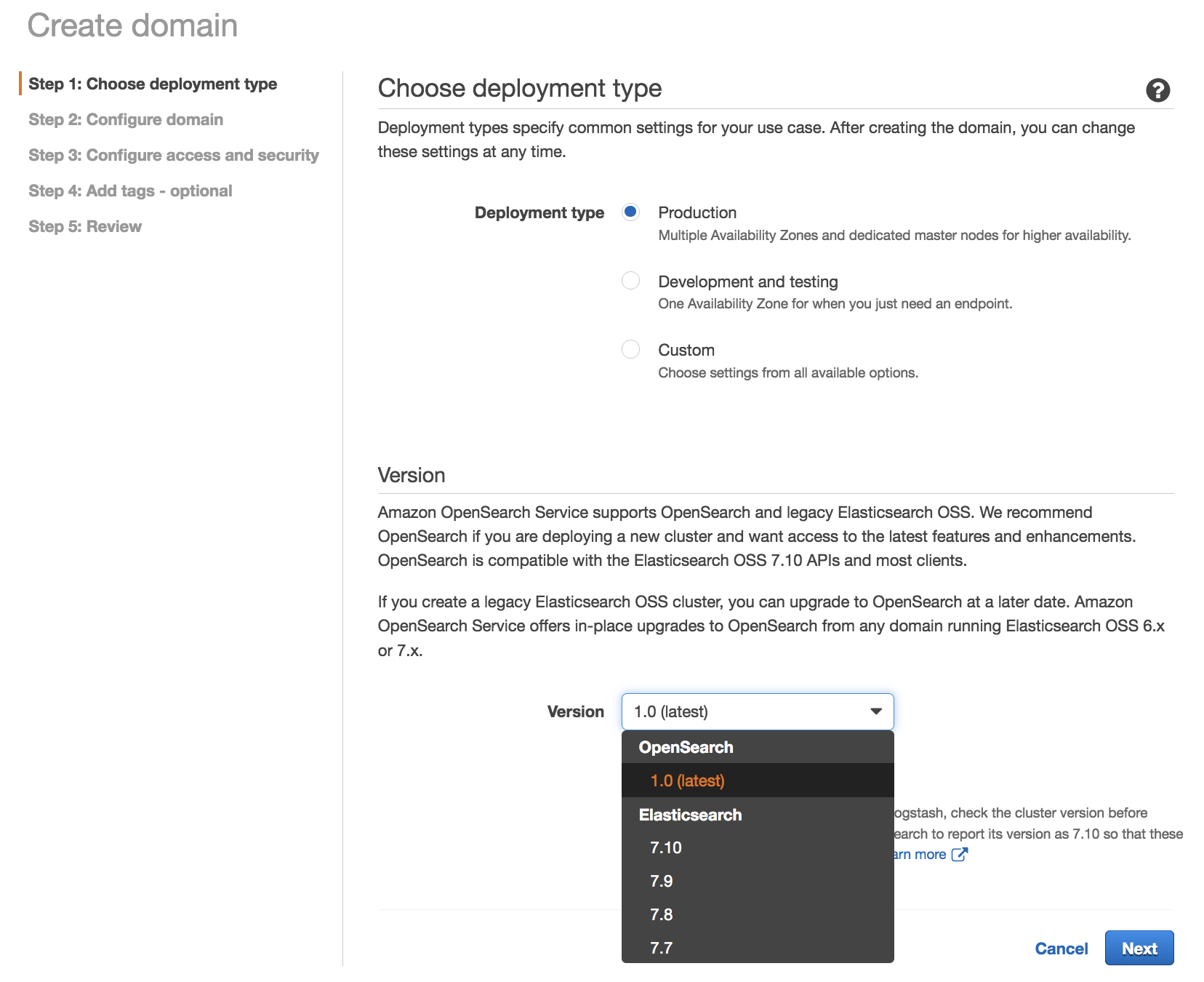
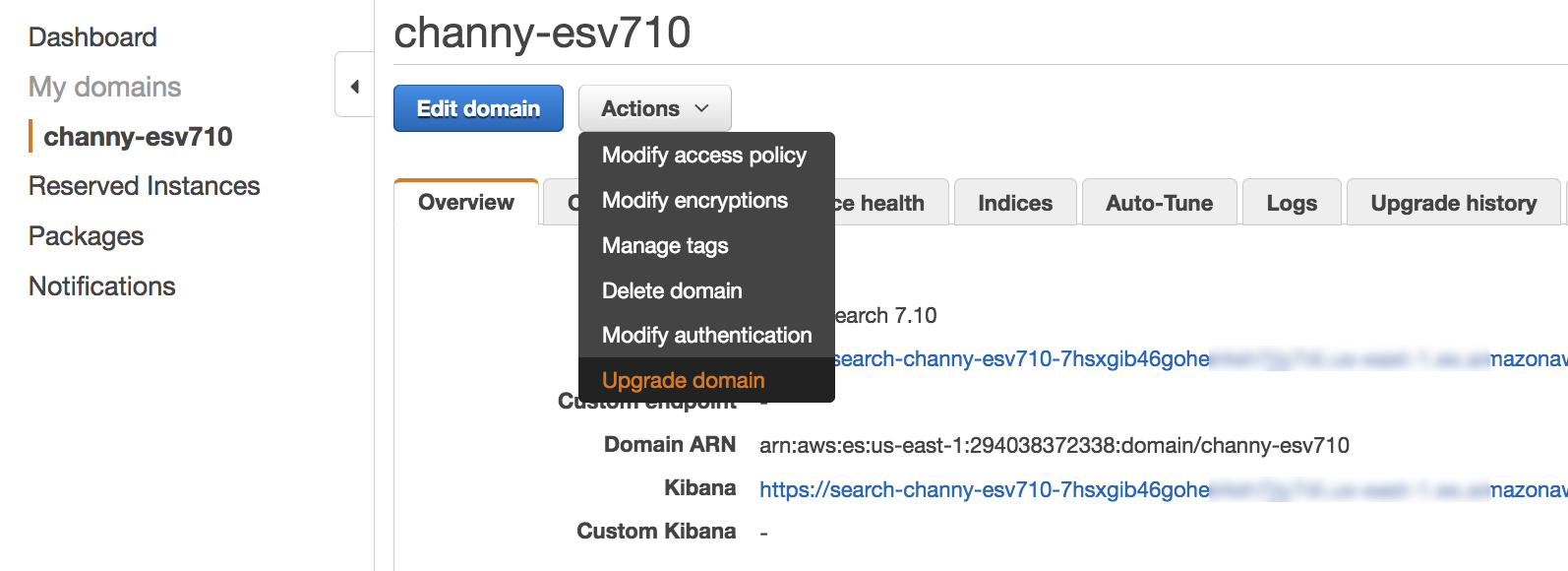
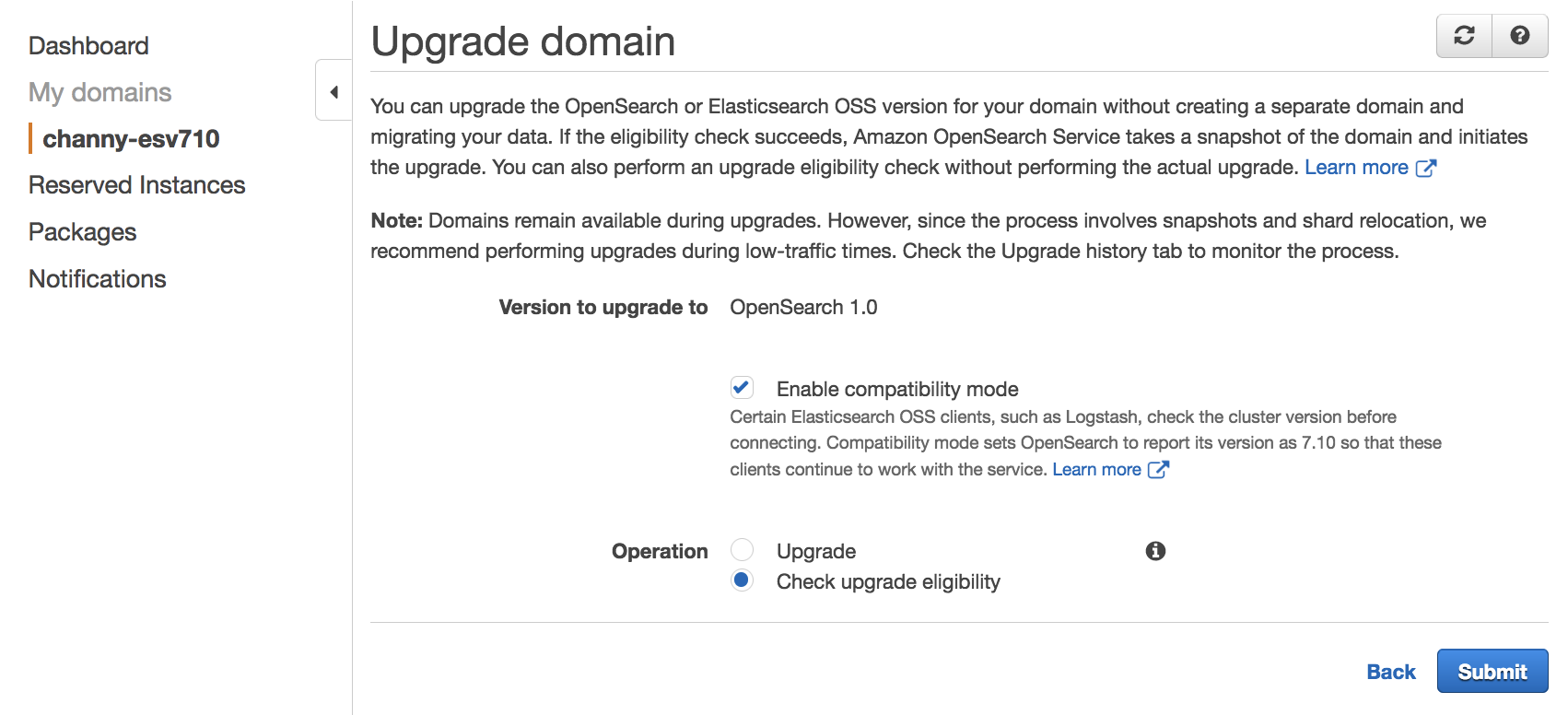
Post Syndicated from Channy Yun original https://aws.amazon.com/blogs/aws/amazon-eks-anywhere-now-generally-available-to-create-and-manage-kubernetes-clusters-on-premises/
At AWS re:Invent 2020, we preannounced new deployment options of Amazon Elastic Container Service (Amazon ECS) Anywhere and Amazon Elastic Kubernetes Service (Amazon EKS) Anywhere in your own data center.
Today, I am happy to announce the general availability of Amazon EKS Anywhere, a deployment option for Amazon EKS that enables you to easily create and operate Kubernetes clusters on premises using VMware vSphere starting today. EKS Anywhere provides an installable software package for creating and operating Kubernetes clusters on premises and automation tooling for cluster lifecycle support.
EKS Anywhere brings a consistent AWS management experience to your data center, building on the strengths of Amazon EKS Distro, an open-source distribution for Kubernetes used by Amazon EKS.
EKS Anywhere is also Open Source. You can reduce the complexity of buying or building your own management tooling to create EKS Distro clusters, configure the operating environment, and update software. EKS Anywhere enables you to automate cluster management, reduce support costs, and eliminate the redundant effort of using multiple open-source or third-party tools for operating Kubernetes clusters. EKS Anywhere is fully supported by AWS. In addition, you can leverage the EKS console to view all your Kubernetes clusters, running anywhere.
We provide several deployment options for your Kubernetes cluster:
| Feature |
Amazon EKS |
EKS on Outposts |
EKS Anywhere |
EKS Distro |
| Hardware |
Managed by AWS |
Managed by customer |
| Deployment types |
Amazon EC2, AWS Fargate (Serverless) |
EC2 on Outposts |
Customer Infrastructure |
| Control plane management |
Managed by AWS |
Managed by customer |
| Control plane location |
AWS cloud |
Customer’s on-premises or data center |
| Cluster updates |
Managed in-place update process for control plane and data plane |
CLI (Flux supported rolling update for data plane, manual update for control plane) |
| Networking and Security |
Amazon VPC Container Network Interface (CNI), Other compatible 3rd party CNI plugins |
Cilium CNI |
3rd party CNI plugins |
| Console support |
Amazon EKS console |
EKS console using EKS Connector |
Self-service |
| Support |
AWS Support |
EKS Anywhere support subscription |
Self-service |
EKS Anywhere integrates with a variety of products from our partners to help customers take advantage of EKS Anywhere and provide additional functionality. This includes Flux for cluster updates, Flux Controller for GitOps, eksctl – a simple CLI tool for creating and managing clusters on EKS, and Cilium for networking and security.
We also provide flexibility for you to integrate with your choice of tools in other areas. To add integrations to your EKS Anywhere cluster, see this list of suggested third-party tools for your consideration.
Get Started with Amazon EKS Anywhere
To get started with EKS Anywhere, you can create a bootstrap cluster in your machine for local development and test purposes. Currently, it allows you to create clusters in a VMWare vSphere environment for production workloads.
Let’s create a cluster on your desktop machine using eksctl! You can install eksctl and eksctl-anywhere with homebrew on Mac. Optionally, you can install some additional tools you may want for your EKS Anywhere clusters, such as kubectl. To learn more on Linux, see the installation guide in EKS Anywhere documentation.
$ brew install aws/tap/eks-anywhere
$ eksctl anywhere version
0.63.0
Generate a cluster config and create a cluster.
$ CLUSTER_NAME=dev-cluster
$ eksctl anywhere generate clusterconfig $CLUSTER_NAME \
--provider docker > $CLUSTER_NAME.yaml
$ eksctl anywhere create cluster -f $CLUSTER_NAME.yaml
[i] Performing setup and validations
[v] validation succeeded {"validation": "docker Provider setup is valid"}
[i] Creating new bootstrap cluster
[i] Installing cluster-api providers on bootstrap cluster
[i] Provider specific setup
[i] Creating new workload cluster
[i] Installing networking on workload cluster
[i] Installing cluster-api providers on workload cluster
[i] Moving cluster management from bootstrap to workload cluster
[i] Installing EKS-A custom components (CRD and controller) on workload cluster
[i] Creating EKS-A CRDs instances on workload cluster
[i] Installing AddonManager and GitOps Toolkit on workload cluster
[i] GitOps field not specified, bootstrap flux skipped
[i] Deleting bootstrap cluster
[v] Cluster created!
Once your workload cluster is created, a KUBECONFIG file is stored on your admin machine with admin permissions for the workload cluster. You’ll be able to use that file with kubectl to set up and deploy workloads.
$ export KUBECONFIG=${PWD}/${CLUSTER_NAME}/${CLUSTER_NAME}-eks-a-cluster.kubeconfig
$ kubectl get ns
NAME STATUS AGE
capd-system Active 21m
capi-kubeadm-bootstrap-system Active 21m
capi-kubeadm-control-plane-system Active 21m
capi-system Active 21m
capi-webhook-system Active 21m
cert-manager Active 22m
default Active 23m
eksa-system Active 20m
kube-node-lease Active 23m
kube-public Active 23m
kube-system Active 23m
You can create a simple test application for you to verify your cluster is working properly. Deploy and see a new pod running in your cluster, and forward the deployment port to your local machine with the following commands:
$ kubectl apply -f "https://anywhere.eks.amazonaws.com/manifests/hello-eks-a.yaml"
$ kubectl get pods -l app=hello-eks-a
NAME READY STATUS RESTARTS AGE
hello-eks-a-745bfcd586-6zx6b 1/1 Running 0 22m
$ kubectl port-forward deploy/hello-eks-a 8000:80
$ curl localhost:8000
⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢
Thank you for using
███████╗██╗ ██╗███████╗
██╔════╝██║ ██╔╝██╔════╝
█████╗ █████╔╝ ███████╗
██╔══╝ ██╔═██╗ ╚════██║
███████╗██║ ██╗███████║
╚══════╝╚═╝ ╚═╝╚══════╝
█████╗ ███╗ ██╗██╗ ██╗██╗ ██╗██╗ ██╗███████╗██████╗ ███████╗
██╔══██╗████╗ ██║╚██╗ ██╔╝██║ ██║██║ ██║██╔════╝██╔══██╗██╔════╝
███████║██╔██╗ ██║ ╚████╔╝ ██║ █╗ ██║███████║█████╗ ██████╔╝█████╗
██╔══██║██║╚██╗██║ ╚██╔╝ ██║███╗██║██╔══██║██╔══╝ ██╔══██╗██╔══╝
██║ ██║██║ ╚████║ ██║ ╚███╔███╔╝██║ ██║███████╗██║ ██║███████╗
╚═╝ ╚═╝╚═╝ ╚═══╝ ╚═╝ ╚══╝╚══╝ ╚═╝ ╚═╝╚══════╝╚═╝ ╚═╝╚══════╝
You have successfully deployed the hello-eks-a pod hello-eks-a-c5b9bc9d8-qp6bg
For more information check out
https://anywhere.eks.amazonaws.com
⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢⬡⬢
EKS Anywhere also supports a VMWare vSphere 7.0 version or higher for production clusters. To create a production cluster, see the requirements for VMware vSphere deployment and follow Create production cluster in EKS Anywhere documentation. It’s almost the same process as creating a test cluster on your machine.
A production-grade EKS Anywhere cluster should include at least three control plane nodes and three worker nodes on the vSphere for high availability and rolling upgrades. See the Cluster management in EKS Anywhere documentation for more information on common operational tasks like scaling, updating, and deleting the cluster.
EKS Connector – Public Preview
EKS Connector is a new capability that allows you to connect any Kubernetes clusters to the EKS console. You can connect any Kubernetes cluster, including self-managed clusters on EC2, EKS Anywhere clusters running on premises, and other Kubernetes clusters running outside of AWS to the EKS console. It makes it easy for you to view all connected clusters centrally.
To connect your EKS Anywhere cluster, visit the Clusters section in EKS console and select Register in the Add cluster drop-down menu.

Define a name for your cluster and select the Provider (if you don’t find an appropriate provider, select Other).

After registering the cluster, you will be redirected to the Cluster Overview page. Select Download YAML file to get the Kubernetes configuration file to deploy all the necessary infrastructure to connect your cluster to EKS.

Apply downloaded eks-connector.yaml and role binding eks-connector-binding.yaml file from the EKS Connector in our documentation. EKS Connector acts as a proxy and forwards the EKS console requests to the Kubernetes API server on your cluster, so you need to associate the connector’s service account with an EKS Connector Role, which gives permission to impersonate AWS IAM entities.
$ kubectl apply -f eks-connector.yaml
$ kubectl apply -f eks-connector-binding.yaml
After completing the registration, the cluster should be in the ACTIVE state.
$ eks describe-cluster --name "my-first-registered-cluster" --region ${AWS_REGION}
Here is the expected output:
{
"cluster": {
"name": "my-first-registered-cluster",
"arn": "arn:aws:eks:{EKS-REGION}:{ACCOUNT-ID}:cluster/my-first-registered-cluster",
"createdAt": 1627672425.765,
"connectorConfig": {
"activationId": "xxxxxxxxACTIVATION_IDxxxxxxxx",
"activationExpiry": 1627676019.0,
"provider": "OTHER",
"roleArn": "arn:aws:iam::{ACCOUNT-ID}:role/eks-connector-agent"
},
"status": "ACTIVE", "tags": {}
}
}
EKS Connector is now in public preview in all AWS Regions where Amazon EKS is available. Please choose a region that’s closest to your cluster location to minimize latency. To learn more, visit EKS Connector in the Amazon EKS User Guide.
Things to Know
Here are a couple of things to keep in mind about EKS Anywhere:
Connectivity: There are three connectivity options: fully connected, partially disconnected, and fully disconnected. For fully connected and partially disconnected connectivity, you can connect your EKS Anywhere clusters to the EKS console via the EKS Connector and see the cluster configuration and workload status. You can leverage AWS services through AWS Controllers for Kubernetes (ACK). You can connect EKS Anywhere infrastructure resources using AWS System Manager Agents and view them using the SSM console.
Security Model: AWS follows the Shared Responsibility Model, where AWS is responsible for the security of the cloud, while the customer is responsible for security in the cloud. However, EKS Anywhere is an open-source tool, and the distribution of responsibility differs from that of a managed cloud service like Amazon EKS. AWS is responsible for building and delivering a secure tool. This tool will provision an initially secure Kubernetes cluster. To learn more, see Security Best Practices in EKS Anywhere documentation.
AWS Support: AWS Enterprise Support is a prerequisite for purchasing an Amazon EKS Anywhere Support subscription. If you would like business support for your EKS Anywhere clusters, please contact your Technical Account Manager (TAM) for details. Also, EKS Anywhere is supported by the open-source community. If you have a problem, open an issue and someone will get back to you as soon as possible.
Available Now
Amazon EKS Anywhere is now available to leverage EKS features with your on-premise infrastructure, accelerate adoption with partner integrations, managed add-ons, and curated open-source tools.
To learn more with a live demo and Q&A, join us for Containers from the Couch on September 13. You can see full demos to create a cluster and show admin workflows for scaling, upgrading the cluster version, and GitOps management.
Please send us feedback either through your usual AWS Support contacts, on the AWS Forum for Amazon EKS or on the container roadmap on Github.
– Channy
 processor (Milan) cores with 384 GB RAM, and offers up to 65 percent better price-performance over comparable x86-based compute-optimized instances.
processor (Milan) cores with 384 GB RAM, and offers up to 65 percent better price-performance over comparable x86-based compute-optimized instances.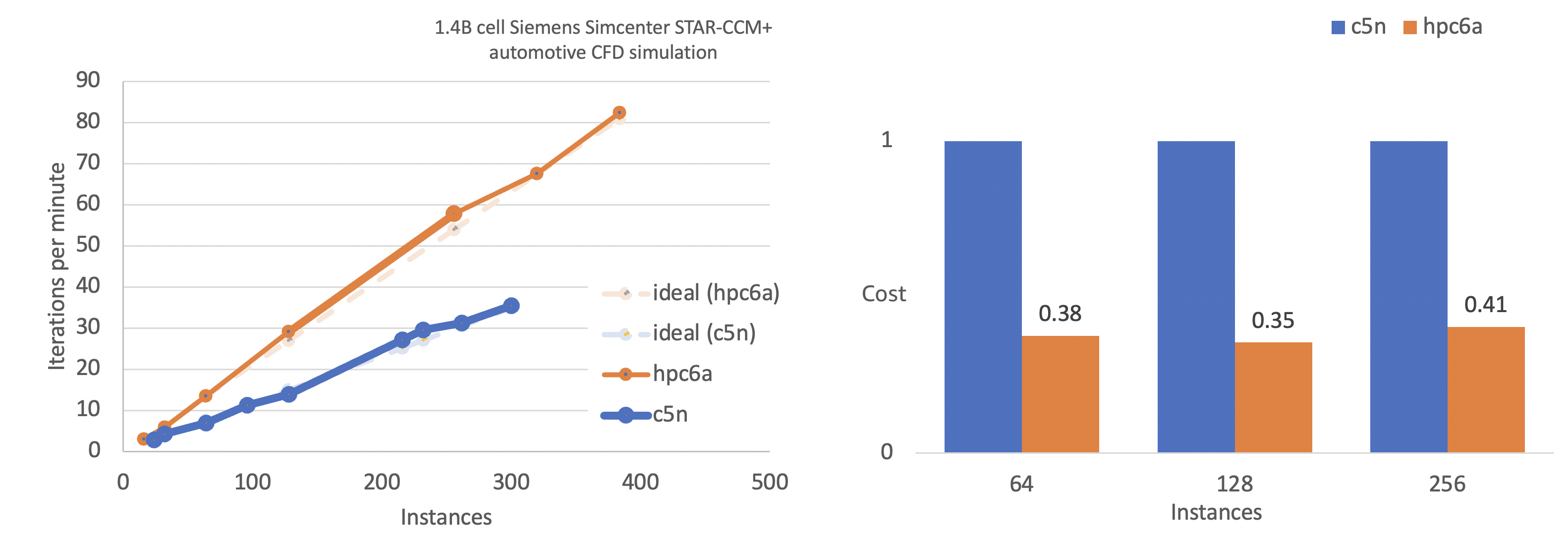
 Before the end of the current LTS period, you will be able to use your AWS account to complete the FreeRTOS EMP registration on the FreeRTOS console, review and agree to the associated terms and conditions, select the LTS version, and buy an annual subscription. You will then gain access to the private repository where you’ll receive .zip files containing a git repo with chosen libraries, patches, and related notifications.
Before the end of the current LTS period, you will be able to use your AWS account to complete the FreeRTOS EMP registration on the FreeRTOS console, review and agree to the associated terms and conditions, select the LTS version, and buy an annual subscription. You will then gain access to the private repository where you’ll receive .zip files containing a git repo with chosen libraries, patches, and related notifications.