Post Syndicated from Sébastien Stormacq original https://aws.amazon.com/blogs/aws/announcing-new-apis-for-amazon-location-service-routes-places-and-maps/
Today, Amazon Location Service released 17 new and enhanced APIs that expand and improve capabilities for the Routes, Places, and Maps functionalities, creating a more cohesive and streamlined experience for developers. By introducing enhanced features and offering simplified migration, these updates make Amazon Location Service more accessible and useful for a wide range of applications.
You can now access advanced route optimization, toll cost calculations, GPS traces snapping, and a variety of map styles with static and dynamic rendering options, and perform proximity-based search and predictive suggestions, with rich, detailed information on points of interest.
At Amazon, the vast majority of our roadmaps are driven by customer feedback. Many customers building applications with Amazon Location Service have shared that they need purpose-built APIs and more granular details, such as contact information and business hours, when working with location-based data. Although the current API set has provided valuable tools for many customers, developers have expressed a desire for additional capabilities, such as detailed route planning, proximity-based searches, additional places details, and static map images. These new APIs address these requests and provide a more comprehensive, out-of-the-box location solution.
New and enhanced capabilities
Today’s launch introduces 10 updated APIs and seven entirely new APIs, responding directly to your feedback. Each service—Routes, Places, and Maps—receives specific enhancements designed to support a broader range of use cases.
Routes
The Amazon Location Routes API now supports advanced route planning and customization options, allowing users to:
CalculateIsolinesto identify service areas within specific travel time, or distanceOptimizeWaypointsto determine the most efficient sequence of waypoints, helping to minimize either travel time or distance- Calculate Toll Costs to provide precise cost estimates for routes involving toll roads
SnapToRoads, to enable precise matching of GPS traces by snapping points to the road network
With these capabilities, you can design more accurate and dynamic route experiences for your users. For example, a logistics company could optimize driver routes in real-time, factoring in live traffic and minimizing travel costs for deliveries.
Maps
The updated Amazon Location Maps API includes more purpose-built map styles crafted by skilled cartographers. These map styles offer professional designs that accelerate time to market and eliminate the need for custom map creation. Additionally, the Static Map Image feature allows developers to integrate static maps within applications, reducing the need for continuous data streaming and improving performance in use cases where interactivity isn’t necessary.
Key features of the Maps API include:
GetTile, to download a tile from a tileset, with a specified X, Y, and Z axis valuesGetStyleDescriptor, to return information about the styleGetStaticMap, which enables the rendering of non-interactive maps for reporting or visualization purposes
Places
The Amazon Location Places API enhancements allow more detailed search capabilities, addressing requests for increased granularity in location data. The new capabilities include:
SearchNearbyandAutocomplete, which support proximity-based queries and enable predictive text features for better user experiences- Enhanced business details with categories such as Business Hours, Contact Information, and additional attributes for points of interest
These features are especially useful for applications where users need detailed information about nearby locations, such as food delivery services or retail applications. Imagine that a customer opens a food delivery application, searches for nearby restaurants using SearchNearby, and retrieves restaurant details such as business hours and contact information to confirm availability. Once multiple delivery orders are assigned to a driver, the application uses OptimizeWaypoints to suggest the most efficient route for pickups and deliveries. As the driver follows the route, SnaptoRoads provides precise visualization of their location, enhancing the customer’s real-time tracking experience.
Enhanced Location Service in action
Calling the API is straightforward. You can use the AWS Command Line Interface (AWS CLI), one of our AWS SDKs, or the plain REST API. However, displaying the information on a map in a web or mobile app requires some additional setup. Although the process is well documented, it’s too detailed to cover fully here. In this demo, I’ll focus on using the API.
Amazon Location Service allows API calls to be authenticated in two ways: through AWS API authentication (AWS Sigv4 authentication) or through API keys. API keys can be more convenient for developers of mobile applications where the end user is not authenticated or when integrating with Amazon Cognito is not feasible. This is the recommended authentication method for front-end applications.
To demonstrate the versatility of the APIs and how easily you can integrate inside your applications, I use a combination of the AWS CLI, cURL, and a graphical REST API client for each step of the demo.
Step 1: Create an API key
First, I create an API key for my application using the AWS CLI. You can also manage API keys in the AWS Management Console.
REGION=eu-central-1
KEYNAME=geo-key-seb
aws location create-key --region ${REGION} --key-name ${KEYNAME} --restrictions \
AllowActions="geo-routes:*","geo-places:*","geo-maps:*",\
AllowResources="arn:aws:geo-routes:${REGION}::provider/default",\
"arn:aws:geo-places:${REGION}::provider/default",\
"arn:aws:geo-maps:${REGION}::provider/default" \
--no-expiry
{
"Key": "v1.public.ey...cy",
"KeyArn": "arn:aws:geo:eu-central-1:02345678901:api-key/geo-key-seb",
"KeyName": "geo-key-seb",
"CreateTime": "2024-09-29T09:35:53.115000+00:00"
}This command generates the API key, which I can now use to call Amazon Location APIs.
Step 2: Get geographic coordinates
Next, I use cURL to retrieve the geographic coordinates (a longitude and latitude) for the city center of Lille, France, by calling GeoCode and passing an address in the QueryText parameter.
$ curl --silent -X "POST" "https://places.geo.eu-central-1.amazonaws.com/v2/geocode?key=v1.public.ey...cy" \
-d $'{ "QueryText": "Grand Place, Lille, France" }'
{"ResultItems":[{"PlaceId":"AQ...5U","PlaceType":"Street","Title":"Grand'Place, 59800 Lille, France",
"Address":{"Label":"Grand'Place, 59800 Lille, France",
"Country":{"Code2":"FR","Code3":"FRA","Name":"France"},
"Region":{"Code":"HDF","Name":"Hauts-de-France"},"SubRegion":{"Name":"Nord"},
"Locality":"Lille","District":"Centre","PostalCode":"59800",
"Street":"Grand'Place","StreetComponents":[{"BaseName":"Grand'Place","Language":"fr"}]},
"Position":[3.06361,50.63706],
"MapView":[3.0628,50.6367,3.06413,50.63729],
"MatchScores":{"Overall":1,"Components":{"Address":{"Country":1,"Locality":1,"Intersection":[1]}}}}]}This returns several data points, including the GPS coordinates for the city center: [3.06361, 50.63706].
Step 3: Search for nearby places
Using the coordinates retrieved, I use a REST API client tool to call the SearchNearby API to find places of interest around Lille’s city center.

On the right side of the screen, I can read the API response: a list of nearby places, such as restaurants, banks, and parking areas. I can further refine the search by specifying categories or restricting the search area.
The SearchNearby API accepts an optional Filter parameter that helps you restrict the search within a bounding box or to include or exclude business chains, categories, countries, or food types.
"Filter": {
"BoundingBox": [ number ],
"ExcludeBusinessChains": [ "string" ],
"ExcludeCategories": [ "string" ],
"ExcludeFoodTypes": [ "string" ],
"IncludeBusinessChains": [ "string" ],
"IncludeCategories": [ "string" ],
"IncludeCountries": [ "string" ],
"IncludeFoodTypes": [ "string" ]
},In my search for nearby points of interest, one of the results returned was a McDonald’s, a well-known international reference  .
.

Step 4: Get driving directions
Finally, I use the AWS CLI to calculate driving directions between two city centers: Brussels, Belgium, and Lille, France.
aws location calculate-routes \
--origin 4.35278 50.84687 \
--destination 3.06361 50.63706 \
--key "v1.public.ey...cy"The response includes a polyline for rendering the path on a map and a step-by-step list of driving directions.
...
"TravelMode": "Car",
"Type": "Vehicle",
"VehicleLegDetails": {
"TravelSteps": [
{
"Duration": 15,
"Distance": 75,
"ExitNumber": [],
"GeometryOffset": 0,
"Type": "Depart"
},
{
"Duration": 10,
"Distance": 8,
"ExitNumber": [],
"GeometryOffset": 2,
"Type": "Turn",
"TurnStepDetails": {
"Intersection": [],
"SteeringDirection": "Right",
"TurnIntensity": "Typical"
}
},
...Step 5: Displaying the driving directions on a map
To visualize the route on a map, I use the MapLibre library, which is a rendering engine for displaying maps in web and mobile applications. Following the Amazon Location Service Developer Guide, I built a basic app to display the route.

In addition to MapLibre, you can use AWS Amplify to integrate and display Amazon Location data in your applications.
Getting started
With these new and updated APIs, Amazon Location Service offers a more comprehensive suite of mapping and location data for your business needs. These will help to accelerate your development lifecyle by increasing developers’ agility and scalability.
To get started, explore the updated Amazon Location Service Developer Guide and begin integrating these features today. You can also visit the Amazon Location Service page to learn more or try out the APIs with your favorite AWS SDKs to see how they can enhance your applications.








 Tony Stricker is a Principal Technologist on the Data Strategy team at AWS, where he helps senior executives adopt a data-driven mindset and align their people/process/technology in ways that foster innovation and drive towards specific, tangible business outcomes. He has a background as a data warehouse architect and data scientist and has delivered solutions in to production across multiple industries including oil and gas, financial services, public sector, and manufacturing. In his spare time, Tony likes to hang out with his dog and cat, work on home improvement projects, and restore vintage Airstream campers.
Tony Stricker is a Principal Technologist on the Data Strategy team at AWS, where he helps senior executives adopt a data-driven mindset and align their people/process/technology in ways that foster innovation and drive towards specific, tangible business outcomes. He has a background as a data warehouse architect and data scientist and has delivered solutions in to production across multiple industries including oil and gas, financial services, public sector, and manufacturing. In his spare time, Tony likes to hang out with his dog and cat, work on home improvement projects, and restore vintage Airstream campers.



















 Alan Peaty is a Senior Partner Solutions Architect at AWS. Alan helps Global Systems Integrators (GSIs) and Global Independent Software Vendors (GISVs) solve complex customer challenges using AWS services. Prior to joining AWS, Alan worked as an architect at systems integrators to translate business requirements into technical solutions. Outside of work, Alan is an IoT enthusiast and a keen runner who loves to hit the muddy trails of the English countryside.
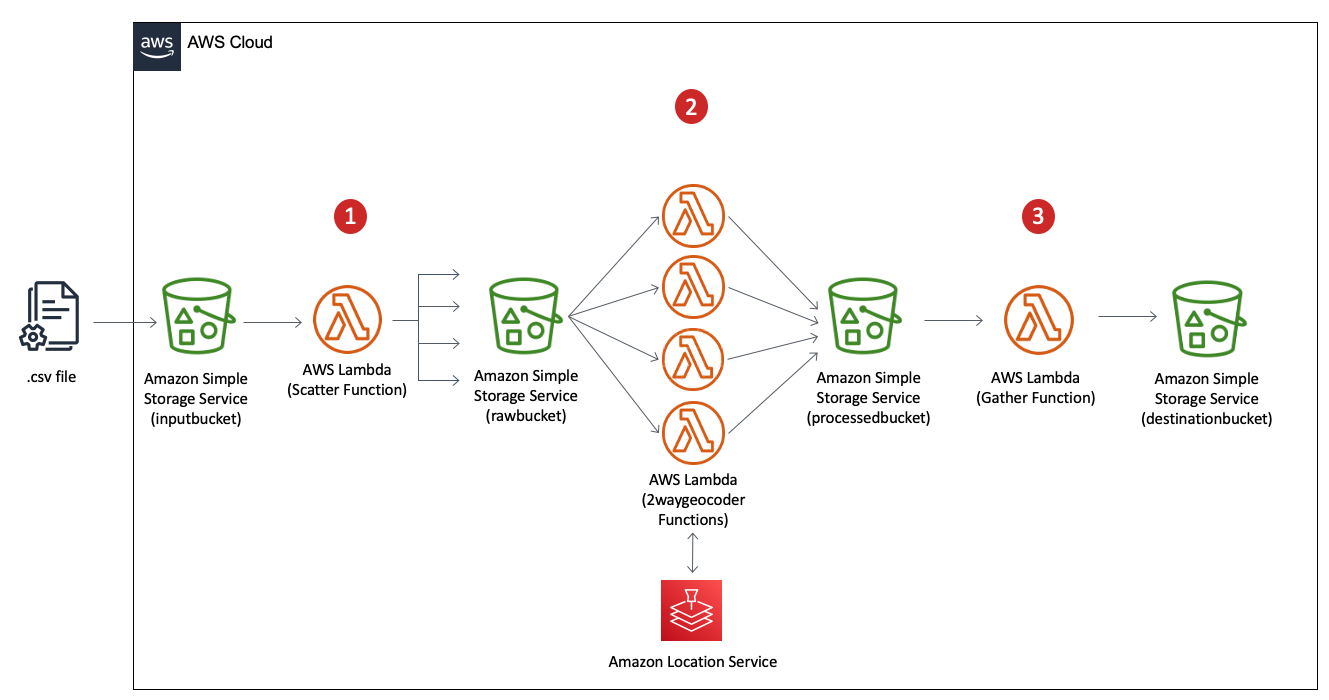
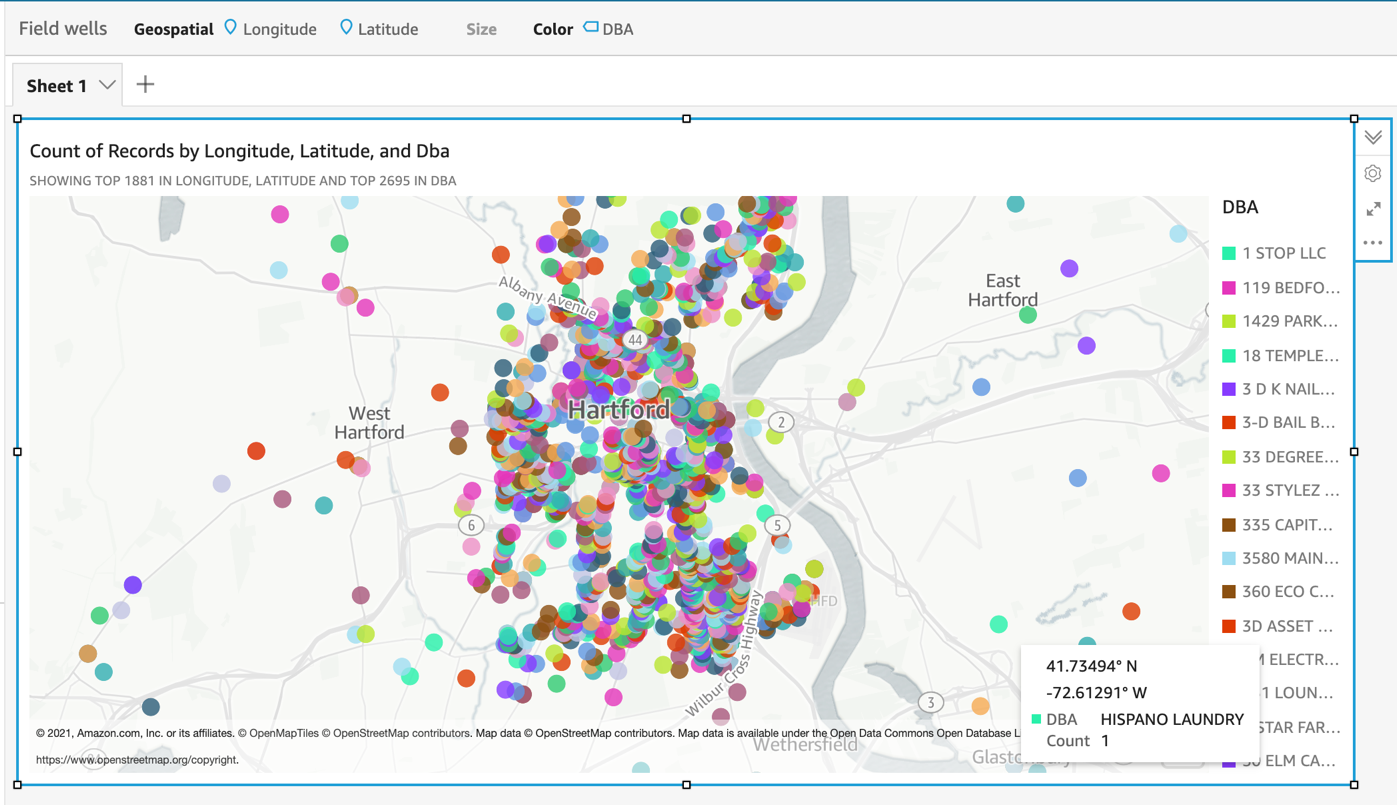
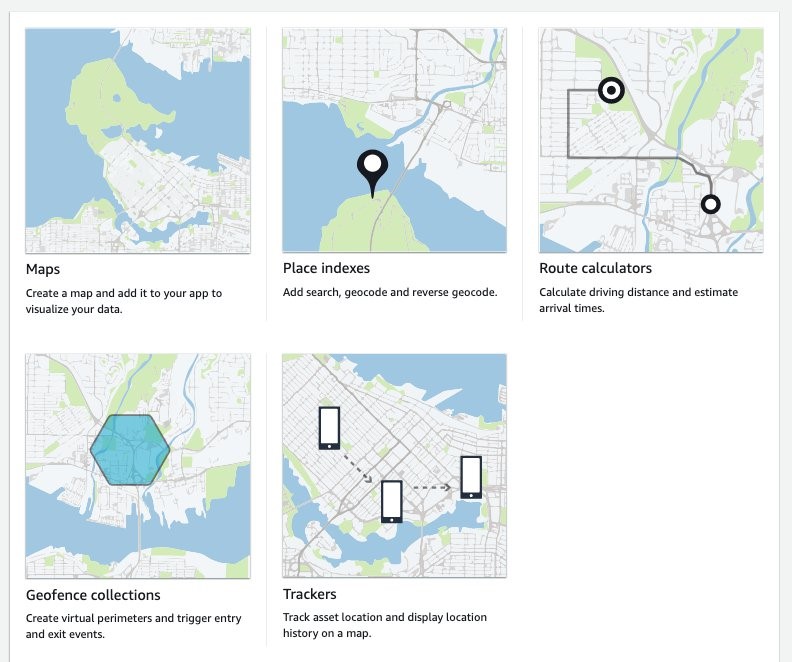
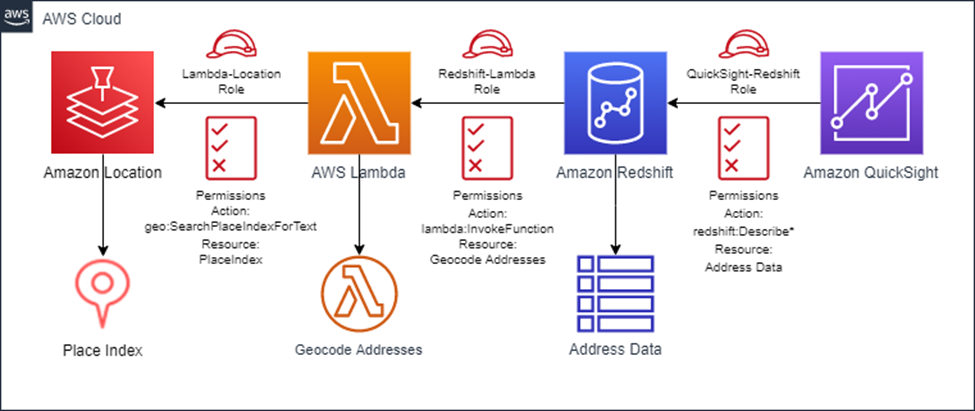
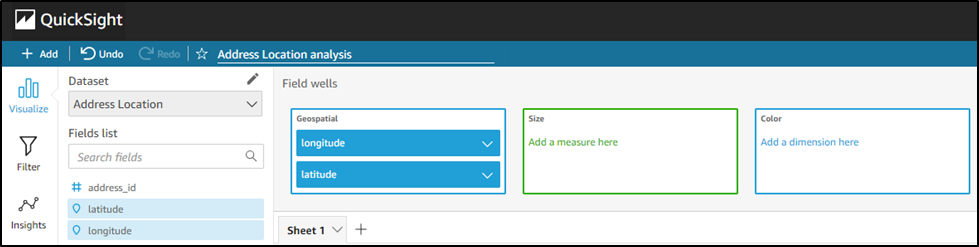
Alan Peaty is a Senior Partner Solutions Architect at AWS. Alan helps Global Systems Integrators (GSIs) and Global Independent Software Vendors (GISVs) solve complex customer challenges using AWS services. Prior to joining AWS, Alan worked as an architect at systems integrators to translate business requirements into technical solutions. Outside of work, Alan is an IoT enthusiast and a keen runner who loves to hit the muddy trails of the English countryside. Parag Srivastava is a Solutions Architect at AWS, helping enterprise customers with successful cloud adoption and migration. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.
Parag Srivastava is a Solutions Architect at AWS, helping enterprise customers with successful cloud adoption and migration. During his professional career, he has been extensively involved in complex digital transformation projects. He is also passionate about building innovative solutions around geospatial aspects of addresses.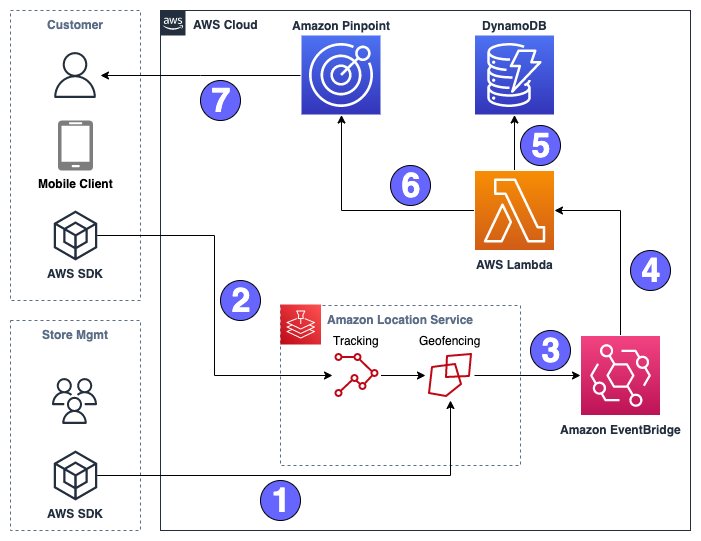











 .
.