Post Syndicated from Benjamin Smith original https://aws.amazon.com/blogs/compute/building-serverless-land-part-2-an-auto-building-static-site/
In this two-part blog series, I show how serverlessland.com is built. This is a static website that brings together all the latest blogs, videos, and training for AWS serverless. It automatically aggregates content from a number of sources. The content exists in a static JSON file, which generates a new static site each time it is updated. The result is a low-maintenance, low-latency serverless website, with almost limitless scalability.
A companion blog post explains how to build an automated content aggregation workflow to create and update the site’s content. In this post, you learn how to build a static website with an automated deployment pipeline that re-builds on each GitHub commit. The site content is stored in JSON files in the same repository as the code base. The example code can be found in this GitHub repository.
The growing adoption of serverless technologies generates increasing amounts of helpful and insightful content from the developer community. This content can be difficult to discover. Serverless Land helps channel this into a single searchable location. By collating this into a static website, users can enjoy a browsing experience with fast page load speeds.
The serverless nature of the site means that developers don’t need to manage infrastructure or scalability. The use of AWS Amplify Console to automatically deploy directly from GitHub enables a regular release cadence with a fast transition from prototype to production.
Static websites
A static site is served to the user’s web browser exactly as stored. This contrasts to dynamic webpages, which are generated by a web application. Static websites often provide improved performance for end users and have fewer or no dependant systems, such as databases or application servers. They may also be more cost-effective and secure than dynamic websites by using cloud storage, instead of a hosted environment.
A static site generator is a tool that generates a static website from a website’s configuration and content. Content can come from a headless content management system, through a REST API, or from data referenced within the website’s file system. The output of a static site generator is a set of static files that form the website.
Serverless Land uses a static site generator for Vue.js called Nuxt.js. Each time content is updated, Nuxt.js regenerates the static site, building the HTML for each page route and storing it in a file.
The architecture
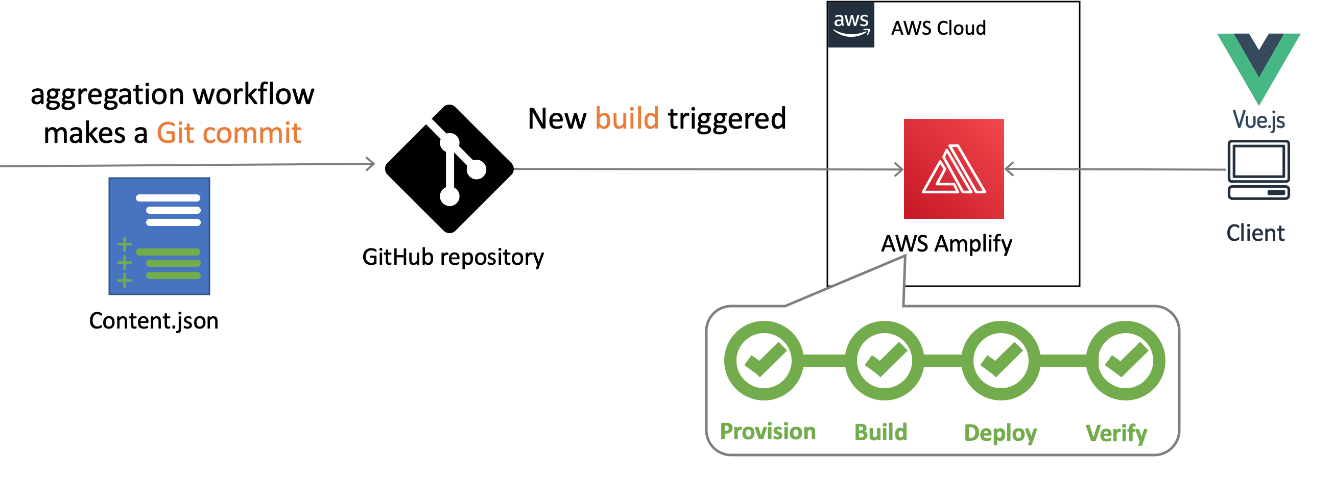
Serverless Land static website architecture
When the content.json file is committed to GitHub, a new build process is triggered in AWS Amplify Console.
Deploying AWS Amplify
AWS Amplify helps developers to build secure and scalable full stack cloud applications. AWS Amplify Console is a tool within Amplify that provides a user interface with a git-based workflow for hosting static sites. Deploy applications by connecting to an existing repository (GitHub, BitBucket Cloud, GitLab, and AWS CodeCommit) to set up a fully managed, nearly continuous deployment pipeline.
This means that any changes committed to the repository trigger the pipeline to build, test, and deploy the changes to the target environment. It also provides instant content delivery network (CDN) cache invalidation, atomic deploys, password protection, and redirects without the need to manage any servers.
Building the static website
- To get started, use the Nuxt.js scaffolding tool to deploy a boiler plate application. Make sure you have npx installed (npx is shipped by default with npm version 5.2.0 and above).
$ npx create-nuxt-app content-aggregatorThe scaffolding tool asks some questions, answer as follows:
 Nuxt.js scaffolding tool inputs
Nuxt.js scaffolding tool inputs - Navigate to the project directory and launch it with:
$ cd content-aggregator $ npm run devThe application is now running on http://localhost:3000.The
pagesdirectory contains your application views and routes. Nuxt.js reads the.vuefiles inside this directory and automatically creates the router configuration. - Create a new file in the
/pagesdirectory namedblogs.vue:$ touch pages/blogs.vue - Copy the contents of this file into
pages/blogs.vue. - Create a new file in
/componentsdirectory namedPost.vue:$ touch components/Post.vue - Copy the contents of this file into
components/Post.vue. - Create a new file in
/assetsnamedcontent.jsonand copy the contents of this file into it.$ touch /assets/content.json
 Nuxt.js scaffolding tool inputs
Nuxt.js scaffolding tool inputsThe blogs Vue component
The blogs page is a Vue component with some special attributes and functions added to make development of your application easier. The following code imports the content.json file into the variable blogPosts. This file stores the static website’s array of aggregated blog post content.
import blogPosts from '../assets/content.json'
An array named blogPosts is initialized:
data(){
return{
blogPosts: []
}
},
The array is then loaded with the contents of content.json.
mounted(){
this.blogPosts = blogPosts
},
In the component template, the v-for directive renders a list of post items based on the blogPosts array. It requires a special syntax in the form of blog in blogPosts, where blogPosts is the source data array and blog is an alias for the array element being iterated on. The Post component is rendered for each iteration. Since components have isolated scopes of their own, a :post prop is used to pass the iterated data into the Post component:
<ul>
<li v-for="blog in blogPosts" :key="blog">
<Post :post="blog" />
</li>
</ul>
The post data is then displayed by the following template in components/Post.vue.
<template>
<div class="hello">
<h3>{{ post.title }} </h3>
<div class="img-holder">
<img :src="post.image" />
</div>
<p>{{ post.intro }} </p>
<p>Published on {{post.date}}, by {{ post.author }} p>
<a :href="post.link"> Read article</a>
</div>
</template>
This forms the framework for the static website. The /blogs page displays content from /assets/content.json via the Post component. To view this, go to http://localhost:3000/blogs in your browser:

The /blogs page
Add a new item to the content.json file and rebuild the static website to display new posts on the blogs page. The previous content was generated using the aggregation workflow explained in this companion blog post.
Connect to Amplify Console
Clone the web application to a GitHub repository and connect it to Amplify Console to automate the rebuild and deployment process:
- Upload the code to a new GitHub repository named ‘content-aggregator’.
- In the AWS Management Console, go to the Amplify Console and choose Connect app.
- Choose GitHub then Continue.
- Authorize to your GitHub account, then in the Recently updated repositories drop-down select the ‘content-aggregator’ repository.
- In the Branch field, leave the default as master and choose Next.

- In the Build and test settings choose edit.
- Replace
- npm run buildwith –npm run generate. - Replace
baseDirectory: /withbaseDirectory: dist

This runs the nuxt generate command each time an application build process is triggered. Thenuxt.config.jsfile has atargetproperty with the value ofstaticset. This generates the web application into static files. Nuxt.js creates adistdirectory with everything inside ready to be deployed on a static hosting service. - Choose Save then Next.
- Review the Repository details and App settings are correct. Choose Save and deploy.

Amplify Console deployment



Once the deployment process has completed and is verified, choose the URL generated by Amplify Console. Append /blogs to the URL, to see the static website blogs page.

Any edits pushed to the repository’s content.json file trigger a new deployment in Amplify Console that regenerates the static website. This companion blog post explains how to set up an automated content aggregator to add new items to the content.json file from an RSS feed.
Conclusion
This blog post shows how to create a static website with vue.js using the nuxt.js static site generator. The site’s content is generated from a single JSON file, stored in the site’s assets directory. It is automatically deployed and re-generated by Amplify Console each time a new commit is pushed to the GitHub repository. By automating updates to the content.json file you can create low-maintenance, low-latency static websites with almost limitless scalability.
This application framework is used together with this automated content aggregator to pull together articles for http://serverlessland.com. Serverless Land brings together all the latest blogs, videos, and training for AWS Serverless. Download the code from this GitHub repository to start building your own automated content aggregation platform.