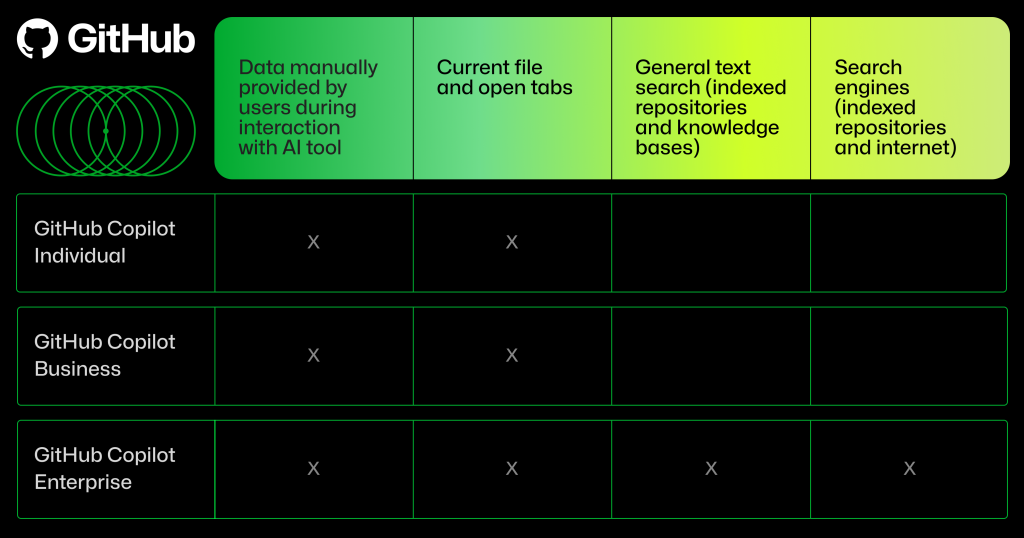
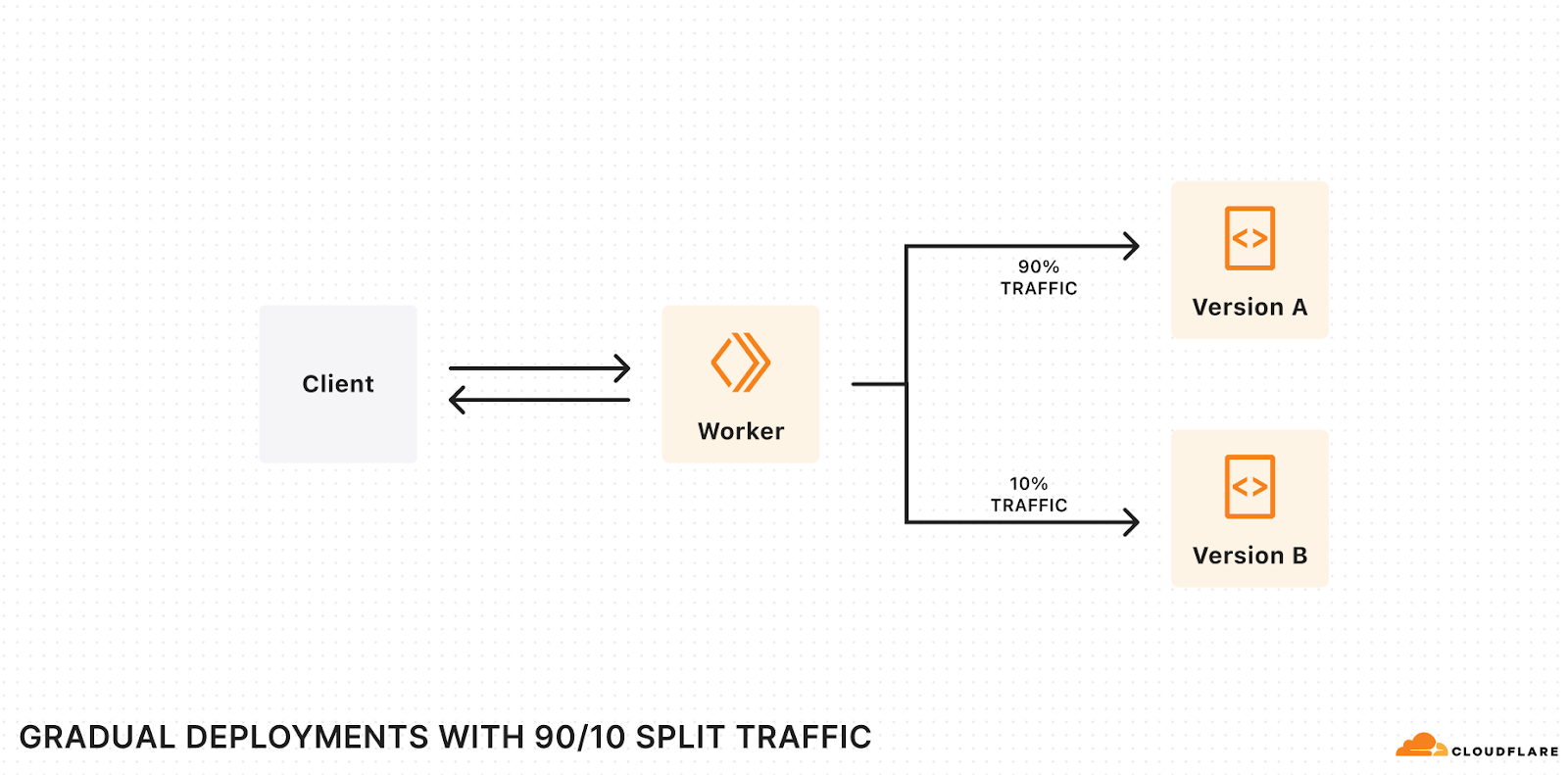
Post Syndicated from original https://www.toest.bg/na-vtoro-chetene-cyaloto-nashe-bezumstvo/
„Цялото наше безумство“ от Ши-Ли Коу

превод от английски Светослава Павлова, изд. „Алтера“, 2022
Обикновено има или целенасочен интерес и изрично любопитство, или някаква странна съпротива и съмнение, когато човек посяга към литература от автори, принадлежащи на крайно далечна от нас култура. Признавам си, че зачетох „Цялото наше безумство“ на малайската авторка Ши-Ли Коу по втория начин само за да установя
колко изумително сходен на нашия е светът, който тя описва –
в устройството на обществото и специфичните му недъзи; в хитрите и често смехотворни преки към справянето с бита, спецификата на отношенията и живописните характери в провинцията; в противопоставянето на глобалния мегаполис и справянето с неумолимо настъпващия „прогрес“; в шегите и езика.
Романът представлява двугласен хор от разкази в първо лице, като едното повествование се води от възрастен етнически китаец, а другото – от подрастващо християнско момиче.
Съдбата на двамата се преплита, когато момичето бива осиновено след катастрофа от близката на мъжа – малайката Мами Биви. Жена, която като че ли сме срещали в редица други любими книги: самодостатъчна особнячка, самотна и самобитна, чудата и доизмисляща истории, всяка от които започва с „Беше/Имаше неестествен…“. Тази дума – неестествен, ще бележи всичко случващо се в измисления градец Лубок Сайонг в щата Перак, така че дори нормалните и обичайни неща ще придобият някакъв друг, извънвремеви и леко магичен привкус. Така както някои от героите ще виждат неспокойни мъртви или ангели, рибите ще имат съзнание, а част от събитията ще се случват като че ли по неведомо съвпадение.
Не, романът далеч не е в традицията на латиноамериканския магически реализъм, макар тук-там да има подобни краски.
Разказът е изключително земен, изпълнен със сладостна ирония и ярък социален сарказъм.
Книгата не представлява също така нито мемоари на възрастния мъж (макар и донякъде да наподобява градски летописи, водени в ние-форма), нито роман на израстването в аз-форма, както се споменава в анотацията. Може би защото героите разказвачи не са наистина важните, фокусът не е тяхната промяна или израстване, те не са в центъра на събитията.
Големият герой на този роман е всъщност самият градец, както и неговите типажи, чешити, местни и случайно приходящи. Това неголямо и не особено уредено място няма как да не ви се стори безкрайно познато – то все още е далеч от инфраструктурата, привилегиите и шаблонния лукс на глобалното, макар „прогресът“ по един или друг начин да пълзи към него. Иска ли питане, че политиците минават през него инцидентно преди избори и с известна погнуса, а ежегодните наводнения са нещо, което жителите са приели като природна даденост, както – уви – често се случва и у нас:
В Лубок Сайонг не виним пътното строителство, обезлесяването, затинените реки, запушените отводнителни тръби или универсалния виновник, корумпираните бюрократи, които работят в отделите, отговарящи за гореспоменатите пътища, гори, реки и тръби.
В този град, където всичко е едно – една болница, едно полицейско управление, една бензиностанция и така нататък – легендата е най-близката възможност за преодоляване на нелицеприятната и скучна истина за реалността такава, каквато е. Дори и тя обаче е оскъдна и не особено атрактивна, за да привлича достатъчно интерес към града, или както разказвачът описва местното предлагане на легендите –
хладни и слабо гарнирани, на порции, недостатъчни да задоволят апетита или въображението.
Ши-Ли Коу е изключително забавна в начина, по който кара разказвача си да (само)иронизира местните поверия, да „героизира“ на шега обикновеното, докато подкача „автентичното“ и „традиционното“, да извежда на преден план смешното, като същевременно буди у нас симпатия към него.
Съпоставяйки от време на време живота с този в столицата Куала Лумпур, авторката очертава ясни дихотомии, без нито за миг да бъде мелодраматична или да идеализира едното за сметка на другото: уж автентичното ръчно труд-и-творчество (често „подпомагано“ от поръчаните в Китай масовки) срещу индустриализацията и големите фабрики, в които в крайна сметка работят същите „мързеливи, глупави и злочести хора, които просто се опитват да си изкарат прехраната“; неугледния локален туризъм, на който се отдават само случайно изпаднали авантюристи, срещу маститите спа комплекси за добре плащащите чуждестранни гости; местната храна, която може да предизвика позиви за често ходене до тоалетната, срещу безличните световни вериги, като „Старбъкс“ и „Макдоналдс“; самодоволните доброволци от големия град и свикналите с бедствията провинциалисти, които се дразнят от тяхната жизнерадостна и клиширана помощ; забавната неприветливост на самобитното срещу абсурда на привнесеното; традиционните ислямски закони и илюзорното приличие срещу реалното съществуване на травестити и други сексуални и личностни свободи зад кулисите.
Възможно е тогава да се каже, че „Цялото наше безумство“ може да се чете като своеобразна социална сатира,
тъй като във всяка възможна ситуация и чрез куп метафори Ши Ли-Коу не пропуска да ни напомни за обществените реалности. Макар и история на един отделно взет малък град, тя е история на съвременна Малайзия встрани от лъскавите туристически брошури. Ши Ли-Коу очертава ежедневието на земния, обикновен човек (чиято практичност измества дори въпросите на живот и смърт) чрез поредица от забавни, полукомични и леко тъжни случки. Ще научим как се клинчи от час, как се спасяват пиявици, как се превъзпитават травестити, как се прави мост в нищото и т.н. И във всичко това ще личи носталгията по непревзетото от глобализма, по малкия град, по твърде човешкото.
Тази книга наистина е изпълнена с неподправено човеколюбие,
с великодушно снизхождение към кривиците и недостатъците на всеки и с обич към доброто и достойното у всеки – независимо от неговата етническа, верска, сексуална и друга принадлежност. В мешавицата от етноси, която Ши-Ли Коу забърква – малайци, индийци, китайци, индонезийци, – човекът в която и да е координатна точка на споменатото в горния абзац остава просто човек: погрешим, в никога незавършен процес на себесъздаване, очарователно комичен. Важното е, че той не е сам за себе си – героите на романа неизбежно намират път един към друг, колкото и криволичещ да е той, образуват сложни, но автентични връзки и в крайна сметка една истинска човечна общност в епруветката на измисления Лубок Сайонг.

В „Цялото наше безумство“ няма поука, както признава чрез героите си авторката:
Искам да кажа на тези, които идват, на всеки, който би ме чул, че урокът не е в разказа, а в живота.
И за да затворим кръга към далечното, което особено на нас, българите, ще ни се стори безкрайно познато, ще ви оставя
кратък списък с някои неща от ежедневния дискурс, които веднага ще разпознаете като родни
и които присъстват в книгата:
- всичко е политика;
- таксиметровите шофьори се оплакват, че държавата е съсипана и никой не се грижи за тях, а всички искат да ги прецакат;
- всичко гнило идва от Китай – отровено мляко за кърмачета, консервирана храна с живак, масово произведените сувенири;
- всички гледат ужасно дублирани сапунени опери;
- хората в крайна сметка си предпочитат съмнителната и мързелива помощ на корумпираните институции;
- те споделят тихото чакане и кротката търпимост по отношение на некадърността, защото общата мизерия свързва;
- политиците раздават пари на калпак преди избори на всички социално ощетени групи освен данъкоплатците на платена работа;
- природните бедствия са по вина на корупцията и нехайството, но са представяни като добри за нацията, защото карат обществото да се обединява около обща кауза;
- младите, които все пак остават в малкия град, просто твърде много обичат мързеливия си живот, за да се бъхтят на някаква работа;
- прогресът не е исторически, а преди всичко търговски и се измерва с потреблението на куп жалонни боклуци.
Завършвам с една присъда на Мама Биви:
Вие сте тези, които погубихте Куала Лумпур. Продължихте да строите магазини, офиси, жилищни сгради и огромни молове. Живеехте си в множеството ви мезонети и вили и те пак не ви бяха достатъчни. Строите още по-големи сгради, за да продавате все повече неща. Настоявате за все повече чуждестранни майстори готвачи и лъскави ресторанти, които трябва да се обновяват на всеки три години. Построихте още пътища за шестте ви коли, с които задушавате града, защото много ще се изпотите, ако се качите в метрото или автобуса. И се оплаквате, че градът бил загубил чара си?
Никой от нас не чете единствено най-новите книги. Тогава защо само за тях се пише? „На второ четене“ е рубрика, в която отваряме списъците с книги, публикувани преди поне година, четем ги и препоръчваме любимите си от тях. Рубриката е част от партньорската програма Читателски клуб „Тоест“. Изборът на заглавия обаче е единствено на авторите – Стефан Иванов и Антония Апостолова, които биха ви препоръчали тези книги и ако имаше как веднъж на две седмици да се разходите с тях в книжарницата.

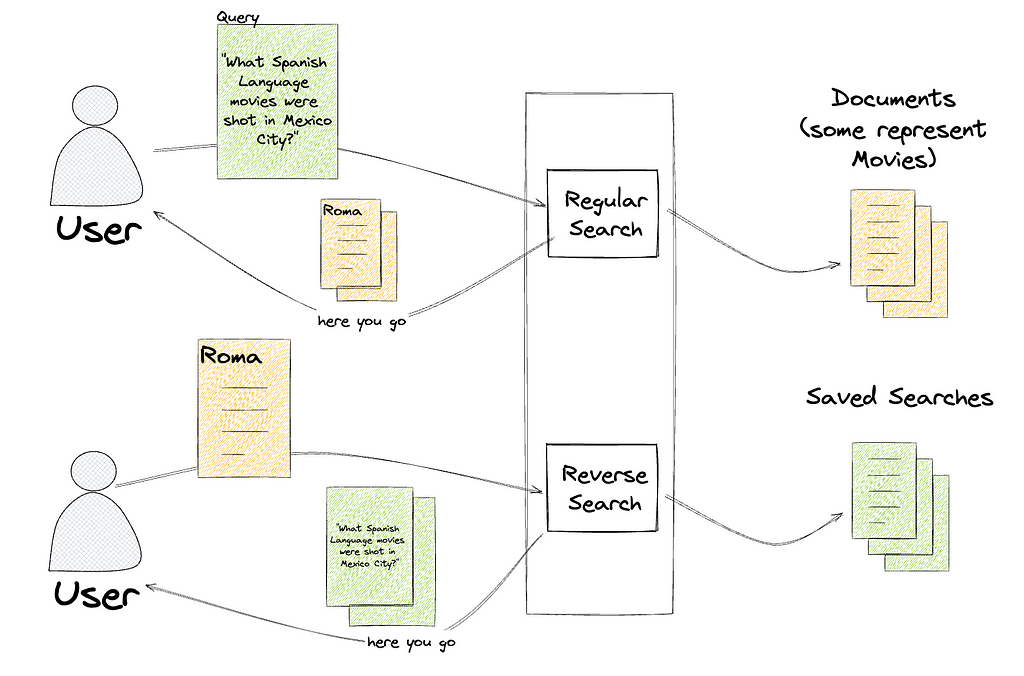
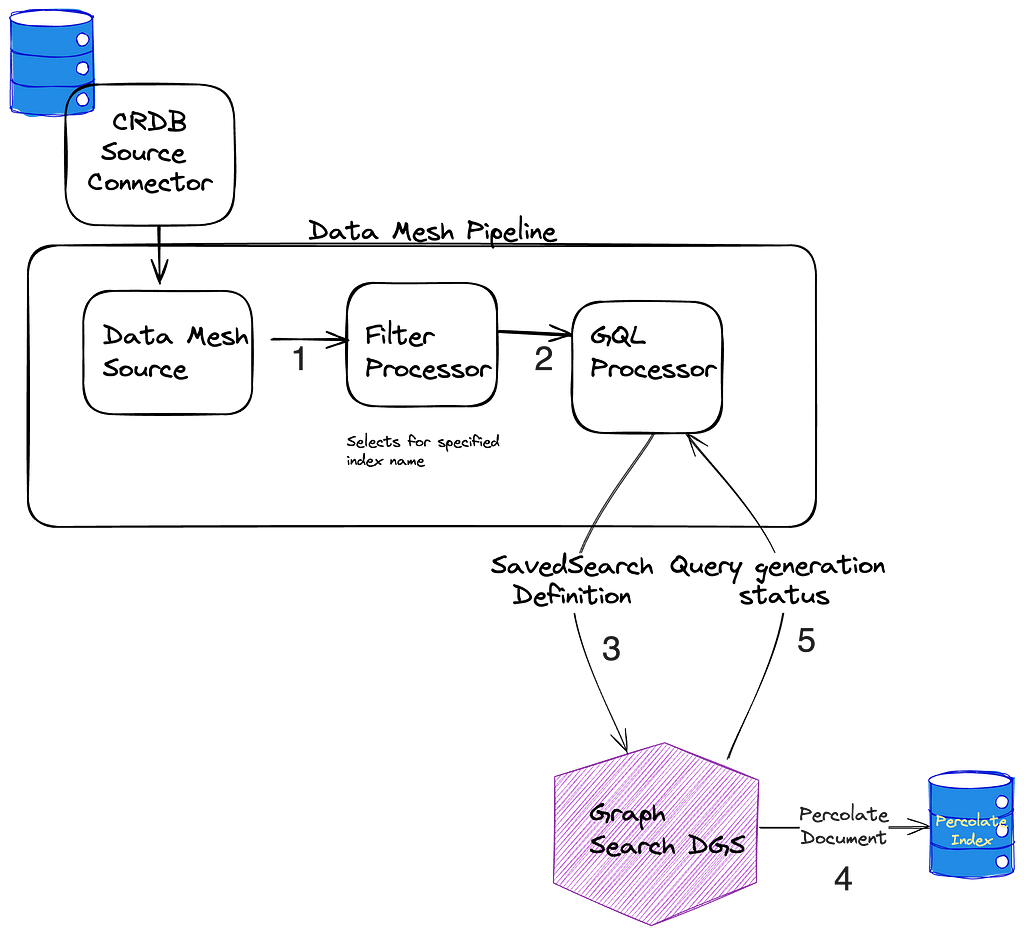

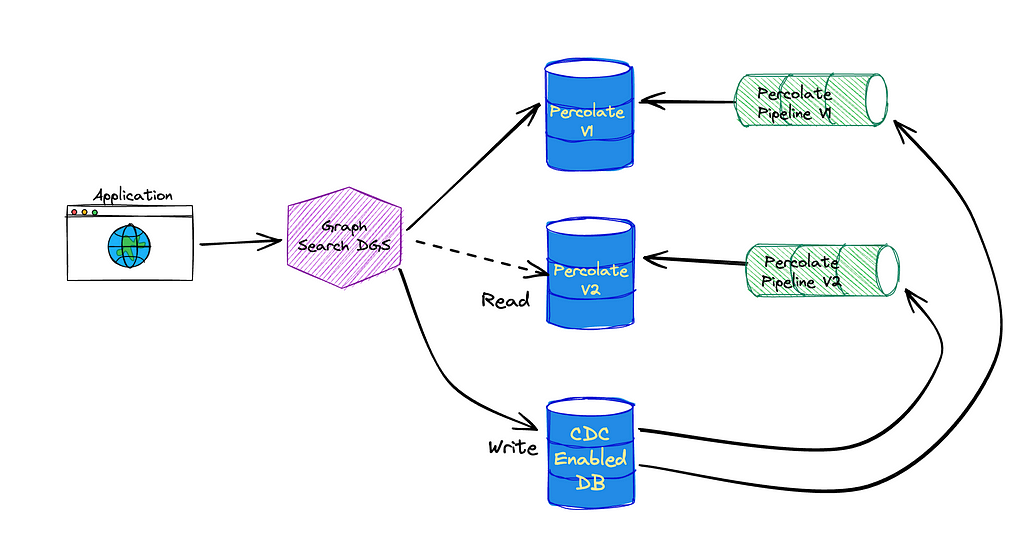


 Amir Souchami, Chief Architect of Aura from Unity, focusing on creating resilient and performant cloud systems and mobile apps at major scale.
Amir Souchami, Chief Architect of Aura from Unity, focusing on creating resilient and performant cloud systems and mobile apps at major scale. Fabian Szenkier is the ML and Big Data Architect at Aura by Unity, works on building modern AI/ML solutions and state of the art data engineering pipelines at scale.
Fabian Szenkier is the ML and Big Data Architect at Aura by Unity, works on building modern AI/ML solutions and state of the art data engineering pipelines at scale. Liat Tzur is a Senior Technical Account Manager at Amazon Web Services. She serves as the customer’s advocate and assists her customers in achieving cloud operational excellence in alignment with their business goals.
Liat Tzur is a Senior Technical Account Manager at Amazon Web Services. She serves as the customer’s advocate and assists her customers in achieving cloud operational excellence in alignment with their business goals. Adi Jabkowski is a Sr. Redshift Specialist in EMEA, part of the Worldwide Specialist Organization (WWSO) at AWS.
Adi Jabkowski is a Sr. Redshift Specialist in EMEA, part of the Worldwide Specialist Organization (WWSO) at AWS. Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value.
Yonatan Dolan is a Principal Analytics Specialist at Amazon Web Services. He is located in Israel and helps customers harness AWS analytical services to leverage data, gain insights, and derive value.












 ) of generative AI:
) of generative AI: