Post Syndicated from Ben "Fuzzy" Shonaldmann original https://aws.amazon.com/blogs/architecture/how-scale-to-win-uses-aws-waf-to-block-ddos-events/
This is a guest post coauthored by Ben “Fuzzy” Shonaldmann of Scale to Win.
Scale to Win was created for organizers by organizers. Born out of the 2020 election cycle, a group of friends and former colleagues came out of a whirlwind presidential primary season with frustrations and ideas to improve campaign technology. With extensive outreach experience on high-profile presidential campaigns such as Biden/Harris 2020, Bernie 2016 and 2020, Warren 2020, and Clinton 2016, we knew the power of organizing. We saw how conversations—neighbor to neighbor, friend to friend, volunteer to voter—could transform communities and drive movements. Yet, the tools available for voter contact programs regularly fell short of our needs. We built and launched our first product in April 2020, a peer-to-peer (P2P) texting tool. We’ve since added a dialer tool that allows organizations to easily call voters, and Scale to Win Text, an all-in-one texting tool for organizing and fundraising.
During the 2024 US presidential election campaign season, we were the target of distributed denial of service (DDoS) events. These events reached peaks of over 2 million requests per second from nearly ten thousand unique IPs. After a brief window of downtime at the start of these events, Scale to Win partnered with Amazon Web Services (AWS) to implement AWS WAF, AWS Shield Advanced, and Amazon CloudFront to mitigate these targeted DDoS events.
One key element of our defense was AWS WAF support for Completely Automated Public Turing test to tell Computers and Humans Apart (CAPTCHA) to automatically present a challenge to suspicious-looking clients. We used this to provide a per-IP rate limit for traffic we expected to see from legitimate clients behind a single IP. For IPs that exceed this rate limit, we present a CAPTCHA and provide a higher rate limit to the maximum amount of traffic we expect to come from a single IP, like a campaign office or college campus.
However, the AWS WAF out-of-the-box CAPTCHA had an important caveat—it doesn’t provide protection against an event using a token that is solved and distributed across a network of machines behind multiple IPs. To prevent this class of event, AWS WAF users need to identify CAPTCHA tokens that are being used from multiple IPs and automatically block this traffic.In this post, you’ll learn how Scale to Win configured our network topology to maximize DDoS protection capacity, configured AWS WAF to block DDoS events, segmented machine-to-machine and browser-to-machine traffic to target CAPTCHA interventions, and blocked token reuse across IP addresses.
Network Topology Overview
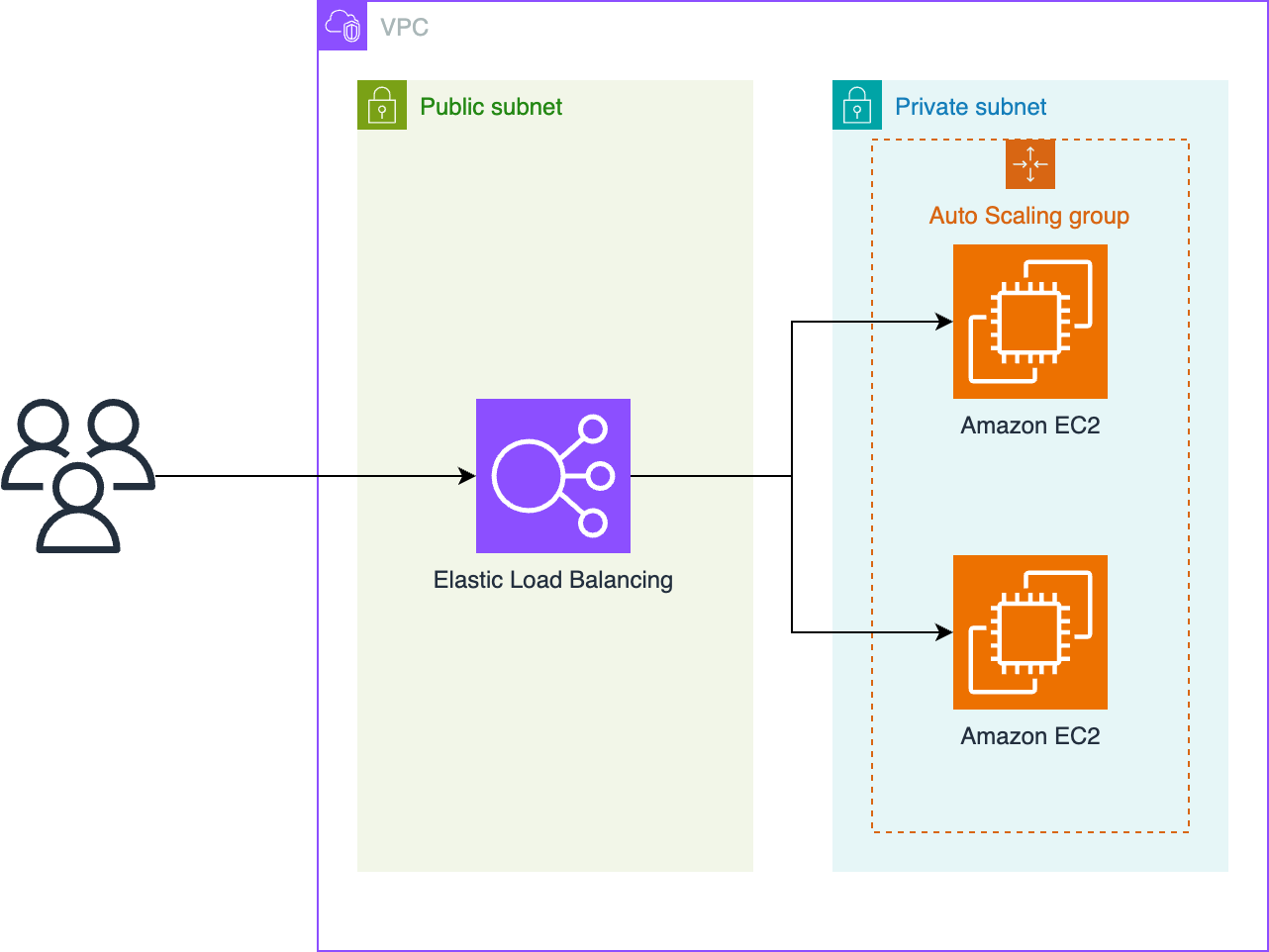
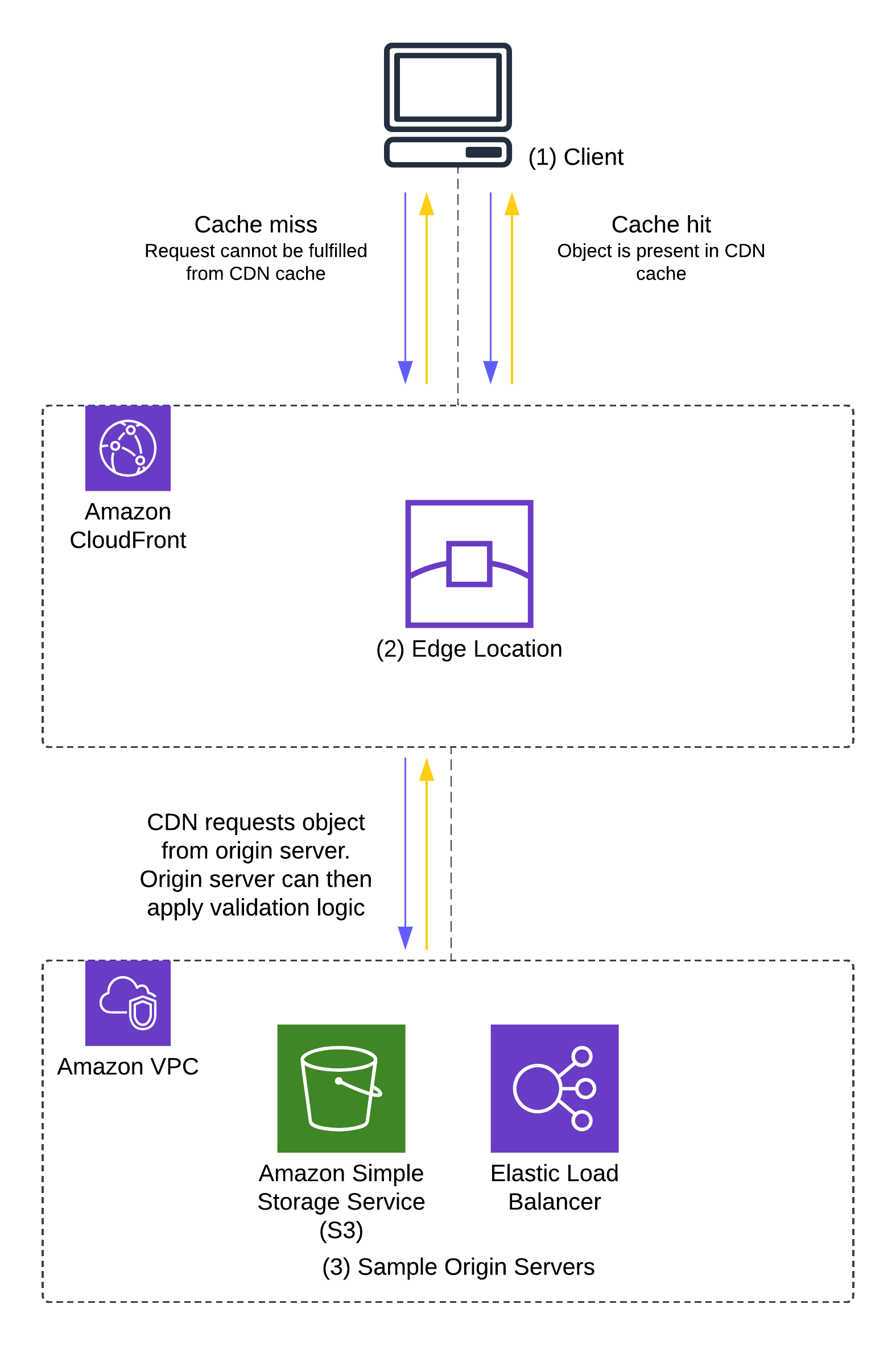
The Scale to Win application runs behind an Application Load Balancer (ALB) that serves as the single point of entry to our application servers. Before implementing AWS WAF, our DNS records resolved to the ALB as shown in the following diagram. The diagram shows a path from users to Elastic Load Balancing to an auto scaling group of Amazon Elastic Compute Cloud (Amazon EC2) instances.
The recommended pattern for using AWS WAF to protect against DDoS events is to instead route traffic through a CloudFront distribution as shown in the following diagram. The diagram shows a path from users to CloudFront with AWS WAF to Elastic Load Balancing to an auto scaling group of EC2 instances.
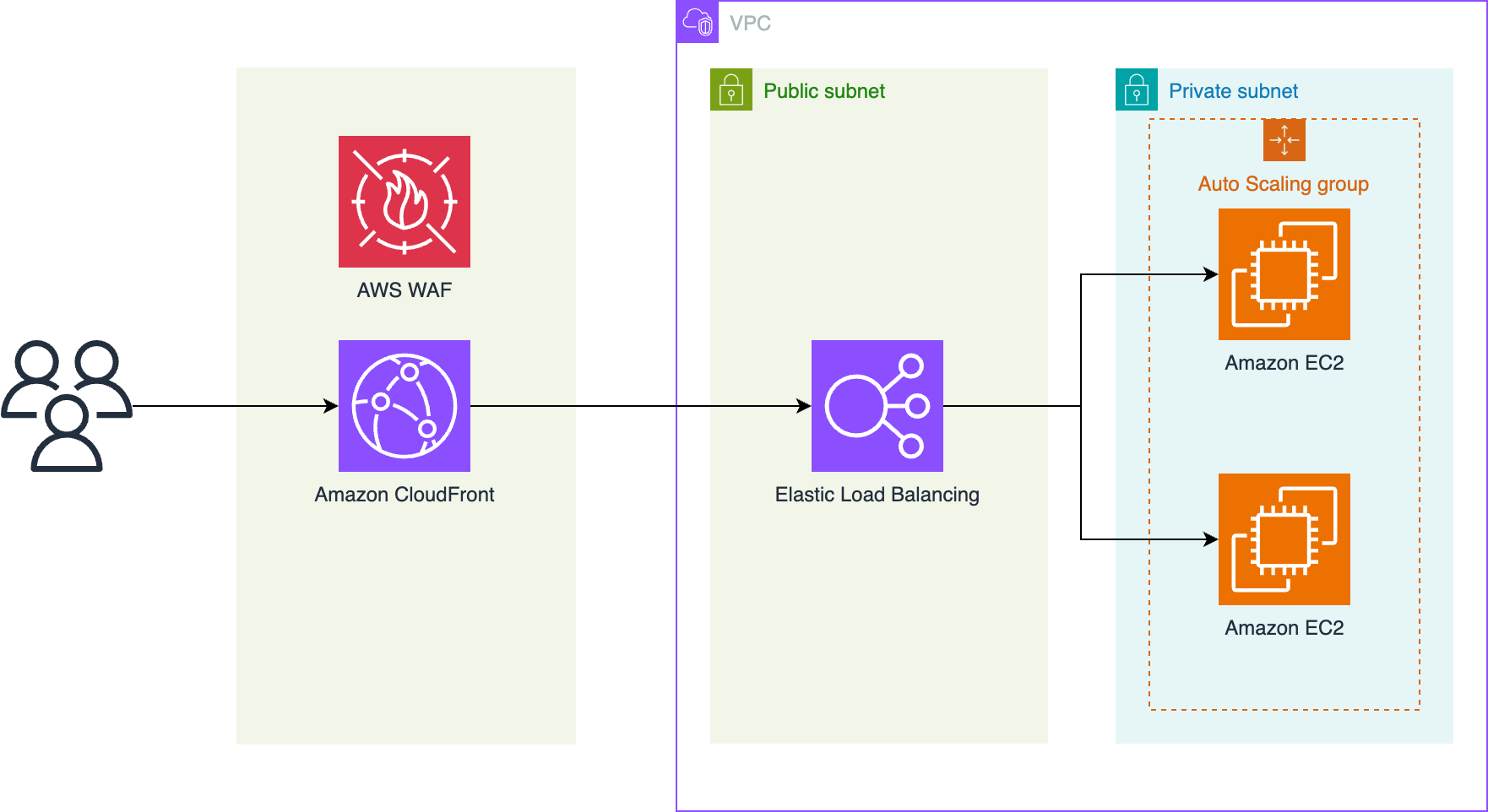
Using this topology, we can take advantage of the following benefits:
- The capacity of CloudFront to handle network-layer events sending TCP traffic that aren’t valid HTTP requests is greater than ALB capacity. Network-level protections are strongest when applied by CloudFront before passing traffic to the ALB.
- The edge deployment of AWS WAF has higher quotas and capacity than Regional deployments. AWS scales AWS WAF capacity one-to-one with CloudFront capacity, so AWS WAF always has enough capacity to handle incoming traffic.
- When implementing a geographic based block strategy, such as blocking specific countries, CloudFront provides a geographic restriction feature. In event patterns we observed, over half of malicious traffic originated from countries that we blocked completely in CloudFront, resulting in cost savings on our AWS WAF deployment.
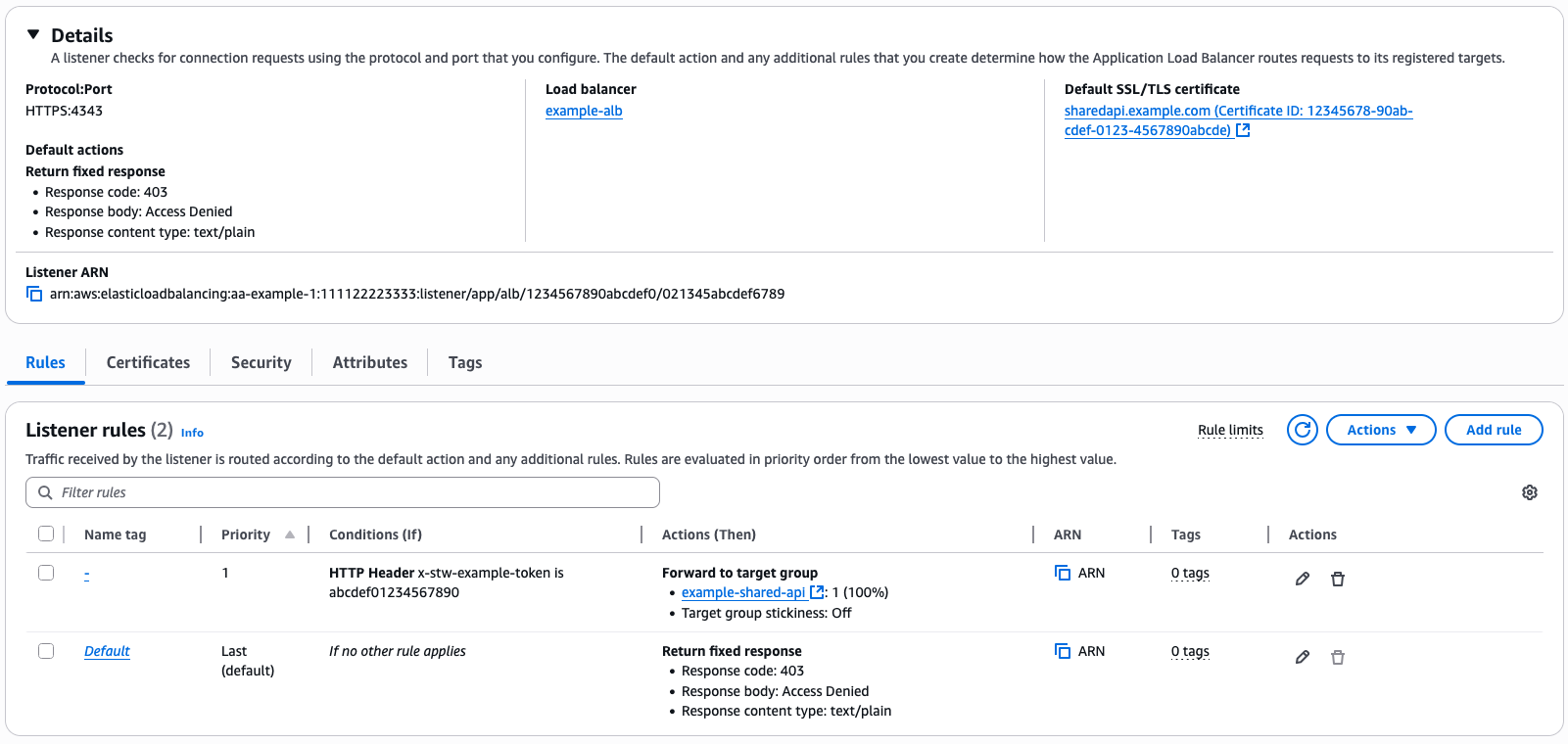
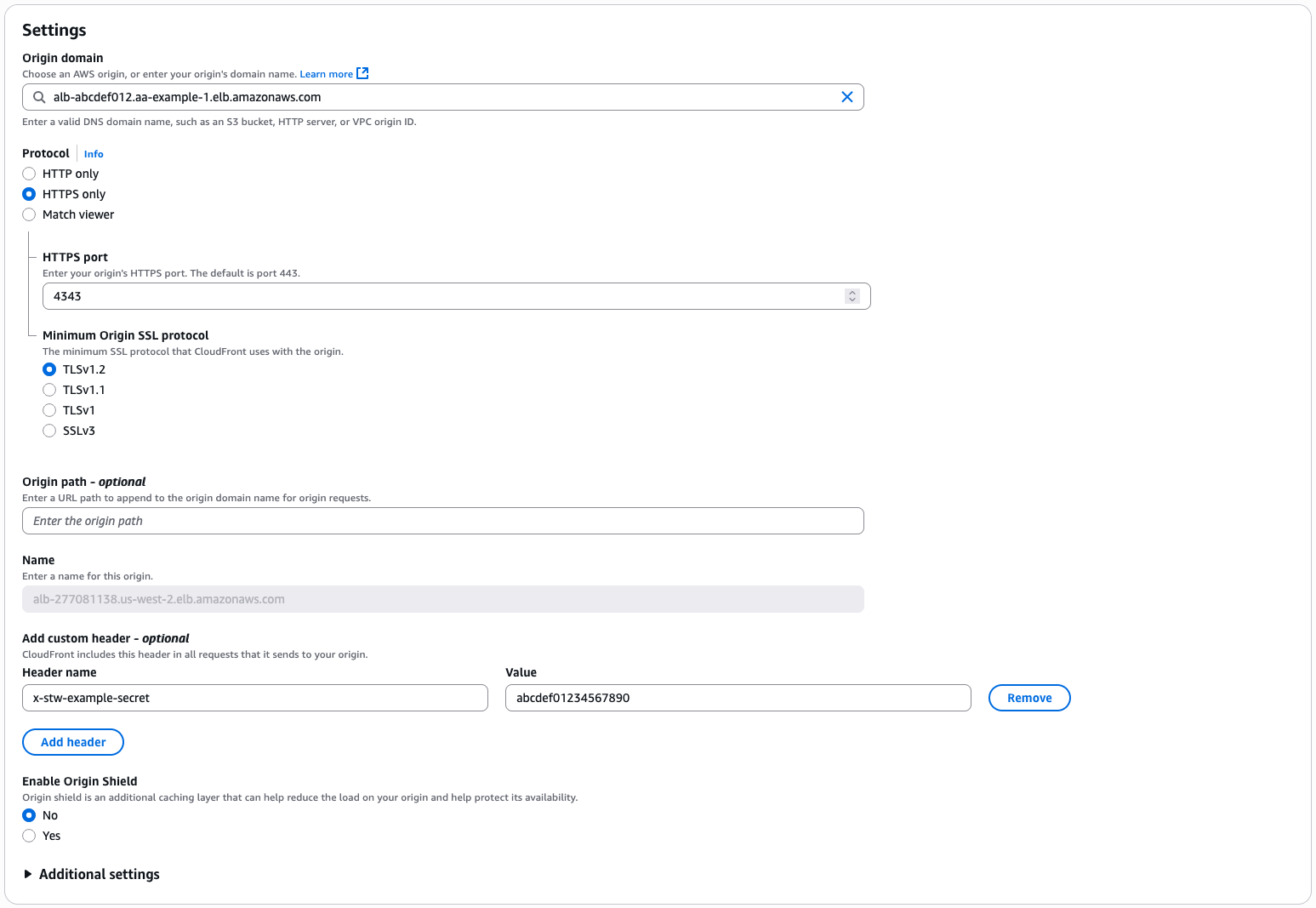
To prevent threat actors from bypassing our CloudFront distribution and AWS WAF, we implemented a security group that allows traffic only from CloudFront edge IP addresses using the managed prefix list to prevent direct connections to the ALB. We then configured the ALB to require a secret, pre-shared token in a request header, for example, our header x-stw-example-secret. We configured the CloudFront distribution to add that request header when forwarding traffic to the origin. This secret isn’t logged to Application Load Balancer logs but is logged to AWS CloudTrail when setting or updating the CloudFront or ALB configuration. It’s possible to rotate this secret on a schedule by generating a random password with AWS Secrets Manager with an AWS Lambda function to update the CloudFront origin configuration and ALB listener configuration, as shown in the following two screenshots. This shared secret between the CloudFront distribution and ALB means that an event can’t bypass the security group control by configuring its own CloudFront distribution with our ALB as an origin.
The following screenshot shows configuration of the Application Load Balancer, showing a priority-1 rule to route traffic to our target group only if the x-stw-example-secret is correct. A default rule returns a 403 if it’s not correct.
The following screenshot shows CloudFront origin settings, showing a custom header configuration to add the shared secret to requests to the origin.
Configuring AWS WAF rules
We use two approaches to identify and block malicious DDoS traffic, a heuristic approach and a hard limit approach.
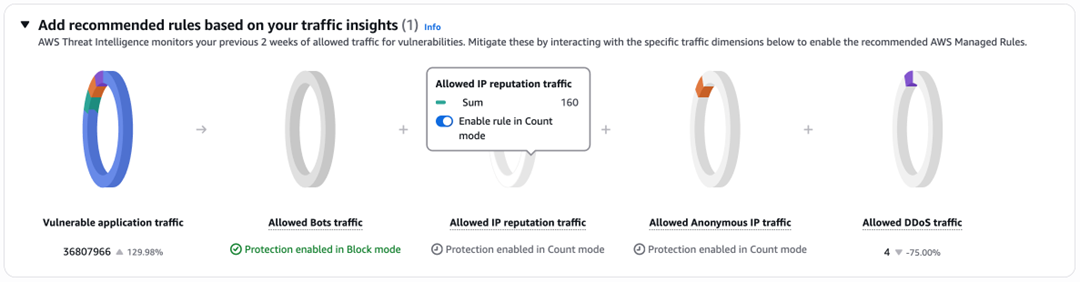
For the heuristic approach, we observe event traffic in AWS WAF sample requests and AWS WAF logs, identify patterns in the event, and block those specific patterns. To use this tactic in your own AWS WAF configuration, first identify a characteristic that is common to all or most event traffic but rare in legitimate traffic, like a HTTP header or query parameter. Create a AWS WAF rule that blocks the traffic. Using the Count rule action is helpful to test your rule and find false-positive and false-negative rates by correlating requests that match the rule with IPs that are sending high volumes of traffic. You can query AWS WAF logs with Amazon Athena to find these correlations. When you’re satisfied with your false-positive and false-negative rates, set the rule action to Block to actively block the matched traffic.
A motivated threat actor will notice the event is being blocked and randomize these parameters to bypass your rules. For example, they might replay legitimate session parameters, so that request URIs, query parameters, and request bodies are identical to legitimate traffic. Ultimately, the heuristic approach is a useful tool, and a good reason to set up logging and Athena to quickly query your AWS WAF logs, but it’s a solution that requires active reconfiguration of your AWS WAF as event patterns change.
One specific heuristic that’s worth calling out is JA4 fingerprints and their predecessor, JA3 fingerprints. A JA4 fingerprint is a hash of several parameters presented by TLS clients in the client hello packet. JA4 fingerprints roughly correspond to the specific TLS client parameters of the request, so they’re usually stable for a specific type of client. For example, a specific version of Google Chrome on a particular operating system has a fingerprint, but a version on a different operating system would have a different fingerprint. This makes JA4 fingerprints a useful heuristic for blocking malicious traffic because the botnet sending the traffic is likely to have a small number of different fingerprints. However, there are two caveats with blocking requests based on JA4 fingerprints:
- Threat actors might have the same JA4 fingerprint as legitimate users. In our case, we saw malicious traffic with the same fingerprint as a common NodeJS API client and were unable to block that fingerprint without blocking legitimate API clients.
- A sophisticated threat actor can randomize some of the TLS connection parameters, such as the order of TLS extensions in the client hello packet, which is done by threat actors to avoid JA3 fingerprint blocking and some browsers to preserve user privacy. Although the newer JA4 specification reduces some randomization elements, the fundamental challenge remains—because end users maintain control over the client hello packet, this creates an ongoing challenge of adaptation and response.
For the hard limit approach, we take advantage of request parameters that the event can’t fake, such as the source IP of the request. Although the source IP of a packet can be forged, these requests are dropped because they don’t successfully complete the TCP or TLS handshake. You can create AWS WAF rules that limit how much traffic can be sent from a single source IP using rate-based rule statements, setting the limit above what a legitimate user would send but below what the event needs to be effective.
The simplest approach with rate-based rule statements would be to have a single limit in the AWS WAF policy, but this has challenges. First, we have APIs that receive high volumes of machine-to-machine traffic. For example, we place outbound phone calls using Twilio, and Twilio sends tens of thousands of webhooks to our API per second to relay delivery status, sometimes from a single Twilio IP. Also, our application is often used by campaign offices or student-led phone banks on college campuses that might have hundreds of users behind a single or handful of IPs, so we can’t assume that a single IP is being used by a single user to calculate our acceptable rates of traffic.
Segmenting human and machine traffic
To address these challenges, we structure our AWS WAF rules to segment human and machine traffic. We do this by request path: AWS WAF rules can match based on request path, so we have a set of rules for machine traffic based on the webhook URLs or API paths where we expect machine traffic. For all other paths, we assume the traffic originates from a user visiting the site from their browser.
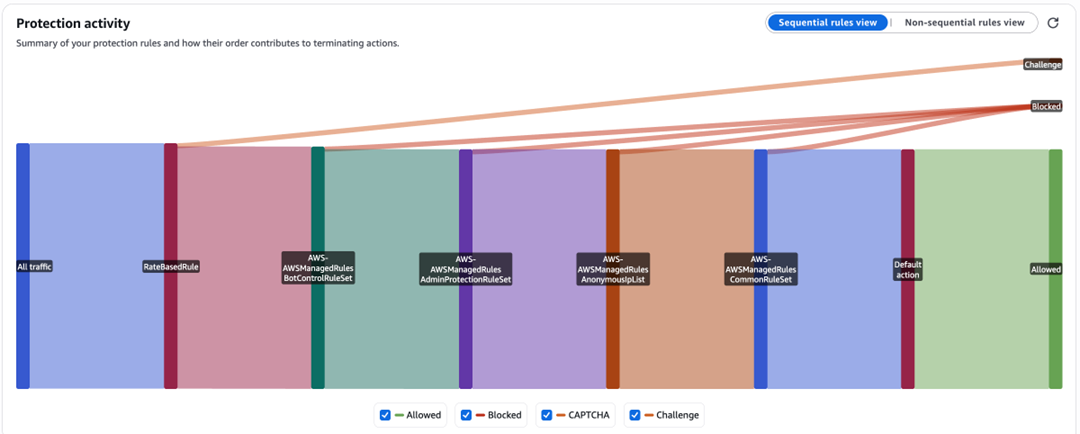
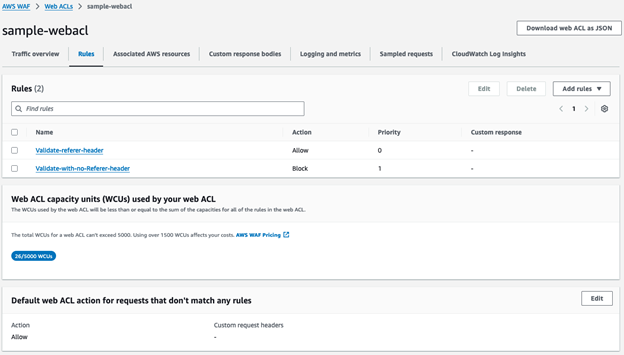
For machine traffic, we can’t use a CAPTCHA. Our API clients and the Twilio webhook infrastructure can’t solve the CAPTCHA, so we validate traffic differently. For our API clients, we set per-IP rate limits to what we expect from a single API client and return a 429 HTTP status when traffic exceeds our limit. We implement automatic retries to handle the occasional 429 error when sending above the limit. For Twilio or other webhook callbacks, we use published IPs from the service provider to create an IP set in AWS WAF. Then, we block requests to our webhook URL that don’t originate from the IP set. Not all service providers use static IPs—for Twilio specifically, we worked with their team to implement their Static Proxy feature to proxy webhook requests from a stable list of IPs. It also makes sense to implement API key authentication, request signing, and certificate-based authentication when possible for your machine traffic. For requests that originate from the IP set, we apply an Allow action in our AWS WAF rule to allow expected machine traffic through, as shown in the following screenshot. These rules allow high-volume machine-to-machine traffic through our AWS WAF configuration before we apply AWS WAF rules to block high volume user-based traffic. The following screenshot shows an example rule allowing expected machine-to-machine traffic.
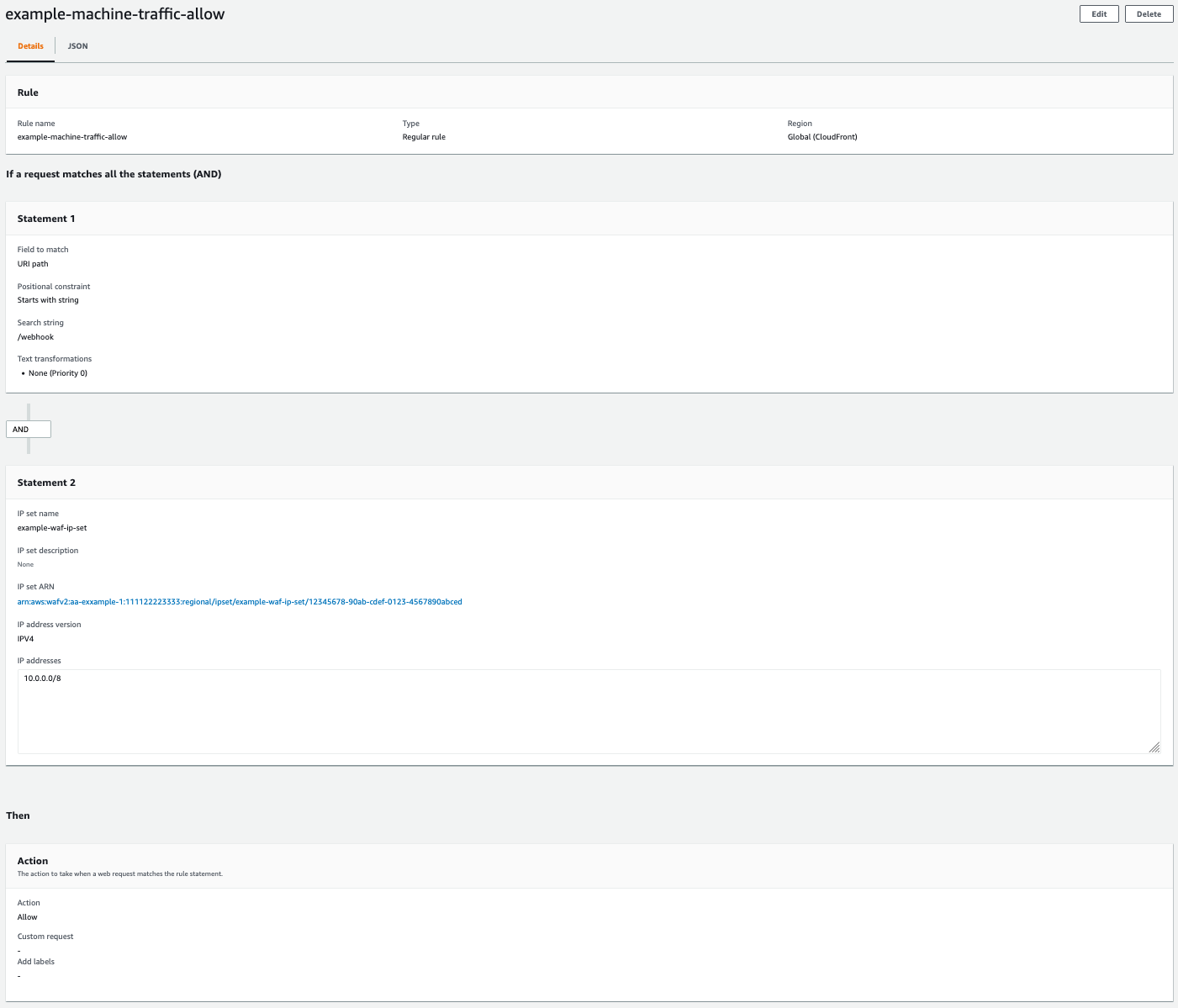
For our browser-based human traffic, we use a tiered rate limit strategy. We implement two tiers of rate limit: a low-level rate limit that corresponds to the maximum rate we expect two to three users to send, and a high-level rate limit that corresponds to the maximum rate we expect from a single IP with hundreds of users sharing the IP. Our low-level rule uses a CAPTCHA rule action when requests exceed the limit. Our high-level rule applies a Block action when requests exceed the limit. We set the high-level rate limit rule priority lower than the low-level rule so it’s processed first, as shown in the following screenshot.
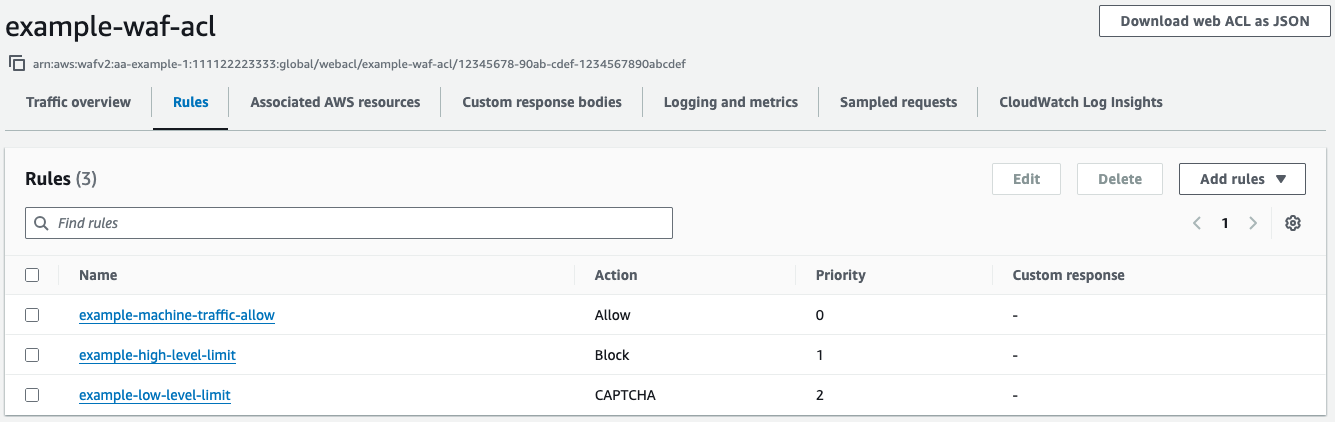
When a few users are sharing an IP address, they’re unlikely to hit either limit and can use the application without interruption. If a large group of users share an IP address, they’ll need to solve a CAPTCHA. After they solve it, they’re still limited by the high-level rate limit rule, which will prevent a threat actor from solving the CAPTCHA and then sending unlimited traffic using the token issued by AWS WAF.
Handling CAPTCHA on the frontend
For server-rendered applications, AWS WAF handles CAPTCHA challenges automatically through the following process:
- When a request matches a CAPTCHA rule without a valid token, AWS WAF presents an AWS managed CAPTCHA challenge page.
- Upon successful CAPTCHA completion, AWS WAF issues a Set-Cookie header containing the CAPTCHA token.
- Subsequent requests with valid CAPTCHA tokens can pass through AWS WAF for the configured immunity period.
For single-page applications (SPAs) or applications making API requests to a AWS WAF protected backend, additional implementation steps are required:
- Configure your frontend to detect blocked requests (HTTP 405 status code indicates CAPTCHA requirement).
- Present the CAPTCHA challenge to the user when required.
- Resubmit the original request after successful CAPTCHA completion.
The following sample code demonstrates how to implement CAPTCHA handling in a React component using the AWS WAF CAPTCHA JavaScript API:
Preventing CAPTCHA token reuse
Although AWS WAF provides built-in CAPTCHA functionality, additional security measures are necessary to prevent token reuse events. In these events, threat actors can solve a CAPTCHA one time and distribute the token across their botnet. AWS WAF Bot Control offers protection against this vulnerability by detecting and blocking CAPTCHA token reuse across multiple IPs, ASNs, or countries.
To implement this protection:
- Configure the AWSManagedRulesBotControlRuleSet managed rule group after your rate-limiting rules.
- Use the targeted protection level.
- Apply Count or Allow actions to specific rules that you don’t want to apply to your traffic instead of a Block or CAPTCHA action.
- Monitor and adjust rule actions based on observed traffic patterns.
Conclusion
In this post, you learned how we implemented comprehensive DDoS protection using AWS WAF by:
- Implementing best practices for AWS WAF network topology using CloudFront
- Segmenting human and machine traffic in our AWS WAF configuration
- Using tiered rate limits and CAPTCHA to allow legitimate requests
- Preventing CAPTCHA token reuse by using AWS WAF Bot Control
To learn more about fine-tuning and optimizing AWS WAF Bot Control, refer to Fine-tune and optimize AWS WAF Bot Control mitigation capability by Dmitriy Novikov in the AWS Security Blog.
About the authors















































































 Charishma Makineni is a Senior Technical Account Manager at AWS. She provides strategic technical guidance for Independent Software Vendors (ISVs) to build and optimize solutions on AWS. She specializes in Big Data and Analytics technologies, helping organizations optimize their data-driven initiatives on AWS.
Charishma Makineni is a Senior Technical Account Manager at AWS. She provides strategic technical guidance for Independent Software Vendors (ISVs) to build and optimize solutions on AWS. She specializes in Big Data and Analytics technologies, helping organizations optimize their data-driven initiatives on AWS. Phaneendra Vuliyaragoli is a Product Management Lead for Amazon Data Firehose at AWS. In this role, Phaneendra leads the product and go-to-market strategy for Amazon Data Firehose.
Phaneendra Vuliyaragoli is a Product Management Lead for Amazon Data Firehose at AWS. In this role, Phaneendra leads the product and go-to-market strategy for Amazon Data Firehose.






















































 Anand Komandooru is a Principal Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “
Anand Komandooru is a Principal Cloud Architect at AWS. He joined AWS Professional Services organization in 2021 and helps customers build cloud-native applications on AWS cloud. He has over 20 years of experience building software and his favorite Amazon leadership principle is “ Rama Krishna Ramaseshu is a Senior Application Architect at AWS. He joined AWS Professional Services in 2022 and with close to two decades of experience in application development and software architecture, he empowers customers to build well architected solutions within the AWS cloud. His favorite Amazon leadership principle is “
Rama Krishna Ramaseshu is a Senior Application Architect at AWS. He joined AWS Professional Services in 2022 and with close to two decades of experience in application development and software architecture, he empowers customers to build well architected solutions within the AWS cloud. His favorite Amazon leadership principle is “ Sachin Vighe is a Senior DevOps Architect at AWS. He joined AWS Professional Services in 2020, and specializes in designing and architecting solutions within the AWS cloud to guide customers through their DevOps and Cloud transformation journey. His favorite leadership principle is “
Sachin Vighe is a Senior DevOps Architect at AWS. He joined AWS Professional Services in 2020, and specializes in designing and architecting solutions within the AWS cloud to guide customers through their DevOps and Cloud transformation journey. His favorite leadership principle is “ Molly Wu is an Associate Cloud Developer at AWS. She joined AWS Professional Services in 2023 and specializes in assisting customers in building frontend technologies in AWS cloud. Her favorite leadership principle is “
Molly Wu is an Associate Cloud Developer at AWS. She joined AWS Professional Services in 2023 and specializes in assisting customers in building frontend technologies in AWS cloud. Her favorite leadership principle is “ Andrew Yankowsky is a Security Consultant at AWS. He joined AWS Professional Services in 2023, and helps customers build cloud security capabilities and follow security best practices on AWS. His favorite leadership principle is “
Andrew Yankowsky is a Security Consultant at AWS. He joined AWS Professional Services in 2023, and helps customers build cloud security capabilities and follow security best practices on AWS. His favorite leadership principle is “



