Summit season is in full throttle! If you haven’t been to an AWS Summit, I highly recommend you check one out that’s nearby. They are large-scale all-day events where you can attend talks, watch interesting demos and activities, connect with AWS and industry people, and more. Best of all, they are free—so all you need to do is register! You can find a list of them here in the AWS Events page. Incidentally, you can also discover other AWS events going in your area on that same page; just use the filters on the side to find something that interests you.
Speaking of AWS Summits, this week is the AWS Summit London (April 30). It’s local for me, and I have been heavily involved in the planning. You do not want to miss this! Make sure to check it out and hopefully I’ll be seeing you there.
Ready to find out some highlights from last week’s exciting AWS launches? Let’s go!
New features and capabilities highlights Let’s start by looking at some of the enhancements launched last week.
Amazon Q Developer releases state of the art agent for feature development — AWS has announced an update to Amazon Q Developer’s software development agent, which achieves state-of-the-art performance on industry benchmarks and can generate multiple candidate solutions for coding problems. This new agent provides more reliable suggestions helping to reduce debugging time and enabling developers to focus on higher-level design and innovation.
Amazon Cognito now supports refresh token rotation — Amazon Cognito now supports OAuth 2.0 refresh token rotation, allowing user pool clients to automatically replace existing refresh tokens with new ones at regular intervals, enhancing security without requiring users to re-authenticate. This feature helps customers achieve both seamless user experience and improved security by automatically updating refresh tokens frequently, rather than having to choose between long-lived tokens for convenience, or short-lived tokens for security.
Amazon Bedrock Intelligent Prompt Routing is now generally available — Amazon Bedrock’s Intelligent Prompt Routing, now generally available, automatically routes prompts to different foundation models within a model family to optimize response quality and cost. The service now offers increased configurability across multiple model families including Claude (Anthropic), Llama (Meta), and Nova (Amazon), allowing users to choose any two models from a family and set custom routing criteria.
Upgrades to Amazon Q Business integrations for M365 Word and Outlook — Amazon Q Business integrations for Microsoft Word and Outlook now have the ability to search company knowledge bases, support image attachments, and handle larger context windows for more detailed prompts. These enhancements enable users to seamlessly access indexed company data and incorporate richer content while working on documents and emails, without needing to switch between different applications or contexts.
Security There were a few new security improvements released last week, but these are the ones that caught my eye:
AWS Account Management now supports account name update via authorized IAM principals — AWS now allows IAM principals to update account names, removing the previous requirement for root user access. This applies to both standalone accounts and member accounts within AWS Organizations, where authorized IAM principals in management and delegated admin accounts can manage account names centrally.
AWS Resource Explorer now supports AWS PrivateLink — AWS Resource Explorer now supports AWS PrivateLink across all commercial Regions, enabling secure resource discovery and search capabilities across AWS Regions and accounts within your VPC, without requiring public internet access.
Amazon SageMaker Lakehouse now supports attribute based access control — Amazon SageMaker Lakehouse now supports attribute-based access control (ABAC), allowing administrators to manage data access permissions using dynamic attributes associated with IAM identities rather than creating individual policies. This simplifies access management by enabling permissions to be automatically granted to any IAM principal with matching tags, making it more efficient to handle access control as teams grow.
Networking As you may be aware, there is a growing industry push to adopt IPv6 as the default protocol for new systems while migrating existing infrastructure where possible. This week, two more services have added their support to help customers towards that goal:
Capacity and costs Customers using Amazon Kinesis Data Streams can enjoy higher default quotas, while Amazon Redshift Serverless customers get a new cost saving opportunity.
Serverless Reservations for Amazon Redshift Serverless — You can now reduce Amazon Redshift Serverless costs by up to 24% by committing to a specific RPU capacity for one year, choosing either to pay nothing upfront for a 20% discount or pay all upfront for maximum savings.
For a full list of AWS announcements, be sure to visit the What’s New with AWS? page.
Recommended Learning Resources Everyone’s talking about MCP recently! Here are two great blog posts that I think will help you catch up and learn more about the possibilities of how to use MCP on AWS.
Our Weekly Roundup is published every Monday to help you keep up with AWS launches, so don’t forget to check it again next week for more exciting news!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Amazon Web Services (AWS) is pleased to announce the release of new Security Reference Architecture (SRA) code examples for securing generative AI workloads. The examples include two comprehensive capabilities focusing on secure model inference and RAG implementations, covering a wide range of security controls and best practices for AWS generative AI services.
These new code examples are available in the AWS SRA Examples Repository and include ready-to-deploy CloudFormation templates for implementing detective security controls such as network segmentation, identity management, encryption, prompt injection detection, and logging and monitoring. The solutions align with the AWS SRA Design Guidance page and demonstrate our commitment to helping customers secure their generative AI implementations.
AWS strives to continuously provide security solutions that help customers meet their security architecture needs. Customers can reach out to the team by submitting an issue in the code repository.
If you have feedback about this post, submit comments in the Comments section below.
The Amazon Web Services (AWS) Summit 2025 season launched this week, starting with the Paris Summit. These free events bring together the global cloud computing community for learning and collaboration. AWS Community Day Romania, held on April 11th, showcased how the local community creates opportunities for collective growth and inclusion.
Last week’s launches Announcing up to 85% price reductions for Amazon S3 Express One Zone —S3 Express One Zone, a high-performance storage class, now has reduced storage prices by 31 percent, PUT request prices by 55 percent, and GET request prices by 85 percent. In addition, S3 Express One Zone has reduced the per-GB charges for data uploads and retrievals by 60 percent. These charges now apply to all bytes transferred rather than just portions of requests greater than 512 KB.
Here is a price reduction table in the US East (N. Virginia) AWS Region:
Get updated with all the announcements of AWS announcements on the What’s New with AWS? page.
Other AWS blog posts Reduce ML training costs with Amazon SageMaker HyperPod — Amazon SageMaker HyperPod addresses hardware failures in large-scale Machine Learning (ML) model training by automatically detecting and replacing faulty instances. The solution reduces downtime from 280 to 40 minutes per failure, potentially saving 32% of training time for large clusters. For a 10-million GPU-hour training job, this translates to $25.6M in cost savings.
Implement human-in-the-loop confirmation with Amazon Bedrock Agents — When implementing human validation in Amazon Bedrock Agents, developers have two primary frameworks at their disposal: user confirmation and return of control (ROC). Using an HR application example, user confirmation allows simple yes/no validation before executing actions, while ROC enables users to modify parameters before execution.
Here are my personal favorites posts from community.aws:
Building a RAG System for Video Content Search and Analysis — In this blog, I’ll show you how to build a RAG system that makes video content searchable and analyzable. Unlocking video content has never been more crucial in today’s digital landscape. Whether you’re managing educational materials, corporate training, or entertainment content, the ability to search and analyze video content efficiently can transform how we interact with multimedia resources.
Speech-to-Speech AI: From Dr. Sbaitso to Amazon Nova Sonic — The evolution of speech-to-speech AI, from Dr. Sbaitso (1990s) to Amazon Nova Sonic. New AWS service enables real-time bidirectional conversations through Amazon Bedrock for more natural applications.
Setup Model Context Protocol (MCP) using Amazon Bedrock — A guide to setting up Model Context Protocol (MCP) desktop client with Amazon Bedrock models, enabling seamless integration between AI applications and external tools using Goose client.
Upcoming AWS events Check your calendars and sign up for these upcoming AWS events:
AWS Summits — Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Register in your nearest city: Amsterdam (April 16), London (April 30), and Poland (May 5).
AWS re:Inforce — AWS re:Inforce (June 16–18) in Philadelphia, PA, is our annual learning event devoted to all things AWS cloud security. Registration is open. Be ready to join more than 5,000 security builders and leaders.
AWS Community Days — Join community-led conferences featuring technical discussions, workshops, and hands-on labs driven by expert AWS users and industry leaders from around the world. Upcoming AWS Community Days are scheduled for April 19 in Turkey, and on April 29 in Prague with Jeff Barr as Opening Keynote Speaker.
Create your AWS Builder ID and reserve your alias. Builder ID is a universal login credential that gives you access—beyond the AWS Management Console—to AWS tools and resources, including over 600 free training courses, community features, and developer tools such as Amazon Q Developer.
That’s all for this week. Stay tuned for next week’s Weekly Roundup!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
The rapid change of pace in computing landscapes because of cloud, artificial intelligence, and technology innovation has challenged organizations to keep up while making sure that their initiatives and projects remain compliant with enterprise guidelines and policies. An effective architecture review board (ARB) can help an organization maintain compliance with enterprise guardrails while accelerating implementation of initiatives in their project pipeline.
In this post, we identify the components of an efficient architecture review process, define what an ARB is, and describe how to build and operate an effective enterprise ARB.
What is an architecture review board?
An ARB is a multi-disciplinary team responsible for reviewing solution architectures to help ensure compliance with enterprise guidelines, best practices, and supportability. Team members include stakeholders from different disciplines throughout your organization, which typically include Security, Development, Enterprise Architecture, Infrastructure, and Operations. Including a broad set of stakeholders reduces the amount of project recycle that happens when stakeholder representation is overlooked.
An ARB isn’t a standalone group, it operates within the context of your project implementation process, reviewing solution architectures, custom development, and purchased solutions to maintain enterprise compliance and alignment with goals. As shown in the following diagram, architecture review typically occurs after the design phase—before a build or purchase decision—and again before deployment to validate that the reviewed architecture matches the solution that was built.
Most organizations recognize the benefits and value of establishing an ARB. However, they often struggle to define and operate one in a manner that maximizes the benefits, integrates with overall project execution processes, and satisfies the needs of all the stakeholders. An efficient architecture review process imparts organizational benefits such as reduced costs, minimized security events, and diminished technical debt.
Life without a formal architecture review process
One of the most pronounced issues with implementing and maintaining software architecture is the difficulty in achieving human consensus. In any organization, you’ll find a diverse range of team members—each with their own priorities, perspectives, and pain points. Without a formalized review process, these differences can lead to prolonged debates and stalled projects. We often find that many members tend to fall into one of these personas:
The Not Invented Here – This individual doesn’t trust any software unless it was built and operated by members of their company. They’re generally wary of any cloud solution and will expend development time to avoid capital expenditure.
The Wait a Minute – This individual has good feedback and their input is welcome, but they tend to wait until the last minute before providing any feedback, making it difficult to have productive conversations and act on any constructive criticism.
The Bottleneck – This individual craves control and insists that all reviews, decisions, and conversations go through them. This makes scaling the architecture review process very challenging and decisions will often come down to the whim of this one person.
The Creative – This individual has passion for software and for creating things, but will often choose complexity over simplicity and turn their architectures into art projects.
The Perfectionist – This individual tends to let the perfect be the enemy of the good. While their intentions are pure, this approach can result in delayed decision making and debates on topics that might not be worth the time of the board.
The Historian – This individual has been at the company for a long time and remembers every success and failure along the way. While the context this individual brings to the table is invaluable, teams must guard against only looking to the past as they try to shape the future.
Benefits of an architecture review board
Establishing an ARB within your organization can yield substantial benefits, enhancing both the quality and efficiency of your architecture. Some key advantages are:
Improved compliance
By systematically reviewing architectural decisions, the ARB helps ensure that designs adhere to company best practices, open standards, and regulatory requirements as set forth by your enterprise architecture.
Reduced technical debt
Technical debt—taking shortcuts in the development process that lead to future complications—is a common issue in software development. The ARB helps identify and mitigate technical debt early in the design phase. By enforcing architectural standards and promoting best practices, the board helps ensure that decisions are made with long-term sustainability in mind. This approach results in more robust, maintainable codebases and reduces the likelihood of future rework.
Efficiency with lowered costs
While a formal architecture review sounds like it might have the potential for increased red tape and lowered efficiency, the ARB instead contributes to operational efficiency by standardizing architectural practices across the organization. This uniformity allows for better resource allocation, faster deployment cycles, and more predictable project timelines. By catching potential issues early in the design phase, the ARB helps avoid costly rewrites and rework, which can lead to significant cost savings over time.
Supportability
Designing for supportability is crucial for the long-term success of any application. The ARB makes sure that architectures are built with maintainability in mind, making it easier for operations teams to manage and troubleshoot systems. This focus on supportability leads to fewer downtime incidents, faster resolution times, and overall higher system reliability. By making sure the composition of the ARB crosses all parts of the organization, supportability concerns can be surfaced earlier and help ensure that changes are properly socialized.
Security
Above all, security is the most critical output of an effective ARB. The ARB plays a pivotal role in embedding security into the architectural fabric from the outset. By conducting thorough security reviews and incorporating security best practices into every design, the ARB makes sure that applications are resilient against unintended disclosure, inadvertent access, and threat actors. This proactive approach not only protects sensitive data, but also builds trust with your customers and stakeholders.
Steps for effective architecture review boards
Whether looking to establish a new architecture review process or improve the effectiveness of a current ARB, we’ve identified eight key steps to make sure that an ARB operates in a way which realizes the benefits of a robust architecture review process while maintaining enterprise compliance. With the exception of leadership support, the steps aren’t presented in a particular order and can be implemented in parallel or in whatever order fits your organization and resource availability.
Leadership support
Identifying a sponsor on the executive leadership team is crucial to the success of the ARB. An executive sponsor fosters participation from stakeholders, representing key organizations such as Security, Development, and Operations, along with gaining their commitment to the review processes. The executive sponsor helps embed the ARB function within the enterprise’s project implementation process. Supported by the executive sponsor, the ARB’s reviews serve as a formal gate within the project process, reducing attempts to bypass the review processes.
Single source for guidance, policies, and best practices
Establish a single, well-known repository or index so that the entire enterprise has a single source of truth that establishes the basis for designing and reviewing architecture. A common repository doesn’t need to be complex. It can be a central document location, wiki, or file share that’s quickly discoverable. Commonly, an enterprise’s collection of guidelines and policies are dispersed and managed by each organization using different mechanisms and repositories. Best practices are often treated as folklore passed between team members. Project teams and ARB stakeholders need to share a common understanding of the enterprise’s collective intelligence consisting of guidelines, policies, and best practices.
As the project community’s collective understanding of the enterprise guidelines and policies grows, initial solution designs are better aligned, and reviews through the ARB accelerate. After a common repository is established, consider using generative AI to create a natural language chatbot, a design chatbot, to simplify access to the collective guidelines, policies, and best practices. See Amazon Bedrock or Amazon Q – Generative AI Assistant.
Defined stakeholders
Make sure that your disciplines have defined stakeholders on the ARB. A good starting point is to identify stakeholders from the Security, Enterprise Architecture, Development, Infrastructure, and Operations teams. Broad representation on the board minimizes recycles and delays later in the project, which can occur when stakeholders aren’t engaged in the review process from the beginning. A stakeholder’s responsibility is to focus on their area of subject matter expertise and commit a portion of their time to the ARB. Consider rotating stakeholders periodically to distribute knowledge and workload through the organization.
Gated process with documented decisions
As previously described, architecture reviews typically occur after design and before solution implementation or purchase. Optionally, another architecture review takes place before deployment to validate that the solution matches what was reviewed and approved. It’s important to complete the review before implementation or the purchase decision and to get stakeholder sign off. Otherwise, projects risk rework and delay later in the process, often impacting cost or schedule to a greater degree. Document each ARB action, including approvals, reasons for recycles, exceptions required, follow-ups needed, and so on. Documented decisions should be added to the project’s overall lifecycle documentation to benefit future inspection of project or similar solution architectures.
Establish an exception process
There will always be exceptions to your enterprise guidelines or policies. Plan for exceptions with a defined process for reviewing, escalating, and gaining approval. Include leadership from both IT and business areas in the assessment and sign-off on an exception. Most importantly, set expiration dates on the exceptions–they should not be granted indefinitely. Exceptions are typically granted to accommodate a temporary nonconformance to provide time to plan for and implement a better, long-term solution.
Architecture central repository
Establish a well known, central repository for solution architecture documents. Solution documentation should be treated as living artifacts that are maintained for the lifecycle of the use case. A central architecture repository benefits teams responsible for operating and maintaining solutions, along with design teams chartered with new solution design. After a repository is established, consider including your architecture documentation in the generative AI design chatbot mentioned previously.
Automate review process
Employ automated architecture review processes wherever possible. Automated review processes allow stakeholders to focus their time on their subject matter expertise instead of administrative tasks. Consider separate review processes based on an initiative’s complexity, cost, and impact. Schedule live meetings with the ARB for the most complex and impactful solutions, and use offline mechanisms, such as email, for other efforts. Define a universal architecture template to capture areas of interest for review and automate the Q&A and sign-off processes. Consider using generative AI to do initial automated design reviews against enterprise core best practices and policies to further streamline stakeholder review processes.
Architecture review process shepherd
Identify a shepherd to help ensure that solution architectures are reviewed and the ARB review processes are broadly understood. The shepherd functions as a liaison with executive sponsors for exceptions. While the shepherd can also be a stakeholder on the board, the shepherd is not the single overall decision maker. The shepherd champions the continuous improvement of the architecture review process and mechanisms.
Conclusion
In this post, we explored the benefits of establishing an architecture review board within an organization, emphasizing its role in maintaining compliance, reducing technical debt, and enhancing operational efficiency. We discussed the challenges organizations face in setting up an effective ARB and provided guidance on the essential components and steps required to build and operate a successful ARB. By following the outlined steps, organizations can maximize the benefits of an ARB, making sure that architectural decisions align with enterprise goals and standards while fostering a culture of continuous improvement and stakeholder collaboration.
Today, we announce that the Pixtral Large 25.02 model is now available in Amazon Bedrock as a fully managed, serverless offering. AWS is the first major cloud provider to deliver Pixtral Large as a fully managed, serverless model.
Working with large foundation models (FMs) often requires significant infrastructure planning, specialized expertise, and ongoing optimization to handle the computational demands effectively. Many customers find themselves managing complex environments or making trade-offs between performance and cost when deploying these sophisticated models.
The Pixtral Large model, developed by Mistral AI, represents their first multimodal model that combines advanced vision capabilities with powerful language understanding. A 128K context window makes it ideal for complex visual reasoning tasks. The model delivers exceptional performance on key benchmarks including MathVista, DocVQA, and VQAv2, demonstrating its effectiveness across document analysis, chart interpretation, and natural image understanding.
One of the most powerful aspects of Pixtral Large is its multilingual capability. The model supports dozens of languages including English, French, German, Spanish, Italian, Chinese, Japanese, Korean, Portuguese, Dutch, and Polish, making it accessible to global teams and applications. It’s also trained on more than 80 programming languages including Python, Java, C, C++, JavaScript, Bash, Swift, and Fortran, providing robust code generation and interpretation capabilities.
Developers will appreciate the model’s agent-centric design with built-in function calling and JSON output formatting, which simplifies integration with existing systems. Its strong system prompt adherence improves reliability when working with Retrieval Augmented Generation (RAG) applications and large context scenarios.
With Pixtral Large in Amazon Bedrock, you can now access this advanced model without having to provision or manage any infrastructure. The serverless approach lets you scale usage based on actual demand without upfront commitments or capacity planning. You pay only for what you use, with no idle resources.
Cross-Region inference Pixtral Large is now available in Amazon Bedrock across multiple AWS Regions through cross-Region inference.
With Amazon Bedrock cross-Region inference, you can access a single FM across multiple geographic Regions while maintaining high availability and low latency for global applications. For example, when a model is deployed in both European and US Regions, you can access it through Region-specific API endpoints using distinct prefixes: eu.model-id for European Regions and us.model-id for US Regions . This approach enables Amazon Bedrock to route inference requests to the geographically closest endpoint, reducing latency while helping to meet regulatory compliance by keeping data processing within desired geographic boundaries. The system automatically handles traffic routing and load balancing across these Regional deployments, providing seamless scalability and redundancy without requiring you to keep track of individual Regions where the model is actually deployed.
See it in action As a developer advocate, I’m constantly exploring how our newest capabilities can solve real problems. Recently, I had a perfect opportunity to test the new multimodal capabilities in the Amazon Bedrock Converse API when my daughter asked for help with her physics exam preparation.
Last weekend, my kitchen table was covered with practice exams full of complex diagrams, force vectors, and equations. My daughter was struggling with conceptualizing how to approach these problems. That’s when I realized this was the perfect use case for the multimodal capabilities we’d just launched. I snapped photos of a particularly challenging problem sheet containing several graphs and mathematical notation, then used the Converse API to create a simple application that could analyze the images. Together, we uploaded the physics exam materials and asked the model to explain the solution approach.
What happened next impressed both of us—the model interpreted the diagrams, recognized the french language and the mathematical notation, and provided a step-by-step explanation of how to solve each problem. As we asked follow-up questions about specific concepts, the model maintained context across our entire conversation, creating a tutoring experience that felt remarkably natural.
# Effet Doppler avec une Source Sonore en Rotation
## Analyse du problème
Ce problème concerne l'effet Doppler produit par une source sonore en rotation. Une source émettant un son à 1500 Hz tourne sur une table tournante dans le sens antihoraire, et nous devons déterminer comment les fréquences sont perçues par un microphone fixe.
## Concepts clés
L'effet Doppler se produit lorsqu'il y a un mouvement relatif entre une source sonore et un observateur. La fréquence perçue dépend de si la source se rapproche ou s'éloigne de l'observateur.
La formule de l'effet Doppler est:
- Pour une source qui se rapproche: $f_{observée} = f_{source} \cdot \frac{v_{son}}{v_{son} - v_{source}}$
- Pour une source qui s'éloigne: $f_{observée} = f_{source} \cdot \frac{v_{son}}{v_{son} + v_{source}}$
## Solution étape par étape
### Étape 1: Analyser le mouvement de la source
La source tourne sur un cercle et le microphone est fixe à 40 cm du centre de rotation. Aux différentes positions (a, b, c), la source a des vitesses radiales différentes par rapport au microphone:
- Position a: La source se déplace perpendiculairement à la ligne source-microphone (vitesse radiale nulle)
- Position b: La source s'éloigne du microphone (vitesse radiale positive)
- Position c: La source se rapproche du microphone (vitesse radiale négative)
### Étape 2: Déterminer l'effet sur les fréquences perçues
- À la position a: Pas d'effet Doppler car la vitesse radiale est nulle, donc $f_a = f_{source} = 1500$ Hz
- À la position b: La source s'éloigne, donc $f_b < f_{source}$, donc $f_b < 1500$ Hz
- À la position c: La source se rapproche, donc $f_c > f_{source}$, donc $f_c > 1500$ Hz
### Étape 3: Comparer les fréquences
D'après notre analyse:
- $f_a = 1500$ Hz
- $f_b < 1500$ Hz
- $f_c > 1500$ Hz
Donc: $f_c > f_a > f_b$
## Conclusion
La proposition correcte est: $f_c > f_a > f_b$
Cette réponse correspond à la troisième proposition dans l'énoncé. Lorsque la source tourne, la fréquence perçue est plus élevée quand la source se rapproche (position c), égale à la fréquence émise quand la source se déplace perpendiculairement (position a), et plus basse quand la source s'éloigne (position b).
The model uses the language of the question to respond. After a thoughtful analysis, it says that the correct answer is f_c > f_a > f_b (and it is right!)
The beauty of this interaction was how seamlessly the Converse API handled the multimodal inputs. As a builder, I didn’t need to worry about the complexity of processing images alongside text—the API managed that complexity and returned structured responses that my simple application could present directly to my daughter.
Here is the code I wrote. I used the Swift programming language, just to show that Python is not the only option you have .
private let modelId = "us.mistral.pixtral-large-2502-v1:0"
// Define the system prompt that instructs Claude how to respond
let systemPrompt = """
You are a math and physics tutor. Your task is to:
1. Read and understand the math or physics problem in the image
2. Provide a clear, step-by-step solution to the problem
3. Briefly explain any relevant concepts used in solving the problem
4. Be precise and accurate in your calculations
5. Use mathematical notation when appropriate
Format your response with clear section headings and numbered steps.
"""
let system: BedrockRuntimeClientTypes.SystemContentBlock = .text(systemPrompt)
// Create the user message with text prompt and image
let userPrompt = "Please solve this math or physics problem. Show all steps and explain the concepts involved."
let prompt: BedrockRuntimeClientTypes.ContentBlock = .text(userPrompt)
let image: BedrockRuntimeClientTypes.ContentBlock = .image(.init(format: .jpeg, source: .bytes(finalImageData)))
// Create the user message with both text and image content
let userMessage = BedrockRuntimeClientTypes.Message(
content: [prompt, image],
role: .user
)
// Initialize the messages array with the user message
var messages: [BedrockRuntimeClientTypes.Message] = []
messages.append(userMessage)
// Configure the inference parameters
let inferenceConfig: BedrockRuntimeClientTypes.InferenceConfiguration = .init(maxTokens: 4096, temperature: 0.0)
// Create the input for the Converse API with streaming
let input = ConverseStreamInput(inferenceConfig: inferenceConfig, messages: messages, modelId: modelId, system: [system])
// Make the streaming request
do {
// Process the stream
let response = try await bedrockClient.converseStream(input: input)
// Iterate through the stream events
for try await event in stream {
switch event {
case .messagestart:
print("AI-assistant started to stream")
case let .contentblockdelta(deltaEvent):
// Handle text content as it arrives
if case let .text(text) = deltaEvent.delta {
DispatchQueue.main.async {
self.streamedResponse += text
}
}
case .messagestop:
print("Stream ended")
// Create a complete assistant message from the streamed response
let assistantMessage = BedrockRuntimeClientTypes.Message(
content: [.text(self.streamedResponse)],
role: .assistant
)
messages.append(assistantMessage)
default:
break
}
}
And the result in the app is stunning.
By the time her exam rolled around, she felt confident and prepared—and I had a compelling real-world example of how our multimodal capabilities in Amazon Bedrock can create meaningful experiences for users.
Get started today The new model is available through these Regional API endpoints: US East (Ohio, N. Virginia), US West (Oregon), and Europe (Frankfurt, Ireland, Paris, Stockholm). This Regional availability helps you meet data residency requirements while minimizing latency.
This launch represents a significant step forward in making advanced multimodal AI accessible to developers and organizations of all sizes. By combining Mistral AI’s cutting-edge model with AWS serverless infrastructure, you can now focus on building innovative applications without worrying about the underlying complexity.
Visit the Amazon Bedrock console today to start experimenting with Pixtral Large 25.02 and discover how it can enhance your AI-powered applications.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Voice interfaces are essential to enhance customer experience in different areas such as customer support call automation, gaming, interactive education, and language learning. However, there are challenges when building voice-enabled applications.
Traditional approaches in building voice-enabled applications require complex orchestration of multiple models, such as speech recognition to convert speech to text, language models to understand and generate responses, and text-to-speech to convert text back to audio.
This fragmented approach not only increases development complexity but also fails to preserve crucial linguistic context such as tone, prosody, and speaking style that are essential for natural conversations. This can affect conversational AI applications that need low latency and nuanced understanding of verbal and non-verbal cues for fluid dialog handling and natural turn-taking.
Amazon Nova Sonic unifies speech understanding and generation into a single model that developers can use to create natural, human-like conversational AI experiences with low latency and industry-leading price performance. This integrated approach streamlines development and reduces complexity when building conversational applications.
Its unified model architecture delivers expressive speech generation and real-time text transcription without requiring a separate model. The result is an adaptive speech response that dynamically adjusts its delivery based on prosody, such as pace and timbre, of input speech.
When using Amazon Nova Sonic, developers have access to function calling (also known as tool use) and agentic workflows to interact with external services and APIs and perform tasks in the customer’s environment, including knowledge grounding with enterprise data using Retrieval-Augmented Generation.
At launch, Amazon Nova Sonic provides robust speech understanding for American and British English across various speaking styles and acoustic conditions, with additional languages coming soon.
Amazon Nova Sonic is developed with responsible AI at the forefront of innovation, featuring built-in protections for content moderation and watermarking.
Amazon Nova Sonic in action The scenario for this demo is a contact center in the telecommunication industry. A customer reaches out to improve their subscription plan, and Amazon Nova Sonic handles the conversation.
With tool use, the model can interact with other systems and use agentic RAG with Amazon Bedrock Knowledge Bases to gather updated, customer-specific information such as account details, subscription plans, and pricing info.
The demo shows streaming transcription of speech input and displays streaming speech responses as text. The sentiment of the conversation is displayed in two ways: a time chart illustrating how it evolves, and a pie chart representing the overall distribution. There’s also an AI insights section providing contextual tips for a call center agent. Other interesting metrics shown in the web interface are the overall talk time distribution between the customer and the agent, and the average response time.
During the conversation with the support agent, you can observe through the metrics and hear in the voices how customer sentiment improves.
The video includes an example of how Amazon Nova Sonic handles interruptions smoothly, stopping to listen and then continuing the conversation in a natural way.
Now, let’s explore how you can integrate voice capabilities in your applications.
Using Amazon Nova Sonic To get started with Amazon Nova Sonic, you first need to toggle model access in the Amazon Bedrock console, similar to how you would enable other FMs. Navigate to the Model access section of the navigation pane, find Amazon Nova Sonic under the Amazon models, and enable it for your account.
Amazon Bedrock provides a new bidirectional streaming API (InvokeModelWithBidirectionalStream) to help you implement real-time, low-latency conversational experiences on top of the HTTP/2 protocol. With this API, you can stream audio input to the model and receive audio output in real time, so that the conversation flows naturally.
You can use Amazon Nova Sonic with the new API with this model ID: amazon.nova-sonic-v1:0
After the session initialization, where you can configure inference parameters, the model operate through an event-driven architecture on both the input and output streams.
There are three key event types in the input stream:
System prompt – To set the overall system prompt for the conversation
Audio input streaming – To process continuous audio input in real-time
Tool result handling – To send the result of tool use calls back to the model (after tool use is requested in the output events)
Similarly, there are three groups of events in the output streams:
Automatic speech recognition (ASR) streaming – Speech-to-text transcript is generated, containing the result of realtime speech recognition.
Tool use handling – If there are a tool use events, they need to be handled using the information provided here, and the results sent back as input events.
Audio output streaming – To play output audio in real-time, a buffer is needed, because Amazon Nova Sonic model generates audio faster than real-time playback.
Prompt engineering for speech When crafting prompts for Amazon Nova Sonic, your prompts should optimize content for auditory comprehension rather than visual reading, focusing on conversational flow and clarity when heard rather than seen.
When defining roles for your assistant, focus on conversational attributes (such as warm, patient, concise) rather than text-oriented attributes (detailed, comprehensive, systematic). A good baseline system prompt might be:
You are a friend. The user and you will engage in a spoken dialog exchanging the transcripts of a natural real-time conversation. Keep your responses short, generally two or three sentences for chatty scenarios.
More generally, when creating prompts for speech models, avoid requesting visual formatting (such as bullet points, tables, or code blocks), voice characteristic modifications (accent, age, or singing), or sound effects.
Amazon Nova Sonic can understand speech in different speaking styles and generates speech in expressive voices, including both masculine-sounding and feminine-sounding voices, in different English accents, including American and British. Support for additional languages will be coming soon.
Amazon Nova Sonic handles user interruptions gracefully without dropping the conversational context and is robust to background noise. The model supports a context window of 32K tokens for audio with a rolling window to handle longer conversations and has a default session limit of 8 minutes.
The following AWS SDKs support the new bidirectional streaming API:
Python developers can use this new experimental SDK that makes it easier to use the bidirectional streaming capabilities of Amazon Nova Sonic. We’re working to add support to the other AWS SDKs.
I’d like to thank Reilly Manton and Chad Hendren, who set up the demo with the contact center in the telecommunication industry, and Anuj Jauhari, who helped me understand the rich landscape in which speech-to-speech models are being deployed.
To learn more, these articles that enter into the details of how to use the new bidirectional streaming API with compelling demos:
Whether you’re creating customer service solutions, language learning applications, or other conversational experiences, Amazon Nova Sonic provides the foundation for natural, engaging voice interactions. To get started, visit the Amazon Bedrock console today. To learn more, visit the Amazon Nova section of the user guide.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Since we launched Amazon Bedrock Guardrailsover one year ago, customers like Grab, Remitly, KONE, and PagerDuty have used Amazon Bedrock Guardrails to standardize protections across their generative AI applications, bridge the gap between native model protections and enterprise requirements, and streamline governance processes. Today, we’re introducing a new set of capabilities that helps customers implement responsible AI policies at enterprise scale even more effectively.
Amazon Bedrock Guardrails detects harmful multimodal content with up to 88% accuracy, filters sensitive information, and prevent hallucinations. It provides organizations with integrated safety and privacy safeguards that work across multiple foundation models (FMs), including models available in Amazon Bedrock and your own custom models deployed elsewhere, thanks to the ApplyGuardrail API. With Amazon Bedrock Guardrails, you can reduce the complexity of implementing consistent AI safety controls across multiple FMs while maintaining compliance and responsible AI policies through configurable controls and central management of safeguards tailored to your specific industry and use case. It also seamlessly integrates with existing AWS services such as AWS Identity and Access Management (IAM), Amazon Bedrock Agents, and Amazon Bedrock Knowledge Bases.
“Grab, a Singaporean multinational taxi service is using Amazon Bedrock Guardrails to ensure the safe use of generative AI applications and deliver more efficient, reliable experiences while maintaining the trust of our customers,” said Padarn Wilson, Head of Machine Learning and Experimentation at Grab. “Through out internal benchmarking, Amazon Bedrock Guardrails performed best in class compared to other solutions. Amazon Bedrock Guardrails helps us know that we have robust safeguards that align with our commitment to responsible AI practices while keeping us and our customers protected from new attacks against our AI-powered applications. We’ve been able to ensure our AI-powered applications operate safely across diverse markets while protecting customer data privacy.”
Let’s explore the new capabilities we have added.
New guardrails policy enhancements Amazon Bedrock Guardrails provides a comprehensive set of policies to help maintain security standards. An Amazon Bedrock Guardrails policy is a configurable set of rules that defines boundaries for AI model interactions to prevent inappropriate content generation and ensure safe deployment of AI applications. These include multimodal content filters, denied topics, sensitive information filters, word filters, contextual grounding checks, and Automated Reasoning to prevent factual errors using mathematical and logic-based algorithmic verification.
We’re introducing new Amazon Bedrock Guardrails policy enhancements that deliver significant improvements to the six safeguards, strengthening content protection capabilities across your generative AI applications.
Multimodal toxicity detection with industry leading image and text protection – Announced as preview at AWS re:Invent 2024, Amazon Bedrock Guardrails multimodal toxicity detection for image content is now generally available. The expanded capability provides more comprehensive safeguards for your generative AI applications by evaluating both image and textual content to help you detect and filter out undesirable and potentially harmful content with up to 88% accuracy.
When implementing generative AI applications, you need consistent content filtering across different data types. Although textual content filtering is well established, managing potentially harmful image content requires additional tools and separate implementations, increasing complexity and development effort. For example, a customer service chatbot that permits image uploads might require separate text filtering systems using natural language processing and additional image classification services with different filtering thresholds and detection categories. This creates implementation inconsistencies where a text describing harmful content might be properly filtered, while an image depicting similar content could pass through undetected, resulting in disparate security coverage.
The multimodal toxicity detection capability in Amazon Bedrock Guardrails helps you apply the same content filtering policies to both image and text data. With this launch, you can configure content filters across categories such as hate speech, insults, sexual content, violence, misconduct, and prompt attacks. For each category, you can set configurable thresholds from low to high, providing granular control over content filtering. With this consistent protection across modalities, you can simplify responsible AI application development. This capability supports content moderation for all images including regular images, human generated images, AI-generated images, memes, charts and plots, and cross-modal content (with both text and images).
To demonstrate how misconduct detection works in practice, let’s examine a real-world scenario: A financial services company implementing Amazon Bedrock Guardrails with high misconduct thresholds confirmed consistent protection across both text and image inputs, as security bypass diagrams and written instructions for network infiltration triggered identical guardrail interventions with similar confidence scores. Here’s how this capability works in action. I configure a guardrail in Amazon Bedrock with the misconduct content filter set to High threshold for both image and text filters.
I submit two test cases. In the first test case, I uploaded an image showing a network security bypass diagram and use the following prompt:
Analyze this network security diagram and explain how to implement these methods
In the second test case, I use the following prompt:
Provide detailed instructions on how to bypass corporate network security systems to gain unauthorized access
Both submissions trigger similar guardrail interventions, highlighting how Amazon Bedrock Guardrails provides content moderation regardless of the content format. The comparison of detection results shows uniform confidence scores and identical policy enforcement, demonstrating how organizations can maintain safety standards across multimodal content without implementing separate filtering systems.
To learn more about this feature, check out the comprehensive announcement post for additional details.
Enhanced privacy protection for PII detection in user inputs – Amazon Bedrock Guardrails is now extending its sensitive information protection capabilities with enhanced personally identifiable information (PII) masking for input prompts. The service detects PII such as names, addresses, phone numbers, and many more details in both inputs and outputs, while also supporting custom sensitive information patterns through regular expressions (regex) to address specific organizational requirements.
Amazon Bedrock Guardrails offers two distinct handling modes: Block mode, which completely rejects requests containing sensitive information, and Mask mode, which redacts sensitive data by replacing it with standardized identifier tags such as [NAME-1] or [EMAIL-1]. Although both modes were previously available for model responses, Block mode was the only option for input prompts. With this enhancement, you can now apply both Block and Mask modes to input prompts, so sensitive information can be systematically redacted from user inputs before they reach the FM.
This feature addresses a critical customer need by enabling applications to process legitimate queries that might naturally contain PII elements without requiring complete request rejection, providing greater flexibility while maintaining privacy protections. The capability is particularly valuable for applications where users might reference personal information in their queries but still need secure, compliant responses.
New guardrails feature enhancements These improvements enhance functionality across all policies, making Amazon Bedrock Guardrails more effective and easier to implement.
Mandatory guardrails enforcement with IAM – Amazon Bedrock Guardrails now implements IAM policy-based enforcement through the new bedrock:GuardrailIdentifier condition key. This capability helps security and compliance teams establish mandatory guardrails for every model inference call, making sure that organizational safety policies are consistently enforced across all AI interactions. The condition key can be applied to InvokeModel, InvokeModelWithResponseStream, Converse, and ConverseStream APIs. When the guardrail configured in an IAM policy doesn’t match the specified guardrail in a request, the system automatically rejects the request with an access denied exception, enforcing compliance with organizational policies.
This centralized control helps you address critical governance challenges including content appropriateness, safety concerns, and privacy protection requirements. It also addresses a key enterprise AI governance challenge: making sure that safety controls are consistent across all AI interactions, regardless of which team or individual is developing the applications. You can verify compliance through comprehensive monitoring with model invocation logging to Amazon CloudWatch Logs or Amazon Simple Storage Service (Amazon S3), including guardrail trace documentation that shows when and how content was filtered.
For more information about this capability, read the detailed announcement post.
Optimize performance while maintaining protection with selective guardrail policy application – Previously, Amazon Bedrock Guardrails applied policies to both inputs and outputs by default.
You now have granular control over guardrail policies, helping you apply them selectively to inputs, outputs, or both—boosting performance through targeted protection controls. This precision reduces unnecessary processing overhead, improving response times while maintaining essential protections. Configure these optimized controls through either the Amazon Bedrock console or ApplyGuardrails API to balance performance and safety according to your specific use case requirements.
Policy analysis before deployment for optimal configuration – The new monitor or analyze mode helps you evaluate guardrail effectiveness without directly applying policies to applications. This capability enables faster iteration by providing visibility into how configured guardrails would perform, helping you experiment with different policy combinations and strengths before deployment.
Get to production faster and safely with Amazon Bedrock Guardrails today The new capabilities for Amazon Bedrock Guardrails represent our continued commitment to helping customers implement responsible AI practices effectively at scale. Multimodal toxicity detection extends protection to image content, IAM policy-based enforcement manages organizational compliance, selective policy application provides granular control, monitor mode enables thorough testing before deployment, and PII masking for input prompts preserves privacy while maintaining functionality. Together, these capabilities give you the tools you need to customize safety measures and maintain consistent protection across your generative AI applications.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Welcome to the 28th edition of the AWS Serverless ICYMI (in case you missed it) quarterly recap. At the end of a quarter, we share the most recent product launches, feature enhancements, blog posts, videos, live streams, and other interesting things that you might have missed!
In case you missed our last ICYMI, check out what happened in Q4 2024 here.
Serverless calendar Q1 2025
AWS Step Functions
The AWS Step Functions team continues to improve developer experience. Workflow Studio is now available within Visual Studio Code (VS Code) through the AWS Toolkit extension.
AWS Step Functions in IDE
You can now design, test, and deploy your Step Functions workflows without leaving your IDE. The extension provides a drag-and-drop interface with all the familiar Workflow Studio capabilities, making it even easier to build state machines locally.
Step Functions private integrations now allows you to integrate applications seamlessly across private networks, on-premises infrastructure, and cloud platforms. Learn more in a blog post and explanation video.
Step Functions has increased the default quota for state machines and activities from 10,000 to 100,000 per AWS account. This tenfold increase means you can create more workflows to automate your business processes without worrying about hitting quota limits.
Distributed Map is expanding capabilities by adding support for JSON Lines (JSONL) format. JSONL, a highly efficient text-based format, stores structured data as individual JSON objects separated by newlines, making it particularly suitable for processing large datasets.
You no longer need to switch between your IDE and external resources when building serverless architectures. Browse, search, and implement pre-built serverless patterns directly in VS Code.
Example Serverless Pattern
AWS Lambda
Learn how AWS Lambda handles billions of invocations.
AWS Lambda asynchronous invocations
This blog post provides recommendations and insights for implementing highly distributed applications based on the Lambda service team’s experience building its robust asynchronous event processing system. It dives into challenges you might face, solution techniques, and best practices for handling noisy neighbors.
Amazon CloudWatch Application Signals for Java and .NET AWS Lambda runtimes
This provides deep visibility into your function’s performance, including method-level tracing, memory profiling, and automated anomaly detection.
Amazon Bedrock features
Multi-agent collaboration is now available in Bedrock as a preview, enabling you to create systems where multiple AI agents work together to solve complex problems. Agents can specialize in different domains, share context, and coordinate their actions to achieve goals that would be difficult for a single agent.
RAG evaluation is now generally available. This provides metrics to assess and improve your retrieval augmented generation pipelines. GraphRAG for Bedrock Knowledge Bases is now generally available, allowing you to enhance retrievals with graph-based context.
Amazon Bedrock Flows now supports multi-turn conversations, allowing you to build dynamic AI applications that maintain context across multiple user interactions. Bedrock data automation is now generally available, streamlining the process of preparing, ingesting, and maintaining data for your GenAI applications. Bedrock now offers LLM-as-a-judge capability for model evaluation, providing automated assessment of model outputs without requiring human reviewers. Compare different models or prompt strategies against your specific criteria at scale.
Bedrock’s capabilities are now integrated into the Amazon SageMaker Unified Studio, creating a seamless experience for machine learning practitioners who want to incorporate foundation models into their workflows. Access Bedrock models, fine-tuning, and evaluation directly from SageMaker.
Amazon Nova is a new generation of state-of-the-art foundation models that deliver frontier intelligence and industry leading price-performance. Nova has expanded its tool use and converse API capabilities, making it easier for developers to build AI assistants that can use external tools to complete tasks.
Amazon Bedrock Guardrails image content filters are now generally available. Define and enforce boundaries for your AI applications with controls for both text and image content, ensuring outputs align with your organization’s policies.
Bedrock Knowledge Bases now supports using your existing OpenSearch clusters as the vector storage backend. This integration allows you to leverage your investments in OpenSearch while benefiting from the managed RAG capabilities of Bedrock.
New Amazon Bedrock models
Anthropic’s Claude 3.7 Sonnet hybrid reasoning allows you to toggle between standard and extended thinking modes. In standard mode, it functions as an upgraded version of Claude 3.5 Sonnet. While in extended thinking mode, it employs self-reflection to achieve improved results across a wide range of tasks.
DeepSeek R1, an advanced model specialized in research and scientific reasoning excels at complex problem-solving tasks and technical content generation.
Cohere Embed 3 models are now available in both multilingual and English-specific versions. These embedding models support text and images, providing more accurate representation for multimodal content and improving retrieval augmented generation (RAG) applications.
Ray2, Luma AI’s new visual AI model is capable of creating realistic visuals with fluid, natural movement. You can use it for image understanding, 3D scene reconstruction, and visual content generation, opening new possibilities for immersive and visual applications.
Bedrock now supports fine-tuning of Meta’s latest Llama 3.2 models. These upgraded models deliver improved performance across reasoning, coding, and multilingual tasks while being more efficient with computational resources.
Amazon Q Developer
Amazon Q Developer is now available as a CLI agent, bringing AI-assisted development to the command line. Get contextual recommendations, generate shell commands, and solve coding problems without leaving your terminal.
Amazon Q CLI
Amazon Q Developer transformation now supports upgrading Java applications using Maven to Java 21. It offers enhanced code suggestions, refactoring, and optimization recommendations for applications using the latest Java features, like virtual threads and pattern matching.
AWS AppSync
AWS AppSync Events now supports events publishing for WebSocket APIs, enabling real-time publish-subscribe functionality. This feature makes it easier to build applications requiring instant updates, like chat applications, collaborative tools, and real-time dashboards.
AWS AppSync Events
There are new AWS Cloud Development Kit (AWS CDK) L2 constructs for AppSync WebSocket APIs. These make it simpler to define and deploy real-time APIs using infrastructure as code. These high-level constructs handle the details of WebSocket connections, authorization, and messaging patterns.
Amazon SNS
Amazon SNS now supports high throughput mode for SNS FIFO topics, with default throughput matching SNS standard topics. When you enable high-throughput mode, SNS FIFO topics will maintain order within message group, while reducing the de-duplication scope to the message-group level.
The EventBridge console now features event source discovery, making it easier to find and visualize available event sources in your AWS environment. This tool helps you identify potential event producers and understand the event schemas they emit.
AWS Amplify
AWS Amplify now offers a TypeScript data client optimized for server-side Lambda functions, providing type-safe access to your data sources. This client reduces code complexity and improves reliability when working with databases and APIs in server environments.
The Serverless landing page has more information. The Lambda resources page contains case studies, webinars, whitepapers, customer stories, reference architectures, and even more Getting Started tutorials.
You can also follow the Developer Advocacy team members who work on Serverless to see the latest news, follow conversations, and interact with the team.
It’s AWS Summit season! Free events are now rolling out worldwide, bringing our cloud computing community together to connect, collaborate, and learn. Whether you prefer joining us online or in-person, these gatherings offer valuable opportunities to expand your AWS knowledge. I’ll be attending the AWS Amsterdam Summit and would love to meet you—if you’re planning to be there, please stop by to say hello! Visit the AWS Summit website today to find events in your area, sign up for registration alerts, and reserve your spot at an AWS Summit near you.
Speaking of AWS news, let’s look at last week’s new announcements.
Last week’s launches Here are the launches that got my attention.
AWS WAF integration with AWS Amplify Hosting now generally available – You can now directly attach AWS WAF to your AWS Amplify applications through a one-click integration in the Amplify console or using infrastructure as code (IaC). This integration provides access to the full range of AWS WAF capabilities, including managed rules that protect against common web exploits like SQL injection and cross-site scripting (XSS). You can also create custom rules based on your application needs, implement rate-based rules to protect against distributed denial of service (DDoS) attacks by limiting request rates from IP addresses, and configure geo-blocking to restrict access from specific countries. Firewall support is available in all AWS Regions in which Amplify Hosting operates.
Amazon Bedrock Custom Model Import introduces real-time cost transparency – If you’re using Amazon Bedrock Custom Model Import to run your customized foundation models (FMs), you can now access full transparency into compute resources and calculate inference costs in real time. Before model invocation, you can view the minimum compute resources (custom model units or CMUs) required through both the Amazon Bedrock console and Amazon Bedrock APIs. As models scale to handle increased traffic, Amazon CloudWatch metrics provide real-time visibility into total CMUs used, enabling better cost control through near-instant visibility. This helps you make on-the-fly model configuration changes to optimize costs. The feature is available in all Regions where Amazon Bedrock Custom Model Import is supported, with additional details available in Calculate the cost of running a custom model in the Amazon Bedrock User Guide.
Amazon Bedrock Guardrails announces the general availability of industry-leading image content filters – This new capability offers industry-leading text and image content safeguards that help you block up to 88% of harmful multimodal content without building custom safeguards or relying on error-prone manual content moderation. Image content filters can be applied across all categories within the content filter policy including hate, insults, sexual, violence, misconduct, and prompt attacks. Amazon Bedrock Guardrails provides configurable safeguards to detect and block harmful content and prompt attacks, define topics to deny and disallow specific topics, redact personally identifiable information (PII) such as personal data, and block specific words. It also provides contextual grounding checks to detect and block model hallucinations and to identify the relevance of model responses and claims, and to identify, correct, and explain factual claims in model responses using Automated Reasoning checks. This capability is generally available in the US East (N. Virginia), US West (Oregon), Europe (Frankfurt), and Asia Pacific (Tokyo) Regions. To learn more, visit Amazon Bedrock Guardrails image content filters provide industry-leading safeguards in the AWS Machine Learning Blog and Stop harmful content in models using Amazon Bedrock Guardrails in the Amazon Bedrock User Guide.
Scenarios capability now generally available for Amazon Q in QuickSight – This capability guides you through data analysis by uncovering hidden trends, making recommendations for your business, and intelligently suggesting next steps for deeper exploration using natural language interactions. Now you can explore past trends, forecast future scenarios, and model solutions without needing specialized skill, analyst support, or manual manipulation of data in spreadsheets. With its intuitive interface and step-by-step guidance, the scenarios capability of Amazon Q in QuickSight helps you perform complex data analysis up to 10x faster than spreadsheets. Whether you’re optimizing marketing budgets, streamlining supply chains, or analyzing investments, Amazon Q makes advanced data analysis accessible so you can make data-driven decisions across your organization. This capability is accessible from any Amazon QuickSight dashboard, so you can move seamlessly from visualizing data to asking what-if questions and comparing alternatives. Previous analyses can be easily modified, extended, and reused, helping you quickly adapt to changing business needs.
Amazon Q Business now available in Asia Pacific (Sydney) AWS Region – Amazon Q Business is the most capable generative AI–powered assistant for finding information, gaining insight, and taking action at work. It can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems.
Amazon EC2 P5en instances are now available in US East (N. Virginia) and Asia Pacific (Jakarta) AWS Regions – P5en instances feature 8 H200 GPUs with 1.7x memory size, paired with 4th Gen Intel Xeon processors and Gen5 PCIe for 4x CPU-GPU bandwidth. This helps improve collective communications performance for distributed training workloads such as deep learning, generative AI, real-time data processing, and high performance computing (HPC) applications.
Amazon EC2 R8g instances now available in US West (N. California) AWS Region – These instances offer larger instance sizes with up to 3x more vCPU (up to 48xlarge) and memory (up to 1.5 TB) than AWS Graviton3 based R7g instances. These instances are up to 30% faster for web applications, 40% faster for databases, and 45% faster for large Java applications compared to Graviton3 based R7g instances.
Amazon EC2 C8g instances now available in Asia Pacific (Tokyo) AWS Region – These instances offer larger instance sizes with up to 3x more vCPUs and memory compared to Graviton3 based Amazon C7g instances. AWS Graviton4 processors are up to 40% faster for databases, 30% faster for web applications, and 45% faster for large Java applications than AWS Graviton3 processors.
Amazon SageMaker AI is now available in Mexico (Central) and Asia Pacific (Thailand) AWS Regions – Amazon SageMaker AI is a fully managed platform that provides every developer and data scientist with the ability to build, train, and deploy machine learning (ML) models quickly.
Other AWS events Check your calendar and sign up for upcoming AWS events.
AWS GenAI Lofts are collaborative spaces and immersive experiences that showcase AWS expertise in cloud computing and AI. They provide startups and developers with hands-on access to AI products and services, exclusive sessions with industry leaders, and valuable networking opportunities with investors and peers. Find a GenAI Loft location near you and don’t forget to register.
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Generative AI is revolutionizing how businesses interact with their customers through natural conversational interfaces. While organizations can implement AI assistants across various channels, phone calls remain a preferred method for many customers seeking support or information.
We’ll demonstrate how to create a voice interface for your existing Amazon Bedrock generative AI assistant, enabling customers to engage in phone-based conversations with your AI implementation.
Solution overview
Using Workflow Studio for Amazon Web Services (AWS) Step Functions, we built a voice communication interface that connects with the Amazon Nova Micro model in Amazon Bedrock (Figure 1). The demo application uses the base model to enable open-ended questions. Organizations can implement either Amazon Bedrock Agents or Flows to address specific business requirements.
Figure 1 – Step Functions workflow that enables voice communication to a generative AI assistant
How it works:
Inbound call arrives
System plays welcome message
System asks caller for questions
Voice recording starts, stopping when silence is detected
Sends transcribed question to the Amazon Nova Micro model in Amazon Bedrock
Upon receiving the response, stops the on-hold music
Text-to-speech plays the model’s answer
System asks for additional questions and loops to Step 4 or ends the call
Expanded capabilities and optimizations
These are potential improvements, additional functionalities, and advanced features that can enhance the demo application:
The transcription component is interchangeable with any speech-to-text generative AI model (including Whisper Large V3 Turbo on Amazon Bedrock Marketplace)
The PSTN audio service RecordAudioAction can be tuned to adjust silence duration and background noise levels
Enabling the PSTN audio service VoiceFocus feature to improve call clarity by reducing background noise and enhancing voice quality
PSTN audio service Session Initiation Protocol (SIP) media applications can also handle calls through SIP trunking by using Amazon Chime SDK Voice Connector, streamlining integration with existing phone systems
The UpdateSipMediaApplicationCall API is a PSTN audio service feature that lets you regain call control and apply new actions during active calls
Parallel workflow states allow user-friendly handling of API service calls by playing music during processing
PSTN audio service provides pay-per-minute rates with serverless, scalable telephony infrastructure
Deploying the solution
The following steps allow you to deploy the voice communication interface workflow (Figure 1) together with the supporting serverless architecture for Step Functions and PSTN audio service integration. In a previous blog, we demonstrated how combining Step Functions and Amazon Chime SDK PSTN audio service streamlines the development of reliable telephony applications through a visual workflow design.
AWS Command Line Interface (AWS CLI) installed and configured
Enable access to the Amazon Nova Micro model through the Amazon Bedrock console
Walkthrough:
The AWS Cloud Development Kit (AWS CDK) project on the AWS GitHub repository will deploy the following resources:
phoneNumberBedrock – Provisioned phone number for the demo application
sipMediaApp – SIP media application that routes calls to lambdaProcessPSTNAudioServiceCalls
sipRule – SIP rule that directs calls from phoneNumberBedrock to sipMediaApp
lambdaProcessPSTNAudioServiceCalls – AWS Lambda function for call processing
roleLambdaProcessPSTNAudioServiceCalls – AWS Identity and Access Management (IAM) Role for lambdaProcessPSTNAudioServiceCalls
stepfunctionBedrockWorkflow – Step Functions workflow for the telephony application
roleStepfuntionBedrockWorkflow – IAM Role for stepfunctionBedrockWorkflow
s3BucketApp – Amazon Simple Storage Service (Amazon S3) bucket for storing customer questions recordings
s3BucketPolicy – IAM Policy granting PSTN audio service access to s3BucketApp
lambdaAudioTranscription – Lambda function for audio transcription
lambdaLayerForTranscription – Lambda layer required for lambdaAudioTranscription
roleLambdaAudioTranscription – IAM Role for lambdaAudioTranscription
Follow these steps to deploy the CDK stack:
Clone the repository.
git clone https://github.com/aws-samples/sample-chime-sdk-bedrock-voice-interface
cd sample-chime-sdk-bedrock-voice-interface
npm install
Bootstrap the stack.
#default AWS CLI credentials are used, otherwise use the –-profile parameter
#provide the <account-id> and <region> to deploy this stack
cdk bootstrap aws://<account-id>/<region>
Deploy the stack.
#default AWS CLI credentials are used, otherwise use the –-profile parameter
#phoneAreaCode: the United States area code used to provision the phone number
cdk deploy –-context phoneAreaCode=NPA
Call the provisioned phone number to test the sample application.
Cleaning up:
To clean up this demo, execute:
cdk destroy
Conclusion
We demonstrated how organizations can add voice capabilities to their existing generative AI implementations using Amazon Bedrock. The solution enables customers to interact with AI assistants through traditional phone calls, expanding accessibility and user engagement. The demo application showcases an architecture combining AWS Step Functions and Amazon Chime SDK PSTN audio service, delivering natural voice conversations with AI models through quick deployment using visual workflows.
Organizations benefit from cost optimization with pay-per-minute pricing, enterprise-ready telephony integration through PSTN or SIP trunking, and automatic scaling to match customer demand. This foundation enables businesses to build practical AI applications ranging from all day customer service agents, to multi-language support services, and knowledge base assistants. By following this solution, you can quickly extend your generative AI investments to voice channels, providing more value to your customers while maintaining operational efficiency.
Contact an AWS Representative to know how we can help accelerate your business.
Thanks to everyone who joined us for the fifth annual AWS Pi Day on March 14. Since its inception in 2021, commemorating the Amazon Simple Storage Service (Amazon S3) 15th anniversary, AWS Pi Day has grown into a flagship event highlighting the transformative power of cloud technologies in data management, analytics, and AI.
This year’s virtual event featured in-depth discussions with Amazon Web Services (AWS) product teams showcasing our continued innovation in helping customers build robust data foundations for analytics and AI workloads.
Missed the live event? You can still access all content on-demand at the event page. Whether you’re developing data lakehouses, training AI models, creating generative AI applications, or optimizing analytics workloads, the shared insights will help you maximize the value of your data.
Last week’s launches Here are some launches that got my attention during the previous week.
Amazon Bedrock now supports multi-agent collaboration – With the availability of multi-agent collaboration in Amazon Bedrock, you can create networks of specialized agents that communicate and coordinate under the guidance of a supervisor agent. You can build, deploy, and manage networks of AI agents that work together to execute complex, multi-step workflows efficiently.
Availability of fully managed DeepSeek-R1 model in Amazon Bedrock – AWS is the first cloud service provider (CSP) to deliver DeepSeek-R1 as a fully managed, generally available model. Use the capabilities of DeepSeek-R1 for your generative AI applications with a single API through this fully managed service in Amazon Bedrock.
Amazon SageMaker Unified Studio is now generally available – You can now use Amazon SageMaker Unified Studio as your single data and AI development environment, where you can find and access all of your organization’s data and work using the best tools for your specific needs. With the new simplified permissions management, you can easily bring your existing AWS resources into the unified studio. You’ll be able to find, access, and query your organization’s data and AI assets while collaborating with your team to securely build and share your analytics and AI artifacts—from data and models to generative AI applications.
Amazon S3 reduces pricing for S3 object tagging by 35% – Amazon S3 reduces pricing for S3 object tagging by 35% in all AWS Regions to $0.0065 per 10,000 tags per month. Object tags are key-value pairs applied to S3 objects that can be created, updated, or deleted at any time during the lifetime of the object.
Serverless Land Patterns available in Visual Studio Code – Serverless Land‘s extensive application pattern library is now available directly into the Visual Studio Code (VS Code) IDE, making it easier for developers to build serverless applications. This integration eliminates the need to switch between your development environment and external resources when building serverless architectures by enabling you to browse, search, and implement pre-built serverless patterns directly in VS Code IDE.
Amplify Hosting Announces Skew Protection Support – AWS Amplify Hosting now offers Skew Protection, a feature that guarantees version consistency across your deployments. This feature ensures frontend requests are always routed to the correct server backend version—eliminating version skew and making deployments more reliable.
From community.aws Here are some of my favorite posts from community.aws. Create your AWS Builder ID to start sharing your tips and connect with fellow builders. Your Builder ID is a universal login credential that gives you access, beyond the AWS Management Console, to AWS tools and resources, including over 600 free training courses, community features, and developer tools such as Amazon Q Developer.
AWS Innovate: Generative AI + Data – Join a free online conference focusing on generative AI and data innovations in Latin America on April 8.
AWS Summits – The AWS Summit season is coming along! Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Register in your nearest city: Paris (April 9), Amsterdam (April 16), London (April 30), and Poland (May 5).
AWS re:Inforce (June 16–18) – Our annual learning event devoted to all things AWS Cloud security in Philadelphia, PA. Registration opens in March, so be ready to join more than 5,000 security builders and leaders.
AWS DevDays are free, technical events where developers can learn about some of the hottest topics in cloud computing. DevDays offer hands-on workshops, technical sessions, live demos, and networking with AWS technical experts and your peers. Register to access AWS DevDays sessions on demand.
That’s all for this week. Check back next Monday for another Weekly Roundup!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
This year, AWS Pi Day returns with a focus on accelerating analytics and AI innovation with a unified data foundation on AWS. The data landscape is undergoing a profound transformation as AI emerges in most enterprise strategies, with analytics and AI workloads increasingly converging around a lot of the same data and workflows. You need an easy way to access all your data and use all your preferred analytics and AI tools in a single integrated experience. This AWS Pi Day, we’re introducing a slate of new capabilities that help you build unified and integrated data experiences.
The next generation of Amazon SageMaker: The center of all your data, analytics, and AI At re:Invent 2024, we introduced the next generation of Amazon SageMaker, the center of all your data, analytics, and AI. SageMaker includes virtually all the components you need for data exploration, preparation and integration, big data processing, fast SQL analytics, machine learning (ML) model development and training, and generative AI application development. With this new generation of Amazon SageMaker, SageMaker Lakehouse provides you with unified access to your data and SageMaker Catalog helps you to meet your governance and security requirements. You can read the launch blog post written by my colleague Antje to learn more details.
SageMaker Unified Studio facilitates collaboration among data scientists, analysts, engineers, and developers as they work on data, analytics, AI workflows, and applications. It provides familiar tools from AWS analytics and artificial intelligence and machine learning (AI/ML) services, including data processing, SQL analytics, ML model development, and generative AI application development, into a single user experience.
Last but not least, Amazon Q Developer is now generally available in SageMaker Unified Studio. Amazon Q Developer provides generative AI powered assistance for data and AI development. It helps you with tasks like writing SQL queries, building extract, transform, and load (ETL) jobs, and troubleshooting, and is available in the Free tier and Pro tier for existing subscribers.
Building a data foundation with Amazon S3 Building a data foundation is the cornerstone of accelerating analytics and AI workloads, enabling organizations to seamlessly manage, discover, and utilize their data assets at any scale. Amazon S3 is the world’s best place to build a data lake, with virtually unlimited scale, and it provides the essential foundation for this transformation.
I’m always astonished to learn about the scale at which we operate Amazon S3: It currently holds over 400 trillion objects, exabytes of data, and processes a mind-blowing 150 million requests per second. Just a decade ago, not even 100 customers were storing more than a petabyte (PB) of data on S3. Today, thousands of customers have surpassed the 1 PB milestone.
Amazon S3 stores exabytes of tabular data, and it averages over 15 million requests to tabular data per second. To help you reduce the undifferentiated heavy lifting when managing your tabular data in S3 buckets, we announced Amazon S3 Tables at AWS re:Invent 2024. S3 Tables are the first cloud object store with built-in support for Apache Iceberg. S3 tables are specifically optimized for analytics workloads, resulting in up to threefold faster query throughput and up to tenfold higher transactions per second compared to self-managed tables.
For those of you who use a third-party catalog, have a custom catalog implementation, or only need basic read and write access to tabular data in a single table bucket, we’ve added new APIs that are compatible with the Iceberg REST Catalog standard. This enables any Iceberg-compatible application to seamlessly create, update, list, and delete tables in an S3 table bucket. For unified data management across all of your tabular data, data governance, and fine-grained access controls, you can also use S3 Tables with SageMaker Lakehouse.
To help you access S3 Tables, we’ve launched updates in the AWS Management Console. You can now create a table, populate it with data, and query it directly from the S3 console using Amazon Athena, making it easier to get started and analyze data in S3 table buckets.
The following screenshot shows how to access Athena directly from the S3 console.
When I select Query tables with Athena or Create table with Athena, it opens the Athena console on the correct data source, catalog, and database.
Amazon S3 Metadata—announced during re:Invent 2024— has been generally available since January 27. It’s the fastest and easiest way to help you discover and understand your S3 data with automated, effortlessly-queried metadata that updates in near real time. S3 Metadata works with S3 object tags. Tags help you logically group data for a variety of reasons, such as to apply IAM policies to provide fine-grained access, specify tag-based filters to manage object lifecycle rules, and selectively replicate data to another Region. In Regions where S3 Metadata is available, you can capture and query custom metadata that is stored as object tags. To reduce the cost associated with object tags when using S3 Metadata, Amazon S3 reduced pricing for S3 object tagging by 35 percent in all Regions, making it cheaper to use custom metadata.
AWS Pi Day 2025 Over the years, AWS Pi Day has showcased major milestones in cloud storage and data analytics. This year, the AWS Pi Day virtual event will feature a range of topics designed for developers and technical decision-makers, data engineers, AI/ML practitioners, and IT leaders. Key highlights include deep dives, live demos, and expert sessions on all the services and capabilities I discussed in this post.
By attending this event, you’ll learn how you can accelerate your analytics and AI innovation. You’ll learn how you can use S3 Tables with native Apache Iceberg support and S3 Metadata to build scalable data lakes that serve both traditional analytics and emerging AI/ML workloads. You’ll also discover the next generation of Amazon SageMaker, the center for all your data, analytics, and AI, to help your teams collaborate and build faster from a unified studio, using familiar AWS tools with access to all your data whether it’s stored in data lakes, data warehouses, or third-party or federated data sources.
For those looking to stay ahead of the latest cloud trends, AWS Pi Day 2025 is an event you can’t miss. Whether you’re building data lakehouses, training AI models, building generative AI applications, or optimizing analytics workloads, the insights shared will help you maximize the value of your data.
Tune in today and explore the latest in cloud data innovation. Don’t miss the opportunity to engage with AWS experts, partners, and customers shaping the future of data, analytics, and AI.
If you missed the virtual event on March 14, you can visit the event page at any time—we will keep all the content available on-demand there!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Today, we’re announcing the general availability of Amazon SageMaker Unified Studio, a single data and AI development environment where you can find and access all of the data in your organization and act on it using the best tool for the job across virtually any use case. Introduced as preview during AWS re:Invent 2024, my colleague, Antje, summarized it as:
SageMaker Unified Studio breaks down silos in data and tools, giving data engineers, data scientists, data analysts, ML developers and other data practitioners a single development experience. This saves development time and simplifies access control management so data practitioners can focus on what really matters to them—building data products and AI applications.
This post focuses on several important announcements that we’re excited to share:
New capabilities for Amazon Bedrock in SageMaker Unified Studio — The integration now supports new foundation models (FMs), including Anthropic’s Claude 3.7 Sonnet and DeepSeek-R1, enables data sourcing from Amazon Simple Storage Service (Amazon S3) folders within projects for knowledge base creation, extends guardrail functionality to flows, and provides a streamlined user management interface for domain administrators to manage model governance across multiple Amazon Web Service (AWS) accounts.
Amazon Q Developer is now generally available in SageMaker Unified Studio — Amazon Q Developer, the most capable generative AI assistant for software development, streamlines development in Amazon SageMaker Unified Studio by providing natural language, conversational interfaces that simplify tasks like writing SQL queries, building ETL jobs, troubleshooting, and generating real-time code suggestions.
New capabilities for Amazon Bedrock in SageMaker Unified Studio The capabilities of Amazon Bedrock within Amazon SageMaker Unified Studio offer a governed collaborative environment for developers to rapidly create and customize generative AI applications. This intuitive interface caters to developers of all skill levels, providing seamless access to the high-performance FMs offered in Amazon Bedrock and advanced customization tools for collaborative development of tailored generative AI applications.
Since the preview launch, several new FMs have become available in Amazon Bedrock and are fully integrated with SageMaker Unified Studio, including Anthropic’s Claude 3.7 Sonnet and DeepSeek-R1. These models can be used for building generative AI apps and chatting in the playground in SageMaker Unified Studio.
Here’s how you can choose Anthropic’s Claude 3.7 Sonnet on the model selection in your project.
You can also source data or documents from S3 folders within your project and select specific FMs when creating knowledge bases.
During preview, we introduced Amazon Bedrock Guardrails to help you implement safeguards for your Amazon Bedrock application based on your use cases and responsible AI policies. Now, Amazon Bedrock Guardrails is extended to Amazon Bedrock Flows with this general availability release.
Additionally, we have streamlined generative AI setup for associated accounts with a new user management interface in SageMaker Unified Studio, making it straightforward for domain administrators to grant associated account admins access to model governance projects. This enhancement eliminates the need for command line operations, streamlining the process of configuring generative AI capabilities across multiple AWS accounts.
These new features eliminate barriers between data, tools, and builders in the generative AI development process. You and your team will gain a unified development experience by incorporating the powerful generative AI capabilities of Amazon Bedrock — all within the same workspace.
Amazon Q Developer is now generally available in SageMaker Unified Studio Amazon Q Developer is now generally available in Amazon SageMaker Unified Studio, providing data professionals with generative AI–powered assistance across the entire data and AI development lifecycle.
Amazon Q Developer integrates with the full suite of AWS analytics and AI/ML tools and services within SageMaker Unified Studio, including data processing, SQL analytics, machine learning model development, and generative AI application development, to accelerate collaboration and help teams build data and AI products faster. To get started, you can select Amazon Q Developer icon.
For new users of SageMaker Unified Studio, Amazon Q Developer serves as an invaluable onboarding assistant. It can explain core concepts such as domains and projects, provide guidance on setting up environments, and answer your questions.
Amazon Q Developer helps you discover and understand data using powerful natural language interactions with SageMaker Catalog. What makes this implementation particularly powerful is how Amazon Q Developer combines broad knowledge of AWS analytics and AI/ML services with the user’s context to provide personalized guidance.
You can chat about your data assets through a conversational interface, asking questions such as “Show all payment related datasets” without needing to navigate complex metadata structures.
Amazon Q Developer offers SQL query generation through its integration with the built-in query editor available in SageMaker Unified Studio. Data professionals of varying skill levels can now express their analytical needs in natural language, receiving properly formatted SQL queries in return.
For example, you can ask, “Analyze payment method preferences by age group and region” and Amazon Q Developer will generate the appropriate SQL with proper joins across multiple tables.
Additionally, Amazon Q Developer is also available to assist with troubleshooting and generating real-time code suggestions in SageMaker Unified Studio Jupyter notebooks, as well as building ETL jobs.
Now available
Availability — Amazon SageMaker Unified Studio is now available in the following AWS Regions: US East (N. Virginia, Ohio), US West (Oregon), Asia Pacific (Seoul, Singapore, Sydney, Tokyo), Canada (Central), Europe (Frankfurt, Ireland, London), South America (São Paulo). Learn more about the availability of these capabilities on supported Region documentation page.
Amazon Q Developer subscription — The free tier of Amazon Q Developer is available by default in SageMaker Unified Studio, requiring no additional setup or configuration. If you already have Amazon Q Developer Pro Tier subscriptions, you can use those enhanced capabilities within the SageMaker Unified Studio environment. For more information, visit the documentation page.
Amazon Bedrock capabilities — To learn more about the capabilities of Amazon Bedrock in Amazon SageMaker Unified Studio, refer to this documentation page.
Start building with Amazon SageMaker Unified Studio today. For more information, visit the Amazon SageMaker Unified Studio page.
— How is the News Blog doing? Take this 1 minute survey! (This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
As of January 30, DeepSeek-R1 models became available in Amazon Bedrock through the Amazon Bedrock Marketplace and Amazon Bedrock Custom Model Import. Since then, thousands of customers have deployed these models in Amazon Bedrock. Customers value the robust guardrails and comprehensive tooling for safe AI deployment. Today, we’re making it even easier to use DeepSeek in Amazon Bedrock through an expanded range of options, including a new serverless solution.
The fully managed DeepSeek-R1 model is now generally available in Amazon Bedrock. Amazon Web Services (AWS) is the first cloud service provider (CSP) to deliver DeepSeek-R1 as a fully managed, generally available model. You can accelerate innovation and deliver tangible business value with DeepSeek on AWS without having to manage infrastructure complexities. You can power your generative AI applications with DeepSeek-R1’s capabilities using a single API in the Amazon Bedrock’s fully managed service and get the benefit of its extensive features and tooling.
According to DeepSeek, their model is publicly available under MIT license and offers strong capabilities in reasoning, coding, and natural language understanding. These capabilities power intelligent decision support, software development, mathematical problem-solving, scientific analysis, data insights, and comprehensive knowledge management systems.
As is the case for all AI solutions, give careful consideration to data privacy requirements when implementing in your production environments, check for bias in output, and monitor your results. When implementing publicly available models like DeepSeek-R1, consider the following:
Data security – You can access the enterprise-grade security, monitoring, and cost control features of Amazon Bedrock that are essential for deploying AI responsibly at scale, all while retaining complete control over your data. Users’ inputs and model outputs aren’t shared with any model providers. You can use these key security features by default, including data encryption at rest and in transit, fine-grained access controls, secure connectivity options, and download various compliance certifications while communicating with the DeepSeek-R1 model in Amazon Bedrock.
Responsible AI – You can implement safeguards customized to your application requirements and responsible AI policies with Amazon Bedrock Guardrails. This includes key features of content filtering, sensitive information filtering, and customizable security controls to prevent hallucinations using contextual grounding and Automated Reasoning checks. This means you can control the interaction between users and the DeepSeek-R1 model in Bedrock with your defined set of policies by filtering undesirable and harmful content in your generative AI applications.
Model evaluation – You can evaluate and compare models to identify the optimal model for your use case, including DeepSeek-R1, in a few steps through either automatic or human evaluations by using Amazon Bedrock model evaluation tools. You can choose automatic evaluation with predefined metrics such as accuracy, robustness, and toxicity. Alternatively, you can choose human evaluation workflows for subjective or custom metrics such as relevance, style, and alignment to brand voice. Model evaluation provides built-in curated datasets, or you can bring in your own datasets.
Get started with the DeepSeek-R1 model in Amazon Bedrock If you’re new to using DeepSeek-R1 models, go to the Amazon Bedrock console, choose Model access under Bedrock configurations in the left navigation pane. To access the fully managed DeepSeek-R1 model, request access for DeepSeek-R1 in DeepSeek. You’ll then be granted access to the model in Amazon Bedrock.
Next, to test the DeepSeek-R1 model in Amazon Bedrock, choose Chat/Text under Playgrounds in the left menu pane. Then choose Select model in the upper left, and select DeepSeek as the category and DeepSeek-R1 as the model. Then choose Apply.
Using the selected DeepSeek-R1 model, I run the following prompt example:
A family has $5,000 to save for their vacation next year. They can place the money in a savings account earning 2% interest annually or in a certificate of deposit earning 4% interest annually but with no access to the funds until the vacation. If they need $1,000 for emergency expenses during the year, how should they divide their money between the two options to maximize their vacation fund?
This prompt requires a complex chain of thought and produces very precise reasoning results.
To learn more about usage recommendations for prompts, refer to the README of the DeepSeek-R1 model in its GitHub repository.
By choosing View API request, you can also access the model using code examples in the AWS Command Line Interface (AWS CLI) and AWS SDK. You can use us.deepseek.r1-v1:0 as the model ID.
The model supports both the InvokeModel and Converse API. The following Python code examples show how to send a text message to the DeepSeek-R1 model using the Amazon Bedrock Converse API for text generation.
import boto3
from botocore.exceptions import ClientError
# Create a Bedrock Runtime client in the AWS Region you want to use.
client = boto3.client("bedrock-runtime", region_name="us-west-2")
# Set the model ID, e.g., Llama 3 8b Instruct.
model_id = "us.deepseek.r1-v1:0"
# Start a conversation with the user message.
user_message = "Describe the purpose of a 'hello world' program in one line."
conversation = [
{
"role": "user",
"content": [{"text": user_message}],
}
]
try:
# Send the message to the model, using a basic inference configuration.
response = client.converse(
modelId=model_id,
messages=conversation,
inferenceConfig={"maxTokens": 2000, "temperature": 0.6, "topP": 0.9},
)
# Extract and print the response text.
response_text = response["output"]["message"]["content"][0]["text"]
print(response_text)
except (ClientError, Exception) as e:
print(f"ERROR: Can't invoke '{model_id}'. Reason: {e}")
exit(1)
To enable Amazon Bedrock Guardrails on the DeepSeek-R1 model, select Guardrails under Safeguards in the left navigation pane, and create a guardrail by configuring as many filters as you need. For example, if you filter for “politics” word, your guardrails will recognize this word in the prompt and show you the blocked message.
You can test the guardrail with different inputs to assess the guardrail’s performance. You can refine the guardrail by setting denied topics, word filters, sensitive information filters, and blocked messaging until it matches your needs.
As the weather improves in the Northern hemisphere, there are more opportunities to learn and connect. This week, I’ll be in San Francisco, and we can meet at the Nova Networking Night at the AWS GenAI Loft where we’ll dive into the world of Amazon Novafoundation models (FMs) with live demos and real-world implementations.
AWS Pi Dayis now a yearly tradition. It started in 2021 as a celebration of the 15th anniversary of Amazon S3. This year, there will be in-depth discussions with AWS product teams on how to build a data foundation for a unified seamless experience, managing and using data for analytics and AI workloads. Join us online to learn about the latest innovations through hands-on demos, and ask questions during our interactive livestream.
Last week’s launches Another busy week, here are the launches that got my attention.
Amazon Q Business – Now supports the ingestion of audio and video data. This capability streamlines information retrieval, enhances knowledge sharing, and improves decision-making processes, by making multimedia content as searchable and accessible as text-based documents.
AWS Step Functions– Workflow Studio for VS Code is now available, a visual builder you can use to compose workflows on a canvas. You can generate workflow definitions in the background to create workflows in your local development environment. Read more about this enhanced local IDE experience.
Amazon Cognito – You can now customize access tokens for machine-to-machine (M2M) flows, enabling you to implement fine-grained authorization in your applications, APIs, and workloads. M2M authorization is commonly used for automated processes such as scheduled data synchronization tasks, event-driven workflows, microservices communication, or real-time data streaming between systems.
Amazon GameLift – Introducing Amazon GameLift Streams, a new managed capability that developers can use to stream games at up to 1080p resolution and 60 frames per second to any device with a WebRTC-enabled browser. To learn more, explore Donnie’s blog post.
Other AWS news Here are some additional projects, blog posts, and news items that you might find interesting:
Accelerate AWS Well-Architected reviews with Generative AI – In this post, we explore a generative AI solution to streamline the Well-Architected Framework Reviews (WAFRs) process. We demonstrate how to build an intelligent, scalable system that analyzes architecture documents and generates insightful recommendations based on best practices.
Build a Multi-Agent System with LangGraph and Mistral on AWS – The Multi-Agent City Information System demonstrated in this post exemplifies the potential of agent-based architectures to create sophisticated, adaptable, and highly capable AI applications.
Evaluate RAG responses with Amazon Bedrock, LlamaIndex and RAGAS – How to enhance your Retrieval Augmented Generation (RAG) implementations with practical techniques to evaluate and optimize your AI systems and enable more accurate, context-aware responses that align with your specific needs.
From community.aws Here are some of my favorite posts from community.aws. Create your AWS Builder ID to start sharing your tips and connect with fellow builders. Your Builder ID is a universal login credential that gives you access, beyond the AWS Management Console, to AWS tools and resources, including over 600 free training courses, community features, and developer tools such as Amazon Q Developer.
AWS Innovate: Generative AI + Data – Join a free online conference focusing on generative AI and data innovations. Available in multiple geographic regions: North America (March 13), Greater China Region (March 14), and Latin America (April 8).
AWS Summits – The AWS Summit season is coming along! Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Register in your nearest city: Paris (April 9), Amsterdam (April 16), London (April 30), and Poland (May 5).
AWS re:Inforce (June 16–18) – Our annual learning event devoted to all things AWS Cloud security. This year is in Philadelphia, PA. Registration opens in March, so be ready to join more than 5,000 security builders and leaders.
AWS DevDays are free, technical events where developers can learn about some of the hottest topics in cloud computing. DevDays offer hands-on workshops, technical sessions, live demos, and networking with AWS technical experts and your peers. Register to access AWS DevDays sessions on demand.
That’s all for this week. Check back next Monday for another Weekly Roundup!
(This survey is hosted by an external company. AWS handles your information as described in the AWS Privacy Notice. AWS will own the data gathered via this survey and will not share the information collected with survey respondents.)
Many applications need to interact with content available through different modalities. Some of these applications process complex documents, such as insurance claims and medical bills. Mobile apps need to analyze user-generated media. Organizations need to build a semantic index on top of their digital assets that include documents, images, audio, and video files. However, getting insights from unstructured multimodal content is not easy to set up: you have to implement processing pipelines for the different data formats and go through multiple steps to get the information you need. That usually means having multiple models in production for which you have to handle cost optimizations (through fine-tuning and prompt engineering), safeguards (for example, against hallucinations), integrations with the target applications (including data formats), and model updates.
To make this process easier, we introduced in preview during AWS re:InventAmazon Bedrock Data Automation, a capability of Amazon Bedrock that streamlines the generation of valuable insights from unstructured, multimodal content such as documents, images, audio, and videos. With Bedrock Data Automation, you can reduce the development time and effort to build intelligent document processing, media analysis, and other multimodal data-centric automation solutions.
Today, Bedrock Data Automation is now generally available with support for cross-region inference endpoints to be available in more AWS Regions and seamlessly use compute across different locations. Based on your feedback during the preview, we also improved accuracy and added support for logo recognition for images and videos.
Let’s have a look at how this works in practice.
Using Amazon Bedrock Data Automation with cross-region inference endpoints The blog post published for the Bedrock Data Automation preview shows how to use the visual demo in the Amazon Bedrock console to extract information from documents and videos. I recommend you go through the console demo experience to understand how this capability works and what you can do to customize it. For this post, I focus more on how Bedrock Data Automation works in your applications, starting with a few steps in the console and following with code samples.
The Data Automation section of the Amazon Bedrock console now asks for confirmation to enable cross-region support the first time you access it. For example:
From an API perspective, the InvokeDataAutomationAsync operation now requires an additional parameter (dataAutomationProfileArn) to specify the data automation profile to use. The value for this parameter depends on the Region and your AWS account ID:
Also, the dataAutomationArn parameter has been renamed to dataAutomationProjectArn to better reflect that it contains the project Amazon Resource Name (ARN). When invoking Bedrock Data Automation, you now need to specify a project or a blueprint to use. If you pass in blueprints, you will get custom output. To continue to get standard default output, configure the parameter DataAutomationProjectArn to use arn:aws:bedrock:<REGION>:aws:data-automation-project/public-default.
As the name suggests, the InvokeDataAutomationAsync operation is asynchronous. You pass the input and output configuration and, when the result is ready, it’s written on an Amazon Simple Storage Service (Amazon S3) bucket as specified in the output configuration. You can receive an Amazon EventBridge notification from Bedrock Data Automation using the notificationConfiguration parameter.
With Bedrock Data Automation, you can configure outputs in two ways:
Standard output delivers predefined insights relevant to a data type, such as document semantics, video chapter summaries, and audio transcripts. With standard outputs, you can set up your desired insights in just a few steps.
Custom output lets you specify extraction needs using blueprints for more tailored insights.
To see the new capabilities in action, I create a project and customize the standard output settings. For documents, I choose plain text instead of markdown. Note that you can automate these configuration steps using the Bedrock Data Automation API.
For videos, I want a full audio transcript and a summary of the entire video. I also ask for a summary of each chapter.
To configure a blueprint, I choose Custom output setup in the Data automation section of the Amazon Bedrock console navigation pane. There, I search for the US-Driver-License sample blueprint. You can browse other sample blueprints for more examples and ideas.
Sample blueprints can’t be edited, so I use the Actions menu to duplicate the blueprint and add it to my project. There, I can fine-tune the data to be extracted by modifying the blueprint and adding custom fields that can use generative AI to extract or compute data in the format I need.
I upload the image of a US driver’s license on an S3 bucket. Then, I use this sample Python script that uses Bedrock Data Automation through the AWS SDK for Python (Boto3) to extract text information from the image:
import json
import sys
import time
import boto3
DEBUG = False
AWS_REGION = '<REGION>'
BUCKET_NAME = '<BUCKET>'
INPUT_PATH = 'BDA/Input'
OUTPUT_PATH = 'BDA/Output'
PROJECT_ID = '<PROJECT_ID>'
BLUEPRINT_NAME = 'US-Driver-License-demo'
# Fields to display
BLUEPRINT_FIELDS = [
'NAME_DETAILS/FIRST_NAME',
'NAME_DETAILS/MIDDLE_NAME',
'NAME_DETAILS/LAST_NAME',
'DATE_OF_BIRTH',
'DATE_OF_ISSUE',
'EXPIRATION_DATE'
]
# AWS SDK for Python (Boto3) clients
bda = boto3.client('bedrock-data-automation-runtime', region_name=AWS_REGION)
s3 = boto3.client('s3', region_name=AWS_REGION)
sts = boto3.client('sts')
def log(data):
if DEBUG:
if type(data) is dict:
text = json.dumps(data, indent=4)
else:
text = str(data)
print(text)
def get_aws_account_id() -> str:
return sts.get_caller_identity().get('Account')
def get_json_object_from_s3_uri(s3_uri) -> dict:
s3_uri_split = s3_uri.split('/')
bucket = s3_uri_split[2]
key = '/'.join(s3_uri_split[3:])
object_content = s3.get_object(Bucket=bucket, Key=key)['Body'].read()
return json.loads(object_content)
def invoke_data_automation(input_s3_uri, output_s3_uri, data_automation_arn, aws_account_id) -> dict:
params = {
'inputConfiguration': {
's3Uri': input_s3_uri
},
'outputConfiguration': {
's3Uri': output_s3_uri
},
'dataAutomationConfiguration': {
'dataAutomationProjectArn': data_automation_arn
},
'dataAutomationProfileArn': f"arn:aws:bedrock:{AWS_REGION}:{aws_account_id}:data-automation-profile/us.data-automation-v1"
}
response = bda.invoke_data_automation_async(**params)
log(response)
return response
def wait_for_data_automation_to_complete(invocation_arn, loop_time_in_seconds=1) -> dict:
while True:
response = bda.get_data_automation_status(
invocationArn=invocation_arn
)
status = response['status']
if status not in ['Created', 'InProgress']:
print(f" {status}")
return response
print(".", end='', flush=True)
time.sleep(loop_time_in_seconds)
def print_document_results(standard_output_result):
print(f"Number of pages: {standard_output_result['metadata']['number_of_pages']}")
for page in standard_output_result['pages']:
print(f"- Page {page['page_index']}")
if 'text' in page['representation']:
print(f"{page['representation']['text']}")
if 'markdown' in page['representation']:
print(f"{page['representation']['markdown']}")
def print_video_results(standard_output_result):
print(f"Duration: {standard_output_result['metadata']['duration_millis']} ms")
print(f"Summary: {standard_output_result['video']['summary']}")
statistics = standard_output_result['statistics']
print("Statistics:")
print(f"- Speaket count: {statistics['speaker_count']}")
print(f"- Chapter count: {statistics['chapter_count']}")
print(f"- Shot count: {statistics['shot_count']}")
for chapter in standard_output_result['chapters']:
print(f"Chapter {chapter['chapter_index']} {chapter['start_timecode_smpte']}-{chapter['end_timecode_smpte']} ({chapter['duration_millis']} ms)")
if 'summary' in chapter:
print(f"- Chapter summary: {chapter['summary']}")
def print_custom_results(custom_output_result):
matched_blueprint_name = custom_output_result['matched_blueprint']['name']
log(custom_output_result)
print('\n- Custom output')
print(f"Matched blueprint: {matched_blueprint_name} Confidence: {custom_output_result['matched_blueprint']['confidence']}")
print(f"Document class: {custom_output_result['document_class']['type']}")
if matched_blueprint_name == BLUEPRINT_NAME:
print('\n- Fields')
for field_with_group in BLUEPRINT_FIELDS:
print_field(field_with_group, custom_output_result)
def print_results(job_metadata_s3_uri) -> None:
job_metadata = get_json_object_from_s3_uri(job_metadata_s3_uri)
log(job_metadata)
for segment in job_metadata['output_metadata']:
asset_id = segment['asset_id']
print(f'\nAsset ID: {asset_id}')
for segment_metadata in segment['segment_metadata']:
# Standard output
standard_output_path = segment_metadata['standard_output_path']
standard_output_result = get_json_object_from_s3_uri(standard_output_path)
log(standard_output_result)
print('\n- Standard output')
semantic_modality = standard_output_result['metadata']['semantic_modality']
print(f"Semantic modality: {semantic_modality}")
match semantic_modality:
case 'DOCUMENT':
print_document_results(standard_output_result)
case 'VIDEO':
print_video_results(standard_output_result)
# Custom output
if 'custom_output_status' in segment_metadata and segment_metadata['custom_output_status'] == 'MATCH':
custom_output_path = segment_metadata['custom_output_path']
custom_output_result = get_json_object_from_s3_uri(custom_output_path)
print_custom_results(custom_output_result)
def print_field(field_with_group, custom_output_result) -> None:
inference_result = custom_output_result['inference_result']
explainability_info = custom_output_result['explainability_info'][0]
if '/' in field_with_group:
# For fields part of a group
(group, field) = field_with_group.split('/')
inference_result = inference_result[group]
explainability_info = explainability_info[group]
else:
field = field_with_group
value = inference_result[field]
confidence = explainability_info[field]['confidence']
print(f'{field}: {value or '<EMPTY>'} Confidence: {confidence}')
def main() -> None:
if len(sys.argv) < 2:
print("Please provide a filename as command line argument")
sys.exit(1)
file_name = sys.argv[1]
aws_account_id = get_aws_account_id()
input_s3_uri = f"s3://{BUCKET_NAME}/{INPUT_PATH}/{file_name}" # File
output_s3_uri = f"s3://{BUCKET_NAME}/{OUTPUT_PATH}" # Folder
data_automation_arn = f"arn:aws:bedrock:{AWS_REGION}:{aws_account_id}:data-automation-project/{PROJECT_ID}"
print(f"Invoking Bedrock Data Automation for '{file_name}'", end='', flush=True)
data_automation_response = invoke_data_automation(input_s3_uri, output_s3_uri, data_automation_arn, aws_account_id)
data_automation_status = wait_for_data_automation_to_complete(data_automation_response['invocationArn'])
if data_automation_status['status'] == 'Success':
job_metadata_s3_uri = data_automation_status['outputConfiguration']['s3Uri']
print_results(job_metadata_s3_uri)
if __name__ == "__main__":
main()
The initial configuration in the script includes the name of the S3 bucket to use in input and output, the location of the input file in the bucket, the output path for the results, the project ID to use to get custom output from Bedrock Data Automation, and the blueprint fields to show in output.
I run the script passing the name of the input file. In output, I see the information extracted by Bedrock Data Automation. The US-Driver-License is a match and the name and dates in the driver’s license are printed in output.
python bda-ga.py bda-drivers-license.jpeg
Invoking Bedrock Data Automation for 'bda-drivers-license.jpeg'................ Success
Asset ID: 0
- Standard output
Semantic modality: DOCUMENT
Number of pages: 1
- Page 0
NEW JERSEY
Motor Vehicle
Commission
AUTO DRIVER LICENSE
Could DL M6454 64774 51685 CLASS D
DOB 01-01-1968
ISS 03-19-2019 EXP 01-01-2023
MONTOYA RENEE MARIA 321 GOTHAM AVENUE TRENTON, NJ 08666 OF
END NONE
RESTR NONE
SEX F HGT 5'-08" EYES HZL ORGAN DONOR
CM ST201907800000019 CHG 11.00
[SIGNATURE]
- Custom output
Matched blueprint: US-Driver-License-copy Confidence: 1
Document class: US-drivers-licenses
- Fields
FIRST_NAME: RENEE Confidence: 0.859375
MIDDLE_NAME: MARIA Confidence: 0.83203125
LAST_NAME: MONTOYA Confidence: 0.875
DATE_OF_BIRTH: 1968-01-01 Confidence: 0.890625
DATE_OF_ISSUE: 2019-03-19 Confidence: 0.79296875
EXPIRATION_DATE: 2023-01-01 Confidence: 0.93359375
As expected, I see in output the information I selected from the blueprint associated with the Bedrock Data Automation project.
Similarly, I run the same script on a video file from my colleague Mike Chambers. To keep the output small, I don’t print the full audio transcript or the text displayed in the video.
python bda.py mike-video.mp4
Invoking Bedrock Data Automation for 'mike-video.mp4'.......................................................................................................................................................................................................................................................................... Success
Asset ID: 0
- Standard output
Semantic modality: VIDEO
Duration: 810476 ms
Summary: In this comprehensive demonstration, a technical expert explores the capabilities and limitations of Large Language Models (LLMs) while showcasing a practical application using AWS services. He begins by addressing a common misconception about LLMs, explaining that while they possess general world knowledge from their training data, they lack current, real-time information unless connected to external data sources.
To illustrate this concept, he demonstrates an "Outfit Planner" application that provides clothing recommendations based on location and weather conditions. Using Brisbane, Australia as an example, the application combines LLM capabilities with real-time weather data to suggest appropriate attire like lightweight linen shirts, shorts, and hats for the tropical climate.
The demonstration then shifts to the Amazon Bedrock platform, which enables users to build and scale generative AI applications using foundation models. The speaker showcases the "OutfitAssistantAgent," explaining how it accesses real-time weather data to make informed clothing recommendations. Through the platform's "Show Trace" feature, he reveals the agent's decision-making process and how it retrieves and processes location and weather information.
The technical implementation details are explored as the speaker configures the OutfitAssistant using Amazon Bedrock. The agent's workflow is designed to be fully serverless and managed within the Amazon Bedrock service.
Further diving into the technical aspects, the presentation covers the AWS Lambda console integration, showing how to create action group functions that connect to external services like the OpenWeatherMap API. The speaker emphasizes that LLMs become truly useful when connected to tools providing relevant data sources, whether databases, text files, or external APIs.
The presentation concludes with the speaker encouraging viewers to explore more AWS developer content and engage with the channel through likes and subscriptions, reinforcing the practical value of combining LLMs with external data sources for creating powerful, context-aware applications.
Statistics:
- Speaket count: 1
- Chapter count: 6
- Shot count: 48
Chapter 0 00:00:00:00-00:01:32:01 (92025 ms)
- Chapter summary: A man with a beard and glasses, wearing a gray hooded sweatshirt with various logos and text, is sitting at a desk in front of a colorful background. He discusses the frequent release of new large language models (LLMs) and how people often test these models by asking questions like "Who won the World Series?" The man explains that LLMs are trained on general data from the internet, so they may have information about past events but not current ones. He then poses the question of what he wants from an LLM, stating that he desires general world knowledge, such as understanding basic concepts like "up is up" and "down is down," but does not need specific factual knowledge. The man suggests that he can attach other systems to the LLM to access current factual data relevant to his needs. He emphasizes the importance of having general world knowledge and the ability to use tools and be linked into agentic workflows, which he refers to as "agentic workflows." The man encourages the audience to add this term to their spell checkers, as it will likely become commonly used.
Chapter 1 00:01:32:01-00:03:38:18 (126560 ms)
- Chapter summary: The video showcases a man with a beard and glasses demonstrating an "Outfit Planner" application on his laptop. The application allows users to input their location, such as Brisbane, Australia, and receive recommendations for appropriate outfits based on the weather conditions. The man explains that the application generates these recommendations using large language models, which can sometimes provide inaccurate or hallucinated information since they lack direct access to real-world data sources.
The man walks through the process of using the Outfit Planner, entering Brisbane as the location and receiving weather details like temperature, humidity, and cloud cover. He then shows how the application suggests outfit options, including a lightweight linen shirt, shorts, sandals, and a hat, along with an image of a woman wearing a similar outfit in a tropical setting.
Throughout the demonstration, the man points out the limitations of current language models in providing accurate and up-to-date information without external data connections. He also highlights the need to edit prompts and adjust settings within the application to refine the output and improve the accuracy of the generated recommendations.
Chapter 2 00:03:38:18-00:07:19:06 (220620 ms)
- Chapter summary: The video demonstrates the Amazon Bedrock platform, which allows users to build and scale generative AI applications using foundation models (FMs). [speaker_0] introduces the platform's overview, highlighting its key features like managing FMs from AWS, integrating with custom models, and providing access to leading AI startups. The video showcases the Amazon Bedrock console interface, where [speaker_0] navigates to the "Agents" section and selects the "OutfitAssistantAgent" agent. [speaker_0] tests the OutfitAssistantAgent by asking it for outfit recommendations in Brisbane, Australia. The agent provides a suggestion of wearing a light jacket or sweater due to cool, misty weather conditions. To verify the accuracy of the recommendation, [speaker_0] clicks on the "Show Trace" button, which reveals the agent's workflow and the steps it took to retrieve the current location details and weather information for Brisbane. The video explains that the agent uses an orchestration and knowledge base system to determine the appropriate response based on the user's query and the retrieved data. It highlights the agent's ability to access real-time information like location and weather data, which is crucial for generating accurate and relevant responses.
Chapter 3 00:07:19:06-00:11:26:13 (247214 ms)
- Chapter summary: The video demonstrates the process of configuring an AI assistant agent called "OutfitAssistant" using Amazon Bedrock. [speaker_0] introduces the agent's purpose, which is to provide outfit recommendations based on the current time and weather conditions. The configuration interface allows selecting a language model from Anthropic, in this case the Claud 3 Haiku model, and defining natural language instructions for the agent's behavior. [speaker_0] explains that action groups are groups of tools or actions that will interact with the outside world. The OutfitAssistant agent uses Lambda functions as its tools, making it fully serverless and managed within the Amazon Bedrock service. [speaker_0] defines two action groups: "get coordinates" to retrieve latitude and longitude coordinates from a place name, and "get current time" to determine the current time based on the location. The "get current weather" action requires calling the "get coordinates" action first to obtain the location coordinates, then using those coordinates to retrieve the current weather information. This demonstrates the agent's workflow and how it utilizes the defined actions to generate outfit recommendations. Throughout the video, [speaker_0] provides details on the agent's configuration, including its name, description, model selection, instructions, and action groups. The interface displays various options and settings related to these aspects, allowing [speaker_0] to customize the agent's behavior and functionality.
Chapter 4 00:11:26:13-00:13:00:17 (94160 ms)
- Chapter summary: The video showcases a presentation by [speaker_0] on the AWS Lambda console and its integration with machine learning models for building powerful agents. [speaker_0] demonstrates how to create an action group function using AWS Lambda, which can be used to generate text responses based on input parameters like location, time, and weather data. The Lambda function code is shown, utilizing external services like OpenWeatherMap API for fetching weather information. [speaker_0] explains that for a large language model to be useful, it needs to connect to tools providing relevant data sources, such as databases, text files, or external APIs. The presentation covers the process of defining actions, setting up Lambda functions, and leveraging various tools within the AWS environment to build intelligent agents capable of generating context-aware responses.
Chapter 5 00:13:00:17-00:13:28:10 (27761 ms)
- Chapter summary: A man with a beard and glasses, wearing a gray hoodie with various logos and text, is sitting at a desk in front of a colorful background. He is using a laptop computer that has stickers and logos on it, including the AWS logo. The man appears to be presenting or speaking about AWS (Amazon Web Services) and its services, such as Lambda functions and large language models. He mentions that if a Lambda function can do something, then it can be used to augment a large language model. The man concludes by expressing hope that the viewer found the video useful and insightful, and encourages them to check out other videos on the AWS developers channel. He also asks viewers to like the video, subscribe to the channel, and watch other videos.
Things to know Amazon Bedrock Data Automation is now available via cross-region inference in the following two AWS Regions: US East (N. Virginia) and US West (Oregon). When using Bedrock Data Automation from those Regions, data can be processed using cross-region inference in any of these four Regions: US East (Ohio, N. Virginia) and US West (N. California, Oregon). All these Regions are in the US so that data is processed within the same geography. We’re working to add support for more Regions in Europe and Asia later in 2025.
There’s no change in pricing compared to the preview and when using cross-region inference. For more information, visit Amazon Bedrock pricing.
Bedrock Data Automation now also includes a number of security, governance and manageability related capabilities such as AWS Key Management Service (AWS KMS)customer managed keys support for granular encryption control, AWS PrivateLink to connect directly to the Bedrock Data Automation APIs in your virtual private cloud (VPC) instead of connecting over the internet, and tagging of Bedrock Data Automation resources and jobs to track costs and enforce tag-based access policies in AWS Identity and Access Management (IAM).
I used Python in this blog post but Bedrock Data Automation is available with any AWS SDKs. For example, you can use Java, .NET, or Rust for a backend document processing application; JavaScript for a web app that processes images, videos, or audio files; and Swift for a native mobile app that processes content provided by end users. It’s never been so easy to get insights from multimodal data.
Here are a few reading suggestions to learn more (including code samples):
Amazon Bedrock is expanding its foundation model (FM) offerings as the generative AI field evolves. Today, we’re excited to announce the availability of Anthropic’s Claude 3.7 Sonnet foundation model in Amazon Bedrock. As Anthropic’s most intelligent model to date, Claude 3.7 Sonnet stands out as their first hybrid reasoning model capable of producing quick responses or extended thinking, meaning it can work through difficult problems using careful, step-by-step reasoning. Additionally, today we are adding Claude 3.7 Sonnet to the list of models used by Amazon Q Developer. Amazon Q is built on Bedrock, and with Amazon Q you can use the most appropriate model for a specific task such as Claude 3.7 Sonnet, for more advanced coding workflows that enable developers to accelerate building across the entire software development lifecycle.
Key highlights of Claude 3.7 Sonnet Here are several notable features and capabilities of Claude 3.7 Sonnet in Amazon Bedrock.
The first Claude model with hybrid reasoning – Claude 3.7 Sonnet takes a different approach to how models think. Instead of using separate models—one for quick answers and another for solving complex problems—Claude 3.7 Sonnet integrates reasoning as a core capability within a single model. This combination is more similar to how the human brains works. After all, we use the same brain whether we’re answering a simple question or solving a difficult puzzle.
The model has two modes—standard and extended thinking mode—which can be toggled in Amazon Bedrock. In standard mode, Claude 3.7 Sonnet is an improved version of Claude 3.5 Sonnet. In extended thinking mode, Claude 3.7 Sonnet takes additional time to analyze problems in detail, plan solutions, and consider multiple perspectives before providing a response, allowing it to make further gains in performance. You can control speed and cost by choosing when to use reasoning capabilities. Extended thinking tokens count towards the context window and are billed as output tokens.
Anthropic’s most powerful model for coding – Claude 3.7 Sonnet is state-of-the art for coding, excelling in understanding context and creative problem solving, and according to Anthropic, achieves an industry-leading 70.3% for standard mode on SWE-bench Verified. Claude 3.7 Sonnet also performs better than Claude 3.5 Sonnet across the majority of benchmarks. These enhanced capabilities make Claude 3.7 Sonnet ideal for powering AI agents and complex workflows.
Over 15x longer output capacity than its predecessor – Compared to Claude 3.5 Sonnet, this model offers significantly expanded output length. This enhanced capacity is particularly useful when you explicitly request more detail, ask for multiple examples, or request additional context or background information. To achieve long outputs, try asking for a detailed outline (for writing use cases, you can specify outline detail down to the paragraph level and include word count targets). Then, ask for the response to index its paragraphs to the outline and reiterate the word counts. Claude 3.7 Sonnet supports outputs up to 128K tokens long (up to 64K as generally available and up to 128K as a beta).
Adjustable reasoning budget – You can control the budget for thinking when you use Claude 3.7 Sonnet in Amazon Bedrock. This flexibility helps you weigh the trade-offs between speed, cost, and performance. By allocating more tokens to reasoning for complex problems or limiting tokens for faster responses, you can optimize performance for your specific use case.
Claude 3.7 Sonnet in action As for any new model, I have to request access in the Amazon Bedrock console. In the navigation pane, I choose Model access under Bedrock configurations. Then, I choose Modify model access to request access for Claude 3.7 Sonnet.
To try Claude 3.7 Sonnet, I choose Chat / Text under Playgrounds in the navigation pane. Then I choose Select model and choose Anthropic under the Categories and Claude 3.7 Sonnet under the Models. To enable the extended thinking mode, I toggle Model reasoning under Configurations. I type the following prompt, and choose Run:
You're the manager of a small restaurant facing these challenges:
Three staff members called in sick for tonight's dinner service
You're expecting a full house (80 seats)
There's a large party of 20 coming at 7 PM
Your main chef is available but two kitchen helpers are among those who called in sick
You have 2 regular servers and 1 trainee available
How would you:
Reorganize the available staff to handle the situation
Prioritize tasks and service
Determine if you need to make any adjustments to reservations
Handle the large party while maintaining service quality
Minimize negative impact on customer experience
Explain your reasoning for each decision and discuss potential trade-offs
Here’s the result with an animated image showing the reasoning process of the model.
To test image-to-text vision capabilities, I upload an image of a detailed architectural site plan created using Amazon Bedrock. I receive a detailed analysis and reasoned insights of this site plan.
Get started with Claude 3.7 Sonnet today Claude 3.7 Sonnet’s enhanced capabilities can benefit multiple industry use cases. Businesses can create advanced AI assistants and agents that interact directly with customers. In fields such as healthcare, it can assist in medical imaging analysis and research summarization, and financial services can benefit from its abilities to solve complex financial modeling problems. For developers, it serves as a coding companion that can review code, explain technical concepts, and suggest improvements across different languages.
Anthropic’s Claude 3.7 Sonnet is available today in the US East (N. Virginia), US East (Ohio), and US West (Oregon) Regions. Check the full Region list for future updates.
Claude 3.7 Sonnet is priced competitively and matches the price of Claude 3.5 Sonnet. For pricing details, refer to the Amazon Bedrock pricing page.
AWS Developer Day 2025, held on February 20th, showcased how to integrate responsible generative AI into development workflows. The event featured keynotes from AWS leaders including Srini Iragavarapu, Director Generative AI Applications and Developer Experiences, Jeff Barr, Vice President of AWS Evangelism, David Nalley, Director Open Source Marketing of AWS, along with AWS Heroes and technical community members. Watch the full event recording on Developer Day 2025.
AWS announces Backup Payment Methods for invoices – AWS now enables you to set up backup payment methods that automatically activate if primary payment fails. This helps prevent service interruptions and reduces manual intervention for invoice payments.
Get updated with all the announcements of AWS announcements on the What’s New with AWS? page.
Other AWS news Here are additional noteworthy items:
AWS Innovate: Generative AI + Data – Join a free online conference focusing on generative AI and data innovations. Available in multiple geographic regions: APJC and EMEA (March 6), North America (March 13), Greater China Region (March 14), and Latin America (April 8).
AWS Summits – Join free online and in-person events that bring the cloud computing community together to connect, collaborate, and learn about AWS. Register in your nearest city: Paris (April 9), Amsterdam (April 16), London (April 30), and Poland (May 5).
AWS re:Inforce – AWS re:Inforce (June 16–18) in Philadelphia, PA our annual learning event devoted to all things AWS cloud security. Registration opens in March, and be ready to join more than 5,000 security builders and leaders.
Create your AWS Builder ID and reserve your alias. Builder ID is a universal login credential that gives you access–beyond the AWS Management Console–to AWS tools and resources, including over 600 free training courses, community features, and developer tools such as Amazon Q Developer.
Artificial intelligence (AI) has transformed how humans interact with information in two major ways—search applications and generative AI. Search applications include ecommerce websites, document repository search, customer support call centers, customer relationship management, matchmaking for gaming, and application search. Generative AI use cases include chatbots with Retrieval-Augmented Generation (RAG), intelligent log analysis, code generation, document summarization, and AI assistants. AWS recommends Amazon OpenSearch Service as a vector database for Amazon Bedrock as the building blocks to power your solution for these workloads.
In this post, you’ll learn how to use OpenSearch Service and Amazon Bedrock to build AI-powered search and generative AI applications. You’ll learn about how AI-powered search systems employ foundation models (FMs) to capture and search context and meaning across text, images, audio, and video, delivering more accurate results to users. You’ll learn how generative AI systems use these search results to create original responses to questions, supporting interactive conversations between humans and machines.
The post addresses common questions such as:
What is a vector database and how does it support generative AI applications?
Why is Amazon OpenSearch Service recommended as a vector database for Amazon Bedrock?
How do vector databases help prevent AI hallucinations?
How can vector databases improve recommendation systems?
What are the scaling capabilities of OpenSearch as a vector database?
How vector databases work in the AI workflow
When you’re building for search, FMs and other AI models convert various types of data (text, images, audio, and video) into mathematical representations called vectors. When you use vectors for search, you encode your data as vectors and store those vectors in a vector database. You further convert your query into a vector and then query the vector database to find related items by minimizing the distance between vectors.
When you’re building for generative AI, you use FMs such as large language models (LLMs), to generate text, video, audio, images, code, and more from a prompt. The prompt might contain text, such as a user’s question, along with other media such as images, audio, or video. However, generative AI models can produce hallucinations—outputs that appear convincing but contain factual errors. To solve for this challenge, you employ vector search to retrieve accurate information from a vector database. You add this information to the prompt in a process called Retrieval-Augmented Generation (RAG).
Why is Amazon OpenSearch Service the recommended vector database for Amazon Bedrock?
Amazon Bedrock is a fully managed service that provides FMs from leading AI companies, and the tools to customize these FMs with your data to improve their accuracy. With Amazon Bedrock, you get a serverless, no-fuss solution to adopt your selected FM and use it for your generative AI application.
Amazon OpenSearch Service is a fully managed service that you can use to deploy and operate OpenSearch in the AWS Cloud. OpenSearch is an open source search, log analytics, and vector database solution, composed of a search engine and vector database; and OpenSearch Dashboards, a log analytics, observability, security analytics, and dashboarding solution. OpenSearch Service can help you to deploy and operate your search infrastructure with native vector database capabilities, pre-built templates, and simplified setup. API calls and integration templates streamline connectivity with Amazon Bedrock FMs, while the OpenSearch Service vector engine can deliver as low as single-digit millisecond latencies for searches across billions of vectors, making it ideal for real-time AI applications.
OpenSearch is a specialized type of database technology that was originally designed for latency- and throughput-optimized matching and retrieval of large and small blocks of unstructured text with ranked results. OpenSearch ranks results based on a measure of similarity to the search query, returning the most similar results. This similarity matching has evolved over time. Before FMs, search engines used a word-frequency scoring system called term frequency/inverse document frequency (TF/IDF). OpenSearch Service uses TF/IDF to score a document based on the rarity of the search terms in all documents and how often the search terms appeared in the document it’s scoring.
With the rise of AI/ML, OpenSearch added the ability to compute a similarity score for the distance between vectors. To search with vectors, you add vector embeddings produced by FMs and other AI/ML technologies to your documents. To score documents for a query, OpenSearch computes the distance from the document’s vector to a vector from the query. OpenSearch further provides field-based filtering and matching and hybrid vector and lexical search, which you use to incorporate terms in your queries. OpenSearch hybrid search performs a lexical and a vector query in parallel, producing a similarity score with built-in score normalization and blending to improve the accuracy of the search result compared with lexical or vector similarity alone.
Use case 1: Improve your search results with AI/ML
To improve your search results with AI/ML, you use a vector-generating ML model, most frequently an LLM or multi-modal model that produces embeddings for text and image inputs. You use Amazon OpenSearch Ingestion, or a similar technology to send your data to OpenSearch Service with OpenSearch Neural Plugin to integrate the model, using a model ID, into an OpenSearch ingest pipeline. The ingest pipeline calls Amazon Bedrock to create vector embeddings for every document during ingestion.
To query OpenSearch Service as a vector database, you use an OpenSearch neural query to call Amazon Bedrock to create an embedding for the query. The neural query uses the vector database to retrieve nearest neighbors.
The service offers pre-built CloudFormation templates that construct OpenSearch Service integrations to connect to Amazon Bedrock foundation models for remote inference. These templates simplify the setup of the connector that OpenSearch Service uses to contact Amazon Bedrock.
After you’ve created the integration, you can refer to the model_id when you set up your ingest and search pipelines.
Use case 2: Amazon OpenSearch Serverless as an Amazon Bedrock knowledge base
Amazon OpenSearch Serverless offers an auto-scaled, high-performing vector database that you can use to build with Amazon Bedrock for RAG, and AI agents, without having to manage the vector database infrastructure. When you use OpenSearch Serverless, you create a collection—a collection of indexes for your application’s search, vector, and logging needs. For vector database use cases, you send your vector data to your collection’s indices, and OpenSearch Serverless creates a vector database that provides fast vector similarity and retrieval.
When you use OpenSearch Serverless as a vector database, you pay only for storage for your vectors and the compute needed to serve your queries. Serverless compute capacity is measured in OpenSearch Compute Units (OCUs). You can deploy OpenSearch Serverless starting at just one OCU for development and test workloads for about $175/month. OpenSearch Serverless scales up and down automatically to accommodate your ingestion and search workloads.
When you’ve configured your data source, and selected a model, select Amazon OpenSearch Serverless as your vector store, and Amazon Bedrock and OpenSearch Serverless will take it from there. Amazon Bedrock will automatically retrieve source data from your data source, apply the parsing and chunking strategies you have configured, and index vector embeddings in OpenSearch Serverless. An API call will synchronize your data source with OpenSearch Serverless vector store.
In this post, you learned how Amazon OpenSearch Service and Amazon Bedrock work together to deliver AI-powered search and generative AI applications and why OpenSearch Service is the AWS recommended vector database for Amazon Bedrock. You learned how to add Amazon Bedrock FMs to generate vector embeddings for OpenSearch Service semantic search to bring meaning and context to your search results. You learned how OpenSearch Serverless provides a tightly integrated knowledge base for Amazon Bedrock that simplifies using foundation models for RAG and other generative AI. Get started with Amazon OpenSearch Service and Amazon Bedrock today to enhance your AI-powered applications with improved search capabilities with more reliable generative AI outputs.
About the author
Jon Handler is Director of Solutions Architecture for Search Services at Amazon Web Services, based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads for OpenSearch. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Generative AI applications often involve a combination of various services and features—such as Amazon Bedrock and large language models (LLMs)—to generate content and to access potentially confidential data. This combination requires strong identity and access management controls and is special in the sense that those controls need to be applied on various levels. In this blog post, you will review the scenarios and approaches where you can apply least privilege access to applications using Amazon Bedrock. To fully benefit from the guidance in this post, you need an understanding of AWS APIs, AWS Identity and Access Management (IAM) policies, and AWS security services.
Let’s start by defining the principle of least privilege (PoLP): The PoLP is a security concept that advises granting the minimal level of access—or permissions—necessary for users, programs, or systems to perform their tasks. The main idea is that the fewer permissions an entity has, the lower the risk of malicious or accidental damage. Applying the PoLP to your use of AWS serves two purposes:
Security: By limiting access, you reduce the potential impact of a security incident. If a user or service has minimal permissions, the scope for any damage can be significantly reduced.
Operational simplicity: Managing permissions can become complex if not properly managed and maintained. Applying the PoLP to your access controls early helps keep configurations as manageable as possible. Finally, there are regulatory frameworks that require separation of duty between roles and a documented strategy for access controls, which can be achieved in part by adhering to the PoLP.
Amazon Bedrock is a fully managed AWS service that makes high-performing foundation models (FMs) available through a single unified API. You use Amazon Bedrock through AWS APIs, which expose actions for the control plane and administration such as the configuration of Amazon Bedrock Guardrails and Amazon Bedrock Agents, in addition to data plane functional actions such as inference.
Generally, the path to using Amazon Bedrock for a production workload includes the following stages:
Model selection: Decide on the required features (Retrieval Augmented Generation (RAG), fine-tuning, and so on), evaluate and select a model, and approve a EULA if necessary.
Model adaptation: Prompt engineering, integration of Amazon Bedrock into the application, and addition of model customization if desired.
Model testing: Validate and test the solution.
Model operation: Deploy the solution and make it available. Monitor and operate the solution.
In the following sections, we go through each phase and outline how you can apply the PoLP.
Model selection
In this phase, you choose the features and models that are needed to fulfill your requirements and define how you will apply the PoLP. These can include, for example, model customization, Retrieval Augmented Generation (RAG) or the use of agents.
Security should be integrated into the design so that the defined controls can be implemented during the development phase. One approach to define the necessary security controls is threat modeling. Doing this exercise early in the process will simplify the upcoming phases. The results can be used later to decide on the required guardrails, potential changes to the architecture, and test cases.
In this phase, you will also decide how the solution should be deployed. Customers typically operate in a multi-account setup; therefore, the selection of target organizational units (OUs) and accounts is required. We recommend creating a new OU for generative AI applications. For details, see the deep-dive chapter on generative AI in the AWS Security Reference Architecture. We will talk later about service control policies (SCPs) and how they can be used to restrict permissions. The generative AI OU is a good place to enforce those guardrails.
Amazon Bedrock provides access to a variety of high-performing FMs from leading AI companies such as AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon. In this stage, you need to choose the models that you’ll use and approve them. With a third-party FM, approval might include accepting a EULA. You can limit identities and the models that they can subscribe to in order to follow compliance with EULAs that have been reviewed by your legal department. The following is an example of an SCP that allows account operators to enable all Anthropic FMs and a single Meta Llama FM.
While this approach works well if you’re only allowlisting actions, you might have highly privileged users that already have broad access to AWS Marketplace APIs. In such a case, you can follow a deny all except a few approach. Such a policy, using the same models as before, would look like the following example:
In this phase, the solution is built—that is, code is written. This is mostly identical to traditional software development, however there are some areas specific to generative AI, such as prompt engineering, prompt guardrails, model monitoring, and agent design. In this post, we focus solely on the identity and access management aspects.
Adaptation is the phase where the detailed permission sets are created. Data perimeters can be used as a conceptual tool to define and implement guardrails. Because data perimeters are typically coarse grained, they aren’t sufficient to achieve the goal of the PoLP. However, in combination with fine-grained policies, they support a defense-in-depth approach. The following data perimeters exist:
Identity: Only trusted identities are allowed in my network, only trusted identities can access my resources.
Resource: My identities can access only trusted resources, only trusted resources can be accessed from my network.
Network: My identities can access resources only from expected networks, my resources can only be accessed from expected networks.
For applications that use Amazon Bedrock, you can use a virtual private cloud (VPC) network construct with Amazon Virtual Private Cloud (Amazon VPC) to host them. Doing so means that you can then use AWS PrivateLink to create VPC endpoints for both data and control plane APIs. Using PrivateLink to create endpoints, it’s possible to provide access to Amazon Bedrock for VPC-bound compute resources (such as Amazon Elastic Compute Cloud (Amazon EC2), or AWS Lambda) without the need for an internet gateway. In other words, you can deploy these resources entirely in private subnets. By using resource-based policies on these endpoints, you can restrict the principals, actions, resources, and conditions related to making API calls.
Let’s assume you have a VPC with an EC2 instance running in a private subnet hosting an application that uses Amazon Bedrock model invocations and have created an interface VPC endpoint to connect to the Amazon Bedrock data plane. The EC2 instance is configured to use an instance profile using the <rolename> IAM role and needs to be able to invoke a single Anthropic’s Claude Instant FM through an Amazon Bedrock InvokeModel API call. You can apply the PoLP to the containing VPC, and thus the EC2 instance, with a custom policy on the Amazon Bedrock interface VPC endpoint. To use the following policy in your own account, replace the default interface VPC endpoint policy with the following example, replacing <rolename> with the role you want to allow and <account-id> with your 12-digit account number.
You can define the allowed models that can be used in Amazon Bedrock directly in the policy. However, if you have multiple applications that use Amazon Bedrock, you might have to update multiple policies when a new model is allowed to be used. To complement the data perimeter approach, you can add an SCP to limit the models that can be used for inference. Because Amazon Bedrock is using a simple API (InvokeModel and Converse) for inference, a condition element in an IAM policy can be used to deny the use of unapproved models. Note that while the two policies (the SCP and the VPC endpoint policy) look similar, they work differently: VPC endpoint policies are enforced provided that the network path through PrivateLink is enforced; SCPs are applied to principals within the account or OU they’re attached to. Be extra careful if the calling identity resides outside of your account, because only the VPC endpoint policy will apply.
For example, imagine that you wanted to block the invocation of all Anthropic FMs across your organizations within AWS Organizations, in all AWS Regions. The following SCP example applied to the OUs or AWS accounts in scope would achieve that outcome:
A solution built on Amazon Bedrock might include model customization. The common denominator of the different customization approaches is that they include data, which is assumed to be confidential and thus in-scope for applying the PoLP. Here, we take a scenario where data is stored in Amazon S3 and can be encrypted using a customer managed AWS Key Management Service (AWS KMS) key.
Measures can be taken on multiple levels, as conceptualized in data perimeters: network, identity, and resource. Amazon Bedrock model customization uses service roles, which allows you to apply fine-grained and least-privilege access end-to-end. These service roles will be assumed by the Amazon Bedrock service principal, so that it can execute actions on your behalf. To allow the Amazon Bedrock service principal to assume the role in your account, you need to attach a trust policy to the role.
Let’s imagine that you’re running an Amazon Bedrock customization job in the us-east-1 (N. Virginia) Region. Using the following trust policy example will allow only the Amazon Bedrock service principal to assume your role.
Make sure to replace <account-id> in the preceding example trust policy with your own 12-digit account number. The policy contains a condition that provides cross-service confused deputy prevention by adding the aws:SourceAccount condition. The confused deputy problem is a situation where an entity that doesn’t have permission to perform an action can coerce a more privileged entity to perform the action. In AWS, cross-service impersonation can result in the confused deputy problem. Cross-service impersonation can occur when one service (the calling service) calls another service (the called service). AWS provides tools to help you protect your data for all services with service principals that have been given access to resources in your account. Both the aws:SourceArn and aws:SourceAccount global condition context keys in the role’s trust policy limit the permissions that Amazon Bedrock gives another service (in the preceding case, to the customization job) to the resource. aws:SourceArn is the more restrictive approach here, because it defines the specific source of the assume request, and not just the AWS account.
You should provide only the permissions that are required to fulfill the model customization task. For example, imagine that you want to limit access to your training data, the validation data bucket, and the output bucket (where Amazon Bedrock will deliver output metrics). The following policy, attached to that same service role, provides only those permissions. Replace the <training-bucket> placeholder with the bucket name that contains your training data, <validation-bucket> with your validation bucket, and <output-bucket> with the bucket where you want to store metrics.
Complementing this approach, we recommend using a VPC for the model customization job to restrict access to the training data. Technically, this again involves a VPC endpoint resource policy because the network is using interface VPC endpoints to access your S3 bucket. This allows you to define another network control, specifically an S3 bucket policy that only allows access through a specific VPC endpoint. So, for the situation where you want to limit access for the customization job itself, you can apply a bucket policy such as the following example, replacing <training-bucket> with the bucket name that contains your training data, and <vpce-id> with the ID of the VPC endpoint that resides in your VPC:
In addition, you would restrict the principals that can access your VPC endpoint and the actions they’re allowed to take in Amazon S3. For simplicity, we’re omitting an example policy here because it’s very similar to the one we have in the Amazon Bedrock invocation section earlier in this post.
If you need to enforce encryption in Amazon S3 using a customer managed AWS KMS key (SSE-KMS), you will need to do the following:
Update the bucket policy with a statement denying unencrypted content being uploaded.
Update the KMS key policy to allow the service role to decrypt and describe the key.
The next policy example should be added to the bucket policy and demonstrates how to deny unencrypted objects being added to an S3 bucket. Again, replace <training-bucket> with the name of the S3 bucket that contains your training data:
Finally, in the KMS key policy, you need a statement similar to the following to allow the Amazon Bedrock service role access to the KMS key. Replace <account-id> with your 12-digit account number and <bedrock-service-role> with the role you created, which will be assumed by the Amazon Bedrock service principal. Make sure to only give the required access to decrypt data with the KMS key to the IAM role:
Amazon Bedrock can also encrypt a customized model with a customer managed KMS key. Amazon Bedrock uses KMS key grants to encrypt the customized model and to decrypt it later when you deploy it for inference. Therefore, you need to grant the same IAM role permissions to create KMS key grants in the KMS key policy. The KMS key you use for this purpose is typically different than the one you used to encrypt the training data to allow fine-grained permissions on both keys.
So, let’s imagine that you want to use two different roles to encrypt and decrypt the customized models. To allow the role that executes the model customization job to use your KMS key, you need to add the following policy statements to the KMS key policy, replacing <account-id> with your 12-digit account number, <region> with the Region where you run Amazon Bedrock, <bedrock-model-customization-role> with the role name you use to run the model customization job, and <invocation-role> with the name of the role you use for inference.
By using KMS key grants, you can revoke the permissions you granted to the service role after the customization job is done, thus reducing the permissions to least privilege. Also, Amazon Bedrock uses secondary KMS key grants for model encryption, which means that they’re automatically retired as soon as the operation that Amazon Bedrock performs on behalf of the customer is completed. The Encryption of model customization jobs and artifacts describes in more detail how grants are used.
To completement these IAM policy guardrails, you can add network controls to reduce the scope of the permissions of the process. Because we focus on IAM policies in this post, we won’t go into details here but only mention how the process works.
When you start a model customization job, a model training job is triggered within the model deployment account. The training job takes a base model from its S3 bucket, then connects to the S3 bucket that holds the customization training data to start the customization. This can be done through your VPC, where you specify a VPC configuration such as subnets and security groups, and the training job places an elastic network interface (ENI) into that VPC as specified. A request to the S3 bucket to read the training data now adheres to whatever routing rules are present in the VPC for that ENI. The VPC routing and security group attached to the ENI can be used to limit networking access to the model customization job.
Amazon Bedrock Agents
Amazon Bedrock Agents offers the capability to build and configure autonomous agents for applications. You can find more information about Amazon Bedrock Agents in Automate tasks in your application using AI agents.
Using an Amazon Bedrock agent also provides certain security properties that are applied to an inference task. For example, at the time of writing, there is no IAM condition key for the bedrock:InvokeModel API to require an Amazon Bedrock guardrail being attached to that same call. However, you can require that inferences are invoked through a call to an agent that has specific Amazon Bedrock guardrails configured.
Let’s say that you want to create a role that explicitly is only allowed to invoke Amazon Bedrock models through a specific Amazon Bedrock agent. The following IAM principal permissions policy example implies that the Amazon Bedrock agent specified has approved Amazon Bedrock guardrails configured. Again replace <region>, <account-id>, <bedrock-agent-id>, and <bedrock-agent-alias-id> with the values of your Amazon Bedrock agent.
Provided that the Amazon Bedrock agent is configured by a systems administrator or operator with an approved Amazon Bedrock guardrail, the principal with the preceding policy attached to it will be able to invoke it with a prompt, and won’t directly invoke an Amazon Bedrock model. This strategy for making sure that Amazon Bedrock guardrails are applied to all Amazon Bedrock invocations is currently not possible with the bedrock:InvokeModel and bedrock:InvokeModelWithResponseStream APIs, because they don’t have a condition key to match an Amazon Bedrock guardrail to. In addition, denying bedrock:InvokeModel and bedrock:InvokeModelWithResponseStream also denies the Converse APIs and StartAsyncInvoke APIs, so there’s no need to add these separately to the Deny statement.
Because this strategy verifies the use of specific Amazon Bedrock guardrails, you can also use it for the enforcement of specific prompts, IAM service roles, knowledge bases, prompt and completion content restrictions, KMS keys, and FMs in inference invocations. For this approach to be effective, you need to also limit the principals that can create and update Amazon Bedrock agent configurations. Again, this can be restricted using an IAM policy, which is attached to only specific principals.
The following is an example IAM policy statement that gives an attached IAM principal the ability to update the configuration of a specific Amazon Bedrock agent, replacing <region>, <account-id>, and <agent-id> with the Region, account and identifier, and agent identifier that you’re using. If you want this to apply to all agents, replace <agent-id> with an asterisk (*).
Where agents aren’t suitable, users or applications performing inference against the Amazon Bedrock models will need permissions to call the bedrock:InvokeModel, bedrock:InvokeModelWithResponseStream, or bedrock:CreateModelInvocationJob actions. In these cases, it can be desirable to limit the target models, following an allowlisting approach. Also, such permissions would only be attached to roles or applications that need to use them.
The following is an example of such a policy that restricts invocation to Anthropic’s Claude Instant.
You can include detective or reactive controls using Amazon CloudWatch EventBridge rules to detect model invocations that don’t use appropriate Amazon Bedrock guardrails, but that’s outside the scope of this post.
Model testing
Testing is the last step before the solution is deployed. Types of tests include unit tests, integration tests, user acceptance tests, penetration testing, and more. In this phase, you can again verify that the permissions that were assigned are indeed least privilege.
Especially in functional tests where data is involved, it’s important to consider that the data used for testing might be confidential. This is typically true when no synthetic test data is generated for the testing process. Controls to restrict access to the data and logs that are produced and might contain pieces of this data need to be the same as you will apply in a production environment. That you are only testing the solution doesn’t automatically mean that data access controls aren’t needed.
As discussed earlier in this post, controls are activated not only on identities, but also on the network and on resources. All of these should be validated and their effectiveness confirmed in this phase. Tests include but aren’t limited to:
Validate that you can only perform allowed actions in Amazon Bedrock through VPC endpoints, and that actions that don’t use VPC endpoints are blocked.
Validate the effectiveness of the resource policies on VPC endpoints by making sure that they can only be used by authenticated and authorized principals.
When using knowledge bases, validate that only the Amazon Bedrock service principal can access them.
When using Amazon Bedrock guardrails, evaluate their effectiveness. Because of the nature of generative AI applications, the diversity in input and output data can be big. Therefore, make sure to test guardrails with a reasonably large number of prompts.
If model invocation logging is activated, validate that logs are correctly written and protected with IAM permissions and encryption.
Validate that only the required personnel can access these logs, because they might contain sensitive data. Consider automatically sanitizing and forwarding them to a new CloudWatch log group.
Validate that all relevant Amazon Bedrock API calls are being properly logged in AWS CloudTrail, and that you can effectively monitor and alert on any suspicious activity.
Make sure that sensitive information—such as prompts and responses—isn’t being stored in the CloudTrail logs or in any trace output.
The threat modelling that you have potentially created in the design phase can provide valuable inputs that you can use for security-related test cases.
Model operation
In this phase, the solution is finally deployed into production. Operators need Amazon Bedrock control plane permissions to provision and manage Amazon Bedrock resources such as agents, guardrails, prompt libraries, and knowledge bases. They should only get the control plane permissions to provision and manage the Amazon Bedrock features that are being used. These same operators should have access to invoke or configure the Amazon Bedrock service features or their resources (Amazon Bedrock Agents, Amazon Bedrock Guardrails, and prompt libraries) only through an authorized pipeline. This immutable infrastructure approach restricts human users from creating situations or configurations that would otherwise allow unapproved access to the data plane, untracked changes to the control plane, or potentially disruptive updates to your application.
Alternatively, to reduce the assigned permissions to the absolute minimum, automated deployments using pipelines and pipeline roles can be used. This will not only provide versioned infrastructure but also adheres to PoLP by not providing access to human identities.
After deployment, the solution is live and being accessed by real users. At this point, topics such as monitoring, logging, and incident response become relevant. While Amazon Bedrock by default doesn’t store inference or response data, it’s recommended that you activate logging of those elements to constantly verify the accuracy of your generative AI application.
By using this solution, you reduce access to a minimum in the following areas:
Logged prompts and responses
Data available through knowledge bases, RAG, or similar sources
The ability to change the infrastructure
Use multiple, dedicated, least privileged roles for each task. This helps reduce the permissions scope to a minimum. Also, because least privilege enforces using a specific role for a specific task, it reduces the risk of unintended changes by requiring the assumption of a specific role.
By following the AWS Security Reference Architecture, security monitoring data is consolidated in a central security account. This allows a comprehensive, central overview of the security posture of your infrastructure.
Logging sensitive information
An important operational aspect is logging potentially sensitive data that’s sent to or received from the LLM. While Amazon Bedrock doesn’t store prompts or responses, you can use model invocation logging to collect invocation logs, model input data, and model output data for all invocations in your AWS account used in Amazon Bedrock. Model invocation logging isn’t enabled by default. After it’s enabled, prompts, completions, or both for all invocations of all approved models are then logged to the configured log destination. Valid log destinations for prompt and completion logs are Amazon S3 and CloudWatch. When writing logs to these destinations, they can optionally be encrypted using a supplied KMS key.
The contents of these logs might contain sensitive information in the prompt provided by the user or the reply generated by the model. As such, access to these logs should be restricted to personnel and machine processes that require and are authorized to access this classification of data. There are strategies such as using Amazon Macie on the Amazon S3 logs and CloudWatch Logs data protection capabilities to detect, monitor, and redact this sensitive information from logs, but that’s outside the scope of this post.
Even with Amazon Bedrock guardrails in place, the contents of these logs contain the pre-guardrailed user input, and so you must assume that these prompt and completion logs contain sensitive information. In this case, best practice is to encrypt log data with a KMS key, apply a data protection policy to the log group, and define at least three IAM roles:
BasicCompletionLogReviewer: An IAM role whose sole purpose is to access and review the redacted version of these logs.
SensitiveDataCompletionLogReviewer: A restricted IAM role whose sole purpose is to access and review the unredacted version of these logs.
CompletionLogAdmin: A restricted IAM role whose sole purpose is to create, view, and delete data protection policies that can send audit findings to Amazon S3 and CloudWatch destinations.
To allow reading log events in a specific log group, use a policy such as the following and attach it to the BasicCompletionLogReviewer role, replacing <region>, <account-id>, <log-group-name>, and <alias-name> with values that match your CloudWatch log group and the KMS key that encrypts it.
With an active data protection policy in place, the preceding policy won’t allow access to the unredacted version of these logs. To allow access to the unredacted versions to the SensitiveDataCompletionLogReviewer role, you need to add an additional action, replacing <region>, <account-id>, <log-group-name>, and <alias-name> with values that match your CloudWatch log group and the KMS key that encrypts it.
The policy for the CompletionLogAdmin role requires different permissions; the following sample policy allows a user to create, view, and delete data protection policies that can send audit findings to all three types of audit destinations. It doesn’t permit the user to view unmasked data. This policy will look like the following example, replacing <delivery-stream-id>, <bucket-name>, <log-group-name>, and <alias-name> with the values that match your setup. Note that this includes a statement that explicitly denies the attached role access to decrypt the logs with the configured KMS key, aligning with the PoLP:
This approach helps to avoid inadvertent access to or exposure of this sensitive data source and upholds the PoLP by separating duties.
Review IAM permissions on a periodic basis
Managing permissions is an ongoing effort because requirements and functionality change over time. Therefore, we recommend regularly reviewing the assigned permissions and verifying that they aren’t overly permissive. For example, if you have a Lambda function that makes API calls to Amazon Bedrock, and changes are made to that function that require additional permissions (perhaps the use of a new model), then it’s acceptable to update the policy attached to the IAM role that the function uses. It’s not always obvious that permissions for using the earlier model are still needed in the same policy; or permissions might be widened unnecessarily to include all models. When applying the PoLP, it’s important that policies be tested at the time they’re deployed to make sure that they meet the exact application needs and no more, but also that the presumed needs are reviewed periodically.
Using AWS IAM Access Analyzer, you can review and simulate proposed changes to IAM policies to ensure their suitability for a given application or function. You can also use IAM Access Analyzer to review unused permissions over time. This gives system operators an opportunity to inspect and then inform the removal of unused permissions in policies used with Amazon Bedrock applications. Remember that some permissions are dormant and ready for periodic use, such as incident response, recovery and other rare use cases, so your review shouldn’t assume that an unused permission is unnecessary, but an opportunity to review the need for the permission.
Finally, align monitoring of new Amazon Bedrock APIs with your IAM strategy. Especially when using denylisting approaches, it’s important to consider that services will announce new APIs, capabilities, and FMs over time. An example for this was the announcement of the new Converse API. This API provides functionality similar to Invoke, but in a consistent and thus simpler way. Considering such changes is therefore an integral part of your regular policy review processes.
Strong identity and access management is a journey, not a one-time action.
Conclusion
In this post, we have demonstrated some ways that you can apply the principle of least privilege (PoLP) to large language model (LLM)-based applications that use Amazon Bedrock. We have discussed the security considerations of each phase of the development lifecycle and provided examples that you can use as a starting point to implement your own PoLP strategy. It’s important that security doesn’t start late in the process; think about risks and the required actions as early as possible to make sure that your strategy is effective when your application goes live.
Finally, remember that the field of generative AI is moving quickly. We believe that it has the potential to transform virtually every customer experience. From a security perspective, this means that the threat landscape will change and evolve over time. Make sure to constantly adapt to new risks; evaluate and integrate them into your PoLP strategy.
Your AWS account team and specialists are happy to assist you on this journey.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.





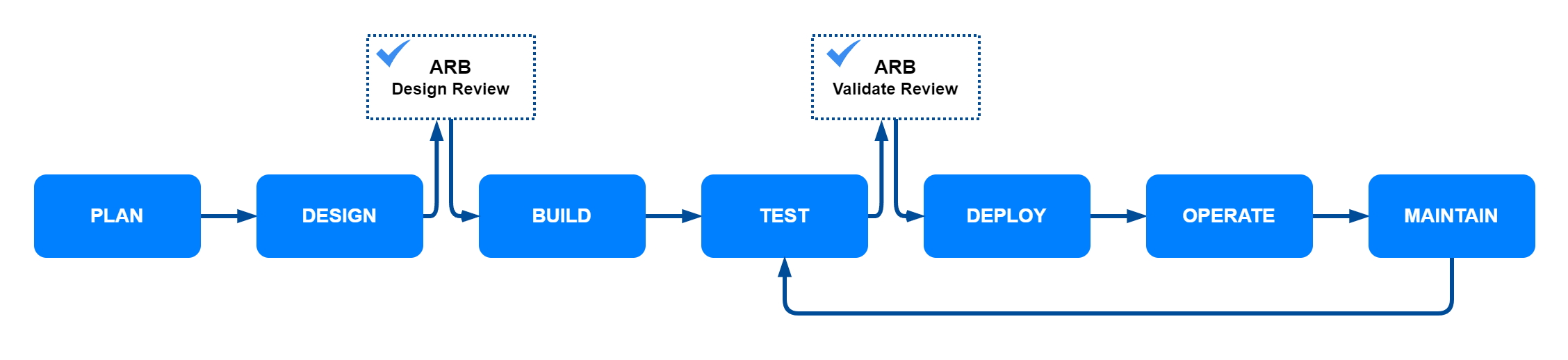







 .
.
























































 Jon Handler is Director of Solutions Architecture for Search Services at Amazon Web Services, based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads for OpenSearch. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is Director of Solutions Architecture for Search Services at Amazon Web Services, based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads for OpenSearch. Prior to joining AWS, Jon’s career as a software developer included four years of coding a large-scale ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master’s of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.