enabling more sources of repo integration — and how it brings a fresh perspective on how you build and deploy your sites on the web.
Check our docs to get started on Cloudflare Pages today!
When Varnish and the Varnish Configuration Language (VCL) were first introduced 15 years ago, they were an incredibly powerful combination to configure caching on servers (and your networks). It seemed a logical choice for a language to configure CDNs — caching in the cloud.
A lot has changed on the Internet since then.
In particular, caching is just one of many things that “CDNs” are expected to do: load balancing, DDoS protection, rate limiting, transformations, synthetic responses, routing and more. But above all what “CDNs” need to be is programmable, not just configurable.
Configuration went from a niche activity to a much more common — and often involved — requirement. We’ve heard from a lot of teams that want to remove critical dependencies on the one person they have who knows how to make configuration changes — because they’re the only one on the team who knows how to write in VCL.
But it’s not just about who can write VCL — it’s what VCL is increasingly being asked to do. A lot of our customers have told us that they have much greater expectations for what they expect the network to do: they don’t just want to configure anymore… they want to be able to program it! VCL is being pushed and stretched into things it was never envisaged to do.
These are often the frustrations we hear from customers about the use of VCL. And yet, at the same time, migrations are always hard. Taking thousands of lines of code that have been built up over the years for a mission critical service, and rewriting it from scratch? Nobody wants to do that.
Today, we are excited to announce a solution to all these problems: Turpentine. Turpentine is a true VCL-to-TypeScript converter: it is the easiest and most effective way for you to migrate your legacy Varnish to a modern, Turing-complete programming language and onto the edge. But don’t think that because you’re moving up in terms of language abstraction that you’re giving up performance — it’s the opposite. Turpentine enables porting your VCL-based configuration to Cloudflare Workers — which is known for its speed. Beyond being able to eliminate the use of VCL, Turpentine enables you to take full advantage of Cloudflare: including proxies, firewall, load balancers, tiered caching/shielding and everything else Cloudflare offers.
And you’ll be able to configure it using one of the most widely used languages in the world. Whether you’re using standard configurations, or have a heavily customized VCL file, Turpentine will generate human-readable and well commented TypeScript code and deploy it to our serverless platform that is… fast.
How It Works
To turn a VCL into TypeScript code that is well optimized, human-readable, and commented, Turpentine takes a three-phase approach:
The VCL is parsed, its meaning is understood, and TypeScript code that preserves its intentions is generated. This is more than transpiling. All the functionality configured in the VCL is rewritten to the best solution available. For example, rate limiting might be custom code on your VCL — but have native functionality on Cloudflare.
The code is cleaned and optimized. During this phase, Turpentine looks for redundancies and inefficiencies, and removes them. Your code will be running on Cloudflare Workers, the fastest serverless platform in the world, and we definitely don’t want to leave behind inefficiencies that would prevent you from enjoying its benefits to the full extent.
The final step is pretty printing. The whole point of this exercise is to make the code easy to understand by as many people as possible on your team — so that virtually any engineer on your team, not just infrastructure experts, can program your network moving forward.
Turpentine in Action
We’ve been perfecting Turpentine in a private beta with some very large customers who have some very complicated VCL files.
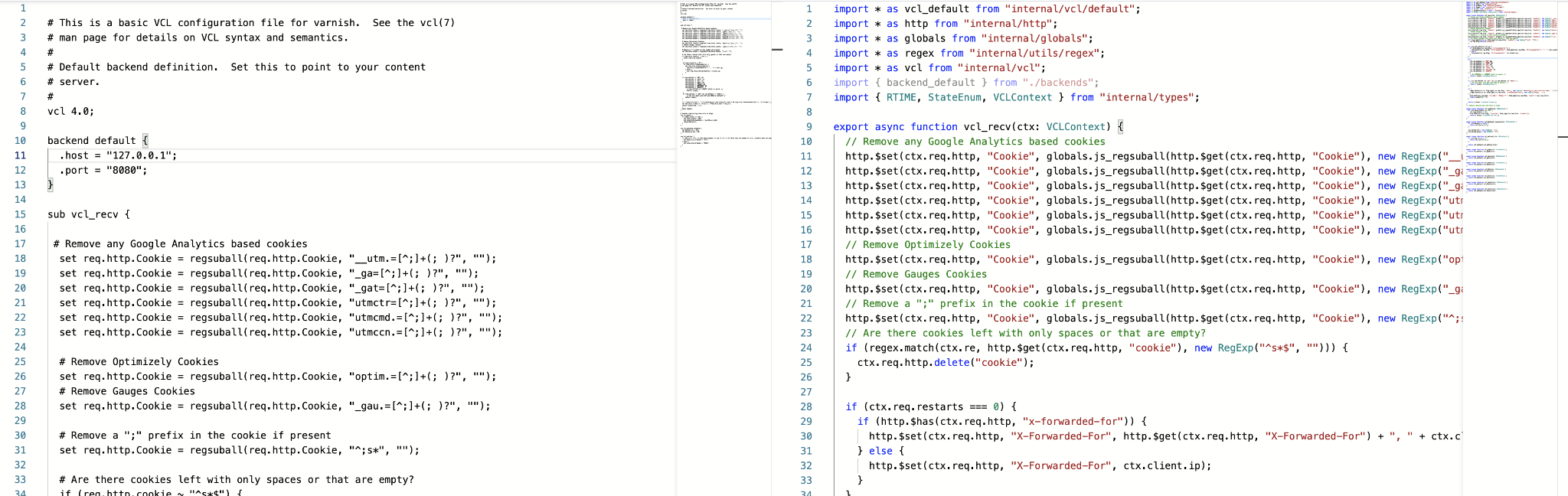
Here’s a demo of a VCL file being converted to a Worker:
Legacy to Modern
Happily, this all occurs without the pains of the usual legacy migration. There’s no project plan. No engineers and IT teams trying to replicate each bit of configuration or investigating whether a specific feature even existed.
If you’re interested in finding out more, please register your interest in the sign-up form here — we’d love to explore with you. For now, we’re staying in private beta, so we can walk every new customer through the process. A Cloudflare engineer will help your team get up to speed and comfortable with the new infrastructure.
Want to know a secret about Internet performance? Browsers spend an inordinate amount of time twiddling their thumbs waiting to be told what to do. This waiting impacts page load performance. Today, we’re excited to announce support for Early Hints, which dramatically improves browser page load performance and reduces thumb-twiddling time.
In initial tests using Early Hints, we have observed more than 30% improvement to page load time for browsers visiting a website for the first time.
Early Hints is available in beta today — Cloudflare customers can request access to Early Hints in the dashboard’s Speed tab. It’s free for all customers because we think the web should be fast!
Early Hints in a nutshell
Browsers need instructions for what to render and what resources need to be fetched to complete “painting” a given web page. These instructions come from a server response. But the servers sending these responses often need time to compile these resources — this is known as “server think time.” While the servers are busy during this time… browsers sit idle and wait.
Early Hints takes advantage of “server think time” to asynchronously send instructions to the browser to begin loading resources while the origin server is compiling the full response. By sending these hints to a browser before the full response is prepared, the browser can figure out what it needs to do to load the webpage faster for the end user. Faster page loads and lower user-perceived latency means happier users!
More formally, Early Hints is a web standard that defines a new HTTP status code (103 Early Hints) that defines new interactions between a client and server. 103s are served to clients while a 200 OK (or error) response is being prepared (the so-called “server think time”), and contain hints on which assets will likely be needed to fully render the web page. This hinting speeds up page loads and generally reduces user-perceived latency.
Sending hints on which assets to expect before the entire response is compiled allows the browser to use think time (when it would otherwise have been waiting) to fetch needed assets, prepare parts of the displayed page, and otherwise get ready for the full response to be returned.
Cloudflare, as an edge network that sits in between client and server, is well positioned to issue these hints to clients on servers’ behalf. This is true for a few reasons:
103 is an experimental status code that origins may not be able to emit on their own, mostly for legacy reasons. Much of the machinery that powers the web incorrectly assumes that HTTP requests always correspond 1:1 with HTTP responses. This mistaken premise is baked into most HTTP server software, making it difficult for origin servers to emit Early Hints 103 responses prior to a “final” 200 OK response.
Cloudflare edge servers handling this complexity on behalf of our customers neatly sidesteps these technical challenges and gets the adoption flywheel spinning faster on this exciting new technology (more on this flywheel later).
Cloudflare’s edge is very close to end users. This means we can serve hints very quickly, filling even the smallest of server think blocks with useful information the client can use to get a jump start on loading assets.
Cloudflare already sees request and response flow from our customers. We use this data to generate hints automatically, without a customer needing to make any origin changes at all.
How can we speed up “slow” dynamic page loads?
The typical request/response cycle between browsers and servers leaves a lot of room for optimization. When you type an address into the search bar of your browser and press Enter, a series of things happen to get you the content you need, as quickly as possible. Your browser first converts the hostname in the URL into an IP address, then establishes an initial connection to the server where the content is stored.
After the connection is established, the actual request is sent. This is often a GET request with a bunch of information about what the browser can and cannot display to the end user. Following the request, the browser must wait for the origin server to send the first bytes of the response before it begins to render the page. In this time, the server is busy executing all sorts of business logic (looking things up in databases, personalizing the page, detecting fraud, etc.) before spitting a response out to the browser.
Once the response for the original HTML page is received, the browser then needs to parse the page, generate a Document Object Model (DOM), and begin loading subresources specified on the page, like images, scripts, and additional stylesheets.
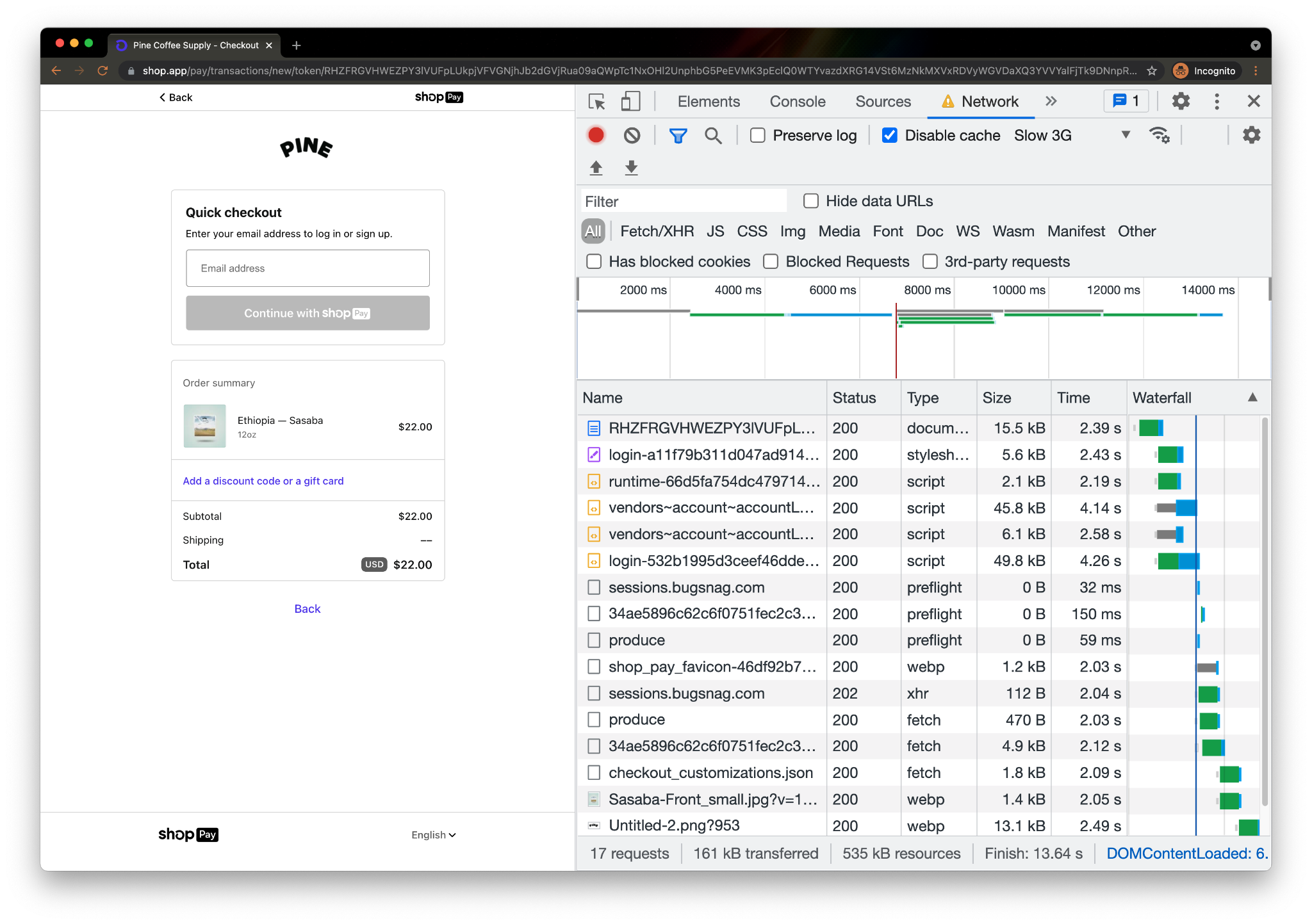
Let’s take a look at this in action. Below is the performance waterfall for a checkout page on pinecoffeesupply.com, a coffee shop with a storefront on Shopify:
Page rendering cannot complete (and the shopper can’t get their coffee fix, and the coffee shop can’t get paid!) until key assets are loaded. Information on subresources needed for the browser to load the page aren’t available until the server has thought about and returned the initial response (the first document in the above table). In the above example, the page load could have been accelerated had the browser known, prior to receiving the full response, that the stylesheet and the four subsequent scripts will be needed to render the page.
Attempting to parallelize this dependency is what Early Hints is all about — productively using that “server think time” to help get the browser going on critical steps to render the page before the full server response arrives. The green “thinking” bar overlaps with the blue “content download” bar, allowing both the browser and server to be preparing the page at the same time. No more waiting. This is what Early Hints is all about!
“Entrepreneurs know that first impressions matter. Shopify’s own data shows that on average, when a store improves the speed of the first page in the buyer journey by 10%, there is a 7% increase in conversion. We see great promise in Early Hints being another tool to help improve the performance and experience for all merchants and customers.” — Colin Bendell, Director Performance Engineering at Shopify
How does Early Hints speed things up?
Early Hints is a status code used in non-final HTTP responses. It is designed to speed up overall page load times by giving the browser an early signal about what certain linked assets might appear in the final response. The browser takes those hints and begins preparing the page for when the final 200 OK response from the server arrives.
The RFC provides this example of how the request/response cycle will look with Early Hints:
Seems simple enough. We’ve neatly communicated information to the browser on what resources it should consider preloading while the server is computing a full response.
This isn’t a new idea though!
Didn’t server push try to solve this problem?
There have been previous attempts at solving this problem, notably HTTP/2 “server push”. However, server push suffered from two major problems:
Server push sent the wrong bytes at the wrong time
The server pushed assets to the client, without great awareness of what was already present in browser caches, without knowing how much “server think time” would elapse and how best to spend it. Web performance guru Pat Meenan summarized server push’s gotchas in a mail thread discussing Chrome’s intent to deprecate and remove server push support:
Push sounds like a great solution, particularly when it can be done intelligently to not push resources already in cache and if it can exactly only fill the wait time while a CDN edge goes back to an origin for the HTML but getting those conditions right in practice is extremely rare. In virtually every case I have seen, the pushed resources end up delaying the HTML itself, the CSS and other render-blocking resources. Delaying the HTML is particularly bad because it delays the browser’s discovery of all of the other resources on the page. Preload works with the normal document parsing and resource discovery, letting preloaded resources intermix with other important resources and giving the dev, browsers and origins more control over prioritization.
Early Hints avoids these issues by “hinting” (vs. push being dictatorial) to clients which assets they should load, allowing them to prioritize resource loads with more complete information about what they will likely need to render a page, what they have cached, and other heuristics.
Using Early Hints with “rel=preload” solves the unsolicited bytes problem, but can still suffer from the ordering issue (forcing clients to load the wrong bytes at the wrong time). Early Hints’ superpower may actually be its use in conjunction with “rel=preconnect”. Many pages load hundreds of third party resources, and setting up connections and TLS sessions with each outside origin is time (but not bandwidth) intensive. Setting up these third party origin connections early, during think time, has practical advantages for page loading experience without the potential collateral damage of using “rel=preload”.
Server push wasn’t broadly implemented
The other notable issue with Server Push was that browsers supported it, and some origin servers implemented the feature, but no major CDN products (Cloudflare’s included) deemed the feature promising enough to implement and support at scale. Support for standards like server push or Early Hints in each key piece of the web content supply chain is critical for mass adoption.
Cracking the chicken and egg problem
Standards like Early Hints often don’t get off the ground because of this chicken and egg problem: clients have no reason to support new standards without server support and servers have no reason to implement support without clients speaking their language. As previously discussed, Early Hints is particularly complicated for origins to directly support, because 103 is an unfamiliar status code and multiple responses to a single request may not be a well-supported pattern in common HTTP server and application stacks.
We’ve tackled this in a few ways:
Close partnership with Google Chrome and other browser teams to build support for the same standard at the same time, ensuring a critical mass of adoption for Early Hints from day one.
Developing ways for hints to be emitted by our edge to clients with support for the standard without requiring support for the standard from the origin. We’ve been fortunate to have a ready, willing, and able design partner in Shopify, whose performance engineering team has been instrumental in shaping our implementation and testing our production deployment.
We plan to support Early Hints in two ways: one enabled now, and the other coming soon.
Now: Turning 200 OK Link: headers into 103 Early Hints
To avoid requiring origins to emit 103 responses from their origins directly, we settled on an approach that takes advantage of something many customers already used to indicate which assets an HTML page depends on, the Link: response header.
When Cloudflare gets a response from the origin, we will parse it for Link headers with preload or preconnect rel types. These rel types indicate to the browser that the asset should be loaded as soon as possible (preload), or that a connection should be established to the specified origin but no bytes should be transferred (preconnect).
Cloudflare takes these headers and caches them at our edge, ready to be served as a 103 Early Hints payload.
When subsequent requests come for that asset, we immediately send the browser the cached Early Hints response while proxying the request to the origin server to generate the full response.
Cloudflare then proxies the full response from origin to the browser when it’s available.
When the full response is available, it will contain Link headers (that’s how we started this whole story). We will compare the Link headers in the 200 response with the cached version to make sure that they are the most up to date. If they have changed since they’ve been cached, we will automatically purge the out-of-date Early Hints and re-cache the new ones.
Coming soon: Smart Early Hints generation at the edge
We’re working hard on the next version of Early Hints. Smart Early Hints will use machine learning to generate Early Hints even when there isn’t a Link header present in the response from which we can harvest a 103. By analyzing historical request/response cycles for our customers, we can infer what assets being preloaded would help browsers load a webpage more quickly.
Look for Smart Early Hints in the next few months.
Browser support
As previously mentioned, we’ve partnered closely with Google Chrome and other browser vendors to ensure that their implementations of Early Hints interoperate well with Cloudflare’s. Google Chrome, Microsoft Edge, and Mozilla Firefox have announced their intention to support Early Hints. Progress for this support can be tracked here and here. We expect more browsers to announce support soon.
Benchmarking the impact of Early Hints
Once you get accepted into the beta and enable the feature, you can see Early Hints in action using Google Chrome, version 94 or higher. As of Sept 16th 2021, the Chrome Dev channel is at version 94.
Testing Early Hints with Chrome version 94 or higher
Early Hints support is available in Chrome by running (assuming a Mac, but the same flag works on Windows or Linux):
open /Applications/Google\ Chrome\ Dev.app --args --enable-features=EarlyHintsPreloadForNavigation
Specify the desired test URL. It should have the necessary preload/preconnect rel types in the Link header of the response.
Choose Chrome Canary (or any Chrome version higher than 94) for the browser
Under advanced settings, select Chromium.
At the bottom of the Chromium section there’s a command-line section where you should paste Chrome’s Early Hints flag: --enable-features=EarlyHintsPreloadForNavigation.
To see the page load comparison, you can remove this flag and Early Hints won’t be enabled.
Using Web Page Test, we’ve been able to observe greater than 30% improvement to a page’s content loading in the browser as measured by Largest Contentful Paint (LCP). An example test filmstrip:
A few other considerations when testing…
Chrome will not support Early Hints on HTTP/1.1 (or earlier protocols).
Chrome will not support Early Hints on subresource requests.
We encourage testers to see how different rel types improve performance along with other Cloudflare performance enhancements like Argo.
It can be hard to see which resources are actually being loaded early as a result of Early Hints. Interrogating the ResourceTiming API will return initiator=EarlyHints for those assets.
Signing up for the Early Hints beta
Early Hints promises to revolutionize web performance. Support for the standard is live at our edge globally and is being tested by customers hungry for speed.
Locate the Early Hints beta sign up card and request access. We’re enabling access for users on the beta list in batches.
Early Hints holds tremendous promise to speed up everyone’s experience on the web. It’s exactly the kind of product we like working on at Cloudflare and exactly the kind of feature we think should be free, for everyone. Be sure to check out the beta and let us know what you think.
You can explore our beta implementation in the Speed tab. And if you’re an engineer interested in improving the performance of the web for all, come join us!
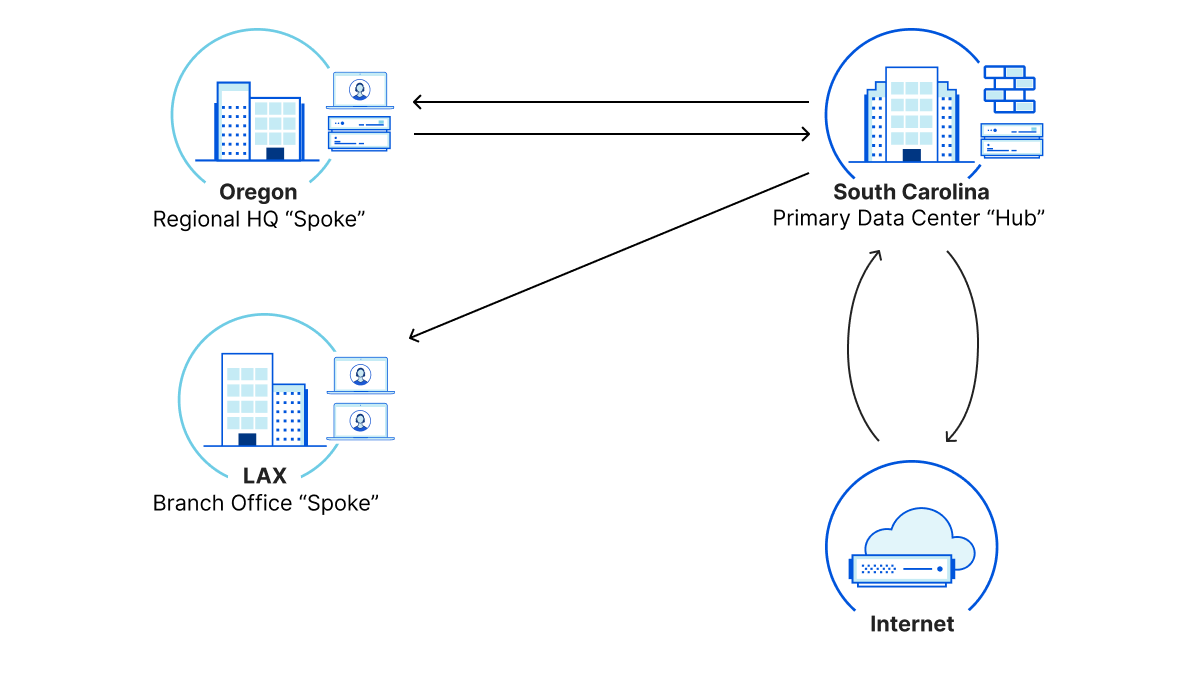
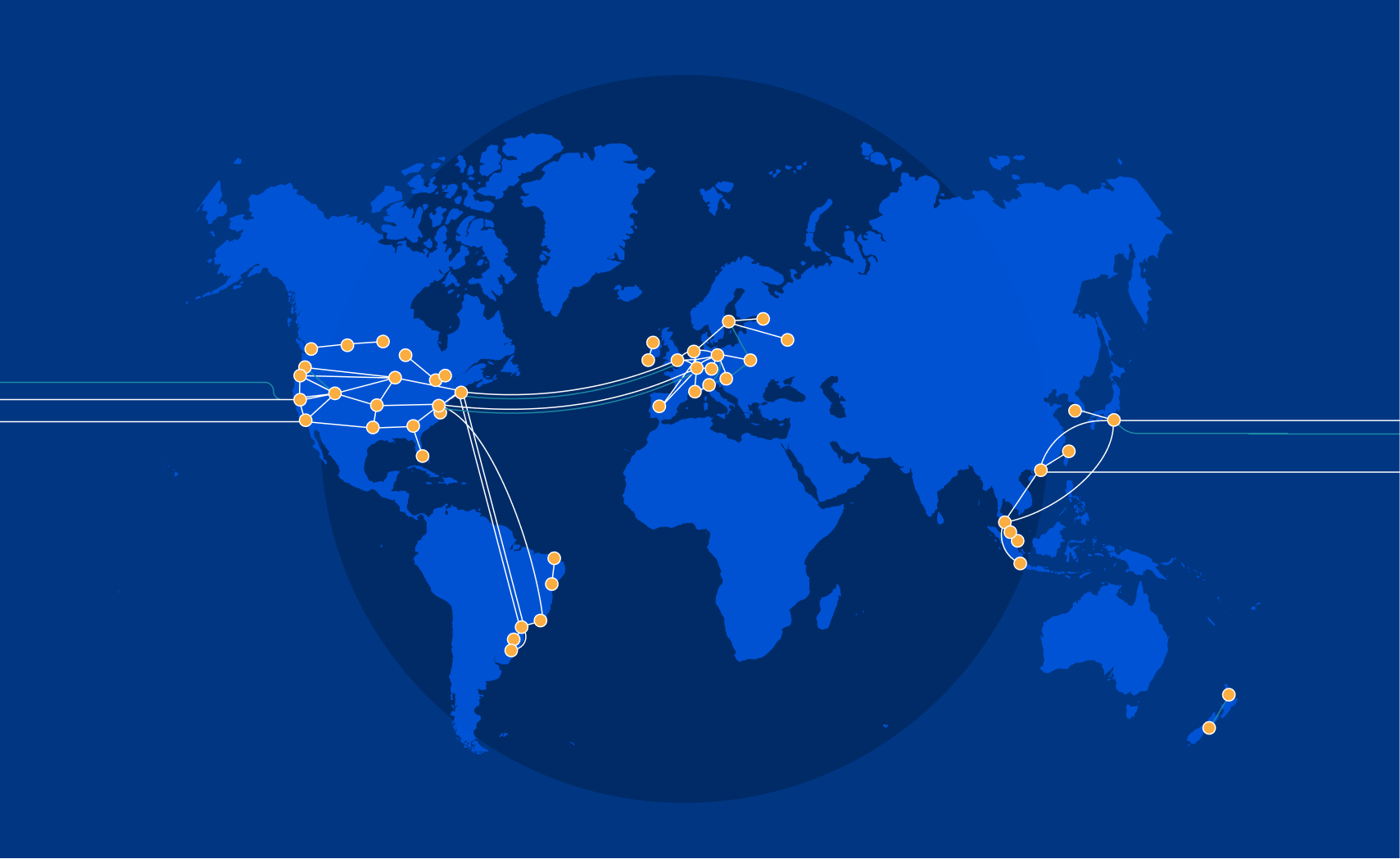
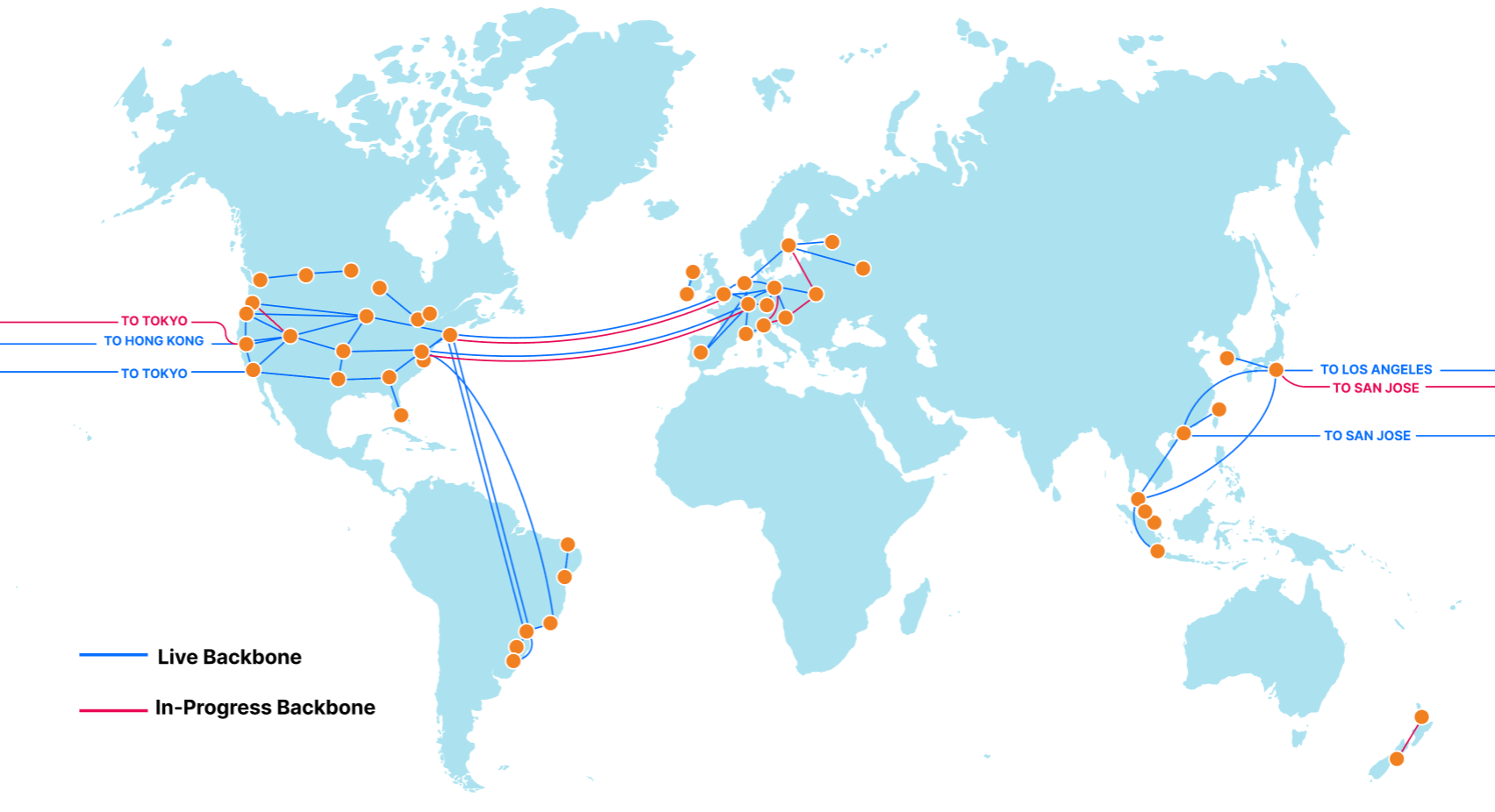
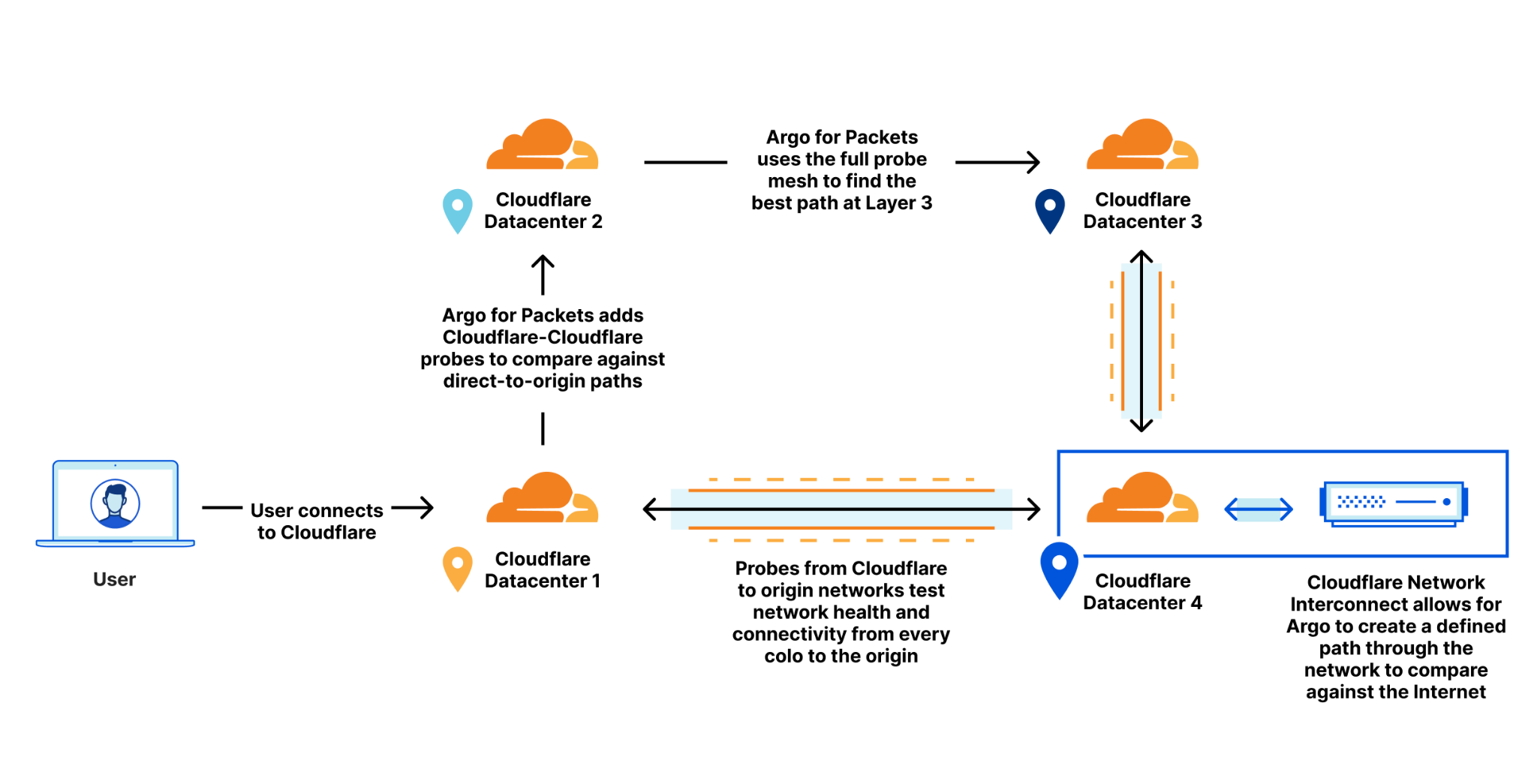
We launched Magic Transit two years ago, followed more recently by its siblings Magic WAN and Magic Firewall, and have talked at length about how this suite of products helps security teams sleep better at night by protecting entire networks from malicious traffic. Today, as part of Speed Week, we’ll break down the other side of the Magic: how using Cloudflare can automatically make your entire network faster. Our scale and interconnectivity, use of data to make more intelligent routing decisions, and inherent architecture differences versus traditional networks all contribute to performance improvements across all IP traffic.
What is Magic?
Cloudflare’s “Magic” services help customers connect and secure their networks without the cost and complexity of maintaining legacy hardware. Magic Transit provides connectivity and DDoS protection for Internet-facing networks; Magic WAN enables customers to replace legacy WAN architectures by routing private traffic through Cloudflare; and Magic Firewall protects all connected traffic with a built-in firewall-as-a-service. All three share underlying architecture principles that form the basis of the performance improvements we’ll dive deeper into below.
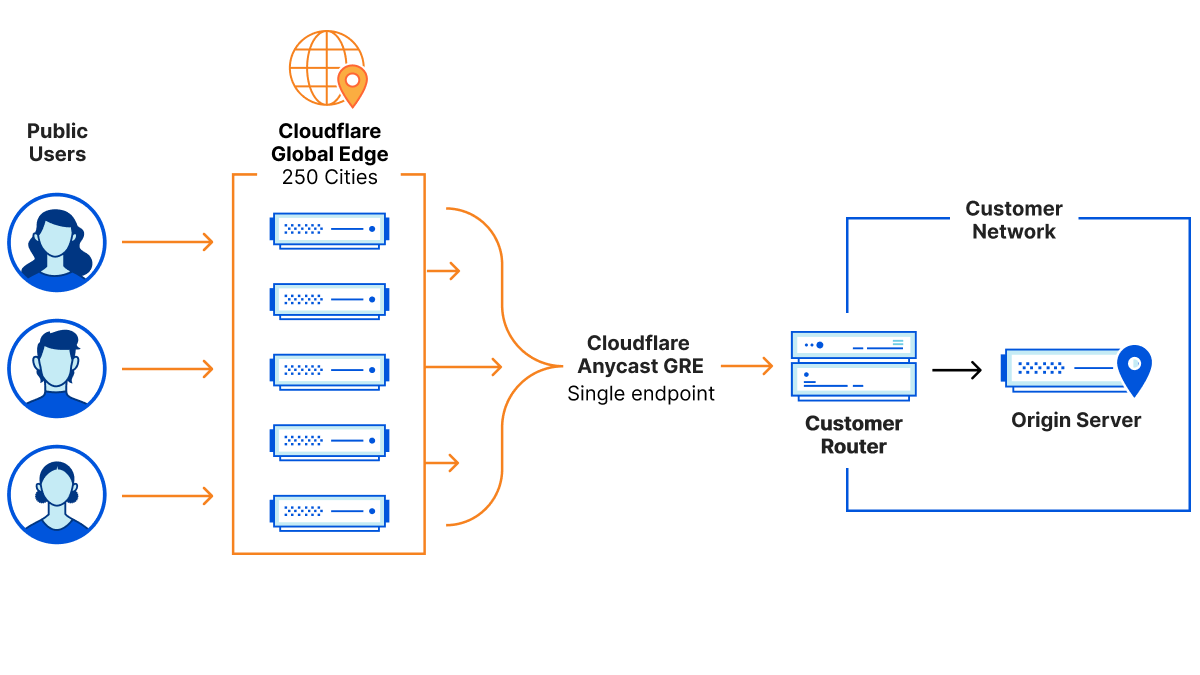
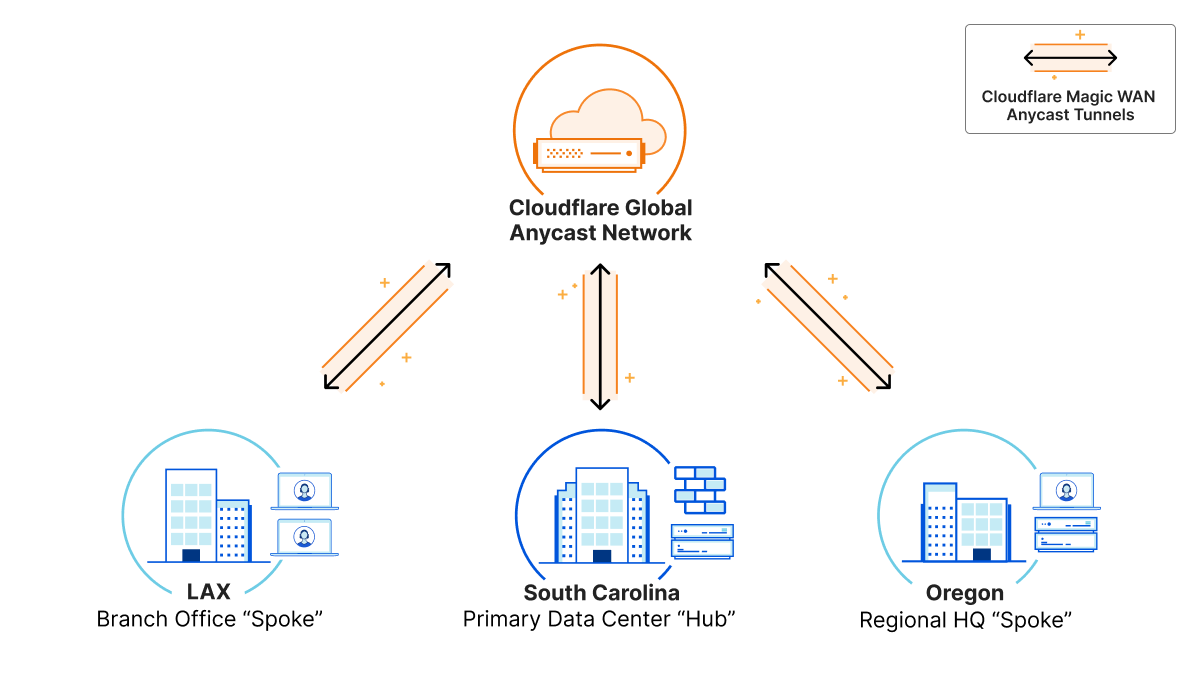
Anycast everything
In contrast to traditional “point-to-point” architecture, Cloudflare uses Anycast GRE or IPsec (coming soon) tunnels to send and receive traffic for customer networks. This means that customers can set up a single tunnel to Cloudflare, but effectively get connected to every single Cloudflare location, dramatically simplifying the process to configure and maintain network connectivity.
Every service everywhere
In addition to being able to send and receive traffic from anywhere, Cloudflare’s edge network is also designed to run every service on every server in every location. This means that incoming traffic can be processed wherever it lands, which allows us to block DDoS attacks and other malicious traffic within seconds, apply firewall rules, and route traffic efficiently and without bouncing traffic around between different servers or even different locations before it’s dispatched to its destination.
Zero Trust + Magic: the next-gen network of the future
With Cloudflare One, customers can seamlessly combine Zero Trust and network connectivity to build a faster, more secure, more reliable experience for their entire corporate network. Everything we’ll talk about today applies even more to customers using the entire Cloudflare One platform – stacking these products together means the performance benefits multiply (check out our post on Zero Trust and speed from today for more on this).
More connectivity = faster traffic
So where does the Magic come in? This part isn’t intuitive, especially for customers using Magic Transit in front of their network for DDoS protection: how can adding a network hop subtract latency?
The answer lies in Cloudflare’s network architecture — our web of connectivity to the rest of the Internet. Cloudflare has invested heavily in building one of the world’s most interconnected networks (9800 interconnections and counting, including with major ISPs, cloud services, and enterprises). We’re also continuing to grow our own private backbone and giving customers the ability to directly connect with us. And our expansive connectivity to last mile providers means we’re just milliseconds away from the source of all your network traffic, regardless of where in the world your users or employees are.
This toolkit of varying connectivity options means traffic routed through the Cloudflare network is often meaningfully faster than paths across the public Internet alone, because more options available for BGP path selection mean increased ability to choose more performant routes. Imagine having only one possible path between your house and the grocery store versus ten or more – chances are, adding more options means better alternatives will be available. A cornucopia of connectivity methods also means more resiliency: if there’s an issue on one of the paths (like construction happening on what is usually the fastest street), we can easily route around it to avoid impact to your traffic.
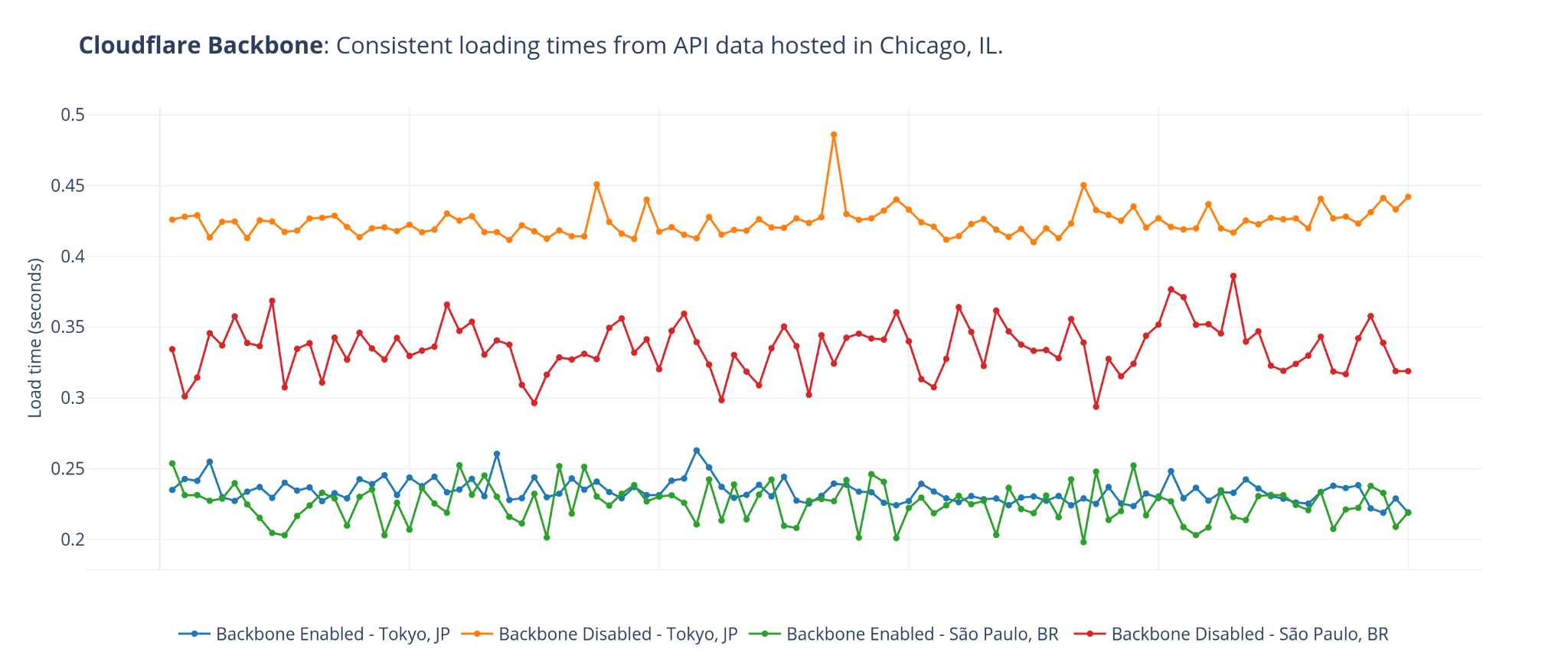
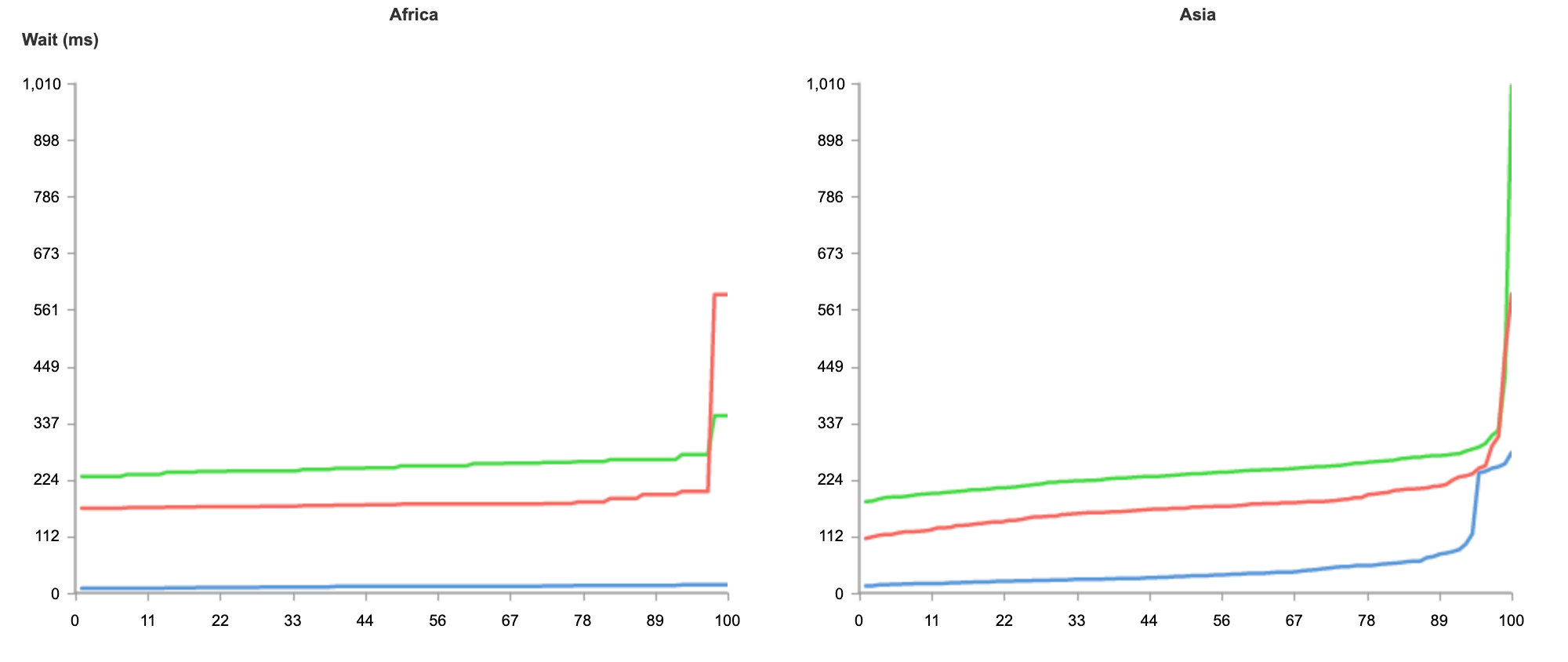
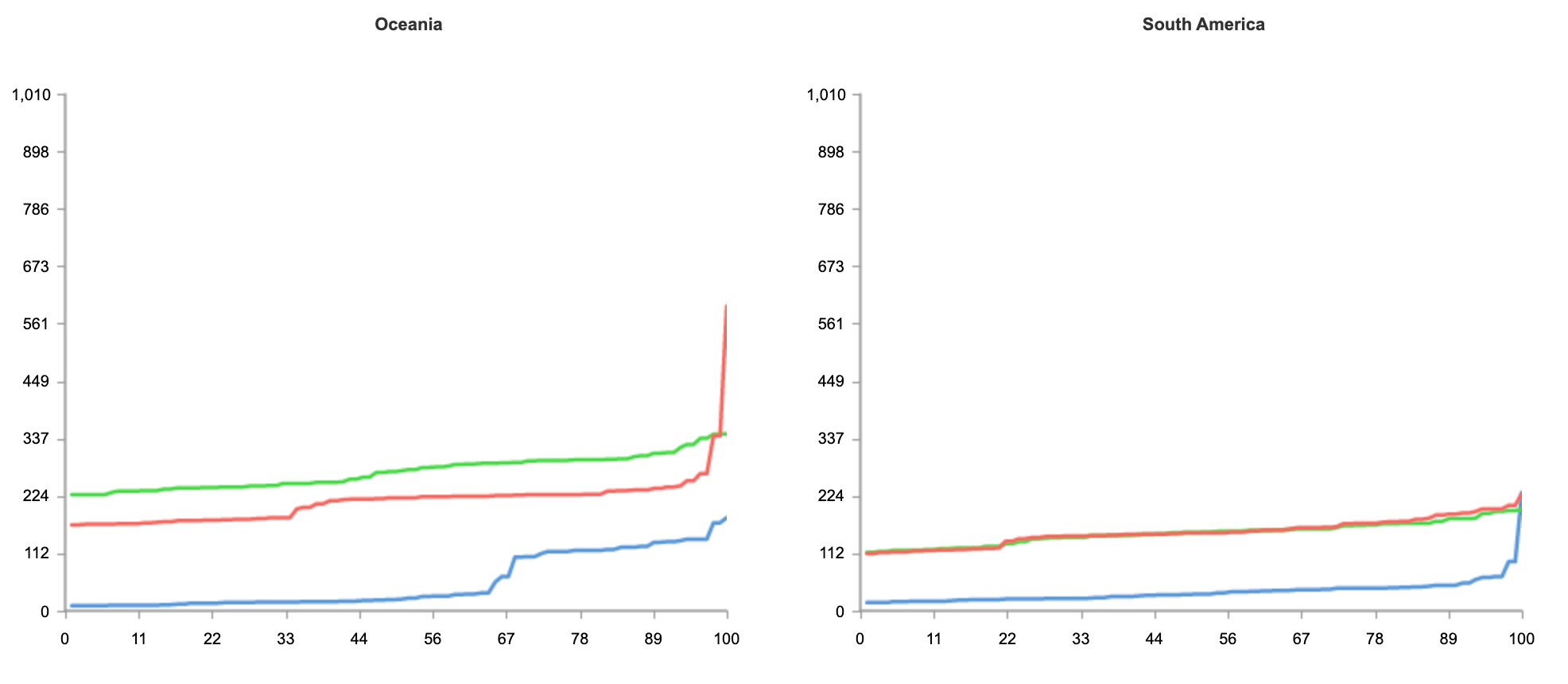
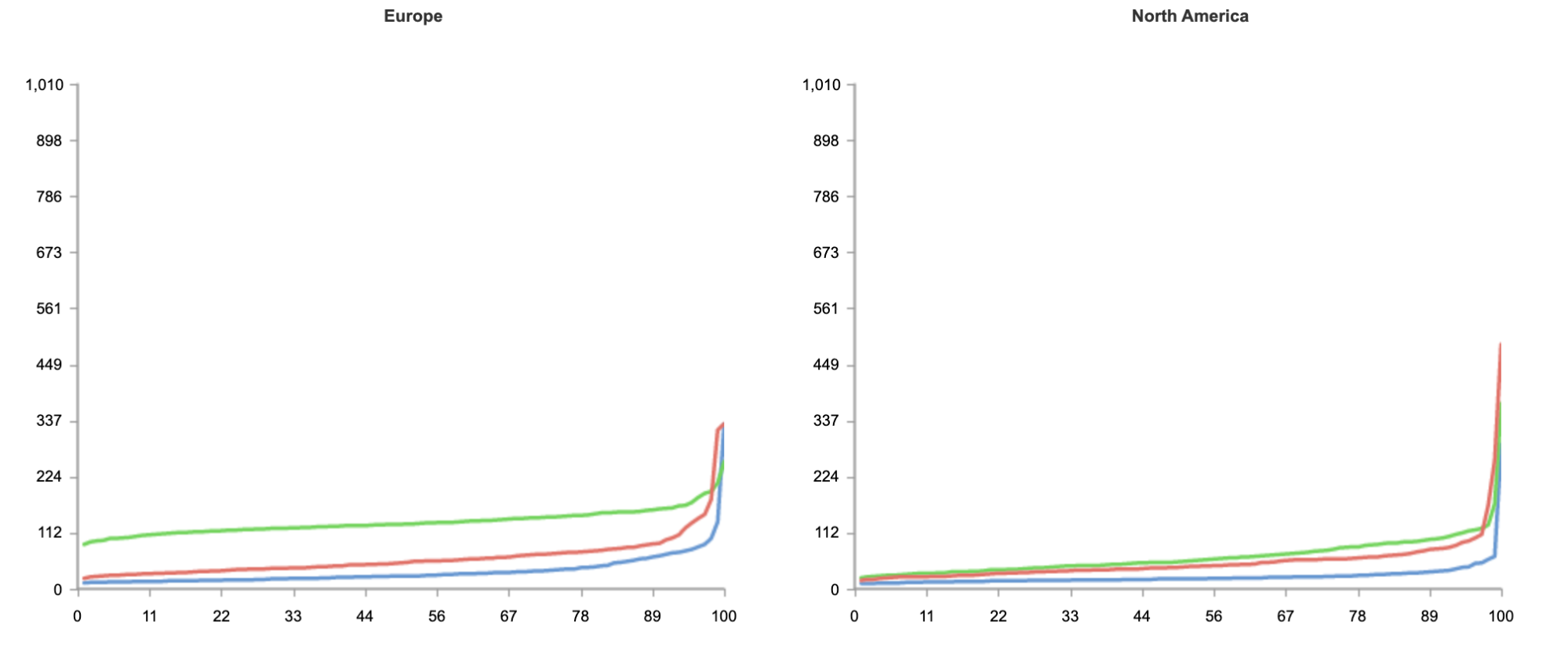
One common comparison customers are interested in is latency for inbound traffic. From the end user perspective, does routing through Cloudflare speed up or slow down traffic to networks protected by Magic Transit? Our response: let’s test it out and see! We’ve repeatedly compared Magic Transit vs standard Internet performance for customer networks across geographies and industries and consistently seen really exciting results. Here’s an example from one recent test where we used third-party probes to measure the ping time to the same customer network location (their data center in Qatar) before and after onboarding with Magic Transit:
Probe location
RTT w/o Magic (ms)
RTT w/ Magic (ms)
Difference (ms)
Difference (% improvement)
Dubai
27
23
4
13%
Marseille
202
188
13
7%
Global (results averaged across 800+ distributed probes)
194
124
70
36%
All of these results were collected without the use of Argo Smart Routing for Packets, which we announced on Tuesday. Early data indicates that networks using Smart Routing will see even more substantial gains.
Modern architecture eliminates traffic trombones
In addition to the performance boost available for traffic routed across the Cloudflare network versus the public Internet, customers using Magic products benefit from a new architecture model that totally removes up to thousands of miles worth of latency.
Traditionally, enterprises adopted a “hub and spoke” model for granting employees access to applications within and outside their network. All traffic from within a connected network location was routed through a central “hub” where a stack of network hardware (e.g. firewalls) was maintained. This model worked great in locations where the hub and spokes were geographically close, but started to strain as companies became more global and applications moved to the cloud.
Now, networks using hub and spoke architecture are often backhauling traffic thousands of miles, between continents and across oceans, just to apply security policies before packets are dispatched to their final destination, which is often physically closer to where they started! This creates a “trombone” effect, where precious seconds are wasted bouncing traffic back and forth across the globe, and performance problems are amplified by packet loss and instability along the way.
Network and security teams have tried to combat this issue by installing hardware at more locations to establish smaller, regional hubs, but this quickly becomes prohibitively expensive and hard to manage. The price of purchasing multiple hardware boxes and dedicated private links adds up quickly, both in network gear and connectivity itself as well as the effort required to maintain additional infrastructure. Ultimately, this cost usually outweighs the benefit of the seconds regained with shorter network paths.
The “hub” is everywhere
There’s a better way — with the Anycast architecture of Magic products, all traffic is automatically routed to the closest Cloudflare location to its source. There, security policies are applied with single-pass inspection before traffic is routed to its destination. This model is conceptually similar to a hub and spoke, except that the hub is everywhere: 95% of the entire Internet-connected world is within 50 ms of a Cloudflare location (check out this week’s updates on our quickly-expanding network presence for the latest). This means instead of tromboning traffic between locations, it can stop briefly at a Cloudflare hop in-path before it goes on its way: dramatically faster architecture without compromising security.
To demonstrate how this architecture shift can make a meaningful difference, we created a lab to mirror the setup we’ve heard many customers describe as they’ve explained performance issues with their existing network. This example customer network is headquartered in South Carolina and has branch office locations on the west coast, in California and Oregon. Traditionally, traffic from each branch would be backhauled through the South Carolina “hub” before being sent on to its destination, either another branch or the public Internet.
In our alternative setup, we’ve connected each customer network location to Cloudflare with an Anycast GRE tunnel, simplifying configuration and removing the South Carolina trombone. We can also enforce network and application-layer filtering on all of this traffic, ensuring that the faster network path doesn’t compromise security.
Here’s a summary of results from performance tests on this example network demonstrating the difference between the traditional hub and spoke setup and the Magic “global hub” — we saw up to 70% improvement in these tests, demonstrating the dramatic impact this architecture shift can make.
LAX <> OR (ms)
ICMP round-trip for “Regular” (hub and spoke) WAN
127
ICMP round-trip for Magic WAN
38
Latency savings for Magic WAN vs “Regular” WAN
70%
This effect can be amplified for networks with globally distributed locations — imagine the benefits for customers who are used to delays from backhauling traffic between different regions across the world.
Getting smarter
Adding more connectivity options and removing traffic trombones provide a performance boost for all Magic traffic, but we’re not stopping there. In the same way we leverage insights from hundreds of billions of requests per day to block new types of malicious traffic, we’re also using our unique perspective on Internet traffic to make more intelligent decisions about routing customer traffic versus relying on BGP alone. Earlier this week, we announced updates to Argo Smart Routing including the brand-new Argo Smart Routing for Packets. Customers using Magic products can enable it to automatically boost performance for any IP traffic routed through Cloudflare (by 10% on average according to results so far, and potentially more depending on the individual customer’s network topology) — read more on this in the announcement blog.
What’s next?
The modern architecture, well-connected network, and intelligent optimizations we’ve talked about today are just the start. Our vision is for any customer using Magic to connect and protect their network to have the best performance possible for all of their traffic, automatically. We’ll keep investing in expanding our presence, interconnections, and backbone, as well as continuously improving Smart Routing — but we’re also already cooking up brand-new products in this space to deliver optimizations in new ways, including WAN Optimization and Quality of Service functions. Stay tuned for more Magic coming soon, and get in touch with your account team to learn more about how we can help make your network faster starting today.
The Internet is an amazing place. It’s a communication superhighway, allowing people and machines to exchange exabytes of information every day. But it’s not without its share of issues: whether it’s DDoS attacks, route leaks, cable cuts, or packet loss, the components of the Internet do not always work as intended.
The reason Cloudflare exists is to help solve these problems. As we continue to grow our rapidly expanding global network in more than 250 cities, while directly connecting with more than 9,800 networks, it’s important that our network continues to help bring improved performance and resiliency to the Internet. To accomplish this, we built our own backbone. Other than improving redundancy, the immediate advantage to you as a Cloudflare user? It can reduce your website loading times by up to 45% — and you don’t have to do a thing.
The Cloudflare Backbone
We began building out our global backbone in 2018. It comprises a network of long-distance fiber optic cables connecting various Cloudflare data centers across North America, South America, Europe, and Asia. This also includes Cloudflare’s metro fiber network, directly connecting data centers within a metropolitan area.
Our backbone is a dedicated network, providing guaranteed network capacity and consistent latency between various locations. It gives us the ability to securely, reliably, and quickly route packets between our data centers, without having to rely on other networks.
This dedicated network can be thought of as a fast lane on a busy highway. When traffic in the normal lanes of the highway encounter slowdowns from congestion and accidents, vehicles can make use of a fast lane to bypass the traffic and get to their destination on time.
Our software-defined network is like a smart GPS device, as we’re always calculating the performance of routes between various networks. If a route on the public Internet becomes congested or unavailable, our network automatically adjusts routing preferences in real-time to make use of all routes we have available, including our dedicated backbone, helping to deliver your network packets to the destination as fast as we can.
Measuring backbone improvements
As we grow our global infrastructure, it’s important that we analyze our network to quantify the impact we’re having on performance.
Here’s a simple, real-world test we’ve used to validate that our backbone helps speed up our global network. We deployed a simple API service hosted on a public cloud provider, located in Chicago, Illinois. Once placed behind Cloudflare, we performed benchmarks from various geographic locations with the backbone disabled and enabled to measure the change in performance.
Instead of comparing the difference in latency our backbone creates, it is important that our experiment captures a real-world performance gain that an API service or website would experience. To validate this, our primary metric is measuring the average request time when accessing an API service from Miami, Seattle, San Jose, São Paulo, and Tokyo. To capture the response of the network itself, we disabled caching on the Cloudflare dashboard and sent 100 requests from each testing location, both while forcing traffic through our backbone, and through the public Internet.
Now, before we claim our backbone solves all Internet problems, you can probably notice that for some tests (Seattle, WA and San Jose, CA), there was actually an increase in response time when we forced traffic through the backbone. Since latency is directly proportional to the distance of fiber optic cables, and since we have over 9,800 direct connections with other Internet networks, there is a possibility that an uncongested path on the public Internet might be geographically shorter, causing this speedup compared to our backbone.
Luckily for us, we have technologies like Argo Smart Routing, Argo Tiered Caching, WARP+, and most recently announced Orpheus, which dynamically calculates the performance of each route at our data centers, choosing the fastest healthy route at that time. What might be the fastest path during this test may not be the fastest at the time you are reading this.
With that disclaimer out of the way, now onto the test.
With the backbone disabled, if a visitor from São Paulo performed a request to our service, they would be routed to our São Paulo data center via BGP Anycast. With caching disabled, our São Paulo data center forwarded the request over the public Internet to the origin server in Chicago. On average, the entire process to fetch data from the origin server and return to the response to the requesting user took 335.8 milliseconds.
Once the backbone was enabled and requests were created, our software performed tests to determine the fastest healthy route to the origin, whether it was a route on the public Internet or through our private backbone. For this test the backbone was faster, resulting in an average total request time of 230.2 milliseconds. Just by routing the request through our private backbone, we improved the average response time by 31%.
We saw even better improvement when testing from Tokyo. When routing the request over the public Internet, the request took an average of 424 milliseconds. By enabling our backbone which created a faster path, the request took an average of 234 milliseconds, creating an average response time improvement of 44%.
Visitor Location
Distance to Chicago
Avg. response time using public Internet (ms)
Avg. response using backbone (ms)
Change in response time
Miami, FL, US
1917 km
84
75
10.7% decrease
Seattle, WA, US
2785 km
118
124
5.1% increase
San Jose, CA, US
2856 km
122
132
8.2% increase
São Paulo, BR
8403 km
336
230
31.5% decrease
Tokyo JP
10129 km
424
234
44.8% decrease
We also observed a smaller deviation in the response time of packets routed through our backbone over larger distances.
Our next generation network
Cloudflare is built on top of lossy, unreliable networks that we do not have control over. It’s our software that turns these traditional tubes of the Internet into a smart, high performing, and reliable network Cloudflare customers get to use today. Coupled with our new, but rapidly expanding backbone, it is this software that produces significant performance gains over traditional Internet networks.
Whether you visit a website powered by Cloudflare’s Argo Smart Routing, Argo Tiered Caching, Orpheus, or use our 1.1.1.1 service with WARP+ to access the Internet, you get direct access to the Internet fast lane we call the Cloudflare backbone.
For Cloudflare, a better Internet means improving Internet security, reliability, and performance. The backbone gives us the ability to build out our network in areas that have typically lacked infrastructure investments by other networks. Even with issues on the public Internet, these initiatives allow us to be located within 50 milliseconds of 95% of the Internet connected population.
In addition to our growing global infrastructure providing 1.1.1.1, WARP, Roughtime, NTP, IPFS Gateway, Drand, and F-Root to the greater Internet, it’s important that we extend our services to those who are most vulnerable. This is why we extend all our infrastructure benefits directly to the community, through projects like Galileo, Athenian, Fair Shot, and Pangea.
And while these thousands of fiber optic connections are already fixing today’s Internet issues, we truly are just getting started.
Want to help build the future Internet? Networks that are faster, safer, and more reliable than they are today? The Cloudflare Infrastructure team is currently hiring!
If you operate an ISP or transit network and would like to bring your users faster and more reliable access to websites and services powered by Cloudflare’s rapidly expanding network, please reach out to our Edge Partnerships team at [email protected].
“The last 20% of the work requires 80% of the effort.” The Pareto Principle applies in many domains — nowhere more so on the Internet, however, than on the Last Mile. Last Mile networks are heterogeneous and independent of each other, but all of them need to be running to allow for everyone to use the Internet. They’re typically the responsibility of Internet Service Providers (ISPs). However, if you’re an organization running a mission-critical service on the Internet, not paying attention to Last Mile networks is in effect handing off responsibility for the uptime and performance of your service over to those ISPs.
Probably not the best idea.
When a customer puts a service on Cloudflare, part of our job is to offer a good experience across the whole Internet. We couldn’t do that without focusing on Last Mile networks. In particular, we’re focused on two things:
Cloudflare needs to have strong connectivity to Last Mile ISPs and needs to be as close as possible to every Internet-connected person on the planet.
Cloudflare needs good observability tools to know when something goes wrong, and needs to be able to surface that data to you so that you can be informed.
Today, we’re excited to announce Last Mile Insights, to help with this last problem in particular. Last Mile Insights allows customers to see where their end-users are having trouble connecting to their Cloudflare properties. Cloudflare can now show customers the traffic that failed to connect to Cloudflare, where it failed to connect, and why. If you’re an enterprise Cloudflare customer, you can sign up to join the beta in the Cloudflare Dashboard starting today: in the Analytics tab under Edge Reachability.
The Last Mile is historically the most complicated, least understood, and in some ways the most important part of operating a reliable network. We’re here to make it easier.
What is the Last Mile?
The Last Mile is the connection between your home and your ISP. When we talk about how users connect to content on the Internet, we typically do it like this:
This is useful, but in reality, there are lots of things in the path between a user and anything on the Internet. Say that a user is connecting to a resource hosted behind Cloudflare. The path would look like this:
Cloudflare is a global Anycast network that takes traffic from the Internet and proxies it to your origin. Because we function as a proxy, we think of the life of a request in two legs: before it reaches Cloudflare (end users to Cloudflare), and after it reaches Cloudflare (Cloudflare to origin). However, in Internet parlance, there are generally three legs: the First Mile tends to represent the path from an origin server to the data that you are requesting. The Middle Mile represents the path from an origin server to any proxies or other network hops. And finally, there is the final hop from the ISP to the user, which is known as the Last Mile.
Issues with the Last Mile are difficult to detect. If users are unable to reach something on the Internet, it is difficult for the resource to report that there was a problem. This is because if a user never reaches the resource, then the resource will never know something is wrong. Multiply that one problem across hundreds of thousands of Last Mile ISPs coming from a diverse set of regions, and it can be really hard for services to keep track of all the possible things that can go wrong on the Internet. The above graphic actually doesn’t really reflect the scope of the problem, so let’s revise it a bit more:
It’s not an easy problem to keep on top of.
Brand New Last Mile Insights
Cloudflare is launching a closed beta of a brand new Last Mile reporting tool, Last Mile Insights. Last Mile Insights allows for customers to see where their end-users are having trouble connecting to their Cloudflare properties. Cloudflare can now show customers the traffic that failed to connect to Cloudflare, where it failed to connect, and why.
Access to this data is useful to our customers because when things break, knowing what is broken and why — and then communicating with your end users — is vital. During issues, users and employees may create support/helpdesk tickets and social media posts to understand what’s going on. Knowing what is going on, and then communicating effectively about what the problem is and where it’s happening, can give end users confidence that issues are identified and being investigated… even if the issues are occurring on a third party network. Beyond that, understanding the root of the problem can help with mitigations and speed time to resolution.
How do Last Mile Insights work?
Our Last Mile monitoring tools use a combination of signals and machine learning to detect errors and performance regressions on the Last Mile.
Among the signals: Network Error Logging (NEL) is a browser-based reporting system that allows users’ browsers to report connection failures to an endpoint specified by the webpage that failed to load. When a user is able to connect to Cloudflare on a site with NEL enabled, Cloudflare will pass back two headers that indicate to the browser that they should report any network failures to an endpoint specified in the headers. The browser will then operate as usual, and if something happens that prevents the browser from being able to connect to the site, it will log the failure as a report and send it to the endpoint. This all happens in real time; the endpoint receives failure reports instantly after the browser experiences them.
The browser can send failure reports for many reasons: it could send reports because the TLS certificate was incorrect, the ISP or an upstream transit was having issues on the request path, the terminating server was overloaded and dropping requests, or a data center was unreachable. The W3C specification outlines specific buckets that the browser should break reports into and uploads those as reasons the browser could not connect. So the browser is literally telling the reporting endpoint why it was unable to reach the desired site. Here’s an example of a sample report a browser gives to Cloudflare’s endpoint:
The report itself is a JSON blob that contains a lot of things, but the things we care about are when in the request the failure occurred (phase), why the request failed (tcp.timed_out), the ASN the request came over, and the metro area where the request came from. This information allows anyone looking at the reports to see where things are failing and why. Personal Identifiable Information is not captured in NEL reports. For more information, please see our KB article on NEL.
Many services can operate their own reporting endpoints and set their own headers indicating that users who connect to their site should upload these reports to the endpoint they specify. Cloudflare is also an operator of one such endpoint, and we’re excited to open up the data collected by us for customer use and visibility. Let’s talk about a customer who used Last Mile Insights to help make a bad day on the Internet a little better.
Case Study: Canva
Canva is a Cloudflare customer that provides a design and collaboration platform hosted in the cloud. With more than 60 million users around the world, having constant access to Canva’s platform is critical. Last year, Canva users connecting through Cox Communications in San Diego started to experience connectivity difficulties. Around 50% of Canva’s users connecting via Cox Communications saw disconnects during that time period, and these users weren’t able to access Canva or Cloudflare at all. This wasn’t a Canva or Cloudflare outage, but rather, was caused by Cox routing traffic destined for Canva incorrectly, and causing errors for mutual Cox/Canva customers as a result.
Normally, this scenario would have taken hours to diagnose and even longer to mitigate. Canva would’ve seen a slight drop in traffic, but as the outage wasn’t on Canva’s side, it wouldn’t have flagged any alerts based on traffic drops. Canva engineers, in this case, would be notified by the users which would then be followed by a lengthy investigation to diagnose the problem.
Fortunately, Cloudflare has invested in monitoring systems to proactively identify issues exactly like these. Within minutes of the routing anomaly being introduced on Cox’s network, Canva was made aware of the issue via our monitoring, and a conversation with Cox was started to remediate the issue. Meanwhile, Canva could advise their users on the steps to fix it.
Cloudflare is excited to be offering our internal monitoring solution to our customers so that they can see what we see.
But providing insights into seeing where problems happen on the Last Mile is only part of the solution. In order to truly deliver a reliable, fast network, we also need to be as close to end users as possible.
Getting close to users
Getting close to end users is important for one reason: it minimizes the time spent on the Last Mile. These networks can be unreliable and slow. The best way to improve performance is to spend as little time on them as possible. And the only way to do that is to get close to our users. In order to get close to our users, Cloudflare is constantly expanding our presence into new cities and markets. We’ve just announced expansion into new markets and are adding even more new markets all the time to get as close to every network and every user as we can.
This is because not every network is the same. Some users may be clustered very close together in cities with high bandwidth, in others, this may not be the case. Because user populations are not homogeneous, each ISP operates their network differently to meet the needs of their users. Physical distance from where servers are matters a great deal, because nobody can outrun the speed of light. If you’re farther away from the content you want, it will take longer to reach it. But distance is not the only variable; bandwidth and speed will also vary, because networks are operated differently all over the world. But one thing we do know is that your network performance will also be impacted by how healthy your Last Mile network is.
Healthier networks perform better
A healthy network has no downtime, minimal congestion, and low packet loss. These things all add latency. If you’re driving somewhere, street closures, traffic, and bad roads will prevent you from going as fast as possible to where you need to be. Healthy networks provide the best possible conditions for you to connect, and Last Mile performance is better because of it. Consider three networks in the same country: ISP A, ISP B, and ISP C. These ISPs have similar distribution among their users. ISP A is healthy and is directly connected with Cloudflare. ISP B is healthy but is not directly connected to Cloudflare. ISP C is an unhealthy network. Our data shows that Last Mile latencies for ISP C are significantly slower than Network A or B because the network quality of ISP C is worse.
This box plot shows that the latencies to Cloudflare for ISP C are 360% higher than ISPs A or B.
We want all networks to be like Network A, but that’s not always the case, and it’s something Cloudflare can’t control. The only thing Cloudflare can do to mitigate performance problems like these is to limit how much time you spend on these networks.
Shrinking the Last Mile gives better performance
By placing data centers close to our users, we reduce the amount of time spent on these Last Mile networks, and the latency between end users and Cloudflare goes down. A great example of this is how bringing up new locations in Africa affected the latency for the Internet-connected population there. Blue shows the latency before these locations were added, and red shows after:
Our efforts globally have brought 95% of the Internet-connected population within 50ms of us:
You will also notice that 80% of the Internet is within 30ms of us. The tail for Last Mile latencies is very long, and every data center we add helps bring that tail closer to great performance. As we expand into more locations and countries, more of the Internet will be even better connected.
But even when the Last Mile is shrunken down by our infrastructure expansions, networks can still have issues that are difficult to detect. Existing logging and monitoring solutions don’t provide a good way to see what the problem is. Cloudflare has built a sophisticated set of tools to identify issues with Last Mile networks outside our control, and help reduce time to resolution for this purpose, and it has already found problems on the Last Mile for our customers.
Cloudflare has unique performance and insight into Last Mile networking
Running an application on the Internet requires customers to look at the whole Internet. Many cloud services optimize latency starting at the first mile and work their way out, because it’s easier to optimize for things they can control. Because the Last Mile is controlled by hundreds or thousands of ISPs, it is difficult to influence how the Last Mile behaves.
Cloudflare is focused on closing performance gaps everywhere, including close to your users and employees. Last mile performance and reliability is critically important to delivering content, keeping employees productive, and all the other things the world depends on the Internet to do. If a Last Mile provider is having a problem, then users connecting to the Internet through them will have a bad day.
Cloudflare’s efforts to provide better Last Mile performance and visibility allow customers to rely on Cloudflare to optimize the Last Mile, making it one less thing they have to think about. Through Last Mile Insights and network expansion efforts — available today in the Cloudflare Dashboard, in the Analytics tab under Edge Reachability — we want to provide you the ability to see what’s really happening on the Internet while knowing that Cloudflare is working on giving your users the best possible Internet experience.
Web Analytics is Cloudflare’s privacy-focused real user measurement solution. It leverages a lightweight JavaScript beacon and does not use any client-side state, such as cookies or localStorage, to collect usage metrics. Nor does it “fingerprint” individuals via their IP address, User Agent string, or any other data.
Cloudflare Web Analytics makes essential web analytics, such as the top-performing pages on your website and top referrers, available to everyone for free, and it’s becoming more powerful than ever.
Focusing on Performance
Earlier this year we merged Web Analytics with our Browser Insights product, which enabled customers proxying their websites through Cloudflare to evaluate visitors’ experience on their web properties through Core Web Vitals such as Largest Contentful Paint (LCP) and First Input Delay (FID).
It was important to bring the Core Web Vitals performance measurements into Web Analytics given the outsized impact that page load times have on bounce rates. A page load time increase from 1s to 3s increases bounce rates by 32% and from 1s to 6s increases it by 106% (source).
Now that you know the impact a slow-loading web page can have on your visitors, it’s time for us to make it a no-brainer to take action. Read on.
Becoming Action-Oriented
We believe that, to deliver the most value to our users, the product should facilitate the following process:
Measure the real user experience
Grade this experience — is it satisfactory or in need of improvement?
Provide actionable insights — what part of the web page should be tweaked to improve the user experience?
Repeat
And it all starts with Web Analytics Vitals Explorer, which started rolling out today.
Introducing Web Analytics Vitals Explorer
Vitals Explorer enables you to easily pinpoint which elements on your pages are affecting users the most, with accurate measurements from the visitors perspective and an easy-to-read impact grading.
To do that, we have automatically updated the Web Analytics JavaScript beacon so that it collects the relevant vital measurements from the browser. As always, we are not collecting any information that would invade your visitors’ privacy.
Usage
Once this new beacon is updated on your sites — and again the update will happen transparently to you — you can then navigate to the Core Web Vitals page on Web Analytics. When entering that page, you will see three graphs grading the user experience for Largest Contentful Paint (LCP), First Input Delay (FID), and Cumulative Layout Shift (CLS). Below each graph you can see the debug section with the top five elements with a negative impact on the metric. Lastly, when clicking on either of these elements shown in the data table, you will be presented with its impact and exact paths so that you can easily decide whether this is worth keeping on your website in its current format.
In addition to this new Core Web Vitals content, we have also added First Paint and First Contentful Paint to the Page Load Time page. When you navigate to this page you will now see the page load summary and a graph representing page load timing. These will allow you to quickly identify any regressions to these important performance metrics.
Measurement details
This additional debugging information for Core Web Vitals is measured during the lifespan of the page (until the user leaves the tab or closes the browser window, which updates visibilityState to a hidden state).
Here’s what we collect:
Common for all Core Web Vitals
Element is a CSS selector representing the DOM node. With this string, the developer can use `document.querySelector(<element_name>)` in their browser’s dev console to find out which DOM node has a negative impact on your scores/values.
Path is the URL path at the time the Core Web Vitals are captured.
Value is the metric value for each Core Web Vitals. This value is in milliseconds for LCP or FID and a score for CLS (Cumulative Layout Shift).
Largest Contentful Paint
URL is the source URL (such as image, text, web fonts).
Size is the source object’s size in bytes.
First Input Delay
Name is the type of event (such as mousedown, keydown, pointerdown).
Cumulative Layout Shift
Layout information is a JSON value that includes width, height, x axis position, y axis position, left, right, top, and bottom. You are able to observe layout shifts that happen on the page by observing these values.
CurrentRect is the largest source element’s layout information after the shift. This JSON value is shown as Current under Layout Shifts section in the Web Analytics UI.
PreviousRect is the largest source element’s layout information before the shift. This JSON value is shown as Previous under Layout Shifts section in the Web Analytics UI.
Paint Timings
Additionally, we have added two important paint timings
First Paint is the time between navigation and when the browser renders the first pixels to the screen.
First Contentful Paint is the time when the browser renders the first bit of content from the DOM.
A lot of this is based on standard browser measurements, which you can read about in detail on this blog post from Google.
Moving forward
And we are by no means done. Moving forward, we will bring this structured approach with grading and actionable insights into as Web Analytics measurements as possible, and keep guiding you through how to improve your visitors’ experience. So stay tuned. And in the meantime, do let us know what you think about this feature and ask questions on the community forums.
Images are a massive part of the Internet. On the median web page, images account for 51% of the bytes loaded, so any improvement made to their speed or their size has a significant impact on performance.
Today, we are excited to announce Cloudflare’s Image Optimization Testing Tool. Simply enter your website’s URL, and we’ll run a series of automated tests to determine if there are any possible improvements you could make in delivering optimal images to visitors.
How users experience speed
Everyone who has ever browsed the web has experienced a website that was slow to load. Often, this is a result of poorly optimized images on that webpage that are either too large for purpose or that were embedded on the page with insufficient information.
Images on a page might take painfully long to load as pixels agonizingly fill in from top-to-bottom; or worse still, they might cause massive shifts of the page layout as the browser learns about their dimensions. These problems are a serious annoyance to users and as of August 2021, search engines punish pages accordingly.
Understandably, slow page loads have an adverse effect on a page’s “bounce rate” which is the percentage of visitors which quickly move off of the page. On e-commerce sites in particular, the bounce rate typically has a direct monetary impact and pages are usually very image-heavy. It is critically important to optimize all the images on your webpages to reduce load on and egress from your origin, to improve your performance in search engine rankings and, ultimately, to provide a great experience for your users.
CLS and LCP are the two metrics we can improve by optimizing images. When CLS is high, this indicates that large amounts of the page layout is shifting as it loads. LCP measures the time it takes for the single largest image or text block in the viewport to render.
One of the most impactful performance improvements a website author can make is ensuring they deliver images with appropriate dimensions. Images taken on a modern camera can be truly massive, and some recent flagship phones have gigantic sensors. The Samsung Galaxy S21 Ultra, for example, has a 108 MP sensor which captures a 12,000 by 9,000 pixel image. That same phone has a screen width of only 1440 pixels. It is physically impossible to show every pixel of the photo on that device: for a landscape photo, only 12% of pixel columns can be displayed.
Embedding this image on a webpage presents the same problem, but this time, that image and all of its unused pixels are sent over the Internet. Ultimately, this creates unnecessary load on the server, higher egress costs, and longer loading times for visitors.. This is exacerbated even further for visitors on mobile since they are often using a slower connection and have limits on their data usage. On a fast 3G connection, that 108 MP photo might consume 26 MB of both the visitor’s data plan and the website’s egress bandwidth, and take more than two minutes to load!
It might be tempting to always deliver images with the highest possible resolution to avoid “blocky” or pixelated images, but when resizing is done correctly, this is not a problem. “Blocky” artifacts typically occur when an image is processed multiple times (for example, an image is repeatedly uploaded and downloaded by users on a platform which compresses that image). Pixelated images occur when an image has been shrunk to a size smaller than the screen it is rendered on.
So, how can website authors avoid these pitfalls and ensure a correctly sized image is delivered to visitors’ devices? There are two main approaches:
Media conditions with srcset and sizes
When embedding an image on a webpage, traditionally the author would simply pass a src attribute on an img tag:
Here, with the srcset attribute, we’re informing the browser that there are three variants of the image, each with a different intrinsic width: 1,500 pixels, 2,000 pixels and the original 12,000 pixels. The browser then evaluates the media conditions in the sizes attribute ( (max-width: 1500px) and (max-width: 2000px)) in order to select the appropriate image variant from the srcset attribute. If the browser’s viewport width is less than 1500px, the hello_world_1500.jpg image variant will be loaded; if the browser’s viewport width is between 1500px and 2000px, the hello_world_2000.jpg image variant will be loaded; and finally, if the browser’s viewport width is larger than 2000px, the browser will fallback to loading the hello_world_12000.jpg image variant.
Similar behavior is also possible with a picture element, using the source child element which supports a variety of other selectors.
Client Hints
Client Hints are a standard that some browsers are choosing to implement, and some not. They are a set of HTTP request headers which tell the server about the client’s device. For example, the browser can attach a Viewport-Width header when requesting an image which informs the server of the width of that particular browser’s viewport (note this header is currently in the process of being renamed to Sec-CH-Viewport-Width).
This simplifies the markup in the previous example greatly — in fact, no changes are required from the original simple HTML:
If Client Hints are supported, when the browser makes a request for hello_world_12000.jpg, it might attach the following header:
Viewport-Width: 1440
The server could then automatically serve a smaller image variant (e.g. hello_world_1500.jpg), despite the request originally asking for hello_world_12000.jpg image.
By enabling browsers to request an image with appropriate dimensions, we save bandwidth and time for both your server and for your visitors.
Format
JPEG, PNG, GIF, WebP, and now, AVIF. AVIF is the latest image format with widespread industry support, and it often outperforms its preceding formats. AVIF supports transparency with an alpha channel, it supports animations, and it is typically 50% smaller than comparable JPEGs (vs. WebP’s reduction of only 30%).
We added the AVIF format to Cloudflare’s Image Resizing product last year as soon as Google Chrome added support. Firefox 93 (scheduled for release on October 5, 2021) will be Firefox’s first stable release, and with both Microsoft and Apple as members of AVIF’s Alliance for Open Media, we hope to see support in Edge and Safari soon. Before these modern formats, we also saw innovative approaches to improving how an image loads on a webpage. BlurHash is a technique of embedding a very small representation of the image inside the HTML markup which can be immediately rendered and acts as a placeholder until the final image loads. This small representation (hash) produced a blurry mix of colors similar to that of the final image and so eased the loading experience for users.
Progressive JPEGs are similar in effect, but are a built-in feature of the image format itself. Instead of encoding the image bytes from top-to-bottom, bytes are ordered in increasing levels of image detail. This again produces a more subtle loading experience, where the user first sees a low quality image which progressively “enhances” as more bytes are loaded.
Quality
The newer image formats (WebP and AVIF) support lossless compression, unlike their predecessor, JPEG. For some uses, lossless compression might be appropriate, but for the majority of websites, speed is prioritized and this minor loss in quality is worth the time and bytes saved.
Optimizing where to set the quality is a balancing act: too aggressive and artifacts become visible on your image; too little and the image is unnecessarily large. Butteraugli and SSIM are examples of algorithms which approximate our perception of image quality, but this is currently difficult to automate and is therefore best set manually. In general, however, we find that around 85% in most compression libraries is a sensible default.
Markup
All of the previous techniques reduce the number of bytes an image uses. This is great for improving the loading speed of those images and the Largest Contentful Paint (LCP) metric. However, to improve the Cumulative Layout Shift (CLS) metric, we must minimize changes to the page layout. This can be done by informing the browser of the image size ahead of time.
On a poorly optimized webpage, images will be embedded without their dimensions in the markup. The browser fetches those images, and only once it has received the header bytes of the image can it know about the dimensions of that image. The effect is that the browser first renders the page where the image takes up zero pixels, and then suddenly redraws with the dimensions of that image before actually loading the image pixels themselves. This is jarring to users and has a serious impact on usability.
It is important to include dimensions of the image inside HTML markup to allow the browser to allocate space for that image before it even begins loading. This prevents unnecessary redraws and reduces layout shift. It is even possible to set dimensions when dynamically loading responsive images: by informing the browser of the height and width of the original image, assuming the aspect ratio is constant, it will automatically calculate the correct height, even when using a width selector.
Finally, lazy-loading is a technique which reduces the work that the browser has to perform right at the onset of page loading. By deferring image loads to only just before they’re needed, the browser can prioritize more critical assets such as fonts, styles and JavaScript. By setting the loading property on an image to lazy, you instruct the browser to only load the image as it enters the viewport. For example, on an e-commerce site which renders a grid of products, this would mean that the page loads faster for visitors, and seamlessly fetches images below the fold, as a user scrolls down. This is supported by all major browsers except Safari which currently has this feature hidden behind an experimental flag.
<img loading="lazy" … />
Hosting
Finally, you can improve image loading by hosting all of a page’s images together on the same first-party domain. If each image was hosted on a different domain, the browser would have to perform a DNS lookup, create a TCP connection and perform the TLS handshake for every single image. When they are all co-located on a single domain (especially so if that is the same domain as the page itself), the browser can re-use the connection which improves the speed it can load those images.
Test your website
Today, we’re excited to announce the launch of Cloudflare’s Image Optimization Testing Tool. Simply enter your website URL, and we’ll run a series of automated tests to determine if there are any possible improvements you could make in delivering optimal images to visitors.
We use WebPageTest and Lighthouse to calculate the Core Web Vitals on two versions of your page: one as the original, and one with Cloudflare’s best-effort automatic optimizations. These optimizations are performed using a Cloudflare Worker in combination with our Image Resizing product, and will transform an image’s format, quality, and dimensions.
We report key summary metrics about your webpage’s performance, including the aforementioned Cumulative Layout Shift (CLS) and Largest Contentful Page (LCP), as well as a detailed breakdown of each image on your page and the optimizations that can be made.
Cloudflare Images
Cloudflare Images can help you to solve a number of the problems outlined in this post. By storing your images with Cloudflare and configuring a set of variants, we can deliver optimized images from our edge to your website or app. We automatically set the optimal image format and allow you to customize the dimensions and fit for your use-cases.
We’re excited to see what you build with Cloudflare Images, and you can expect additional features and integrations in the near future. Get started with Images today from $6/month.
This post explains how we implemented the Cloudflare Images product with reusable Rust libraries and Cloudflare Workers. It covers the technical design of Cloudflare Image Resizing and Cloudflare Images. Using Rust and Cloudflare Workers helps us quickly iterate and deliver product improvements over the coming weeks and months.
Reuse of code in Rusty image projects
We developed Image Resizing in Rust. It’s a web server that receives HTTP requests for images along with resizing options, fetches the full-size images from the origin, applies resizing and other image processing operations, compresses, and returns the HTTP response with the optimized image.
Rust makes it easy to split projects into libraries (called crates). The image processing and compression parts of Image Resizing are usable as libraries.
We also have a product called Polish, which is a Golang-based service that recompresses images in our cache. Polish was initially designed to run command-line programs like jpegtran and pngcrush. We took the core of Image Resizing and wrapped it in a command-line executable. This way, when Polish needs to apply lossy compression or generate WebP images or animations, it can use Image Resizing via a command-line tool instead of a third-party tool.
Reusing libraries has allowed us to easily unify processing between Image Resizing and Polish (for example, to ensure that both handle metadata and color profiles in the same way).
Cloudflare Images is another product we’ve built in Rust. It added support for a custom storage back-end, variants (size presets), support for signing URLs and more. We made it as a collection of Rust crates, so we can reuse pieces of it in other services running anywhere in our network. Image Resizing provides image processing for Cloudflare Images and shares libraries with Images to understand the new URL scheme, access the storage back-end, and database for variants.
How Image Resizing works
The Image Resizing service runs at the edge and is deployed on every server of the Cloudflare global network. Thanks to Cloudflare’s global Anycast network, the closest Cloudflare data center will handle eyeball image resizing requests. Image Resizing is tightly integrated with the Cloudflare cache and handles eyeball requests only on a cache miss.
There are two ways to use Image Resizing. The default URL scheme provides an easy, declarative way of specifying image dimensions and other options. The other way is to use a JavaScript API in a Worker. Cloudflare Workers give powerful programmatic control over every image resizing request.
How Cloudflare Images work
Cloudflare Images consists of the following components:
The Images core service that powers the public API to manage images assets.
The Image Resizing service responsible for image transformations and caching.
The Image delivery Cloudflare Worker responsible for serving images and passing corresponding parameters through to the Imaging Resizing service.
Image storage that provides access and storage for original image assets.
To support Cloudflare Images scenarios for image transformations, we made several changes to the Image Resizing service:
Added access to Cloudflare storage with original image assets.
Added access to variant definitions (size presets).
Added support for signing URLs.
Image delivery
The primary use case for Cloudflare Images is to provide a simple and easy-to-use way of managing images assets. To cover egress costs, we provide image delivery through the Cloudflare managed imagedelivery.net domain. It is configured with Tiered Caching to maximize the cache hit ratio for image assets. imagedelivery.net provides image hosting without a need to configure a custom domain to proxy through Cloudflare.
A Cloudflare Worker powers image delivery. It parses image URLs and passes the corresponding parameters to the image resizing service.
How we store Cloudflare Images
There are several places we store information on Cloudflare Images:
image metadata in Cloudflare’s core data centers
variant definitions in Cloudflare’s edge data centers
original images in core data centers
optimized images in Cloudflare cache, physically close to eyeballs.
Image variant definitions are stored and delivered to the edge using Cloudflare’s distributed key-value store called Quicksilver. We use a single source of truth for variants. The Images core service makes calls to Quicksilver to read and update variant definitions.
The rest of the information about the image is stored in the image URL itself: https://imagedelivery.net/<encoded account id>/<image id>/<variant name>
<image id> contains a flag, whether it’s publicly available or requires access verification. It’s not feasible to store any image metadata in Quicksilver as the data volume would increase linearly with the number of images we host. Instead, we only allow a finite number of variants per account, so we responsibly utilize available disk space on the edge. The downside of storing image metadata as part of <image id> is that <image id> will change on access change.
How we keep Cloudflare Images up to date
The only way to access images is through the use of variants. Each variant is a named image resizing configuration. Once the image asset is fetched, we cache the transformed image in the Cloudflare cache. The critical question is how we keep processed images up to date. The answer is by purging the Cloudflare cache when necessary. There are two use cases:
access to the image is changed
the variant definition is updated
In the first instance, we purge the cache by calling a URL: https://imagedelivery.net/<encoded account id>/<image id>
Then, the customer updates the variant we issue a cache purge request by tag: account-id/variant-name
To support cache purge by tag, the image resizing service adds the necessary tags for all transformed images.
How we restrict access to Cloudflare Images
The Image resizing service supports restricted access to images by using URL signatures with expiration. URLs are signed with an SHA-256 HMAC key. The steps to produce valid signatures are:
Take the path and query string (the path starts with /).
Compute the path’s SHA-256 HMAC with the query string, using the Images’ URL signing key as the secret. The key is configured in the Dashboard.
If the URL is meant to expire, compute the Unix timestamp (number of seconds since 1970) of the expiration time, and append ?exp= and the timestamp as an integer to the URL.
Append ? or & to the URL as appropriate (? if it had no query string; & if it had a query string).
Append sig= and the HMAC as hex-encoded 64 characters.
A signed URL looks like this:
A signed URL with an expiration timestamp looks like this:
Signature of /hello/world URL with a secret ‘this is a secret’ is 6293f9144b4e9adc83416d1b059abcac750bf05b2c5c99ea72fd47cc9c2ace34.
Direct creator uploads with Cloudflare Worker and KV
Similar to Cloudflare Stream, Images supports direct creator uploads. That allow users to upload images without API tokens. Everyday use of direct creator uploads is by web apps, client-side applications, or mobile apps where users upload content directly to Cloudflare Images.
Once again, we used our serverless platform to support direct creator uploads. The successful API call stores the account’s information in Workers KV with the specified expiration date. A simple Cloudflare Worker handles the upload URL, which reads the KV value and grants upload access only on a successful call to KV.
Future Work
Cloudflare Images product has an exciting product roadmap. Let’s review what’s possible with the current architecture of Cloudflare Images.
Resizing hints on upload
At the moment, no image transformations happen on upload. That means we can serve the image globally once it is uploaded to Image storage. We are considering adding resizing hints on image upload. That won’t necessarily schedule image processing in all cases but could provide a valuable signal to resize the most critical image variants. An example could be to generate an AVIF variant for the most vital image assets.
Serving images from custom domains
We think serving images from a domain we manage (with Tiered Caching) is a great default option for many customers. The downside is that loading Cloudflare images requires additional TLS negotiations on the client-side, adding latency and impacting loading performance. On the other hand, serving Cloudflare Images from custom domains will be a viable option for customers who set up a website through Cloudflare. The good news is that we can support such functionality with the current architecture without radical changes in the architecture.
Conclusion
The Cloudflare Images product runs on top of the Cloudflare global network. We built Cloudflare Images in Rust and Cloudflare Workers. This way, we use Rust reusable libraries in several products such as Cloudflare Images, Image Resizing, and Polish. Cloudflare’s serverless platform is an indispensable tool to build Cloudflare products internally. If you are interested in building innovative products in Rust and Cloudflare Workers, we’re hiring.
Imagine how a customer would feel if they get to your website, and it takes forever to load all the images you serve. This would become a negative user experience that might lead to lower overall site traffic and high bounce rates.
The good news is that regardless of whether you need to store and serve 100,000 or one million images, Cloudflare Images gives you the tools you need to build an entire image pipeline from scratch.
Customer pains
After speaking with many of Cloudflare customers, we quickly understood that whether you are an e-commerce retailer, a blogger or have a platform for creators, everyone shares the same problems:
Egress fees. Each time an image needs to go from Product A (storage) to Product B (optimize) and to Product C (delivery) there’s a fee. If you multiply this by the millions of images clients serve per day it’s easy to understand why their bills are so high.
Buckets everywhere. Our customers’ current pipelines involve uploading images to and from services like AWS, then using open source products to optimize images, and finally to serve the images they need to store them in another cloud bucket since CDN don’t have long-term storage. This means that there is a dependency on buckets at each step of the pipeline.
Load times. When an image is not correctly optimized the image can be much larger than needed resulting in an unnecessarily long download time. This can lead to a bad end user experience that might result in loss of overall site traffic.
High Maintenance. To maintain an image pipeline companies need to rely on several AWS and open source products, plus an engineering team to build and maintain that pipeline. This takes the focus away from engineering on the product itself.
How can Cloudflare Images help?
Zero Egress Costs
The majority of cloud providers allow you to store images for a small price, but the bill starts to grow every time you need to retrieve that image to optimize and deliver. The good news is that with Cloudflare Images customers don’t need to worry about egress costs, since all storage, optimization and delivery are part of the same tool.
The buckets stop with Cloudflare Images
One small step for humankind, one giant leap for image enthusiasts!
With Cloudflare Images the bucket pain stops now, and customers have two options:
One image upload can generate up to 100 variants, which allows developers to stop placing image sizes in URLs. This way, if a site gets redesigned there isn’t a need to change all the image sizes because you already have all the variants you need stored in Cloudflare Images.
Give your users a one-time permission to upload one file to your server. This way developers don’t need to write additional code to move files from users into a bucket — they will be automatically uploaded into your Cloudflare storage.
Minimal engineering effort
Have you ever dreamed about your team focusing entirely on product development instead of maintaining infrastructure? We understand, and this is why we created a straightforward set of APIs as well as a UI in the Cloudflare Dashboard. This allows your team to serve and optimize images without the need to set up and maintain a pipeline from scratch.
Once you get access to Cloudflare Images your team can start:
Uploading, deleting and updating images via API.
Setting up preferred variants.
Editing with Image Resizing both with the UI and API.
Serving an image with one click.
Process images on the fly
We all know that Google and many other search engines use the loading speed as one of their ranking factors; Cloudflare Images helps you be on the top of that list. We automatically detect what browser your clients are using and serve the most optimized version of the image, so that you don’t need to worry about file extensions, configuring origins for your image sets or even cache hit rates.
Curious to have a sneak peek at Cloudflare Images? Sign up now!
This is the story of how we decided to work with Google to build Signed Exchanges support at Cloudflare. But, more generally, it’s also a story of how Cloudflare thinks about building disruptive new products and how we’ve built an organization designed around continuous innovation and long-term thinking.
A Threat to the Open Web?
The story starts with me pretty freaked out. In May 2015, Facebook had announced a new format for the web called Instant Articles. The format allowed publishers to package up their pages and serve them directly from Facebook’s infrastructure. This was a threat to Google, so the company responded in October with Accelerated Mobile Pages (AMP). The idea was generally the same as Facebook’s but using Google’s infrastructure.
As a general Internet user, if these initiatives were successful they were pretty scary. The end game was that the entirety of the web would effectively be slurped into Facebook and Google’s infrastructure.
But as the cofounder and CEO of Cloudflare, this presented an even more immediate risk. If everyone moved their infrastructure to Facebook and Google, there wasn’t much left for us to do. Our mission is to help build a better Internet, but we’ve always assumed there would be an Internet. If Facebook and Google were successful, there was real risk there would just be Facebook and Google.
That said, the rationale behind these initiatives was compelling. While they ended with giving Facebook and Google much more control, they started by trying to solve a real problem. The web was designed with the assumption that the devices connecting to it would be on a fixed, wired connection. As more of the web moved to being accessed over wireless, battery-powered, relatively low-power devices, many of the assumptions of the web were holding back its performance.
This is particularly true in the developing world. While a failed connection can happen anywhere, the further you get from where content is hosted, the more likely it is to happen. Facebook and Google both reasoned that if they could package up the web and serve complete copies of pages from their infrastructure, which spanned the developing world, they could significantly increase the usability of the web in areas where there was still an opportunity for Internet usage to grow. Again, this is a laudable goal. But, if successful, the results would have been dreadful for the Internet as we know it.
Seeds of Disruption
So that’s why I was freaked out. In our management meetings at Cloudflare I’d walk through how this was a risk to the Internet and our business, and we needed to come up with a strategy to address it. Everyone on our team listened and agreed but ultimately and reasonably said: that’s in the future, and we have immediate priorities of things our customers need, so we’ll need to wait until next quarter to prioritize it.
That’s all correct, and probably the right decision if you are forced to make one, but it’s also how companies end up getting disrupted. So, in 2016, we decided to fund a small team led by Dane Knecht, Cloudflare’s founding product manager, to set up a sort of skunkworks team in Austin, TX. The idea was to give the team space away from headquarters, so it could work on strategic projects with a long payoff time horizon.
Today, Dane’s team is known as the Emerging Technologies & Incubation (ETI) team. It was where products like Cloudflare for Teams, 1.1.1.1, and Workers were first dreamed up and prototyped. And it remains critical to how Cloudflare continues to be so innovative. Austin, since 2016, has also grown from a small skunkworks outpost to what will, before the end of this year, be our largest office. That office now houses members from every Cloudflare team, not just ETI. But, in some ways, it all started with trying to figure out how we should respond to Instant Articles and AMP.
We met with both Facebook and Google. Facebook’s view of the world was entirely centered around their app, and didn’t leave much room for partners. Google, on the other hand, was born out of the open web and still ultimately wanted to foster it. While there has been a lot of criticism of AMP, much of which we discussed with them directly, it’s important to acknowledge that it started from a noble goal: to make the web faster and easier to use for those with limited Internet resources.
We built a number of products to extend the AMP ecosystem and make it more open. Viewed on their own, those products have not been successes. But they catalyzed a number of other innovations. For instance, building a third party AMP cache on Cloudflare required a more programmable network. That directly resulted in us prototyping a number of different serverless computing strategies and finally settling on Workers. In fact, many of the AMP products we built were the first products built using Workers.
Part of the magic of our ETI team is that they are constantly trying new things. They’re set up differently, in order to take lots of “shots on goal.” Some won’t work, in which case we want them to fail fast. And, even for those that don’t, we are always learning, collaborating, and innovating. That’s how you create a culture of innovation that produces products at the rate we do at Cloudflare.
Signed Exchanges: Helping Build a Better Internet
Importantly also, working with the AMP team at Google helped us better collaborate on ideas around Internet performance. Cloudflare’s mission is to “help build a better Internet.” It’s not to “build a better Internet.” The word “help” is essential and something I’ll always correct if I hear someone leave it out. The Internet is inherently a collection of networks, and also a collection of work from a number of people and organizations. Innovation doesn’t happen in a vacuum but is catalyzed by collaboration and open standards. Working with other great companies who are aligned with democratizing performance optimization technology and speeding up the Internet is how we believe we can make significant and meaningful leaps in terms of performance.
And that’s what Signed Exchanges have the opportunity to be. They take the best parts of AMP — in terms of allowing pages to be preloaded to render almost instantly — but give back control over the content to the individual publishers. They don’t require you to exclusively use Google’s infrastructure and are extensible well beyond just traffic originating from search results. And they make the web incredibly fast and more accessible even in those areas where Internet access is slow or expensive.
We’re proud of the part we played in bringing this new technology to the Internet. We’re excited to see how people use it to build faster services available more broadly. And the ETI team is back at work looking over the innovation horizon and continuously asking the question: what’s next?
Cloudflare’s mission is to help build a better Internet for everyone. Building a better Internet means helping build more reliable and efficient services that everyone can use. To help realize this vision, we’re announcing the free distribution of two products, one old and one new:
Tiered Caching is now available to all customers for free. Tiered Caching reduces origin data transfer and improves performance, making web properties cheaper and faster to operate. Tiered Cache was previously a paid addition to Free, Pro, and Business plans as part of Argo.
Orpheus is now available to all customers for free. Orpheus routes around problems on the Internet to ensure that customer origin servers are reachable from everywhere, reducing the number of errors your visitors see.
Tiered Caching: improving website performance and economics for everyone
Tiered Cache uses the size of our network to reduce requests to customer origins by dramatically increasing cache hit ratios. With data centers around the world, Cloudflare caches content very close to end users, but if a piece of content is not in cache, the Cloudflare edge data centers must contact the origin server to receive the cacheable content. This can be slow and places load on an origin server compared to serving directly from cache.
Tiered Cache works by dividing Cloudflare’s data centers into a hierarchy of lower-tiers and upper-tiers. If content is not cached in lower-tier data centers (generally the ones closest to a visitor), the lower-tier must ask an upper-tier to see if it has the content. If the upper-tier does not have it, only the upper-tier can ask the origin for content. This practice improves bandwidth efficiency by limiting the number of data centers that can ask the origin for content, reduces origin load, and makes websites more cost-effective to operate.
Dividing data centers like this results in improved performance for visitors because distances and links traversed between Cloudflare data centers are generally shorter and faster than the links between data centers and origins. It also reduces load on origins, making web properties more economical to operate. Customers enabling Tiered Cache can achieve a 60% or greater reduction in their cache miss rate as compared to Cloudflare’s traditional CDN service.
Additionally, Tiered Cache concentrates connections to origin servers so they come from a small number of data centers rather than the full set of network locations. This results in fewer open connections using server resources.
Tiered Cache is simple to enable:
Log into your Cloudflare account.
Navigate to the Caching in the dashboard.
Under Caching, select Tiered Cache.
Enable Tiered Cache.
From there, customers will automatically be enrolled in Smart Tiered Cache Topology without needing to make any additional changes. Enterprise Customers can select from different prefab topologies or have a custom topology created for their unique needs.
Smart Tiered Cache dynamically selects the single best upper tier for each of your website’s origins with no configuration required. We will dynamically find the single best upper tier for an origin by using Cloudflare’s performance and routing data. Cloudflare collects latency data for each request to an origin. Using this latency data, we can determine how well any upper-tier data center is connected with an origin and can empirically select the best data center with the lowest latency to be the upper-tier for an origin.
Today, Smart Tiered Cache is being offered to ALL Cloudflare customers for free, in contrast to other CDNs who may charge exorbitant fees for similar or worse functionality. Current Argo customers will get additional benefits described here. We think that this is a foundational improvement to the performance and economics of running a website.
But what happens if an upper-tier can’t reach an origin?
Orpheus: solving origin reachability problems for everyone
Cloudflare is a reverse proxy that receives traffic from end users and proxies requests back to customer servers or origins. To be successful, Cloudflare needs to be reachable by end users while simultaneously being able to reach origins. With end users around the world, Cloudflare needs to be able to reach origins from multiple points around the world at the same time. This is easier said than done! The Internet is not homogenous, and diverse Cloudflare network locations do not necessarily take the same paths to a given customer origin at any given time. A customer origin may be reachable from some networks but not from others.
Cloudflare developed Argo to be the Waze of the Internet, allowing our network to react to changes in Internet traffic conditions and route around congestion and breakages in real-time, ensuring end users always have a good experience. Argo Smart Routing provides amazing performance and reliability improvements to our customers.
Enter Orpheus. Orpheus provides reachability benefits for customers by finding unreachable paths on the Internet in real time, and guiding traffic away from those paths, ensuring that Cloudflare will always be able to reach an origin no matter what is happening on the Internet.
Today, we’re excited to announce that Orpheus is available to and being used by all our customers.
Fewer 522s
You may have seen this error before at one time or another.
This error indicates that a user was unable to reach content because Cloudflare couldn’t reach the origin. Because of the unpredictability of the Internet described above, users may see this error even when an origin is up and able to receive traffic.
So why do you see this error? The 522 error occurs when network instability causes traffic sent by Cloudflare to fail either before it reaches the origin, or on the way back from the origin to Cloudflare. This is the equivalent of either Cloudflare or your origin sending a request and never getting a response. Both sides think that they’re fine, but the network path between them is not reachable at all. This causes customer pain.
Orpheus solves that pain, ensuring that no matter where users are or where the origin is, an Internet application will always be reachable from Cloudflare.
How it works
Orpheus builds and provisions routes from Cloudflare to origins by analyzing data from users on every path from Cloudflare and ordering them on a per-data center level with the goal of eliminating connection errors and minimizing packet loss. If Orpheus detects errors on the current path from Cloudflare back to a customer origin, Orpheus will steer subsequent traffic from the impacted network path to the healthiest path available.
This is similar to how Argo works but with some key differences: Argo is always steering traffic down the fastest path, whereas Orpheus is reactionary and steers traffic down healthy (and not necessarily the fastest) paths when needed.
Improving origin reachability for customers
Let’s look at an example.
Barry has an origin hosted in WordPress in Chicago for his daughter’s band. This zone primarily sees traffic from three locations: the location closest to his daughter in Seattle, the location closest to him in Boston, and the location closest to his parents in Tampa, who check in on their granddaughter’s site daily for updates.
One day, a link between Tampa and the Chicago origin gets cut by a wandering backhoe. This means that Tampa loses some connectivity back to the Chicago origin. As a result, Barry’s parents start to see failures when connecting back to origin when connecting to the site. This reflects in origin reachability decreasing. Orpheus helps here by finding alternate paths for Barry’s parents, whether it’s through Boston, Seattle, or any location in between that isn’t impacted by the fiber cut seen in Tampa.
So even though there is packet loss between one of Cloudflare’s data centers and Barry’s origin, because there is a path through a different Cloudflare data center that doesn’t have loss, the traffic will still succeed because the traffic will go down the non-lossy path.
How much does Orpheus help my origin reachability?
In our rollout of Orpheus for customers, we observed that Orpheus improved Origin reachability by 23%, from 99.87% to 99.90%. Here is a chart showing the improvement Orpheus provides (lower is better):
We measure this reachability improvement by measuring 522 rates for every data center-origin pair and then comparing traffic that traversed Orpheus routes with traffic that went directly back to origin. Orpheus was especially helpful at improving reachability for slightly lossy paths that could present small amounts of failure over a long period of time, whereas direct to origin would see those failures.
Note that we’ll never get this number to 0% because, with or without Orpheus, some origins really are unreachable because they are down!
Orpheus makes Cloudflare products better
Orpheus pairs well with some of our products that are already designed to provide highly available services on an uncertain Internet. Let’s go over the interactions between Orpheus and three of our products: Load Balancing, Cloudflare Network Interconnect, and Tiered Cache.
Load Balancing
Orpheus and Load Balancing go together to provide high reachability for every origin endpoint. Load balancing allows for automatic selection of endpoints based on health probes, ensuring that if an origin isn’t working, customers will still be available and operational. Orpheus finds reachable paths from Cloudflare to every origin. These two products in tandem provide a highly available and reachable experience for customers.
Cloudflare Network Interconnect
Orpheus and Cloudflare Network Interconnect (CNI) combine to always provide a highly reachable path, no matter where in the world you are. Consider Acme, a company who is connected to the Internet by only one provider that has a lot of outages. Orpheus will do its best to steer traffic around the lossy paths, but if there’s only one path back to the customer, Orpheus won’t be able to find a less-lossy path. Cloudflare Network Interconnect solves this problem by providing a path that is separate from the transit provider that any Cloudflare data center can access. CNI provides a viable path back to Acme’s origin that will allow Orpheus to engage from any data center in the world if loss occurs.
Shields for All
Orpheus and Tiered Cache can combine to build an adaptive shield around an origin that caches as much as possible while improving traffic back to origin. Tiered Cache topologies allow for customers to deflect much of their static traffic away from their origin to reduce load, and Orpheus helps ensure that any traffic that has to go back to the origin traverses over highly available links.
Improving origin performance for everyone
The Internet is a growing, ever-changing ecosystem. With the release of Orpheus and Tiered Cache for everyone, we’ve given you the ability to navigate whatever the Internet has in store to provide the best possible experience to your customers.
We launched Argo in 2017 to improve performance on the Internet. Argo uses real-time global network information to route around brownouts, cable cuts, packet loss, and other problems on the Internet. Argo makes the network that Cloudflare relies on—the Internet—faster, more reliable, and more secure on every hop around the world.
Without any complicated configuration, Argo is able to use real-time traffic data to pick the fastest path across the Internet, improving performance and delivering more satisfying experiences to your customers and users.
Today, Cloudflare is announcing several upgrades to Argo’s intelligent routing:
When it launched, Argo was entirely focused on the “middle mile,” speeding up connections from Cloudflare to our customers’ servers. Argo now delivers optimal routes from clients and users to Cloudflare, further reducing end-to-end latency while still providing the impressive edge to origin performance that Argo is known for. These last-mile improvements reduce end user round trip times by up to 40%.
We’re also adding support for accelerating pure IP workloads, allowing Magic Transit and Magic WAN customers to build IP networks to enjoy the performance benefits of Argo.
Starting today, all Free, Pro, and Business plan Argo customers will see improved performance with no additional configuration or charge. Enterprise customers have already enjoyed the last mile performance improvements described here for some time. Magic Transit and WAN customers can contact their account team to request Early Access to Argo Smart Routing for Packets.
What’s Argo?
Argo finds the best and fastest possible path for your traffic on the Internet. Every day, Cloudflare carries hundreds of billions of requests across our network and the Internet. Because our network, our customers, and their end users are well distributed globally, all of these requests flowing across our infrastructure paint a great picture of how different parts of the Internet are performing at any given time.
Just like Waze examines real data from real drivers to give you accurate, uncongested — and sometimes unorthodox — routes across town, Argo Smart Routing uses the timing data Cloudflare collects from each request to pick faster, more efficient routes across the Internet.
In practical terms, Cloudflare’s network is expansive in its reach. Some Internet links in a given region may be congested and cause poor performance (a literal traffic jam). By understanding this is happening and using alternative network locations and providers, Argo can put traffic on a less direct, but faster, route from its origin to its destination.
These benefits are not theoretical: enabling Argo Smart Routing shaves an average of 33% off HTTP time to first byte (TTFB).
One other thing we’re proud of: we’ve stayed super focused on making it easy to use. One click in the dashboard enables better, smarter routing, bringing the full weight of Cloudflare’s network, data, and engineering expertise to bear on making your traffic faster. Advanced analytics allow you to understand exactly how Argo is performing for you around the world.
We’ve continuously improved Argo since the day it was launched, making it faster, quicker to respond to changes on the Internet, and allowing more types of traffic to flow over smart routes.
Argo’s new performance optimizations improve last mile latencies and reduce time to first byte even further. Argo’s last mile optimizations can save up to 40% on last mile round trip time (RTT) with commensurate improvements to end-to-end latency.
Running benchmarks against an origin server in the central United States, with visitors coming from around the world, Argo delivered the following results:
The Argo improvements on the last mile reduced overall time to first byte by 39%, and reduced end-to-end latencies by 5% overall:
Faster, better caching
Argo customers don’t just see benefits to their dynamic traffic. Argo’s new found skills provide benefits for static traffic as well. Because Argo now finds the best path to Cloudflare, client TTFB for cache hits sees the same last mile benefit as dynamic traffic.
Getting access to faster Argo
The best part about all these improvements? They’re already deployed and enabled for all Argo customers! These optimizations have been live for Enterprise customers for some time and were enabled for Free, Pro, and Business plans this week.
Moving Down the Stack: Argo Smart Routing for Packets
Customers use Magic Transit and Magic WAN to create their own IP networks on top of Cloudflare’s network, with access to a full suite of network functions (firewalls, DDoS mitigation, and more) delivered as a service. This allows customers to build secure, private, global networks without the need to purchase specialized hardware. Now, Argo Smart Routing for Packets allows these customers to create these IP networks with the performance benefits of Argo.
Consider a fictional gaming company, Golden Fleece Games. Golden Fleece deployed Magic Transit to mitigate attacks by malicious actors on the Internet. They want to be able to provide a quality game to their users while staying up. However, they also need their service to be as fast as possible. If their game sees additional latency, then users won’t play it, and even if their service is technically up, the increased latency will show a decrease in users. For Golden Fleece, being slow is just as bad as being down.
Finance customers also have similar requirements for low latency, high security scenarios. Consider Jason Financial, a fictional Magic Transit customer using Packet Smart Routing. Jason Financial employees connect to Cloudflare in New York, and their requests are routed to their data center which is connected to Cloudflare through a Cloudflare Network Interconnect attached to Cloudflare in Singapore. For Jason Financial, reducing latency is extraordinarily important: if their network is slow, then the latency penalties they incur can literally cost them millions of dollars due to how fast the stock market moves. Jason wants Magic Transit and other Cloudflare One products to secure their network and prevent attacks, but improving performance is important for them as well.
Argo’s Smart Routing for Packets provides these customers with the security they need at speeds faster than before. Now, customers can get the best of both worlds: security and performance. Now, let’s talk a bit about how it works.
A bird’s eye view of the Internet
Argo Smart Routing for Packets picks the fastest possible path between two points. But how does Argo know that the chosen route is the fastest? As with all Argo products, the answer comes by analyzing a wealth of network data already available on the Cloudflare edge. In Argo for HTTP or Argo for TCP, Cloudflare is able to use existing timing data from traffic that’s already being sent over our edge to optimize routes. This allows us to improve which paths are taken as traffic changes and congestion on the Internet happens. However, to build Smart Routing for Packets, the game changed, and we needed to develop a new approach to collect latency data at the IP layer.
Let’s go back to the Jason Financial case. Before, Argo would understand that the number of paths that are available from Cloudflare’s data centers back to Jason’s data center is proportional to the number of data centers Cloudflare has multiplied by the number of distinct interconnections between each data center. By looking at the traffic to Singapore, Cloudflare can use existing Layer 4 traffic and network analytics to determine the best path. But Layer 4 is not Layer 3, and when you move down the stack, you lose some insight into things like round trip time (RTT), and other metrics that compose time to first byte because that data is only produced at higher levels of the application stack. It can become harder to figure out what the best path actually is.
Optimizing performance at the IP layer can be more difficult than at higher layers. This is because protocol and application layers have additional headers and stateful protocols that allow for further optimization. For example, connection reuse is a performance improvement that can only be realized at higher layers of the stack because HTTP requests can reuse existing TCP connections. IP layers don’t have the concept of connections or requests at all: it’s just packets flowing over the wire.
To help bridge the gap, Cloudflare makes use of an existing data source that already exists for every Magic Transit customer today: health check probes. Every Magic Transit customer leverages existing health check probes from every single Cloudflare data center back to the customer origin. These probes are used to determine tunnel health for Magic Transit, so that Cloudflare knows which paths back to origin are healthy. These probes contain a variety of information that can also be used to improve performance as well. By examining health check probes and adding them to existing Layer 4 data, Cloudflare can get a better understanding of one-way latencies and can construct a map that allows us to see all the interconnected data centers and how fast they are to each other. Once this customer gets a Cloudflare Network Interconnect, Argo can use the data center-to-data center probes to create an alternate path for the customer that’s different from the public Internet.
Using this map, Cloudflare can construct dynamic routes for each customer based on where their traffic enters Cloudflare’s network and where they need to go. This allows us to find the optimal route for Jason Financial and allows us to always pick the fastest path.
Packet-Level Latency Reductions
We’ve kind of buried the lede here! We’ve talked about how hard it is to optimize performance for IP traffic. The important bit: despite all these difficulties, Argo Smart Routing for Packets is able to provide a 10% average latency improvement worldwide in our internal testing!
Depending on your network topology, you may see latency reductions that are even higher!
How do I get Argo Smart Routing for Packets?
Argo Smart Routing for Packets is in closed beta and is available only for Magic Transit customers who have a Cloudflare Network Interconnect provisioned. If you are a Magic Transit customer interested in seeing the improved performance of Argo Smart Routing for Packets for yourself, reach out to your account team today! If you don’t have Magic Transit but want to take advantage of bigger performance gains while acquiring uncompromised levels of network security, begin your Magic Transit onboarding process today!
What’s next for Argo
Argo’s roadmap is simple: get ever faster, for any type of traffic.
Argo’s recent optimizations will help customers move data across the Internet at as close to the speed of light as possible. Internally, “how fast are we compared to the speed of light” is one of our engineering team’s key success metrics. We’re not done until we’re even.
Just about four years ago, we announced Cloudflare Workers, a serverless platform that runs directly on the edge.
Throughout this week, we will talk about the many ways Cloudflare is helping make applications that already exist on the web faster. But if today is the day you decide to make your idea come to life, building your project on the Cloudflare edge, and deploying it directly to the tubes of the Internet is the best way to guarantee your application will always be fast, for every user, regardless of their location.
It’s been a few years since we talked about how Cloudflare Workers compares to other serverless platforms when it comes to performance, so we decided it was time for an update. While most of our work on the Workers platform over the past few years has gone into making the platform more powerful: introducing new features, APIs, storage, debugging and observability tools, performance has not been neglected.
Today, Workers is 30% faster than it was three years ago at P90. And it is 210% faster than Lambda@Edge, and 298% faster than Lambda.
How do you measure the performance of serverless platforms?
I’ve run hundreds of performance benchmarks between CDNs in the past — the formula is simple: we use a tool called Catchpoint, which makes requests from nodes all over the world to the same asset, and reports back on the time it took for each location to return a response.
Measuring serverless performance is a bit different — since the thing you’re comparing is the performance of compute, rather than a static asset, we wanted to make sure all functions performed the same operation.
In our 2018 blog on speed testing, we had each function simply return the current time. For the purposes of this test, “serverless” products that were not able to meet the minimum criteria of being able to perform this task were disqualified. Serverless products used in this round of testing executed the same function, of identical computational complexity, to ensure accurate and fair results.
It’s also important to note what it is that we’re measuring. The reason performance matters, is because it impacts the experience of actual end customers. It doesn’t matter what the source of latency is: DNS, network congestion, cold starts… the customer doesn’t care what the source is, they care about wasting time waiting for their application to load.
It is therefore important to measure performance in terms of the end user experience — end to end, which is why we use global benchmarks to measure performance.
The result below shows tests run from 50 nodes all over the world, across North America, South America, Europe, Asia and Oceania.
As you can see from the results, no matter where users are in the world, when it comes to speed, Workers can guarantee the best experience for customers.
In the case of Workers, getting the best performance globally requires no additional effort on the developers’ part. Developers do not need to do any additional load balancing, or configuration of regions. Every deployment is instantly live on Cloudflare’s extensive edge network.
Even if you’re not seeking to address a global audience, and your customer base is conveniently located on the East coast of the United States, Workers is able to guarantee the fastest response on all requests.
Above, we have the results just from Washington, DC, as close as we could get to us-east-1. And again, without any optimization, Workers is 34% faster.
Why is that?
What defines the performance of a serverless platform?
Other than the performance of the code itself, from the perspective of the end user, serverless application performance is fundamentally a function of two variables: distance an application executes from the user, and the time it takes the runtime itself to spin up. The realization that distance from the user is becoming a greater and greater bottleneck on application performance is causing many serverless vendors to push deeper and deeper into the edge. Running applications on the edge — closer to the end user — increases performance. As 5G comes online, this trend will only continue to accelerate.
However, many cloud vendors in the serverless space run into a critical problem when addressing the issue when competing for faster performance. And that is: the legacy architecture they’re using to build out their offerings doesn’t work well with the inherent limitations of the edge.
Since the goal behind the serverless model is to intentionally abstract away the underlying architecture, not everyone is clear on how legacy cloud providers like AWS have created serverless offerings like Lambda. Legacy cloud providers deliver serverless offerings by spinning up a containerized process for your code. The provider auto-scales all the different processes in the background. Every time a container is spun up, the entire language runtime is spun up with it, not just your code.
To help address the first graph, measuring global performance, vendors are attempting to move away from their large, centralized architecture (a few, big data centers) to a distributed, edge-based world (a greater number of smaller data centers all over the world) to close the distance between applications and end users. But there’s a problem with their approach: smaller data centers mean fewer machines, and less memory. Each time vendors pursue a small but many data centers strategy to operate closer to the edge, the likelihood of a cold start occurring on any individual process goes up.
This effectively creates a performance ceiling for serverless applications on container-based architectures. If legacy vendors with small data centers move your application closer to the edge (and the users), there will be fewer servers, less memory, and more likely that an application will need a cold start. To reduce the likelihood of that, they’re back to a more centralized model; but that means running your applications from one of a few big centralized data centers. These larger centralized data centers, by definition, are almost always going to be further away from your users.
You can see this at play in the graph above by looking at the results of the tests when running in Lambda@Edge — despite the reduced proximity to the end user, p90 performance is slower than that of Lambda’s, as containers have to spin up more frequently.
Serverless architectures built on containers can move up and down the frontier, but ultimately, there’s not much they can do to shift that frontier curve.
What makes Workers so fast?
Workers was designed from the ground up for an edge-first serverless model. Since Cloudflare started with a distributed edge network, rather than trying to push compute from large centralized data centers out into the edge, working under those constraints forced us to innovate.
In one of our previous blog posts, we’ve discussed how this innovation translated to a new paradigm shift with Workers’ architecture being built on lightweight V8 isolates that can spin up quickly, without introducing a cold start on every request.
Not only has running isolates given us advantage out of the box, but as V8 gets better, so does our platform. For example, when V8 announced Liftoff, a compiler for WASM, all WASM Workers instantly got faster.
Similarly, whenever improvements are made to Cloudflare’s network (for example, when we add new data centers) or stack (e.g., supporting new, faster protocols like HTTP/3), Workers instantly benefits from it.
Additionally, we’re always seeking to make improvements to Workers itself to make the platform even faster. For example, last year, we released an improvement that helped eliminate cold starts for our customers.
One key advantage that helps Workers identify and address performance gaps is the scale at which it operates. Today, Workers services hundreds of thousands of developers, ranging from hobbyists to enterprises all over the world, serving millions of requests per second. Whenever we make improvements for a single customer, the entire platform gets faster.
Performance that matters
The ultimate goal of the serverless model is to enable developers to focus on what they do best — build experiences for their users. Choosing a serverless platform that can offer the best performance out of the box means one less thing developers have to worry about. If you’re spending your time optimizing for cold starts, you’re not spending your time building the best feature for your customers.
Just like developers want to create the best experience for their users by improving the performance of their application, we’re constantly striving to improve the experience for developers building on Workers as well.
In the same way customers don’t want to wait for slow responses, developers don’t want to wait on slow deployment cycles.
This is where the Workers platform excels yet again.
Any deployment on Cloudflare Workers takes less than a second to propagate globally, so you don’t want to spend time waiting on your code deploy, and users can see changes as quickly as possible.
Of course, it’s not just the deployment time itself that’s important, but the efficiency of the full development cycle, which is why we’re always seeking to improve it at every step: from sign up to debugging.
Don’t just take our word for it!
Needless to say, much as we try to remain neutral, we’re always going to be just a little biased. Luckily, you don’t have to take our word for it.
We invite you to sign up and deploy your first Worker today — it’ll just take a few minutes!
Today, we’re excited to announce support for Vary, an HTTP header that ensures different content types can be served to user-agents with differing capabilities.
At Cloudflare, we’re obsessed with performance. Our job is to ensure that content gets from our network to visitors quickly, and also that the correct content is served. Serving incompatible or unoptimized content burdens website visitors with a poor experience while needlessly stressing a website’s infrastructure. Lots of traffic served from our edge consists of image files, and for these requests and responses, serving optimized image formats often results in significant performance gains. However, as browser technology has advanced, so too has the complexity required to serve optimized image content to browsers all with differing capabilities — not all browsers support all image formats! Providing features to ensure that the correct images are served to the correct requesting browser, device, or screen is important!
Serving images on the modern web
In the web’s early days, if you wanted to serve a full color image, JPEGs reigned supreme and were universally supported. Since then, the state of the art in image encoding has advanced by leaps and bounds, and there are now increasingly more advanced and efficient codecs like WebP and AVIF that promise reduced file sizes and improved quality.
This sort of innovation is exciting, and delivers real improvements to user experience. However, it makes the job of web servers and edge networks more complicated. As an example, until very recently, WebP image files were not universally supported by commonly used browsers. A specific browser not supporting an image file becomes a problem when “intermediate caches”, like Cloudflare, are involved in delivering content.
Let’s say, for example, that a website wants to provide the best experience to whatever browser requests the site. A desktop browser sends a request to the website and the origin server responds with the website’s content including images. This response is cached by a CDN prior to getting sent back to the requesting browser.
Now let’s say a mobile browser comes along and requests that same website with those images. In the situation where a cached image is a WebP file, and WebP is not supported by the mobile browser, the website will not load properly because the content returned from cache is not supported by the mobile browser. That’s a problem.
To help solve this issue, today we’re excited to announce our support of the Vary header for images.
How Vary works
Vary is an HTTP response header that allows origins to serve variants of the same content from a single URL, and have intermediate caches serve the correct variant to each user-agent that comes along.
Smashing Magazine has an excellent deep dive on how Vary negotiation works here.
When browsers send a request for a website, they include a variety of request headers. A fairly common example might look something like:
GET /page.html HTTP/1.1
Host: example.com
Connection: keep-alive
Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.164 Safari/537.36
Accept-Encoding: gzip, deflate, br
As we can see above, the browser sends a lot of information in these headers along with the GET request for the URL. What’s important for Vary for Images is the Accept header. The Accept header tells the origin what sort of content the browser is capable of handling (file types, etc.) and provides a list of content preferences.
When the origin gets the request, it sees the Accept header which details the content preference for the browser’s request. In the origin’s response, Vary tells the browser that content returned was different depending on the value of the Accept header in the request. Thus if a different browser comes along and sends a request with different Accept header values, this new browser can get a different response from the origin. An example origin response may look something like:
HTTP/1.1 200 OK
Content-Length: 123456
Vary: Accept
How Vary works with Cloudflare’s cache
Now, let’s add Cloudflare to the mix. Cloudflare sits in between the browser and the origin in the above example. When Cloudflare receives the origin’s response, we cache the specific image variant so that subsequent requests from browsers with the same image preferences can be served from cache. This also means that serving multiple image variants for the same asset will create distinct cache entries.
Accept header normalization
Caching variants in intermediate caches can be difficult to get right. Naive caching of variants can cause problems by serving incorrect or unsupported image variants to browsers. Some solutions that reduce the potential for caching incorrect variants generally provide those safeguards at the expense of performance.
For example, through a process known as content-negotiation, the correct variant is directed to the requesting browser through a process of multiple requests and responses. The browser could send a request to the origin asking for a list of available resource variants. When the origin responds with the list, the browser can make an additional request for the desired resources from that list, which the server would then respond to. These redundant calls to narrow down which type of content that the browser accepts and the server has available can cause performance delays.
Vary for Images reduces the need for these redundant negotiations to an origin by parsing the request’s Accept header and sending that on to the origin to ensure that the origin knows exactly what content it needs to deliver to the browser. Additionally because the expected variant values can be set in Cloudflare’s API (see below), we make an end-run around the negotiation process because we are sure what to ask for and expect from the origin. This reduces the needless back-and-forth between browsers and servers.
How to Enable Vary for Images
You can enable Vary for Images from Cloudflare’s API for Pro, Business, and Enterprise Customers.
Things to keep in mind when using Vary:
Vary for Images enables varying on the following file extensions: avif, bmp, gif, jpg, jpeg, jp2, jpg2, png, tif, tiff, webp. These extensions can have multiple variants served so long as the origin server sends the Vary: Accept response header.
If the origin server sends Vary: Accept but does not serve the expected variant, the response will not be cached. This will be indicated with the BYPASS cache status in the response headers.
The list of variant types the origin serves for each extension must be configured so that Cloudflare can decide which variant to serve without having to contact the origin server.
Enabling Vary in action
Enabling Vary functionality currently requires the use of the Cloudflare API. Here’s an example of how to enable variant support for a zone that wants to serve JPEGs in addition to WebP and AVIF variants for jpeg and jpg extensions.
Any purge of varied images will purge all content variants for that URL. That way, if the image changes, you can easily update the cache with a single purge versus chasing down how many potential out-of-date variants may exist. This behavior is true regardless of purge type (single file, tag, or hostname) used.
Other image optimization tools available at Cloudflare
Providing an additional option for customers to optimize the delivery of images also allows Cloudflare to support more customer configurations. For other ways Cloudflare can help you serve images to visitors quickly and efficiently, you can check out:
Polish — Cloudflare’s automatic product that strips image metadata and applies compression. Polish accelerates image downloads by reducing image size.
Image Resizing — Cloudflare’s image resizing product works as a proxy on top of the Cloudflare edge cache to apply the adjustments to an image’s size and quality.
Cloudflare for Images — Cloudflare’s all-in-one service to host, resize, optimize, and deliver all of your website’s images.
Try Vary for Images Out
Vary for Images provides options that ensure the best images are served to the browser based on the browser’s capabilities and preferences. If you’re looking for more control over how your images are delivered to browsers, we encourage you to try this new feature out.
No one likes to wait. Internet impatience is something we all suffer from.
Waiting for an app to update to show when your lunch is arriving; a website that loads slowly on your phone; a movie that hasn’t started to play… yet.
But building a waitless Internet is hard. And that’s where Cloudflare comes in. We’ve built the global network for Internet applications, be they websites, IoT devices or mobile apps. And we’ve optimized it to cut the wait.
If you believe ISP advertising then you’d think that bandwidth (100Mbps! 1Gbps! 2Gbps!) is the be all and end all of Internet speed. That’s a small component of what it takes to deliver the always on, instant experience we want and need.
The reality is you need three things: ample bandwidth, to have content and applications close to the end user, and to make the software as fast as possible. Simple really. Except not, because all three things require a lot of work at different layers.
In this blog post I’ll look at the factors that go into building our fast global network: bandwidth, latency, reliability, caching, cryptography, DNS, preloading, cold starts, and more; and how Cloudflare zeroes in on the most powerful number there is: zero.
I will focus on what happens when you visit a website but most of what I say below applies to the fitness tracker on your wrist sending information up to the cloud, your smart doorbell alerting you to a visitor, or an app getting you the weather forecast.
Faster than the speed of sight
Imagine for a moment you are about to type in the name of a website on your phone or computer. You’ve heard about an exciting new game “Silent Space Marine” and type in silentspacemarine.com.
The very first thing your computer does is translate that name into an IP address. Since computers do absolutely everything with numbers under the hood this “DNS lookup” is the first necessary step.
It involves your computer asking a recursive DNS resolver for the IP address of silentspacemarine.com. That’s the first opportunity for slowness. If the lookup is slow everything else will be slowed down because nothing can start until the IP address is known.
The DNS resolver you use might be one provided by your ISP, or you might have changed it to one of the free public resolvers like Google’s 8.8.8.8. Cloudflare runs the world’s fastest DNS resolver, 1.1.1.1, and you can use it too. Instructions are here.
With fast DNS name resolution set up your computer can move on to the next step in getting the web page you asked for.
Aside: how fast is fast? One way to think about that is to ask yourself how fast you are able to perceive something change. Research says that the eye can make sense of an image in 13ms. High quality video shows at 60 frames per second (about 16ms per image). So the eye is fast!
What that means for the web is that we need to be working in tens of milliseconds not seconds otherwise users will start to see the slowness.
Slowly, desperately slowly it seemed to us as we watched
Why is Cloudflare’s 1.1.1.1 so fast? Not to downplay the work of the engineering team who wrote the DNS resolver software and made it fast, but two things help make it zoom: caching and closeness.
Caching means keeping a copy of data that hasn’t changed, so you don’t have to go ask for it. If lots of people are playing Silent Space Marine then a DNS resolver can keep its IP address in cache so that when a computer asks for the IP address the software can reply instantly. All good DNS resolvers cache information for speed.
But what happens if the IP address isn’t in the resolver’s cache. This happens the first time someone asks for it, or after a timeout period where the resolver needs to check that the IP address hasn’t changed. In order to get the IP address the resolver asks an authoritative DNS server for the information. That server is ‘authoritative’ for a specific domain (like silentspacemarine.com) and knows the correct IP address.
Since DNS resolvers sometimes have to ask authoritative servers for IP addresses it’s also important that those servers are fast too. That’s one reason why Cloudflare runs one of the world’s largest and fastest authoritative DNS services. Slow authoritative DNS could be another reason an end user has to wait.
So much for caching, what about ‘closeness’. Here’s the problem: the speed of light is really slow. Yes, I know everyone tells you that the speed of light is really fast, but that’s because us sentient water-filled carbon lifeforms can’t move very fast.
But electrons shooting through wires, and lasers blasting data down fiber optic cables, send data at or close to light speed. And sadly light speed is slow. And this slowness shows up because in order to get anything on the Internet you need to go back and forth to a server (many, many times).
In the best case of asking for silentspacemarine.com and getting its IP address there’s one roundtrip:
“Hello, can you tell me the address of silentspacemarine.com?” “Yes, it’s…”
Even if you made the DNS resolver software instantaneous you’d pay the price of the speed of light. Sounds crazy, right? Here’s a quick calculation. Let’s imagine at home I have fiber optic Internet and the nearest DNS resolver to me is the city 100 km’s away. And somehow my ISP has laid the straightest fiber cable from me to the DNS resolver.
The speed of light in fiber is roughly 200,000,000 meters per second. Round trip would be 200,000 meters and so in the best possible case a whole one ms has been eaten up by the speed of light. Now imagine any worse case and the speed of light starts eating into the speed of sight.
The solution is quite simple: move the DNS resolver as close to the end user as possible. That’s partly why Cloudflare has built out (and continues to grow) our network. Today it stands at 250 cities worldwide.
Aside: actually it’s not “quite simple” because there’s another wrinkle. You can put servers all over the globe, but you also have to hook them up to the Internet. The beauty of the Internet is that it’s a network of networks. That also means that you don’t just plug into the Internet and get the lowest latency, you need to connect to multiple ISPs, transit networks and more so that end users, whatever network they use, get the best waitless experience they want.
That’s one reason why Cloudflare’s network isn’t simply all over the world, it’s also one of the most interconnected networks.
So far, in building the waitless Internet, we’ve identified fast DNS resolvers and fast authoritative DNS as two needs. What’s next?
Hello. Hello. OK.
So your web browser knows the IP address of Silent Space Marine and got it quickly. Great. Next step is for it to ask the web server at that IP address for the web page. Not so fast! The first step is to establish a connection to that server.
This is almost always done using a protocol called TCP that was invented in the 1970s. The very first step is for your computer and the server to agree they want to communicate. This is done with something called a three-way handshake.
Your computer sends a message saying, essentially, “Hello”, the server replies “I heard you say Hello” (that’s one round trip) and then your computer replies “I heard you say you heard me say Hello, so now we can chat” (actually it’s SYN then SYN-ACK and then ACK).
So, at least one speed-of-light troubled round trip has occurred. How do we fight the speed of light? We bring the server (in this case, web server) close to the end user. Yet another reason for Cloudflare’s massive global network and high interconnectedness.
Now the web browser can ask the web server for the web page of Silent Space Marine, right? Actually, no. The problem is we don’t just need a fast Internet we also need one that’s secure and so pretty much everything on the Internet uses an encryption protocol called TLS (which some old-timers will call SSL) and so next a secure connection has to be established.
Aside: astute readers might be wondering why I didn’t mention security in the DNS section above. Yep, you’re right, that’s a whole other wrinkle. DNS also needs to be secure (and fast) and resolvers like 1.1.1.1 support the encrypted DNS standards DoH and DoT. Those are built on top of… TLS. So in order to have fast, secure DNS you need the same thing as fast, secure web, and that’s fast TLS.
Oh, and by the way, you don’t want to get into some silly trade off between security and speed. You need both, which is why it’s helpful to use a service provider, like Cloudflare, that does everything.
Is this line secure?
TLS is quite a complicated protocol involving a web browser and a server establishing encryption keys and at least one of them (typically the web server) providing that they are who they purport to be (you wouldn’t want a secure connection to your bank’s website if you couldn’t be sure it was actually your bank).
The back and forth of establishing the secure connection incurs more hits on the speed of light. And so, once again, having servers close to end users is vital. And having really fast encryption software is vital too. Especially since encryption will need to happen on a variety of devices (think an old phone vs. a brand new laptop).
So, staying on top of the latest TLS standard is vital (we’re currently on TLS 1.3), and implementing all the tricks that speed TLS up is important (such as session resumption and 0-RTT resumption), and making sure your software is highly optimized.
So far getting to a waitless Internet has involved fast DNS resolvers, fast authoritative DNS, being close to end users to fast TCP handshakes, optimized TLS using the latest protocols. And we haven’t even asked the web server for the page yet.
If you’ve been counting round trips we’re currently standing at four: one for DNS, one for TCP, two for TLS. Lots of opportunity for the speed of light to be a problem, but also lots of opportunity for wider Internet problems to cause a slow-down.
Skybird, this is Dropkick with a red dash alpha message in two parts
Actually, before we let the web browser finally ask for the web page there are two things we need to worry about. And both are to do with when things go wrong. You may have noticed that sometimes the Internet doesn’t work right. Sometimes it’s slow.
The slowness is usually caused by two things: congestion and packet loss. Dealing with those is also vital to giving the end user the fastest experience possible.
In ancient times, long before the dawn of history, people used to use telephones that had physical wires connected to them. Those wires connected to exchanges and literal electrical connections were made between two phones over long distances. That scaled pretty well for a long time until a bunch of packet heads came along in the 1960s and said “you know you could create a giant shared network and break all communication up into packets and share the network”. The Internet.
But when you share something you can also get congestion and congestion control is a huge part of ensuring that the Internet is shared equitably amongst users. It’s one of the miracles of the Internet that theory done in the 1970s and implemented in the 1980s has allowed the network to support real time gaming and streaming video while allowing simultaneous chat and web browsing.
The flip side of congestion control is that in order to prevent a user from overwhelming the network you have to slow them down. And we’re trying to be as fast as possible! Actually, we need to be as fast as possible while remaining fair.
And congestion control is closely related to packet loss because one way that servers and browsers and computers know that there’s congestion is when their packets get lost.
We stay on top of the latest congestion control algorithms (such as BBR) so that users get the fastest, fairest possible experience. And we do something else: we actively try to work around packet loss.
Technologies like Argo and our private fiber backbone help us route around bad Internet weather that’s causing packet loss and send connections over dedicated fiber optic links that span the globe.
More on that in the coming week.
It’s happening!
And so, finally your web browser asks the web server for the web page with an innocent looking GET / command. And the web server responds with a big blob of HTML and just when you thought things were going to be simple, they are super complicated.
The complexity comes from two places: the HTTP protocol is now on its third major version, and the content of web pages is under the control of the designer.
First, protocols. HTTP/2 and HTTP/3 both provide significant speedups for web sites by introducing parallel request/response handling, better compression and ways to work around congestion and packet loss. Although HTTP/1.1 is still widely used, these newer protocols are the majority of traffic.
Cloudflare Radar shows HTTP/1.1 has dropped into the 20% range globally.
As people upgrade to recent browsers on their computers and devices the new protocols become more and more important. Staying on top of these, and optimizing them is vital as part of the waitless Internet.
And then comes the content of web pages. Images are a vital part of the web and delivering optimized images right-sized and right-formatted for the end user device plays a big part in a fast web.
But before the web browser can start loading the images it has to get and understand the HTML of the web page. This is wasteful as the browser could be downloading images (and other assets like fonts of JavaScript) while still processing the HTML if it knew about them in advance. The solution to that is for the web server to send a hint about what’s needed along with the HTML.
More on that in the coming week.
Imagical
One of the largest categories of content we deliver for our customers consists of static and animated images. And they are also a ripe target for optimization. Images tend to be large and take a while to download and there are a vast variety of end user devices. So getting the right size and format image to the end user really helps with performance.
Getting it there at the right time also means that images can be loaded lazily and only when the user scrolls them into visibility.
But, traditionally, handling different image formats (especially as new ones like WebP and AVIF get invented), different device types (think of all the different screen sizes out there), and different compression schemes has been a mess of services.
And chained services for different aspects of the image pipeline can be slow and expensive. What you really want is simple storage and an integrated way to deliver the right image to the end user tailored just for them.
More on that in the coming week.
Cache me if you can
As I mentioned in the section about DNS, a few thousand words ago, caching is really powerful and caching content near the end user is super powerful. Cloudflare makes extensive use of caching (particularly of images but also things like GraphQL) on its servers. This makes our customers’ websites fast as images can be delivered quickly from servers near the end user.
But it introduces a problem. If you have a lot of servers around the world then the caches need to be filled with content in order for it to be ready for end users. And the more servers you add the harder it gets to keep them all filled. You want the ‘cache hit ratio’ (how often content is served from cache without having to go back to the customer’s server) to be as high as possible.
But if you’ve got the content cached in Casablanca, and a user visits your website in Chennai they won’t have the fastest content delivery. To solve this some service providers make a deliberate decision not to have lots of servers near end users.
Sounds a bit crazy but their logic is “it’s hard to keep all those caches filled in lots of cities, let’s have only a few cities”. Sad. We think smart software can solve that problem and allow you to have your cache and eat it. We’ve used smart software to solve global load balancing problems and are doing the same for global cache. That way we get high cache hit ratios, super low latency to end users and low load on customer web servers.
More on that in the coming week.
Zero Cool
You know what’s cooler than a millisecond? Zero milliseconds.
But people were often concerned about cold start times because they were thinking about other serverless platforms that had significant spool up times for code that wasn’t ready to run.
Last year we announced that we eliminated cold starts from Workers. You don’t have to worry. And we’ll go deeper into why Cloudflare Workers is the fastest serverless platform out there.
More on that in the coming week.
And finally…
If you run a large global network and want to know if it’s really the fastest there is, and where you need to do work to keep it fast, the only way is to measure. Although there are third-party measurement tools available they can suffer from biases and their methodology is sometimes unclear.
We decided the only way we could understand our performance vs. other networks was to build our own like-for-like testing tool and measure performance across the Internet’s 70,000+ networks.
We’ll also talk about how we keep everything fast, from lightning quick configuration updates and code deploys to logs you don’t have to wait for to ludicrously fast cache purges to real time analytics.
More on that in the coming week.
Welcome to Speed Week*
*Can’t wait for tomorrow? Go play Silent Space Marine. It uses the technologies mentioned above.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.