The POSIX
realtime model, which is implemented in the Linux kernel, can ensure
that a realtime process obtains the CPU time it needs to get its job done.
It can be less effective, though, when there are multiple realtime
processes competing for the available CPU resources. The hierarchical
constant bandwidth server patch series, posted by Yuri Andriaccio with
work by Luca Abeni, Alessio Balsini, and Andrea Parri, is a modification to
the Linux scheduler intended to make it possible to configure systems with
multiple realtime tasks in a deterministic and correct manner.
Amazon Cognito is a managed customer identity and access management (CIAM) service that enables seamless user sign-up and sign-in for web and mobile applications. Through user pools, Amazon Cognito provides a user directory with strong authentication features, including passkeys, federation to external identity providers (IdPs), and OAuth 2.0 flows for secure machine-to-machine (M2M) authorization.
This post demonstrates how Amazon Cognito enables AI agents to perform authorized actions on behalf of users through user-contextualized access tokens for OAuth 2.0-enabled resource servers. AI agents represent a class of autonomous services that require robust identity management and precise access control, especially when acting on behalf of users. By using the Amazon Cognito client credentials flow with access token customization, you can establish distinct identities for AI agents that carry critical information about their capabilities, scope of access, and intended use cases. This approach provides a foundation for more secure, auditable AI agent operations while maintaining clear boundaries around their authorized activities.
The identity of an AI agent can be represented within Amazon Cognito as an app client. The AI agent obtains an access token (JSON Web Token (JWT)) through an OAuth 2.0 client credentials grant. This JWT can be customized to contain claims that represent the authenticated human user whom the AI agent is acting on behalf of. This token can then be used to authorize access to other services that has established trust with the Amazon Cognito user pool by trusting the issuer and audience of the token. For example, this third-party service could be a claims processor, a travel agency service, or a scheduling service acting on behalf of a user. The focus of this post is on foundational building blocks using Amazon Cognito for AI agents and how to obtain a customized access token with user context.
Solution overview and reference architecture
Looking at an example architecture (Figure 1), a user signs in to a web or mobile application using an Amazon Cognito user pool, and tokens for the user are returned to the client. Here, the application could be a serverless digital assistant using an Amazon Bedrock agent that needs to gather and process data residing in a third-party cross-domain service. The AI agent obtains its own access token by performing an OAuth 2.0 client credentials grant while passing the user’s access token as context using the aws_client_metadata request parameter. The AI agent receives the user contextualized access token and calls an external, third-party, or cross-domain service that trusts the issuer and audience of the AI agent’s access token issued from an Amazon Cognito user pool. The cross-domain service can obtain the JSON Web Key Set (JWKS) to verify the token and extract claims presenting both the AI agent and most importantly, the underlying user. Authorization takes place within the cross-domain service using the claims of the customized access token and for fine-grain authorization, Amazon Verified Permissions is used. See Figure 1 for a detailed flow of this example.
Figure 1: AI agent identity reference architecture
The user navigates to the application through the client.
There is no existing session or token for the user, so the user authentication flow with the Amazon Cognito user pool begins.
After a successful sign-in, Amazon Cognito returns access, ID, and refresh tokens to the client for the user.
As the user interacts with AI agent through the application, the client sends the user’s access token to an Amazon API Gateway endpoint.
The AI agent obtains its own access token from an Amazon Cognito user pool using an OAuth 2.0 client credentials grant. The user’s access token, obtained in step 1, is sent with the token request in the aws_client_metadata request parameter.
Note: You can use different Amazon Cognito user pools for user authentication and for agent (machine) authentication. This promotes separation and provides the ability to apply different settings and controls on each user pool if needed to meet security requirements.
Amazon Cognito validates the client ID and secret from the AI agent and invokes the pre token generation Lambda trigger to customize the access token for the AI agent.
Note: Within the pre token generation Lambda trigger, the user’s access token is verified before returning a customized access token to the AI agent using the aws-jwt-verify library.
The customized access token is returned to the AI agent, including custom claims representing the user.
The AI agent, using its own access token, calls the cross-domain service to perform the requested action on behalf of the user. For example, this can be a third-party reservation system or a photo sharing service.
The resource server in the cross-domain service verifies that the access token from the AI agent is valid. The resource server must be pre-configured to trust the user pool that issued the agent access token.
Coarse- and fine-grained authorization can happen either locally in the service code or using Verified Permissions.
A response from the cross-domain service flows back to the AI agent, if necessary.
A response from the AI agent to the user application or client is returned, if necessary.
Actions that take place throughout the flow are logged in AWS CloudTrail, providing end-to-end logging and auditing.
Implementation details
Let’s take a deeper look into the three core components of this scenario:
The AI agent obtaining its own OAuth 2.0 access token
The Amazon Cognito pre token generation Lambda trigger used to enrich the AI agent’s access token with user context
The cross-domain resource server performing fine-grained authorization
AI agent
Figure 2: AI agent obtaining a user access token from the frontend application through API Gateway
Amazon Bedrock Agents is used in this solution with a custom orchestration configured to use Lambda. When the application interacts with the Amazon Bedrock agent, the custom orchestrator initiation begins with the agent passing the user’s access token to a Lambda function as part of the custom orchestration (shown in Figure 2). The Lambda function validates the user’s token to verify that it’s not expired and hasn’t been tampered with. This custom orchestrator begins the process for the agent to obtain its own OAuth access token and to access downstream and cross-domain resources on behalf of the user. The human user’s access token is included in the call from the application through the client. To learn more about Amazon Bedrock Agents custom orchestrator, see Getting started with Amazon Bedrock Agents custom orchestrator. The following is an example of what a human user’s decoded access token provided through an API Gateway REST API might look like.
The following is a Node.js code sample that an AI agent can use to obtain its own access token from Amazon Cognito. This can be the Lambda function part of the custom orchestration for the Amazon Bedrock agent. Notice the clientMetadata variable being set, which will be passed to the Cognito /token endpoint using the aws_client_metadata request parameter. This request parameter is where the user’s access token is provided. In the following code example, you will find an attribute called callerApp, which is set to ExampleChatApplication, which serves as a unique identifier for the application. The callerApp value is preconfigured in the backend of the solution. This unique application identifier is included in the customized access token for the agent and used for additional authorization checks later. It’s a security best practice to use AWS Secrets Manager to store the client ID and client secret and obtain these credentials at runtime. As a security best practice, the user’s access token should be verified prior to passing it to the AI agent backend.
The access token for the AI agent is returned only if the client ID and secret are correct and the provided user access token is valid. However, before it’s returned, the AI agent’s access token is customized by the Amazon Cognito pre token generation Lambda trigger.
Amazon Cognito pre token generation Lambda trigger
Figure 3: AI agent access token customization with Cognito pre token generation Lambda trigger
After the AI agent’s action calls the Amazon Cognito /token endpoint with a valid client ID and secret, Cognito invokes the pre token generation Lambda trigger. The following is an example Lambda function that takes the aws_client_metadata request parameter, which contains the access token of the user and the callerApp attribute that was defined while the user was authenticating. In the following Lambda function, the access token provided from the user is verified (shown in Figure 3). The aws-jwt-verify library is used to verify the token is not expired, the token has not been tampered with by verifying the signature, and it’s making sure that an access token was provided. The Lambda function is also pre-configured to accept user tokens from a specific issuer and audience, this protects against malicious context injection risks. This is also an opportunity to perform additional authorization. For example, check if the user is a member of certain groups.
After the token is verified, the Lambda function customizes the access token to be returned to the AI agent.
import { CognitoJwtVerifier } from "aws-jwt-verify";
// Initialize the JWT verifier to verify the user’s access token
// Provide the user pool ID, token use, and client ID
const jwtVerifier = CognitoJwtVerifier.create({
userPoolId: process.env.USER_POOL_ID, // user pool for user authentication
clientId: process.env.CLIENT_ID,
// groups: "exampleChatApplicationAccess", // optional group membership authorization
tokenUse: 'access'
});
export const handler = async function(event, context) {
try {
const onBehalfOfToken = event.request.clientMetadata?.onBehalfOfToken || '';
// It’s recommended that the provided “callerApp” value from the application is authorized for use with the app client for the AI agent
const callerApp = event.request.clientMetadata?.callerApp || '';
// The below console log will display the authenticated user’s JWT
// Keep this logging with caution in a production environment
console.log('Original event:', event);
// Verify the access token from the human user
// You could optionally also perform some authorization checks here as well
// Example: check for the membership of a group
let decodedJWT;
if (onBehalfOfToken) {
try {
decodedJWT = await jwtVerifier.verify(onBehalfOfToken);
console.log('Decoded JWT:', decodedJWT);
} catch (err) {
console.error('Token verification failed:', err);
throw new Error('Token verification failed');
}
}
// Create the onBehalfOf claim structure
const behalfOfClaim = decodedJWT ? {
sub: decodedJWT.sub,
username: decodedJWT.username,
groups: decodedJWT['cognito:groups'] || []
} : {};
// Customized token returned to client
event.response = {
"claimsAndScopeOverrideDetails": {
"accessTokenGeneration": {
"claimsToAddOrOverride": {
"onBehalfOf": behalfOfClaim,
"callerApp": callerApp
},
}
}
};
return event;
} catch (error) {
console.error('Error in Lambda execution:', error);
throw error;
}
};
Notice in the preceding Lambda function that two custom claims are being dynamically created within the event.response: onBehalfOf and callerApp. The onBehalfOf claim contains nested claims that were extracted from the human user’s access token. The callerApp is carried forward from the frontend application and provided alongside the user access token. It’s recommended for the callerApp value to also be verified against some custom logic to add additional layer of protection. The return AI agent’s access token would look like the following JWT.
At this point, shown in Figure 4, the human user has successfully authenticated to the web application, the human user’s access token was sent as context to the backend, an AI agent obtained its own customized access token containing the human user context, and now the agent is ready to call an external cross-domain service.
Figure 4: Cross-domain resource server performing fine-grained authorization with Amazon Verified Permissions
As shown in Figure 4, the cross-domain service is the resource server and therefore needs to perform an authorization check. For this example, we’ll keep things straightforward and make sure that three core things are verified:
The AI agent’s OAuth access token is valid
The AI agent is authorized to access this service
The AI agent is authorized to interact with the user data
Depending on your use case and requirements, you might also need to verify that the user’s consent has been obtained prior to the AI agent acting on their behalf. Ultimately, you want to verify that the AI agent can access a user’s data on their behalf and only for the purpose for which consent has been provided by the user.
For the token verification, use the aws-jwt-verify library again. The following is a Node.js example to verify the AI agent’s access token.
import { CognitoJwtVerifier } from "aws-jwt-verify";
// add custom logic to verify that AI agent is authorized to perform this action on behalf of the user
// Verifier that expects valid access tokens:
const verifier = CognitoJwtVerifier.create({
userPoolId: "<user_pool_id>", // user pool for AI agent authentication
tokenUse: "access",
clientId: "<client_id>",
});
try {
const payload = await verifier.verify(
"eyJraWQeyJhdF9oYXNoIjoidk..." //this will be the AI agent's access token
);
console.log("Token is valid. Payload:", payload);
} catch {
console.log("Token not valid!");
}
Fine-grained authorization with Verified Permissions
As a security best practice, the zero trust principle of enforcing fine-grained identity-based authorization should take place using Verified Permissions. The preceding Node.js code sample is a basic validation of the AI agents access token that can happen within the application logic. Instead of keeping authorization logic within the resource server, you can use Verified Permissions to offload the authorization policies to a managed service. The following is an example Cedar policy for this use case.
With the preceding Cedar policy example, you are permitting the AI agent to read userData from the crossDomainService123 resource. This is only permitted when the AI agent’s access token contains the crossDomainService/read scope and when the resource owner and the onBehalfOf user (from the access token) are the same—the human user in this case. There’s also an additional when clause in the policy to make sure that this interaction initiated from ExampleChatApplication.
Based on the preceding examples of the AI agent’s access token (with user context), the Cedar policy, and the IsAuthorizedWithToken API call, the resource server would get an Allow decision for this action to take place. The following is an example of the authorization decision response.
Before this policy can be evaluated, you must define a schema that includes the relevant entity types (Agent, User, Resource, Scope, and so on), and create corresponding entities in your policy store that match the IDs used in the policy and request.
Bringing it all together, the requested data from the AI agent, on behalf of the user, is returned from the cross-domain service to the AI agent. This additional data can now be used within the context of the AI agent workload. The entire solution can be used for a chat application, such as the one described in Protect sensitive data in RAG applications with Amazon Bedrock.
Conclusion
Amazon Cognito M2M access token customization and support for passing client metadata provides you the extensibility to solve complex use cases and enables emerging ones like AI agent identity and access management. For example, passing contextual client metadata and customizing access tokens at runtime can help software as a service (SaaS) and multi-tenant service providers scale to an unlimited number of resource servers, because these can be dynamically determined at runtime. As organizations increasingly explore the use of AI agents, having a secure, scalable identity management solution becomes crucial for maintaining control and accountability. By using these new features, you can build more secure and scalable solutions with Amazon Cognito to prepare for the future of autonomous AI agent use cases.
Use the comments section to leave feedback about this post. If you have questions about this post, start a new thread on Amazon Cognito re:Post or contact AWS Support.
The variations seem to be endless. Here’s a fake ghostwriting scam that seems to be making boatloads of money.
This is a big story about scams being run from Texas and Pakistan estimated to run into tens if not hundreds of millions of dollars, viciously defrauding Americans with false hopes of publishing bestseller books (a scam you’d not think many people would fall for but is surprisingly huge). In January, three people were charged with defrauding elderly authors across the United States of almost $44 million by “convincing the victims that publishers and filmmakers wanted to turn their books into blockbusters.”
The Lustre filesystem has a long
history, some of which intersects with Linux. It was added to the staging
tree in 2013, but was bounced out of
staging in 2018, due to a lack of progress and a development model
that was incompatible with the kernel’s. Lustre may be working its way
back into the kernel, though. In a filesystem-track session at
the 2025 Linux Storage, Filesystem, Memory Management, and BPF Summit
(LSFMM+BPF), Timothy Day and James Simmons led a discussion on how to get
Lustre into the mainline.
The KDE Project has announced the
Plasma 6.4 release. New features include more flexible tiling
features, improvements to the Spectacle screen capture utility, a
number of accessibility enhancements, and much more. See the changelog
for a complete list of new features, enhancements, and bug fixes.
Една от най-поразителни черти на българската политическа действителност е начинът, по който определени групи в обществото изразяват недоволството си. В много европейски страни позицията на една група по интереси се формира след доста четене, информираност и съвместна работа, докато у нас процесите на когнитивни възприятия по отношение на един или друг проблем в обществото често вкарват българските граждани в капана на дезинформацията.
Дебатът – ако изобщо може да го наречем така – около присъединяването на България към еврозоната е болезнено белязан от тази действителност, която се дължи на два фактора: неспособността на политическия елит да сподели с избирателите си предимствата и недостатъците от приемането на общата европейска валута и силната вълна от дезинформация, представяща еврото като събирателен образ на всичко лошо, което очаква България.
Казано с други думи, кампанията срещу еврото не е толкова успешна, колкото е слаба информираността на хората какво ни очаква в еврозоната. Ето защо в тази статия ще се постараем да анализираме кои са политическите ефекти от присъединяването на България към еврозоната, като ще се убедим, че те далеч надхвърлят като ползи и изгоди икономическите.
Защо ни е еврозоната? Да не би датчани и поляци да са по-глупави от нас!?
Едва ли противниците на единната европейска валута си дават сметка, че основната причина за приемането на еврото всъщност се крие в историята и спецификата на Прехода. Краят на социализма през 1989 г. отвори вратата за частната собственост и пазарната инициатива – двете характеристики на капитализма, които в политическо и социално отношение далеч надхвърлят легендарната предвидимост и спокойствие на „развитото“ социалистическо общество.
В рамките на няколко години българите, които останаха или се завърнаха в страната след промените, се опитаха да се позиционират трайно в тази нова система, която даваше на мнозина надежди за по-добро бъдеще. Оптимизмът рухна, когато България преживя най-сериозната икономическа криза след края на Втората световна война, останала в историята ни като печално известната Виденова зима. По-дълбоки като психологическо отражение от това злощастно събитие са единствено годините на сеч и гибел, сполетели страната ни по време на Междусъюзническата и двете световни войни.
Казано накратко, през януари 1997 г. българската икономика рухна безславно, а левът беше поставен на животоподдържащи системи в условията на валутен борд. Тези години бяха най-унизителните в историята на българската валута, която дори през социализма се ползва със златно покритие и е фиксирана стабилно към курса на щатския долар. Щетите, нанесени върху валутата ни, бяха особено дълбоки и поради факта, че тя никога повече нямаше да успее да се възстанови от девалвацията, а трябваше раболепно да следва курса на марката, за да може парите да възстановят покупателната си способност, а икономиката да бъде изградена отново.
В дните, когато Германия извърши символично погребение на марката и я замени с еврото, стана ясно, че България се превръща в прецедент, тъй като нейната полуфункционираща валута на практика е вързана за курса на друга несъществуваща валута.
След тази кратка историческа ретроспекция е редно да си дадем сметка, че причината, поради която България стигна дотук, е икономическото фиаско от 1997 г. Приемането на еврото на практика ще завърши започнатото от валутния борд. Ако все пак се опитаме да пресъздадем една алтернативна историческа реалност, в която Виденовата зима отсъства, то тогава левът би успял да запази фиксиран курс към долара и днес успешно да се вмести в датския, полския или пък румънския сценарий. Но тъй като в историята няма „ако“, дилемата пред нашата страна е тази: да избере лева – валута с фиктивна покупателна стойност, която ще девалвира все повече с времето, или да избере еврото, чието златно покритие му гарантира позицията на втората най-силна валута в света.
Политическите ефекти от приемането на еврото
Първият и най-важен политически ефект засяга трайното и категорично позициониране на България като европейска държава в глобалния икономически ред. Понятието „глобален икономически ред“ е особено важно за осмислянето на предимствата на еврозоната, тъй като този ред на практика е едно неголямо семейство, в което съжителстват няколко резервни валути. С най-голям дял от тях са щатският долар и еврото, а с периферен – японската йена, китайският юан и британският паунд – остатък от колониалното минало на Британия. Еврото на практика е по-силно и от азиатските валути, и от паунда, като единствено доларът е в състояние да го конкурира. Негативните ефекти от тази конкуренция често се тушират от стабилните отношения между икономиките на САЩ и Европа, които очевидно ще надживеят сегашните турбуленции.
Важно е да поясним, че когато имаш резервна валута, която е закрепена за стойността на златото, можеш да печаташ пари. Колкото поискаш. Чудили ли сте се как Америка винаги намира пари да воюва и да отстоява интересите си по света? Защото валутата ѝ е най-силната в света и хазната може да печата неограничено количество долари, които редовно да инжектира в американската военна машина и икономика.
Същата логика е приложима и за еврото – винаги когато страна членка е заплашена от икономическа криза, Европейската централна банка във Франкфурт е в състояние да печата валута. В тези условия политическата стабилност и увереност на България ще се засилят, защото противниците на еврото няма да могат да легитимират твърденията си, че сме позорният длъжник на Международния валутен фонд и Световната банка, чиито заеми ще плащат идните поколения българи. България ще се сдобие с паричен и икономически суверенитет, а не с псевдовалутен васалитет.
Вторият политически ефект е отражението, което присъединяването ни към еврозоната ще окаже върху корупцията и сивия сектор. Те ще продължат да съществуват, тъй като няма развита демокрация, която да е напълно имунизирана против ефектите от корупцията, противно на претенциите на автокрациите и тоталитарните режими, които са най-яркият съвременен символ на самата корупция. Но общественият статут на корупцията и на сивия сектор, както и нивото на съществуването им ще се променят. Ефектите им няма да са толкова осезаеми за гражданите, а упражняването на корупционни практики ще е привилегия на политическите елити и кръговете около тях, която ще приема далеч по-изтънчени форми.
Казано иначе, корупцията у нас вече няма да е балканска, а европейскa, коeто ще даде лице и мандат на България да претендира за развита демократична държава, чиито корупционни практики следват европейските стандарти и санкцията на Франкфурт. И ако за прозападните кръгове у нас това е добре дошло, то за онези, които искат България да остане извън европейското семейство, подобна крачка ще е крайно делегитимираща, тъй като няма да могат да вземат пари директно от руските си спонсори.
Третият политически ефект се отнася до скъсването на зависимостта с евразийското икономическо пространство. България ще стане част от онова глобално икономическо пространство, което смели мъже като Хенри Моргентау-младши, Хари Декстър Уайт, Густав Щреземан и Жак Делор разчертават за бъдните поколения. Всъщност една от причините, поради които еврото е толкова недолюбвано, е, че компактни маси в българското общество не желаят да се разделят със спомените от социализма, но в същото време отказват да признаят факта, че ниските стойности на пенсионното осигуряване се дължат на инфлацията, която посече българската икономика през 1997 г.
По същия начин стои въпросът с онези групи, които гледат на европейския капитализъм като на нещо страшно и враждебно, без да си дават сметка, че на фона на англосаксонския той гарантира развитието на средна класа. Такива проблеми са плод на сериозна дезинформация в българското общество, която цели да го убеди, че единната европейска валута ще направи от България колония.
Ако трябва да обобщим, присъединяването на България към еврозоната не просто ще допринесе страната ни да придобие паричен суверенитет и по-значима роля в глобалната икономика, но и трайно да се позиционира като част от Европа.
В тези условия еврото ще спомогне за затваряне на ножицата между много богати и много бедни и при последователна и градивна икономическа политика ще насърчи формирането на европейска средна класа.
Неудобната истина е, че приемането на еврото ще наложи и много по-стриктни стандарти и условия за динамиката на труда, което ще изисква от страната да стане доста по-прозрачна при прилагането на националното и европейското законодателство. Това ще изтръгне много противници на еврото от удобната роля на бездействащи критици на НАТО и ЕС, които сглобяват аргументите си с помощта на конспиративни теории, а не на рационални аргументи, и ще даде възможност на реално критичния поглед към функционирането на общността и Алианса да излезе на преден план. Този поглед неведнъж е сблъсквал европейските и американските представители, но в крайна сметка изходът винаги е бил един и същ: от двете страни на океана са осъзнавали, че са като едно семейство, чийто икономически възход е двигателят на световната икономика.
Ами ако не успеем?
Какво би се случило в една паралелна реалност, в която България остава извън еврозоната? Или пък какво би станало, ако липсата на консенсус в политическия дебат у нас доведе до нестабилност, на която Брюксел и Франкфурт няма да погледнат добре?
Ако България не се присъедини към еврозоната, това ще създаде доста благоприятна почва за ръст на антизападните настроения у нас и за изолиране на страната. Това на практика е път обратно към Малтийския консенсус, но тъй като той отдавна не функционира, България може да се окаже в позицията на failed state вътре в Европа. В крайна сметка едно е съществуването на българската икономика, без еврото изобщо да е на дневен ред, друго е тя да функционира в условия, при които приемането на единната европейска валута се е провалило.
Това ще консолидира антиевропейските кръгове и ще даде възможност за създаването на икономически климат, който да препозиционира България в рамките на евроатлантическото пространство. Нашата страна за пореден път ще се окаже в ролята на мост между Изтока и Запада, а както е известно, през годините тази роля ни е довлякла много проблеми.
Провалът на приемането на единната европейска валута ще даде мандат да бъде поставена под въпрос цялостната геополитическа ориентация на нашата страна.
Това няма да се случи изведнъж и веднага, но ще придобие по-осезаеми форми с наративите, че Европейският съюз няма бъдеще и упадъкът му е неизбежен.
Тук е мястото да кажем, че никой не знае какво точно е бъдещето и че общността неведнъж е изпадала в трудни моменти. По-старото поколение от европейски политици помни периода на „eвросклероза“ и кризата на европейската валутна змия. Но Европа винаги е намирала начин да оцелее, защото се е реформирала. Тази реформа и днес предстои да бъде много болезнена предвид геополитическите предизвикателства, които стоят пред Стария континент, но рано или късно ще започне. Показателни са плановете на Германия и Франция да разделят общността на концентрични кръгове, които да се ползват в различна степен от облагите, предоставяни от интеграционния процес. Ако България се окаже в някой от външните кръгове – това е неизбежно, ако не се присъединим към еврозоната, – едва ли в бъдещите десетилетия ще ни се удаде да бъдем пълноценен член на Европейския съюз.
В дългосрочен план, ако се провалим с приемането на еврото, твърде е възможно отново да се озовем на входа на тунела, от който се опитваме да излезем вече три десетилетия. Това ще се случи, когато животоподдържащите системи на лева откажат и валутният борд спре да работи. И когато страната изпадне в икономическа криза и спре да обслужва главоломно нарастващия си външен дълг, което рано или късно ще стане, ако навлезем в нова икономическа криза в резултат на глобална рецесия или латентна политическа нестабилност. Мнозина биха определили такова твърдение като заблуда, но малко хора през славното лято на 1994 г. очакваха, че само три години по-късно ще се редят на опашки в банките, за да изтеглят спестяванията си. И всъщност, ако тези събития се повторят, политическата цена, която ще платят гражданите и бъдещите поколения, ще бъде много висока.
We are thrilled to announce the General Availability of Cloudflare Log Explorer, a powerful new product designed to bring observability and forensics capabilities directly into your Cloudflare dashboard. Built on the foundation of Cloudflare’s vast global network, Log Explorer leverages the unique position of our platform to provide a comprehensive and contextualized view of your environment.
Security teams and developers use Cloudflare to detect and mitigate threats in real-time and to optimize application performance. Over the years, users have asked for additional telemetry with full context to investigate security incidents or troubleshoot application performance issues without having to forward data to third party log analytics and Security Information and Event Management (SIEM) tools. Besides avoidable costs, forwarding data externally comes with other drawbacks such as: complex setups, delayed access to crucial data, and a frustrating lack of context that complicates quick mitigation.
Log Explorer has been previewed by several hundred customers over the last year, and they attest to its benefits:
“Having WAF logs (firewall events) instantly available in Log Explorer with full context — no waiting, no external tools — has completely changed how we manage our firewall rules. I can spot an issue, adjust the rule with a single click, and immediately see the effect. It’s made tuning for false positives faster, cheaper, and far more effective.”
“While we use Logpush to ingest Cloudflare logs into our SIEM, when our development team needs to analyze logs, it can be more effective to utilize Log Explorer. SIEMs make it difficult for development teams to write their own queries and manipulate the console to see the logs they need. Cloudflare’s Log Explorer, on the other hand, makes it much easier for dev teams to look at logs and directly search for the information they need.”
With Log Explorer, customers have access to Cloudflare logs with all the context available within the Cloudflare platform. Compared to external tools, customers benefit from:
Reduced cost and complexity: Drastically reduce the expense and operational overhead associated with forwarding, storing, and analyzing terabytes of log data in external tools.
Faster detection and triage: Access Cloudflare-native logs directly, eliminating cumbersome data pipelines and the ingest lags that delay critical security insights.
Accelerated investigations with full context: Investigate incidents with Cloudflare’s unparalleled contextual data, accelerating your analysis and understanding of “What exactly happened?” and “How did it happen?”
Minimal recovery time: Seamlessly transition from investigation to action with direct mitigation capabilities via the Cloudflare platform.
Log Explorer is available as an add-on product for customers on our self serve or Enterprise plans. Read on to learn how each of the capabilities of Log Explorer can help you detect and diagnose issues more quickly.
Monitor security and performance issues with custom dashboards
Custom dashboards allow you to define the specific metrics you need in order to monitor unusual or unexpected activity in your environment.
Getting started is easy, with the ability to create a chart using natural language. A natural language interface is integrated into the chart create/edit experience, enabling you to describe in your own words the chart you want to create. Similar to the AI Assistant we announced during Security Week 2024, the prompt translates your language to the appropriate chart configuration, which can then be added to a new or existing custom dashboard.
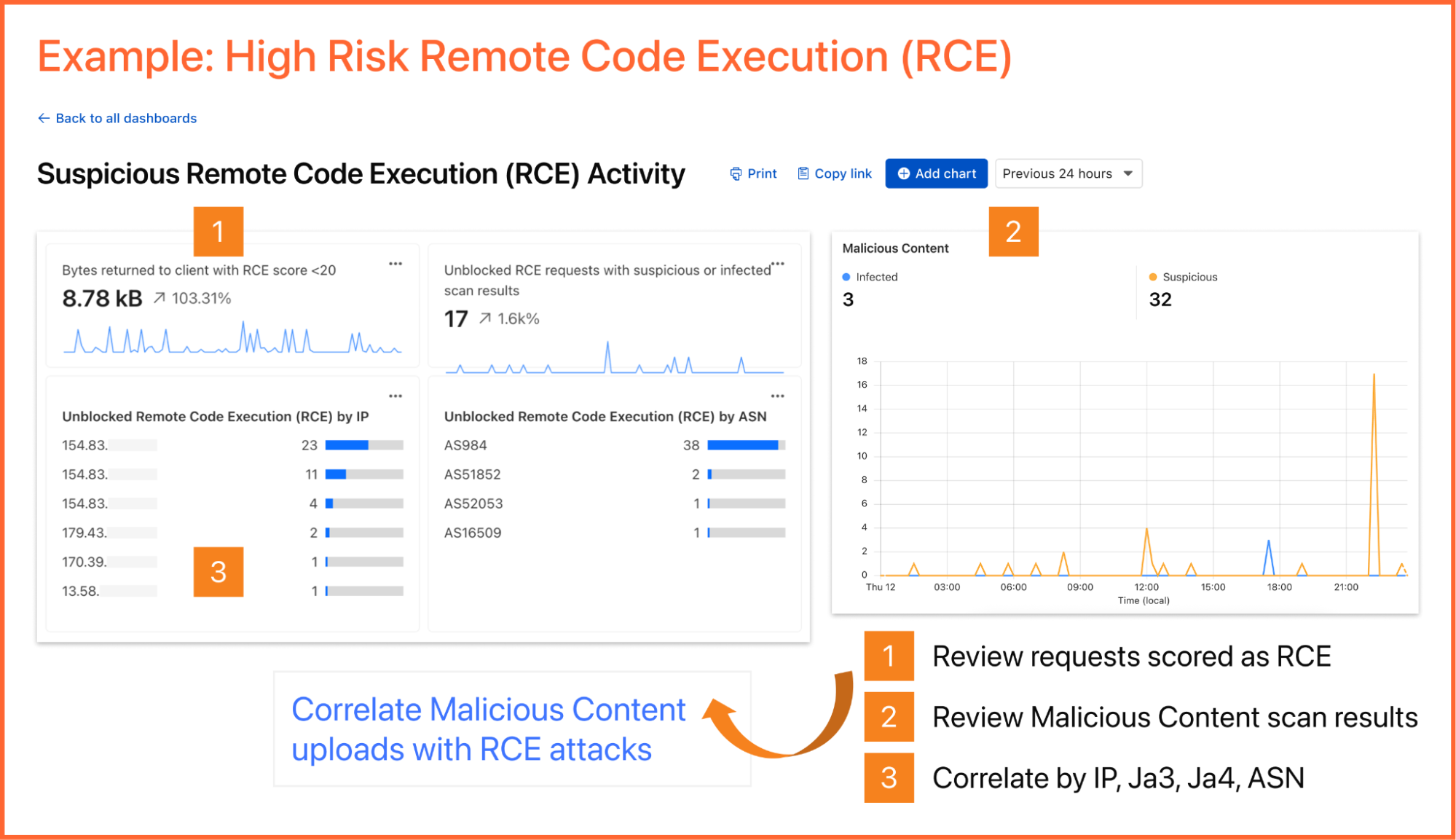
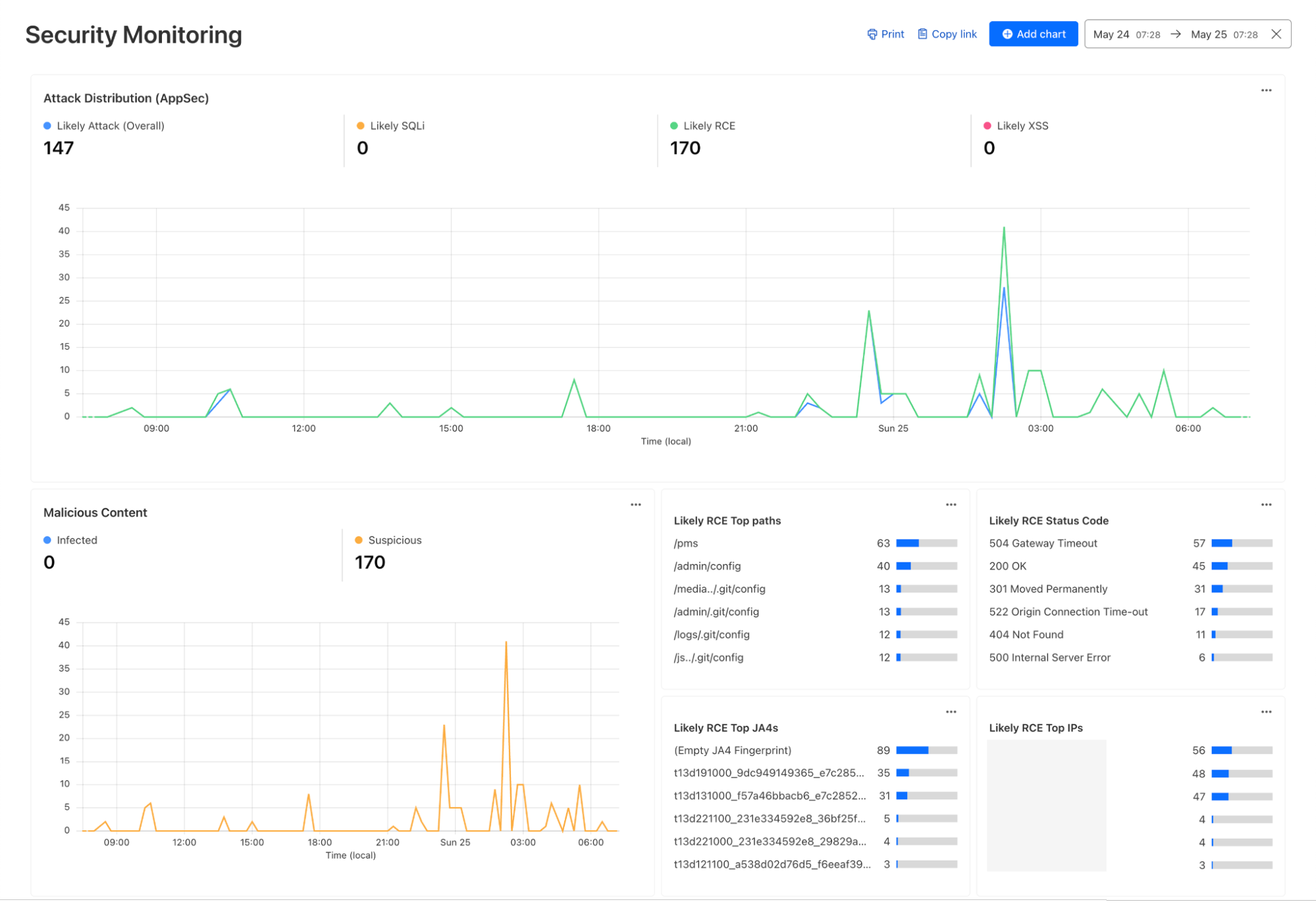
As an example, you can create a dashboard for monitoring for the presence of Remote Code Execution (RCE) attacks happening in your environment. An RCE attack is where an attacker is able to compromise a machine in your environment and execute commands. The good news is that RCE is a detection available in Cloudflare WAF. In the dashboard example below, you can not only watch for RCE attacks, but also correlate them with other security events such as malicious content uploads, source IP addresses, and JA3/JA4 fingerprints. Such a scenario could mean one or more machines in your environment are compromised and being used to spread malware — surely, a very high risk incident!
A reliability engineer might want to create a dashboard for monitoring errors. They could use the natural language prompt to enter a query like “Compare HTTP status code ranges over time.” The AI model then decides the most appropriate visualization and constructs their chart configuration.
While you can create custom dashboards from scratch, you could also use an expert-curated dashboard template to jumpstart your security and performance monitoring.
Available templates include:
Bot monitoring: Identify automated traffic accessing your website
API Security: Monitor the data transfer and exceptions of API endpoints within your application
API Performance: See timing data for API endpoints in your application, along with error rates
Account Takeover: View login attempts, usage of leaked credentials, and identify account takeover attacks
Performance Monitoring: Identify slow hosts and paths on your origin server, and view time to first byte (TTFB) metrics over time
Security Monitoring: monitor attack distribution across top hosts and paths, correlate DDoS traffic with origin Response time to understand the impact of DDoS attacks.
Investigate and troubleshoot issues with Log Search
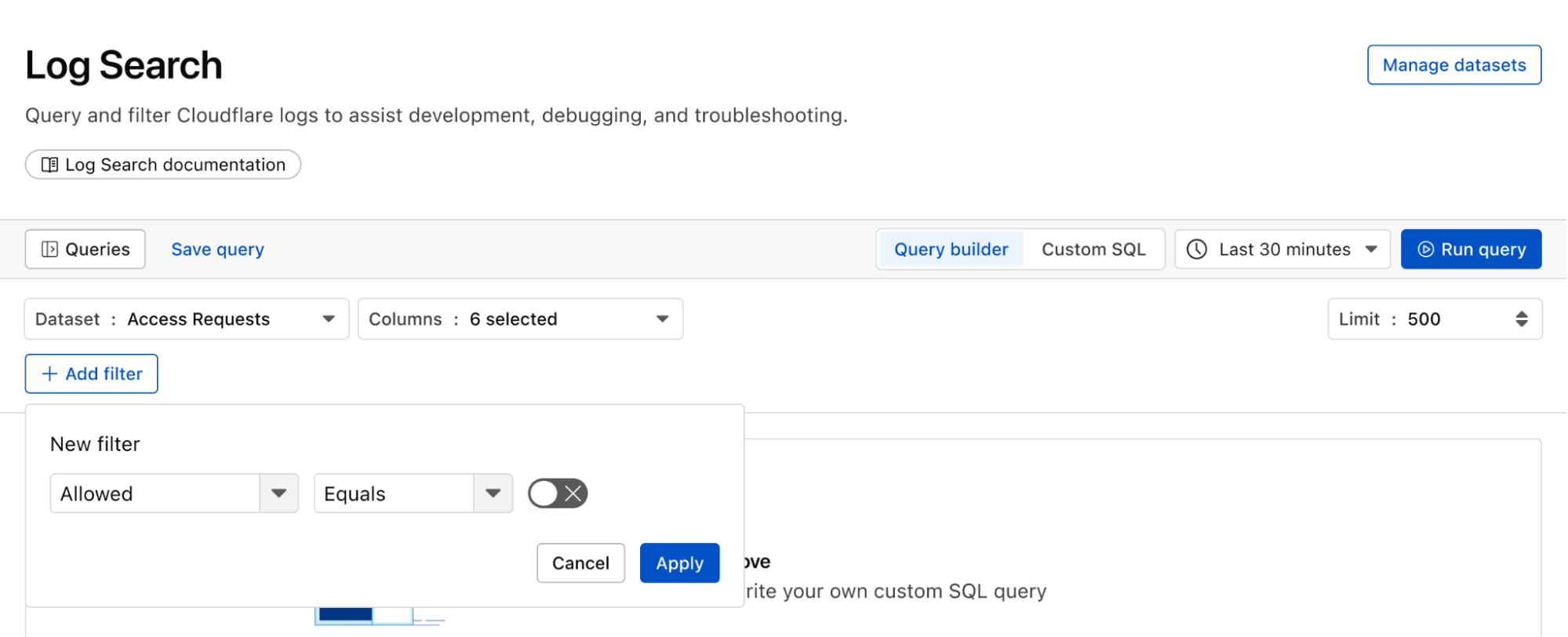
Continuing with the example from the prior section, after successfully diagnosing that some machines were compromised through the RCE issue, analysts can pivot over to Log Search in order to investigate whether the attacker was able to access and compromise other internal systems. To do that, the analyst could search logs from Zero Trust services, using context, such as compromised IP addresses from the custom dashboard, shown in the screenshot below:
Log Search is a streamlined experience including data type-aware search filters, or the ability to switch to a custom SQL interface for more powerful queries. Log searches are also available via a public API.
Save time and collaborate with saved queries
Queries built in Log Search can now be saved for repeated use and are accessible to other Log Explorer users in your account. This makes it easier than ever to investigate issues together.
Monitor proactively with Custom Alerting (coming soon)
With custom alerting, you can configure custom alert policies in order to proactively monitor the indicators that are important to your business.
Starting from Log Search, define and test your query. From here you can opt to save and configure a schedule interval and alerting policy. The query will run automatically on the schedule you define.
Tracking error rate for a custom hostname
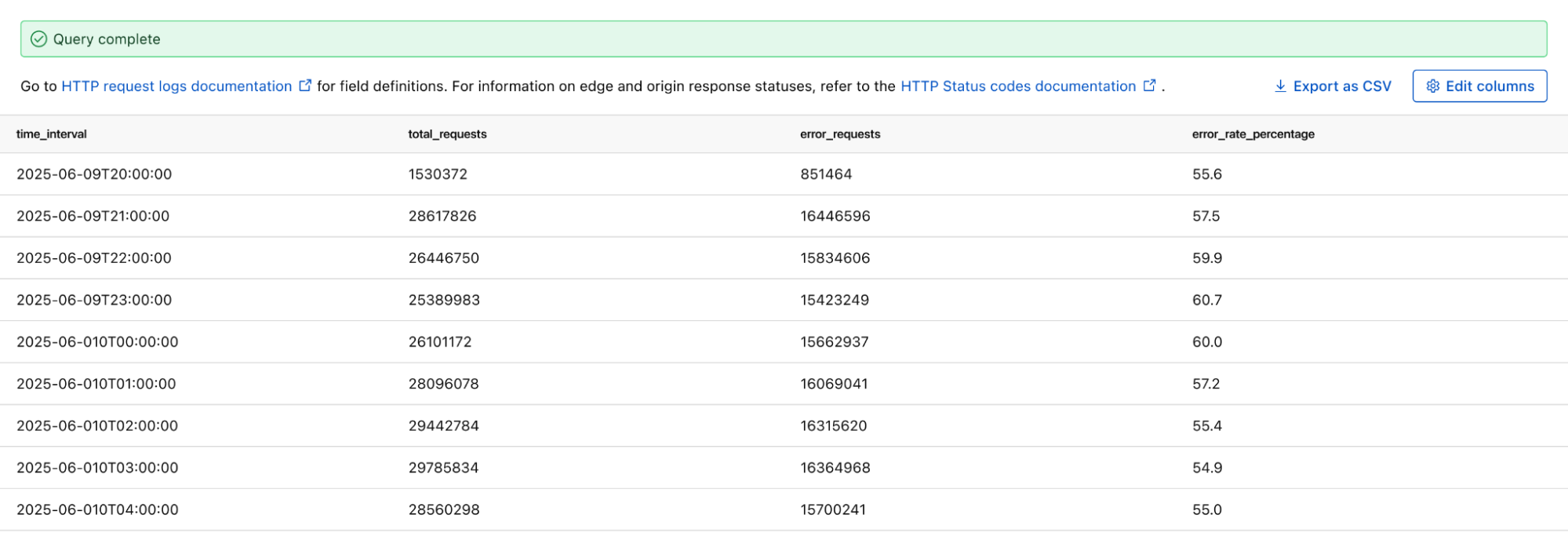
If you want to monitor the error rate for a particular host, you can use this Log Search query to calculate the error rate per time interval:
SELECT SUBSTRING(EdgeStartTimeStamp, 1, 14) || '00:00' AS time_interval,
COUNT() AS total_requests,
COUNT(CASE WHEN EdgeResponseStatus >= 500 THEN 1 ELSE NULL END) AS error_requests,
COUNT(CASE WHEN EdgeResponseStatus >= 500 THEN 1 ELSE NULL END) * 100.0 / COUNT() AS error_rate_percentage
FROM http_requests
WHERE EdgeStartTimestamp >= '2025-06-09T20:56:58Z'
AND EdgeStartTimestamp <= '2025-06-10T21:26:58Z'
AND ClientRequestHost = 'customhostname.com'
GROUP BY time_interval
ORDER BY time_interval ASC;
Running the above query returns the following results. You can see the overall error rate percentage in the far right column of the query results.
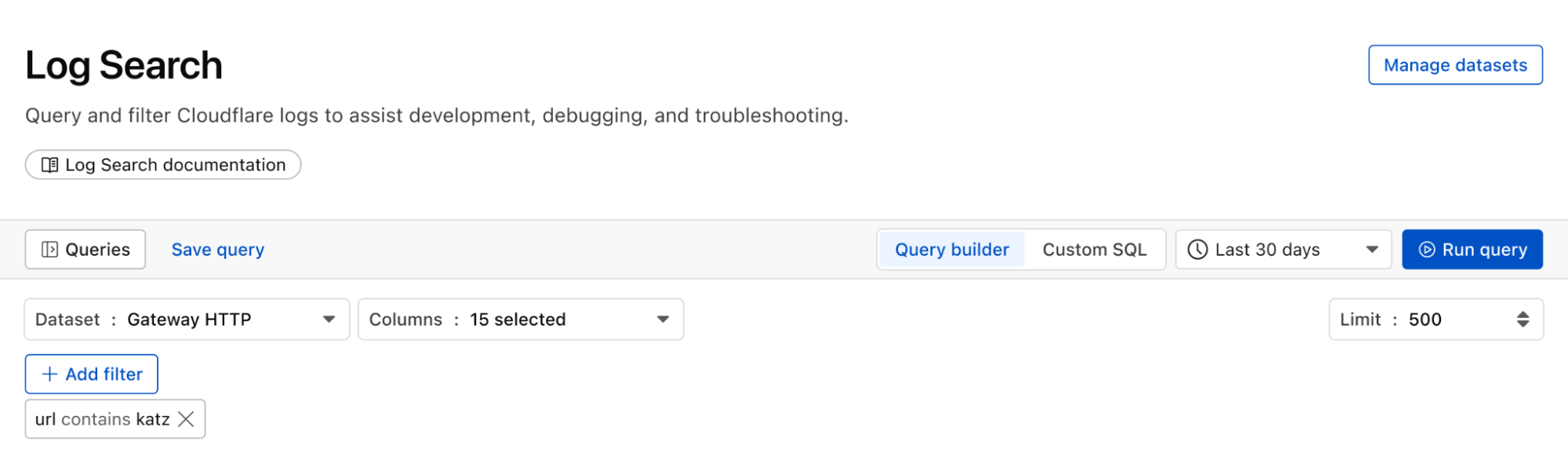
Proactively detect malware
We can identify malware in the environment by monitoring logs from Cloudflare Secure Web Gateway. As an example, Katz Stealer is malware-as-a-service designed for stealing credentials. We can monitor DNS queries and HTTP requests from users within the company in order to identify any machines that may be infected with Katz Stealer malware.
And with custom alerts, you can configure an alert policy so that you can be notified via webhook or PagerDuty.
Maintain audit & compliance with flexible retention (coming soon)
With flexible retention, you can set the precise length of time you want to store your logs, allowing you to meet specific compliance and audit requirements with ease. Other providers require archiving or hot and cold storage, making it difficult to query older logs. Log Explorer is built on top of our R2 storage tier, so historical logs can be queried as easily as current logs.
How we built Log Explorer to run at Cloudflare scale
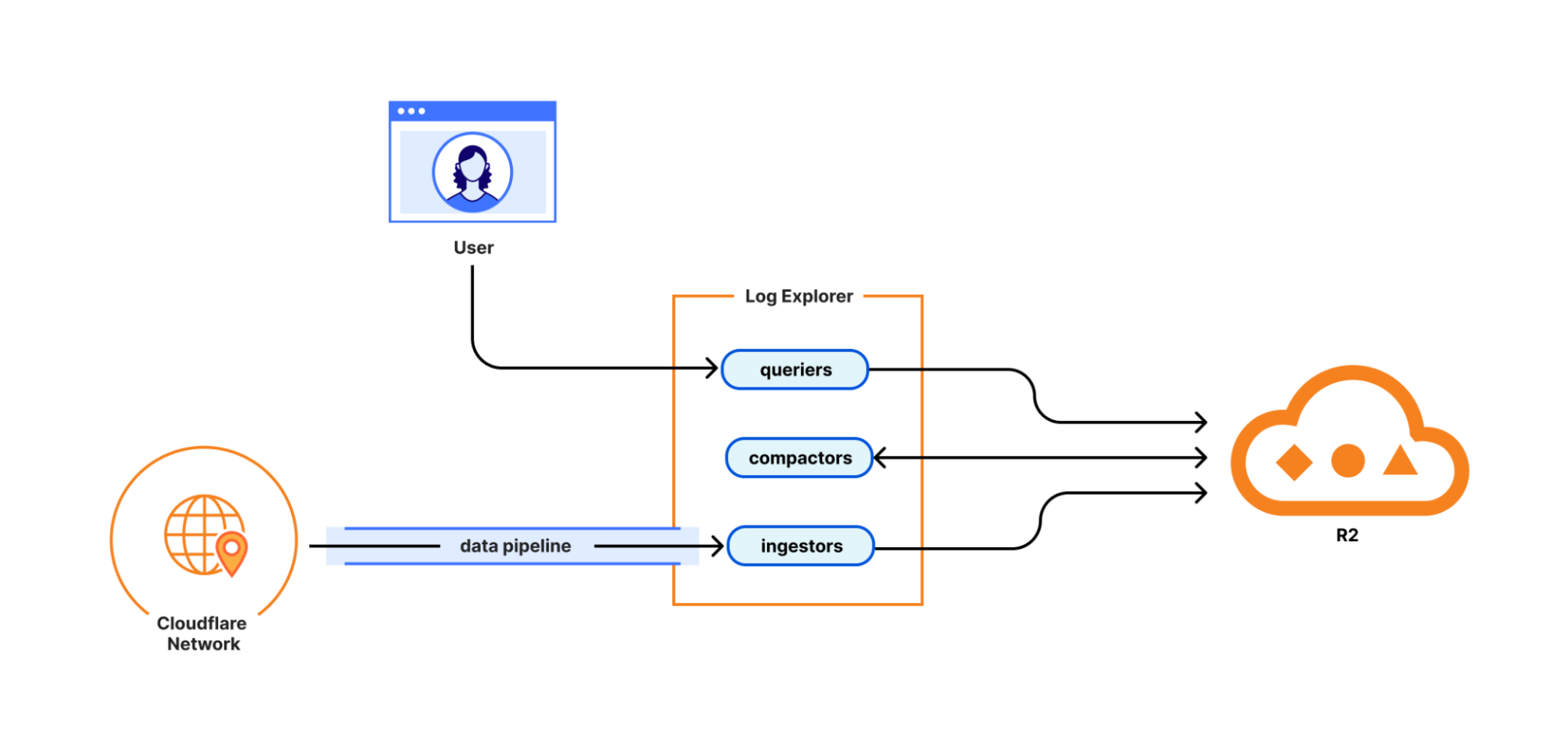
With Log Explorer, we have built a scalable log storage platform on top of Cloudflare R2 that lets you efficiently search your Cloudflare logs using familiar SQL queries. In this section, we’ll look into how we did this and how we solved some technical challenges along the way.
Log Explorer consists of three components: ingestors, compactors, and queriers. Ingestors are responsible for writing logs from Cloudflare’s data pipeline to R2. Compactors optimize storage files, so they can be queried more efficiently. Queriers execute SQL queries from users by fetching, transforming, and aggregating matching logs from R2.
During ingestion, Log Explorer writes each batch of log records to a Parquet file in R2. Apache Parquet is an open-source columnar storage file format, and it was an obvious choice for us: it’s optimized for efficient data storage and retrieval, such as by embedding metadata like the minimum and maximum values of each column across the file which enables the queriers to quickly locate the data needed to serve the query.
Log Explorer stores logs on a per-customer level, just like Cloudflare D1, so that your data isn’t mixed with that of other customers. In Q3 2025, per-customer logs will allow you the flexibility to create your own retention policies and decide in which regions you want to store your data.
But how does Log Explorer find those Parquet files when you query your logs? Log Explorer leverages the Delta Lake open table format to provide a database table abstraction atop R2 object storage. A table in Delta Lake pairs data files in Parquet format with a transaction log. The transaction log registers every addition, removal, or modification of a data file for the table – it’s stored right next to the data files in R2.
Given a SQL query for a particular log dataset such as HTTP Requests or Gateway DNS, Log Explorer first has to load the transaction log of the corresponding Delta table from R2. Transaction logs are checkpointed periodically to avoid having to read the entire table history every time a user queries their logs.
Besides listing Parquet files for a table, the transaction log also includes per-column min/max statistics for each Parquet file. This has the benefit that Log Explorer only needs to fetch files from R2 that can possibly satisfy a user query. Finally, queriers use the min/max statistics embedded in each Parquet file to decide which row groups to fetch from the file.
Log Explorer processes SQL queries using Apache DataFusion, a fast, extensible query engine written in Rust, and delta-rs, a community-driven Rust implementation of the Delta Lake protocol. While standing on the shoulders of giants, our team had to solve some unique problems to provide log search at Cloudflare scale.
Log Explorer ingests logs from across Cloudflare’s vast global network, spanning more than 330 cities in over 125 countries. If Log Explorer were to write logs from our servers straight to R2, its storage would quickly fragment into a myriad of small files, rendering log queries prohibitively expensive.
Log Explorer’s strategy to avoid this fragmentation is threefold. First, it leverages Cloudflare’s data pipeline, which collects and batches logs from the edge, ultimately buffering each stream of logs in an internal system named Buftee. Second, log batches ingested from Buftee aren’t immediately committed to the transaction log; rather, Log Explorer stages commits for multiple batches in an intermediate area and “squashes” these commits before they’re written to the transaction log. Third, once log batches have been committed, a process called compaction merges them into larger files in the background.
While the open-source implementation of Delta Lake provides compaction out of the box, we soon encountered an issue when using it for our workloads. Stock compaction merges data files to a desired target size S by sorting the files in reverse order of their size and greedily filling bins of size S with them. By merging logs irrespective of their timestamps, this process distributed ingested batches randomly across merged files, destroying data locality. Despite compaction, a user querying for a specific time frame would still end up fetching hundreds or thousands of files from R2.
For this reason, we wrote a custom compaction algorithm that merges ingested batches in order of their minimum log timestamp, leveraging the min/max statistics mentioned previously. This algorithm reduced the number of overlaps between merged files by two orders of magnitude. As a result, we saw a significant improvement in query performance, with some large queries that had previously taken over a minute completing in just a few seconds.
Follow along for more updates
We’re just getting started! We’re actively working on even more powerful features to further enhance your experience with Log Explorer. Subscribe to the blog and keep an eye out for more updates in our Change Log to our observability and forensics offering soon.
Get access to Log Explorer
To get access to Log Explorer, reach out for a consultation or contact your account manager. Additionally, you can read more in our Developer Documentation.
This will get you started with a remote MCP server that supports the latest MCP standards and is the reason why thousands of remote MCP servers have been deployed on Cloudflare, including ones from companies like Atlassian, Linear, PayPal, and more.
But deploying servers is only half of the equation — we also wanted to make it just as easy to build and deploy remote MCP clients that can connect to these servers to enable new AI-powered service integrations. That’s why we built use-mcp, a React library for connecting to remote MCP servers, and we’re excited to contribute it to the MCP ecosystem to enable more developers to build remote MCP clients.
Today, we’re open-sourcing two tools that make it easy to build and deploy MCP clients:
use-mcp — A React library that connects to any remote MCP server in just 3 lines of code, with transport, authentication, and session management automatically handled. We’re excited to contribute this library to the MCP ecosystem to enable more developers to build remote MCP clients.
The AI Playground — Cloudflare’s AI chat interface platform that uses a number of LLM models to interact with remote MCP servers, with support for the latest MCP standard, which you can now deploy yourself.
Whether you’re building an AI-powered chat bot, a support agent, or an internal company interface, you can leverage these tools to connect your AI agents and applications to external services via MCP.
Ready to get started? Click on the button below to deploy your own instance of Cloudflare’s AI Playground to see it in action.
use-mcp: a React library for building remote MCP clients
use-mcp is a React library that abstracts away all the complexity of building MCP clients. Add the useMCP() hook into any React application to connect to remote MCP servers that users can interact with.
Here’s all the code you need to add to connect to a remote MCP server:
mport { useMcp } from 'use-mcp/react'
function MyComponent() {
const { state, tools, callTool } = useMcp({
url: 'https://mcp-server.example.com'
})
return <div>Your actual UI code</div>
}
Just specify the URL, and you’re instantly connected.
Behind the scenes, use-mcp handles the transport protocols (both Streamable HTTP and Server-Sent Events), authentication flows, and session management. It also includes a number of features to help you build reliable, scalable, and production-ready MCP clients.
Connection management
Network reliability shouldn’t impact user experience. use-mcp manages connection retries and reconnections with a backoff schedule to ensure your client can recover the connection during a network issue and continue where it left off. The hook exposes real-time connection states (“connecting”, “ready”, “failed”), allowing you to build responsive UIs that keep users informed without requiring you to write any custom connection handling logic.
const { state } = useMcp({ url: 'https://mcp-server.example.com' })
if (state === 'connecting') {
return <div>Establishing connection...</div>
}
if (state === 'ready') {
return <div>Connected and ready!</div>
}
if (state === 'failed') {
return <div>Connection failed</div>
}
Authentication & authorization
Many MCP servers require some form of authentication in order to make tool calls. use-mcp supports OAuth 2.1 and handles the entire OAuth flow. It redirects users to the login page, allows them to grant access, securely stores the access token returned by the OAuth provider, and uses it for all subsequent requests to the server. The library also provides methods for users to revoke access and clear stored credentials. This gives you a complete authentication system that allows you to securely connect to remote MCP servers, without writing any of the logic.
const { clearStorage } = useMcp({ url: 'https://mcp-server.example.com' })
// Revoke access and clear stored credentials
const handleLogout = () => {
clearStorage() // Removes all stored tokens, client info, and auth state
}
Dynamic tool discovery
When you connect to an MCP server, use-mcp fetches the tools it exposes. If the server adds new capabilities, your app will see them without any code changes. Each tool provides type-safe metadata about its required inputs and functionality, so your client can automatically validate user input and make the right tool calls.
Debugging & monitoring capabilities
To help you troubleshoot MCP integrations, use-mcp exposes a log array containing structured messages at debug, info, warn, and error levels, with timestamps for each one. You can enable detailed logging with the debug option to track tool calls, authentication flows, connection state changes, and errors. This real-time visibility makes it easier to diagnose issues during development and production.
Future-proofed & backwards compatible
MCP is evolving rapidly, with recent updates to transport mechanisms and upcoming changes to authorization. use-mcp supports both Server-Sent Events (SSE) and the newer Streamable HTTP transport, automatically detecting and upgrading to newer protocols, when supported by the MCP server.
As the MCP specification continues to evolve, we’ll keep the library updated with the latest standards, while maintaining backwards compatibility. We are also excited to contribute use-mcp to the MCP project, so it can grow with help from the wider community.
MCP Inspector, built with use-mcp
In use-mcp’s examples directory, you’ll see a minimal MCP Inspector that was built with the use-mcp hook. . Enter any MCP server URL to test connections, see available tools, and monitor interactions through the debug logs. It’s a great starting point for building your own MCP clients or something you can use to debug connections to your MCP server.
Open-sourcing the AI Playground
We initially built the AI Playground to give users a chat interface for testing different AI models supported by Workers AI. We then added MCP support, so it could be used as a remote MCP client to connect to and test MCP servers. Today, we’re open-sourcing the playground, giving you the complete chat interface with the MCP client built in, so you can deploy it yourself and customize it to fit your needs.
The playground comes with built-in support for the latest MCP standards, including both Streamable HTTP and Server-Sent Events transport methods, OAuth authentication flows that allow users to sign-in and grant permissions, as well as support for bearer token authentication for direct MCP server connections.
How the AI Playground works
The AI Playground is built on Workers AI, giving you access to a full catalog of large language models (LLMs) running on Cloudflare’s network, combined with the Agents SDK and use-mcp library for MCP server connections.
The AI Playground uses the use-mcp library to manage connections to remote MCP servers. When the playground starts up, it initializes the MCP connection system with const{tools: mcpTools} = useMcp(), which provides access to all tools from connected servers. At first, this list is empty because it’s not connected to any MCP servers, but once a connection to a remote MCP server is established, the tools are automatically discovered and populated into the list.
Once connected, the playground immediately has access to any tools that the MCP server exposes. The use-mcp library handles all the protocol communication and tool discovery, and maintains the connection state. If the MCP server requires authentication, the playground handles OAuth flows through a dedicated callback page that uses onMcpAuthorization from use-mcp to complete the authentication process.
When a user sends a chat message, the playground takes the mcpTools from the use-mcp hook and passes them directly to Workers AI, enabling the model to understand what capabilities are available and invoke them as needed.
To monitor and debug connections to MCP servers, we’ve added a Debug Log interface to the playground. This displays real-time information about the MCP server connections, including connection status, authentication state, and any connection errors.
During the chat interactions, the debug interface will show the raw message exchanged between the playground and the MCP server, including the tool invocation and its result. This allows you to monitor the JSON payload being sent to the MCP server, the raw response returned, and track whether the tool call succeeded or failed. This is especially helpful for anyone building remote MCP servers, as it allows you to see how your tools are behaving when integrated with different language models.
Contributing to the MCP ecosystem
One of the reasons why MCP has evolved so quickly is that it’s an open source project, powered by the community. We’re excited to contribute the use-mcp library to the MCP ecosystem to enable more developers to build remote MCP clients.
If you’re looking for examples of MCP clients or MCP servers to get started with, check out theCloudflare AI GitHub repository for working examples you can deploy and modify. This includes the complete AI Playground source code, a number of remote MCP servers that use different authentication & authorization providers, and the MCP Inspector.
We’re also building the Cloudflare MCP servers in public and welcome contributions to help make them better.
Whether you’re building your first MCP server, integrating MCP into an existing application, or contributing to the broader ecosystem, we’d love to hear from you. If you have any questions, feedback, or ideas for collaboration, you can reach us via email at [email protected].
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.