Post Syndicated from Veliswa Boya original https://aws.amazon.com/blogs/aws/aws-weekly-roundup-kiro-cli-latest-features-aws-european-sovereign-cloud-ec2-x8i-instances-and-more-january-19-2026/
At the end of 2025 I was happy to take a long break to enjoy the incredible summers that the southern hemisphere provides. I’m back and writing my first post in 2026 which also happens to be my last post for the AWS News Blog (more on this later).
The AWS community is starting the year strong with various AWS re:invent re:Caps being hosted around the globe, with some communities already hosting their AWS Community Day events, the AWS Community Day Tel Aviv 2026 was hosted last week.
 |
 |
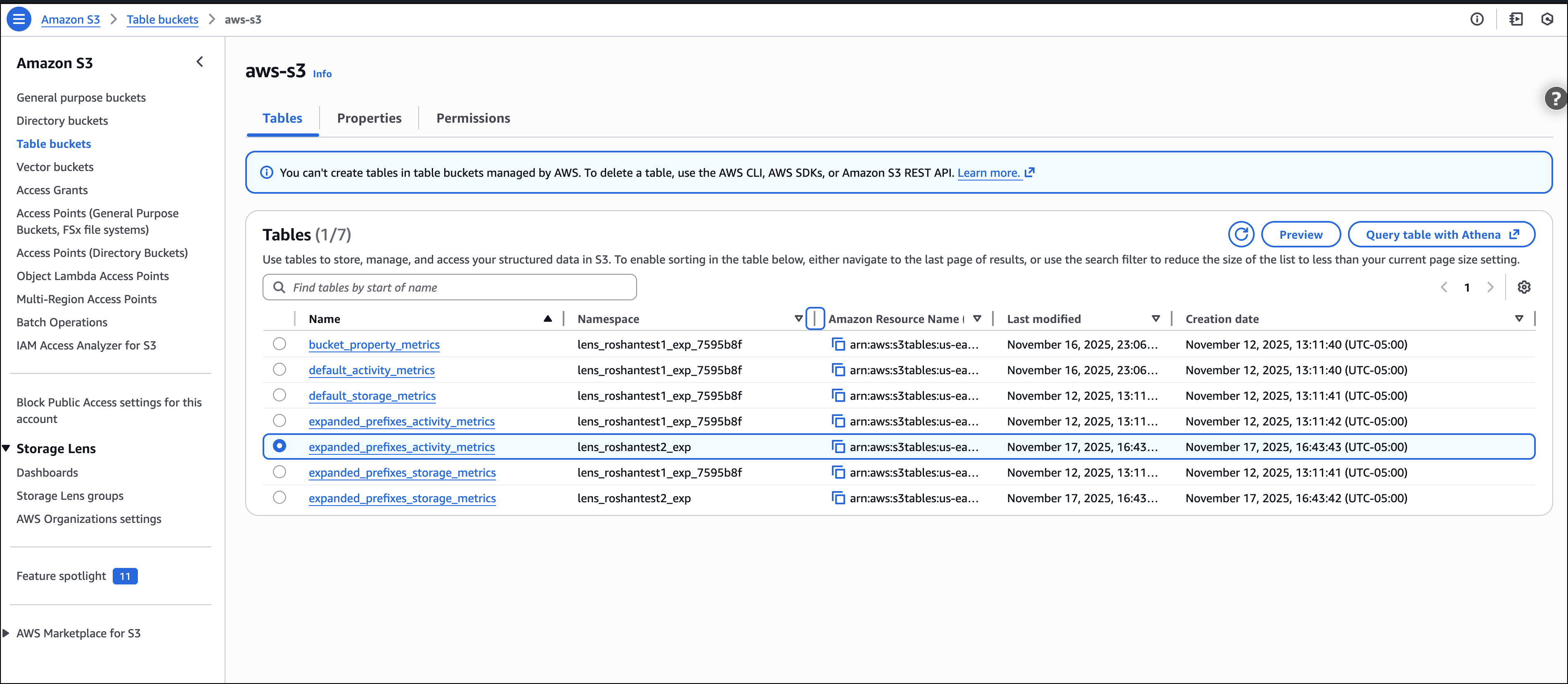
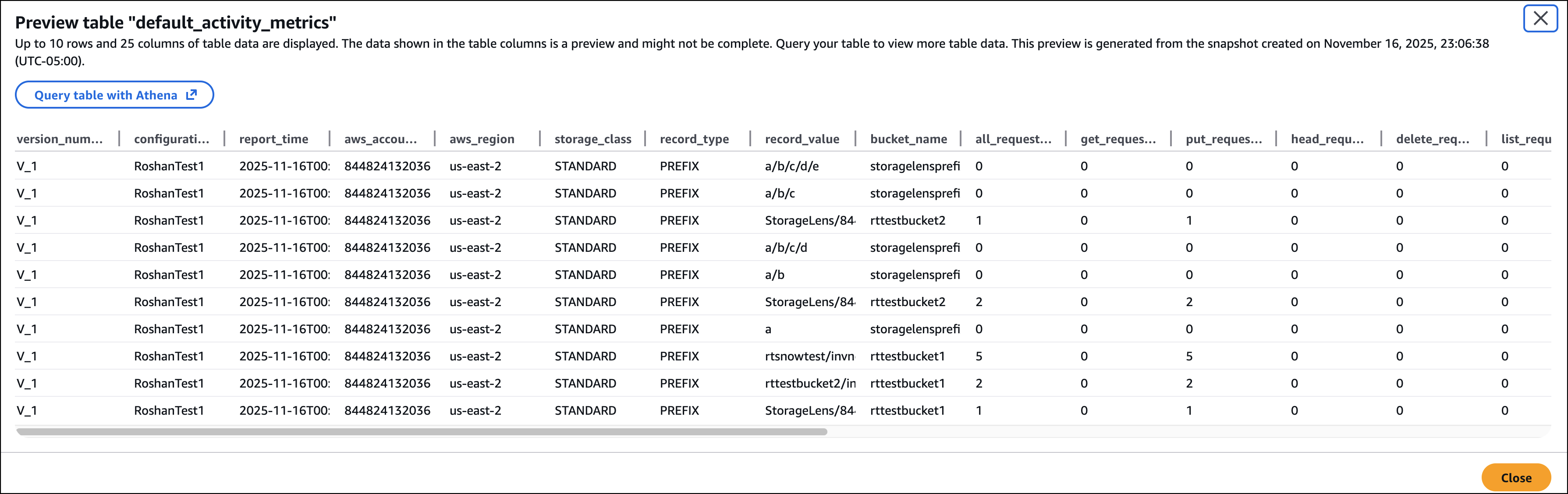
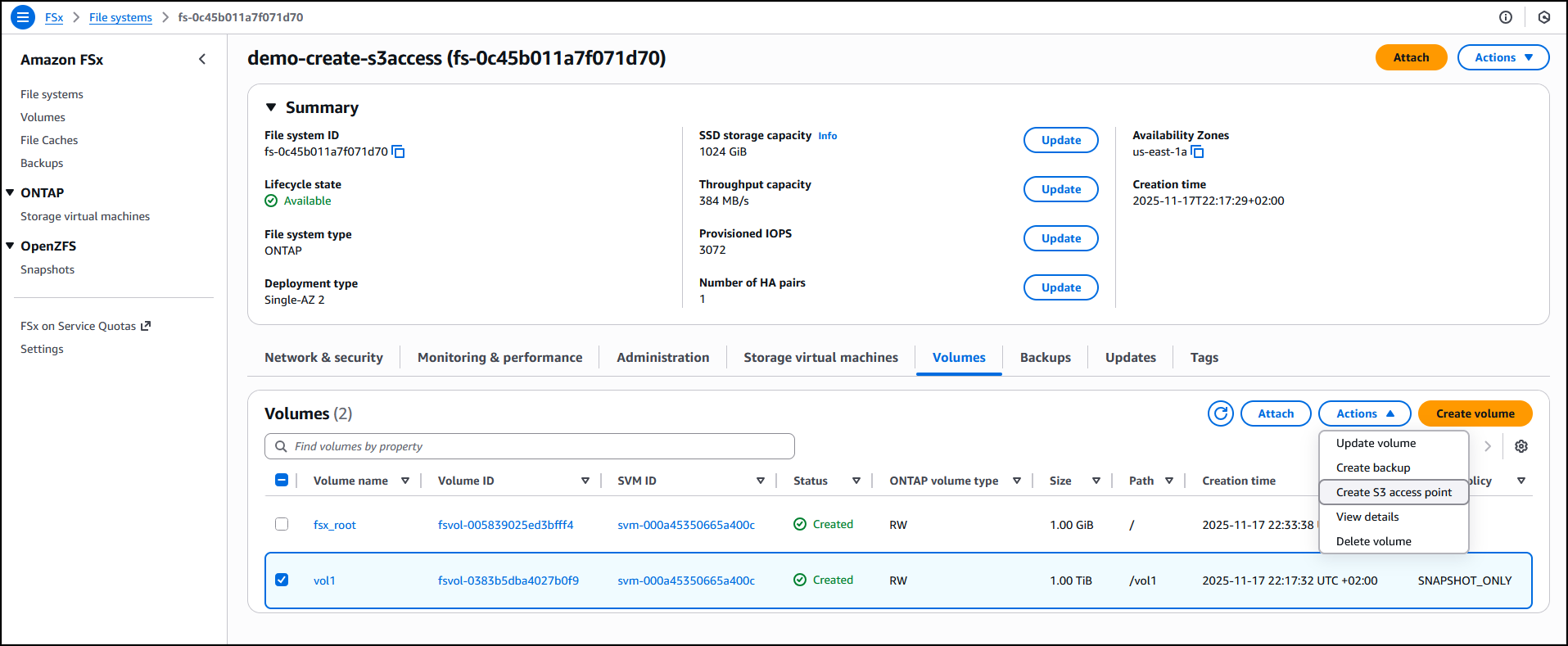
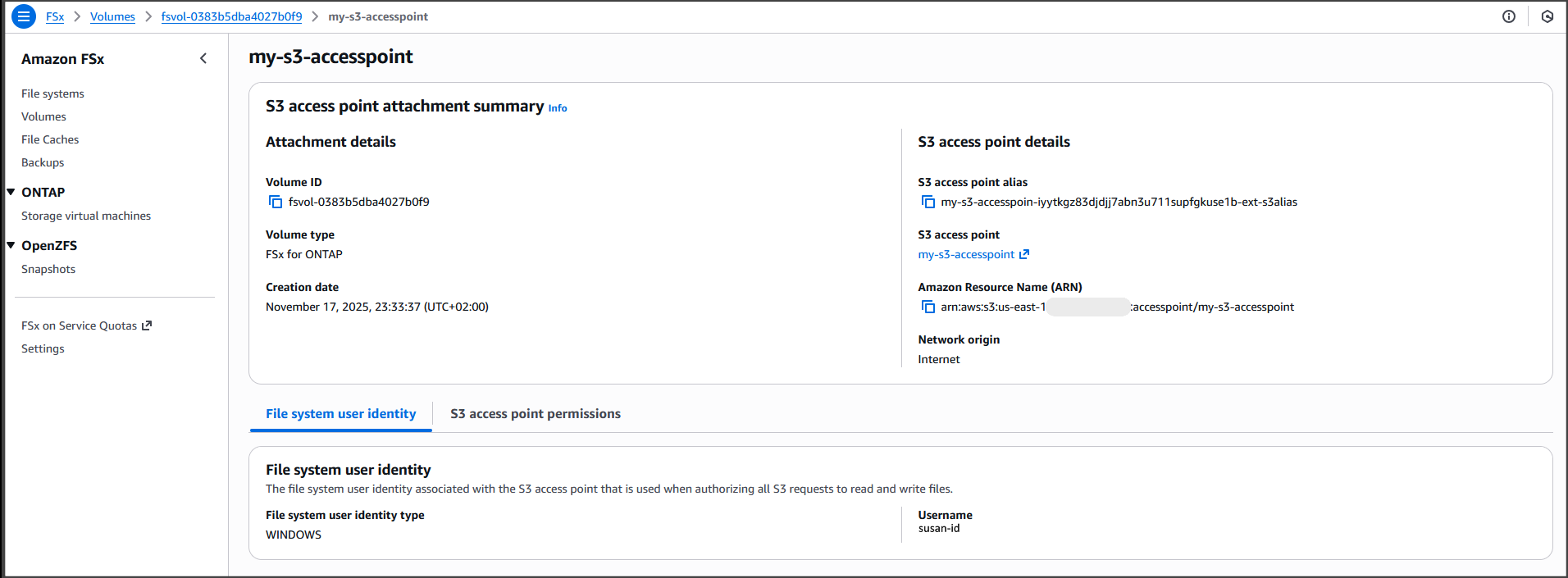
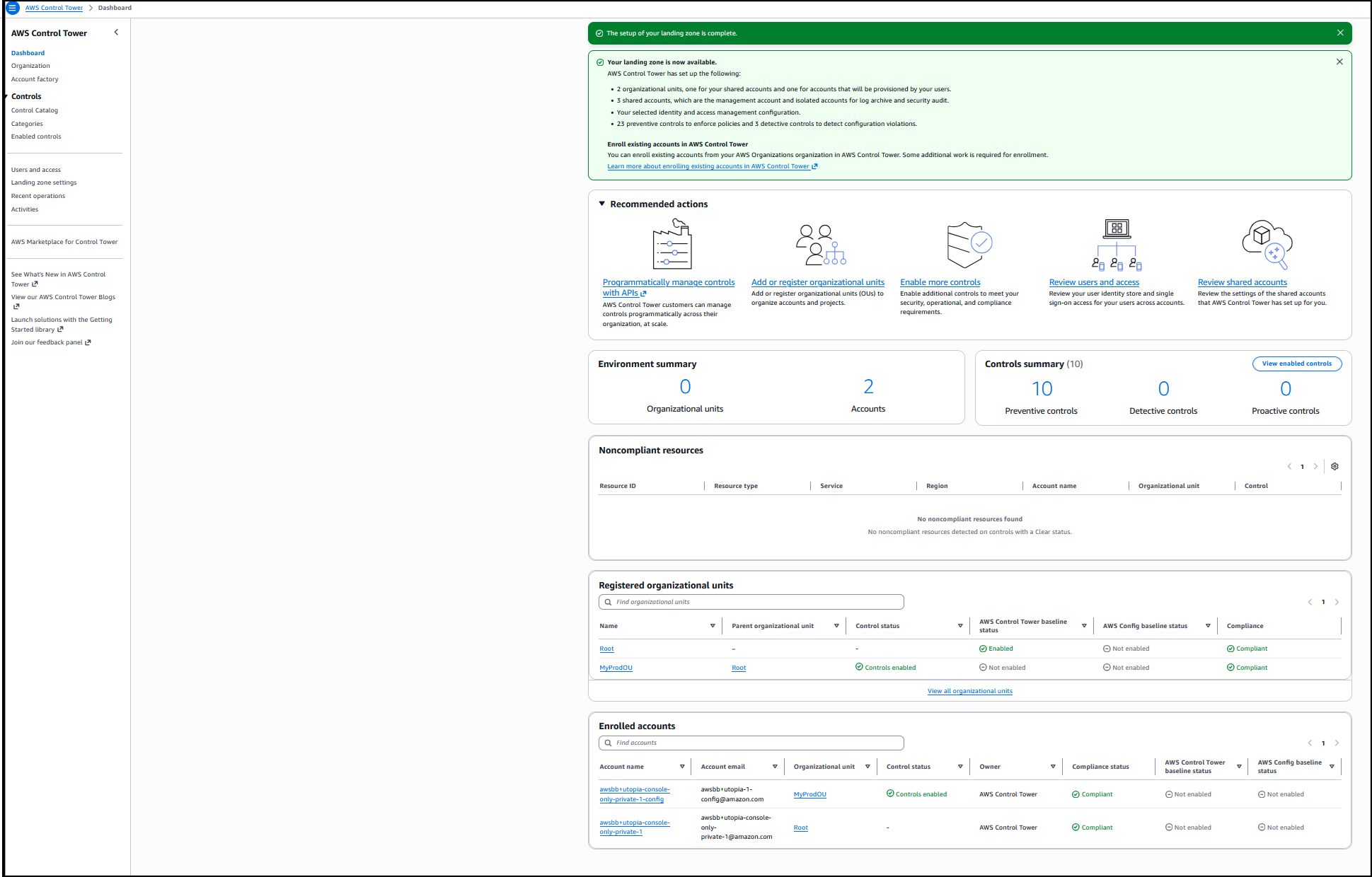
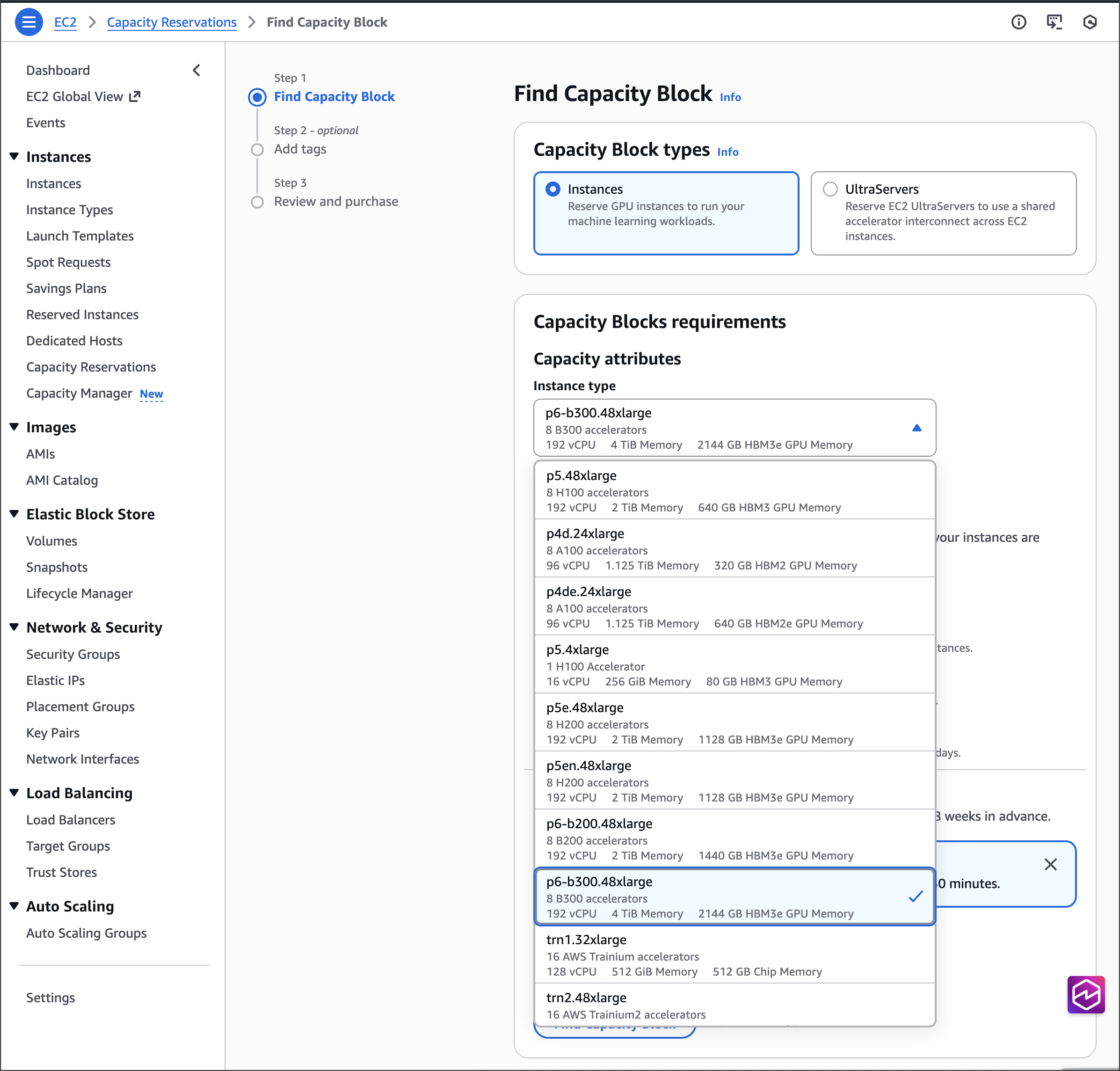
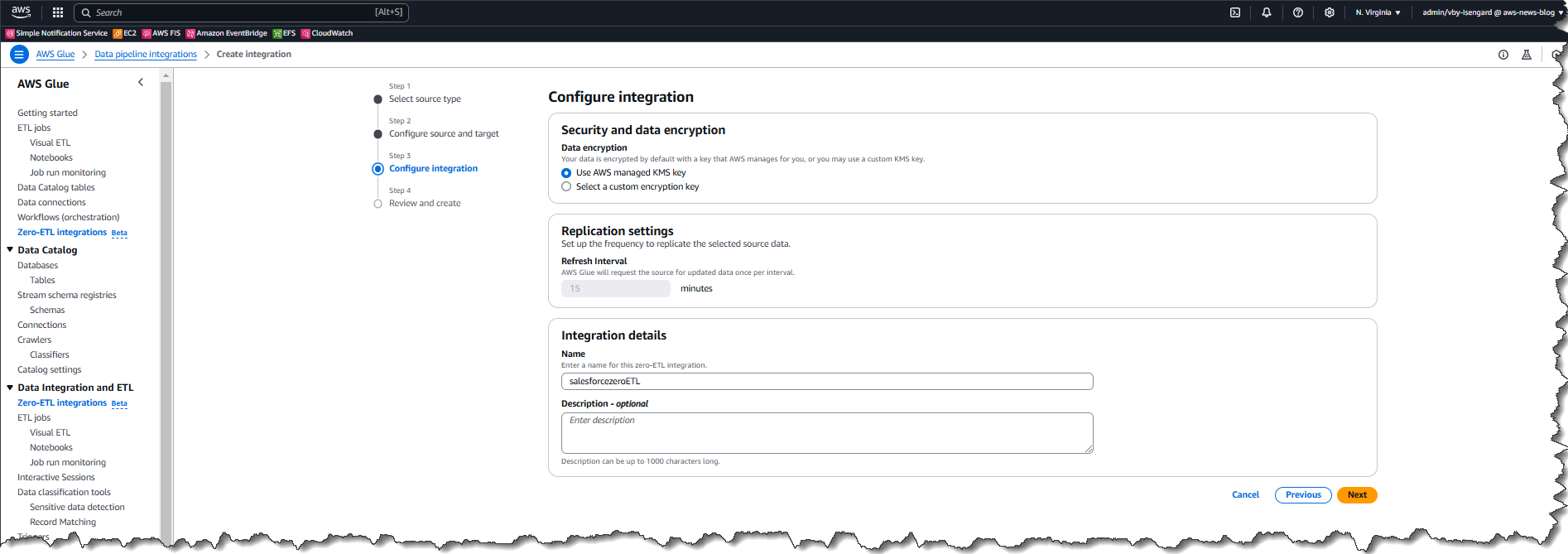
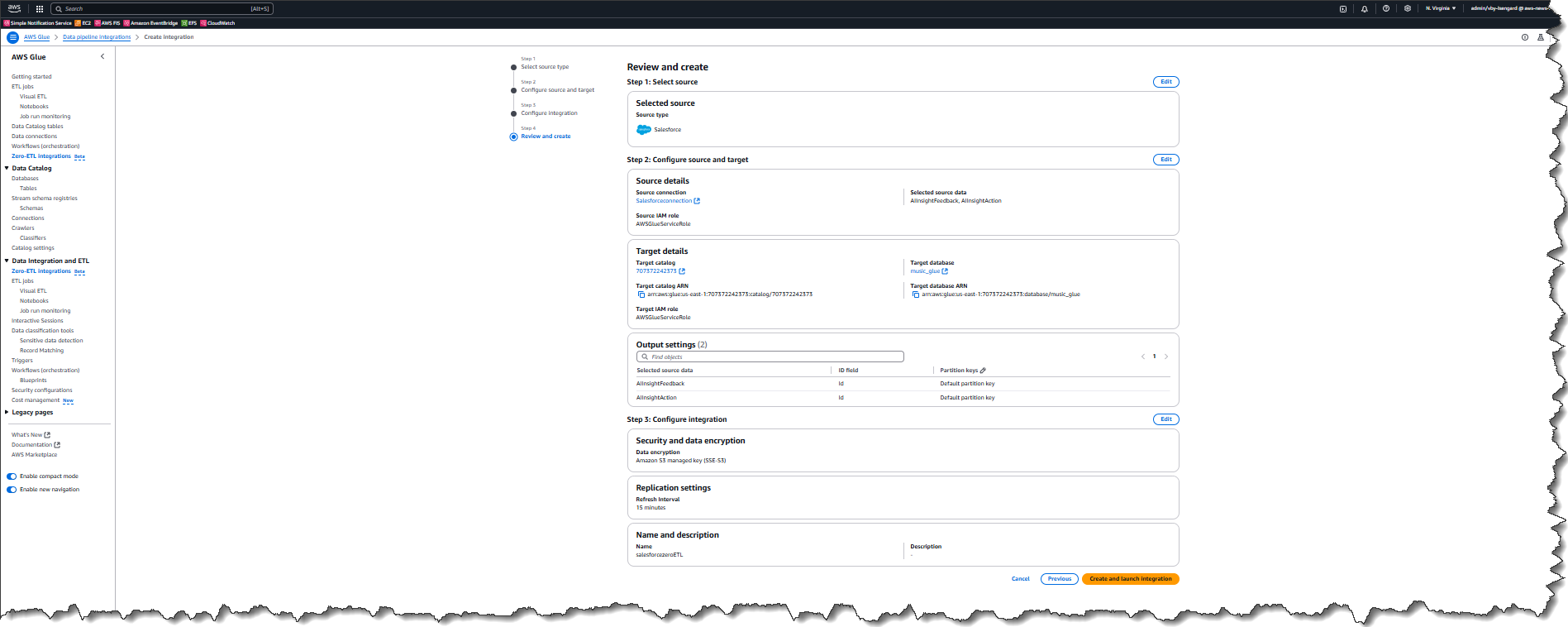
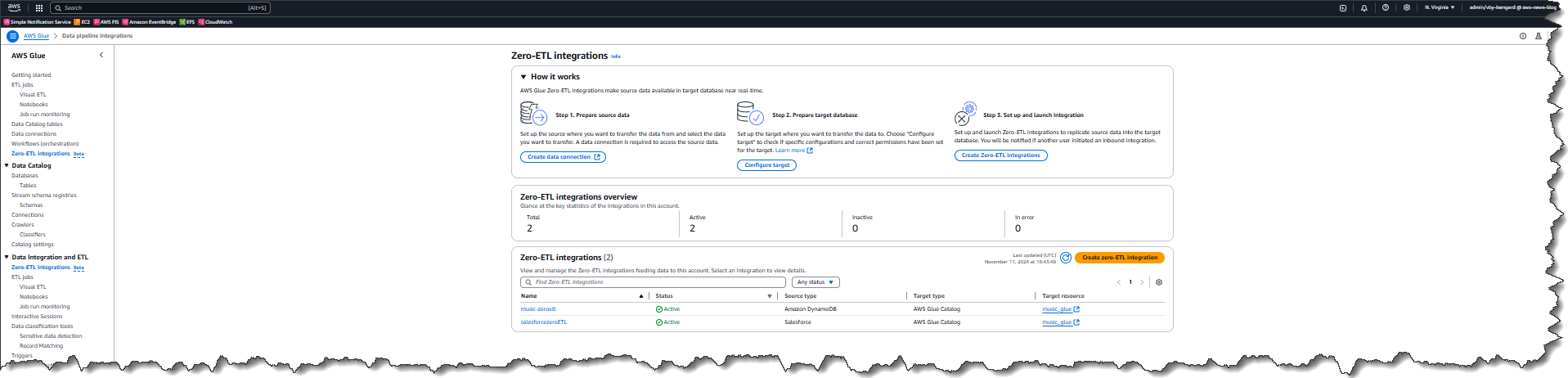
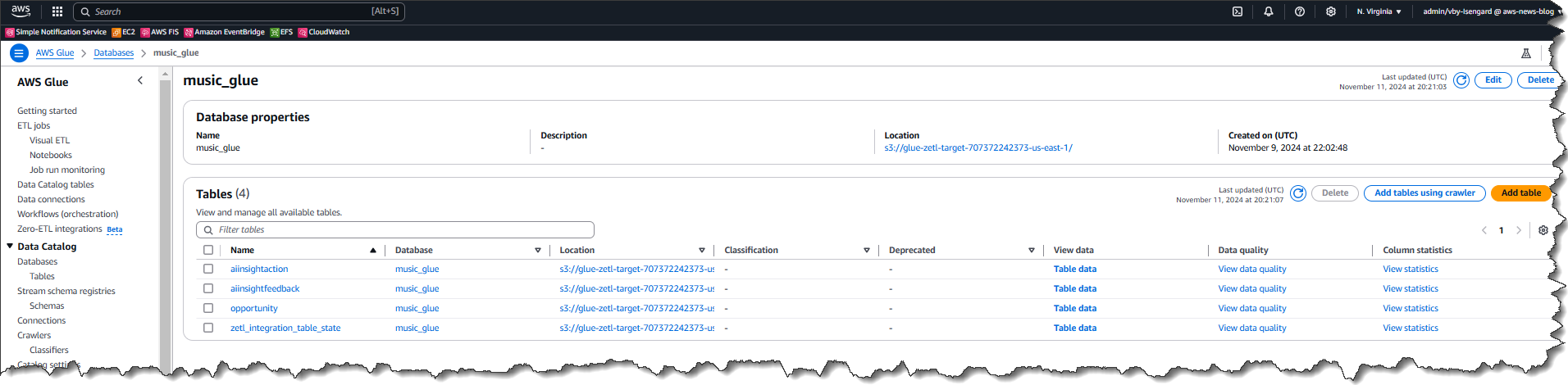
Last week’s launches
Here are last week’s launches that caught my attention:
- Kiro CLI latest features – Kiro CLI now has granular controls for web fetch URLs, keyboard shortcuts for your custom agents, enhanced diff views, and much more. With these enhancements, you can now use allowlists or blocklists to restrict which URLs the agent can access, ensure a frictionless experience when working with multiple specialized agents in a single session, to name a few.
- AWS European Sovereign Cloud – Following an announcement in 2023 of plans to build a new, independent cloud infrastructure, last week we announced the general availability of the AWS European Sovereign Cloud to all customers. The cloud is ready to meet the most stringent sovereignty requirements of European customers with a comprehensive set of AWS services.
- Amazon EC2 X8i instances – Previously launched in preview at AWS re:Invent 2025, last week we announced the general availability of new memory-optimized Amazon Elastic Compute Cloud (Amazon EC2) X8i instances. These instances are powered by custom Intel Xeon 6 processors with a sustained all-core turbo frequency of 3.9 GHz, available only on AWS. These SAP certified instances deliver the highest performance and fastest memory bandwidth among comparable Intel processors in the cloud.
Additional updates
These projects, blog posts, and news articles also caught my attention:
- 5 core features in Amazon Quick Suite – AWS VP Agentic AI Swami Sivasubramanian talks about how he uses Amazon Quick Suite for just about everything. In October 2025 we announced Amazon Quick Suite, a new agentic teammate that quickly answers your questions at work and turns insights into actions for you. Amazon Quick Suite has become one of my favorite productivity tools, helping me with my research on various topics in addition to providing me with multiple perspectives on a topic.
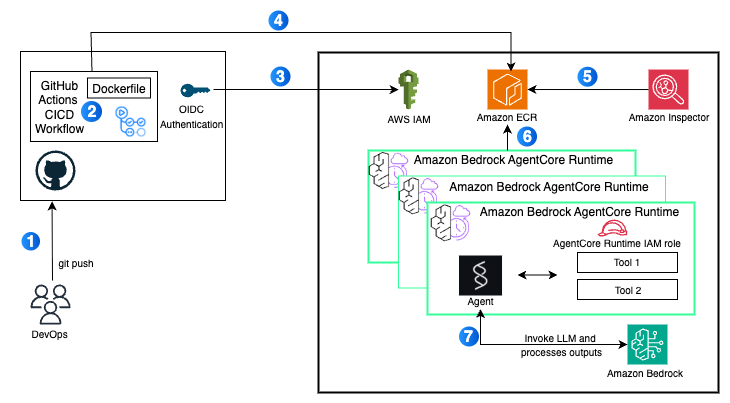
- Deploy AI agents on Amazon Bedrock AgentCore using GitHub Actions – Last year we announced Amazon Bedrock AgentCore, a flexible service that helps you seamlessly create and manage AI agents across different frameworks and models, whether hosted on Amazon Bedrock or other environments. Learn how to use a GitHub Actions workflow to automate the deployment of AI agents on AgentCore Runtime. This approach delivers a scalable solution with enterprise-level security controls, providing complete continuous integration and delivery (CI/CD) automation.
Upcoming AWS events
Join us January 28 or 29 (depending on your time zone) for Best of AWS re:Invent, a free virtual event where we bring you the most impactful announcements and top sessions from AWS re:Invent. Jeff Barr, AWS VP and Chief Evangelist, will share his highlights during the opening session.
There is still time until January 21 to compete for $250,000 in prizes and AWS credits in the Global 10,000 AIdeas Competition (yes, the second letter is an I as in Idea, not an L as in like). No code required yet: simply submit your idea, and if you’re selected as a semifinalist, you’ll build your app using Kiro within AWS Free Tier limits. Beyond the cash prizes and potential featured placement at AWS re:Invent 2026, you’ll gain hands-on experience with next-generation AI tools and connect with innovators globally.
Earlier this month, the 2026 application for the Community Builders program launched. The application is open until January 21st, midnight PST so here’s your last chance to ensure that you don’t miss out.
If you’re interested in these opportunities, join the AWS Builder Center to learn with builders in the AWS community.
With that, I close one of my most meaningful chapters here at AWS. It’s been an absolute pleasure to write for you and I thank you for taking the time to read the work that my team and I pour our absolute hearts into. I’ve grown from the close collaborations with the launch teams and the feedback from all of you. The Sub-Sahara Africa (SSA) community has grown significantly, and I want to dedicate more time focused on this community, I’m still at AWS and I look forward to meeting at an event near you!
Check back next Monday for another Weekly Roundup!