Post Syndicated from Chris King original https://aws.amazon.com/blogs/big-data/build-and-deploy-custom-connectors-for-amazon-redshift-with-amazon-lookout-for-metrics/
Amazon Lookout for Metrics detects outliers in your time series data, determines their root causes, and enables you to quickly take action. Built from the same technology used by Amazon.com, Lookout for Metrics reflects 20 years of expertise in outlier detection and machine learning (ML). Read our GitHub repo to learn more about how to think about your data when setting up an anomaly detector.
In this post, we discuss how to build and deploy custom connectors for Amazon Redshift using Lookout for Metrics.
Introduction to time series data
You can use time series data to measure and monitor any values that shift from one point in time to another. A simple example is stock prices over a given time interval or the number of customers seen per day in a garage. You can use these values to spot trends and patterns and make better decisions about likely future events. Lookout for Metrics enables you to structure important data into a tabular format (like a spreadsheet or database table), to provide historical values to learn from, and to provide continuous values of data.
Connect your data to Lookout for Metrics
Since launch, Lookout for Metrics has supported providing data from the following AWS services:
It also supports external data sources such as Salesforce, Marketo, Dynatrace, ServiceNow, Google Analytics, and Amplitude, all via Amazon AppFlow.
These connectors all support continuous delivery of new data to Lookout for Metrics to learn to build a model for anomaly detection.
Native connectors are an effective option to get started quickly with CloudWatch, Amazon S3, and via Amazon AppFlow for the external services. Additionally, these work great for your relational database management system (RDBMS) data if you have stored your information in a singular table, or you can create a procedure to populate and maintain that table going forward.
When to use a custom connector
In cases where you want more flexibility, you can use Lookout for Metrics custom connectors. If your data is in a state that requires an extract, transform, and load (ETL) process, such as joining from multiple tables, transforming a series of values into a composite, or performing any complex postprocessing before delivering the data to Lookout for Metrics, you can use custom connectors. Additionally, if you’re starting with data in an RDBMS and you wish to provide a historical sample for Lookout for Metrics to learn from first, you should use a custom connector. This allows you to feed in a large volume of history first, bypassing the coldstart requirements and achieving a higher quality model sooner.
For this post, we use Amazon Redshift as our RDBMS, but you can modify this approach for other systems.
You should use custom connectors in the following situations:
- Your data is spread over multiple tables
- You need to perform more complex transformations or calculations before it fits to a detector’s configuration
- You want to use all your historical data to train your detector
For a quicker start, you can use built-in connectors in the following situations:
- Your data exists in a singular table that only contains information used by your anomaly detector
- You’re comfortable using your historical data and then waiting for the coldstart period to elapse before beginning anomaly detection
Solution overview
All content discussed in this post is hosted on the GitHub repo.
For this post, we assume that you’re storing your data in Amazon Redshift over a few tables and that you wish to connect it Lookout for Metrics for anomaly detection.
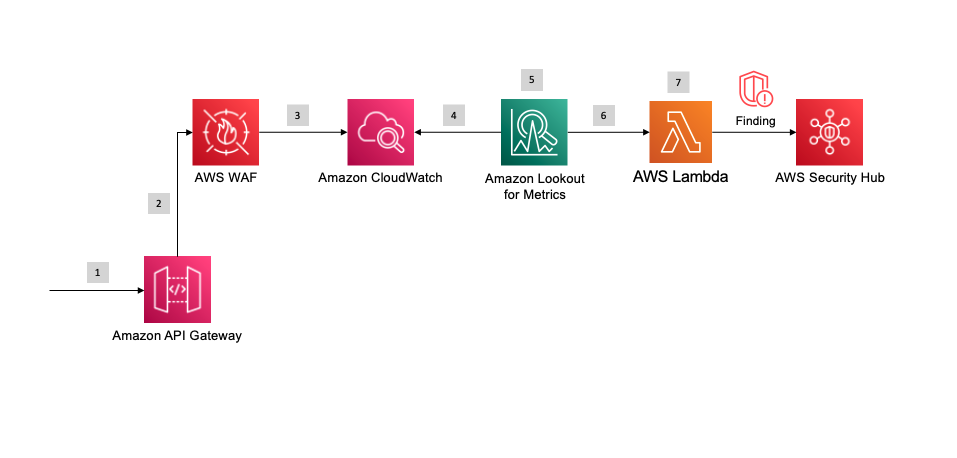
The following diagram illustrates our solution architecture.

At a high level, we start with an AWS CloudFormation template that deploys the following components:
- An Amazon SageMaker notebook instance that deploys the custom connector solution.
- An AWS Step Functions workflow. The first step performs a historical crawl of your data; the second configures your detector (the trained model and endpoint for Lookout for Metrics).
- An S3 bucket to house all your AWS Lambda functions as deployed (omitted from the architecture diagram).
- An S3 bucket to house all your historical and continuous data.
- A CloudFormation template and Lambda function that starts crawling your data on a schedule.
To modify this solution to fit your own environment, update the following:
- A JSON configuration template that describes how your data should look to Lookout for Metrics and the name of your AWS Secrets Manager location used to retrieve authentication credentials.
- A SQL query that retrieves your historical data.
- A SQL query that retrieves your continuous data.
After you modify those components, you can deploy the template and be up and running within an hour.
Deploy the solution
To make this solution explorable from end to end, we have included a CloudFormation template that deploys a production-like Amazon Redshift cluster. It’s loaded with sample data for testing with Lookout for Metrics. This is a sample ecommerce dataset that projects roughly 2 years into the future from the publication of this post.
Create your Amazon Redshift cluster
Deploy the provided template to create the following resources in your account:
- An Amazon Redshift cluster inside a VPC
- Secrets Manager for authentication
- A SageMaker notebook instance that runs all the setup processes for the Amazon Redshift database and initial dataset loading
- An S3 bucket that is used to load data into Amazon Redshift
The following diagram illustrates how these components work together.

We provide Secrets Manager with credential information for your database, which is passed to a SageMaker notebook’s lifecycle policy that runs on boot. Once booted, the automation creates tables inside your Amazon Redshift cluster and loads data from Amazon S3 into the cluster for use with our custom connector.
To deploy these resources, complete the following steps:
- Choose Launch Stack:

- Choose Next.

- Leave the stack details at their default and choose Next again.

- Leave the stack options at their default and choose Next again.

- Select I acknowledge that AWS CloudFormation might create IAM resources, then Choose Create stack.

The job takes a few minutes to complete. You can monitor its progress on the AWS CloudFormation console.

When the status changes to CREATE_COMPLETE, you’re ready to deploy the rest of the solution.

Data structure
We have taken our standard ecommerce dataset and split it into three specific tables so that we can join them later via the custom connector. In all probability, your data is spread over various tables and needs to be normalized in a similar manner.
The first table indicates the user’s platform, (what kind of device users are using, such as phone or web browser).
The next table indicates our marketplace (where the users are located).
Our ecommerce table shows the total values for views and revenue at this time.
| ID |
TS |
Platform |
Marketplace |
Views |
Revenue |
| 1 |
01/10/2022 10:00:00 |
1 |
1 |
90 |
2458.90 |
When we run queries later in this post, they’re against a database with this structure.
Deploy a custom connector
After you deploy the previous template, complete the following steps to deploy a custom connector:
- On the AWS CloudFormation console, navigate to the Outputs tab of the template you deployed earlier.

- Note the value of
RedshiftCluster and RedshiftSecret, then save them in a temporary file to use later.

- Choose Launch stack to deploy your resources with AWS CloudFormation:
- Choose Next.

- Update the value for the RedshiftCluster and
RedshiftSecret with the information you copied earlier.
- Choose Next.

- Leave the stack options at their default and choose Next.

- Select I acknowledge that AWS CloudFormation might create IAM resources, then choose Create stack.

The process takes 30–40 minutes to complete, after which you have a fully deployed solution with the demo environment.
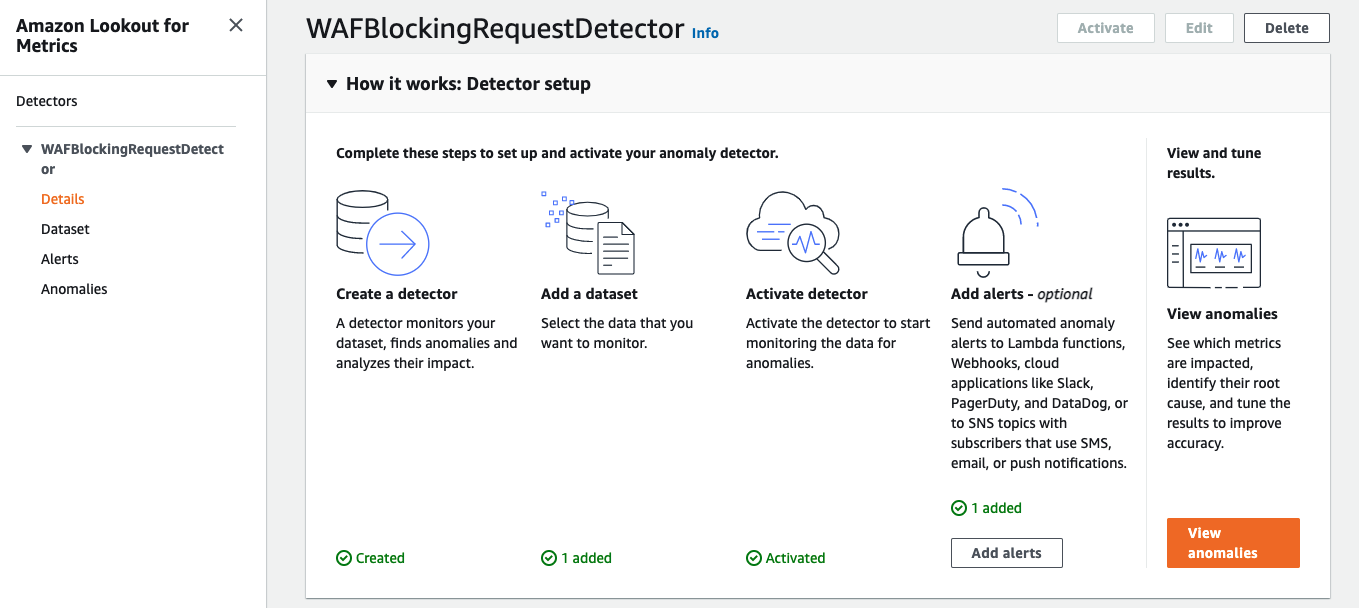
View your anomaly detector
After you deploy the solution, you can locate your detector and review any found anomalies.
- Sign in to the Lookout for Metrics console in
us-east-1.
- In the navigation pane, choose Detectors.

The Detectors page lists all your active detectors.
- Choose the detector
l4m-custom-redshift-connector-detector. 
Now you can view your detector’s configuration, configure alerts, and review anomalies.
To view anomalies, either choose Anomalies in the navigation page or choose View anomalies on the detector page.

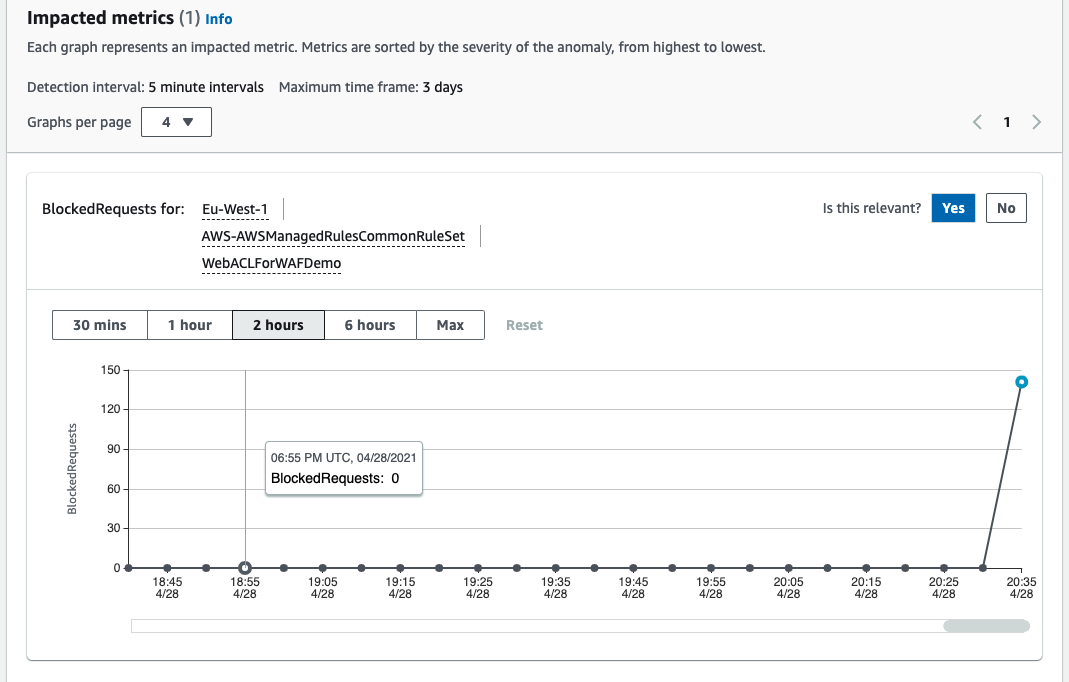
After a period of time, usually no more than a few days, you should see a list of anomalies on this page. You can explore them in depth to view how the data provided seemed anomalous. If you provided your own dataset, the anomalies may only show up after an unusual event.

Now that you have the solution deployed and running, let’s discuss how this connector works in depth.
How a custom connector works
In this section, we discuss the connector’s core components. We also demonstrate how to build a custom connector, authenticate to Amazon Redshift, modify queries, and modify the detector and dataset.
Core components
You can run the following components and modify them to support your data needs:
When you deploy ai_ops/l4m-redshift-solution.yaml, it creates the following:
- An S3 bucket for storing all Lambda functions.
- A role for a SageMaker notebook that has access to modify all relevant resources.
- A SageMaker notebook lifecycle config that contains the startup script to clone all automation onto the notebook and manage the params.json file. And runs the shell script (
ai_ops/deploy_custom_connector.sh) to deploy the AWS SAM applications and further update the params.json file.
ai_ops/deploy_custom_connector.sh starts by deploying ai_ops/template.yaml, which creates the following:
- An S3 bucket for storing the
params.json file and all input data for Lookout for Metrics.
- An S3 bucket policy to allow Lookout for Metrics to communicate with Amazon S3.
- A Lambda function that is invoked on the bucket when the
params.json file is uploaded and starts the Step Functions state machine.
- An AWS Identity and Access Management (IAM) role to run the state machine.
- A shared Lambda layer of support functions.
- A role for Lookout for Metrics to access data in Amazon S3.
- A Lambda function to crawl all historical data.
- A Lambda function to create and activate a Lookout for Metrics detector.
- A state machine that manages the flow between creating that historical dataset and the detector.
After ai_ops/deploy_custom_connector.sh creates the first batch of items, it updates the params.json file with new relevant information from the detector and the IAM roles. It also modifies the Amazon Redshift cluster to allow the new role for Lookout for Metrics to communicate with the cluster. After sleeping for 30 seconds to facilitate IAM propagation, the script copies the params.json file to the S3 bucket, which invokes the state machine deployed already.
Then the script deploys another AWS SAM application defined in l4m-redshift-continuous-crawl.yaml. This simple application defines and deploys an event trigger to initiate the crawling of live data on a schedule (hourly for example) and a Lambda function that performs the crawl.
Both the historical crawled data and the continuously crawled data arrives in the same S3 bucket. Lookout for Metrics uses the information first for training, then as inference data, where it’s checked for anomalies as it arrives.
Each Lambda function also contains a query.sql file that provides the base query that is handed to Amazon Redshift. Later the functions append UNLOAD to each query and deliver the data to Amazon S3 via CSV.
Build a custom connector
Start by forking this repository into your own account or downloading a copy for private development. When making substantial changes, make sure that the references to this particular repository in the following files are updated and point to publicly accessible endpoints for Git:
Authenticate to Amazon Redshift
When exploring how to extend this into your own environment, the first thing to consider is the authentication to your Amazon Redshift cluster. You can accomplish this by using the Amazon Redshift Data API and by storing the credentials inside AWS Secrets Manager.
In Secrets Manager, this solution looks for the known secret name redshift-l4mintegration and contains a JSON structure like the following:
{
"password": "DB_PASSWORD",
"username": "DB_USERNAME",
"dbClusterIdentifier": "REDSHIFT_CLUSTER_ID",
"db": "DB_NAME",
"host": "REDSHIFT_HOST",
"port": 8192
}
If you want to use a different secret name than the one provided, you need to update the value in ai_ops/l4m-redshift-solution.yaml. If you want to change the other parameters’ names, you need to search for them in the repository and update their references accordingly.
Modify queries to Amazon Redshift
This solution uses the Amazon Redshift Data API to allow for queries that can be run asynchronously from the client calling for them.
Specifically, it allows a Lambda function to start a query with the database and then let the DB engine manage everything, including the writing of the data in a desired format to Amazon S3. Because we let the DB engine handle this, we simplify the operations of our Lambda functions and don’t have to worry about runtime limits. If you want to perform more complex transformations, you may want to build out more Step Functions-based AWS SAM applications to handle that work, perhaps even using Docker containers over Lambda.
For most modifications, you can edit the query files stored in the two Lambda functions provided:
Pay attention to the continuous crawl to make sure that the date ranges coincide with your desired detection interval. For example:
select ecommerce.ts as timestamp, ecommerce.views, ecommerce.revenue, platform.name as platform, marketplace.name as marketplace
from ecommerce, platform, marketplace
where ecommerce.platform = platform.id
and ecommerce.marketplace = marketplace.id
and ecommerce.ts < DATEADD(hour, 0, getdate())
and ecommerce.ts > DATEADD(hour, -1, getdate())
The preceding code snippet is our demo continuous crawl function and uses the DATEADD function to compute data within the last hour. Coupled with the CloudWatch Events trigger that schedules this function for hourly, it allows us to stream data to Lookout for Metrics reliably.
The work defined in the query.sql files is only a portion of the final computed query. The full query is built by the respective Python files in each folder and appends the following:
- IAM role for Amazon Redshift to use for the query
- S3 bucket information for where to place the files
- CSV file export defined
It looks like the following code:
unload ('select ecommerce.ts as timestamp, ecommerce.views, ecommerce.revenue, platform.name as platform, marketplace.name as marketplace
from ecommerce, platform, marketplace
where ecommerce.platform = platform.id
and ecommerce.marketplace = marketplace.id
and ecommerce.ts < DATEADD(hour, 0, getdate())
and ecommerce.ts > DATEADD(hour, -1, getdate())')
to 's3://BUCKET/ecommerce/live/20220112/1800/'
iam_role 'arn:aws:iam::ACCOUNT_ID:role/custom-rs-connector-LookoutForMetricsRole-' header CSV;
As long as your prepared query can be encapsulated by the UNLOAD statement, it should work with no issues.
If you need to change the frequency for how often the continuous detector function runs, update the cron expression in ai_ops/l4m-redshift-continuous-crawl.yaml. It’s defined in the last line as Schedule: cron(0 * * * ? *).
Modify the Lookout for Metrics detector and dataset
The final components focus on Lookout for Metrics itself, mainly the detector and dataset configurations. They’re both defined in ai_ops/params.json.
The included file looks like the following code:
{
"database_type": "redshift",
"detector_name": "l4m-custom-redshift-connector-detector",
"detector_description": "A quick sample config of how to use L4M.",
"detector_frequency": "PT1H",
"timestamp_column": {
"ColumnFormat": "yyyy-MM-dd HH:mm:ss",
"ColumnName": "timestamp"
},
"dimension_list": [
"platform",
"marketplace"
],
"metrics_set": [
{
"AggregationFunction": "SUM",
"MetricName": "views"
},
{
"AggregationFunction": "SUM",
"MetricName": "revenue"
}
],
"metric_source": {
"S3SourceConfig": {
"FileFormatDescriptor": {
"CsvFormatDescriptor": {
"Charset": "UTF-8",
"ContainsHeader": true,
"Delimiter": ",",
"FileCompression": "NONE",
"QuoteSymbol": "\""
}
},
"HistoricalDataPathList": [
"s3://id-ml-ops2-inputbucket-18vaudty8qtec/ecommerce/backtest/"
],
"RoleArn": "arn:aws:iam::ACCOUNT_ID:role/id-ml-ops2-LookoutForMetricsRole-IZ5PL6M7YKR1",
"TemplatedPathList": [
""
]
}
},
"s3_bucket": "",
"alert_name": "alerter",
"alert_threshold": 1,
"alert_description": "Exports anomalies into s3 for visualization",
"alert_lambda_arn": "",
"offset": 300,
"secret_name": "redshift-l4mintegration"
}
ai_ops/params.json manages the following parameters:
- database_type
- detector_name
- detector_description
- detector_frequency
- timestamp_column and details
- dimension_list
- metrics_set
- offset
Not every value can be defined statically ahead of time; these are updated by ai_ops/params_builder.py:
- HistoricalDataPathList
- RoleArn
- TemplatedPathList
- s3_bucket
To modify any of these entities, update the file responsible for them and your detector is modified accordingly.
Clean up
Follow the steps in this section to clean up all resources created by this solution and make sure you’re not billed after evaluating or using the solution.
- Empty all data from the S3 buckets that were created from their respective templates:
- ProductionRedshiftDemo –
S3ContentBucket
- CustomRedshiftConnector –
S3LambdaBucket
- custom-rs-connector –
InputBucket
- Delete your detector via the Lookout for Metrics console.
- Delete the CloudFormation stacks in the following order (wait for one to complete before moving onto the next):
- custom-rs-connector-crawl
- custom-rs-connector
- CustomRedshiftConnector
- ProductionRedshiftDemo
Conclusion
You have now seen how to connect an Amazon Redshift database to Lookout for Metrics using the native Amazon Redshift Data APIs, CloudWatch Events, and Lambda functions. This approach allows you to create relevant datasets based on your information in Amazon Redshift to perform anomaly detection on your time series data in just a few minutes. If you can draft the SQL query to obtain the information, you can enable ML-powered anomaly detection on your data. From there, your anomalies should showcase anomalous events and help you understand how one anomaly may be caused or impacted by others, thereby reducing your time to understanding issues critical to your business or workload.
About the Authors
 Chris King is a Principal Solutions Architect in Applied AI with AWS. He has a special interest in launching AI services and helped grow and build Amazon Personalize and Amazon Forecast before focusing on Amazon Lookout for Metrics. In his spare time he enjoys cooking, reading, boxing, and building models to predict the outcome of combat sports.
Chris King is a Principal Solutions Architect in Applied AI with AWS. He has a special interest in launching AI services and helped grow and build Amazon Personalize and Amazon Forecast before focusing on Amazon Lookout for Metrics. In his spare time he enjoys cooking, reading, boxing, and building models to predict the outcome of combat sports.
 Alex Kim is a Sr. Product Manager for Amazon Forecast. His mission is to deliver AI/ML solutions to all customers who can benefit from it. In his free time, he enjoys all types of sports and discovering new places to eat.
Alex Kim is a Sr. Product Manager for Amazon Forecast. His mission is to deliver AI/ML solutions to all customers who can benefit from it. In his free time, he enjoys all types of sports and discovering new places to eat.


 to securely and efficiently access the remote macOS machines. You can connect from anywhere, using a PCoIP client application or from thin terminals such as Thin Clients or Zero Clients workstations.
to securely and efficiently access the remote macOS machines. You can connect from anywhere, using a PCoIP client application or from thin terminals such as Thin Clients or Zero Clients workstations.
























 Chris King is a Principal Solutions Architect in Applied AI with AWS. He has a special interest in launching AI services and helped grow and build Amazon Personalize and Amazon Forecast before focusing on Amazon Lookout for Metrics. In his spare time he enjoys cooking, reading, boxing, and building models to predict the outcome of combat sports.
Chris King is a Principal Solutions Architect in Applied AI with AWS. He has a special interest in launching AI services and helped grow and build Amazon Personalize and Amazon Forecast before focusing on Amazon Lookout for Metrics. In his spare time he enjoys cooking, reading, boxing, and building models to predict the outcome of combat sports. Alex Kim is a Sr. Product Manager for Amazon Forecast. His mission is to deliver AI/ML solutions to all customers who can benefit from it. In his free time, he enjoys all types of sports and discovering new places to eat.
Alex Kim is a Sr. Product Manager for Amazon Forecast. His mission is to deliver AI/ML solutions to all customers who can benefit from it. In his free time, he enjoys all types of sports and discovering new places to eat.