Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=tMFTiI8wTIU
Mike Pence on the Future of Conservatism | The Atlantic Festival 2025
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=lBDMkEyK3X0
Trellix achieved 35% cost savings and enhanced security with Amazon OpenSearch Service
Post Syndicated from Leeneksh Dubey original https://aws.amazon.com/blogs/big-data/trellix-achieved-35-cost-savings-and-enhanced-security-with-amazon-opensearch-service/
This is a guest post by Leeneksh Dubey, Cloud Engineer at Trellix, in partnership with AWS.
Trellix, a global leader in cybersecurity solutions, emerged in 2022 from the merger of McAfee Enterprise and FireEye. Serving over 40,000 enterprise customers worldwide, Trellix delivers the industry’s most comprehensive, open, and native AI-powered security platform. Their solution helps organizations build operational resilience against advanced threats through automated detection, investigation, and response capabilities.
Today security teams face an increasingly complex landscape of cybersecurity threats, while the volume of security and application logs grows exponentially. With limited resources and personnel, teams struggle to investigate all security events, potentially missing emerging threats. Trellix addresses these challenges by unifying security tools across endpoints, networks, cloud, and email into a single, AI-powered platform. By automating threat detection, investigation, and response, it enables security teams to identify and neutralize threats faster while reducing operational complexity.
To address exponential log growth across their multi-tenant, multi-Region infrastructure, Trellix used Amazon OpenSearch Service, Amazon OpenSearch Ingestion, and Amazon Simple Storage Service (Amazon S3) to modernize their log infrastructure. Facing challenges with self-managed Elasticsearch clusters on Amazon Elastic Compute Cloud (Amazon EC2), Trellix’s migration to managed OpenSearch Service significantly optimized their operations. This strategic implementation enabled them to process terabytes of daily security data across multiple AWS Regions while achieving a 35% reduction in storage costs as of Q3 2024. The shift to managed services saved up to 10 hours of infrastructure maintenance time weekly, helping developers focus more on value-added tasks.
In this post, we share how, by adopting these AWS solutions, Trellix enhanced their system’s performance, availability, and scalability while reducing operational overhead.
Solution overview
Trellix’s innovative log management solution, built on AWS services, addresses the challenges of processing large volumes of security data across multiple Regions. This enterprise-grade architecture demonstrates how organizations can effectively manage security logs at scale while optimizing costs. The solution addresses three critical business challenges: efficient management of long-term log storage, scalable distribution of analytics and alerting functions, and optimization of storage costs across their multi-regional infrastructure. The architecture is illustrated in the following diagram, demonstrating how Trellix managed the security logs at scale while optimizing costs.
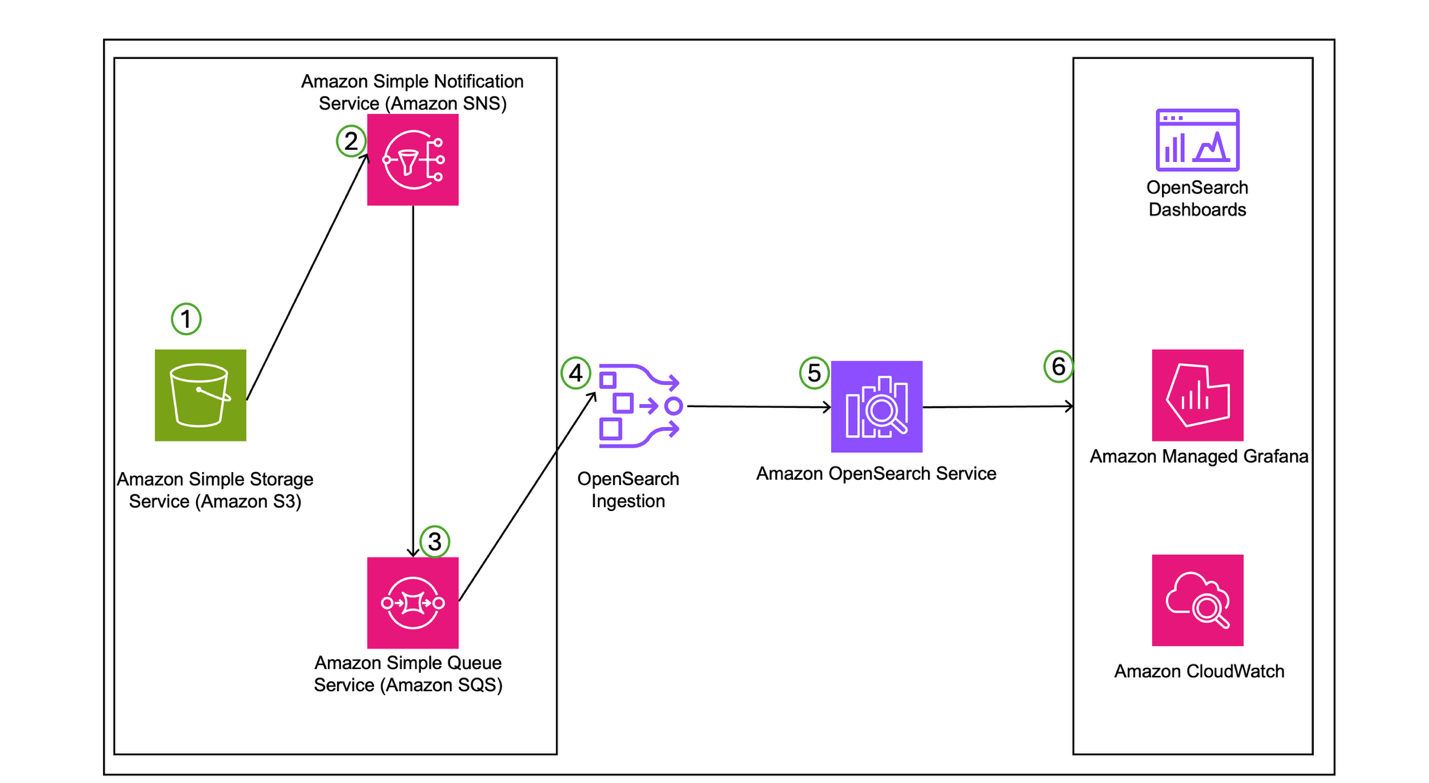
The Trellix security log management solution on AWS implements a comprehensive data pipeline that seamlessly handles log ingestion, processing, storage, and analysis. In the following sections, we explore the six steps of the workflow in more detail.
Step 1: Load data to Amazon S3
The solution begins with a data ingestion process using the Amazon S3 globally distributed and highly scalable infrastructure. Raw security and application logs are captured from multiple Regional deployments, helping Trellix maintain both data sovereignty and low latency access across various jurisdictions. These logs are then processed by the Trellix internal engine, which enriches them using proprietary security logic. This enriched dataset is subsequently stored back in Amazon S3, establishing a secure, scalable foundation for further security analytics and downstream processing.
Step 2: Amazon SNS notification triggered by S3 Events
After the enriched data is successfully stored in Amazon S3, the system initiates an event-driven automation sequence. Amazon S3 is configured to emit event notifications to an Amazon Simple Notification Service (Amazon SNS) topic whenever new data is uploaded. Amazon SNS acts as a notification hub, efficiently broadcasting these events to subscribed services or endpoints. This approach helps the architecture remain responsive and decoupled, because it allows various consumers to be alerted in real time as new data becomes available in the system.
Step 3: Message queuing in Amazon SQS
As the next step in the workflow, the SNS notifications are routed to Amazon Simple Queue Service (Amazon SQS), which serves as a durable and scalable queuing layer between producers and consumers. This queue acts as a buffer, facilitating reliable and asynchronous delivery of event metadata to downstream processing components. The use of Amazon SQS provides message persistence and fault tolerance, particularly under high-throughput or failure scenarios, allowing OpenSearch Ingestion to process incoming data in a controlled and resilient manner.
Step 4: Automated data processing with OpenSearch Ingestion
OpenSearch Ingestion continuously polls the SQS queue for new messages indicating the availability of data in Amazon S3. Upon receiving these messages, it uses its built-in integration capabilities to fetch the corresponding data directly from Amazon S3. After the data is retrieved, the ingestion pipeline performs the necessary transformations before forwarding it to the OpenSearch Service domain. To facilitate optimal cost-efficiency and performance, Trellix selected OR1 instances types for their OpenSearch deployment. These instances offer a high memory-to-vCPU ratio and are specifically optimized for intensive indexing and search workloads, making them ideal for handling large-scale log analytics operations.
Step 5: Log lifecycle setup using Index State Management
To optimize storage usage and manage data retention, Trellix has implemented Index State Management (ISM) policies within the OpenSearch Service. These policies automate the lifecycle of ingested log data by transitioning it through defined stages based on age and access patterns. Initially, logs reside in the hot tier for up to 24 hours, enabling immediate access for real-time security analysis. As logs age beyond this threshold, they are automatically transitioned to the UltraWarm storage, which offers a more cost-effective storage option while keeping the data queryable. Finally, after the predefined retention period expires, the ISM policy deletes the data from the system. This fully automated lifecycle management approach balances performance, compliance, and cost-efficiency.
Step 6: Comprehensive monitoring and visualization
Using the extensive monitoring capabilities of Amazon CloudWatch, complemented by Trellix’s in-house automations using OpenSearch public APIs for custom monitoring, the solution provides end-to-end visibility through integrated visualization tools. OpenSearch Dashboards provides security teams with powerful log analysis and search capabilities, so they can dive deep into security events and identify potential threats. Additionally, the solution uses Amazon Managed Grafana to create customized dashboards that monitor both the data pipeline health and OpenSearch cluster performance.
This dual visualization approach delivers multiple benefits: real-time security event monitoring and analysis, comprehensive performance metrics across the infrastructure, automated alerting for rapid threat response, custom dashboard views for different security operations needs, and unified visibility across the multiple Regional deployments. The combined power of these tools creates a robust monitoring framework that helps Trellix maintain a strong security posture while facilitating optimal performance across their global infrastructure.This six-step implementation demonstrates how AWS services can be combined to create a scalable, cost-efficient security log management solution that processes terabytes of daily security data while maintaining high performance and operational efficiency.
Key benefits
Trellix’s implementation of OpenSearch Service as their logging solution delivered three significant advantages that transformed their security operations.
Simplified log management architecture
Trellix streamlined their security operations by implementing a cohesive log management architecture that avoids the complexity of managing multiple disparate tools. By using OpenSearch Ingestion, a fully managed serverless data pipeline, Trellix simplified their data pipeline for processing real-time security data. The integration with Managed Grafana provides a unified visualization layer, enabling security teams to focus on threat detection rather than infrastructure management.
Scalability and resilience
The implementation of OpenSearch Service enables Trellix to achieve unprecedented scalability and resilience in their security operations. Trellix’s architecture uses an OpenSearch Ingestion pipeline to provide effortless handling of sudden log volume spikes across multiple Regional deployments. OpenSearch Ingestion enables dynamic scaling with automated resource optimization, facilitating seamless capacity management as data volumes grow. This capability helps Trellix maintain consistent performance even during periods of increased security event logging. The solution also implements a robust Multi-AZ deployment strategy to maintain maximum resilience and continuous service availability. During self-healing testing, the architecture demonstrated impressive recovery times under 9 minutes when a node was rebooted, showcasing its ability to maintain business continuity even in case of node failure. The automated failover capabilities facilitate minimal disruption to security operations, so Trellix can maintain constant vigilance over their customers’ security posture. Lastly, the solution uses automated Amazon S3 backups combined with hourly snapshots for comprehensive point-in-time recovery capabilities. Each Region maintains additional customer data replicas, creating a multi-layered data protection strategy that maintains the integrity and availability of critical security information.
Effortless scalability with optimized cost
Trellix’s exponential growth in security data processing demanded a solution that could scale dynamically while maintaining cost-efficiency. The strategic implementation of Amazon S3 and OpenSearch Service with UltraWarm storage provided the foundation for this scalable architecture. UltraWarm, a fully managed warm storage tier for OpenSearch Service, revolutionized how Trellix manages their extensive security data across multiple Regions. The solution uses UltraWarm’s innovative architecture, which uses Amazon S3 for durable storage while maintaining fast query performance for security analysis. A key advantage of UltraWarm’s Amazon S3 backed architecture is the removal of index replicas, significantly reducing cluster size and associated costs while maintaining data durability.The intelligent log prioritization framework forms the backbone of Trellix’s data management strategy, categorizing incoming data based on security significance. This systematic approach enables efficient routing of P2 and P3 log sources, optimized processing paths for different security priorities, reduced load on primary SIEM infrastructure, and customized handling based on customer requirements. The implementation has proven particularly valuable for security log analytics, where historical data analysis is crucial for threat detection and compliance requirements.The implementation delivered substantial operational and financial benefits for Trellix. By combining priority-based routing and tiered storage management, the organization achieved a 35% reduction in storage and compute costs while maintaining high-performance security operations. The solution enables efficient storage and analysis of extensive historical data, supporting Trellix’s commitment to comprehensive security monitoring while optimizing operational costs. This implementation demonstrates how AWS services can help organizations optimize costs without compromising security capabilities or operational efficiency.
What’s next
The successful implementation of this solution has positioned Trellix to explore additional AWS capabilities and emerging technologies to enhance their security operations:
- Integration of AWS ML/AI services to analyze petabytes of security log data
- Implementation of ML-based anomaly detection within OpenSearch Service
- Using security analytics plugins for advanced threat detection
- Custom configurations and pre-built security rules implementation
Summary
Trellix successfully modernized its log management infrastructure through collaboration with AWS, implementing a sophisticated architecture that addresses the challenges of processing terabytes of daily security data across multiple Regions. By using OpenSearch Service with UltraWarm nodes and integrating Amazon S3, the solution delivered significant performance enhancements, including faster log ingestion and streamlined operational management. The architecture’s innovative tiered storage approach, combined with optimized retention policies, resulted in a 35% reduction in storage costs while maintaining compliance requirements.This transformation has positioned Trellix to efficiently handle growing data volumes and evolving security challenges, demonstrating how strategic use of cloud services can simultaneously improve performance, reduce costs, and enhance operational efficiency.
About the authors
Jennifer Doudna on Medical Innovation | The Atlantic Festival 2025
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=-EY_mRwFl5k
Home Assistant Jukebox: Play ANY Song with Simple Steps! #shorts
Post Syndicated from BeardedTinker original https://www.youtube.com/shorts/qKPhXowd0IE
Announcing cross-account ingestion for Amazon OpenSearch Service
Post Syndicated from David Venable original https://aws.amazon.com/blogs/big-data/announcing-cross-account-ingestion-for-amazon-opensearch-service/
Amazon OpenSearch Ingestion is a powerful data ingestion pipeline that AWS customers use for many different purposes, such as observability, analytics, and zero-ETL search. Many customers today push logs, traces, and metrics from their applications to OpenSearch Ingestion to store and analyze this data.
Today, we are happy to announce that OpenSearch Ingestion pipelines now support cross-account ingestion for push-based sources such as HTTP and OpenTelemetry (OTel). Organizations can now use this feature to effortlessly share data across teams. For example, many organizations have central observability teams—now these teams can create OpenSearch Ingestion pipelines and share them with other teams in their organization. You can also use this feature to ingest data into Amazon OpenSearch Service domains or Amazon OpenSearch Serverless collections in other accounts.
Previously, sharing OpenSearch Ingestion pipelines across accounts required teams to use virtual private cloud (VPC) features to share access. For example, teams could use VPC peering, which is not always feasible, or AWS Transit Gateway. The new cross-account ingestion features in OpenSearch Ingestion can simplify your deployment and reduce cost for sharing pipelines.
Solution overview
Let’s look at how to share a pipeline from a central logging account with two other development accounts (A and B). The central logging account can create an OpenSearch Ingestion pipeline using a push-based source, for example, HTTP. After creating the pipeline, a member of the central logging team can grant access to the other teams. They can use a resource policy that gives permissions to the two other team accounts to create pipeline endpoints. After making this change, the OpenSearch Ingestion pipeline is available for use by the other teams.
The following diagram illustrates this configuration.
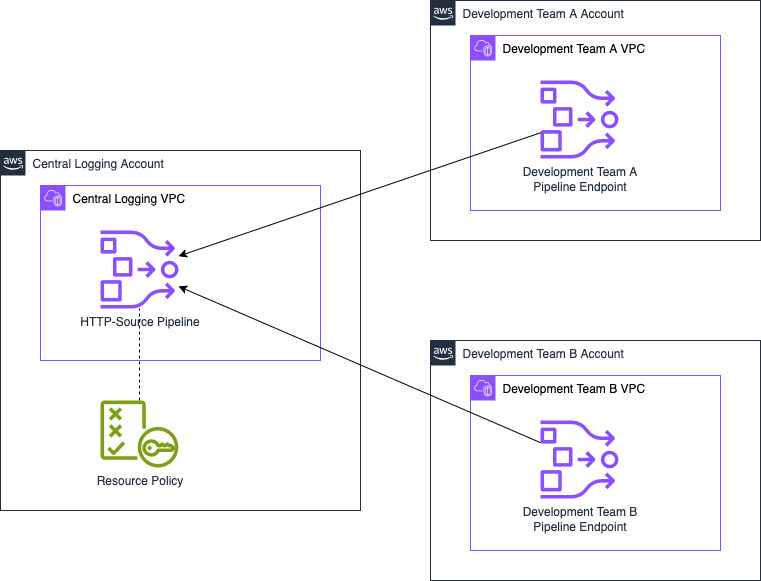
In the following sections, we demonstrate how to implement this solution.
Prerequisites
First, the central logging account must have a VPC with two options enabled.
- enableDnsSupport must be set to true
- enableDnsHostnames must be set to true
The central logging account must also create a push-based OpenSearch Ingestion pipeline in the VPC. This can be a pipeline receiving logs from FluentBit or OpenTelemetry telemetry.
The development accounts that are going to connect to the pipeline also must have VPCs in the same region with the same DNS options enabled.
- enableDnsSupport must be set to true
- enableDnsHostnames must be set to true
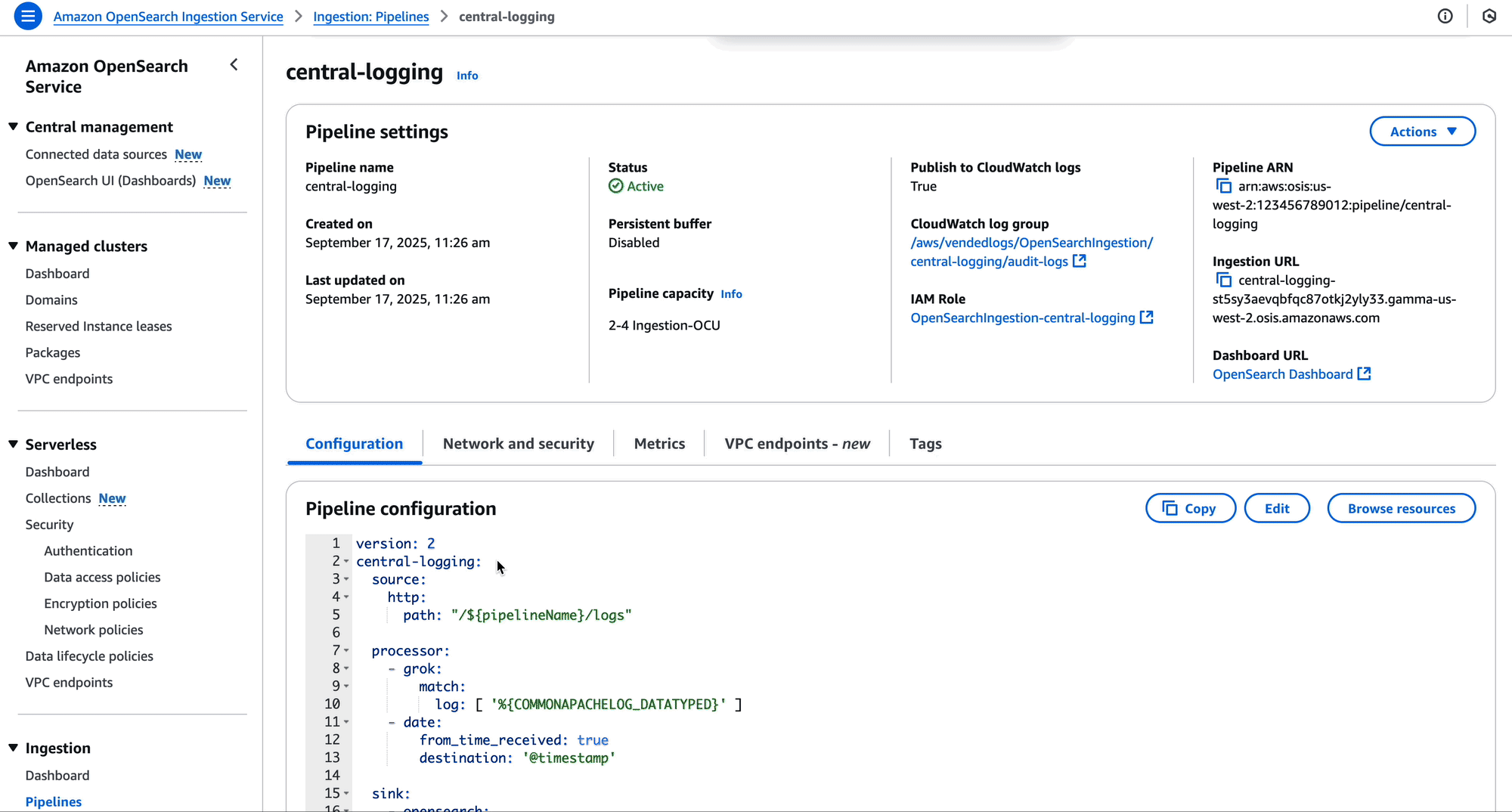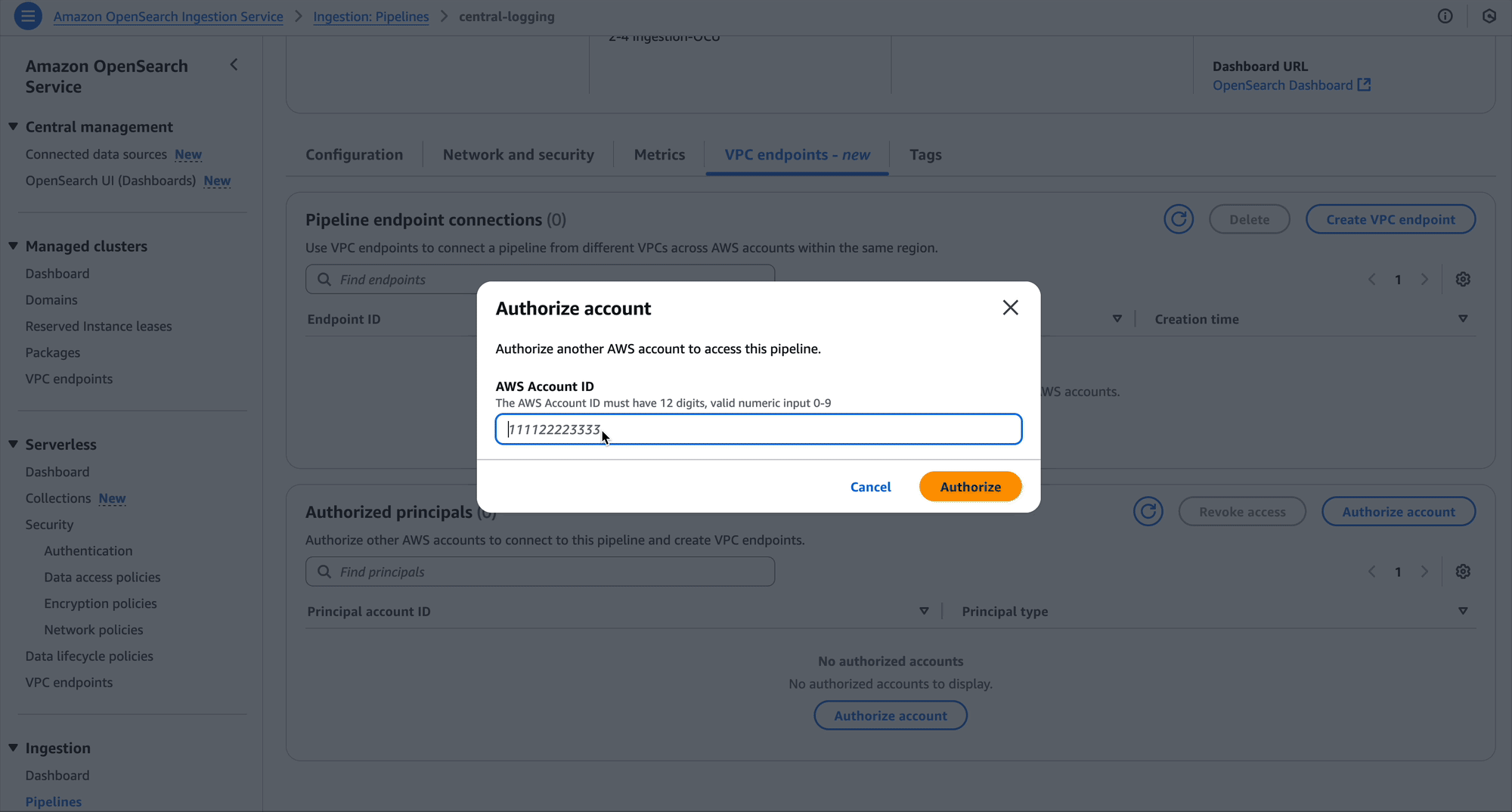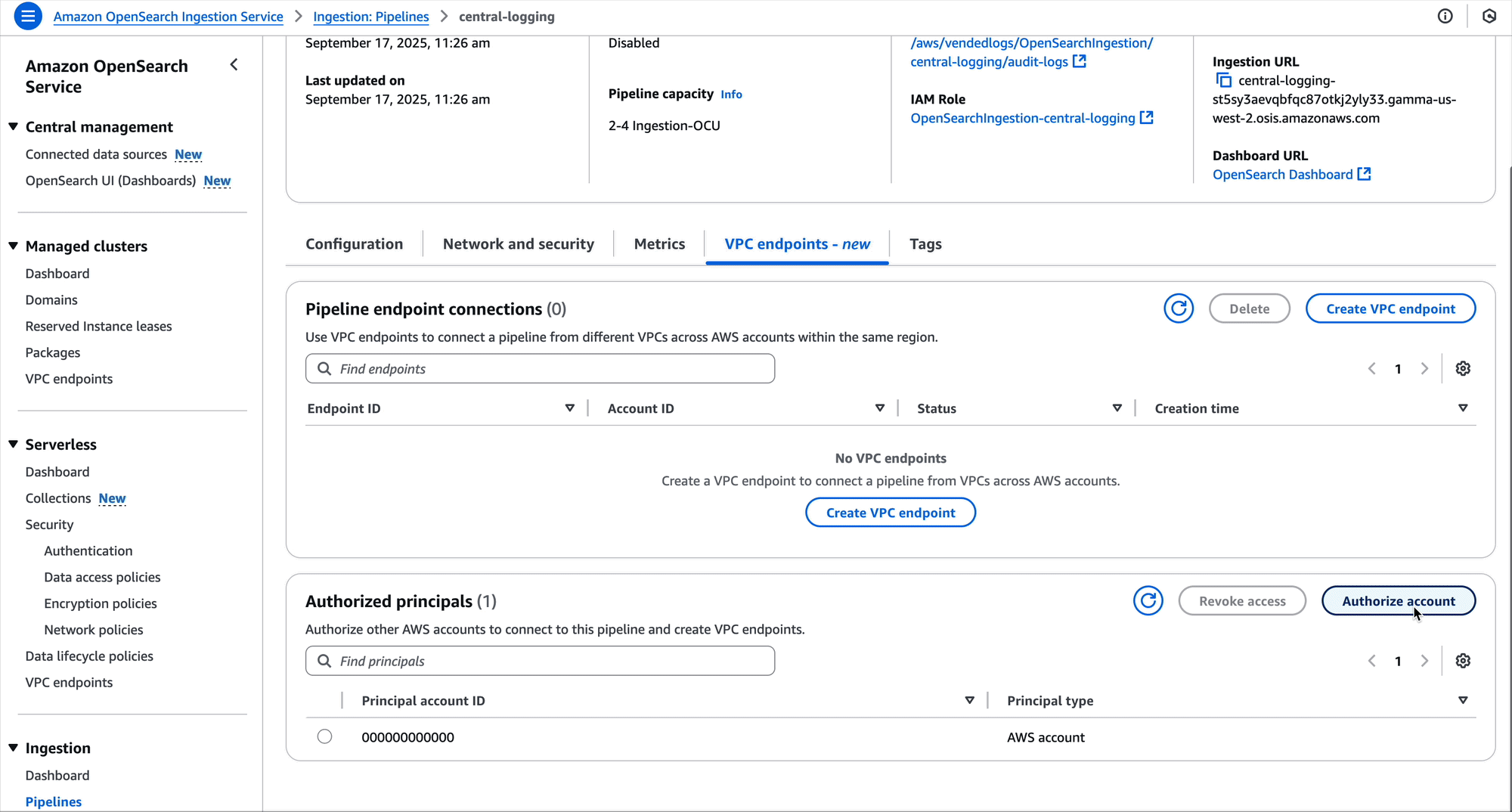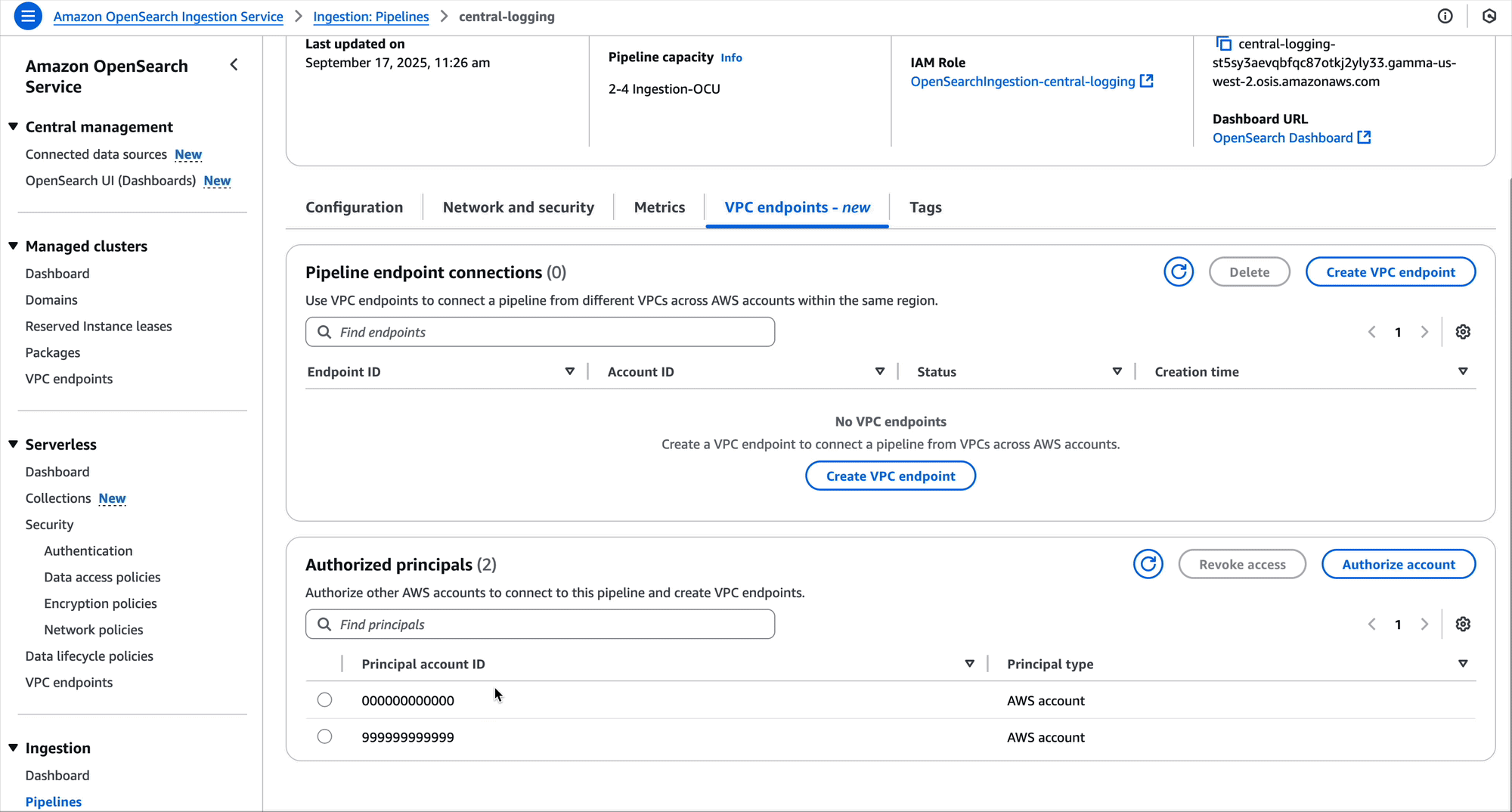
Create resource policy
As the owner of the pipeline, you can create a resource policy that allows the two development accounts to create pipeline endpoints against your pipeline.
The following is an example resource policy for this scenario:
The OpenSearch Ingestion console makes it straightforward to create these policies, as shown in the following screenshot.
Create pipeline endpoint
Now that the central logging account has shared permissions on their pipeline, the development accounts can create pipeline endpoints. A pipeline endpoint is a connection from one VPC to an OpenSearch Ingestion pipeline.
The development accounts are responsible for creating the pipeline endpoints in the VPCs they want to connect from. They create this in the subnets they need and provide a security group. The security group should have an inbound rule allowing access port HTTPS over port 443 from any source that the development accounts need to ingest logs.
Development team A can create a pipeline endpoint using a command similar to the following:
Development team A can also use the OpenSearch Ingestion console to create the pipeline endpoint.
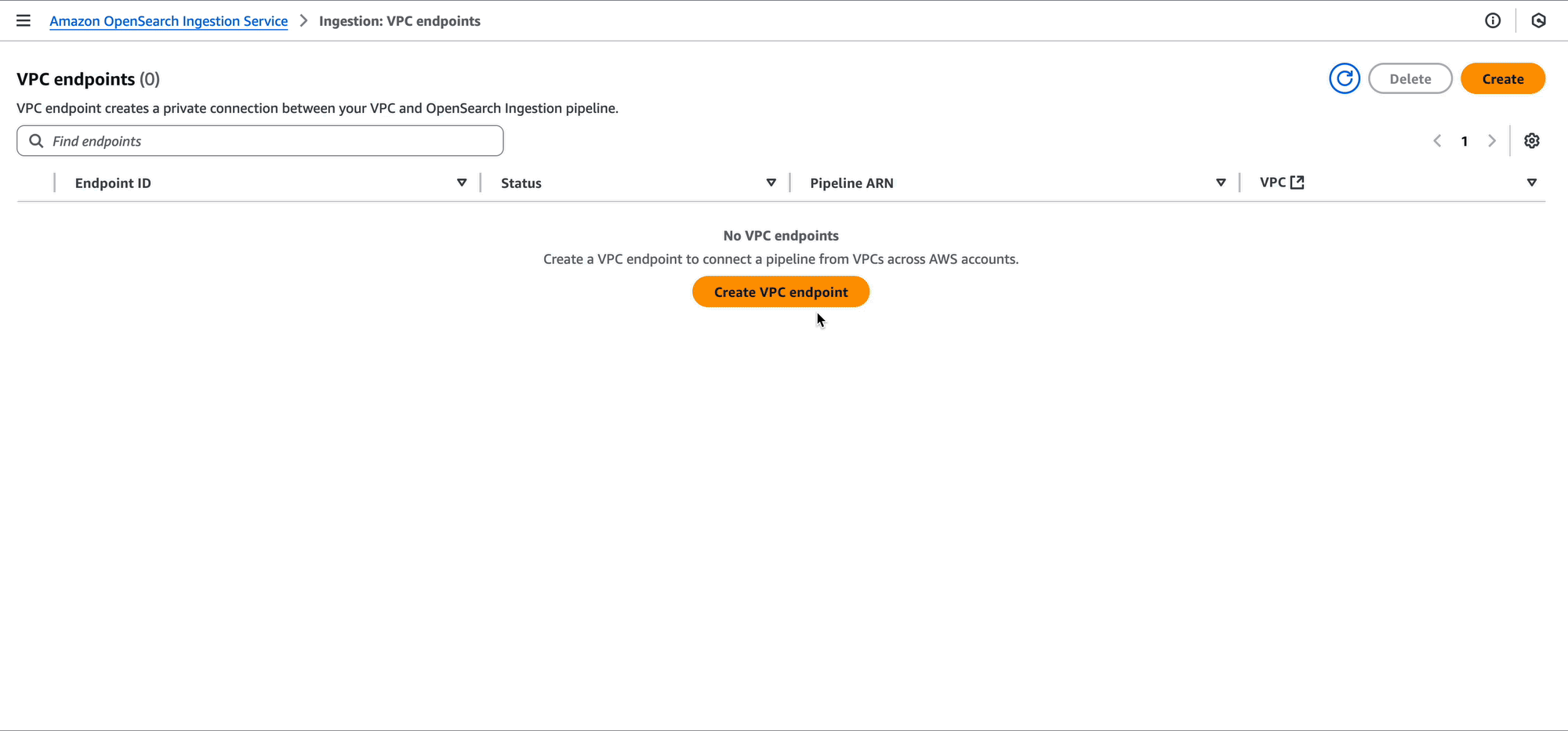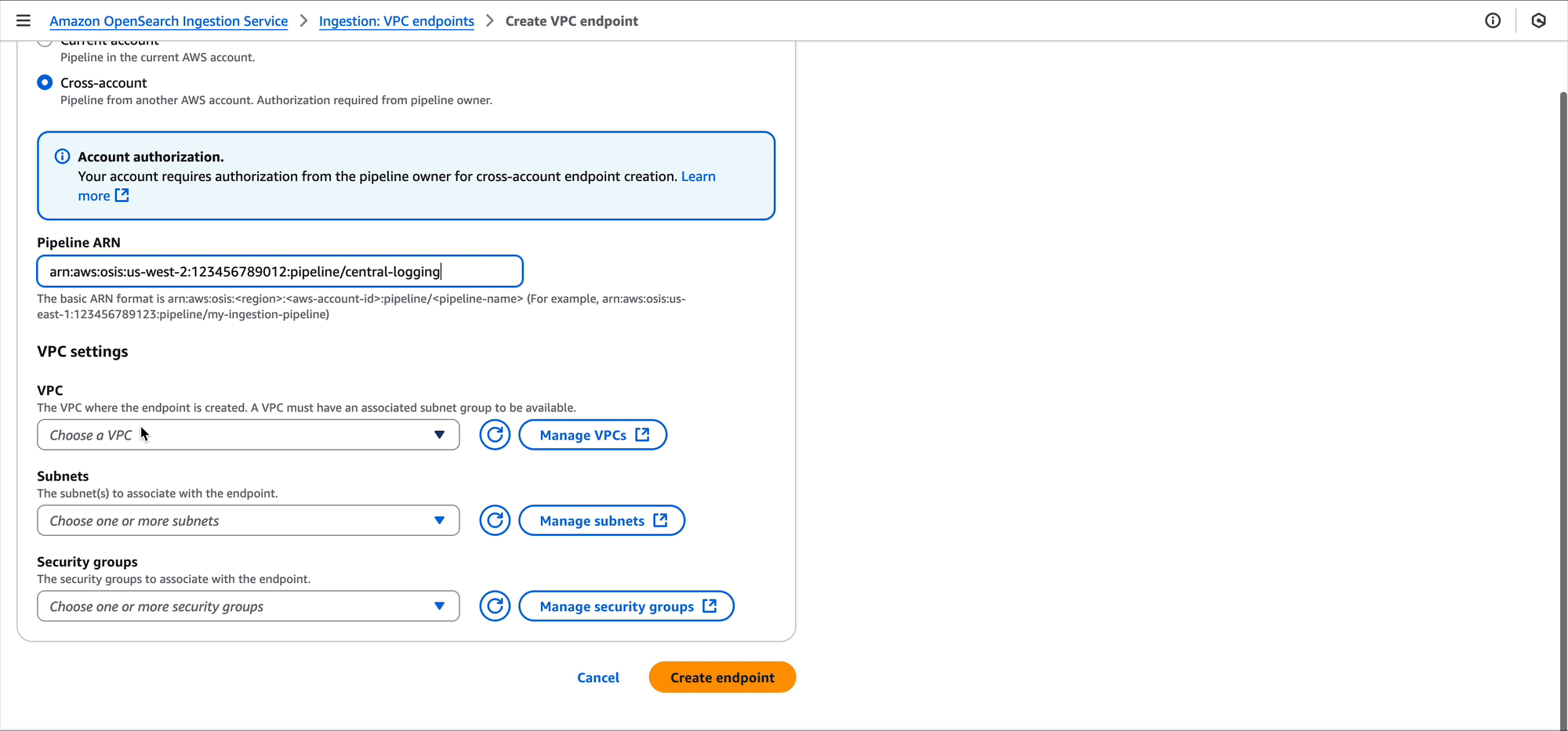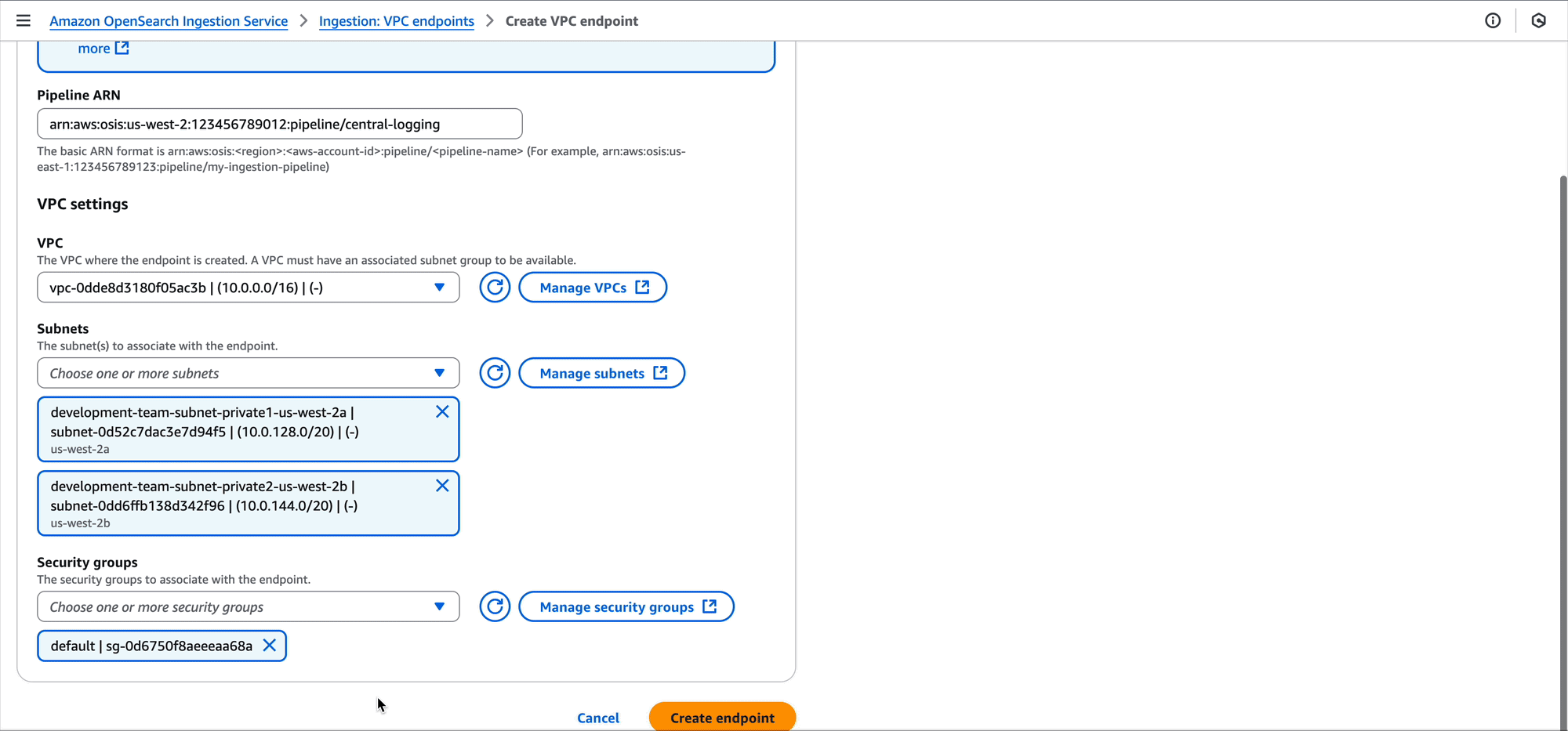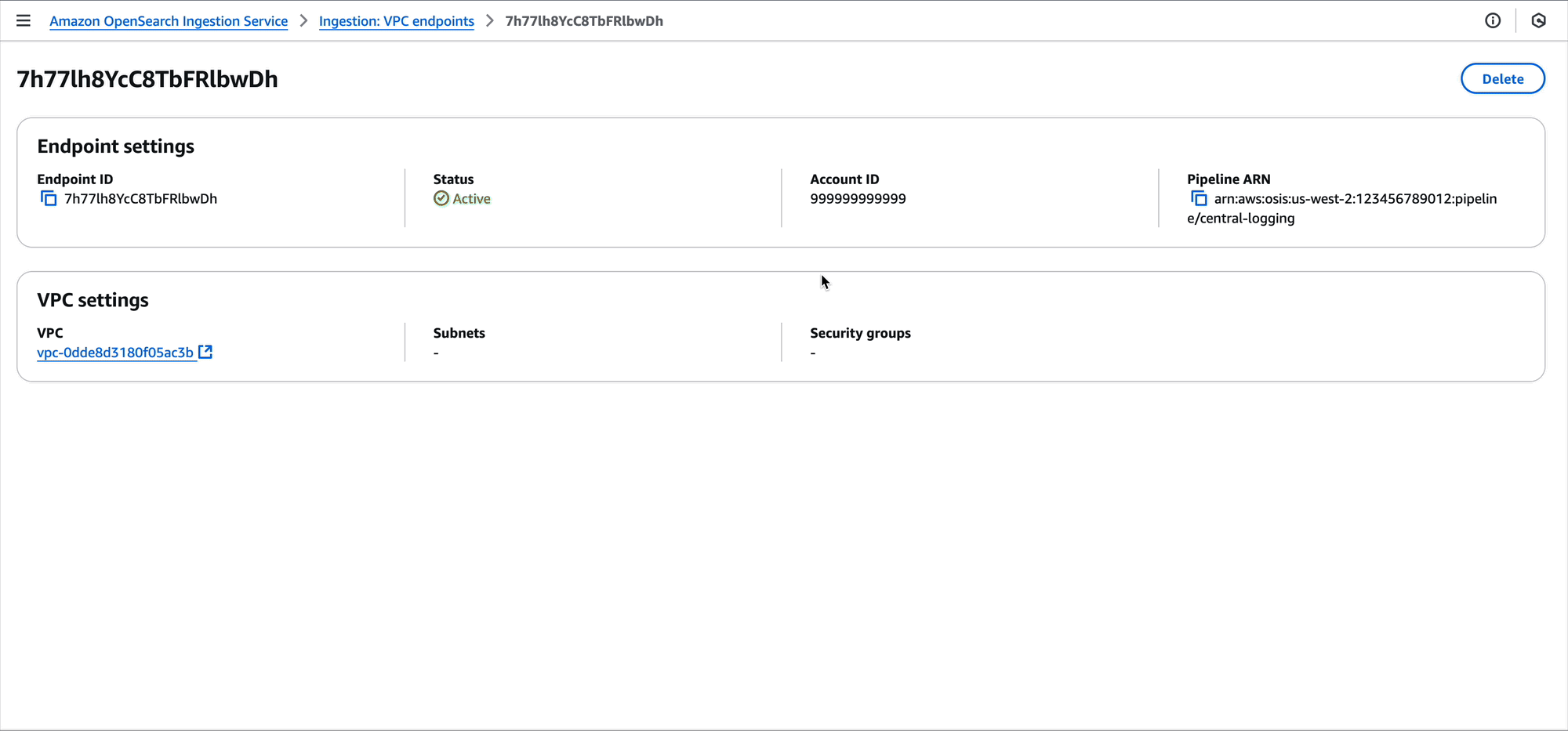
After performing this change, the VPC for development team A will have a pipeline endpoint. This pipeline endpoint now allows for ingesting data into the central logging pipeline. Now, Amazon Elastic Compute Cloud (Amazon EC2) instances, Amazon Elastic Container Service (Amazon ECS) tasks, Kubernetes pods, and other compute running in the VPC can ingest their log data into the pipeline using tools such as FluentBit.
At the same time or at a later time, development team B can create a pipeline endpoint as well. This team will create it for their own VPC.
After this, the pipeline will now have two pipeline endpoints, so both teams can ingest their log data into the central logging VPC.
Clean up
After a pipeline endpoint is created, either account can remove it. The development teams in our scenario can use the DeletePipelineEndpoint API to delete it from their accounts. Additionally, if the central logging account needs to remove a pipeline endpoint from a pipeline, it can use the RevokePipelineEndpointConnections API. Both options are available on the OpenSearch Ingestion console as well.
After the pipeline endpoints are removed, the central logging team can also remove the pipeline if they no longer need it.
Conclusion
The new pipeline endpoint feature for OpenSearch Ingestion simplifies how you can share pipelines for cross-account ingestion. This can help teams use the powerful features of OpenSearch Ingestion and open up new possibilities for teams or organizations using multiple accounts and VPCs. The new pipeline endpoint feature is available today in AWS Regions where OpenSearch Ingestion is available.
To get started with cross-account ingestion in OpenSearch Ingestion, refer to OpenSearch Ingestion documentation or try creating your first cross-account pipeline on the OpenSearch Ingestion console.
About the authors
Four Friday stable kernel updates
[$] Blender 4.5 brings big changes
Post Syndicated from jzb original https://lwn.net/Articles/1036262/
Blender 4.5 LTS was released
on July 15, 2025, and will be supported through 2027. This is the last
feature release of the 3D graphics-creation suite’s 4.x series; it
includes quality-of-life improvements, including work to bring the Vulkan backend up to
par with the default OpenGL backend. With 4.5 released, Blender
developers are turning their attention toward Blender 5.0, planned for
release later this year. It will introduce substantial changes,
particularly in the Geometry
Nodes system, a central feature of Blender’s procedural
workflows.
David Letterman responds to Jimmy Kimmel suspension
Post Syndicated from The Atlantic original https://www.youtube.com/shorts/VwjELoM8qag
You don’t need quantum hardware for post-quantum security
Post Syndicated from Luke Valenta original https://blog.cloudflare.com/you-dont-need-quantum-hardware/
Organizations have finite resources available to combat threats, both by the adversaries of today and those in the not-so-distant future that are armed with quantum computers. In this post, we provide guidance on what to prioritize to best prepare for the future, when quantum computers become powerful enough to break the conventional cryptography that underpins the security of modern computing systems. We describe how post-quantum cryptography (PQC) can be deployed on your existing hardware to protect from threats posed by quantum computing, and explain why quantum key distribution (QKD) and quantum random number generation (QRNG) are neither necessary nor sufficient for security in the quantum age.
“Quantum” is becoming one of the most heavily used buzzwords in the tech industry. What does it actually mean, and why should you care?
At its core, “quantum” refers to technologies that harness principles of quantum mechanics to perform tasks that are not feasible with classical computers. Quantum computers have exciting potential to unlock advancements in materials science and medicine, but also pose a threat to computer security systems. The term Q-day refers to the day that adversaries possess quantum computers that are large and stable enough to break the conventional public-key cryptography that secures much of today’s data and communications. Recent advances in quantum computing have made it clear that it is no longer a question of if Q-day will arrive, but when.
What does it mean, then, for your organization to be quantum ready? At Cloudflare, our definition is simple: your systems and communications should be secure even after Q-day.
However, this definition often gets muddied by vendors insisting that products built using quantum technology are required in order to secure an organization against quantum adversaries. In this blog post we explain why quantum technologies are neither necessary nor sufficient to protect against attacks by a quantum adversary.
The good news is that there is already a solution: post-quantum cryptography (PQC). PQC protects against attacks by quantum adversaries, but PQC is not a quantum technology — it runs on conventional computers without specialized hardware. You can use PQC today on the computers you already have, without buying expensive new hardware.
We’ve written quite a few blog posts on post-quantum cryptography already, so we will keep this section brief.
The public-key cryptography that we’ve used for decades to secure our data and communications is based on math problems (like factoring large numbers) that are believed to be computationally hard to solve on conventional computers. If you can efficiently solve the underlying math problem, you can efficiently break the cryptography and the systems that depend on it. As it turns out, the math problems underlying much of today’s public-key cryptography can be efficiently solved by specialized algorithms, like Shor’s algorithm, on large-scale quantum computers.
The solution? Pick new hard math problems (like finding “short” vectors in algebraic lattices) that are no easier to solve with a quantum computer than with a conventional computer. Then, build new cryptographic systems around them. The US National Institute of Standards and Technologies (NIST) launched an international competition in 2016 to identify and standardize such cryptographic systems, which resulted in several new standards for post-quantum cryptography being published in 2024, and several more under consideration for future standardization.
Post-quantum cryptography (PQC) runs on your existing phones, laptops, and servers. PQC runs at Internet scale and can even be more performant than classical cryptography. Except in rare cases, like when you need additional hardware acceleration in cheap smartcards or to replace legacy systems that lack cryptographic agility, there is no need to purchase new hardware to migrate to PQC.
If you want to know how to protect your organization from security threats posed by quantum computers, you can stop reading now. Post-quantum cryptography is the solution.

Alternatively, you can read below for our perspective on hardware-based quantum security technologies that are sometimes marketed as security solutions.
Quantum technologies capture the imagination. Quantum computers (possibly linked together in a quantum Internet) promise to deliver breakthroughs in drug discovery and materials science via advanced molecular simulation. Measurement of physical quantum processes can be used to generate entropy with mathematically provable properties.
This is exciting technology and fundamental scientific research. But this technology is not required to secure data and communications against quantum attackers.
In this section, we’ll explain why quantum security technologies do not need to be part of your quantum readiness strategy, and any decision to invest in quantum technology should not be based on a desire to defend data and communications systems against the threat of quantum adversaries. Instead, investments should be based on a desire to improve quantum technologies in their own right, for example to help with applications like chemistry, machine learning, and financial modeling.
Our position here is largely in agreement with the strategies towards quantum security technologies of the US National Security Agency (NSA), UK National Cyber Security Centre (NCSC), NL Nationaal Cyber Security Centrum (NCSC), and DE Federal Office for Information Security (BSI). We’ll focus on two quantum technologies widely marketed as security products: quantum key distribution (QKD) and quantum random number generation (QRNG).
Quantum key distribution (QKD) is a hardware-based solution to secure communications across point-to-point links. Rather than relying on hard mathematical problems, QKD relies on principles of quantum physics to establish a shared symmetric secret between two parties, while ensuring that eavesdropping can be detected. QKD provides security guarantees that are based on physical properties of the communication channel. Once a shared secret is established, parties can switch to traditional symmetric-key cryptography for secure communication. QKD is the first step towards a futuristic “quantum Internet.” However, there are some fundamental reasons why QKD cannot be a general replacement for classical cryptography running on conventional hardware.
Most importantly, QKD does not operate at Internet scale. QKD is used to establish an unauthenticated secret between pairs of parties with a direct physical link between them. The parties can then use an authentication mechanism based on conventional cryptography to bootstrap a secure communication channel over that link. While building dedicated physical links may be feasible for cross-datacenter communication or across major Internet backbones, it is not possible for most pairs of parties on the Internet. In particular, deploying QKD for the “last-mile” connection to end-user devices would require that each device has a direct physical connection to every server or device it needs to securely communicate with.
Connectivity aside, there’s a good reason why the Internet doesn’t rely on secure point-to-point links: they do not scale (or rather, they scale exponentially). Bringing a new device online would require a change to every other device it needs to communicate with, a massive operational burden on everyone. Fortunately, there’s a better way. The OSI model for networking provides an abstraction such that two parties can communicate even if they don’t share a direct physical link, so long as some chain of physical links exists between them. Public-key cryptography, invented in the seminal “New Directions in Cryptography” paper in 1976, allows two parties participating in the same public-key infrastructure to establish a secure end-to-end encrypted communication channel, without requiring any prior setup between them. The massive scaling enabled by these technologies is why the secure Internet exists as we know it. Secure point-to-point links are not part of the solution.
Lack of scalability is enough for us to disqualify QKD outright: if a technology can’t bring security to the whole Internet, we’re not going to spend much time on it.
The challenges with QKD don’t stop there though.
QKD touts theoretical security guarantees, but achieving security in practice is not so simple. QKD systems have been plagued by implementation attacks, both classical sidechannel attacks and new ones specific to the technology. Further, QKD works best over a special medium: either fiber or a vacuum. QKD has been demonstrated over the air, but performance and the implementation security mentioned before suffers. We still have not seen QKD work on a mobile phone or over Wi-Fi networks.
Further, neither QKD nor any other quantum technologies provide authentication to prove that the party on the other end of the key exchange is who you think they are. This opens the door for a classic monster in the middle (MITM) attack, where an adversary intercepts your connection, establishes a separate secure QKD link to you and your intended destination, and then sits in the middle reading and relaying all traffic. To prevent this, you must authenticate the identity of the party you are connecting to, using either pre-shared keys or conventional public-key cryptography. The bottom line is, whether or not you invest in QKD, you still need a solution for authentication to protect against active attackers armed with quantum computers. Practically speaking, that means you need PQC, but PQC is already a standalone solution that provides both authentication and key agreement, which leads to questions of why use QKD in the first place.
Some proponents argue that QKD should be integrated into existing systems as an extra security layer. The value proposition of QKD relates to the “harvest now, decrypt later” threat. In public-key cryptography, the key exchange messages used to set up encryption keys to secure a communication channel are exchanged in full view of a potential adversary. If an adversary records the key exchange messages, they might hope to use improved techniques in the future to solve the hard math problems upon which the security of the key exchange relies, allowing them to recover the encryption keys and decrypt the communication. If encryption keys are exchanged directly via QKD instead, the eavesdropper protections provided by QKD stop an adversary from recording messages that could later allow them to recover the encryption key (e.g. by using a quantum computer or other advances in cryptanalysis). The problem is, however, that this “extra security layer” is brittle, and limited to a single physical link. As soon as the data is transmitted elsewhere — for instance at an Internet exchange point or to travel to an end-user — the QKD security ends. For the rest of its journey, the data is protected by standard protocols like TLS, making the value of the initial QKD link questionable.
While we hope the technology progresses, QKD is neither necessary nor sufficient for security against a quantum adversary. PQC is sufficient for security against a quantum adversary, already runs on your existing hardware, and works everywhere.
Quantum random number generators (QRNGs) are a type of “true” random number generator (TRNG) that work by harnessing inherent unpredictability of quantum mechanics, for example by measuring atomic decay or shooting photons at a beam splitter. Other types of classical (non-quantum) TRNGs use physical phenomena that exhibit random properties, such as thermal noise from electrical components, the motion of hot wax in lava lamps, double pendulums, hanging mobiles, or water wave machines.

In cryptography and computer security, the essential property required from a random number generator is that the outputs are unpredictable and unbiased. This can be achieved by taking a small seed (say, 256 bits) of true randomness and feeding it to a cryptographically-secure pseudorandom number generator (CSPRNG) to produce an essentially limitless stream of pseudorandom output indistinguishable from true randomness. The randomness used to seed the CSPRNG can be based on either classical or quantum physical processes, as long as it is not known to the adversary. Whether or not you use a QRNG to generate the seed, a CSPRNG is essential for cryptographic applications.
We are the first to get excited about fun new sources of randomness. However, we’d like to emphasize that randomness derived from quantum effects is not necessary to combat threats from quantum computers. Quantum computers do not enable any practical new attacks against classical TRNGs in widespread use today. Your decision to invest in QRNGs should be based on a perceived improvement in the quality of randomness they produce and not on a perceived threat to classical TRNGs from quantum computing.
Cloudflare has been at the forefront of developing and deploying PQC, and we are committed to making PQC available for free and by default for all of our products. And we run it at scale — already over 40% of the human-generated traffic to our network uses PQC.

So what’s in that 40%? PQC is supported for all website and API traffic served through Cloudflare, most of Cloudflare’s internal network traffic, and traffic running over our Zero-Trust platform. All these connections use post-quantum key agreement to protect against the “harvest now, decrypt later” threat, where an adversary intercepts and stores encrypted data today with the hope of decrypting with a quantum computer or other cryptanalytic advances in the future. Key agreement is an important first step, but there’s still more work to be done. We’re actively working with stakeholders in the industry to prepare for the upcoming migration to post-quantum signatures to prevent active impersonation attacks from quantum adversaries (after Q-day).
If purchasing quantum hardware is not necessary, how should organizations prepare for a quantum future? The most effective strategy will depend on your organization’s individual needs, but some general strategies will pay off for most organizations:
Investing in basic security practices is a good start. Hire the right expertise if you don’t already have it. Find vendors that support post-quantum encryption in their offerings today, and whose products are cryptographically agile so you can enjoy a seamless transition to post-quantum signatures and certificates when the industry migrates before Q-day. Follow a tunneling strategy: routing application traffic over the Internet via secure quantum safe tunnels allows you to reduce your attack surface area with minimal changes to existing systems. If you’re already a Cloudflare customer (or want to be), our Content Distribution Network and Zero Trust platform makes this easy. Learn more about how we can help at our Post-Quantum Cryptography webpage.
Security updates for Friday
Post Syndicated from jzb original https://lwn.net/Articles/1038802/
Security updates have been issued by Debian (chromium, cjson, and firefox-esr), Fedora (expat, gh, scap-security-guide, and xen), Oracle (container-tools:rhel8, firefox, grub2, and mysql:8.4), SUSE (busybox, busybox-links, element-web, kernel, shadowsocks-v2ray-plugin, and yt-dlp), and Ubuntu (imagemagick, linux, linux-aws, linux-gcp, linux-gke, linux-gkeop, linux-hwe-6.8, linux-lowlatency, linux-lowlatency-hwe-6.8, linux-oracle, linux-azure, linux-azure-5.15, linux-azure-fips, linux-ibm, linux-ibm-6.8, linux-nvidia, linux-nvidia-6.8, linux-nvidia-lowlatency, linux-raspi, linux-oracle-6.8, linux-realtime, and openjpeg2).
Richard Ayoade and David Letterman on Their Approach to Comedy | The Atlantic Festival 2025
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=120joDZclfo
Ayad Akhtar on Technology and the Future of Art | The Atlantic Festival 2025
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=-gAcymTUGRI
David Letterman on the Future of Free Speech | The Atlantic Festival 2025
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=mpAHFlZqIKw
The Guns of Saratoga
Post Syndicated from The History Guy: History Deserves to Be Remembered original https://www.youtube.com/watch?v=ifsFnsSHiNQ
Surveying the Global Spyware Market
Post Syndicated from Bruce Schneier original https://www.schneier.com/blog/archives/2025/09/surveying-the-global-spyware-market.html
The Atlantic Council has published its second annual report: “Mythical Beasts: Diving into the depths of the global spyware market.”
Too much good detail to summarize, but here are two items:
First, the authors found that the number of US-based investors in spyware has notably increased in the past year, when compared with the sample size of the spyware market captured in the first Mythical Beasts project. In the first edition, the United States was the second-largest investor in the spyware market, following Israel. In that edition, twelve investors were observed to be domiciled within the United States—whereas in this second edition, twenty new US-based investors were observed investing in the spyware industry in 2024. This indicates a significant increase of US-based investments in spyware in 2024, catapulting the United States to being the largest investor in this sample of the spyware market. This is significant in scale, as US-based investment from 2023 to 2024 largely outpaced that of other major investing countries observed in the first dataset, including Italy, Israel, and the United Kingdom. It is also significant in the disparity it points to the visible enforcement gap between the flow of US dollars and US policy initiatives. Despite numerous US policy actions, such as the addition of spyware vendors on the Entity List, and the broader global leadership role that the United States has played through imposing sanctions and diplomatic engagement, US investments continue to fund the very entities that US policymakers are making an effort to combat.
Second, the authors elaborated on the central role that resellers and brokers play in the spyware market, while being a notably under-researched set of actors. These entities act as intermediaries, obscuring the connections between vendors, suppliers, and buyers. Oftentimes, intermediaries connect vendors to new regional markets. Their presence in the dataset is almost assuredly underrepresented given the opaque nature of brokers and resellers, making corporate structures and jurisdictional arbitrage more complex and challenging to disentangle. While their uptick in the second edition of the Mythical Beasts project may be the result of a wider, more extensive data-collection effort, there is less reporting on resellers and brokers, and these entities are not systematically understood. As observed in the first report, the activities of these suppliers and brokers represent a critical information gap for advocates of a more effective policy rooted in national security and human rights. These discoveries help bring into sharper focus the state of the spyware market and the wider cyber-proliferation space, and reaffirm the need to research and surface these actors that otherwise undermine the transparency and accountability efforts by state and non-state actors as they relate to the spyware market.
Really good work. Read the whole thing.
The Columnist
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=X3b9rzeZAGI
Д. Анатомия на властта
Post Syndicated from Емилия Милчева original https://www.toest.bg/d-anatomiya-na-vlastta/

Ако българите допуснат Делян Пеевски да им гради държава с главно Д, значи са слуги, не граждани. Още не е късно да се попречи на „строителя“ и отговорността да го направят пада върху двете политически сили, които го легитимираха и утвърдиха: „Продължаваме промяната“ – „Демократична България“ (ПП–ДБ) и ГЕРБ. На първите не им достигат сили, на вторите – смелост. Но ако ГЕРБ не се осмели, лидерът Бойко Борисов ще бъде тотално обезличен, също и политическите му заслуги.
Как иска Борисов да слезе от сцената?
Досега ГЕРБ успяваше да погълне като боа партньорите си във властта. Не и Пеевски. Олигархолидерът на ДПС – Ново начало къса живо месо от всяка партия, която му падне, включително и от ГЕРБ. С просто око се вижда, че на лидера на ГЕРБ никак не му е лесно, принуден да изпълнява ежедневни поръчения от крепителя на управлението, и при всеки сгоден случай признава, че е в тази коалиция не по своя воля, а заради „стабилността“.
Само преди 7–8 месеца, след осмия поред избор, всички се чудехме как да направим правителство. Аз буквално дадох под наем на това управление партията. Не станах премиер. В ГЕРБ не сме свикнали лидерът ѝ да не е премиер. Трудно ни е, но за да има някаква стабилност, го направихме.
Почти четвърт век във властта прави Борисов най-дълголетния политик, при това в почти непрекъснат възход, и сега рискува силната зависимост от Пеевски да се превърне в епилог на кариерата му. Защото този финал наближава и при три премиерски мандата и поредица от спечелени избори няма его, което да понесе срама, че генералът се е превърнал в пешка.
От друга страна, предизвика ли предсрочни избори, може да пострада от компроматни атаки, затова вероятно ще изчака удобен момент за такъв вот. Председателят на партията, с чийто мандат правителството управлява, обаче не се яви да гласува на петия вот на недоверие – знаково отсъствие, макар че мнозинството се запази със 133 гласа.
Едни протести биха дали основание на Борисов да направи заявка за вот на доверие чрез предсрочни избори или с мотива, че след като ГЕРБ е изпълнил обещанието си да вкара България в еврозоната, гражданите отново трябва да имат думата.
Докато реши как точно да се измъкне от мечешката прегръдка на Пеевски, Борисов ще трябва да изпълнява разпорежданията му и да търпи ироничните забележки на депутати от опозицията, като Ивайло Мирчев например:
Бойко Борисов се е превърнал в рекламен агент на ортака си Главното Д. Колеги от ГЕРБ, усетихте ли как от мандатоносител се превърнахте в компаньонка на Главното Д? Вие сте обикновени пионки на Главното Д, то превзема вашата партия.
Протестните акции на ПП–ДБ
Като политическа акция петият вот на недоверие, внесен от ПП–ДБ с подкрепата на МЕЧ и Алианса за права и свободи (АПС), показа най-странното обединение на опозицията, която е про- и антиевропейска в този парламент. Заедно с вносителите гласуваха и евроскептиците с руски уклон от „Възраждане“ и „Величие“. Като инструмент за влияние обаче вотът се провали. Не бе предаван пряко по БНТ и БНР и остана невидим за гражданите, макар да е за „провала в секторите вътрешна сигурност и правосъдие, задълбочаващ проблема със завладяната държава“.
Слабост на този и на предишните вотове на недоверие е тяхната констативност – всичко казано е добре известно. Истинската роля на опозицията е да разкрие слабите звена, също така да покаже компетентност и готовност да управлява, предлагайки решения и алтернативи.
В деня на гласуване на вота обаче протестна акция на „Продължаваме промяната“ блокира служебния паркинг – „входовете, през които, без да слизат от колите на НСО, Борисов и Пеевски се озовават в пленарна зала и служебни входове на парламента“ (Лена Бориславова). В тениски с надписи „Свобода за Благо!“ депутати от ПП заедно с подалия оставка като съпредседател и като депутат Кирил Петков препречиха пътя заради задържаните техни кметове. Петков обясни и целта на протеста:
Целта ни е да кажем, че през 2025 г. не може да имаме политически затворници в България. Не е нормално четирима души без осъдителна присъда да стоят вече втори месец в ареста с право по един час на ден на слънчева светлина и са хапани от дървеници сигурно по 20 пъти на вечер.
Политическите акции често са пакетирани като зрелище – за да продават емоции и да въздействат. А ПП са заложили на радикалния дизайн. Заради акцията се наложи Пеевски да стигне пеша до работното си място, обграден от гардове, и да избълва куп простащини към лидера на ПП Асен Василев. Но те започнаха преди това, когато Кирил Петков изкрещя:
Ей, дебело прасе!
В екстатично състояние пред входа на парламента лидерът на ДПС крещеше как ще направи държава с главно Д.
А Д-то бе разчетено като монограм.
Един човек не може да направи държава, но един човек с контрол върху правителство, медии и съдебна система може да създаде автокрация. Основите ѝ вече се наливат в България, но не Пеевски ще седне в премиерското кресло, независимо от амбициите му. Разгащеният му език и поведение на „нацепен батка“ може да вдигне адреналина на собствения му електорат, но в същото време показва деградацията на политическия език и култура. Когато един олигарх се държи като мутра, това не е случайност, това е послание – че грубата сила и безнаказаността са върховният закон.
Кой е с г-н Радев?
Към лагера на опозицията неформално се е присъединил още един политик, който няма партия, но има рейтинг. С такъв капитал разполагаше и Борисов преди създаването на ГЕРБ. Дали одобрението на президента Румен Радев е достатъчно да зариби поне 200–300 000 избиратели, които да захранят с гласове партиен проект? Тестът са избори. А за да се стигне до тях, както предупреди и самият Радев, са необходими протести.
Дотогава обаче управляващото мнозинство ще е окастрило доста от правомощията на президента – процес, започнал още с конституционните промени на сглобката (ПП–ДБ, ГЕРБ и ДПС), част от които Конституционният съд запази. Държавният глава вече не може да избира служебното правителство, освен министър-председател измежду председателя на Народното събрание, управителя и подуправителите на БНБ, омбудсмана и неговия заместник, шефа на Сметната палата и неговите заместници.
Сега, заради отказа на президента да подпише указа за назначаване на временно изпълняващия функцията председател на Държавна агенция „Национална сигурност“ (ДАНС) Деньо Денев за постоянно на поста, управляващото мнозинство ще отнеме законодателно правото му да одобрява назначенията на шефове на службите. Впрочем те бяха сменени още при първия служебен кабинет на президента през 2021 г. с негови кадри.
Тази седмица на извънредно заседание на парламентарната Комисия по вътрешен ред и обществена сигурност депутатите приеха промени в трите закона за спецслужбите – за контраразузнаването, за разузнаването и за специалните разузнавателни средства. Така ще бъде предложено да се отнемат правомощията на президента да назначава шефове на ДАНС, Държавна агенция „Разузнаване“ (ДАР) и Държавна агенция „Технически операции“ (ДАТО).
Законодателни промени заради една персона никога не са водили до нищо добро. Схватката за службите, особено за ДАНС, винаги е била ожесточена заради информационните масиви и възможността да се използват за всякакви цели. Понякога и за националната сигурност.
Парадоксалното е, че през 2013 г. законовата възможност назначението на шефа на ДАНС да става с президентски указ бе премахната, за да бъде избран Делян Пеевски за шеф на ДАНС, който беше принуден да се оттегли след протестите #ДАНСwithme. А след година падна и кабинетът, който го предложи. През 2015 г., благодарение на ГЕРБ, президентското одобрение бе възстановено, за да бъде предложено отново да отпадне сега.
Управляващото мнозинство в лицето на ГЕРБ–СДС, ДПС – Ново начало, БСП и „Има такъв народ“ е на път да остави администрацията на президента и без транспорт от Националната служба за охрана (НСО), която е подчинена на президента. Промените, приети на първо четене, бяха предложени от депутата на Пеевски и бивш вътрешен министър Калин Стоянов:
Не съм съгласен тези достойни служители – военизирани, с ранг, с чин, да отварят вратите на множеството хора, незнайно колко, от администрацията на президента или да им пренасят бурканите и зимнината от родните места до София, примерно. […] Не става въпрос за противопоставяне, а за един пропуск, който години наред дава възможност на множество лица да се възползват от привилегии, предвидени за друг кръг от хора. Не виждам какъв е проблемът те да се приравнят на всички останали.
Без право на служебен кабинет и без право да подписва указите за шефовете на службите, на президента ще му останат назначенията на посланици и на членове в няколко ключови регулатора. Партиите систематично ограничават инструментите на държавния глава, който след една година няма да се нарича Румен Радев. Дори детайли като транспорта от НСО се превръщат в политически знак: администрацията на президента е третиранa като второстепенна, лишавана от ресурси и авторитет.
Това не е просто технически дебат, а съзнателно маргинализиране на институцията.
Най-важният извод обаче е, че системата на „взаимни спирачки“ между властите, фундамент на демокрацията, се разпада. Президентът остава със сведени до минимум функции, докато парламентът и управляващата коалиция концентрират все повече контрол върху изпълнителната власт, службите и дори върху символичните механизми на държавността.
Вместо разделение на властите България върви към сгъстяване на властта в един център, което отваря вратата не към стабилност, а към автократичен модел на управление.
Опитите промените да се покажат като принципни позиции само потвърждават, че политическите сили са в схватка за контрола на информацията. Отнемането на екстра като луксозния транспорт, който е за сметка на данъкоплатците, е за назидание.
Като кафкианския „К.“, анонимен и с незавършена история, България също заслужава да бъде обозначена с една-единствена буква – „Д“. Без ясна същност, просто опит за съществуване.
Тоест разговаряме – епизод 1
Post Syndicated from Владислав Севов original https://www.toest.bg/toest-razgovaryame-epizod-1/

В първия епизод на „Тоест разговаряме“ с Донка Дойчева-Попова потърсихме отговор на въпроса дали училището може да е пространство за мислене, а не за принуда и натиск. Обсъдихме промените в училищното образование – забраната на телефоните (между демонизация и реални ползи), новия предмет добродетели и религии (смисъл и липсваща концепция), корекциите в НВО след VII клас (интердисциплинарни задачи по математика, въведени в последния момент). Разговаряхме за реформите „на парче“ и непредвидимостта в системата, ролята на родителските и ученическите съвети, протестите срещу образователните промени. Акцентирахме върху неефективното чуждоезиково обучение и „невидимите деца“ – тези с дислексия и дискалкулия, за които липсват диагностика и специалисти. Говорихме и за смисъла на обучението по изкуства, за нуждата от интердисциплинарност и човечност в клас.
Гледайте целия разговор в нашия YouTube канал:
Може да го чуете и като аудиозапис в SoundCloud:
По време на нашия разговор на живо включихме и много въпроси от публиката, но за съжаление, ограниченото време не ни даде възможност да обхванем всички. Затова помолих Донка да отговори тук на още един, за мен доста важен въпрос на зрител:
Защо се налага децата да ходят на уроци, за да изкарат изпитите след VII клас?
Основната причина е, че учебните програми са препълнени и не оставят достатъчно време за пълно усвояване на материала. Нищо извънредно няма в изпитите след VII клас, просто съотношението учебен материал – време е нереалистично. В същото време познавам много деца, които не ходят на частни уроци и се справят отлично с тези изпити. Това, което е различно при тях, е: едните са имали късмет с изключително адекватен и вдъхновяващ учител, което е направило възможно усвояването на материала. Другата група имат късмет с родители, които са в състояние да помогнат – тоест хора, които отделят нужното време и имат капацитета да обърнат допълнително внимание на децата си. А сега да си представим всички онези деца, мнозинството, които нямат нито едното, нито другото…
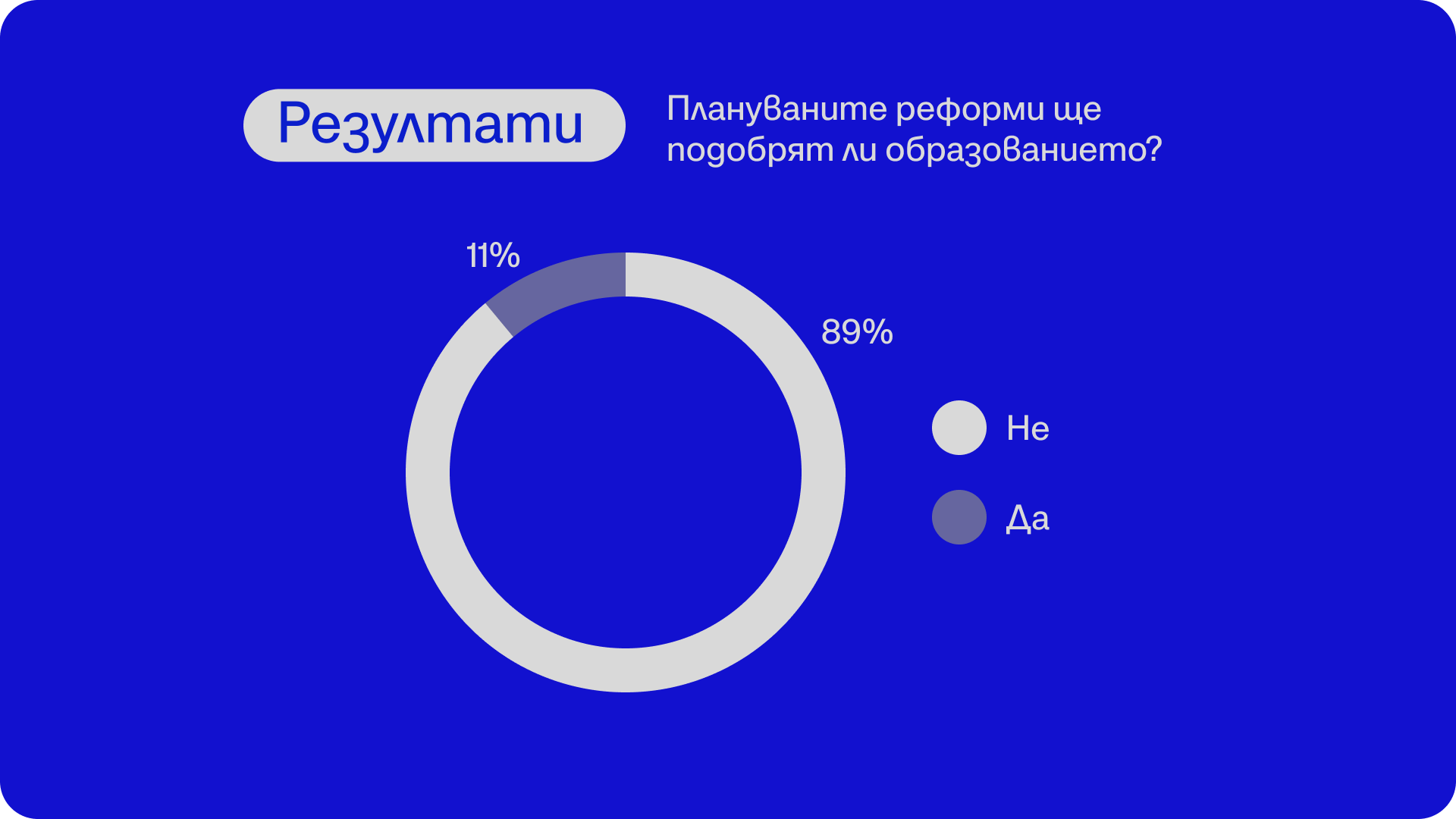
Преди срещата ви помолихме да отговорите на кратката ни анкета. Резултатите от нея са повече от красноречиви.
Донка Дойчева-Попова е учебна терапевтка, гражданска активистка и водеща на рубриката „Възможното образование“ в „Тоест“. Завършила е организационна психология и политически науки в Мюнхен и има специализация по дискалкулия в Германия. Работи с деца със специфични образователни затруднения и обучава учители как да преподават математика с емпатия и разбиране. Има дългогодишен опит като преводач и преподавател по немски език с фокус върху ранното езиково обучение. В текстовете си в „Тоест“ обръща внимание на дефицитите в българското образование – и на редките острови на смисъл в него.
Следващата среща на „Тоест разговаряме“ ще бъде с Емилия Милчева, вътрешнополитическата анализаторка на „Тоест“, и ще се проведе на живо в YouTube Live на 11 октомври 2025 г., събота, от 16:00 ч.
В „Тоест разговаряме“ всеки месец ви срещаме с автори, които познавате добре от анализите или от рубриките им в „Тоест“, но този път ще ги видите и чуете в по-личен и непосредствен формат. Във видеоразговорите, предавани на живо, активно участие имате и вие, нашата публика – със своите въпроси, коментари и включване в тематичната анкета. Водещ на поредицата е Владислав Севов, дългогодишен телевизионен журналист и съосновател на „Тоест“.

„Тоест разговаряме“ е поредица, подкрепена от Институт „Отворено общество – София“ и съфинансирана от Европейския съюз в рамките на проекта Media Resilience. Изразените възгледи и мнения са само и изцяло на техните автори и не отразяват непременно възгледите и мненията на Европейския съюз, на Европейската изпълнителна агенция за образование и култура (EACEA) или на Институт „Отворено общество – София“ (ИООС). Нито Европейският съюз, нито EACEA, нито ИООС могат да бъдат държани отговорни за тях.
David Letterman on the Threats to Late-Night Hosts
Post Syndicated from The Atlantic original https://www.youtube.com/watch?v=-lxAJUmjol8