Post Syndicated from Phillip Jones original https://blog.cloudflare.com/r2-data-catalog-public-beta/
Apache Iceberg is quickly becoming the standard table format for querying large analytic datasets in object storage. We’re seeing this trend firsthand as more and more developers and data teams adopt Iceberg on Cloudflare R2. But until now, using Iceberg with R2 meant managing additional infrastructure or relying on external data catalogs.
So we’re fixing this. Today, we’re launching the R2 Data Catalog in open beta, a managed Apache Iceberg catalog built directly into your Cloudflare R2 bucket.
If you’re not already familiar with it, Iceberg is an open table format built for large-scale analytics on datasets stored in object storage. With R2 Data Catalog, you get the database-like capabilities Iceberg is known for – ACID transactions, schema evolution, and efficient querying – without the overhead of managing your own external catalog.
R2 Data Catalog exposes a standard Iceberg REST catalog interface, so you can connect the engines you already use, like PyIceberg, Snowflake, and Spark. And, as always with R2, there are no egress fees, meaning that no matter which cloud or region your data is consumed from, you won’t have to worry about growing data transfer costs.
Ready to query data in R2 right now? Jump into the developer docs and enable a data catalog on your R2 bucket in just a few clicks. Or keep reading to learn more about Iceberg, data catalogs, how metadata files work under the hood, and how to create your first Iceberg table.
Apache Iceberg is an open table format for analyzing large datasets in object storage. It brings database-like features – ACID transactions, time travel, and schema evolution – to files stored in formats like Parquet or ORC.
Historically, data lakes were just collections of raw files in object storage. However, without a unified metadata layer, datasets could easily become corrupted, were difficult to evolve, and queries often required expensive full-table scans.
Iceberg solves these problems by:
-
Providing ACID transactions for reliable, concurrent reads and writes.
-
Maintaining optimized metadata, so engines can skip irrelevant files and avoid unnecessary full-table scans.
-
Supporting schema evolution, allowing columns to be added, renamed, or dropped without rewriting existing data.
Iceberg is already widely supported by engines like Apache Spark, Trino, Snowflake, DuckDB, and ClickHouse, with a fast-growing community behind it.
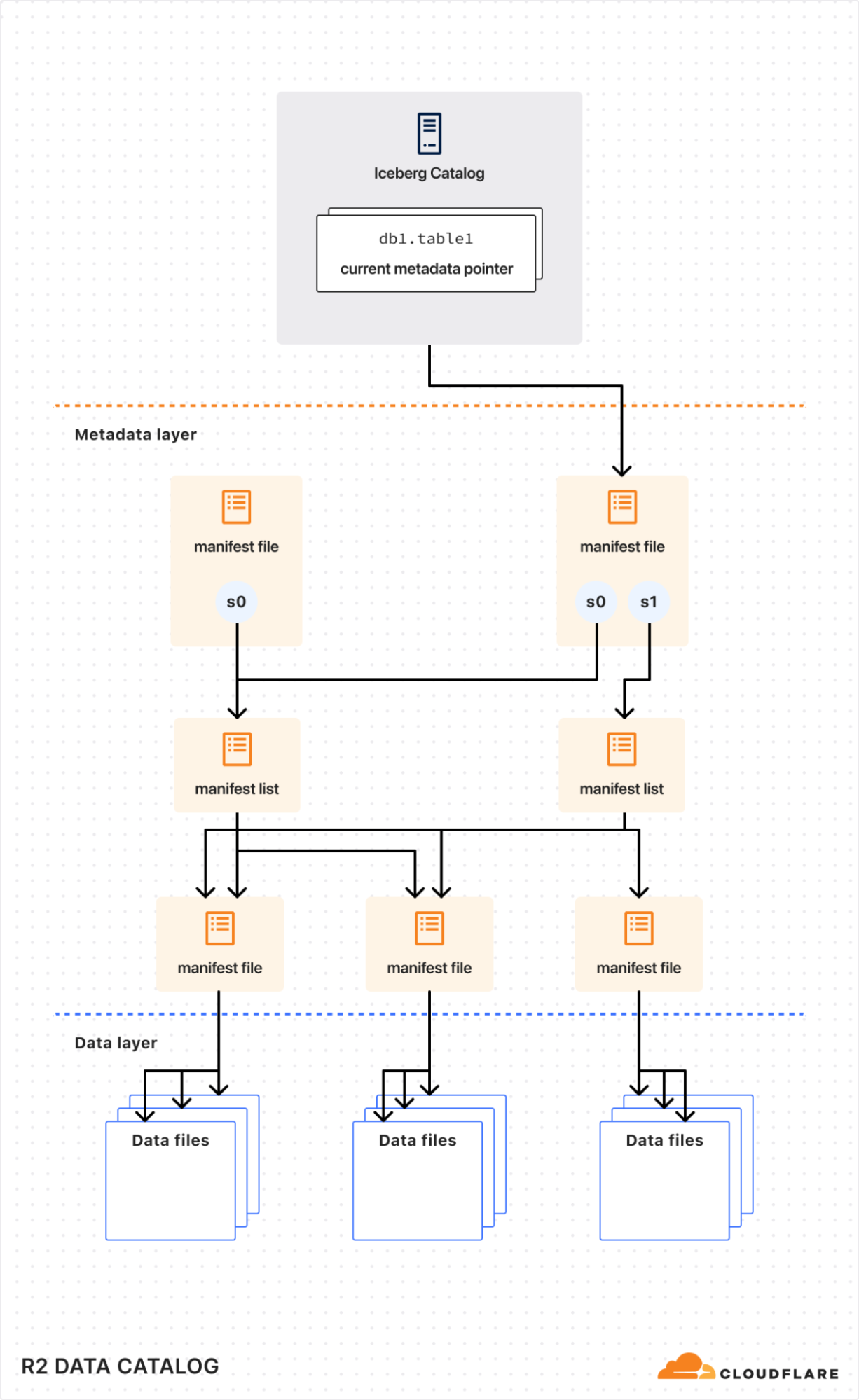
Internally, an Iceberg table is a collection of data files (typically stored in columnar formats like Parquet or ORC) and metadata files (typically stored in JSON or Avro) that describe table snapshots, schemas, and partition layouts.
To understand how query engines interact efficiently with Iceberg tables, it helps to look at an Iceberg metadata file (simplified):
{
"format-version": 2,
"table-uuid": "0195e49b-8f7c-7933-8b43-d2902c72720a",
"location": "s3://my-bucket/warehouse/0195e49b-79ca/table",
"current-schema-id": 0,
"schemas": [
{
"schema-id": 0,
"type": "struct",
"fields": [
{ "id": 1, "name": "id", "required": false, "type": "long" },
{ "id": 2, "name": "data", "required": false, "type": "string" }
]
}
],
"current-snapshot-id": 3567362634015106507,
"snapshots": [
{
"snapshot-id": 3567362634015106507,
"sequence-number": 1,
"timestamp-ms": 1743297158403,
"manifest-list": "s3://my-bucket/warehouse/0195e49b-79ca/table/metadata/snap-3567362634015106507-0.avro",
"summary": {},
"schema-id": 0
}
],
"partition-specs": [{ "spec-id": 0, "fields": [] }]
}A few of the important components are:
-
schemas: Iceberg tracks schema changes over time. Engines use schema information to safely read and write data without needing to rewrite underlying files. -
snapshots: Each snapshot references a specific set of data files that represent the state of the table at a point in time. This enables features like time travel. -
partition-specs: These define how the table is logically partitioned. Query engines leverage this information during planning to skip unnecessary partitions, greatly improving query performance.
By reading Iceberg metadata, query engines can efficiently prune partitions, load only the relevant snapshots, and fetch only the data files it needs, resulting in faster queries.
Although the Iceberg data and metadata files themselves live directly in object storage (like R2), the list of tables and pointers to the current metadata need to be tracked centrally by a data catalog.
Think of a data catalog as a library’s index system. While books (your data) are physically distributed across shelves (object storage), the index provides a single source of truth about what books exist, their locations, and their latest editions. Without this index, readers (query engines) would waste time searching for books, might access outdated versions, or could accidentally shelve new books in ways that make them unfindable.
Similarly, data catalogs ensure consistent, coordinated access, allowing multiple query engines to safely read from and write to the same tables without conflicts or data corruption.
Ready to try it out? Here’s a quick example using PyIceberg and Python to get you started. For a detailed step-by-step guide, check out our developer docs.
1. Enable R2 Data Catalog on your bucket:
npx wrangler r2 bucket catalog enable my-bucketOr use the Cloudflare dashboard: Navigate to R2 Object Storage > Settings > R2 Data Catalog and click Enable.
2. Create a Cloudflare API token with permissions for both R2 storage and the data catalog.
3. Install PyIceberg and PyArrow, then open a Python shell or notebook:
pip install pyiceberg pyarrow4. Connect to the catalog and create a table:
import pyarrow as pa
from pyiceberg.catalog.rest import RestCatalog
# Define catalog connection details (replace variables)
WAREHOUSE = "<WAREHOUSE>"
TOKEN = "<TOKEN>"
CATALOG_URI = "<CATALOG_URI>"
# Connect to R2 Data Catalog
catalog = RestCatalog(
name="my_catalog",
warehouse=WAREHOUSE,
uri=CATALOG_URI,
token=TOKEN,
)
# Create default namespace
catalog.create_namespace("default")
# Create simple PyArrow table
df = pa.table({
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Charlie"],
})
# Create an Iceberg table
table = catalog.create_table(
("default", "my_table"),
schema=df.schema,
)You can now append more data or run queries, just as you would with any Apache Iceberg table.
While R2 Data Catalog is in open beta, there will be no additional charges beyond standard R2 storage and operations costs incurred by query engines accessing data. Storage pricing for buckets with R2 Data Catalog enabled remains the same as standard R2 buckets – \$0.015 per GB-month. As always, egress directly from R2 buckets remains \$0.
In the future, we plan to introduce pricing for catalog operations (e.g., creating tables, retrieving table metadata, etc.) and data compaction.
Below is our current thinking on future pricing. We’ll communicate more details around timing well before billing begins, so you can confidently plan your workloads.
|
Pricing |
|
|
R2 storage For standard storage class |
$0.015 per GB-month (no change) |
|
R2 Class A operations |
$4.50 per million operations (no change) |
|
R2 Class B operations |
$0.36 per million operations (no change) |
|
Data Catalog operations e.g., create table, get table metadata, update table properties |
$9.00 per million catalog operations |
|
Data Catalog compaction data processed |
$0.05 per GB processed $4.00 per million objects processed |
|
Data egress |
$0 (no change, always free) |
We’re excited to see how you use R2 Data Catalog! If you’ve never worked with Iceberg – or even analytics data – before, we think this is the easiest way to get started.
Next on our roadmap is tackling compaction and table optimization. Query engines typically perform better when dealing with fewer, but larger data files. We will automatically re-write collections of small data files into larger files to deliver even faster query performance.
We’re also collaborating with the broad Apache Iceberg community to expand query-engine compatibility with the Iceberg REST Catalog spec.
We’d love your feedback. Join the Cloudflare Developer Discord to ask questions and share your thoughts during the public beta. For more details, examples, and guides, visit our developer documentation.













