Post Syndicated from Crosstalk Solutions original https://www.youtube.com/watch?v=cSevNQDCa18
Getting the Most Out of Your NAS
Post Syndicated from Molly Clancy original https://www.backblaze.com/blog/getting-the-most-out-of-your-nas/

Who has the original copy of that report on their machine? Which hard drive has the footage from that shoot a few years ago? Are those photos from our vacation on the laptop, the external hard drive, or the sync service? If you’ve ever asked yourself a question like these, you have felt the pain of digital scatter. In today’s world, with as many devices as we use, it’s almost unavoidable.
Almost. When you start to feel the pain of digital scatter, either at work or at home, take it as a sign that it’s time to look into upgrading your data storage systems. One of the best ways to do that is investing in a NAS device.
As you start exploring more sophisticated data storage options than juggling external drives or managing sync services, understanding what you can do with a NAS system can help your decision making. This post explains what NAS is and all the different ways you can use NAS to supercharge your business or home office setup.
What Is NAS?
Network attached storage, or NAS, is a computer connected to a network that provides file-based data storage services to other devices on the network. It’s primarily used to expand storage capacity and enable file sharing across an organization or across devices in a home.
The primary strength of NAS is how simple it is to set up and deploy. NAS volumes appear to the user as network mounted volumes. The files to be served are typically contained on one or more hard drives in the system, often arranged in a RAID scheme. Generally, the more drive bays available within the NAS, the larger and more flexible storage options you have. The device itself is a network node—much like computers and other TCP/IP devices, all of which maintain their own IP address—and the NAS file service uses the Ethernet network to send and receive files.
NAS devices offer an easy way for multiple users in diverse locations to access data, which is valuable when users are collaborating on projects or sharing information. NAS provides good access controls and security to support collaboration, while also enabling someone who is not an IT professional to administer and manage access to the data via an onboard web server. It also offers good fundamental data resiliency through the use of redundant data structures—often RAID—making multiple drives appear like a single, large volume that can tolerate failure of a few of its individual drives.
How Does RAID Work?
A redundant array of independent disks, or RAID, combines multiple hard drives into one or more storage volumes. RAID distributes data and parity (drive recovery information) across the drives in different ways, and each layout provides different degrees of data protection.
A redundant array of independent disks, or RAID, combines multiple hard drives into one or more storage volumes. RAID distributes data and parity (drive recovery information) across the drives in different ways, and each layout provides different degrees of data protection.

Getting the Most Out of Your NAS: NAS Use Cases
The first two NAS use cases are fairly straightforward. They are exactly what NAS was built for:
- File storage and file sharing: NAS is ideal for centralizing data storage for your home or business and making files available to multiple users. The primary benefits of a NAS system are the added storage capacity and file sharing compared to relying on workstations and hard drives.
- Local backups and data protection: NAS can serve as a storage repository for local backups of machines on your network. Most NAS systems have built-in software where you can configure automatic backups, including what you back up and when. Furthermore, the RAID configuration in a NAS system ensures that the data you store can survive the failure of one or more of its hard drives. Hard drives fail. NAS helps to make that statement of fact less scary.
But that’s not all NAS can do. With large storage capacity and a whole host of add-ons, NAS offers a lot of versatility. Here are a few additional use cases that you can take advantage of.
Host Business Applications on NAS
Small to medium-sized businesses find NAS useful for running shared business applications like customer relationship management software, human resources management software, messaging, and even office suites. Compared to expensive, server-based versions of these applications, companies can install and run open-source versions quickly and easily on NAS. Some NAS devices may have these features built in or available on a proprietary app store.
Create a Private Cloud With NAS
Most NAS devices give you the ability to access your data over the public internet in addition to accessing it through your private network, essentially functioning as a cloud service. If a NAS device manufacturer doesn’t already have a cloud application built in, there are a number of open-source cloud applications like Nextcloud or ownCloud.
Use NAS to Run Virtual Machines
Virtualization software providers, like VMware, support running their products on NAS. With proper configuration, including potentially adding RAM to your device, you can easily spin up virtual machines using NAS.
Develop and Test Applications on NAS
Many NAS devices offer developer packages, including apps for different programming languages and tools like Docker and Git Server. With these add-ons, you can turn your NAS into your own private lab for developing and testing applications before moving them to a server for production.
Use NAS as a File Server
Although a NAS device is usually not designed to be a general-purpose server (it’s underpowered compared to a file server and comes with less robust access management capabilities), NAS vendors and third parties are increasingly offering other software to provide server-like functionality. For home use or for a small team, higher-end NAS devices can function as a file server.
Manage Security Cameras on NAS
Apps like Synology’s Surveillance Station allow you to set up a security camera system yourself using IP cameras rather than paying for a more expensive enterprise or home system. With a large storage capacity, NAS is perfect for storing large amounts of video footage.
Stream Media With NAS
NAS is a great place to store large media files, and apps like Plex allow you to stream directly to a device or smart TV in your home or business. You can consolidate video or audio files from your devices into one place and stream them anywhere.
Ready to Get Started With NAS?
Understanding the many use cases can help you see where NAS might fit into your business or make file sharing at home easier. There are many ways to make your NAS device work for you and ensure you get the most out of it in the process.
Do you have more questions about shopping for or buying a NAS? Check out our Complete NAS Guide. It provides comprehensive information on NAS and what it can do for your business, how to evaluate and purchase a NAS system, and how to deploy your NAS.
The post Getting the Most Out of Your NAS appeared first on Backblaze Blog | Cloud Storage & Cloud Backup.
Gentoo Linux 2021 retrospective
Post Syndicated from original https://lwn.net/Articles/880334/rss
The Gentoo Linux project looks back at
2021.
The number of commits to the main ::gentoo repository has once more
clearly grown in 2021, from 104507 to 126920, i.e., by 21%. While
the number of commits by external contributors, 11775, has remained
roughly constant, this number now distributes across 435 unique
external authors compared to 391 last year.
NumPy 1.22.0 has been released
Post Syndicated from original https://lwn.net/Articles/880332/rss
Version 1.22.0 of the NumPy scientific computing module is out.
“NumPy 1.22.0 is a big release featuring the work of 153
contributors spread over 609 pull requests. There have been many
improvements“. Those improvements include the “essentially
complete” annotation of the main namespace, a preliminary version of
the proposed Array API, and more.
Security updates for Tuesday
Post Syndicated from original https://lwn.net/Articles/880327/rss
Security updates have been issued by Debian (salt and thunderbird), Red Hat (xorg-x11-server), and Scientific Linux (xorg-x11-server).
ICYMI: Serverless Q4 2021
Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/icymi-serverless-q4-2021/
Welcome to the 15th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. Every quarter, we share all of the most recent product launches, feature enhancements, blog posts, webinars, Twitch live streams, and other interesting things that you might have missed!
In case you missed our last ICYMI, check out what happened last quarter here.
AWS Lambda
For developers using Amazon MSK as an event source, Lambda has expanded authentication options to include IAM, in addition to SASL/SCRAM. Lambda also now supports mutual TLS authentication for Amazon MSK and self-managed Kafka as an event source.
Lambda also launched features to make it easier to operate across AWS accounts. You can now invoke Lambda functions from Amazon SQS queues in different accounts. You must grant permission to the Lambda function’s execution role and have SQS grant cross-account permissions. For developers using container packaging for Lambda functions, Lambda also now supports pulling images from Amazon ECR in other AWS accounts. To learn about the permissions required, see this documentation.
The service now supports a partial batch response when using SQS as an event source for both standard and FIFO queues. When messages fail to process, Lambda marks the failed messages and allows reprocessing of only those messages. This helps to improve processing performance and may reduce compute costs.
Lambda launched content filtering options for functions using SQS, DynamoDB, and Kinesis as an event source. You can specify up to five filter criteria that are combined using OR logic. This uses the same content filtering language that’s used in Amazon EventBridge, and can dramatically reduce the number of downstream Lambda invocations.
Amazon EventBridge
Previously, you could consume Amazon S3 events in EventBridge via CloudTrail. Now, EventBridge receives events from the S3 service directly, making it easier to build serverless workflows triggered by activity in S3. You can use content filtering in rules to identify relevant events and forward these to 18 service targets, including AWS Lambda. You can also use event archive and replay, making it possible to reprocess events in testing, or in the event of an error.
AWS Step Functions
The AWS Batch console has added support for visualizing Step Functions workflows. This makes it easier to combine these services to orchestrate complex workflows over business-critical batch operations, such as data analysis or overnight processes.
Additionally, Amazon Athena has also added console support for visualizing Step Functions workflows. This can help when building distributed data processing pipelines, allowing Step Functions to orchestrate services such as AWS Glue, Amazon S3, or Amazon Kinesis Data Firehose.
Synchronous Express Workflows now supports AWS PrivateLink. This enables you to start these workflows privately from within your virtual private clouds (VPCs) without traversing the internet. To learn more about this feature, read the What’s New post.
Amazon SNS
Amazon SNS announced support for token-based authentication when sending push notifications to Apple devices. This creates a secure, stateless communication between SNS and the Apple Push Notification (APN) service.
SNS also launched the new PublishBatch API which enables developers to send up to 10 messages to SNS in a single request. This can reduce cost by up to 90%, since you need fewer API calls to publish the same number of messages to the service.
Amazon SQS
Amazon SQS released an enhanced DLQ management experience for standard queues. This allows you to redrive messages from a DLQ back to the source queue. This can be configured in the AWS Management Console, as shown here.
Amazon DynamoDB
The NoSQL Workbench for DynamoDB is a tool to simplify designing, visualizing and querying DynamoDB tables. The tools now supports importing sample data from CSV files and exporting the results of queries.
DynamoDB announced the new Standard-Infrequent Access table class. Use this for tables that store infrequently accessed data to reduce your costs by up to 60%. You can switch to the new table class without an impact on performance or availability and without changing application code.
AWS Amplify
AWS Amplify now allows developers to override Amplify-generated IAM, Amazon Cognito, and S3 configurations. This makes it easier to customize the generated resources to best meet your application’s requirements. To learn more about the “amplify override auth” command, visit the feature’s documentation.
Similarly, you can also add custom AWS resources using the AWS Cloud Development Kit (CDK) or AWS CloudFormation. In another new feature, developers can then export Amplify backends as CDK stacks and incorporate them into their deployment pipelines.
AWS Amplify UI has launched a new Authenticator component for React, Angular, and Vue.js. Aside from the visual refresh, this provides the easiest way to incorporate social sign-in in your frontend applications with zero-configuration setup. It also includes more customization options and form capabilities.
AWS launched AWS Amplify Studio, which automatically translates designs made in Figma to React UI component code. This enables you to connect UI components visually to backend data, providing a unified interface that can accelerate development.
AWS AppSync
You can now use custom domain names for AWS AppSync GraphQL endpoints. This enables you to specify a custom domain for both GraphQL API and Realtime API, and have AWS Certificate Manager provide and manage the certificate.
To learn more, read the feature’s documentation page.
News from other services
- Introducing Amazon Redshift Serverless – Run Analytics At Any Scale Without Having to Manage Data Warehouse Infrastructure
- Amazon Kinesis Data Streams On-Demand – Stream Data at Scale Without Managing Capacity
- AWS re:Post – A Reimagined Q&A Experience for the AWS Community
- Announcing General Availability of Construct Hub and AWS Cloud Development Kit Version 2
- Real-User Monitoring for Amazon CloudWatch
- Introducing Amazon EMR Serverless in preview
- Introducing Amazon MSK Serverless in public preview
Serverless blog posts
October
- Oct 4 – Simplifying B2B integrations with AWS Step Functions Workflow Studio
- Oct 6 – Operating serverless at scale: Implementing governance – Part 1
- Oct 7 – Using Okta as an identity provider with Amazon MWAA
- Oct 11 – Avoiding recursive invocation with Amazon S3 and AWS Lambda
- Oct 12 – Operating serverless at scale: Improving consistency – Part 2
- Oct 14 – Using JSONPath effectively in AWS Step Functions
- Oct 14 – Accepting API keys as a query string in Amazon API Gateway
- Oct 14 – Visualizing AWS Step Functions workflows from the AWS Batch console
- Oct 18 – Building dynamic Amazon SNS subscriptions for auto scaling container workloads
- Oct 19 – Operating serverless at scale: Keeping control of resources – Part 3
- Oct 21 – Creating AWS Serverless batch processing architectures
- Oct 25 – Building a difference checker with Amazon S3 and AWS Lambda
- Oct 26 – Monitoring and tuning federated GraphQL performance on AWS Lambda
- Oct 27 – Accelerating serverless development with AWS SAM Accelerate
- Oct 28 – Creating AWS Lambda environment variables from AWS Secrets Manager
November
- Nov 1 – Build workflows for Amazon Forecast with AWS Step Functions
- Nov 2 – Choosing between storage mechanisms for ML inferencing with AWS Lambda
- Nov 4 – Introducing cross-account Amazon ECR access for AWS Lambda
- Nov 8 – Implementing header-based API Gateway versioning with Amazon CloudFront
- Nov 9 – Creating static custom domain endpoints with Amazon MQ for RabbitMQ
- Nov 9 – Token-based authentication for iOS applications with Amazon SNS
- Nov 11 – Understanding how AWS Lambda scales with Amazon SQS standard queues
- Nov 17 – Modernizing deployments with container images in AWS Lambda
- Nov 18 – Deploying AWS Lambda layers automatically across multiple Regions
- Nov 18 – Publishing messages in batch to Amazon SNS topics
- Nov 19 – Introducing mutual TLS authentication for Amazon MSK as an event source
- Nov 22 – Expanding cross-Region event routing with Amazon EventBridge
- Nov 22 – Offset lag metric for Amazon MSK as an event source for Lambda
- Nov 23 – Visualizing AWS Step Functions workflows from the Amazon Athena console
- Nov 26 – Filtering event sources for AWS Lambda functions
December
- Dec 1 – Introducing Amazon Simple Queue Service dead-letter queue redrive to source queues
- Dec 13 – Using an Amazon MQ network of broker topologies for distributed microservices
- Dec 27 – Building a serverless multi-player game that scales: Part 3
AWS re:Invent breakouts
AWS re:Invent was held in Las Vegas from November 29 to December 3, 2021. The Serverless DA team presented numerous breakouts, workshops and chalk talks. Rewatch all our breakout content:
- What’s new in serverless
- Serverless security best practices
- Building real-world serverless applications with AWS SAM and Capital One
- Architecting your serverless applications for hyperscale
- Best practices for building interactive applications with AWS Lambda
- Getting started building your first serverless application
- Best practices of advanced serverless developers

We also launched an interactive serverless application at re:Invent to help customers get caffeinated!
Serverlesspresso is a contactless, serverless order management system for a physical coffee bar. The architecture comprises several serverless apps that support an ordering process from a customer’s smartphone to a real espresso bar. The customer can check the virtual line, place an order, and receive a notification when their drink is ready for pickup.

You can learn more about the architecture and download the code repo at https://serverlessland.com/reinvent2021/serverlesspresso. You can also see a video of the exhibit.
Videos

Serverless Office Hours – Tues 10 AM PT
Weekly live virtual office hours. In each session we talk about a specific topic or technology related to serverless and open it up to helping you with your real serverless challenges and issues. Ask us anything you want about serverless technologies and applications.
YouTube: youtube.com/serverlessland
Twitch: twitch.tv/aws
October
- Oct 5 – Serverless Surprise! Ben Kehoe & security
- Oct 12 – AWS Lambda – ARM support for Lambda functions
- Oct 19 – AWS Step Functions – AWS SDK Service Integrations
- Oct 20 – Using the AWS Serverless Application Model (AWS SAM) to Build Serverless Applications
- Oct 26 – API Gateway – Migration tips for API keys
November
- Nov 2 – pre:Invent session #1 – The serverless sessions
- Nov 3 – DynamoDB Office Hours – Data Modeling with Dynobase
- Nov 9 – pre:Invent session #2
- Nov 16 – pre:Invent session #3
- Nov 23 – pre:Invent session #4
- Nov 29 – Heroes @ re:Invent part one
- Nov 30 – Secret projects @ re:Invent
December
- Dec 1 – Serverless leadership @ re:Invent
- Dec 2 – Heroes @ re:Invent part two
Still looking for more?
The Serverless landing page has more information. The Lambda resources page contains case studies, webinars, whitepapers, customer stories, reference architectures, and even more Getting Started tutorials.
You can also follow the Serverless Developer Advocacy team on Twitter to see the latest news, follow conversations, and interact with the team.
- Eric Johnson: @edjgeek
- James Beswick: @jbesw
- Ben Smith: @benjamin_l_s
- Julian Wood: @julian_wood
- Talia Nassi: @talia_nassi
THG Podcast: Forgotten Fruits: Bananas and Oranges
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=4NN-fX9G0WE
A guide to migrating to Zabbix 6.0 LTS by Edgars Melveris / Zabbix Summit Online 2021
Post Syndicated from Edgars Melveris original https://blog.zabbix.com/a-guide-to-migrating-to-zabbix-6-0-lts-by-edgars-melveris-zabbix-summit-online-2021/18569/
Upgrading to a new software version can be an intimidating process, especially if you are upgrading your Zabbix instance for the first time. In this blog post, we will take a look at the upgrade process itself, the necessary pre-requisites, and also what changes you can expect to the existing functionality when you’ve migrated to Zabbix 6.0 LTS.
The full recording of the speech is available on the official Zabbix Youtube channel.
Pre-upgrade checklist
Database versions
The first step before performing the upgrade to a new Zabbix version is ensuring that your underlying infrastructure is ready for the upgrade process. There are some changes in Zabbix that you should be aware of and address before the upgrade. One of these changes is the list of supported database engines and their versions for Zabbix 6.0 LTS:
- MySQL/Percona 8.0.x
- MariaDB 10.5.0 -10.6.x
- PostgreSQL 13.x
- Oracle 19c – 21c
And if you’re using PostgreSQL + TimescaleDB or Zabbix proxies:
- TimescaleDB 2.0.1-2.3
- SQLite 3.3.5 – 3.34.x
You may have noticed that we have increased the version requirements for the Zabbix backend databases. The reason for this is Zabbix utilizes the features that only these newer database versions provide, thus ensuring optimal Zabbix performance. If you’re using an unsupported database version, Zabbix will not start. There will be a configuration parameter to override this behavior, but that is not recommended since we cannot ensure that your Zabbix version will work without encountering any performance issues or crashes. A database upgrade to a supported version should be performed first before moving to Zabbix 6.0 LTS.
Supported operating systems
Zabbix supports all Linux distributions and many other Unix-like operating systems. Unfortunately, it is not feasible to provide Zabbix packages for each and every distribution out there. One of the major changes that were made back in Zabbix 5.2 – we no longer provide packages for RHEL/CentOS 7. This is because some of the libraries included in these distributions are outdated, and it becomes more and more complicated to build Zabbix on these OS versions. Though it is still possible to build Zabbix from sources if you provide the correct versions of the required libraries.
Some of the officially supported operating systems for Zabbix 6.0 LTS:
- RHEL/CentOS/Oracle Linux 8
- Ubuntu 18.04+
- Debian 10+
- SLES 12+
Other installation options
There are additional Zabbix deployment options:
- Docker – all of the dependencies are already provided in the official docker images
- Cloud image – the image includes all of the required dependencies
- Zabbix appliance – All of the available Zabbix appliance images contain the required dependencies
Environment review
Before upgrading between major Zabbix versions, it is very much recommended to do an environment review and take a look at the pending maintenance tasks for our environment and also do a health check. Some of the things that we should consider before performing the upgrade to Zabbix 6.0 LTS:
- Apply any required OS or DB upgrades before upgrading Zabbix and check for any issues before moving on
- Check for any customizations in your installation – are there any DB schema changes? Any custom modules or patches?
- The best way to test this is to make a copy of your existing Zabbix instance and test the upgrade in a QA environment.
- Are the required packages available for all of the Zabbix components?
- Are all proxies installed on the supported OS versions?
- Check the documentation for any known issues in the version to which you are upgrading
Important changes that affect the upgrade process
There are some changes in Zabbix 6.0 LTS that could potentially affect the upgrade process or your existing Zabbix workflows.
API Changes
Below is a list of documentation pages related to API changes between versions 5.0 and 6.0:
- https://www.zabbix.com/documentation/6.0/manual/api/changes_5.4_-_6.0
- https://www.zabbix.com/documentation/current/manual/api/changes_5.2_-_5.4
- https://www.zabbix.com/documentation/5.2/manual/api/changes_5.0_-_5.2
Some of the more important API changes:
- Trigger and calculated/aggregated item syntax change introduced in Zabbix 5.4 also change the API calls responsible for creating triggers (ZBXNEXT-6451)
- You will need to change the trigger syntax in your API calls to avoid any issues
- For user.create and user.update methods the user_medias parameter was renamed to medias (ZBX-17955)
- user_medias parameter is now deprecated
- The type property is no longer supported for user.create, user.update, and user.get methods (ZBXNEXT-6148)
- The type property is not supported for the user object since we now define it in user roles
- Items no longer support applications. Applications have been replaced with tags (ZBXNEXT-2976)
- Since value maps can no longer be defined globally, the valuemap.create and valuemap.get methods now require a hostid field (ZBXNEXT-5868)
Other important changes
There are a couple of important changes that users should be aware of when migrating to Zabbix 6.0 LTS:
- Previously, trailing spaces in passwords – both when setting a password and entering it, were trimmed. This has been changed, and trailing spaces in passwords are no longer trimmed.
- Global value maps that remain unused will be removed
- Existing audit log records will be removed due to major changes in the audit log design.
Upgrade steps
Next, let’s discuss the steps that you should take to perform the upgrade procedure in a correct and safe manner:
- Backup your database, as well as any customizations (external scripts, alert scripts) and configuration files
- Update the Zabbix server and Zabbix frontend
- Once the new Zabbix server process is started, it will automatically check the database schema version and automatically upgrade it
- Depending on the database size and the version from which you are migrating – this can take a while
- Once the automatic database schema upgrade is done, the Zabbix server will be started automatically
- Update your proxies. Proxies are required to have the same major version as the Zabbix server
- Check if there are no issues and your Zabbix instance is up and running
- Check if the metrics are being collected by your Zabbix server and Zabbix proxies
- Check if the triggers are detecting any problems and if you’re receiving notifications about them
Backup
Let’s take a more in-depth look at the backup process and discuss the required steps with some examples:
- Backup the database – methods depend on the DB type
- In most cases, you can ignore history and trends tables – simply backing up only your configuration data
- History and trends tables tend to be extremely large. That’s why the above approach is a lot faster
- If at some point you are required to perform a restore from this backup, history, and trends tables will have to be manually recreated
- Backup the Zabbix configuration files
- Optionally – backup any custom alert scripts, external scripts, and any other customizations
Example MySQL database backup with history and trends tables ignored:
mysqldump -uroot -p --single-transaction --ignore-table=zabbix.history --ignore-table=zabbix.history_uint --ignoretable=zabbix.history_text --ignore-table=zabbix.history_log --ignore-table=zabbix.history_str --ignore-table=zabbix.trends --ignore-table=zabbix.trends_uint zabbix | gzip > zabbix_backup.sql.gz
Backing up the configuration
At the very least, you should back up the configuration files located in:
- /etc/zabbix/*
- external scripts from /usr/lib/zabbix/externalscripts/
- alert scripts from /usr/lib/zabbix/alertscripts
- /etc/httpd/conf.d/zabbix.conf
- /etc/php-fpm.d/zabbix.conf
Upgrade process with docker
There are multiple approaches to running Zabbix in docker. For this example, we will assume that you’re running Zabbix server and Zabbix frontend in docker and using the official Zabbix docker images with a MySQL backend database and apache web backend.
Stop the Zabbix server, frontend, and proxy containers:
docker stop my-zabbix-server
docker stop my-zabbix-frontend
Start the Zabbix 6.0 LTS container and point it at the same backend database:
docker run --name my-zabbix-server-6.0 -e DB_SERVER_HOST="some-mysql-server" -e MYSQL_USER="some-user" -e MYSQL_PASSWORD="some-password" -d zabbix/zabbixserver-mysql:6.0-latest
Once again, an automatic DB schema upgrade will be started
Lastly, start the Zabbix frontend container:
docker run --name my-zabbix-web-apache-6.0 -e DB_SERVER_HOST="some-mysqlserver" -e MYSQL_USER="some-user" -e MYSQL_PASSWORD="some-password" -e ZBX_SERVER_HOST= "my-zabbix-server-6.0" -d zabbix/zabbix-web-apache-mysql:6.0-latest
Upgrade process with Zabbix packages
Upgrading the main Zabbix components
If you’re using the official Zabbix packages, then the upgrade process will take a few more steps and can seem a bit more complicated. Let’s take a look at the required upgrade steps in detail. For our example, we will use a CentOS 8 OS distribution.
Install the Zabbix 6.0 LTS release package. This will add the necessary Zabbix 6.0 LTS repository information:
rpm -Uvh https://repo.zabbix.com/zabbix/6.0/rhel/8/x86_64/zabbix-release-6.0-1.el8.noarch.rpm
Clear the DNF package manager cache:
dnf clean all
Install all of the required packages:
dnf install zabbix-server-mysql zabbix-web zabbix-web-mysql zabbix-web-deps zabbix-apache-conf zabbix-selinux-policy
Start Zabbix components and observe the log file. You should see that the database schema upgrade is in progress. Once it has finished, all of the internal Zabbix processes should be started without any issues:
17602:20210921:131335.333 completed 96% of database upgrade 17602:20210921:131335.355 completed 97% of database upgrade 17602:20210921:131335.379 completed 98% of database upgrade 17602:20210921:131335.606 completed 99% of database upgrade 17602:20210921:131335.711 completed 100% of database upgrade 17602:20210921:131335.711 database upgrade fully completed 17602:20210921:131335.804 server #0 started [main process] 17602:20210921:131335.808 server #2 started [configuration syncer #1] 17602:20210921:131335.810 server #1 started [service manager #1]
Upgrading the Zabbix proxies
In addition, we are also required to update our Zabbix proxies. The procedure is very similar to what we did in our previous steps:
Install the Zabbix 6.0 LTS release package:
rpm -Uvh https://repo.zabbix.com/zabbix/6.0/rhel/8/x86_64/zabbix-release-6.0-1.el8.noarch.rpm
Clear the DNF package manager cache:
dnf clean all
Update the Zabbix proxy packages:
dnf update zabbix-proxy-mysql(pgsql, sqlite3)
For MySQL, PostgreSQL, and Oracle proxy backend databases, the DB schema is performed automatically.
For Zabbix proxies using SQLite3 backend databases, automatic database schema upgrade is not supported. We will simply have to remove the old SQLite3 database file – it will then be automatically recreated once we start the Zabbix proxy.
rm –rf /tmp/proxy.sqlite
Post-upgrade tasks
After the upgrade to Zabbix 6.0 LTS, there are a few additional tasks that we should take care of. Let’s take a look at what needs to be done.
History table primary key
Zabbix 6.0 LTS backend database history table schema has been changed. These tables now contain primary keys. The upgrade or these history tables is not done automatically since it can cause additional downtime. Depending on the size of the database, executing the required changes can be extremely slow since every record in the history tables needs to be altered. In addition, duplicate entries in history tables could potentially cause this manual database schema upgrade to fail. There are multiple benefits to the history table schema changes:
- All history tables will now have primary keys
- Decreased history table storage size
- Increased history table query performance
- Not recommended when upgrading an existing instance
For new Zabbix 6.0 LTS installations, this change will be included by default, while for the existing installations, it is recommended to thoroughly test the history table schema change procedure and evaluate the potential downtimes. The exact history table upgrade steps will be documented with the release of Zabbix 6.0 LTS.
Check new processes
There are some new Zabbix processes that have been added to Zabbix 6.0 LTS that yous should be aware of:
- StartHistoryPollers
- The process responsible for handling calculated, aggregated, and internal checks requiring a database connection
- The default value is 5. Consider increasing this number if you have many such items
- If migrating from 4.0: StartLLDProcessors
- Worker process for low-level discovery tasks
- The default value is 2. Consider increasing if you have many low-level discovery rules.
Update the existing templates
If you’ve performed a Zabbix upgrade before, you will be aware of the fact that Zabbix does not update your existing templates automatically since we assume there could be some custom changes performed by the end-users on said templates. Therefore, to see the aforementioned new processes in the Zabbix server internal monitoring graphs, you should download and import the latest Zabbix server template.
You can download the templates from the official Zabbix git page. You can read the release notes to see the full list of the updated templates and changes that have been performed on said templates.
Update the Zabbix agents
You may also consider upgrading your Zabbix agents. This is not mandatory since Zabbix agents are backward compatible, so you can use an older version of Zabbix agents with Zabbix 6.0 LTS. All of the previous functionality will continue to function, but you may still consider updating the agents since the updates could contain some bug fixes or support for a brand new set of items.
Upgrading the Zabbix agent:
dnf install zabbix-agent
Upgrading the Zabbix agent 2:
dnf install zabbix-agent2
New Zabbix packages
You may have noticed that in Zabbix 6.0 LTS, there are multiple new packages. Most of these packages are repackagings of some of the old components for better package management, but there are exceptions:
- zabbix-selinux-policy – basic SELinux policy for Zabbix
- zabbix-sql-scripts – All of the .sql backend database scripts
- These used to be a part of the zabbix-server package
- This package is required to, for example, deploy the initial Zabbix database schema or data during the Zabbix install process.
- zabbix-web-service – The service responsible for the scheduled report generation
Questions
Q: Are my custom templates going to be affected in any way by the upgrade process?
A: Yes, all of your templates will continue to work. Any changes that we have made to trigger syntax, for example, will be automatically applied to your existing entities.
Q: How long will the migration process take? How can I estimate the downtime?
A: Unfortunately, it’s impossible to estimate a precise downtime duration without creating a QA copy of your existing Zabbix instance with the same exact hardware and checking the downtime duration there with a test upgrade. At the end of the day, this will depend not only on the size of the database but also on the size of individual tables, the version from which you are upgrading, and how optimized your software and hardware are.
Q: What about migrating from a very old version – say Zabbix 3.0 or older?
A: It should work, but there can be some caveats and additional pre-requisites required for the older version upgrades. I would recommend going through our previous Summit recordings since we have covered the upgrade process for older versions in previous years. Those should provide you a pre-requisite checklist that you can perform before upgrading to Zabbix 6.0 LTS.
The post A guide to migrating to Zabbix 6.0 LTS by Edgars Melveris / Zabbix Summit Online 2021 appeared first on Zabbix Blog.
Don’t Reinvent Date Formats
Post Syndicated from Bozho original https://techblog.bozho.net/dont-reinvent-date-formats/
Microsoft Exchange has a bug that practically stops email. (The public sector is primarily using Exchange, so many of the institutions I’m responsible for as a minister, have their email “stuck”). The bug is described here, and fortunately, has a solution.
But let me say something simple and obvious: don’t reinvent date formats, please. When in doubt, use ISO 8601 or epoch millis (in UTC), or RFC 2822. Nothing else makes sense.
Certainly treating an int as a date is an abysmal idea (it doesn’t even save that much resources). 202201010000 is not a date format worth considering.
(As a side note, another advice – add automate tests for future timestamps. Sometiimes they catch odd behavior).
I’ll finish with Jon Skeet’s talk on dates, strings and numbers.
The post Don’t Reinvent Date Formats appeared first on Bozho's tech blog.
[$] LWN’s unreliable predictions for 2022
Post Syndicated from original https://lwn.net/Articles/878573/rss
It is 2022 already, and that can only mean one thing: it’s time for your
editor to make a (bigger) fool of himself by posting a set of
predictions for what may come in the new year. One should never pass up an
opportunity for a humbling experience, after all. There can be no doubt
that interesting things will happen this year; let’s see how many random
darts thrown in that direction can hit close to the mark.
How to configure an incoming email security gateway with Amazon WorkMail
Post Syndicated from Jesse Thompson original https://aws.amazon.com/blogs/security/how-to-configure-an-incoming-email-security-gateway-with-amazon-workmail/
This blog post will walk you through the steps needed to integrate Amazon WorkMail with an email security gateway. Configuring WorkMail this way can provide a versatile defense strategy for inbound email threats.
Amazon WorkMail is a secure, managed business email and calendar service. WorkMail leverages the email receiving capabilities of Amazon Simple Email Service (Amazon SES) to scan all incoming and outgoing email for spam, malware, and viruses to help protect your users from harmful email. AWS Lambda for Amazon WorkMail functions can tap into the capabilities of other AWS services to accomplish additional business objectives, such as controlling message delivery or message modification.
For many organizations, existing features and integrations with Amazon SES are sufficient for their spam, malware, and virus detection. Other organizations may need either a dedicated on-premise security solution, or have other reasons to use an additional inspection point in the overall mail flow. A number of commercial and community-supported tools include features like special encryption capabilities, data loss prevention (DLP) content inspection engines, and embedded-hyperlink transformation features to protect end-user mailboxes.
Prerequisites
To implement this solution, you need:
- A domain name and permission to alter domain name system (DNS) records in Amazon Route 53 or your existing DNS provider. This could be your organization’s existing domain (such as example.org), a new domain (such as example.net), or a subdomain (such as sub.example.org).
- Access to an AWS account so you can configure WorkMail and Amazon SES. Optionally, you may also need the ability to create AWS Lambda functions to integrate with WorkMail.
- Access to configure the email security gateway of your choosing.
How email flows with an email security gateway
Email security gateways function by handling the initial ingress of email via the Simple Mail Transport Protocol (SMTP). When email servers send messages to your domain’s email addresses, they look at your domain’s mail exchange (MX) record in the DNS. After processing an email message, the email security gateway delivers it to the downstream mailbox hosting service, such as WorkMail, by means of Amazon SES via SMTP. You can also optionally configure an AWS Lambda for Amazon WorkMail function to synchronously deliver messages into end-user junk email folders, or to take other actions.
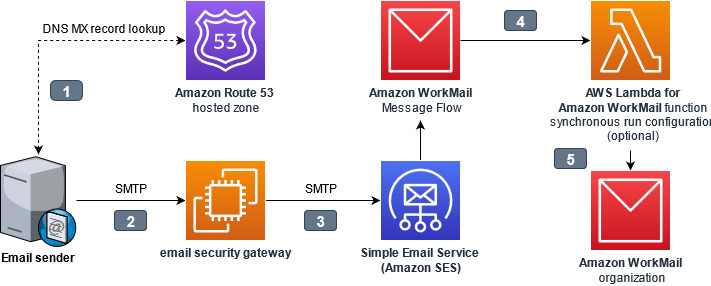
Figure 1. Interaction points while architecting an email security gateway
The interaction points are as follows:
- The email sender looks up the mail exchange (MX) record for the domain hosted by WorkMail. The domain name system (DNS) domain may be hosted in Route 53, or by another DNS hosting provider. The value of the MX record contains the internet protocol (IP) address of the email security gateway.
- The email sender connects to the email security gateway, and sends the message using the Simple Mail Transfer Protocol (SMTP)
- The email security gateway accepts, processes, and then delivers the message to the ingress SMTP endpoint for WorkMail. Amazon Simple Email Service (Amazon SES) handles inbound email receiving for WorkMail.
- Optionally, an AWS Lambda for Amazon WorkMail function can synchronously process messages before delivery to WorkMail.
- WorkMail receives the message for final delivery to the end-user.
The gateway assumes responsibility for inspecting incoming email, because the initial point of ingress is an important component of a multi-layer defense strategy against email-borne threats. The gateway could refuse or quarantine risky messages, it could modify the email subjects and body to add warnings visible to recipients, or it could append metadata to the email headers for downstream processing by an AWS Lambda function.
Why point of ingress email authentication is important
What is email authentication
SMTP was built at a time when networking was less reliable than it is today, and consequently, it was designed to be able to allow any domain to store and later forward messages on behalf of other domains to mitigate connection problems. While that helped at the time, today it presents real problems in authenticating who truly sent a message: the owner of the domain, or just someone else claiming to be the owner? To overcome this issue, the messaging industry has adopted three protocols to help verify the authenticity of a message: SPF, DKIM, and DMARC. These protocols aren’t perfect, but understanding how to use them is important when adding new steps to your message processing workflow, because they can affect how you receive inbound mail.
Sender Policy Framework
Sender Policy Framework (SPF) permits domain owners to declare which SMTP servers are allowed to send email messages claiming to be from their domain. This establishes an identity relationship between the owner of the domain and the authorized party that controls the SMTP server. When SPF is used, a message can only be handed off directly from an authorized SMTP server; it cannot be relayed through a second, unauthorized server without changing the originating address.
DomainKeys Identified Mail (DKIM)
DomainKeys Identified Mail (DKIM) permits domain owners to advertise a public key that a mail recipient’s system can use to verify the sender’s digital signature. This allows SMTP servers and other downstream applications to check the validity of the digital signature against the public key of the domain which had the matching private key to create the signature. DKIM signatures attached to messages can remain intact through intermediary SMTP servers, but if message contents (email body or email headers) are modified by intermediary servers, the final destination will find that the signature is no longer valid.
Domain-based Message Authentication, Reporting and Conformance (DMARC)
Domain-based Message Authentication, Reporting and Conformance (DMARC) permits domain owners to publish a policy telling receiving servers what to do when SPF or DKIM are not valid, such as if a message originated from an unauthorized server, or if it was tampered with after being sent. DMARC checks if a message matches what it knows about the sender via SPF and DKIM, a process known as alignment. The recipient’s server can then enforce the DMARC policy, for example by rejecting or quarantining non-aligned messages.
Tying it all together
Amazon WorkMail normally performs DMARC enforcement for inbound messages, based on their alignment when they were received by Amazon SES. But when an email security gateway acts as an intermediary SMTP server between the original sender and WorkMail, that breaks the relationship with the SMTP servers authorized by SPF, and if the gateway modifies the message, that invalidates the DKIM signature. This is why it’s necessary for the SMTP server at the point of ingress to perform the evaluation of SPF, DKIM, and DMARC. The email security gateway at the border should be made responsible for enforcing DMARC on messages that don’t align, and WorkMail DMARC enforcement should be disabled.
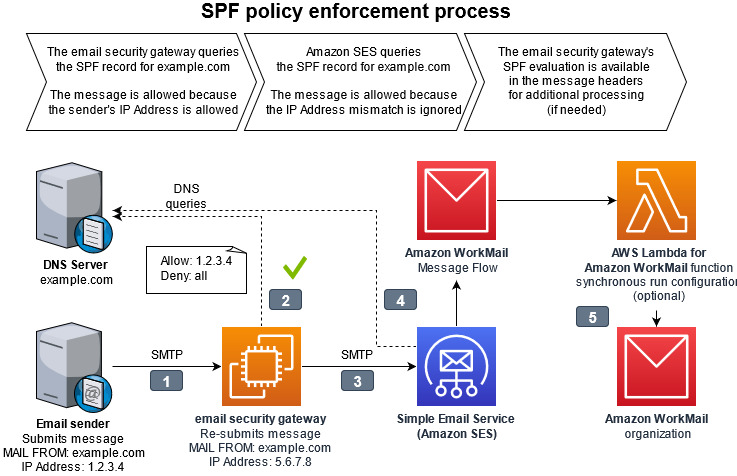
Figure 2. Diagram of SPF policy enforcement process. The full details of the interaction points are outlined below.
The interaction points for SPF policy enforcement are as follows:
- The email sender delivers the message to the email security gateway with a MAIL FROM address within a domain the sender owns.
- The email security gateway looks up the sender’s domain’s Sender Permitted From (SPF) policy in DNS to determine if the sending mail server’s IP address is authorized.
- The email security gateway delivers the message to Amazon SES with the same MAIL FROM address. The email security gateway has a different IP address than the original sending email server.
- When Amazon SES looks up the MAIL FROM domain’s SPF, it will not find the email security gateway’s IP address as authorized. From the perspective of Amazon SES, and the resulting logs in Amazon Cloudwatch, the message will appear to be unauthorized by the SPF policy. This result is ignored by disabling DMARC checks in the WorkMail organization configuration.
- The message continues delivery to WorkMail with an optional integration with AWS Lambda for Amazon WorkMail synchronous run configuration, which can analyze message headers to get a more complete picture of the message’s authenticity.
Choosing an email security gateway
Many email security vendors offer software as a service (SaaS) solutions. This offloads all management responsibilities to the software vendor’s platform. These solutions work as long as they support the email gateway features necessary for this solution as depicted in Figure 2 and described in the Why point of ingress email authentication is important section above.
If you wish to build and maintain your own email security gateway, you may deploy one available from the AWS Marketplace or add an open source application into your Amazon Virtual Private Cloud (Amazon VPC). You will need to remove port 25 restriction from your EC2 instance for the email security gateway within your Amazon VPC to send email to Amazon WorkMail.
How to configure Amazon WorkMail
Follow this procedure to configure your WorkMail organization and Amazon SES IP address filters to allow the email security gateway to process inbound email receiving.
To configure Amazon WorkMail
- From the WorkMail console, select your organization, navigate to Organization settings, and select Advanced. Edit the Inbound DMARC Settings and set Enforcement enabled to Off. This ensures that WorkMail does not re-evaluate DMARC.

Figure 3. Picture of the AWS WorkMail console showing the advanced configuration depicting Inbound DMARC enforcement disabled
- From the Amazon SES console, navigate to Email receiving and create IP address filters to allow the IP address or IP address range of the gateway(s).
- Add another rule to block 0.0.0.0/0. This prevents malicious actors from bypassing your email security gateway.

Figure 4. Picture of the Amazon SES console showing example IP address filters to allow the email security gateway IP addresses and blocking every other IP Address
- From the Route 53 console, navigate to Hosted zones, select the domain and edit the MX record to the IP address or hostname of the gateway. This causes all email senders to deliver to your gateway, instead of delivering directly to WorkMail.
Follow the instructions of your DNS provider if the domain’s DNS is hosted elsewhere.
Figure 5. Picture of the Amazon Route 53 console showing that the DMS MX record for the domain needs to be configured with the IP address of the email security gateway
- From the WorkMail console, navigate to Domains, select your domain to show the Domain verification status page.
- Copy the host name from the value of the MX record type as depicted in Figure 6.

Figure 6. Picture showing the section of the MX record value to copy from the WorkMail console.
- Configure your email security gateway with the value that you just copied (e.g. inbound-smtp.us-east-1.amazonaws.com) to send inbound messages to your WorkMail organization. Instructions for doing this will vary depending on which email security gateway you are using.




Some specifics of this configuration depend on which gateway you are using, how it is designed for high availability, and the type of features configured. Test your WorkMail integration with a non-production domain before changing your production domain.
It is normal for Amazon CloudWatch logs for WorkMail, as well as the individual message headers, to show that SPF fails for all messages which traverse the gateway. Configure the email security gateway to record its SPF evaluation in the message headers so that it remains available for troubleshooting and further processing.
Junk E-Mail folder integration
WorkMail normally moves spam messages into the Junk E-mail folder within each recipient’s mailbox. To replicate this behavior for spam messages identified by the email security gateway, use AWS Lambda for Amazon WorkMail with a synchronous run configuration to run a function for every inbound message to a group of recipients.
To configure an AWS Lambda function for every inbound message (optional)
- Configure the email security gateway to include a spam verdict in the message headers for all incoming mail.
- Create a synchronous run configuration using AWS Lambda for Amazon WorkMail to interpret the message headers and return a response to WorkMail with type: BYPASS_SPAM_CHECK or MOVE_TO_JUNK. A sample Amazon WorkMail Upstream Gateway Filter solution is available in the AWS Serverless Application Repository.
Conclusion
By integrating an email security gateway and leveraging AWS Lambda for Amazon WorkMail, you will gain additional security and management control over your organization’s inbound email. To learn more, read the Amazon WorkMail FAQs and Amazon WorkMail documentation.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
The Hate-Crime Conundrum—The Experiment Podcast
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=BTn60QHjTg8
How Meshify Built an Insurance-focused IoT Solution on AWS
Post Syndicated from Grant Fisher original https://aws.amazon.com/blogs/architecture/how-meshify-built-an-insurance-focused-iot-solution-on-aws/
The ability to analyze your Internet of Things (IoT) data can help you prevent loss, improve safety, boost productivity, and even develop an entirely new business model. This data is even more valuable, with the ever-increasing number of connected devices. Companies use Amazon Web Services (AWS) IoT services to build innovative solutions, including secure edge device connectivity, ingestion, storage, and IoT data analytics.
This post describes Meshify’s IoT sensor solution, built on AWS, that helps businesses and organizations prevent property damage and avoid loss for the property-casualty insurance industry. The solution uses real-time data insights, which result in fewer claims, better customer experience, and innovative new insurance products.
Through low-power, long-range IoT sensors, and dedicated applications, Meshify can notify customers of potential problems like rapid temperature decreases that could result in freeze damage, or rising humidity levels that could lead to mold. These risks can then be averted, instead of leading to costly damage that can impact small businesses and the insurer’s bottom line.
Architecture building blocks
The three building blocks of this technical architecture are the edge portfolio, data ingestion, and data processing and analytics, shown in Figure 1.

Figure 1. Building blocks of Meshify’s technical architecture
I. Edge portfolio (EP)
Starting with the edge sensors, the Meshify edge portfolio covers two types of sensors:
- LoRaWAN (Low power, long range WAN) sensor suite. This sensor provides the long connectivity range (> 1000 feet) and extended battery life (~ 5 years) needed for enterprise environments.
- Cellular-based sensors. This sensor is a narrow band/LTE-M device that operates at LTE-M band 2/4/12 radio frequency and uses edge intelligence to conserve battery life.
II. Data ingestion (DI)
For the LoRaWAN solution, aggregated sensor data at the Meshify gateway is sent to AWS using AWS IoT Core and Meshify’s REST service endpoints. AWS IoT Core is a managed cloud platform that lets IoT devices easily and securely connect using multiple protocols like HTTP, MQTT, and WebSockets. It expands its protocol coverage through a new fully managed feature called AWS IoT Core for LoRaWAN. This gives Meshify the ability to connect LoRaWAN wireless devices with the AWS Cloud. AWS IoT Core for LoRaWAN delivers a LoRaWAN network server (LNS) that provides gateway management using the Configuration and Update Server (CUPS) and Firmware Updates Over-The-Air (FUOTA) capabilities.
III. Data processing and analytics (DPA)
Initial processing of the data is done at the ingestion layer, using Meshify REST API endpoints and the Rules Engine of AWS IoT Core. Meshify applies filtering logic to route relevant events to Amazon Managed Streaming for Apache Kafka (Amazon MSK). Amazon MSK is an AWS streaming data service that manages Apache Kafka infrastructure and operations, streamlining the process of running Apache Kafka applications on AWS.
Meshify’s applications then consume the events from Amazon MSK per the configured topic subscription. They enrich and correlate the events with the records with a managed service, Amazon Relational Database Service (RDS). These applications run as scalable containers on another managed service, Amazon Elastic Kubernetes Service (EKS), which runs container applications.
Bringing it all together – technical workflow
In Figure 2, we illustrate the technical workflow from the ingestion of field events to their processing, enrichment, and persistence. Finally, we use these events to power risk avoidance decision-making.

Figure 2. Technical workflow for Meshify IoT architecture
- After installation, Meshify-designed LoRa sensors transmit information to the cloud through Meshify’s gateways. LoRaWAN capabilities create connectivity between the sensors and the gateways. They establish a low power, wide area network protocol that securely transmits data over a long distance, through walls and floors of even the largest buildings.
- The Meshify Gateway is a redundant edge system, capable of sending sensor data from various sensors to the Meshify cloud environment. Once the LoRa sensor information is received by the Meshify Gateway, it converts the incoming radio frequency (RF) signals, which support faster transfer rate to Meshify’s cloud environment.
- Data from the Meshify Gateway and sensors is initially processed at Meshify’s AWS IoT Core and REST service endpoints. These destinations for IoT streaming data help with the initial intake and introduce field data to the Meshify cloud environment. The initial ingestion points can scale automatically based upon the volume of sensor data received. This enables rapid scaling and ease of implementation.
- After the data has entered the Meshify cloud environment, Meshify uses Amazon EKS and Amazon MSK to process the incoming data stream. Amazon MSK producer and consumer applications within the EKS systems enrich the data streams for the end users and systems to consume.
- Producer applications running on EKS send processed events to the Amazon MSK service. These events include storing and retrieval of raw data, enriched data, and system-level data.
- Consumer applications hosted on the EKS pods receive events per the subscribed Amazon MSK topic. Web, mobile, and analytic applications enrich and use these data streams to display data to end users, business teams, and systems operations.
- Processed events are persisted in Amazon RDS. The databases are used for reporting, machine learning, and other analytics and processing services.
Building a scalable IoT solution
Meshify first began work on the Meshify sensors and hosted platform in 2012. In the ensuing decade, Meshify has successfully created a platform to auto-scale upon demand with steady, predictable performance. This gave Meshify both the ability to use only the resources needed, and still have the capacity to handle unexpected voluminous data.
As the platform scaled, so did the volume of sensor data, operations and diagnostics data, and metadata from installations and deployments. Building an end-to-end data pipeline that integrates these different data sources and delivers co-related insights at low latency was time well spent.
Conclusion
In this post, we’ve shown how Meshify is using AWS services to power their suite of IoT sensors, software, and data platforms. Meshify’s most important architectural enhancements have involved the introduction of managed services, notably AWS IoT Core for LoRaWAN and Amazon MSK. These improvements have primarily focused on the data ingestion, data processing, and analytics stages.
Meshify continues to power the data revolution at the intersection of IoT and insurance at the edge, using AWS. Looking ahead, Meshify and HSB are excited at the prospect of scaling the relationship with AWS from cloud computing to the world of edge devices.
Learn more about how emerging startups and large enterprises are using AWS IoT services to build differentiated products.
Meshify is an IoT technology company and subsidiary of HSB, based in Austin, TX. Meshify builds pioneering sensor hardware, software, and data analytics solutions that protect businesses from property and equipment damage.
Comprehensive Cyber Security Framework for Primary (Urban) Cooperative Banks (UCBs)
Post Syndicated from Vikas Purohit original https://aws.amazon.com/blogs/security/comprehensive-cyber-security-framework-for-primary-urban-cooperative-banks/
We are pleased to announce a new Amazon Web Services (AWS) workbook designed to help India Primary (UCBs) customers align with the Reserve Bank of India (RBI) guidance in Comprehensive Cyber Security Framework for Primary (Urban) Cooperative Banks (UCBs) – A Graded Approach.
In addition to RBI’s basic cyber security framework for Primary (Urban) Cooperative Banks (UCBs), RBI issued guidance on its comprehensive cyber security framework, which sets the expectations for the Indian Primary UCBs regarding their cyber security frameworks. This guidance divides the framework into four levels, starting with a common level that applies to all UCBs; the remaining levels apply to specific UCBs based upon their digital depth, and interconnectedness to the payment systems landscape based on RBI-defined criteria. The guidance aims to increase the awareness among the Primary UCBs in India of the controls they should look for as they progress on their digital journey.
Security and compliance is a shared responsibility between AWS and the customer. This differentiation of responsibility is commonly referred to as the AWS Shared Responsibility Model, in which AWS is responsible for security of the cloud, and the customer is responsible for their security in the cloud.
The new AWS Comprehensive Cyber Security Framework for Primary (Urban) Cooperative Banks (UCBs) – A Graded Approach workbook helps customers align with the RBI cyber security framework by providing control mappings for the following:
- Security in the cloud by mapping RBI’s cyber security framework to the five pillars of the AWS Well-Architected Framework
- Security of the cloud by mapping RBI’s cyber security framework to control statements from the AWS Compliance Program
The downloadable AWS RBI Comprehensive Cyber Security Framework for Primary UCBs workbook is available in AWS Artifact, a self-service portal for on-demand access to AWS Compliance Reports, and it contains two embedded formats:
- Microsoft Excel: Coverage includes AWS responsibility control statements and Well-Architected Framework best practices
- Dynamic HTML: Coverage is the same as in the Microsoft Excel format, with the added feature that the Well Architected Framework best practices are mapped to AWS Config managed rules and Amazon GuardDuty findings, where available or applicable.
The AWS RBI Comprehensive Cyber Security Framework for Primary UCBs and AWS RBI Basic Cyber Security Framework for Primary UCBs Workbook are available for download in AWS Artifact. Sign into AWS Artifact via the AWS Management Console, or learn more at Getting Started with AWS Artifact.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
Koch: A New Future for GnuPG
Post Syndicated from original https://lwn.net/Articles/880248/rss
Longtime GnuPG maintainer Werner Koch has posted an update on the project,
mostly focused on the new associated “GnuPG VS-Desktop” business that is,
it seems, going quite well:
For many years our work was mainly financed by donations and smaller
projects. Now we have reached a point where we can benefit from a
continuous revenue stream to maintain and extend the software without
asking for donations or grants. This is quite a new experience to us
and I am actually a bit proud to lead one of the few self-sustaining
free software projects who had not to sacrifice the goals of the
movement.
He concludes with a request for individuals who have been donating to GnuPG
to redirect their generosity toward another deserving project. This is
good news; GnuPG ran on a shoestring for far too long.
GIMP 2021 annual report
Post Syndicated from original https://lwn.net/Articles/880241/rss
The GIMP project has put out a
report summarizing a year of development on this image-manipulation
application.
With 4 development versions released already, you know that we are
working very hard on the future: GIMP 3.0.Some features took a lot of time, mostly when we changed core
logics. I am thinking in particular about the code for
multi-selection of layers. It’s not that selecting multiple items
in a list is hard to implement, it’s that any feature in the whole
application has been forever expecting just one layer or one
channel selected. So what happens when there are 2, 3 or any number
of items selected? Every feature, every tool, every plug-in and
filter has to be rethought for this new use case.
Long Range Zigbee Smart Home 2 – The HOW? and WHY?
Post Syndicated from digiblurDIY original https://www.youtube.com/watch?v=4Sdppe1_-jA
Sharing the Gifts of Cybersecurity – Or, a Lesson From My First Year Without Santa
Post Syndicated from Amy Hunt original https://blog.rapid7.com/2022/01/03/sharing-the-gifts-of-cybersecurity-or-a-lesson-from-my-first-year-without-santa/

Editor’s note: We had planned to publish our Hacky Holidays blog series throughout December 2021 – but then Log4Shell happened, and we dropped everything to focus on this major vulnerability that impacted the entire cybersecurity community worldwide. Now that it’s 2022, we’re feeling in need of some holiday cheer, and we hope you’re still in the spirit of the season, too. Throughout January, we’ll be publishing Hacky Holidays content (with a few tweaks, of course) to give the new year a festive start. So, grab an eggnog latte, line up the carols on Spotify, and let’s pick up where we left off.
My kid stopped believing this year.
I did what they recommend: said she was big enough to know the truth, that we are all Santas, and now she must be one, too. Every one of us — whether December means Christmas, Hanukkah, Kwanzaa, or just winter — is expected to give generously and sometimes anonymously, just to spread the goodness. And ideally, we do it a whole lot more than once a year.
Then, the a-ha moment arrived. You know who some of the best Santas on Earth are? The cybersecurity community. It’s full of givers, mostly with names we’ll never know.
Rewind to the early years of the internet: A 15-year-old hacked the source code for NASA’s International Space Station; Russians extracted $10 million from Citibank; the Department of Justice and Los Alamos National Laboratory (site of the Manhattan Project and home to classified nuclear and weapons secrets) were breached.
What happened next? Organized beneficence
In 1999, MITRE researchers released the first searchable public record of 321 common vulnerabilities. In less than 3 years, there were 2,000+ vulnerabilities shared. By 2013, the effort resulted in the MITRE ATT&CK Framework that documented attacker tactics and techniques based on real-world observations of advanced persistent threat actors. With this framework, the security community has a common language and library to understand attackers — and what we can do to stop them.
MITRE ATT&CK is open and available to anyone for use at no charge. Of course, detailed ATT&CK mapping is part of InsightIDR’s vast library of critical attacker behaviors and endpoint detections.
Not long after MITRE published its first vulnerabilities, military systems at the Pentagon and NASA were breached by a guy looking for evidence of UFOs. The fun never ends. That same year, security expert and open source guru H.D. Moore released the first edition of his Metaspoit Project with 11 exploits. Metasploit 2.0 followed quickly. With the 3.0 release, users began to contribute and a community was born.
Today, Rapid7’s Metasploit is a voluntary collaboration between 300,000+ users and contributors around the world, including Rapid7 security engineers. It includes more than 1677 exploits organized over 25 platforms, and nearly 500 payloads. And it’s a favorite of pen testers and red teamers worldwide.
The Cyber Threat Alliance took everything up a notch
A nonprofit working to improve the security of our global digital ecosystem by enabling near real-time, high-quality threat information sharing, the Cyber Threat Alliance (CTA) has staff and a technology platform for sharing advanced threat data. CTA members — often competitors — work together in good faith to distribute timely, actionable, contextualized, and campaign-based intelligence.
Rapid7 is among the members who, on average, share 5 million observable events per month. And the result: We all get ever-better at thwarting adversaries and improving our collective security.
In 2017, the holiday spirit became a quarterly thing for us
That’s the year Rapid7 released our first threat intelligence report. Today, our quarterly Threat Reports share clear, distilled learnings and practical guidance from the wealth of data we continuously gather. Our sources include:
- Metasploit, now the world’s most used pen testing framework
- Rapid7’s Insight platform, covering vulnerability management, application security, detection and response, external threat intelligence, orchestration and automation, and more
- Rapid7’s Project Sonar, which conducts internet-wide surveys across more than 70 different services and protocols to gain insights into global exposure to common vulnerabilities typically unknown to IT teams
- Project Heisenberg, a globally distributed, low-interaction honeypot network that monitors for malicious inbound connections, and a forum for collaboration and confirmation relationships with other internet-scale researchers
- Our global network of Managed Detection and Response (MDR) SOCs that use and vet Rapid7 products, do proactive threat hunting along with daily triage and remote incident response, and provide raw intelligence around emergent threats
The Internet connects everyone and everything with no centralized control. We put it together that way, and there’s clearly no grand plan to make it secure. So we step up. Every time the malware operation Emotet resurfaces, a group of security researchers and system administrators reunites to fight it. (The only name we really know is what they call themselves: “Cryptolaemus.” That’s a mealy bug that goes after unhealthy plants.)
Yes, humans are cybersecurity’s weakest link, but…
My father-in-law sent a $300 gift card to a hacker. We’re easy marks, ruled by emotions that haven’t changed much since we were cave-dwelling Paleolithic hominins.
But we’re also us. You.
Whatever winter holiday you celebrated, here’s hoping it was a good one. And that you raised a glass to all the good folks, the good fight. Don’t stop believing.
More Hacky Holidays blogs
Security updates for Monday
Post Syndicated from original https://lwn.net/Articles/880232/rss
Security updates have been issued by Debian (thunderbird), Fedora (kernel, libopenmpt, and xorg-x11-server), Mageia (gegl, libgda5.0, log4j, ntfs-3g, and wireshark), openSUSE (log4j), and Red Hat (grafana).
Zip Codes: A History
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=s7gcO-Qs9eY