Post Syndicated from Saqlain Tahir original https://aws.amazon.com/blogs/architecture/field-notes-sql-server-deployment-options-on-aws-using-amazon-ec2/
Many enterprise applications run Microsoft SQL Server as their backend relational database. There are various options for customers to benefit from deploying their SQL Server on AWS. This blog will help you choose the right architecture for your SQL Server Deployment with high availability options, using Amazon EC2 for mission-critical applications.
SQL Server on Amazon EC2 offers more efficient control of deployment options and enables customers to fine-tune their Microsoft workload performance with full control. Most importantly you can bring your own licenses (BYOL) on AWS. You can re-host, aka “lift and shift”, your SQL Server to Amazon Elastic Compute Cloud (Amazon EC2) for large scale Enterprise applications. If you are re-hosting, you can still use your existing SQL Server license on AWS. Lifting and shifting your on-premises MS SQL Server environment to AWS using Amazon EC2 is recommended to migrate your SQL Server workloads to the cloud.
First, it is important to understand the considerations for deploying a SQL Server using Amazon EC2. For example, when would you want to use Failover Cluster over Availability Groups?
The following table will help you to choose the right architecture for SQL Server architecture based on the type of workload and availability requirements:

Self-managed MS SQL Server on EC2 usually means hosting MS SQL on EC2 backed by Amazon Elastic Block Store (EBS) or Amazon FSx for Windows File Server. Persistent storage from Amazon EBS and Amazon FSx delivers speed, security, and durability for your business-critical relational databases such as Microsoft SQL Server.
- Amazon EBS delivers highly available and performant block storage for your most demanding SQL Server deployments to achieve maximum performance.
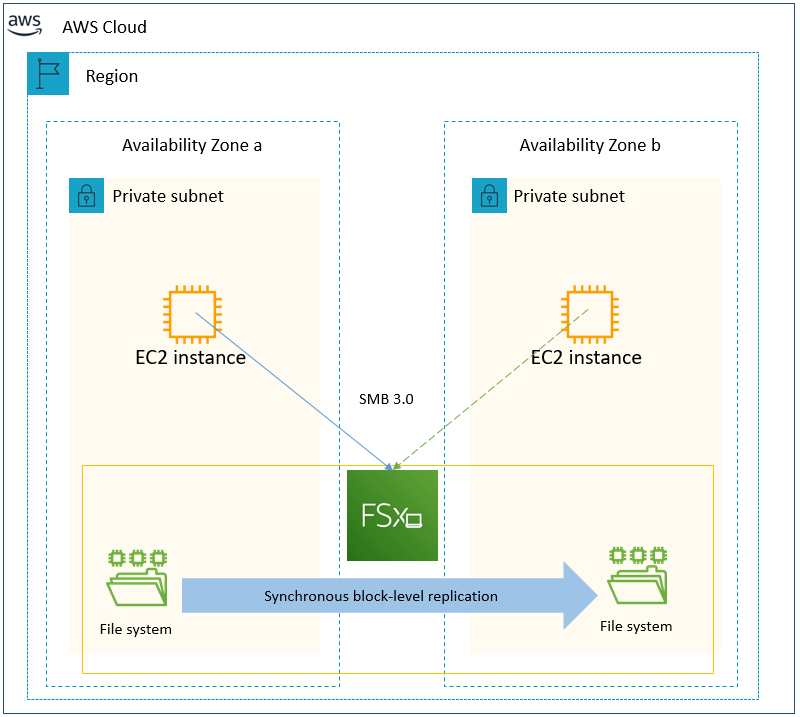
- Amazon FSx delivers fully managed Windows native shared file storage (SMB) with a multi-Availability Zone (AZ) design for highly available (HA) SQL environments.
Previously, if you wanted to migrate your Failover Cluster SQL databases to AWS, there was no native shared storage option. You would need to implement third party solutions that added a cost and complexity to install, set up, and maintain the storage configuration.
Amazon FSx for Windows File Server provides shared storage that multiple SQL databases can connect to across multiple AZs for a DR and HA solution. It is also helpful to achieve throughput and certain IOPS without scaling up the instance types to get the same IOPS from EBS volumes.
Overview of solution
Most customers need High Availability (HA) for their SQL Server production environment to ensure uptime and availability. This is important to minimize changes to the SQL Server applications while migrating. Customers may want to protect their investment in Microsoft SQL Server licenses by taking a Bring your own license (BYOL) approach to cloud migration.
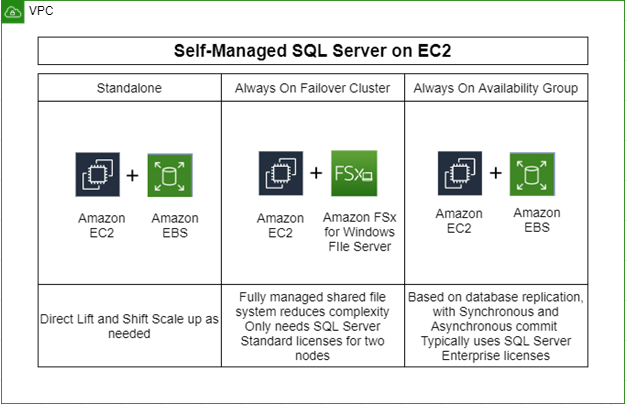
There are some scenarios where applications running on Microsoft SQL Server need full control of the infrastructure and software. If customers require it, they can deploy their SQL Server to AWS on Amazon EC2. Currently, there are three ways to deploy SQL Server workloads on AWS as shown in the following diagram:

Walkthrough
Now the question comes, how do you deploy the preceding SQL Server architectures?
First, let’s discuss the high-level breakdown of deployment options including the two types of SQL HA modes:
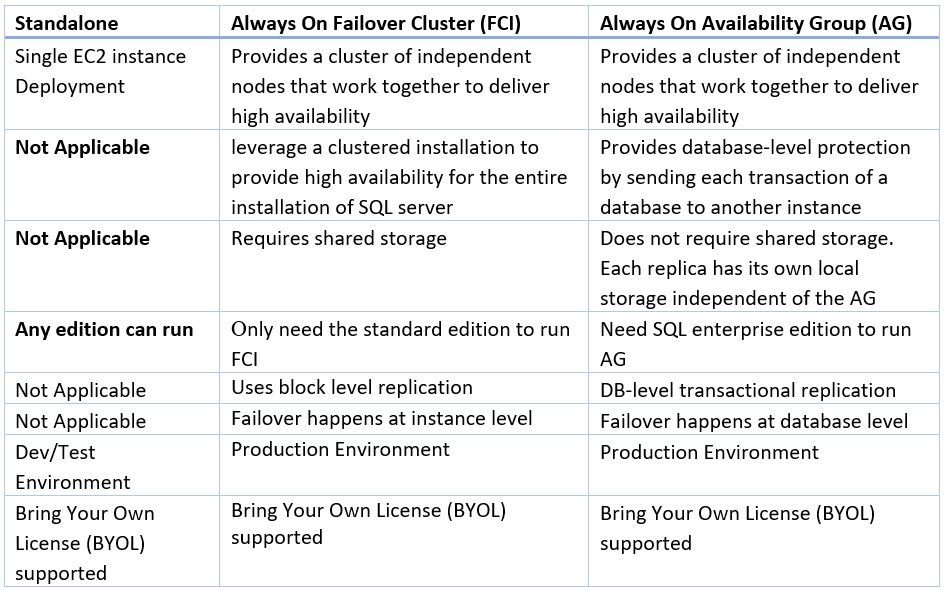
- Standalone
- Single SQL Server Node without HA
- Provision Amazon EC2 instance with EBS volume
- Single Availability Zone deployment
- Always On Failover Cluster Instance (FCI): EC2 and FSx for Windows File Server
- Protects the whole instance, including system databases
- Failovers over at the instance level
- Requires Shared Storage, Amazon FSx for Windows File Server is a great option
- Can be used in conjunction with Availability Groups to provide read-replicas and DR copies (dependent upon SQL Server Edition)
- Can be implemented at the Enterprise or Standard Edition level (with limitations)
- Multi Availability Zone Deployment
- Always On Availability Groups (AG): EC2 and EBS
- Protects one or more user databases (Standard Edition is limited to a single user database per AG)
- Failover is at the Availability Group level, meaning potentially only a subset of user databases can failover versus the whole instance
- System databases are not replicated, meaning users, jobs etc. will not automatically appear on passive nodes, manual creation is needed on all nodes
- Natively provides access to read-replicas and DR copies (dependent upon Edition)
- Can be implemented at the Enterprise or Standard
- Multi Availability Zone Deployment
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account
- SQL Server Licenses in case of BYOL Deployment
- Identify Software and Hardware requirements for SQL Server Environment
- Identify SQL Server application requirements based on best practices in this deployment guide
Deployment options on AWS
Here are some tools and services provided by AWS to deploy the SQL Server production ready environment by following best practices.
SQL Server on the AWS Cloud: Quick Start Reference Deployment
Use Case:
You want to deploy SQL Server on AWS for a Proof of Concept (PoC) or Pilot deployment using CloudFormation templates within hours by following these best practices.
Overview:
The Quick Start deployment guide provides step-by-step instructions for deploying SQL Server on the Amazon Web Services (AWS) Cloud, using AWS CloudFormation templates and AWS Systems Manager Automation documents that automate the deployment.

Implementation:
Quick Start Link: SQL Server with WSFC Quick Start
Source Code: GitHub
SQL Server Always On Deployments with AWS Launch Wizard
Use Case:
You intend to deploy SQL Server on AWS for your production workloads to benefit from automation, time and cost savings, and most importantly by leveraging proven deployment best practices from AWS.
Overview:
AWS Launch Wizard is a service that guides you through the sizing, configuration, and deployment of Microsoft SQL Server applications on AWS, following the AWS Well-Architected Framework. AWS Launch Wizard supports both single instance and high availability (HA) application deployments.
AWS Launch Wizard reduces the time it takes to deploy SQL Server solutions to the cloud. You input your application requirements, including performance, number of nodes, and connectivity, on the service console. AWS Launch Wizard identifies the right AWS resources to deploy and run your SQL Server application. You can also receive an estimated cost of deployment, modify your resources and instantly view the updated cost assessment.
When you approve, AWS Launch Wizard provisions and configures the selected resources in a few hours to create a fully-functioning production-ready SQL Server application. It also creates custom AWS CloudFormation templates, which can be reused and customized for subsequent deployments.
Once deployed, your SQL Server application is ready to use and can be accessed from the EC2 console. You can manage your SQL Server application with AWS Systems Manager.

Implementation:
AWS Launch Wizard Link: AWS Launch Wizard for SQL Server
Simplify your Microsoft SQL Server high availability deployments using Amazon FSx for Windows File Server
Use Case:
You need SQL enterprise edition to run an Always on Availability Group (AG), whereas you only need the standard edition to run Failover Cluster Instance (FCI). You want to use standard licensing to save costs but want to achieve HA. SQL Server Standard is typically 40–50% less expensive than the Enterprise Edition.
Overview:
Always On Failover Cluster (FCI) uses block level replication rather than database-level transactional replication. You can migrate to AWS without re-architecting. As the shared storage handles replication you don’t need to use SQL nodes for it, and frees up CPU/Memory for primary compute jobs. With FCI, the entire instance is protected – if the primary node becomes unavailable, the entire instance is moved to the standby node. This takes care of the SQL Server logins, SQL Server Agent jobs, and certificates that are stored in the system databases. These are physically stored in shared storage.

Implementation:
FCI implementation: SQL Server Deployment using FCI, FSx QuickStart.
Clustering for SQL Server High Availability using SIOS Data Keeper
Use Case:
Windows Server Failover Clustering is a requirement if you are using SQL Server Enterprise or the SQL Server Standard edition and it might appear to be the perfect HA solution for applications running on Windows Server. But like FCIs, it requires the use of shared storage. If you want to use software SAN across multiple instances, then SIOS Data Keeper can be an option.
Overview:
WSFC has a potential role to play in many HA configurations, including for SQL Server FCIs, but its use requires separate data replication provisions in a SANless environment, whether in an enterprise datacenter or in the cloud. SIOS data keeper is a partner solution software SAN across multiple instances. Instead of FSx, you deploy another cluster for SIOS data keeper to host the shared volumes or use a hyper-converged model to deploy SQL Server on the same server as the SIOS data keeper. You can also use SIOS DataKeeper Cluster Edition, a highly optimized, host-based replication solution.

Implementation:
QuickStart: SIOS DataKeeper Cluster Edition on the AWS Cloud
Conclusion
In this blog post, we covered the different options of SQL Server Deployment on AWS using EC2. The options presented showed how you can have the exact same experience from an administration point of view, as well as full control over your EC2 environment, including sysadmin and root-level access.
We also showed various ways to achieve High Availability, by deploying SQL Server on AWS as a new environment using AWS QuickStart and AWS Launch Wizard. We also showed how you can deploy SQL Server using AWS managed windows storage Amazon FSx to handle shared storage constraint, cost and IOPS requirement scenarios. If you need shared storage in the cloud outside the Windows FSx option, AWS supports a partner solution using SIOS DataKeeper Cluster Edition.
We hope you found this blog post useful and welcome your feedback in the comments!
Field Notes provides hands-on technical guidance from AWS Solutions Architects, consultants, and technical account managers, based on their experiences in the field solving real-world business problems for customers.