Post Syndicated from Stuart Gregg original https://aws.amazon.com/blogs/security/evolving-cyber-threats-demand-new-security-approaches-the-benefits-of-a-unified-and-global-it-ot-soc/
In this blog post, we discuss some of the benefits and considerations organizations should think through when looking at a unified and global information technology and operational technology (IT/OT) security operations center (SOC). Although this post focuses on the IT/OT convergence within the SOC, you can use the concepts and ideas discussed here when thinking about other environments such as hybrid and multi-cloud, Industrial Internet of Things (IIoT), and so on.
The scope of assets has vastly expanded as organizations transition to remote work, and from increased interconnectivity through the Internet of Things (IoT) and edge devices coming online from around the globe, such as cyber physical systems. For many organizations, the IT and OT SOCs were separate, but there is a strong argument for convergence, which provides better context for the business outcomes of being able to respond to unexpected activity. In the ten security golden rules for IIoT solutions, AWS recommends deploying security audit and monitoring mechanisms across OT and IIoT environments, collecting security logs, and analyzing them using security information and event management (SIEM) tools within a SOC. SOCs are used to monitor, detect, and respond; this has traditionally been done separately for each environment. In this blog post, we explore the benefits and potential trade-offs of the convergence of these environments for the SOC. Although organizations should carefully consider the points raised throughout this blog post, the benefits of a unified SOC outweigh the potential trade-offs—visibility into the full threat chain propagating from one environment to another is critical for organizations as daily operations become more connected across IT and OT.
Traditional IT SOC
Traditionally, the SOC was responsible for security monitoring, analysis, and incident management of the entire IT environment within an organization—whether on-premises or in a hybrid architecture. This traditional approach has worked well for many years and ensures the SOC has the visibility to effectively protect the IT environment from evolving threats.
Note: Organizations should be aware of the considerations for security operations in the cloud which are discussed in this blog post.
Traditional OT SOC
Traditionally, OT, IT, and cloud teams have worked on separate sides of the air gap as described in the Purdue model. This can result in siloed OT, IIoT, and cloud security monitoring solutions, creating potential gaps in coverage or missing context that could otherwise have improved the response capability. To realize the full benefits of IT/OT convergence, IIoT, IT and OT must collaborate effectively to provide a broad perspective and the most effective defense. The convergence trend applies to newly connected devices and to how security and operations work together.
As organizations explore how industrial digital transformation can give them a competitive advantage, they’re using IoT, cloud computing, artificial intelligence and machine learning (AI/ML), and other digital technologies. This increases the potential threat surface that organizations must protect and requires a broad, integrated, and automated defense-in-depth security approach delivered through a unified and global SOC.
Without full visibility and control of traffic entering and exiting OT networks, the operations function might not be able to get full context or information that can be used to identify unexpected events. If a control system or connected assets such as programmable logic controllers (PLCs), operator workstations, or safety systems are compromised, threat actors could damage critical infrastructure and services or compromise data in IT systems. Even in cases where the OT system isn’t directly impacted, the secondary impacts can result in OT networks being shut down due to safety concerns over the ability to operate and monitor OT networks.
The SOC helps improve security and compliance by consolidating key security personnel and event data in a centralized location. Building a SOC is significant because it requires a substantial upfront and ongoing investment in people, processes, and technology. However, the value of an improved security posture is of great consideration compared to the costs.
In many OT organizations, operators and engineering teams may not be used to focusing on security; in some cases, organizations set up an OT SOC that’s independent from their IT SOC. Many of the capabilities, strategies, and technologies developed for enterprise and IT SOCs apply directly to the OT environment, such as security operations (SecOps) and standard operating procedures (SOPs). While there are clearly OT-specific considerations, the SOC model is a good starting point for a converged IT/OT cybersecurity approach. In addition, technologies such as a SIEM can help OT organizations monitor their environment with less effort and time to deliver maximum return on investment. For example, by bringing IT and OT security data into a SIEM, IT and OT stakeholders share access to the information needed to complete security work.
Benefits of a unified SOC
A unified SOC offers numerous benefits for organizations. It provides broad visibility across the entire IT and OT environments, enabling coordinated threat detection, faster incident response, and immediate sharing of indicators of compromise (IoCs) between environments. This allows for better understanding of threat paths and origins.
Consolidating data from IT and OT environments in a unified SOC can bring economies of scale with opportunities for discounted data ingestion and retention. Furthermore, managing a unified SOC can reduce overhead by centralizing data retention requirements, access models, and technical capabilities such as automation and machine learning.
Operational key performance indicators (KPIs) developed within one environment can be used to enhance another, promoting operational efficiency such as reducing mean time to detect security events (MTTD). A unified SOC enables integrated and unified security, operations, and performance, which supports comprehensive protection and visibility across technologies, locations, and deployments. Sharing lessons learned between IT and OT environments improves overall operational efficiency and security posture. A unified SOC also helps organizations adhere to regulatory requirements in a single place, streamlining compliance efforts and operational oversight.
By using a security data lake and advanced technologies like AI/ML, organizations can build resilient business operations, enhancing their detection and response to security threats.
Creating cross-functional teams of IT and OT subject matter experts (SMEs) help bridge the cultural divide and foster collaboration, enabling the development of a unified security strategy. Implementing an integrated and unified SOC can improve the maturity of industrial control systems (ICS) for IT and OT cybersecurity programs, bridging the gap between the domains and enhancing overall security capabilities.
Considerations for a unified SOC
There are several important aspects of a unified SOC for organizations to consider.
First, the separation of duty is crucial in a unified SOC environment. It’s essential to verify that specific duties are assigned to individuals based on their expertise and job function, allowing the most appropriate specialists to work on security events for their respective environments. Additionally, the sensitivity of data must be carefully managed. Robust access and permissions management is necessary to restrict access to specific types of data, maintaining that only authorized analysts can access and handle sensitive information. You should implement a clear AWS Identity and Access Management (IAM) strategy following security best practices across your organization to verify that the separation of duties is enforced.
Another critical consideration is the potential disruption to operations during the unification of IT and OT environments. To promote a smooth transition, careful planning is required to minimize any loss of data, visibility, or disruptions to standard operations. It’s crucial to recognize the differences in IT and OT security. The unique nature of OT environments and their close ties to physical infrastructure require tailored cybersecurity strategies and tools that address the distinct missions, challenges, and threats faced by industrial organizations. A copy-and-paste approach from IT cybersecurity programs will not suffice.
Furthermore, the level of cybersecurity maturity often varies between IT and OT domains. Investment in cybersecurity measures might differ, resulting in OT cybersecurity being relatively less mature compared to IT cybersecurity. This discrepancy should be considered when designing and implementing a unified SOC. Baselining the technology stack from each environment, defining clear goals and carefully architecting the solution can help ensure this discrepancy has been accounted for. After the solution has moved into the proof-of-concept (PoC) phase, you can start to testing for readiness to move the convergence to production.
You also must address the cultural divide between IT and OT teams. Lack of alignment between an organization’s cybersecurity policies and procedures with ICS and OT security objectives can impact the ability to secure both environments effectively. Bridging this divide through collaboration and clear communication is essential. This has been discussed in more detail in the post on managing organizational transformation for successful IT/OT convergence.
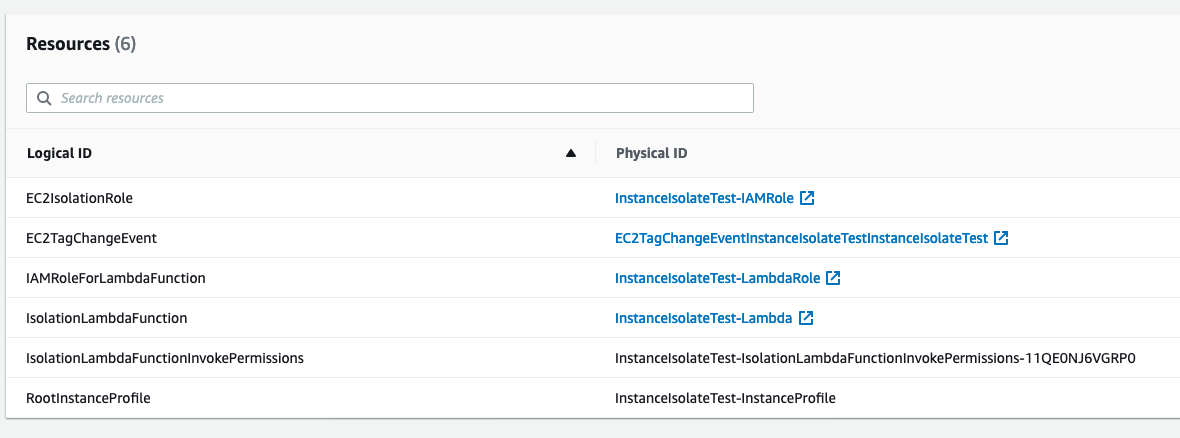
Unified IT/OT SOC deployment:
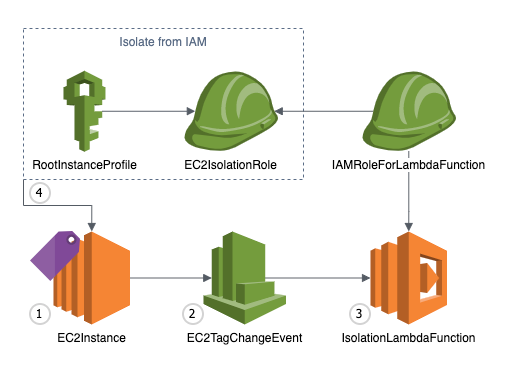
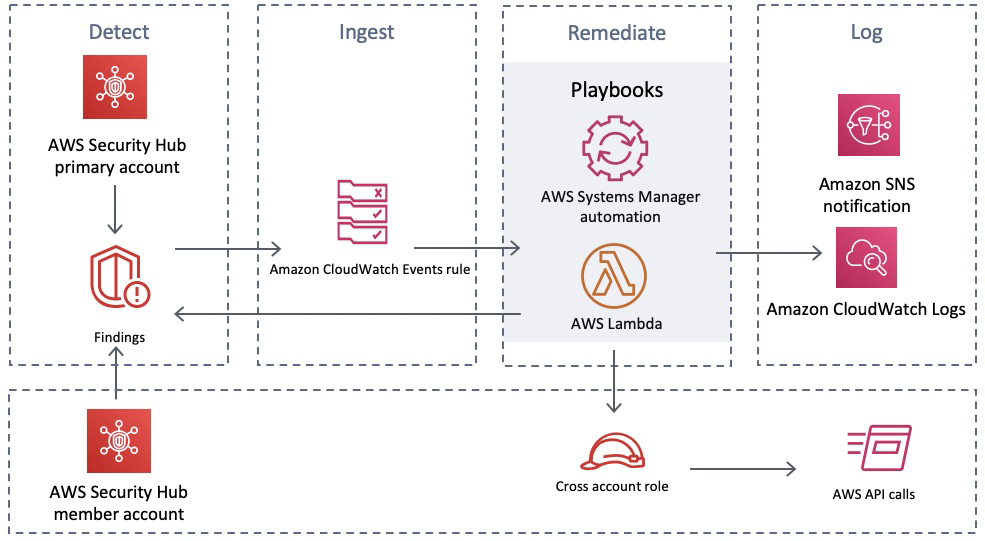
Figure 1 shows the deployment that would be expected in a unified IT/OT SOC. This is a high-level view of a unified SOC. In part 2 of this post, we will provide prescriptive guidance on how to design and build a unified and global SOC on AWS using AWS services and AWS Partner Network (APN) solutions.

Figure 1: Unified IT/OT SOC architecture
The parts of the IT/OT unified SOC are the following:
Environment: There are multiple environments, including a traditional IT on-premises organization, OT environment, cloud environment, and so on. Each environment represents a collection of security events and log sources from assets.
Data lake: A centralized place for data collection, normalization, and enrichment to verify that raw data from the different environments is standardized into a common scheme. The data lake should support data retention and archiving for long term storage.
Visualize: The SOC includes multiple dashboards based on organizational and operational needs. Dashboards can cover scenarios for multiple environments including data flows between IT and OT environments. There are also specific dashboards for the individual environments to cover each stakeholder’s needs. Data should be indexed in a way that allows humans and machines to query the data to monitor for security and performance issues.
Security analytics: Security analytics are used to aggregate and analyze security signals and generate higher fidelity alerts and to contextualize OT signals against concurrent IT signals and against threat intelligence from reputable sources.
Detect, alert, and respond: Alerts can be set up for events of interest based on data across both individual and multiple environments. Machine learning should be used to help identify threat paths and events of interest across the data.
Conclusion
Throughout this blog post, we’ve talked through the convergence of IT and OT environments from the perspective of optimizing your security operations. We looked at the benefits and considerations of designing and implementing a unified SOC.
Visibility into the full threat chain propagating from one environment to another is critical for organizations as daily operations become more connected across IT and OT. A unified SOC is the nerve center for incident detection and response and can be one of the most critical components in improving your organization’s security posture and cyber resilience.
If unification is your organization’s goal, you must fully consider what this means and design a plan for what a unified SOC will look like in practice. Running a small proof of concept and migrating in steps often helps with this process.
In the next blog post, we will provide prescriptive guidance on how to design and build a unified and global SOC using AWS services and AWS Partner Network (APN) solutions.
Learn more:
- Implement security monitoring across OT, IIoT and Cloud
- Improve your security posture with Claroty xDome integration with AWS Security Hub
- Improve your security posture with AWS IoT Device Defender direct integration with AWS Security Hub
- A cloud based SOC helps improve your security detection and response
- AWS security monitoring blogs
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.