Post Syndicated from Harunobu Kameda original https://aws.amazon.com/blogs/aws/new-vpc-insights-analyzes-reachability-and-visibility-in-vpcs/
With Amazon Virtual Private Cloud (VPC), you can launch a logically isolated customer-specific virtual network on the AWS Cloud. As customers expand their footprint on the cloud and deploy increasingly complex network architectures, it can take longer to resolve network connectivity issues caused by misconfiguration. Today, we are happy to announce VPC Reachability Analyzer, a network diagnostics tool that troubleshoots reachability between two endpoints in a VPC, or within multiple VPCs.
Ensuring Your Network Configuration is as Intended
You have full control over your virtual network environment, including choosing your own IP address range, creating subnets, and configuring route tables and network gateways. You can also easily customize the network configuration of your VPC. For example, you can create a public subnet for a web server that has access to the Internet with Internet Gateway. Security-sensitive backend systems such as databases and application servers can be placed on private subnets that do not have internet access. You can use multiple layers of security, such as security groups and network access control list (ACL), to control access to entities of each subnet by protocol, IP address, and port number.
You can also combine multiple VPCs via VPC peering or AWS Transit Gateway for region-wide, or global network connections that can route traffic privately. You can also use VPN Gateway to connect your site with your AWS account for secure communication. Many AWS services that reside outside the VPC, such as AWS Lambda, or Amazon S3, support VPC endpoints or AWS PrivateLink as entities inside the VPC and can communicate with those privately.
When you have such rich controls and feature set, it is not unusual to have unintended configuration that could lead to connectivity issues. Today, you can use VPC Reachability Analyzer for analyzing reachability between two endpoints without sending any packets. VPC Reachability analyzer looks at the configuration of all the resources in your VPCs and uses automated reasoning to determine what network flows are feasible. It analyzes all possible paths through your network without having to send any traffic on the wire. To learn more about how these algorithms work checkout this re:Invent talk or read this paper.
How VPC Reachability Analyzer Works
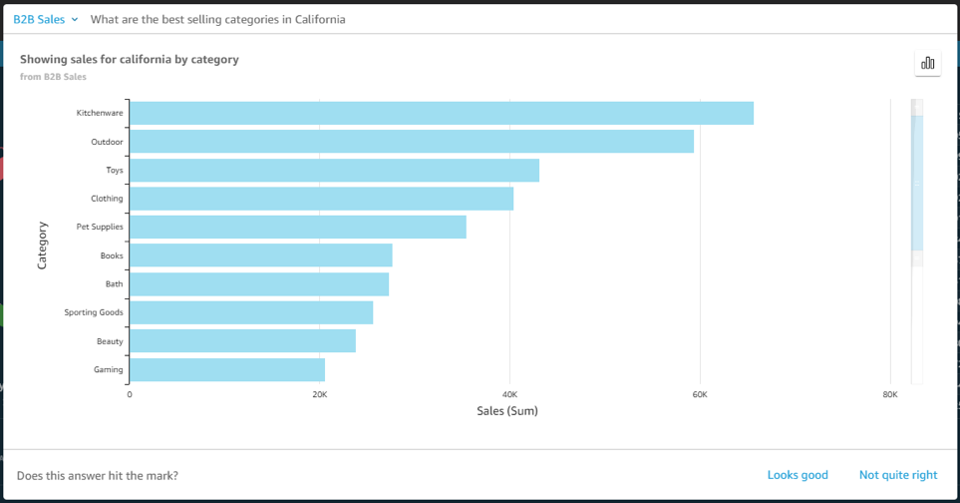
Let’s see how it works. Using VPC Reachability Analyzer is very easy, and you can test it with your current VPC. If you need an isolated VPC for test purposes, you can run the AWS CloudFormation YAML template at the bottom of this article. The template creates a VPC with 1 subnet, 2 security groups and 3 instances as A, B, and C. Instance A and B can communicate with each other, but those instances cannot communicate with instance C because the security group attached to instance C does not allow any incoming traffic.
You see Reachability Analyzer in the left navigation of the VPC Management Console.
Click Reachability Analyzer, and also click Create and analyze path button, then you see new windows where you can specify a path between a source and destination, and start analysis.
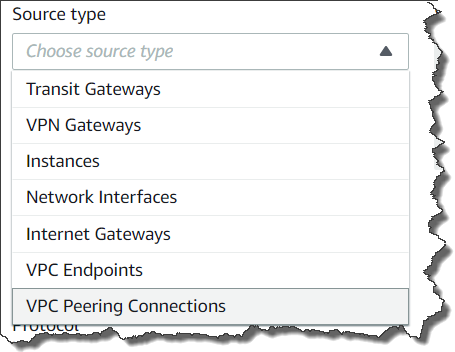
You can specify any of the following endpoint types: VPN Gateways, Instances, Network Interfaces, Internet Gateways, VPC Endpoints, VPC Peering Connections, and Transit Gateways for your source and destination of communication. For example, we set instance A for source and the instance B for destination. You can choose to check for connectivity via either the TCP or UDP protocols. Optionally, you can also specify a port number, or source, or destination IP address.

Finally, click the Create and analyze path button to start the analysis. The analysis can take up to several minutes depending on the size and complexity of your VPCs, but it typically takes a few seconds.

You can now see the analysis result as Reachable. If you click the URL link of analysis id nip-xxxxxxxxxxxxxxxxx, you can see the route hop by hop.
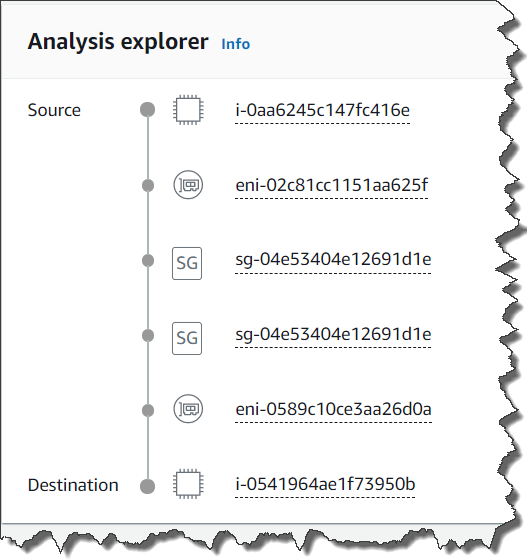
The communication from instance A to instance C is not reachable because the security group attached to instance C does not allow any incoming traffic.

If you click nip-xxxxxxxxxxxxxxxxx for more detail, you can check the Explanations for details.

Here we see the security group that blocked communication. When you click on the security group listed in the upper right corner, you can go directly to the security group editing window to change the security group rules. In this case adding a properly scoped ingress rule will allow the instances to communicate.
Available Today
This feature is available for all AWS commercial Regions except for China (Beijing), and China (Ningxia) regions. More information is available in our technical documentation, and remember that to use this feature your IAM permissions need to be set up as documented here.
– Kame
CloudFormation YAML template for test