Post Syndicated from Pascal Vogel original https://aws.amazon.com/blogs/compute/introducing-amazon-mq-cross-region-data-replication-for-activemq-brokers/
This post is written by Dominic Gagné, Senior Software Development Engineer, and Vinodh Kannan Sadayamuthu, Senior Solutions Architect
Amazon MQ now supports cross-Region data replication for ActiveMQ brokers. This feature enables you to build regionally resilient messaging applications and makes it easier to set up cross-Region message replication between ActiveMQ brokers in Amazon MQ. This blog post explains how cross-Region data replication works in Amazon MQ, how to setup cross-Region replica brokers for ActiveMQ, and how to test promoting a replica broker.
Amazon MQ is a managed message broker service for Apache ActiveMQ and RabbitMQ that simplifies setting up and operating message brokers on AWS.
Cross-Region replication improves the resilience and disaster recovery capabilities of your systems. This new Amazon MQ feature makes it easier to increase resilience of your ActiveMQ messaging systems across AWS Regions.
How cross-Region data replication works in Amazon MQ for ActiveMQ
The Amazon MQ for ActiveMQ cross-Region data replication feature replicates broker state from the primary broker in one AWS Region to the replica broker in another Region. Broker state consists of messages that have been sent to a broker by a message producer. Additionally, message acknowledgments and transactions are replicated. Scheduled messages and broker XML configuration are not replicated from the primary to the replica broker.
State replication occurs asynchronously and runs in the background. When a message is sent to a cross-Region data replication enabled broker, the data is persisted both to the primary data store and also on a queue used to replicate data. The replica broker acts as a client of this queue and consumes data that represents broker state from the primary broker.
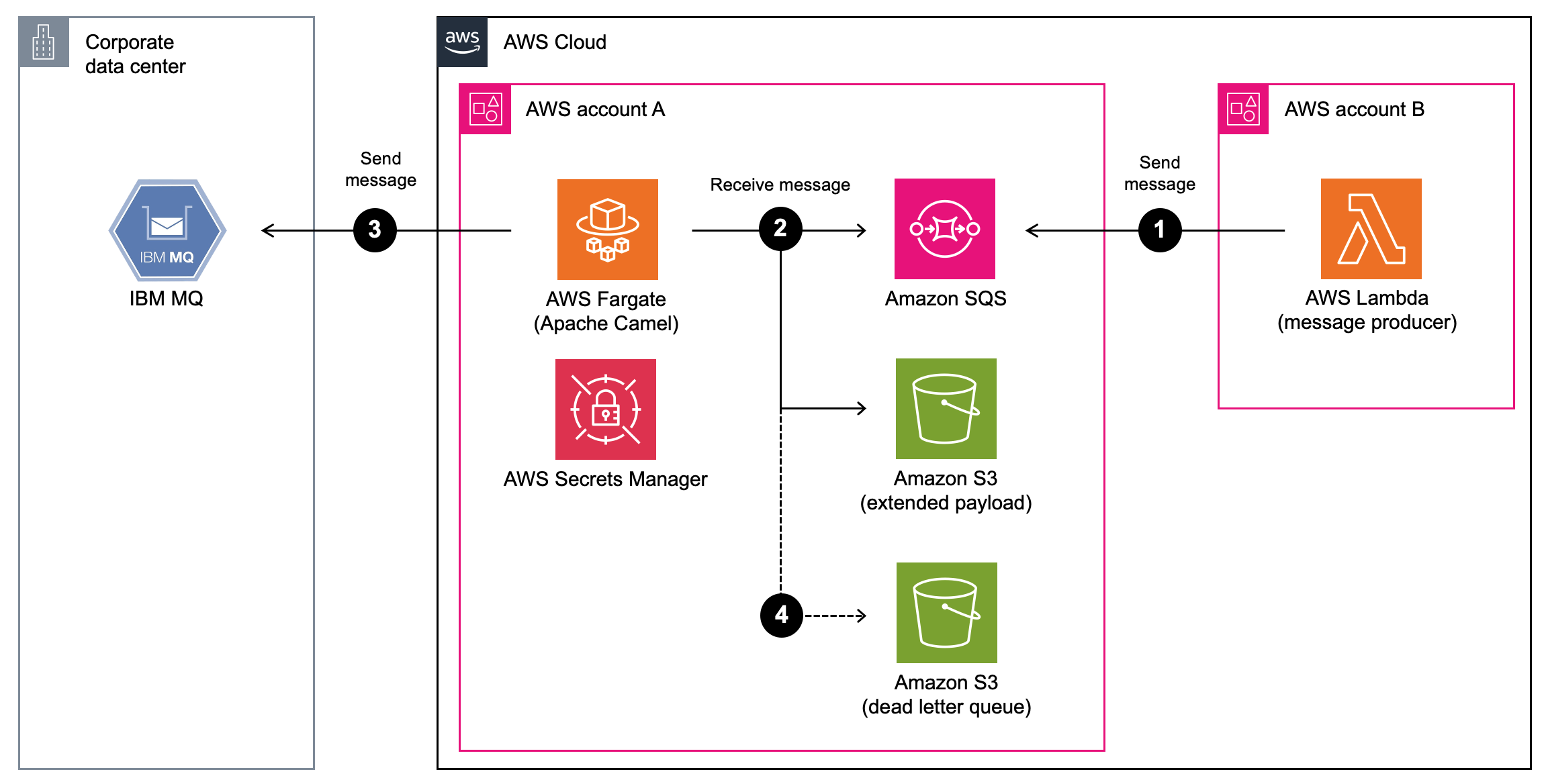
At any given moment, only the primary broker is available for client connections. The replica broker is a hot standby and passively replicates the primary broker’s state. However, it does not accept client connections. The following diagram shows a simplified version of a cross-Region data replication broker pair. All replication traffic is encrypted using TLS and remains within AWS’ private backbone.

Configuring cross-Region replica brokers for Amazon MQ for ActiveMQ
To set up a cross-Region replica broker, your Amazon MQ for ActiveMQ primary broker must meet the following eligibility criteria:
- ActiveMQ version 5.17.6 or above
- Instance size m5.large or higher
- Active/standby broker deployment enabled
- Be in the Running state
If you do not have an ActiveMQ broker that meets these criteria, see Creating and configuring an ActiveMQ broker for instructions on how to create a primary broker.
To configure cross-Region replication
- Navigate to the Amazon MQ console and choose Create replica broker.

- Select a primary broker from the list of eligible primary brokers and choose Next.

- Under Replica broker details, select the Region for your replica broker and enter a Replica broker name.

- In the ActiveMQ console user for replica broker panel, enter a Username and Password for broker access.

- In the Data replication user to bridge access between brokers panel, enter a replication user Username and Password.

- In the Additional settings panel, keep the defaults and choose Next.
- Review the settings and choose Create replica broker.
Note: The broker access type is automatically set based on the primary broker access type.

- The creation process takes up to 25 minutes. Once the replica broker creation is complete, begin replication between the primary and the replica brokers by rebooting the primary broker.
- Once the primary broker is rebooted and its status is Running, you can see the replica details in the Data replication panel of the primary broker.








Both brokers now synchronize with each other to establish an inter-Region network and connection through which broker state is replicated. Once both brokers are in the Running state, the primary broker accepts client connections and passes all broker state changes (messages, acknowledgments, transactions, etc.) to the replica broker.
The replica broker now asynchronously mirrors the state of the primary broker. However, it does not become available for client connections until it is promoted via a switchover or a failover. These operations are covered in the following section.
Testing data replication and promoting the replica broker
There are two ways to promote a replica broker: initiating a switchover or a failover.
| Switchover | Failover |
|
|
|
|
|
|
To initiate a failover or switchover
-
- Navigate to the Amazon MQ console, choose your primary broker, and log in to the ActiveMQ Web Console using the URLs located in the Connections panel.
- In the top menu, select Queues. You should be able to see four
ActiveMQ.Plugin.Replicationqueues used by the replication feature.

- To test message replication from the primary to a replica broker, create a queue and send messages. To create the queue:
- For Queue Name, enter TestQueue.
- Choose Create.

- Under Operations for the
TestQueue, choose Send To and perform the following steps:- For Number of messages to send, enter 10 and keep the other defaults.
- Under Message body, enter a test message.
- Choose Send.

- To promote the replica broker, navigate to the Amazon MQ console and change the Region to the AWS Region where the replica broker is located.
- Select the replica broker (in this example called
Secondarybroker) and choose Promote replica.

- In the Promote replica broker pop-up window:
- Select Failover or Switchover.
- Enter confirm in text box.
- Choose Confirm.

- While a replica broker is being promoted, its replication status changes to Promotion in progress. The corresponding primary broker’s replication status changes to Demotion in progress.





Replica Secondarybroker status – Promotion in progress:

Primary broker status – Demotion in progress:

Secondarybroker status – Promoted to new primary broker:

- Once the
Secondarybrokerstatus is Running, log in to the ActiveMQ Web Console from the URLs located in the Connections panel. You can see the replicated messages sent from the former primary broker in Step 4 in theTestQueue:


Monitoring cross-Region data replication
To monitor cross-Region data replication progress, you can use the Amazon CloudWatch metrics TotalReplicationLag and ReplicationLag.

You can use these two metrics to monitor the progress of a switchover. When their value reaches zero, the switchover will complete because the broker states have been synchronized and the replica broker begins accepting client connections. If the switchover does not progress fast enough, or if you need the replica broker to be immediately available to serve client traffic, you can request a failover at any time.
Note: A failover can interrupt an ongoing switchover. However, a switchover cannot interrupt an ongoing failover.
Issuing a failover request causes the replica broker to become immediately available, but does not provide any guarantees about what data has been replicated to the replica broker. This means that a failover can make data tracking and reconciliation more challenging for your client application than a switchover.
For this reason, we recommend that you always start with a switchover and interrupt it with a failover if necessary. To interrupt an ongoing switchover, follow the same steps as for promoting a replica broker, select the failover option, and confirm.
Note: If you fail back to the original primary broker, messages that are not replicated from the primary to the replica broker during the failover will still exist on the primary broker. Therefore, consumers must manage these messages. We recommend tracking the processed message IDs in a data store such as Amazon DynamoDB global tables and comparing the message to the processed message IDs.
If you no longer need to replicate broker data across Regions or if you need to delete a primary or replica broker, you must unpair the replica broker and reboot the primary broker. You can unpair the replica broker in the Amazon MQ console by following Delete a CRDR broker.
To unpair the broker using the AWS Command Line Interface (AWS CLI), run the following command, replacing the --broker-id with your primary broker ID:
aws mq update-broker --broker-id <primary broker ID> \
--data-replication-mode "NONE" \
--region us-east-1Conclusion
Using the cross-Region data replication feature for Amazon MQ for ActiveMQ provides a straightforward way to implement cross-Region replication to improve the resilience of your architecture and meet your business continuity and disaster recovery requirements. This post explains how cross-Region data replication works in Amazon MQ, how to set up a cross-Region replica broker, and how to test and promote the replica broker.
For more details, see the Amazon MQ documentation.
For more serverless learning resources, visit Serverless Land.