Post Syndicated from Mickie Betz original https://blog.cloudflare.com/stream-automatic-captions-with-ai

With one click, customers can now generate video captions effortlessly using Stream’s newest feature: AI-generated captions for on-demand videos and recordings of live streams. As part of Cloudflare’s mission to help build a better Internet, this feature is available to all Stream customers at no additional cost.
This solution is designed for simplicity, eliminating the need for third-party transcription services and complex workflows. For videos lacking accessibility features like captions, manual transcription can be time-consuming and impractical, especially for large video libraries. Traditionally, it has involved specialized services, sometimes even dedicated teams, to transcribe audio and deliver the text along with video, so it can be displayed during playback. As captions become more widely expected for a variety of reasons, including ethical obligation, legal compliance, and changing audience preferences, we wanted to relieve this burden.
With Stream’s integrated solution, the caption generation process is seamlessly integrated into your existing video management workflow, saving time and resources. Regardless of when you uploaded a video, you can easily add automatic captions to enhance accessibility. Captions can now be generated within the Cloudflare Dashboard or via an API request, all within the familiar and unified Stream platform.
This feature is designed with utmost consideration for privacy and data protection. Unlike other third-party transcription services that may share content with external entities, your data remains securely within Cloudflare’s ecosystem throughout the caption generation process. Cloudflare does not utilize your content for model training purposes. For more information about data protection, review Your Data and Workers AI.
Getting Started
Starting June 20th, 2024, this beta is available for all Stream customers as well as subscribers of the Professional and Business plans, which include 100 minutes of video storage.
To get started, upload a video to Stream (from the Cloudflare Dashboard or via API).
Next, navigate to the “Captions” tab on the video, click “Add Captions,” then select the language and “Generate captions with AI.” Finally, click save and within a few minutes, the new captions will be visible in the captions manager and automatically available in the player, too. Captions can also be generated via the API.
Captions are usually generated in a few minutes. When captions are ready, the Stream player will automatically be updated to offer them to users. The HLS and DASH manifests are also updated so third party players that support text tracks can display them as well.
On-demand videos and recordings of live streams, regardless of when they were created, are supported. While in beta, only English captions can be generated, and videos must be shorter than 2 hours. The quality of the transcription is best on videos with clear speech and minimal background noise.
We’ve been pleased with how well the AI model transcribes different types of content during our tests. That said, there are times when the results aren’t perfect, and another method might work better for some use cases. It’s important to check if the accuracy of the generated captions are right for your needs.
Technical Details
Built using Workers AI
The Stream engineering team built this new feature using Workers AI, allowing us to access the Whisper model – an open source Automatic Speech Recognition model – with a single API call. Using Workers AI radically simplified the AI model deployment, integration, and scaling with an out-of-the-box solution. We eliminated the need for our team to handle infrastructure complexities, enabling us to focus solely on building the automated captions feature.
Writing software that utilizes an AI model can involve several challenges. First, there’s the difficulty of configuring the appropriate hardware infrastructure. AI models require substantial computational resources to run efficiently and require specialized hardware, like GPUs, which can be expensive and complex to manage. There’s also the daunting task of deploying AI models at scale, which involve the complexities of balancing workload distribution, minimizing latency, optimizing throughput, and maintaining high availability. Not only does Workers AI solve the pain of managing underlying infrastructure, it also automatically scales as needed.
Using Workers AI transformed a daunting task into a Worker that transcribes audio files with less than 30 lines of code.
import { Ai } from '@cloudflare/ai'
export interface Env {
AI: any
}
export type AiVTTOutput = {
vtt?: string
}
export default {
async fetch(request: Request, env: Env) {
const blob = await request.arrayBuffer()
const ai = new Ai(env.AI)
const input = {
audio: [...new Uint8Array(blob)],
}
try {
const response: AiVTTOutput = (await ai.run(
'@cf/openai/whisper-tiny-en',
input
)) as any
return Response.json({ vtt: response.vtt })
} catch (e) {
const errMsg =
e instanceof Error
? `${e.name}\n${e.message}\n${e.stack}`
: 'unknown error type'
return new Response(`${errMsg}`, {
status: 500,
statusText: 'Internal error',
})
}
},
}
Quickly captioning videos at scale
The Stream team wanted to ensure this feature is fast and performant at scale, which required engineering work to process a high volume of videos regardless of duration.
First, our team needed to pre-process the audio prior to running AI inference to ensure the input is compatible with Whisper’s input format and requirements.
There is a wide spectrum of variability in video content, from a short grainy video filmed on a phone to a multi-hour high-quality Hollywood-produced movie. Videos may be silent or contain an action-driven cacophony. Also, Stream’s on-demand videos include recordings of live streams which are packaged differently from videos uploaded as whole files. With this variability, the audio inputs are stored in an array of different container formats, with different durations, and different file sizes. We ensured our audio files were properly formatted to be compatible with Whisper’s requirements.
One aspect for pre-processing is ensuring files are a sensible duration for optimized inference. Whisper has an “sweet spot” of 30 seconds for the duration of audio files for transcription. As they note in this Github discussion: “Too short, and you’d lack surrounding context. You’d cut sentences more often. A lot of sentences would cease to make sense. Too long, and you’ll need larger and larger models to contain the complexity of the meaning you want the model to keep track of.” Fortunately, Stream already splits videos into smaller segments to ensure fast delivery during playback on the web. We wrote functionality to concatenate those small segments into 30-second batches prior to sending to Workers AI.
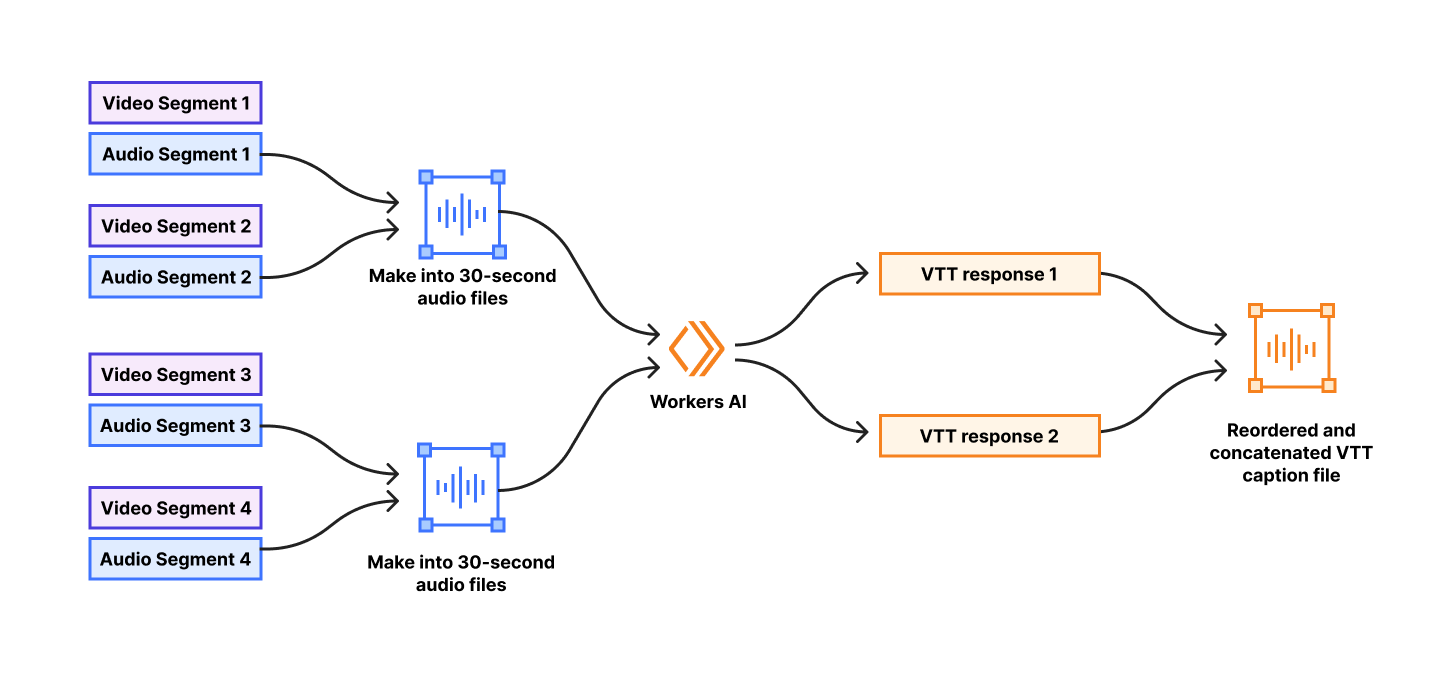
To optimize processing speed, our team parallelized as many operations as possible. By concurrently creating the 30-second audio batches and sending requests to Workers AI, we take full advantage of the scalability of the Workers AI platform. Doing this greatly reduces the time it takes to generate captions, but adds some additional complexity. Because we are sending requests to Workers AI in parallel, transcription responses may arrive out-of-order. For example, if a video is one minute in duration, the request to generate captions for the second 30 seconds of a video may complete before the request for the first 30 seconds of the video. The captions need to be sequential to align with the video, so our team had to maintain an understanding of the audio batch order to ensure our final combined WebVTT caption file is properly synced with the video. We sort the incoming Workers AI responses and re-order timestamps for a final accurate transcript.
The end result is the ability to generate captions for longer videos quickly and efficiently at scale.
Try it now
We are excited to bring this feature to open beta for all of our subscribers as well as Pro and Business plan customers today! Get started by uploading a video to Stream. Review our documentation for tutorials and current beta limitations. Up next, we will be focused on adding more languages and supporting longer videos.
































































 Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga. Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 15+ years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking.
Tahir Aziz is an Analytics Solution Architect at AWS. He has worked with building data warehouses and big data solutions for over 15+ years. He loves to help customers design end-to-end analytics solutions on AWS. Outside of work, he enjoys traveling and cooking. Omama Khurshid is an Acceleration Lab Solutions Architect at Amazon Web Services. She focuses on helping customers across various industries build reliable, scalable, and efficient solutions. Outside of work, she enjoys spending time with her family, watching movies, listening to music, and learning new technologies.
Omama Khurshid is an Acceleration Lab Solutions Architect at Amazon Web Services. She focuses on helping customers across various industries build reliable, scalable, and efficient solutions. Outside of work, she enjoys spending time with her family, watching movies, listening to music, and learning new technologies.