Post Syndicated from xkcd.com original https://xkcd.com/3134/

Post Syndicated from xkcd.com original https://xkcd.com/3134/
Post Syndicated from Ryan Smith original https://www.servethehome.com/nvidia-outlines-gb10-soc-architecture-at-hot-chips-2025/
Back from our Hot Chips 2025 ice cream break, NVIDIA is starting off the second session of machine learning presentations. As with yesterday’s graphics presentation, NVIDIA isn’t so much showing off future hardware as much as they are offering a better lay of the land on their latest generation of hardware that is already on […]
The post NVIDIA Outlines GB10 SoC Architecture at Hot Chips 2025 appeared first on ServeTheHome.
Post Syndicated from Ryan Smith original https://www.servethehome.com/huawei-presents-ub-mesh-interconnect-for-large-ai-supernodes-at-hot-chips-2025/
The third and final machine learning presentation before the afternoon break comes from Huawei. Unlike many of the other ML vendors who are here to pitch products, Huawei’s presentation is more focused on fundamental technology. In this case, how to use efficiently use meshes to interconnect the chips within large AI systems. Eyeing so-called SuperNodes […]
The post Huawei Presents UB-Mesh Interconnect for Large AI SuperNodes at Hot Chips 2025 appeared first on ServeTheHome.
Post Syndicated from Ryan Smith original https://www.servethehome.com/d-matrix-presents-corsair-an-in-memory-computing-architecture-for-inference-at-hot-chips-2025/
The second machine learning presentation of the afternoon comes from d-Matrix. The company specializes in hardware for AI inference, and as of late has been tackling the matter of how to improve inference performance by using in-memory computing. Along those lines, the company is presenting their Corsair in-memory computing chiplet architecture at Hot Chips. Not […]
The post d-Matrix Presents Corsair, An In-Memory Computing Architecture For Inference, at Hot Chips 2025 appeared first on ServeTheHome.
Post Syndicated from Ryan Smith original https://www.servethehome.com/marvell-shows-dense-sram-custom-hbm-and-cxl-with-arm-compute-at-hot-chips-2025/
Marvell showed its massively dense SRAM, its custom HBM solution, and how it is adding Arm cores to CXL memory controllers at Hot Chips 2025
The post Marvell Shows Dense SRAM Custom HBM and CXL with Arm Compute at Hot Chips 2025 appeared first on ServeTheHome.
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/fabric8labs-ecam-enabled-thermal-solutions-at-hot-chips-2025/
Fabric8Labs ECAM uses the electrical current from an OLED display to manufacture copper liquid cooling 3D coldplates with pixel precision
The post Fabric8Labs ECAM Enabled Thermal Solutions at Hot Chips 2025 appeared first on ServeTheHome.
Post Syndicated from Prashanth Dudipala, Madhuri Andhale original https://aws.amazon.com/blogs/big-data/how-appzen-enhances-operational-efficiency-scalability-and-security-with-amazon-opensearch-serverless/
AppZen is a leading provider of AI-driven finance automation solutions. The company’s core offering centers around an innovative AI platform designed for modern finance teams, featuring expense management, fraud detection, and autonomous accounts payable solutions. AppZen’s technology stack uses computer vision, deep learning, and natural language processing (NLP) to automate financial processes and ensure compliance. With this comprehensive solution approach, AppZen has a well-established enterprise customer base that includes one-third of the Fortune 500 companies.
AppZen hosts all its workloads and application infrastructure on Amazon Web Services (AWS), continuously modernizing its technology stack to effectively operationalize and host its applications. Centralized logging, a critical component of this infrastructure, is essential for monitoring and managing operations across AppZen’s diverse workloads. As the company experienced rapid growth, the legacy logging solution struggled to keep pace with expanding needs. Consequently, modernizing this system became one of AppZen’s top priorities, prompting a comprehensive overhaul to enhance operational efficiency and scalability.
In this blog we show, how AppZen modernizes its central log analytics solution from Elasticsearch to Amazon OpenSearch Serverless providing an optimized architecture to meet above mentioned requirements.
With a growing number of business applications and workloads, AppZen had an increasing need for comprehensive operational analytics using log data across its multi-account organization in AWS Organizations. AppZen’s legacy logging solution created several key challenges. It lacked the flexibility and scalability to efficiently index and make the logs available for real-time analysis, which was crucial for tracking anomalies, optimizing workloads, and ensuring efficient operations.
The legacy logging solution consisted of a 70-node Elasticsearch cluster (with 30 hot nodes and 40 warm nodes), it struggled to keep up with the growing volume of log data as AppZen’s customer base expanded and new mission-critical workloads were added. This led to performance issues and increased operational complexity. Maintaining and managing the self-hosted Elasticsearch cluster required frequent software updates and infrastructure patching, resulting in system downtime, data loss, and added operational overhead for the AppZen CloudOps team.
Migrating the data to a patched node cluster took 7 days, far exceeding industry standard and AppZen’s operational requirements. This extended downtime introduced data integrity risk and directly impacted the operational availability of the centralized logging system crucial for teams to troubleshoot across critical workloads. The system also suffered frequent data loss that impacted real-time metrics monitoring, dashboarding, and alerting because its application log-collecting agent Fluent Bit lacked essential features such as backoff and retry.
AppZen has an NGINX proxy instance controlling authorized user access to data hosted on Elasticsearch. Upgrades and patching of the instance introduced frequent system downtimes. All user requests are routed through this proxy layer, where the user’s permission boundary is evaluated. This had an added operations overhead for administrators to manage users and group mapping at the proxy layer.
AppZen re-platformed its central log analytics solution with Amazon OpenSearch Serverless and Amazon OpenSearch Ingestion. Amazon OpenSearch Serverless lets you run OpenSearch in the AWS Cloud, so you can run large workloads without configuring, managing, and scaling OpenSearch clusters. You can ingest, analyze, and visualize your time-series data without infrastructure provisioning. OpenSearch Ingestion is a fully managed data collector that simplifies data processing with built-in capabilities to filter, transform, and enrich your logs before analysis.
This new serverless architecture, shown in the following architecture diagram, is cost-optimized, secure, high-performing, and designed to scale efficiently for future business needs. It serves the following use cases:
Together, OpenSearch Ingestion and OpenSearch Serverless provide a serverless infrastructure capable of running large workloads without configuring, managing, and scaling the cluster. It provides data resilience with persistent buffers that can support the current 2 TB per day pipeline data ingestion requirement. IAM Identity Center support for OpenSearch Serverless helped manage users and their access centrally eliminating a need for NGINX proxy layer.
The architecture diagram also shows how separate ingestion pipelines were deployed. This configuration option improves deployment flexibility based on the workload’s throughput and latency requirements. In this architecture, Flow-1 is a push-based data source (such as HTTP and OTel logs) where the workload’s Fluent Bit DaemonSet is configured to ingest log messages into the OpenSearch Ingestion pipeline. These messages are retained in the pipeline’s persistent buffer to provide data durability. After processing the message, it’s inserted into OpenSearch Serverless.
And Flow-2 is a pull-based data source such as Amazon Simple Storage Service (Amazon S3) for OpenSearch Ingestion where the workload’s Fluent Bit DaemonSets are configured to sync data to an S3 bucket. Using S3 Event Notifications, the new log records creation notifications are sent to Amazon Simple Queue Service (Amazon SQS). OpenSearch Ingestion consumes this notification and processes the record to insert into OpenSearch Serverless, delegating the data durability to the data source. For both Flow-1 and Flow-2, the OpenSearch Ingestion pipelines are configured with a dead-letter queue to record failed ingestion messages to the S3 source, making them accessible for further analysis.
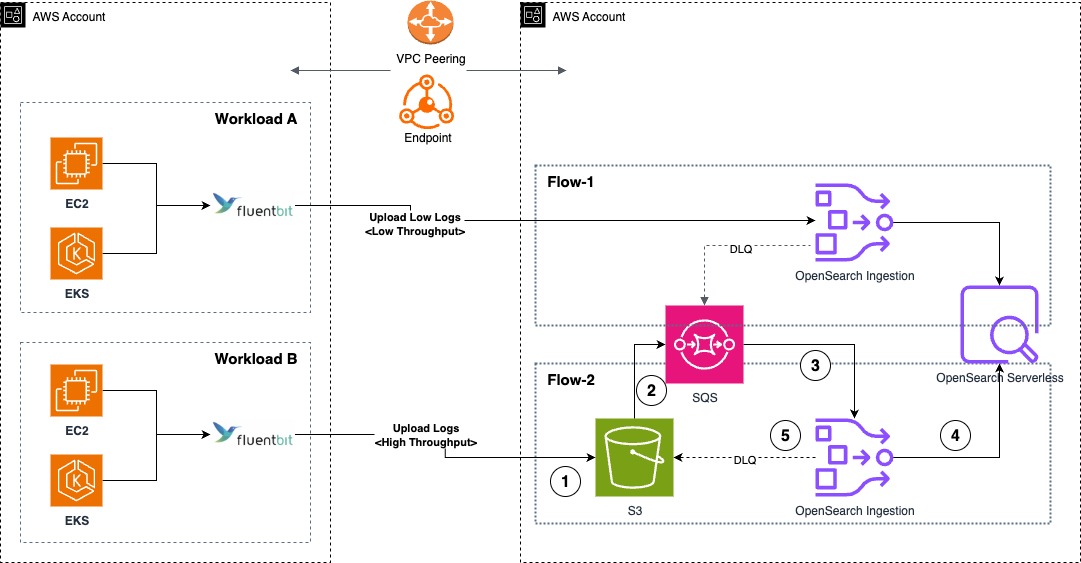
For service log analytics, AppZen adopted a pull-based approach as shown in the following figure, where all service logs published to Amazon CloudWatch are migrated an S3 bucket for further processing. An AWS Lambda processor is triggered when every new message is ingested to the S3 bucket, and the processed message is then uploaded to the S3 bucket for OpenSearch ingestion. The following diagram shows the OpenSearch Serverless architecture for the service log analytics pipeline.

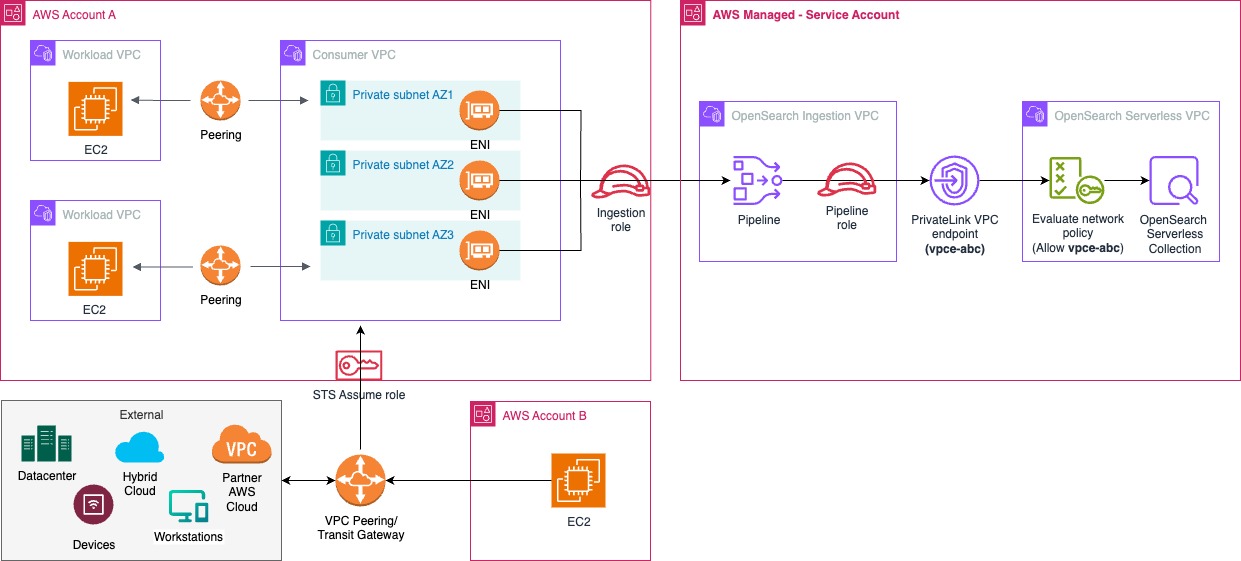
Workloads and infrastructure spread across multiple AWS accounts can securely send logs to the central log analytics platform over a private network using virtual private cloud (VPC) peering and AWS PrivateLink endpoints, as shown in the following figure. Both OpenSearch Ingestion and OpenSearch Serverless are provisioned in the same account and Region, with cross-account ingestion enabled for workloads in other member accounts of the AWS Organizations account.
The migration to OpenSearch Serverless and OpenSearch Ingestion involved performance evaluation and fine-tuning the configuration of the logging stack, followed by migration of production traffic to new platform. The first step was to configure and benchmark the infrastructure for cost-optimized performance.
OpenSearch Ingestion scales elastically to meet throughput requirements during workload spikes. Enabling persistent buffering on ingestion pipelines with push-based data sources provided data durability and reliability. Data ingestion pipelines are ingesting at a rate of 2 TB per day. Due to AppZen’s 90-day data retention requirement around its ingested data, at any time, there is approximately 200 TB of indexed historical data stored in the OpenSearch Serverless cluster. To evaluate performance and costs before deploying to production, data sources were configured to ingest data in parallel into the new OpenSearch Serverless environment along with an existing setup already running in production with Elasticsearch.
To achieve parallel ingestion, AppZen installed another Fluent Bit DaemonSet configured to ingest into the new pipeline. This was for two reasons: 1) To avoid interruption due to changes to existing ingestion flow and 2) New workflows are much more straightforward when the data preprocessing step is offloaded to OpenSearch Ingestion, eliminating the need for custom lua script use in Fluent Bit.
The production pipeline configuration was implemented with different strategies based on data source types. Push-based data sources were configured with persistent buffer enabled for data durability and a minimum of three OpenSearch Compute Units (OCUs) to provide high availability across three Availability Zones. In contrast, pull-based data sources, which used Amazon S3 as their source, didn’t require persistent buffering due to the inherent durability features of Amazon S3. Both pipeline types were initially configured with a minimum of three OCUs and a maximum of 50 OCUs to establish baseline performance metrics. This setup meant the team could monitor and analyze actual workload patterns, and therefore fine-tune worker configurations for optimal OCU usage. Through continuous monitoring and adjustment, the pipeline configurations were changed and optimized to efficiently handle both daily average loads and peak traffic periods, providing cost-effective and reliable data processing operations.
For AppZen’s throughput requirement, in the pull-based approach, they identified six Amazon S3 workers in the OpenSearch Ingestion pipelines optimally processing 1 OCU at 80% efficiency. Following the best practices recommendation, at this system.cpu.usage.value metrics threshold, the pipeline was configured to auto scale. With each worker capable of processing 10 messages, AppZen identified cost-optimized configuration of 50 OCUs as maximum OCU configuration for its pipelines that is capable of processing up to 3,000 messages in parallel. This pipeline configuration shown below supports its peak throughput requirements
When working with search engine, understanding index and shard management is crucial. Indexes and their corresponding shards consume memory and CPU resources to maintain metadata. A key challenge emerges when having numerous small shards in a system because it leads to higher resource consumption and operational overhead. In the traditional approach, you typically create indices at the microservice level for each environment (prod, qa, and dev). For example, indices would be named like prod-k1-service or prod-k2-service, where k1 and k2 represent different microservices. With hundreds of services and daily index rotation, this approach results in thousands of indices, making management complex and resource intensive. When implementing OpenSearch Serverless, you should adopt a consolidated indexing strategy that moves away from microservice-level index creation. Rather than creating individual indices like prod-k1-service and prod-k2-service for each microservice and environment, you should consolidate the data into broader environment-based indices such as prod-service, which contains all service data for the production environment. This consolidation is essential because OpenSearch Serverless scales based on resources and has specific limitations on the number of shards per OCU. This means that having a higher number of small shards will lead to higher OCU consumption.
However, although this consolidated approach can significantly reduce operational costs and simplify management through built-in data lifecycle policies, it presents a notable challenge for multi-tenant scenarios. Organizations with strict security requirements, where different teams need access to specific indices only, might find this consolidated approach challenging to implement. For such cases, a more granular indices approach might be necessary to maintain proper access control, even though it can result in higher resource consumption.
By carefully evaluating your security requirements and access control needs, you can choose between a consolidated approach for optimized resource utilization or a more granular approach that better supports fine-grained access control. Both approaches are supported in OpenSearch Serverless, so you can balance resource optimization with security requirements based on your specific use case.
OpenSearch Ingestion allocates some OCUs from configured pipeline capacity for persistent buffering, which provides data durability. While monitoring, AppZen observed higher OCU usage for this persistent buffer when processing high-throughput workloads. To optimize this capacity configuration, AppZen decided to classify its workloads into push-based and pull-based categories depending on their throughput and latency requirements. Achieving this created new parallel pipelines to operate these flows in parallel, as shown in the architecture diagram earlier in the post. Fluent Bit agent collector configurations were accordingly modified based on the workload classification.
Depending on the cost and performance requirements for the workload, AppZen adopted the appropriate ingestion flow. For low latency and low-throughput workload requirements, AppZen chose the push-based approach. For high-throughput workload requirements, AppZen adopted the pull-based approach, which helped lower the persistent buffer OCU usage by relying on durability to the data source. In the pull-based approach, AppZen further optimized on the storage cost by configuring the pipeline to automatically delete the processed data from the S3 bucket after successful ingestion
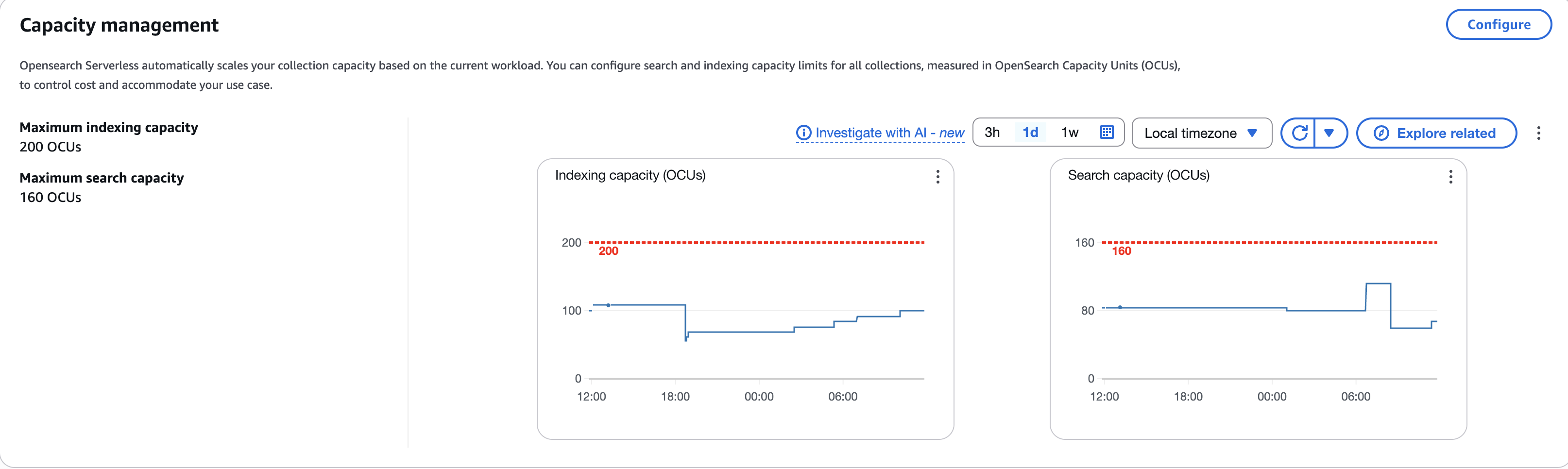
One of the key design principles for operational excellence in the cloud is to implement observability for actionable insights. This helps gain a comprehensive understanding of the workloads to help improve performance, reliability, and the cost involved. Both OpenSearch Serverless and OpenSearch Ingestion publish all metrics and logs data to Amazon CloudWatch. After identifying key operational OpenSearch Serverless metrics and OpenSearch Service pipeline metrics, AppZen set up CloudWatch alarms to send a notification when certain defined thresholds are met. The following screenshot shows the number of OCUs used to index and search collection data.
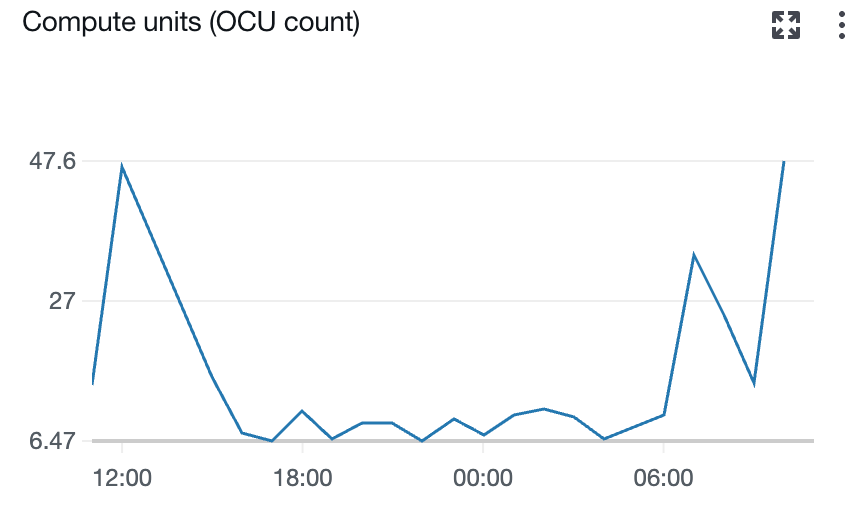
The following screenshot shows the number of Ingestion OCUs in use by the pipeline.
The following screenshot shows the percentage of available CPU usage for OCU.
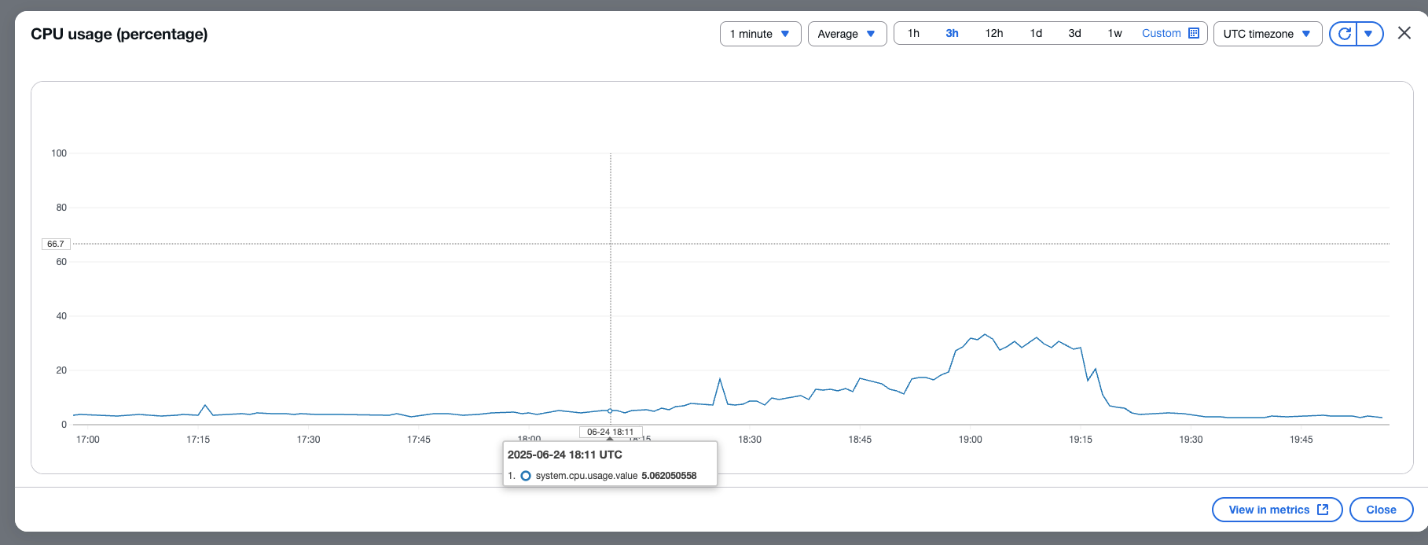
The following screenshot shows the percent usage of buffer based on the number of records in the buffer.
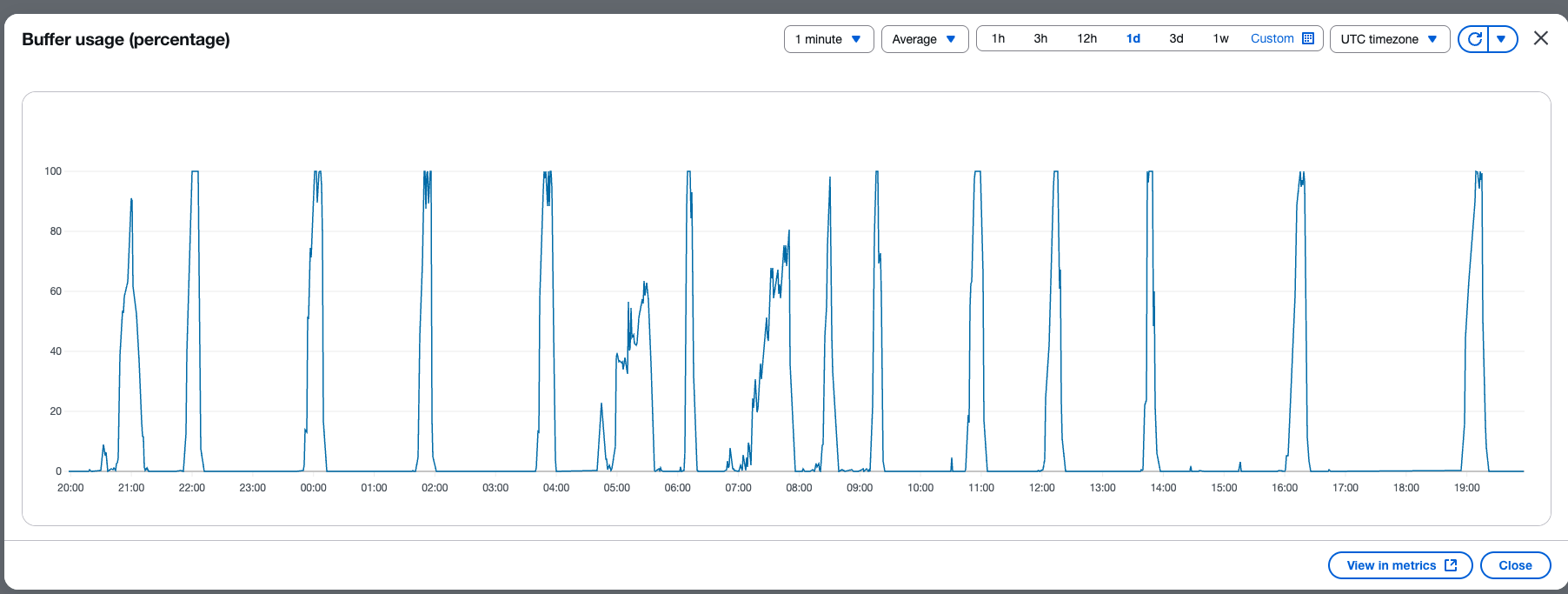
AppZen successfully modernized their logging infrastructure by migrating to a serverless architecture using Amazon OpenSearch Serverless and OpenSearch Ingestion. By adopting this new serverless solution, AppZen eliminated an operations overhead that involved 7 days of data migration effort during each quarterly upgrade and patching cycle of Kubernetes cluster hosting Elasticsearch nodes. Also, with the serverless approach, AppZen was able to avoid index mapping conflicts by using index templates and a new indexing strategy. This helped the team save an average 5.2 hours per week of operational effort and instead use the time to focus on other priority business challenges. AppZen achieved a better security posture through centralized access controls with OpenSearch Serverless, eliminating the overhead of managing a duplicate set of user permissions at the proxy layer. The new solution helped AppZen handle growing data volume and build real-time operational analytics while optimizing cost, improving scalability and resiliency. AppZen optimized costs and performance by classifying workloads into push-based and pull-based flows, so they could choose the appropriate ingestion approach based on latency and throughput requirements.
With this modernized logging solution, AppZen is well positioned to efficiently monitor their business operations, perform in-depth data analysis, and effectively monitor and troubleshooting the application as they continue to grow. Looking ahead, AppZen plans to use OpenSearch Serverless as a vector database, incorporating Amazon S3 Vectors, generative AI, and foundation models (FMs) to enhance operational tasks using natural language processing.
To implement a similar logging solution for your organization, begin by exploring AWS documentation on migrating to Amazon OpenSearch Serverless and setting up OpenSearch Serverless. For guidance on creating ingestion pipelines, refer to the AWS guide on OpenSearch Ingestion to begin modernizing your logging infrastructure.
 Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community.
Prashanth Dudipala is a DevOps Architect at AppZen, where he helps build scalable, secure, and automated cloud platforms on AWS. He’s passionate about simplifying complex systems, enabling teams to move faster, and sharing practical insights with the cloud community.
 Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges.
Madhuri Andhale is a DevOps Engineer at AppZen, focused on building and optimizing cloud-native infrastructure. She is passionate about managing efficient CI/CD pipelines, streamlining infrastructure and deployments, modernizing systems, and enabling development teams to deliver faster and more reliably. Outside of work, Madhuri enjoys exploring emerging technologies, traveling to new places, experimenting with new recipes, and finding creative ways to solve everyday challenges.
 Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family.
Manoj Gupta is a Senior Solutions Architect at AWS, based in San Francisco. With over 4 years of experience at AWS, he works closely with customers like AppZen to build optimized cloud architectures. His primary focus areas are Data, AI/ML, and Security, helping organizations modernize their technology stacks. Outside of work, he enjoys outdoor activities and traveling with family.
 Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Prashant Agrawal is a Sr. Search Specialist Solutions Architect with Amazon OpenSearch Service. He works closely with customers to help them migrate their workloads to the cloud and helps existing customers fine-tune their clusters to achieve better performance and save on cost. Before joining AWS, he helped various customers use OpenSearch and Elasticsearch for their search and log analytics use cases. When not working, you can find him traveling and exploring new places. In short, he likes doing Eat → Travel → Repeat.
Post Syndicated from Nikki Rouda original https://aws.amazon.com/blogs/big-data/zero-etl-how-aws-is-tackling-data-integration-challenges/
In this blog post, we show you how Amazon Web Services (AWS) is simplifying data integration with zero-ETL while realizing performance benefits and cost optimizations. As organizations gather data for analytics and AI, they are increasingly finding themselves caught in a complex web of extract, transform, and load (ETL) pipelines—the traditional backbone of data integration. While these pipelines still serve their purpose, they’ve also become a costly bottleneck, consuming valuable staff time and resources that could be better spent on innovation. Now, zero-ETL integrations are simplifying how businesses handle data integration. Zero-ETL can eliminate the need for complex data pipelines while still maintaining seamless data flow between your operational databases and analytics environments, including data warehouses, data lakes, and the combination of these into lakehouses.
Thousands of AWS customers have used zero-ETL to process petabytes of data with thousands of integrations. AWS customers are using integrations with services such as Amazon Aurora, Amazon Relational Database Service (Amazon RDS), Amazon Redshift, Amazon DynamoDB, and Amazon SageMaker, along with multiple third-party software as a service (SaaS) applications. These zero-ETL integrations are transforming data integration from a technical burden into a strategic advantage, so that businesses can focus on deriving actionable insights from their data.
Traditionally, organizations have relied on ETL processes to move data between operational databases and analytics systems. This approach, while functional, presents several key challenges that can hinder an organization’s ability to derive timely insights from their data.
Building and maintaining ETL pipelines requires significant engineering resources, often diverting talent from core business initiatives. These pipelines need constant attention, updates, and optimization, creating an ongoing operational burden. As data volumes grow, updates happen faster, and schemas evolve, the complexity of these pipelines increases exponentially.
Pipeline failures can cause delays in data availability, impacting decision-making processes. When a pipeline breaks, it can take hours or even days to diagnose and fix the issue, during which time critical business decisions might be made with outdated information. This lag between data creation and availability for analysis can be a significant competitive disadvantage in fast-moving industries.
Complex transformations introduce potential points of failure, increasing the risk of data inconsistencies. Each transformation step is an opportunity for errors to creep in, whether through bugs in the transformation logic or unexpected edge cases in the data. Making sure of data quality and consistency across these transformations requires rigorous testing and validation processes.
Furthermore, as organizations add new data sources, the operational overhead of managing multiple pipelines increases exponentially. Each new source typically requires its own pipeline, complete with custom logic for extraction, transformation, and loading. This proliferation of pipelines can quickly become unwieldy, making it difficult to maintain a coherent data strategy across the organization.
AWS zero-ETL integrations provide automated, fully managed data replication from both AWS services and third-party applications to AWS data warehouses, data lakes, and lakehouses without requiring custom pipeline development. This innovative approach offers numerous benefits across several key areas, fundamentally changing how organizations approach data integration.
Zero-ETL integrations offer low-code or no-code setup, which means that organizations can quickly establish data access and flows without specialized expertise. This democratization of data integration means that teams across the organization can set up and manage their own data integration, reducing bottlenecks and accelerating time-to-insight.
Zero-ETL integrations automatically handle data definition languages (DDLs), schema changes, and data type mapping, so that data in your analytics store is correct and complete. This data is immediately available for business consumption, helping to ensure consistency between source and target systems. This automatic mapping significantly reduces the risk of errors that can occur with manual mapping processes, helping to ensure that data types and structures are correctly translated between systems.
Built-in monitoring and error handling capabilities provide visibility into the replication process and help maintain data integrity. Administrators can set up alerts for specific conditions, such as replication lag or failed transfers, allowing for proactive management of the data integration process.
Zero-ETL integrations automatically handle full load and ongoing changes through change data capture (CDC) for quick access to the latest data. Organizations can use this dual capability to migrate existing data while also making sure that new data is continuously replicated, providing a seamless transition to the new integration model.
With zero-ETL integrations, data is typically available in the target system within seconds or minutes of updates in the source system. This near real-time capability supports even high-volume transactional workloads, enabling timely insights for fast-moving businesses. For example, an ecommerce company can analyze purchase patterns almost immediately, enabling real-time inventory management and personalized recommendations.
The solution maintains consistent performance at scale, accommodating growing data volumes without degradation. As businesses grow and data volumes increase, the zero-ETL integration scales automatically, keeping performance consistent even as the demands on the system increase.
Built-in fault tolerance and recovery mechanisms help ensure high availability and data consistency. If an issue occurs during replication, manual or automatic retries of failed operations help resume from the last successful point, minimizing data loss and helping to ensure consistency between source and target systems.
By eliminating the need for custom pipeline maintenance, zero-ETL integrations free up valuable engineering resources. Data engineers can focus on higher-value tasks such as data modeling, advanced analytics, and machine learning, rather than spending time on routine pipeline maintenance.
There is no additional infrastructure to manage, reducing complexity and cost. The zero-ETL integration runs on AWS-managed infrastructure, eliminating the need for customers to provision and manage servers, storage, or networking components for data integration.
The system automatically handles schema changes, adapting to evolving data structures without manual intervention. When a new column is added to a source table, for example, the zero-ETL integration will automatically detect this change and update the target schema accordingly, helping to ensure that the data remains in sync without any manual effort.
Native integration with AWS security controls helps ensure that data remains protected throughout the replication process. This includes support for encryption at rest and in transit, and integration with AWS Key Management Service (AWS KMS) for compliance with various regulatory standards.
Since launch, zero-ETL integrations have seen rapid customer adoption. The versatility and benefits of zero-ETL integrations are demonstrated through diverse customer implementations across industries.
Yossi Shlomo, Director of Payment Systems Architecture at MassPay, a leading global payment solutions provider, stated, “Zero-ETL has been transformative for teams at MassPay. By using Amazon Aurora MySQL-Compatible Edition zero-ETL integration with Amazon Redshift, we’ve streamlined data flow from our core payment systems into analytics environments used for fraud detection, compliance case management, and business insights. This shift reduced latency by >90% and gives our teams near-instant access to critical data to optimize processes and decisions.” Because of this dramatic improvement in data freshness and availability, MassPay can make more timely and informed decisions, improving their service to customers and their competitive position in the market.
AWS currently offers zero-ETL integrations designed to seamlessly connect popular AWS database services with Amazon Redshift, a fully managed data warehouse service. These include Amazon Aurora MySQL-Compatible, Amazon Aurora PostgreSQL-Compatible Edition, Amazon RDS for MySQL, and Amazon DynamoDB. This means that organizations can use the strengths of each service—the transactional capabilities of Aurora and Amazon RDS, the flexibility of DynamoDB, and the analytical power of Amazon Redshift—while minimizing the complexity of data movement between these systems.
Zero-ETL integrations have expanded beyond AWS services to support a wide range of third-party data too. AWS has zero-ETL integrations with sources including SAP OData, Salesforce, Salesforce Marketing Cloud Account Engagement, ServiceNow, Zendesk, and Zoho CRM, plus Facebook Ads and Instagram Ads. Targets include Amazon Redshift and a lakehouse with Amazon SageMaker.
Recent updates include:
Traditional relational databases from various vendors can also link to a lakehouse through zero-ETL integrations. This comprehensive support means that organizations can consolidate data from virtually any source into their AWS analytics environment without building custom integration pipelines. By using zero-ETL to break down data silos—even between multiple vendors’ solutions—and simplifying the data integration process, organizations can focus on deriving insights rather than managing complex data movements.
Additional integrations are in development to support more AWS services and data sources, further expanding the ecosystem. AWS is committed to continually expanding the range of zero-ETL integrations, responding to customer needs and evolving data landscapes.
AWS zero-ETL capabilities include several sophisticated features that set them apart from other clouds. For example, by using the refresh interval control, you can customize how frequently data is synchronized, helping to ensure that analytics are based on data that is as current as necessary for each use case. Meanwhile, History Mode maintains historical versions of data, enabling trend analysis, insightful dashboards, and meeting audit requirements. You can also create type 2 slowly changing dimensions (SCD 2) tables in Amazon Redshift.
You can use the data filtering capabilities to selectively replicate specific objects and data subsets, optimizing storage use and focusing on the most relevant data. Comprehensive logging and monitoring features provide visibility into data movement and system health, so that administrators can quickly identify and address any issues.
You can also combine two primary integration approaches. Zero-ETL provides full data replication (movement) for comprehensive analytics in a central repository, complementing federation allows querying data in place when real-time access to source data is critical. You can use this flexibility to tailor your data integration strategy to your organization’s specific needs and use cases.
To begin using zero-ETL integrations, you should first identify your source database and target analytics service. This involves assessing your current data architecture and determining which data flows would benefit most from a zero-ETL approach.
Next, you need to configure the necessary permissions and networking requirements. This typically involves setting up either an AWS Identity and Access Management (IAM) identity or single sign-on using AWS IAM Identity Center and making sure that the source and target services can communicate securely.
As shown in the following image, after the prerequisites are in place, creating the integration is a click-through experience within the AWS Management Console. The intuitive interface guides you through the process, prompting you to specify source and target details, select tables for replication, and configure any additional options.
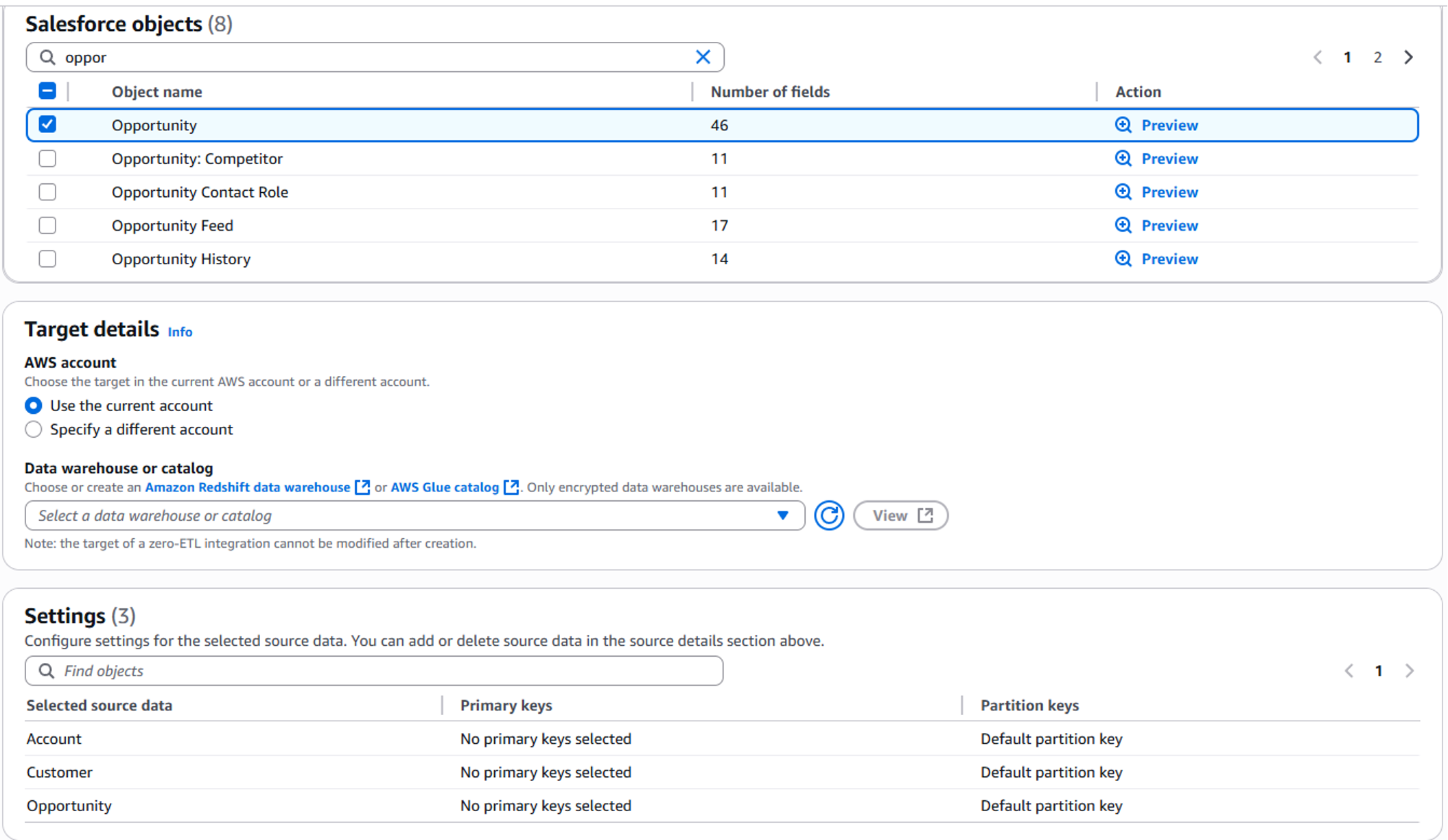
After setup, you can monitor replication status and performance to help ensure optimal operation. AWS provides detailed metrics and logs to help you track the health and performance of your zero-ETL integrations.
For detailed setup instructions, visit the AWS documentation for zero-ETL integrations, which provides step-by-step guides for each supported integration.
AWS has an active roadmap for support of additional AWS services and data sources, expanding the reach of zero-ETL integrations so that more customers can benefit from simplified data integration across a broader range of use cases.
Zero-ETL integrations represent a fundamental shift in how organizations approach data integration. Without the complexity of ETL pipelines, customers can focus on deriving value from their data rather than managing infrastructure. This approach aligns with the AWS commitment to simplifying cloud operations and empowering customers to innovate faster.
To learn more about zero-ETL integrations and how they can benefit your organization, see the following topics:
Get started today and discover how you can streamline your data operations and unlock the full potential of your data with AWS zero-ETL integrations.
 Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.
Nikki Rouda works in product marketing at AWS. He has many years experience across a wide range of IT infrastructure, storage, networking, security, IoT, analytics, and modern applications.
Post Syndicated from Matt Howard original https://aws.amazon.com/blogs/compute/implementing-advanced-aws-graviton-adoption-strategies-across-aws-regions/
AWS Graviton Processors can offer cost savings, improved performance, and reduce your carbon footprint when using Amazon Elastic Compute Cloud (Amazon EC2) instances. When expanding your Graviton deployment across multiple AWS Regions, careful planning helps you navigate considerations around regional instance type availability and capacity optimization. This post shows how to implement advanced configuration strategies for Graviton-enabled EC2 Auto Scaling groups across multiple Regions, helping you maximize instance availability, reduce costs, and maintain consistent application performance even in AWS Regions with limited Graviton instance type availability.
One of the most effective strategies for maximizing Graviton availability is to be flexible across multiple instance types and families. Instance families (such as m7g, c7g, and r7g) group similar instances with different sizes, where each size offers proportionally more vCPUs and memory. When configuring EC2 Auto Scaling groups, aim for at least 10 instance types rather than limiting to just one or two specific types. EC2 Auto Scaling supports this flexibility through the mixed instances group, which allows you to specify multiple instance types in a single group. Consider this example AWS CloudFormation template snippet for an EC2 Auto Scaling group MixedInstancesPolicy that only specifies two Graviton instance types across two different families:
This limited selection significantly reduces your ability to access available capacity pools. Assuming this workload needs a minimum of 2 vCPU and 8 GiB of memory, you can add these additional eight Graviton instance types: m6g.large, m8g.large, m6gd.large, m7gd.large, m8gd.large, c6g.xlarge, c6gd.xlarge, and c8g.xlarge. These allow you to meet the recommendation of being flexible across 10 instance types. While some of these instance types may have different price points, you can manage these cost implications through allocation strategies discussed later in this post.
To efficiently identify all compatible Graviton instance types available for your workload, you can use the GetInstanceTypesFromInstanceRequirements Amazon EC2 API. This approach removes the manual effort of researching and choosing individual instance types.
This example command returns dozens of compatible Graviton instance types across multiple families (c7g, c7gd, c7gn, m7g, m7gd, etc.), thus expanding your capacity options. An EC2 Auto Scaling group’s mixed instance policy can allow up to 40 instance types, thus you have more room for even greater flexibility.
After expanding your instance type selection, you need to configure how EC2 Auto Scaling chooses between the available instance types. The OnDemandAllocationStrategy CloudFormation property controls this behavior, offering two approaches: “lowest-price” and “prioritized”. With the “lowest-price” strategy, EC2 Auto Scaling launches instances from the lowest-priced capacity pool available:
This strategy helps manage costs when you’ve included a variety of instance types. Even with expanded instance type flexibility, your workloads will automatically select the most cost-effective option from available capacity pools. Alternatively, you can use the “prioritized” strategy when you want more control over which instance types are chosen first:
Not all AWS Regions have the same Graviton instance types available. Regional variation in instance type availability creates a challenge when deploying applications consistently across multiple AWS Regions. To handle these differences, expand your instance type flexibility beyond the minimum 10 types to make sure of sufficient options in each AWS Region where you operate.
To implement this flexibility across AWS Regions, you must determine which Graviton instance types are available in each target AWS Region. AWS provides several methods to access this information: check the Amazon EC2 Instance Types by Region documentation for a comprehensive list, use the DescribeInstanceTypeOfferings Amazon EC2 API to programmatically identify available types, or visit the EC2 Instance Types page in the AWS Management Console.
You can also run the GetInstanceTypesFromInstanceRequirements API across different AWS Regions to understand Regional differences. For example, running identical queries in the US East (N. Virginia) and Asia Pacific (Taipei) Regions reveals significant variations: over 70 compatible instance types in the US East (N. Virginia) and 27 in Asia Pacific (Taipei) Regions.
When operating across multiple AWS Regions, design a single mixed instance policy that works everywhere by including instance types available in all AWS Regions where you operate. Based on the previous query results, you might include these 10 instance types that are available in both AWS Regions: m6g.large, m7g.large, m6gd.large, m7gd.large, c6g.xlarge, c7g.xlarge, m6g.xlarge, m7g.xlarge, c6gn.xlarge, and m6gd.xlarge.
You should also span your EC2 Auto Scaling group across multiple Availability Zones (AZs) for greater resiliency and access to deeper capacity pools. To determine available AZs in your AWS Region, refer to the Availability Zones documentation or check your Amazon Virtual Private Cloud (Amazon VPC) to identify which AZs its subnets use through the DescribeSubnets Amazon EC2 API. Configure your EC2 Auto Scaling group to use all available AZs using the CloudFormation AWS::AutoScaling::AutoScalingGroup AvailabilityZones parameter:
Although optimizing for regional availability and AZ distribution provides a strong foundation, further enhancing your Graviton deployment strategy with proper Amazon EC2 Spot Instances configuration can significantly improve cost efficiency without sacrificing reliability. When using Spot Instances with Graviton, you should implement strategies that maximize your chances of obtaining and maintaining capacity.
First, the Spot Instance Advisor provides valuable information about the interruption frequency of different instance types across AWS Regions. Use this tool to identify Graviton instance types with lower interruption rates in your target AWS Regions. Then, expand your mixed instance group to include these other instance types. Especially for Spot Instance workloads, maximize your instance type flexibility by specifying up to the full limit of 40 instance types for EC2 Auto Scaling groups mixed instance policies. This broad selection increases your chances of finding available Spot Instances capacity.
Beyond instance type selection, the allocation strategy you choose significantly impacts your ability to maintain Spot Instances capacity. Configure your Spot allocation strategy using the AWS::AutoScaling::AutoScalingGroup InstancesDistribution property with the SpotAllocationStrategy parameter set to price-capacity-optimized to choose Spot pools with the lowest interruption risk while still considering price:
For workloads that can benefit from more time beyond the standard two-minute Spot interruption notice, enable Capacity Rebalancing. This feature, configured using the AWS::AutoScaling::AutoScalingGroup CapacityRebalanceproperty, enables EC2 Auto Scaling to proactively respond to rebalance recommendations by launching a new Spot Instance before a running instance receives the two-minute Spot Instance interruption notice, which provides more time for graceful transitions:
For maximum flexibility and capacity access, consider mixing x86 and ARM architectures in your launch templates. Although the Graviton capacity pools are newer and sometimes smaller than their x86 counterparts, a mixed architecture approach makes sure that you can still launch instances even when one architecture has limited availability. For detailed instructions, refer to the AWS post: Supporting AWS Graviton2 and x86 instance types in the same Auto Scaling group.
Although mixed instance policies with explicit instance type lists provide excellent flexibility, AWS offers an even more powerful approach for dynamic instance selection: attribute-based instance type selection. This streamlines management by allowing you to specify the attributes your application needs rather than specific instance types, automatically adapting to new instance types and handling Regional differences in availability.
Implement attribute-based instance type selection in your EC2 Launch Template through the AWS::EC2::LaunchTemplate InstanceRequirements property:
The BaselinePerformanceFactors parameter of the AWS::EC2::LaunchTemplate InstanceRequirements property enables performance protection. This feature makes sure that your EC2 Auto Scaling group uses instance types that meet or exceed a specified performance baseline. When you specify an instance family such as “c7g” as the baseline reference, Amazon EC2 automatically excludes instance types that fall below this performance level, even if they match your other specified attributes. For Graviton deployments, specifying “c7g” makes sure that only instance types with performance like or better than Graviton3 processors are chosen.
Attribute-based instance type selection also allows you to specify instance types in your template that may not yet be available in an AWS Region by using the AllowedInstanceTypes parameter:
This approach allows your EC2 Auto Scaling group to use newer instance types where available and automatically deploy them in other AWS Regions as soon as they become available. This single template approach simplifies the deployment and management of your EC2 instance selection in EC2 Auto Scaling groups across many regions.
The following special considerations should be taken into account.
When implementing instance type flexibility, a common concern is the need to test all instance types with your application. Testing 40 different instance types isn’t practical for most organizations. Instead, consider these streamlined approaches to reduce testing overhead while maintaining performance confidence. First, Graviton instance families within the same generation (for example, c7g, m7g, and r7g) use the same processor, providing similar performance profiles across families. Therefore, you can include multiple instance types from the same generation after testing a representative instance. Second, you should also consider including variants within families (such as c7gd with NVMe storage), because these provide specialized capabilities without changing the fundamental CPU architecture. Third, for maximum flexibility, include multiple instance generations. If your application runs well on Graviton3, then it likely performs even better on Graviton4, allowing you to specify both in your EC2 Auto Scaling group.
If your workload needs a specific Graviton instance type, then we recommend that you use EC2 Capacity Reservations, which allow you to reserve compute capacity for EC2 instances in a specific AZ for any duration. On-Demand Capacity Reservations (ODCR) are for immediate use and come with no term commitment. Alternatively, Future-dated Capacity Reservations allow you to specify when you need the capacity to become available along with a commitment duration.
Although Amazon EMR clusters must exist in only one AZ, you can use Amazon EMR instance fleets to choose multiple subnets across different AZs. Then, when launching a cluster, Amazon EMR searches across these subnets to find specified instances and purchasing options, thus providing access to a deeper capacity pool. For Instance Fleets you can specify up to 30 EC2 instance types for each primary, core, and task node group, which significantly improves instance flexibility and availability. For more information go to the Responding to Amazon EMR cluster insufficient instance capacity events documentation.
In this post, we covered advanced strategies for maximizing AWS Graviton adoption across multiple AWS Regions. You can use the AWS CloudFormation examples provided in this post as templates for your own implementations. Following these approaches allows you to maintain consistent application performance and maximize Graviton instance availability across all AWS Regions where you operate, even as Graviton availability continues to expand across the AWS global infrastructure. For comprehensive guidance on maximizing your Graviton deployment, explore the AWS Graviton Technical Guide.
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/nvidia-co-packaged-optics-with-silcion-photonics-for-switching-and-spectrum-xgs-scale-across/
At Hot Chips 2025, NVIDIA showed its co-packaged optics solutions and its next-generation Spectrum-XGS for scale-across long-distance AI clusters
The post NVIDIA Co-Packaged Optics with Silcion Photonics for Switching and Spectrum-XGS Scale-Across appeared first on ServeTheHome.
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/lightmatter-passage-m1000-at-hot-chips-2025/
The Lightmatter Passage M1000 is an optical interposer that will allow for massive chips with 114Tbps of bandwidth
The post Lightmatter Passage M1000 at Hot Chips 2025 appeared first on ServeTheHome.
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/ayar-labs-ucie-optical-io-retimer-at-hot-chips-2025/
Ayar Labs has a UCIe optical I/O retimer that it is showing off at Hot Chips 2025. The basic idea is to make a UCIe chiplet that makes it easy to integrate optical I/O into a package, since it is standards-based. The chiplet also provides a lot of off-package bandwidth since it is an 8Tbps […]
The post Ayar Labs UCIe Optical IO Retimer at Hot Chips 2025 appeared first on ServeTheHome.
Post Syndicated from Channy Yun (윤석찬) original https://aws.amazon.com/blogs/aws/aws-services-scale-to-new-heights-for-prime-day-2025-key-metrics-and-milestones/
Amazon Prime Day 2025 was the biggest Amazon Prime Day shopping event ever, setting records for both sales volume and total items sold during the 4-day event. Prime members saved billions while shopping Amazon’s millions of deals during the event.
This year marked a significant transformation in the Prime Day experience through advancements in the generative AI offerings from Amazon and AWS. Customers used Alexa+—the Amazon next-generation personal assistant now available in early access to millions of customers—along with the AI-powered shopping assistant, Rufus, and AI Shopping Guides. These features, built on more than 15 years of cloud innovation and machine learning expertise from AWS, combined with deep retail and consumer experience from Amazon, helped customers quickly discover deals and get product information, complementing the fast, free delivery that Prime members enjoy year-round.
As part of our annual tradition to tell you about how AWS powered Prime Day for record-breaking sales, I want to share the services and chart-topping metrics from AWS that made your amazing shopping experience possible.

Prime Day 2025 – all the numbers
During the weeks leading up to big shopping events like Prime Day, Amazon fulfillment centers and delivery stations work to get ready and ensure operations run efficiently and safely. For example, the Amazon automated storage and retrieval system (ASRS) operates a global fleet of industrial mobile robots that move goods around Amazon fulfillment centers.
AWS Outposts, a fully managed service that extends the AWS experience on-premises, powers software applications that manage the command-and-control of Amazon ASRS and supports same-day and next-day deliveries through low-latency processing of critical robotic commands.
During Prime Day 2025, AWS Outposts at one of the largest Amazon fulfillment centers sent more than 524 million commands to over 7,000 robots, reaching peak volumes of 8 million commands per hour—a 160 percent increase compared to Prime Day 2024.

Here are some more interesting, mind-blowing metrics:
Prepare to scale
If you’re preparing for similar business-critical events, product launches, and migrations, I recommend that you take advantage of our newly branded AWS Countdown (formerly known as AWS Infrastructure Event Management, or IEM). This comprehensive support program helps assess operational readiness, identify and mitigate risks, and plan capacity, using proven playbooks developed by AWS experts. We’ve expanded to include: generative AI implementation support to help you confidently launch and scale AI initiatives; migration and modernization support, including mainframe modernization; and infrastructure optimization for specialized sectors including election systems, retail operations, healthcare services, and sports and gaming events.
I look forward to seeing what other records will be broken next year!
— Channy
Post Syndicated from Patrick Kennedy original https://www.servethehome.com/celestial-ai-photonic-fabric-module-at-hot-chips-2025/
Celestial AI has a new Photonic Fabric Module that frees chip designers to place high-bandwidth optical interconnects even in the center of packages
The post Celestial AI Photonic Fabric Module at Hot Chips 2025 appeared first on ServeTheHome.
Post Syndicated from Боян Юруков original https://yurukov.net/blog/2025/appk-stopped/

След като МРРБ скри списъка на Желазков и НН ГЕРБ/ДПС с държавни имоти за продажба, вчера са затворили изцяло и публичния регистър на търгове на АППК – агенцията, която провежда електронните търгове. Това се е случило на 25-ти август между 15:45 и 18:45. Очаква да се възстанови до 12-ти септември. Така за следващите почти три седмици освен, че нямаме информация за движението на актуалните търгове или обявени нови, липсват документите за кандидатстване и детайли какво, за колко се продава и кой го е получил.
В 17:28 са пуснали съобщение, че „е налице прекъсване във функционирането на платформата“, както и че се работи по архивиране и „пълен анализ на данните“. Не се казва пряко, но внушението изглежда е, че имат технически проблем. Изречението за анализа създава впечатление, че нямат представа каква е причината. Скоростта, в която сайтът е отговарял до тогава не дава индикации, че е бил претоварен или нещо друго. Цитират чл. 9 от наредбата определяща реда за тези търгове, която говори за непредвидено прекъсване на системата.
Ако е системен проблем, не става ясно защо ще им трябват три седмици да го възстановят. Буди притеснение и фактът, че тепърва ще архивират данните, при условие, че минималните изисквания за всички системи на държавната администрация задължават да се пазят редовно такива копия. Съдейки по публичната информация, регистърът представлява изключително лек сайт с информация и функционалност значително по-малка от това, което виждате на този блог или дори картата ми с държавните имоти. Затова ще е интересно да разберем какво се е случило и дали сайтът не е бил нарочно спрян.
Друга интерпретация на „архивиране“ може да е, че няма да е достъпна вече старата информация на сайта. Циниците сред вас може да решат също че Желязков отново козирува на Пеевски и ефективно спира работата на АППК за политически, но крайно вредни за държавата в същността си цели. Също както Киселова му козирува на Пеевски за извънредна комисия, регулатори му козируват при инструкции за проверки, а Борисов му козирува с 5 млн. лв. за новата Лафка. Няма да е нетипично в процеса на вътрешно овладяване след външна изолация.
Към момента на спирането на публичния регистър е имало 8 търга с насрочени дати:
Само миналата седмица, т.е. преди да спрат регистъра, са обявени 12 търга, с които активните стават 41. От тях повечето не са насрочени. Не става ясно какво следва. Доколкото наредбата говори какво се случва при активни търгове по време на непредвидено спиране – каквито днес е нямало – не става ясно какво се прави при три седмици прекъсване. Вероятно ще бъде спряно всичко. Предвид какво видяхме като прозрачност до сега, не изключвам и да ги правят по стария начин без особена публичност и шум.
Както писах наскоро, въпреки заявките на Желязков и опитът да отклони вниманието и прехвърли отговорността към парламента, правителството продължаваше с пълна пара да продава държавни имоти. Оправдава се, че не били свързани с програмата, макар доста от тях да са включени в ония списък. Така в най-лошия случай, сега ще продължат под масата, а в най-добрия – търговете ще спрат докато не свърши ваканцията на парламента. Дори след това обаче контролираното от НН ГЕРБ/ДПС мнозинство в НС надали ще спре или дори ще говори сериозно по темата.
До тогава обаче всякаква публичност за държавните имоти е заличена. Оправданията им защо са изтрили специално списъка са празни. Когато стана известен и се разкриха грешките и скандалните имоти в него, Желязков започна да настоява, че е индикативен и щяло да има промени след анализи. Такива не видяхме, но не видяхме и краен списък или дори работен такъв. Вместо да публикуват нов, за какъвто искахме и питахме, за да сравним какво е отпаднало, те изтриха стария. За това няма никакво оправдание или логично обяснение отвъд елементарна човешка паника. От обясненията им се разкри единствено, че не само не са говорили с местната власт, но и самите институции в рамките на правителството не си говорят помежду си и са искали имоти един от друг вместо да се продават. При това са научили за тях именно от картата ми, тъй като служители на министерства и кметства многократно изтъкнаха, че списъкът на Желязков като формат е бил невъзможен са работа.
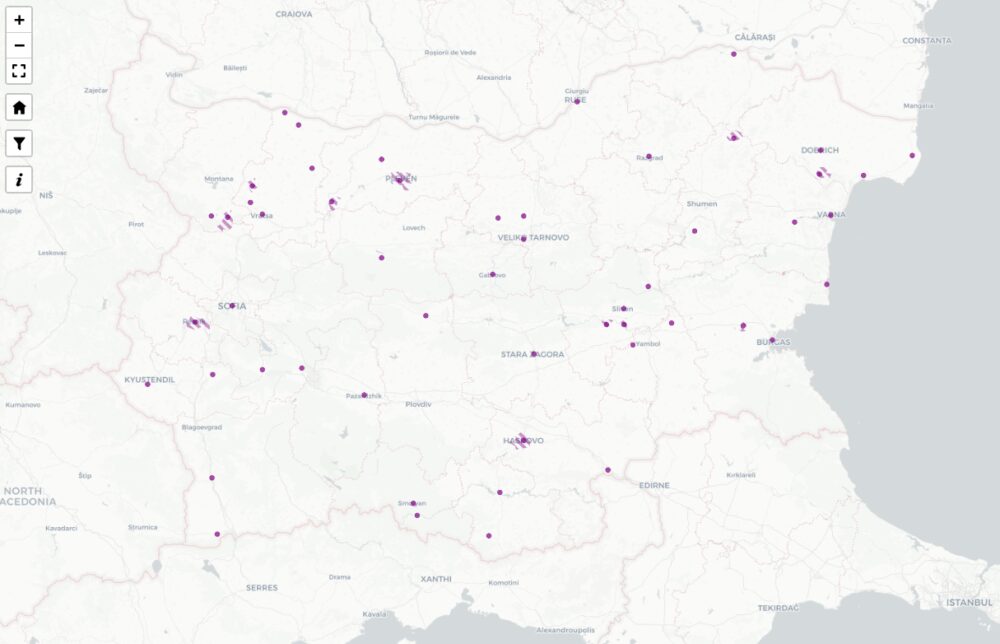
Всички данни за имотите от изтрития списък и търговете от падналия регистър са достъпни на картата заедно с проектите за бъдещи търгове. Линковете горе, както и от картата обаче няма да работят докато регистърът им не бъде възстановен в оригиналния си вид. Ключовата информация какво се продава, къде и за колко все още се пази при мен. Горе виждате всички търгове обявени от Желязков след решението на МС от 8-ми май, с което се започна тази сага.
The post След списъка с държавните имоти изчезна и регистърът с търговете им first appeared on Блогът на Юруков.
Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=Lb3LlzxhIXw
Post Syndicated from Kenny Johnson original https://blog.cloudflare.com/zero-trust-mcp-server-portals/
Large Language Models (LLMs) are rapidly evolving from impressive information retrieval tools into active, intelligent agents. The key to unlocking this transformation is the Model Context Protocol (MCP), an open-source standard that allows LLMs to securely connect to and interact with any application — from Slack to Canva, to your own internal databases.
This is a massive leap forward. With MCP, an LLM client like Gemini, Claude, or ChatGPT can answer more than just “tell me about Slack.” You can ask it: “What were the most critical engineering P0s in Jira from last week, and what is the current sentiment in the #engineering-support Slack channel regarding them? Then propose updates and bug fixes to merge.”
This is the power of MCP: turning models into teammates.
But this great power comes with proportional risk. Connecting LLMs to your most critical applications creates a new, complex, and largely unprotected attack surface. Today, we change that. We’re excited to announce Cloudflare MCP Server Portals are now available in Open Beta. MCP Server Portals are a new capability that enable you to centralize, secure, and observe every MCP connection in your organization. This feature is part of Cloudflare One, our secure access service edge (SASE) platform that helps connect and protect your workspace.
Think of MCP as a universal translator or a digital switchboard for AI. It’s a standardized set of rules that lets two very different types of software—LLMs and everyday applications—talk to each other effectively. It consists of two primary components:
MCP Clients: These are the LLMs you interact with, like ChatGPT, Claude, or Gemini. The client is the front end to the AI that you use to ask questions and give commands.
MCP Servers: These can be developed for any application you want to connect to your LLM. SaaS providers like Slack or Atlassian may offer MCP servers for their products, or your own developers can also build custom ones for internal tools.

Credit: Architecture Overview – Model Context Protocol
For a useful connection, MCP relies on a few other key concepts:
Resources: A mechanism for the server to give the LLM context. This could be a specific file, a database schema, or a list of users in an application.
Prompts: Standardized questions the server can ask the client to get the information it needs to fulfill a request (e.g., “Which user do you want to search for?”).
Tools: These are the actions the client can ask the server to perform, like querying a database, calling an API, or sending a message.
Without MCP, your LLM is isolated. With MCP, it’s integrated, capable of interacting with your entire software ecosystem in a structured and predictable way.
Think of an LLM as the most brilliant and enthusiastic junior hire you’ve ever had. They have boundless energy and can produce incredible work, but they lack the years of judgment to know what they shouldn’t do. The current, decentralized approach to MCP is like giving that junior hire a master key to every office and server room on their first day.
It’s not a matter of if something will go wrong, but when.
This “shadow AI” infrastructure is the modern equivalent of the early Internet, where every server had a public IP address, fully exposed to the world. It’s the Wild West of unmanaged connections, impossible to secure. And the risks go far beyond accidental data deletion. Attackers are actively exploiting the unique vulnerabilities of LLM-driven ecosystems:
Prompt and tool injection: This is more than just telling a model to “ignore previous instructions.” Attackers are now hiding malicious commands inside the descriptions of MCP tools themselves. Consider an LLM seeking to use a seemingly harmless “WebSearch” tool. A poisoned description could trick it into also running a query against a financial database and exfiltrating the results.
Supply chain attacks: How can you trust the third-party MCP servers used by your teams? In mid-2025, a critical vulnerability (CVE-2025-6514) was discovered in a popular npm package used for MCP authentication, exposing countless servers. In another incident dubbed “NeighborJack,” security researchers found hundreds of MCP servers inadvertently exposed to the public Internet because they were bound to 0.0.0.0 without a firewall, allowing for potential OS command injection and host takeover.
Privilege escalation and the “confused deputy”: An attacker doesn’t need to break your LLM; they just need to confuse it. In one documented case, an AI agent running with high-level privileges was tricked into executing SQL commands embedded in a support ticket. The agent, acting as a “confused deputy,” couldn’t distinguish the malicious SQL from the legitimate ticket data and dutifully executed the commands, compromising an entire database.
Data leakage: Without centralized controls, data can bleed between systems in unexpected ways. In June 2025, a popular team collaboration tool’s MCP integration suffered a privacy breach where a bug caused some customer information to become visible in other customers’ MCP instances, forcing them to take the integration offline for two weeks.
You can’t protect what you can’t see. Cloudflare MCP Server Portals solve this problem by providing a single, centralized gateway for all your MCP servers, somewhat similar to an application launcher for single sign-on. Instead of developers distributing dozens of individual server endpoints, they register their servers with Cloudflare. You provide your users with a single, unified Portal endpoint to configure in their MCP client.

This changes the security posture and user experience immediately. By routing all MCP traffic through Cloudflare, you get:
Centralized policy enforcement: You can integrate MCP Server Portals directly into Cloudflare One. This means you can enforce the same granular access policies for your AI connections that you do for your human users. Require multi-factor authentication, check for device posture, restrict by geography, and ensure only the right users can access specific servers and tools.
Comprehensive visibility and logging: Who is accessing which MCP server and which toolsets are they engaging with? What prompts are being run? What tools are being invoked? Previously, this data was scattered across every individual server. Server Portals aggregate all MCP request logs into a single place, giving you the visibility needed to audit activity and detect anomalies before they become breaches.
A curated AI user experience based on least privilege: Administrators can now review and approve MCP servers before making them available to users through a Portal. When a user authenticates through their Portal, they are only presented with the curated list of servers and tools they are authorized to use, preventing the use of unvetted or malicious third-party servers. This approach adheres to the Zero Trust security best practice of least privilege.
Simplified user configuration: Instead of having to load individual MCP server configurations into a MCP Client, users can load a single URL that pulls down all accessible MCP Servers. This drastically simplifies how many URLs need to be shared out and known by users. As new MCP Servers are added, they become dynamically available through the portal, instead of sharing each new URL on publishing of a server.
When a user connects to their MCP Server Portal, Access prompts them to authenticate with their corporate identity provider. Once authenticated, Cloudflare enforces which MCP Servers the user has access to, regardless of the underlying server’s authorization policies.
For MCP servers with domains hosted on Cloudflare, Access policies can be used to enforce the server’s direct authorization. This is done by creating an OAuth server that is linked to the domain’s existing Access Application. For MCP servers with domains outside Cloudflare and/or hosted by a third party, they require authorization controls outside of Cloudflare Access, this is usually done using OAuth.
MCP Server Portals are a foundational step in our mission to secure the AI revolution. This is just the beginning. In the coming months, we plan to build on this foundation by:
Mechanisms to lock down MCP Servers: Unless an MCP Server author enforces Authorization controls, users can still technically access MCPs outside of a Portal. We will build additional enforcement mechanisms to prevent this.
Integrating with Firewall for AI: Imagine applying the power of our WAF to your MCP traffic, detecting and blocking prompt injection attacks before they ever reach your servers.
Cloudflare hosted MCP Servers: We will make it easy to deploy MCP Servers using Cloudflare’s AI Gateway. This will allow for deeper prompt filtering and controls.
Applying machine learning to detect abuse: We will layer our own machine learning models on top of your MCP logs to automatically identify anomalous behavior, such as unusual data exfiltration patterns or suspicious tool usage.
Enhancing the protocol: We are committed to working with the open-source community to strengthen the MCP standard itself, contributing to a more secure and robust ecosystem for everyone.
This is our commitment: to provide the tools you need to innovate with confidence.
Progress doesn’t have to come at the expense of security. With MCP Server Portals, you can empower your teams to build the future with AI, safely. This is a critical piece of helping to build a better Internet, and we are excited to see what you will build with it.
MCP Server Portals are now available in Open Beta for all Cloudflare One customers. To get started, navigate to the Access > AI Controls page in the Zero Trust Dashboard. If you don’t have an account, you can sign up today and get started with up to 50 free seats or contact our experts to explore larger deployments.
Cloudflare is also starting a user research program focused on AI security. If you are interested in previews of new functionality or want to help shape our roadmap, please express your interest here.
Post Syndicated from Ayush Kumar original https://blog.cloudflare.com/confidence-score-rubric/
The availability of SaaS and Gen AI applications is transforming how businesses operate, boosting collaboration and productivity across teams. However, with increased productivity comes increased risk, as employees turn to unapproved SaaS and Gen AI applications, often dumping sensitive data into them for quick productivity wins.
The prevalence of “Shadow IT” and “Shadow AI” creates multiple problems for security, IT, GRC and legal teams. For example:
Gen AI applications may train their models on user inputs, which could expose proprietary corporate information to third parties, competitors, or even through clever attacks like prompt injection.
Applications may retain user data for long periods, share data with third parties, have lax security practices, suffer a data breach, or even go bankrupt, leaving sensitive data exposed to the highest bidder.
Gen AI applications may produce outputs that are biased, unsafe or incorrect, leading to compliance violations or bad business decisions.
In spite of these problems, blanket bans of Gen AI don’t work. They stifle innovation and push employee usage underground. Instead, organizations need smarter controls.
Security, IT, legal and GRC teams therefore face a difficult challenge: how can you appropriately assess each third-party application, without auditing and crafting individual policies for every single one of them that your employees might decide to interact with? And with the rate at which they’re proliferating — how could you possibly hope to keep abreast of them all?
Today, we’re excited to announce that we’re helping these teams automate assessment of SaaS and Gen AI applications at scale with the introduction of our new Cloudflare Application Confidence Scores. Scores will soon be available as part of our new suite of AI Security Posture Management (AI-SPM) features in the Cloudflare One SASE platform, enabling IT and Security administrators to identify confidence levels associated with third-party SaaS and AI applications, and ultimately write policies informed by those confidence scores. We’re starting by scoring AI applications, because that’s where the need is most urgent.
In this blog, we’ll be covering the design of our Cloudflare Application Confidence Score, focusing specifically about the features of the score and our scoring rubric. Our current goal is to reveal the details of our scoring rubric, which is designed to be as transparent and objective as possible — while simultaneously helping organizations of all sizes safely adopt AI, and encouraging the industry and AI providers to adopt best practices for AI safety and security.
In the future, as part of our mission to help build a better Internet, we also plan to make Cloudflare Application Confidence Scores available for free to all our customer tiers. And even if you aren’t a Cloudflare customer, you will easily be able to browse through these Scores by creating a free account on the Cloudflare dashboard and navigating to our new Application Library.
Cloudflare Application Confidence Scores is a transparent, understandable, and accountable metric that measures app safety, security, and data protection. It’s designed to give Security, IT, legal and GRC teams a rapid way of assessing the rapidly burgeoning space of AI applications.
Scores are not based on vibes or black-box “learning algorithms” or “artificial intelligence engines”. We avoid subjective judgments or large-scale red-teaming as those can be tough to execute reliably and consistently over time. Instead, scores will be computed against an objective rubric that we describe in detail in this blog. Our rubric will be publicly maintained and kept up to date in the Cloudflare developer docs.
Many providers of the applications that we score are also our customers and partners, so our overarching goal is to be as fair and accountable as possible. We believe that transparency will build trust in our scoring rubric and guide the industry to adopt the best practices that our scoring rubric encourages.
Each component of our rubric requires a simple answer based on publicly available data like privacy policies, security documentation, compliance certifications, model cards and incident reports. If something isn’t publicly disclosed, we assign zero points to that component of the rubric, with no further assumptions or guesswork. Scores are computed according to our rubric via an automated system that incorporates human oversight for accuracy. We use crawlers to collect public information (e.g. privacy policies, compliance documents), process it using AI for extraction and to compute the resulting scores, and then send them to human analysts for a final review.
Scores are reviewed on a periodic basis. If a vendor believes that we have mis-scored their application, they can submit supporting documentation via [email protected], and we will update their score if appropriate.
Scores are on a scale from 1 to 5, with 5 being the highest confidence and 1 being the most risky. We decided to use a “confidence score” instead of a “risk score” because we can express confidence in an application when it provides clear positive evidence of good security, compliance and safety practices. An application may have good practices internally, but we cannot express confidence in these practices if they are not publicly documented. Moreover, a confidence score allows us to give customers transparent information, so they can make their own informed decisions. For example, an application might get a low confidence score because it lacks a documented data retention policy. While that might be a concern for some, your organization might find it acceptable and decide to allow the application anyway.
We separately evaluate different account tiers for the same application provider, because different account tiers can provide very different levels of enterprise risk. For instance, consumer plans (e.g. ChatGPT Free) may involve training on user prompts and score lower, whereas enterprise plans (e.g. ChatGPT Enterprise) do not train on user prompts and thus score higher.
That said, we are quite opinionated about components we selected in our rubric, drawing from deep experience of our own internal product, engineering, legal, GRC, and security teams. We prioritize factors like data retention policies and encryption standards because we believe they are foundational to protecting sensitive information in an AI-driven world. We included certifications, security frameworks and model cards because they provide evidence of maturity, stability, safety and adherence with industry best practices.
As AI applications emerge at an unprecedented pace, the problem of “Shadow AI” intensifies traditional risks associated with Shadow IT. Shadow IT applications create risk when they retain user data for long periods, have lax security practices, are financially unstable, or widely share data with third parties. Meanwhile, AI tools create new risks when they retain and train on user prompts, or generate responses that are biased, toxic, inaccurate or unsafe.
To separate out these different risks, we provide two different Scores:
Application Confidence Score (5 points) covers general SaaS maturity, and
Gen-AI Confidence Score (5 points) focused on Gen AI-specific risks.
We chose to focus on two separate areas to make our metric extensible (so that, in the future, we can apply it to applications that are not focused on Gen AI) and to make the Scores easier to understand and reason about.
Each Score is applied to each account tier of a given Gen AI provider. For example, here’s how we scored OpenAI’s ChatGPT:
ChatGPT Free (App Confidence 3.3, GenAI Confidence 1) received a low score due to limited enterprise controls and higher data exposure risk since by default, input data is used for model training.
ChatGPT Plus (App Confidence 3.3, GenAI Confidence 3) scored slightly higher as it allows users to opt out of training on their input data.
ChatGPT Team (App Confidence 4.3, GenAI Confidence 3) improved further with added collaboration safeguards and configurable data retention windows.
ChatGPT Enterprise (App Confidence 4.3, GenAI Confidence 4) achieved the highest score, as training on input data is disabled by default while retaining the enhanced controls from the Team tier.
We now walk through the details of the rubric behind each of our Scores.
This half evaluates the app’s overall maturity as a SaaS service, drawing from enterprise best practices.
Regulatory Compliance: Checks for key certifications that signal operational maturity. We selected these because they represent proven frameworks that demonstrate a commitment to widely-adopted security and data protection best practices.
Data Management Practices: Focuses on how data is retained and shared to minimize exposure. These criteria were chosen as they directly impact the risk of data leaks or misuse, based on common vulnerabilities we’ve observed in SaaS environments and our own legal/GRC team’s experience assessing third-party SaaS applications at Cloudflare.
Documented data retention window: Shorter retention limits risk.
0 day retention: .5 points
30 day retention: .4 points
60 day retention: .3 points
90 day retention: .1 point
No documented retention window: 0 points
Third-party sharing: No sharing means less external exposure of enterprise data. Sharing for advertising purposes means high risk of third parties mining and using the data.
No third-party sharing: .5 points.
Sharing only for troubleshooting/support: .25 points
Sharing for other reasons like advertising or end user targeting: 0 points
Security Controls: We prioritized these because they form the foundational defenses against unauthorized access, drawing from best practices that have prevented incidents in cloud services.
MFA support: .2 points.
Role-based access: .2 points.
Session monitoring: .2 points.
TLS 1.3: .2 points.
SSO support: .2 points.
Security reports and incident history: Rewards transparency and deducts for recent issues. This was included to emphasize accountability, as a history of breaches or proactive transparency often indicates how seriously a provider takes security.
Published safety framework and bug bounty: 1 point.
To get full points the company needs to have both of the following:
A publicly accessible page (e.g., security, trust, or safety) that includes a comprehensive whitepaper, framework overview, OR detailed security documentation that covers:
Encryption in transit and at rest
Authentication and authorization mechanisms
Network or infrastructure security design
Incident Response Transparency – Published vulnerability disclosure or bug bounty policy OR a documented incident response process and security advisory archive.
Example: Google has a bug bounty program, a whitepaper providing an overview of their security posture, as well as a transparency report.
No commitments or weak security framework with the lack of any of the above criteria. If the company only has one of the criteria above but lacks the other they will also receive no credit: 0 points.
Example: Lovable who has a security page but seems to lack many other parts of the criteria: https://lovable.dev/security
If there has been a material breach in the last two years. If the company has experienced a material cybersecurity incident that resulted in the unauthorized disclosure of customer data to external parties (e.g., data posted, sold, or otherwise made accessible outside the organization). Incident must be publicly acknowledged by the company through a trust center update, press release, incident notification page, or an official regulatory filing: Full deduction to 0.
Example: 23andMe suffered credential stuffing attack in 2023 that resulted in the exposure of user data.
Financial Stability: Gauges long-term viability of the company behind the application. We added this because a company’s financial health affects its ability to invest in ongoing security and support, and reduces the risk of sudden disruptions, corner-cutting, bankruptcy or sudden sale of user data to unknown third parties.
Public company or private with >$300M raised: .8 points.
Private with >$100M raised: .5 points.
Private with <$100M raised: .2 point.
Recent bankruptcy/distress (e.g. recent bankruptcy filings, major layoffs tied to funding shortfalls, failure to meet debt obligations): 0 points.
This Score zooms in on AI-specific risks, like data usage in training and input vulnerabilities.
Regulatory Compliance, ISO 42001: ISO 42001 is a new certification for AI management systems. We chose this emerging standard because it specifically addresses AI governance, filling a gap in traditional certifications and signaling forward-thinking risk management.
ISO 42001 Compliant: 1 point.
Not ISO 42001 Compliant: 0 points.
Deployment Security Model: Stronger access controls get higher points. Authentication not only controls access but also enables monitoring and logging. This makes it easier to detect misuse and investigate incidents. Public, unauthenticated access is a red flag for shadow IT risk.
Authenticated web portal or key-protected API with rate limiting: 1 point.
Unprotected public access: 0 points.
Model Card: A model card is a concise document that provides essential information about an AI model, similar to a nutrition label for a food product. It is crucial for AI safety and security because it offers transparency into a model’s design, training data, limitations, and potential biases, enabling developers and users to understand its risks and use it responsibly. Some leading AI providers have committed to providing model cards as public documentation of safety evaluations. We included this in our rubric to encourage the industry to broadly adopt model cards as a best practice. As the practice of model cards is further developed and standardized across the industry, we hope to incorporate more fine-grained details from model cards into our own risk scores. But for now, we only include the existence (or lack thereof) of a model card in our score.
Has its own model card: 1 point.
Uses a model with a model card: .5 points.
None: 0 points.
Training on user prompts: This is one of the most important components of our score. Models that train on user prompts are very risky because users might share sensitive corporate information in user prompts. We weighted this heavily because control over training data is central to preventing unintended data exposure, a core risk in generative AI that can lead to major incidents.
Explicit opt-in is required for training on user prompts: 2 points.
Opt-out of training on user prompts is explicitly available to users: 1 point.
No way to opt out of training on user prompts: 0 points.
Here’s an example of these Scores applied to a few popular AI providers. As expected, enterprise tiers typically earn higher Confidence Scores than consumer tiers of the same AI provider.
| Company | Application Score | Gen AI Score |
|---|---|---|
| Gemini Free | 3.8 | 4.0 |
| Gemini Pro | 3.8 | 5.0 |
| Gemini Ultra | 4.1 | 5.0 |
| Gemini Business | 4.7 | 5.0 |
| Gemini Enterprise | 4.7 | 5.0 |
| OpenAI Free | 3.3 | 1.0 |
| OpenAI Plus | 3.3 | 3.0 |
| OpenAI Pro | 3.3 | 3.0 |
| OpenAI Team | 4.3 | 3.0 |
| OpenAI Enterprise | 4.3 | 4.0 |
| Anthropic Free | 3.9 | 5.0 |
| Anthropic Pro | 3.9 | 5.0 |
| Anthropic Max | 3.9 | 5.0 |
| Anthropic Team | 4.9 | 5.0 |
| Anthropic Enterprise | 4.9 | 5.0 |
Note: Confidence scores are provided “as is” for informational purposes only and should not be considered a substitute for independent analysis or decision-making. All actions taken based on the scores are the sole responsibility of the user.
We’re actively refining our scoring methodology. To that end, we’re collaborating with a diverse group of experts in the AI ecosystem (including researchers, legal professionals, SOC teams, and more) to fine-tune our scores, optimize for transparency, accountability and extensibility. If you have insights, suggestions, or want to get involved testing new functionality, we’d love for you to express interest in our user research program. We’d very much welcome your feedback on this scoring rubric.
Today, we’re just releasing our scoring rubric in order to solicit feedback from the community. But soon, you’ll start seeing these Cloudflare Application Confidence Scores integrated into the Application Library in our SASE platform. Customers can simply click or hover over any score to reveal a detailed breakdown of the rubric and underlying components of the score. Again, if you see any issues with our scoring, please submit your feedback to [email protected], and our team will review it and make adjustments if appropriate.
Looking even further ahead, we plan to enable integration of these scores directly into Cloudflare Gateway and Access, allowing our customers to write policies that block or redirect traffic, apply data loss prevention (DLP) or remote browser isolation (RBI) or otherwise control access to sites based directly on their Cloudflare Application Confidence Score.
This is just the beginning. By prioritizing transparency in our approach, we’re not only bridging a critical gap in SASE capabilities but also driving the industry toward stronger AI safety practices. Let us know what you think!
If you’re ready to manage risk more effectively with these Confidence Scores, reach out to Cloudflare experts for a conversation.
Post Syndicated from Alex Dunbrack original https://blog.cloudflare.com/casb-ai-integrations/
Starting today, all users of Cloudflare One, our secure access service edge (SASE) platform, can use our API-based Cloud Access Security Broker (CASB) to assess the security posture of their generative AI (GenAI) tools: specifically, OpenAI’s ChatGPT, Claude by Anthropic, and Google’s Gemini. Organizations can connect their GenAI accounts and within minutes, start detecting misconfigurations, Data Loss Prevention (DLP) matches, data exposure and sharing, compliance risks, and more — all without having to install cumbersome software onto user devices.
As Generative AI adoption has exploded in the enterprise, IT and Security teams need to hustle to keep themselves abreast of newly emerging security and compliance challenges that come alongside these powerful tools. In this rapidly changing landscape, IT and Security teams need tools that help enable AI adoption while still protecting the security and privacy of their enterprise networks and data.
Cloudflare’s API CASB and inline CASB work together to help organizations safely adopt AI tools. The API CASB integrations provide out-of-band visibility into data at rest and security posture inside popular AI tools like ChatGPT, Claude, and Gemini. At the same time, Cloudflare Gateway provides in-line prompt controls and Shadow AI identification. It applies policies and DLP to traffic as it moves to these AI providers. Together, these features give organizations a unified control plane for securing their use of GenAI.
ChatGPT, Claude and Gemini are now all live in the integrations supported by Cloudflare’s API CASB. These integrations are available to all Cloudflare One users, account owners can easily connect their GenAI tenants, and CASB will scan for security issues across multiple domains:
Agentless Connections: Connect ChatGPT, Claude, and Gemini via agentless, API‑based integrations to scan posture and data risks; no endpoint software to install.
Posture Management: Detect insecure settings and misconfigurations that can lead to data exposure or misuse.
DLP Detection: Identify where sensitive data has been uploaded in chat attachments (prompts coming soon).
GenAI-specific Insights: Surface risks associated with the unique capability of a given AI provider’s toolsets.
Admins can now answer questions like: What are our employees doing in ChatGPT? What data is being uploaded and used in Claude? Is Gemini configured correctly in Google Workspace?
Now let’s take a closer look at each integration.

Cloudflare’s CASB integration with OpenAI’s ChatGPT scans for several types of insights, including:
Capability Activation: Highlights capabilities that are specific to ChatGPT’s feature set, like actions, code execution, web access.
External Exposure: Finds chats and GPTs that are shared beyond the tenant, like GPTs shared publicly or listed on the GPT Store, and ties them back to their owners for quick triage.
Secrets, Keys and Invites: Identifies API keys that aren’t rotated or are no longer used to maintain credential hygiene. Identifies over‑privileged or stale invites.
Sensitive Content (via DLP): Detects sensitive data (e.g. credential and secrets, financial / health information, source code, etc.) via DLP profile matches in uploaded chat attachments to enable targeted response.
For Claude, Cloudflare is able to provide the following out-of-band detections:
Secrets, Keys and Invites: Surfaces high‑risk invites and entitlement drift early so the least‑privilege access control stays tight. Spots unused API keys and rotation gaps before they turn into forgotten open doors.
Sensitive Content (via DLP): Monitors for sensitive data in uploaded files to help organizations safely enable Claude usage while maintaining compliance. Security teams get this information as quickly as CASB scans, giving them the visibility they need to help employees use Claude productively and securely with sensitive data.
As Anthropic continues to expand Claude’s API capabilities and features, Cloudflare will add corresponding security detections to match new functionality as it becomes available.
Cloudflare’s detections for Google Gemini appear as part of our API CASB integration for Google Workspace:
Identity & MFA: Identifies Gemini users and admins without MFA, leaving them prime targets for compromise. Imagine if an IT admin relied on Gemini daily to process corporate data, but their Google Workspace account lacked multi-factor authentication. One successful phishing email could give an attacker privileged access to Gemini and the wider Google Workspace environment — turning a minor oversight into an organization-wide breach.
License Hygiene: Flags suspended accounts still holding Gemini or AI Ultra licenses to cut cost and reduce exposure. An AI Ultra user has access to more powerful and riskier features, like Project Mariner, a research prototype that acts as an autonomous agent, capable of automating up to 10 tasks simultaneously across web browsers. An attacker can cause more damage by compromising an AI Ultra user, which is why we include this in our set of detections.
The Gemini integration has a narrower scope because Google has structured their product and API differently than OpenAI or Anthropic. For organizations, Gemini is delivered as a Google Workspace add-on. Enterprises enable Gemini features in Gmail, Docs, Sheets, and other Google Workspace apps through add-on licenses such as Gemini Enterprise or AI Ultra. Our CASB detections focus on identity, MFA, and license hygiene, rather than posture issues like public sharing or custom assistant publishing because Gemini does not yet provide those API endpoints.
Like countless other organizations, Cloudflare is adopting GenAI, on the same journey to make these environments even safer than they are today. We are excited to extend our management coverage to our customers so they can continue to innovate with GenAI. But looking ahead, we’re encouraged to see GenAI providers take concrete steps towards making security, compliance, and data privacy even more important tenets of their platforms.
Generative AI adoption brings new security requirements. Cloudflare CASB delivers out-of-band visibility across these tools, surfacing insights on top of inline controls. With posture, access, and data under control, organizations can embrace GenAI confidently and securely.
How to get started:
For existing Cloudflare One customers: Contact your account manager or enable the integrations directly in your dashboard today.
New to Cloudflare One? Sign up now for 50 free seats to begin securely using Gen AI immediately. For larger deployments, request a consultation with our experts.
If you want to preview other new functionality and help shape our roadmap, express interest in our user research program for AI security.
Post Syndicated from Radwa Radwan original https://blog.cloudflare.com/block-unsafe-llm-prompts-with-firewall-for-ai/
Security teams are racing to secure a new attack surface: AI-powered applications. From chatbots to search assistants, LLMs are already shaping customer experience, but they also open the door to new risks. A single malicious prompt can exfiltrate sensitive data, poison a model, or inject toxic content into customer-facing interactions, undermining user trust. Without guardrails, even the best-trained model can be turned against the business.
Today, as part of AI Week, we’re expanding our AI security offerings by introducing unsafe content moderation, now integrated directly into Cloudflare Firewall for AI. Built with Llama, this new feature allows customers to leverage their existing Firewall for AI engine for unified detection, analytics, and topic enforcement, providing real-time protection for Large Language Models (LLMs) at the network level. Now with just a few clicks, security and application teams can detect and block harmful prompts or topics at the edge — eliminating the need to modify application code or infrastructure.
This feature is immediately available to current Firewall for AI users. Those not yet onboarded can contact their account team to participate in the beta program.
Cloudflare’s Firewall for AI protects user-facing LLM applications from abuse and data leaks, addressing several of the OWASP Top 10 LLM risks such as prompt injection, PII disclosure, and unbound consumption. It also extends protection to other risks such as unsafe or harmful content.
Unlike built-in controls that vary between model providers, Firewall for AI is model-agnostic. It sits in front of any model you choose, whether it’s from a third party like OpenAI or Gemini, one you run in-house, or a custom model you have built, and applies the same consistent protections.
Just like our origin-agnostic Application Security suite, Firewall for AI enforces policies at scale across all your models, creating a unified security layer. That means you can define guardrails once and apply them everywhere. For example, a financial services company might require its LLM to only respond to finance-related questions, while blocking prompts about unrelated or sensitive topics, enforced consistently across every model in use.
Effective AI moderation is more than blocking “bad words”, it’s about setting boundaries that protect users, meeting legal obligations, and preserving brand integrity, without over-moderating in ways that silence important voices.
Because LLMs cannot be fully scripted, their interactions are inherently unpredictable. This flexibility enables rich user experiences but also opens the door to abuse.
Key risks from unsafe prompts include misinformation, biased or offensive content, and model poisoning, where repeated harmful prompts degrade the quality and safety of future outputs. Blocking these prompts aligns with the OWASP Top 10 for LLMs, preventing both immediate misuse and long-term degradation.
One example of this is Microsoft’s Tay chatbot. Trolls deliberately submitted toxic, racist, and offensive prompts, which Tay quickly began repeating. The failure was not only in Tay’s responses; it was in the lack of moderation on the inputs it accepted.
Cloudflare has integrated Llama Guard directly into Firewall for AI. This brings AI input moderation into the same rules engine our customers already use to protect their applications. It uses the same approach that we created for developers building with AI in our AI Gateway product.
Llama Guard analyzes prompts in real time and flags them across multiple safety categories, including hate, violence, sexual content, criminal planning, self-harm, and more.
With this integration, Firewall for AI not only discovers LLM traffic endpoints automatically, but also enables security and AI teams to take immediate action. Unsafe prompts can be blocked before they reach the model, while flagged content can be logged or reviewed for oversight and tuning. Content safety checks can also be combined with other Application Security protections, such as Bot Management and Rate Limiting, to create layered defenses when protecting your model.
The result is a single, edge-native policy layer that enforces guardrails before unsafe prompts ever reach your infrastructure — without needing complex integrations.
Before diving into the architecture of Firewall for AI engine and how it fits within our previously mentioned module to detect PII in the prompts, let’s start with how we detect unsafe topics.
A key challenge in building safety guardrails is balancing a good detection with model helpfulness. If detection is too broad, it can prevent a model from answering legitimate user questions, hurting its utility. This is especially difficult for topic detection because of the ambiguity and dynamic nature of human language, where context is fundamental to meaning.
Simple approaches like keyword blocklists are interesting for precise subjects — but insufficient. They are easily bypassed and fail to understand the context in which words are used, leading to poor recall. Older probabilistic models such as Latent Dirichlet Allocation (LDA) were an improvement, but did not properly account for word ordering and other contextual nuances.
Recent advancements in LLMs introduced a new paradigm. Their ability to perform zero-shot or few-shot classification is uniquely suited for the task of topic detection. For this reason, we chose Llama Guard 3, an open-source model based on the Llama architecture that is specifically fine-tuned for content safety classification. When it analyzes a prompt, it answers whether the text is safe or unsafe, and provides a specific category. We are showing the default categories, as listed here. Because Llama 3 has a fixed knowledge cutoff, certain categories — like defamation or elections — are time-sensitive. As a result, the model may not fully capture events or context that emerged after it was trained, and that’s important to keep in mind when relying on it.
For now, we cover the 13 default categories. We plan to expand coverage in the future, leveraging the model’s zero-shot capabilities.
We designed Firewall for AI to scale without adding noticeable latency, including Llama Guard, and this remains true even as we add new detection models.
To achieve this, we built a new asynchronous architecture. When a request is sent to an application protected by Firewall for AI, a Cloudflare Worker makes parallel, non-blocking requests to our different detection modules — one for PII, one for unsafe topics, and others as we add them.
Thanks to the Cloudflare network, this design scales to handle high request volumes out of the box, and latency does not increase as we add new detections. It will only be bounded by the slowest model used.

We optimize to keep the model utility at its maximum while keeping the guardrail detection broad enough.
Llama Guard is a rather large model, so running it at scale with minimal latency is a challenge. We deploy it on Workers AI, leveraging our large fleet of high performance GPUs. This infrastructure ensures we can offer fast, reliable inference throughout our network.
To ensure the system remains fast and reliable as adoption grows, we ran extensive load tests simulating the requests per second (RPS) we anticipate, using a wide range of prompt sizes to prepare for real-world traffic. To handle this, the number of model instances deployed on our network scales automatically with the load. We employ concurrency to minimize latency and optimize for hardware utilization. We also enforce a hard 2-second threshold for each analysis; if this time limit is reached, we fall back to any detections already completed, ensuring your application’s requests latency is never further impacted.
Firewall for AI follows the same familiar pattern as other Application Security features like Bot Management and WAF Attack Score, making it easy to adopt.
Once enabled, the new fields appear in Security Analytics and expanded logs. From there, you can filter by unsafe topics, track trends over time, and drill into the results of individual requests to see all detection outcomes, for example: did we detect unsafe topics, and what are the categories. The request body itself (the prompt text) is not stored or exposed; only the results of the analysis are logged.

After reviewing the analytics, you can enforce unsafe topic moderation by creating rules to log or block based on prompt categories in Custom rules.
For example, you might log prompts flagged as sexual content or hate speech for review.
You can use this expression:
If (any(cf.llm.prompt.unsafe_topic_categories[*] in {"S10" "S12"})) then Log
Or deploy the rule with the categories field in the dashboard as in the below screenshot.

You can also take a broader approach by blocking all unsafe prompts outright:
If (cf.llm.prompt.unsafe_topic_detected)then Block

These rules are applied automatically to all discovered HTTP requests containing prompts, ensuring guardrails are enforced consistently across your AI traffic.
In the coming weeks, Firewall for AI will expand to detect prompt injection and jailbreak attempts. We are also exploring how to add more visibility in the analytics and logs, so teams can better validate detection results. A major part of our roadmap is adding model response handling, giving you control over not only what goes into the LLM but also what comes out. Additional abuse controls, such as rate limiting on tokens and support for more safety categories, are also on the way.
Firewall for AI is available in beta today. If you’re new to Cloudflare and want to explore how to implement these AI protections, reach out for a consultation. If you’re already with Cloudflare, contact your account team to get access and start testing with real traffic.
Cloudflare is also opening up a user research program focused on AI security. If you are curious about previews of new functionality or want to help shape our roadmap, express your interest here.