Post Syndicated from Marta Taggart original https://aws.amazon.com/blogs/security/aws-reinvent-2021-security-track-recap/
Another AWS re:Invent is in the books! We were so pleased to be able to host live in Las Vegas again this year. And we were also thrilled to be able to host a large virtual audience. If you weren’t able to participate live, you can now view some of the security sessions by visiting the AWS Events Channel on YouTube and checking out the AWS re:Invent 2021 Breakout Sessions for Security playlist. The following is a list of some of the security-focused sessions you’ll find on the playlist:
Security Leadership Session: Continuous security improvement: Strategies and tactics – SEC219
Steve Schmidt, Sarah Cecchetti, and Thomas Avant
In this session, Stephen Schmidt, Chief Information Security Officer at AWS, addresses best practices for security in the cloud, feature updates, and how AWS handles security internally. Discover the potential future of tooling for security, identity, privacy, and compliance.
AWS Security Reference Architecture: Visualize your security – SEC203
Neal Rothleder and Andy Wickersham
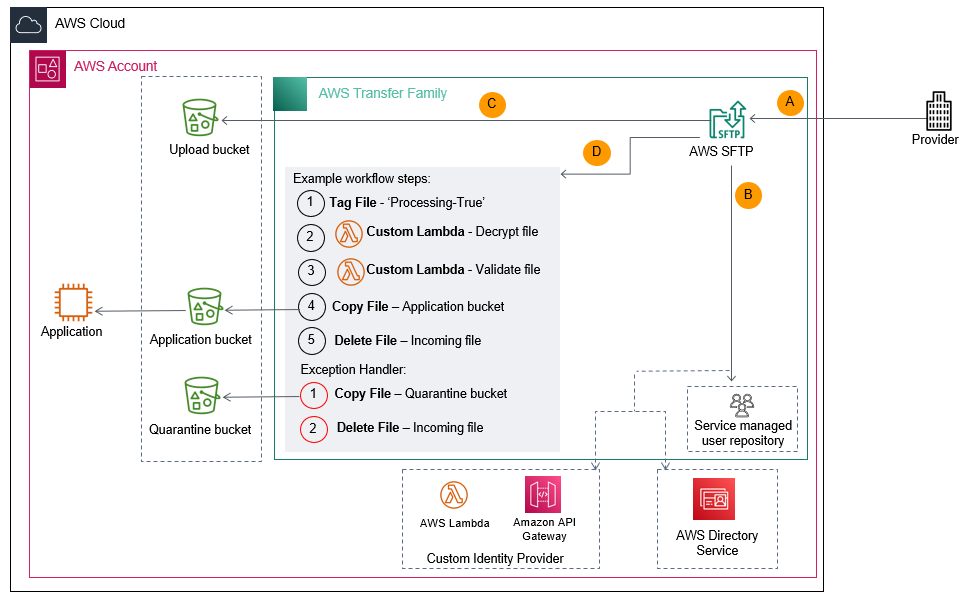
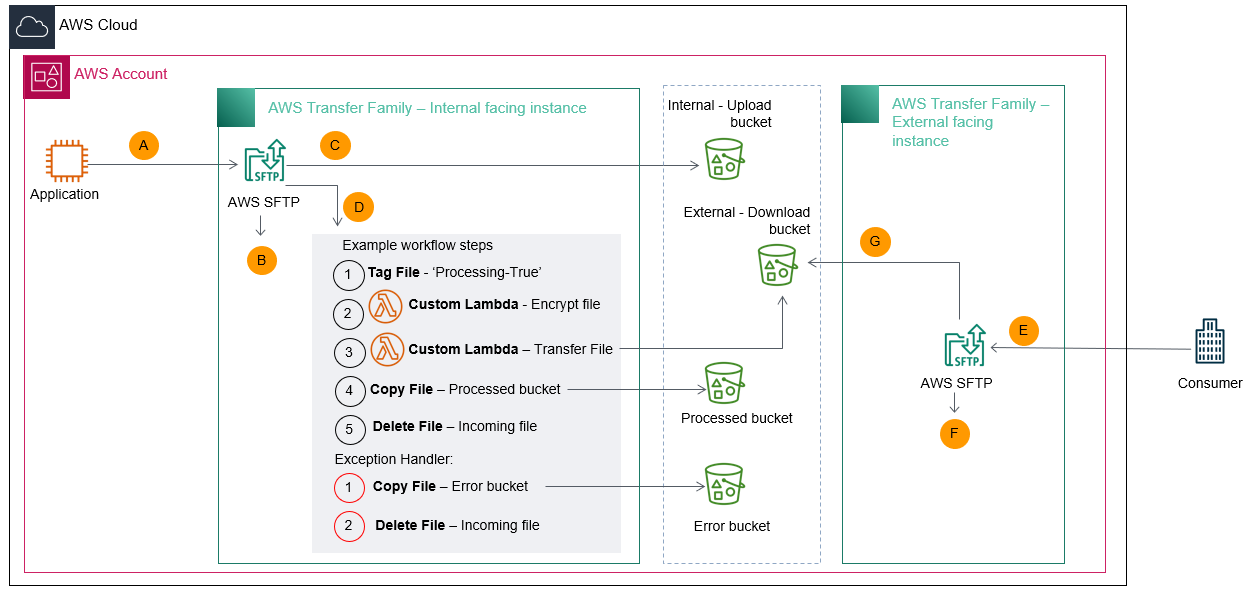
How do AWS security services work together and how do you deploy them? The new AWS Security Reference Architecture (AWS SRA) provides prescriptive guidance for deploying the full complement of AWS security services in a multi-account environment. AWS SRA describes and demonstrates how security services should be deployed and managed, the security objectives they serve, and how they interact with one another. In this session, learn about these assets, the AWS SRA team’s design decisions, and guidelines for how to use AWS SRA for your security designs. Discover an authoritative reference to help you design and implement your own security architecture on AWS.
Introverts and extroverts collide: Build an inclusive workforce – SEC204
Jenny Brinkley and Eric Brandwine
In this session, hear from the odd couple of AWS security on how to build diverse teams and develop proactive security cultures. Jenny Brinkley, Director of AWS Security, and Eric Brandwine, VP and Distinguished Engineer for AWS Security, provide best practices for and insights into the mechanisms applied to the AWS Security organization. Learn how to not only scale your programs, but also drive real business change.
Security posture monitoring with AWS Security Hub at Panasonic Avionics – SEC205
Himanshu Verma and Anand Desikan
In this session, learn to proactively monitor, identify, and protect data to help maintain security and compliance with low operational investment. Panasonic Avionics shares their robust security solution for migrating to Amazon S3 to reduce data center costs by more than 85 percent while remaining secure and compliant with comprehensive industry regulations. Discover best practices for deploying layered security to monitor data using Amazon Macie, learn how to detect threats using Amazon GuardDuty, and consider how automating responses can help protect your data and meet your compliance requirements. Explore how you can use AWS Security Hub as a central monitoring and posture-management control point.
[New Launch] AWS Shield: Automated layer 7 DDoS mitigation – SEC226
Kevin Lee and Chido Chemambo
In this session, learn how you can use automated application layer 7 (L7) DDoS mitigations with AWS Shield Advanced to protect your web applications. You can now use on AWS Shield Advanced to automatically recommend AWS WAF rules in response to an L7 DDoS event instead of manually crafting an AWS WAF rule to isolate the malicious traffic, evaluating the rule’s effectiveness, and then deploying it throughout your environment. AWS Shield Advanced is effective at alerting application owners when spikes in traffic may impact the availability of applications. Now, AWS Shield Advanced can automatically detect and mitigate L7 traffic anomalies that risk impacting application availability and responsiveness.
Locks without keys: AWS and confidentiality – SEC301
Colm MacCárthaigh
Every day AWS works with organizations and regulators to host some of the most sensitive workloads in industry and government. In this session, hear how AWS secures data even from trusted AWS operators and services. Learn about the AWS Nitro System and how it provides confidential computing and a trusted execution environment. Also, learn about the cryptographic chains of custody that are built into the AWS Identity and Access Management service, including how encryption is used to provide defense in depth and why AWS focuses on verified isolation and customer transparency.
Use AWS to improve your security posture against ransomware – SEC308
Merritt Baer and Megan O’Neil
Ransomware is not specific to the cloud—in fact, AWS can provide increased visibility and control over your security posture against malware. In this session, learn ways that enterprises can empower and even inoculate themselves against malware, including ransomware. From IAM policies and the principle of least privilege to AWS services like Amazon GuardDuty, AWS Security Hub for actionable insights, and CloudEndure Disaster Recovery and AWS Backup for retention and recovery, this session provides clarity into tools and approaches that can help you feel confident in your security posture against current malware.
Securing your data perimeter with VPC endpoints – SEC318
Becky Weiss
In this session, learn how to use your network perimeter as a straightforward defensive perimeter around your data in the cloud. VPC endpoints were first introduced for Amazon S3 in 2015 and have since incorporated many improvements, enhancements, and expansions. They enable you to lock your data into your networks as well as assert network-wide security invariants. This session provides practical guidance on what you can do with VPC endpoints and details how to configure them as part of your data perimeter strategy.
A least privilege journey: AWS IAM policies and Access Analyzer – SEC324
Brigid Johnson
Are you looking for tips and tools for applying least privilege permissions for your users and workloads? Love demonstrations and useful examples? In this session, explore advanced skills to use on your journey to apply least privilege permissions in AWS Identity and Access Management (IAM) by granting the right access to the right identities under the right conditions. For each stage of the permissions lifecycle, learn how to look at IAM policy specifics and use IAM Access Analyzer to set, verify, and refine fine-grained permissions. Get a review of the foundations of permissions in AWS and dive into conditions, tags, and cross-account access.
If watching these sessions has you thinking about your next hands-on learning opportunity with AWS Security, we invite you to save the date for AWS re:Inforce 2022. AWS re:Inforce, our learning conference focused on cloud security, compliance, identity, and privacy, will be held June 28-29, 2022 in Houston, Texas. We hope to see you there!
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.