Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/amazon-textract-updates-up-to-32-price-reduction-in-8-aws-regions-and-up-to-50-reduction-in-asynchronous-job-processing-times/
Introduced at AWS re:Invent 2018, Amazon Textract is a machine learning service that automatically extracts text, handwriting and data from scanned documents that goes beyond simple optical character recognition (OCR) to identify, understand, and extract data from forms and tables.
In the past few months, we introduced specialized support for processing invoices and receipts and enhanced the quality of the underlying computer vision models that power extraction of handwritten text, forms, and tables with printed text support for English, Spanish, German, Italian, Portuguese, and French.
Third-party auditors assess the security and compliance of Amazon Textract as part of multiple AWS compliance programs. We also added IRAP compliance support and achieved US FedRAMP authorization to add to the existing list such as HIPAA, PCI DSS, ISO SCO, and MTCS.
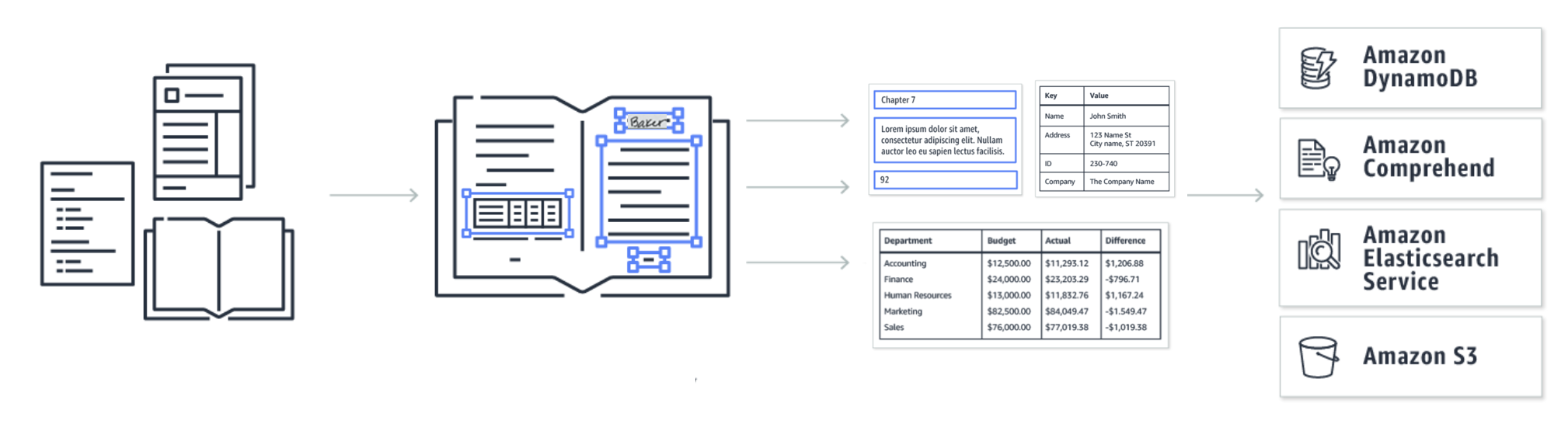
Customers use Amazon Textract to automate critical business process workflows (for example, in claims and tax form processing, loan applications, and accounts payable). It can reduce human review time, improve accuracy, lower costs, and accelerate the pace of innovation on a global scale. At the same time, Textract customers told us that we could be doing even more to reduce costs and improve latency.
Today we are excited to announce two major updates to Amazon Textract:
- Up to 32 percent price reduction in 8 AWS Regions to help global customers save even more with Textract.
- Up to 50 percent reduction in end-to-end job processing times for Textract’s asynchronous operations worldwide.
Up to 32% price reduction in 8 AWS Regions
We are pleased to announce an up to 32 percent price reduction in eight AWS Regions: Asia Pacific (Mumbai), Asia Pacific (Seoul), Asia Pacific (Singapore), Asia Pacific (Sydney), Canada (Central), Europe (Frankfurt), Europe (London), and Europe (Paris).
The API pricing for DetectDocumentText (OCR) and AnalyzeDocument (both forms and tables) in these AWS Regions is now the same as the US East (N. Virginia) Region pricing. Customers in those identified Regions will see a 9-32 percent reduction in API pricing.
Before the price reduction, a customer’s usage of the DetectDocumentText and AnalyzeDocument APIs would have been billed at different rates, by Region, for their usage tier. That customer will now be billed at the same rate, no matter from which AWS commercial Region Textract is being called.
| AWS Regions | DetectDocumentText API | AnalyzeDocument API (forms + tables) | ||||
| Old | New | Reduction | Old | New | Reduction | |
| Asia Pacific (Mumbai) | $1.830 | $1.50 | 18% | $79.30 | $65.0 | 18% |
| Asia Pacific (Seoul) | $1.845 | 19% | $79.95 | 19% | ||
| Asia Pacific (Singapore) | $2.200 | 32% | $95.00 | 32% | ||
| Asia Pacific (Sydney) | $1.950 | 23% | $84.50 | 23% | ||
| Canada (Central) | $1.655 | 9% | $72.15 | 10% | ||
| Europe (Frankfurt) | $1.875 | 20% | $81.25 | 20% | ||
| Europe (London) | $1.750 | 14% | $75.00 | 13% | ||
| Europe (Paris) | $1.755 | 15% | $76.05 | 15% | ||
This table shows two examples of effective price per 1,000 pages for processing the first 1 million monthly pages before and after this price reduction. Customers with usage above the 1 million monthly pages tier will also see a similar reduction in prices, the details of which can be found on the Amazon Textract pricing page.
The new pricing goes into effect on September 1, 2021. It will be applied to your bill automatically. This pricing change does not apply to the Europe (Ireland), US-based commercial Regions, and US GovCloud Regions. There is no change to the pricing for the recently launched AnalyzeExpense API for invoices and receipts.
As part of the AWS Free Tier, you can get started with Amazon Textract for free. The Free Tier lasts 3 months and new AWS customers can analyze up to 1,000 pages per month using the Detect Document Text API and up to 100 pages per month using the Analyze Document API or Analyze Expense API.
Up to 50% reduction in end-to-end job processing times
Customers can invoke Textract synchronously (on single-page documents) and asynchronously (on multi-page documents) for detecting printed and handwritten lines and words (via the DetectDocumentText API) as well as for forms and tables extraction (via the AnalyzeDocument API). We see that the vast majority of customers invoke Textract asynchronously today for at-scale processing of their document pipeline.
Based on customer feedback, we have made a number of enhancements to Textract’s asynchronous API operations that reduce the end-to-end latency by as much as 50 percent. Specifically, these updates reduce the end-to-end job processing times experienced by Textract customers on worldwide asynchronous operations by as much as 50 percent. The lower the processing time, the faster customers are able to process their documents, achieve scale and improve their overall productivity.
To learn more about Amazon Textract, see this tutorial for extracting text and structured data from a document, this code sample on GitHub, Amazon Textract documentation, and blog posts about Amazon Textract on the AWS Machine Learning Blog.
— Channy