Rapid7 managed services teams are observing exploitation of a critical vulnerability in Progress Software’s MOVEit Transfer solution across multiple customer environments. We have observed an uptick in related cases since the vulnerability was disclosed publicly yesterday (May 31, 2023); file transfer solutions have been popular targets for attackers, including ransomware groups, in recent years. We strongly recommend that MOVEit Transfer customers prioritize mitigation on an emergency basis.
Progress Software published an advisory on Wednesday, May 31, 2023 warning of a critical SQL injection vulnerability in their MOVEit Transfer solution. The vulnerability, which currently does not have a CVE, is a SQL injection flaw that allows for “escalated privileges and potential unauthorized access” on target systems. While the advisory does not explicitly confirm the vulnerability was exploited by threat actors as a zero-day, Progress Software is advising MOVEit customers to check for indicators of unauthorized access over “at least the past 30 days,” which implies that attacker activity was detected before the vulnerability was disclosed.
As of May 31, there were roughly 2,500 instances of MOVEit Transfer exposed to the public internet, the majority of which look to be in the United States. Rapid7 has previously analyzed similar SQLi-to-RCE flaws in network edge systems; these types of vulnerabilities can provide threat actors with initial access to corporate networks.
Observed attacker behavior
Our teams have so far observed the same webshell name in multiple customer environments, which may indicate automated exploitation. Rapid7 analyzed a sample webshell payload associated with successful exploitation. The webshell code would first determine if the inbound request contained a header named X-siLock-Comment, and would return a 404 "Not Found" error if the header was not populated with a specific password-like value. As of June 1, 2023, all instances of Rapid7-observed MOVEit Transfer exploitation involve the presence of the file human2.aspx in the wwwroot folder of the MOVEit install directory.
We will update this section as our investigations progress.
Mitigation guidance
The MOVEit Transfer advisory has contradictory wording on patch availability, but as of June 1, it does appear that fixed versions of the software are available. Patches should be applied on an emergency basis. Per the MOVEit advisory published on May 31, 2023, organizations should look for indicators of compromise dating back at least a month.
Rapid7 is tracking reports of ongoing exploitation of CVE-2023-28771, a critical unauthenticated command injection vulnerability affecting multiple Zyxel networking devices.
The vulnerability is present in the default configuration of vulnerable devices and is exploitable in the Wide Area Network (WAN) interface, which is intended to be exposed to the internet. A VPN does not need to be configured on a device for it to be vulnerable. Successful exploitation of CVE-2023-28771 allows an unauthenticated attacker to execute code remotely on the target system by sending a specially crafted IKEv2 packet to UDP port 500 on the device.
Zyxel released an advisory for CVE-2023-28771 on April 25, 2023. On May 19, Rapid7 researchers published a technical analysis of the vulnerability on AttackerKB, underscoring the likelihood of exploitation.
As of May 19, there were at least 42,000 instances of Zyxel devices on the public internet. However, as Rapid7 researchers noted, this number only includes devices that expose their web interfaces on the WAN, which is not a default setting. Since the vulnerability is in the VPN service, which is enabled by default on the WAN, we expect the actual number of exposed and vulnerable devices to be much higher.
As of May 26, the vulnerability is being widely exploited, and compromised Zyxel devices are being leveraged to conduct downstream attacks as part of a Mirai-based botnet. Mirai botnets are frequently used to conduct DDoS attacks.
While CVE-2023-28771 is currently garnering large-scale threat actor attention, Zyxel published an advisory for two additional vulnerabilities — CVE-2023-33009 and CVE-2023-33010 — on May 24, 2023. CVE-2023-33009 and CVE-2023-33010 are buffer overflow vulnerabilities that can allow unauthenticated attackers to cause a DoS condition or execute arbitrary code on affected devices.
We strongly recommend that users of the affected Zyxel products update to the latest firmware on an emergency basis. At time of writing, the latest firmware version is 5.36 Patch 2, or 4.73 Patch 2 for ZyWALL/USG. See Zyxel’s advisory for additional details.
Rapid7 Customers
For InsightVM and Nexpose customers, a remote vulnerability check for CVE-2023-28771 has been available since the May 19, 2023 content release.
Additional remote vulnerability checks for CVE-2023-33009 and CVE-2023-33010 are expected to ship in the May 31, 2023 content release.
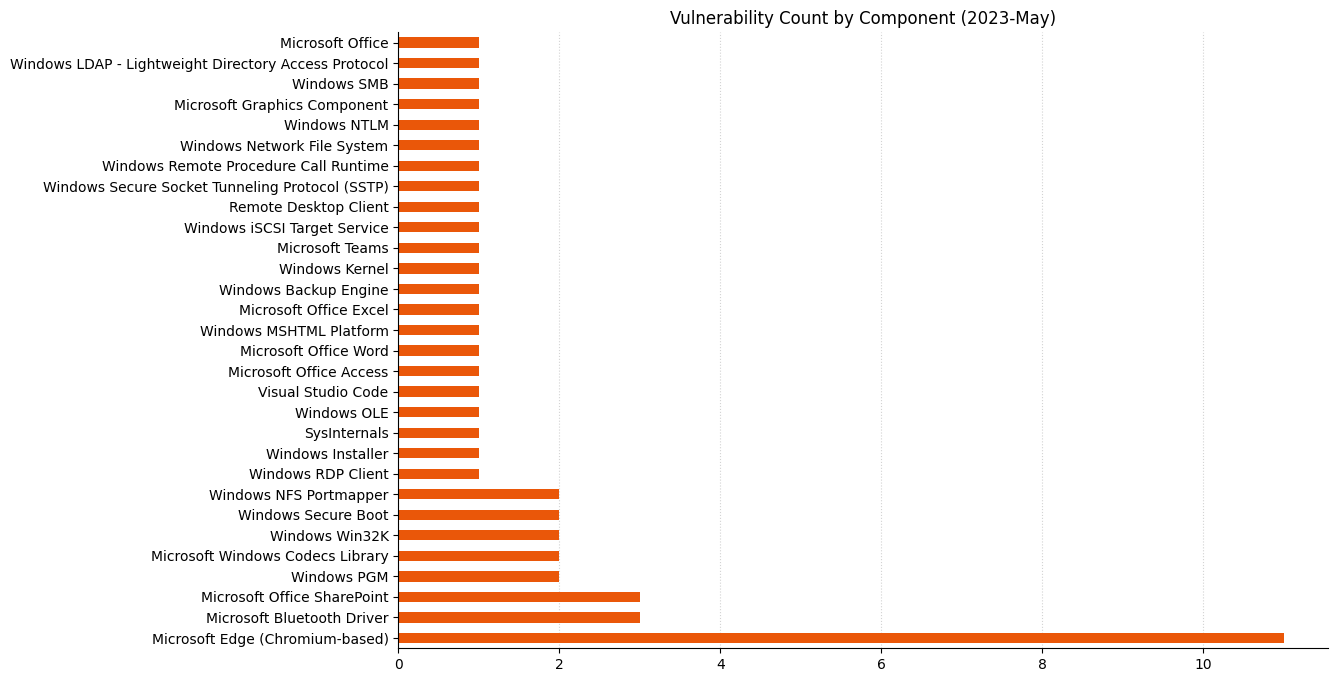
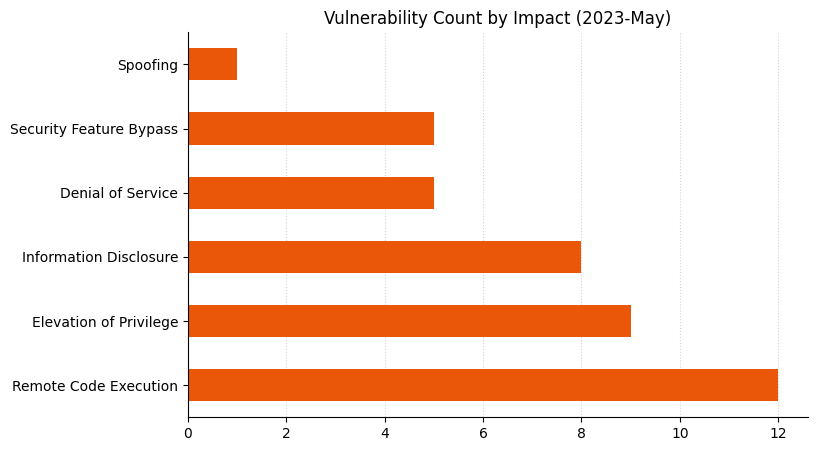
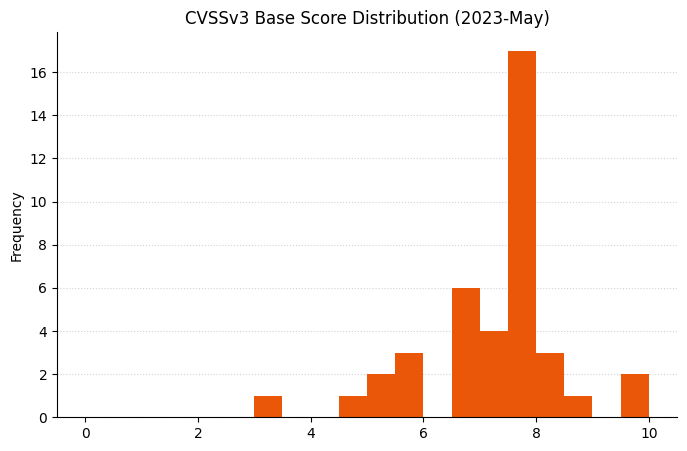
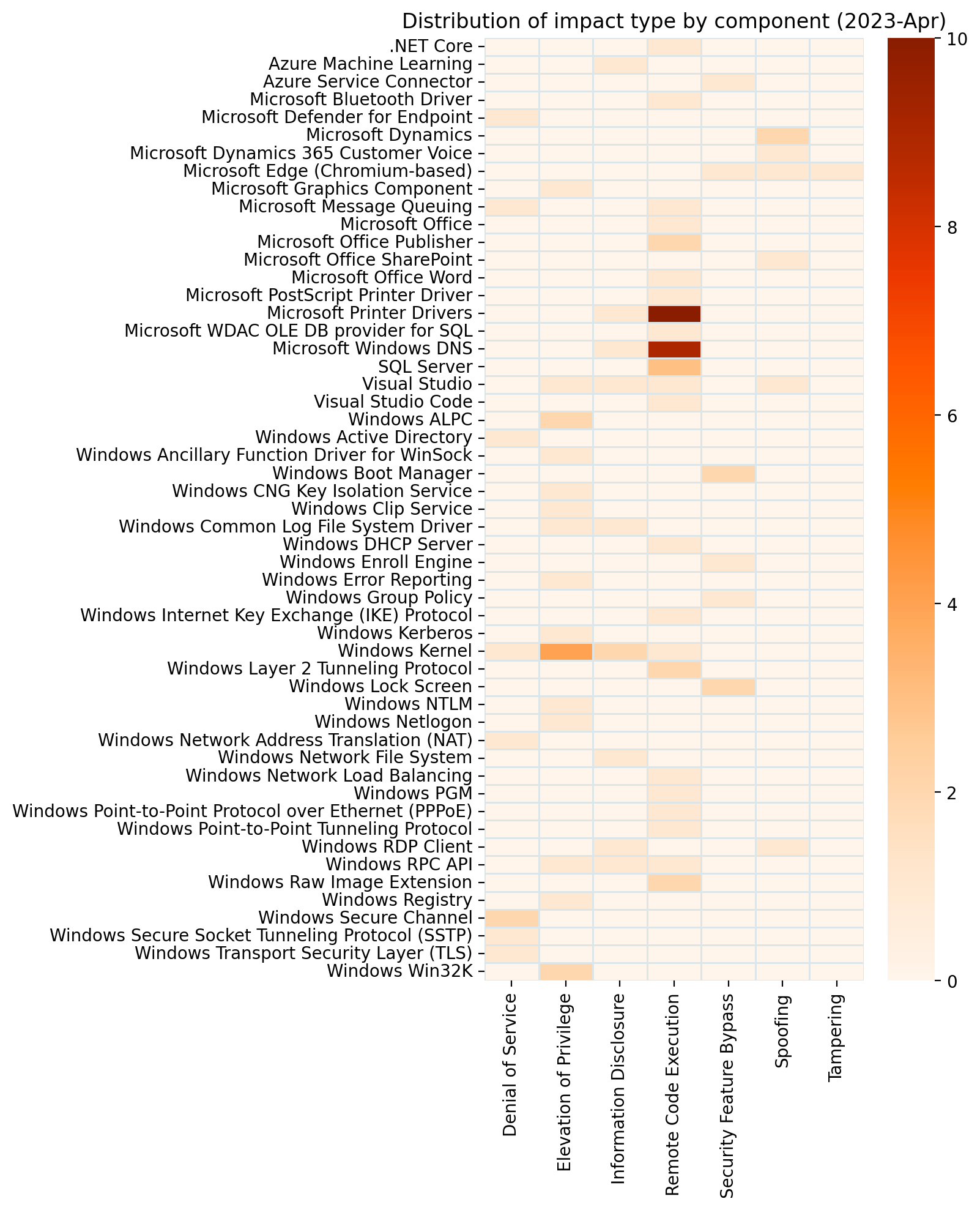
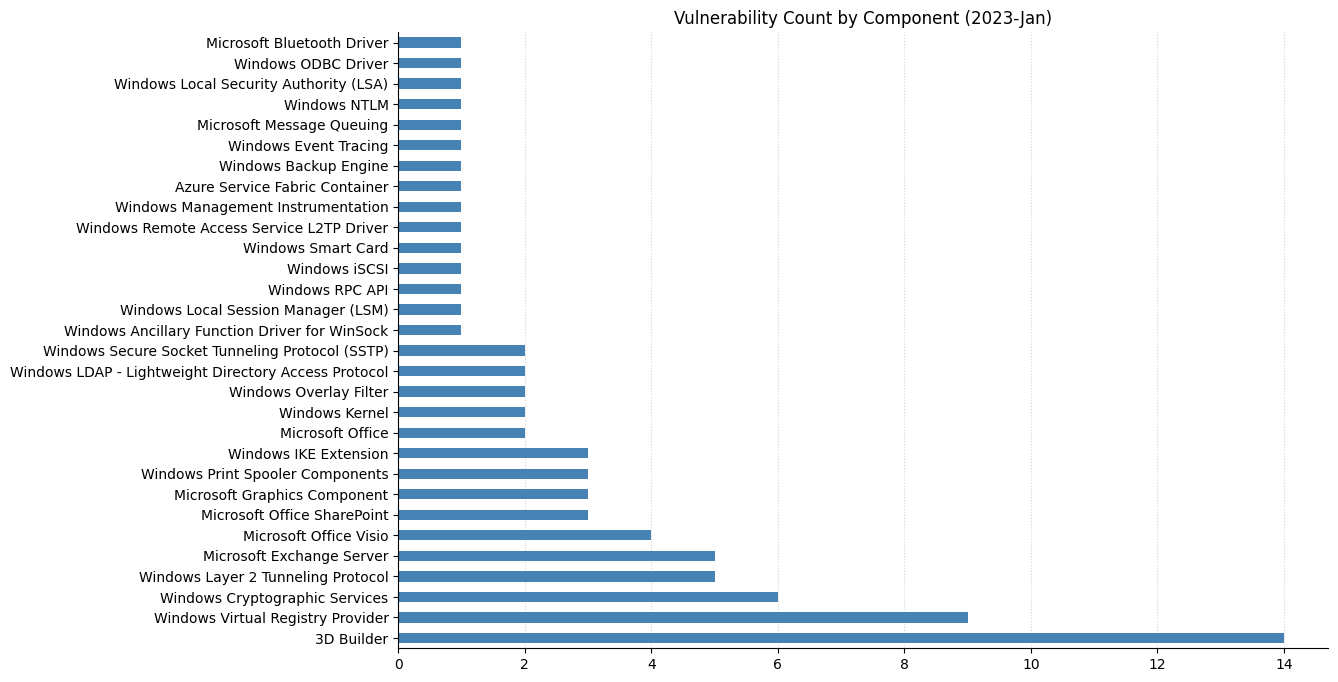
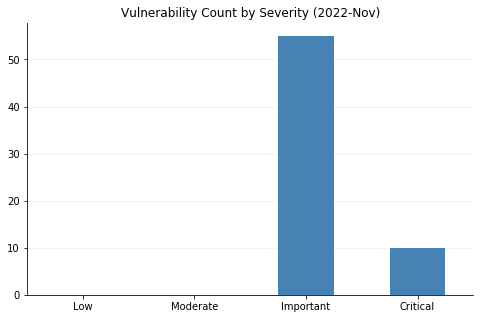
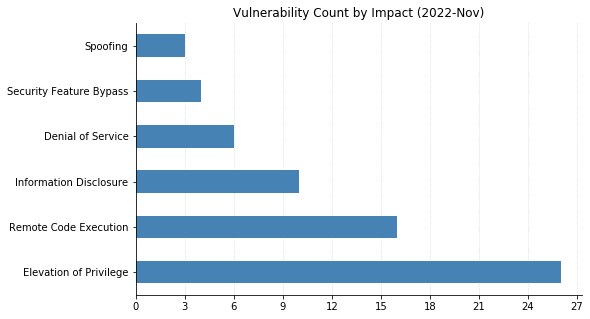
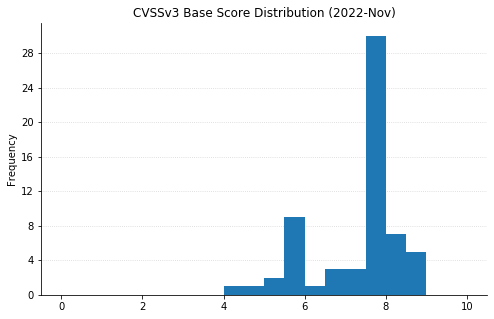
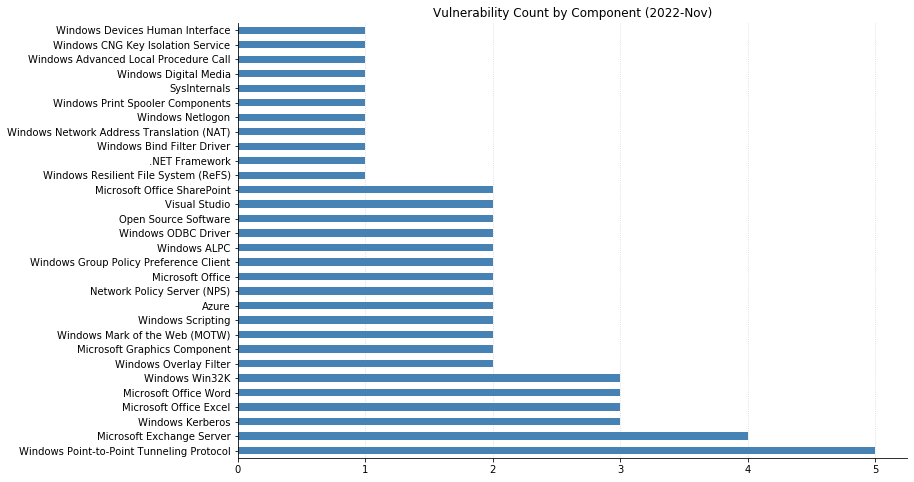
A less crowded Patch Tuesday for May 2023: Microsoft is offering fixes for just 49 vulnerabilities this month. There are no fixes this month for printer drivers, DNS, or .NET, three components which have featured heavily in recent months. Three zero-day vulnerabilities are patched, alongside a further five critical Remote Code Execution (RCE) vulnerabilities. None of the three zero-day vulnerabilities have a particularly high CVSSv3 base score, but timely patching is always indicated.
First up: a zero-day Secure Boot Security Feature Bypass vulnerability which is actively exploited by the BlackLotus bootkit malware. Microsoft warns that an attacker who already has Administrator access to an unpatched asset could exploit CVE-2023-24932 without necessarily having physical access. The relatively low CVSSv3 base score of 6.7 isn’t necessarily a reliable metric in this case.
Microsoft has provided a supplementary guidance article specifically calling out the threat posed by BlackLotus malware, which loads ahead of the operating system on compromised assets, and provides attackers with an array of powerful evasion, persistence, and Command & Control (C2) techniques, including deploying malicious kernel drivers, and disabling Microsoft Defender or Bitlocker.
Administrators should be aware that additional actions are required for remediation of CVE-2023-24932 beyond simply applying the patches. The patch enables the configuration options necessary for protection, but administrators must apply changes to UEFI config after patching. Attack surface is not limited to physical assets, either; Windows assets running on some VMs, including Azure assets with Secure Boot enabled, also require these extra remediation steps for protection. Rapid7 has noted in the past that enabling Secure Boot is a foundational protection against driver-based attacks. Defenders ignore this vulnerability at their peril.
Zero-day vulnerability: RTF OLE RCE
The second of this month’s zero-day trio is an RCE vulnerability targeting Outlook users, as well as Windows Explorer. The vulnerability is in the proprietary Microsoft Object Linking and Embedding (OLE) layer, which allows embedding and linking to documents and other objects, and the Microsoft bulletin for CVE-2023-29336 suggests that the attack is likely conducted via a specially-crafted Rich Text File (RTF). All current versions of Windows are vulnerable, and viewing the malicious file via the Preview pane is one route to exploitation; however, successful exploitation requires an attacker to win a race condition and to otherwise prepare the target environment. This should significantly reduce the real-world impact of this vulnerability. Mitigations include disabling the Preview Pane, as well as configuring Outlook to read all emails in plain text mode. Microsoft is not aware of public disclosure, but has detected in-the-wild exploitation.
Zero-day vulnerability: Win32k LPE to SYSTEM
Rounding out this month’s trio of zero-day vulnerabilities is a Win32k Local Privilege Escalation (LPE) vulnerability. Successful exploitation will result in SYSTEM privileges. Win32k is a kernel-space driver responsible for aspects of the Windows GUI. As Rapid7 has noted in the past, the Win32k sub-system offers reliable attack surface that is not configuration-dependent. Although LPE vulnerabilities may seem less immediately concerning than a remote exploit, attackers frequently chain them together with other vulnerabilities to achieve full control over remote resources. Microsoft assesses attack complexity as low, and is aware of in-the-wild exploitation.
The remaining five RCE vulnerabilities this month include two with high CVSSv3 base scores of 9.8.
Although Microsoft is not aware of public disclosure or in-the-wild exploitation, Network File System (NFS) RCE vulnerability CVE-2023-24941 is a network attack with low complexity affecting Windows assets running NFS v4.1. As a mitigation prior to patching, Microsoft recommends disabling NFSv4.1 and then re-enabling it once the patch is applied, although this may impact functionality. OIder versions of NFS (NFSv3 and NFSv2) are not affected by this vulnerability. Microsoft warns that assets which haven’t been patched for over a year would be vulnerable to CVE-2022-26937 which is a Critical vulnerability in NFSV2.0 and NFSV3.0. In other words: applying today’s mitigation to an asset missing the May 2022 patches would effectively cause a downgrade attack.
CVE-2023-24943 describes a vulnerability in Windows Pragmatic General Multicast (PGM), and is a concern only for assets running Windows Message Queuing Service (MSQS) in a PGM environment. Microsoft recommends newer alternatives to PGM in the advisory. A further two critical RCE for MSQS were patched last month, and the continued flow of vulnerabilities suggests that MSQS will continue to be an area of interest for security researchers. Although MSQS is not installed by default, some software, including some versions of Microsoft Exchange Server, will helpfully enable it as part of their own installation routine.
Another candidate for inclusion in an exploit chain is SharePoint RCE CVE-2023-24955, which requires the attacker to authenticate as Site Owner to run code on the SharePoint Server host. Microsoft assesses this one as Exploitation More Likely, due in part to the low attack complexity. SharePoint Server 2016, 2019, and Subscription Edition are all vulnerable until patched. Anyone still running SharePoint Server 2013 should upgrade immediately, as May 2023 is the first Patch Tuesday after the end of ESU; absence of evidence of vulnerability is by no means evidence of absence.
Long-standing Patch Tuesday entrant Windows Secure Socket Tunneling Protocol (SSTP) provides CVE-2023-24903 this month, which is a critical RCE involving sending a specially crafted SSTP packet to an SSTP server and winning a race condition. This qualifies as high attack complexity, and Microsoft considers exploitation less likely.
The final Critical RCE this month is CVE-2023-28283, which is also a high-complexity network-vector attack involving a race condition. In this case, the attack is conducted via a specially-crafted set of LDAP calls.
Summary Charts
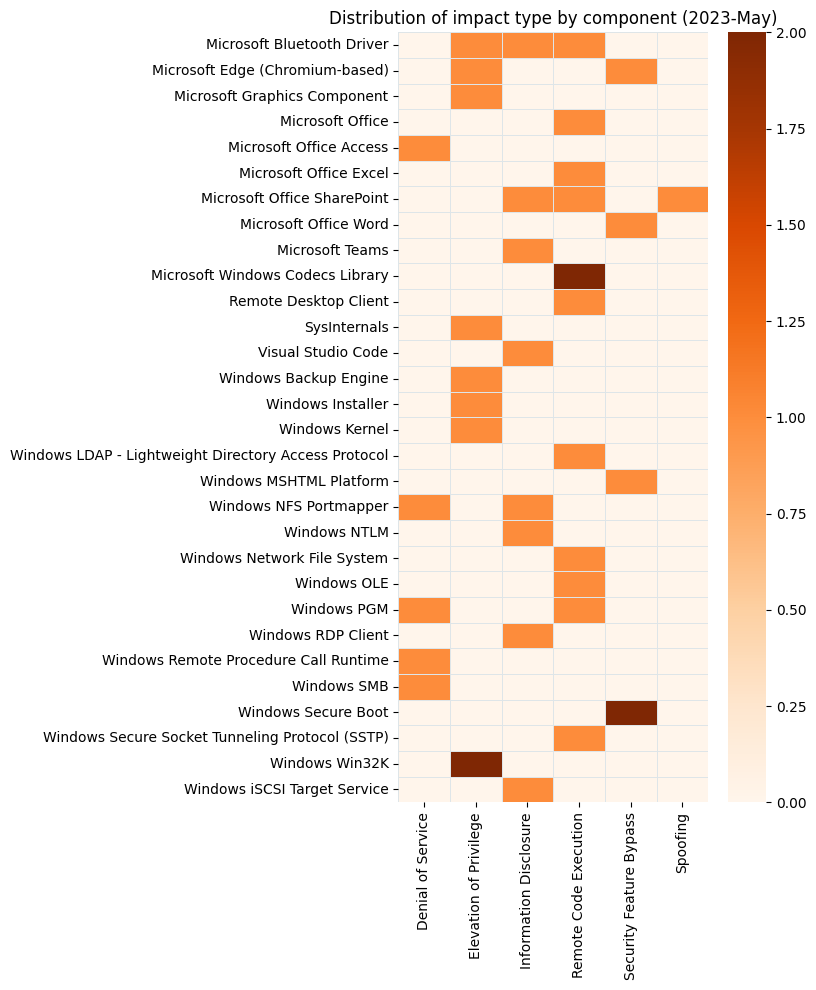
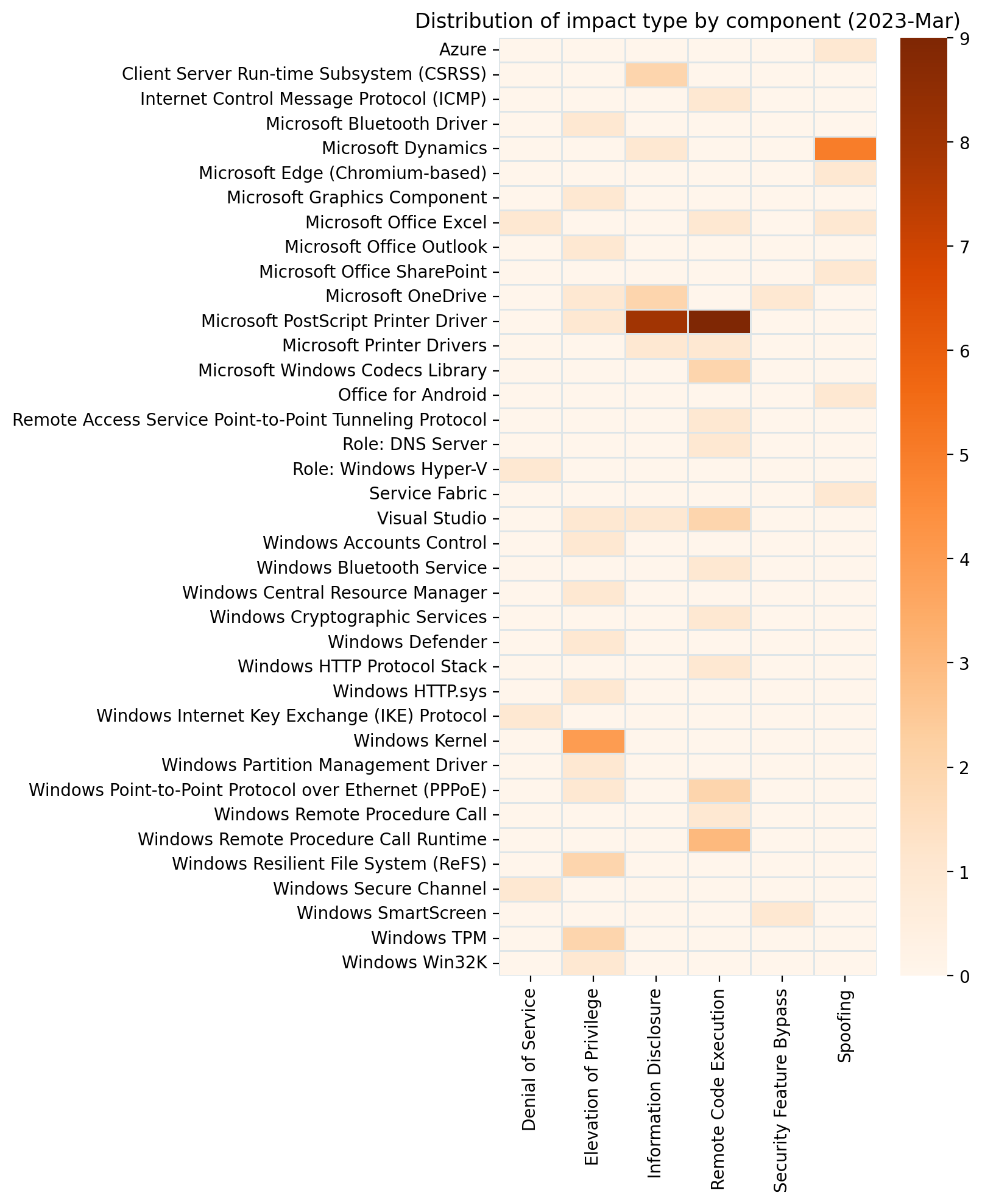
Several of the usual suspects are notable by their absence this month.It’s hard to imagine Patch Tuesday without Remote Code Execution vulnerabilities.It would be surprising if the CVSSv3 base score chart for almost any random sample of vulnerabilities didn’t look similar to this.Perhaps a coincidence, but two of the three most prominent cells in this heatmap include zero-day vulnerabilities.
Rapid7 Insight Agent and InsightVM Scan Assistant are executables that can be deployed to assist in understanding the vulnerabilities in your environment. Frequently there are questions around when and where you would deploy each, if you need both, what they actually monitor, etc. This article will answer those questions, but first let’s look at each executable in more detail.
Rapid7 Insight Agent
Notice the name of this starts with Rapid7. This is important, because the Insight Agent can be used for multiple tools, primarily InsightVM and InsightIDR. However, the agent does different things for each. For InsightIDR, the agent monitors process start and stop events and has log collection abilities. For InsightVM, the Insight Agent is used for assessment of vulnerabilities. In this article, we’ll focus on using Insight Agent for InsightVM.
The Insight Agent performs an “assessment” roughly every six hours. Notice the word “assessment” and not “scan”. The Insight Agent has the permissions necessary to gather information about the asset that it is installed on and then forward that information directly to the Insight Platform. The Insight Platform then forwards that data to the InsightVM Security Console. The Security Console then takes that data and runs it against a scan template to determine what vulnerabilities that asset has. Once done, the Security Console updates its own database with the results for that asset and then on the interval of communication with the Insight Platform it will forward the assessment results back to the Insight Platform.
With the Insight Agent, you do not determine a scan schedule or have the ability to kick off ad hoc or remediation scans on that asset. As noted above, assessments occur every six hours. However, not every agent is being assessed on the same six hour interval. The schedule is maintained entirely by the Insight Platform.
Another key takeaway about the communication path mentioned above: The Insight Agent does not communicate directly to the console. This makes Insight Agent particularly beneficial when it comes to protecting your remote workforce. Given that remote assets are not on your network, you typically cannot scan them directly. So, Insight Agent is the main option to view the vulnerabilities for those assets.
Recently, Rapid7 released the ability to perform Policy Scans using the Insight Agent as well. This ability is limited to assets that are available for the installation of the InsightAgent though (Windows, Linux, Mac), however that typically covers a large portion of the policy scanning needed. Policy scanning occurs every 12 hours.
The InsightVM Scan Assistant executable is solely dedicated to InsightVM and is configured to display a certificate on port 21047. The Scan Assistant can only be used when being accessed from a scan engine (distributed or local). Unlike the Insight Agent, which monitors and performs assessments on a scheduled basis, the Scan Assistant is dormant unless called upon by a Scan Engine either through a manual or scheduled scan configured from the Security Console.
For this to work, first you must generate a certificate from InsightVM in the credential setup. Then, you need to edit any scan templates being used to additionally look for port TCP 21047 on both Asset and Service discovery. From there, the Scan Engine will use those credentials and look for that port to be open on the endpoint servers. If the certificate being presented on that port matches the certificate created within InsightVM, the scan engine will use it to authenticate to the endpoint asset. The Scan Assistant has the permissions necessary to perform all local checks on the endpoint asset.
Using the Scan Assistant instead of regular domain credentials offers better security, as it eliminates the possibility of a domain account with elevated permissions to be used in your environment. Additionally, the Scan Assistant has proven to be more efficient and perform scans quicker than domain credentials.
As stated above, the two executables are completely independent of each other. The Insight Agent communicates to the platform whereas the Scan Assistant talks directly to the Scan Engine performing the scan. The Insight Agent is not configurable in its scheduled assessment whereas the Scan Assistant is completely dormant until scanned and is completely reliant on an administrator configuring scanning.
So, WHERE should each executable be installed? I would suggest having the Insight Agent on all local and remote assets—everything capable of having the Insight Agent installed. For the Scan Assistant, only internal assets would be applicable. You could install the Scan Assistant on remote assets as well, if you have a policy that requires users to connect to the VPN on set schedules and you plan to scan through that VPN or office wi-fi. However, in most situations, the Insight Agent is the only way to assess your remote assets.
So that brings us to the internal assets that should have BOTH the Insight Agent and the Scan Assistant installed. You might be asking ‘why in the world would I want to deploy yet another executable if the Insight Agent is already performing the assessment on those assets?’ Well, let’s circle back to the fact that the Insight Agent is only performing the local checks. So, you will need to perform at least monthly scanning of those assets to view network vulnerabilities. Additionally, as mentioned above, the Insight Agent is incapable of kicking off an ad-hoc scan. This is where the Scan Assistant comes into play for remediation scans specifically.
Scenario: I have an asset “abc.company.com.” InsightAgent discovers a local vulnerability on the asset at 10AM and it’s only 1030AM. I send the finding off to my system administrator to patch the vulnerability immediately. By 11AM the vulnerability is patched, and I want to verify that the vulnerability has been remediated. Without a credentialed scan, I have to wait another five hours before InsightAgent conducts another assessment. However, with the Scan Assistant I can immediately kick off an authenticated vulnerability scan against that asset to determine that the vulnerability is no longer present.
The other main use case for the Scan Assistant is to take advantage of the full breadth of the Policy Scanning. Currently, InsightAgent can only assess up to 100 different policies and can only assess for the default values of the policies through CIS or DISA.
Using the Scan Assistant with the scan engine you have access to ALL categories of Policy Scans, including CIS, DISA, FDCC, and USGCB. Additionally, you can use the custom policy builder to edit values within typical benchmarks. For example, you might change the minimum password length from 14 characters to 20 characters if that’s what your internal policy dictates.
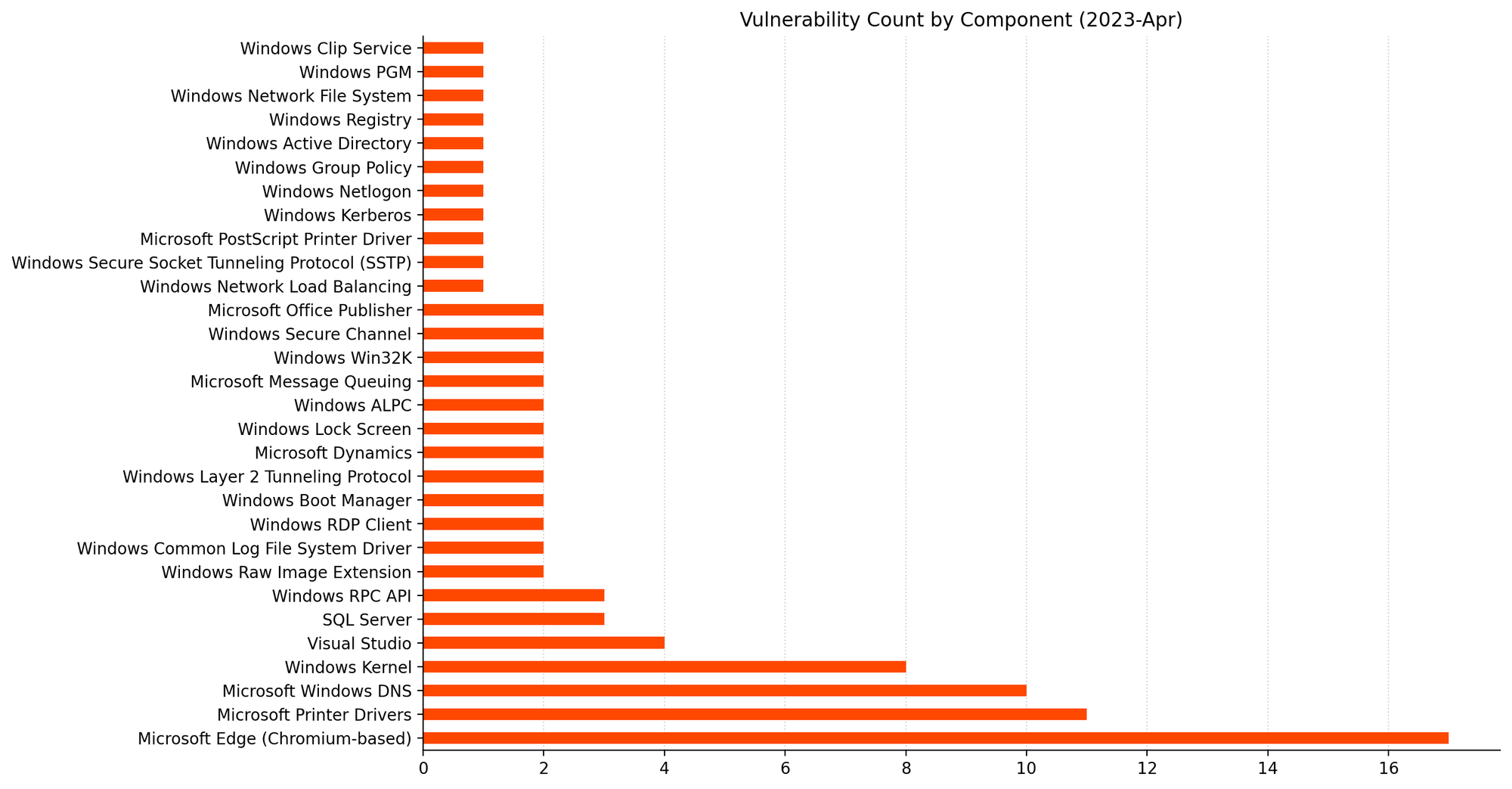
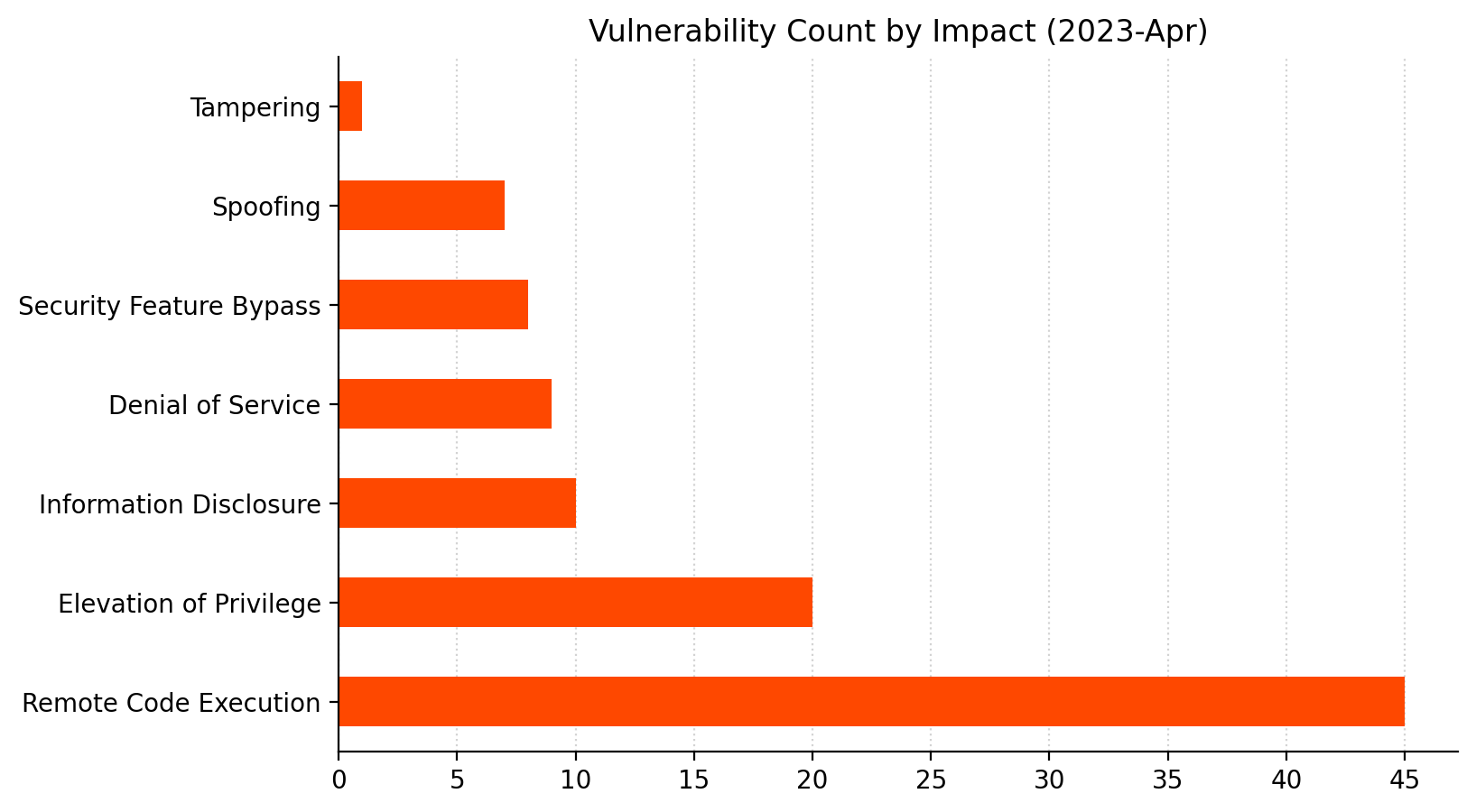
Microsoft is offering fixes for 114 vulnerabilities for in April 2023. This month’s haul includes a single zero-day vulnerability, as well as seven critical Remote Code Execution (RCE) vulnerabilities. There is a strong focus on fixes for Windows OS this month.
Over the last 18 months or so, Rapid7 has written several times about the prevalence of driver-based attacks. This month’s sole zero-day vulnerability – a driver-based elevation of privilege – will only reinforce the popularity of the vector among threat actors. Successful exploitation of CVE-2023-28252 allows an attacker to obtain SYSTEM privileges via a vulnerability in the Windows Common Log File System (CLFS) driver. Microsoft has patched more than one similar CLFS driver vulnerability over the past year, including CVE-2023-23376 in February 2023 and CVE-2022-37969 in September 2022.
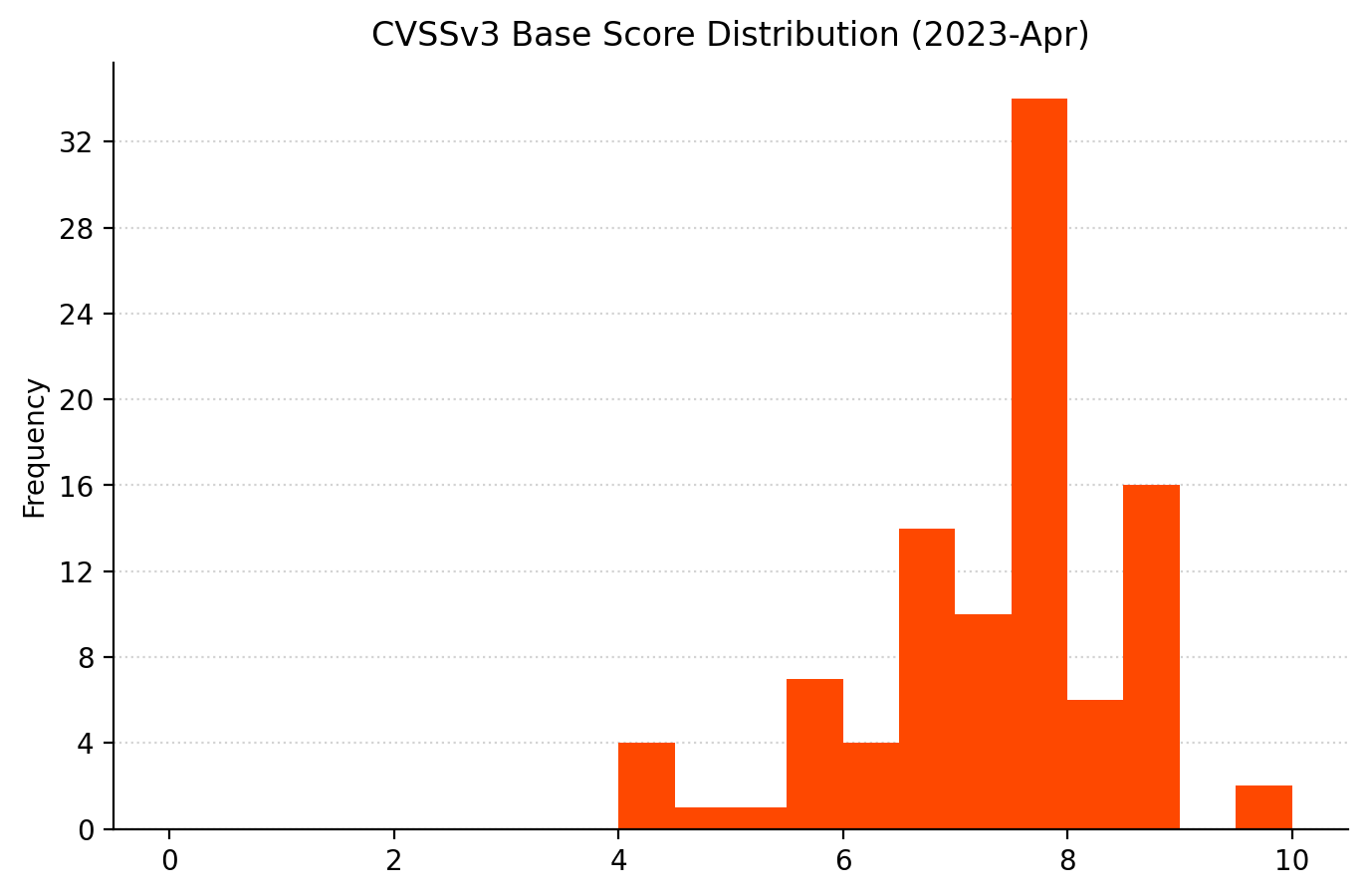
Microsoft has released patches for the zero-day vulnerability CVE-2023-28252 for all current versions of Windows. Microsoft is not aware of public disclosure, but has detected in-the-wild exploitation and is aware of functional exploit code. The assigned base CVSSv3 score of 7.8 lands this vulnerability near the top of the High severity range, which is expected since it gives complete control of an asset, but a remote attacker must first find some other method to access the target.
April 2023 also sees 45 separate Remote Code Execution (RCE) vulnerabilities patched, which is a significant uptick from the average of 33 per month over the past three months. Microsoft rates seven of this month’s RCE vulnerabilities as Critical, including two related vulnerabilities with a CVSSv3 base score of 9.8. CVE-2023-28250 describes a vulnerability in Windows Pragmatic General Multicast (PGM) which allows an attacker to achieve RCE by sending a specially crafted file over the network. CVE-2023-21554 allows an attacker to achieve RCE by sending a specially crafted Microsoft Messaging Queue packet. In both cases, the Microsoft Message Queueing Service must be enabled and listening on port 1801 for an asset to be vulnerable. The Message Queueing Service is not installed by default. Even so, Microsoft considers exploitation of CVE-2023-21554 more likely.
The other five Critical RCE this month are spread across various Windows components: Windows Raw Image Extension, Windows DHCP Protocol, and two frequent fliers: Windows Point-to-Point Tunneling Protocol and the Windows Layer 2 Tunneling Protocol.
The RAW Image Extension vulnerability CVE-2023-28921 is another example of what Microsoft refers to as an Arbitrary Code Execution (ACE), explaining “The attack itself is carried out locally. This means an attacker or victim needs to execute code from the local machine to exploit the vulnerability.” For some defenders, this may stretch the definition of the word Remote in Remote Code Execution, but there are many ways to deliver a file to a user, and an unpatched system remains vulnerable regardless.
DHCP server vulnerability CVE-2023-28231 requires an attacker to be on the same network as the target, but offers RCE via a specially crafted RPC call. Microsoft considers that exploitation is more likely.
The hunter becomes the hunted as Microsoft patches a Denial of Service vulnerability in Defender. The advisory for CVE-2023-24860 includes some unusual guidance: “Systems that have disabled Microsoft Defender are not in an exploitable state.” In practice this vulnerability is less likely to be exploited, and the default update cadence for Defender should mean that most assets are automatically patched in a short timeframe.
Windows Server administrators should take note of CVE-2023-28247. Successful exploitation allows an attacker to view contents of kernel memory remotely from the context of a user process. Microsoft lists Windows Server 2012, 2016, 2019, and 2022 as vulnerable. Although Microsoft assesses that exploitation is less likely, Windows stores many secrets in kernel memory, including cryptographic keys.
Machine learning is everywhere these days, and this month’s Patch Tuesday is no exception: CVE-2023-28312 describes a vulnerability in Azure Machine Learning which allows an attacker to access system logs, although any attack would need to be launched from within the same secure network. The advisory contains links to Microsoft detection and remediation guidance.
The other Azure vulnerability this month is a Azure Service Connector Security Feature Bypass. Microsoft rates Attack Complexity for CVE-2023-28300 as High, since this vulnerability is only useful when chained with other exploits to defeat other security measures. However, the Azure Service Connector only updates when the Azure Command-Line Interface is updated, and automatic updates are not enabled by default.
Final curtain call tonight for a raft of familiar names, since April 2023 Patch Tuesday includes the very last round of Extended Security Updates (ESU) for a number of Microsoft products. These include:
As always, the end of ESU means that Microsoft does not expect to patch or even disclose any future vulnerabilities which might emerge in these venerable software products, so it is no longer possible to secure them; these dates have been well-publicized far in advance under the fixed lifecycle policy. No vendor can feasibly support ancient software indefinitely, and some administrators may be glad that they will never have to install another Exchange Server 2013 patch.
Summary Charts
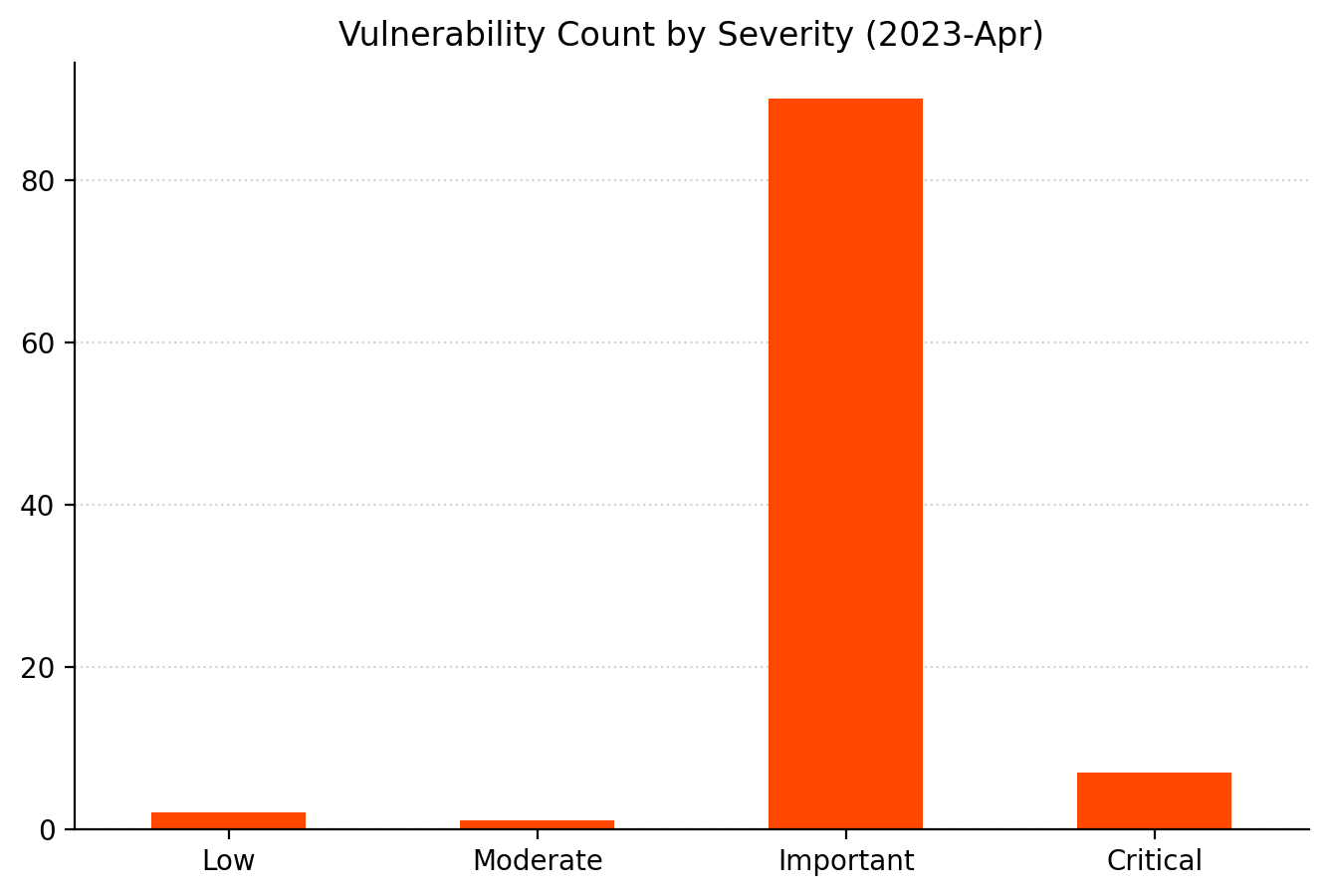
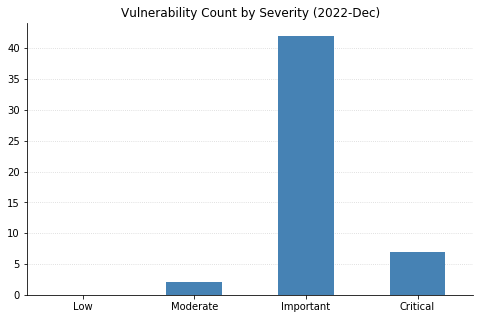
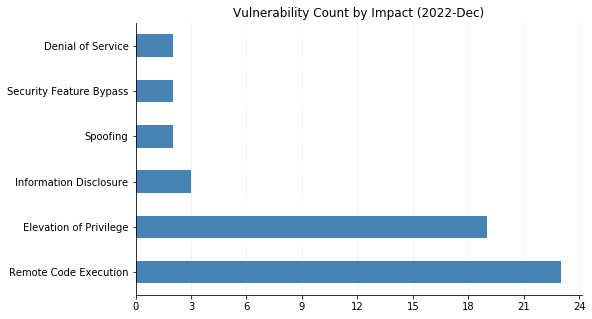
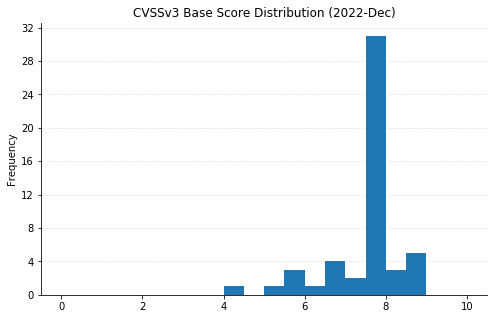
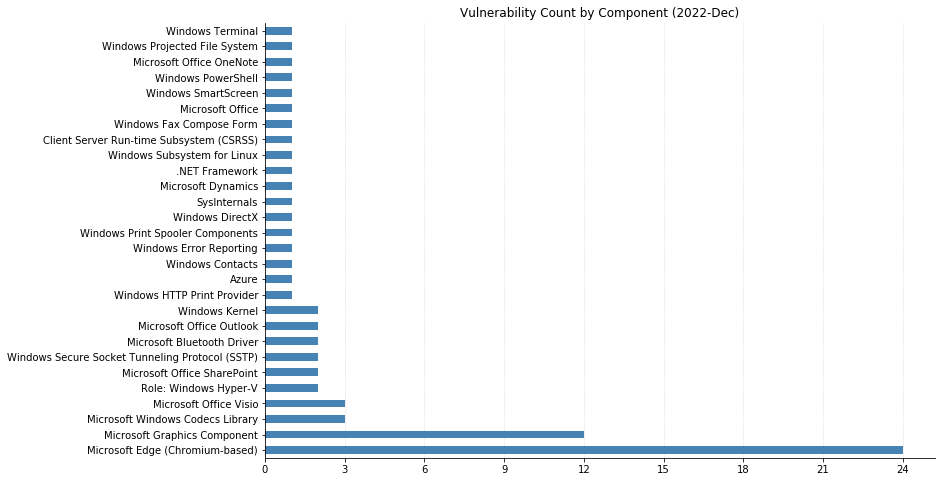
Printer Drivers, DNS, and the Windows Kernel.Remote Code Execution and Elevation of Privilege account for the majority as usual. A rare appearance for Tampering.CVSSv3 scoring tends to cluster around certain values.As usual, the distribution of severity skews towards Very Important.Printer drivers and CVEs go hand in hand.
One benefit of InsightVM reporting is that it enables security teams to build accountability into remediation projects. There are a number of ways this can be accomplished and the approach you take will be dictated by your organization’s specific structure and needs.
In this blog, we’ll look at two types of console-driven reports and two types of cloud-driven reports (projects). Depending on who will be conducting remediations, you may choose one over the others. We’ll explore why in detail below.
Reporting Prerequisites
Before we can get too deep into reporting, some prerequisites need to be met. Mainly, we need scan data in the InsightVM console. To get scan data, we need to perform at least one site run against at least one asset (preferably with credentials or Scan Assistant) or at least one Insight Agent deployed. Whether agent-driven or traditionally scanned, the data will be in the form of a Site in InsightVM.
We can then organize the Site data into logical filters called Dynamic Asset Groups, or DAGs. We can create DAGs based on numerous filters; the most common filters are ‘OS’ or ‘IP address in the range of.’ Using these types of Dynamic Asset Groups allows us to create both OS and location-based organization of our scan data, which can later be used to scope both reports and query builder.
Remember: Use Sites and Agents to obtain asset and vulnerability data. Use DAGs and Tags to organize the data.
Recommended Console Reports
Console reports are run from the Reporting link in the left-hand menu of the InsightVM console. There are two console reports that I recommend to customers. The first is called Top Remediation w/ details.
Top Remediation w/ details reports include a variety of actionable information, such as:
Real Risk Prioritization: Real Risk is great because it factors in CVSSv2 base metrics, potential malware kits and exploit kits, and the publish date (aka how long the vulnerability has been exposed to hackers).
The Risk score value is not the important metric, but instead, how that number compares to the other risk score numbers in the report. Prioritizing the biggest risk score first for maximum impact is a really good way to prioritize.
Solution Driven Remediation: Remediations, also known as Solutions, are the second primary reason to use this report. Solutions are usually cumulative and allow many vulnerabilities to be remediated with a single solution. The Top Remediation report only shows solutions, and when combined with risk, it enables you to see the maximum impact solutions, that will have the most significant impact on reducing risk in your environment.
Ability to change the total number of solutions: The number of solutions can be changed using the reports Advanced Options, so the report is not so intimidating. 25 Solutions is very intimidating/overwhelming, but 5 or 10 solutions are much more consumable by the remediation team.
Details show the Solution and the Assets affected: Details, being the last attribute, allows you to see the solutions for each of the Top Remediations and the assets affected.
The second console-driven report type I like to call out is called a SQL Query Export report. These reports allow customers to use the SQL Query data model to create custom CSV reports that meet their needs. Rapid7 maintains a repository of over 100 example queries on Github.
Both of these reports are highly impactful, however, there is one fundamental question I always ask before recommending them:
Is the security team performing the remediation, or will the reports be sent to another team?
If the security team is responsible for remediation, these console-driven reports are amazing because of self-accountability. However, if reports are going to another team, then one of the cloud-driven reports, aka Remediation Projects, are a better fit. Why? Remediation Projects provide the built-in accountability necessary to make progress. The key word is: Accountability
Accountability is the number one reason I recommend using Remediation Projects over the Top Remediation or SQL Query Export reports. If you generate a Top Remediation report and send it over to say, Bob, Bob may say ‘thanks’, walk around the corner, and throw it in the trash. A month goes by, and you ask, ‘so Bob, how are things going? I’m not seeing much progress’, to which Bob might answer, “prove it”.
If this sounds familiar, that’s because I hear it from many customers I work with that send reports to other teams. With PDF-based, it can be very hard to “prove it”—and then nothing ever gets done.
This is where remediation projects come in. With Remediation Projects, you can track whenever a solution is resolved, and the number cannot be manually manipulated. This means the only way to increase the ‘solutions resolved’ number is to actually fix the vulnerabilities and validate them with either a scan or an agent assessment. Now when Bob responds with ‘prove it’ you can simply reply with ‘sure, let’s loop in your manager’.
I know this sounds harsh, but it’s a reality many security practitioners have to work with daily.
Built-in accountability makes remediation projects the number one choice for businesses that send reports to other teams for remediation. So, how do you create the best possible Remediaiton Projects? I usually recommend creating projects by using Dashboards. My personal favorite Dashboard is the Threat Feed Dashboard. This Dashboard can be found by clicking on “See more in the R7 Library”
Then search for Threat, and Add the ‘Threat Feed Dashboard’.
Once this Dashboard comes up, there are three cards that I like to focus on:
First, let’s talk about the ‘Most Common Actively Targeted Vulnerabilities card. This card is driven by Project Heisenberg, which has deployed over 150 honeypots worldwide across five continents.
Prioritization utilizes CVSS, or the Common Vulnerability Scoring System. We also have Real Risk, which enhances CVSS prioritization using additional metrics (exploits, malware, publish age). Lastly, Threat feed, in my opinion, is the next level of Prioritization and should be prioritized highly within your vulnerability remediation program.
How to use Dashboard Cards to create team-based or location-based (scoped) Remediation Projects
Before we dive any further into the Most Common Actively Targeted Vulnerabilities card, I first recommend clicking on the Query Builder. The query builder link can be found in the upper right of the page:
Query Builder is a way to see all of your data, and create filters for that data and save those filters in the form of queries. If you have been following along, then we should already have some DAGs created within the console for data organization. We can use one of those DAG’s to create a filter in Query Builder. For example we can Add a filter for “asset.groups IN” and select one of your asset groups, in my example, I am using Windows Devices:
On my test console, this filters only Windows devices, and I can now Save that query so I can use it to scope my Dashboards and Projects based on the Windows Team.
Once it is saved, hit the X in the upper right corner to exit out of Query Builder.
Now that we have a Saved Query, we can Load that query into our Threat Feed Dashboard by clicking on ‘Load Dashboard Query’:
Once the query is loaded, our Threat Feed Dashboard will now only show assets defined by the Windows Devices query, which is scoped by the Windows Devices DAG within the Console.
This can be helpful if you want to create a custom team-based Dashboard for each team.
Next, if we click on the ‘<Expand Card>’ option within the Most Common Actively Targeted Vulnerability card we can see that the card is also scoped with our Dashboard query. We can then select All of the solutions (Or just the top 10 sorted by risk) and click on ‘Create a Static Remediation Project’ to use the scoped threat feed dashboard card to create a static project. For more information on reating a remediation project, click here.
Lastly, I like to focus on the following two cards with or without a query loaded into the Dashboard:
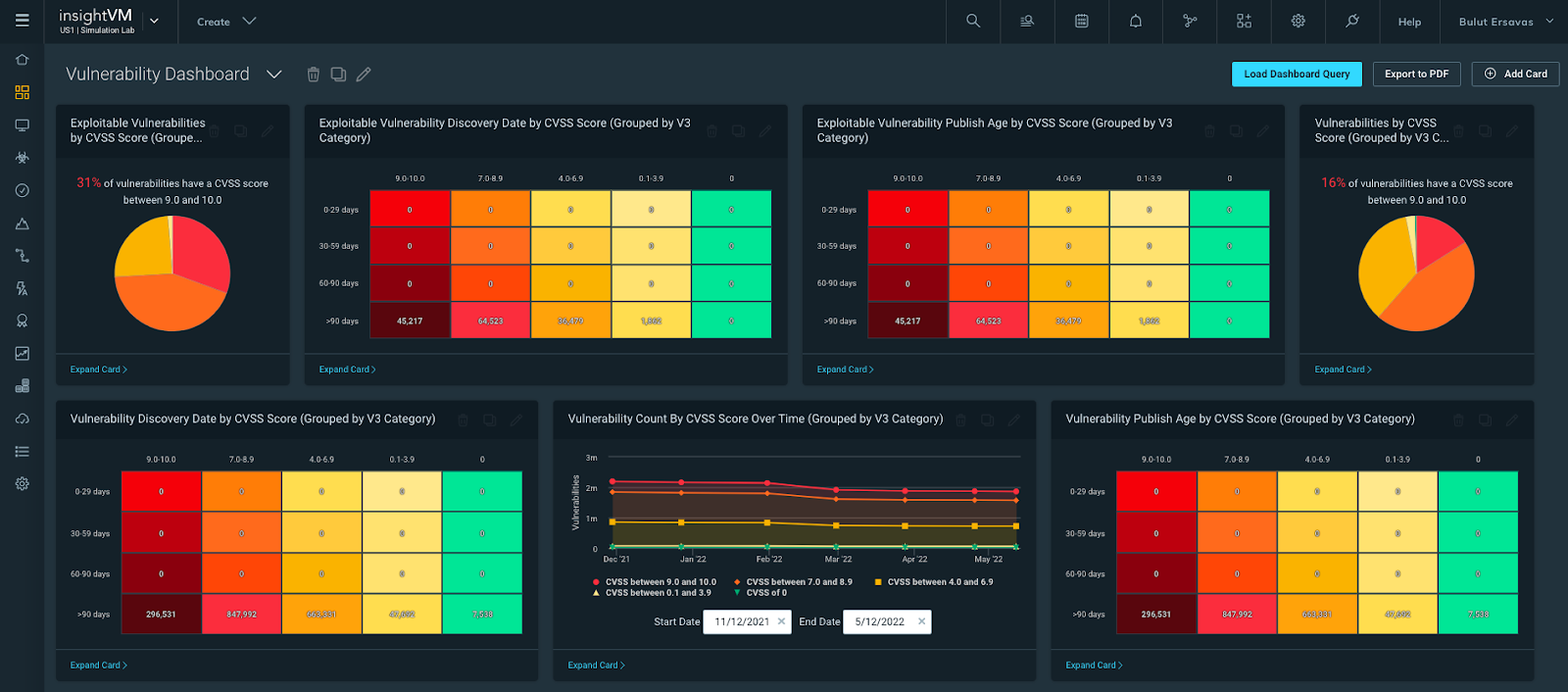
The above screenshot is lab data by the way, hopefully this doesn’t look familiar. The Most Common Actively Targeted card is amazing and should be prioritized, but I also really like this card as it focuses on Exploitable vulnerabilities by Severity.
Based on the card labeled ‘Exploitable Assets by Skill Level’, we can see in my test environment that 72% of exploitable assets can be exploited by a novice. This should be a very scary number, and we should prioritize reducing this number as quickly as we can.
If we look at the ‘Exploitable Vulnerability Discovery Date by Severity’ card, we can see how long we have known about exploitable vulnerabilities in our environment. The Discovery date is the same as the find date in our own personal environments. Based on the example above, we have over 35,000 critical exploitable vulnerabilities that we have known about for over 90 days and have not fixed. This environment is all test data, but if your environment looks similar this should be a very scary thing to be seeing.
For example, as security practitioners, we should ask the fundamental question, ‘What if I get breached?’. One answer might be to determine the vulnerability that caused the breach. Another might be, how long have we known about the vulnerability and not fixed it? If the answer to that second statement is less than 60 days, hopefully, you can already start thinking about the many excuses we could use; however, if it’s over 90 days, the excuses start to get pretty difficult to come up with.
To prevent not only a breach but also to prevent being in a situation where you need to explain why the breach happened on a vulnerability that has been known about for over 90 days, I highly recommend using this card as a source of data for additional Remediation Projects.
Conclusion
To summarize our journey: We created some sites to bring in vulnerability data into our console. We then organized that data using Dynamic Asset Groups (DAGs). We then used those DAGs to scope query’s (in Query Builder) so we could scope Dashboards. With the scoped dashboard, we get scoped cards which we used to create Projects.
With the Query Builder we get organization. Combining the query with the Threat Feed Dashboard, we get Organized Prioritization. If we then use this data to create Projects we get OrganizedPrioritization with Accountability. This is a perfect combo to get some work done in reducing vulnerabilities using Reporting.
Remember that the number one reason to use projects is Accountability.
To learn more about InsightVM remediation capabilities, check out the following blog posts:
In Q1, our team continued to focus on driving better customer outcomes with InsightVM and Nexpose by further improving efficiency and performance. While many of these updates are under the hood, you may have started to notice faster vulnerability checks available for the recent ETRs or an upgraded user interface for the console Admin page. Let’s take a look at some of the key updates in InsightVM and Nexpose from Q1.
[InsightVM and Nexpose] View expiration date for Scan Assistant digital certificates
Scan Assistant, a lightweight service deployed on the asset, leverages the Scan Engine and digital certificates to securely deliver the core benefits of authenticated scanning without the need to manage traditional account-based credentials.
Customers can now easily determine the validity of a Scan Assistant digital certificate by viewing the Expiration Date on the Shared Scan Credential Configuration page.
[InsightVM and Nexpose] A new look for the Console Administration page
We updated the user interface (UI) of the Console Administration page to facilitate a more intuitive and consistent user experience across InsightVM and the Insight Platform. You can even switch between light mode and dark mode for this page. This update is part of our ongoing Security Console experience transformation to enhance its usability and workflow—stay tuned for more updates!
[InsightVM and Nexpose] Checks for notable vulnerabilities
Rapid7’s Emergent Threat Response (ETR) program flagged multiple CVEs this quarter. InsightVM and Nexpose customers can assess their exposure to many of these CVEs with vulnerability checks, including:
Oracle E-Business Suite CVE-2022-21587: Added to the CISA Known Exploited Vulnerabilities (KEV) catalog, this vulnerability affected a collection of Oracle enterprise applications and can lead to unauthenticated remote code execution. Part of our recurring coverage, learn more about the vulnerability and our response.
VMware ESXi Servers CVE-2021-21974: VMware ESXi is used by enterprises to deploy and serve virtual computers. VMware ESXi servers worldwide were targeted by a ransomware that leveraged CVE-2021-21974. Part of our recurring coverage, learn more about the vulnerability and our response.
ManageEngine CVE-2022-47966: ManageEngine offers a variety of enterprise IT management tools to manage IT operations. At least 24 on-premise ManageEngine products were impacted from the exploitation of CVE-2022-47966, a pre-authentication remote code execution (RCE) vulnerability. Learn more about the vulnerability and our response.
Control Web Panel CVE-2022-44877: Control Web Panel is a popular free interface for managing web servers. In early January, security researcher Numan Türle published a proof-of-concept exploit for CVE-2022-44877, an unauthenticated remote code execution vulnerability in Control Web Panel (CWP, formerly known as CentOS Web Panel). Learn more about the vulnerability and our response.
GoAnywhere MFT CVE-2023-0669: Fortra’s GoAnywhere MFT offers managed file transfer solutions for enterprises. CVE-2023-0669, an actively exploited zero-day vulnerability affected the on-premise instances of Fortra’s GoAnywhere MFT. Learn more about the vulnerability and our response.
Jira Service Management Products CVE-2023-22501: Atlassian’s Jira Service Management Server and Data Center offerings were impacted by CVE-2023-22501, a critical broken authentication vulnerability that allows an attacker to impersonate another user and gain access to a Jira Service Management instance under certain circumstances. Learn more about the vulnerability and our response.
ZK Framework CVE-2022-36537: The vulnerability in ZK Framework, an open-source Java framework for creating web applications, was actively exploited due to its use in ConnectWise R1Soft Server Backup Manager, and allowed remote code execution and the installation of malicious drivers that function as backdoors. Learn more about the vulnerability and our response.
Want to know how you can refine your existing vulnerability management practices and use InsightVM to improve your readiness for the next emergent threat? Join our upcoming webinar:
Up Next for InsightVM | Custom Policies with Agent-Based Policy Assessment
Guidelines from Center for Internet Security (CIS) and Security Technical Implementation Guides (STIG) are widely used industry benchmarks for configuration assessment. However, a benchmark or guideline as-is may not meet the unique needs of your business. Very soon (next quarter soon), you can start using Agent-Based Policy for custom policy assessment.
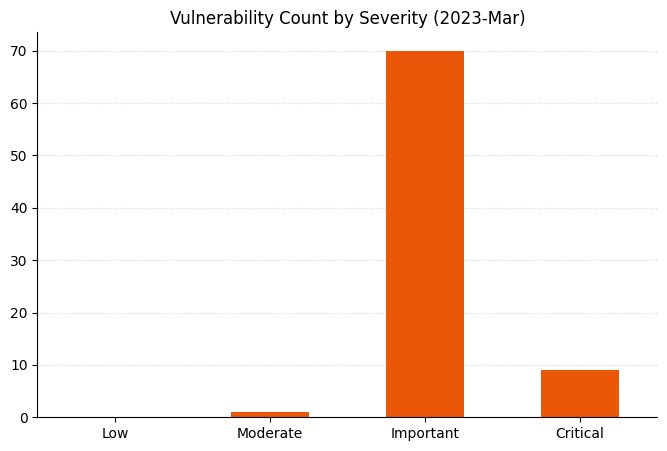
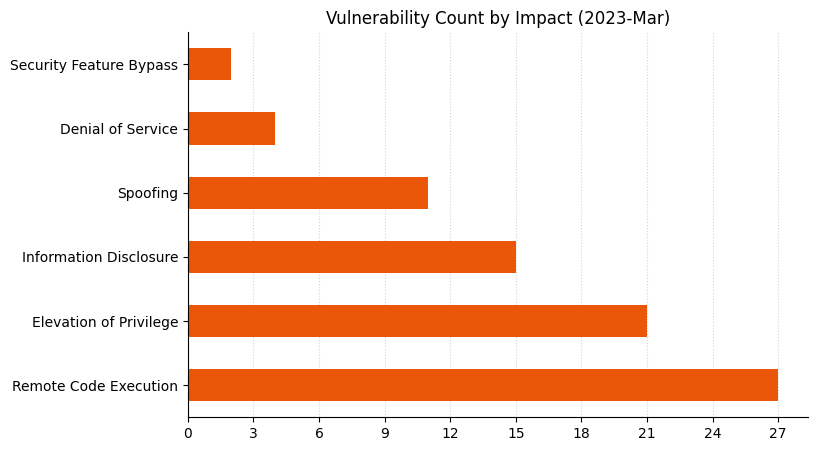
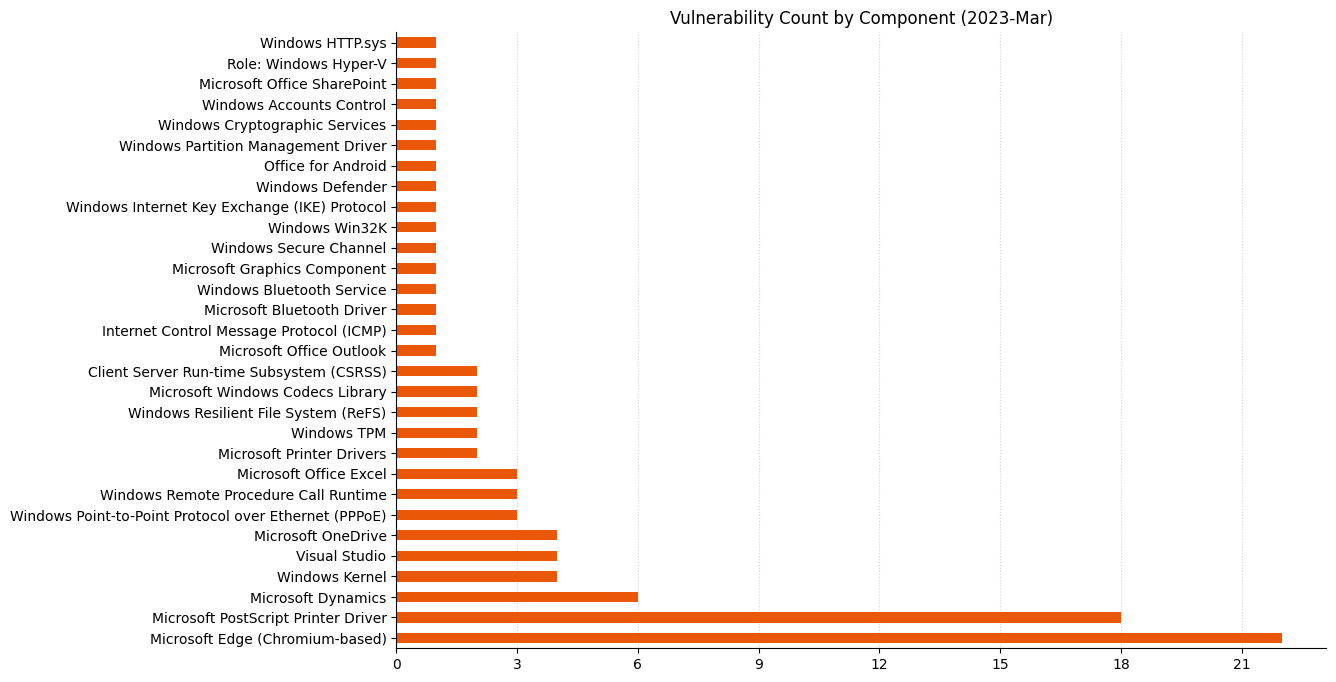
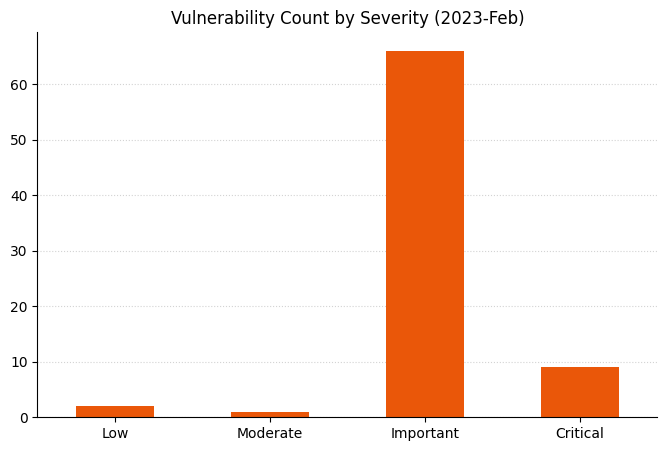
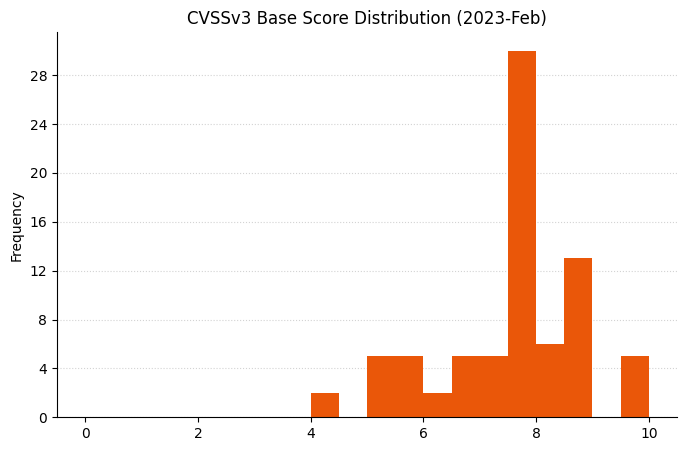
Microsoft is offering fixes for 101 security issues for March 2023 Patch Tuesday, including two zero-day vulnerabilities; the most interesting of the two zero-day vulnerabilities is a flaw in Outlook which allows an attacker to authenticate against arbitrary remote resources as another user.
CVE-2023-23397 describes a Critical Elevation of Privilege vulnerability affecting Outlook for Windows, which is concerning for several reasons. Microsoft has detected in-the-wild exploitation by a Russia-based threat actor targeting government, military, and critical infrastructure targets in Europe.
An attacker could use a specially-crafted email to cause Outlook to send NTLM authentication messages to an attacker-controlled SMB share, and can then use that information to authenticate against other services offering NTLM authentication. Given the network attack vector, the ubiquity of SMB shares, and the lack of user interaction required, an attacker with a suitable existing foothold on a network may well consider this vulnerability a prime candidate for lateral movement.
The vulnerability was discovered by Microsoft Threat Intelligence, who have published a Microsoft Security Research Center blog post describing the issue in detail, and which provides a Microsoft script and accompanying documentation to detect if an asset has been compromised using CVE-2023-23397.
Current self-hosted versions of Outlook – including Microsoft 365 Apps for Enterprise – are vulnerable to CVE-2023-23397, but Microsoft-hosted online services (e.g., Microsoft 365) are not vulnerable. Microsoft has calculated a CVSSv3 base score of 9.8.
The other zero-day vulnerability this month, CVE-2023-24880, describes a Security Feature Bypass in Windows SmartScreen, which is part of Microsoft’s slate of endpoint protection offerings. A specially crafted file could avoid receiving Mark of the Web and thus dodge the enhanced scrutiny usually applied to files downloaded from the internet.
Although Microsoft has detected in-the-wild exploitation, and functional exploit code is publicly available, Microsoft has marked CVE-2023-24880 as Moderate severity – the only one this month – and assessed it with a relatively low CVSSv3 score of 5.4; the low impact ratings and requirement for user interaction contribute to the lower scoring. This vulnerability thus has the unusual distinction of being both an exploited-in-the-wild zero-day vulnerability and also the lowest-ranked vulnerability on Microsoft’s severity scale in this month’s Patch Tuesday. Only more recent versions of Windows are affected: Windows 10 and 11, as well as Server 2016 onwards.
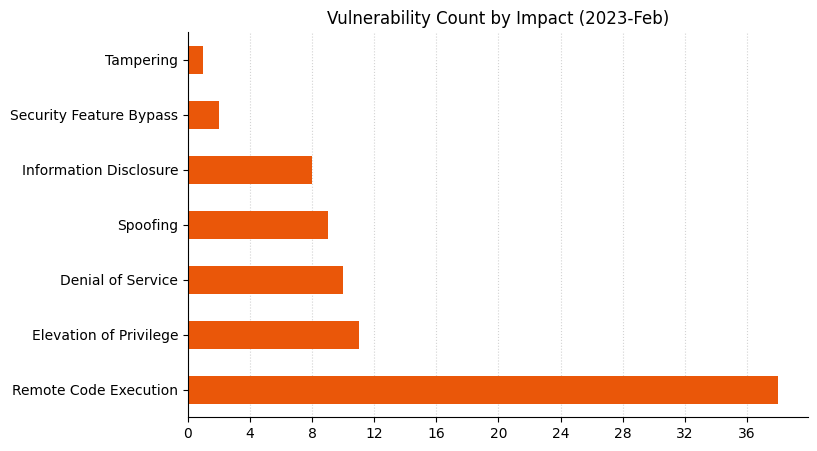
A further five critical Remote Code Execution (RCE) vulnerabilities are patched this month in Windows low-level components. Three of these are assessed as Exploitation More Likely, and most of them affect a wide range of Windows versions, with the exception of CVE-2023-23392 which affects only Windows 11 and Windows Server 2022. Only assets where HTTP/3 has been enabled are potentially vulnerable – it is disabled by default – yet Microsoft still assesses this vulnerability as Exploitation More Likely, perhaps because HTTP endpoints are typically accessible.
CVE-2023-21708 is a Remote Procedure Call (RPC) vulnerability with a base CVSSv3 of 9.8. Microsoft recommends blocking TCP port 135 at the perimeter as a mitigation; given the perennial nature of RPC vulnerabilities, defenders will know that this has always been good advice.
Another veteran class of vulnerability makes a return this month: CVE-2023-23415 describes an attack involving a fragmented packet inside the header of another ICMP packet. Insufficient validation of ICMP packets has been a source of vulnerabilities since the dawn of time; the original and still-infamous Ping of Death vulnerability, which affected a wide range of vendors and operating systems, was one of the first vulnerabilities ever to be assigned a CVE, way back in 1999.
Microsoft has addressed two related vulnerabilities introduced via the Trusted Platform Module (TPM) 2.0 reference implementation code published by the Trusted Computing Group industry alliance. CVE-2023-1017 is an out-of-bounds write, and CVE-2023-1018 is an out-of-bounds read. Both may be triggered without elevated privileges, and may allow an attacker to access or modify highly-privileged information inside the TPM itself. Defenders managing non-Microsoft assets should note that a wide range of vendors including widely used Linux distros are also affected by this pair of vulnerabilities.
Admins who still remember the aptly-named PrintNightmare vulnerability from the summer of 2021 may well raise a wary eyebrow at this month’s batch of 18 fixes for the Microsoft PostScript and PCL6 Class Printer Driver, but there’s no sign that any of these are cause for the same level of concern, not least because there has been no known public disclosure prior to Microsoft releasing patches.
Azure administrators who update their Service Fabric Cluster manually should note that CVE-2023-23383 describes a spoofing vulnerability in the web management client where a user clicking a suitably-crafted malicious link could unwittingly execute actions against the remote cluster. Azure estates with automatic upgrades enabled are already protected.
Summary charts
Lots of Important vulnerabilitiesRemote Code Execution and Elevation of Privilege vulnerabilities remain a key focusAs always, vulnerability count is not necessarily a proxy for risk or exposurePrinter drivers and Microsoft Dynamics received a significant number of fixes
Windows SmartScreen Security Feature Bypass Vulnerability
Yes
Yes
5.4
Note that Microsoft has not provided CVSSv3 scores for vulnerabilities in Chromium, which is an open-source software consumed by Microsoft Edge. Chrome, rather than Microsoft, is the assigning CNA for Chromium vulnerabilities. Microsoft documents this class of vulnerability in the Security Upgrade Guide to announce that the latest version of Microsoft Edge (Chromium-based) is no longer vulnerable.
When it comes to protecting your cloud or hybrid networks, what you don’t know can most certainly hurt your enterprise. Today’s NetOps teams are tasked with monitoring the health and performance of both on-premises and cloud applications, as well as software, devices, and instances. As if this wasn’t complicated enough, malicious threat actors relentlessly seek to capitalize on the vulnerabilities in an enterprise’s network.
These attacks affect enterprises across all industries. Recently, Gartner predicted that 45% of global organizations will have experienced attacks on their software supply chains by 2025. Statista also reported that approximately 15M data records were exposed worldwide through data breaches in the third quarter of 2022. This staggering figure represented a quarterly increase of over 37%.
Network attacks are costly, too. In fact, the average cost of a data breach increased to $9.44M in the United States in 2022. Keep in mind, this figure doesn’t include the frustration, lost productivity, and negative impact on brand reputation that often accompany cyber attacks.
Vulnerability assessment (VA) and vulnerability management (VM) are two of the best ways to protect your enterprise against threats, but these terms are often used incorrectly and interchangeably. A better understanding of these concepts and how they relate to one another can help you significantly boost the security posture of your hybrid and cloud environments.
What is a vulnerability assessment?
TechTarget defines vulnerability assessment as “the process of defining, identifying, classifying and prioritizing vulnerabilities in computer systems, applications and network infrastructures.” These vulnerabilities usually fall into one of three categories:
Hardware: Hardware refers to the physical devices in your network infrastructure, such as servers or routers. These require firmware upgrades and patches to remain secure. Vulnerabilities result from failure to perform upgrades and using outdated devices.
Software: Software refers to the applications an organization uses. Software vulnerabilities might be a flaw, glitch, or weakness in the software code. Again, patching and other updates are required to maintain security.
Human: These vulnerabilities stem from user security issues like weak (or leaked) passwords, clicking links on malicious websites, and human error such as opening a phishing email. Of the three categories, this is often the hardest for NetOps teams to control and enforce.
Vulnerability assessments scan your network for potential issues in each of these categories, and provide your team with crucial insight into the weaknesses of your IT infrastructure. Ideally, a vulnerability assessment will also prioritize the risks by level of severity, showing your team which to address first.
Enterprises looking to shift from reactive security measures like firewalls to a more proactive security approach look to vulnerability assessment as the first step in building an information security program.
What is vulnerability management?
Vulnerability management is the process of identifying, evaluating, treating, and reporting on security vulnerabilities in systems and the software that runs on them. Sounds a lot like vulnerability assessment, right? The key difference between the two, however, is that vulnerability management is a continuous cycle that includes vulnerability assessment. Where VA identifies and classifies the risks in your network infrastructure, VM goes a step further and includes decisions on whether to remediate, mitigate, or accept risks. VM is also concerned with general infrastructure improvement and reporting.
According to Gartner, vulnerability management runs on a cycle—a five-step process (not including pre-work like selecting vulnerability assessment tools) that most organizations follow.
The vulnerability management cycle
Assess: Here’s where vulnerability assessments come in. In this step of the cycle, NetOps teams will identify assets, scan them, and build a report.
Prioritize: The report generated in the first phase is used to prioritize risks. The NetOps team will also add threat context to the risks, which requires a thorough knowledge of the existing threat landscape as well as consideration of how threats may evolve over time.
Act: The prioritized threats are then sorted into remediate, mitigate, and accept buckets. Remediation calls for removing the threat completely, if possible. Mitigation, on the other hand, reduces the likelihood of a vulnerability being exploited. Mitigation may be used if remediation is too disruptive to the system or if a patch isn’t available yet. You may also have threats that fall under the acceptance category. These may include devices/software soon to be replaced, which wouldn’t require any action.
Reassess: Once the team has processed the risks according to their final recommendations, they’ll need to rescan and validate that the risks have been properly remediated, mitigated, or accepted.
Improve: In this final step, the team should evaluate their metrics, checking that they’re accurate and up to date to ensure that they’re correctly assessing risks. Additionally, this phase should be used to eliminate any other underlying issues that may be contributing to system vulnerabilities.
Benefits of vulnerability management and vulnerability assessment
Vulnerability assessments are an important part of the vulnerability management cycle, and the VM cycle should be a key component of your NetOps team’s security strategy. Organizations today simply can’t afford to ignore the risks in their network infrastructure. As networks grow more complex, teams struggle to maintain visibility into their network. This creates an ideal environment for threat actors looking to exploit system vulnerabilities. Often, risks and attacks go unnoticed until they’ve caused irreparable damage at considerable cost to the organization.
VM has benefits that extend beyond security. For example, regularly evaluating your network’s devices and applications can help your team identify outdated technology or potential patches that will not only improve the general security of the network, but also optimize its performance. VM can also help your organization meet federal and internal compliance requirements. Regularly identifying and resolving risks through vulnerability assessments and the VM cycle can help your organization stay ahead of changing compliance requirements and prevent non-compliance penalties like fines.
Get started with vulnerability assessment and vulnerability management
With the obvious benefits, it should be clear that vulnerability assessment and vulnerability management are crucial to reducing overall risk in an organization’s infrastructure. And yet, many NetOps teams struggle to implement these processes. Whether your team is just getting started with vulnerability management, or looking to optimize your VM cycle to meet the challenges of an increasingly complex network and threat landscape, Rapid7 has the solutions that will empower your team to tackle vulnerabilities head on.
Ready to see the benefits of the vulnerability management cycle in your network?
Emergent threats evolve quickly, and as we learn more about this vulnerability, this blog post will evolve, too.
Rapid7 is aware of active exploitation of CVE-2022-36537 in vulnerable versions of ConnectWise R1Soft Server Backup Manager software. The root cause of the vulnerability is an information disclosure flaw in ZK Framework, an open-source Java framework for creating web applications. ConnectWise uses ZK Framework in its popular R1Soft and Recovery products; the vulnerability is being used for remote code execution and the installation of malicious drivers that function as backdoors. After initial access is obtained, attackers have reportedly been able to execute commands on all systems running the agent connected to the R1Soft server.
The advisory and NVD entry for CVE-2022-36537 indicate that ostensibly, the flaw is merely an information disclosure vulnerability. Rapid7 believes this categorization significantly downplays the risk and the impact of CVE-2022-36537 and should not be used as a basis for lower prioritization.
Overview
In May 2022, software company Potix released an update to ZK Framework, an open-source Java framework used to create enterprise web and mobile applications in pure Java. The update addressed CVE-2022-36537, which had been reported to Potix by Code White GmbH’s Markus Wulftange. The vulnerability arises from an issue in ZK Framework’s AuUploader component that allows an attacker to forward a HTTP request to an internal URI. Successful exploitation allows an attacker to obtain sensitive information or target an endpoint that might otherwise be unreachable. Since ZK Framework is a library, CVE-2022-36537 is likely to affect a range of other products in addition to the core framework itself.
In October 2022, security firm Huntress published a blog on a Lockbit 3.0 ransomware incident that included exploitation of CVE-2022-36537 in ConnectWise R1Soft Server Backup Manager software. Threat actors exploited the vulnerability to bypass authentication, deployed a malicious JDBC database driver that allowed for arbitrary code execution, and finally used the REST API to send commands to registered agents—commands that instructed the agents to push ransomware to downstream systems. The malicious JDBC driver also functions as a backdoor into compromised systems.
On February 22, 2023, the NCC Group’s FOX IT team published a similar account of an incident where they had observed threat actors exploiting CVE-2022-36537 against ConnectWise R1Soft servers as far back as November 29, 2022. According to FOX IT’s research, several hundred R1Soft servers were backdoored as of January 2023, of which more than 140 remain compromised. They have a full account of the attack chain and a list of IOCs here.
FOX IT said that the adversary used R1Soft “as both an initial point of access and as a platform to control downstream systems connected via the R1Soft Backup Agent. This agent is installed on systems to support being backed up by the R1Soft server software and typically runs with high privileges. This means that after the adversary initially gained access via the R1Soft server software it was able to execute commands on all systems running the agent connected to this R1Soft server.”
Shodan reports 3,643 instances of ConnectWise R1Soft Server Backup Manager as of March 1, 2023. Multiple public proof-of-concept (PoC) exploits are available dating back to December 2022. On February 27, 2023, the U.S. Cybersecurity and Infrastructure Security Agency (CISA) added CVE-2022-36537 to its Known Exploited Vulnerabilities (KEV) list and published a warning that “This type of vulnerability is a frequent attack vector for malicious cyber actors and poses a significant risk to the federal enterprise.”
As mentioned above, the primary advisory and NVD entry for CVE-2022-36537 both note that the core vulnerability in ZK Framework is an information disclosure flaw (hence the 7.5 CVSSv3 score). In the context of ConnectWise R1Soft, however, the impact of the flaw is remote code execution, not merely information disclosure.
The public PoCs include code that uses the vulnerability to leak the contents of the file /Configuration/database-drivers.zul and expose a unique ID value that is intended to be secret. Once the attacker has this ID value, they can exploit the vulnerability once more to reach an otherwise inaccessible endpoint and upload the malicious database driver.
Affected products
ZK Framework (core)
All versions of ZK Framework from 9.6.1 and below are vulnerable to CVE-2022-36537. Potix released version 9.6.2 to fix this issue on May 4, 2022, alongside several hotfixes for earlier branches (9.6.0, 9.5.1, 9.0.1, and 8.6.4).
Fixed versions of ZK Framework are:
9.6.2
9.6.0.2 (security release)
9.5.1.4 (security release)
9.0.1.3 (security release)
8.6.4.2 (security release)
Workarounds are available, but as always, we strongly recommend applying patches. See Potix’s advisory for further details on affected ZK Framework versions.
ConnectWise products
According to ConnectWise’s advisory, CVE-2022-36537 affects the following products and versions:
ConnectWiseRecover v2.9.7 and earlier versions are vulnerable
ConnectWise R1Soft Server Backup Manager (SBM): SBM v6.16.3 and earlier versions are vulnerable
ConnectWise R1Soft users should upgrade the server backup manager to SBM v6.16.4 released October 28, 2022 using the R1Soft upgrade wiki.
The advisory also indicates that “affected ConnectWise Recover SBMs have automatically been updated to the latest version of Recover (v2.9.9)” as of October 28, 2022.
Mitigation guidance
ConnectWise R1Soft Server Backup Manager users should update their R1Soft installations to a fixed version (v6.16.4) on an emergency basis, without waiting for a regular patch cycle to occur, and examine their environments for signs of compromise. Both Huntress and FOX IT have information on observed indicators of compromise.
ZK Framework users should likewise update to a fixed version immediately, without waiting for a regular patch cycle to occur. As with many library vulnerabilities, assessing exposure may be complex. It’s likely there are additional applications that implement ZK Framework; downstream advisories may include other information about ease or impact of exploitation.
Since ConnectWise R1Soft appears to be the primary vector for known attacks as of March 1, 2023, we strongly advise prioritizing those patches.
Rapid7 customers
Our researchers are currently evaluating the feasibility of adding a vulnerability check for InsightVM and Nexpose.
Each year, the research team at Rapid7 analyzes thousands of vulnerabilities in order to identify their root causes, broaden understanding of attacker behavior, and provide actionable intelligence that guides security professionals at critical moments. Our annual Vulnerability Intelligence Report examines notable vulnerabilities and high-impact attacks from 2022 to highlight trends that drive significant risk for organizations of all sizes.
Today, we’re excited to release Rapid7’s 2022 Vulnerability Intelligence Report—a deep dive into 50 of the most notable vulnerabilities our research team investigated throughout the year. The report offers insight into critical vulnerabilities, widespread threats, prominent attack surface area, and changing exploitation trends.
2022 attack trends
The threat landscape today is radically different than it was even a few years ago. Over the past three years, we’ve seen zero-day exploits and widespread attacks chart a meteoric rise that’s strained security teams to their breaking point and beyond. While 2022 saw a modest decline in zero-day and widespread exploitation from 2021’s record highs, the multi-year trend of rising attack speed and scale remains strikingly consistent overall.
Report findings include:
Widespread exploitation of newvulnerabilities decreased 15% year over year in 2022, but mass exploitation events were still the norm. Our 2022 vulnerability intelligence dataset tracks 28 net-new widespread threats, many of which were used to deploy webshells, cryptocurrency miners, botnet malware, and/or ransomware on target systems.
Zero-day exploitation remained a significant challenge for security teams, with 43% of widespread threats arising from a zero-day exploit.
Attackers are still developing and deploying exploits faster than ever before. More than half of the vulnerabilities in our report dataset were exploited within seven days of public disclosure—a 12% increase from 2021 and an 87% increase over 2020.
Vulnerabilities mapped definitively to ransomware operations dropped 33% year over year—a troubling trend that speaks more to evolving attacker behavior and lower industry visibility than to any actual reprieve for security practitioners. This year’s report explores the growing complexity of the cybercrime ecosystem, the rise of initial access brokers, and industry-wide ransomware reporting trends.
How to manage risk from critical vulnerabilities
In today’s threat landscape, security teams are frequently forced into reactive positions, lowering security program efficacy and sustainability. Strong foundational security program components, including vulnerability and asset management processes, are essential to building resilience in a persistently elevated threat climate.
Have emergency patching procedures and incident response playbooks in place so that in the event of a widespread threat or breach, your team has a well-understood mechanism to drive immediate action.
Have a defined, regular patch cycle that includes prioritization of actively exploited CVEs, as well as network edge technologies like VPNs and firewalls. These network edge devices continue to be popular attack vectors and should adhere to a zero-day patch cycle wherever possible, meaning that updates and/or downtime should be scheduled as soon as new critical advisories are released.
Keep up with operating system-level and cumulative updates. Falling behind on these regular updates can make it difficult to install out-of-band security patches at critical moments.
Limit and monitor internet exposure of critical infrastructure and services, including domain controllers and management or administrative interfaces. The exploitation of many of the CVEs in this year’s report could be slowed down or prevented by taking management interfaces off the public internet.
2022 Vulnerability Intelligence Report
Read the report to see our full list of high-priority CVEs and learn more about attack trends from 2022.
It’s Patch Tuesday again. Microsoft is addressing fewer individual vulnerabilities this month than last, but there’s still plenty to keep admins and defenders occupied.
Three zero-day vulnerabilities are vying for your attention today: a lone Microsoft Publisher vulnerability as well as a couple affecting Windows itself. None is marked as publicly disclosed, but Microsoft has already observed in-the-wild exploitation of all three.
One zero-day vulnerability is a Security Features Bypass vulnerability in Microsoft Publisher. Successful exploitation of CVE-2023-21715 allows an attacker to bypass Office macro defenses using a specially-crafted document and run code which would otherwise be blocked by policy. Only Publisher installations delivered as part of Microsoft 365 Apps for Enterprise are listed as affected.
CVE-2023-23376 describes a vulnerability in the Windows Common Log File System Driver which allows Local Privilege Escalation (LPE) to SYSTEM. Although Microsoft isn’t necessarily aware of mature exploit code at time of publication, this is worth patching at the first opportunity, since it affects essentially all current Windows hosts.
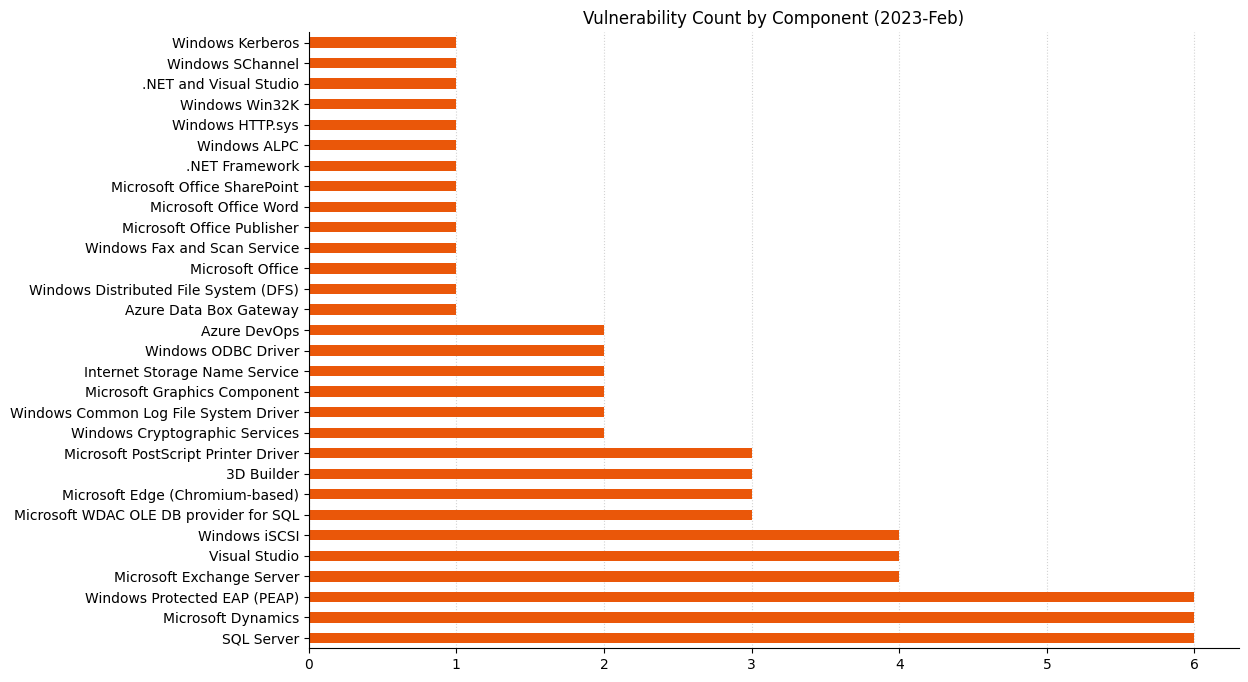
CVE-2023-21823 is described as a Remote Code Execution (RCE) vulnerability in Windows Graphics Component, but has Attack Vector listed as Local. This apparent inconsistency is often accompanied with a clarification like: “The word Remote in the title refers to the location of the attacker. […] The attack itself is carried out locally.” No such clarification is available in this case, but this is likely applicable here also. Microsoft also notes the existence of mature exploit code.
Microsoft is also releasing patches for nine critical RCE vulnerabilities. A more varied selection than last month, February 2023 includes critical RCE in an SQL Server ODBC driver, the iSCSI Discovery Service, .NET/Visual Studio, three in network authentication framework PEAP, one in Word, and two in Visual Studio only. Microsoft has not observed in-the-wild exploitation for any of these vulnerabilities, nor is any of them marked as publicly disclosed. Microsoft predicts that most of these are less likely to be exploited, with the exception of the PEAP vulnerabilities.
SharePoint Server makes another appearance today with CVE-2023-21717, which allows an authenticated user with the Manage List permission to achieve RCE. Admins responsible for a SharePoint Server 2013 instance may be interested in the FAQ, which includes what Microsoft optimistically describes as a clarification of the existing servicing model for SharePoint Server 2013.
This is the first Patch Tuesday after the end of Extended Security Updates (ESU) for Windows 8.1. Admins responsible for Windows Server 2008 instances should note that ESU for Windows Server 2008 is now only available for instances hosted in Azure or on-premises instances hosted via Azure Stack. Instances of Windows Server 2008 hosted in a non-Azure context will no longer receive security updates, so will forever remain vulnerable to any new vulnerabilities, including the two zero-days covered above.
We are happy to announce that Rapid7’s solutions have been added to the NASPO ValuePoint Cloud Solutions contract held by Carahsoft Technology Corp. The addition of this contract enables Carahsoft and its reseller partners to provide Rapid7’s Insight platform to participating States, Local Governments, and Educational (SLED) institutions.
“Rapid7’s Insight platform goes beyond threat detection by enabling organizations to quickly respond to attacks with intelligent automation,” said Alex Whitworth, Sales Director who leads the Rapid7 Team at Carahsoft.
“We are thrilled to work with Rapid7 and our reseller partners to deliver these advanced cloud risk management and threat detection solutions to NASPO members to further protect IT environments across the SLED space.”
NASPO ValuePoint is a cooperative purchasing program facilitating public procurement solicitations and agreements using a lead-state model. The program provides the highest standard of excellence in public cooperative contracting. By leveraging the leadership and expertise of all states and the purchasing power of their public entities, NASPO ValuePoint delivers the highest valued, reliable and competitively sourced contracts, offering public entities outstanding prices.
“In partnership with Carahsoft and their reseller partners, we look forward to providing broader availability of the Insight platform to help security teams better protect their organizations from an increasingly complex and volatile threat landscape,” said Damon Cabanillas, Vice President of Public Sector Sales at Rapid7.
The Rapid7 Insight platform is available through Carahsoft’s NASPO ValuePoint Master Agreement #AR2472. For more information, visit https://www.carahsoft.com/rapid7/contracts.
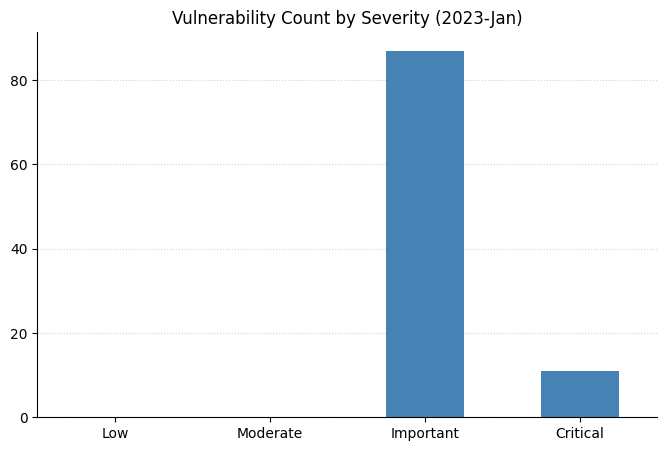
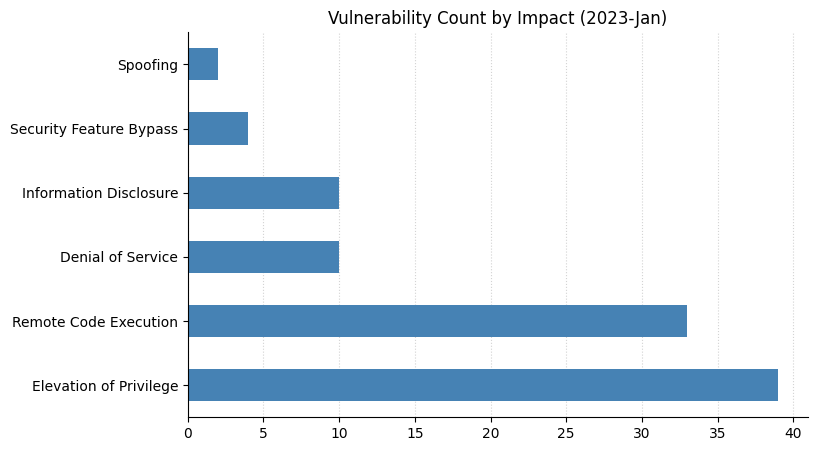
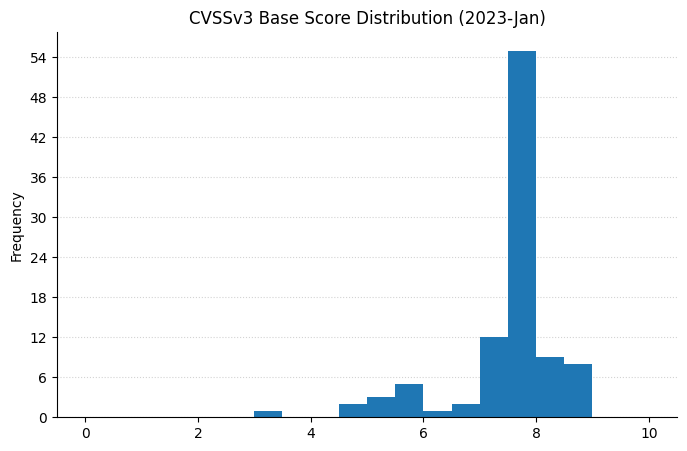
Microsoft is starting the new year with a bang! Today’s Patch Tuesday release addresses almost 100 CVEs. After a relatively mild holiday season, defenders and admins now have a wide range of exciting new vulnerabilities to consider.
Two zero-day vulnerabilities emerged today, both affecting a wide range of current Windows operating systems.
CVE-2023-21674 allows Local Privilege Escalation (LPE) to SYSTEM via a vulnerability in Windows Advanced Local Procedure Call (ALPC), which Microsoft has already seen exploited in the wild. Given its low attack complexity, the existence of functional proof-of-concept code, and the potential for sandbox escape, this may be a vulnerability to keep a close eye on. An ALPC zero-day back in 2018 swiftly found its way into a malware campaign.
CVE-2023-21549 is Windows SMB elevation for which Microsoft has not yet seen in-the-wild exploitation or a solid proof-of-concept, although Microsoft has marked it as publicly disclosed.
This Patch Tuesday also includes a batch of seven Critical Remote Code Execution (RCE) vulnerabilities. These are split between Windows Secure Socket Tunneling Protocol (SSTP) – source of another Critical RCE last month – and Windows Layer 2 Tunneling Protocol (L2TP). Happily, none of these has yet been seen exploited in the wild, and Microsoft has assessed all seven as “exploitation less likely” (though time will tell).
Today’s haul includes two Office Remote Code Execution vulnerabilities. Both CVE-2023-21734 and CVE-2023-21735 sound broadly familiar: a user needs to be tricked into running malicious files. Unfortunately, the security update for Microsoft Office 2019 for Mac and Microsoft Office LTSC for Mac 2021 are not immediately available, so admins with affected assets will need to check back later and rely on other defenses for now.
On the server side, five CVEs affecting Microsoft Exchange Server were addressed today: two Spoofing vulnerabilities, two Elevation of Privilege, and an Information Disclosure. Any admins who no longer wish to run on-prem Exchange may wish to add these to the evidence pile.
Anyone responsible for a SharePoint Server instance has three new vulnerabilities to consider. Perhaps the most noteworthy is CVE-2023-21743, a remote authentication bypass. Remediation requires additional admin action after the installation of the SharePoint Server security update; however, exploitation requires no user interaction, and Microsoft already assesses it as “Exploitation More Likely”. This regrettable combination of properties explains the Critical severity assigned by Microsoft despite the relatively low CVSS score.
Another step further away from the Ballmer era: Microsoft recently announced the potential inclusion of CBL-Mariner CVEs as part of Security Update Guide guidance starting as early as tomorrow (Jan 11). First released on the carefully-selected date of April 1, 2020, CBL-Mariner is the Microsoft-developed Linux distro which acts as the base container OS for Azure services, and also underpins elements of WSL2.
For Rapid7’s vulnerability management team, 2022 began with a lot of introspection on how we can add more value and keep meeting our customer needs in the best possible ways.
Over the course of 2022, we launched many new features and improvements — some highly anticipated, many customer-requested. Log4J was difficult, but we learned from it, particularly when it comes to Emergent Threat Response.
Additionally, we recently refreshed our coordinated vulnerability disclosure (CVD) policy and philosophy. We found that we couldn’t treat every vulnerability equally and there was a need to be more agile with our CVD approach. So, we came up with six classes of vulnerabilities (and a meta-classification of “more than one”) and some broad strokes of what we intend to accomplish with our CVD for each of them.
We reimagined many of our internal processes and teams to drive better customer outcomes. For instance, we are making a significant investment in re-architecting the InsightVM/Nexpose database to ensure VM programs scale with the customers evolving IT environment.
We will continue to prioritize what really matters, even if it means making some hard decisions, and further improve communication with our customers. Here’s a snapshot of 2022 in InsightVM.
Key Product Improvements
Agent-based policyassessment
A robust vulnerability management program should assess IT assets for misconfigurations along with vulnerabilities. That’s why we were thrilled to introduce Agent-Based Policy in InsightVM. Customers can now use Insight Agents to conduct configuration assessments of IT assets against widely used industry benchmarks from the Center for Internet Security (CIS) and the U.S. Defense Information Systems Agency (DISA) to help prevent breaches and ensure compliance.
Remediation Project improvements
Remediation Projects help security teams collaborate and track progress of remediation work (often assigned to their IT ops counterparts). Here are our favorite updates:
Remediator Export – a new solution-based CSV export option, Remediator Export contains detailed information about the assets, vulnerabilities, proof data, and more for a given solution.
Better way to track project progress – The new metric that calculates progress for Remediation Projects will advance for each individual asset remediated within a “solution” group. This means customers no longer have to wait for all the affected assets to be remediated to see progress.
Scan Assistant
Scan Assistant provides an innovative alternative to traditional credentialed scanning. Instead of account-based credentials, it uses digital certificates, which increases security and simplifies administration for authenticated scans.
Scan Assistant is now generally available for Linux
Automatic Scan Assistant credential generation – taking some more burden off the vulnerability management teams, customers can use the Shared Credentials management UI to automatically generate Scan Assistant credentials
Improved scalability – automated Scan Assistant software updates and digital certificate rotation for customers seeking to deploy and maintain a fleet of Scan Assistants.
Dashboards and reports
Customers like to use dashboards to visualize the impact of a specific vulnerability or vulnerabilities to their environment, and we made quite a few updates in that area:
New dashboard cards based on CVSS v3 severity – we expanded CVSS dashboard cards to include a version that sorts the vulnerabilities based on CVSS v3 scores (along with CVSS v2 scores).
Threat feed dashboard includes CISA’s KEV catalog – we extended the scope of vulnerabilities tracked to incorporate CISA’s KEV catalog in the InsightVM Threat Feed Dashboard to help customers prioritize faster.
5 New Dashboard Cards – We launched a set of five new dashboard cards that utilize line charts to show trends in vulnerability severity and allow for easy comparison when reporting.
Distribute Reports via Email – Customers can now send InsightVM reports to their teammates through email.
Agent improvements for virtual desktops
Pandemic fueled remote work and with it the use of virtual desktops. InsightVM can now identify agent-based assets that are Citrix VDI instances and correlate them to the user, enabling more accurate asset/instance tagging. This will create a smooth, streamlined experience for organizations that deploy and scan Citrix VDIs. Expect similar improvements for VMware Horizon VDIs in 2023.
Improved support
A new, opt-in feature eliminates the need for customers to attach logs to support cases and/or send logs manually, ensuring a faster, more intuitive support process.
Notable Emergent Threat Responses and Recurring Coverages
In 2022, we added support for enterprise systems like Windows Server 2022, AlmaLinux, VMware Horizon (server and client), and more to the recurring coverage list. Learn about the systems with recurring coverage.
Rapid7’s Emergent Threat Response (ETR) program is part of an ongoing process to deliver fast, expert analysis alongside first-rate security content for the highest-priority security threats. This year we flagged a number of critical vulnerabilities. To list a few:
That’s not all. We added over 21,000 new checks across close to 9000 CVEs to help customers understand their risk better and thus secure better.
Check out our past blogs – Q1, Q2, and Q3 – to get more information on product improvements and key vulnerability coverages.
Customer Stories and Resources
The past year, we had the privilege to share stories of how our customers are using Insight VM to secure their environment. Check out how your peers are leveraging InsightVM.Here’s what one customer had to say:
“That is one of the things we value most about InsightVM; it has the capacity to pinpoint actively-exploited vulnerabilities, so we can prioritize and direct our attention where it’s needed most.”
For customers looking to improve the utilization of the Vulnerability Management tool, check out this webcast series that covers the different phases of VM lifecycle – Discovery, Analyze, Communicate, and Remediate. Lastly, customers can always leverage Rapid7 Academy to participate in workshops and training to continue their learning journey.
Looking forward to 2023
We will maintain the customer-centricity in 2023 as we continue to deliver features and improvements in customers’ best interests. We will be holding a webinar on January 24 around configuration assessment in InsightVM agent-based policy. And, as always, be on the lookout for our annual vulnerability intelligence report coming soon to a Q1 near you (here’s last year’s)!
Emergent threats evolve quickly, and as we learn more about this vulnerability, this blog post will evolve, too.
On Tuesday, December 13, 2022, Citrix published Citrix ADC and Citrix Gateway Security Bulletin for CVE-2022-27518 announcing fixes for a critical unauthenticated remote code execution (RCE) vulnerability that exists in certain configurations of its Gateway and ADC products. This vulnerability has reportedly been exploited in the wild by state-sponsored threat actors.
In a blog post, Citrix states that no workarounds are available for this vulnerability and that customers running an impacted version (those with a SAML SP or IdP configuration) should update immediately.
Citrix is a high-value target for any capable attacker; earlier today, the National Security Agency (NSA) published Citrix ADC Threat Hunting Guidance warning that Citrix ADC is being targeted by state-sponsored adversaries.
Affected products
The following customer-managed product versions are affected by this vulnerability so long as the ADC or Gateway is configured as a SAML SP or a SAML IdP:
Citrix ADC and Citrix Gateway 13.0 before 13.0-58.32
Citrix ADC and Citrix Gateway 12.1 before 12.1-65.25
As far as Patch Tuesdays go, defenders have a relatively light month to close out the year with only 48 CVEs being published by Microsoft today. (This does not include the 24 previously disclosed vulnerabilities affecting their Chromium-based Edge browser.)
There are two zero-days in the mix today. CVE-2022-44698 is a bypass of the Windows SmartScreen security feature, and has been seen exploited in the wild. It allows attackers to craft documents that won’t get tagged with Microsoft’s “Mark of the Web” despite being downloaded from untrusted sites. This means no Protected View for Microsoft Office documents, making it easier to get users to do sketchy things like execute malicious macros. Publicly disclosed, but not seen actively exploited, is CVE-2022-44710. It’s a classic elevation of privilege vulnerability affecting the DirectX graphics kernel on Windows 11 22H2 systems.
Administrators for SharePoint and Microsoft Dynamics deployments should be aware of Critical Remote Code Execution (RCE) vulnerabilities that need to be patched. Other Critical RCEs this month affect the Windows Secure Socket Tunneling Protocol (CVE-2022-44676 and CVE-2022-44670), .NET Framework (CVE-2022-41089), and PowerShell (CVE-2022-41076).
Happy holidays, and may your patching be merry and bright!
With 2022 rapidly coming to a close, this is the time of year where it makes sense to take a step back and look at the year in cybersecurity, and make a few critical predictions for what the industry could face in the year ahead.
In order to give the security community some insight into where we’ve been and where we are going, Rapid7 has put together a webinar featuring some of Rapid7’s leading thinkers on the subject — and an important voice from a valued customer — to discuss some of the lessons learned and give their take on what 2023 will look like.
Featured in the webinar are Jason Hart, Rapid7’s Chief Technology Officer for EMEA; Simon Goldsmith, InfoSec Director at OVO Energy, the United Kingdom’s third largest energy retailer; Raj Samani, Senior Vice President and Chief Scientist at Rapid7; and Rapid7’s Vice President of Sales for APAC, Rob Dooley.
2022 – “A Challenging Year”
It may seem like the pace of critical vulnerabilities has only increased in 2022, and to our panel, it feels that way because it has. Whereas in years past, the cybersecurity industry would deal with a major vulnerability once a quarter or so (Heartbleed came to mind for some on our panel), this year it seemed like those vulnerabilities were coming to the fore nearly every week. Many of those vulnerabilities appeared to be actively exploited, raising the urgency for security teams to address them as quickly as possible.
This puts the onus on security teams to not only sift through the noise to find the signal (a spot where automation can be key), it also requires expert analysis all at a pace that the industry really hasn’t seen before.
For some, the fast pace of these vulnerabilities were an opportunity to test the mettle of their security operations. Even if their organizations weren’t a victim of those attacks, they can serve as “a lesson learned” putting their incident response plans through their paces. This gives them the confidence to perform well during an actual attack and evangelizes the need for strong vulnerability management across their entire organization, not just within their security teams.
Prediction 1: Information Sharing and the Ever-Expanding Attack Landscape
To give some context for this first prediction, it is important to express that zero-day attacks are on the rise, the time to exploitation is getting shorter, and the social media giants — often a critical component of security community vulnerability information sharing — are becoming less and less reliable.
But the desire for the community to publish and share information about vulnerabilities is still strong. This form of asymmetry between threat actors and the security community has long existed and there is still the inherent risk of transparency on one side benefiting those who seek opacity on the other. Information sharing between the community will be as critical as ever, especially as the reliable avenues for sharing that information dwindle in the coming months.
The way to combat this is by operationalizing cybersecurity — moving away from the binary approach of “patch or don’t patch” — and instead incorporating stronger context through a better understanding of past attack trends in order to prioritize actions and cover your organization from the actual risks.
Another key component is instituting better security hygiene across the organization. What Simon Goldsmith called “controlling the controllables.” This also includes tech stack modernization and the other infrastructural improvements organizations can take to put them in a better position to repel and ultimately respond to an ever more present threat across their networks.
Prediction 2: Cybersecurity Budgets and the Security Talent Shortage
At the same time that threat actors are making it harder on security teams across nearly every industry, the stakes are getting higher for those that are caught up in a breach. Governments are levying hefty fines for organizations that suffer data breaches and there is a real shortage of well-rounded security talent in the newest generation of security professionals.
In some cases this is due to an increase in specialization, but to harken back to the previous prediction, there is some level of “controlling the controllables” at play wherein organizations need to better nurture security talent. There are perennial components to the talent churn and shortfalls (i.e., reduced budgets, a lack of buy-in across the organization, etc.). However, there are more ways in which organizations can bolster their security teams.
Focusing on diversity and inclusion within your security team is one way to improve not only the morale of your security team, but the efficacy that comes from having wide-ranging viewpoints and expertise present on a team all working together.
Another way to strengthen your team is to help them get out of the cybersecurity bubble. Finding ways to work across teams will not only increase the amount of expertise thrown at a particular problem, but will open avenues for innovation that may not have been considered by a completely siloed infosec team. This means opening up communication with engineering or development teams, and often bringing in a managed services partner to help boost the number of smart voices singing together.
Finally, move beyond the search for the mythical unicorn and acknowledge that experience and expertise count just as much or more than having the right certifications on paper. This should mean fostering career development for more junior team members, engaging current teammates in ways that make the work they do more of a passion and less of a grind, and also ensuring that your team’s culture is an asset working to bring everyone together.
Prediction 3: Operationalizing Security
The gap between technical stakeholders and the business leaders within organizations is getting wider, and will continue to do so, if changes aren’t made to the ways in which the two sides of the house understand each other.
Part of this disconnect comes from the question of “whether or not we’re safe.” In cybersecurity, there are no absolutes; despite compliance with all best practices, there will always be some level of risk. And security operations can often fall into the trap of asking for more funding to better identify more risk, identifying that risk, and then asking for more money to address it. This is not a sustainable approach to closing the understanding gap.
Stakeholders outside of the SOC should understand the ways in which security teams reduce risk through clear metrics and KPIs that demonstrate just how much improvement is being made in infosec, thus justifying the investment. This operationalization of security — the demonstration of improvements — is critical.
Another component of this disconnect lies in which parts of the organization are responsible for different security actions and ensuring they are working together clearly, cohesively, and most importantly, predictably. Protection Level Agreements can go a long way in ensuring that vulnerabilities are handled within a certain amount of time. This requires security teams to provide the relevant information about the vulnerability and how to remediate it to other stakeholders within a predictable window after the vulnerability is identified, so that team can take the steps necessary to remediate it.
Conclusion: Uniting Cybersecurity
It may seem that this blog post (and its sister webinar) offer up doom, gloom, and tons of FUD. And while that’s not entirely untrue, there is a silver lining. The commonality between all three of these predictions is the concept of uniting cybersecurity. Security is integrated within every component of an organization and each group should understand what goals the security operation is striving for, how they will get there, how they themselves are accountable for moving that goal forward, and how that success will ultimately be measured. The cybersecurity community has an opportunity, and maybe even a mandate, to help bring these changes to their organizations as it will be one of the most critical components of a safer, cybersecurity operation.
All of these points (and so many more) are eloquently made on the webinar available here.
It’s a relatively light Patch Tuesday this month by the numbers – Microsoft has only published 67 new CVEs, most of which affect their flagship Windows operating system. However, four of these are zero-days, having been observed as exploited in the wild.
The big news is that two older zero-day CVEs affecting Exchange Server, made public at the end of September, have finally been fixed. CVE-2022-41040 is a “Critical” elevation of privilege vulnerability, and CVE-2022-41082 is considered Important, allowing Remote Code Execution (RCE) when PowerShell is accessible to the attacker. Both vulnerabilities have been exploited in the wild. Four other CVEs affecting Exchange Server have also been addressed this month. Three are rated as Important, and CVE-2022-41080 is another privilege escalation vulnerability considered Critical. Customers are advised to update their Exchange Server systems immediately, regardless of whether any previously recommended mitigation steps have been applied. The mitigation rules are no longer recommended once systems have been patched.
Three of the new zero-day vulnerabilities are:
CVE-2022-41128, a Critical RCE affecting the JScript9 scripting language (Microsoft’s legacy JavaScript dialect, used by their Internet Explorer browser).
CVE-2022-41073 is the latest in a storied history of vulnerabilities affecting the Windows Print Spooler, allowing privilege escalation and considered Important.
CVE-2022-41125 is also an Important privilege escalation vulnerability, affecting the Windows Next-generation Cryptography (CNG) Key Isolation service.
The fourth zero-day, CVE-2022-41091, was previously disclosed and widely reported on in October. It is a Security Feature Bypass of “Windows Mark of the Web” – a mechanism meant to flag files that have come from an untrusted source.
Exchange Server admins are not the only ones on the hook this month: SharePoint Server is affected by CVE-2022-41062, an Important RCE that could allow an attacker who has Site Member privileges to execute code remotely on the server. CVE-2022-41122, a Spoofing vulnerability that Microsoft rates as “Exploitation more likely” than not, was actually addressed in September’s SharePoint patches but not included in their Security Update Guide at the time.
This month also sees Microsoft’s third non-CVE security advisory of the year, ADV220003, which is a “defense-in-depth” update for older versions of Microsoft Office (2013 and 2016) that improves validation of documents protected via Microsoft’s Information Rights Management (IRM) technology – a feature of somewhat dubious value, meant to help prevent sensitive information from being printed, forwarded, or copied without authorization.
Perhaps your organization is in the beginning stages of planning a digital transformation, and it’s time to start considering how the security team will adapt. Or maybe your digital transformation is well underway, and the security team is struggling to keep up with the pace of change. Either way, you’ve likely realized that the approach you’ve used with traditional infrastructure will need to evolve as you think about managing risk in your modern ecosystem. After all, a cloud instance running Kubernetes clusters to support application development is quite different from an on-premise Exchange server!
A recent webinar led by two of Rapid7’s leaders, Peter Scott (VP, Product Marketing) and Cindy Stanton (SVP, Product and Customer Marketing), explored the specific challenges of managing the evolution of risk across traditional and cloud environments. The challenges may be plentiful, but the strategies for success are just as numerous!
Over the course of several years, Rapid7 has helped many customers evolve their security programs in order to keep pace with the evolution of technology, and Peter and Cindy have noticed some themes of what tends to make these organizations successful. They advise working with your team & other stakeholders to find answers to the following questions:
What sorts of resources does your organization run in the cloud, and who owns them?
What does “good” look like when securing your cloud assets, and how will you measure success?
Which standards and frameworks is your company subject to, compliance or otherwise?
Gathering answers to these questions as early as possible will not only aid in the efficacy of your security program, it will also help to establish strong relationships & understanding amongst key stakeholders.
Establishing Ownership
Proactively identifying teams and individuals that own the assets in your environment will go a long way towards ensuring speed of resolution when risk is present. Peter strongly suggests working with your organization’s Product or Project Development teams to figure out who owns what and get it documented. This way, when you see a misconfiguration, vulnerability or threat that needs to be dealt with, you know exactly who to talk to to get it resolved, saving important time.
The owners that you identify will not only have a hand to play in fixing problems, they can help make the necessary changes to “shift left” and prevent problems in the first place. The sooner you can identify these stakeholders and build relationships with them, the more successful you’ll be in the long run.
Defining “Good” and Tracking Achievement
Since we’ve established that securing traditional environments is not the same as securing modern environments, we can also agree that the definition of success may not be the same either! After you’ve established ownership, Cindy notes that it’s also important to define what “good” looks like, and how you plan to measure & report on it. Once you’ve created a definition of “good” within your immediate team, it’s also important to socialize that with stakeholders across your organization and track progress towards achieving that state. Tracking & sharing progress is valuable whether your organization meets, exceeds or falls short of your goals; celebrating the wins is just as important as seeking to understand the losses!
Aligning to Standards and Frameworks
Every industry comes with its own set of compliance and regulatory standards that must be adhered to, and it’s important to understand how security fits in. Your team can use these frameworks as a North Star of sorts when considering how to secure your environment, and the cloud aspects of your environment are no exception. Ben Austin, the moderator of the webinar, provides some perspective on the utility of compliance as a method for demonstrating progress in risk reduction. If your assets are more compliant today than they were 3 months ago, that’s a win for every stakeholder involved. If assets are getting less compliant, then you can work with your already-identified asset owners to make a plan to turn the ship around, and contextualize the importance of remaining compliant with them.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.